Go语言爬虫系列教程4:使用正则表达式解析HTML内容
Go语言爬虫系列教程4:使用正则表达式解析HTML内容
正则表达式(Regular Expression,简称RegEx)是处理文本数据的利器。在网络爬虫中,我们经常需要从HTML页面中提取特定的信息,正则表达式就像一个智能的"文本筛子",能够精确地找到我们需要的内容。
想象你在一本厚厚的电话簿中找所有以"138"开头的手机号码。如果用人工查找会很累,但如果有一个魔法筛子,你告诉它"找所有138开头的11位数字",它就能快速找出所有符合条件的号码。正则表达式就是这样的"魔法筛子"。
一、简单演示
package mainimport ("fmt""regexp"
)// 演示基础正则表达式语法
func main() {// 1\. 字面量匹配(最简单的情况)text1 := "Hello World"pattern1 := "Hello"matched, _ := regexp.MatchString(pattern1, text1)fmt.Printf("文本: %s\n模式: %s\n匹配结果: %t\n\n", text1, pattern1, matched)输出结果:
文本: Hello World
模式: Hello
匹配结果: true这个代码演示的是最简单的字面量匹配
二、基础语法
正则表达式由两种基本元素组成:
- 字面量:直接匹配文本中的字符
- 元字符:具有特殊含义的字符,用于描述模式
2.1 字面量匹配 - 最简单的精确匹配
text1 := "Hello World"pattern1 := "Hello"matched, _ := regexp.MatchString(pattern1, text1)fmt.Printf("文本: %s\n模式: %s\n匹配结果: %t\n\n", text1, pattern1, matched)
运行结果:
文本: Hello World
模式: Hello
匹配结果: true
作用:直接匹配指定的字符串,不使用任何特殊符号
2.2 点号(.) - 万能字符匹配器
text2 := "cat bat hat"pattern2 := ".at" // 匹配任意字符+atre2 := regexp.MustCompile(pattern2)matches2 := re2.FindAllString(text2, -1)fmt.Printf("文本: %s\n模式: %s (点号匹配任意字符)\n匹配结果: %v\n\n", text2, pattern2, matches2)
运行结果:
文本: cat bat hat
模式: .at (点号匹配任意字符)
匹配结果: [cat bat hat]
作用:点号.是一个特殊字符,可以匹配除换行符外的任意单个字符
.at匹配"任意字符+at"的模式- 在文本中找到了:
cat(c+at)、bat(b+at)、hat(h+at) - 所有三个单词都符合模式
2.3 星号(*) - 贪婪的重复匹配
text3 := "goooooogle"pattern3 := "go*gle" // g + 0个或多个o + glematched3, _ := regexp.MatchString(pattern3, text3)fmt.Printf("文本: %s\n模式: %s (星号表示0次或多次)\n匹配结果: %t\n\n", text3, pattern3, matched3)
运行结果:
文本: goooooogle
模式: go*gle (星号表示0次或多次)
匹配结果: true
作用:星号*表示前面的字符可以出现0次或多次
go*gle意思是:g + (0个或多个o) + gle- "goooooogle"中有g + 5个o + gle,符合模式
- 这个模式也能匹配"ggle"(0个o)、“google”(2个o)等
2.4 加号(+) - 至少一次的重复匹配
text4 := "ggle google gooogle"pattern4 := "go+gle" // g + 1个或多个o + glere4 := regexp.MustCompile(pattern4)matches4 := re4.FindAllString(text4, -1)fmt.Printf("文本: %s\n模式: %s (加号表示1次或多次)\n匹配结果: %v\n\n", text4, pattern4, matches4)
运行结果:
文本: ggle google gooogle
模式: go+gle (加号表示1次或多次)
匹配结果: [google gooogle]
作用:加号+表示前面的字符必须出现1次或多次
go+gle意思是:g + (1个或多个o) + gle- "ggle"不匹配(没有o)
- "google"匹配(2个o)
- "gooogle"匹配(3个o)
2.5 问号(?) - 可选字符匹配
text5 := "color colour"pattern5 := "colou?r" // colou + 0个或1个rre5 := regexp.MustCompile(pattern5)matches5 := re5.FindAllString(text5, -1)fmt.Printf("文本: %s\n模式: %s (问号表示0次或1次)\n匹配结果: %v\n\n", text5, pattern5, matches5)
运行结果:
文本: color colour
模式: colou?r (问号表示0次或1次)
匹配结果: [color colour]
作用:问号?表示前面的字符可以出现0次或1次(可选)
colou?r意思是:colou + (0个或1个u) + r- "color"匹配(0个u)
- "colour"匹配(1个u)
2.6 方括号[] - 字符集合匹配
text1 := "cat bat rat mat"
pattern1 := "[cbr]at" // 匹配cat、bat或rat
运行结果:
文本: cat bat rat mat
模式: [cbr]at ([cbr]匹配c、b或r中的一个)
匹配结果: [cat bat rat]
作用:方括号[]定义一个字符集合,匹配其中任意一个字符
[cbr]at表示:(c或b或r) + at- 匹配到:
cat、bat、rat - 不匹配:
mat(因为m不在[cbr]中)
2.7 范围表示法 - 连续字符的简写
text2 := "a1 b2 c3 d4"
pattern2 := "[a-c][1-3]" // 匹配a-c中的一个字母 + 1-3中的一个数字
运行结果:
文本: a1 b2 c3 d4
模式: [a-c][1-3] ([a-c]匹配a到c,[1-3]匹配1到3)
匹配结果: [a1 b2 c3]
作用:用连字符-表示字符范围,避免逐个列举
[a-c]等同于[abc][1-3]等同于[123]- 匹配到:
a1、b2、c3 - 不匹配:
d4(d不在a-c范围,4不在1-3范围)
常用范围:
[a-z]:小写字母[A-Z]:大写字母[0-9]:数字[a-zA-Z0-9]:字母和数字
2.8 否定字符类[^] - 排除匹配
text3 := "cat bat rat mat"
