Redis初入门
Nosql:Not-Only SQL(泛指非关系型数据库),作为关系型数据库的补充
作用:应对基于海量用户和海量数据前提下的数据处理问题
redis:C语言开发的一个开源的高性能键值对数据库
特征:
1、数据之间没有必然的关联关系
2、内部采用单线程机制工作
3、高性能
4、多数据类型支持(string、list、hash、set、sorted_set)
5、支持持久化(可以进行数据灾难恢复)
redis应用:
1、为热点数据加速查询(热点商品、热点新闻等)
2、任务队列(秒杀、抢购、购票排队等)
3、即时信息查询(各类排行榜、网站访问统计等)
4、时效性信息控制(验证码控制)
5、分布式数据共享(分布式集群架构中的session共享)
6、消息队列
7、分布式锁
数据类型相关命令:
string:字符串
| 命令 | 说明 |
|---|---|
| set [key] [value] | 添加、修改数据 |
| get [key] | 获取数据 |
| del [key] | 删除数据 |
| mset [key1] [value1] [key2] [value2] ... | 添加、修改多个数据 |
| mget [key1] [key2] ... | 获取多个数据 |
| strlen [key] | 获取数据字符个数(字符串长度) |
| append [key] [value] | 追加信息到原信息尾部(如果原来信息存在就追加,否则新建) |
| incr [key] | 数据自增1 |
| incrby [key] [increment] | 数据增加指定整数范围 |
| incrbyfloat [key] [increment] | 数据增加指定小数范围 |
| decr [key] | 数据自减1 |
| decrby [key] [increment] | 数据减去自定范围整数 |
| setex [key] [seconds] [value] | 设置数据具有制定的生命周期(秒) |
| psetex [key] [milliseconds] [value] | 设置数据具有制定的生命周期(毫秒) |
hash:哈希表结构
| 命令 | 说明 |
|---|---|
| hset [key] [field] [vaule] | 添加、修改数据 |
| hget [key] [field] | 获取数据 |
| hgetall [key] | 获取全部数据 |
| hdel [key] [field1] [field2] ... | 删除数据 |
| hlen [key] | 获取哈希表中字段的数量 |
| hexists [key] [field] | 哈希表中是否存在该字段(返回存在的个数) |
| hkeys [key] | 获取哈希表中所有字段名 |
| hvals [key] | 获取哈希表中所有字段值 |
| hincrby [key] [field] [increment] | 设置指定字段的数值数据增加指定范围的值(整数) |
| hincrbyfloat [key] [field] [increment] | 设置指定字段的数值数据增加指定范围的值(小数) |
| hsetnx [key] [field] [value] | 存在字段不更新,不存在新增 |
list:有序的双向链表
| 命令 | 说明 |
|---|---|
| lpush [key] [value1] [value2] ... | 添加、修改数据(左) |
| rpush [key] [value1] [value2] ... | 添加、修改数据(右) |
| lrange [key] [start] [stop] | 从左边获取数据,start(从0)开始,stop(-1代表倒1位置)结束 |
| lindex [key] [index] | 从左边读取index位置的数据,index从0开始 |
| llen [key] | 获取数据个数 |
| lpop [key] | 从左边获取一个数据并移除 |
| rpop [key] | 从右边获取一个数据并移除 |
| blpop [key1] [key2] ... [timeout] | 规定时间内从左边获取并移除数据,timeout秒级 |
| brpop [key1] [key2] ... [timeout] | 规定时间内从右边获取并移除数据,timeout秒级 |
| lrem [key] [count] [value] | 从左移除指定数据,count移除个数,value移除的数据 |
set:数据不重复
| 命令 | 说明 |
|---|---|
| sadd [key] [member1] [member2] ... | 添加数据 |
| smembers [key] | 获取全部数据 |
| srem [key] [member1] [member2] ... | 删除数据 |
| scard [key] | 获取集合数据总量 |
| sismember [key] [member] | 判断集合中是否包含指定数据,返回个数 |
| srandmember [key] [count] | 随机从集合中抽取count个数据,原集合不变 |
| spop [key] | 随机获取集合中的某个数据,并移出集合 |
| sinter [key1] [key2] | 求两个集合的交集 |
| sunion [key1] [key2] | 求两个集合的并集 |
| sdiff [key1] [key2] | 求两个集合的差集,有顺序的,key1 - key2的差集 |
| sinterstore [key3] [key1] [key2] | 求(key1,key2)两个集合的交集,并存储到key3中 |
| sunionstore [key3] [key1] [key2] | 求(key1,key2)两个集合的并集,并存储到key3中 |
| sdiffstore [key3] [key1] [key2] | 求(key1,key2)两个集合的差集,并存储到key3中 |
| smove [source] [destination] [member] | 把数据member从集合source移动到集合destination中 |
sorted_set:有序的set集合
| 命令 | 说明 |
|---|---|
| zadd [key] [score1] [member1] [score1] [member1] ... | 添加(多个)数据,按照score排序 |
| zrange [key] [start] [stop] [withscores] | 获取数据(升序),withscores会展示score值,start、stop为索引 |
| zrevrange [key] [start] [stop] [withscores] | 获取数据(降序) |
| zrem [key] [member1] [member2] ... | 删除(多个)数据 |
| zrangebyscore [key] [min] [max] [withscores] [limit] | 按条件升序获取,min < score值 < max,limit限制条数 |
| zrevrangebyscore [key] [max] [min] [withscores] [limit] | 按条件降序获取 |
| zremrangebyrank [key] [start] [stop] | 根据索引范围删除 |
| zremrangebyscore [key] [min] [max] | 根据score值范围删除 |
| zcard [key] | 获取集合数据总量 |
| zcount [key] [min] [max] | 获取指定的score值范围中的数据条数 |
| zinterstore [destination] [keynumber] [key1] [key2] ... | 集合交集,keynumber为要操作的集合个数 |
| zunionstore [destination] [keynumber] [key1] [key2] ... | 集合并集,keynumber为要操作的集合个数 |
| zrank [key] [member] | 获取指定数据的索引(升序) |
| zrevrank [key] [member] | 获取指定数据的索引(降序) |
| zscore [key] [member] | 获取指定数据的score值 |
| zincrby [key] [increment] [member] | 给指定的member数据的score值增加increment |
key通用操作:
| 命令 | 说明 |
|---|---|
| del [key] | 删除指定key |
| exists [key] | 获取key是否存在 |
| type [key] | 获取key的类型 |
| expire [key] [second] | 为指定key设置有效期,秒级 |
| pexpire [key] [milliseconds] | 为指定key设置有效期,毫秒级 |
| ttl [key] | 获取key的有效时间(秒),返回-2说明key不存在,返回-1说明key存在 |
| pttl [key] | 获取key的有效时间(毫秒) |
| persist [key] | 切换key从时效性转换为永久性 |
| rename [key] [newkey] | 为key改名,newkey如果已存在会覆盖原先的值 |
| renamenx | 为key改名,newkey如果已存在不会改名 |
| sort | 排序 |
key查询模式规则:
keys pattern

