DrissionPage爬虫包实战分享
一、爬虫
1.1 爬虫解释
爬虫简单的说就是模拟人的浏览器行为,简单的爬虫是request请求网页信息,然后对html数据进行解析得到自己需要的数据信息保存在本地。
1.2 爬虫的思路
# 1.发送请求
# 2.获取数据
# 3.解析数据
# 4.保存数据
1.3 爬虫工具
DrissionPage的个人空间-DrissionPage个人主页-哔哩哔哩视频
DrissionPage® 是一个基于 Python 的网页自动化工具。
既能控制浏览器,也能收发数据包,还能把两者合而为一。
可兼顾浏览器自动化的便利性和 requests 的高效率。
功能强大,语法简洁优雅,代码量少,对新手友好。
可以参考官网视频学习基本概念。
二、爬虫实战
2.1 爬虫需求
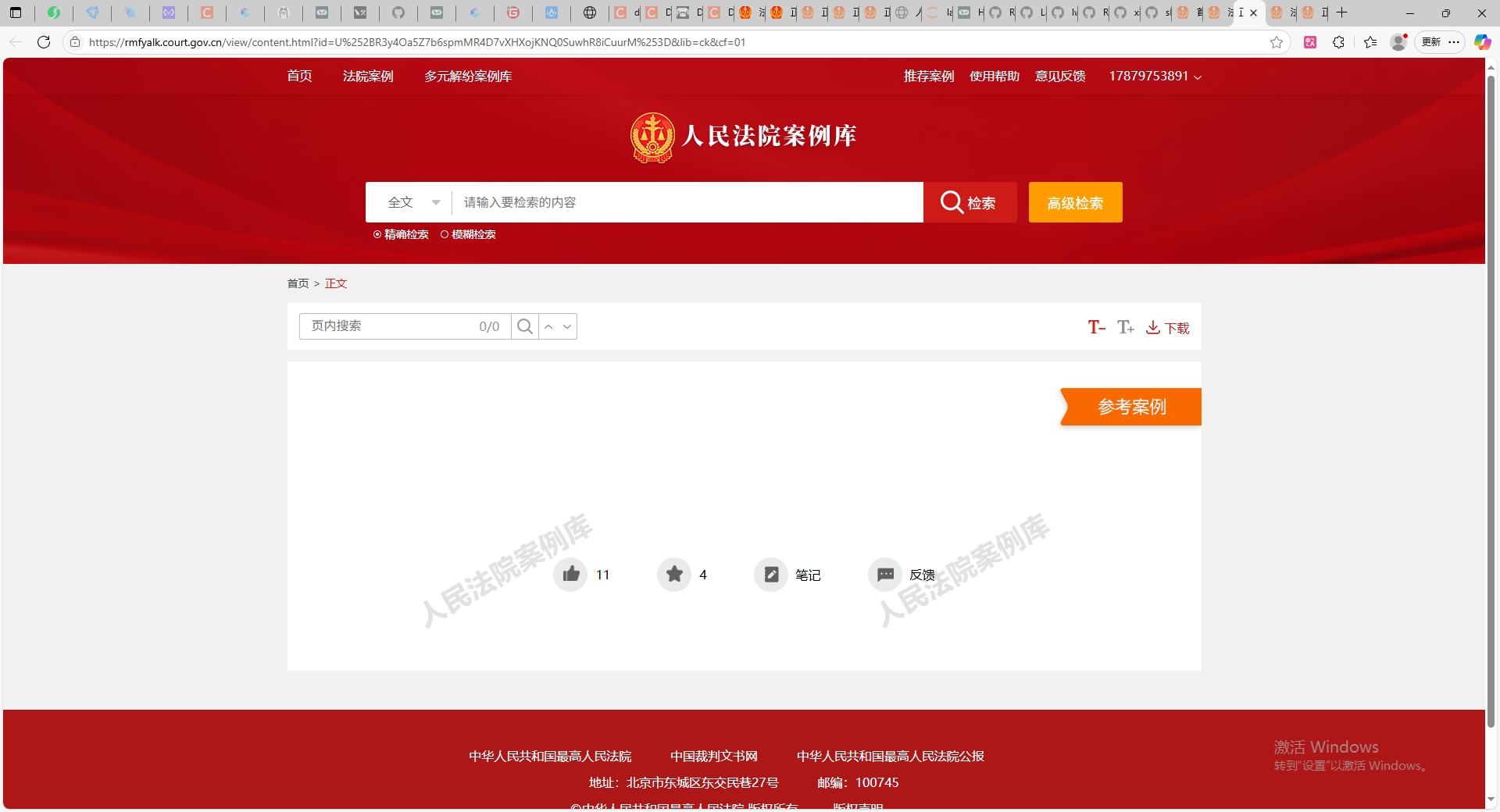
对首页 - 人民法院案例库的4884条法律案件信息进行csv保存。
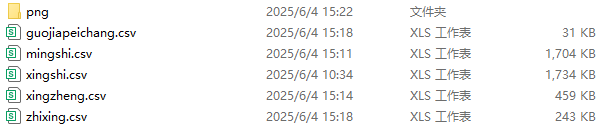
2.2 爬虫效果
爬虫后的效果图:

