指纹识别+精准化POC攻击
开发目的
解决漏洞扫描器的痛点
第一就是扫描量太大,对一个站点扫描了大量的无用 POC,浪费时间
指纹识别后还需要根据对应的指纹去进行 payload 扫描,非常的麻烦
开发思路
我们的思路分为大体分为指纹+POC+扫描
所以思路大概从这几个方面入手
首先就是 POC,我们得寻找一直在更新的 POC,而且是实时更新的,因为自己写的话有点太费时间了
但是这 POC 的决定是根据我们扫描器来的,因为世面上已经有许多不错的扫描器了,目前打算使用的是 nuclei 扫描器
https://github.com/projectdiscovery/nuclei
Nuclei 是一种现代、高性能的漏洞扫描程序,它利用基于 YAML 的简单模板。它使您能够设计自定义漏洞检测场景,以模拟真实世界的条件,从而实现零误报。
目前也在不断维护更新,当然还有 Xray,Goby 等工具也是不错的选择
然后回到指纹识别技术,这个需要大量的指纹样本,但是世面上的各种工具已经可以做得很好了
指纹识别
这里就的学习一下指纹识别的技术
首先我们需要知道收集指纹目前大概有哪些方法
指纹识别方式
特定文件
比如举一个例子,我们通常是如何判断一个框架是 thinkphp 呢?
我们随便找几个 thinkphp 的网站
特征就是它的图标是非常明显的
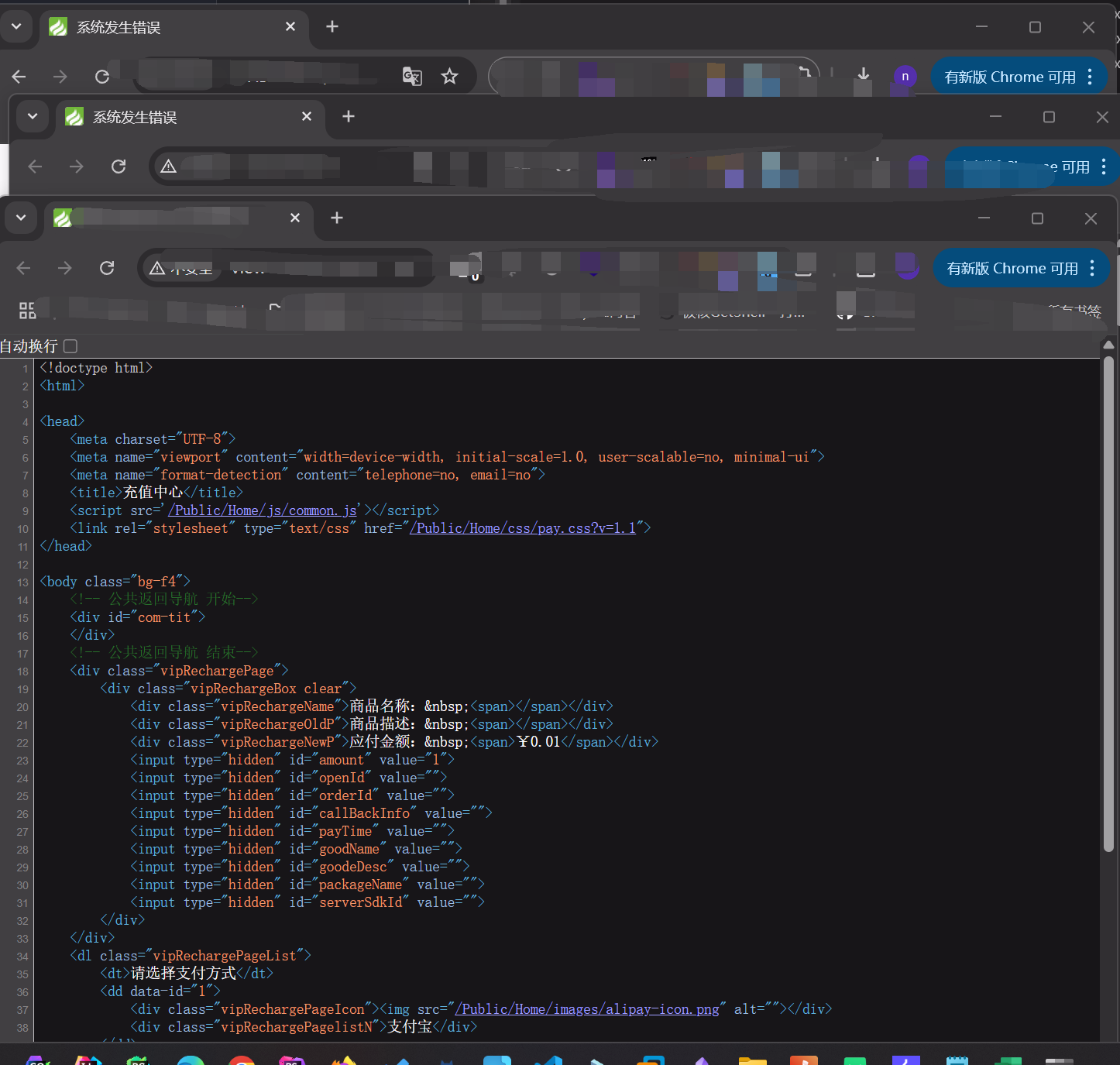
可以看到图标都是一样的,目前 fofa 和 hunter 已经有这种查找的方法了,一般都是把我们的图标换算为我们的 hash 值
这个就是我们的 favicon.ico 图标
一般网站是通过在路径后加入 favicon.ico 比如
http://xxxxxx/favicon.ico
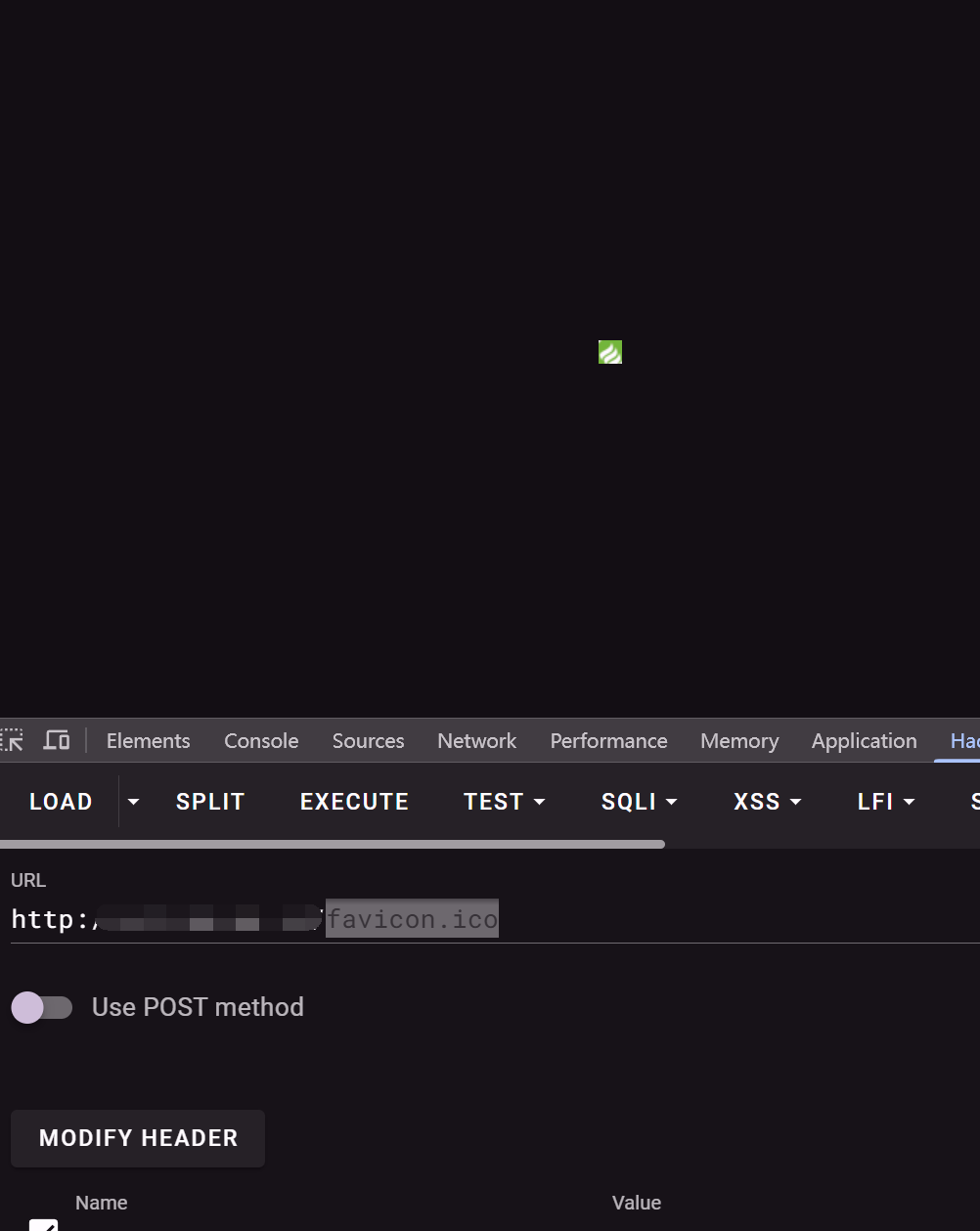
然后就能获取这个图标了,而在 fofa 中可以直接拖动查询了,可以直接算出 hash 值