db基本操作:
| 命令 | 说明 |
|---|---|
| select [index] | 切换数据库(0-16) |
| ping | 返回pong说明数据库是连通的 |
| quit | 退出 |
| move [key] [dbindex] | 数据移动 |
| dbsize | 当前库中key的总量 |
| flushdb | 清除当前库的数据 |
| flushall | 清除所有库的数据 |
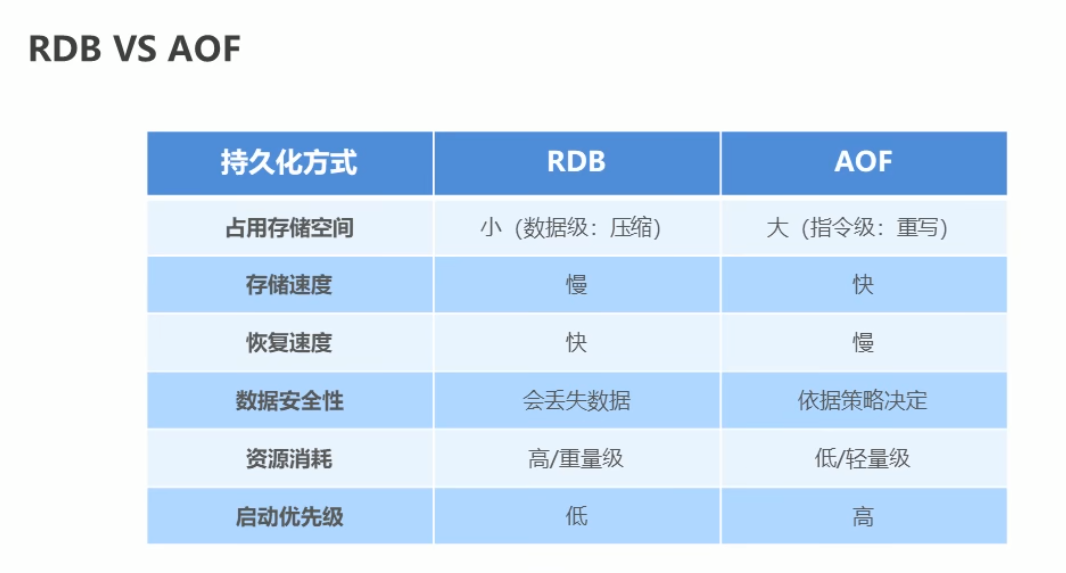
redis持久化:
1、rdb:以快照的形式记录数据
save:保存命令
bgsave:后台保存,会开启子进程进行数据保存
save [second] [count]:自动保存,在second(秒)时间内,改变count次
2、aof:记录历史命令,后台会重写
重写的作用:
1)、降低磁盘占用量,提高磁盘利用率
2)、提高持久化效率,降低持久化写时间,提高IO性能
3)、降低数据恢复用时,提高数据恢复效率
重写规则:
1、已超时的数据不再写入
2、忽略无效指令,只保留最终数据的写入命令
3、对同一数据的多条写命令合并为一条命令(list,set,hash,zset指令一次性最多写入64个元素)
bgrewriteaof:手动重写

redis事务:
multi:开启事务(设定事务的开启位置,此命令执行后,后续的所有命令均加入到该事务中)
exec:执行事务(设定事务的结束位置,同时执行事务。与multi成对使用)
discard:取消事务(终止当前事务,发生在multi之后)
redis监控锁:
watch [key1] [key2] ... :对key添加监视锁,在执行exec前如果key发生变化,终止事务执行
unwatch:取消对所有key的监视
redis:分布式锁(公共锁):
setnx lock-[key] value:设置公共锁
del lock-[key]:释放锁
expire lock-[key] [second]:为锁key添加时间限定,到时不释放,自动释放锁(秒)
pexpire lock-[key] [milliseconds]:为锁key添加时间限定,到时不释放,自动释放锁(毫秒)
redis删除策略:
1、定时删除:用时间换空间
好:节约内存,无占用
坏:不分时段占用CPU资源,频度高
2、惰性删除:访问某个key时,判断该key是否过期,过期则清除
好:延时执行,CPU利用率高
坏:内存占用严重
3、定期删除:每隔一定的时间,扫描一定数量的key,并清除其中过期的key。
redis同时使用惰性删除和定期删除这两种过期策略
redis逐出策略:
相关配置
maxmemory:最大可使用内存
maxmemory-samples:每次选取待删除的数据个数