2.3 爬虫实现过程
2.3.1 环境配置
最好先再本地安装好anaconda,然后创建虚拟环境和安装这个包。如何安装anaconda可以参考我之前的博客手把手教你使用云服务器和部署相关环境!!!-CSDN博客
conda create -n pachong python=3.10.16 -y
conda activate pachong
pip install DrissionPage==4.1.0.18
DrissionPage 4.1.0.18
python 3.10.16
2.3.2 学习DrissionPage的基本操作
设置好DrissionPage的默认浏览器启动路径,找到自己的chrome浏览器或者edge浏览器,得到路径,注意是需要.exe的执行文件路径,运行下面的代码就设置好了浏览器的启动环境。
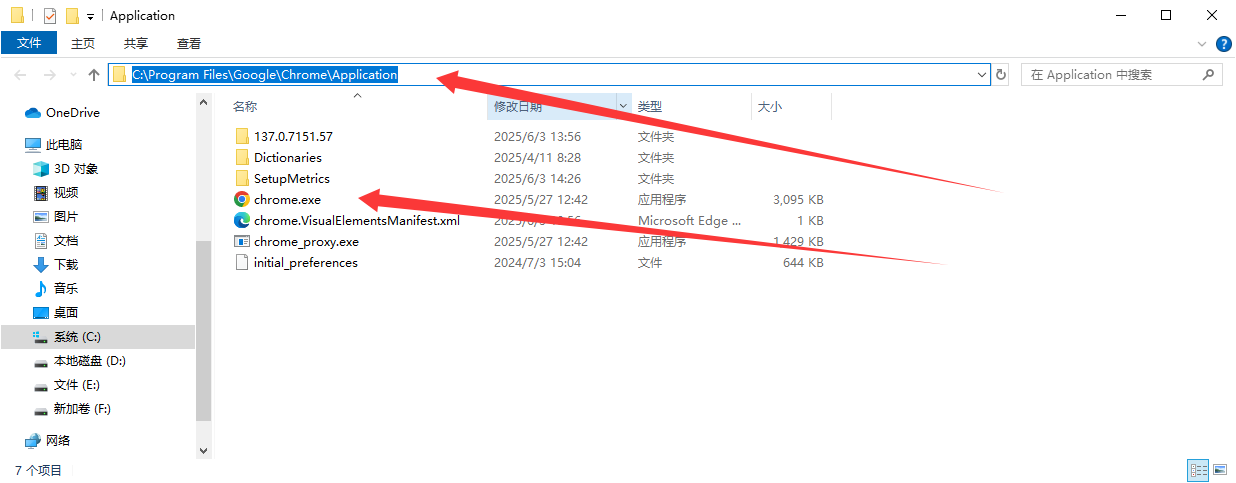
from DrissionPage import ChromiumOptions
path = r'C:\Program Files\Google\Chrome\Application\Chrome.exe' # 请改为你电脑内Chrome可执行文件路径
ChromiumOptions().set_browser_path(path).save()
实例化浏览器对象和关闭浏览器对象操作
# 浏览器对象,标签页对象,页面元素对象
from DrissionPage import Chromium
# 链接浏览器
browser = Chromium()
browser.set.retry_interval(5)# 设置重试间隔
tab = browser.latest_tab
# 关闭浏览器
browser.quit()
标签页的相关函数
# 浏览器对象,标签页对象,页面元素对象
from DrissionPage import Chromium
# 链接浏览器
browser = Chromium()
browser.set.retry_interval(5)# 设置重试间隔
tab = browser.latest_tab
tab.get('http://DrissionPage.cn') # 使用标签页访问url函数
tab2 = browser.new_tab("http://www.baidu.com") # 新建标签页函数
tab3 = browser.get_tab(title="DrissionPage") # 访问标签页函数
# 关闭标签页对象
tab.close()
# 标签页的后退前进与刷新
tab.back(2) # 后退2次
tab.forward(1) # 前进
tab.refresh() # 刷新
# 关闭浏览器
browser.quit()
html元素对象的相关函数,元素可以使用Xpath语法进行定位
from DrissionPage import Chromium
# 链接浏览器
browser = Chromium()
browser.set.retry_interval(5)# 设置重试间隔
tab = browser.latest_tab
tab.get('http://DrissionPage.cn')
# 获取页面元素
# tab对象中直接查找
ele = tab.ele('使用文档') # 获取文本中包含“使用文档”的元素
