从0到1,带你走进Flink的世界
目录
一、Flink 是什么?
二、Flink 能做什么?
三、Flink 架构全景概览
3.1 分层架构剖析
3.2 核心组件解析
四、Flink 的核心概念
4.1 数据流与数据集
4.2 转换操作
4.3 窗口
4.4 时间语义
4.5 状态与检查点
五、Flink 安装与快速上手
5.1 安装准备
5.2 安装步骤
5.3 运行示例程序
六、总结与展望
一、Flink 是什么?
在大数据处理的广袤领域中,Apache Flink 宛如一颗璀璨的明星,占据着极为重要的地位。随着数据量呈指数级增长,实时处理和分析海量数据的需求愈发迫切,Flink 凭借其卓越的性能和丰富的功能,成为众多企业和开发者的首选工具。
Flink 是一个开源的分布式流处理框架,由 Apache 软件基金会开发,使用 Java 和 Scala 编写。它的核心是一个分布式流数据引擎,能够以数据并行和流水线方式执行任意流数据程序。Flink 的设计目标是提供高吞吐量、低延迟的流数据处理能力,同时支持对有界和无界数据流进行有状态的计算。
这里提到的有界数据流,就像是一个装满数据的固定大小的箱子,数据量是有限的,处理完这些数据任务就结束了,比如处理一份固定的历史订单数据报表。而无界数据流则如同一条源源不断流淌的河流,数据持续不断地产生,没有尽头,像网站的实时访问日志数据,新的访问记录随时都会添加进来。Flink 能够同时处理这两种类型的数据,展现出强大的通用性。
Flink 的分布式特性使其可以在多台机器组成的集群上运行,充分利用集群的计算资源,实现大规模数据的快速处理。它就像一个高效的工厂,有多个工人(机器节点)协同工作,每个工人负责处理一部分数据,最终共同完成整个数据处理任务。并且,Flink 支持有状态的计算,在处理数据的过程中,它可以记住之前处理过的数据的相关信息,也就是状态。比如在计算用户的累计登录次数时,Flink 会保存之前统计的登录次数,当新的登录记录到来时,基于之前的状态进行更新计算。
二、Flink 能做什么?
Flink 的应用场景极为广泛,在许多领域都发挥着关键作用,为企业和开发者提供了强大的数据处理支持。
实时数据处理:在电商领域,Flink 可以实时处理用户的购物行为数据,如商品浏览、添加购物车、下单等操作。通过对这些数据的实时分析,电商平台能够实现实时推荐功能,根据用户当前的行为和历史偏好,为其精准推荐相关商品。在金融交易场景中,交易数据瞬息万变,Flink 能够实时处理股票、期货等金融产品的交易数据,实时监控交易风险。一旦发现异常交易行为,如短期内大量的异常订单,能够立即触发预警机制,保障金融交易的安全。
批处理数据处理:对于历史数据的分析统计,Flink 同样表现出色。例如,企业需要对过去一年的销售数据进行分析,以了解销售趋势、热门产品等信息。Flink 可以高效地处理这些大规模的历史数据,通过 Map、Reduce 等操作,快速得出统计结果,为企业的决策提供有力的数据支持。在科学研究领域,Flink 也可以用于处理大规模的实验数据,帮助科研人员分析实验结果,发现潜在的规律。
数据分析:Flink 能够实时处理传感器产生的大量数据,通过对这些数据的分析,实现对设备状态的实时监控和预测性维护。比如在智能工厂中,通过对生产设备传感器数据的实时分析,Flink 可以及时发现设备的异常情况,提前预警设备故障,避免生产中断,提高生产效率和设备的使用寿命。在城市交通管理中,Flink 可以实时处理交通流量数据、车辆位置数据等,分析交通拥堵状况,为交通调度提供决策依据,优化交通信号灯的时间设置,缓解交通拥堵。
数据管道:Flink 可以从各种数据源(如 Kafka、HDFS 等)读取数据,对数据进行清洗、转换等操作后,将处理后的数据输出到其他存储系统或数据平台,如 MySQL、Hive 等。例如,企业需要将业务系统中的原始数据经过清洗和转换后,加载到数据仓库中,Flink 就可以构建这样的数据管道,实现数据的高效传输和处理,为后续的数据分析和应用提供高质量的数据。
三、Flink 架构全景概览
3.1 分层架构剖析
Flink 采用了精妙的分层架构设计,犹如一座结构严谨的大厦,每一层都肩负着独特而关键的使命,它们相互协作,共同支撑起 Flink 强大的数据处理能力。
最上层是高级 API 层,它宛如大厦的华丽外观,为用户提供了便捷且强大的工具。这一层包含了机器学习库以及 Flink SQL API 等丰富的组件。以 Flink SQL API 为例,它允许熟悉 SQL 语法的用户通过简单的 SQL 语句就能对数据进行复杂的查询和处理,极大地降低了数据处理的门槛。在电商领域,分析师可以利用 Flink SQL 快速分析用户的购买行为,统计不同地区、不同时间段的商品销售情况,为企业的营销策略制定提供有力的数据支持。
往下一层是 API 层,这是连接用户与底层执行引擎的桥梁。它主要涵盖了 Flink 的流处理 API 和批处理 API。DataStream API 专门用于处理无界的数据流,就像一条奔腾不息的河流,能实时处理源源不断的数据。在金融交易场景中,DataStream API 可以实时监控股票价格的波动,一旦价格达到预设的阈值,就能立即触发警报,让投资者及时做出决策。而 DataSet API 则专注于处理有界的批处理数据,如同对静止的湖泊进行全面的梳理和分析。例如在对企业历史财务数据进行年度审计时,DataSet API 可以高效地对大量的财务记录进行汇总、分析,找出潜在的问题和风险。
再往下是执行引擎层,它是 Flink 的核心动力源泉,就像大厦的坚固地基,为整个系统提供了强大的计算能力。Flink 的执行引擎基于先进的流处理技术实现,能够将用户编写的代码转化为高效的执行计划,并在分布式环境中进行任务调度和数据处理。它支持分布式 Stream 处理,能够将大规模的数据处理任务分解为多个子任务,分布到集群中的各个节点上并行执行,大大提高了处理效率。同时,执行引擎还负责将 JobGraph(作业图)转换为 ExecutionGraph(执行图),这一过程就像是将建筑蓝图转化为实际的施工方案,确保每个任务都能准确无误地执行。
最底层是资源层,它为 Flink 任务的执行提供了物理基础,如同大厦所依托的土地。Flink 任务可以在多种物理资源上运行,包括本地的 JVM 环境、集群环境(如 YARN)以及云端环境(如 GCE/EC2)。在实际应用中,企业可以根据自身的需求和资源状况选择合适的部署环境。如果是小型企业或者进行开发测试,本地 JVM 环境可能就足够了;而对于大型企业,处理海量的数据时,YARN 集群能够提供强大的资源管理和调度能力,确保任务高效稳定地运行;云端环境则具有弹性伸缩的优势,能够根据业务量的变化自动调整资源配置,降低成本。
3.2 核心组件解析
在 Flink 的架构体系中,有两个核心组件犹如大厦的支柱,支撑着整个系统的稳定运行,它们就是 JobManager 和 TaskManager。