比如 thinkphp 的
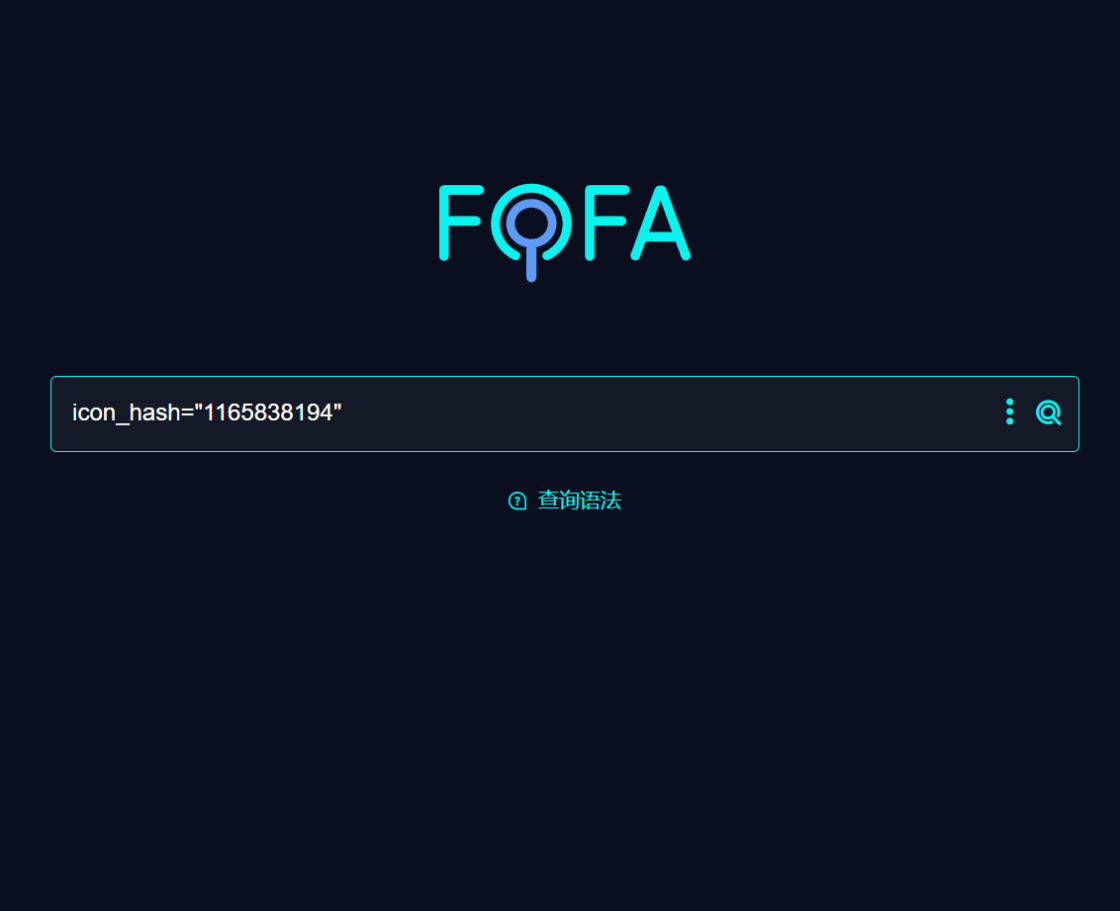
然后再次查询
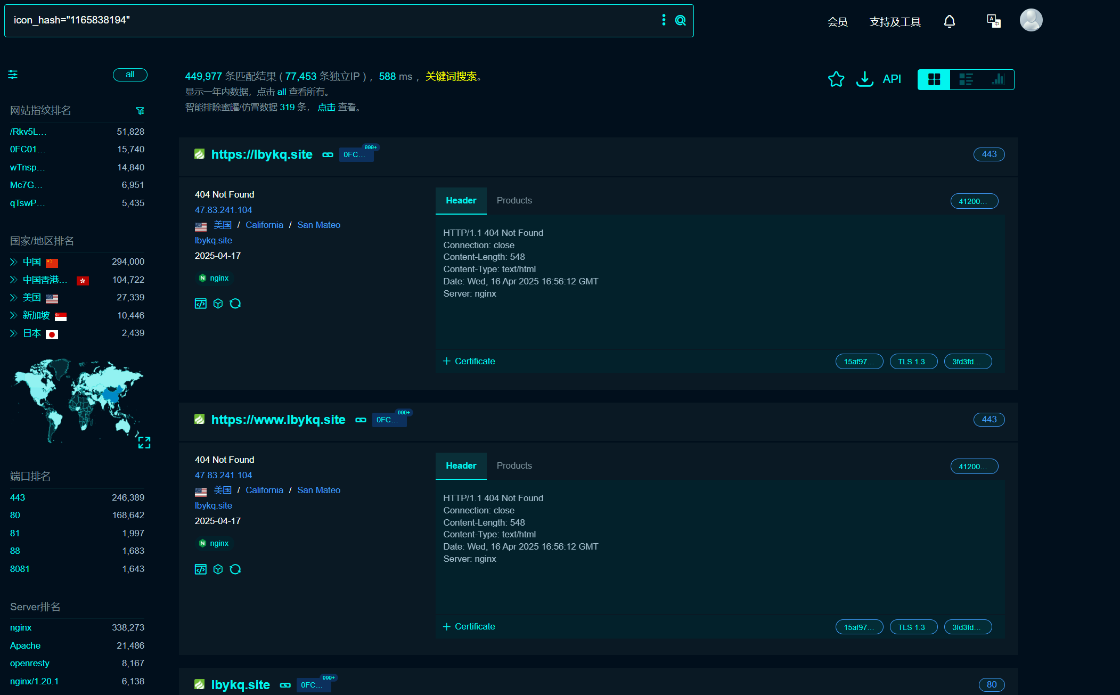
全是 tp 的网站
参考https://github.com/TideSec/TideFinger/blob/master/Web%E6%8C%87%E7%BA%B9%E8%AF%86%E5%88%AB%E6%8A%80%E6%9C%AF%E7%A0%94%E7%A9%B6%E4%B8%8E%E4%BC%98%E5%8C%96%E5%AE%9E%E7%8E%B0.md
当然除了我们的 ico 文件,还有其他很多的文件
帮助网安学习,全套资料S信免费领取:
① 网安学习成长路径思维导图
② 60+网安经典常用工具包
③ 100+SRC分析报告
④ 150+网安攻防实战技术电子书
⑤ 最权威CISSP 认证考试指南+题库
⑥ 超1800页CTF实战技巧手册
⑦ 最新网安大厂面试题合集(含答案)
⑧ APP客户端安全检测指南(安卓+IOS)
一些网站的特定图片文件、js 文件、CSS 等静态文件,如 favicon.ico、css、logo.ico、js 等文件一般不会修改,通过爬虫对这些文件进行抓取并比对 md5 值,如果和规则库中的 Md5 一致则说明是同一 CMS。这种方式速度比较快,误报率相对低一些,但也不排除有些二次开发的 CMS 会修改这些文件。
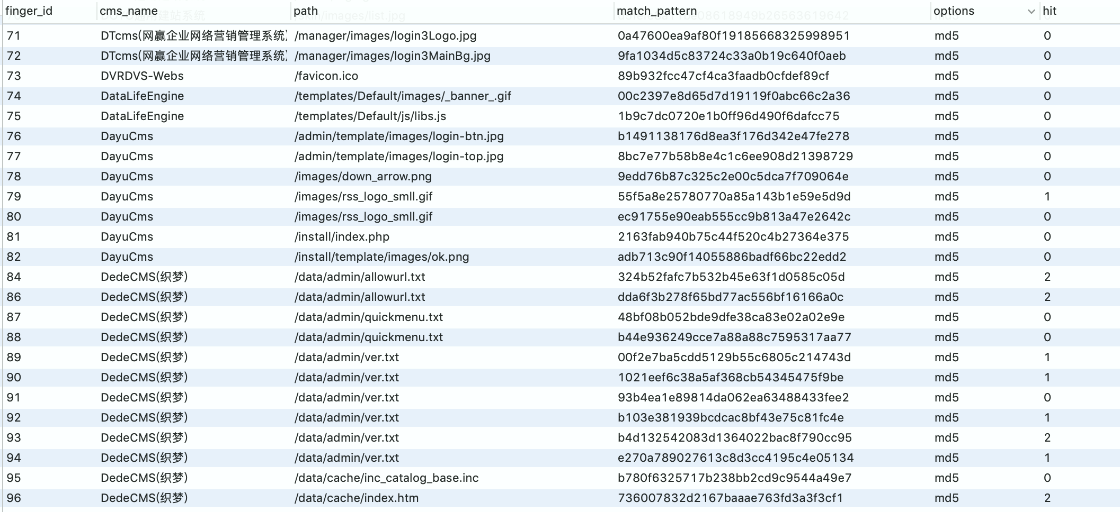
页面关键字
比如 tp 的错误页面大多数都是
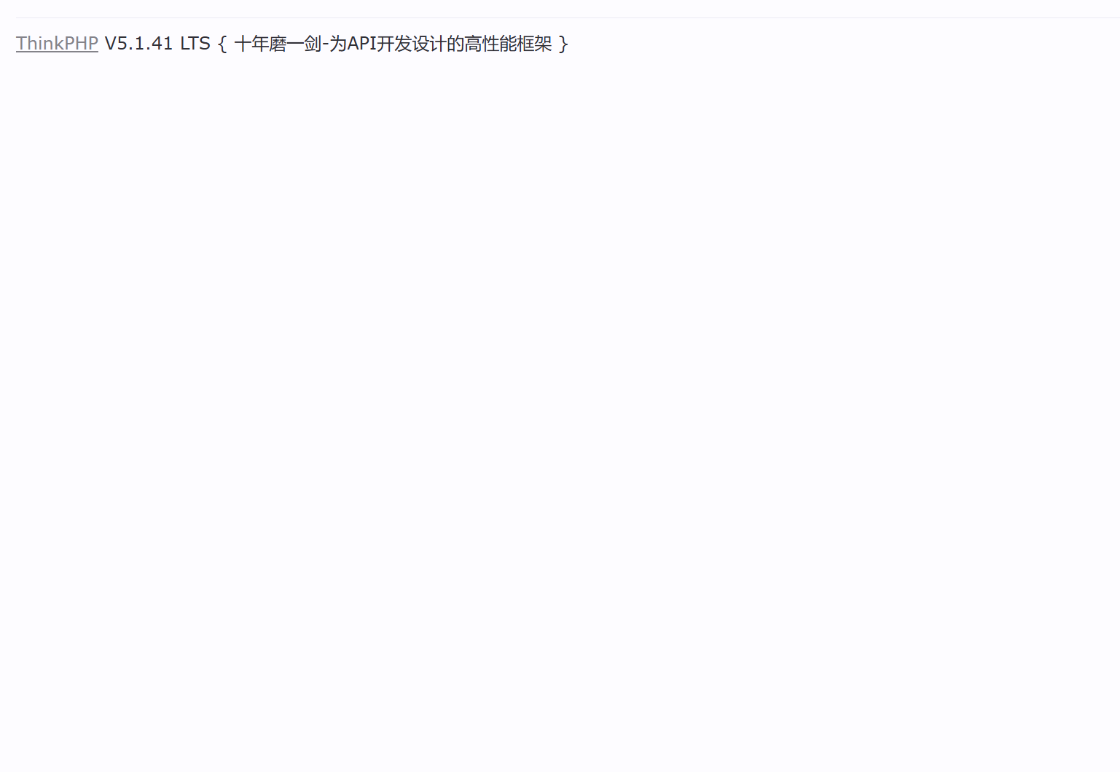
我们 body 就可以包含这个关键字了
或者可以构造错误页面,根据报错信息来判断使用的 CMS 或者中间件信息,比较常见的如 tomcat 和 spring 的报错页面。
根据 response header 一般有以下几种识别方式:
请求头关键字
根据网站 response 返回头信息进行关键字匹配,这个一般是 ningx 这种
能够识别我们的服务器
URL 路径
根据总结
wordpress 默认存在 wp-includes 和 wp-admin 目录,织梦默认管理后台为 dede 目录,solr 平台可能使用/solr 目录,weblogic 可能使用 wls-wsat 目录等。
大部分还是根据我们的 body
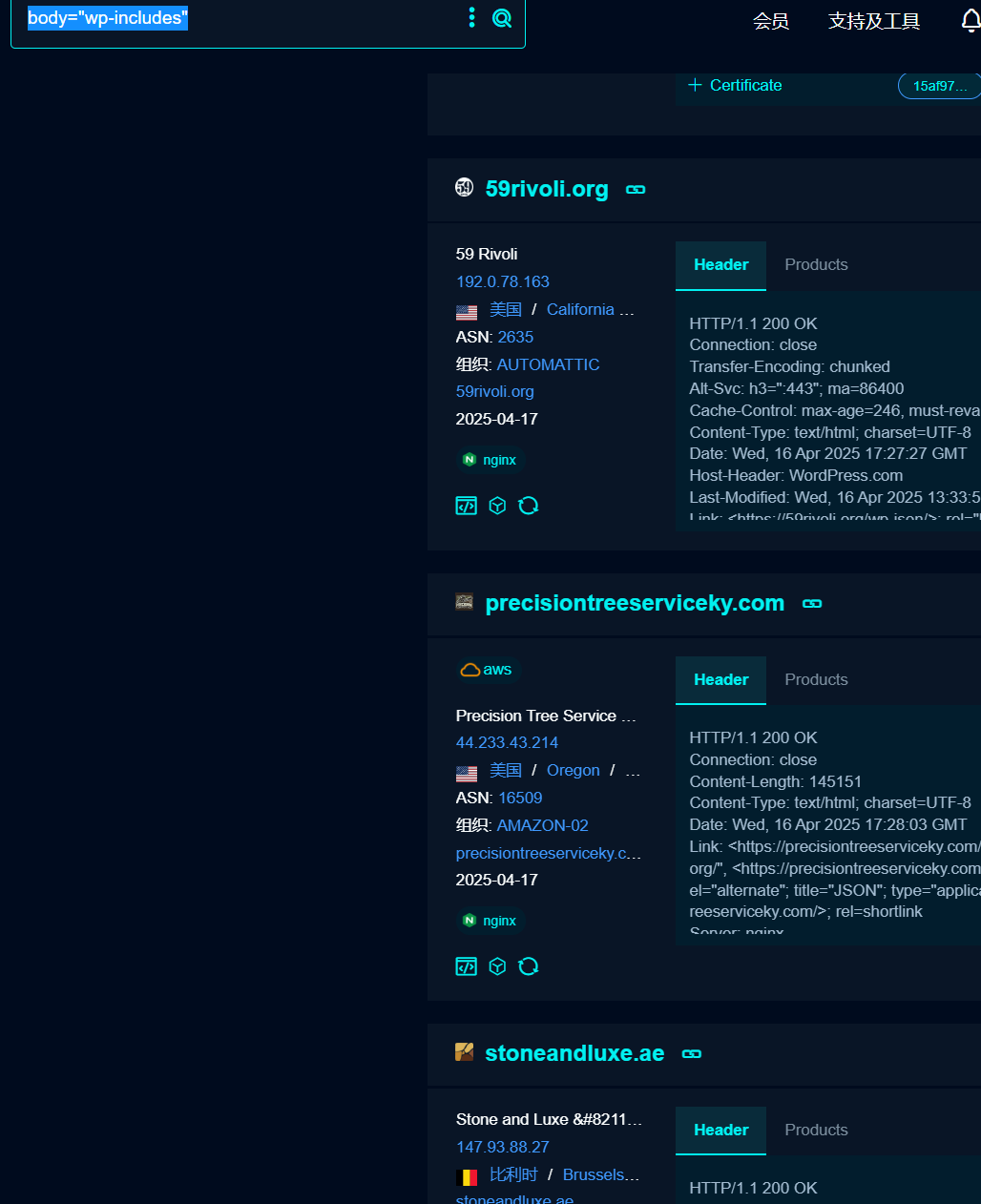
然后点一个进去
可以看到都是我们的 wordPress 的站点
指纹识别方法
有了我们上面的识别技术,那么我们大概是如何来识别一个指纹的呢
首先使用 python 简单举一个实现
首先就是需要一个配置文件,这个配置文件就需要包含我们的大体指纹和验证方法
- name: ThinkPHP
matchers:- type: headerrule: X-Powered-Bykeyword: ThinkPHP- type: bodykeyword: "http://www.thinkphp.cn"- type: bannerkeyword: thinkphp- type: pathpath: /thinkphp/library/think/keyword: class- type: favicon_hashhash: 1165838194然后就是我们的后端处理逻辑了
import yaml
import requests
import socket
import base64
import mmh3def get_http_response(url, path=""):try:full_url = url.rstrip("/") + pathreturn requests.get(full_url, timeout=5)except:return Nonedef get_tcp_banner(ip, port=80):try:with socket.create_connection((ip, port), timeout=5) as s:banner = s.recv(1024).decode(errors="ignore")return bannerexcept:return ""def get_favicon_hash(url):try:res = requests.get(url.rstrip("/") + "/favicon.ico", timeout=5)favicon = base64.encodebytes(res.content)return mmh3.hash(favicon.decode('utf-8'))except:return Nonedef load_fingerprints(path="fingerprints.yaml"):with open(path, "r", encoding="utf-8") as f:return yaml.safe_load(f)def match_fingerprint(url, ip=None):fingerprints = load_fingerprints()results = []res = get_http_response(url)banner = get_tcp_banner(ip or url.replace("http://", "").replace("https://", ""), 80)favicon_hash = get_favicon_hash(url)for fp in fingerprints:matched = Falsefor matcher in fp["matchers"]:if matcher["type"] == "header" and res:if matcher["rule"] in res.headers and matcher["keyword"].lower() in res.headers[matcher["rule"]].lower():matched = Trueelif matcher["type"] == "body" and res:if matcher["keyword"].lower() in res.text.lower():matched = Trueelif matcher["type"] == "banner":if matcher["keyword"].lower() in banner.lower():matched = Trueelif matcher["type"] == "path":res2 = get_http_response(url, matcher["path"])if res2 and matcher["keyword"].lower() in res2.text.lower():matched = Trueelif matcher["type"] == "favicon_hash":if favicon_hash == matcher["hash"]:matched = Trueif matched:results.append(fp["name"])return results# 示例使用
if __name__ == "__main__":target_url = "http://101.200.50.94:8009/"result = match_fingerprint(target_url)print("识别结果:", result)大体逻辑就是这样了
首先就是 yaml 文件为我们的判断依据,对应不同的判断方法我们都有对应的后端处理
一个是对 body 的处理,一个是对 hash 文件的处理
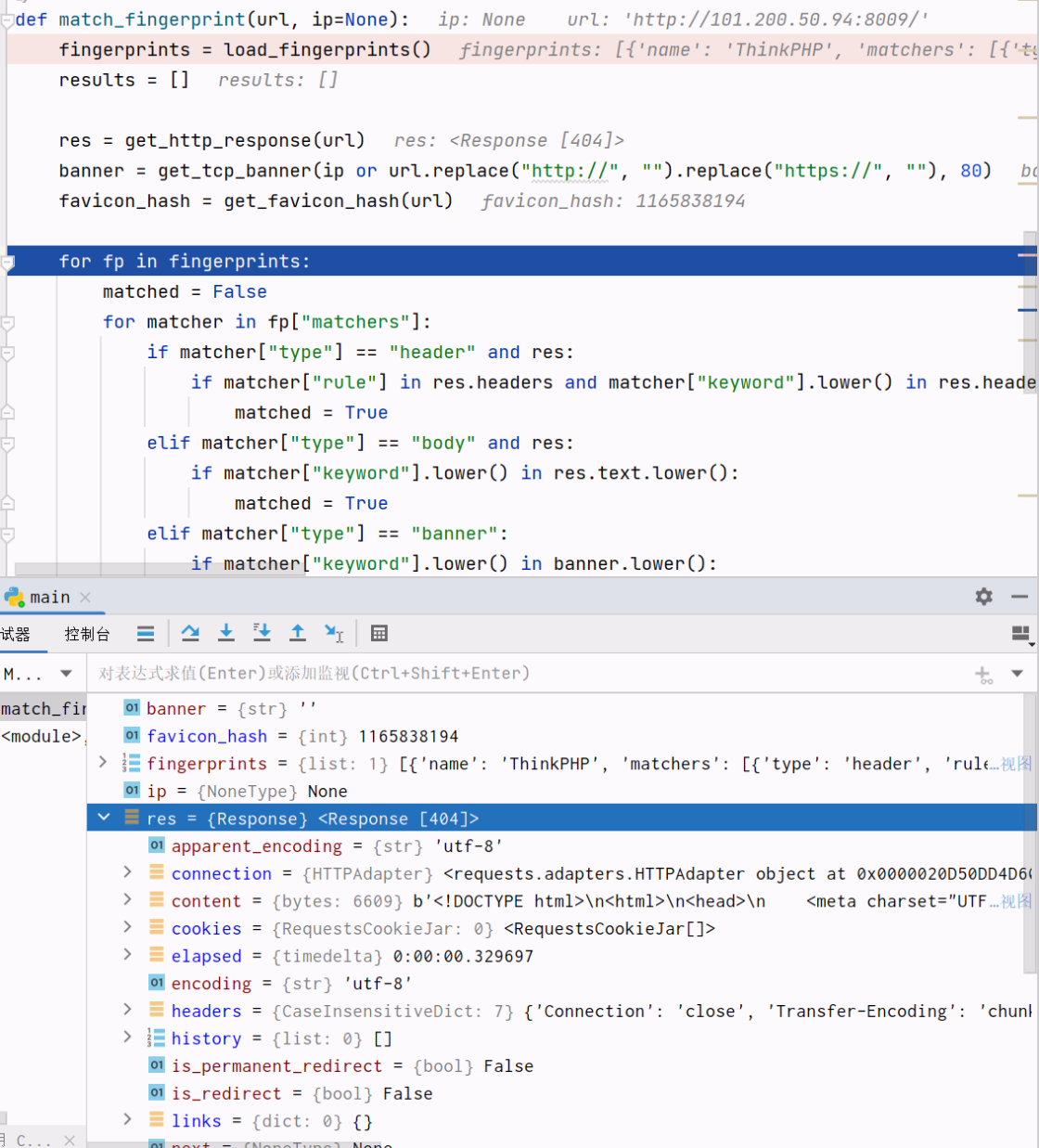
然后再根据规则去匹配
