TDengine 高级功能——流计算

简介
在时序数据的处理中,经常要对原始数据进行清洗、预处理,再使用时序数据库进行长久的储存,而且经常还需要使用原始的时序数据通过计算生成新的时序数据。在传统的时序数据解决方案中,常常需要部署 Kafka、Flink 等流处理系统,而流处理系统的复杂性,带来了高昂的开发与运维成本。
TDengine 的流计算引擎提供了实时处理写入的数据流的能力,使用 SQL 定义实时流变换,当数据被写入流的源表后,数据会被以定义的方式自动处理,并根据定义的触发模式向目的表推送结果。它提供了替代复杂流处理系统的轻量级解决方案,并能够在高吞吐的数据写入的情况下,提供毫秒级的计算结果延迟。
流计算可以包含数据过滤,标量函数计算(含 UDF),以及窗口聚合(支持滑动窗口、会话窗口与状态窗口),能够以超级表、子表、普通表为源表,写入到目的超级表。在创建流时,目的超级表将被自动创建,随后新插入的数据会被流定义的方式处理并写入其中,通过 partition by 子句,可以以表名或标签划分 partition,不同的 partition 将写入到目的超级表的不同子表。
TDengine 的流计算能够支持分布在多个节点中的超级表聚合,能够处理乱序数据的写入。它提供 watermark 机制以度量容忍数据乱序的程度,并提供了 ignore expired 配置项以决定乱序数据的处理策略 —— 丢弃或者重新计算。
注意:windows 平台不支持流计算。
下面详细介绍流计算使用的具体方法。
创建流计算
语法如下:
CREATE STREAM [IF NOT EXISTS] stream_name [stream_options] INTO stb_name
[(field1_name, ...)] [TAGS (column_definition [, column_definition] ...)]
SUBTABLE(expression) AS subquerystream_options: {TRIGGER [AT_ONCE | WINDOW_CLOSE | MAX_DELAY time | FORCE_WINDOW_CLOSE | CONTINUOUS_WINDOW_CLOSE [recalculate rec_time_val] ]WATERMARK timeIGNORE EXPIRED [0|1]DELETE_MARK timeFILL_HISTORY [0|1] [ASYNC]IGNORE UPDATE [0|1]
}column_definition:col_name col_type [COMMENT 'string_value']
其中 subquery 是 select 普通查询语法的子集。
subquery: SELECT select_listfrom_clause[WHERE condition][PARTITION BY tag_list][window_clause]window_cluse: {SESSION(ts_col, tol_val)| STATE_WINDOW(col)| INTERVAL(interval_val [, interval_offset]) [SLIDING (sliding_val)]| EVENT_WINDOW START WITH start_trigger_condition END WITH end_trigger_condition| COUNT_WINDOW(count_val[, sliding_val])
}
subquery 支持会话窗口、状态窗口、时间窗口、事件窗口与计数窗口。其中,状态窗口、事件窗口与计数窗口搭配超级表时必须与 partition by tbname 一起使用。
-
其中,SESSION 是会话窗口,tol_val 是时间间隔的最大范围。在 tol_val 时间间隔范围内的数据都属于同一个窗口,如果连续的两条数据的时间间隔超过 tol_val,则自动开启下一个窗口。
-
STATE_WINDOW 是状态窗口,col 用来标识状态量,相同的状态量数值则归属于同一个状态窗口,col 数值改变后则当前窗口结束,自动开启下一个窗口。
-
INTERVAL 是时间窗口,又可分为滑动时间窗口和翻转时间窗口。INTERVAL 子句用于指定窗口相等时间周期,SLIDING 字句用于指定窗口向前滑动的时间。当 interval_val 与 sliding_val 相等的时候,时间窗口即为翻转时间窗口,否则为滑动时间窗口,注意:sliding_val 必须小于等于 interval_val。
-
EVENT_WINDOW 是事件窗口,根据开始条件和结束条件来划定窗口。当 start_trigger_condition 满足时则窗口开始,直到 end_trigger_condition 满足时窗口关闭。start_trigger_condition 和 end_trigger_condition 可以是任意 TDengine 支持的条件表达式,且可以包含不同的列。
-
COUNT_WINDOW 是计数窗口,按固定的数据行数来划分窗口。count_val 是常量,是正整数,必须大于等于 2,小于 2147483648。count_val 表示每个 COUNT_WINDOW 包含的最大数据行数,总数据行数不能整除 count_val 时,最后一个窗口的行数会小于 count_val。sliding_val 是常量,表示窗口滑动的数量,类似于 INTERVAL 的 SLIDING。
窗口的定义与时序数据窗口查询中的定义完全相同,具体可参考 TDengine 窗口函数部分。
如下 SQL 将创建一个流计算,执行后 TDengine 会自动创建名为 avg_vol 的超级表,此流计算以 1min 为时间窗口、30s 为前向增量统计这些智能电表的平均电压,并将来自 meters 的数据的计算结果写入 avg_vol,不同分区的数据会分别创建子表并写入不同子表。