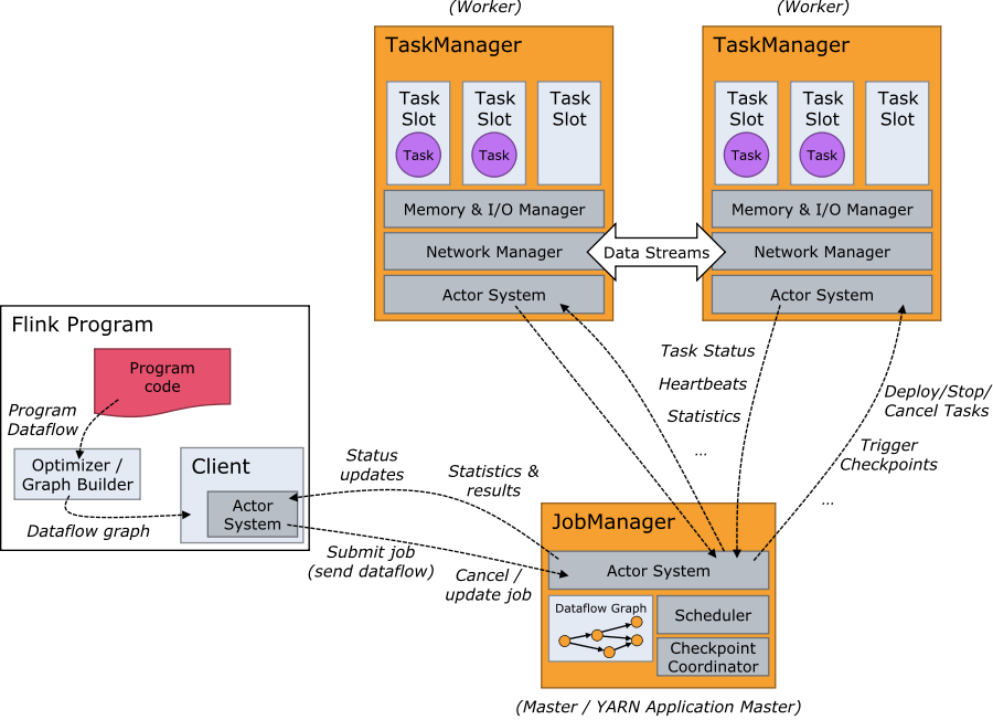
JobManager 是 Flink 集群的指挥中枢,负责协调和管理整个作业的执行,犹如交响乐团的指挥家,掌控着全局的节奏和协调。它主要由三个重要的子组件构成:Dispatcher(分发器)、ResourceManager(资源管理器)和 JobMaster(作业管理器)。
- Dispatcher 就像是一个繁忙的交通枢纽,提供了一个 REST 接口,专门用于接收客户端提交的 Flink 应用程序执行请求。当客户端提交一个作业时,Dispatcher 会迅速响应,为每个提交的作业启动一个新的 JobMaster 组件,就像为每一辆驶入枢纽的车辆安排好行驶路线。同时,Dispatcher 还肩负着运行 Flink WebUI 的重任,这个 WebUI 就像是一个实时的仪表盘,为用户提供了直观的作业执行信息展示,用户可以通过它轻松查看作业的运行状态、进度以及各种性能指标,方便及时做出调整和决策。
- ResourceManager 则是资源世界的掌控者,负责管理 Flink 集群中的资源,包括资源的提供、回收和分配。它管理的 task slots 是 Flink 集群中资源调度的基本单位,就像一个个小的资源容器,每个容器都可以容纳一定数量的任务。在一个拥有多个节点的 Flink 集群中,ResourceManager 会根据各个节点的资源状况和作业的需求,合理地分配 task slots,确保每个作业都能获得足够的资源来运行。同时,当某个作业完成或者某个节点出现故障时,ResourceManager 会及时回收闲置的资源,以便重新分配给其他需要的作业,从而提高整个集群的资源利用率。
- JobMaster 是每个作业的专属管理者,负责管理单个 JobGraph 的执行,就像每个项目都有一个项目经理,对项目的各个环节进行细致的把控。在作业提交时,JobMaster 会率先接收到客户端提交的应用,包括 Jar 包、数据流图和 JobGraph 等重要信息。它会将 JobGraph 精心转换为一个物理层面的数据流图,即 ExecutionGraph,这个 ExecutionGraph 就像是一份详细的施工图纸,包含了所有可以并发执行的任务以及它们之间的依赖关系。然后,JobMaster 会向 ResourceManager 发出资源请求,申请执行任务所必需的资源。一旦获得了足够的资源,JobMaster 就会将 ExecutionGraph 分发到真正运行它们的 TaskManager 上,就像项目经理将施工任务分配给各个施工队伍。在作业运行过程中,JobMaster 还会负责所有需要中央协调的操作,比如检查点的协调,确保在出现故障时能够快速恢复作业,保证数据的一致性和完整性。
TaskManager 是 Flink 集群中的工作主力,也被称为 Worker,负责执行具体的任务,就像建筑工人,将设计蓝图变为现实。每一个 TaskManager 都包含了一定数量的任务槽(task slots),这些 task slots 是资源调度的最小单位,它们的数量限制了 TaskManager 能够并行处理的任务数量。例如,一个 TaskManager 有 4 个 task slots,就意味着它最多可以同时并行执行 4 个任务。
当 TaskManager 启动后,它会积极地向 ResourceManager 注册自己的 task slots,就像工人向包工头报到,表明自己的工作能力和可承担的任务量。收到 ResourceManager 的指令后,TaskManager 会将一个或者多个槽位提供给 JobMaster 调用,JobMaster 则可以根据任务的需求,将任务分配到这些槽位上执行。在执行过程中,TaskManager 不仅要负责执行用户代码,还要处理数据流的缓存和交换。不同的 TaskManager 之间会以流的形式进行数据的传输,就像施工队伍之间需要相互传递建筑材料一样,确保整个作业流程的顺畅进行。同时,每个 TaskManager 还负责管理其所在节点上的资源信息,如内存、磁盘、网络等,在启动的时候将资源的状态向 JobManager 汇报,以便 JobManager 能够全面了解集群的资源状况,做出更加合理的调度决策。
四、Flink 的核心概念
4.1 数据流与数据集
在 Flink 的世界里,数据流(DataStream)和数据集(DataSet)是两个基础且重要的数据结构,它们有着各自鲜明的特点和应用场景。数据流代表着无界或有界的实时数据序列,数据像流水一样持续不断地流动。以电商平台的实时订单数据为例,新订单会随时产生并加入到数据流中,这些数据需要被及时处理,以实现如实时库存更新、订单状态实时监控等功能。数据流处理注重数据的实时性,在数据到达时就立即进行处理,不能预先存储所有数据,并且数据具有时间和空间顺序。
而数据集则是有界的、可被处理的静态数据集合,所有数据在处理之前已经全部存在。比如分析过去一年的电商销售记录报表,这些历史销售数据构成了一个数据集。数据集中的元素没有顺序要求,处理时可以在所有数据到达后进行,更侧重于批量数据的离线处理。 这两者的区别就好比快递运输,数据流是源源不断从各个发货点发出的快递包裹流,需要快递员随时接收和派送;而数据集则像是一批已经集中在仓库等待统一配送的包裹,等包裹都到齐后再安排运输。
4.2 转换操作
Flink 提供了丰富多样的转换操作(Transformation),这些操作是构建数据处理逻辑的基石,就像搭建积木一样,通过不同转换操作的组合,可以实现复杂的数据处理任务。常见的转换操作有 Map、Filter、KeyBy 等。Map 操作可以对数据流或数据集中的每个元素进行一对一的转换。比如有一个包含商品价格的数据流,通过 Map 操作可以将每个商品价格乘以汇率,转换成另一种货币的价格。代码示例如下:
DataStream<Double> priceStream = env.fromElements(10.0, 20.0, 30.0);
DataStream<Double> convertedPriceStream = priceStream.map(new MapFunction<Double, Double>() {@Overridepublic Double map(Double price) throws Exception {// 假设汇率为6.5return price * 6.5;}
});Filter 操作用于根据指定条件对数据进行筛选。例如,在一个包含用户信息的数据流中,使用 Filter 操作可以筛选出年龄大于 18 岁的用户数据。代码如下:
DataStream<User> userStream = env.addSource(new UserSource());
