如何爬取google应用商店的应用分类呢?
以下是爬取Google Play商店应用包名(package name)和对应分类的完整解决方案,采用Scrapy+Playwright组合应对动态渲染页面,并处理反爬机制:
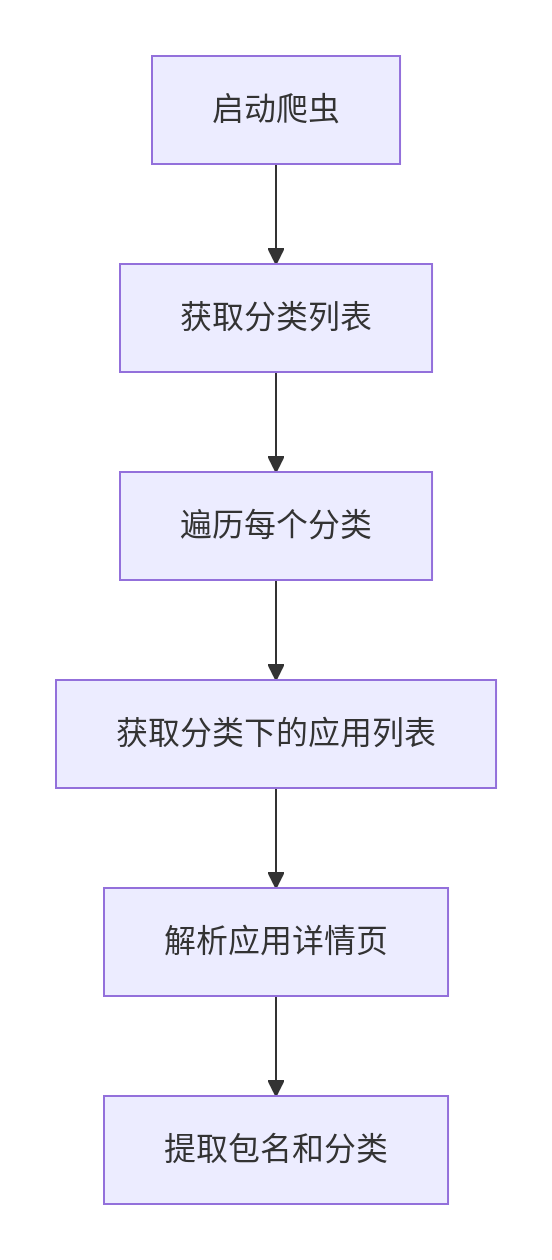
完整爬虫实现
1. 安装必要库
# 卸载现有安装pip uninstall playwright scrapy-playwright -y# 重新安装(指定国内镜像加速)pip install playwright scrapy-playwright -i https://pypi.tuna.tsinghua.edu.cn/simple# 安装浏览器二进制文件playwright install chromiumplaywright install-deps # Linux系统需要额外依赖
2. 创建Scrapy项目
scrapy startproject google_play_crawler cd google_play_crawler
3. 修改settings.py
# 启用Playwright和中间件DOWNLOAD_HANDLERS = {"http": "scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler","https": "scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler",}TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"# 反爬配置USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"ROBOTSTXT_OBEY = FalseCONCURRENT_REQUESTS = 2DOWNLOAD_DELAY = 3# Playwright设置PLAYWRIGHT_BROWSER_TYPE = "chromium"PLAYWRIGHT_LAUNCH_OPTIONS = {"headless": True,"timeout": 30000,}
4. 爬虫主代码spiders/google_play.py
import scrapyfrom scrapy.http import Requestimport refrom urllib.parse import urljoinclass GooglePlaySpider(scrapy.Spider):name = 'google_play'start_urls = ['https://play.google.com/store/apps']custom_settings = {'FEEDS': {'apps.csv': {'format': 'csv','fields': ['package_name', 'app_name', 'main_category', 'sub_category'],'overwrite': True}}}def start_requests(self):for url in self.start_urls:yield Request(url,callback=self.parse_categories,meta={"playwright": True})def parse_categories(self, response):"""解析所有分类链接"""# 新版Google Play分类选择器category_links = response.xpath('//a[contains(@href, "/store/apps/category/")]/@href').extract()for link in set(category_links): # 去重full_url = urljoin(response.url, link)category_name = link.split('/')[-1]yield Request(full_url,callback=self.parse_app_list,meta={"playwright": True,"category": category_name})def