Linux进程间通信----简易进程池实现
进程池的模拟实现
1.进程池的原理:
是什么
进程池是一种多进程编程模式,核心思想是先创建好一定数量的子进程用作当作资源,这些进程可以帮助完成任务并且重复利用,避免频繁的进程的创建和销毁的开销。
下面我们举例子来帮助理解:
完成任务需要工作人员,在主任务执行的途中源源不断的有新的支线任务来临。比如校园社团展览大会的场地布置是主任务,但是不同的场地要有不同的布置任务布置结构,在整理真个场地的途中你需要帮手去帮你解决小任务,社团A来发任务,你现场去找一个人让他去做A任务,社团B来发放任务,你又得去找一个人去完成B任务,效率极低。这时候你提前找好了10个帮手,让他们待命,来了任务直接将帮手派发出去,帮手完成任务后回到等待任务队列,整体效率就提高了很多并且免去了频繁找人的过程。
上面的故事里,帮手就是组成进程池的子进程,你作为父进程需要组织并管理这些子进程,让他们去帮你完成任务。
为什么
为什么要有进程池?操作系统在创建进程时要给进程分配内存等资源,在任务短频率高的情况下消耗极高。同时子进程可以反复利用,可以将这些子进程的创建成本分摊到多次任务中。
怎么做
首先创建进程池就需要预设好一定数量的进程,第一步就是创建一定数量的子进程
第二步,为了能让子进程帮我们完成任务,我们需要和子进程通信,利用上次讲到的管道
第三步,任务的发布和负载均衡,发布任务的时候尽量让每个进程都被平均的使用到,发挥进程池的优势。
实现类似下图的结构:
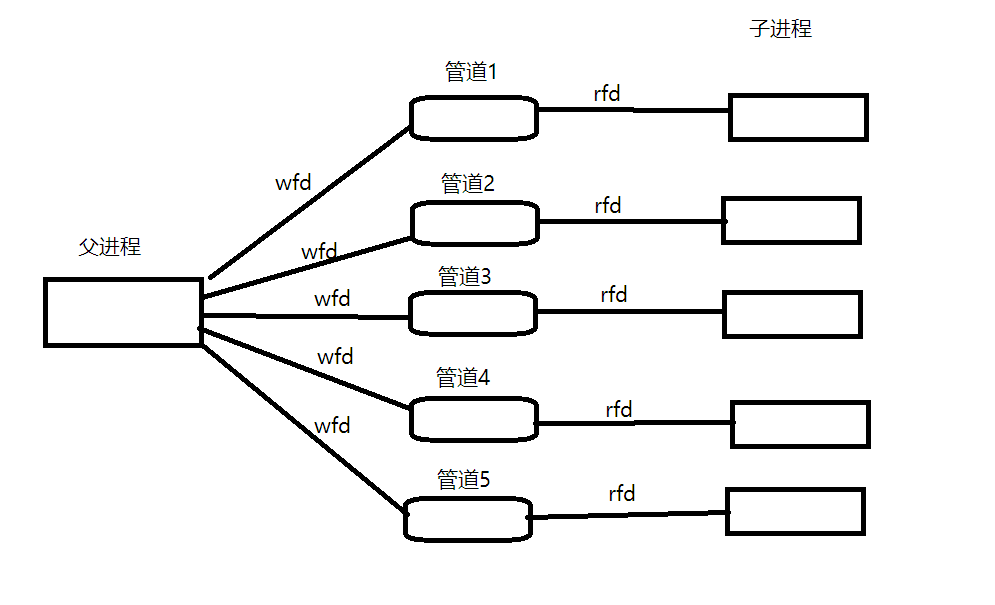
代码实现:
第一步,完成任务一:所需数量的创建管道和子进程
#include <iostream>
#include <vector>
#include <unistd.h>using namespace std;
#define PIPEERRO 1int num = 5; // 全局变量,表示进程池内的进程数量int main()
{for (int i = 0; i < num; i++){// 1.创建管道和子进程int pipefd[2];int n = pipe(pipefd);if (n < 0){return PIPEERRO;}//2.创建子进程pid_t id=fork();if(id==0){//子进程代码//子进程负责读取任务 ,关闭写端close(pipefd[1]);//读取任务//执行任务//退出exit(0);}//父进程代码//父进程负责写任务,关闭读端close(pipefd[0]);}return 0;
}
框架搭建完毕后,我们需要对创建出来的管道和子进程进行管理,管理的6字真言:先描述再组织
为了管理好我们创建的这么多管道和子进程我们创建一个管道类Channel去描述管道和子进程的关系,然后用vector去组织他们。
创建的所有管道都被放入channels vector数组里管理起来,以后我们想对单个子进程发送任务就只需要发给对应的数组成员就行了,操作十分方便。
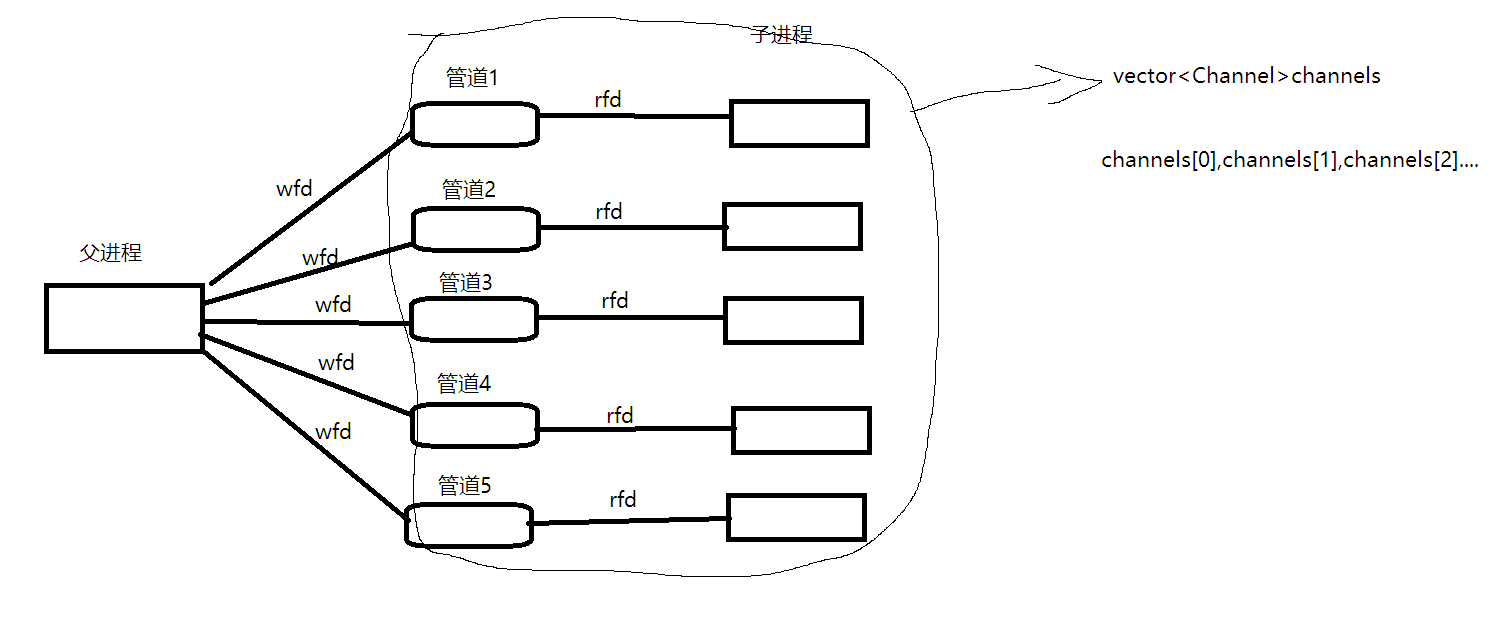
现在我们完成了第一步,写一个假的work函数看看能不能工作吧:
void work()
{cout<<"I am child process: "<<getpid()<<endl;
} int main()
{vector<Channel> channels;for (int i = 0; i < num; i++){// 1.创建管道和子进程int pipefd[2];int n = pipe(pipefd);if (n < 0){return PIPEERRO;}//2.创建子进程pid_t id=fork();if(id==0){//子进程代码//子进程负责读取任务 ,关闭写端close(pipefd[1]);//读取任务//执行任务work();//退出exit(0);}//父进程代码//父进程负责写任务,关闭读端close(pipefd[0]);channels.emplace_back(id,pipefd[1]);}return 0;
}执行结果:
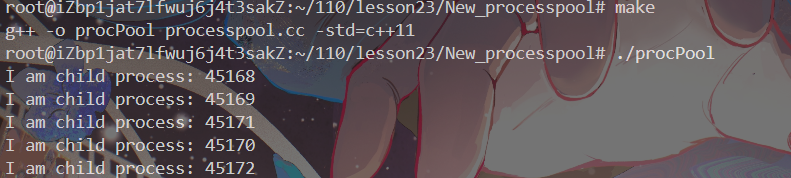
十分成功,接下来我们去实现第二步:任务的发放
我们首先实现几种不同的任务函数,利用回调函数的方式让我们的子进程随机执行任务,为了完成这一步我们利用数组将task(任务)函数用数组管理起来,形成任务清单,任务的发放方式也改为向管道内发送task函数数组的下标,即发放task清单序号,子进程根据从管道内收到的序号去执行清单上对应task。
为了统一接口,我们定义一个进程池类统一接口去管理操作函数
class ProcessPool
{
