性能优化 - 理论篇:CPU、内存、I/O诊断手段
文章目录
- Pre
- 引言
- 1. CPU 性能瓶颈
- 1.1 top 命令 —— 多维度 CPU 使用率指标
- 1.2 负载(load)——任务排队情况
- 1.3 vmstat 命令 —— CPU 繁忙与等待
- 2. 内存性能瓶颈
- 2.1 操作系统层面的内存分布
- 2.2 top 命令 —— VIRT / RES / SHR 三个关键列
- 2.3 CPU 缓存与伪共享
- 2.4 HugePage 技术
- 2.5 预先加载(AlwaysPreTouch)
- 3. I/O 性能瓶颈
- 3.1 硬盘读写性能差异
- “磁盘的速度这么慢,为什么 Kafka 操作磁盘,吞吐量还能那么高?”
- 3.2 top/vmstat 中的 wa 指标
- 3.3 iostat 命令 —— 磁盘 I/O 细节指标
- 3.4 零拷贝原理与实践
- 传统流程(无零拷贝)
- 零拷贝(以 sendfile 为例)
- 小结

Pre
性能优化 - 理论篇:常见指标及切入点
性能优化 - 理论篇:性能优化的七类技术手段
- 引言:木桶理论及短板概念,以及为何关注 CPU、内存、I/O 三大组件。
- CPU 性能瓶颈
2.1 top 命令——多维度 CPU 使用率指标介绍;
2.2 负载(load)——任务排队与多核计算机下的正确理解;
2.3 vmstat 命令——Uninterruptible Sleep、交换分区及上下文切换指标。 - 内存性能瓶颈
3.1 操作系统层面的内存分布(物理内存、虚拟内存、共享内存、逻辑内存、Swap);
3.2 top 命令——VIRT/RES/SHR 三个关键列;
3.3 CPU 缓存与伪共享——多级缓存结构、Cache line、@sun.misc.Contended;
3.4 HugePage 技术——TLB、页表与大页优势;
3.5 预先加载(AlwaysPreTouch)——JVM 堆内存预分配。 - I/O 性能瓶颈
4.1 硬盘读写性能差异说明(顺序写 vs 随机写与 CPU/内存对比);
4.2 top/vmstat 中 wa 指标;
4.3 iostat 命令——%util、avgqu-sz、await、svctm 的含义与阈值;
4.4 零拷贝原理与实践——传统拷贝流程 vs sendfile 零拷贝流程。
引言
在性能优化 - 理论篇:性能优化的七类技术手段 中,我们已经简要介绍了解决性能问题的常见切入点,如算法优化、缓存策略、并发模型等。但是,在实际运维与性能调优过程中,往往需要首先判断“系统的短板在哪儿”,才能更有针对性地展开优化工作。正如木桶理论所强调的,整体系统的性能取决于最薄弱的那一块。当 CPU、内存、I/O 这三大计算机资源之间存在速度差异时,就会产生性能瓶颈,拖累整个系统。
目标:
- 哪些系统组件容易成为性能瓶颈;
- 如何通过常用命令和指标判断它们是否真的已经成为瓶颈。
我们接下来将以 Linux 下常见的 top、vmstat、iostat 等工具为切入口,分别从 CPU、内存和 I/O 三个维度进行,快速锁定系统可疑短板,为后续深入分析提供方向。
1. CPU 性能瓶颈
CPU(中央处理器)是系统中最核心的计算单元,当 CPU 无法及时处理任务时,就会导致其他任务排队等待,进而产生明显的性能问题。下面介绍三种常用命令和思路,用于判断 CPU 是否出现瓶颈。
1.1 top 命令 —— 多维度 CPU 使用率指标
启动 top(或 htop)后,可以按下数字键 1 来查看每个逻辑核心的使用情况。
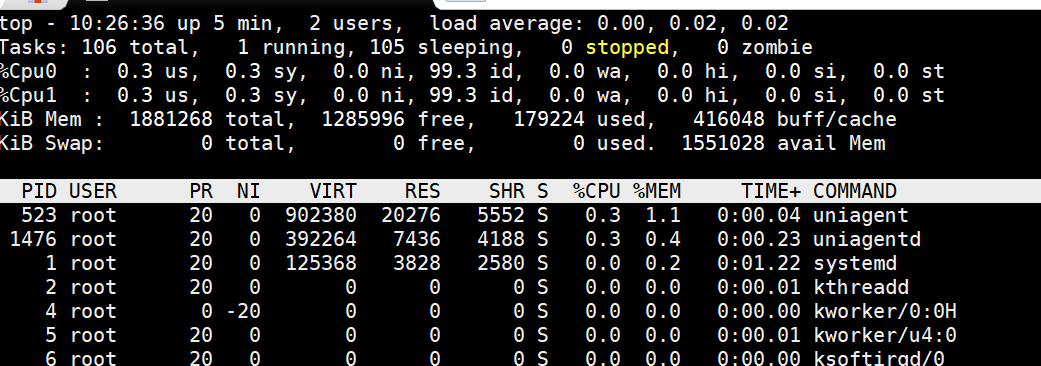
典型输出中,我们重点关注以下几列指标:
- us(user):用户态占用的 CPU 百分比,即由普通应用程序耗费的 CPU 时间;
- sy(system):内核态占用的 CPU 百分比,用于判断系统调用、驱动中断等是否频繁;
- ni(nice):修改过优先级的进程占用的 CPU 百分比,通常比较少见;
- wa(iowait):CPU 因等待 I/O 完成而空闲的时间百分比,当该值过高时,往往意味着 I/O 子系统可能成为瓶颈;
- hi(hardware interrupts):硬中断所占用的 CPU 百分比,用来评估中断处理对系统的开销;
- si(soft interrupts):软中断所占用的 CPU 百分比;
- st(steal time):在虚拟化环境中,虚拟机因等待宿主机 CPU 而被“偷取”的时间百分比,常出现在超卖(overcommit)严重的云服务器上;
- id(idle):空闲 CPU 百分比,即未被任何用户态或内核态程序占用的时间。
关注要点:通常,当
id(空闲)低于 10% 时,就有必要进一步分析。
- 如果
us≫sy,说明大多数开销来自应用程序本身的计算;- 如果
sy较高,且伴随cs(上下文切换)急剧上升,则可能是锁竞争或系统调用过于频繁;- 如果
wa持续超过 10%以上,需重点检查磁盘或网络 I/O。
1.2 负载(load)——任务排队情况
除了 top,uptime 、cat /proc/loadavg 也能查看系统负载(load average),通常显示最近 1 分钟、5 分钟、15 分钟的平均值。Load 本质上表示系统可运行队列(包括正在运行与可运行状态)的长度。
-
单核 CPU:
- Load < 1:CPU 有闲置;
- Load ≈ 1:CPU 满负载;
- Load > 1:存在任务排队,开始出现瓶颈。