parse_app_list(self, response):"""解析应用列表页"""app_links = response.xpath('//a[contains(@href, "/store/apps/details?id=")]/@href').extract()for link in set(app_links):package_name = link.split('=')[-1]full_url = urljoin(response.url, link)yield Request(full_url,callback=self.parse_app_detail,meta={"playwright": True,"package_name": package_name,"main_category": response.meta["category"]})# 分页处理next_page = response.xpath('//a[contains(@aria-label, "Next page")]/@href').extract_first()if next_page:yield Request(urljoin(response.url, next_page),callback=self.parse_app_list,meta={"playwright": True,"category": response.meta["category"]})def parse_app_detail(self, response):"""解析应用详情页"""item = {"package_name": response.meta["package_name"],"app_name": response.xpath('//h1[@itemprop="name"]/span/text()').get(),"main_category": response.meta["main_category"],"sub_category": response.xpath('//a[@itemprop="genre"]/text()').get()}# 额外信息(可选)item['rating'] = response.xpath('//div[@class="TT9eCd"]/@aria-label').get()item['downloads'] = response.xpath('//div[contains(text(), "Downloads")]/following-sibling::span//text()').get()yield item
5.google_play_crawler目录启动Google商店爬虫
scrapy crawl google_play -O Google.csv
执行后可以看到开始进行Google 应用商店的应用分类可视化爬虫
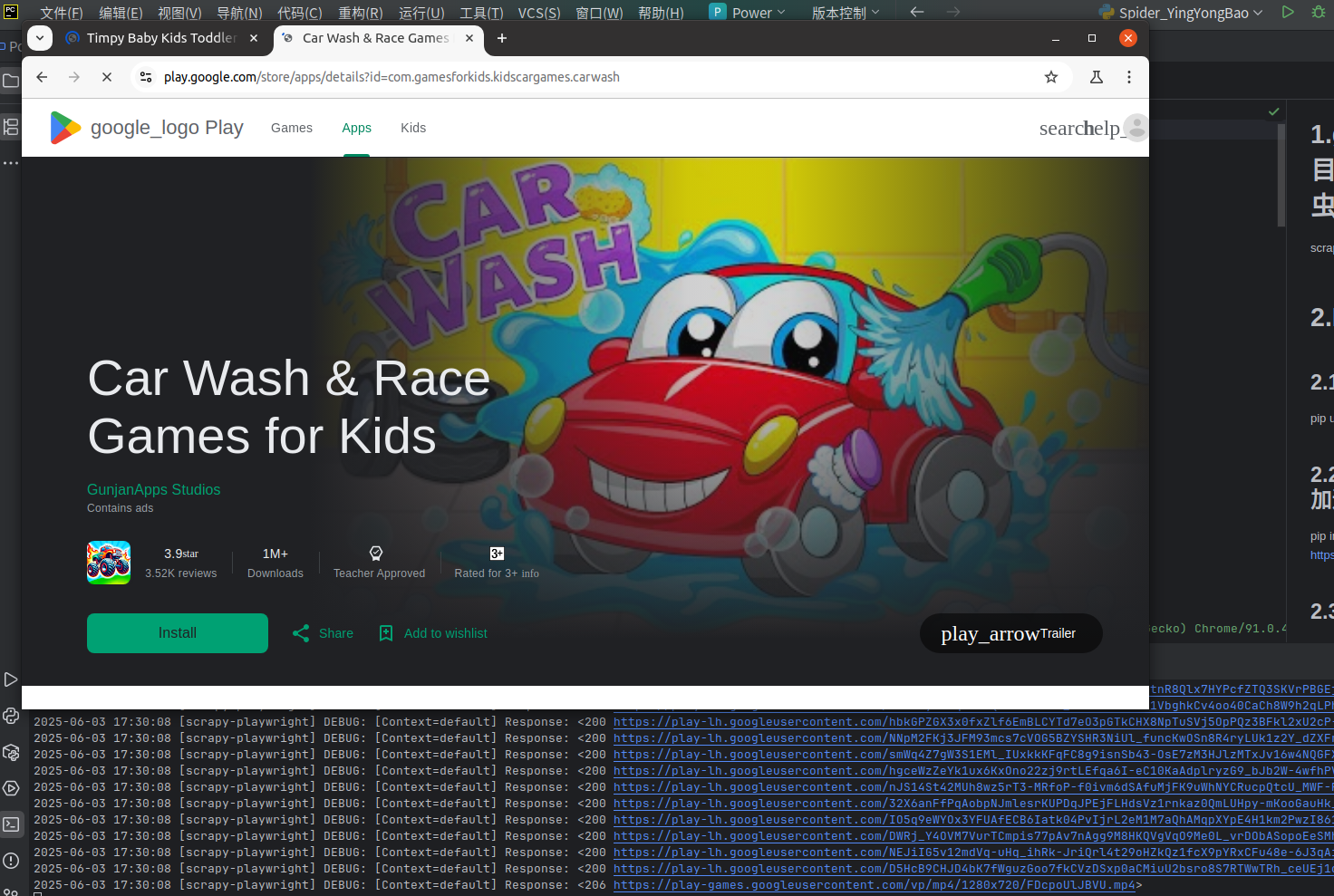
6.运行结果
可以爬取应用的分类,但是感觉稳定哈。可能是国内VPN不稳定,且爬虫很费时间,感觉跑完也需要好几小时以上哈。
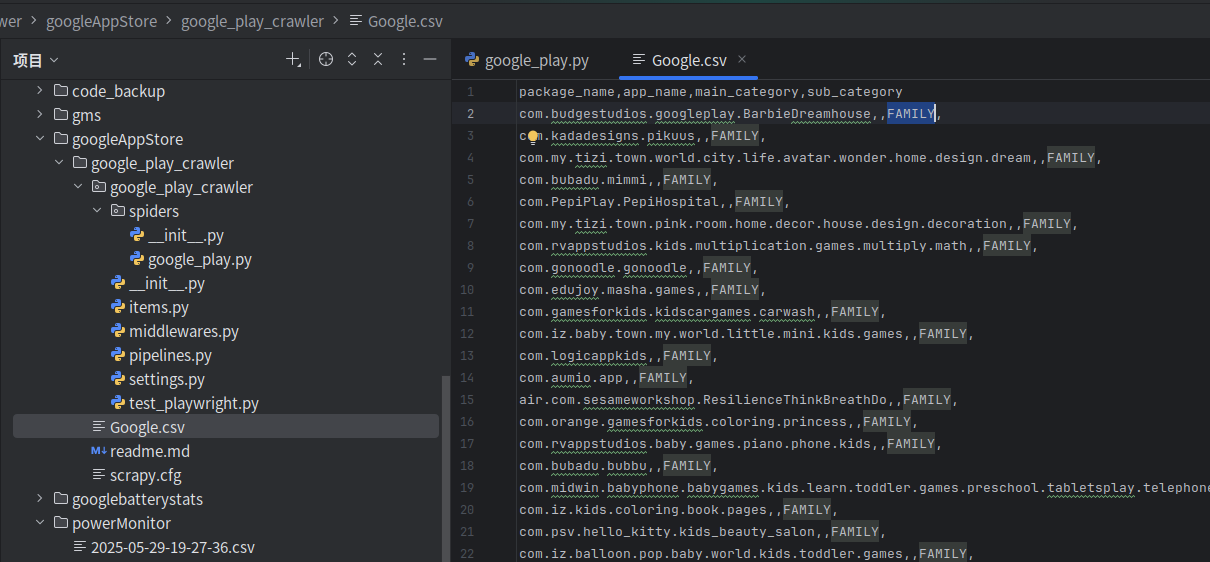
我家公司没有自己的应用商店,故应用类型需要自己爬虫生成数据库,供后续代码查询实现了。
相关文章:
如何爬取google应用商店的应用分类呢?
以下是爬取Google Play商店应用包名(package name)和对应分类的完整解决方案,采用ScrapyPlaywright组合应对动态渲染页面,并处理反爬机制: 完整爬虫实现 1. 安装必要库 # 卸载现有安装pip uninstall playwright scrapy-playwright -y# 重新…...
SQL Relational Algebra(数据库关系代数)
目录 What is an “Algebra” What is Relational Algebra? Core Relational Algebra Selection Projection Extended Projection Product(笛卡尔积) Theta-Join Natural Join Renaming Building Complex Expressions Sequences of Assignm…...