public:ProcessPool(int num) : sub_proc_num(num){}int CreateProcessPool(){//vector<Channel> channels; 类成员变量无需再次定义for (int i = 0; i < num; i++){// 1.创建管道和子进程int pipefd[2];int n = pipe(pipefd);if (n < 0){return PIPEERRO;}// 2.创建子进程pid_t id = fork();if (id == 0){// 子进程代码// 子进程负责读取任务 ,关闭写端close(pipefd[1]);// 读取任务// 执行任务// 退出exit(0);}// 父进程代码// 父进程负责写任务,关闭读端close(pipefd[0]);channels.emplace_back(id, pipefd[1]);}}~ProcessPool(){}private:vector<Channel> channels;int sub_proc_num;
};int main()
{ProcessPool * pp=new ProcessPool(num);//num 个进程的进程池pp->CreateProcessPool();return 0;
}接下来:创建一个头文件专门放置任务函数
#pragma once#include<iostream>
#include <unistd.h>
using namespace std;
typedef void(*work_t)();//执行任务总接口函数指针
typedef void(*task_t)();//任务函数指针,用于管理任务函数//task函数实现
void Singing()
{cout<<"I am singing.... lalala~"<<endl;
}void Dancing()
{cout<<"I am dancing.... siusiusiu~"<<endl;
}void Playing()
{cout<<"I am playing piano.... DoReMi~"<<endl;
}uint32_t NextTask()
{return rand()%3;//task数组下标
}task_t task[3]{Singing,Dancing,Playing};//数组管理task函数void worker()//总接口函数
{while(true){uint32_t command_code;//任务码ssize_t byte_read = read(0,&command_code,sizeof(command_code));//读取管道内容(任务码)if(byte_read == sizeof(command_code)){if(command_code>3)continue;task[command_code]();//任务码用作下标}}
}实现任务清单,同时给出work总接口,兼具读取任务码和执行动作。
说明:
为什么死循环?死循环的目的是让子进程反复接受任务反复执行任务,这样能最大化利用进程池特性。
为什么command_code>3就continue?为了让子进程收到非法任务码时也能继续执行不影响后续任务执行。
主程序代码只需修改几个地方:
pp->CreateProcessPool(worker);//传总接口函数进去int CreateProcessPool(work_t worker){// vector<Channel> channels; 类成员变量无需再次定义for (int i = 0; i < num; i++){// 1.创建管道和子进程int pipefd[2];int n = pipe(pipefd);if (n < 0){return PIPEERRO;}// 2.创建子进程pid_t id = fork();if (id == 0){// 子进程代码// 子进程负责读取任务 ,关闭写端close(pipefd[1]);// 读取任务dup2(pipefd[0], 0); // 重定向,将从stdin读取重定向到从管道读端读取// 执行任务worker(); // 总接口内有真正的读取管道操作// 退出exit(0);}// 父进程代码// 父进程负责写任务,关闭读端close(pipefd[0]);channels.emplace_back(id, pipefd[1]);}return 0;}说明:
因为在create函数里面进行了重定向,所有worker接口里的read是从0也就是stdin里读取
准备好了任务码的读取,接下来我们来完成任务码的发放:
注意两点:
1.任务码随机发方
2.子进程的轮询调度(为了让所有进程分摊任务)