匹配成功输出结果
当然这只是一个简单的逻辑,如果需要实现更高高效快捷第一就是指纹库,第二就是代码运行的速率,提高线程
最终识别代码
首先就是指纹库的获取,这个的话我们就不直接获取了,使用的是 EHole 的指纹库
我们大概看看部分代码
{
"fingerprint": [{"cms": "seeyon","method": "keyword","location": "body","keyword": ["/seeyon/USER-DATA/IMAGES/LOGIN/login.gif"]
}, {"cms": "seeyon","method": "keyword","location": "body","keyword": ["/seeyon/common/"]
}, {"cms": "Spring env","method": "keyword","location": "body","keyword": ["servletContextInitParams"]
}, {"cms": "微三云管理系统","method": "keyword","location": "body","keyword": ["WSY_logo","管理系统 MANAGEMENT SYSTEM"]
}, {"cms": "Spring env","method": "keyword","location": "body","keyword": ["logback"]
}, {"cms": "Weblogic","method": "keyword","location": "body","keyword": ["Error 404--Not Found"]
}, {"cms": "Weblogic","method": "keyword","location": "body","keyword": ["Error 403--"]
}{"cms": "Atlassian – JIRA","method": "faviconhash","location": "body","keyword": ["981867722"]
}, {"cms": "OpenStack","method": "faviconhash","location": "body","keyword": ["-923088984"]
}, {"cms": "Aplikasi","method": "faviconhash","location": "body","keyword": ["494866796"]
}, {"cms": "Ubiquiti Aircube","method": "faviconhash","location": "body","keyword": ["1249285083"]
}
简单看了一下逻辑可以发现和我们的指定方法应该差不多,逻辑就是首先根据 method 去选择方法,一个是 keyword 方法,一个是 faviconhash 方法,是一个大的判断,然乎下面就是根据具体的比如 body,title 等去识别了
代码如下
import json
import requests
import hashlib
import base64
from bs4 import BeautifulSoup
from urllib.parse import urljoin
from concurrent.futures import ThreadPoolExecutor, as_completed
import argparse# 加载指纹
def load_fingerprints(file='finger.json'):with open(file, 'r', encoding='utf-8') as f:data = json.load(f)if "fingerprint" in data:return data["fingerprint"]raise ValueError("指纹文件格式不正确,应包含 'fingerprint' 字段。")# 获取 HTTP 响应
def get_http_response(url):try:headers = {"User-Agent": "Mozilla/5.0"}return requests.get(url, headers=headers, timeout=8, verify=False)except:return None# 计算 favicon hash
def get_favicon_hash(url):try:favicon_url = urljoin(url, '/favicon.ico')res = requests.get(favicon_url, timeout=5, verify=False)if res.status_code == 200:m = hashlib.md5()b64 = base64.b64encode(res.content)m.update(b64)return int(m.hexdigest(), 16)except:return None# 匹配单条指纹
def match_one(fpr, res, fav_hash):method = fpr["method"]loc = fpr.get("location", "body").lower()kws = fpr["keyword"]if method == 'keyword':text_body = res.text or ""text_head = "\n".join(f"{k}: {v}" for k, v in res.headers.items())# 处理 title 和 header 等if loc == 'header':spaces = [text_head, text_body]elif loc == 'title':soup = BeautifulSoup(text_body, "html.parser")title = soup.title.string if soup.title and soup.title.string else ""spaces = [title, text_body]elif loc == 'body':spaces = [text_body]else:spaces = [text_body]for space in spaces:for kw in kws:if kw.lower() in space.lower():return Trueif method == 'faviconhash' and fav_hash is not None:for kw in kws:try:if fav_hash == int(kw):return Trueexcept:continuereturn False# 识别单个 URL 指纹
def match_fingerprint(url, fps=None):fps = fps or load_fingerprints()res = get_http_response(url)fav_hash = get_favicon_hash(url)matched = []for fpr in fps:if 'cms' not in fpr or 'method' not in fpr or 'keyword' not in fpr:continueif match_one(fpr, res, fav_hash):matched.append(fpr['cms'])print(f"[✓] {url} 指纹识别结果:{list(set(matched))}")return {url: list(set(matched))}# 多线程执行