哨兵模式:
定义:监控主从结构中各个redis服务器工作过程,当master出现故障时,通过投票机制选出新的master,并将所有的slave连接到新的master
工作原理:
1、监控master和各个slave
2、各个哨兵之间互通信息
3、当一个哨兵发现master出现故障,会通知其他哨兵复核,超出一半的哨兵发现master故障,会投票选出一个哨兵进行故障处理,选出一台slave作为新master,通知其他slave连接到新的master
缓存预热:系统启动前,提前将相关的缓存数据直接加载到缓存系统,避免在用户请求的时候,直接查询数据库,再将数据进行缓存的问题。让用户直接查询事先被预热的缓存数据。
缓存雪崩:一段时间内,大量的缓存数据过期,请求直接访问数据库,导致数据库服务器造成大量压力。
解决:
1、热点数据使用永久key
2、为key设置不同的有效期
缓存击穿:单个key数据过期瞬间,数据访问量较大,大量对数据库访问,导致对数据库服务器造成压力。
解决:
1、热点数据使用永久key
2、为key设置不同的有效期
缓存穿透:大量访问不存在的数据,对数据库服务器造成压力。
解决:
1、返回结果为null也进行缓存,有效时间短
2、采用布隆过滤器
布隆过滤器:二进制数组,key经过多个hash函数得出的值就是数组的索引,索引对应位置的值会设置为1。新的key经过同样步骤得出索引值,如果对应位置的值不全是1,说明这个key不存在,直接过滤掉。
问题:存在误判。不同的值hash后可能结果一致,会导致不存在的key判断为存在。
如何保证redis和数据库数据一致性
1、先更新数据库,再删除redis(下次读取时重新加载)
2、更新redis,同步更新数据库(两步操作在同一个事务中)
3、更新redis,发送消息同步到数据库(redis挂了,未同步数据容易丢失)
4、更新数据库,Canal监听Binglog,通过MQ更新redis
5、延迟双删,更新数据库前后删除redis(第二次删除延迟500ms)
6、分布式锁,加锁,更新数据库和删除缓存,释放锁
相关文章:
Redis初入门
Nosql:Not-Only SQL(泛指非关系型数据库),作为关系型数据库的补充 作用:应对基于海量用户和海量数据前提下的数据处理问题 redis:C语言开发的一个开源的高性能键值对数据库 特征: 1、数据之…...