DataStream<User> adultUserStream = userStream.filter(new FilterFunction<User>() {@Overridepublic boolean filter(User user) throws Exception {return user.getAge() > 18;}
});KeyBy 操作则是按照指定的键对数据进行分组,将相同键的数据分配到同一个分区中进行处理。在电商订单数据处理中,可以按照订单所属的店铺 ID 进行 KeyBy 操作,这样就能对每个店铺的订单分别进行统计分析,如计算每个店铺的订单总金额、订单数量等。代码示例如下:
DataStream<Order> orderStream = env.addSource(new OrderSource());
KeyedStream<Order, String> keyedOrderStream = orderStream.keyBy(new KeySelector<Order, String>() {@Overridepublic String getKey(Order order) throws Exception {return order.getShopId();}
});4.3 窗口
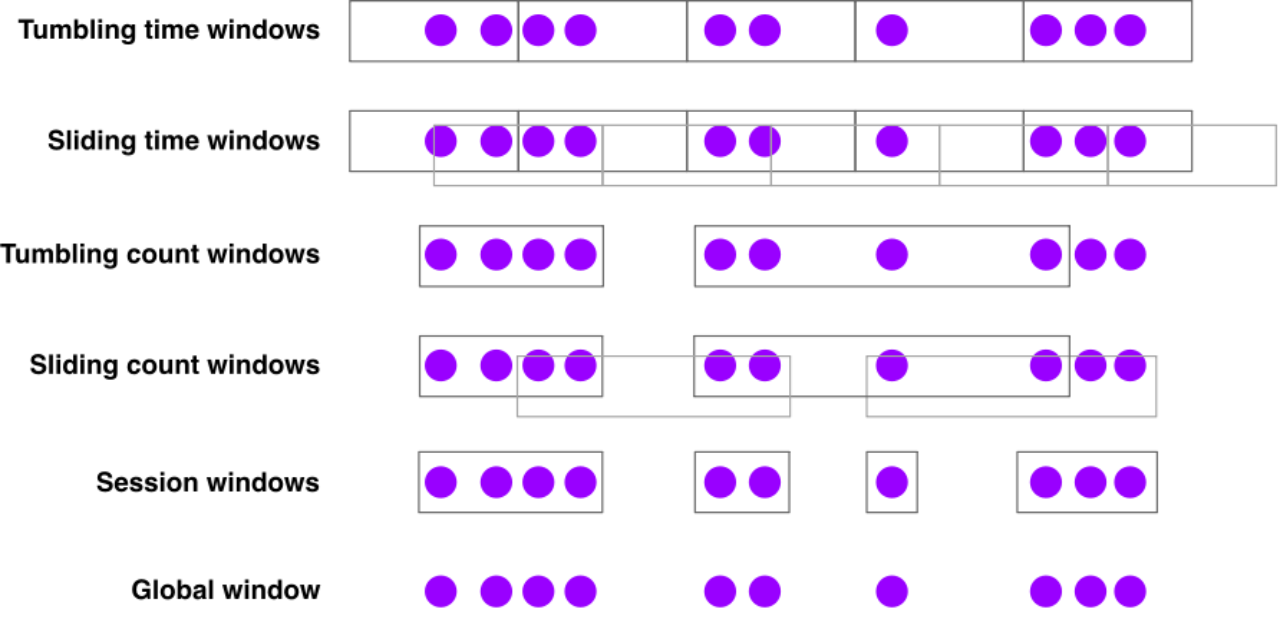
在流处理中,由于数据流是无限的,直接对整个数据流进行处理往往不太现实,这时窗口(Window)就发挥了重要作用。窗口用于将无限流切割成有限块,以便对每个有限块的数据进行处理和分析。Flink 支持多种基于时间或元素数量定义的窗口类型。
- 滚动窗口(Tumbling Window):是一种固定大小的窗口,窗口之间没有重叠。比如统计每 5 分钟内网站的访问量,就可以使用大小为 5 分钟的滚动窗口,每个窗口包含 5 分钟内的所有访问记录,处理完一个窗口的数据后,再处理下一个窗口,就像切蛋糕一样,一块一块地处理。
- 滑动窗口(Sliding Window):是一种可变大小的窗口,它可以在数据流中按照指定的滑动步长进行滑动,窗口之间可能存在重叠。例如,还是统计网站访问量,使用大小为 10 分钟、滑动步长为 5 分钟的滑动窗口,第一个窗口包含 0 - 10 分钟的访问记录,第二个窗口包含 5 - 15 分钟的访问记录,以此类推。这样可以更灵活地对数据进行分析,获取不同时间范围内的统计信息。
- 会话窗口(Session Window):是根据连续数据事件划分的窗口,当连续事件间隔超过设定时间时,会话窗口结束。比如在分析用户在 APP 上的操作行为时,若用户一段时间没有操作,就认为一个会话结束,通过会话窗口可以统计每个会话内用户的操作次数、停留时间等信息。
4.4 时间语义
Flink 支持三种时间语义:事件时间(Event Time)、处理时间(Processing Time)和摄入时间(Ingestion Time),它们在窗口操作和状态管理等方面有着不同的作用。事件时间是指事件在数据源端实际发生的时间,通常保存在事件数据的元数据或者数据内容中。以电商订单为例,用户下单的那一刻就是事件时间。在处理电商订单数据时,如果要按照用户实际下单时间来统计每小时的订单金额,就需要使用事件时间语义。它的优势在于能够处理乱序或者延迟的数据,保证处理结果的正确性,但实现相对复杂,通常需要结合水位线(Watermark)技术来处理乱序和延迟数据。处理时间是指事件在 Flink 处理程序实际处理的时间,即依赖于系统时钟。比如在一些对实时性要求极高的监控场景中,需要快速得到当前系统处理的数据结果,这时使用处理时间语义就可以简单高效地实现。但由于它完全依赖系统处理速度,在分布式和异步环境中,可能会导致结果的不稳定,因为它容易受到记录到达系统的速度、系统内部操作员之间记录流的速度以及停机等因素的影响。摄入时间是指事件进入 Flink 处理程序的时间,它是在数据进入 Flink 时自动附加的时间戳。例如,从 Kafka 读取数据进入 Flink 时,为每条数据添加的时间戳就是摄取时间。它可以看作是事件时间与处理时间的折衷,与处理时间相比,使用摄取时间依然可以利用时间进行窗口等操作,但是与事件时间相比,不能处理乱序数据。
4.5 状态与检查点
在 Flink 的数据处理过程中,状态(State)用于保存和访问中间结果,这对于一些需要依赖历史数据进行计算的场景非常重要。比如在计算用户的累计登录次数时,就需要保存之前统计的登录次数,每次有新的登录记录时,基于之前的状态进行更新计算。Flink 提供了多种状态类型,如键控状态(Keyed State)和操作符状态(Operator State)。键控状态是基于键的状态,每个键都有对应的状态,不同键之间的状态相互隔离。例如,在电商系统中,对于每个用户的购物车信息,就可以使用键控状态来保存,每个用户作为一个键,其购物车中的商品信息就是对应的状态。操作符状态则是与特定操作符相关联的状态,所有输入到该操作符的数据都可以访问和修改这个状态。
检查点(Checkpoint)是 Flink 实现容错的关键机制,它定期保存任务状态。当任务发生故障时,可以从最近的检查点恢复状态,继续执行任务,从而保证数据的一致性和可靠性。就像玩游戏时定期保存游戏进度一样,当游戏出现异常退出后,可以从保存的进度点重新开始游戏。Flink 通过协调各个任务的状态保存,将任务的状态和进度信息保存到持久化存储中,如 HDFS 等。在恢复时,从持久化存储中加载状态,使得任务能够继续处理数据,仿佛没有发生过故障一样。
五、Flink 安装与快速上手
5.1 安装准备
在安装 Flink 之前,需要做好一些准备工作。首先,Flink 是基于 Java 开发的,所以必须安装 Java 运行环境(JRE),推荐使用 JDK 8 或以上版本。可以通过在终端输入 java -version 命令来检查系统是否已经安装了 JDK 以及其版本。如果未安装,可从 Oracle 官方网站或者 OpenJDK 官方网站下载适合系统的 JDK 版本进行安装。
其次,需要从 Flink 官方网站(https://flink.apache.org/)下载最新版本的 Flink 发行包。在下载页面,会看到不同格式和版本的安装包,一般选择与操作系统对应的二进制发行版(bin),例如 flink-1.16.0-bin-scala_2.12.tgz。这里的 1.16.0 是 Flink 的版本号,scala_2.12 表示该版本是基于 Scala 2.12 开发的。在选择版本时,对于生产环境,建议优先选择稳定版。同时,如果计划在 Flink 中使用 Hadoop 分布式文件系统(HDFS),可以安装 Hadoop,但这不是必需的。还需确保机器能够正常访问网络,因为在安装过程中可能需要下载 Flink 的安装包以及相关依赖。如果 Flink 应用需要与外部数据源(如 Kafka、HDFS 等)进行通信,要保证网络连接的稳定性和相应的网络端口是开放的。
5.2 安装步骤