CREATE STREAM avg_vol_s INTO avg_vol AS
SELECT _wstart, count(*), avg(voltage) FROM power.meters PARTITION BY tbname INTERVAL(1m) SLIDING(30s);
本节涉及的相关参数的说明如下。
- stb_name 是保存计算结果的超级表的表名,如果该超级表不存在,则会自动创建;如果已存在,则检查列的 schema 信息。
- tags 子句定义了流计算中创建标签的规则。通过 tags 字段可以为每个分区对应的子表生成自定义的标签值。
流式计算的规则和策略
流计算的分区
在 TDengine 中,我们可以利用 partition by 子句结合 tbname、标签列、普通列或表达式,对一个流进行多分区的计算。每个分区都拥有独立的时间线和时间窗口,它们会分别进行数据聚合,并将结果写入目的表的不同子表中。如果不使用 partition by 子句,所有数据将默认写入同一张子表中。
特别地,partition by + tbname 是一种非常实用的操作,它表示对每张子表进行流计算。这样做的好处是可以针对每张子表的特点进行定制化处理,以提高计算效率。
在创建流时,如果不使用 substable 子句,流计算所创建的超级表将包含一个唯一的标签列 groupId。每个分区将被分配一个唯一的 groupId,并通过 MD5 算法计算相应的子表名称。TDengine 将自动创建这些子表,以便存储各个分区的计算结果。这种机制使得数据管理更加灵活和高效,同时也方便后续的数据查询和分析。
若创建流的语句中包含 substable 子句,用户可以为每个分区对应的子表生成自定义的表名。示例如下。
CREATE STREAM avg_vol_s INTO avg_vol SUBTABLE(CONCAT('new-', tname)) AS SELECT _wstart, count(*), avg(voltage) FROM meters PARTITION BY tbname tname INTERVAL(1m);
PARTITION 子句中,为 tbname 定义了一个别名 tname,在 PARTITION 子句中的别名可以用于 SUBTABLE 子句中的表达式计算,在上述示例中,流新创建的子表规则为 new- + 子表名 + _超级表名 + _groupId。
注意:子表名的长度若超过 TDengine 的限制,将被截断。若要生成的子表名已经存在于另一超级表,由于 TDengine 的子表名是唯一的,因此对应新子表的创建以及数据的写入将会失败。
流计算处理历史数据
在正常情况下,流计算任务不会处理那些在流创建之前已经写入源表的数据。这是因为流计算的触发是基于新写入的数据,而非已有数据。然而,如果我们需要处理这些已有的历史数据,可以在创建流时设置 fill_history 选项为 1。
通过启用 fill_history 选项,创建的流计算任务将具备处理创建前、创建过程中以及创建后写入的数据的能力。这意味着,无论数据是在流创建之前还是之后写入的,都将纳入流计算的范围,从而确保数据的完整性和一致性。这一设置为用户提供了更大的灵活性,使其能够根据实际需求灵活处理历史数据和新数据。
注意:
-
开启 fill_history 时,创建流需要找到历史数据的分界点,如果历史数据很多,可能会导致创建流任务耗时较长,此时可以通过 fill_history 1 async(v3.3.6.0 开始支持)语法将创建流的任务放在后台处理,创建流的语句可立即返回,不阻塞后面的操作。async 只对 fill_history 1 起效,fill_history 0 时建流很快,不需要异步处理。
-
通过 show streams 可查看后台建流的进度(ready 状态表示成功,init 状态表示正在建流,failed 状态表示建流失败,失败时 message 列可以查看原因。对于建流失败的情况可以删除流重新建立)。
-
另外,不要同时异步创建多个流,可能由于事务冲突导致后面创建的流失败。
比如,创建一个流,统计所有智能电表每 10s 产生的数据条数,并且计算历史数据。SQL 如下:
create stream if not exists count_history_s fill_history 1 into count_history as select count(*) from power.meters interval(10s)
结合 fill_history 1 选项,可以实现只处理特定历史时间范围的数据,例如只处理某历史时刻(2020 年 1 月 30 日)之后的数据。
create stream if not exists count_history_s fill_history 1 into count_history as select count(*) from power.meters where ts > '2020-01-30' interval(10s)
再如,仅处理某时间段内的数据,结束时间可以是未来时间。
create stream if not exists count_history_s fill_history 1 into count_history as select count(*) from power.meters where ts > '2020-01-30' and ts < '2023-01-01' interval(10s)
如果该流任务已经彻底过期,并且不再想让它检测或处理数据,您可以手动删除它,被计算出的数据仍会被保留。
流计算的触发模式
在创建流时,可以通过 TRIGGER 指令指定流计算的触发模式。对于非窗口计算,流计算的触发是实时的,对于窗口计算,目前提供 4 种触发模式,默认为 WINDOW_CLOSE。
- AT_ONCE:写入立即触发。
- WINDOW_CLOSE:窗口关闭时触发(窗口关闭由事件时间决定,可配合 watermark 使用)。
