【DAY39】图像数据与显存
内容来自@浙大疏锦行python打卡训练营
@浙大疏锦行
- 图像数据的格式:灰度和彩色数据
- 模型的定义
- 显存占用的4种地方
- 模型参数+梯度参数
- 优化器参数
- 数据批量所占显存
- 神经元输出中间状态
- batchisize和训练的关系
作业:今日代码较少,理解内容即可
一、 图像数据的介绍
1.1 灰度图像
从这里开始我们进入到了图像数据相关的部分,也是默认你有之前复试班计算机视觉相关的知识,但是一些基础的概念我仍然会提。
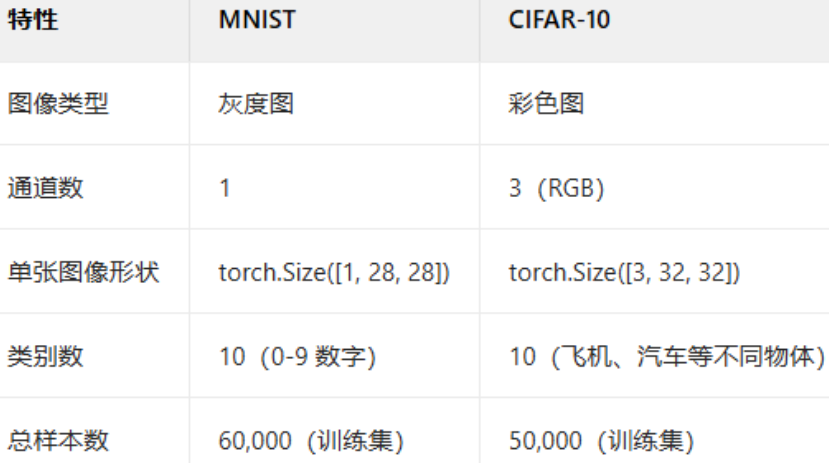
昨天我们介绍了minist这个经典的手写数据集,作为图像数据,相较于结构化数据(表格数据)他的特点在于他每个样本的的形状并不是(特征数),而是(宽,高,通道数)。
# 先继续之前的代码
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader , Dataset # DataLoader 是 PyTorch 中用于加载数据的工具
from torchvision import datasets, transforms # torchvision 是一个用于计算机视觉的库,datasets 和 transforms 是其中的模块
import matplotlib.pyplot as plt
# 设置随机种子,确保结果可复现
torch.manual_seed(42)# 1. 数据预处理,该写法非常类似于管道pipeline
# transforms 模块提供了一系列常用的图像预处理操作# 先归一化,再标准化
transform = transforms.Compose([transforms.ToTensor(), # 转换为张量并归一化到[0,1]transforms.Normalize((0.1307,), (0.3081,)) # MNIST数据集的均值和标准差,这个值很出名,所以直接使用
])
import matplotlib.pyplot as plt# 2. 加载MNIST数据集,如果没有会自动下载
train_dataset = datasets.MNIST(root='./data',train=True,download=True,transform=transform
)test_dataset = datasets.MNIST(root='./data',train=False,transform=transform
)# 随机选择一张图片,可以重复运行,每次都会随机选择
sample_idx = torch.randint(0, len(train_dataset), size=(1,)).item() # 随机选择一张图片的索引
# len(train_dataset) 表示训练集的图片数量;size=(1,)表示返回一个索引;torch.randint() 函数用于生成一个指定范围内的随机数,item() 方法将张量转换为 Python 数字
image, label = train_dataset[sample_idx] # 获取图片和标签
# 可视化原始图像(需要反归一化)
def imshow(img):img = img * 0.3081 + 0.1307 # 反标准化npimg = img.numpy()plt.imshow(npimg[0], cmap='gray') # 显示灰度图像plt.show()print(f"Label: {label}")
imshow(image)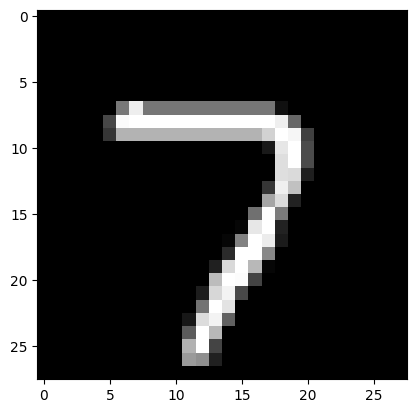
上述是昨天的代码,我们介绍了图像数据的预处理,这是我们首次接触图像数据,他和之前的结构化数据有什么差异点呢?
结构化数据(如表格)的形状通常是 (样本数, 特征数),例如 (1000, 5) 表示 1000 个样本,每个样本有 5 个特征。图像数据的形状更复杂,需要保留空间信息(高度、宽度、通道),因此不能直接用一维向量表示。其中颜色信息往往是最开始输入数据的通道的含义,因为每个颜色可以用红绿蓝三原色表示,因此一般输入数据的通道数是 3

MNIST 数据集是手写数字的 灰度图像,每个像素点的取值范围为 0-255(黑白程度),因此 通道数为 1。图像尺寸统一为 28×28 像素。
# 打印下图片的形状
image.shape![]()
1.2 彩色图像
在 PyTorch 中,图像数据的形状通常遵循 (通道数, 高度, 宽度) 的格式(即 Channel First 格式),这与常见的 (高度, 宽度, 通道数)(Channel Last,如 NumPy 数组)不同。---注意顺序关系
注意点:
1. 如果用matplotlib库来画图,需要转换下顺序,我们后续介绍
2. 模型输入通常需要 批次维度(Batch Size),形状变为 (批次大小, 通道数, 高度, 宽度)。例如,批量输入 10 张 MNIST 图像时,形状为 (10, 1, 28, 28)。
# 打印一张彩色图像,用cifar-10数据集
import torch
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np# 设置随机种子确保结果可复现
torch.manual_seed(42)
# 定义数据预处理步骤
transform = transforms.Compose([transforms.ToTensor(), # 转换为张量并归一化到[0,1]transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 标准化处理
])# 加载CIFAR-10训练集
trainset = torchvision.datasets.CIFAR10(root='./data',train=True,download=True,transform=transform
)# 创建数据加载器
trainloader = torch.utils.data.DataLoader(trainset,batch_size=4,shuffle=True
)# CIFAR-10的10个类别
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')# 随机选择一张图片
sample_idx = torch.randint(0, len(trainset), size=(1,)).item()
image, label = trainset[sample_idx]# 打印图片形状
print(f"图像形状: {image.shape}") # 输出: torch.Size([3, 32, 32])
print(f"图像类别: {classes[label]}")# 定义图像显示函数(适用于CIFAR-10彩色图像)
def imshow(img):img = img / 2 + 0.5 # 反标准化处理,将图像范围从[-1,1]转回[0,1]npimg = img.numpy()plt.imshow(np.transpose(npimg, (1, 2, 0))) # 调整维度顺序:(通道,高,宽) → (高,宽,通道)plt.axis('off') # 关闭坐标轴显示plt.show()# 显示图像
imshow(image)

