复杂业务场景下 JSON 规范设计:Map<String,Object>快速开发 与 ResponseEntity精细化控制HTTP 的本质区别与应用场景解析
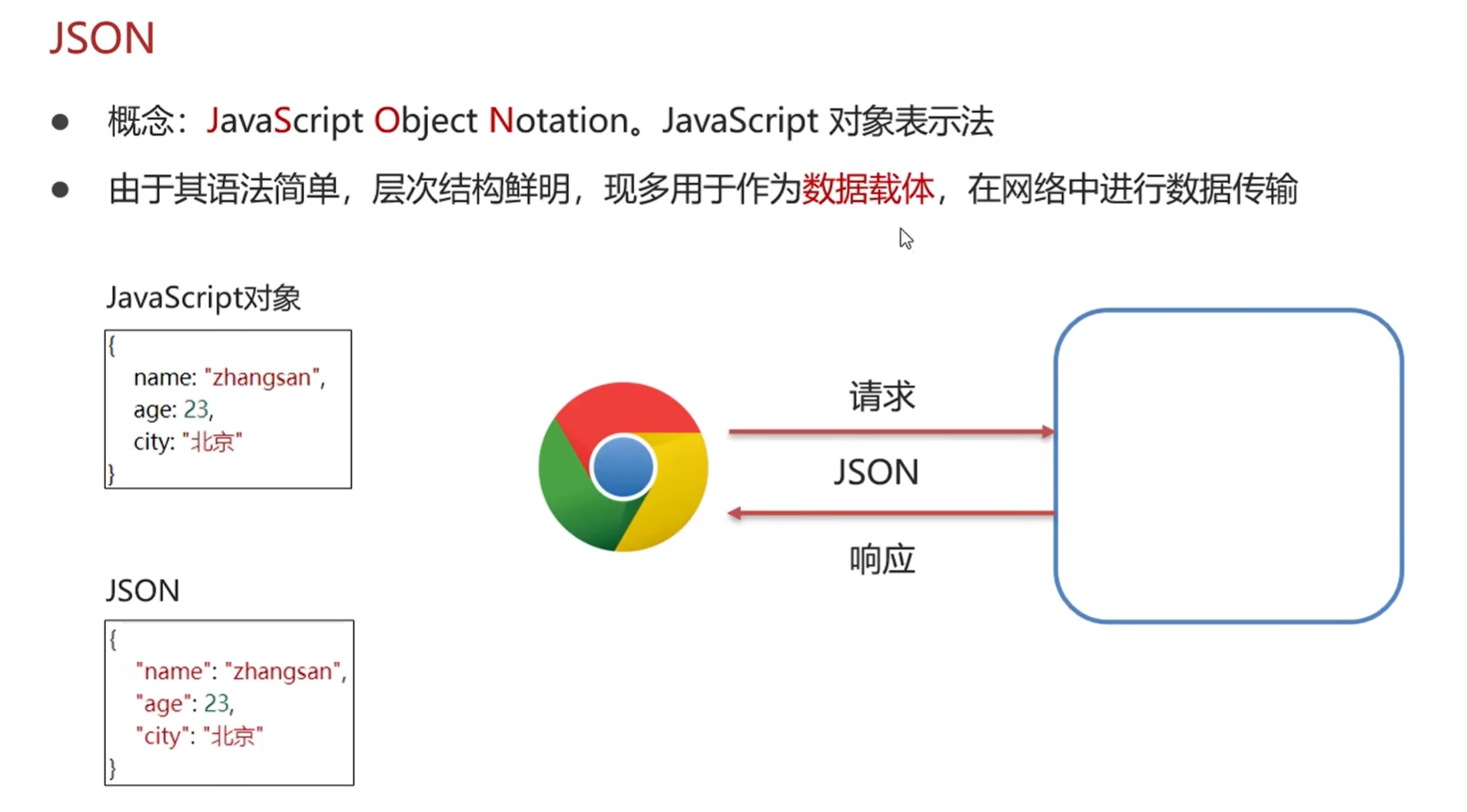
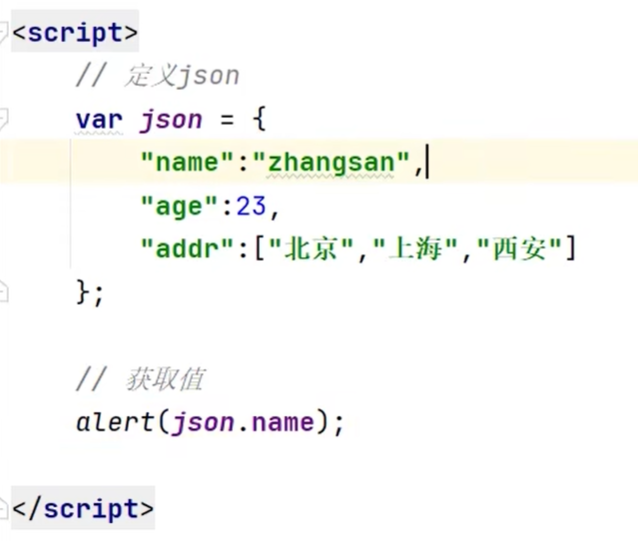
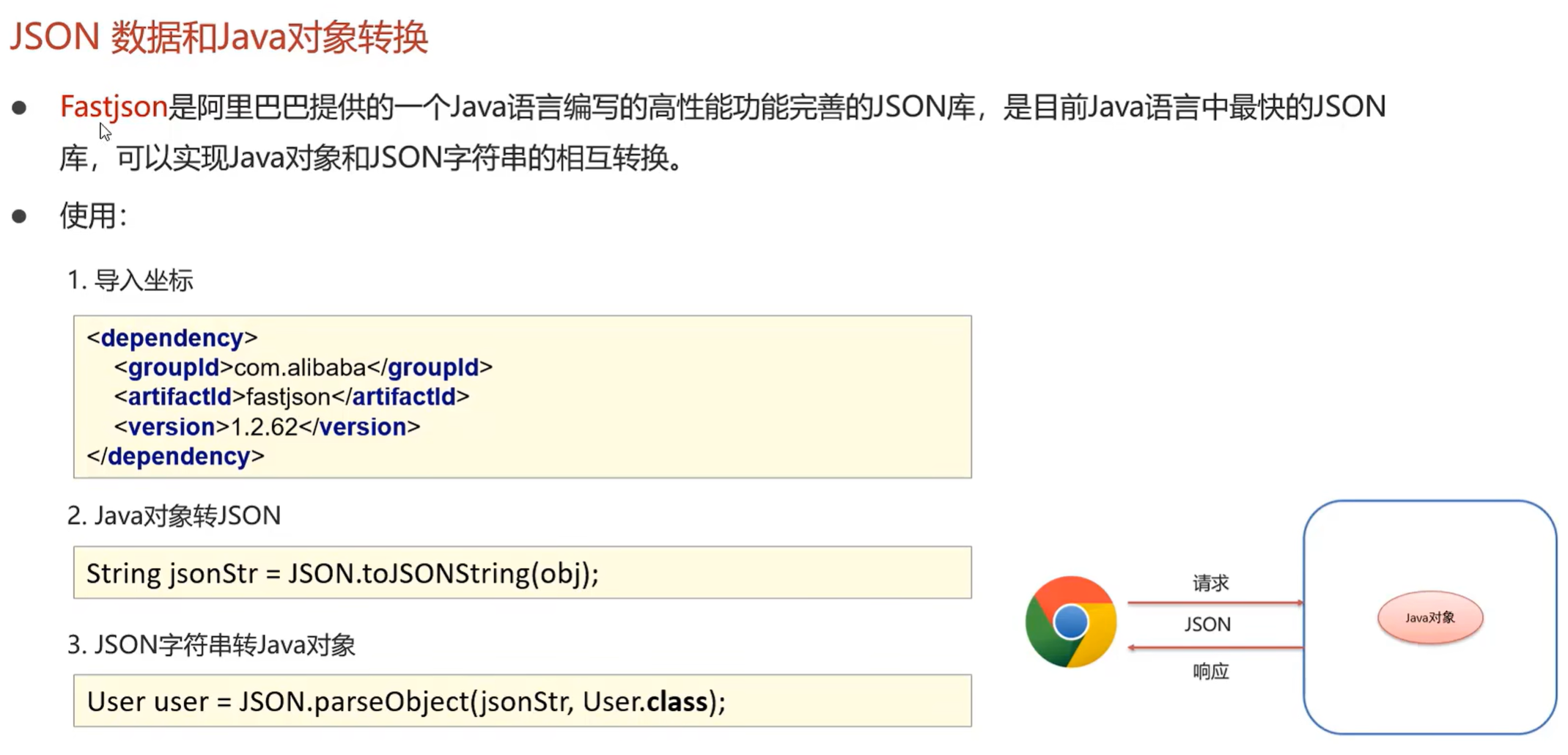
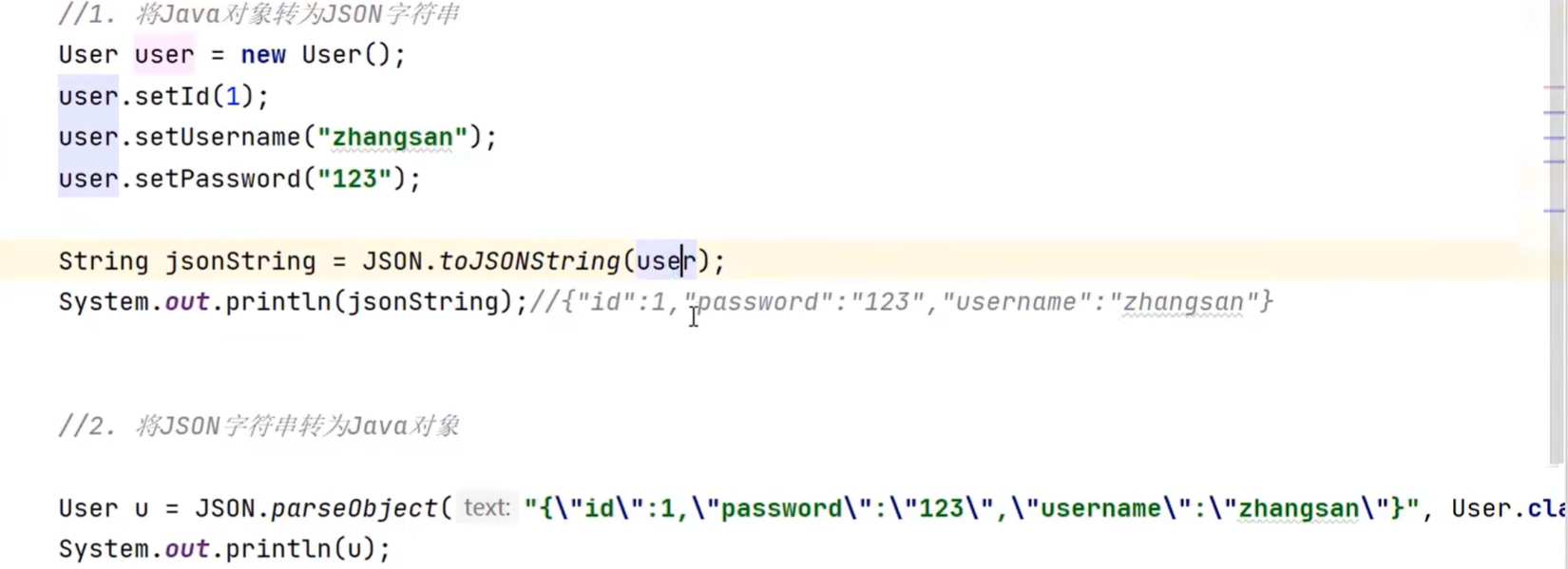
Moudle 1 Json使用示例
在企业开发中,构造 JSON 格式数据的方式需兼顾 可读性、兼容性、安全性和开发效率,以下是几种常用方式及适用场景:
一、直接使用 Map / 对象转换(简单场景)
通过 键值对集合(如 Map<String, Object>) 或 POJO 对象 直接序列化为 JSON,适用于简单接口或内部数据处理。链接
实现方式:
- 依赖 JSON 工具库(如 Jackson、Gson、FastJSON):java
// 使用 Jackson 将 Map 转为 JSON
ObjectMapper mapper = new ObjectMapper();
Map<String, Object> data = new HashMap<>();
data.put("code", 200);
data.put("msg", "成功");
data.put("data", Arrays.asList("苹果", "香蕉"));
String json = mapper.writeValueAsString(data);
json
{"code": 200,"msg": "成功","data": ["苹果", "香蕉"]
}- 优势:
- 灵活轻便,无需定义额外类。
- 适合快速开发或临时接口。
2.缺点:
- 缺乏统一规范,易导致字段名不一致(如大小写、驼峰 / 下划线)。
- 复杂场景下(如嵌套对象、类型转换)维护成本高。
- 适用场景:
简单的单表查询结果返回。
