Mysql常用知识3:Kafka和数据库优化
文章目录
- 一、分布式消息系统(Kafka相关问题5-10)
- 5. Kafka如何保证消息不丢失?
- 6. 项目中Kafka具体怎么使用的?
- 7. 消息异常未发送成功怎么解决?
- 8. 重试具体怎么做的,循环吗?
- 9. 重试多次失败怎么办,抛出异常吗?
- 10. 消息一直没发出去是什么原因?
- 二、数据库设计与优化(问题11-18)
- 11. SQL怎么优化?
- 12. 怎么判断是慢查询?
- 13. 怎么设计一个好的数据库?
- 14. 项目中数据库表怎么设计的?
- 15. 主键怎么设计?普通递增 vs 分布式雪花算法
- 16. 除了雪花算法和UUID,还有什么主键不重复方案?
- 17. 具体字段类型设计:用户名用什么类型?
- 18. 什么时候用到JOIN?
- 三、加密算法(问题19-20)
- 19. 左连接、右连接、外连接的区别?
- 20. 加密算法有哪些,什么区别?
以下是针对您提出的20个问题的详细解答,分为分布式消息系统(Kafka)、数据库设计与优化、加密算法三个模块:
一、分布式消息系统(Kafka相关问题5-10)
5. Kafka如何保证消息不丢失?
Kafka通过生产者、Broker、消费者三端机制确保消息不丢失:
- 生产者端:
- 设置
acks=all(或acks=-1):等待所有ISR副本确认接收消息。 - 启用
retries重试机制(默认10次),处理网络抖动等临时错误。 - 记录
producer.send()返回的RecordMetadata,用于故障后重试(需避免幂等性问题,可通过enable.idempotence=true开启幂等生产者)。
- 设置
- Broker端:
- 副本机制:消息写入分区的Leader副本后,需等待ISR(In-Sync Replicas)中的Follower副本同步完成才标记为“已提交”。
- 持久化:消息写入磁盘时使用
fsync强制刷盘(可通过log.flush.interval.messages等参数控制)。
- 消费者端:
- 手动提交offset:关闭自动提交(
auto.commit.offset=false),确保消费成功后再提交。 - 重复消费处理:通过业务层去重(如利用消息唯一ID+Redis存储已消费记录)。
- 手动提交offset:关闭自动提交(
6. 项目中Kafka具体怎么使用的?
典型应用场景:
- 异步解耦:订单系统下单后,通过Kafka通知库存、物流、支付等系统,避免同步调用超时。
- 流量削峰:秒杀活动中,将用户请求写入Kafka,消费者(如Java服务)按限流速度处理,防止数据库被瞬时流量冲垮。
- 日志采集:将应用日志发送到Kafka,供ELK(Elasticsearch+Logstash+Kibana)或Flink等系统进行实时分析。
代码示例(Java生产者):
Properties props = new Properties();
props.put("bootstrap.servers", "kafka:9092");
props.put("acks", "all");
props.put("retries", 3);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");KafkaProducer<String, String> producer = new KafkaProducer<>(props);
ProducerRecord<String, String> record = new ProducerRecord<>("order-topic", "123", "{\"orderId\":\"1001\",\"amount\":1000}");try {producer.send(record, (metadata, exception) -> {if (exception != null) {log.error("消息发送失败:{}", exception.getMessage());} else {log.info("消息已发送至分区{},偏移量{}", metadata.partition(), metadata.offset());}});
} finally {producer.close();
}
7. 消息异常未发送成功怎么解决?
排查步骤:
- 生产者日志:查看是否有网络异常(如
org.apache.kafka.common.errors.NetworkException)、分区不存在等错误。 - Broker状态:检查Kafka集群是否正常(节点存活、分区Leader是否存在),使用
kafka-topics.sh --describe查看分区ISR状态。 - 重试机制:若为临时性错误(如分区负载过高),通过
retries自动重试;若为永久性错误(如消息格式错误),需捕获异常并记录到死信队列(Dead Letter Queue,DLQ)。 - 监控告警:通过Prometheus+Grafana监控
producer_request_error_rate等指标,及时发现发送失败趋势。
8. 重试具体怎么做的,循环吗?
- Kafka内置重试:
生产者通过retries参数设置重试次数(默认10次),每次重试间隔由retry.backoff.ms控制(默认100ms)。重试逻辑为指数退避(如第1次重试间隔100ms,第2次200ms,避免频繁重试加剧网络负载)。 - 业务层重试:
若内置重试耗尽仍失败,可将消息存入数据库(如MySQL)或Redis,通过定时任务(如Spring Task)或分布式调度框架(如Elastic-Job)进行循环重试,直至成功或标记为“需要人工处理”。
9. 重试多次失败怎么办,抛出异常吗?
- 有限重试后终止:
设定最大重试次数(如5次),超过后不再自动重试,而是:- 发送告警(邮件/短信通知运维人员)。
- 将消息写入死信队列(如Kafka的
dead-letter-topic),供人工排查(如消息格式错误、下游系统故障)。
- 异常处理:
在生产者的回调函数中捕获最终异常,记录详细日志(如消息内容、失败原因),但不建议直接抛出异常中断业务流程,应保证主流程继续运行,仅对失败消息做异步处理。
10. 消息一直没发出去是什么原因?
常见原因分析:
- 网络问题:
- 生产者与Broker之间网络断开(如防火墙拦截、VPN中断)。
- Broker节点负载过高,无法处理新请求(可通过
kafka-consumer-groups.sh查看分区Lag)。
- 元数据问题:
- 生产者未正确获取分区元数据(如首次连接时未等待
metadata.max.age.ms刷新)。 - 主题被删除或分区数变更,导致生产者缓存的元数据失效。
- 生产者未正确获取分区元数据(如首次连接时未等待
- 配置错误:
acks设置为0(不等待Broker确认),但网络故障导致消息丢失。- 消息大小超过Broker限制(
message.max.bytes默认1MB)。
- 权限问题:
- 生产者未被授予主题的写入权限(如使用ACL认证时未正确配置)。
- 下游系统故障:
- 消费者组挂掉或消费速度过慢,导致分区积压,Broker拒绝新消息写入(需调整分区数或消费者并行度)。
二、数据库设计与优化(问题11-18)
11. SQL怎么优化?
优化方向:
- 索引优化:
- 为高频查询字段添加索引(如
WHERE、JOIN、ORDER BY字段),避免全表扫描。 - 避免过度索引(索引会增加写入成本),使用
EXPLAIN分析执行计划,查看type是否为range/ref(优于ALL)。
- 为高频查询字段添加索引(如
- 分页优化:
- 大偏移量分页(如
LIMIT 100000, 10)性能差,可通过子查询或WHERE id > last_id优化。
- 大偏移量分页(如
- 查询语句优化:
- 避免在索引字段上使用函数(如
SELECT * FROM users WHERE YEAR(create_time) = 2023)。 - 用
EXISTS替代IN查询子集(如SELECT * FROM A WHERE EXISTS (SELECT 1 FROM B WHERE B.a_id = A.id))。
- 避免在索引字段上使用函数(如
- 分库分表:
- 单表数据量超过500万行时,可按业务维度(如用户ID取模)拆分到多个库/表。
12. 怎么判断是慢查询?
方法:
- 开启慢查询日志:
MySQL中通过SET GLOBAL slow_query_log = ON;开启,设置long_query_time阈值(默认10秒,可调整为0.5秒)。 - 监控工具:
- 使用
pt-query-digest分析慢查询日志,统计执行频率、平均耗时、锁等待等。 - 数据库监控平台(如Prometheus+MySQL Exporter)实时监控
slow_queries指标。
- 使用
- 执行计划分析:
对疑似慢查询执行EXPLAIN,查看:type:ALL表示全表扫描,需优化索引。rows:扫描行数是否过大(理论上应小于总数据量的5%)。Extra:是否包含Using filesort(文件排序)或Using temporary(临时表),这两者通常性能较差。
13. 怎么设计一个好的数据库?
设计原则:
- 需求分析:
- 明确业务场景(如电商订单、社交动态),识别核心实体(用户、订单、商品)及关系(一对一、一对多)。
- 范式设计:
- 遵循3范式(如消除重复数据、确保依赖关系正确),但可适当反范式(如冗余字段)提升查询性能。
- 字段设计:
- 选择合适的数据类型(如
INT存储用户ID,VARCHAR(255)存储用户名),避免TEXT等大字段滥用。 - 允许
NULL的字段需添加默认值(如create_time DEFAULT CURRENT_TIMESTAMP)。
- 选择合适的数据类型(如
- 性能考量:
- 主键设计:使用自增ID或雪花算法(分布式场景),确保主键查询高效。
- 分区分表:按时间(如按年/月分表)或业务维度拆分,降低单表数据量。
- 扩展性:
- 预留字段(如
extend_info JSON)应对未来需求变化,避免频繁修改表结构。
- 预留字段(如
14. 项目中数据库表怎么设计的?
示例:电商订单系统核心表
-- 用户表
CREATE TABLE user (user_id BIGINT PRIMARY KEY AUTO_INCREMENT, -- 自增主键username VARCHAR(50) NOT NULL UNIQUE, -- 用户名(唯一索引)password VARCHAR(64) NOT NULL, -- 密码(加密存储)mobile CHAR(11) UNIQUE, -- 手机号(唯一索引)create_time DATETIME DEFAULT CURRENT_TIMESTAMP
) ENGINE=InnoDB CHARSET=utf8mb4;-- 商品表
CREATE TABLE product (product_id BIGINT PRIMARY KEY AUTO_INCREMENT,product_name VARCHAR(100) NOT NULL,category_id INT NOT NULL, -- 分类ID(外键关联category表)price DECIMAL(10, 2) NOT NULL, -- 价格(精确到分)stock INT NOT NULL DEFAULT 0
) ENGINE=InnoDB;-- 订单表
CREATE TABLE order (order_id BIGINT PRIMARY KEY, -- 雪花算法生成user_id BIGINT NOT NULL, -- 买家ID(外键)total_amount DECIMAL(10, 2) NOT NULL,status TINYINT NOT NULL DEFAULT 0, -- 订单状态(0待支付,1已支付,2已发货)create_time DATETIME DEFAULT CURRENT_TIMESTAMP,FOREIGN KEY (user_id) REFERENCES user(user_id)
) ENGINE=InnoDB;-- 订单详情表
CREATE TABLE order_detail (order_id BIGINT NOT NULL, -- 订单ID(联合主键)product_id BIGINT NOT NULL, -- 商品ID(联合主键)quantity INT NOT NULL,price DECIMAL(10, 2) NOT NULL,PRIMARY KEY (order_id, product_id),FOREIGN KEY (order_id) REFERENCES order(order_id),FOREIGN KEY (product_id) REFERENCES product(product_id)
) ENGINE=InnoDB;
15. 主键怎么设计?普通递增 vs 分布式雪花算法
- 单库场景:
使用AUTO_INCREMENT自增主键,简单高效,适合单节点数据库。 - 分布式场景:
- 雪花算法(Snowflake):生成64位唯一ID(时间戳+工作节点+序列号),支持高并发,如Java的
Twitter雪花算法实现。 - UUID:生成36位字符串(如
550e8400-e29b-41d4-a716-446655440000),虽全球唯一但占用空间大,不适合作为主键(可作为业务唯一标识)。
- 雪花算法(Snowflake):生成64位唯一ID(时间戳+工作节点+序列号),支持高并发,如Java的
16. 除了雪花算法和UUID,还有什么主键不重复方案?
- 数据库自增+分库键:
分库场景下,为每个库设置不同的自增起始值和步长(如库1起始1,步长2;库2起始2,步长2),确保跨库唯一。 - Redis生成ID:
使用INCR命令原子性生成递增ID,适合分布式系统,如:import redis r = redis.Redis(host='localhost', port=6379) order_id = r.incr('order_id_counter') - UUID变种:
- UUID without hyphens:去掉连字符(如
550e8400e29b41d4a716446655440000),节省空间。 - ULID(Universally Unique Lexicographical Identifier):比UUID更短(26字符),按字典序排列,适合索引。
- UUID without hyphens:去掉连字符(如
17. 具体字段类型设计:用户名用什么类型?
- 推荐类型:
- VARCHAR(n):
n根据业务需求设定(如VARCHAR(50)),存储用户名文本(支持中文、字母、数字混合)。 - CHAR(n):固定长度(如
CHAR(20)),适合长度一致的场景(如学号),但浪费空间,不推荐用户名。
- VARCHAR(n):
- 注意事项:
- 字符集使用
utf8mb4(支持Emoji和生僻字):CREATE TABLE ... CHARSET=utf8mb4; - 唯一性约束:
UNIQUE KEY(username),避免重复注册。 - 密码字段:绝不存储明文,使用
SHA-256+盐值加密(如password VARCHAR(64) NOT NULL存储哈希值)。
- 字符集使用
18. 什么时候用到JOIN?
适用场景:
- 关联多张表查询数据(如查询订单对应的用户姓名和商品信息)。
- 替代子查询,提升性能(如
SELECT u.name, o.total_amount FROM user u JOIN order o ON u.user_id = o.user_id;)。
JOIN类型选择:
- INNER JOIN:仅返回两张表中匹配的行(如用户存在且订单存在)。
- LEFT JOIN:返回左表所有行,右表匹配不到的行用
NULL填充(如查询所有用户及其订单,包括未下单用户)。 - RIGHT JOIN:与LEFT JOIN相反,返回右表所有行,实际中较少使用,可用LEFT JOIN+表交换替代。
- FULL OUTER JOIN(外连接):返回左右表所有行,匹配不到的用
NULL填充(MySQL不支持,需用LEFT JOIN UNION RIGHT JOIN模拟)。
三、加密算法(问题19-20)
19. 左连接、右连接、外连接的区别?
| 类型 | 定义 | 示例(表A: 用户,表B: 订单) |
|---|---|---|
| INNER JOIN | 仅返回A和B中ON条件匹配的行 | 只返回有订单的用户 |
| LEFT JOIN | 返回A的所有行,B中无匹配的行用NULL填充 | 返回所有用户,无订单的用户订单字段为NULL |
| RIGHT JOIN | 返回B的所有行,A中无匹配的行用NULL填充 | 返回所有订单,无用户的订单(异常数据)字段为NULL |
| FULL OUTER JOIN | 返回A和B的所有行,无匹配的行用NULL填充(MySQL不支持) | 需用A LEFT JOIN B UNION A RIGHT JOIN B模拟 |
20. 加密算法有哪些,什么区别?
常见加密算法分类及对比:
| 类别 | 算法名称 | 密钥类型 | 用途 | 特点 |
|---|---|---|---|---|
| 对称加密 | AES(AES-128/256) | 单密钥 | 数据加密(如敏感字段存储、通信加密) | 速度快,密钥需安全传输(常用作HTTPS底层加密) |
| DES/3DES | 单密钥 | 历史系统兼容(已逐渐被AES取代) | 密钥长度短(56位),安全性低 | |
| Blowfish | 单密钥 | 快速加密(如VPN) | 可变密钥长度(32-448位),适合资源受限环境 | |
| 非对称加密 | RSA(2048/4096位) | 公钥+私钥 | 数字签名、密钥交换(如HTTPS证书) | 安全性高,但速度慢,适合少量数据加密 |
| ECC(椭圆曲线) | 公钥+ |
相关文章:

Mysql常用知识3:Kafka和数据库优化
文章目录 一、分布式消息系统(Kafka相关问题5-10)5. Kafka如何保证消息不丢失?6. 项目中Kafka具体怎么使用的?7. 消息异常未发送成功怎么解决?8. 重试具体怎么做的,循环吗?9. 重试多次失败怎么办…...

Milvus单机模式安装和试用
1.安装ollama的package包; # install package pip install -U langchain-ollama2.我们直接使用ChatOllama实例化模型,并通过invoke进行调用; from langchain_ollama import ChatOllamallm ChatOllama(model"deepseek-r1") messa…...
飞牛NAS+Docker技术搭建个人博客站:公网远程部署实战指南
文章目录 前言1. Docker下载源设置2. Docker下载WordPress3. Docker部署Mysql数据库4. WordPress 参数设置5. 飞牛云安装Cpolar工具6. 固定Cpolar公网地址7. 修改WordPress配置文件8. 公网域名访问WordPress总结 前言 在数字化浪潮中,传统网站搭建方式正面临前所未…...
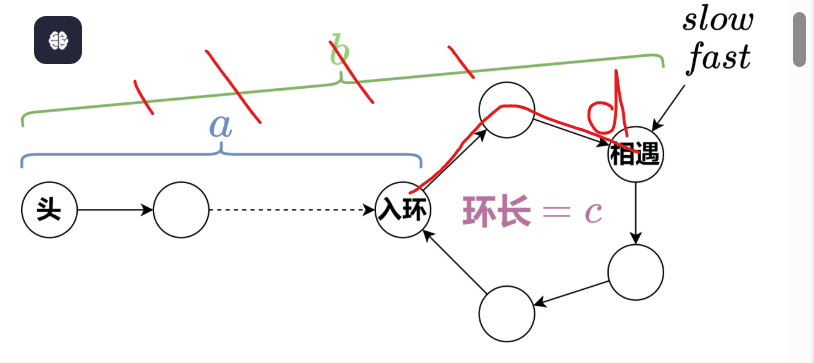
刷leetcode hot100返航必胜版--链表6/3
链表初始知识 链表种类:单链表,双链表,循环链表 链表初始化 struct ListNode{ int val; ListNode* next; ListNode(int x): val(x),next(nullptr) {} }; //初始化 ListNode* head new ListNode(5); 删除节点、添加…...