注意,因为这里设计到图像的显示,所以就需要调整维度顺序:(通道,高,宽) → (高,宽,通道)
介绍下超参数的优化 优化器
优化手写数字问题 引出cnn
如何计算显存一次性可以读取多少张
随机种子
二、 图像相关的神经网络的定义
考虑课程内容的推进,今日的内容只提定义,不涉及训练和测试过程
2.1 黑白图像模型的定义
# 先归一化,再标准化
transform = transforms.Compose([transforms.ToTensor(), # 转换为张量并归一化到[0,1]transforms.Normalize((0.1307,), (0.3081,)) # MNIST数据集的均值和标准差,这个值很出名,所以直接使用
])
import matplotlib.pyplot as plt# 2. 加载MNIST数据集,如果没有会自动下载
train_dataset = datasets.MNIST(root='./data',train=True,download=True,transform=transform
)test_dataset = datasets.MNIST(root='./data',train=False,transform=transform
)
# 定义两层MLP神经网络
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.flatten = nn.Flatten() # 将28x28的图像展平为784维向量self.layer1 = nn.Linear(784, 128) # 第一层:784个输入,128个神经元self.relu = nn.ReLU() # 激活函数self.layer2 = nn.Linear(128, 10) # 第二层:128个输入,10个输出(对应10个数字类别)def forward(self, x):x = self.flatten(x) # 展平图像x = self.layer1(x) # 第一层线性变换x = self.relu(x) # 应用ReLU激活函数x = self.layer2(x) # 第二层线性变换,输出logitsreturn x# 初始化模型
model = MLP()device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device) # 将模型移至GPU(如果可用)from torchsummary import summary # 导入torchsummary库
print("\n模型结构信息:")
summary(model, input_size=(1, 28, 28)) # 输入尺寸为MNIST图像尺寸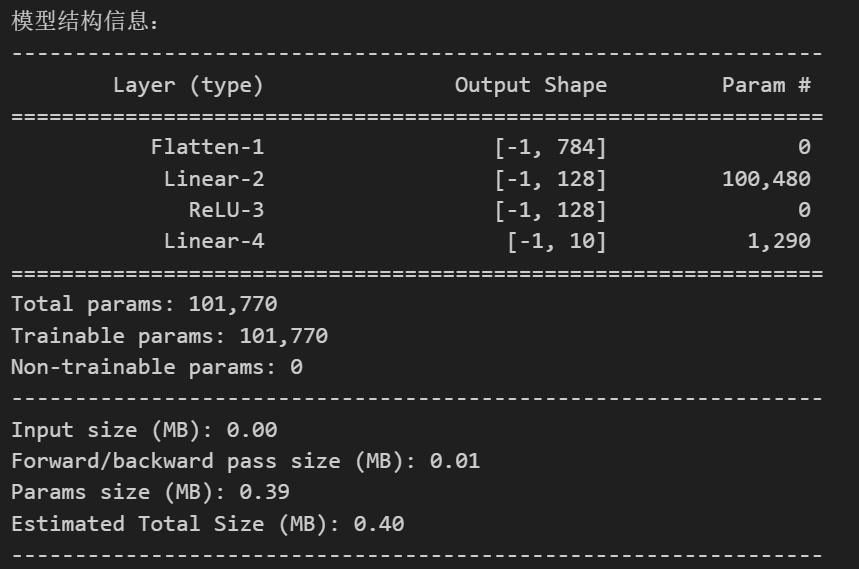
我们关注和之前结构化MLP的差异
1. 输入需要展平操作
MLP 的输入层要求输入是一维向量,但 MNIST 图像是二维结构(28×28 像素),形状为 [1, 28, 28](通道 × 高 × 宽)。nn.Flatten()展平操作 将二维图像 “拉成” 一维向量(784=28×28 个元素),使其符合全连接层的输入格式。
其中不定义这个flatten方法,直接在前向传播的过程中用 x = x.view(-1, 28 * 28) 将图像展平为一维向量也可以实现
2. 输入数据的尺寸包含了通道数input_size=(1, 28, 28)
3. 参数的计算
- 第一层 layer1(全连接层)
权重参数:输入维度 × 输出维度 = 784 × 128 = 100,352
偏置参数:输出维度 = 128
合计:100,352 + 128 = 100,480
- 第二层 layer2(全连接层)
权重参数:输入维度 × 输出维度 = 128 × 10 = 1,280
偏置参数:输出维度 = 10
合计:1,280 + 10 = 1,290
- 总参数:100,480(layer1) + 1,290(layer2) = 101,770
2.2 彩色图像模型的定义
class MLP(nn.Module):def __init__(self, input_size=3072, hidden_size=128, num_classes=10):super(MLP, self).__init__()# 展平层:将3×32×32的彩色图像转为一维向量# 输入尺寸计算:3通道 × 32高 × 32宽 = 3072self.flatten = nn.Flatten()# 全连接层self.fc1 = nn.Linear(input_size, hidden_size) # 第一层self.relu = nn.ReLU()self.fc2 = nn.Linear(hidden_size, num_classes) # 输出层def forward(self, x):x = self.flatten(x) # 展平:[batch, 3, 32, 32] → [batch, 3072]x = self.fc1(x) # 线性变换:[batch, 3072] → [batch, 128]x = self.relu(x) # 激活函数x = self.fc2(x) # 输出层:[batch, 128] → [batch, 10]return x# 初始化模型
model = MLP()device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device) # 将模型移至GPU(如果可用)from torchsummary import summary # 导入torchsummary库
print("\n模型结构信息:")
summary(model, input_size=(3, 32, 32)) # CIFAR-10 彩色图像(3×32×32)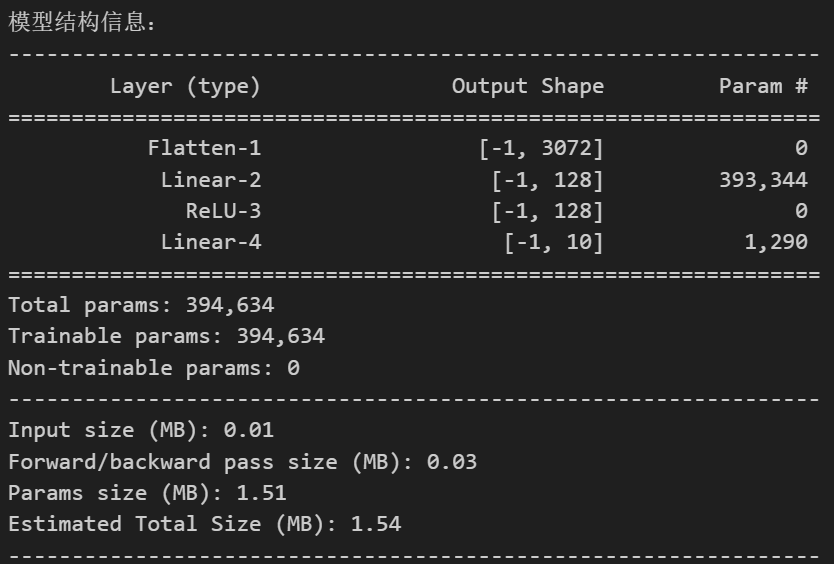
- 第一层 layer1(全连接层)
权重参数:输入维度 × 输出维度 = 3072 × 128 = 393,216
偏置参数:输出维度 = 128
合计:393,216 + 128 = 393,344
- 第二层 layer2(全连接层)
权重参数:输入维度 × 输出维度 = 128 × 10 = 1,280
偏置参数:输出维度 = 10
合计:1,280 + 10 = 1,290
- 总参数:393,344(layer1) + 1,290(layer2) = 394,634
2.3 模型定义与batchsize的关系
实际定义中,输入图像还存在batchsize这一维度
在 PyTorch 中,模型定义和输入尺寸的指定不依赖于 batch_size,无论设置多大的 batch_size,模型结构和输入尺寸的写法都是不变的。
class MLP(nn.Module):def __init__(self):super().__init__()self.flatten = nn.Flatten() # nn.Flatten()会将每个样本的图像展平为 784 维向量,但保留 batch 维度。self.layer1 = nn.Linear(784, 128)self.relu = nn.ReLU()self.layer2 = nn.Linear(128, 10)def forward(self, x):x = self.flatten(x) # 输入:[batch_size, 1, 28, 28] → [batch_size, 784]x = self.layer1(x) # [batch_size, 784] → [batch_size, 128]x = self.relu(x)x = self.layer2(x) # [batch_size, 128] → [batch_size, 10]return xPyTorch 模型会自动处理 batch 维度(即第一维),无论 batch_size 是多少,模型的计算逻辑都不变。batch_size 是在数据加载阶段定义的,与模型结构无关。
summary(model, input_size=(1, 28, 28))中的input_size不包含 batch 维度,只需指定样本的形状(通道 × 高 × 宽)。
总结:batch_size与模型定义的关系