// 任务码发放while (true){// 选择任务码uint32_t code = NextTask();// 选择管道int index = pp->Select_Channel();// 发送任务码pp->SendCode(index,code);sleep(1);} int Select_Channel() // 轮询选择管道{static int next = 0; // static变量只定义一次int c = next;next++;next %= channels.size(); // next只能在channels的下标中循环return c;}void SendCode(int index, int code) // 向管道写入任务码{cout << "sending code : " << code << " to " << channels[index].getid()<< " " << channels[index].getname() << endl;write(channels[index].getfd(), &code, sizeof(code)); // 向管道写入任务码}uint32_t NextTask()
{return rand()%3;//task数组下标
}接下来看执行结果:
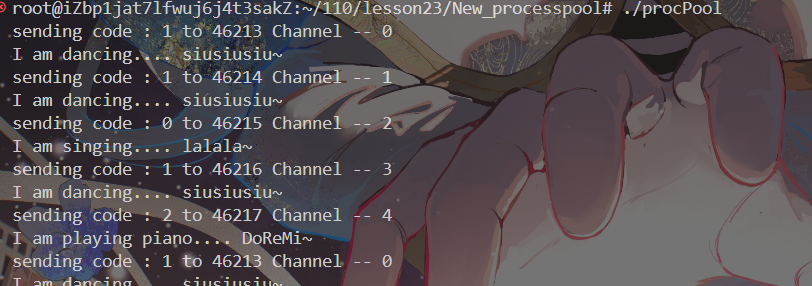
非常完美,任务自动不停的发送给每个管道内,由不同的子进程执行。
完整代码:
processpool.cc:
#pragma once#include<iostream>
#include <unistd.h>
using namespace std;
typedef void(*work_t)();//执行任务总接口函数指针
typedef void(*task_t)();//任务函数指针,用于管理任务函数//task函数实现
void Singing()
{cout<<"I am singing.... lalala~"<<endl;
}void Dancing()
{cout<<"I am dancing.... siusiusiu~"<<endl;
}void Playing()
{cout<<"I am playing piano.... DoReMi~"<<endl;
}uint32_t NextTask()
{return rand()%3;//task数组下标
}task_t task[3]{Singing,Dancing,Playing};//数组管理task函数void worker()//总接口函数
{while(true){uint32_t command_code;//任务码ssize_t byte_read = read(0,&command_code,sizeof(command_code));//读取管道内容(任务码)if(byte_read == sizeof(command_code)){if(command_code>3)continue;task[command_code]();//任务码用作下标}}
}Task.hpp:
#pragma once#include <iostream>
#include <unistd.h>using namespace std;typedef void (*work_t)(int);
typedef void (*task_t)();void Singing()
{cout << "I am singing.... lalala" << endl;
}void Dancing()
{cout << "I am dancing.... hahaha" << endl;
}void Playing()
{cout << "I am playing piano.... doremi~" << endl;
}task_t task[3] = {Singing, Dancing, Playing};uint32_t Select_Task()
{return rand()%3;
}void worker(int task_num)
{while (task_num){uint32_t commandcode;ssize_t byte_read = read(0, &commandcode, sizeof(commandcode));if (byte_read == sizeof(commandcode)){if (commandcode > 3)continue;task[commandcode]();task_num--;}}
}
相关文章:
Linux进程间通信----简易进程池实现
进程池的模拟实现 1.进程池的原理: 是什么 进程池是一种多进程编程模式,核心思想是先创建好一定数量的子进程用作当作资源,这些进程可以帮助完成任务并且重复利用,避免频繁的进程的创建和销毁的开销。 下面我们举例子来帮助理…...
解锁Java多级缓存:性能飞升的秘密武器
一、引言 文末有彩蛋 在当今高并发、低延迟的应用场景中,传统的单级缓存策略往往难以满足性能需求。随着系统规模扩大,数据访问的瓶颈逐渐显现,如何高效管理缓存成为开发者面临的重大挑战。多级缓存架构应运而生,通过分层缓存设…...