- MAX_DELAY time:若窗口关闭,则触发计算。若窗口未关闭,且未关闭时长超过 max delay 指定的时间,则触发计算。
- FORCE_WINDOW_CLOSE:以操作系统当前时间为准,只计算当前关闭窗口的结果,并推送出去。窗口只会在被关闭的时刻计算一次,后续不会再重复计算。该模式当前只支持 INTERVAL 窗口(支持滑动);该模式时,FILL_HISTORY 自动设置为 0,IGNORE EXPIRED 自动设置为 1,IGNORE UPDATE 自动设置为 1;FILL 只支持 PREV、NULL、NONE、VALUE。
- 该模式可用于实现连续查询,比如,创建一个流,每隔 1s 查询一次过去 10s 窗口内的数据条数。SQL 如下:
create stream if not exists continuous_query_s trigger force_window_close into continuous_query as select count(*) from power.meters interval(10s) sliding(1s) - CONTINUOUS_WINDOW_CLOSE:窗口关闭时输出结果。修改、删除数据,并不会立即触发重算,每等待 rec_time_val 时长,会进行周期性重算。如果不指定 rec_time_val,那么重算周期是 60 分钟。如果重算的时间长度超过 rec_time_val,在本次重算后,自动开启下一次重算。该模式当前只支持 INTERVAL 窗口。如果使用 FILL,需要配置 adapter 的相关信息:adapterFqdn、adapterPort、adapterToken。adapterToken 为
{username}:{password}经过 Base64 编码之后的字符串,例如root:taosdata编码后为cm9vdDp0YW9zZGF0YQ==。
窗口关闭是由事件时间决定的,如事件流中断、或持续延迟,此时事件时间无法更新,可能导致无法得到最新的计算结果。
因此,流计算提供了以事件时间结合处理时间计算的 MAX_DELAY 触发模式:MAX_DELAY 模式在窗口关闭时会立即触发计算,它的单位可以自行指定,具体单位:a(毫秒)、s(秒)、m(分)、h(小时)、d(天)、w(周)。此外,当数据写入后,计算触发的时间超过 MAX_DELAY 指定的时间,则立即触发计算。
流计算的窗口关闭
流计算的核心在于以事件时间(即写入记录中的时间戳主键)为基准来计算窗口的关闭时间,而不是依赖于 TDengine 服务器的时间。采用事件时间作为基准可以有效地规避客户端与服务器时间不一致所带来的问题,并且能够妥善解决数据乱序写入等挑战。
为了进一步控制数据乱序的容忍程度,流计算引入了 watermark 机制。在创建流时,用户可以通过 stream_option 参数指定 watermark 的值,该值定义了数据乱序的容忍上界,默认情况下为 0。
假设 T= 最新事件时间- watermark,那么每次写入新数据时,系统都会根据这个公式更新窗口的关闭时间。具体而言,系统会将窗口结束时间小于 T 的所有打开的窗口关闭。如果触发模式设置为 window_close 或 max_delay,则会推送窗口聚合的结果。下图展示了流计算的窗口关闭流程。
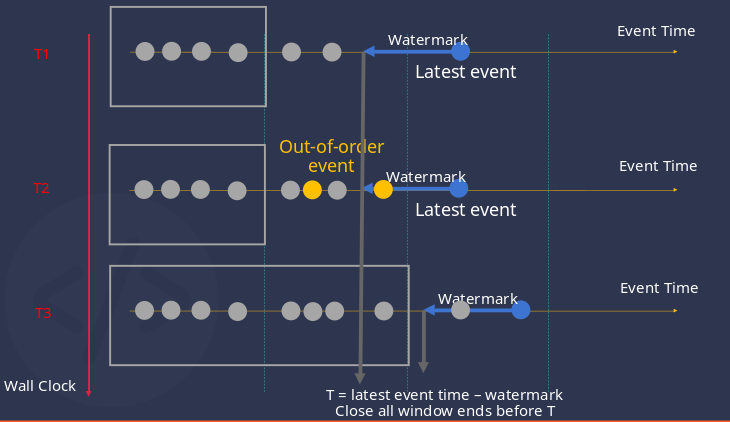
在上图中,纵轴表示时刻,横轴上的圆点表示已经收到的数据。相关流程说明如下。
- T1 时刻,第 7 个数据点到达,根据 T = Latest event - watermark,算出的时间在第二个窗口内,所以第二个窗口没有关闭。
- T2 时刻,第 6 和第 8 个数据点延迟到达 TDengine,由于此时的 Latest event 没变,T 也没变,乱序数据进入的第二个窗口还未被关闭,因此可以被正确处理。
- T3 时刻,第 10 个数据点到达,T 向后推移超过了第二个窗口关闭的时间,该窗口被关闭,乱序数据被正确处理。
在 window_close 或 max_delay 模式下,窗口关闭直接影响推送结果。在 at_once 模式下,窗口关闭只与内存占用有关。
过期数据处理策略
对于已关闭的窗口,再次落入该窗口中的数据被标记为过期数据。TDengine 对于过期数据提供两种处理方式,由 IGNORE EXPIRED 选项指定。
- 重新计算,即 IGNORE EXPIRED 0:从 TSDB 中重新查找对应窗口的所有数据并重新计算得到最新结果
- 直接丢弃,即 IGNORE EXPIRED 1:默认配置,忽略过期数据
无论在哪种模式下,watermark 都应该被妥善设置,来得到正确结果(直接丢弃模式)或避免频繁触发重算带来的性能开销(重新计算模式)
数据更新的处理策略
TDengine 对于修改数据提供两种处理方式,由 IGNORE UPDATE 选项指定。
- 检查数据是否被修改,即 IGNORE UPDATE 0:默认配置,如果被修改,则重新计算对应窗口。
- 不检查数据是否被修改,全部按增量数据计算,即 IGNORE UPDATE 1。
流计算的其它策略
写入已存在的超级表
当流计算结果需要写入已存在的超级表时,应确保 stb_name 列与 subquery 输出结果之间的对应关系正确。如果 stb_name 列与 subquery 输出结果的位置、数量完全匹配,那么不需要显式指定对应关系;如果数据类型不匹配,系统会自动将 subquery 输出结果的类型转换为对应的 stb_name 列的类型。创建流计算时不能指定 stb_name 的列和 TAG 的数据类型,否则会报错。
对于已经存在的超级表,系统会检查列的 schema 信息,确保它们与 subquery 输出结果相匹配。以下是一些关键点。
- 检查列的 schema 信息是否匹配,对于不匹配的,则自动进行类型转换,当前只有数据长度大于 4096 bytes 时才报错,其余场景都能进行类型转换。