临时接口或内部微服务间的数据传递。
二、定义统一响应实体类(推荐)
通过定义 全局统一的响应格式类(如 Result<T>),将数据、状态码、消息等封装为固定结构,提升接口规范性。
实现方式:
- 定义通用响应类:java
public class Result<T> {private int code; // 状态码(如 200、400、500)private String msg; // 提示信息private T data; // 业务数据// 构造方法、Getter/Setter 省略
}- 使用示例:java
// 返回成功结果
Result<List<String>> result = new Result<>();
result.setCode(200);
result.setMsg("操作成功");
result.setData(Arrays.asList("苹果", "香蕉"));
String json = mapper.writeValueAsString(result);
json
{"code": 200,"msg": "操作成功","data": ["苹果", "香蕉"]
}优势:
统一规范:标准化的接口响应格式,显著提升前端解析效率和异常处理能力
类型安全:通过泛型机制确保数据类型明确,有效降低运行时错误风险
可扩展性:灵活支持全局字段扩展(如时间戳、追踪ID等)
- 适用场景:
- 对外提供的RESTful API服务(包括Web服务和OpenAPI)
- 复杂业务逻辑场景(涉及分页查询、嵌套数据结构或精细化错误处理)
- 需要预先定义数据结构类,带来一定的初期开发成本
三、使用 ResponseEntity(Spring 生态)
在 Spring MVC/Spring Boot 中,通过 ResponseEntity 类封装 HTTP 响应,可直接控制 HTTP 状态码、响应头和 Body,适合细粒度控制接口行为。
实现方式:
@GetMapping("/api/data")