-
多核 CPU:
我们需要把 Load 与 CPU 核心数进行对比,比如一台 8 核机器,如果 Load ≈ 8,表明所有核心基本都在满负载;如果 Load ≈ 16,则代表有 8 个任务在排队等待。
正确理解:
- 若某时刻 Load = 10,而你使用的是一台 16 核服务器,说明系统还有剩余计算能力(仍可并行处理多达 6 个任务)。
- 若 Load ≈ CPU 核心数 × 1.2 时,已有一定排队压力;若 Load ≈ CPU 核心数 × 1.5 或更高,则问题严重。
通过 Load 我们能够大致判断“CPU 是否不堪重负”,但无法区分是 CPU 本身饱和,还是等待 I/O 导致的大量进程处于可运行队列。
1.3 vmstat 命令 —— CPU 繁忙与等待
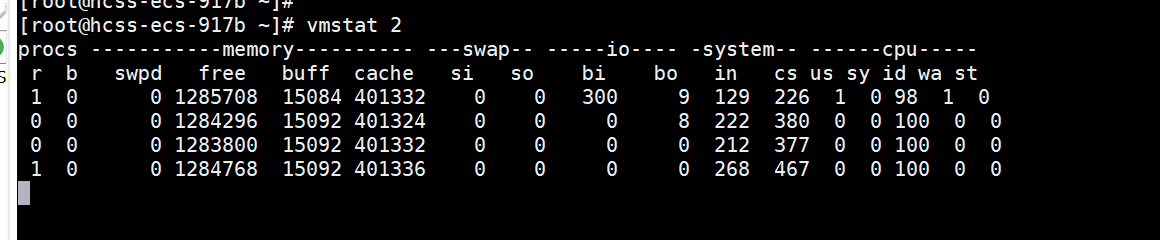
vmstat 2(每 2 秒刷新一次)能输出更细粒度的系统指标,其中几列指标与 CPU 相关:
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----r b swpd free buff cache si so bi bo in cs us sy id wa st2 1 0 10240 40844 124536 0 0 3 12 185 210 30 5 60 5 0
- b(blocked):处于“不可中断睡眠(D 状态)”的进程数,通常是因 I/O 等待。如果
b值持续大于 0,表明存在 I/O 队列或其他资源等待,可能是 I/O 瓶颈。它的意思是等待 I/O,可能是读盘或者写盘动作比较多. - si(swap in)/ so(swap out):每秒发生的换入换出页数;如果这两列不为 0,说明系统正在频繁地使用 Swap,这会严重影响性能,应尽快检查内存压力。
- cs(context switches):每秒发生的上下文切换次数;当
cs过高,且同时伴随sy较高时,说明进程/线程切换开销大,可能是线程数过多或锁竞争激烈。 - us/sy/id/wa:与
top中类似,判断用户/内核占用、空闲与 I/O 等待情况。
综合判断:
- 当
b持续上升、wa较高时,初步判断可能是 I/O 瓶颈,需要结合iostat等工具深入排查;- 当
si/so不为 0,说明系统在用 Swap 分区,需检查内存是否不足;- 当
cs过高且sy上升,需分析是否存在锁竞争或短生命周期进程过多。
此外,可以通过查看单个进程的上下文切换次数来判断某个进程是否“频繁切换”,例如:
cat /proc/<PID>/status | grep ctxt_switches
voluntary_ctxt_switches: 93950
nonvoluntary_ctxt_switches: 171204
- voluntary_ctxt_switches:该进程主动自愿让出 CPU(如等待某个事件完成);
- nonvoluntary_ctxt_switches:该进程被操作系统抢占而发生的上下文切换次数。
如果某进程这两个值都非常高,说明它在不断被抢占或频繁等待,可能是线程数过多或锁等待。
2. 内存性能瓶颈
内存层面容易出现的问题,主要分为“物理内存不足导x致 Swap 大量使用”与“CPU 缓存相关的并发伪共享”两种大类。下面我们逐项介绍如何通过系统工具进行排查。
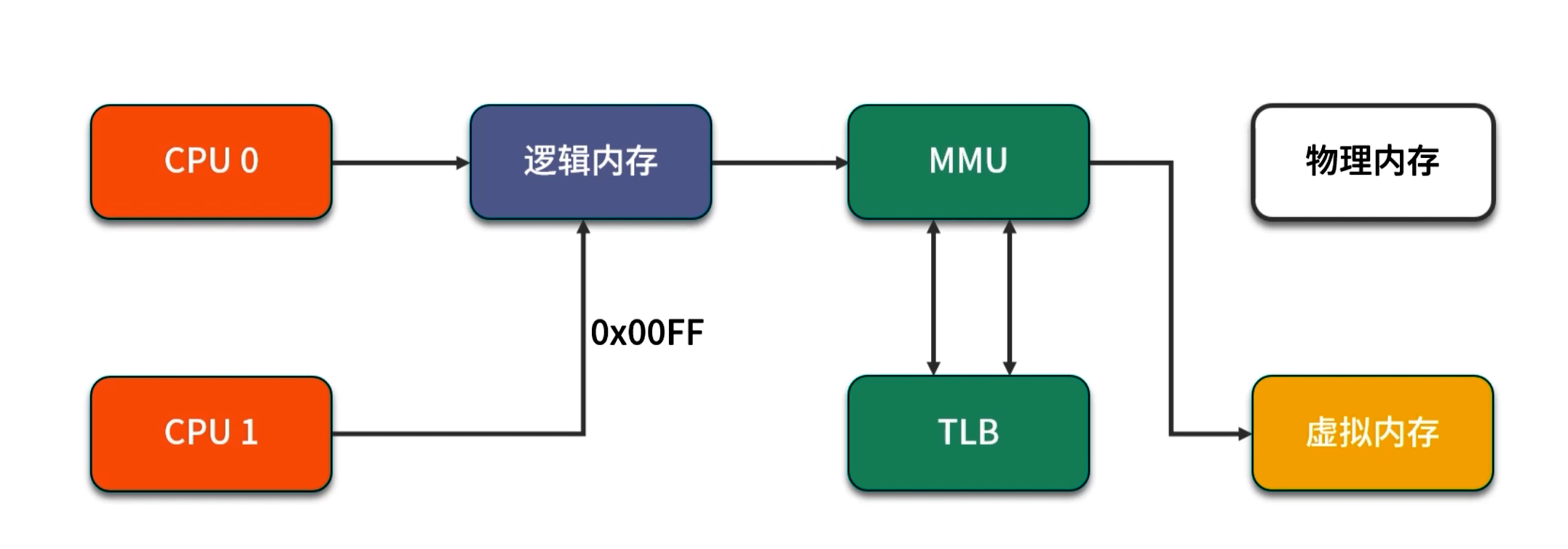
2.1 操作系统层面的内存分布
- 物理内存(RAM):实际安装在主板上的内存条容量,例如 4GB、8GB 等。
- 虚拟内存(Swap):将磁盘划分一部分用作内存,当物理内存不足时,操作系统会将部分冷数据迁移到 Swap 以腾出空间。虚拟内存容量 = 物理内存 + Swap 分区。
- 共享内存(Shared Memo ry):多个进程可以映射同一段物理内存,用于进程间高速通信。例如,
/dev/shm、某些动态链接库(.so 文件)加载到内存后可被多个进程复用。 - 逻辑内存(Virtual Address):每个进程看到的“线性地址空间”,操作系统通过页表将其映射到实际的物理内存或 Swap。这也是为什么你在程序中看到的指针地址并非物理地址的原因。
注意:当物理内存 + Swap 均被占满时,新的内存请求会导致 OOM(OutOfMemory)或进程被杀死。
2.2 top 命令 —— VIRT / RES / SHR 三个关键列
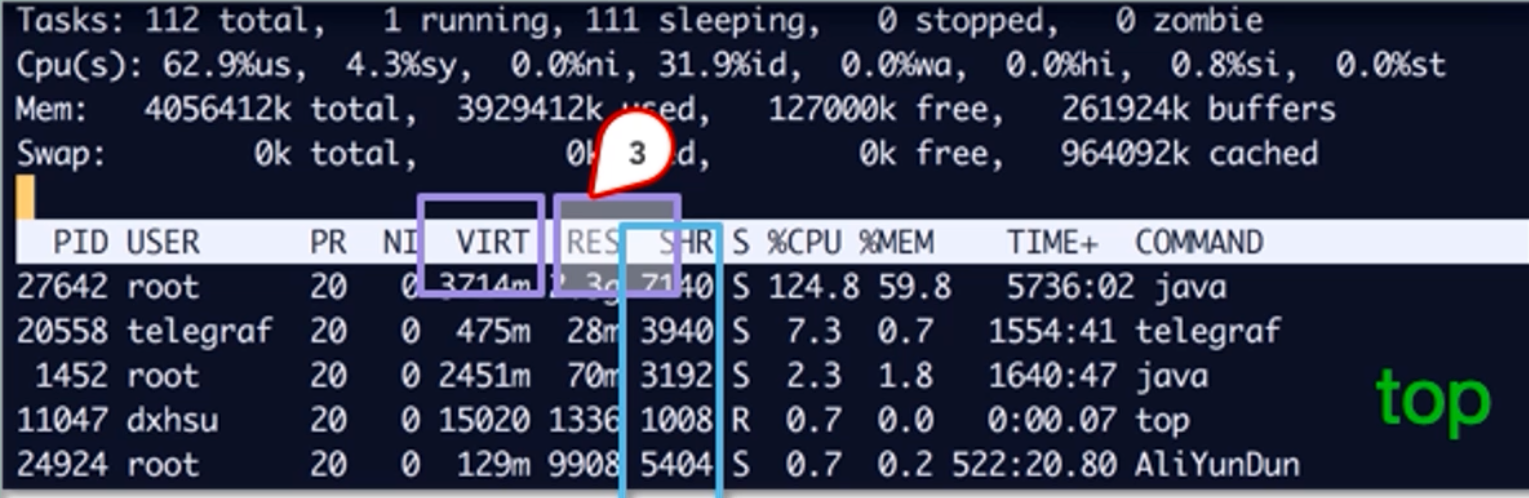
在 top 中查看进程时,内存相关列通常有:
- VIRT(Virtual Memory Size):进程使用的虚拟内存大小,包括代码段、库、堆、栈以及已映射但未实际占用物理内存的区域。通常很大,但并不代表真正占用物理内存。