ele.check() # 点击元素
# 相对位置查找
ele2 = ele.next() # 获取ele的下一个兄弟元素
ele2.click() # 点击元素
# 关闭浏览器
# browser.quit()
一个实例
from DrissionPage import Chromium
# 链接浏览器
browser = Chromium()
browser.set.retry_interval(5)# 设置重试间隔
tab2 = browser.new_tab("http://www.baidu.com")
# 定位一个元素,输入按钮 , x表示xpath语法
input_btn = tab2.ele('x://*[@id="kw"]')
print(input_btn.html)
# 输入搜索内容
input_btn.input("python")
# 定位一个搜索按钮
search_btn = tab2.ele('x://*[@id="su"]')
search_btn.click()
2.3.3 获取目标网页的数据
2.3.3.1 抓包分析得到数据,需要先监听标识符
按F12进入开发者模式,刷新页面,再network中可以搜索相关的数据包
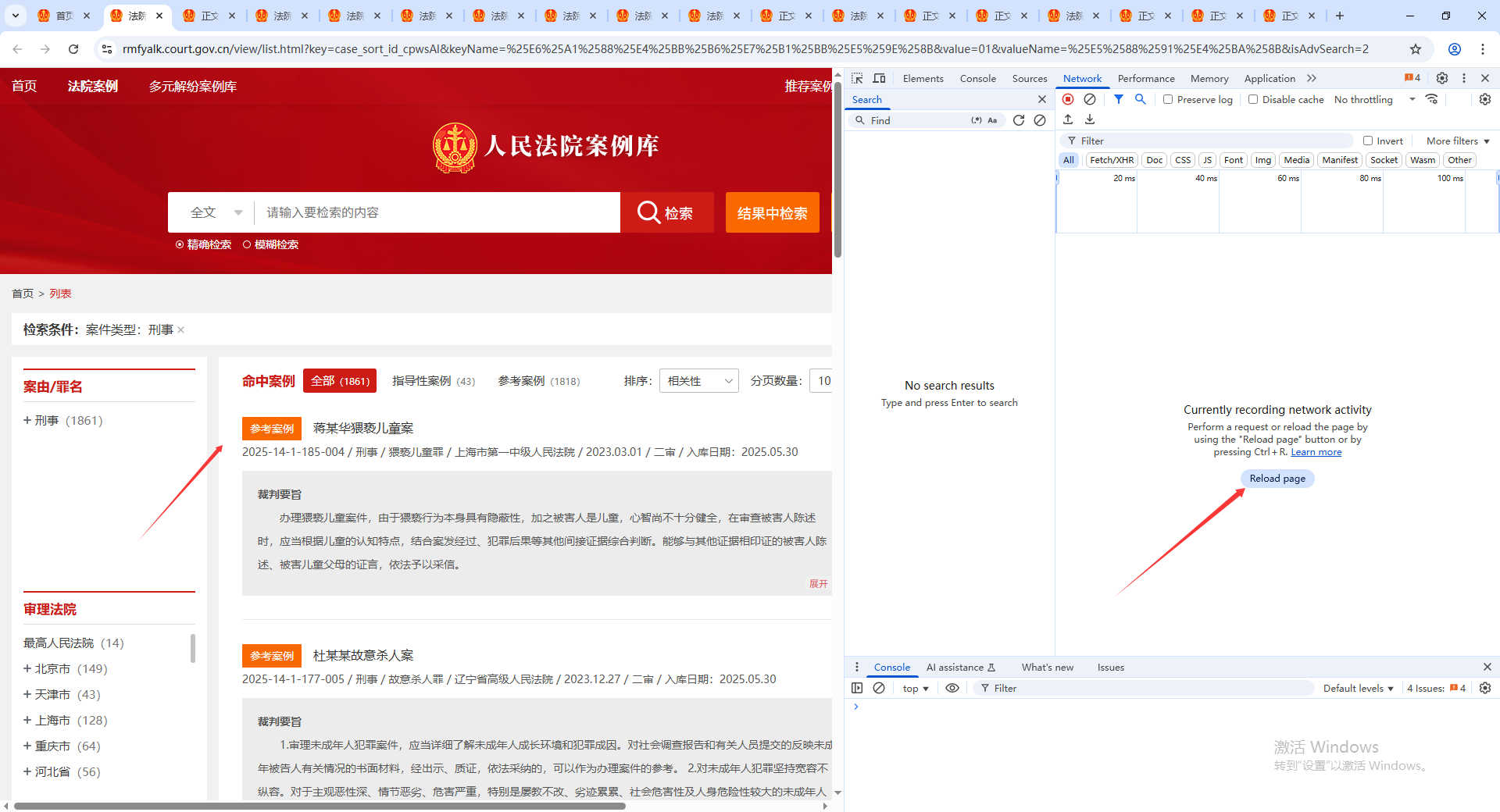
比如我们搜索,蒋某华猥亵儿童案。只有一个搜索结果,headers是前端请求后端的信息,preview是请求结果的预览信息,response是请求结果的详细信息。我们对数据抓包主要是看这三部分信息。
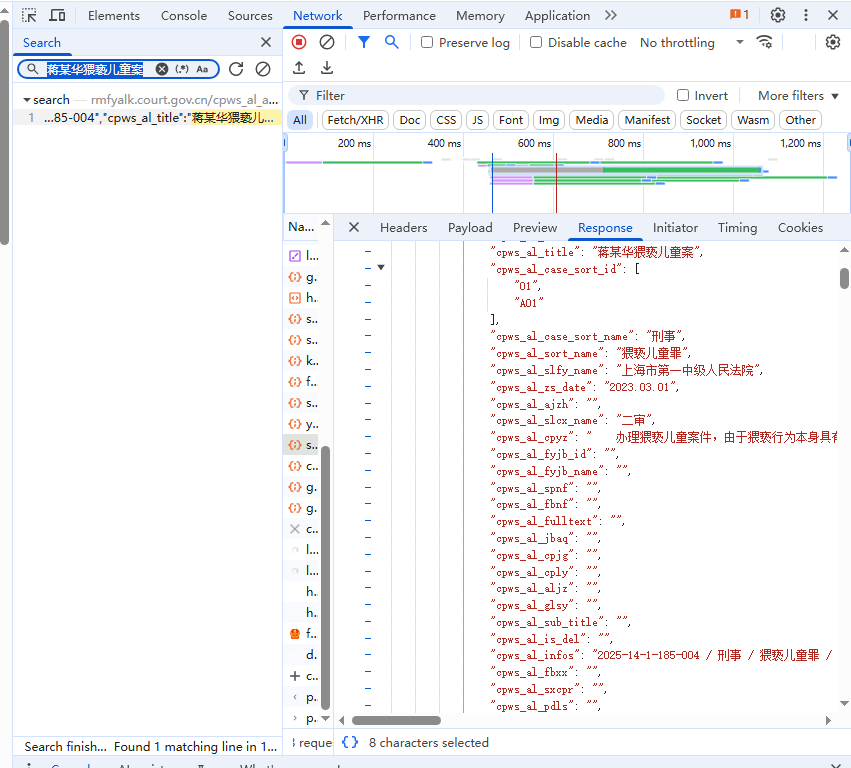 我们再preview中可以看到数据包中的['data']['datas']刚好有这页的10个案件信息,我们对这个信息中抽取我们需要的信息再保存再本地就行。
我们再preview中可以看到数据包中的['data']['datas']刚好有这页的10个案件信息,我们对这个信息中抽取我们需要的信息再保存再本地就行。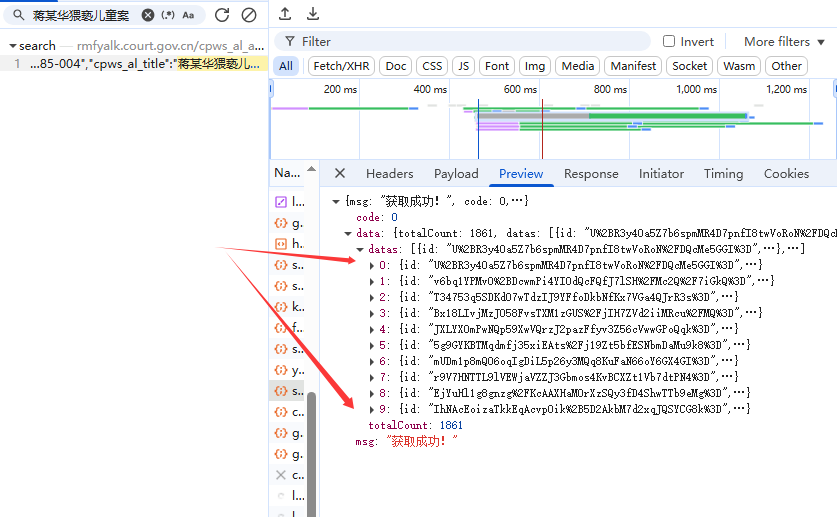
我们此时监听的是:蒋某华猥亵儿童案,虽然也可以用,但是我们一般选择监听请求头的信息,一般是“?”前面的https(如果有的话),复制一下,检索一下看一下是不是唯一值。
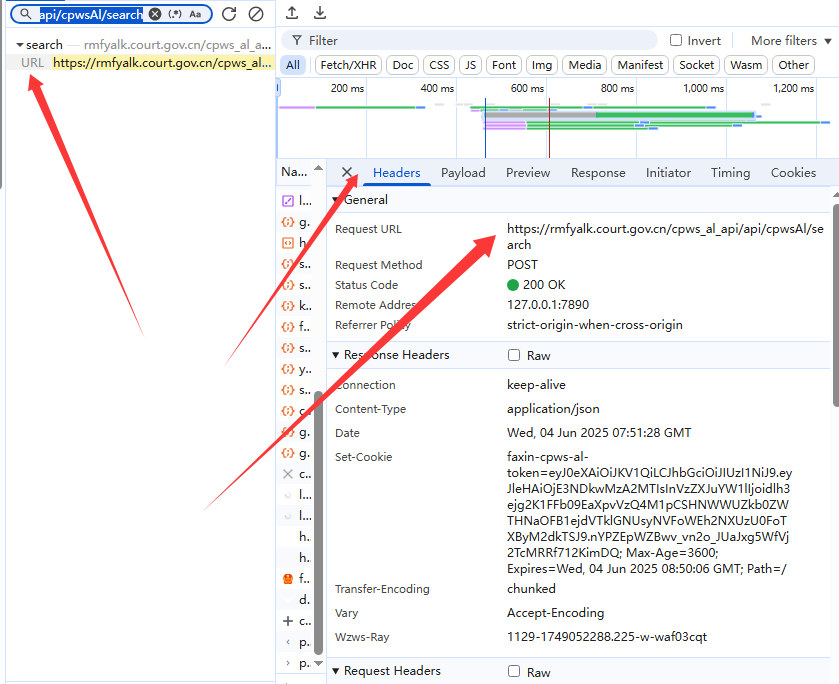
2.3.3.2 html元素定位xpath得到html元素,得到数据
DrissionPage非常好的功能是通过xpath语法定位到html元素,就可以使用元素.text 、元素.html等获得相关数据,定位元素过程,F12打开开发者工具,最左边的定位标识符选择你想定位的网页元素,比如我定位的是下一页的按钮元素,得到位置后,右键选择copy,XPath,然后按ctrl+f进行搜索模式,就可以看到你的这个XPath语法定位的元素再当前标签页中有几个了。
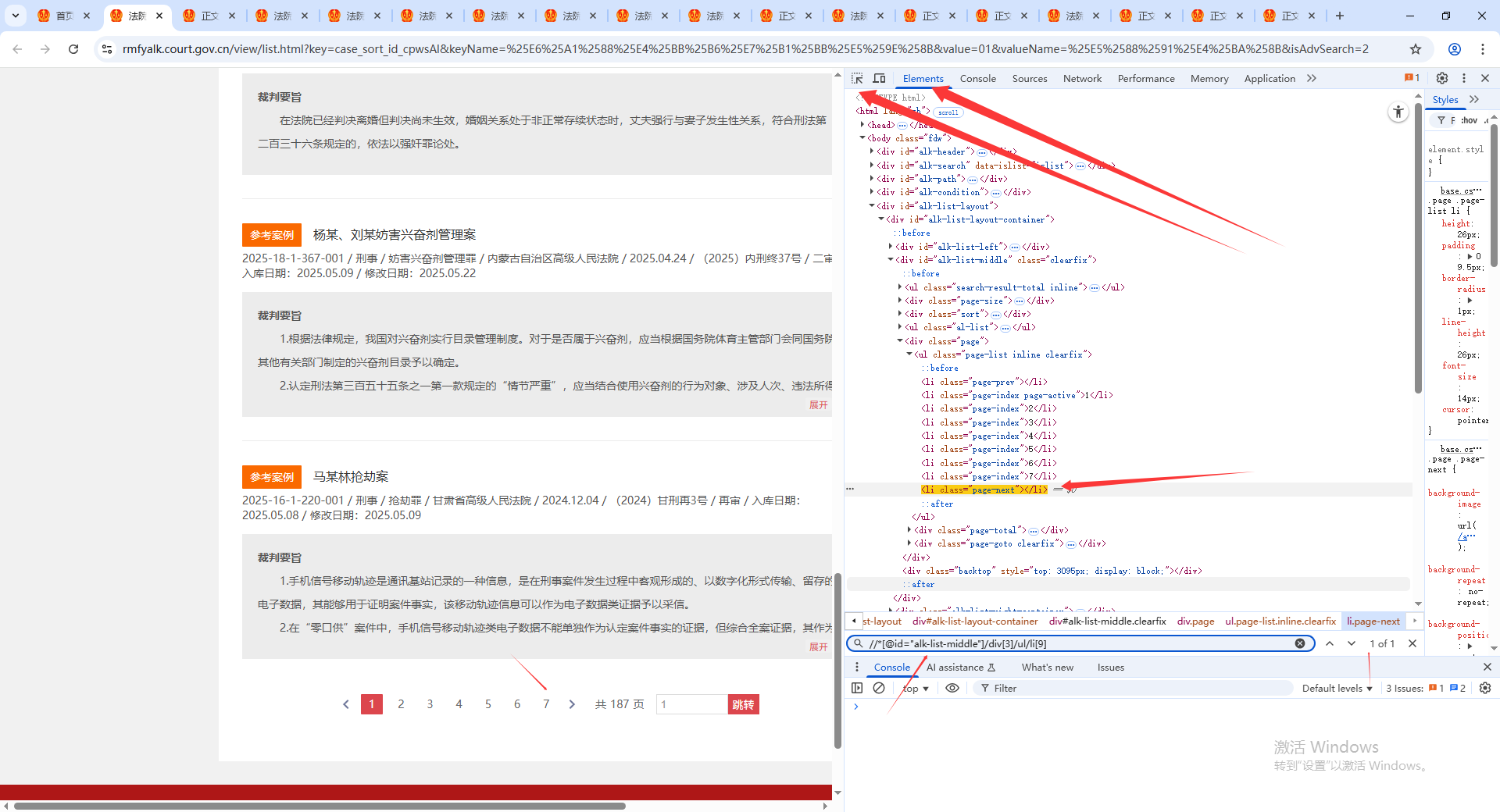
2..3.4 爬取全部信息
我们平时怎么操作浏览器,就怎么写代码。