pattern3 := "[^m]at" // 匹配不是m开头的at
运行结果:
文本: cat bat rat mat
模式: [^m]at ([^m]匹配除了m以外的字符)
匹配结果: [cat bat rat]
作用:^在方括号内表示否定,匹配除了指定字符外的任意字符
[^m]at表示:(除了m以外的任意字符) + at- 匹配到:
cat、bat、rat - 不匹配:
mat(因为开头是m)
2.9 预定义字符类 - 常用模式的简写
text4 := "abc 123 XYZ !@#"
patterns := map[string]string{`\d`: "匹配数字 [0-9]",`\w`: "匹配单词字符 [a-zA-Z0-9_]",`\s`: "匹配空白字符",`\D`: "匹配非数字字符",`\W`: "匹配非单词字符",`\S`: "匹配非空白字符",
}
2.10 精确量词{n} - 确切次数匹配
text1 := "1 12 123 1234"
pattern1 := `\d{3}` // 匹配恰好3个数字
运行结果:
文本: 1 12 123 1234
模式: \d{3} (恰好3个数字)
匹配结果: [123 123]
作用:{n}表示前面的字符或模式必须出现恰好n次
\d{3}匹配恰好3个连续数字- 在"1234"中找到"123"(前3位)
- 注意:会优先匹配较长的数字串中的前3位
2.11 范围量词{n,m} - 区间次数匹配
text2 := "1 12 123 1234 12345"
pattern2 := `\d{2,4}` // 匹配2到4个数字
运行结果:
文本: 1 12 123 1234 12345
模式: \d{2,4} (2到4个数字)
匹配结果: [12 123 1234 1234]
作用:{n,m}表示前面的字符出现n到m次(包含n和m)
- 匹配2-4个连续数字
- "1"不匹配(只有1个数字)
- “12345"中匹配前4个"1234”(贪婪匹配,取最大值)
2.12 最少量词{n,} - 至少n次匹配
text3 := "a aa aaa aaaa"
pattern3 := `a{3,}` // 匹配3个或更多的a
运行结果:
文本: a aa aaa aaaa
模式: a{3,} (3个或更多的a)
匹配结果: [aaa aaaa]
作用:{n,}表示前面的字符至少出现n次,没有上限
- "a"和"aa"不匹配(少于3个)
- "aaa"和"aaaa"匹配(3个或更多)
2.13 行边界^和$ - 位置匹配
text4 := "hello world\nworld hello\nhello"// 匹配行开始的hello
pattern4a := `^hello`
// 运行结果: [hello hello]// 匹配行结束的hello
pattern4b := `hello$`
// 运行结果: [hello hello]
作用:
^:匹配行的开始位置 ,^hello匹配每行开头的"hello"$:匹配行的结束位置 ,hello$匹配每行结尾的"hello"
2.14 单词边界\b - 完整单词匹配
text5 := "cat catch catch22"
pattern5 := `\bcat\b` // 完整的单词cat
运行结果:
文本: cat catch catch22
模式: \bcat\b (完整单词cat)
匹配结果: [cat]
作用:\b表示单词边界,确保匹配完整的单词
\bcat\b只匹配作为独立单词的"cat"- "catch"中的"cat"不匹配(后面还有字母ch)
- "catch22"中的"cat"也不匹配
三、regexp包常用方法介绍
3.1 regexp包的核心结构
package mainimport ("fmt""regexp""strings"
)// RegexpDemo 正则表达式演示结构体
type RegexpDemo struct {name stringpattern stringtext string
}// 演示regexp包的主要方法
func demonstrateRegexpPackage() {fmt.Println("=== regexp包方法演示 ===")// 1\. 编译正则表达式的两种方式fmt.Println("1\. 编译正则表达式:")// 方式1:Compile - 返回错误pattern := `\d+`re1, err := regexp.Compile(pattern)if err != nil {fmt.Printf("编译错误: %v\n", err)return}fmt.Printf("Compile成功: %v\n", re1)// 方式2:MustCompile - 编译失败会panic(适合确定正确的模式)re2 := regexp.MustCompile(pattern)fmt.Printf("MustCompile成功: %v\n\n", re2)// 2\. 基本匹配方法text := "我的电话是138-1234-5678,朋友的是139-8765-4321"phonePattern := `1[3-9]\d-\d{4}-\d{4}`phoneRe := regexp.MustCompile(phonePattern)// 2.1 MatchString - 检查是否匹配fmt.Println("2\. 基本匹配方法:")matched := phoneRe.MatchString(text)fmt.Printf("MatchString: %t\n", matched)// 2.2 FindString - 找到第一个匹配firstMatch := phoneRe.FindString(text)fmt.Printf("FindString: %s\n", firstMatch)// 2.3 FindAllString - 找到所有匹配allMatches := phoneRe.FindAllString(text, -1) // -1表示找到所有fmt.Printf("FindAllString: %v\n", allMatches)// 2.4 FindStringIndex - 找到第一个匹配的位置firstIndex := phoneRe.FindStringIndex(text)fmt.Printf("FindStringIndex: %v\n", firstIndex)if firstIndex != nil {fmt.Printf("第一个匹配的内容: %s\n", text[firstIndex[0]:firstIndex[1]])}// 2.5 FindAllStringIndex - 找到所有匹配的位置allIndexes := phoneRe.FindAllStringIndex(text, -1)fmt.Printf("FindAllStringIndex: %v\n\n", allIndexes)
}3.2 分组和捕获
// 演示分组和捕获