以 Linux 系统为例,详细介绍 Flink 的安装步骤。假设已经下载好了 Flink 安装包 flink-1.16.0-bin-scala_2.12.tgz,并将其放置在 /opt/software/ 目录下。首先,使用tar命令解压安装包,命令如下:
tar -zxvf /opt/software/flink-1.16.0-bin-scala_2.12.tgz -C /opt/module上述命令中,-zxvf 是解压命令参数,-C 指定解压后的目录为 /opt/module/。解压完成后,会在 /opt/module/ 目录下生成一个名为 flink-1.16.0 的文件夹,这就是 Flink 的主目录。接下来,可以根据需要配置环境变量,以便在任何目录下都能方便地使用 Flink 命令。编辑 ~/.bashrc 文件(如果使用的是其他 Shell,如 zsh,则编辑相应的配置文件),添加如下内容:
export FLINK_HOME=/opt/module/flink-1.16.0
export PATH=$PATH:$FLINK_HOME/bin添加完成后,执行 source ~/.bashrc 命令使环境变量生效。
单机安装方式较为简单,在解压并配置好环境变量后,进入 Flink 的bin目录,执行 ./start-cluster.sh 命令,即可启动一个本地的 Flink 集群,包括一个 JobManager 和一个 TaskManager。启动成功后,可以打开浏览器,访问 http://localhost:8081,如果能够看到 Flink 的 Web 界面,显示集群的相关信息,如 JobManager 和 TaskManager 的状态等,说明 Flink 安装成功并且集群已经正常启动。
对于集群安装方式,假设要在三台 Linux 机器(node1、node2、node3)上搭建 Flink 集群。首先在 node1 上完成上述解压和环境变量配置步骤。然后,修改 /opt/module/flink-1.16.0/conf/flink-conf.yaml 配置文件,找到 jobmanager.rpc.address 配置项,将其值修改为 node1 的主机名或 IP 地址。接着,修改 /opt/module/flink-1.16.0/conf/masters 文件,添加 node1:8081,表示 node1 作为 JobManager 节点,端口为 8081。再修改 /opt/module/flink-1.16.0/conf/workers 文件,添加 node2 和 node3,表示这两台机器作为 TaskManager 节点。完成配置后,将 /opt/module/flink-1.16.0 目录拷贝到 node2 和 node3 机器上,可以使用 scp 命令进行拷贝。最后,在 node1 上进入 Flink 的 bin 目录,执行 ./start-cluster.sh 命令启动集群。启动过程中,会在 node1 上启动 JobManager,在 node2 和 node3 上启动 TaskManager。同样,可以通过访问 http://node1:8081 来查看 Flink 集群的 Web 界面,确认集群是否正常启动。
5.3 运行示例程序
Flink 安装目录下的 examples 文件夹中包含了许多示例作业,通过运行这些示例程序,可以快速了解 Flink 的运行效果和功能。以批处理的 WordCount 示例程序和流处理的 SocketWindowWordCount 示例程序为例。
运行批处理的 WordCount 示例程序,它的作用是统计文本中单词出现的次数。进入 Flink 的安装目录,执行以下命令:
./bin/flink run examples/batch/WordCount.jar执行该命令后,Flink 会运行 WordCount 程序,统计默认输入数据集中的单词出现次数,并将结果输出到控制台。如果想要指定输入文件,可以使用 --input 参数,例如:
./bin/flink run examples/batch/WordCount.jar --input /path/to/input.txt上述命令中,/path/to/input.txt 是实际的输入文件路径。如果想要将结果输出到文件中,可以使用 --output 参数,例如:
./bin/flink run examples/batch/WordCount.jar --input /path/to/input.txt --output /path/to/output.txt运行流处理的 SocketWindowWordCount 示例程序,它会从 Socket 端口读取文本数据,并统计单词出现的次数。首先,需要启动一个 Netcat 服务器来发送数据,在一个终端中执行以下命令:
nc -lk 9999上述命令中,-l 表示监听模式,-k 表示保持连接,9999 是监听的端口号。然后,在另一个终端中进入 Flink 的安装目录,执行以下命令来运行 SocketWindowWordCount 程序:
./bin/flink run examples/streaming/SocketWindowWordCount.jar --port 9999执行该命令后,Flink 会监听 9999 端口,等待接收数据。此时,在启动 Netcat 服务器的终端中输入一些文本数据,每输入一行按回车键,Flink 会实时统计输入数据中的单词出现次数,并将结果输出到控制台。
六、总结与展望
Flink 作为大数据处理领域的杰出框架,以其独特的优势和丰富的功能,为我们打开了高效处理和分析海量数据的大门。它在实时数据处理、批处理、数据分析和数据管道等众多场景中都展现出了强大的能力,能够满足不同行业和领域对数据处理的多样化需求。
Flink 的核心概念,如数据流与数据集、转换操作、窗口、时间语义以及状态与检查点,相互协作,构成了其强大的数据处理能力的基础。这些概念不仅是理解 Flink 工作原理的关键,也是我们在实际应用中灵活构建数据处理逻辑的有力工具。通过安装 Flink 并运行示例程序,我们已经迈出了使用 Flink 的第一步,对其运行效果和功能有了初步的认识。
随着大数据技术的不断发展和应用场景的日益丰富,Flink 的未来充满了无限可能。它将继续在实时计算、机器学习与大数据的融合、物联网数据处理等前沿领域发挥重要作用。希望读者能够深入学习 Flink 的相关知识,将其应用到实际项目中,挖掘数据的潜在价值,为企业的发展和创新提供有力的数据支持。在探索 Flink 的道路上,不断实践和总结经验,你会发现更多关于大数据处理的精彩与奥秘。
相关文章:
从0到1,带你走进Flink的世界
目录 一、Flink 是什么? 二、Flink 能做什么? 三、Flink 架构全景概览 3.1 分层架构剖析 3.2 核心组件解析 四、Flink 的核心概念 4.1 数据流与数据集 4.2 转换操作 4.3 窗口 4.4 时间语义 4.5 状态与检查点 五、Flink 安装与快速上手 5.1 …...