如何安装huaweicloud-sdk-core-3.1.142.jar到本地仓库?
如何安装huaweicloud-sdk-core-3.1.142.jar到本地仓库? package com.huaweicloud.sdk.core.auth does not exist 解决方案 # 下载huaweicloud-sdk-core-3.1.142.jar wget https://repo1.maven.org/maven2/com/huaweicloud/sdk/huaweicloud-sdk-core/3.1.142/huawe…...

Electron桌面应用下,在拍照、展示pdf等模块时,容易导致应用白屏
Electron 应用白屏问题分析与解决方案 Electron 应用中拍照、PDF展示等模块导致白屏的常见原因通常与内存泄漏、渲染进程崩溃或资源加载超时有关。以下是具体排查与解决方法: 检查内存泄漏 项目中,分析代码,高频操作或未释放的资源可能导致…...

智能工业时代:工业场景下的 AI 大模型体系架构与应用探索
自工业革命以来,工业生产先后经历了机械化、电气化、自动化、信息化的演进,正从数字化向智能化迈进,人工智能技术是新一轮科技革命和产业变革的重要驱动力量,AI 大模型以其强大的学习计算能力掀开了人工智能通用化的序幕ÿ…...

【git stash切换】
问题 当前正在修改对应某个bug,突然来了个更紧急的工作,需要保留现场,去对应更紧急的事务,git该如何操作? 1. 查看当前工作状态(确认修改) git status 2. 保存当前工作现场(包含…...

React 18 生命周期详解与并发模式下的变化
1. React 生命周期概述 React 组件的生命周期可以分为三个阶段:挂载(Mounting)、更新(Updating)和卸载(Unmounting),以及错误处理阶段。 1.1. 挂载阶段(Mounting&#…...
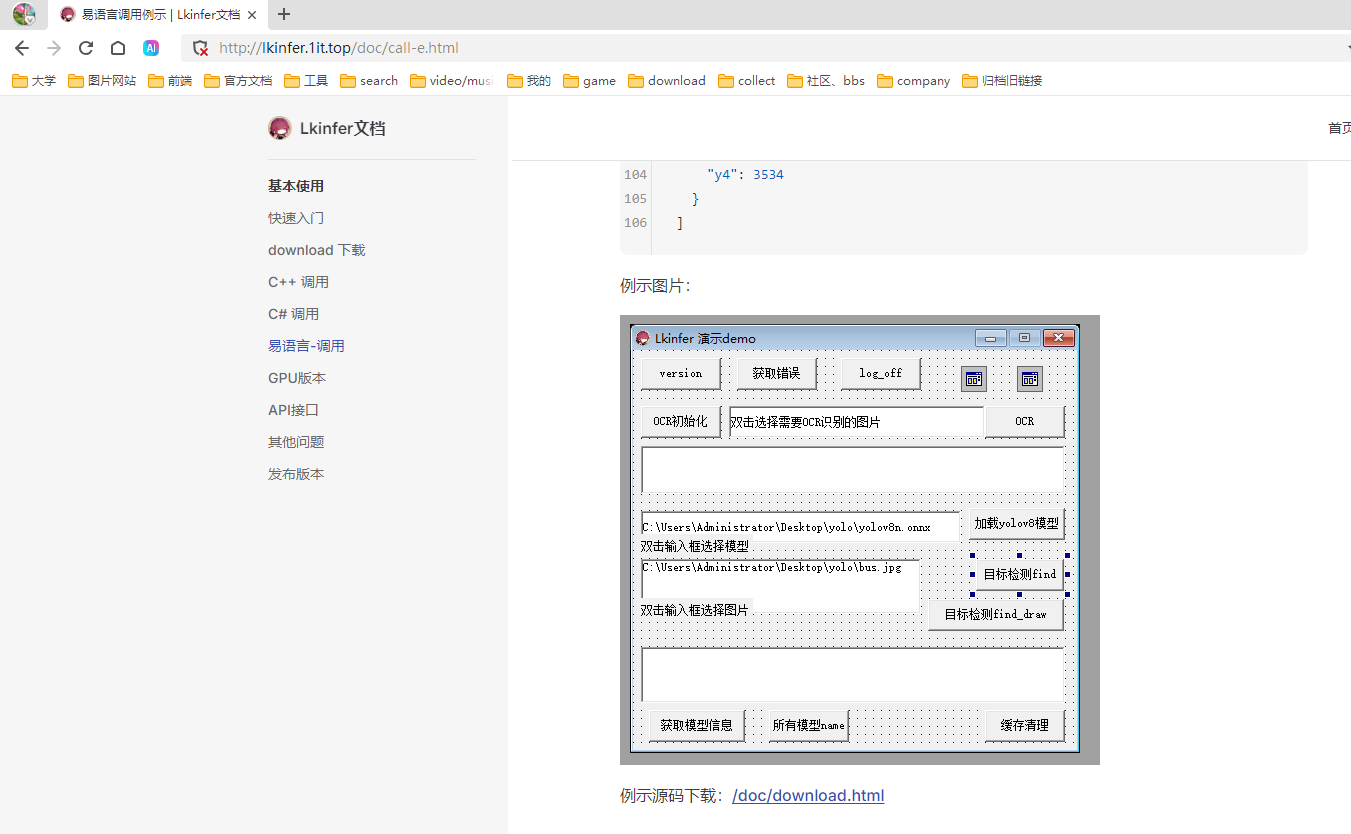
易语言使用OCR
易语言使用OCR 用易语言写个脚本,需要用到OCR,因此我自己封装了一个OCR到DLL。 http://lkinfer.1it.top/ 视频演示:https://www.bilibili.com/video/BV1Zg7az2Eq3/ 支持易语言、c、c#使用,平台限制:window 10 介绍…...