(纳芯微)NCA9548- DTSXR 具有复位功能的八通道 I²C 开关、所有I/O端子均可承受5.5V输入电压
深圳市润泽芯电子有限公司 推荐NOVOSENSE(纳芯微)品牌 NCA9548- DTSXR TSSOP-24封装 NCA9548- DTSXR 具有复位功能的八通道 IC 开关、所有I/O端子均可承受5.5V输入电压 产品描述 NCA9548是通过I2C总线控制的八路双向转换开关。 SCL / SDA上行数据分散到八对下行数据或通道。…...
013旅游网站设计技术详解:打造一站式旅游服务平台
旅游网站设计技术详解:打造一站式旅游服务平台 在互联网与旅游业深度融合的时代,旅游网站成为人们规划行程、预订服务的重要工具。一个功能完备的旅游网站,通过用户管理、订单管理等核心模块,实现用户与管理员的高效交互。本文将…...
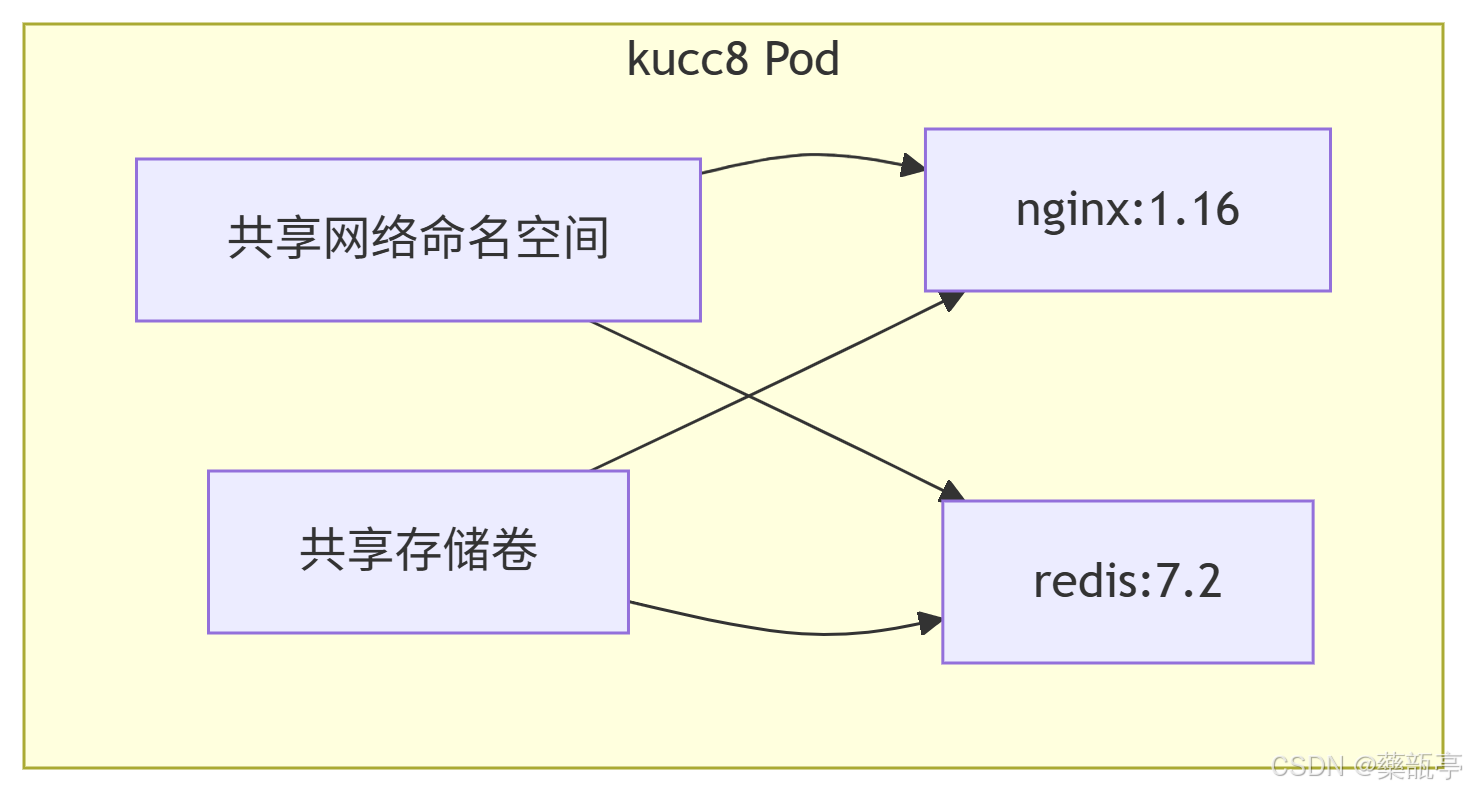
2024 CKA模拟系统制作 | Step-By-Step | 12、题目搭建-创建多容器Pod
目录 免费获取题库配套 CKA_v1.31_模拟系统 一、题目 二、考点分析 1. 多容器 Pod 的理解 2. YAML 配置规范 3. 镜像版本控制 三、考点详细讲解 1. 多容器 Pod 的工作原理 2. 容器端口冲突处理 3. 资源隔离机制 四、实验环境搭建步骤 总结 免费获取题库配套 CKA_v…...
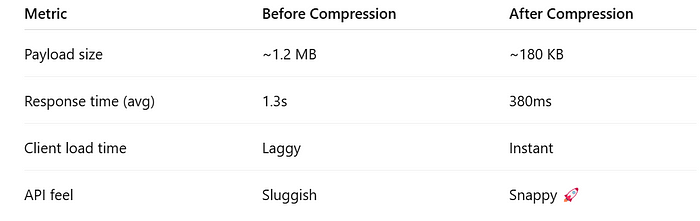
优化 Spring Boot API 性能:利用 GZIP 压缩处理大型有效载荷
引言 在构建需要处理和传输大量数据的API服务时,响应时间是一个关键的性能指标。一个常见的场景是,即使后端逻辑和数据库查询已得到充分优化,当API端点返回大型数据集(例如,数千条记录的列表)时࿰…...