- 检查列的个数是否相同,如果不同,需要显示的指定超级表与 subquery 的列的对应关系,否则报错。如果相同,可以指定对应关系,也可以不指定,不指定则按位置顺序对应。
注意 虽然流计算可以将结果写入已经存在的超级表,但不能让两个已经存在的流计算向同一张(超级)表中写入结果数据。这是为了避免数据冲突和不一致,确保数据的完整性和准确性。在实际应用中,应根据实际需求和数据结构合理设置列的对应关系,以实现高效、准确的数据处理。
自定义目标表的标签
用户可以为每个 partition 对应的子表生成自定义的 TAG 值,如下创建流的语句,
CREATE STREAM output_tag trigger at_once INTO output_tag_s TAGS(alias_tag varchar(100)) as select _wstart, count(*) from power.meters partition by concat("tag-", tbname) as alias_tag interval(10s);
在 PARTITION 子句中,为 concat(“tag-”,tbname)定义了一个别名 alias_tag,对应超级表 output_tag_s 的自定义 TAG 的名字。在上述示例中,流新创建的子表的 TAG 将以前缀 ‘tag-’ 连接原表名作为 TAG 的值。会对 TAG 信息进行如下检查。
- 检查 tag 的 schema 信息是否匹配,对于不匹配的,则自动进行数据类型转换,当前只有数据长度大于 4096 bytes 时才报错,其余场景都能进行类型转换。
- 检查 tag 的 个数是否相同,如果不同,需要显示的指定超级表与 subquery 的 tag 的对应关系,否则报错。如果相同,可以指定对应关系,也可以不指定,不指定则按位置顺序对应。
清理流计算的中间状态
DELETE_MARK time
DELETE_MARK 用于删除缓存的窗口状态,也就是删除流计算的中间结果。缓存的窗口状态主要用于过期数据导致的窗口结果更新操作。如果不设置,默认值是 10 年。
流计算的具体操作
删除流计算
仅删除流计算任务,由流计算写入的数据不会被删除,SQL 如下:
DROP STREAM [IF EXISTS] stream_name;
展示流计算
查看流计算任务的 SQL 如下:
SHOW STREAMS;
若要展示更详细的信息,可以使用
SELECT * from information_schema.`ins_streams`;
暂停流计算任务
暂停流计算任务的 SQL 如下:
PAUSE STREAM [IF EXISTS] stream_name;
没有指定 IF EXISTS,如果该 stream 不存在,则报错。如果存在,则暂停流计算。指定了 IF EXISTS,如果该 stream 不存在,则返回成功。如果存在,则暂停流计算。
恢复流计算任务
恢复流计算任务的 SQL 如下。如果指定了 ignore expired,则恢复流计算任务时,忽略流计算任务暂停期间写入的数据。
RESUME STREAM [IF EXISTS] [IGNORE UNTREATED] stream_name;
没有指定 IF EXISTS,如果该 stream 不存在,则报错。如果存在,则恢复流计算。指定了 IF EXISTS,如果 stream 不存在,则返回成功。如果存在,则恢复流计算。如果指定 IGNORE UNTREATED,则恢复流计算时,忽略流计算暂停期间写入的数据。
流计算升级故障恢复
升级 TDengine 后,如果流计算不兼容,需要删除流计算,然后重新创建流计算。步骤如下:
1.修改 taos.cfg,添加 disableStream 1
2.重启 taosd。如果启动失败,修改 stream 目录的名称,避免 taosd 启动的时候尝试加载 stream 目录下的流计算数据信息。不使用删除操作避免误操作导致的风险。需要修改的文件夹: d a t a D i r / v n o d e / v n o d e ∗ / t q / s t r e a m , dataDir/vnode/vnode*/tq/stream, dataDir/vnode/vnode∗/tq/stream,dataDir 指 TDengine 存储数据的目录,在 $dataDir/vnode/ 目录下会有多个类似 vnode1、vnode2…vnode* 的目录,全部需要修改里面的 tq/stream 目录的名字,改为 tq/stream.bk
3.启动 taos
drop stream xxxx; ---- xxx 指 stream name
flush database stream_source_db; ---- 流计算读取数据的超级表所在的 database
flush database stream_dest_db; ---- 流计算写入数据的超级表所在的 database
举例:
create stream streams1 into test1.streamst as select _wstart, count(a) c1 from test.st interval(1s) ;
drop stream streams1;
flush database test;
flush database test1;
4.关闭 taosd
5.修改 taos.cfg,去掉 disableStream 1,或将 disableStream 改为 0
6.启动 taosd
访问官网
更多内容欢迎访问 TDengine 官网
相关文章:
TDengine 高级功能——流计算
简介 在时序数据的处理中,经常要对原始数据进行清洗、预处理,再使用时序数据库进行长久的储存,而且经常还需要使用原始的时序数据通过计算生成新的时序数据。在传统的时序数据解决方案中,常常需要部署 Kafka、Flink 等流处理系统…...