- RES(Resident Memory Size):进程当前实际占用的物理内存大小,也是最需要关注的数值。如果某个 Java 进程的 RES 一直飙高,说明物理内存压力较大。
- SHR(Shared Memory Size):进程占用的可被其他进程共享的内存大小,例如共享库部分。如果多进程复用同一 .so 文件,这部分会重复显示在各个进程的 SHR 中。
监控要点:
- 持续监测关键服务(如 JVM 进程、数据库进程)的 RES 值。
- 若系统物理内存使用已接近
phy_total – (buffer + cache),并且 Swap 使用量不断增长,则要警惕可能发生的内存抖动与性能下降。
2.3 CPU 缓存与伪共享
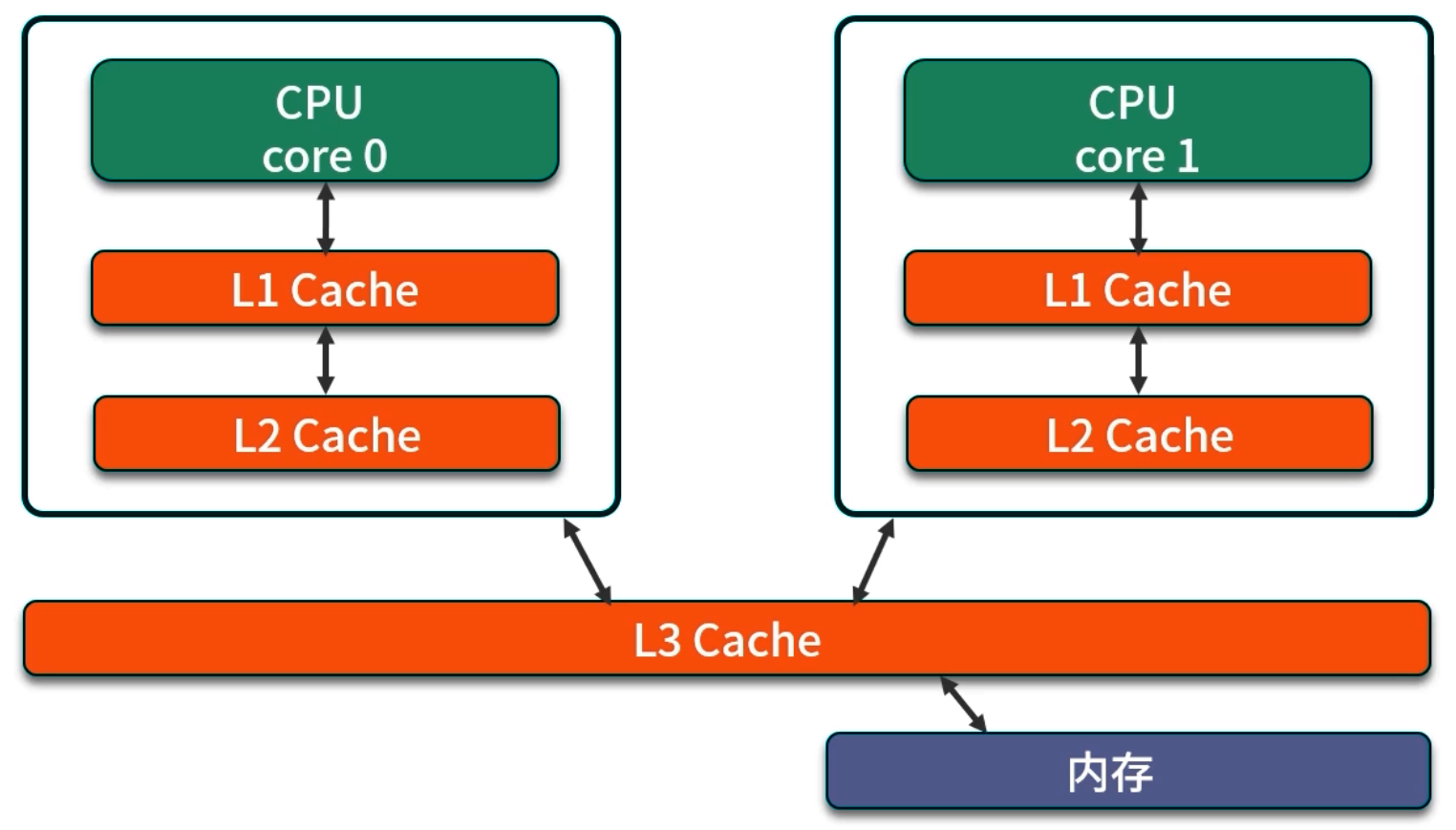
CPU 与主内存(DRAM)之间的速度差通常超过百倍,因而多级缓存(L1、L2、L3)成为不可或缺的高速存储层次:
- L1 Cache:通常 32KB 左右(分为数据缓存与指令缓存),访问延迟约 4 ~ 5 周期;
- L2 Cache:通常 256KB ~ 512KB,访问延迟约 12 ~ 15 周期;
- L3 Cache(若存在):几 MB 级别,延迟约 30 ~ 40 周期;
伪共享(False Sharing) 是并发编程中常见的性能陷阱:
- 当多个线程频繁修改位于同一个 Cache line(通常 64 字节)内的不同变量时,每次写操作会导致该整行缓存失效,并在其他 CPU 核之间反复淘汰与重载,极大增加内存系统开销。
- 举例:假设两个线程分别修改位于同一 64 字节 Cache line 内的
a、b两个变量。线程 A 写a时,整个 Cache line 被标记为 Modified,线程 B 如果此后写b,则需要从主内存或其他 CPU 的缓存中重新加载该 Cache line,才可再写;如此反复执行,会导致大量缓存一致性流量,严重拖慢性能。
要获得 Cache line 大小,可以执行:
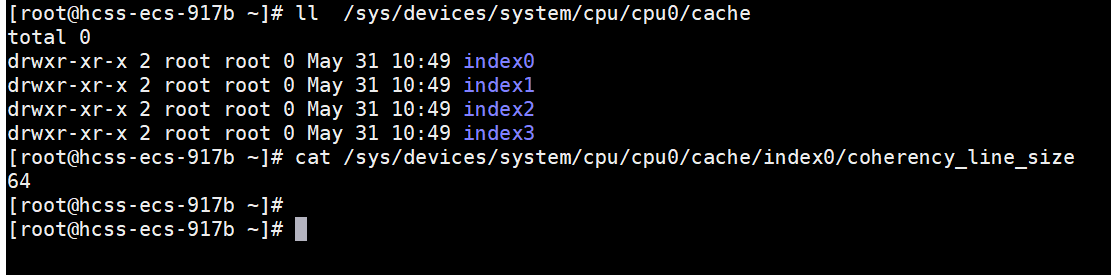
cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size
cat /sys/devices/system/cpu/cpu0/cache/index1/coherency_line_size
cat /sys/devices/system/cpu/cpu0/cache/index2/coherency_line_size
cat /sys/devices/system/cpu/cpu0/cache/index3/coherency_line_sizecat /proc/cpuinfo | grep cache_alignment
通常返回 64 表示 64 字节的 Cache line 大小。
在 Java 8+ 中,可以通过在类字段上添加 @sun.misc.Contended 注解(并在启动参数中加上 -XX:-RestrictContended)来避免某些字段被放在同一 Cache line 中,从而缓解伪共享。但要谨慎使用,因为开启 @Contended 会导致对象头占用增加。更常见的做法是:
- 手动在频繁并发写的变量之间插入“填充字段”(padding),确保它们位于不同 Cache 行;
- 尽可能使用无锁/弱同步的数据结构,如
LongAdder、ConcurrentHashMap等,减少多个线程对同一变量的写冲突。
2.4 HugePage 技术
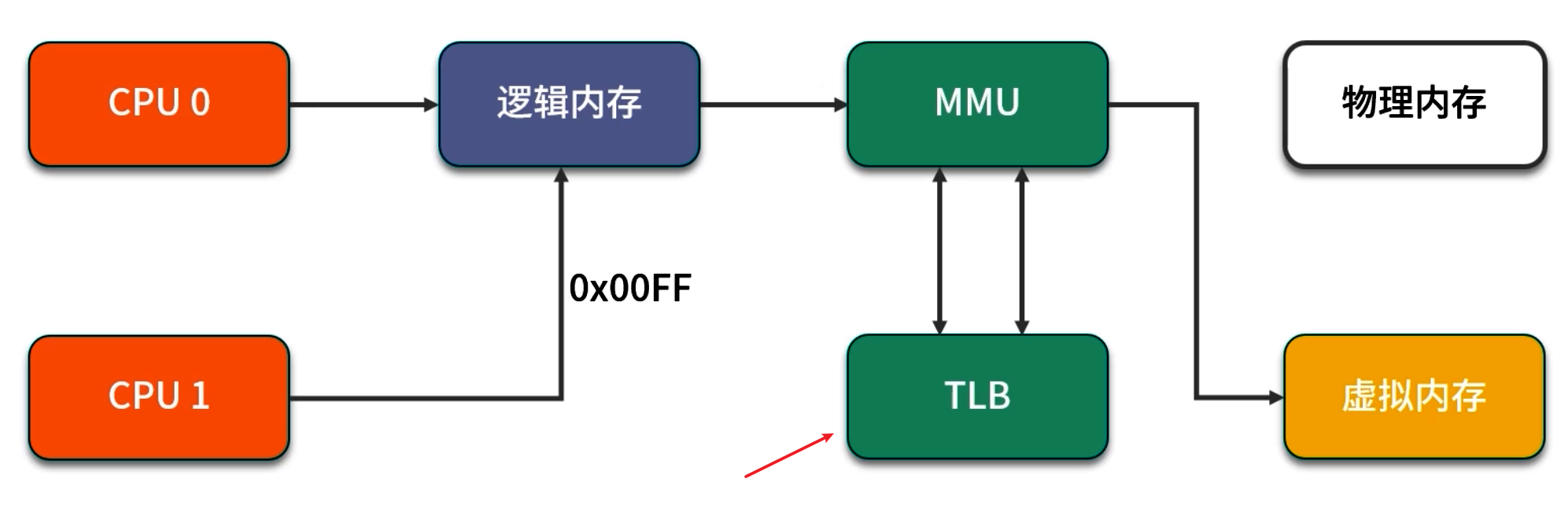
当系统物理内存较大时,传统 4KB 大小的页表(Page)在 TLB(Translation Lookaside Buffer)中能映射的页数量有限,频繁发生 TLB miss 会带来高昂的页表查找开销。HugePage(大页)通过将单页大小从 4KB 改为 2MB(或甚至 1GB,在某些架构上),可以显著减少页表条目数量与 TLB miss 的几率。
-
TLB:CPU 内部的一个小型缓存,用来保存最近访问的虚拟地址与物理地址映射,当访问的页不在 TLB 中时,会发生 TLB miss,引发多次内存访问以查找页表。
-
使用 HugePage 的好处:
- 减少页表条目数量,从而提升 TLB 命中率;
- 减少内核在处理 TLB 缺失时的访问开销;
- 对于大内存数据库、高并发 Java 堆环境(如需要分配 几十 GB 堆),HugePage 能带来更稳定的访问延迟。
-
配置方式(Linux 示例):
-
编辑
/etc/sysctl.conf,例如:vm.nr_hugepages = 1024 # 预留 1024 个 2MB 大页(约 2GB) -
重新加载:
sysctl -p,并在 JVM 启动时添加-XX:+UseLargePages或-XX:UseTransparentHugePages(内核支持自动管理)。
-
-
注意:HugePage 在申请时需要连续物理内存,如果系统已经运行很久并且内存较为分散,可能会申请失败;常见做法是在系统启动时一并保留大页。
2.5 预先加载(AlwaysPreTouch)
默认情况下,JVM 在启动过程中会根据 -Xms(初始堆)和 -Xmx(最大堆)设置为堆预留地址空间,但实际物理内存分配仅在真正访问某个页面时才发生(所谓“按需分配”)。
-
添加参数
-XX:+AlwaysPreTouch后,JVM 会在启动时预先触碰(touch)堆内存中的所有页面,使操作系统一次性分配所有物理页面。 -
优点:
- 在后续运行时能保证页面映射已经就绪,减少首次访问时因页面分配带来的延迟;
- 对于实时性要求较高的服务,可以避免运行过程中出现大规模“页面分配阻塞”。
-
缺点:启动时间会明显变长,尤其是堆较大时需触摸的页更多;而且如果常驻内存要占用大量物理页,系统需要保证提前就有足够空闲内存。
3. I/O 性能瓶颈
I/O 子系统通常是整台机器中最慢的部分,因此一旦 I/O 无法跟上 CPU 和内存的处理速度,就会导致 iowait 升高、响应延迟拉长。下面介绍如何使用常用工具判断与排查 I/O 瓶颈。
3.1 硬盘读写性能差异
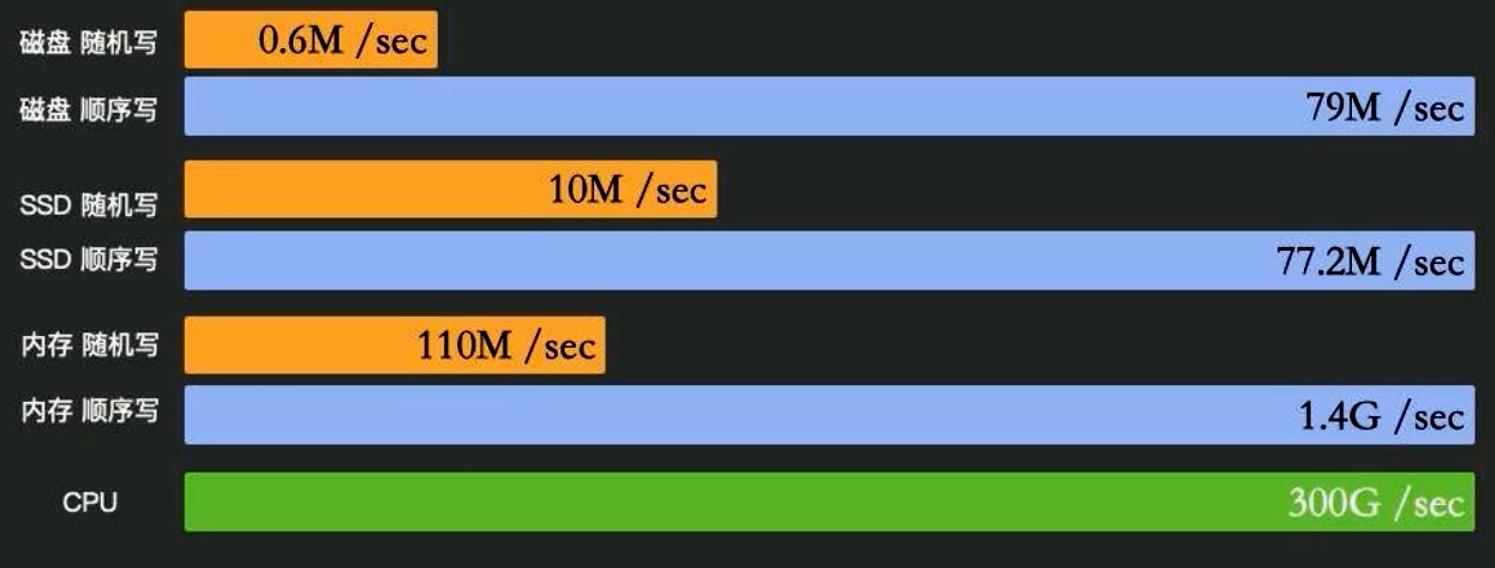
首先,了解不同存储介质的读写特性:
- 机械硬盘(HDD):顺序读写性能较好(几十 MB/s 到上百 MB/s),但随机读写性能极差(可能只有几 MB/s)。
- SSD(固态硬盘):顺序读写与随机读写性能都较高,但相对机械盘而言,顺序写入略逊一筹;而随机小文件 I/O 性能可达数十万 IOPS。
- 内存(RAM):读写带宽可达数十 GB/s,延迟仅几十纳秒。
由于 CPU 与内存之间的速度差已经很大(百倍以上),因此存储层与内存层之间的速度差则更为悬殊:
CPU 缓存(L1):几十 GB/s,延迟 ~4 周期
内存(DRAM):几十 GB/s,延迟 ~100 纳秒
SSD 顺序写:500 MB/s ~ 1 GB/s,延迟数十 微秒
SSD 随机写:1 ~ 10 MB/s (取决于块大小),延迟 ~100 微秒 ~ 1 毫秒
机械盘随机写:1 ~ 5 MB/s,延迟 >1 毫秒
因此,在某些高并发场景下,尤其要尽量减少随机 I/O、避免小文件频繁读写。
“磁盘的速度这么慢,为什么 Kafka 操作磁盘,吞吐量还能那么高?”
磁盘之所以“慢”,主要瓶颈在“寻道”(seek time)操作上。根据 Kafka 官方测试,机械硬盘的寻道时长平均可达到 10ms 左右。与此同时,磁盘对顺序写入与随机写入的性能差距极大——顺序写的吞吐往往是随机写的数千倍。Kafka 恰好将写日志(append log)设计为顺序写:
- 每条消息追加到分区对应的日志文件末尾,磁头仅需在当前写入位置连续移动,不要频繁跳转;
- 借助操作系统页缓存(PageCache)和批量刷盘(batch flush)策略,将多条消息合并为一次大块写入,进一步降低寻道带来的延迟;
- 通过零拷贝(sendfile)技术,将磁盘页缓存直接传输给网络套接字,减少内核与用户空间之间的内存拷贝。
因此,虽然机械磁盘的“随机写”极慢,但 Kafka 最大化地利用了“顺序写”的高吞吐特性,进而在每秒百万级消息写入场景下依然能够保持很高的磁盘利用率与整体吞吐。
3.2 top/vmstat 中的 wa 指标
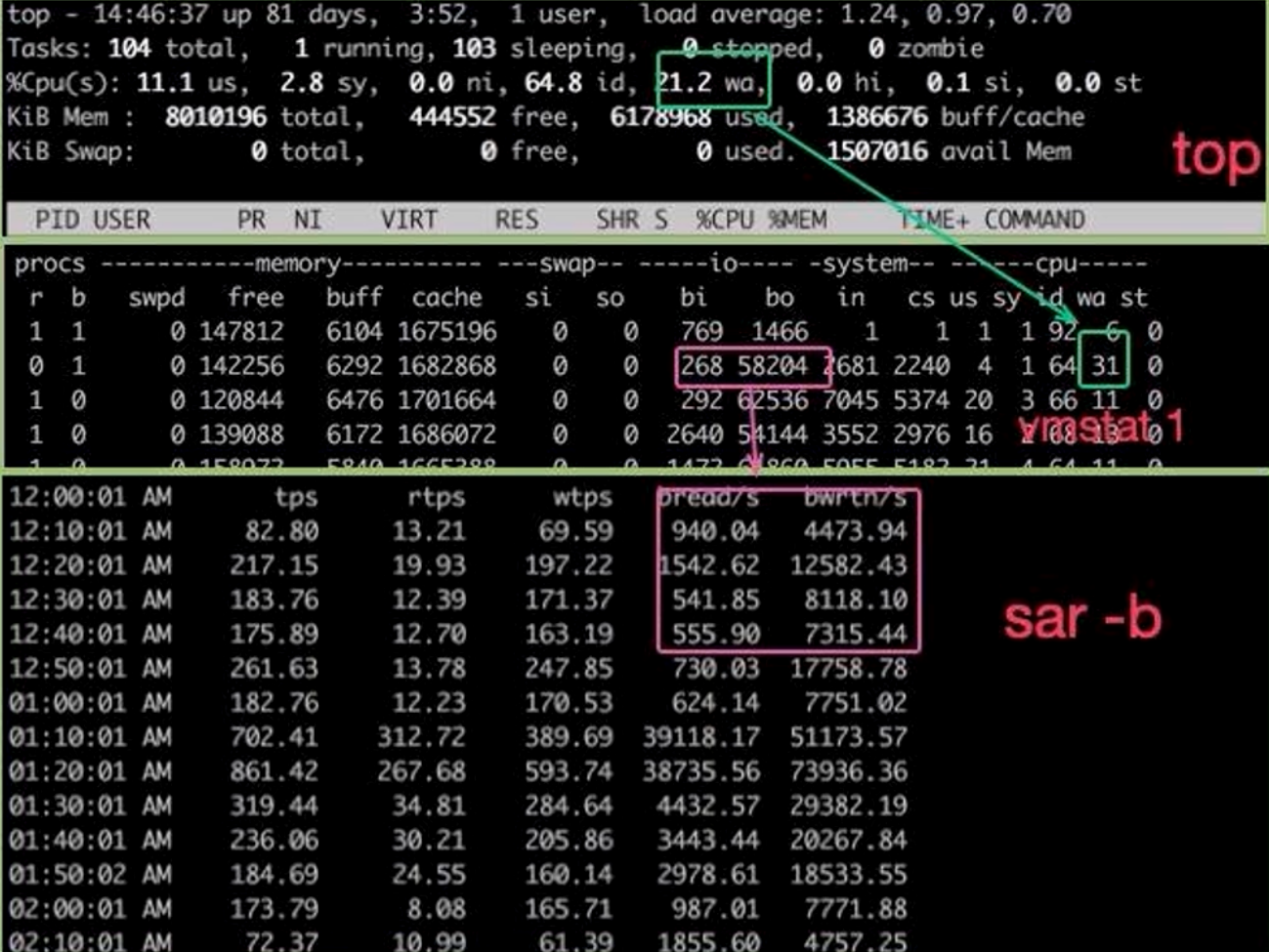
在 top 中,wa(iowait)列显示 CPU 因等待 I/O 完成而空闲的百分比;在 vmstat 输出中同样会显示 wa。
- 如果
wa持续超过 10%,意味着有大量进程在等待 I/O 完成,此时系统整体吞吐将明显下降。 - 当
b(Uninterruptible Sleep) 大于 0 时,也表明某些进程在等待 I/O。
案例:某 Web 服务在高并发下突然响应变慢,
top发现id几乎为 0,wa常驻 20% 左右,说明大量请求在等待磁盘写日志或数据库 IO,可结合iostat查明是日志盘还是数据库盘出现瓶颈。
3.3 iostat 命令 —— 磁盘 I/O 细节指标
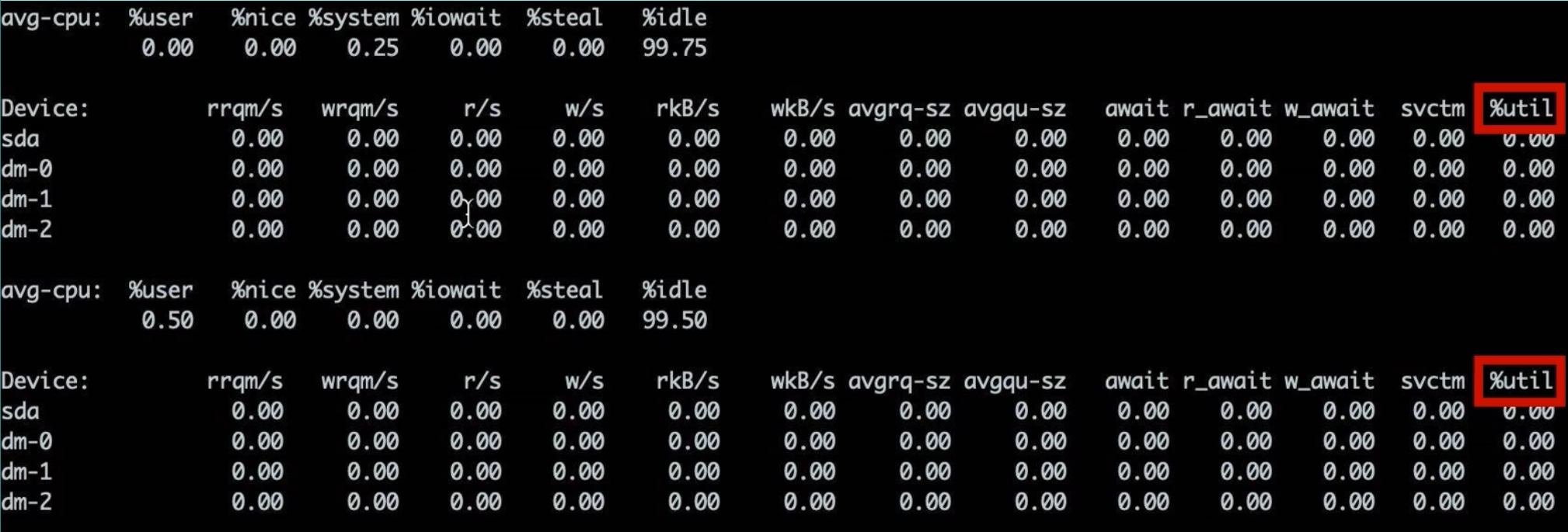
iostat -x 2(每 2 秒刷新一次扩展统计)能够展示各块设备(Device)的详细 I/O 性能指标,例如:
Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 20.00 0.50 10.00 0.02 0.80 160.00 5.20 30.40 10.20 35.80 2.80 28.00