PostgreSQL 修改表结构卡住不动
[] 查找卡住的进程 ID(PID) -- 查看当前所有数据库连接及进程信息 SELECTpid,usename,query,age(clock_timestamp(), query_start) AS query_duration FROMpg_stat_activity WHEREquery LIKE %ALTER TABLE%; -- 过滤出正在执行 ALTER TABLE 的语句今天遇…...

【C盘瘦身】给DevEco Studio中HarmonyOSEmulator(鸿蒙模拟器)换个地方,一键移动给C盘瘦身
文章目录 一、HarmonyOSEmulator的安装路径二、修改路径 一、HarmonyOSEmulator的安装路径 之前安装了华为的DevEco Studio,当时没注意,后来C盘告急,想着估计是鸿蒙的模拟器占用空间比较大,一检查还真是躺在C盘。路径如下&#x…...

AutoCompose - 携程自动编排【开源】
AutoCompose - 携程自动编排【开源】 AutoCompose是一款单事件驱动(无状态)的流程引擎。使用本框架,能够轻松实现复杂服务的自动化编排【零配置、零编码】,能够显著提高开发维护效率。支持同步编程、异步编程(已支持Co…...

mybatis和hibernate区别
MyBatis 和 Hibernate 都是 Java 生态中主流的持久层框架,但设计理念和适用场景有显著区别。以下是核心对比: 1. 本质区别 特性HibernateMyBatis框架类型全自动 ORM(对象关系映射)框架半自动 SQL 映射框架核心思想对象优先&#…...
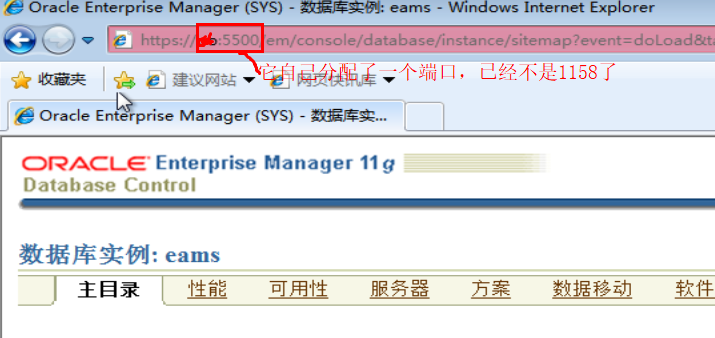
ORACLE 缺失 OracleDBConsoleorcl服务导致https://xxx:port/em 不能访问
这个原因是,操作过一下 ORCL的服务配置变更导致的。 再PATH中添加个环境变量,路径如下 管理员权限运行cmd 等待创建完成 大概3分钟 查看服务 点击第一个访问,下图登录后的截图...

unix/linux source 命令,其历史争议、兼容性、生态、未来展望
现在把目光投向unix/linux source命令的历史争议、兼容性、生态和未来展望,这能让我们更全面地理解一个技术点在更广阔的图景中所处的位置。 一、历史争议与设计权衡 虽然 source (或 .) 命令功能强大且不可或缺,但在其发展和使用过程中,也存在一些微妙的争议或设计上的权衡…...

day42 简单CNN
目录 一、从图像分类任务谈起 二、CNN架构解剖实验室 2.1 卷积层:空间特征的魔法师 2.2 归一化层:加速收敛的隐形推手 2.3 激活函数:非线性的灵魂 三、工程实践避坑指南 3.1 数据增强工程 3.2 调度器工程实战 四、典型问题排查手册 …...
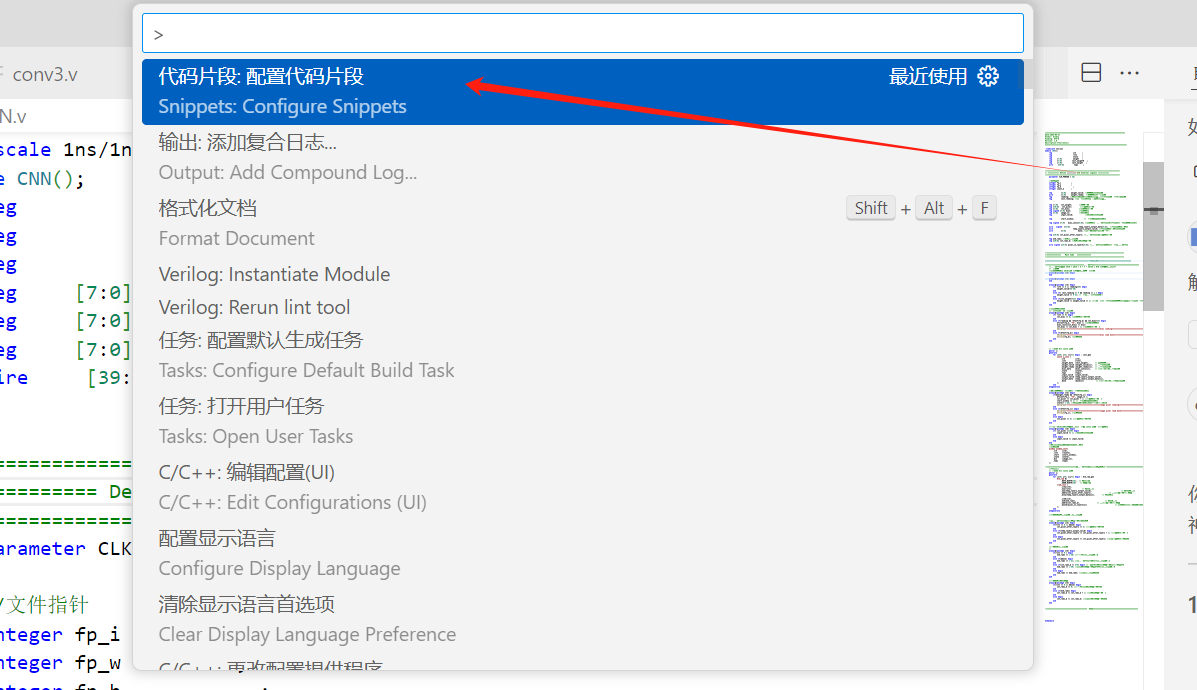
VScode自动添加指定内容
在 VS Code 中,可以通过配置 用户代码片段(User Snippets) 或使用 文件模板扩展 来实现新建指定文件类型时自动添加指定内容。以下是具体方法: 方法 1:使用 VS Code 内置的「用户代码片段」 适用场景:适用…...

Ubuntu 22.04 安装 Nacos 记录
Ubuntu 22.04 安装 Nacos 记录 本文记录了在 Ubuntu 22.04 系统上安装 Nacos 的完整过程,适用于本地测试或生产部署的基础搭建。 一、官方资源 官网下载地址:https://nacos.io/download/nacos-server/官网文档:https://nacos.io/docs/lates…...