C# 序列化技术全面解析:原理、实现与应用场景
在软件开发中,数据持久化和网络通信是两个至关重要的环节。想象一下,当我们需要将一个复杂的对象保存到文件中,或者通过网络发送到另一台计算机时,如何有效地表示这个对象?这就是序列化技术要解决的问题。序列化&#…...

isp调试 blend模式指什么
isp调试 blend模式指什么 答案摘自豆包: 在图像信号处理(ISP,Image Signal Processor)调试中,Blend 模式(混合模式) 是指将不同处理阶段的图像数据或不同来源的图像信息按照特定规则进行叠加或…...
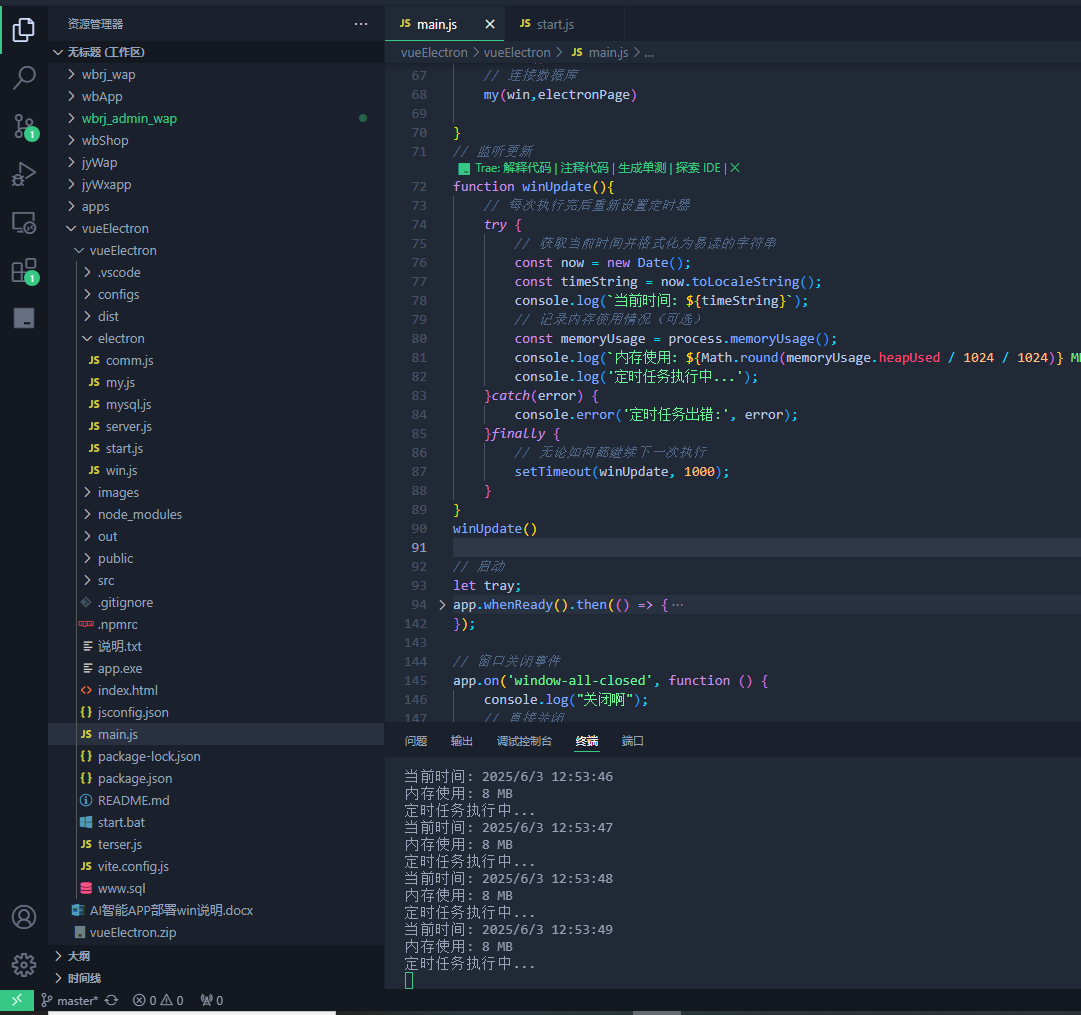
electron定时任务,打印内存占用情况
// 监听更新 function winUpdate(){// 每次执行完后重新设置定时器try {// 获取当前时间并格式化为易读的字符串const now new Date();const timeString now.toLocaleString();console.log(当前时间: ${timeString});// 记录内存使用情况(可选)const m…...