sdb 0.00 0.00 0.00 0.10 0.00 0.01 80.00 0.02 20.00 0.00 20.00 2.00 0.20
重点关注以下几列:
- %util:设备利用率,表示磁盘忙碌时间占比。一般当
%util超过 80% 时,就说明该块设备压力过大。 - avgqu-sz(Average Queue Size):平均请求队列长度,类似“路口排队汽车数”。数值越小越好;若大于 5 左右,就要警惕排队严重。
- await(Average Wait Time):平均请求等待时长(ms),包括排队时间与服务时间,经验上若
await> 5 ms,就说明磁盘响应变慢;若await> 10 ms,说明磁盘 I/O 瓶颈明显。 - svctm(Service Time):平均服务时间(ms),只包含处理时间(不含排队)。当
await与svctm差距很大时,说明排队时间占比大;当两者接近时,说明磁盘本身速度接近瓶颈。
阈值参考:
%util> 80%:磁盘带宽已接近极限;avgqu-sz> 5 :队列较长,建议分散 I/O 或扩容;await> 10 ms:I/O 响应明显变慢。
3.4 零拷贝原理与实践
在传统的数据从磁盘写入网络的流程中,需要 CPU 较多参与:
- read():将磁盘数据从内核空间拷贝到用户空间;
- write():将用户空间的数据再次拷贝回内核空间的网络缓冲区;
- 网络发送:内核将网络缓冲区数据通过网卡发出。
中间的两次拷贝(磁盘→内核→用户、用户→内核→网卡)都要经过内存拷贝,且需要在用户态与内核态之间频繁切换,增加了 CPU 与内存总线负担。
传统流程(无零拷贝)
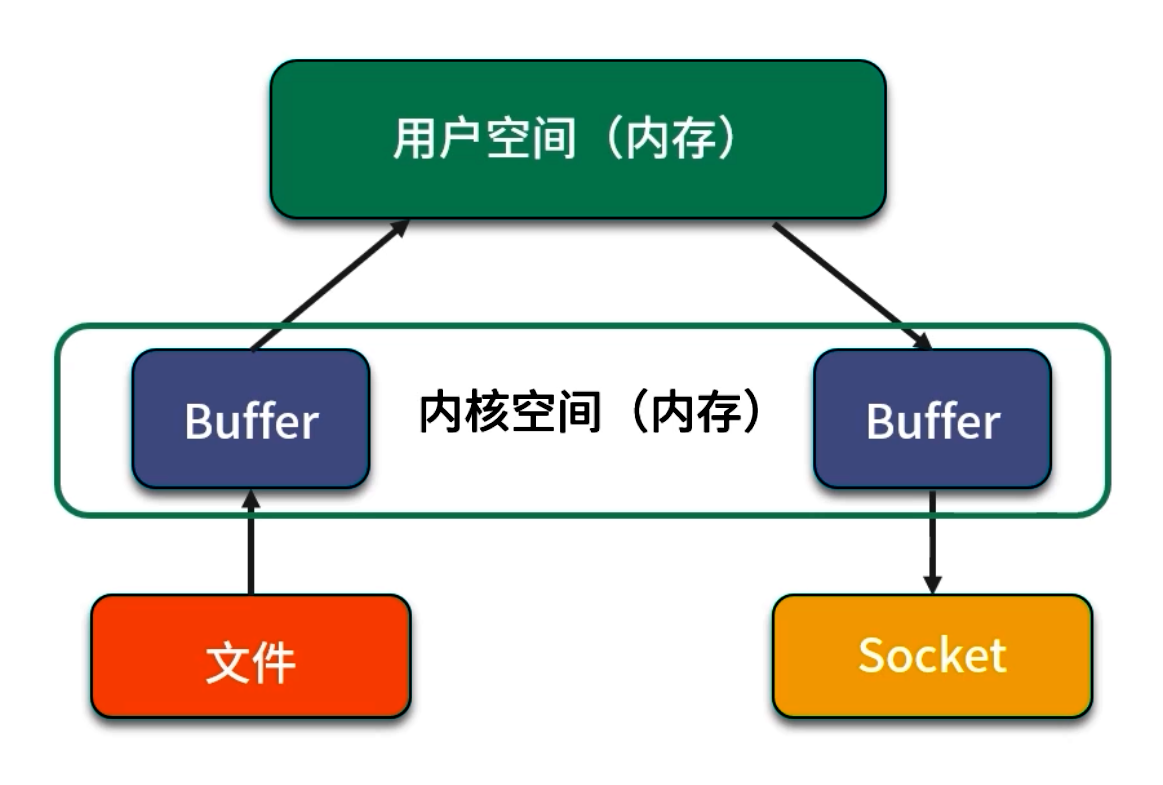
磁盘 → [内核页缓存] → <拷贝> → [用户缓冲区] → <拷贝> → [网络缓冲区] → 网络发送
零拷贝(以 sendfile 为例)
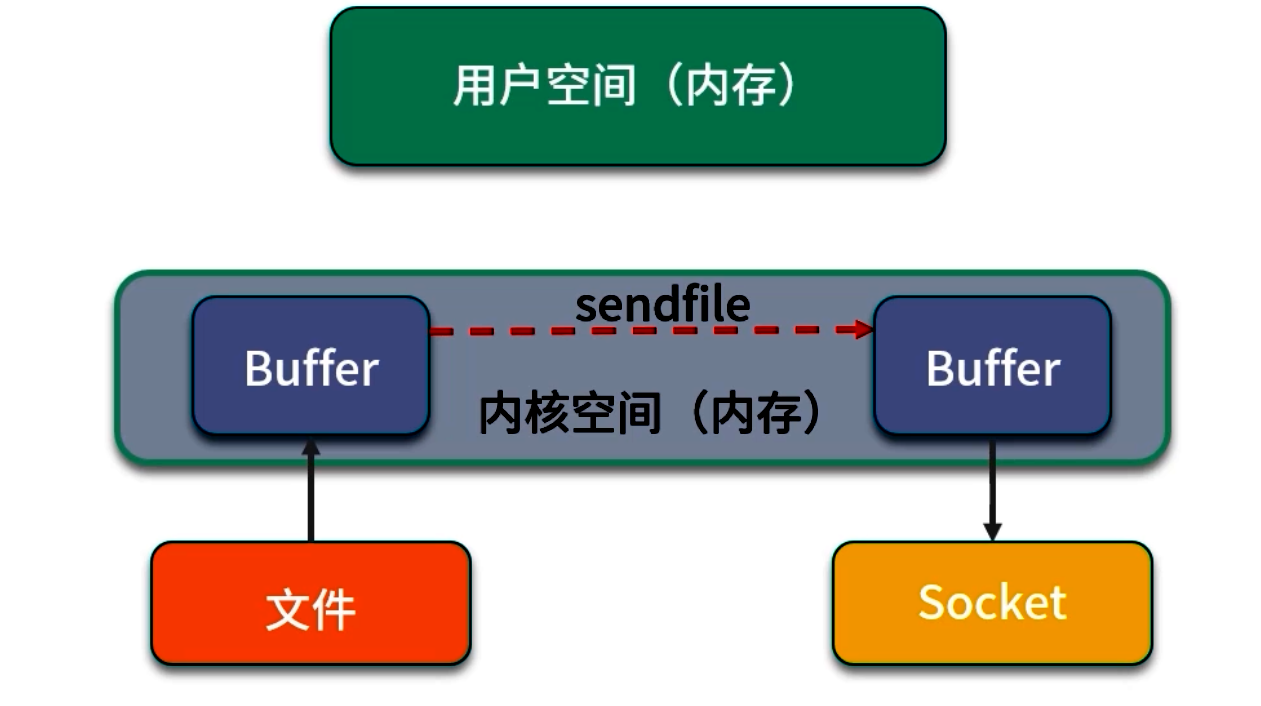
磁盘 → [内核页缓存] ——sendfile——> [网络缓冲区] → 网络发送
- 减少一次内存拷贝:sendfile 系统调用让内核直接将页缓存映射到网络缓冲区,省去磁盘→用户空间→内核网络缓存的拷贝。
- 减少用户态/内核态切换:应用直接调用
sendfile(fd_in, fd_out, ...),内核内部完成整条链路数据流动,无需在中间将数据暴露到用户空间。
应用场景:
- Kafka:批量顺序写入磁盘并直接 sendfile 将日志 segment 切片零拷贝到 socket;
- Nginx:静态文件服务时,使用 sendfile 减少 CPU 拷贝开销;
- Netty:在 Linux 平台可结合
FileRegion与sendfile实现高效大文件传输。
并非所有场景都适合零拷贝:
- 如果需要对文件内容做二次加工(如压缩、加密、转换等),就无法直接用 sendfile;
- 若数据源并非文件而是来自内存生成的动态内容,则零拷贝价值有限。
小结
重点从“计算机资源短板”角度,阐述了 CPU、内存与 I/O 三大组件易成瓶颈的典型特征,以及如何通过 Linux 工具进行初步诊断:
-
CPU
- 用
top查看 us、sy、ni、wa、hi、si、st、id 等多维度指标; - 用
load average结合 CPU 核心数评估任务排队情况; - 用
vmstat查看b、si/so、cs等指标,判断 I/O 等待与上下文切换开销。
- 用
-
内存
- 理解物理内存、虚拟内存(Swap)、共享内存与逻辑内存的关系;
- 关注
top中的 VIRT/RES/SHR,重点监控进程实际占用物理内存(RES)与 Swap 使用情况; - 理解多级 CPU 缓存架构及伪共享带来的惨重开销,学会使用
@Contended或手动填充(Padding)缓解问题; - 掌握 HugePage 技术以减少 TLB miss 开销,了解 JVM
-XX:+AlwaysPreTouch预先加载对启动与运行性能的影响。
-
I/O
- 认识机械盘、SSD、内存之间的性能差异;
- 在
top和vmstat中关注wa与b,结合iostat的%util、avgqu-sz、await、svctm指标判断磁盘负载与响应状况; - 理解零拷贝原理,掌握何时通过
sendfile等机制减少内核与用户空间拷贝,以提升大数据量传输效率。
这些方法只能帮助我们对 CPU、内存与 I/O 的基本瓶颈进行“定性判定”,但要精准到“真正的问题根源”——例如,哪个具体线程在抢占 CPU?哪个函数导致频繁上下文切换?哪个文件或逻辑请求引起高磁盘 I/O?——还需要依赖更深入的性能分析工具(如 perf、eBPF、JVM Flight Recorder、系统追踪工具等)收集更细粒度的数据。