C++和C#界面开发方式的全面对比
文章目录 C界面开发方式1. **MFC(Microsoft Foundation Classes)**2. **Qt**3. **WTL(Windows Template Library)**4. **wxWidgets**5. **DirectUI** C#界面开发方式1. **WPF(Windows Presentation Foundation…...

监控 100 台服务器磁盘内存CPU利用率
监控 100 台服务器磁盘,内存,CPU利用率脚本 以下是一个优化后的监控脚本,用于同时监控100台服务器的磁盘、内存和CPU利用率,并支持并发执行以提高效率: #!/bin/bash # 服务器监控脚本 - 支持并发获取100台服务器系统指标 # 功能…...

Linux远程连接主机——ssh命令详解
摘要:SSH是OpenSSH套件中的加密远程连接工具,基于SSH协议提供安全的服务器管理通道。本文详解连接参数、认证方法和功能,提供实用操作示例。 一、SSH核心特性 SSH(Secure Shell)是行业标准的远程管理协议:…...
算法-集合的使用
1、set常用操作 set<int> q; //以int型为例 默认按键值升序 set<int,greater<int>> p; //降序排列 int x; q.insert(x); //将x插入q中 q.erase(x); //删除q中的x元素,返回0或1,0表示set中不存在x q.clear(); //清空q q.empty(); //判断q是否为空&a…...

性能优化 - 理论篇:CPU、内存、I/O诊断手段
文章目录 Pre引言1. CPU 性能瓶颈1.1 top 命令 —— 多维度 CPU 使用率指标1.2 负载(load)——任务排队情况1.3 vmstat 命令 —— CPU 繁忙与等待 2. 内存性能瓶颈2.1 操作系统层面的内存分布2.2 top 命令 —— VIRT / RES / SHR 三个关键列2.3 CPU 缓存…...

