【Go-补充】ioReader + ioWriter + bufio
一、io.Reader 和 io.Writer 接口介绍
在 Go 语言中,io 包定义了两个最基础和最重要的接口:io.Reader 和 io.Writer。它们是 Go 语言中进行输入/输出操作的核心抽象,实现了极大的灵活性和可组合性。
io.Reader 接口
io.Reader 接口定义了一个 Read 方法:
type Reader interface {Read(p []byte) (n int, err error)
}
Read(p []byte) (n int, err error):- 该方法尝试将数据读取到字节切片
p中。 n是实际读取的字节数。err是读取过程中可能发生的错误。- 当数据流结束时,
Read通常返回n > 0且err == io.EOF,或者在后续调用中返回n == 0且err == io.EOF。 - 当
Read返回n < len(p)但没有错误时,表示部分读取,即数据源没有足够的数据填充p。 - 如果
Read返回n == 0且err == nil,表示目前没有数据可用,但这不是错误,调用者应再次尝试读取。
- 当数据流结束时,
- 该方法尝试将数据读取到字节切片
io.Reader 的作用:
- 统一读取行为:任何实现了
Read方法的类型都可以被视为一个数据源。这包括文件 (*os.File)、网络连接 (net.Conn)、内存中的字节切片 (bytes.Reader)、字符串 (strings.Reader),甚至加密解密流、压缩解压缩流等。 - 可组合性:由于所有这些类型都实现了相同的
Reader接口,它们可以无缝地相互连接和传递。例如,你可以用bufio.NewReader封装一个*os.File,也可以封装一个bytes.Reader。 - 流式处理:
Read方法的参数是一个字节切片,它鼓励分块读取和处理数据流,而不是一次性加载所有数据到内存,这对于处理大文件或无限数据流非常高效。
常见实现者:*os.File, *net.TCPConn, *bytes.Buffer, *bytes.Reader, *strings.Reader, *bufio.Reader 等。
io.Writer 接口
io.Writer 接口定义了一个 Write 方法:
type Writer interface {Write(p []byte) (n int, err error)
}
Write(p []byte) (n int, err error):- 该方法尝试将字节切片
p中的数据写入到输出目标。 n是实际写入的字节数。err是写入过程中可能发生的错误。- 如果
Write返回n < len(p)但err == nil,通常表示部分写入,即目标无法一次性接受所有数据。 - 如果
Write返回n > 0但err != nil,表示在写入部分数据后发生了错误。
- 如果
- 该方法尝试将字节切片
io.Writer 的作用:
- 统一写入行为:任何实现了
Write方法的类型都可以被视为一个数据目标。这包括文件 (*os.File)、网络连接 (net.Conn)、内存中的字节缓冲区 (bytes.Buffer)、os.Stdout等。 - 可组合性:同样,所有实现了
Writer接口的类型都可以互换使用。你可以将数据写入到*os.File,也可以通过bufio.NewWriter写入到*os.File。 - 流式处理:与
Reader类似,Writer也支持分块写入,适用于处理大数据。
常见实现者:*os.File, *net.TCPConn, *bytes.Buffer, os.Stdout, os.Stderr, *bufio.Writer 等。
io.Reader 和 io.Writer 是 Go 语言 I/O 设计的基石,它们通过简单的接口定义实现了强大的抽象和可组合性,使得 Go 语言的 I/O 操作既高效又灵活。bufio 包正是基于这两个接口之上构建的,通过引入缓冲区进一步优化了性能。
二、bufio
在 Go 语言中,bufio 包提供了缓冲 I/O 操作的功能。它封装了 io.Reader 或 io.Writer 对象,创建了另一个同样实现这些接口但提供了缓冲以及一些文本 I/O 辅助功能的 Reader 或 Writer 对象。
为什么需要缓冲 I/O?
直接对底层 I/O 对象(例如文件或网络连接)进行每次读写操作可能会非常低效。每次系统调用都会产生开销。通过使用缓冲,bufio 包可以在内存中积累数据,然后一次性进行更大块的读写操作,从而减少系统调用的次数,提高 I/O 性能。
bufio 包的主要类型和功能:
-
bufio.Reader:- 作用:为
io.Reader提供缓冲读取功能。 - 创建:
bufio.NewReader(rd io.Reader):创建一个带有默认缓冲区大小(通常为 4096 字节)的Reader。bufio.NewReaderSize(rd io.Reader, size int):创建一个指定缓冲区大小的Reader。
- 常用方法:
Read(p []byte) (n int, err error):从输入中读取最多len(p)字节到p中。ReadByte() (byte, error):读取并返回下一个字节。ReadRune() (r rune, size int, err error):读取并返回下一个 UTF-8 编码的 Unicode 字符(rune)。ReadLine() (line []byte, isPrefix bool, err error):读取一行数据,直到遇到换行符。如果一行太长,isPrefix会为true。ReadString(delim byte) (string, error):读取直到遇到指定的分隔符,并返回读取到的字符串(包含分隔符)。ReadBytes(delim byte) ([]byte, error):与ReadString类似,但返回字节切片。Peek(n int) ([]byte, error):查看接下来的n字节,但不会消耗它们(下一次读取仍然会读到这些字节)。Buffered() int:返回当前缓冲区中可读取的字节数。Size() int:返回底层缓冲区的大小。
- 作用:为
-
bufio.Writer:- 作用:为
io.Writer提供缓冲写入功能。 - 创建:
bufio.NewWriter(wr io.Writer):创建一个带有默认缓冲区大小的Writer。bufio.NewWriterSize(wr io.Writer, size int):创建一个指定缓冲区大小的Writer。
- 常用方法:
Write(p []byte) (n int, err error):将p中的数据写入缓冲区。WriteByte(c byte) error:写入一个字节到缓冲区。WriteRune(r rune) (size int, err error):写入一个 Unicode 字符到缓冲区。WriteString(s string) (n int, err error):写入一个字符串到缓冲区。Flush() error:将缓冲区中的所有数据写入到底层io.Writer。这是非常重要的方法,如果忘记调用,数据可能不会被写入!Available() int:返回缓冲区中可用的字节空间。Buffered() int:返回缓冲区中已填充的字节数。Size() int:返回底层缓冲区的大小。
- 作用:为
-
bufio.Scanner:- 作用:提供方便的逐行(或其他自定义分隔符)扫描输入的功能。它适用于处理文本文件,特别是当你不确定行长度时。