public ResponseEntity<Map<String, Object>> getJsonData() {Map<String, Object> data = new HashMap<>();data.put("message", "Hello ResponseEntity");// 设置响应状态码(如 OK、NOT_FOUND)// 设置响应头(如 Content-Type、Cache-Control)HttpHeaders headers = new HttpHeaders();headers.setContentType(MediaType.APPLICATION_JSON);return new ResponseEntity<>(data, headers, HttpStatus.OK);
}json
{"message": "Hello ResponseEntity"
}优势:
- 完全控制 HTTP 协议:可灵活设置状态码(如
201 Created、404 Not Found)和响应头(如跨域Access-Control-Allow-Origin)。 - 与 Spring 生态无缝集成:适合基于 Spring 的 Web 项目。
缺点:
- 若仅需返回 JSON 数据,使用
@ResponseBody配合Result<T>更简洁。
适用场景:
- 需要精确控制 HTTP 响应细节的场景(如自定义错误处理、文件下载)。
- Spring 框架下的 RESTful 接口开发。
Moudle 2 Map<String,Object>与RepsonseEntity<>
问题:构建JSON数据,返回Map<String,Object> 与返回 RepsonseEntity<>有什么区别
误区纠正:我认为,Map<String,Object>是直接构建Json格式的关键,RepsonseEntity<>与构建Json格式并无直接关系。然而,它是用来提供HTTP相应的封装类。要说关系的话,RepsonseEntity<>应该是Map<String,Object>的上级。因为前者是后者plus版本。
例如 :