相关文章:
性能优化 - 理论篇:CPU、内存、I/O诊断手段
文章目录 Pre引言1. CPU 性能瓶颈1.1 top 命令 —— 多维度 CPU 使用率指标1.2 负载(load)——任务排队情况1.3 vmstat 命令 —— CPU 繁忙与等待 2. 内存性能瓶颈2.1 操作系统层面的内存分布2.2 top 命令 —— VIRT / RES / SHR 三个关键列2.3 CPU 缓存…...

算法:二分查找
1.二分查找 704. 二分查找 - 力扣(LeetCode) 二分查找算法要确定“二段性”,时间复杂度为O(lonN)。为了防止数据溢出,所以求mid时要用防溢出的方式。 class Solution { public:int search(vector<int>& nums, int tar…...

Spring Boot3.4.1 集成 mybatis plus
Spring Boot 集成 mybatis plus 第一步 引入依赖 <dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.16</version> </dependency><dependency><groupId>com.bao…...

Ubuntu 22.04 上安装 PostgreSQL(使用官方 APT 源)
Ubuntu 22.04 上安装 PostgreSQL(使用官方 APT 源) 步骤 1:更新系统 sudo apt update sudo apt upgrade -y步骤 2:添加 PostgreSQL 官方仓库 # 安装仓库管理工具 sudo apt install wget ca-certificates gnupg lsb-release -y#…...
Linux随记(十八)
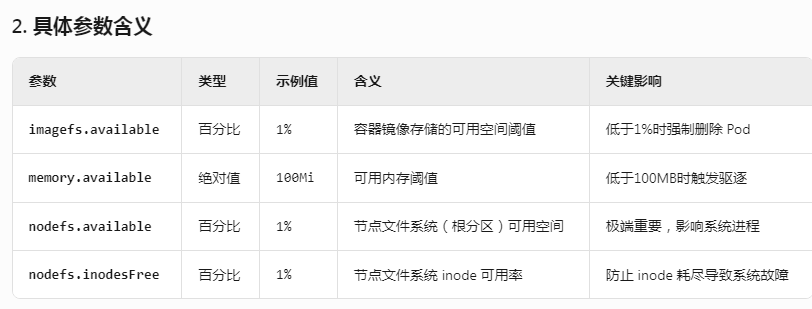
一、k8s的node节点磁盘 /data已使用率超过 85% , 出现disk pressure ,驱逐pod现象 evicted , the node had condition:[DiskPressure] #修改/var/lib/kubelet/config.yaml ]# cat /var/lib/kubelet/config.yaml apiVersion: kubelet.config.k8s.io/v1…...
Windows MongoDB C++驱动安装
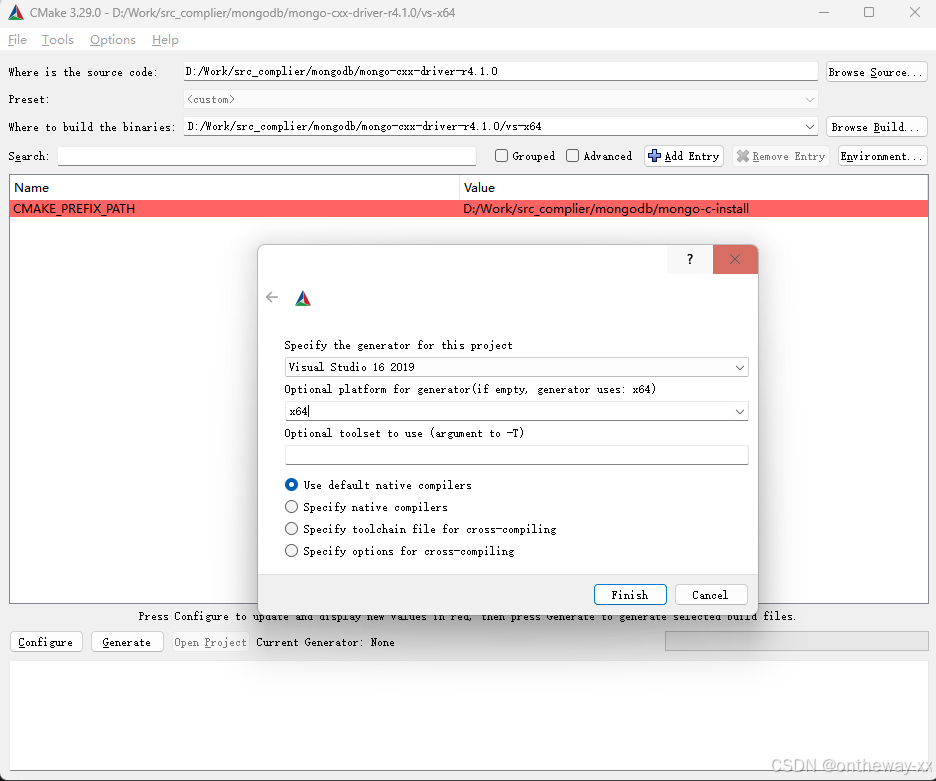
MongoDB驱动下载 MongoDB 官网MongoDB C驱动程序入门MongoDB C驱动程序入门 安装环境 安装CMAKE安装Visual Studio 编译MongoDB C驱动 C驱动依赖C驱动,需要先编译C驱动 下载MongoDB C驱动源码 打开CMAKE(cmake-gui) 选择源码及输出路径,然后点击configure …...
MS1023/MS1224——10MHz 到 80MHz、10:1 LVDS 并串转换器(串化器)/串并转换器(解串器)
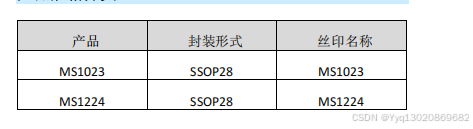
产品简述 MS1023 串化器和 MS1224 解串器是一对 10bit 并串 / 串并转 换芯片,用于在 LVDS 差分底板上传输和接收 10MHz 至 80MHz 的并行字速率的串行数据。起始 / 停止位加载后,转换为负载编 码输出,串行数据速率介于 120Mbps…...