func demonstrateGroupsAndCapture() {fmt.Println("=== 分组和捕获演示 ===")// 1\. 基本分组()text := "张三的邮箱是zhangsan@example.com,李四的邮箱是lisi@gmail.com"// 使用分组捕获邮箱的用户名和域名emailPattern := `(\w+)@(\w+\.\w+)`emailRe := regexp.MustCompile(emailPattern)// FindStringSubmatch - 返回第一个匹配及其分组firstSubmatch := emailRe.FindStringSubmatch(text)fmt.Printf("邮箱分组匹配:\n")if len(firstSubmatch) > 0 {fmt.Printf("完整匹配: %s\n", firstSubmatch[0])fmt.Printf("用户名: %s\n", firstSubmatch[1])fmt.Printf("域名: %s\n", firstSubmatch[2])}fmt.Println()// FindAllStringSubmatch - 返回所有匹配及其分组allSubmatches := emailRe.FindAllStringSubmatch(text, -1)fmt.Printf("所有邮箱分组匹配:\n")for i, submatch := range allSubmatches {fmt.Printf("第%d个邮箱:\n", i+1)fmt.Printf(" 完整匹配: %s\n", submatch[0])fmt.Printf(" 用户名: %s\n", submatch[1])fmt.Printf(" 域名: %s\n", submatch[2])}fmt.Println()// 2\. 命名分组(?P<name>pattern)urlText := "访问我们的网站:https://www.example.com:8080/path?query=value"urlPattern := `(?P<protocol>https?)://(?P<domain>[\w.]+):?(?P<port>\d*)/(?P<path>[\w/]*)\??(?P<query>.*)`urlRe := regexp.MustCompile(urlPattern)matches := urlRe.FindStringSubmatch(urlText)names := urlRe.SubexpNames()fmt.Printf("URL命名分组匹配:\n")for i, name := range names {if i != 0 && name != "" && i < len(matches) {fmt.Printf("%s: %s\n", name, matches[i])}}fmt.Println()// 3\. 非捕获分组(?:pattern) - 分组但不捕获text3 := "电话: 010-12345678 或 021-87654321"// 使用非捕获分组匹配区号格式,但只捕获完整号码phonePattern2 := `(?:010|021)-(\d{8})`phoneRe2 := regexp.MustCompile(phonePattern2)allPhoneMatches := phoneRe2.FindAllStringSubmatch(text3, -1)fmt.Printf("非捕获分组示例:\n")for i, match := range allPhoneMatches {fmt.Printf("第%d个匹配:\n", i+1)fmt.Printf(" 完整匹配: %s\n", match[0])fmt.Printf(" 后8位号码: %s\n", match[1])}
}3.3 替换操作
// 演示替换操作
func demonstrateReplacement() {fmt.Println("=== 替换操作演示 ===")// 1\. ReplaceAllString - 简单替换text1 := "今天是2023年12月25日,明天是2023年12月26日"datePattern := `\d{4}年\d{1,2}月\d{1,2}日`dateRe := regexp.MustCompile(datePattern)replaced1 := dateRe.ReplaceAllString(text1, "[日期]")fmt.Printf("原文: %s\n", text1)fmt.Printf("替换后: %s\n\n", replaced1)// 2\. ReplaceAllStringFunc - 使用函数替换text2 := "苹果5元,香蕉3元,橙子8元"pricePattern := `(\w+)(\d+)元`priceRe := regexp.MustCompile(pricePattern)replaced2 := priceRe.ReplaceAllStringFunc(text2, func(match string) string {// 可以在这里做复杂的处理return "[商品价格]"})fmt.Printf("原文: %s\n", text2)fmt.Printf("函数替换后: %s\n\n", replaced2)// 3\. 使用分组进行替换text3 := "联系人:张三,电话:138-1234-5678"contactPattern := `联系人:(\w+),电话:([\d-]+)`contactRe := regexp.MustCompile(contactPattern)// $1, $2引用捕获的分组replaced3 := contactRe.ReplaceAllString(text3, "姓名: $1, 手机: $2")fmt.Printf("原文: %s\n", text3)fmt.Printf("分组替换后: %s\n\n", replaced3)// 4\. 复杂的分组替换 - 格式化电话号码text4 := "电话号码:13812345678, 15987654321, 18611112222"phonePattern3 := `(\d{3})(\d{4})(\d{4})`phoneRe3 := regexp.MustCompile(phonePattern3)formatted := phoneRe3.ReplaceAllString(text4, "$1-$2-$3")fmt.Printf("原文: %s\n", text4)fmt.Printf("格式化后: %s\n", formatted)
}3.4 常用方法表
| 方法名 | 功能描述 | 性能建议 |
|---|---|---|
MatchString | 直接判断是否匹配,内部自动编译正则表达式 | 适用于单次匹配,频繁调用需预编译 |
Compile / MustCompile | 预编译正则表达式,返回可重复使用的*Regexp对象 | 必须用于高频匹配场景 |
FindString / FindAllString | 查找匹配的子串,不捕获分组内容 | 简单查找场景 |
FindStringSubmatch / FindAllStringSubmatch | 查找匹配的子串并捕获分组内容 | 需要提取分组时使用 |
ReplaceAllString / ReplaceAllStringFunc | 替换匹配的子串,支持静态替换或函数式动态替换 | 替换场景通用方法 |