expect程序交互学习
文章目录 一、初级语法学习二、例子 一、初级语法学习 1.使用expect进行ssh另一台机器 [rootlocalhost ~]# yum install -y expect #先安装expect [rootlocalhost ~]# vim expect1.sh #!/usr/bin/expect spawn ssh root192.168.68.244 expect {"yes/no" {send "…...

05.字母异位词分组
题意理解 🧠 什么是“字母异位词”? 字母异位词是指由相同的字母组成,只是排列顺序不同的单词。 比如: "eat" 和 "tea" 是异位词,它们都包含 e、a 和 t。"ate" 也是它们的异位词。但…...

Mac查看MySQL版本的命令
通过 Homebrew 查看(如果是用 Homebrew 安装的) brew info mysql 会显示你安装的版本、路径等信息。 你的终端输出显示:你并没有安装 MySQL,只是查询了 brew 中的 MySQL 安装信息。我们一起来看下重点: 🧾…...
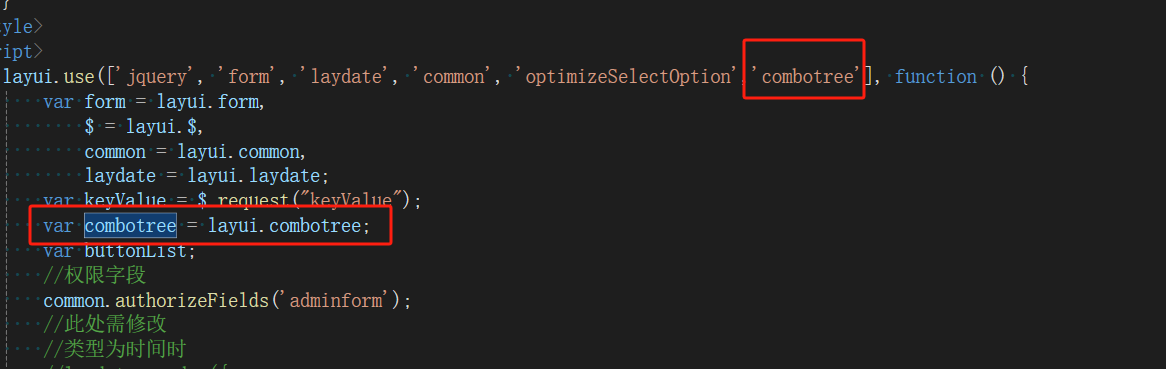
【.net core】【watercloud】树形组件combotree导入及调用
源码下载:combotree: 基于layui及zTree的树下拉框组件 链接中提供了组件的基本使用方法 框架修改内容 1.文件导入(路径可更具自身情况自行设定) 解压后将文件夹放在图示路径下,修改文件夹名称为combotree 2.设置路径(设置layu…...

[Java 基础]面向对象-封装
封装是构建健壮、可维护和安全软件的基础。 什么是封装? 想象一下你的手机。你不需要知道手机内部复杂的电路、芯片和各种组件是如何协同工作的,你只需要知道如何使用屏幕、按键或触摸操作来打电话、发短信或玩游戏。手机的内部细节被“包裹”起来&…...

2021 RoboCom 世界机器人开发者大赛-高职组(复赛)解题报告 | 珂学家
前言 题解 2021 RoboCom 世界机器人开发者大赛-高职组(复赛)解题报告。 模拟题为主,包含进制转换等等。 最后一题,是对向量/自定义类型,重定义小于操作符。 7-1 人工智能打招呼 分值: 15分 考察点: 分支判定&…...

Python趣学篇:Pygame实现3D星空穿越动画
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 专栏介绍:《Python星球日记》🪐 目录 一、项目概览与技术栈二、核心技术原理解析1. 透视投影:让3D世界"压扁"到2D屏幕2. Z轴深度:创造…...

基于Web的安全漏洞分析与修复平台设计与实现
基于Web的安全漏洞分析与修复平台设计与实现 摘要 随着信息化进程的加快,Web系统和企业IT架构愈发复杂,安全漏洞频发已成为影响系统安全运行的主要因素。为解决传统漏洞扫描工具定位不准确、修复建议不完善、响应周期长等问题,本文设计并实…...
34.1STM32下的can总线实现知识(区分linux)_csdn
看过我之前的文章就知道,正点原子下的linux中CAN总线并没有讲的很明白,都是系统自带的! 这里我找到江科大学长的can总线的讲解视频! CAN总线入门教程-全面细致 面包板教学 多机通信_哔哩哔哩_bilibili 在这里我也会一步一步讲解CA…...