思路: 打开浏览器,新建标签页,搜索目标url,通过监听唯一的标识符:“https://rmfyalk.court.gov.cn/cpws_al_api/api/cpwsAl/search”得到当前页面的10个案件的数据包,对数据包列表的每个数据进行抽取我们需要的信息,再保存到csv表格中。下滑,点击下一页,重复上述操作。
from DrissionPage import Chromium
from pprint import pprint
import csv
# 打来浏览器
tab = Chromium().latest_tab
# 监听数据包
tab.listen.start("https://rmfyalk.court.gov.cn/cpws_al_api/api/cpwsAl/search")
# 访问页面
url = "https://rmfyalk.court.gov.cn/view/list.html?key=case_sort_id_cpwsAl&keyName=%25E6%25A1%2588%25E4%25BB%25B6%25E7%25B1%25BB%25E5%259E%258B&value=05&valueName=%25E6%2589%25A7%25E8%25A1%258C&isAdvSearch=2"
tab.get(url)
f = open(r'E:\gdzd_hb\pachoong\zhixing.csv', 'w', encoding='utf-8', newline='')
# 字典写入方法
csv_writer = csv.DictWriter(f, fieldnames=['案件名称', '案件标签', '裁判要旨'])
# 写入表头
csv_writer.writeheader()
for page in range(1, 208):
print(f'正在爬取第{page}页')
# 等待数据包加载
resp = tab.listen.wait()
# 获取响应数据-->json
json_data = resp.response.body
# # 打印数据
# print(json_data)
# print(type(json_data))
# 遍历jobInfo列表
jobList = json_data['data']['datas']
for job in jobList:
pprint(job) # 打印字典格式
break # 打印一个结束
# 抽取需要的数据
for job in jobList:
dit = {
'案件名称': job['cpws_al_title'],
'案件标签': job['cpws_al_infos'],
'裁判要旨': job['cpws_al_cpyz']
}
pprint(dit)
# 字典写入数据
csv_writer.writerow(dit)
# 下滑到最底部
tab.scroll.to_bottom()
# 点击下一页
tab.ele('css:.page-next').click()
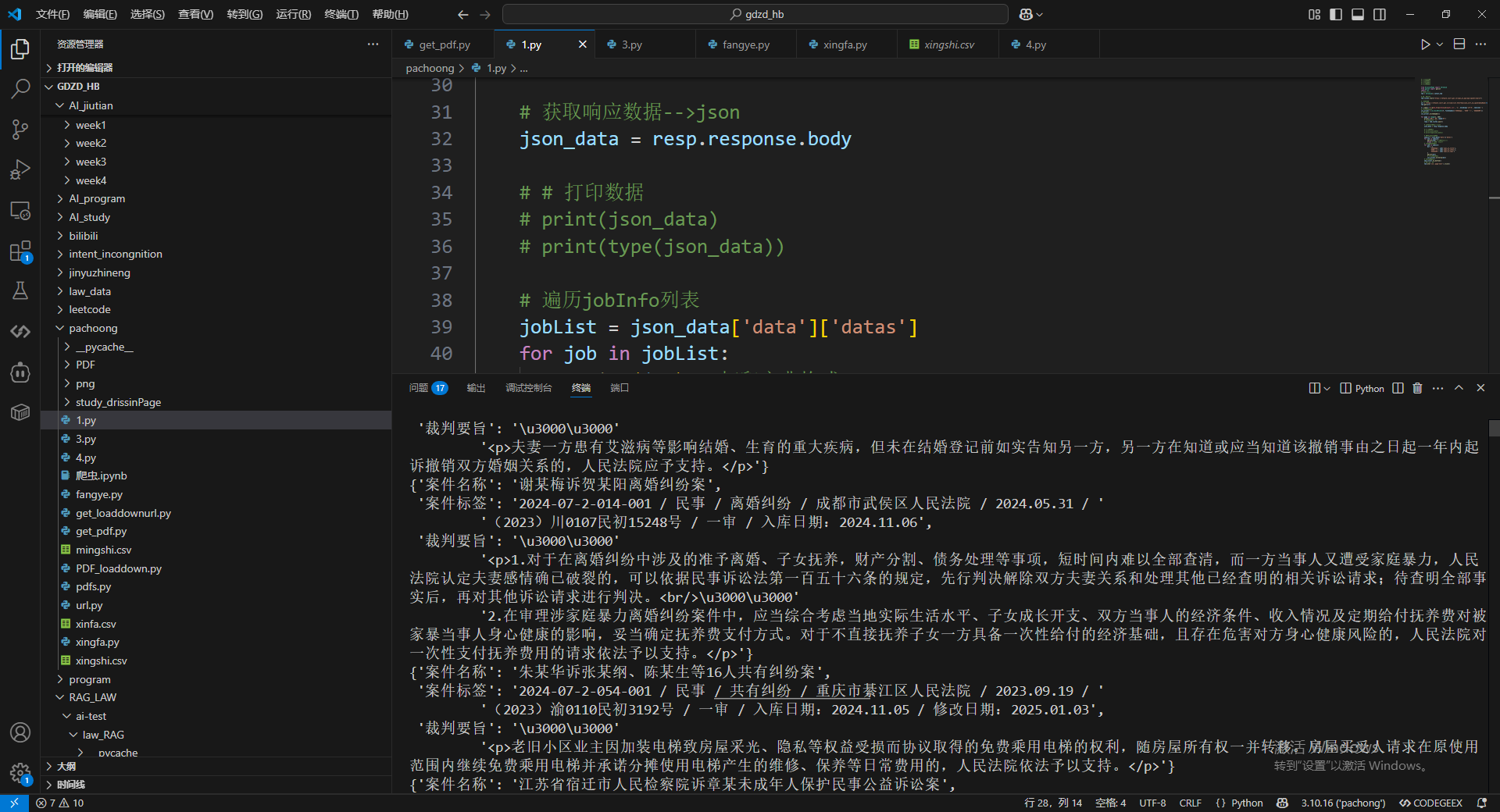
三、问题和小结
进阶需求:爬取每个案件的对应的详细PDF信息。
方法一:通过点击每个案件,进去后再点击下载PDF的案件到指定文件夹中实现。
存在问题:网站做了限制,每个账号下载了20个左右的PDF,就会显示下面的报错,就算是人工手动下载PDF文件也是一样的。