在 Spring MVC 中,返回 Map<String, Object> 和 ResponseEntity 的主要区别体现在对 HTTP 响应的控制粒度和功能丰富性上。以下是详细对比:
一、本质区别
| 维度 | 返回 | 返回 |
| 类型 | 普通 Java 对象(需配合 ) | Spring 提供的 HTTP 响应封装类 |
| 功能定位 | 仅用于封装响应体数据(JSON 内容) | 可封装完整的 HTTP 响应(状态码、头信息、体数据) |
| HTTP 控制 | 无法直接设置状态码、响应头 | 可直接设置 状态码(Status)、响应头(Headers)、响应体(Body) |
| 序列化方式 | 依赖 Spring 的默认 JSON 转换器(如 Jackson) | 同上,但可通过 自定义 Content-Type 等 |
二、核心差异详解
1. HTTP 状态码控制
Map<String, Object>
无法直接设置 HTTP 状态码,默认返回 200 OK。
如需自定义状态码(如 404、500 等),需通过@ResponseStatus注解或全局异常处理实现。
@GetMapping("/example")
@ResponseStatus(HttpStatus.CREATED) // 需手动添加注解设置状态码
public Map<String, Object> getMap() {return Collections.singletonMap("data", "success");
}ResponseEntity
可在返回值中直接指定状态码,无需额外注解。
@GetMapping("/example")
public ResponseEntity<Map<String, Object>> getResponseEntity() {Map<String, Object> data = Collections.singletonMap("data", "success");return new ResponseEntity<>(data, HttpStatus.CREATED); // 直接设置状态码
}2. 响应头(Headers)控制
Map<String, Object>
无法直接设置响应头,需通过HttpServletResponse或@RequestHeader间接操作,代码较繁琐。
@GetMapping("/example")
public Map<String, Object> addHeader(HttpServletResponse response) {response.setHeader("Custom-Header", "value"); // 通过原生 Servlet API 设置return Collections.singletonMap("data", "success");
}ResponseEntity
可通过HttpHeaders对象直接设置响应头,支持链式调用,更优雅。
@GetMapping("/example")
public ResponseEntity<Map<String, Object>> addHeader() {HttpHeaders headers = new HttpHeaders();headers.add("Custom-Header", "value");Map<String, Object> data = Collections.singletonMap("data", "success");return new ResponseEntity<>(data, headers, HttpStatus.OK); // 同时设置头和状态码
}3. 响应体序列化与类型安全
- 两者均依赖 Jackson 等 JSON 序列化工具,将对象转为 JSON 格式。
- 区别:
-
Map<String, Object>的键值对类型灵活(适合动态数据),但缺乏编译期类型检查。ResponseEntity可搭配具体类型(如User对象),增强类型安全性,例如:
public ResponseEntity<User> getUser() { ... } // 明确响应体类型为 User 对象三、适用场景对比
| 场景 | 推荐使用 | 推荐使用 |
| 简单业务接口(默认 200 OK) | ✅ 代码简洁,无需额外配置 | ❌ 杀鸡用牛刀 |
| 需要自定义 HTTP 状态码 | ❌ 需借助注解或全局处理 | ✅ 直接在返回值中设置状态码 |
| 需要添加自定义响应头 | ❌ 需操作原生 Servlet API | ✅ 直接通过 设置 |
| 统一异常处理返回标准格式 | ❌ 需全局拦截处理返回值 | ✅ 可在异常处理器中直接返回封装好的 ResponseEntity |
| 复杂响应逻辑(如文件下载等) | ❌ 无法控制 Content-Disposition 等头信息 | ✅ 可精准设置头信息和状态码 |
四、最佳实践建议
- 简单场景优先用
Map<String, Object>
当接口仅需返回 JSON 数据且使用默认状态码(200 OK)时,直接返回Map或自定义对象(如ResultVO),代码更简洁。 - 复杂场景使用
ResponseEntity
-
- 需要精细控制 HTTP 协议层面的细节(如状态码、响应头)。
- 实现 RESTful 规范(如返回 201 Created、400 Bad Request 等标准状态码)。
- 统一接口返回格式(可结合泛型封装通用的
ResponseEntity<Result>)。
- 结合全局异常处理
通过 Spring 的@ControllerAdvice统一处理异常,返回ResponseEntity格式的错误信息,避免在每个接口中重复处理错误状态。
小结
Map<String, Object>是 “轻量化” 选择,专注于数据本身,适合简单场景。ResponseEntity是 “全功能” 选择,提供对 HTTP 响应的完整控制,适合需要严格遵循 REST 规范或需要自定义响应细节的场景。- 根据业务需求选择合适的方式,复杂项目中推荐使用
ResponseEntity或自定义统一返回类(如Result<T>)来提升接口的规范性和可维护性。
Moudle 3 @ResponseBody何时要写
提问:该方法返回Json格式的数据,是否应该添加@Response注解?
@ApiOperation(value = "获取指定帖子所有评论的方法")
@GetMapping("/postsComments")
public ResponseEntity<?> getPostsComments(@RequestParam int postId,HttpServletRequest request) {