三、显存占用的主要组成部分
昨天说到了在面对数据集过大的情况下,由于无法一次性将数据全部加入到显存中,所以采取了分批次加载这种方式。即一次只加载一部分数据,保证在显存的范围内。
那么显存设置多少合适呢?如果设置的太小,那么每个batchsize的训练不足以发挥显卡的能力,浪费计算资源;如果设置的太大,会出现OOT(out of memory)
显存一般被以下内容占用:
1. 模型参数与梯度:模型的权重(Parameters)和对应的梯度(Gradients)会占用显存,尤其是深度神经网络(如 Transformer、ResNet 等),一个 1 亿参数的模型(如 BERT-base),单精度(float32)参数占用约 400MB(1e8×4Byte),加上梯度则翻倍至 800MB(每个权重参数都有其对应的梯度)。
2. 部分优化器(如 Adam)会为每个参数存储动量(Momentum)和平方梯度(Square Gradient),进一步增加显存占用(通常为参数大小的 2-3 倍)
3. 其他开销
显存超出限制怎么办?一文解决深度学习中的 CUDA OOM 问题(附代码+实战技巧)-腾讯云开发者社区-腾讯云
下面以手写数据集为例
from torch.utils.data import DataLoader# 定义训练集的数据加载器,并指定batch_size
train_loader = DataLoader(dataset=train_dataset, # 加载的数据集batch_size=64, # 每次加载64张图像shuffle=True # 训练时打乱数据顺序
)# 定义测试集的数据加载器(通常batch_size更大,减少测试时间)
test_loader = DataLoader(dataset=test_dataset,batch_size=1000,shuffle=False
)手写数据集(MNIST)和当前 MLP 模型,显存占用的计算可以简化为以下几个部分
3.1 模型参数与梯度(FP32 精度)
参数总量:101,770 个参数
- 1字节(Byte)= 8位(bit),是计算机存储的最小寻址单位。
- 位(bit)是二进制数的最小单位(0或1),例如 0b1010 表示4位二进制数。
- 1KB=1024字节;1MB=1024KB=1,048,576字节
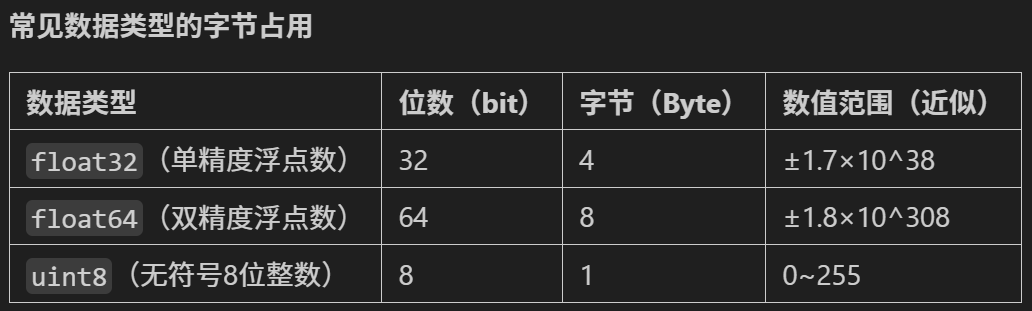
- MNIST数据集的原始图像像素值为0-255的整数(uint8类型,占1字节),表示灰度值(0=黑,255=白)
- 但PyTorch的transforms.ToTensor()会将其归一化到[0, 1]范围,并转换为 `float32`类型(浮点型更适合神经网络计算)。
计算示例:单张MNIST图像的显存占用
1. 原始像素值(uint8,未转换时)
- 尺寸:28×28像素
- 单像素占用:1字节(uint8)
- 总占用:28×28×1 = 784字节 ≈ 0.766 KB
2. 转换为 float32 张量后
- 尺寸: 1×28×28 (通道×高×宽)
- 单像素占用:4字节(float32)
- 总占用: 1×28×28×4 = 3136字节 ≈ 3.06 KB
单精度(float32)参数占用:101,770 × 4 Byte ≈ 403 KB
梯度是损失函数对模型参数的导数(∂Loss/∂Weight),用于指示参数更新的方向和幅度。梯度是损失函数对模型参数的导数(∂Loss/∂Weight),用于指示参数更新的方向和幅度。因此在默认情况下,梯度的数据类型和数目与参数相同。
梯度占用(反向传播时):与参数相同,合计约 806 KB
3.2 优化器状态
SGD
- SGD优化器不存储额外动量,因此无额外显存占用。
- SGD 随机梯度下降,最基础的优化器,直接沿梯度反方向更新参数。
- 参数更新公式:w = w - learning_rate * gradient
Adam
- Adam优化器:自适应学习率优化器,结合了动量(Momentum)和梯度平方的指数移动平均。
- 每个参数存储动量(m)和平方梯度(v),占用约 101,770 × 8 Byte ≈ 806 KB
- 动量(m):每个参数对应一个动量值,数据类型与参数相同(float32),占用 403 KB。
- 梯度平方(v):每个参数对应一个梯度平方值,数据类型与参数相同(float32),占用 403 KB。
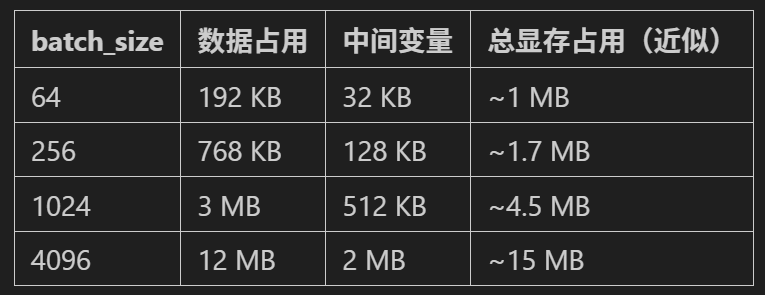
3.3 数据批量(batch_size)的显存占用
- 单张图像尺寸:`1×28×28`(通道×高×宽),归一化转换为张量后为`float32`类型
- 单张图像显存占用:`1×28×28×4 Byte = 3,136 Byte ≈ 3 KB`
- 批量数据占用:`batch_size × 单张图像占用`
- 例如:`batch_size=64` 时,数据占用为`64×3 KB ≈ 192 KB`
- `batch_size=1024`时,数据占用为 `1024×3 KB ≈ 3 MB`
3.4. 前向/反向传播中间变量
- 对于两层MLP,中间变量(如`layer1`的输出)占用较小:
- `batch_size×128`维向量:`batch_size×128×4 Byte = batch_size×512 Byte`
- 例如`batch_size=1024`时,中间变量约 512 KB
以SGD为例,此时其他参数占用固定,batchsize会影响显存占用
在 PyTorch 中,在使用DataLoader加载数据时,如果不指定batch_size参数,默认值是1,即每次迭代返回一个样本。这与一次性使用全部数据进行训练是完全不同的概念。如果想要一次性使用全部数据进行训练,需要手动将batch_size设置为数据集的大小,但对于大型数据集,这样做通常会导致内存不足,因为一次性将所有数据加载到内存中可能会超出硬件的内存限制。
大规模数据时,通常从16开始测试,然后逐渐增加,确保代码运行正常且不报错,直到出现 内存不足(OOM)报错 或训练效果下降,此时选择略小于该值的 batch_size。
训练时候搭配 nvidia-smi 监控显存占用,合适的 batch_size = 硬件显存允许的最大值 × 0.8(预留安全空间),并通过训练效果验证调整。
补充说明: batchsize对于训练的影响
在深度学习中,使用较大的 batch_size(批量大小)相比单样本训练(batch_size=1)有以下核心优势
- 并行计算能力最大化,减小训练时间;且大幅减少更新次数
- 梯度方向更准确,单样本训练的梯度仅基于单个数据点,可能包含大量噪声(尤其是数据分布不均或存在异常值时)。大 batch_size 的梯度是多个样本的平均值,能抵消单个样本的随机性,梯度方向更接近真实分布的 “全局最优方向”。会让训练过程更稳定,波动更小。