相机Camera日志分析之二十四:高通相机Camx 基于预览1帧的process_capture_request三级日志分析详解
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了:相机Camera日志分析之二十三:高通相机Camx 基于预览1帧的process_capture_request二级日志分析详解 这一篇我们开始讲: 相机Camera日志分析之二十四:高通相机Camx 基于预览1帧的process_capture_req…...

Linux 内核中 skb_dst_drop 的深入解析:路由缓存管理与版本实现差异
引言 在 Linux 内核网络子系统中,sk_buff(简称 SKB)是数据包在内核态流转的核心数据结构。为了高效处理网络数据包的路由选择,内核通过 dst_entry 结构体缓存路由信息,而 skb_dst_drop 函数则是管理这些路由缓存引用的关键工具。本文将从作用、实现原理、内核版本差异等多…...
)
考研系列—操作系统:冲刺笔记(4-5章)
目录 第四章 文件管理 1.真题总结文件管理方式 (1)目录文件的FCB就是“目录名-目录地址” (2)普通文件的FCB (3)区分索引文件、顺序文件、索引分配 (4)文件的物理结构 ①连续分配方式 ②链接分配 ③索引分配-使用索引表(一个文件对应一张索引表!!!) 计算考点:超级…...

功能管理:基于 ABP 的 Feature Management 实现动态开关
🚀 功能管理:基于 ABP 的 Feature Management 实现动态开关 📚 目录 🚀 功能管理:基于 ABP 的 Feature Management 实现动态开关📚 一、背景分析🧩 二、核心功能设计2.1 定义 Feature 常量与分组…...

2025年想冲网安方向,该考华为安全HCIE还是CISSP?
打算2025年往网络安全方向转,现在考证是不是来得及?考啥证? 说实话,网络安全这几年热得发烫,但热归热,入门门槛也不低,想进这个赛道,技术、项目经验、证书,缺一不可。 …...

ES6 深克隆与浅克隆详解:原理、实现与应用场景
ES6 深克隆与浅克隆详解:原理、实现与应用场景 一、克隆的本质与必要性 在 JavaScript 中,数据分为两大类型: 基本类型:Number、String、Boolean、null、undefined、Symbol、BigInt引用类型:Object、Array、Functio…...

Go Gin框架深度解析:高性能Web开发实践
Go Gin框架深度解析:高性能Web开发实践 Gin框架核心特性概览 Gin是用Go语言编写的高性能Web框架,以其闪电般的路由性能(基于httprouter)和极简的API设计著称: package mainimport "github.com…...
)
mybatis 参数绑定错误示范(1)
采用xml形式的mybatis 错误示例: server伪代码为: Map<String, Object> findMapNew MapUtil.<String, Object>builder().put("applyUnit", appUnit).put("planYear", year ! null ? year : -1).put("code&quo…...

每天掌握一个Linux命令 - rpm
Linux 命令工具 rpm 使用指南 Linux 命令工具 rpm 使用指南一、工具概述二、安装方式1. 系统预装2. 源码编译安装(极少场景) 三、核心功能四、基础用法1. 安装软件包2. 升级软件包3. 查询软件包信息4. 卸载软件包5. 验证文件完整性 五、进阶操作1. 批量操…...