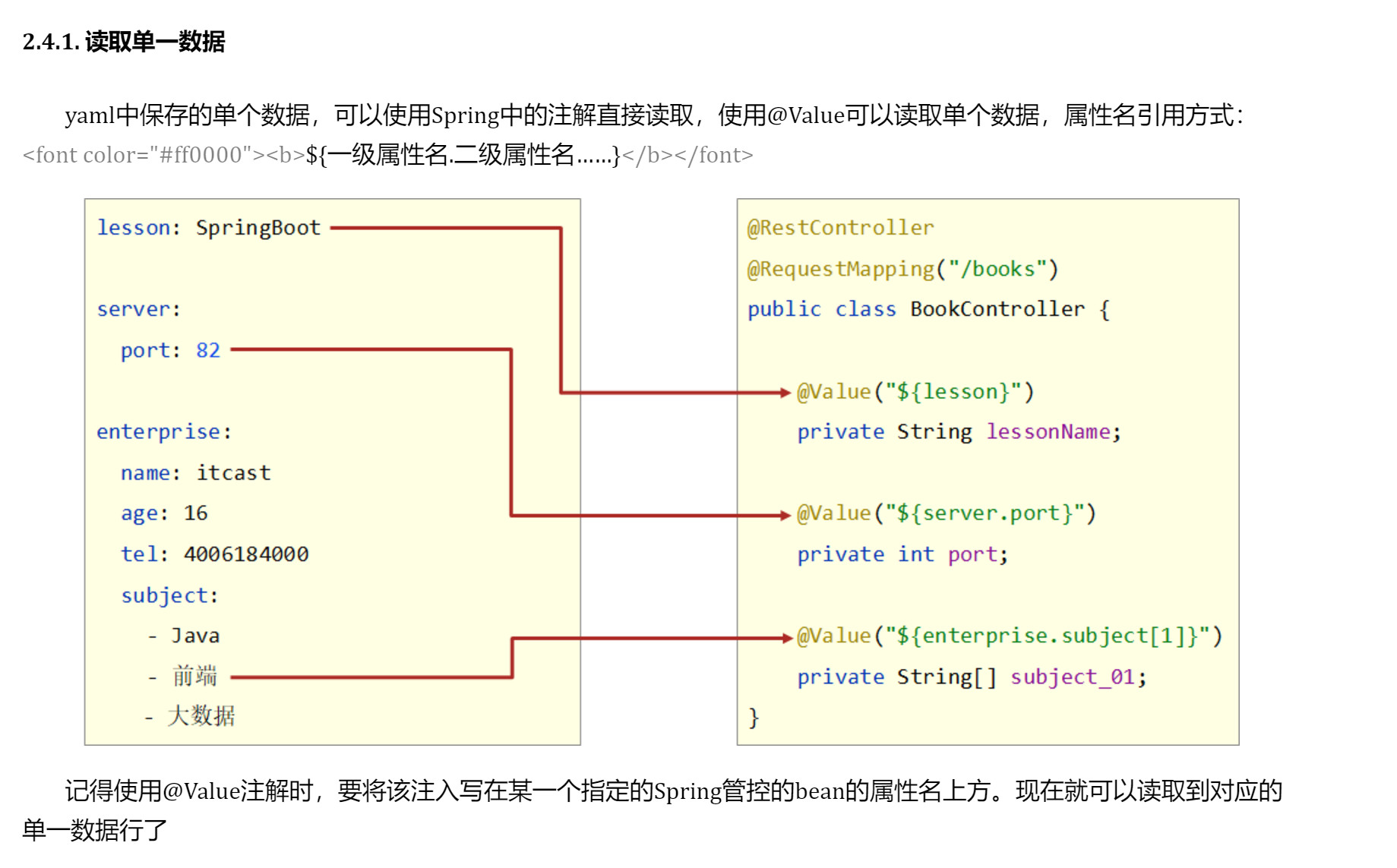
springboot @value
#springboot value value 可以读取 yaml 中 的数据...
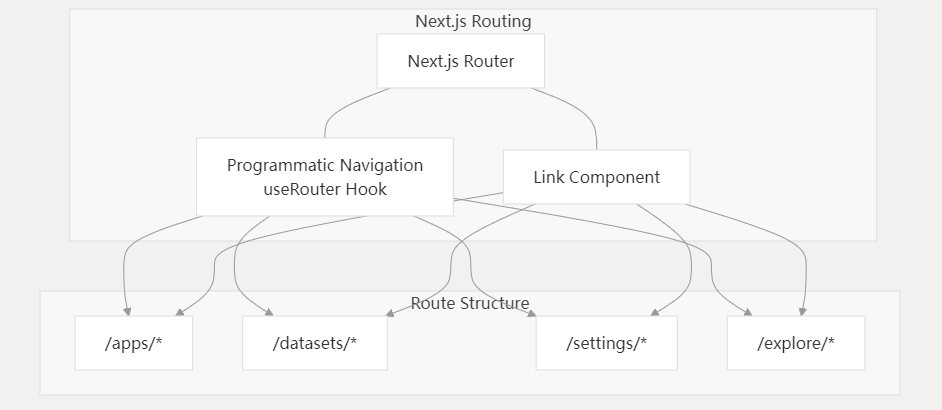
Dify-5:Web 前端架构
本文档提供了 Dify Web 前端架构的技术概述,包括核心组件、结构和关键技术。它解释了前端如何组织、组件如何通信以及国际化功能如何实现。 技术栈 Dify 的 Web 前端基于现代 JavaScript 技术栈构建: 框架:Next.js(基于 React …...
深度学习赋能图像识别:技术、应用与展望
论文: 一、引言 1.1 研究背景与意义 在当今数字化时代,图像作为信息的重要载体,广泛存在于各个领域。图像识别技术旨在让计算机理解和识别图像内容,将图像中的对象、场景、行为等信息转化为计算机能够处理的符号或数据 &am…...
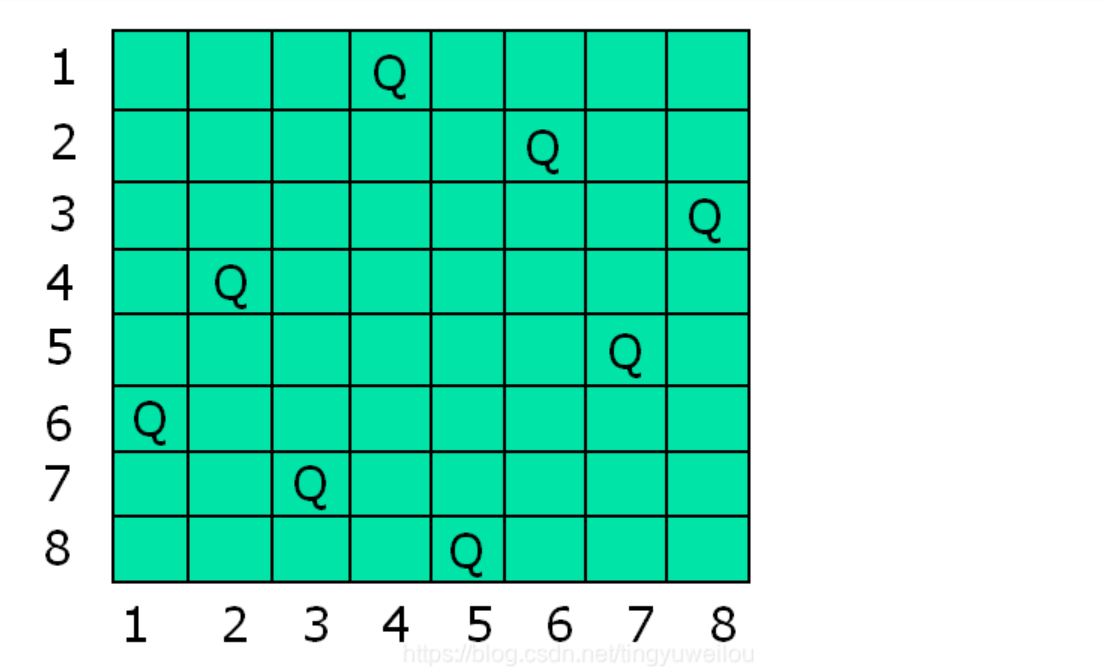
八N皇后问题
1 问题的提出 在8X8格的国际象棋上摆放八个皇后,使其不能互相攻击,即任意两个皇后都不能处于同一行、同一列或同一斜线上,问有多少种摆法 我们的任务就是用MATLAB进行求解 2 数学模型的构建 首先我们分析题目就是 任意两个皇后都不能处于…...
TMS320F28388D使用sysconfig配置IPC
第1章 配置IPC底层代码 使用IPC的动机: 我计划我的项目中要使用RS485,CANFD通信和EtherCAT通信,由于通信种类较多,而对于电机控制来说大部分数据都是重复的,并且有些数据可以很久才改变一次,所以我计划使…...