try {Posts post = postsService.selectById(postId);if (post == null) {throw new BusinessException(Code.PROJECT_DATA_NOT_FOUND, "帖子不存在");}List<Comments> comments = postsService.getCommentsByPostId(postId);int commentsCount = postsService.selectCommentCount(postId);if (comments == null || comments.isEmpty()) {throw new BusinessException(Code.PROJECT_DATA_NOT_FOUND, "该帖子暂无评论");}List<User> users = new ArrayList<>();for (Comments comment : comments) {User user = userService.getUserById(comment.getUserId());if (user == null) {throw new BusinessException(Code.PROJECT_DATA_NOT_FOUND, "用户信息缺失");}users.add(user);}User postAuthor = userService.getUserById(post.getUserId());for (Comments comments1 : comments) {System.out.println(comments1);System.out.println();}Integer userId = (Integer) request.getSession().getAttribute("userId");if (userId != null) {for (Comments comment : comments) {int isLiked = commentsService.isLikedByUser(userId, comment.getId()); // 关键:判断当前评论的点赞状态comment.setIsLiked(isLiked); //}}// 构建返回的 JSON 结构Map<String, Object> response = new HashMap<>();response.put("userId", userId);response.put("post", post);response.put("comments", comments);response.put("commentsCount", commentsCount);response.put("postAuthor", postAuthor);response.put("commentUsers", users);return ResponseEntity.ok(response);
} catch(BusinessException e){Map<String, Object> error = new HashMap<>();error.put("code", e.getErrorCode());error.put("message", e.getErrorMessage());return new ResponseEntity<>(error, HttpStatus.NOT_FOUND);
} catch(Exception e){e.printStackTrace();Map<String, Object> error = new HashMap<>();error.put("code", Code.SYSTEM_DB_ERROR);error.put("message", "获取评论失败");return new ResponseEntity<>(error, HttpStatus.INTERNAL_SERVER_ERROR);
}
}在 Spring MVC 中,是否需要添加 @ResponseBody 注解取决于返回类型。以下是详细分析:
1. @ResponseEntity 的本质
ResponseEntity 是 Spring MVC 提供的 HTTP 响应封装类,它直接代表了整个 HTTP 响应(包括状态码、Headers、Body)。
当方法返回 ResponseEntity<?> 时,Spring 会自动将其序列化为 HTTP 响应,无需额外注解。
原因:ResponseEntity 本身已经隐含了将对象转为 JSON/XML 等格式的逻辑(通过 HttpMessageConverter),相当于内置了 @ResponseBody 的功能。
2. 示例代码分析
你当前的代码返回类型是 ResponseEntity<?>,因此:
不需要添加 @ResponseBody 注解。
Spring 会自动处理 ResponseEntity 的序列化,包括其中的 Map、对象等数据。
3. 对比:返回普通对象(如 Map)时的情况
如果方法返回的是普通对象(如 Map<String, Object>),必须添加 @ResponseBody 注解,否则 Spring 会尝试解析为视图(如 JSP),导致报错。
例如:
@GetMapping("/postsComments")
@ResponseBody // 必须添加
public Map<String, Object> getPostsComments(...) {// 返回 Map
}4. 总结:何时需要 @ResponseBody?
| 返回类型 | 是否需要 | 说明 |
|
| 不需要 | 内置响应序列化逻辑,自动处理 Body、状态码等。 |
| 普通对象(如 、POJO) | 需要 | 需显式声明将对象转为响应 Body,否则视为视图解析。 |
5. 最佳实践建议
- 使用
ResponseEntity时:无需额外注解,代码更简洁,且能灵活控制 HTTP 状态码和 Headers(如示例中的HttpStatus.NOT_FOUND)。 - 返回普通对象时:必须添加
@ResponseBody,或直接使用@RestController(类上添加该注解时,方法默认启用@ResponseBody)。
相关文章:
复杂业务场景下 JSON 规范设计:Map<String,Object>快速开发 与 ResponseEntity精细化控制HTTP 的本质区别与应用场景解析
Moudle 1 Json使用示例 在企业开发中,构造 JSON 格式数据的方式需兼顾 可读性、兼容性、安全性和开发效率,以下是几种常用方式及适用场景: 一、直接使用 Map / 对象转换(简单场景) 通过 键值对集合(如 M…...
二叉数-965.单值二叉数-力扣(LeetCode)
一、题目解析 顾名思义,就是二叉树中所存储的值是相同,如果有不同则返回false 二、算法原理 对于二叉树的遍历,递归无疑是最便捷、最简单的方法,本题需要用到递归的思想。 采取前序遍历的方法,即根、左、右。 我们…...