Gitee Wiki:以知识管理赋能 DevSecOps,推动关键领域软件自主演进
关键领域软件研发中的知识管理困境 传统文档管理模式问题显著 关键领域软件研发领域,传统文档管理模式问题显著:文档存储无系统,查找困难,降低效率;更新不及时,与实际脱节,误导开发࿱…...

学习STC51单片机24(芯片为STC89C52RCRC)
每日一言 把 “我不行” 换成 “我试试”,你会发现一片新的天地。 那关于优化 白盒测试 我们之前不是通过这个接线方式可以看到返回到信息嘛因为安信可的特性就是返回Esp8266的反馈,可以看到代码死在哪里了,导致连接不上,因为我们…...
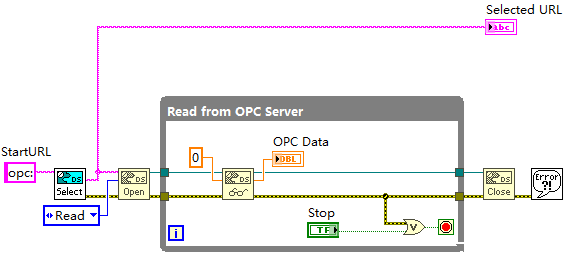
LabVIEW基于 DataSocket从 OPC 服务器读取数据
LabVIEW 中基于 DataSocket 函数从 OPC 服务器读取数据的功能,为工业自动化等场景下的数据交互提供了解决方案。通过特定函数实现 URL 指定、连接建立与管理、数据读取,相比传统 Socket 通信和 RESTful API ,在 OPC 服务器数据交互场景有适配…...

阿里云无影云桌面深度测评
阿里云无影桌面深度测评:解锁云端工作“新范式”的“未来之钥”! 在数字化浪潮席卷全球的2025年,远程办公与混合办公已不再是权宜之计,而是职场不可逆转的新常态。然而,如何确保员工无论身在何处,都能拥有…...

【208】VS2022 C++ 32位整数和unsigned char数组之间互相转换
一、场景 在实际应用中,特别是在数据传输的时候,需要读取unsigned char数组,再转换成 32 位整数;或者把 32 位整数转换成 unsigned char数组进行写入。比如对接西门子PLC的 snap7 就是这样。32 位整数分成有符号的无符号的&#…...