ESOP股权管理平台完整解决方案
——全生命周期合规化、智能化、价值化的资本中枢系统 一、平台顶层架构 1.1 四层驱动模型 #mermaid-svg-QrD0g5nIuRtsMl7c {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-QrD0g5nIuRtsMl7c .error-icon{fill:#552…...
线性调频波形测距测速信号处理——全代码+注释
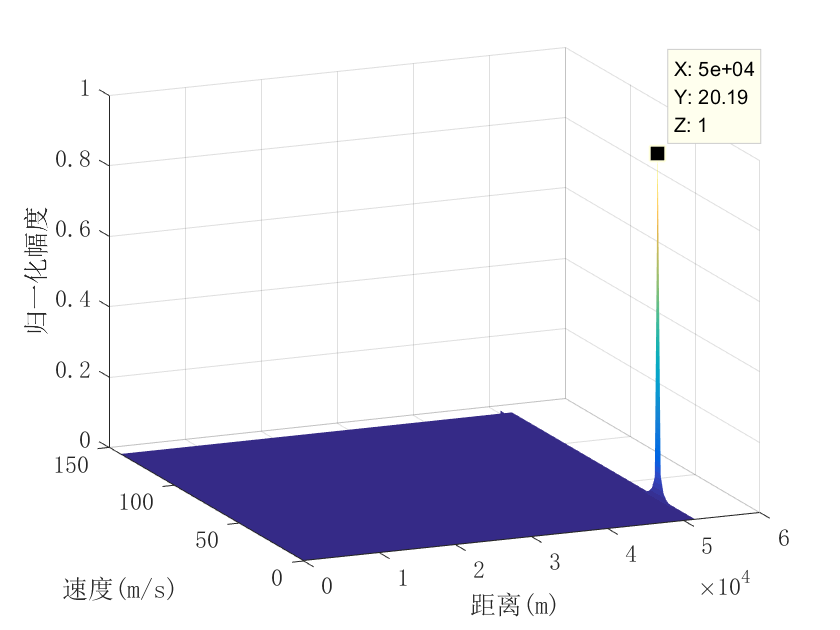
clear all close all clc %% 参数设置 fs600e6;%采样率 fc10.45e9;% 波形发射载频 t10e-6;%脉宽 f050e6;%波形中频频率 B10e6;%带宽 uB/(2*t);%调频斜率 Tv100e-6;% 脉冲重复周期 Num64;% 测速脉冲数 lamdfs/B;% 抽取带宽 Nsround(fs*t); NTvround(fs*Tv); tt0:1/fs:t-1/fs; ff…...
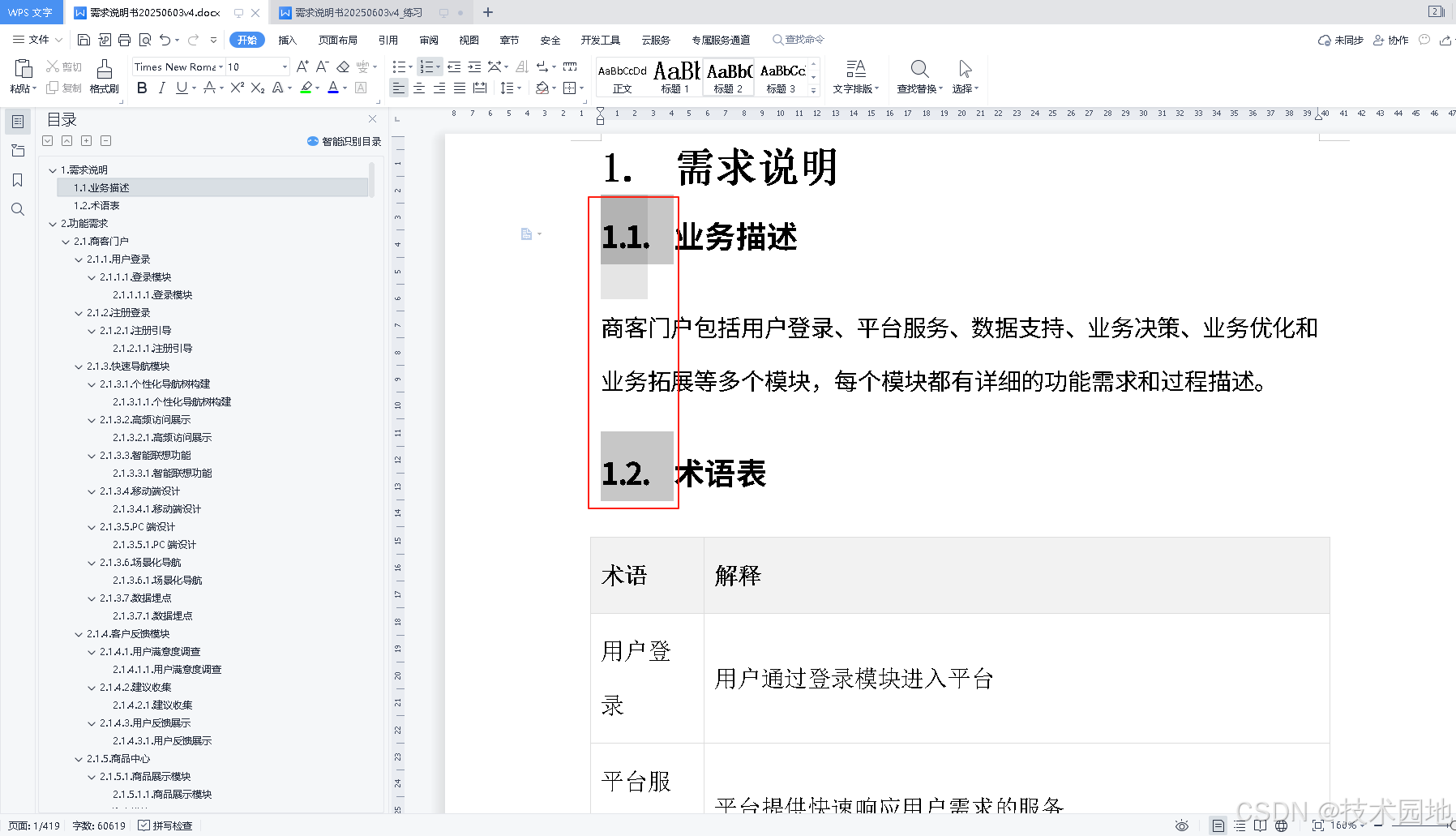
WPS word 已有多级列表序号
wps的word中,原来已生成的文档里,已存在序号。比如,存在2、2.1、2.1.1、2.1.1.1、2.1.1.1.1 5层序号,而且已分为5级。但增加内容的时候,并不会自动增加序号,应该如何解决? 原来长这样ÿ…...
)
Vue 3 源码层核心原理剖析(完整详解版)
一、Compiler 编译过程解密:多框架实现对比 Vue 3 编译流程深度解析(基于 /packages/compiler-core/src/parse.ts) 完整编译链条及技术实现: #mermaid-svg-S8ScpxdjkcJv0YWT {font-family:"trebuchet ms",verdana,ari…...
)
数据库操作-MySQL-4(JDBC编程)
JDBC:通过Java代码操作mysql数据库,数据库会提供一些API供我们调用 MySQL、Oracle、等API有差异,但是Java统一了所有接口,即JDBC; 原始api-驱动包(类似转接头)-统一的api-Java 驱动包࿱…...

Linux打开.img镜像文件
kparkx 可以查看和修改img文件的内容 1.安装kparkx 1.安装 kpartx sudo apt-get update sudo apt-get install kpartx2.使用kpartx映射镜像文件 假设镜像文件名为 example.img ,以下命令会将其分区映射到 dev/mapper/ sudo kpartx -av example.img• -a表示添加…...
)
【FAQ】HarmonyOS SDK 闭源开放能力 —Account Kit(5)
1.问题描述: 集成华为一键登录的LoginWithHuaweiIDButton, 但是Button默认名字叫 “华为账号一键登录”,太长无法显示,能否简写成“一键登录”与其他端一致? 解决方案: 问题分两个场景: 一、…...
【科研绘图系列】R语言绘制论文组合图形(multiple plots)
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍加载R包数据下载导入数据数据预处理画图1画图2画图3画图4画图5系统信息介绍 这篇文章详细介绍了如何使用R语言进行科研绘图,特别是绘制论文组合图形(multiple plots)。文章从数…...
springMVC-9数据格式化
数据格式化 学习目标: 理解在我们提交数据(比如表单时),SpringMVC怎样对提交的数据进行转换和处理的 Spring MVC 上下文中内建了很多转换器,可完成大多数 Java 类型的转换工作。 基本数据类型可以和字符串之间自动完成转换 应用实例-页面…...

Kafka 和Redis 在系统架构中的位置
Kafka 位置:位于应用层和数据存储层之间,作为消息队列和数据传输中间件。作用: 数据收集与传输:收集应用层产生的数据,传输到后端数据存储系统。消息队列:实现应用层各服务之间的异步通信和解耦。与应用层…...

【Spring AI】如何实现文生图功能
在人工智能与软件开发深度融合的当下,Spring AI 作为构建 AI 驱动应用的有力框架,能够便捷集成各类 AI 能力。 文生图技术可将文本描述转化为图像,极具应用价值。接下来,我给大家详细讲解一下如何使用 Spring AI 调用文生图功能。…...