def run_multithread(urls, threads):fps = load_fingerprints()results = []with ThreadPoolExecutor(max_workers=threads) as executor:future_to_url = {executor.submit(match_fingerprint, url, fps): url for url in urls}for future in as_completed(future_to_url):results.append(future.result())return results# 主程序入口
def main():parser = argparse.ArgumentParser(description="指纹识别脚本 - 支持多线程")group = parser.add_mutually_exclusive_group(required=True)group.add_argument("-u", "--url", help="单个目标 URL")group.add_argument("-f", "--file", help="包含多个 URL 的文件")parser.add_argument("-t", "--threads", type=int, default=10, help="线程数(默认10)")args = parser.parse_args()if args.url:match_fingerprint(args.url)elif args.file:with open(args.file, 'r', encoding='utf-8') as f:urls = [line.strip() for line in f if line.strip()]results = run_multithread(urls, args.threads)if __name__ == '__main__':main()加入了支持多线程和支持多目标的思路
结合漏洞扫描
我们光目标识别后,还需要实现精准化打击,正好 Nuclei 引擎支持根据 tag 去寻找我们的目标,完美了
实现思路就是首先寻找我们的 tag,然后在漏洞库里面查询,把有 tag 的和没有 tag 的分别分开放好,然后根据有 tag 的去精准化识别运行,完成最后的精准化 POC 攻击
初步的代码如下
import json
import os
import threading
import time
import base64
import hashlib
import requests
import argparse
from bs4 import BeautifulSoup
from urllib.parse import urljoin
from concurrent.futures import ThreadPoolExecutor, as_completed
from queue import Queuerequests.packages.urllib3.disable_warnings()# ---------- 指纹识别部分 ----------def load_fingerprints(file='finger.json'):with open(file, 'r', encoding='utf-8') as f:data = json.load(f)return data["fingerprint"]def get_http_response(url):try:headers = {"User-Agent": "Mozilla/5.0"}return requests.get(url, headers=headers, timeout=8, verify=False)except:return Nonedef get_favicon_hash(url):try:favicon_url = urljoin(url, '/favicon.ico')res = requests.get(favicon_url, timeout=5, verify=False)if res.status_code == 200:m = hashlib.md5()b64 = base64.b64encode(res.content)m.update(b64)return int(m.hexdigest(), 16)except:return Nonedef match_one(fpr, res, fav_hash):method = fpr["method"]loc = fpr.get("location", "body").lower()kws = fpr["keyword"]if method == 'keyword':text_body = res.text or ""text_head = "\n".join(f"{k}: {v}" for k, v in res.headers.items())if loc == 'header':spaces = [text_head]elif loc == 'title':soup = BeautifulSoup(text_body, "html.parser")title = soup.title.string if soup.title and soup.title.string else ""spaces = [title]else:spaces = [text_body]for space in spaces:for kw in kws:if kw.lower() in space.lower():return Trueelif method == 'faviconhash' and fav_hash is not None:for kw in kws:try:if fav_hash == int(kw):return Trueexcept:continuereturn Falsedef match_fingerprint(url, fps):res = get_http_response(url)fav_hash = get_favicon_hash(url)matched = []for fpr in fps:if 'cms' not in fpr or 'method' not in fpr or 'keyword' not in fpr:continueif match_one(fpr, res, fav_hash):matched.append(fpr['cms'])print(f"[✓] {url} 指纹识别结果:{list(set(matched))}")return {"url": url, "cms": list(set(matched))[0] if matched else ""}def run_fingerprint_scan(urls, threads, output='res.json'):fps = load_fingerprints()results = []with ThreadPoolExecutor(max_workers=threads) as executor:future_to_url = {executor.submit(match_fingerprint, url, fps): url for url in urls}for future in as_completed(future_to_url):results.append(future.result())with open(output, 'w', encoding='utf-8') as f:json.dump(results, f, ensure_ascii=False, indent=2)# ---------- Nuclei 扫描部分 ----------class AutoNuclei:def __init__(self, res_file='res.json', tag_file='C:\\Users\\86135\\nuclei-templates\\TEMPLATES-STATS.json', thread_count=5):self.res_file = res_fileself.tag_file = tag_fileself.havetag_file = 'havetag.txt'self.notag_file = 'notag.txt'self.result_dir = 'result'self.thread_count = thread_countself.cms_targets = {} # {cms: [url1, url2]}self.nuclei_tags = set()self.tagged_targets = {} # {tag: [url1, url2]}self.untagged_targets = []self.task_queue = Queue()self.load_res_json()self.load_tags()self.classify_targets()self.save_targets()self.start_scan_threads()def load_res_json(self):with open(self.res_file, 'r', encoding='utf-8') as f:data = json.load(f)for entry in data:cms = entry.get("cms", "").lower()url = entry.get("url")if cms and url:self.cms_targets.setdefault(cms, []).append(url)def load_tags(self):with open(self.tag_file, 'r', encoding='utf-8') as f:tags_data = json.load(f)for item in tags_data.get("tags", []):if item["name"]:self.nuclei_tags.add(item["name"].lower())def classify_targets(self):for cms, urls in self.cms_targets.items():if cms in self.nuclei_tags:self.tagged_targets.setdefault(cms, []).extend(urls)else:self.untagged_targets.extend(urls)def save_targets(self):with open(self.havetag_file, 'w', encoding='utf-8') as f:for tag, urls in self.tagged_targets.items():for url in urls:f.write(f"{tag}||{url}\n")with open(self.notag_file, 'w', encoding='utf-8') as f:for url in self.untagged_targets:f.write(url + '\n')if not os.path.exists(self.result_dir):os.makedirs(self.result_dir)def scan_worker(self):while not self.task_queue.empty():try:tag, url = self.task_queue.get(timeout=1)target_file = f"temp_{int(time.time() * 1000)}.txt"with open(target_file, 'w', encoding='utf-8') as f:f.write(url)output_file = os.path.join(self.result_dir, f"{tag}_{int(time.time())}.txt")cmd = f"F:\\gj\\Vulnerability_Scanning\\nuclei\\nuclei.exe -l {target_file} -tags {tag} -o {output_file} -stats"print(f"[+] 扫描任务启动: {url} -> {tag}")os.system(cmd)os.remove(target_file)except Exception as e:print(f"[!] 线程错误: {e}")def start_scan_threads(self):for tag, urls in self.tagged_targets.items():for url in urls:self.task_queue.put((tag, url))threads = []for _ in range(self.thread_count):t = threading.Thread(target=self.scan_worker)t.start()threads.append(t)for t in threads:t.join()print("[✓] 所有扫描任务完成!")# ---------- 主程序入口 ----------def main():parser = argparse.ArgumentParser(description="指纹识别 + Nuclei自动化工具")group = parser.add_mutually_exclusive_group(required=True)group.add_argument("-u", "--url", help="目标 URL")group.add_argument("-f", "--file", help="URL列表文件")parser.add_argument("--fp-threads", type=int, default=10, help="指纹识别线程数")parser.add_argument("--scan-threads", type=int, default=5, help="Nuclei 扫描线程数")args = parser.parse_args()urls = []if args.url:urls = [args.url]elif args.file:with open(args.file, 'r', encoding='utf-8') as f:urls = [line.strip() for line in f if line.strip()]print("[*] 正在执行指纹识别...")run_fingerprint_scan(urls, threads=args.fp_threads, output='res.json')print("[*] 指纹识别完成,开始 Nuclei 扫描...")AutoNuclei(res_file='res.json',tag_file=os.path.join(os.environ['USERPROFILE'], 'nuclei-templates', 'TEMPLATES-STATS.json'),thread_count=args.scan_threads)if __name__ == '__main__':main()
相关文章:
指纹识别+精准化POC攻击
开发目的 解决漏洞扫描器的痛点 第一就是扫描量太大,对一个站点扫描了大量的无用 POC,浪费时间 指纹识别后还需要根据对应的指纹去进行 payload 扫描,非常的麻烦 开发思路 我们的思路分为大体分为指纹POC扫描 所以思路大概从这几个方面…...