终极陷阱:Java序列化漏洞的内爆原理与防御体系重建
引言:被遗忘的后门 2019年Equifax公司因Java反序列化漏洞导致1.43亿用户数据泄露,最终以7亿美元达成和解。令人震惊的是,问题源头竟是一个简单的序列化接口: public class UserSession implements Serializable {private String…...

Git 中移除已追踪的文件
你已经成功提交了部分文件到 Git,但 sqlserver/data/ 目录下的一些日志文件(如 .xel 和 machine-key)仍然被追踪或未被忽略。你想 彻底忽略整个 sqlserver/data/* 目录下的所有内容。 ✅ 目标 让 Git 忽略以下路径: sqlserver/d…...
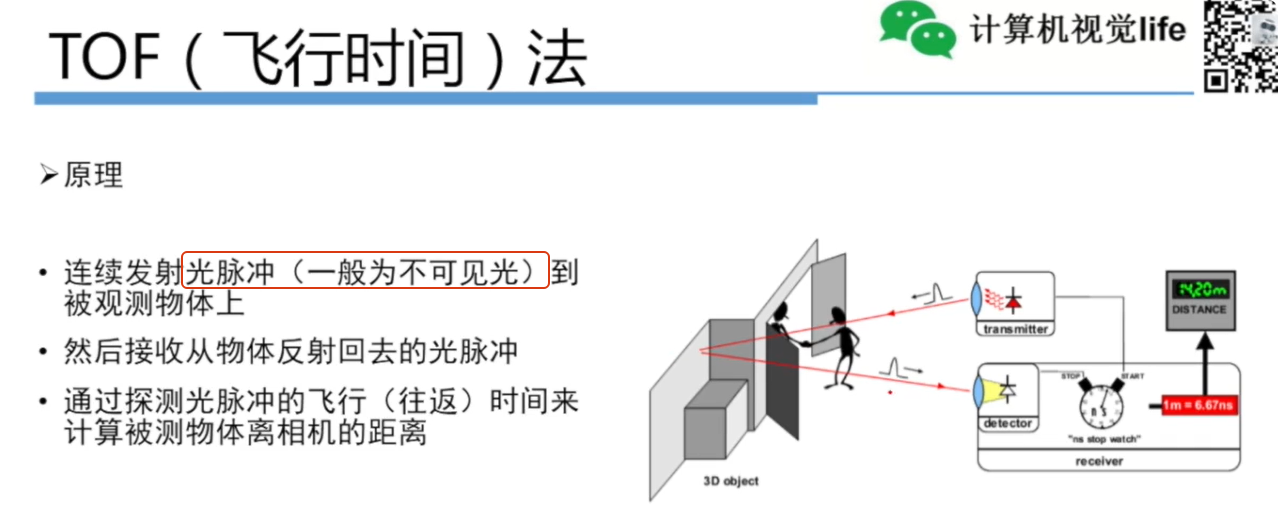
相机--RGBD相机
教程 分类原理和标定 原理 视频总结 双目相机和RGBD相机原理 作用 RGBD相机RGB相机深度; RGB-D相机同时获取两种核心数据:RGB彩色图像和深度图像(Depth Image)。 1. RGB彩色图像 数据格式: 标准三通道矩阵&#…...

Flask中secret_key设置解析
app.secret_key os.urandom(24) 在 Flask 中,app.secret_key os.urandom(24) 这行代码用于生成并设置一个安全的随机密钥(Secret Key),这是 Flask 应用中非常重要的配置之一。以下是详细解析: 1. app.secret_key …...