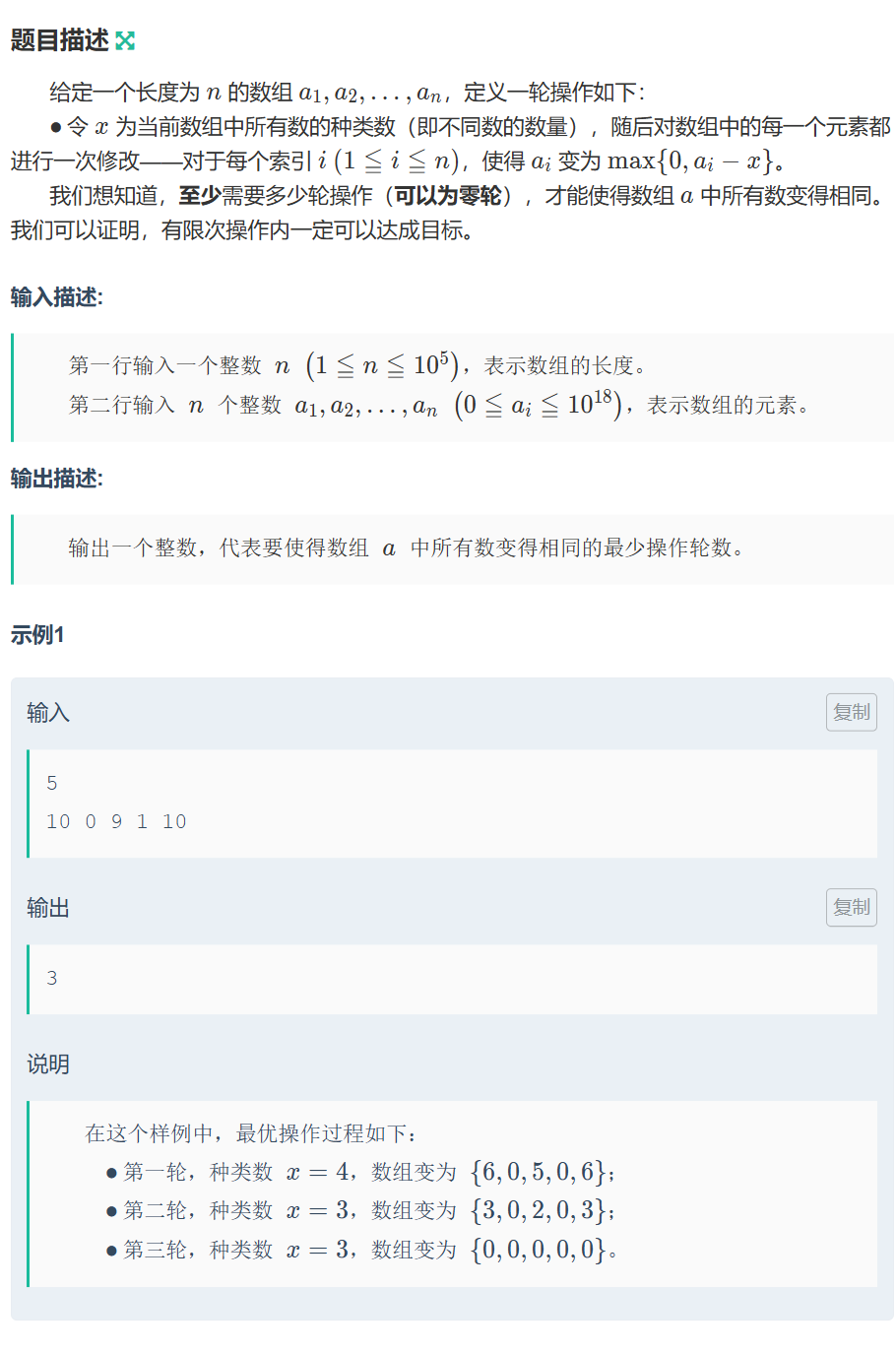
算法:二分查找
1.二分查找 704. 二分查找 - 力扣(LeetCode) 二分查找算法要确定“二段性”,时间复杂度为O(lonN)。为了防止数据溢出,所以求mid时要用防溢出的方式。 class Solution { public:int search(vector<int>& nums, int tar…...

Spring Boot3.4.1 集成 mybatis plus
Spring Boot 集成 mybatis plus 第一步 引入依赖 <dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.16</version> </dependency><dependency><groupId>com.bao…...

Ubuntu 22.04 上安装 PostgreSQL(使用官方 APT 源)
Ubuntu 22.04 上安装 PostgreSQL(使用官方 APT 源) 步骤 1:更新系统 sudo apt update sudo apt upgrade -y步骤 2:添加 PostgreSQL 官方仓库 # 安装仓库管理工具 sudo apt install wget ca-certificates gnupg lsb-release -y#…...
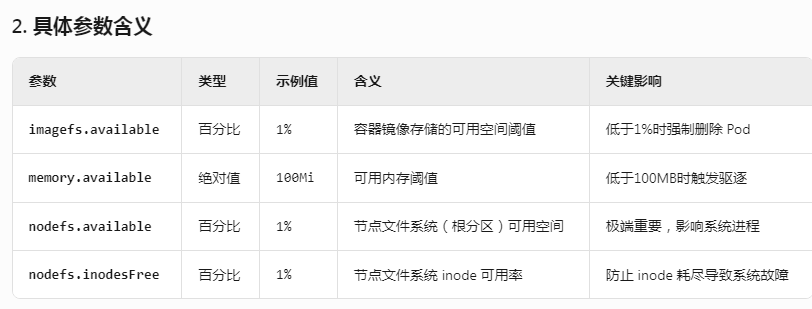
Linux随记(十八)