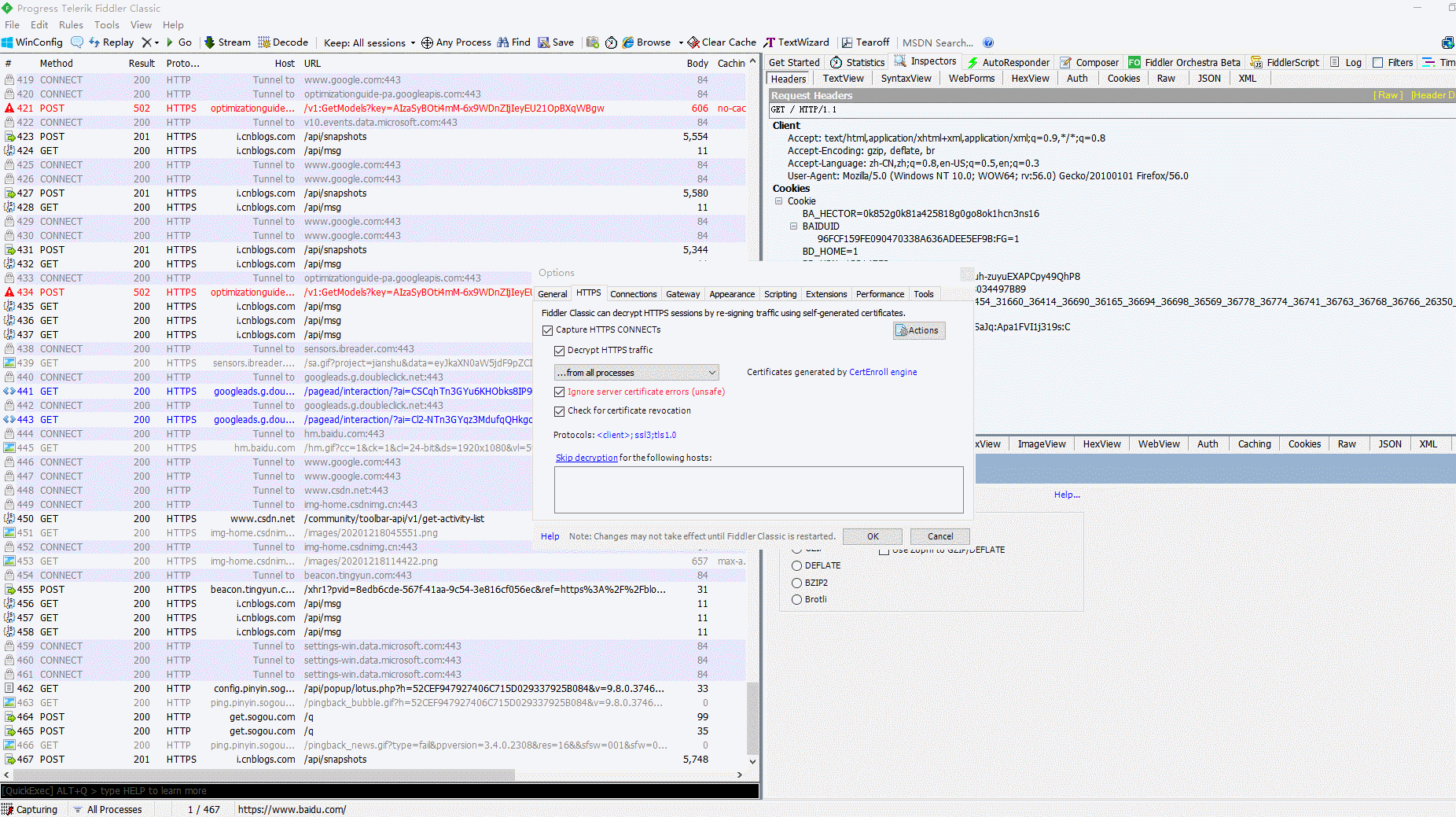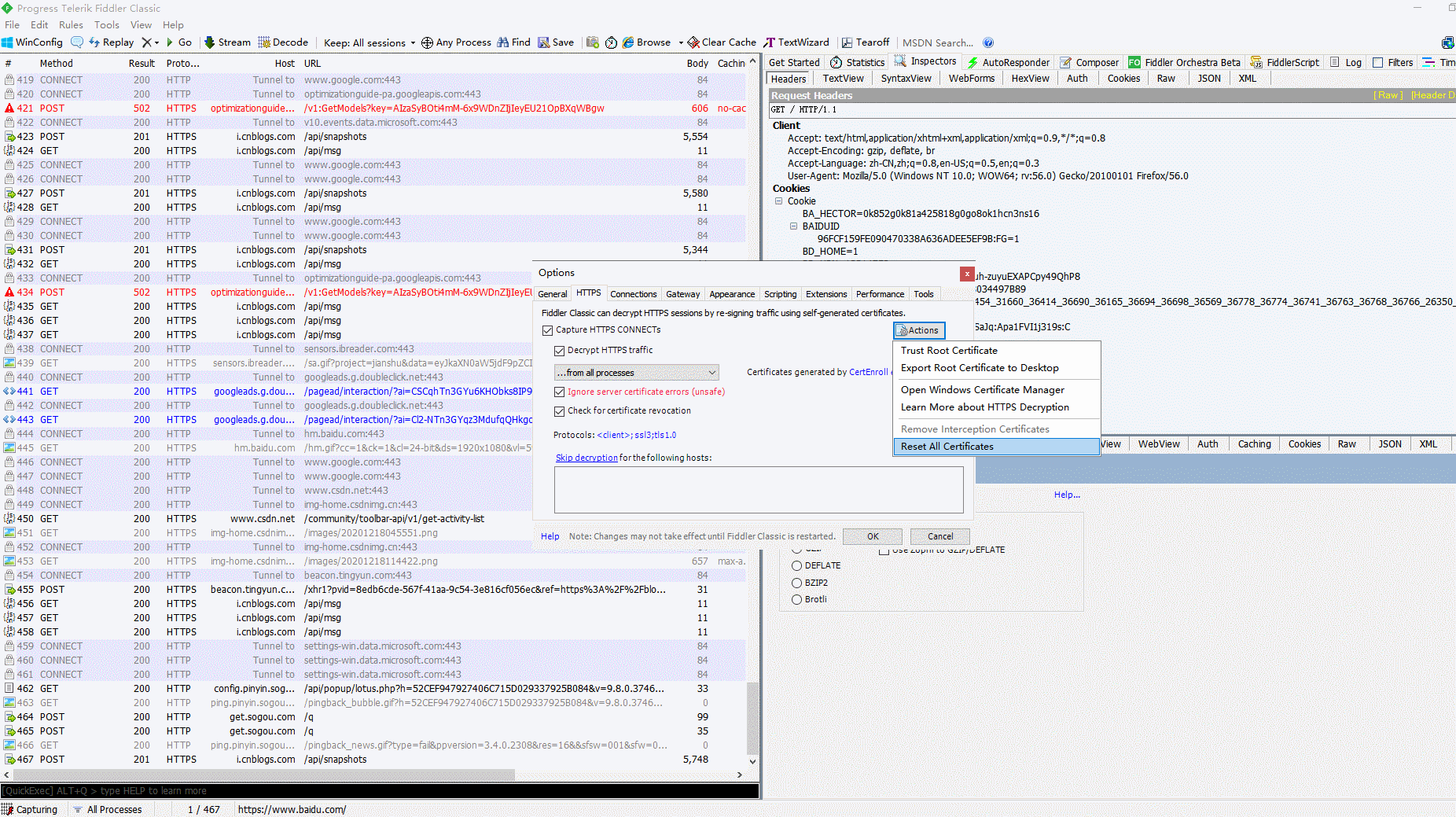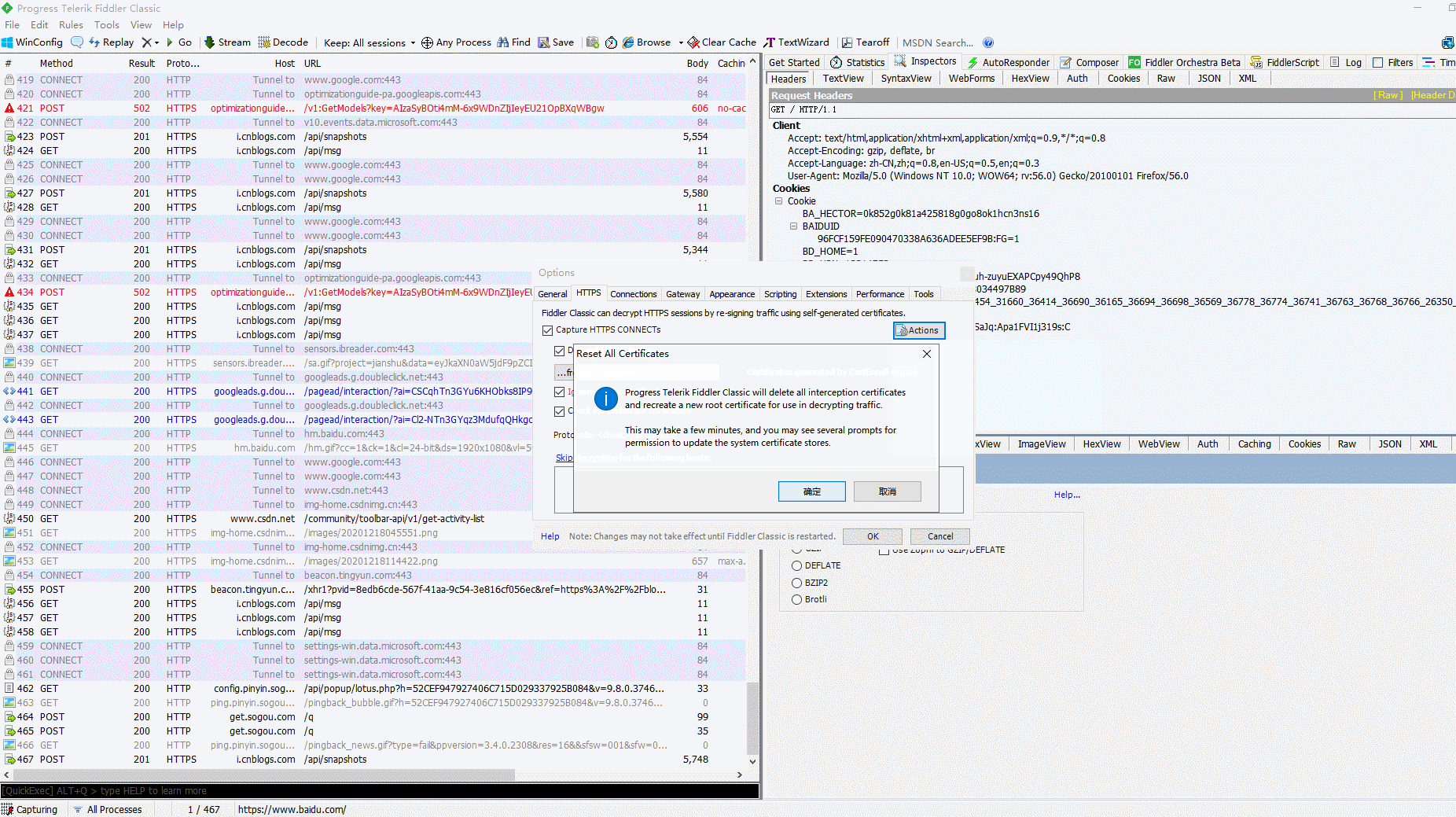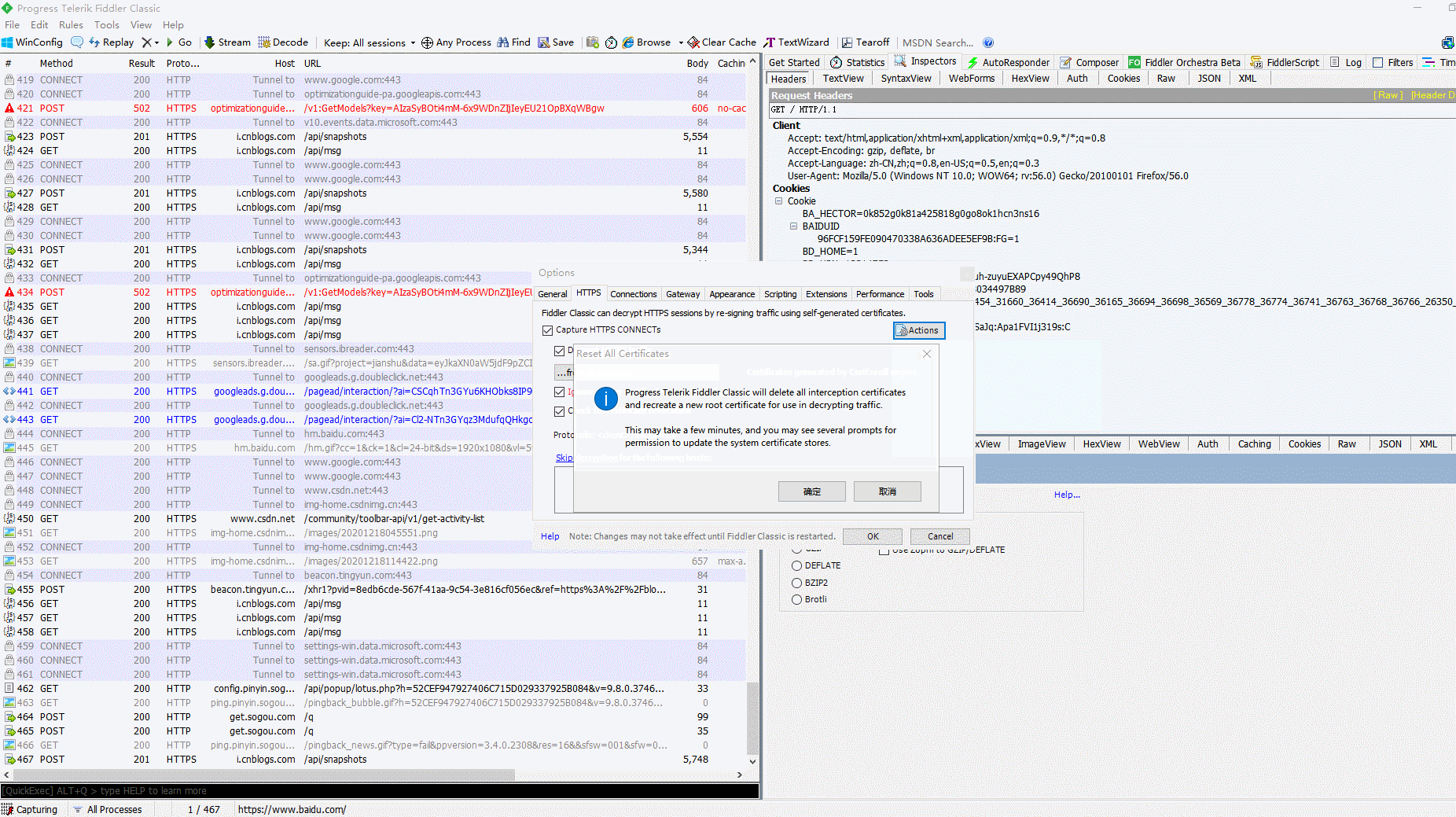
(10)Fiddler抓包-Fiddler如何设置捕获Firefox浏览器的Https会话
1.简介 经过上一篇对Fiddler的配置后,绝大多数的Https的会话,我们可以成功捕获抓取到,但是有些版本的Firefox浏览器仍然是捕获不到其的Https会话,需要我们更进一步的配置才能捕获到会话进行抓包。 2.环境 1.环境是Windows 10版…...
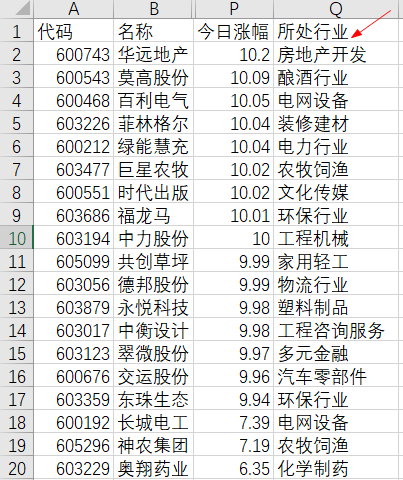
使用pandas实现合并具有共同列的两个EXCEL表
表1: 表2: 表1和表2,有共同的列“名称”,而且,表1的内容(行数)<表2的行数。 目的,根据“名称”列的对应内容,将表2列中的“所处行业”填写到表1相应的位置。 实现代…...