LeetCode[404]左叶子之和
思路: 题目要求求出左叶子的和,左叶子的条件是左右节点为空且是左子树的叶子节点才叫左叶子节点,那么右子树的左叶子节点的和是什么呢?这样想就引出了递归的顺序,后序遍历,求出左右子树的节点和,…...

mac环境下的python、pycharm和pip安装使用
Python安装 Mac环境下的python安装 下载地址:https://www.jetbrains.com.cn/pycharm/ 一直点击下一步即可完成 在应用程序中会多了两个图标 IDLE 和 Python launcher IDLE支持在窗口中直接敲python命令并立即执行,双击即可打开 Python launcher双击打…...

C语言多级指针深度解析:从一级到三级的奥秘
资料合集下载链接: https://pan.quark.cn/s/472bbdfcd014 在C语言中,指针是理解内存和进行底层编程的关键。我们知道,一个一级指针存储的是一个变量的内存地址。但C语言的强大之处在于,指针本身也可以有自己的地址,而存储这个指针的地址的变量,就是一个更高层次…...

uni-app学习笔记十九--pages.json全局样式globalStyle设置
pages.json 页面路由 pages.json 文件用来对 uni-app 进行全局配置,决定页面文件的路径、窗口样式、原生的导航栏、底部的原生tabbar 等。 导航栏高度为 44px (不含状态栏),tabBar 高度为 50px (不含安全区)。 它类似微信小程序中app.json的页面管理部…...

BUUCTF[极客大挑战 2019]Havefun 1题解
BUUCTF[极客大挑战 2019]Havefun 1题解 题目分析解题理解代码逻辑:构造Payload: 总结 题目分析 生成靶机,进入网址: 首页几乎没有任何信息,公式化F12打开源码,发现一段被注释的源码: 下面我们…...

【基础】Unity中Camera组件知识点
一、投影模式 (Projection) 1. 透视模式 (Perspective) 原理:模拟人眼,近大远小(锥形体视锥) 核心参数: Field of View (FOV):垂直视场角 典型值:第一人称 60-90,驾驶舱 30-45 特…...

Tomcat优化篇
目录 一、Tomcat自身配置 1.Tomcat管理页面 2. 禁用AJP服务 3.Executor优化 4.三种运行模式 5.web.xml 6.Host标签 7.Context标签 8.启动速度优化 9.其他方面 二、JMeter测试 笔者推荐 一、Tomcat自身配置 1.Tomcat管理页面 我们可以打开Tomcat的管理页面ÿ…...
Temporal Fusion Transformer(TFT)扩散模型时间序列预测模型
1. TFT 简介 Temporal Fusion Transformer(TFT)模型是一种专为时间序列预测设计的高级深度学习模型。它结合了神经网络的多种机制处理时间序列数据中的复杂关系。TFT 由 Lim et al. 于 2019年提出,旨在处理时间序列中的不确定性和多尺度的依…...

【LangServe部署流程】5 分钟部署你的 AI 服务
目录 一、LangServe简介 二、环境准备 1. 安装必要依赖 2. 编写一个 LangChain 可运行链(Runnable) 3. 启动 LangServe 服务 4. 启动服务 5. 使用 API 进行调用 三、可选:访问交互式 Swagger 文档 四、基于 LangServe 的 RAG 应用部…...
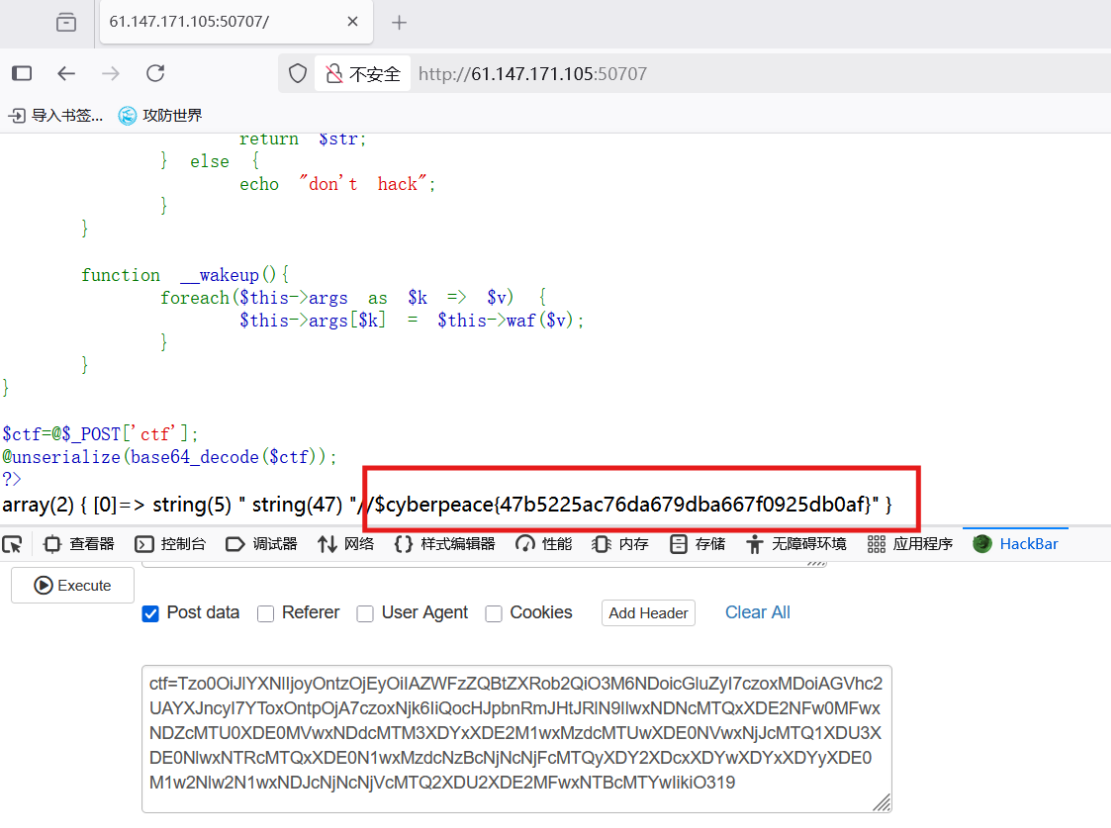
攻防世界-unseping
进入环境 在获得的场景中发现PHP代码并进行分析 编写PHP编码 得到 Tzo0OiJlYXNlIjoyOntzOjEyOiIAZWFzZQBtZXRob2QiO3M6NDoicGluZyI7czoxMDoiAGVhc2UAYXJncyI7YToxOntpOjA7czozOiJwd2QiO319 将其传入 想执行ls,但是发现被过滤掉了 使用环境变量进行绕过 $a new…...