数据库技术
InnoDB是什么?MySQL 和 InnoDB的关系是什么? InnoDB是MySQL数据库系统中最重要且默认的存储引擎。MySQL采用插件式存储引擎架构,作为数据库管理系统本身不直接处理数据存储,而是通过存储引擎接口与InnoDB等引擎交互。InnoDB作为M…...
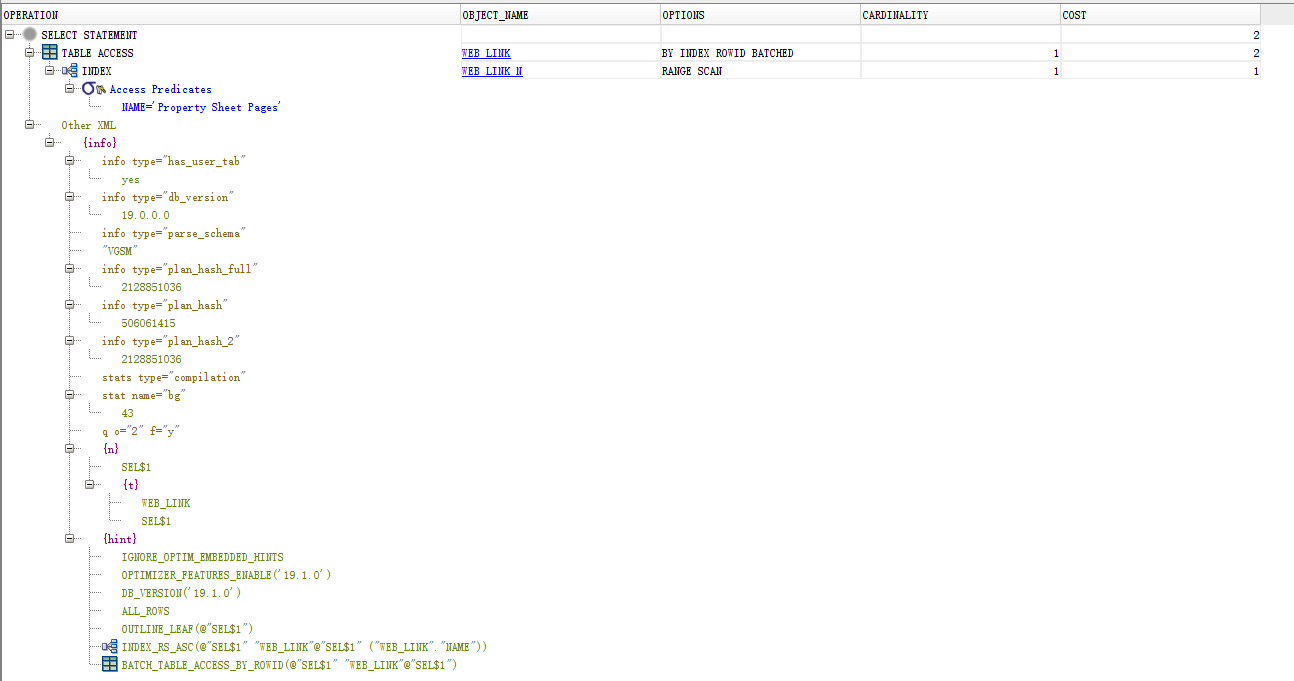
深入浅出:Oracle 数据库 SQL 执行计划查看详解(1)——基础概念与查看方式
背景 在当今的软件开发领域,尽管主流开发模式往往倾向于采用单表模式,力图尽可能地减少表之间的连接操作,以期达到提高数据处理效率、简化应用逻辑等目的。然而,对于那些已经上线运行多年的运维老系统而言,它们内部往…...

前端HTML contenteditable 属性使用指南
什么是 contenteditable? HTML5 提供的全局属性,使元素内容可编辑类似于简易富文本编辑器兼容性 支持所有现代浏览器(Chrome、Firefox、Safari、Edge) 移动端(iOS/Android)部分键盘行为需测试 &l…...

自动化采集脚本与隧道IP防封设计
最近群里讨论问如何编写一个自动化采集脚本,要求使用隧道IP(代理IP池)来防止IP被封。这样的脚本通常用于爬虫或数据采集任务,其中目标网站可能会因为频繁的请求而封禁IP。对于这些我还是有些经验的。 核心思路: 1、使…...

【设计模式-4.7】行为型——备忘录模式
说明:本文介绍行为型设计模式之一的备忘录模式 定义 备忘录模式(Memento Pattern)又叫作快照模式(Snapshot Pattern)或令牌模式(Token Pattern)指在不破坏封装的前提下,捕获一个对…...

docker离线镜像下载
背景介绍 在某些网络受限的环境中,直接从Docker Hub或其他在线仓库拉取镜像可能会遇到困难。为了在这种情况下也能顺利使用Docker镜像,我们可以提前下载好所需的镜像,并通过离线方式分发和使用。 当前镜像有:python-3.8-slim.ta…...

Vert.x学习笔记-Verticle原理解析
Vert.x学习笔记 一、设计理念:事件驱动的组件化模型二、生命周期管理三、部署方式与策略四、通信机制:事件总线(Event Bus)五、底层实现原理六、典型应用场景七、Verticle与EventLoop的关系1、核心关系:一对一绑定与线…...