- 创建:
bufio.NewScanner(r io.Reader):创建一个新的Scanner。
- 常用方法:
Scan() bool:推进扫描器到下一个 token(默认是下一行),成功返回true,遇到文件末尾或错误返回false。Text() string:返回当前 token 的文本内容。Bytes() []byte:返回当前 token 的字节切片内容。Err() error:返回Scan过程中遇到的任何非 EOF 错误。Split(splitFunc SplitFunc):设置扫描器的分割函数。bufio包提供了几个预定义的分割函数:bufio.ScanLines:按行分割(默认)。bufio.ScanWords:按单词分割。bufio.ScanBytes:按字节分割。bufio.ScanRunes:按 UTF-8 字符分割。- 你也可以自定义
SplitFunc来实现更复杂的分割逻辑。
示例:
使用 bufio.Reader 读取文件:
package mainimport ("bufio""fmt""io""os"
)func main() {file, err := os.Open("example.txt")if err != nil {fmt.Println("Error opening file:", err)return}defer file.Close()reader := bufio.NewReader(file)// 逐行读取for {line, err := reader.ReadString('\n')if err != nil {if err == io.EOF {fmt.Print(line) // 打印最后一行(可能没有换行符)break}fmt.Println("Error reading file:", err)return}fmt.Print(line)}fmt.Println("\n--- 读取特定字节 ---")// 重新打开文件或Seek到开头进行第二次读取file.Seek(0, io.SeekStart)reader.Reset(file) // 重置Reader,使用新的底层io.Readerb, err := reader.ReadByte()if err != nil {fmt.Println("Error reading byte:", err)return}fmt.Printf("第一个字节: %c\n", b)// PeekpeekedBytes, err := reader.Peek(5)if err != nil {fmt.Println("Error peeking:", err)return}fmt.Printf("Peeked 5 bytes: %s\n", string(peekedBytes))// 再次读取一个字节,会是Peeked之后第一个字节b2, err := reader.ReadByte()if err != nil {fmt.Println("Error reading byte:", err)return}fmt.Printf("第二个字节: %c\n", b2) // 会是Peeked之后第一个字节
}
使用 bufio.Writer 写入文件:
package mainimport ("bufio""fmt""os"
)func main() {file, err := os.Create("output.txt")if err != nil {fmt.Println("Error creating file:", err)return}defer file.Close()writer := bufio.NewWriter(file)_, err = writer.WriteString("Hello, Go bufio!\n")if err != nil {fmt.Println("Error writing string:", err)return}_, err = writer.WriteString("This is another line.\n")if err != nil {fmt.Println("Error writing string:", err)return}fmt.Println("Buffer size:", writer.Size())fmt.Println("Buffered bytes:", writer.Buffered())fmt.Println("Available bytes in buffer:", writer.Available())// !!!非常重要:调用 Flush() 将缓冲区中的数据写入文件err = writer.Flush()if err != nil {fmt.Println("Error flushing writer:", err)return}fmt.Println("数据已写入 output.txt")
}
使用 bufio.Scanner 逐行读取文件:
package mainimport ("bufio""fmt""os""strings"
)func main() {content := `Line 1: Hello world
Line 2: Go programming
Line 3: bufio package`// 从字符串读取(也可以从文件读取)reader := strings.NewReader(content)scanner := bufio.NewScanner(reader)lineNum := 1for scanner.Scan() { // 每次调用 Scan() 都会读取下一行line := scanner.Text() // 获取当前行的文本fmt.Printf("Line %d: %s\n", lineNum, line)lineNum++}if err := scanner.Err(); err != nil {fmt.Println("Error scanning:", err)}fmt.Println("\n--- 单词扫描 ---")wordContent := "This is a sentence with several words."wordReader := strings.NewReader(wordContent)wordScanner := bufio.NewScanner(wordReader)wordScanner.Split(bufio.ScanWords) // 设置为按单词分割wordNum := 1for wordScanner.Scan() {word := wordScanner.Text()fmt.Printf("Word %d: %s\n", wordNum, word)wordNum++}if err := wordScanner.Err(); err != nil {fmt.Println("Error scanning words:", err)}
}
总结:
bufio 包是 Go 语言中进行高效 I/O 操作的重要组成部分。
- 使用
bufio.Reader可以提高读取效率,并提供方便的文本读取方法(如ReadString、ReadLine)。 - 使用
bufio.Writer可以提高写入效率,减少系统调用。切记在使用Writer后调用Flush()将缓冲区内容强制写入底层。 bufio.Scanner提供了一种非常方便且高效的方式来逐行、逐词或按自定义规则处理输入流,特别适合处理文本数据。
相关文章:

【Go-补充】ioReader + ioWriter + bufio
一、io.Reader 和 io.Writer 接口介绍 在 Go 语言中,io 包定义了两个最基础和最重要的接口:io.Reader 和 io.Writer。它们是 Go 语言中进行输入/输出操作的核心抽象,实现了极大的灵活性和可组合性。 io.Reader 接口 io.Reader 接口定义了一…...

leetcode 3403. 从盒子中找出字典序最大的字符串 I 中等
给你一个字符串 word 和一个整数 numFriends。 Alice 正在为她的 numFriends 位朋友组织一个游戏。游戏分为多个回合,在每一回合中: word 被分割成 numFriends 个 非空 字符串,且该分割方式与之前的任意回合所采用的都 不完全相同 。所有分…...
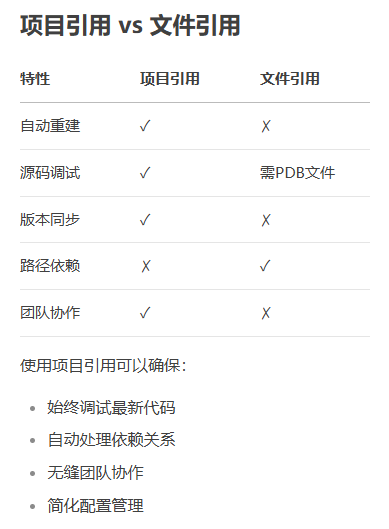
C# 一个解决方案放一个dll项目,一个dll测试项目 ,调试dll项目的源码
一个解决方案(sln)中放入2个项目(project,通常是一个文件夹),一个dll项目,一个dll测试项目 右键dll测试项目,设为启动项目。 在dll测试项目添加引用 1)右键测试项目 → 添加 → 引用 → 项目…...