微软推出 Bing Video Creator,免费助力用户轻松创作 AI 视频
2025 年 6 月 2 日,微软正式在自家 Bing 应用中上线了一项名为 “Bing Video Creator” 的新功能,为广大用户带来了全新的创作体验。 Bing Video Creator 背靠 OpenAI 当红的 Sora 视频生成模型,用户只需输入文字描述,就能直接生…...
java+ selenium->元素定位大法之By_partial_link_text)
(13)java+ selenium->元素定位大法之By_partial_link_text
1.简介 在上一篇中我们说了link_text,目前我们接着看partial link text,顾名思义是通过链接定位的(官方说法:超链接文本定位)。我们在上一篇的文章末尾有提到,这种方式的定位属于模糊匹配定位,什么是partial link text呢,看到part这个单词我们就可以知道,当这个文字超…...

Xget 正式发布:您的高性能、安全下载加速工具!
您可以通过 star 我固定的 GitHub 存储库来支持我,谢谢!以下是我的一些 GitHub 存储库,很有可能对您有用: tzst Xget Prompt Library 原文 URL:https://blog.xi-xu.me/2025/06/02/xget-launch-high-performance-sec…...
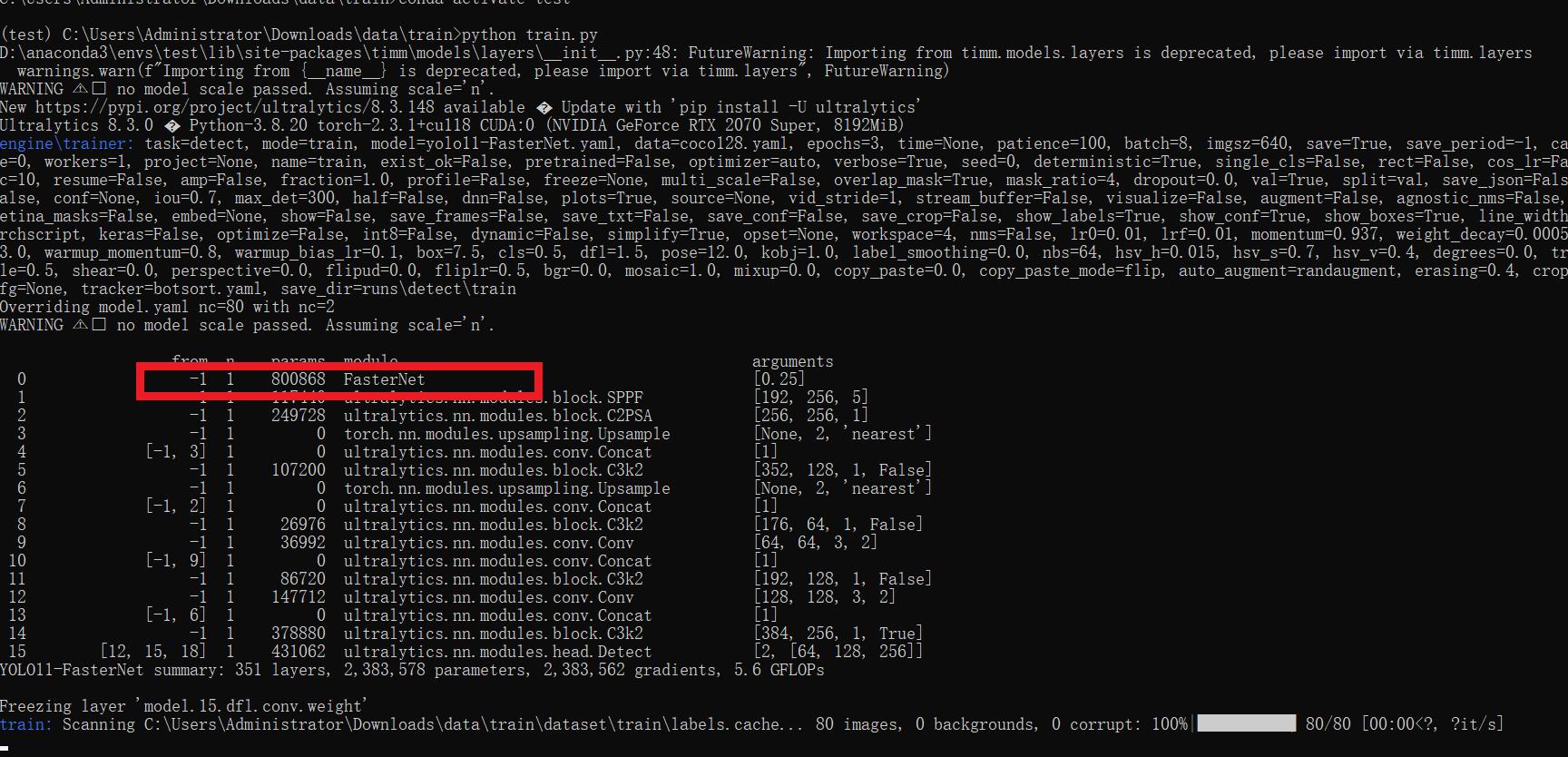
[yolov11改进系列]基于yolov11使用FasterNet替换backbone用于轻量化网络的python源码+训练源码
【FasterNet介绍】 为了设计快速神经网络,许多工作都集中在减少浮点运算的数量(FLOPs)上。 然而,我们观察到FLOPs的减少并不一定会导致延迟的类似程度的减少。 这主要源于低效率的每秒浮点运算(FLOPS)。 为了实现更快的网络&#…...
一周学会Pandas2之Python数据处理与分析-Pandas2数据绘图与可视化
锋哥原创的Pandas2 Python数据处理与分析 视频教程: 2025版 Pandas2 Python数据处理与分析 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili Pandas 集成了 Matplotlib,提供了简单高效的绘图接口,使数据可视化变得直观便捷。本指南将详…...

企业级安全实践:SSL/TLS 加密与权限管理(一)
引言 ** 在数字化转型的浪潮中,企业对网络的依赖程度与日俱增,从日常办公到核心业务的开展,都离不开网络的支持。与此同时,网络安全问题也日益严峻,成为企业发展过程中不可忽视的重要挑战。 一旦企业遭遇网络安全事…...

2025——》VSCode Windows 最新安装指南/VSCode安装完成后如何验证是否成功?2025最新VSCode安装配置全攻略
1.VSCode Windows 最新安装指南: 以下是 2025 年 Windows 系统下安装 Visual Studio Code(VSCode)的最新指南,结合官方文档与实际操作经验整理而成: 一、下载官方安装包: 1.访问官网: 打开浏览器,进入 VSCode 官方下载页面https://code.visualstudio.com/Download 2…...

RabbitMQ如何保证消息可靠性
RabbitMQ是一个流行的开源消息代理,它提供了可靠的消息传递机制,广泛应用于分布式系统和微服务架构中。在现代应用中,确保消息的可靠性至关重要,以防止消息丢失和重复处理。本文将详细探讨RabbitMQ如何通过多种机制保证消息的可靠…...

【MATLAB代码】制导——三点法,二维平面下的例程|运动目标制导,附完整源代码
三点法制导是一种导弹制导策略,主要用于确保导弹能够准确追踪并击中移动目标。该方法通过计算导弹、目标和制导站之间的相对位置关系,实现对目标的有效制导。 本文给出MATLAB下的三点法例程,模拟平面上捕获运动目标的情况订阅专栏后可直接查看源代码,粘贴到MATLAB空脚本中即…...