轮转数组)
代码训练LeetCode(19)轮转数组
代码训练(19)LeetCode之轮转数组 Author: Once Day Date: 2025年6月3日 漫漫长路,才刚刚开始… 全系列文章可参考专栏: 十年代码训练_Once-Day的博客-CSDN博客 参考文章: 189. 轮转数组 - 力扣(LeetCode)力扣 (LeetCode) 全球极客挚爱的…...

每日算法 -【Swift 算法】将整数转换为罗马数字
💡 Swift:将整数转换为罗马数字(含思路讲解与详细注释) 罗马数字是一种古老的数字表示方式,虽然在现代我们不再使用它进行计算,但在表盘、章节、纪念碑等地方依然很常见。今天我们就来实现一个经典算法题&…...
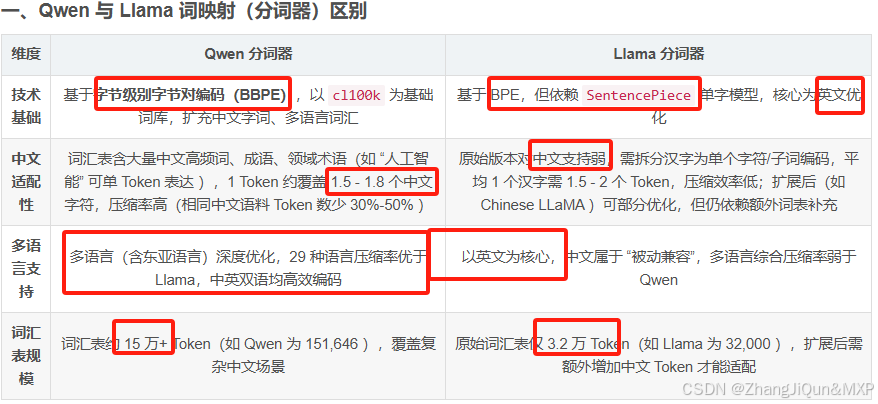
Qwen与Llama分词器核心差异解析
Qwen和 Llama 词映射(分词器)的区别及通用词映射逻辑 一、Qwen 与 Llama 词映射(分词器)区别 维度Qwen 分词器Llama 分词器技术基础基于字节级别字节对编码(BBPE),以 cl100k 为基础词库,扩充中文字词、多语言词汇基于 BPE,但依赖 SentencePiece 单字模型,核心为英文优…...
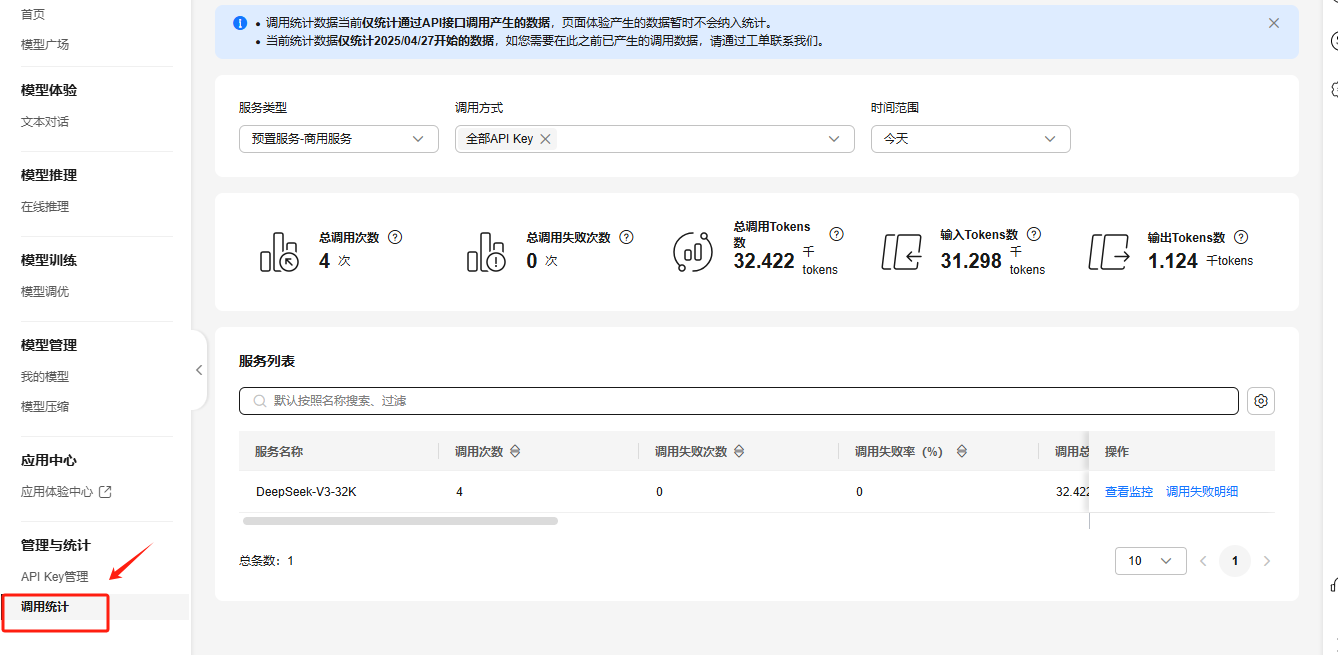
华为云Flexus+DeepSeek征文 | 基于ModelArts Studio 与 Cline 快速构建AI编程助手
目录 一、前言 二、ModelArts Studio(MaaS)介绍与应用场景 2.1ModelArts Studio(MaaS)介绍 2.2 ModelArts Studio(MaaS)使用场景 2.3 开通MaaS服务 2.4 开通DeepSeek-V3商用服务 三、Cline简介和安装 3.1 C…...
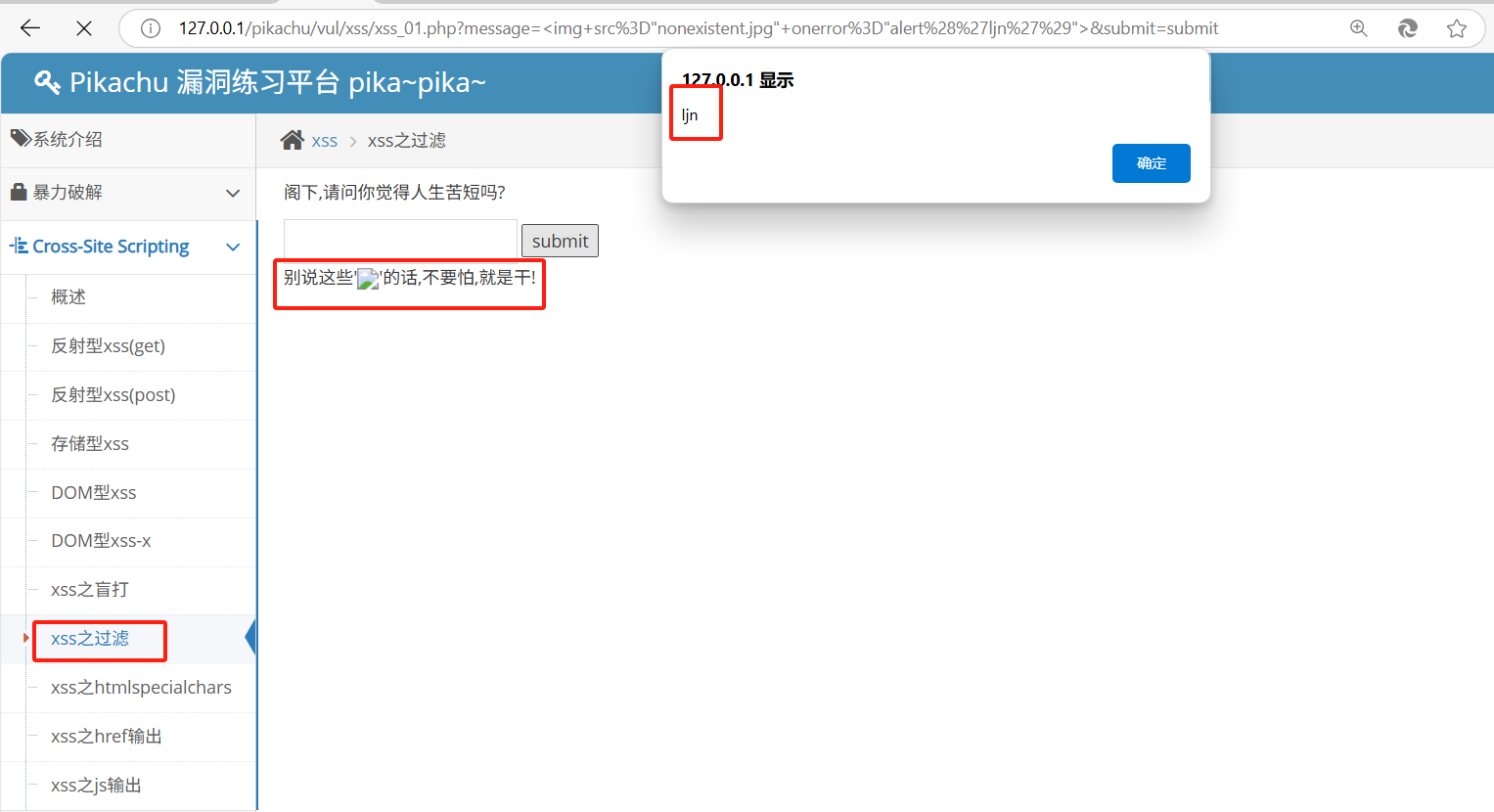
pikachu靶场通关笔记11 XSS关卡07-XSS之关键字过滤绕过(三种方法渗透)
目录 一、源码分析 1、进入靶场 2、代码审计 3、攻击思路 二、渗透实战 1、探测过滤信息 2、注入Payload1 3、注入Payload2 4、注入Payload3 本系列为通过《pikachu靶场通关笔记》的XSS关卡(共10关)渗透集合,通过对XSS关卡源码的代码审计找到安…...