相关文章:
【DAY39】图像数据与显存
内容来自浙大疏锦行python打卡训练营 浙大疏锦行 知识点: 图像数据的格式:灰度和彩色数据模型的定义显存占用的4种地方 模型参数梯度参数优化器参数数据批量所占显存神经元输出中间状态 batchisize和训练的关系 作业:今日代码较少࿰…...
AI代码库问答引擎Folda-Scan
简介 什么是 Folda-Scan ? Folda-Scan 是一款革命性的智能项目问答工具, 完全在浏览器中本地运行 。它使用高级语义矢量化将您的代码库转变为对话伙伴,使代码理解和 AI 协作变得前所未有的简单和安全。其采用尖端的 Web 技术和 AI 算法构建&…...
Kafka深度技术解析:架构、原理与最佳实践
一、 消息队列的本质价值与核心特性 1.1 分布式系统的“解耦器” 异步通信模型 代码列表 graph LRA[生产者] -->|异步推送| B[(消息队列)]B -->|按需拉取| C[消费者1]B -->|按需拉取| D[消费者2] 生产者发送后立即返回,消费者以自己的节奏处理消息。典…...

基于cnn的通用图像分类项目
背景 项目上需要做一个图像分类的工程。本人希望这么一个工程可以帮助学习ai的新同学快速把代码跑起来,快速将自己的数据集投入到实战中! 代码仓库地址:imageClassifier: 图片分类器 数据处理 自己准备的分类图像,按照文件夹分…...

Kotlin-协程
文章目录 什么是协程协程的好处协程的挂起和恢复协程原理 什么是协程 协程是一种用户态的轻量级程序组件,其核心特点是通过协作式调度实现单线程内的伪并发。 协程的好处 传统的线程切换通过回调,Handler各种调度,繁琐,代码不清…...

pycharm 左右箭头 最近编辑
目录 经典界面: 快捷键 经典界面: 如果你使用的是新 UI(新版 PyCharm 默认启用的),导航按钮可能被精简了,你可以: File Settings(齿轮图标)→ UI Appearance 或 New …...

Linux环境管道通信介绍
目录 前言 一、通信的本质 二、匿名管道 1.通信资源——文件缓冲区 2.为什么叫匿名管道? 编辑 3.匿名管道的创建过程 4.pipe函数 小结 5.一些问题 1)匿名管道为什么要求父子进程将原本的读/写权限只保留一个 2)为什么一开始父进程要以读/写…...
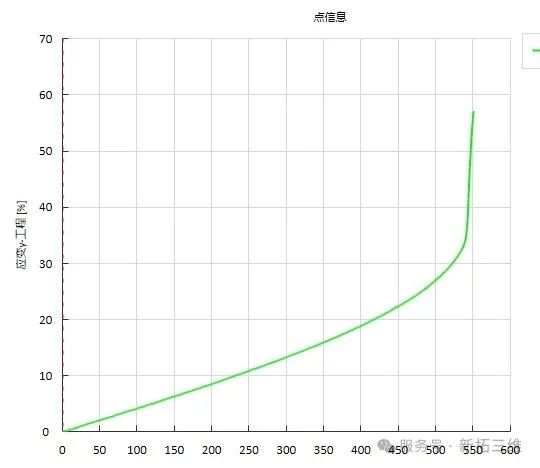
DIC技术助力金属管材全场应变测量:高效解决方案
在石油管道、汽车排气系统、航空航天液压管路等工业场景中,金属管作为关键承力部件,其拉伸性能(如弹性极限、颈缩行为、断裂韧性)直接影响结构安全性和使用寿命。 实际应用中,选用合适的管材非常重要,通过…...

python基础day04
1.两大编程思想的异同点: 面向过程面向对象区别事物比较简单,可以用线性的思维去解决事物比较复杂,使用简单的线性思维无法解决共同点面向过程和面向对象都是解决实际问题的一种思维方式二者相辅相成,并不是对立的解决复杂问题,通…...
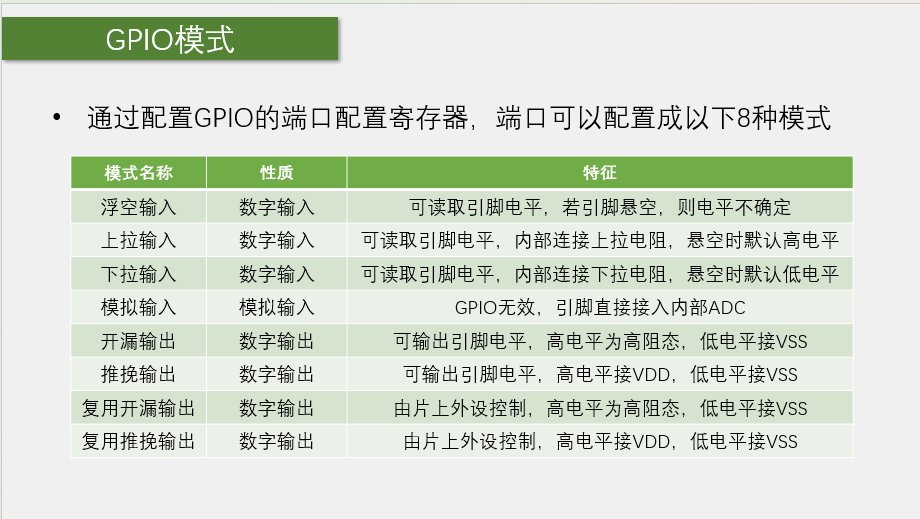
嵌入式学习--江协stm32day1
失踪人口回归了,stm32的学习比起51要慢一些,因为涉及插线,可能存在漏插,不牢固等问题。 相对于51直接对寄存器的设置,stm32因为是32位修改起来比较麻烦,江协课程是基于标准库的,是对封装函数进…...

湖北理元理律师事务所:债务化解中的心理重建与法律护航
专业法律顾问视角 一、债务危机的双重属性:法律问题与心理困境 在对173名债务人的调研中发现: 68%存在焦虑引发的决策障碍(如不敢接听银行电话) 42%因羞耻感隐瞒债务导致雪球效应 湖北理元理律师事务所创新采用法律-心理双轨…...