Split | 按正则表达式分割字符串 | 替代strings.Split处理复杂分隔符 |
标志位(?i)(?s)(?m) | 修改正则表达式匹配规则(不区分大小写、点号匹配换行、多行模式) | 复杂文本匹配时使用 |
四、常见的正则表达式
以下是一些常见的正则表达式示例,用于匹配不同类型的文本。
注意:这些示例是基于常见的文本格式,可能需要根据实际需求进行调整。
1. 匹配邮箱
^[a-zA-Z0-9._%+\-]+@[a-zA-Z0-9.\-]+\.[a-zA-Z]{2,}$
2. 匹配手机号(以中国大陆为例)
^1[3-9][0-9]{9}$
3. 匹配身份证号(中国18位)
^\d{6}(18|19|20)?\d{2}(0[1-9]|1[0-2])(0[1-9]|[12][0-9]|3[01])\d{3}(\d|X|x)$
4. 匹配URL
^https?://[^\s/$.?#].[^\s]*$
5. 匹配IP地址(IPv4)
^(?:[0-9]{1,3}\.){3}[0-9]{1,3}$
⚠️注意:上面的正则没有严格验证0-255,可用下面更严格的版本:
^(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$
6. 匹配数字字符串
^\d+$
7. 匹配仅包含字母(不区分大小写)
^[a-zA-Z]+$
8. 匹配密码复杂性(8-20位,包含字母和数字)
^(?=.*[A-Za-z])(?=.*\d)[A-Za-z\d]{8,20}$
9. 匹配日期(YYYY-MM-DD)
^\d{4}-(0[1-9]|1[0-2])-(0[1-9]|[12]\d|3[01])$
10. 匹配正整数
^[1-9]\d*$
11. 匹配负整数
^-[1-9]\d*$
12. 匹配浮点数(正负均可)
^-?\d+(\.\d+)?$
13. 匹配由字母、数字和下划线组成的字符串
^\w+$
14. 匹配中文字符
[\p{Han}]+
需要 go 1.13+ 支持,更通用。
15. 匹配邮政编码(中国6位)
^\d{6}$
16. 匹配含有 HTML 标签的文本
<([a-zA-Z][a-zA-Z0-9]*)\b[^>]*>(.*?)</\1>
17. 匹配空白行
^\s*$
18. 匹配 MAC 地址
^([0-9A-Fa-f]{2}[:-]){5}([0-9A-Fa-f]{2})$
19. 匹配单行注释
^//.*$
20. 匹配多行注释
(?s)/\*.*?\*/
4厄3
五、实战演示
package mainimport ("fmt""regexp""strings"
)// Link 链接结构体
type Link struct {URL stringText string
}// String 返回链接的字符串表示
func (l Link) String() string {return fmt.Sprintf("URL: %s, 文本: %s", l.URL, l.Text)
}// HTMLDataExtractor HTML数据提取器
type HTMLDataExtractor struct {patterns map[string]*regexp.Regexp
}// NewHTMLDataExtractor 创建HTML数据提取器,带错误处理
func NewHTMLDataExtractor() (*HTMLDataExtractor, error) {extractor := &HTMLDataExtractor{patterns: make(map[string]*regexp.Regexp),}// 编译正则表达式并处理错误if err := extractor.compilePatterns(); err != nil {return nil, fmt.Errorf("编译正则表达式失败: %w", err)}return extractor, nil
}// compilePatterns 编译常用的正则表达式模式,带错误处理
func (e *HTMLDataExtractor) compilePatterns() error {patterns := map[string]string{"title": `<title[^>]*>([^<]+)</title>`,// 优化meta标签匹配,支持更灵活的属性顺序和引号"meta_desc": `(?i)<meta\s+(?:[^>]*\s+)?name\s*=\s*["']description["'][^>]*\s+content\s*=\s*["']([^"']*)["']`,// 优化链接匹配,支持单引号/双引号和更多属性格式"links": `<a[^>]*href\s*=\s*(?:["'])([^"']+)["'][^>]*>([^<]*)</a>`,"images": `<img[^>]*src\s*=\s*(?:["'])([^"']+)["'][^>]*>`,"emails": `[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}`,"phones": `1[3-9]\d{9}`,"prices": `¥\s*(\d+(?:\.\d{2})?)`,// 修复:使用十六进制范围表示中文汉字"chinese_text": `[\x{4e00}-\x{9fa5}]+`,}for name, pattern := range patterns {re, err := regexp.Compile(pattern)if err != nil {return fmt.Errorf("编译模式 %s 失败: %w", name, err)}e.patterns[name] = re}return nil
}// ExtractTitle 提取标题
func (e *HTMLDataExtractor) ExtractTitle(html string) string {matches := e.patterns["title"].FindStringSubmatch(html)if len(matches) > 1 {return strings.TrimSpace(matches[1])}return ""
}// ExtractMetaDescription 提取meta描述
func (e *HTMLDataExtractor) ExtractMetaDescription(html string) string {matches := e.patterns["meta_desc"].FindStringSubmatch(html)if len(matches) > 1 {return strings.TrimSpace(matches[1])}return ""
}// ExtractLinks 提取所有链接