Android App引用vendor编写的jni动态库
简单描述一下,就是我自己基于FastDDS写了一个Jni的so,然后编写了jar包引用该so,最后写了一个Android的测试apk使用jar包,调用jni中的接口去创建Participant,Subscriber等。 实际将jni的so放到 /system_ext/lib64&#…...

React从基础入门到高级实战:React 核心技术 - 错误处理与错误边界:构建稳定的应用
React 错误处理与错误边界:构建稳定的应用 在开发 React 应用时,错误处理是确保应用稳定性和用户体验的重要环节。无论是运行时错误、API 请求失败还是用户操作失误,合理的错误处理机制都能防止应用崩溃,并为用户提供清晰友好的反…...
与后台数据库进行交互时常用的两种方式)
页面输入数据的表格字段(如 Web 表单或表格控件)与后台数据库进行交互时常用的两种方式
“从页面输入数据的表格字段(如 Web 表单或表格控件)在与后台数据库进行交互时,常用的有两种方式:” 🎯 两种方式(操作调用数据库、绑定数据) 🚀 方式1:前端代码提交数据到后端,再由后端调用数据库 💡 原理和逻辑: 用户在页面上(比如输入表单、表格)输入数据…...

碰一碰发视频-源码系统开发技术分享
#碰一碰营销系统# #碰一碰系统# #碰一碰发视频# 架构设计哲学:近场通信的优雅平衡 一、核心通信技术选型 1. 双模协同传输引擎 技术协议栈延迟控制适用场景NFCISO 14443-A<100ms精准触发场景BLE 5.0GATT Profile300-500ms中距传输场景 工程决策依据&…...

C++学习过程分享
空指针:int *p NULL; 空指针:指针变量指向内存中编号为0的空间;用途:初始化指针变量注意:空指针指向的内存不允许访问注意:内存编号为0-255为系统占用空间,不允许用户访问 野指针:…...

C语言 — 动态内存管理
目录 1.malloc和free函数1.1 malloc函数1.2 free函数1.3 malloc函数的使用 2.calloc函数2.1 calloc函数2.2 calloc函数的使用 3.realloc函数3.1 realloc函数3.2 realloc函数的使用 4.动态内存管理笔试题4.1 笔试题(1)4.2 笔试题(2)…...

《TCP/IP 详解 卷1:协议》第5章:Internet协议
IPv4和IPv6头部 IP是TCP/IP协议族中的核心协议。所有TCP、UDP、ICMP和IGMP 数据都通过IP数据报传输。IP提供了一种尽力而为、无连接的数据报交付服务。 IP头部字段 IPv4 头部通常为 20 字节(无选项时),而 IPv6 头部固定为 40 字节。IPv6 不…...

C#面向对象实践项目--贪吃蛇
目录 一、项目整体架构与核心逻辑 二、关键类的功能与关系 1. 游戏核心管理类:Game 2. 场景接口与基类 3. 具体场景类 4. 游戏元素类 5. 基础结构体与接口 三.类图 四、核心流程解析 五、项目可优化部分 一、项目整体架构与核心逻辑 该项目运用场景管理模…...

学习STC51单片机26(芯片为STC89C52RCRC)
每日一言 真正的强者,不是没有眼泪,而是含着泪依然奔跑。 硬件:4G模块 这个是接线原理,我们也只要知道这个4根线的连接就好了,我们也是连接到USB转TTL的模块上 要插卡哈......... 随后我们下载一个叫做亿佰特的调试助…...

Web前端为什么要打包?Webpack 和 Vite 如何助力现代开发?
一. 为什么要使用框架库? 1.1 传统网页与现代前端的差异 在最早期的网页开发中,我们只需要写几个.html文件,配上.css和.js文件,浏览器直接加载就能展现页面,每个文件都是独立的静态资源,简单且直观 但现在网站越来越复杂了: 需要用到最新的js语法(比如ES6)使用框架(Vue…...
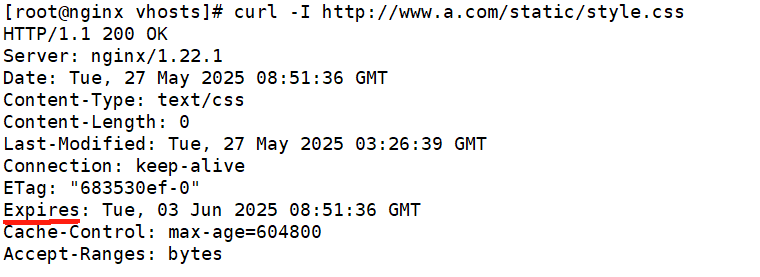
Nginx详解(三):ngx_http_rewrite_module模块核心指令详解
概要: 在 Nginx 的众多功能模块中,ngx_http_rewrite_module是实现请求动态处理的核心组件,它通过一系列指令实现 URI 重写、条件判断、响应返回等功能。本文将以 CentOS 7.9 环境为例(主机名www.a.com,IP 172.25.0.10…...

C++ 建造者模式:简单易懂的设计模式解析
一、引言 在软件开发中,我们经常会遇到一些复杂对象的创建过程,这些对象通常由多个部分组成,并且每个部分的构建过程可能非常复杂。建造者模式(Builder Pattern)就是为了解决这类问题而诞生的一种创建型设计模式。本文将以简单易懂的方式介绍C++中的建造者模式,帮助你理…...