Cobra CLI 工具使用指南:构建 Go 语言命令行应用的完整教程
Cobra CLI 工具使用指南:构建 Go 语言命令行应用的完整教程 在 Go 语言开发中,构建功能强大的命令行界面(CLI)应用是常见需求。Cobra 作为 Go 生态中最受欢迎的 CLI 库,凭借其灵活的设计和丰富的功能,成为…...
jQuery和CSS3卡片列表布局特效
这是一款jQuery和CSS3卡片列表布局特效。该卡片布局使用owl.carousel.js来制作轮播效果,使用简单的css代码来制作卡片布局,整体效果时尚大方。 预览 下载 使用方法 在页面最后引入jquery和owl.carousel.js相关文件。 <link rel"stylesheet&qu…...
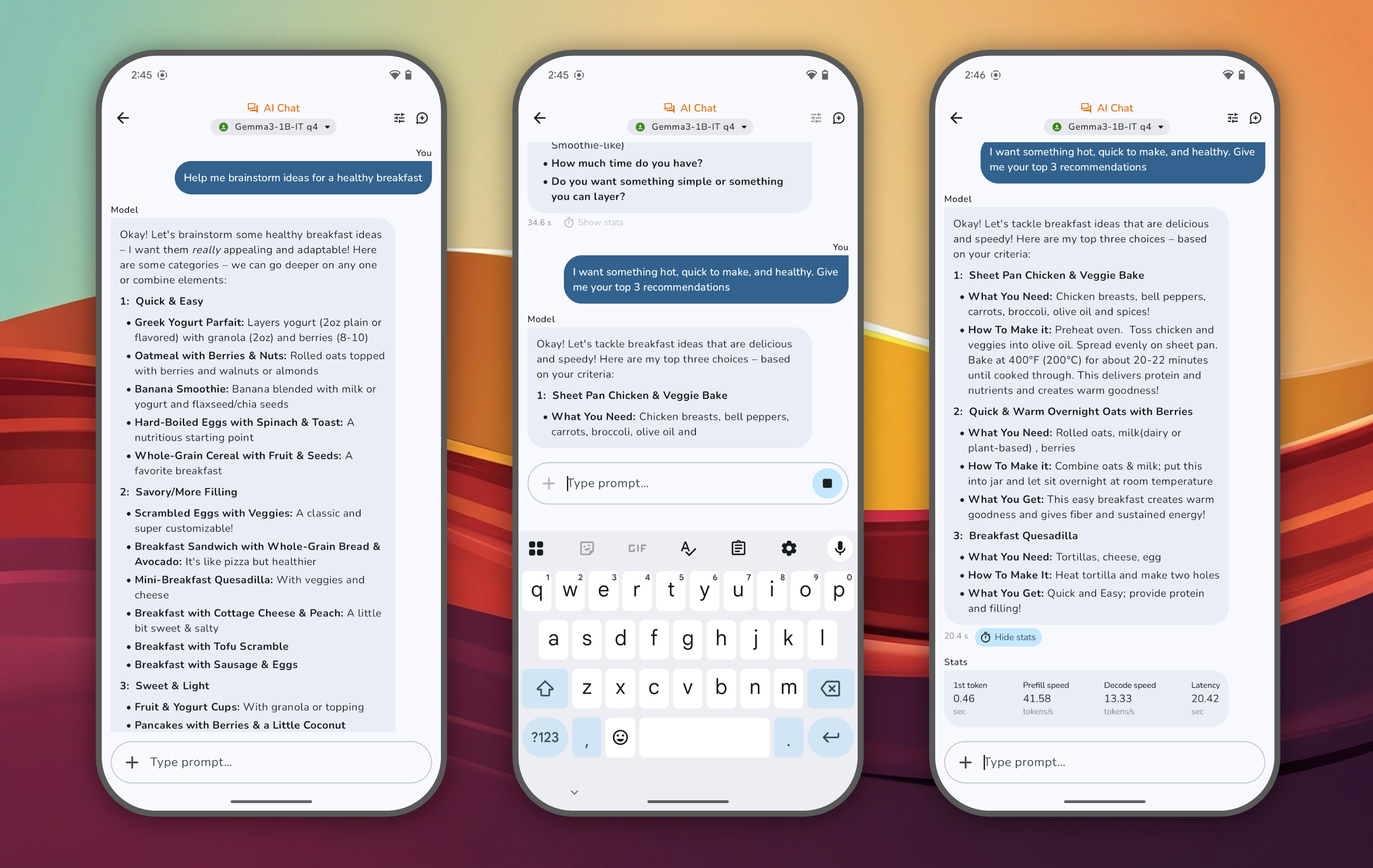
不连网也能跑大模型?
一、这是个什么 App? 你有没有想过,不用连网,你的手机也能像 ChatGPT 那样生成文字、识别图片、甚至回答复杂问题?Google 最近悄悄发布了一个实验性 Android 应用——AI Edge Gallery,就是为此而生的。 这个应用不在…...
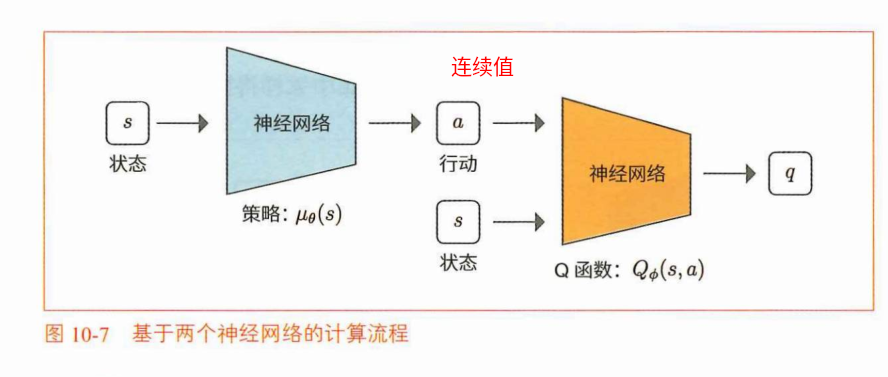
强化学习鱼书(10)——更多深度强化学习的算法
:是否使用环境模型(状态迁移函数P(s’|s,a)和奖 励函数r(s,a,V))。不使用环境模型的方法叫作无模型(model-free)的方法,使用环境模型的方法叫作有模型(model-based&#…...
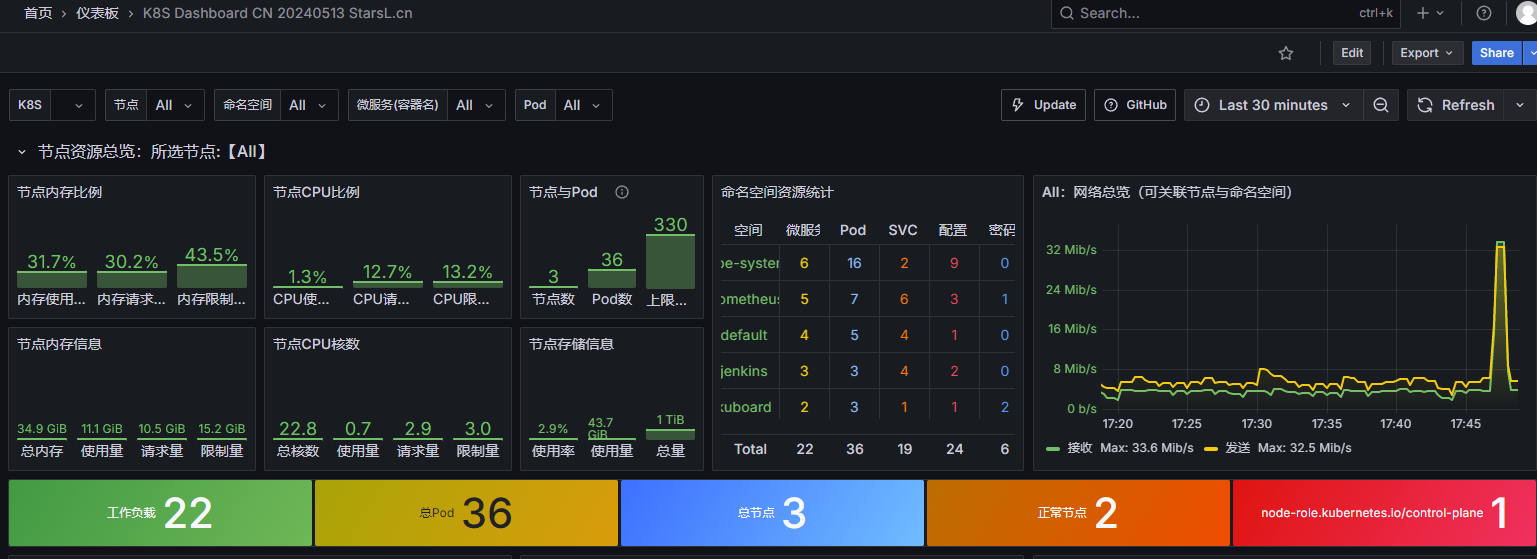
K8S上使用helm部署 Prometheus + Grafana
一、使用 Helm 安装 Prometheus 1. 配置源 地址:prometheus 27.19.0 prometheus/prometheus-community # 添加repo $ helm repo add prometheus-community https://prometheus-community.github.io/helm-charts "prometheus-community" has been added…...
)
十四、【测试执行篇】让测试跑起来:API 接口测试执行器设计与实现 (后端执行逻辑)
@[TOC](【测试执行篇】让测试跑起来:API 接口测试执行器设计与实现 (后端执行逻辑)) 前言 测试执行是测试平台的核心价值所在。一个好的测试执行器需要能够: 准确解析测试用例: 正确理解用例中定义的请求参数和断言条件。可靠地发送请求: 模拟真实的客户端行为与被测 API…...
Java面试八股--07-项目篇
致谢:2025年 Java 面试八股文(20w字)_java面试八股文-CSDN博客 目录 1、介绍一下最近做的项目 1.1 项目背景: 1.2 项目功能 1.3 技术栈 1.4自己负责的功能模块 1.5项目介绍参考: 1.6整体业务介绍: 1.8后台管理系统功能: 1.8.1后台主页: 1.8.2 商品模块: 1.8…...