【ISAQB大纲解读】Kafka消息总线被视为“自下而上设计”?
Kafka消息总线被视为“自下而上设计”的典型案例,核心在于其设计路径和演化逻辑完全符合自下而上方法的本质特征: 自下而上设计的核心逻辑 #mermaid-svg-pDSqW0S2h0bj15iN {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16…...
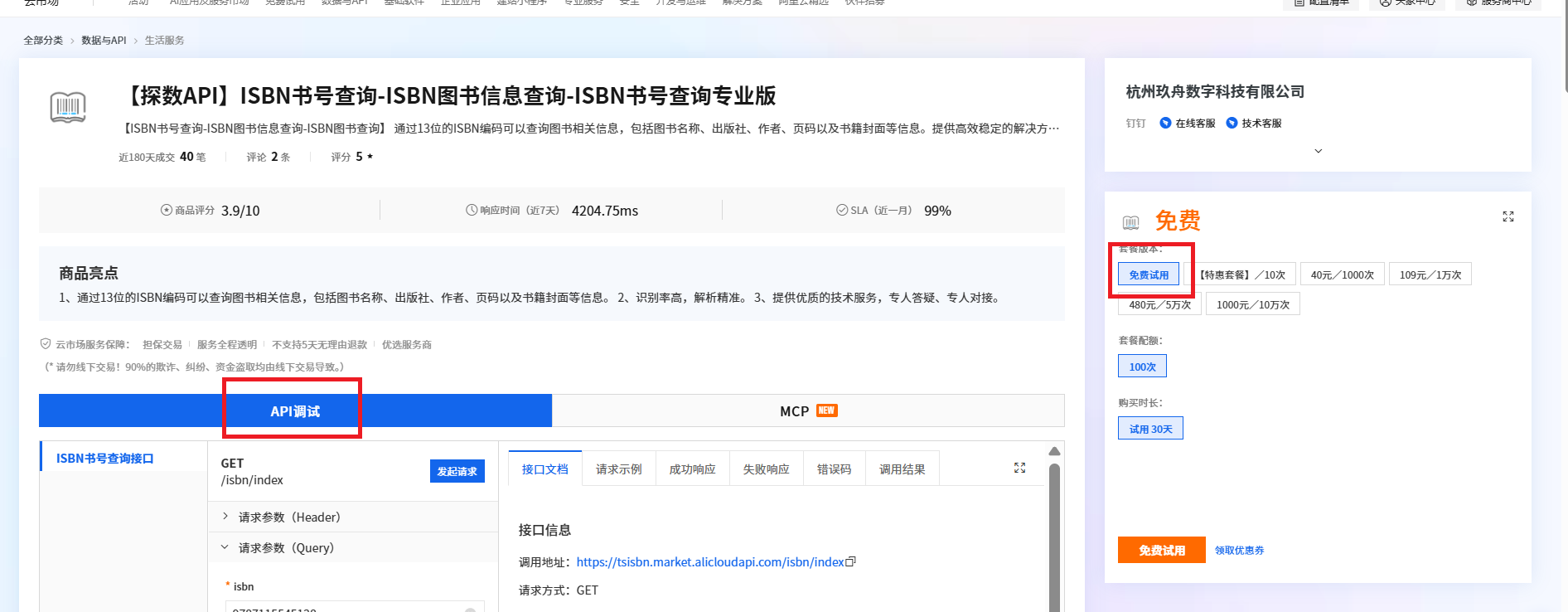
ISBN书号查询接口如何用PHP实现调用?
一、什么是ISBN书号查询接口 ISBN数据查询接口是一项图书信息查询服务。它基于全球通用的ISBN编码系统,帮助用户快速获取图书的详细信息,包括书名、作者、出版社、出版时间、价格、封面等关键字段。 该接口广泛应用于电商平台、图书馆管理系统、二手书…...
,为什么你需要它,它是怎么工作的)
什么是 Docker Compose 的网络(network),为什么你需要它,它是怎么工作的
Docker Compose 的网络就是:让多个容器之间能像“连上同一个局域网”一样互相通信,不用管 IP,用服务名就能访问彼此。 就像家里连接到同一个 WiFi 的手机、电脑、电视,它们都能互相发现对方,Docker 里的容器也是一样 …...
)
嵌入式Linux 期末复习指南(上)
鉴于互联网上针对本科目相关复习视频及资料过少, 撰写本篇期末复习指南用作期末复习知识点扫盲,以应对本科期末考试及格之用。 由于任课老师并透露考试范围或任何有关试卷的相关信息,本篇指南基于教材、上机实验报告及作者经验编写࿰…...

SpringBoot3.2新特性:JdbcClient
文章目录 一、简介二、使用1、支持隐式位置参数2、通过索引设置位置参数3、支持 Name / Value 对命名参数4、通过 Map 设置命名参数5、使用 JdbClient 执行更新操作6、使用示例 参考资料 一、简介 Spring 6.1 中新添加了 JdbcClient 接口,它提供了 Fluent 风格的 A…...

Dify:启动 Web 服务的详细指南
1. 进入 web 目录 cd web解释: cd 是 “change directory” 的缩写,用于切换当前工作目录。您需要进入项目的 web 目录,这是前端代码所在的位置。在这个目录下,您可以执行构建和启动 Web 服务的相关命令。 2. 安装依赖 pnpm in…...

3.1 HarmonyOS NEXT分布式数据管理实战:跨设备同步、端云协同与安全保护
HarmonyOS NEXT分布式数据管理实战:跨设备同步、端云协同与安全保护 在万物互联的时代,数据的跨设备流转与安全共享是全场景应用的核心需求。HarmonyOS NEXT通过分布式数据管理技术,实现了设备间数据的实时同步与端云协同,为开发…...

Aop + 注解实现数据字典类型转换 EasyExcel导出
Aop 注解 实现数据字典类型转换 文章目录 Aop 注解 实现数据字典类型转换一、基础方式✅字典转换简介👉实现步骤✅ 1. 定义自定义注解Dict ✅ 2. 定义查询字典项的两个方法✅ 3. 定义Aop拦截我们查询的方法✅ 4. VO映射类✅ 5. Controller层✅ 6. serviceImpl✅ 7. …...

Python 元组方法全集详解
Python 元组方法全集详解 在 Python 中,元组(tuple)是不可变序列类型,因此支持的操作比列表少。以下是元组支持的所有方法和操作: 一、元组核心方法 1. 创建元组 # 标准创建 t = (1, 2, 3) # (1, 2, 3) t = tuple(...

Selenium 中 JavaScript 点击操作的原理及应用
在 Selenium 中使用 JavaScript 执行点击操作(如 driver.execute_script("arguments[0].click();", element))的原理涉及 WebDriver 架构、浏览器事件机制以及 JavaScript 对 DOM 的直接操作,以下是详细解释: 1. Selen…...
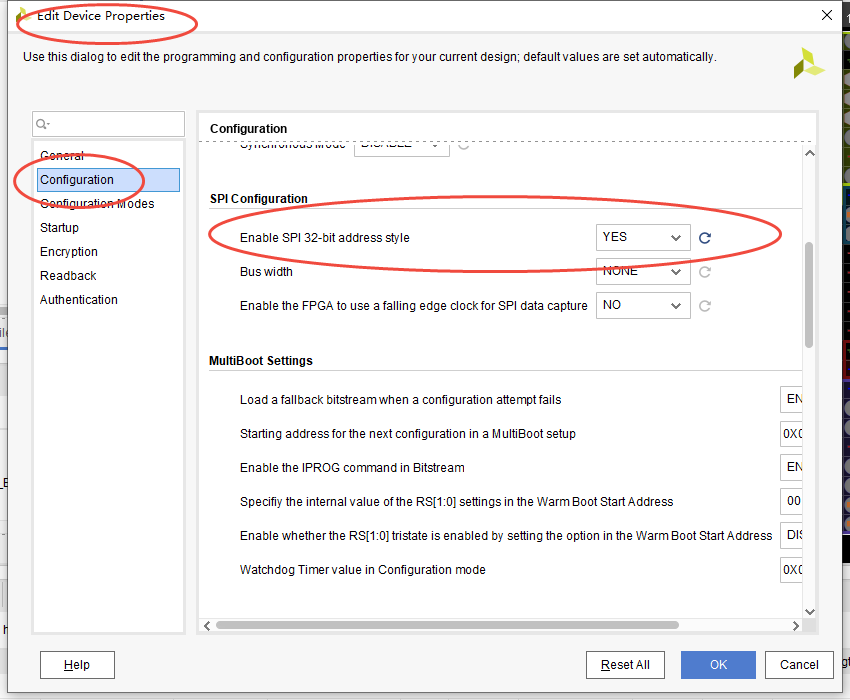
Xilinx超过256m bit flash固件跳转失败问题
问题描述 按照 链接: Xilinx 7系列fpga在线升级和跳转 这个方式跳转失败 问题排查 进一步排查现象如下 上面这个现象呈现出明显的以16m为周期的规律。感觉很大概率是因为flash超过了16m(256bit)导致的地址越界问题。另外我在CSDN上也找到类似的问题…...
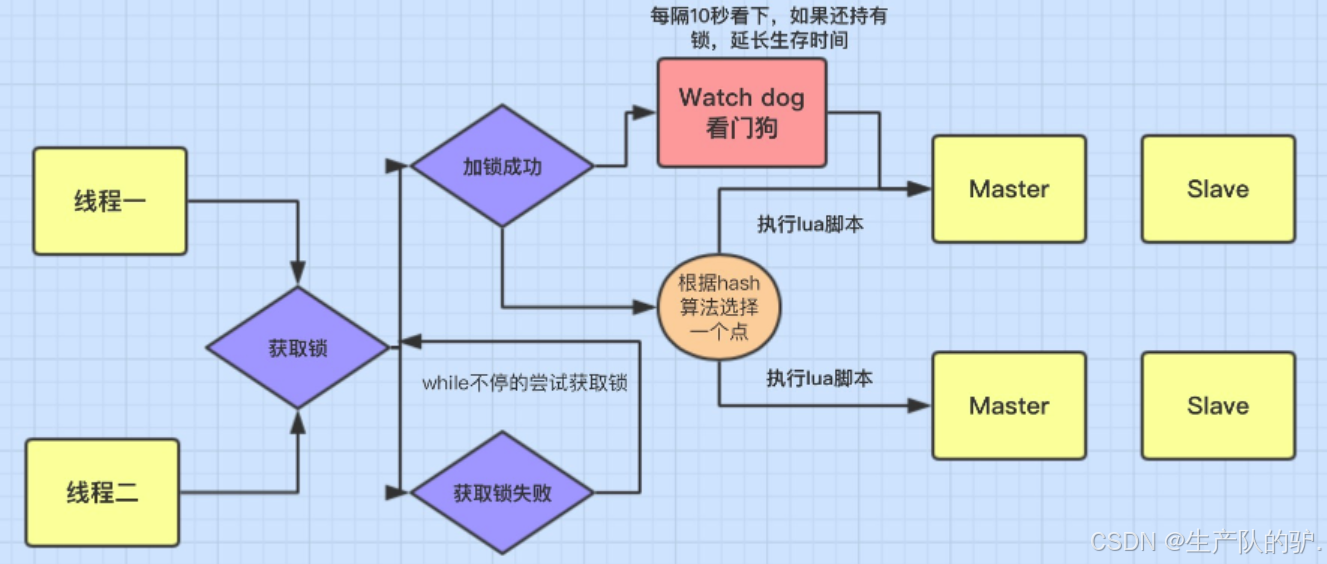
SpringCloud 分布式锁Redisson锁的重入性与看门狗机制 高并发 可重入
可重入 Redisson 的锁支持 可重入性,这意味着同一个线程在获取锁后,如果再次尝试获取该锁,它可以成功地获得锁,而不会被阻塞。 每次一个线程成功获取锁后,它的持有次数会增加。当线程再次获取该锁时,Redi…...