方法二:通过获取每个案件的详情url地址,使用元素来获取相关信息,用字典保存,再保存到csv文件中。
存在的问题:网站做了限制,我们一个账号连续访问40个左右的案件详情网页后,就会显示空的网页,从而无法获得html元素。
这两个问题我暂时没有解决办法,因为DrissionPage已经是模拟人的行为进行抓包了,但是网站对每个账号进行了限制。
相关文章:
DrissionPage爬虫包实战分享
一、爬虫 1.1 爬虫解释 爬虫简单的说就是模拟人的浏览器行为,简单的爬虫是request请求网页信息,然后对html数据进行解析得到自己需要的数据信息保存在本地。 1.2 爬虫的思路 # 1.发送请求 # 2.获取数据 # 3.解析数据 # 4.保存数据 1.3 爬虫工具 Dris…...
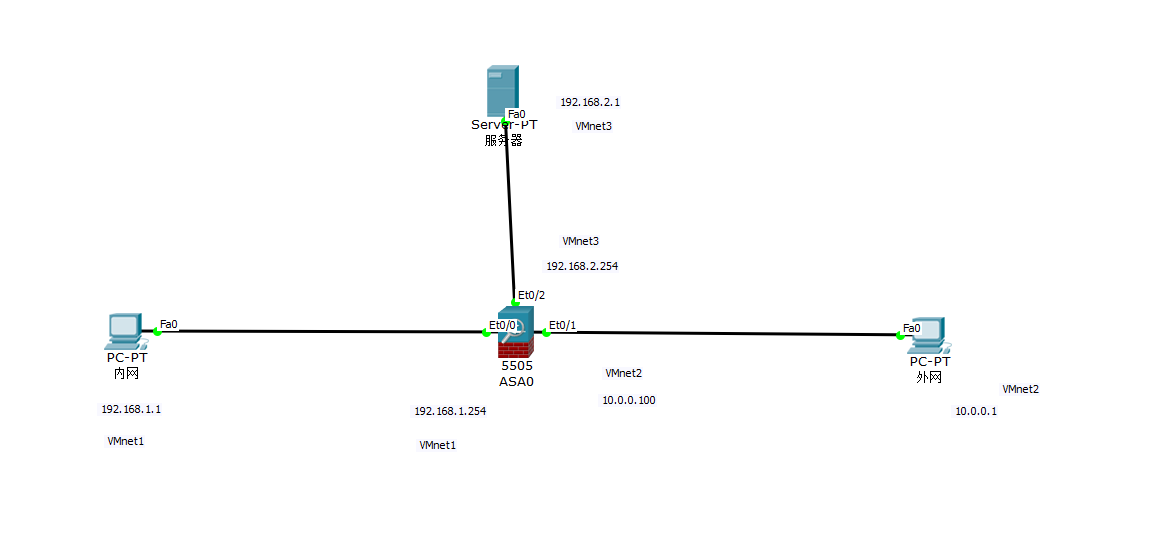
iptables实战案例
目录 一、实验拓扑 二、网络规划 三、实验要求 四、环境准备 1.firewall (1)配置防火墙各大网卡IP并禁用 firewall和selinux (2)打开firewall路由转发 2.PC1(内网) (1)配置防…...