事件不触发、交互失效?基于 WebDebugX 的移动端事件调试实战总结
在移动端开发中,“点击没反应”“滑动卡住”“长按无效”等事件类问题时常困扰开发者。这类问题不仅和逻辑代码有关,更常见的是出现在浏览器事件模型与设备行为之间的不一致,特别是在 WebView 环境下尤为显著。 本文结合多个真实案例&#x…...
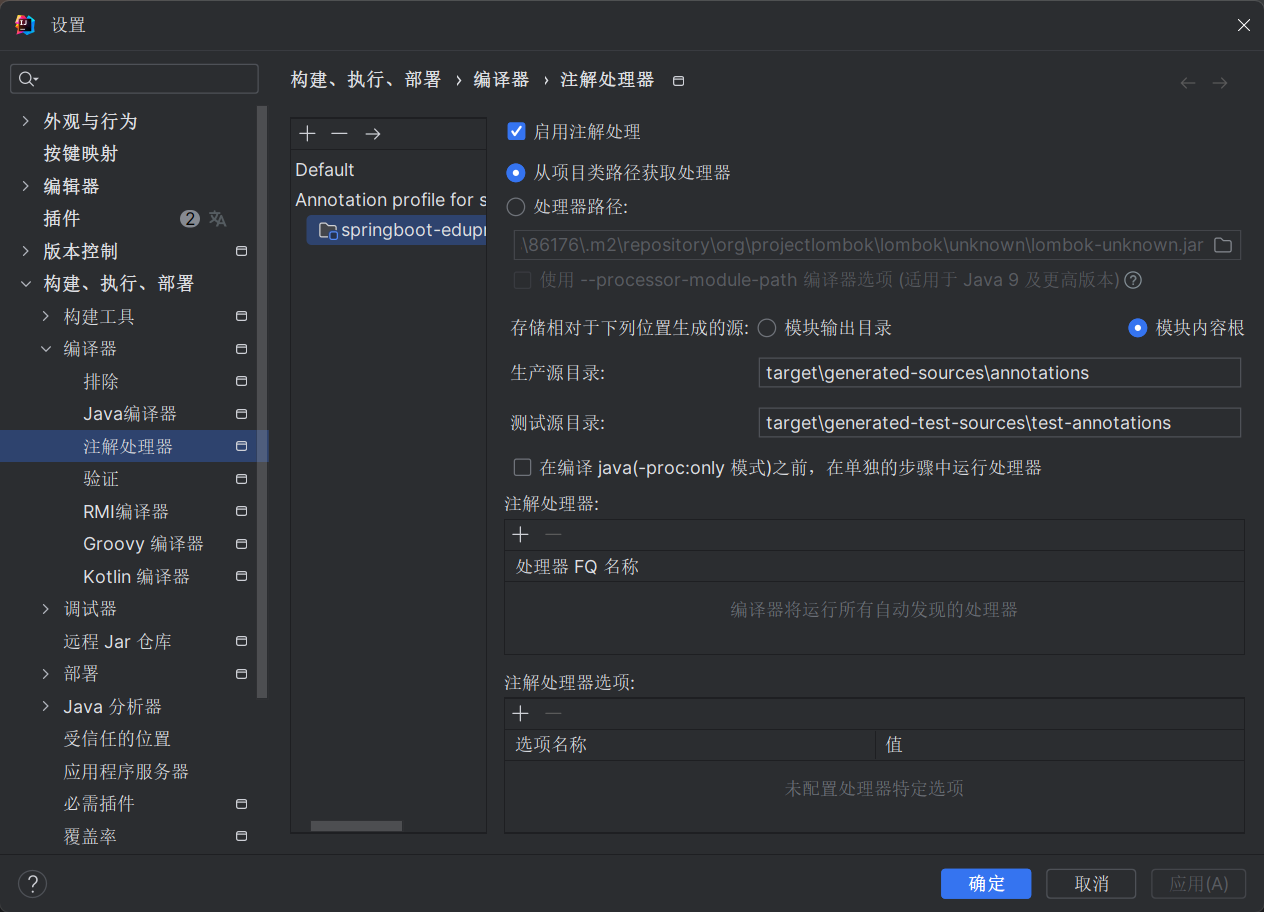
记一次idea中lombok无法使用的解决方案
在注解处理器下,一般 Default 为“启用注解处理”和“从项目类路径获取处理器”,但是我的项目中的为选择“处理器路径”,导致了无法识别lombok,因此,需要改为使用“从项目类路径获取处理器”这个选项。如下图所示&…...
)
【Redis】笔记|第7节|大厂生产级Redis高并发分布式锁实战(二)
一、Redis主从架构锁失效问题解析 1. 核心问题背景 在Redis主从架构中,分布式锁失效的核心风险源于主从复制的异步特性和主节点故障后的角色切换。即使客户端仅操作主节点写入,主节点宕机时未同步的锁数据可能导致新主节点允许重复加锁。 2. 主从切换…...

WebRTC中sdp多媒体会话协议报文详细解读
sdp介绍 在WebRTC(Web实时通信)中,SDP(Session Description Protocol)是用来描述和协商多媒体会话的协议。它定义了会话的参数和媒体流的信息,如音视频编码格式、传输方式、网络地址等。SDP是WebRTC中一个…...

贪心算法应用:硬币找零问题详解
贪心算法与硬币找零问题详解 贪心算法(Greedy Algorithm)在解决优化问题时表现出简洁高效的特点,尤其适用于特定结构的组合优化问题。本文将用2万字篇幅,深入探讨贪心算法在硬币找零问题中的应用,覆盖算法原理、正确性…...

深入理解 x86 汇编中的重复前缀:REP、REPZ/REPE、REPNZ/REPNE(进阶详解版)
一、重复前缀:串操作的 “循环加速器” 如果你写过汇编代码,一定遇到过需要重复处理大量数据的场景: 复制 1000 字节的内存块比较两个长达 200 字符的字符串在缓冲区中搜索特定的特征值 手动用loop指令编写循环?代码冗长不说&a…...