2025年- H69-Lc177--78.子集(回溯,组合)--Java版
1.题目描述 2.思路 3.代码实现 class Solution {public List<List<Integer>> subsets(int[] nums) {List<List<Integer>> resnew ArrayList<>();List<Integer> curnew ArrayList<>();//从索引0开始递归backtracking(res,cur,nums,0…...

目标检测任务的评估指标mAP50和mAP50-95
mAP50 和 mAP50-95 是目标检测任务中常用的评估指标,用于衡量模型在不同 交并比(IoU)阈值 下的平均精度(Average Precision, AP)。它们的区别主要体现在 IoU 阈值范围 上。 ✅ 1. mAP50(mean Average Prec…...

C++String的学习
1、C语言中的字符串 C语言中,字符串是以’\0’结尾的一些字符的集合,为了操作方便,C标准库中提供了一些str系列的库函数,但是这些库函数与字符串是分离开的,不太符合OOP的思想(即面向对象编程(…...
java day15 (数据库)
进入数据库的学习 DB 因为数据太多了,方便统一管理的软件 操作就不用改代码了,直接改数据库则可; 命令就是sql语句 这些都是关系型数据库,sql可以控制全部,至于具体的环境我以前就有安装过了; 理解&am…...

SQL 中 IN 和 EXISTS 的区别
SQL 中 IN 和 EXISTS 的区别 1. 基本概念 1.1 IN 运算符 IN 是一个条件运算符,用于检查某个值是否存在于指定的值列表中或子查询返回的结果集中。 SELECT * FROM employees WHERE department_id IN (SELECT id FROM departments WHERE location = New York)...