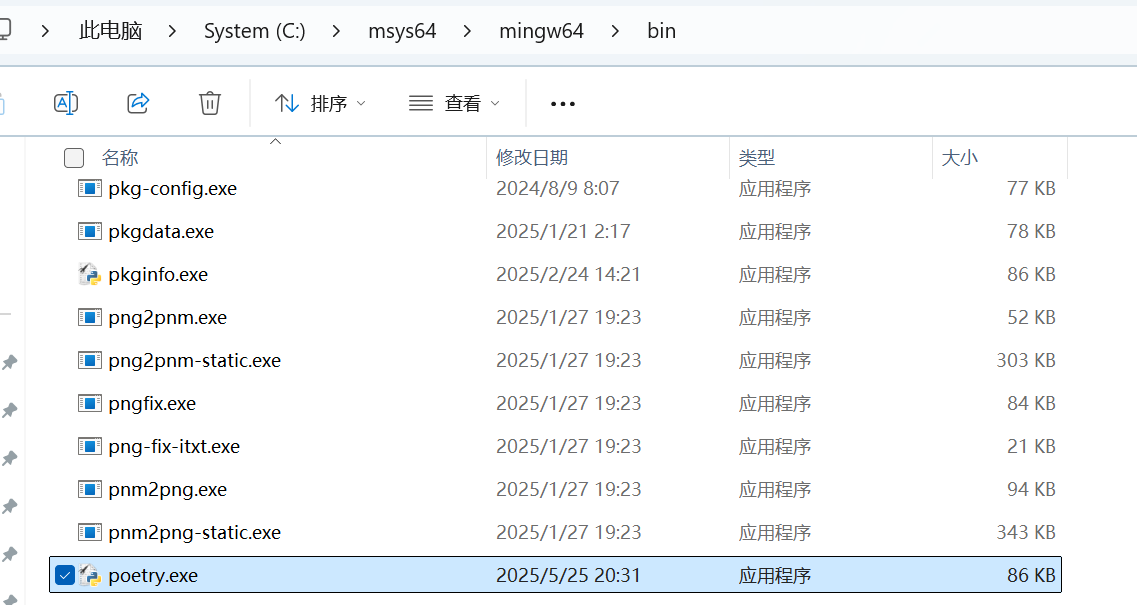
【笔记】在 MSYS2(MINGW64)中正确安装 Poetry 的指南
#工作记录 在 MSYS2(MINGW64)中正确安装 Poetry 的指南 一、背景说明 在 MSYS2(MINGW64)环境中,即使已经安装了 pip,也不建议直接使用 pip install poetry 来安装 Poetry。 这是因为 MSYS2 使用自己的包…...
IDEA项目推送到远程仓库
打开IDEA——>VCS——>Creat Git 选择项目 push提交到本地 创建远程仓库 复制地址 定义远程仓库 推送 推送成功...

DeepSeek 赋能 NFT:数字艺术创作与交易的革新密码
目录 一、NFT:数字世界的独特资产1.1 NFT 的定义与本质1.2 NFT 的价值支撑1.3 NFT 的丰富类型 二、DeepSeek:AI 领域的创新力量2.1 DeepSeek 的发展历程与成就2.2 DeepSeek 的核心技术与能力 三、DeepSeek 在 NFT 创作中的神奇应用3.1 高效生成数字艺术作…...

【后端架构师的发展路线】
后端架构师的发展路线是从基础开发到技术领导的系统性进阶过程,需融合技术深度、架构思维和业务洞察力。以下是基于行业实践的职业发展路径和关键能力模型: 一、职业发展阶梯 初级工程师(1-3年) 核心能力:掌…...
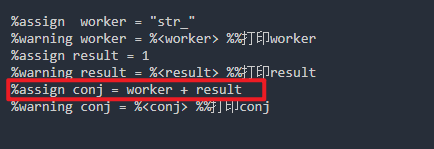
matlab/simulink TLC语法基础练习实例
一、基本语法测试方法 1.新建一个脚本,保存扩展名为tlc,本例中是tst.tlc,设置当前工作路径为保存的tlc文件路径,在tlc文件里面输入下面的代码,然后保存: %warning test 2.在MATLAB的命令窗口输入: tlc …...

MAU算法流程理解
参考文献:湘江船闸的过闸调度算法研究(李 楠,李桂华,尹剑平) (湖南湘江航运建设开发有限公司,湖南 长沙 410011) MAU算法流程 图4展示的是一种船舶排档算法(MAU算法),它…...
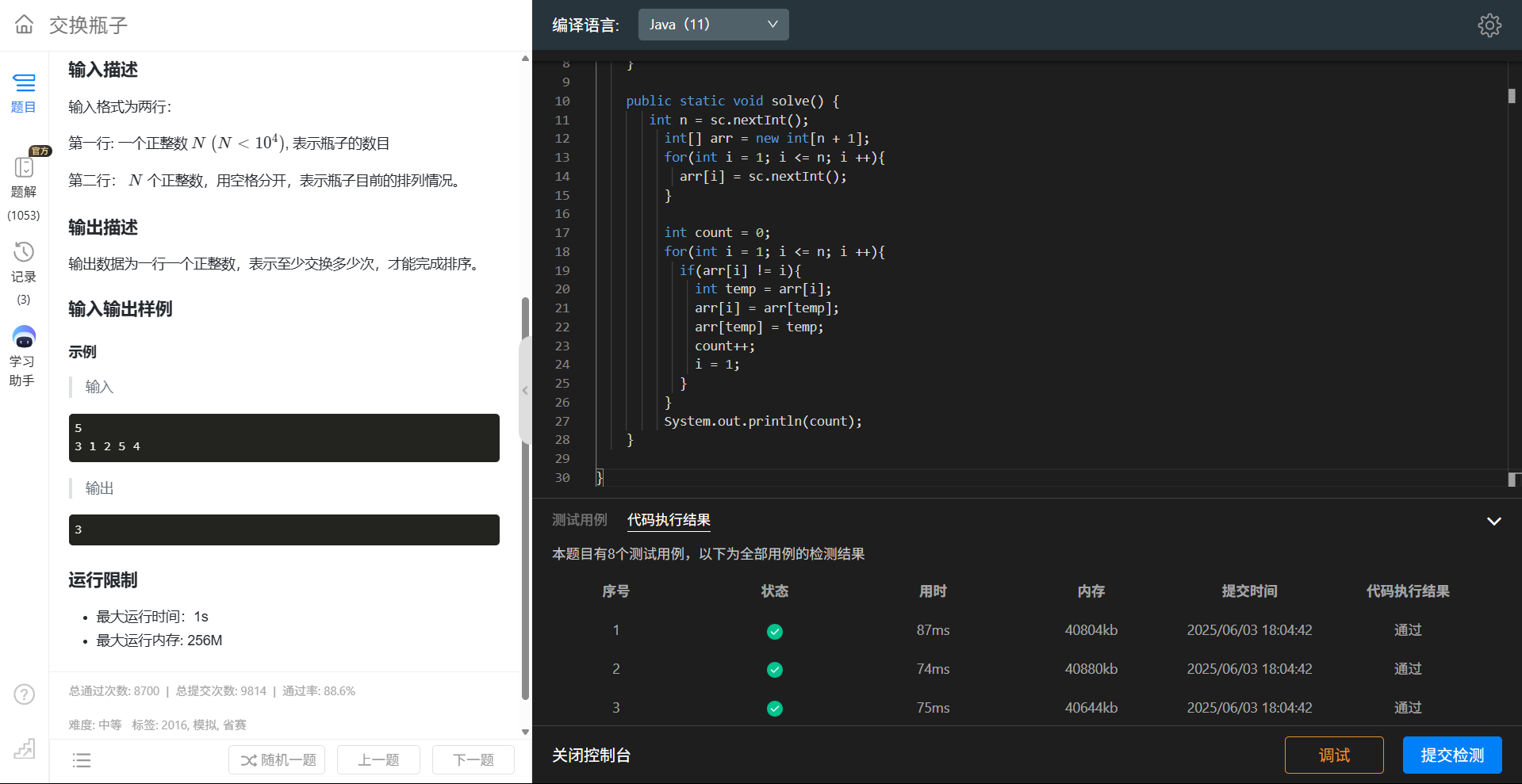
蓝桥杯国赛训练 day1
目录 k倍区间 舞狮 交换瓶子 k倍区间 取模后算组合数就行 import java.util.HashMap; import java.util.Map; import java.util.Scanner;public class Main {static Scanner sc new Scanner(System.in);public static void main(String[] args) {solve();}public static vo…...