一、k8s的node节点磁盘 /data已使用率超过 85% , 出现disk pressure ,驱逐pod现象 evicted , the node had condition:[DiskPressure] #修改/var/lib/kubelet/config.yaml ]# cat /var/lib/kubelet/config.yaml apiVersion: kubelet.config.k8s.io/v1…...
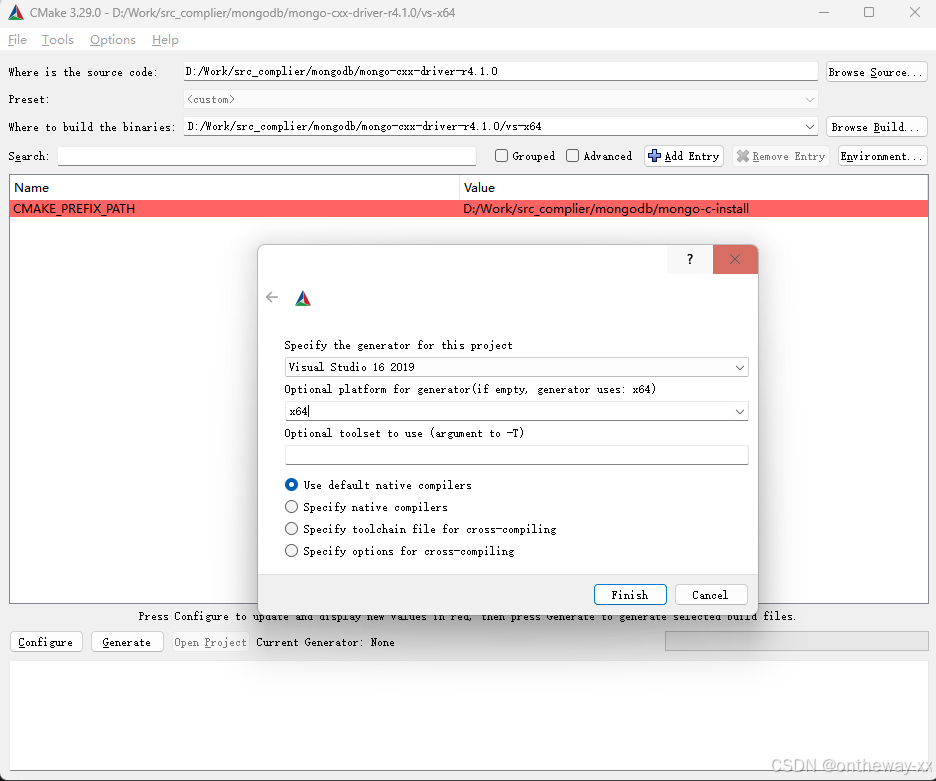
Windows MongoDB C++驱动安装
MongoDB驱动下载 MongoDB 官网MongoDB C驱动程序入门MongoDB C驱动程序入门 安装环境 安装CMAKE安装Visual Studio 编译MongoDB C驱动 C驱动依赖C驱动,需要先编译C驱动 下载MongoDB C驱动源码 打开CMAKE(cmake-gui) 选择源码及输出路径,然后点击configure …...
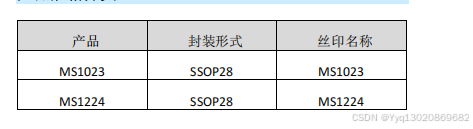
MS1023/MS1224——10MHz 到 80MHz、10:1 LVDS 并串转换器(串化器)/串并转换器(解串器)
产品简述 MS1023 串化器和 MS1224 解串器是一对 10bit 并串 / 串并转 换芯片,用于在 LVDS 差分底板上传输和接收 10MHz 至 80MHz 的并行字速率的串行数据。起始 / 停止位加载后,转换为负载编 码输出,串行数据速率介于 120Mbps…...