机器学习与深度学习07-随机森林01
目录 前文回顾1.随机森林的定义2.随机森林中的过拟合3.随机森林VS单一决策树4.随机森林的随机性 前文回顾 上一篇文章链接:地址 1.随机森林的定义 随机森林(Random Forest)是一种集成学习算法,用于解决分类和回归问题。它基于决…...

回归分析-非线性回归及岭回归.docx
一.题目要求1.用SPSS软件练习建立多元线性回归方程,分析数据的多重共线性,利用后退法和逐步回归法选择变量,练习用岭回归方法处理该模型数据并作比较 2.用SPSS软件练习建立模型的非线性回归方程 二.数据分析(一)题目:课本7.6 1、数据 一家大型商业银行有多家分行,近年来…...
Google AI 模式下的SEO革命:生成式搜索优化(GEO)与未来营销策略
一、搜索范式转变:从链接引导到答案交付 Google自2023年起逐步推出AI搜索功能,经历了SGE(Search Generative Experience)和Gemini阶段,最终在2025年全面上线了「AI Mode」搜索模式。与此同时,也保留了一种过…...

docker创建postgreSql带多个init的sql
好的!下面是一个完整的可运行项目结构,包含: ✅ docker-compose.yml:启动 PostgreSQL(支持 pgvector) ✅ init-db.sql:创建数据库 myapp ✅ init-schema.sql:在 myapp 中建表并初始…...