redis集群和哨兵的区别
Redis Sentinel系统监控并确保主从数据库的正常运行,当主数据库故障时自动进行故障迁移。哨兵模式提供高可用性,客户端通过Sentinel获取主服务器地址,简化管理。Redis集群实现数据分布式存储,通过槽分区提高并发量,解决…...

[蓝桥杯]对局匹配
对局匹配 题目描述 小明喜欢在一个围棋网站上找别人在线对弈。这个网站上所有注册用户都有一个积分,代表他的围棋水平。 小明发现网站的自动对局系统在匹配对手时,只会将积分差恰好是 K 的两名用户匹配在一起。如果两人分差小于或大于 KK,…...

BBU 电源市场报告:深入剖析与未来展望
在当今数字化时代,数据中心的稳定运行至关重要。BBU 电源作为保障数据中心设备在停电或电压下降期间临时电力供应的关键系统,其市场发展备受关注。本文将从市场规模、竞争格局、产品类型、应用领域等多个维度对 BBU 电源市场进行深入分析,并为…...

Redis 持久化机制详解:RDB 与 AOF 的原理、优缺点与最佳实践
目录 前言1. Redis 持久化机制概述2. RDB 持久化机制详解2.1 RDB 的工作原理2.2 RDB 的优点2.3 RDB 的缺点 3. AOF 持久化机制详解3.1 AOF 的工作原理3.2 AOF 的优点3.3 AOF 的缺点 4. RDB 与 AOF 的对比分析5. 持久化机制的组合使用与最佳实践6. 结语 前言 Redis 作为一款高性…...

Hadoop企业级高可用与自愈机制源码深度剖析
Hadoop企业级高可用与自愈机制源码深度剖析 前言 在大数据平台生产环境中,高可用(HA)与自动化自愈能力直接决定了数据安全与服务稳定性。本文结合源码与实战,深入剖析Hadoop生态中YARN高可用、HDFS自动扩容、故障自愈三大核心机…...
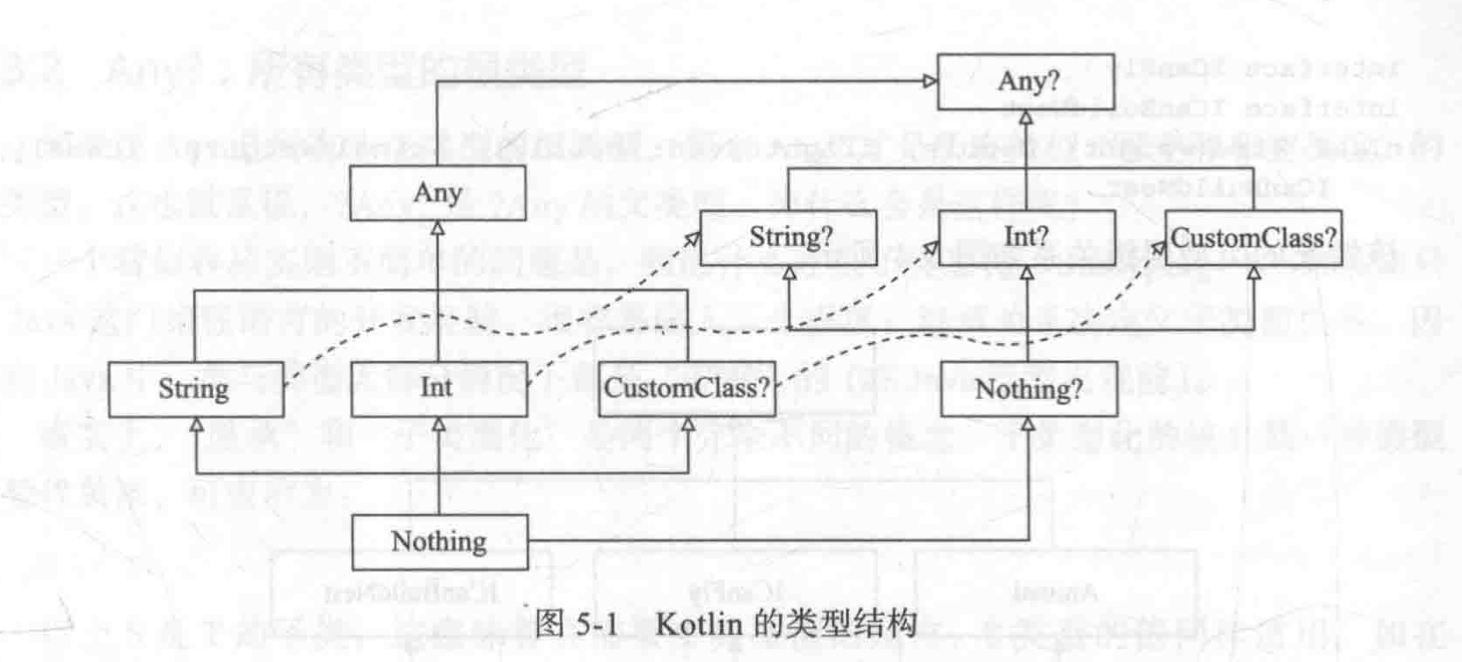
【Kotlin】简介变量类接口
【Kotlin】简介&变量&类&接口 【Kotlin】数字&字符串&数组&集合 【Kotlin】高阶函数&Lambda&内联函数 【Kotlin】表达式&关键字 文章目录 Kotlin_简介&变量&类&接口Kotlin的特性Kotlin优势创建Kotlin项目变量变量保存了指向对…...
Mybatis入门到精通
一:什么是Mybatis 二:Mybatis就是简化jdbc代码的 三:Mybatis的操作步骤 1:在数据库中创建一个表,并添加数据 我们这里就省略了 2:Mybatis通过maven来导入坐标(jar包) 3:…...
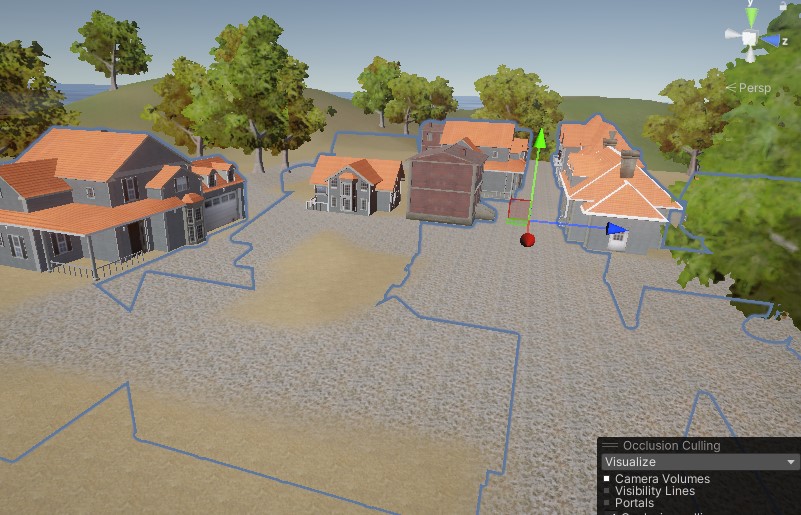
Unity性能优化笔记
降低Draw Call 降低draw call(unity里叫batches)的方法有: 模型减少材质; 多模型共用材质; 烘焙灯光; 关闭阴影和雾; 遮挡剔除; 使用LOD; 模型减少材质 > 见…...