MCP架构全解析:从核心原理到企业级实践
💝💝💝欢迎莅临我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:「storms…...
从0到1认识EFK
一、ES集群部署 操作系统Ubuntu22.04LTS/主机名IP地址主机配置elk9110.0.0.91/244Core8GB100GB磁盘elk9210.0.0.92/244Core8GB100GB磁盘elk9310.0.0.93/244Core8GB100GB磁盘 1. 什么是ElasticStack? # 官网 https://www.elastic.co/ ElasticStack早期名称为elk。 elk分别…...

快速了解GO+ElasticSearch
更多个人笔记见: (注意点击“继续”,而不是“发现新项目”) github个人笔记仓库 https://github.com/ZHLOVEYY/IT_note gitee 个人笔记仓库 https://gitee.com/harryhack/it_note 个人学习,学习过程中还会不断补充&…...

定制开发开源AI智能名片驱动下的海报工厂S2B2C商城小程序运营策略——基于社群口碑传播与子市场细分的实证研究
摘要 本文聚焦“定制开发开源AI智能名片S2B2C商城小程序”技术与海报工厂业务的融合实践,探讨其如何通过风格化海报矩阵的精细化开发、AI技术驱动的用户体验升级,以及S2B2C模式下的社群裂变机制,实现“工具功能-社交传播-商业变现”的生态…...