常见的MySQL索引类型
在MySQL中,索引是用来提高数据库查询效率的一种数据结构。根据不同的使用场景和需求,MySQL提供了多种类型的索引,每种索引都有其特定的应用场景和优化效果。下面是一些常见的MySQL索引类型: 1. B-Tree索引: 这是最常…...
与集合之间存在天然的对应关系 ← bitset)
01串(二进制串)与集合之间存在天然的对应关系 ← bitset
【集合的二进制表示】 ● 01 串(二进制串)与集合之间存在天然的对应关系。对应机理为每个二进制位可以表示集合中一个元素的存在(1)或不存在(0)。例如,集合 {a, b, c} 的子集 {a, c} 可以表示…...
153页PPT麦肯锡咨询流程管理及企业五年发展布局构想与路径规划
麦肯锡咨询的流程管理以其高度结构化、数据驱动和结果导向的核心特点著称,旨在为客户提供清晰、可行且价值最大化的解决方案。其典型流程可概括为以下几个关键阶段:下载资料请查看文章中图片右下角信息 问题界定与结构化: 这是流程的基石。麦…...
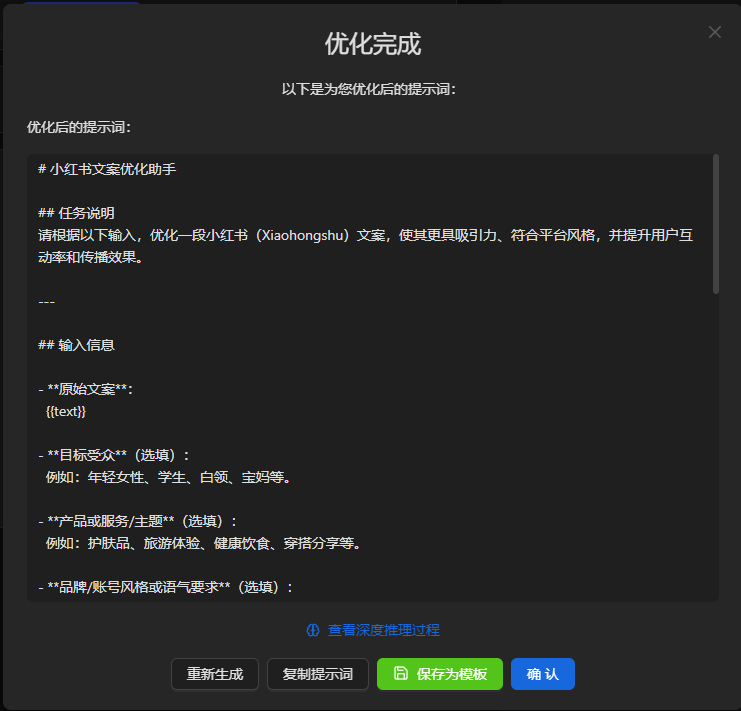
[特殊字符] 革命性AI提示词优化平台正式开源!
AI时代最强大的Prompt工程师已经到来! 你是否还在为写不出高质量提示词而头疼?是否羡慕那些能够驾驭AI、让ChatGPT、Claude乖乖听话的"提示词大师"?今天,我们为你带来一个颠覆性的解决方案——TokenAI Auto-Prompt&…...
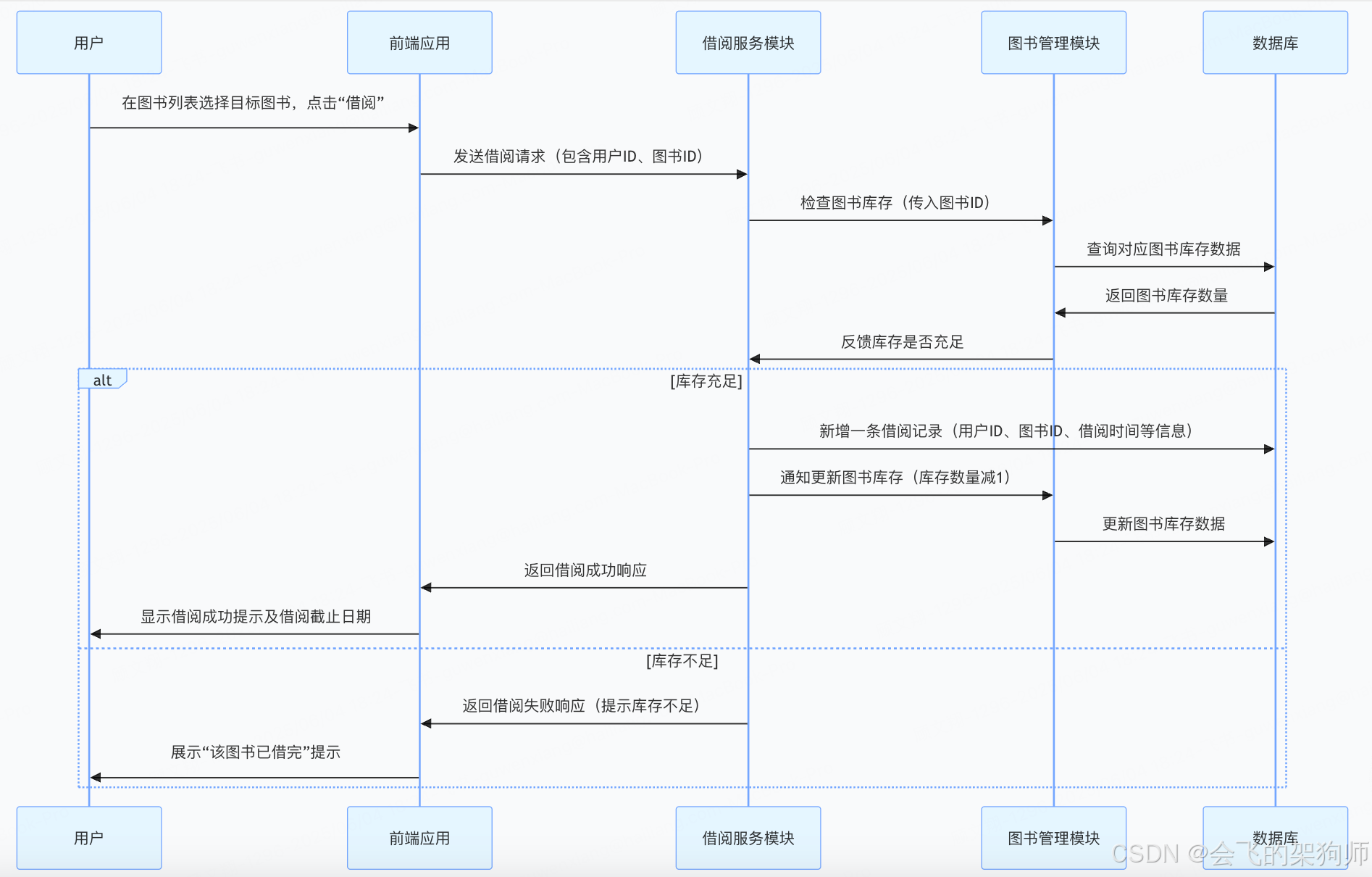
我的概要设计模板(以图书管理系统为例)
一、总述 1.1 需求或目标 随着数字化阅读普及,传统图书馆管理方式效率低下、资源检索不便。为提升图书管理效率,方便读者借阅与查询,公司计划开发 “在线图书管理系统”,实现图书的电子化管理、快速检索、在线借阅等功能&#x…...