掌握 MotionLayout:交互动画开发
前言 在 Android 开发中,系统自带的属性动画(如 ObjectAnimator 和 ValueAnimator)虽然功能强大,但在复杂动画场景下,第三方动画库能提供更高效的开发体验和更丰富的效果。本文将深入解析 Lottie、MotionLayout、Andr…...
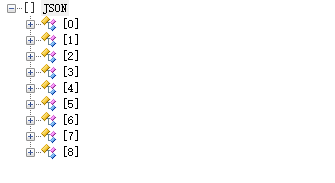
SpringBoot中缓存@Cacheable出错
SpringBoot中使用Cacheable: 错误代码: Cacheable(value "FrontAdvertiseVOList", keyGenerator "cacheKey") Override public List<FrontAdvertiseVO> getFrontAdvertiseVOList(Integer count) {return this.list(Wrappers.<Adve…...
iOS UIActivityViewController 组头处理
0x00 情形一 - (void)shareAction1 {// 当前 View 转成图片UIImage *image [self snapshotImage:self.view];NSArray *activityItems [image];UIActivityViewController *activityVC [[UIActivityViewController alloc] initWithActivityItems:activityItems applicationAc…...

分布式电源接入配电网的自适应电流保护系统设计与实现
分布式电源接入配电网的自适应电流保护系统设计与实现 一、引言 随着可再生能源的快速发展,分布式电源(Distributed Generation, DG)大规模接入配电网,传统保护系统面临以下挑战: 潮流方向改变导致保护误动/拒动故障电流水平波动影响保护灵敏度多类型故障(单相/两相/三…...

鸿蒙版Taro 搭建开发环境
鸿蒙版Taro 搭建开发环境 一、配置鸿蒙环境 下载安装 DevEco 建议使用最新版本的 IDE,当前为 5.0.5Release 版本。 二、创建鸿蒙项目 打开 DevEco,点击右上角的 Create Project,在 Application 处选择 Empty Ability,点击 Ne…...

论对生产力决定生产关系的批判:突破决定论的桎梏
笔言: 在学生时代认为"生产力决定生产关系"很有道理,但是进入社会参与市场竞争时候,才发现这种想法太天真了,当生产力一只赔钱时候谁也不会感兴趣;当生产力产生利润,比如1%30%,100%,3…...

ESOP交易系统搭建全景指南:从合规基石到价值跃迁
第一章 重新定义ESOP:合规性与流动性的平衡艺术 1.1 ESOP的本质演进 传统认知误区:员工持股计划股权分配工具 现代定义: ESOP是企业资本运作的中枢神经系统,贯穿“激励授予→行权管理→减持流通→市值协同”全链条,需…...

GICv3电源管理
在符合GICv3体系结构的实现中,CPU接口和PE必须位于相同的电源域,但这不必与关联的Redistributor所在的电源域相同。 这意味着可能会出现PE及其CPU interface断电,而Redistributor、Distributor和its上电的情况。在这种情况下,GIC架…...

《TCP/IP 详解 卷1:协议》第3章:链路层
以太网和IEEE802局域网/城域网标准 IEEE802局域网/城域网标准 IEEE 802 是一组由 IEEE(电气与电子工程师协会)定义的局域网和城域网通信标准系列,涵盖了从物理层到链路层的多个网络技术。其中: IEEE 802.3 定义的是传统的以太网…...

centos 9/ubuntu 一次性的定时关机
方法一 # 15 表示15分钟以后自动关机 sudo shutdown -h 15方法二: sudo dnf install at -y # 晚上十点半关机 echo "shutdown -h now" | at 22:30 # 检查是否设置成功命令 atq [rootdemo-192 ~]# atq 1 Wed Jun 4 11:12:00 2025 a root # 取消定时计划…...
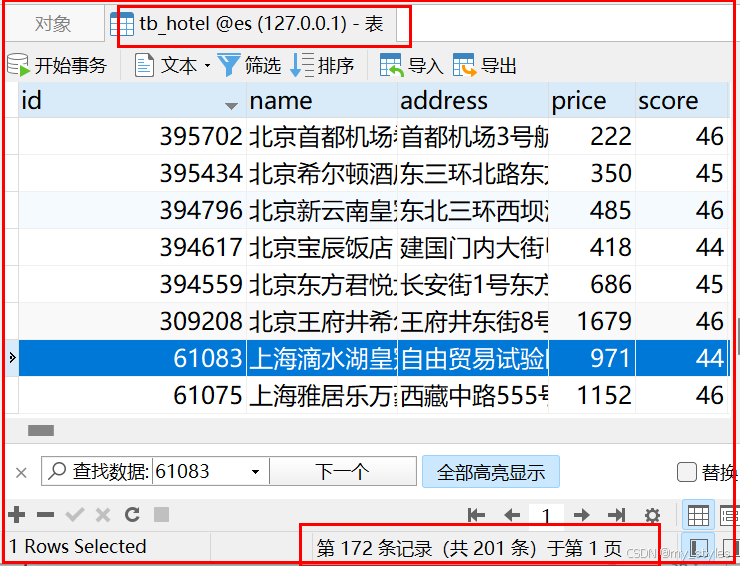
Elasticsearch从安装到实战、kibana安装以及自定义IK分词器/集成整合SpringBoot详细的教程(二)
package com.test.xulk.es.entity.mapper;import com.baomidou.mybatisplus.core.mapper.BaseMapper; import com.test.xulk.es.entity.Hotel;public interface HotelMapper extends BaseMapper<Hotel> { }集成Springboot 项目里面 官方地址: Elasticsearch …...