constexpr 是 C++11 引入的关键字
constexpr 是 C11 引入的关键字,用于在编译期进行常量表达式计算,从而提高程序性能和安全性。以下是其核心作用和用法: 一.作用 1编译期 计算 constexpr 变量或函数的值在编译时确定,避免运行时计算开销。例如,数组大…...
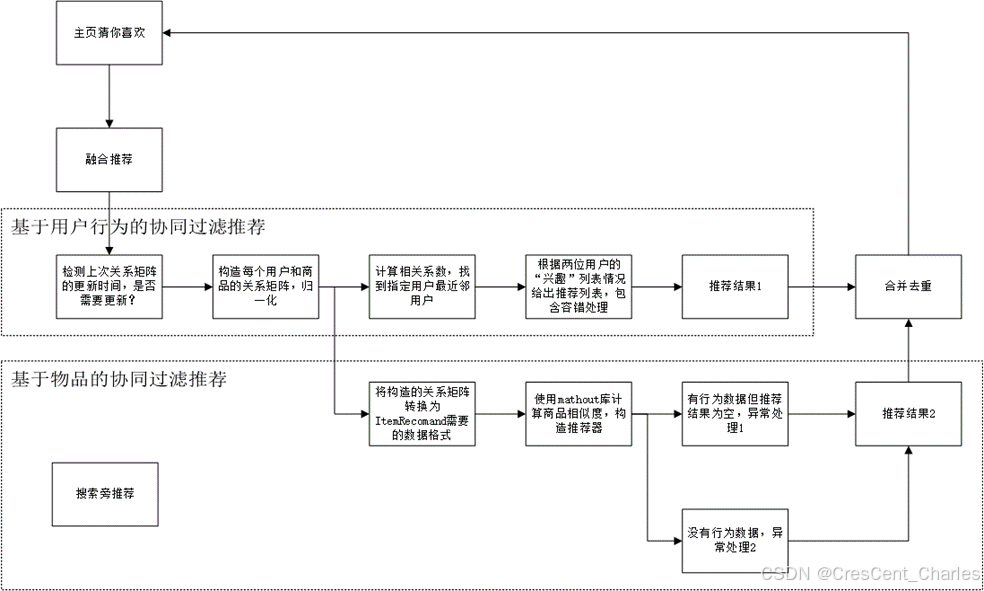
【更新中】(文档+代码)基于推荐算法和Springboot+Vue的购物商城
概要设计 本节规划和定义了Woodnet桌游电商平台的软件概要设计说明书,描述了软件的总体设计、接口设计、运行设计、系统数据库结构设计以及系统出错处理设计,从整体上说明了系统设计的结构层次、处理流程、系统用例等。 本系统是一个独立的系统&#x…...

六种高阶微分方程的特解(原创:daode3056)
高阶微分方程的通解是指包含所有可能解的解的表达式。对于一个 n 阶微分方程,其通解通常包含 n 个任意常数。这些任意常数可以通过初始条件或边界条件来确定。高阶微分方程的特解是指在通解中,特定地选择了一组常数,使得解满足给定的初始条件…...

【C++11(上)】—— 我与C++的不解之缘(三十)