多线程爬虫使用代理IP指南
多线程爬虫能有效提高工作效率,如果配合代理IP爬虫效率更上一层楼。作为常年使用爬虫做项目的人来说,选择优质的IP池子尤为重要,之前我讲过如果获取免费的代理ip搭建自己IP池,虽然免费但是IP可用率极低。 在多线程爬虫中使用代理I…...
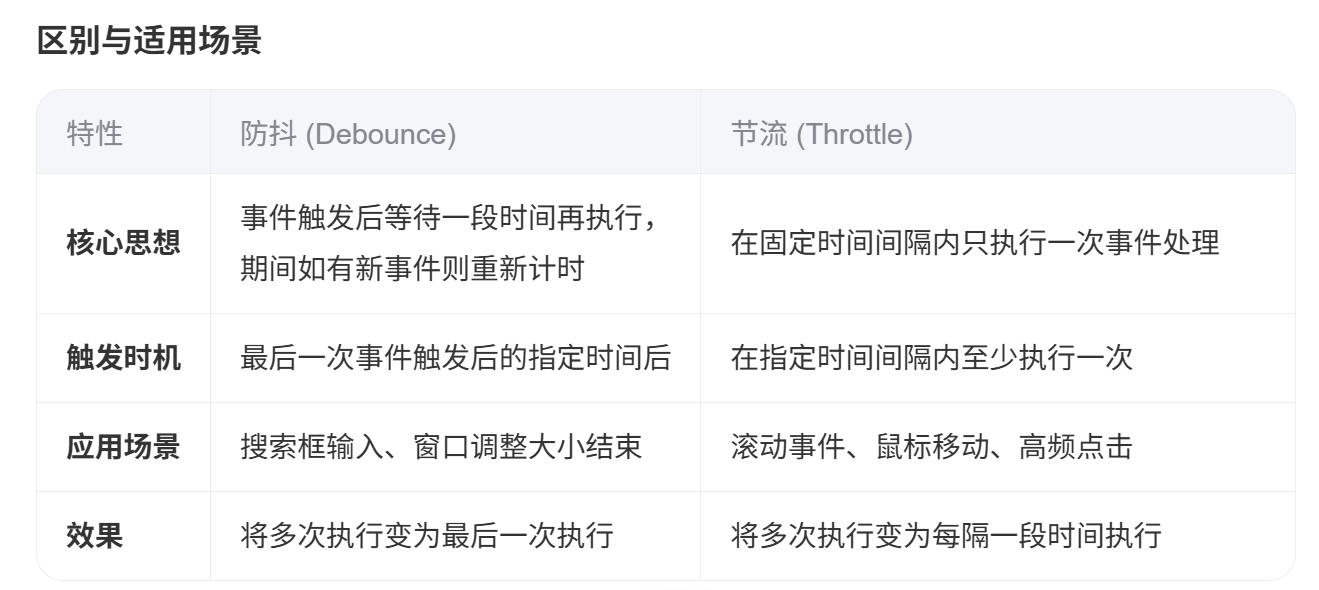
前端面试真题(第一集)
目录标题 1、跨域问题及解决方法同源策略生产环境解决方案开发环境解决方案其他解决方案 2、组件间通信方式Vue2中的组件通信方式Vue3中的组件通信方式通用注意事项 3、微信小程序生命周期微信小程序原生生命周期UniApp生命周期 4、微信小程序授权登录流程登录流程手机号获取 5…...

电脑安装系统蓝屏的原因
1. 内存故障 原因:内存条接触不良、损坏或兼容性问题(如不同品牌 / 频率的内存混用)。表现:蓝屏代码可能包含 MEMORY_MANAGEMENT、PAGE_FAULT_IN_NONPAGED_AREA 等。排查方法: 重新插拔内存条,清理金手指灰…...
TDengine 高级功能——流计算
简介 在时序数据的处理中,经常要对原始数据进行清洗、预处理,再使用时序数据库进行长久的储存,而且经常还需要使用原始的时序数据通过计算生成新的时序数据。在传统的时序数据解决方案中,常常需要部署 Kafka、Flink 等流处理系统…...

expect程序交互学习
文章目录 一、初级语法学习二、例子 一、初级语法学习 1.使用expect进行ssh另一台机器 [rootlocalhost ~]# yum install -y expect #先安装expect [rootlocalhost ~]# vim expect1.sh #!/usr/bin/expect spawn ssh root192.168.68.244 expect {"yes/no" {send "…...

05.字母异位词分组
题意理解 🧠 什么是“字母异位词”? 字母异位词是指由相同的字母组成,只是排列顺序不同的单词。 比如: "eat" 和 "tea" 是异位词,它们都包含 e、a 和 t。"ate" 也是它们的异位词。但…...

Mac查看MySQL版本的命令
通过 Homebrew 查看(如果是用 Homebrew 安装的) brew info mysql 会显示你安装的版本、路径等信息。 你的终端输出显示:你并没有安装 MySQL,只是查询了 brew 中的 MySQL 安装信息。我们一起来看下重点: 🧾…...
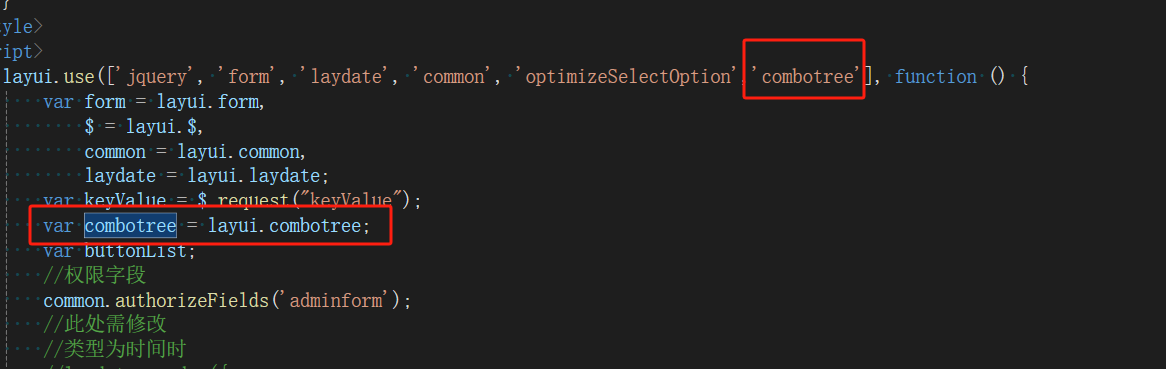
【.net core】【watercloud】树形组件combotree导入及调用
源码下载:combotree: 基于layui及zTree的树下拉框组件 链接中提供了组件的基本使用方法 框架修改内容 1.文件导入(路径可更具自身情况自行设定) 解压后将文件夹放在图示路径下,修改文件夹名称为combotree 2.设置路径(设置layu…...