func (e *HTMLDataExtractor) ExtractLinks(html string) []Link {matches := e.patterns["links"].FindAllStringSubmatch(html, -1)var links []Linkfor _, match := range matches {if len(match) > 2 {links = append(links, Link{URL: strings.TrimSpace(match[1]),Text: strings.TrimSpace(match[2]),})}}return links
}// ExtractImages 提取所有图片URL
func (e *HTMLDataExtractor) ExtractImages(html string) []string {matches := e.patterns["images"].FindAllStringSubmatch(html, -1)var images []stringfor _, match := range matches {if len(match) > 1 {images = append(images, strings.TrimSpace(match[1]))}}return images
}// ExtractEmails 提取所有邮箱地址
func (e *HTMLDataExtractor) ExtractEmails(html string) []string {return e.patterns["emails"].FindAllString(html, -1)
}// ExtractPhones 提取所有手机号码
func (e *HTMLDataExtractor) ExtractPhones(html string) []string {return e.patterns["phones"].FindAllString(html, -1)
}// ExtractPrices 提取所有价格
func (e *HTMLDataExtractor) ExtractPrices(html string) []string {matches := e.patterns["prices"].FindAllStringSubmatch(html, -1)var prices []stringfor _, match := range matches {if len(match) > 1 {prices = append(prices, match[1])}}return prices
}// ExtractChineseText 提取中文文本
func (e *HTMLDataExtractor) ExtractChineseText(html string) []string {return e.patterns["chinese_text"].FindAllString(html, -1)
}// 使用示例
func main() {fmt.Println("=== HTML数据提取演示 ===\n")// 示例HTML内容sampleHTML := `<!DOCTYPE html><html><head><title>购物网站 - 最优质的商品</title><meta NAME="description" content='这是一个专业的购物网站,提供优质商品和服务'></head><body><h1>欢迎来到我们的商店</h1><p>联系我们:info@example.com 或者 support@shop.com</p><p>客服电话:13812345678,18611112222</p><div class="products"><h2>热门商品</h2><div class="product"><img src='/images/phone.jpg' alt='手机'><h3>智能手机</h3><p>价格:¥2999.00</p><a href='/product/phone' class='btn'>查看详情</a></div><div class="product"><img src=/images/laptop.jpg alt=笔记本><h3>笔记本电脑</h3><p>价格:¥5999.99</p><a href='/product/laptop'>立即购买</a></div></div><footer><p>更多信息请访问 <a href='https://www.example.com'>我们的官网</a></p></footer></body></html>`// 创建提取器并处理错误extractor, err := NewHTMLDataExtractor()if err != nil {fmt.Printf("错误: %s\n", err)return}// 提取各种数据fmt.Println("📌 页面标题:")fmt.Printf(" %s\n\n", extractor.ExtractTitle(sampleHTML))fmt.Println("📝 页面描述:")fmt.Printf(" %s\n\n", extractor.ExtractMetaDescription(sampleHTML))fmt.Println("📧 邮箱地址:")emails := extractor.ExtractEmails(sampleHTML)for i, email := range emails {fmt.Printf(" %d. %s\n", i+1, email)}fmt.Println()fmt.Println("📞 手机号码:")phones := extractor.ExtractPhones(sampleHTML)for i, phone := range phones {fmt.Printf(" %d. %s\n", i+1, phone)}fmt.Println()fmt.Println("🔗 链接:")links := extractor.ExtractLinks(sampleHTML)for i, link := range links {fmt.Printf(" %d. %s\n", i+1, link)}fmt.Println()fmt.Println("🖼️ 图片:")images := extractor.ExtractImages(sampleHTML)for i, img := range images {fmt.Printf(" %d. %s\n", i+1, img)}fmt.Println()fmt.Println("💰 价格:")prices := extractor.ExtractPrices(sampleHTML)for i, price := range prices {fmt.Printf(" %d. ¥%s\n", i+1, price)}fmt.Println()fmt.Println("中文文本片段:")chineseTexts := extractor.ExtractChineseText(sampleHTML)for i, text := range chineseTexts {if len(text) > 2 { // 过滤短文本fmt.Printf(" %d. %s\n", i+1, text)}}
}
记住:正则表达式是一把双刃剑,用好了事半功倍,用错了可能带来性能问题。关键是要在合适的场景使用合适的工具!
相关文章:

Go语言爬虫系列教程4:使用正则表达式解析HTML内容
Go语言爬虫系列教程4:使用正则表达式解析HTML内容 正则表达式(Regular Expression,简称RegEx)是处理文本数据的利器。在网络爬虫中,我们经常需要从HTML页面中提取特定的信息,正则表达式就像一个智能的&quo…...
6.4 C++作业
刷题...

rabbitmq Topic交换机简介
1. Topic交换机 说明 尽管使用 direct 交换机改进了我们的系统,但是它仍然存在局限性——比方说我们的交换机绑定了多个不同的routingKey,在direct模式中虽然能做到有选择性地接收日志,但是它的选择性是单一的,就是说我的一条消息…...

网络交换机:构建高效、安全、灵活局域网的基石
在数字化时代,网络交换机作为局域网(LAN)的核心设备,承担着数据转发、通信优化和安全防护的关键任务。其通过独特的MAC地址学习、冲突域隔离、VLAN划分等技术,显著提升了网络性能,成为企业、学校、医院等场景不可或缺的基础设施。…...

【ArcGIS微课1000例】0148:Geographic Imager6.2使用教程
文章目录 一、Geographic Imager6.2下载安装二、Geographic Imager6.2使用方法1. 打开Geographic Imager2. 导入地理影像3. 导入DEM地形渲染4. 设置地理坐标系统5. 进行地理影像的处理6. 导出地理影像一、Geographic Imager6.2下载安装 在专栏上一篇文章中已经详细讲述了Geogr…...