【PmHub面试篇】PmHub 整合 TransmittableThreadLocal(TTL)缓存用户数据面试专题解析
你好,欢迎来到本次关于PmHub整合TransmittableThreadLocal (TTL)缓存用户数据的面试系列分享。在这篇文章中,我们将深入探讨这一技术领域的相关面试题预测。若想对相关内容有更透彻的理解,强烈推荐参考之前发布的博文:【PmHub后端…...

unity随机生成未知符号教程
目录 前言方法1方法2脚本后言示例代码 前言 在某些游戏中,有一些让人感到意味不明的未知符号,例如在游戏《巴别塔圣歌》中,就有这样一些能让人在初次就看不懂的未知符号。 或者在其他时候,这些未知符号如果跟粒子系统结合在一起的…...

基于RK3576+FPGA+AI工业控制器的工地防护检测装备解决方案
1.2.1 工地防护检测技术研究现状 在建筑施工的过程中,工人被要求暴露在危险的环境中作业 [2]。因此,防护装备 对于工人的安全与健康具有非常重要的意义[3]。工地工人必须佩戴适当的防护装备, 以降低意外伤害的风险。在过去的几十年里&#x…...

推荐一款PDF压缩的工具
今天一位小伙伴找来,问我有没有办法将PDF变小的办法。 详细了解了一下使用场景: 小伙伴要在某系统上传一个PDF文件,原文件是11.6MB,但是上传时系统做了限制,只能上传小于10MB的文件,如图: 我听…...
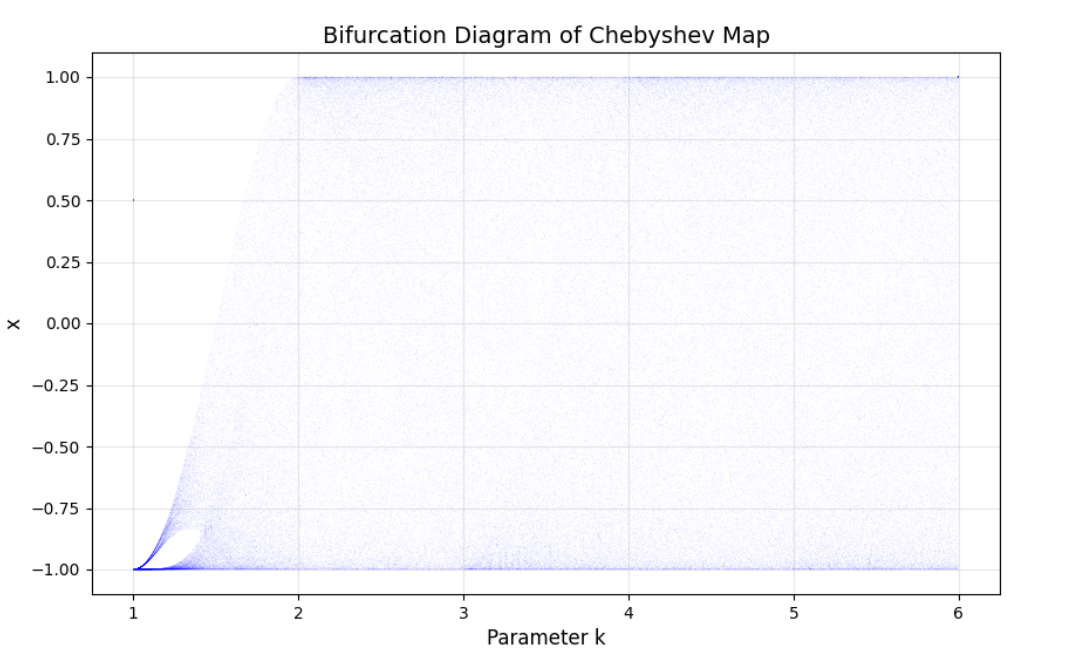
混沌映射(Chaotic Map)
一.定义 混沌映射是指一类具有混沌行为的离散时间非线性动力系统,通常由递推公式定义。其数学形式为 ,其中 f 是非线性函数,θ 为参数。它们以简单的数学规则生成复杂的、看似随机的轨迹,是非线性动力学和混沌理论的重要研究对象…...