[Java 基础]面向对象-封装
封装是构建健壮、可维护和安全软件的基础。 什么是封装? 想象一下你的手机。你不需要知道手机内部复杂的电路、芯片和各种组件是如何协同工作的,你只需要知道如何使用屏幕、按键或触摸操作来打电话、发短信或玩游戏。手机的内部细节被“包裹”起来&…...

2021 RoboCom 世界机器人开发者大赛-高职组(复赛)解题报告 | 珂学家
前言 题解 2021 RoboCom 世界机器人开发者大赛-高职组(复赛)解题报告。 模拟题为主,包含进制转换等等。 最后一题,是对向量/自定义类型,重定义小于操作符。 7-1 人工智能打招呼 分值: 15分 考察点: 分支判定&…...

Python趣学篇:Pygame实现3D星空穿越动画
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 专栏介绍:《Python星球日记》🪐 目录 一、项目概览与技术栈二、核心技术原理解析1. 透视投影:让3D世界"压扁"到2D屏幕2. Z轴深度:创造…...

基于Web的安全漏洞分析与修复平台设计与实现
基于Web的安全漏洞分析与修复平台设计与实现 摘要 随着信息化进程的加快,Web系统和企业IT架构愈发复杂,安全漏洞频发已成为影响系统安全运行的主要因素。为解决传统漏洞扫描工具定位不准确、修复建议不完善、响应周期长等问题,本文设计并实…...
34.1STM32下的can总线实现知识(区分linux)_csdn
看过我之前的文章就知道,正点原子下的linux中CAN总线并没有讲的很明白,都是系统自带的! 这里我找到江科大学长的can总线的讲解视频! CAN总线入门教程-全面细致 面包板教学 多机通信_哔哩哔哩_bilibili 在这里我也会一步一步讲解CA…...

相机Camera日志分析之二十四:高通相机Camx 基于预览1帧的process_capture_request三级日志分析详解
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了:相机Camera日志分析之二十三:高通相机Camx 基于预览1帧的process_capture_request二级日志分析详解 这一篇我们开始讲: 相机Camera日志分析之二十四:高通相机Camx 基于预览1帧的process_capture_req…...

Linux 内核中 skb_dst_drop 的深入解析:路由缓存管理与版本实现差异
引言 在 Linux 内核网络子系统中,sk_buff(简称 SKB)是数据包在内核态流转的核心数据结构。为了高效处理网络数据包的路由选择,内核通过 dst_entry 结构体缓存路由信息,而 skb_dst_drop 函数则是管理这些路由缓存引用的关键工具。本文将从作用、实现原理、内核版本差异等多…...
)
考研系列—操作系统:冲刺笔记(4-5章)
目录 第四章 文件管理 1.真题总结文件管理方式 (1)目录文件的FCB就是“目录名-目录地址” (2)普通文件的FCB (3)区分索引文件、顺序文件、索引分配 (4)文件的物理结构 ①连续分配方式 ②链接分配 ③索引分配-使用索引表(一个文件对应一张索引表!!!) 计算考点:超级…...

功能管理:基于 ABP 的 Feature Management 实现动态开关
🚀 功能管理:基于 ABP 的 Feature Management 实现动态开关 📚 目录 🚀 功能管理:基于 ABP 的 Feature Management 实现动态开关📚 一、背景分析🧩 二、核心功能设计2.1 定义 Feature 常量与分组…...

2025年想冲网安方向,该考华为安全HCIE还是CISSP?
打算2025年往网络安全方向转,现在考证是不是来得及?考啥证? 说实话,网络安全这几年热得发烫,但热归热,入门门槛也不低,想进这个赛道,技术、项目经验、证书,缺一不可。 …...

ES6 深克隆与浅克隆详解:原理、实现与应用场景
ES6 深克隆与浅克隆详解:原理、实现与应用场景 一、克隆的本质与必要性 在 JavaScript 中,数据分为两大类型: 基本类型:Number、String、Boolean、null、undefined、Symbol、BigInt引用类型:Object、Array、Functio…...

Go Gin框架深度解析:高性能Web开发实践
Go Gin框架深度解析:高性能Web开发实践 Gin框架核心特性概览 Gin是用Go语言编写的高性能Web框架,以其闪电般的路由性能(基于httprouter)和极简的API设计著称: package mainimport "github.com…...
)
mybatis 参数绑定错误示范(1)
采用xml形式的mybatis 错误示例: server伪代码为: Map<String, Object> findMapNew MapUtil.<String, Object>builder().put("applyUnit", appUnit).put("planYear", year ! null ? year : -1).put("code&quo…...

每天掌握一个Linux命令 - rpm
Linux 命令工具 rpm 使用指南 Linux 命令工具 rpm 使用指南一、工具概述二、安装方式1. 系统预装2. 源码编译安装(极少场景) 三、核心功能四、基础用法1. 安装软件包2. 升级软件包3. 查询软件包信息4. 卸载软件包5. 验证文件完整性 五、进阶操作1. 批量操…...