ESOP股权管理平台完整解决方案
——全生命周期合规化、智能化、价值化的资本中枢系统 一、平台顶层架构 1.1 四层驱动模型 #mermaid-svg-QrD0g5nIuRtsMl7c {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-QrD0g5nIuRtsMl7c .error-icon{fill:#552…...
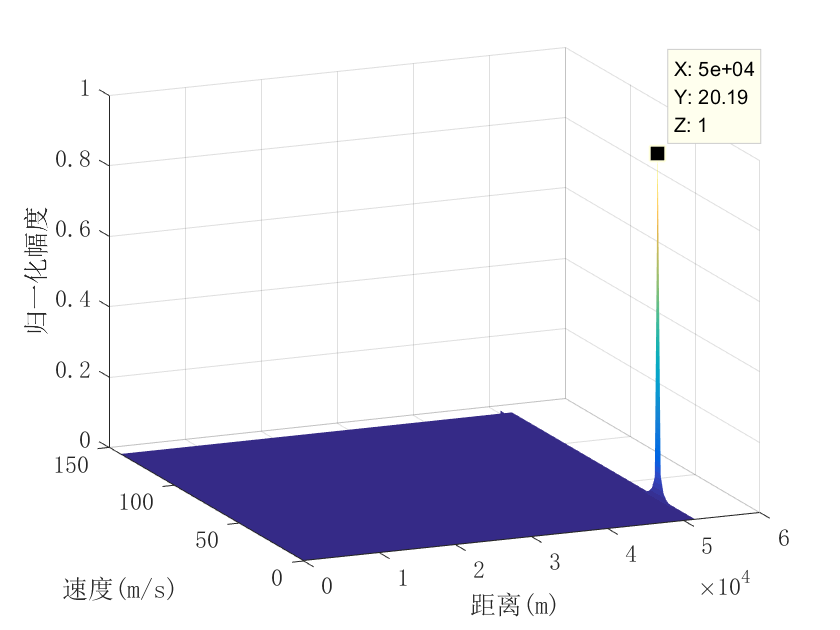
线性调频波形测距测速信号处理——全代码+注释
clear all close all clc %% 参数设置 fs600e6;%采样率 fc10.45e9;% 波形发射载频 t10e-6;%脉宽 f050e6;%波形中频频率 B10e6;%带宽 uB/(2*t);%调频斜率 Tv100e-6;% 脉冲重复周期 Num64;% 测速脉冲数 lamdfs/B;% 抽取带宽 Nsround(fs*t); NTvround(fs*Tv); tt0:1/fs:t-1/fs; ff…...
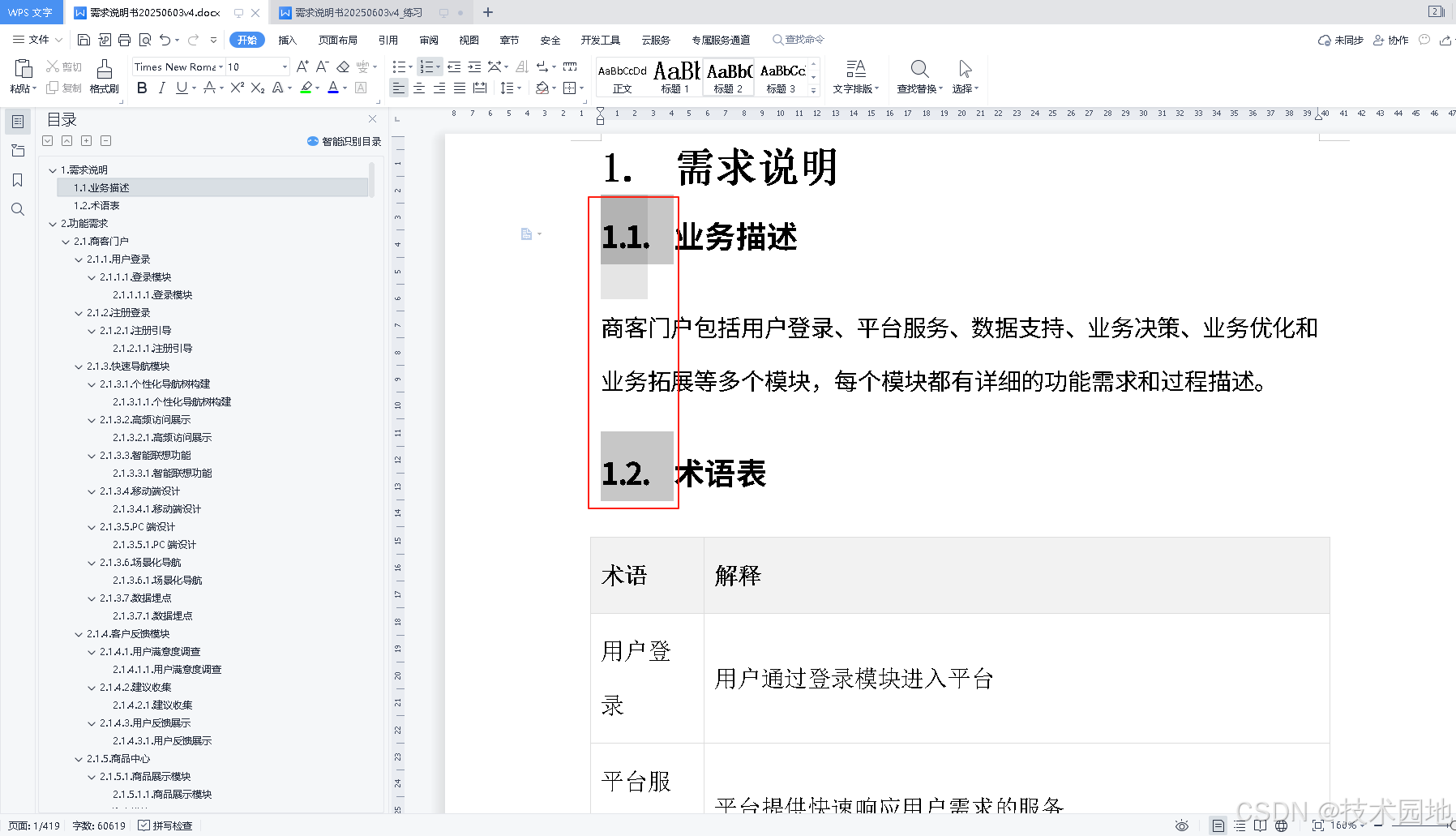
WPS word 已有多级列表序号
wps的word中,原来已生成的文档里,已存在序号。比如,存在2、2.1、2.1.1、2.1.1.1、2.1.1.1.1 5层序号,而且已分为5级。但增加内容的时候,并不会自动增加序号,应该如何解决? 原来长这样ÿ…...
)
Vue 3 源码层核心原理剖析(完整详解版)
一、Compiler 编译过程解密:多框架实现对比 Vue 3 编译流程深度解析(基于 /packages/compiler-core/src/parse.ts) 完整编译链条及技术实现: #mermaid-svg-S8ScpxdjkcJv0YWT {font-family:"trebuchet ms",verdana,ari…...
)
数据库操作-MySQL-4(JDBC编程)
JDBC:通过Java代码操作mysql数据库,数据库会提供一些API供我们调用 MySQL、Oracle、等API有差异,但是Java统一了所有接口,即JDBC; 原始api-驱动包(类似转接头)-统一的api-Java 驱动包࿱…...