MySQL对数据库用户的操作
注:‘%’:表示允许远程连接,‘localhost’ :限制本地登陆 – 根据用户名、权限查询用户 SELECT USER FROM mysql.user WHERE USER‘your_name’ AND HOST‘%’; – 彻底删除用户 DROP USER ‘appuser’‘%’; – 刷新使其生效 FL…...

《PyTorch Hub:解锁深度学习模型的百宝箱》
走进 PyTorch Hub 在当今的深度学习领域,模型的复用和共享已成为推动技术飞速发展的关键力量。随着深度学习在计算机视觉、自然语言处理、语音识别等众多领域取得突破性进展,研究人员和开发者们不断探索更高效、更强大的模型架构。然而,从头开始训练一个深度学习模型往往需要…...
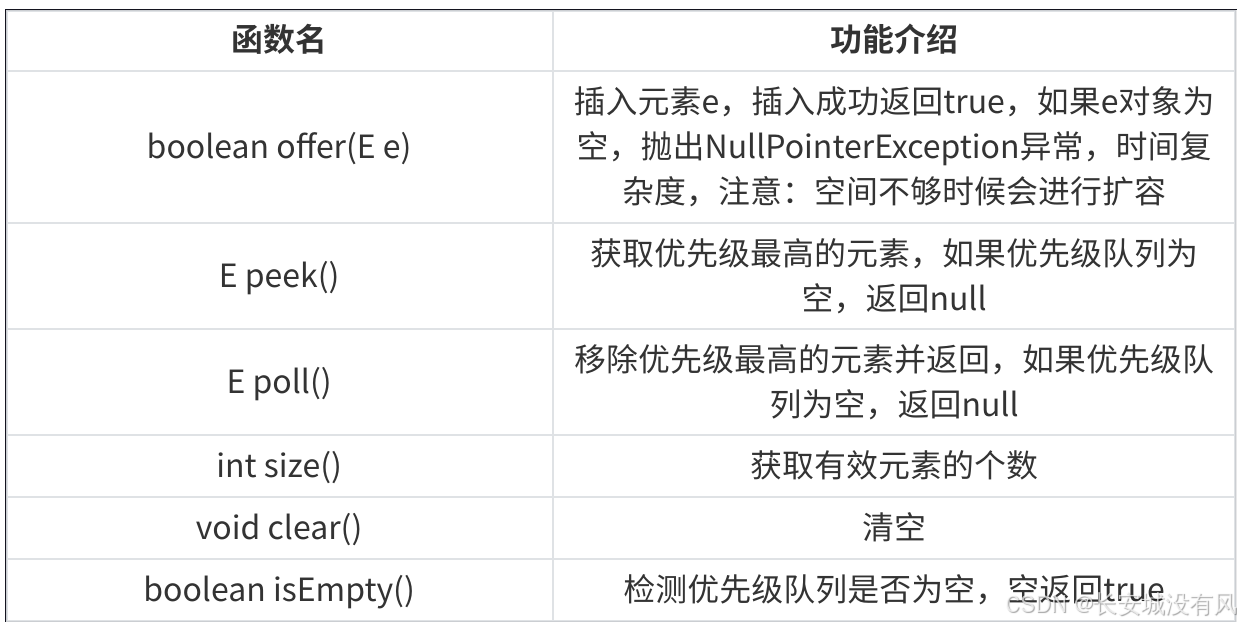
数据结构 堆与优先级队列
文章目录 📕1. 堆(Heap)✏️1.1 堆的概念✏️1.2 堆的存储方式✏️1.3 堆的创建✏️1.4 堆的插入✏️1.5 堆的删除 📕2. 优先级队列(PriorityQueue)✏️2.1 堆与优先级队列的关系✏️2.2 优先级队列的构造方法✏️2.3 优先级队列的常用方法 3. Java对象的…...