一、C11 这里简单了解一下C发展好吧: C11是C的第二个大版本,也是自C98以来最重要的一个版本。 它引入了大量的更改,它曾被人们称为C0x,因为它被期待在2010年之前发布;但在2011年8月12日才被采纳。 C03到C11花了8年时间…...
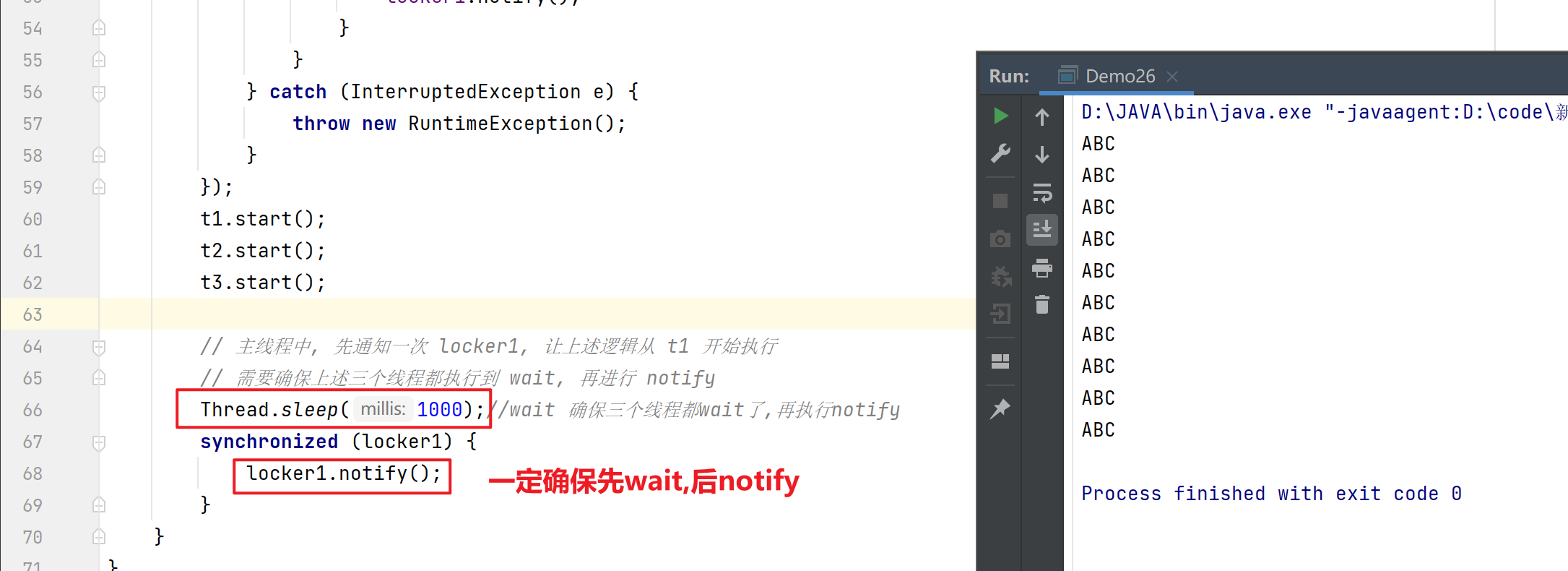
【多线程初阶】wait() notify()
文章目录 协调多个线程间的执行顺序join 和 wait 区别sleep 和 wait 区别 wait()方法线程饿死调用 wait()唤醒 wait() notify()方法wait() 和 notify() 需对同一对象使用确保先 wait ,后 notify多个线程在同一对象上wait notify随机唤醒一个wait notifyAll()方法应用 wait() 和…...
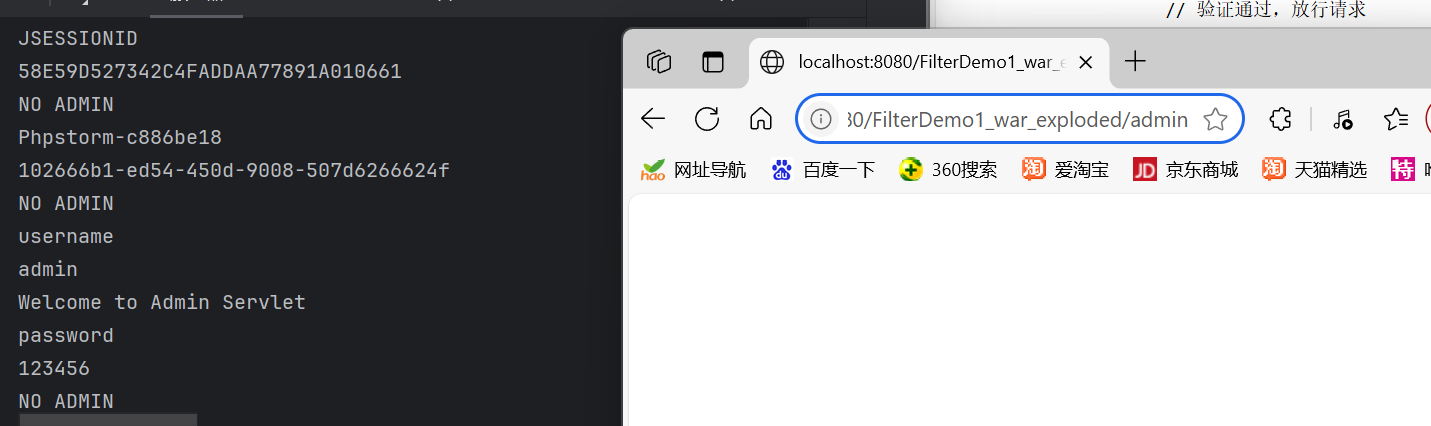
安全-JAVA开发-第二天
Web资源访问的流程 由此可见 客户访问JAVA开发的应用时 会先通过 监听器(Listener)和 过滤器(Filter) 今天简单的了解下这两个模块的开发过程 监听器(Listener) 主要是监听 我们触发了什么行为 并进行反应…...