【使用】【经验】docker 清理未使用的镜像的命令
docker images prune在 Docker 中清理未使用的镜像(包括悬空镜像和完全未被引用的镜像),可以使用以下命令: 1. 删除所有悬空镜像(推荐常用) docker image prune悬空镜像 (dangling images) 是指…...
DrissionPage爬虫包实战分享
一、爬虫 1.1 爬虫解释 爬虫简单的说就是模拟人的浏览器行为,简单的爬虫是request请求网页信息,然后对html数据进行解析得到自己需要的数据信息保存在本地。 1.2 爬虫的思路 # 1.发送请求 # 2.获取数据 # 3.解析数据 # 4.保存数据 1.3 爬虫工具 Dris…...
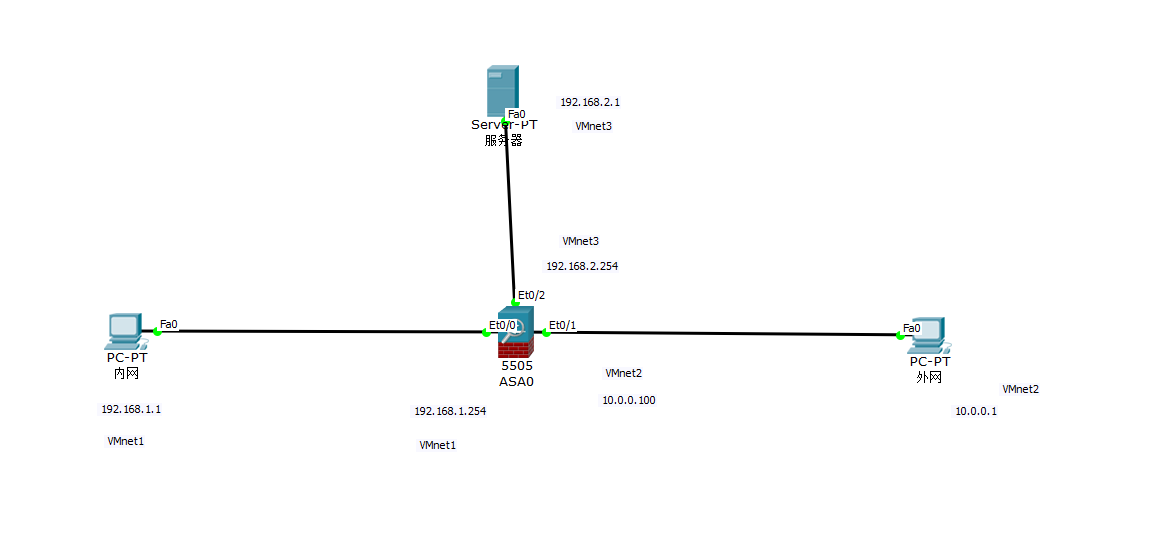
iptables实战案例
目录 一、实验拓扑 二、网络规划 三、实验要求 四、环境准备 1.firewall (1)配置防火墙各大网卡IP并禁用 firewall和selinux (2)打开firewall路由转发 2.PC1(内网) (1)配置防…...

机器学习与深度学习07-随机森林01
目录 前文回顾1.随机森林的定义2.随机森林中的过拟合3.随机森林VS单一决策树4.随机森林的随机性 前文回顾 上一篇文章链接:地址 1.随机森林的定义 随机森林(Random Forest)是一种集成学习算法,用于解决分类和回归问题。它基于决…...

回归分析-非线性回归及岭回归.docx
一.题目要求1.用SPSS软件练习建立多元线性回归方程,分析数据的多重共线性,利用后退法和逐步回归法选择变量,练习用岭回归方法处理该模型数据并作比较 2.用SPSS软件练习建立模型的非线性回归方程 二.数据分析(一)题目:课本7.6 1、数据 一家大型商业银行有多家分行,近年来…...
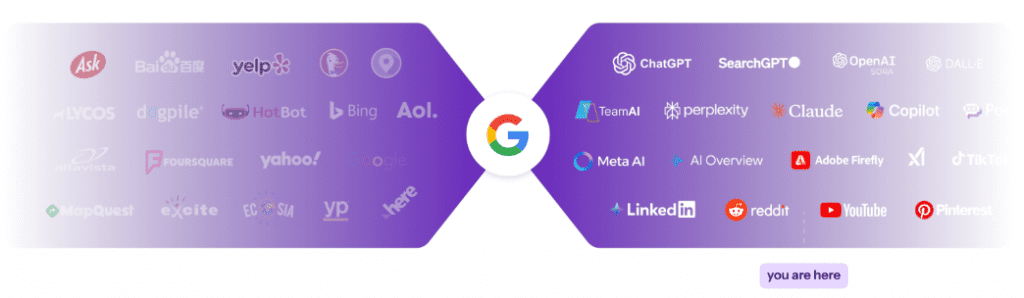
Google AI 模式下的SEO革命:生成式搜索优化(GEO)与未来营销策略
一、搜索范式转变:从链接引导到答案交付 Google自2023年起逐步推出AI搜索功能,经历了SGE(Search Generative Experience)和Gemini阶段,最终在2025年全面上线了「AI Mode」搜索模式。与此同时,也保留了一种过…...