【Oracle】存储过程
个人主页:Guiat 归属专栏:Oracle 文章目录 1. 存储过程基础概述1.1 存储过程的概念与特点1.2 存储过程的组成结构1.3 存储过程的优势 2. 基础存储过程2.1 简单存储过程2.1.1 创建第一个存储过程2.1.2 带变量的存储过程 2.2 带参数的存储过程2.2.1 输入参…...

CppCon 2015 学习A Few Good Types
代码重构前后,用现代C更安全、更简洁的方式来处理数组和长度问题,并且利用静态分析(SA,Static Analysis)工具来捕获潜在错误。 代码重构前(Before) void f(_In_reads_(num) Thing* things, un…...

winrm登录失败,指定的凭据被服务器拒绝
winrm登录失败,指定的凭据被服务器拒绝。 异常提示:the specified credentials were rejected by the server 在windows power shell执行 set-executionpolicy remotesigned winrm quickconfig winrm set winrm/config/service/auth {Basic"true…...
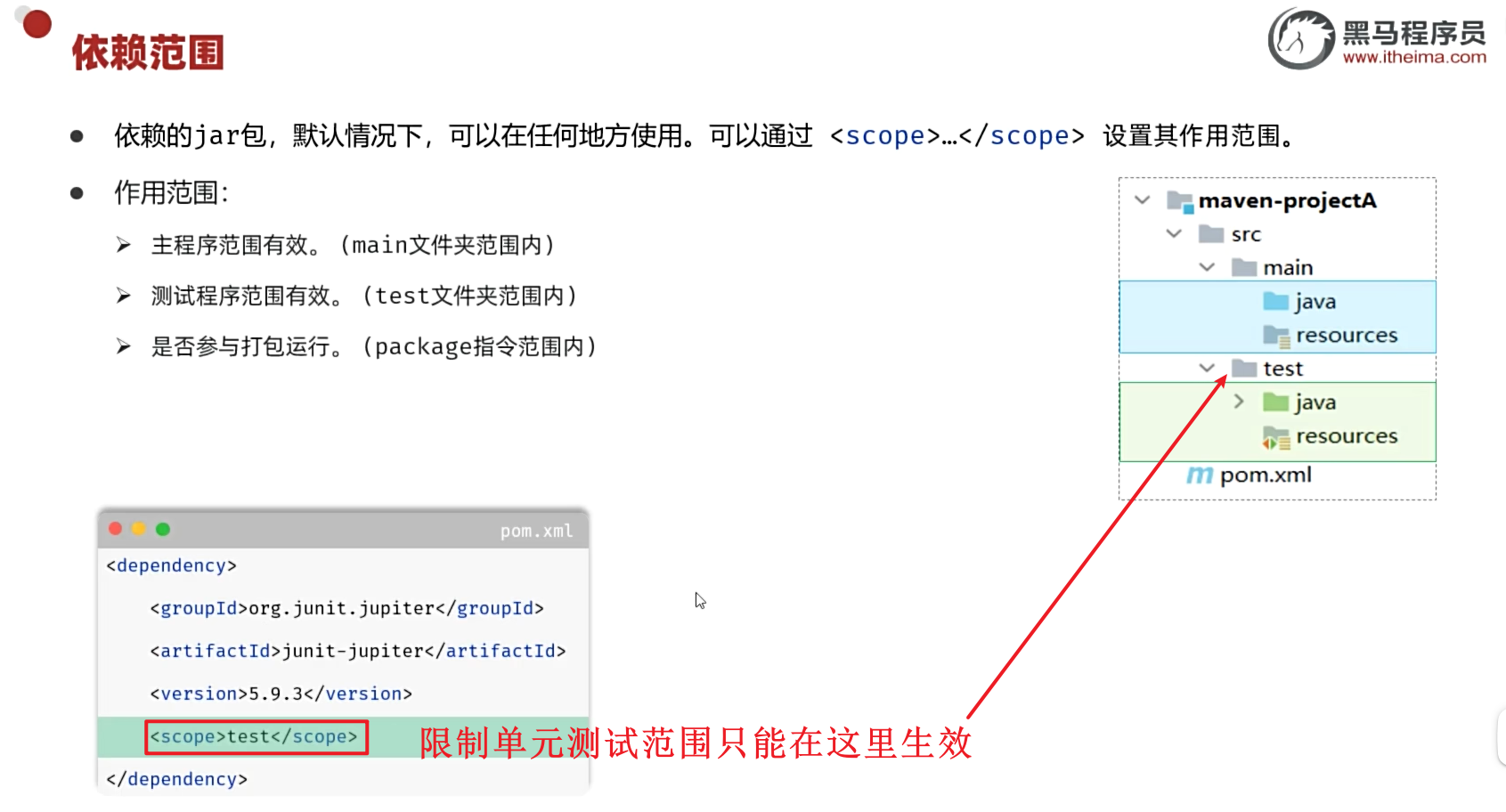
单元测试-断言常见注解
目录 1.断言 2.常见注解 3.依赖范围 1.断言 断言练习 package com.gdcp;import org.junit.jupiter.api.Assertions; import org.junit.jupiter.api.Test;//测试类 public class UserServiceTest {Testpublic void testGetGender(){UserService userService new UserService…...

TDengine 在电力行业如何使用 AI ?
在你面前摆着一堆机器运行日志、传感器读数、电表数据,几十万、几百万条每秒增长的数据流,你会怎么处理?是加人、加脚本,还是干脆放弃实时分析? 过去,时序数据是工业的“副产品”:只是存着、查…...

Java抽象工厂模式详解
Java 抽象工厂模式是一种创建型设计模式,它提供了一种方式,可以将一组具有共同主题的单个工厂封装起来,而不必指定它们具体的类。这种模式属于创建型模式,它隐藏了对象创建的逻辑,将客户端与具体类的实现解耦。 一、核…...

matlab实现高斯烟羽模型算法
高斯烟羽模型的matlab代码 Code.m , 441 Cross.m , 1329 fit.m , 2080 fitness.m , 2160 fitness1.m , 2191 gaosiyanyu.m , 1936 jixian.m , 169 main.m , 155 mGA.m , 10415 mGA_new.fig , 7218 mGA_new.m , 18196 mPSO.m , 6681 Mutation.m , 1234 point.m , 1976 Select.m…...

SpringBoot parent依赖高版本覆盖低版本问题
问题 在Spring Boot项目中,有时候我们会遇到这样的情况:当我们引入了多个依赖库,而这些库中有相同的依赖项但版本不同。这种情况下,高版本的依赖可能会覆盖低版本的依赖,导致项目运行时出现不期望的行为或错误。为了解…...
OpenCV C/C++ 视频播放器 (支持调速和进度控制)
OpenCV C/C 视频播放器 (支持调速和进度控制) 本文将引导你使用 C 和 OpenCV 库创建一个功能稍复杂的视频播放器。该播放器不仅能播放视频,还允许用户通过滑动条来调整播放速度(加速/减速)以及控制视频的播放进度。 使用opencv打开不会压缩画…...
【Linux庖丁解牛】—自定义shell的编写!
1. 打印命令行提示符 在我们使用系统提供的shell时,每次都会打印出一行字符串,这其实就是命令行提示符,那我们自定义的shell当然也需要这一行字符串。 这一行字符串包含用户名,主机名,当前工作路径,所以&a…...

C++抽象类与多态实战解析
这段 C 代码演示了 抽象类(Abstract Class) 和 多态(Polymorphism) 的使用,它定义了一个表示教师的抽象基类 Teacher,并派生出两个具体的子类:EnglishTeacher(英语老师)和…...