BERT vs Rasa 如何选择 Hugging Face 与 Rasa 的区别 模型和智能体的区别
我在之前的一篇文章中提到我的短期目标的问题,即想通过Hugging Face的BERT或Rasa搭建一个简单的意图识别模型,针对发票业务场景来展示其效果 [如:开发票、查询发票]。 开篇,有必要记录几个英文缩写或术语 (如果喜欢&a…...
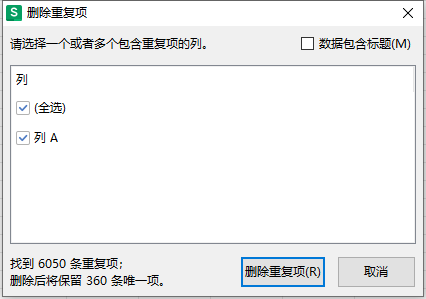
Excel 重复项标记,删除重复项时出现未响应的情况
目录 一、重复值标记: 二、删除重复值: 三、未响应问题 一、重复值标记: 方法1:开始 》条件格式 》突出显示单元格规则 》重复值 》设置颜色 》确定 PS:样式可自定义(边框、字体、背景填充...࿰…...

CppCon 2015 学习:Beyond Sanitizers
Sanitizers,一类基于编译时插桩(instrumentation)的动态测试工具,用来检测程序运行时的各种错误。 Sanitizers 简介 基于编译时插桩:编译器在编译代码时自动插入检测代码。动态运行时检测:程序运行时实时…...

Mysql选择合适的字段创建索引
1. 考虑字段的选择性 选择性:字段的选择性是指字段中不重复值的比例。选择性越高(即不重复值越多),索引的效率越高。 示例: 如果一个字段有100万行数据,但只有2个不重复值(如性别字段ÿ…...

Python:操作 Excel 格式化
🔧Python 操作 Excel 格式化完整指南(openpyxl 与 xlsxwriter 双方案) 在数据处理和报表自动化中,Python 是一把利器,尤其是配合 Excel 文件的读写与格式化处理。本篇将详细介绍两大主流库: openpyxl:适合读取与修改现有 Excel 文件xlsxwriter:适合创建新文件并进行复…...

ant-design-vue select 下拉框不好用解决
将optionFilterProp设置为label和a-select-option的:label"item.name"自定义属性 <a-selectshowSearchallowClearoptionFilterProp"label"placeholder"请选择选项"style"width: 120px; margin-right: 16px"><a-select-optio…...

[Java 基础]创建人类这个类小练习
请根据如下的描述完成一个小练习: 定义一个名为 Human 的 Java 类在该类中定义至少三个描述人类特征的实例变量(例如:姓名、年龄、身高)为 Human 类定义一个构造方法,该构造方法能够接收所有实例变量作为参数…...

Day43 Python打卡训练营
作业: kaggle找到一个图像数据集,用cnn网络进行训练并且用grad-cam做可视化 进阶:并拆分成多个文件 选取Kaggle上的CIFAR-10数据集进行CNN训练,并使用Grad-CAM进行可视化,代码将拆分为多个文件以保持模块化。CIFAR-10是…...

雷卯针对易百纳 SS524多媒体处理演示评估板防雷防静电方案
一、 应用场景 1. 远程视频会议 2. 安防监控 3. 人/车检测 4. 人脸检测、比对 5. 屏幕拼接墙 二、 功能概述 1 四核 ARM Cortex-A7 1.2GHz 2 AI算力 1.0Tops 3 4K30fps 4*1080P30编解码 三、 扩展接口 l RAM:板载 2*DDR4,共 2GB; …...