Python基础:文件简单操作
🍃引言 手把手带你快速上手Python Python基础专栏 一、🍃文件是什么 变量是把数据保存到内存中. 如果程序重启/主机重启, 内存中的数据就会丢失。 要想能让数据被持久化存储, 就可以把数据存储到硬盘中. 也就是在文件中保存。 通过文件的后缀名, 可以看…...

深度学习项目之RT-DETR训练自己数据集
RT-DETR 1.模型介绍📌 什么是 RT-DETR ?📖 核心改进点📊 结构示意🎯 RT-DETR 优势⚠️ RT-DETR 缺点📈 应用场景📑 论文 & 官方仓库2.模型框架3.Yaml配置文件4.训练脚本5.训练完成截图6.总结…...
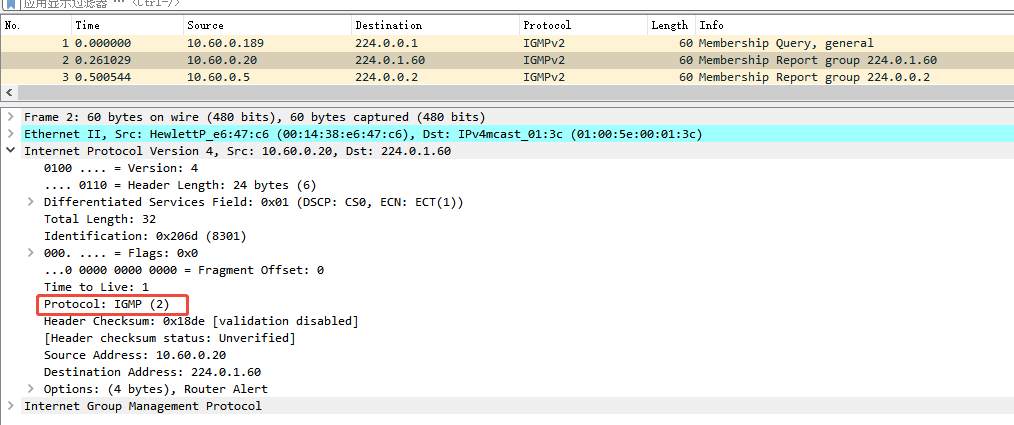
以太网帧结构和封装【二】-- IP头部信息
1字节 byte 8比特 bit 【位和比特是同一个概念】 比特/位,字节之间的关系是: 位(Bit) 中文名:位(二进制位)。 英文名:Bit(Binary Digit 的缩写)。 含义&…...
)
mysql 悲观锁和乐观锁(—悲观锁)
适合悲观锁的使用场景: 悲观锁更适合在,写操作较多、并发冲突高、业务需要强一致性等场景下使用悲观锁。 如何使用悲观锁: 悲观锁主要通过以下两个 SQL语句实现: 1、SELECT...FOR UPDATE; 这个语句会在所查询中的数据行上设置排…...
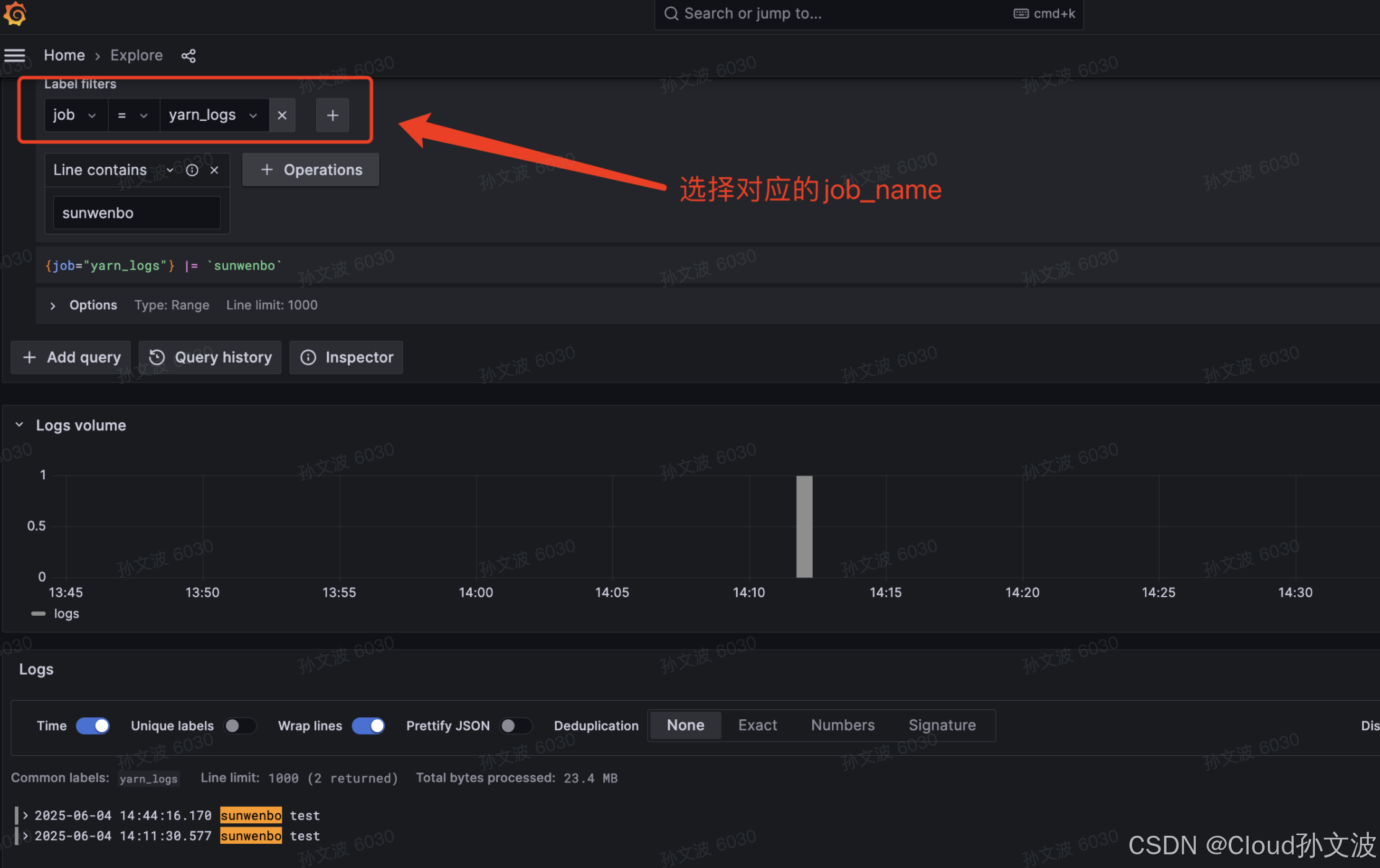
Promtail采集服务器本地日志存储到Loki
✅ 一、前提条件 已安装 Loki 服务 日志文件目录可访问(如 /var/log) 具备 sudo 权限 🧩 二、下载 Promtail 二进制文件 # 替换为你想要的版本 VERSION"3.5.1"# 创建目录 sudo mkdir -p /opt/promtail cd /opt/promtail# 下载并…...