OpenAI API 流式传输
OpenAI API 流式传输教程 🌊 本教程将详细解释 OpenAI API 如何进行数据流式传输,从基本的文本块到复杂的工具调用指令。流式传输允许你逐步从模型接收数据,这对于构建响应灵敏的用户界面和处理长输出非常有用。 1. 基础知识:Ser…...

嵌入式分析利器:DuckDB与SqlSugar实战
一、DuckDB 的核心特性与适用场景 DuckDB 是一款 嵌入式分析型数据库(OLAP) ,专为高效查询设计,主要特点包括: 列式存储与向量化引擎 数据按列存储,提升聚合统计效率(如 SUM/AVG…...

嵌入式学习笔记 - freeRTOS任务设计要点
一 中断函数中不允许操作任务 因为中断函数使用的上下文环境是MSP环境,而非PSP环境,不允许挂起任务,不允许阻塞任务的任何操作。 可以使用FromISR函数进行操作。 二 中断的频率与处理时间 中断的处理时间要远低于任务的运行时间ÿ…...

Linux运维笔记:1010实验室电脑资源规范使用指南
文章目录 一. 检查资源使用情况,避免冲突1. 检查在线用户2. 检查 CPU 使用情况3. 检查 GPU 使用情况4. 协作建议 二. 备份重要文件和数据三. 定期清理硬盘空间四. 退出 ThinLinc 时注销,释放内存五. 校外使用时配置 VPN注意事项 总结 实验室的电脑配备了…...

12:点云处理—调平,角度,平面度,高度,体积
1.调平 2.夹角、平面度 3.高度、体积...

Marketo 集成 8x8 Connect 短信 API 指南
一、🔍 项目背景与目标 在营销自动化流程中,需要在用户完成特定行为(如填写表单、完成注册)后,自动发送一条短信进行提醒、欢迎或验证。 Marketo 原生不具备短信发送能力,但支持通过 Webhook 集成第三方 A…...

【Docker 从入门到实战全攻略(二):核心概念 + 命令详解 + 部署案例】
5. Docker Compose Docker Compose 是一个用于定义和运行多容器 Docker 应用的工具。通过一个 YAML 文件来配置应用服务,然后使用一个命令即可创建并启动所有服务。 基本命令 docker-compose up # 创建并启动所有服务 docker-compose down # 停止并移除容器、网络等…...
介绍,它与数据库中的表有什么区别?)
Elasticsearch索引(Index)介绍,它与数据库中的表有什么区别?
在Elasticsearch(ES)中,索引(Index)是存储和组织文档(Document)的逻辑容器,类似于关系型数据库(如MySQL)中的“数据库(Database)”或“表(Table)”,但设计理念和实现机制有显著差异。以下从定义、核心特性、与数据库表的对比三方面详细解析。 一、索引的定义与…...
?它由哪些组件组成?)
Elasticsearch中什么是分析器(Analyzer)?它由哪些组件组成?
在Elasticsearch(ES)中,分析器(Analyzer)是处理文本的核心组件,负责将原始文本转换为适合索引和搜索的词项(Term)。它直接影响搜索的准确性和性能,是构建高效搜索系统的关键。 一、分析器的核心作用 1. 分词(Tokenization):将文本拆分为独立的词(Token)。 例如…...

使用 SseEmitter 实现 Spring Boot 后端的流式传输和前端的数据接收
1.普通文本消息的发送和接收 GetMapping("/stream")public SseEmitter streamResponse() {SseEmitter emitter new SseEmitter(0L); // 0L 表示永不超时Executors.newSingleThreadExecutor().execute(() -> {try {for (int i 1; i < 5; i) {emitter.send(&q…...

.net Avalonia 在centos部署
.NET Avalonia 在 CentOS 部署指南 在跨平台应用开发中,.NET Avalonia 凭借其强大的功能和灵活性受到了广泛关注。而将基于 .NET Avalonia 开发的应用程序部署到 CentOS 系统上,是很多开发者会面临的任务。下面就为大家详细介绍在 CentOS 上部署 .NET A…...

MyBatis深度解析:XML/注解配置与动态SQL编写实战
引言 在现代Java企业级应用开发中,MyBatis作为一款优秀的持久层框架,因其灵活性和易用性广受开发者喜爱。相比Hibernate等全自动ORM框架,MyBatis提供了更接近SQL的开发体验,同时又不失面向对象的优雅。本文将深入探讨MyBatis的核…...
的熟悉程度和实践经验)
面试经验 对常用 LLM 工具链(如 LlamaFactory)的熟悉程度和实践经验
面试场景: 你正在面试一个大型语言模型(LLM)工程师或研究员的职位,面试官想了解你对常用 LLM 工具链(如 LlamaFactory)的熟悉程度和实践经验。 面试经验分享:LlamaFactory-CLI 工具实践 面试官…...
【conda配置深度学习环境】
好的!我们从头开始配置一个基于Conda的虚拟环境,覆盖深度学习(如PyTorch)和传统机器学习(如XGBoost),并适配你的显卡(假设为NVIDIA,若为AMD请告知)。以下是完…...