Linux打开.img镜像文件
kparkx 可以查看和修改img文件的内容 1.安装kparkx 1.安装 kpartx sudo apt-get update sudo apt-get install kpartx2.使用kpartx映射镜像文件 假设镜像文件名为 example.img ,以下命令会将其分区映射到 dev/mapper/ sudo kpartx -av example.img• -a表示添加…...
)
【FAQ】HarmonyOS SDK 闭源开放能力 —Account Kit(5)
1.问题描述: 集成华为一键登录的LoginWithHuaweiIDButton, 但是Button默认名字叫 “华为账号一键登录”,太长无法显示,能否简写成“一键登录”与其他端一致? 解决方案: 问题分两个场景: 一、…...
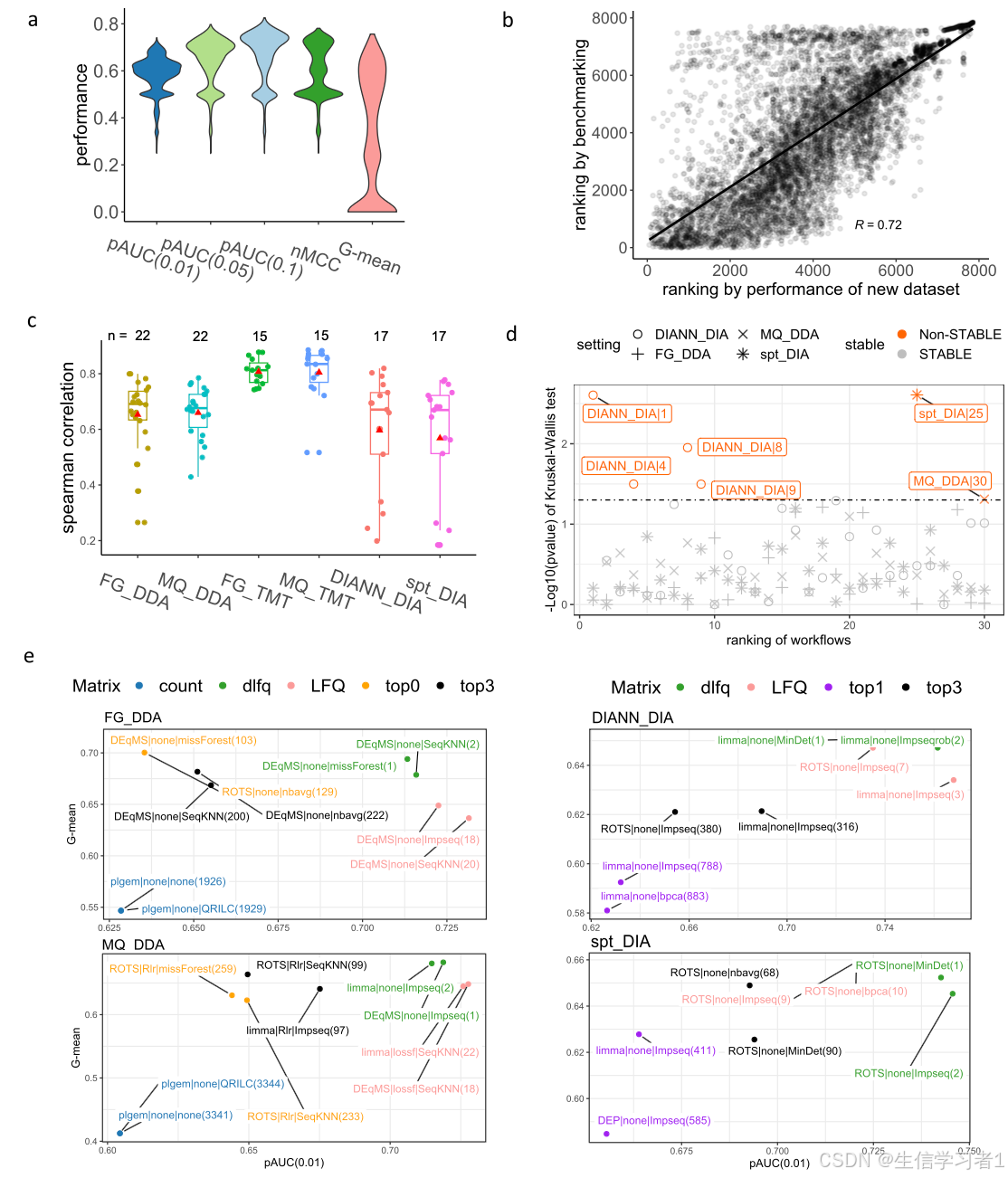
【科研绘图系列】R语言绘制论文组合图形(multiple plots)
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍加载R包数据下载导入数据数据预处理画图1画图2画图3画图4画图5系统信息介绍 这篇文章详细介绍了如何使用R语言进行科研绘图,特别是绘制论文组合图形(multiple plots)。文章从数…...
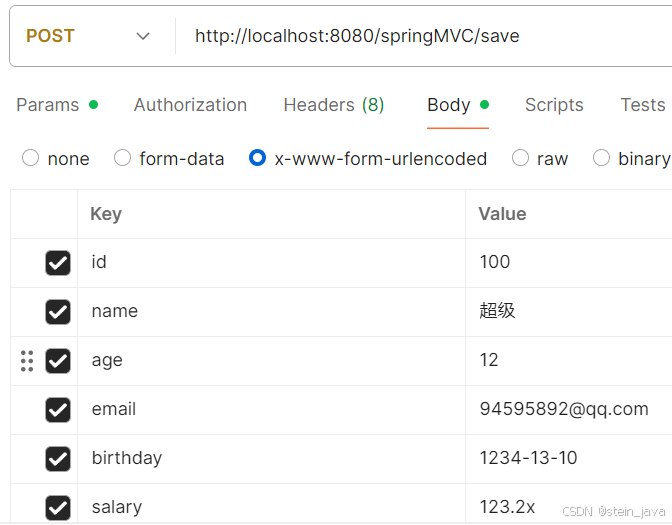
springMVC-9数据格式化
数据格式化 学习目标: 理解在我们提交数据(比如表单时),SpringMVC怎样对提交的数据进行转换和处理的 Spring MVC 上下文中内建了很多转换器,可完成大多数 Java 类型的转换工作。 基本数据类型可以和字符串之间自动完成转换 应用实例-页面…...

Kafka 和Redis 在系统架构中的位置
Kafka 位置:位于应用层和数据存储层之间,作为消息队列和数据传输中间件。作用: 数据收集与传输:收集应用层产生的数据,传输到后端数据存储系统。消息队列:实现应用层各服务之间的异步通信和解耦。与应用层…...

【Spring AI】如何实现文生图功能
在人工智能与软件开发深度融合的当下,Spring AI 作为构建 AI 驱动应用的有力框架,能够便捷集成各类 AI 能力。 文生图技术可将文本描述转化为图像,极具应用价值。接下来,我给大家详细讲解一下如何使用 Spring AI 调用文生图功能。…...