python第31天打卡
import numpy as np from tensorflow import keras from tensorflow.keras import layers, optimizers, utils, datasets# 数据加载和预处理函数 def load_and_preprocess_data():(x_train, y_train), (x_test, y_test) datasets.mnist.load_data()# 重塑并归一化图像数据x_tr…...

4.1 HarmonyOS NEXT原生AI能力集成:盘古大模型端侧部署与多模态交互实战
HarmonyOS NEXT原生AI能力集成:盘古大模型端侧部署与多模态交互实战 在HarmonyOS NEXT的全场景生态中,原生AI能力成为连接设备、服务与用户的核心纽带。通过盘古大模型端侧轻量化部署、多模态交互技术及环境感知系统,开发者能够构建"主…...

学习STC51单片机27(芯片为STC89C52RCRC)
每日一言 你读过的书、走过的路、流过的汗,终将成就独一无二的你。 硬件:LCD1602液晶显示 非标协议外设 概述 LCD1602(Liquid Crystal Display)是一种工业字符型液晶,能够同时显示 1602 即 32 字符(16列两行) 那我…...
)
PAT-甲级JAVA题解(更新中...)
使用JAVA语言进行算法练习,但是有些会出现运行超时情况. 题目链接A1001A1001-PAT甲级JAVA题解 AB FormatA1005A1005-PAT甲级JAVA题解 Spell It RightA1006A1006-PAT甲级JAVA题解 Sign In and Sign OutA1011A1011-PAT甲级JAVA题解World Cup BettingA1012A1012 PAT甲级JAVA题解 …...

Deep Chat:重塑人机对话边界的开源智能对话框架—— 让下一代AI交互无缝融入你的应用
在AI助手泛滥的今天,开发体验碎片化、功能扩展性差、多模态支持不足成为行业痛点。由开发者Ovidijus Parsiunas发起的开源项目 Deep Chat(https://github.com/OvidijusParsiunas/deep-chat),正以模块化设计 全栈兼容性颠覆传统聊…...
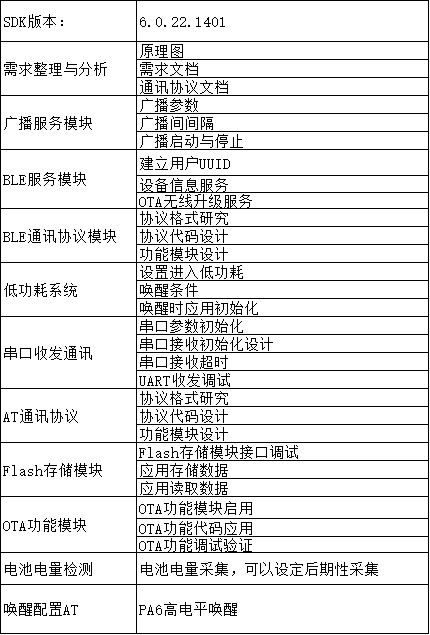
DA14531_beacon_大小信标设备开发
蓝牙信标是一款通过广播指定蓝牙信号,实现信标信号扫描、识别和获得辅助信息的电子产品。 不同品名的蓝牙信标采用相同的 UUID 和广播信号格式,但在 MAC 地址、工作寿命、体积和广播周期上有所差异。 小武编程巧用DA14531开发一款蓝牙信标....
【算法训练营Day06】哈希表part2
文章目录 四数相加赎金信三数之和四数之和 四数相加 题目链接:454. 四数相加 II 这个题注意它只需要给出次数,而不是元组。所以我们可以分治。将前两个数组的加和情况使用map存储起来,再将后两个数组的加和情况使用map存储起来,ke…...

Word双栏英文论文排版攻略
word写双栏英文论文的注意事项 排版首先改字体添加连字符还没完呢有时候设置了两端对齐会出现这样的情况: 公式文献 等我下学期有时间了,一定要学习Latex啊,word写英文论文,不论是排版还是公式都很麻烦的,而Latex一键就…...