计算机网络全维度解析:架构协议、关键设备、安全机制与新兴技术深度融合
计算机网络作为当今数字化社会的基石,其复杂性和应用广泛性远超想象。本文将从基础架构、协议体系、关键设备、安全机制到新兴技术,进行全方位、深层次的解析,并辅以实际应用场景和案例分析。 一、网络架构与分类的深度剖析 1.1 网络分类的立…...
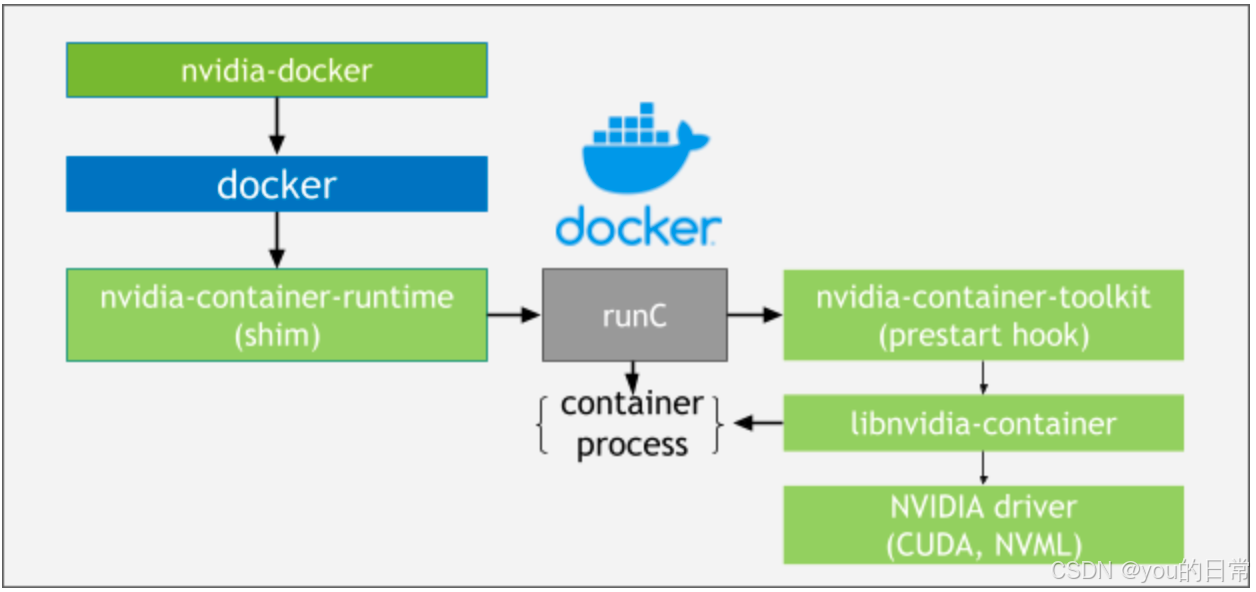
Docker 在 AI 开发中的实践:GPU 支持与深度学习环境的容器化
人工智能(AI)和机器学习(ML),特别是深度学习,正以前所未有的速度发展。然而,AI 模型的开发和部署并非易事。开发者常常面临复杂的依赖管理(如 Python 版本、TensorFlow/PyTorch 版本、CUDA、cuDNN)、异构硬件(CPU 和 GPU)支持以及环境复现困难等痛点。这些挑战严重阻…...
学习NuxtLink标签
我第一次接触这个标签,我都不知道是干嘛的,哈哈哈哈,就是他长得有点像routerLink,所以我就去查了一下!哎!!!真是一样的,哈哈哈哈,至少做的事情是一样的&#…...
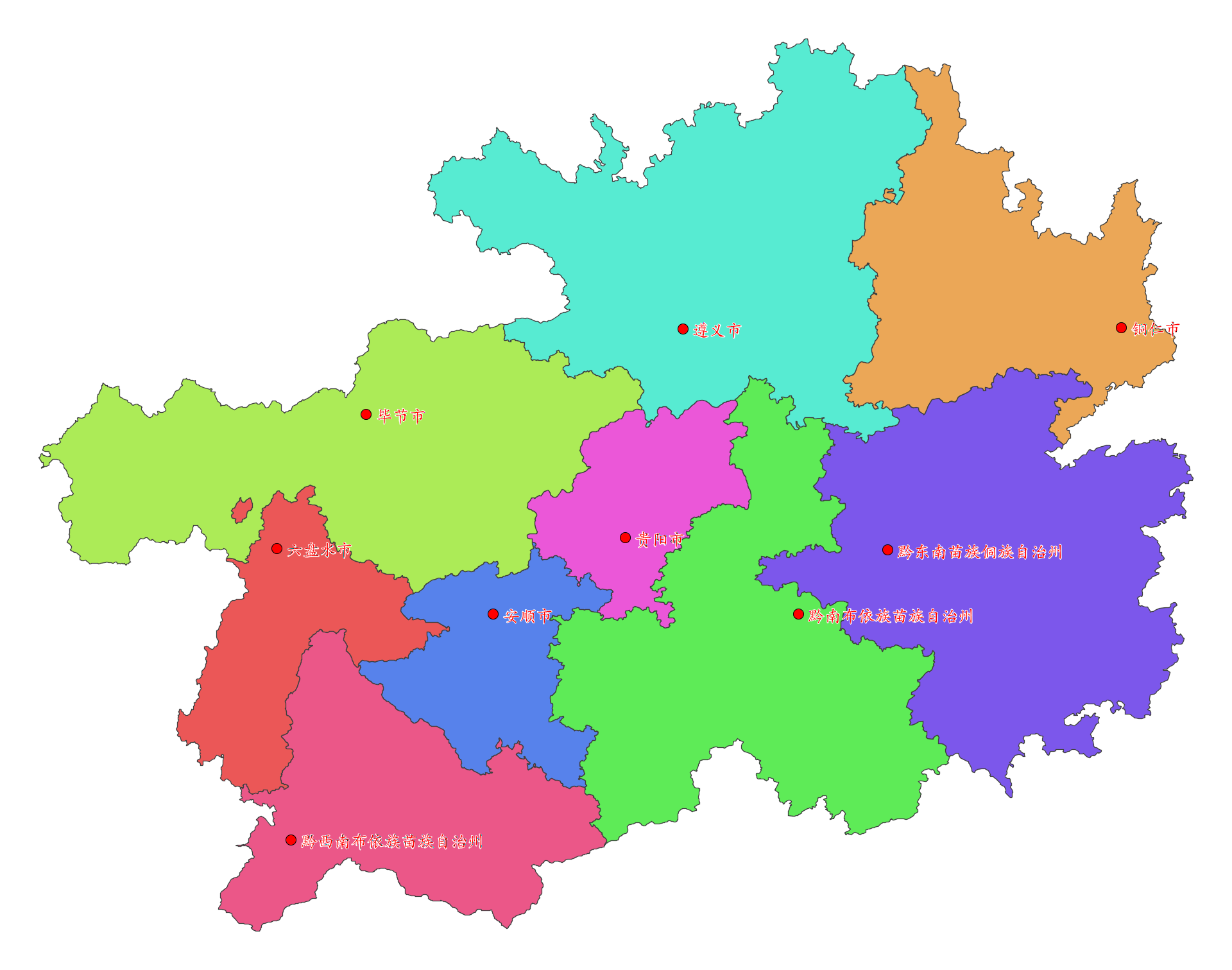
基于PostGIS的GeoTools执行原生SQL查询制图实践-以贵州省行政区划及地级市驻地为例
目录 前言 一、空间相关表简介 1、地市行政区划表 2、地市驻地信息表 3、空间查询检索 二、GeoTools制图实现 1、数据类型绑定 2、WKT转Geometry 3、原生SQL转SimpleFeatureCollection 4、集成调用 5、成果预览 三、总结 前言 在当今这个信息爆炸的时代,…...

MySQL字段类型完全指南:选型策略与实战应用
引言 在数据库设计中,字段类型的选择直接影响数据存储效率、查询性能和系统稳定性。本文将系统梳理MySQL支持的字段类型,结合典型应用场景与避坑指南,助你构建高性能、易维护的数据库结构。 一、字段类型全景图 MySQL字段类型主要分为以下五…...