Spring Security用户管理机制详解
UserDetailsService契约解析 核心方法解析 UserDetailsService接口仅定义了一个关键方法loadUserByUsername(),其方法签名如下: public interface UserDetailsService {UserDetails loadUserByUsername(String username) throws UsernameNotFoundException; }该方法作为用…...
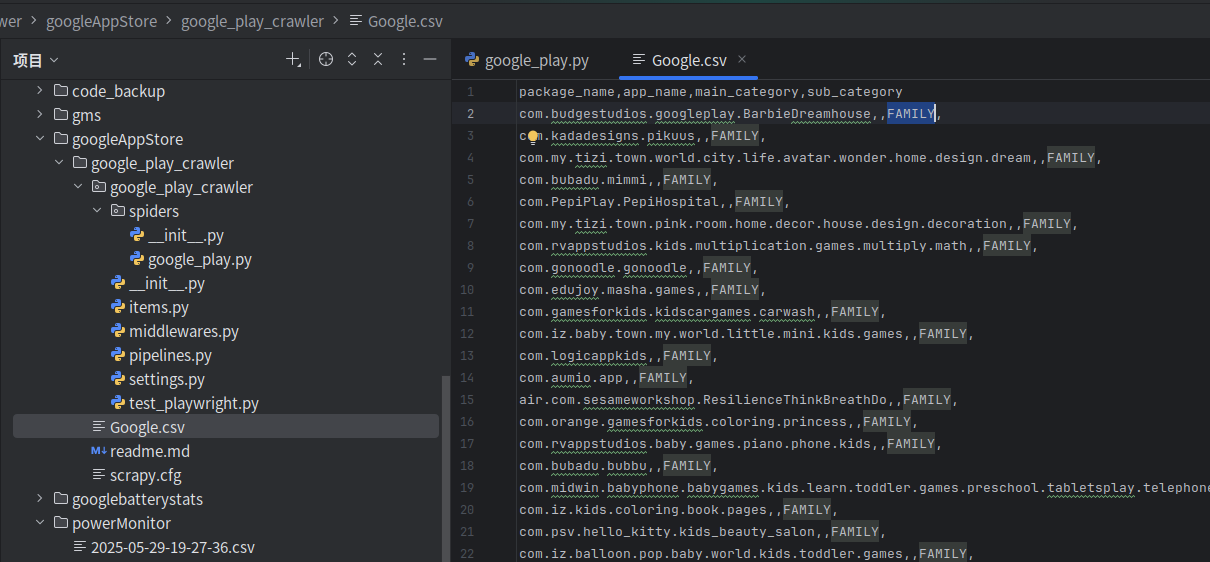
如何爬取google应用商店的应用分类呢?
以下是爬取Google Play商店应用包名(package name)和对应分类的完整解决方案,采用ScrapyPlaywright组合应对动态渲染页面,并处理反爬机制: 完整爬虫实现 1. 安装必要库 # 卸载现有安装pip uninstall playwright scrapy-playwright -y# 重新…...
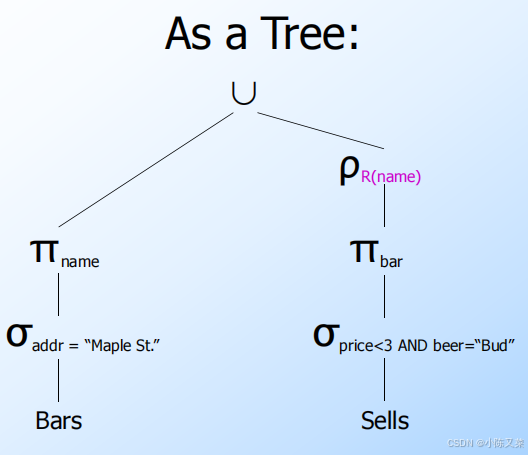
SQL Relational Algebra(数据库关系代数)
目录 What is an “Algebra” What is Relational Algebra? Core Relational Algebra Selection Projection Extended Projection Product(笛卡尔积) Theta-Join Natural Join Renaming Building Complex Expressions Sequences of Assignm…...

如何安装huaweicloud-sdk-core-3.1.142.jar到本地仓库?
如何安装huaweicloud-sdk-core-3.1.142.jar到本地仓库? package com.huaweicloud.sdk.core.auth does not exist 解决方案 # 下载huaweicloud-sdk-core-3.1.142.jar wget https://repo1.maven.org/maven2/com/huaweicloud/sdk/huaweicloud-sdk-core/3.1.142/huawe…...

Electron桌面应用下,在拍照、展示pdf等模块时,容易导致应用白屏
Electron 应用白屏问题分析与解决方案 Electron 应用中拍照、PDF展示等模块导致白屏的常见原因通常与内存泄漏、渲染进程崩溃或资源加载超时有关。以下是具体排查与解决方法: 检查内存泄漏 项目中,分析代码,高频操作或未释放的资源可能导致…...

智能工业时代:工业场景下的 AI 大模型体系架构与应用探索
自工业革命以来,工业生产先后经历了机械化、电气化、自动化、信息化的演进,正从数字化向智能化迈进,人工智能技术是新一轮科技革命和产业变革的重要驱动力量,AI 大模型以其强大的学习计算能力掀开了人工智能通用化的序幕ÿ…...

【git stash切换】
问题 当前正在修改对应某个bug,突然来了个更紧急的工作,需要保留现场,去对应更紧急的事务,git该如何操作? 1. 查看当前工作状态(确认修改) git status 2. 保存当前工作现场(包含…...

React 18 生命周期详解与并发模式下的变化
1. React 生命周期概述 React 组件的生命周期可以分为三个阶段:挂载(Mounting)、更新(Updating)和卸载(Unmounting),以及错误处理阶段。 1.1. 挂载阶段(Mounting&#…...
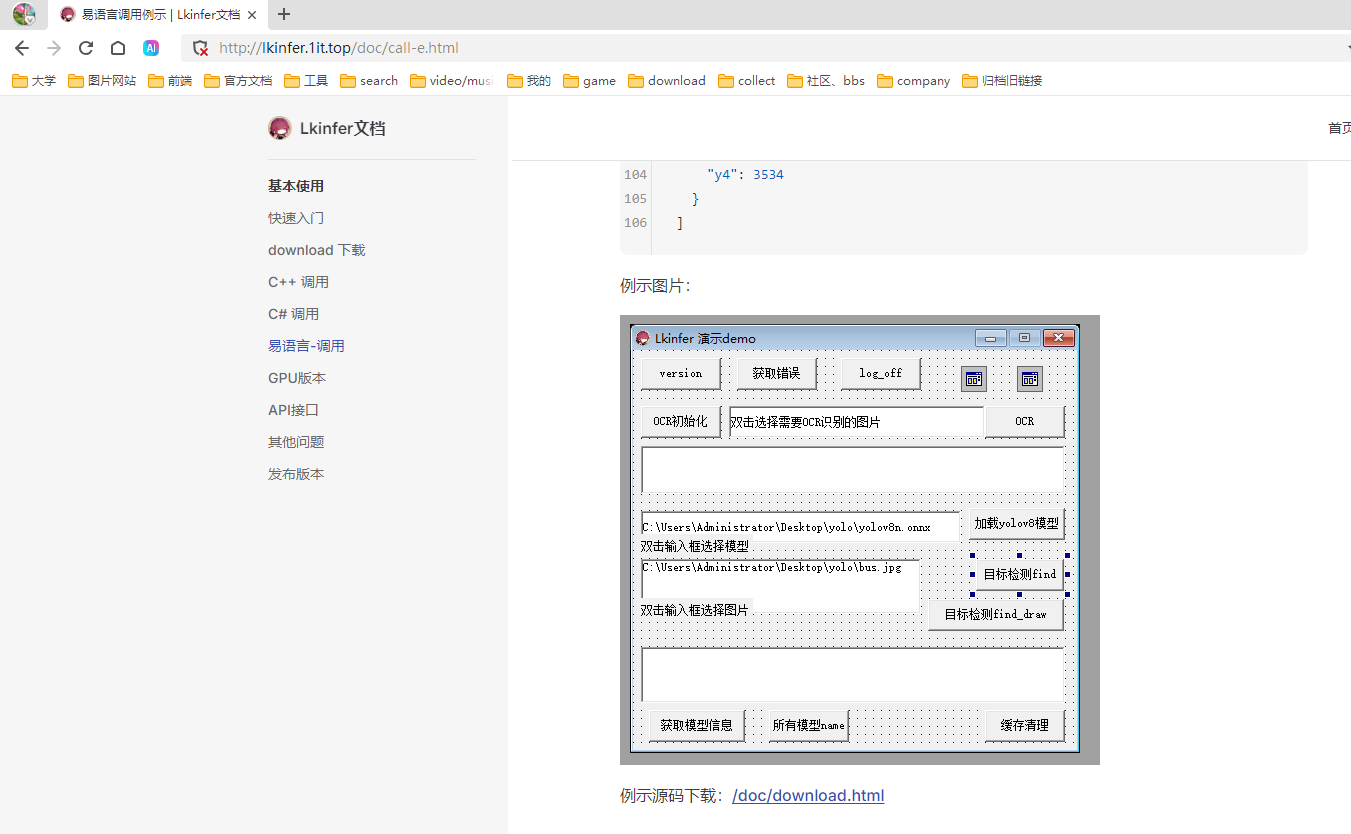
易语言使用OCR
易语言使用OCR 用易语言写个脚本,需要用到OCR,因此我自己封装了一个OCR到DLL。 http://lkinfer.1it.top/ 视频演示:https://www.bilibili.com/video/BV1Zg7az2Eq3/ 支持易语言、c、c#使用,平台限制:window 10 介绍…...

C++和C#界面开发方式的全面对比
文章目录 C界面开发方式1. **MFC(Microsoft Foundation Classes)**2. **Qt**3. **WTL(Windows Template Library)**4. **wxWidgets**5. **DirectUI** C#界面开发方式1. **WPF(Windows Presentation Foundation…...