【BUG解决】关于BigDecimal与0的比较问题
这是一个很细小的知识点,但是很容易被忽略掉,导致系统问题,因此记录下来 问题背景 明明逻辑上看a和b都不为0才会调用除法,但是系统会报错:java.lang.ArithmeticException异常: if (!a.equals(BigDecimal…...

Spring Bean 为何“难产”?攻克构造器注入的依赖与歧义
本文已收录在Github,关注我,紧跟本系列专栏文章,咱们下篇再续! 🚀 魔都架构师 | 全网30W技术追随者🔧 大厂分布式系统/数据中台实战专家🏆 主导交易系统百万级流量调优 & 车联网平台架构&a…...
)
LeetCodeHot100(图论篇)
目录 图论岛屿数量题目代码 腐烂的橘子题目代码 课程表题目代码 实现 Trie (前缀树)题目代码 后续内容持续更新~~~ 图论 岛屿数量 题目 给你一个由 ‘1’(陆地)和 ‘0’(水)组成的的二维网格,请你计算网格中岛屿的数…...

【Lecture01】动手开发科研智能体(WIN11系统)
1. 配置win11系统中的环境,安装管理器Choco: # Download and install Chocolatey: powershell -c "irm https://community.chocolatey.org/install.ps1|iex" # Download and install Node.js: choco install nodejs-lts --version"22&qu…...
“packageManager“: “pnpm@9.6.0“ 配置如何正确启动项目?
今天在学习开源项目的时候,在安装依赖时遇到了一个报错 yarn add pnpm9.6.0 error This projects package.json defines "packageManager": "yarnpnpm9.6.0". However the current global version of Yarn is 1.22.22.Presence of the "…...

Git Github Gitee GitLab
Git的工作流程 工作区(Workspace):电脑本地目录,即平时存放项目代码的地方 暂存区(Index/Stage):临时存放改动信息的地方 本地仓库(Repository):存放所有提交的版本数据 远程仓库(Remote):托管代码的服务器&#x…...

华为设备OSPF配置与实战指南
一、基础配置架构 sysname HUAWEI-ABR ospf 100 router-id 1.1.1.1area 0.0.0.0network 10.1.1.0 0.0.0.255 # 将接口加入区域0 interface GigabitEthernet0/0/1ospf enable 100 area 0.0.0.0 # 华为支持点分十进制区域号bandwidth-reference 10000 # 设置10Gbps参考带宽…...
Paraformer分角色语音识别-中文-通用 FunASR
https://github.com/modelscope/FunASR/blob/main/README_zh.md https://github.com/modelscope/FunASR/blob/main/model_zoo/readme_zh.md PyTorch / 2.3.0 / 3.12(ubuntu22.04) / 12.1 Paraformer分角色语音识别-中文-通用 https://www.modelscope.cn/models/iic/speech_p…...

Spitfire:Codigger 生态中的高性能、安全、分布式浏览器
Spitfire 是 Codigger 生态系统中的一款现代化浏览器,专为追求高效、隐私和分布式技术的用户设计。它结合了 Codigger 的分布式架构优势,在速度、安全性和开发者支持方面提供了独特的解决方案,同时确保用户对数据的完全控制。 1. 高性能浏览…...

vimadbgit命令
vim 全部选中 全选(高亮显示):按esc后,然后ggvG或者ggVG 全部复制:按esc后,然后ggyG 全部删除:按esc后,然后dG -----------------------------------------------------------------…...
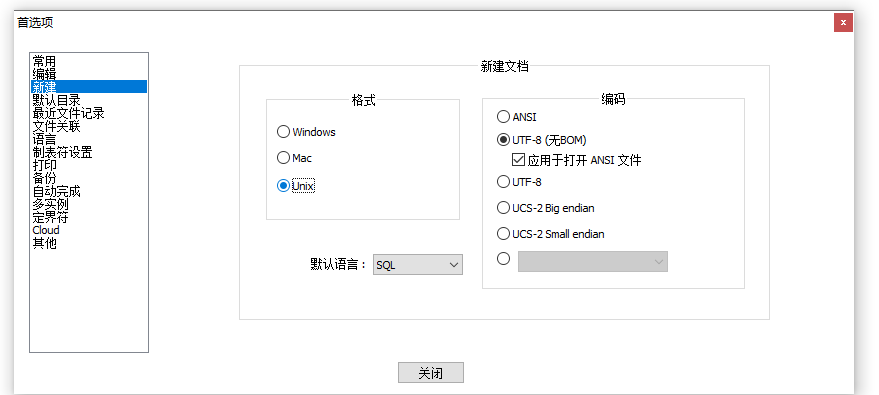
运行shell脚本时报错/bin/bash^M: 解释器错误: 没有那个文件或目录
Windows的换行符为\r\n,而linux换行符为\n。先查看一下文件是什么格式的 :set ff --查询一下格式是什么 由于使用nodepad新建的脚本,首选项中格式设置成了windows,上传到linux中报错。 解决方法 1、nodepad中【设置》首选项】修改为unix&am…...