Java自动类型转换的妙用
Java中的自动类型转换(也称为隐式类型转换)是指在不需要显式指定转换的情况下,Java编译器自动将一种数据类型转换为另一种数据类型。这种特性在编程中有许多妙用,以下是一些常见的应用场景和优点: 1. 简化代码 自动类…...

数据库管理-第333期 Oracle 23ai:RAC打补丁完全不用停机(20250604)
数据库管理333期 2025-06-04 数据库管理-第333期 Oracle 23ai:RAC打补丁完全不用停机(20250604)1 概念2 要求3 操作流程4 转移失败处理总结 数据库管理-第333期 Oracle 23ai:RAC打补丁完全不用停机(20250604࿰…...

【DAY39】图像数据与显存
内容来自浙大疏锦行python打卡训练营 浙大疏锦行 知识点: 图像数据的格式:灰度和彩色数据模型的定义显存占用的4种地方 模型参数梯度参数优化器参数数据批量所占显存神经元输出中间状态 batchisize和训练的关系 作业:今日代码较少࿰…...
AI代码库问答引擎Folda-Scan
简介 什么是 Folda-Scan ? Folda-Scan 是一款革命性的智能项目问答工具, 完全在浏览器中本地运行 。它使用高级语义矢量化将您的代码库转变为对话伙伴,使代码理解和 AI 协作变得前所未有的简单和安全。其采用尖端的 Web 技术和 AI 算法构建&…...
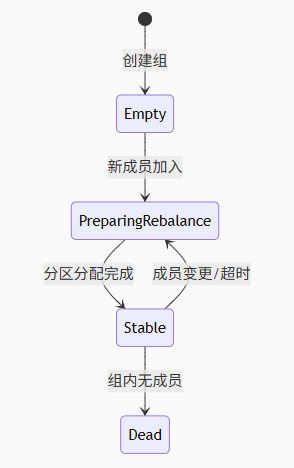
Kafka深度技术解析:架构、原理与最佳实践
一、 消息队列的本质价值与核心特性 1.1 分布式系统的“解耦器” 异步通信模型 代码列表 graph LRA[生产者] -->|异步推送| B[(消息队列)]B -->|按需拉取| C[消费者1]B -->|按需拉取| D[消费者2] 生产者发送后立即返回,消费者以自己的节奏处理消息。典…...

基于cnn的通用图像分类项目
背景 项目上需要做一个图像分类的工程。本人希望这么一个工程可以帮助学习ai的新同学快速把代码跑起来,快速将自己的数据集投入到实战中! 代码仓库地址:imageClassifier: 图片分类器 数据处理 自己准备的分类图像,按照文件夹分…...

Kotlin-协程
文章目录 什么是协程协程的好处协程的挂起和恢复协程原理 什么是协程 协程是一种用户态的轻量级程序组件,其核心特点是通过协作式调度实现单线程内的伪并发。 协程的好处 传统的线程切换通过回调,Handler各种调度,繁琐,代码不清…...

pycharm 左右箭头 最近编辑
目录 经典界面: 快捷键 经典界面: 如果你使用的是新 UI(新版 PyCharm 默认启用的),导航按钮可能被精简了,你可以: File Settings(齿轮图标)→ UI Appearance 或 New …...

Linux环境管道通信介绍
目录 前言 一、通信的本质 二、匿名管道 1.通信资源——文件缓冲区 2.为什么叫匿名管道? 编辑 3.匿名管道的创建过程 4.pipe函数 小结 5.一些问题 1)匿名管道为什么要求父子进程将原本的读/写权限只保留一个 2)为什么一开始父进程要以读/写…...
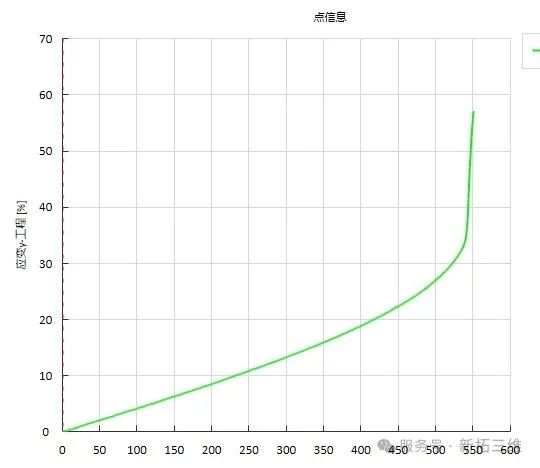
DIC技术助力金属管材全场应变测量:高效解决方案
在石油管道、汽车排气系统、航空航天液压管路等工业场景中,金属管作为关键承力部件,其拉伸性能(如弹性极限、颈缩行为、断裂韧性)直接影响结构安全性和使用寿命。 实际应用中,选用合适的管材非常重要,通过…...

python基础day04
1.两大编程思想的异同点: 面向过程面向对象区别事物比较简单,可以用线性的思维去解决事物比较复杂,使用简单的线性思维无法解决共同点面向过程和面向对象都是解决实际问题的一种思维方式二者相辅相成,并不是对立的解决复杂问题,通…...
嵌入式学习--江协stm32day1
失踪人口回归了,stm32的学习比起51要慢一些,因为涉及插线,可能存在漏插,不牢固等问题。 相对于51直接对寄存器的设置,stm32因为是32位修改起来比较麻烦,江协课程是基于标准库的,是对封装函数进…...

湖北理元理律师事务所:债务化解中的心理重建与法律护航
专业法律顾问视角 一、债务危机的双重属性:法律问题与心理困境 在对173名债务人的调研中发现: 68%存在焦虑引发的决策障碍(如不敢接听银行电话) 42%因羞耻感隐瞒债务导致雪球效应 湖北理元理律师事务所创新采用法律-心理双轨…...