Leetcode 3569. Maximize Count of Distinct Primes After Split
Leetcode 3569. Maximize Count of Distinct Primes After Split 1. 解题思路2. 代码实现 题目链接:3569. Maximize Count of Distinct Primes After Split 1. 解题思路 这一题的话思路倒是还好,显然,要找出所有distinct的质数的切分&…...
用好 ImageFX,解锁游戏素材生成新姿势:从入门到进阶
用好 ImageFX,解锁游戏素材生成新姿势:从入门到进阶 (备注)大陆ip无法访问到imagefx 地址:https://labs.google/fx/zh/tools/image-fx 对于独立游戏开发者和小型团队而言,美术资源往往是项目推进中的一大痛点。预算有限、专业美术人员缺乏…...

unix/linux,sudo,其基本属性、语法、操作、api
现在我们要深入到sudo的“微观结构”了——它的属性、语法、操作以及是否有传统意义上的“API”。这就像我们从宏观的宇宙现象深入到基本粒子的相互作用一样,充满了探索的乐趣! 一、 sudo 的基本属性 (Fundamental Attributes) 这些属性是sudo作为一款软件和系统工具的核心…...

文本内容变化引起布局尺寸变化 导致的 UI 适配问题
在使用 Flutter 开发应用时,配合 easy_localization 实现多语言切换是一个非常常见的做法。但正如你所说,在不同语言下文字长度差异较大(如英文和中文、阿拉伯语等)会导致界面布局错位、UI 不美观的问题。 这个问题本质上是 文本…...
01-Redis介绍与安装
01-Redis介绍与安装 SQL与NoSQL SQLNoSQL数据结构结构化非结构化数据关联关联的非关联的查询方式SQL查询非SQL事务特性ACIDBASE存储方式磁盘内存拓展性垂直水平使用场景1、数据结构固定2、相关业务对数据安全性、一致性要求较高1、数据结构不固定2、对安全性、一致性要求不高…...

十六、【前端强化篇】完善 TestCase 编辑器:支持 API 结构化定义与断言配置
【前端强化篇】完善 TestCase 编辑器:支持 API 结构化定义与断言配置 前言准备工作第一步:更新前端 `TestCase` 类型定义第二步:改造 `TestCaseEditView.vue` 表单第三步:修改后端代码中的TestCase模型和序列化器第四步:测试强化后的用例编辑器总结前言 在之前的后端文章…...

Kafka broker 写消息的过程
Producer → Kafka Broker → Replication → Consumer|Partition chosen (by key or round-robin)|Message appended to end of log (commit log)上面的流程是kafka 写操作的大体流程。 kafka 不会特意保留message 在内存中,而是直接写入了disk。 那么消费的时候&…...
VR博物馆推动现代数字化科技博物馆
VR博物馆:推动现代数字化科博馆新篇章 随着科技的飞速发展,虚拟现实(Virtual Reality, VR)技术已经逐渐渗透到我们生活的方方面面,其中,VR博物馆作为现代数字化科博馆的重要形式之一,以独特的优…...

Python爬虫之数据提取
本章节主要会去学习在爬虫中的如何去解析数据的方法,要学习的内容有: 响应数据的分类结构化数据如何提取非结构化数据如何提取正则表达式的语法以及使用jsonpath解析嵌套层次比较复杂的json数据XPath语法在Python代码中借助lxml模块使用XPath语法提取非…...

第2讲、Odoo深度介绍:开源ERP的领先者
一、Odoo深度介绍:开源ERP的领先者 Odoo,其前身为OpenERP,是一款在全球范围内广受欢迎的开源企业管理软件套件。它不仅仅是一个ERP系统,更是一个集成了客户关系管理(CRM)、电子商务、网站构建、项目管理、…...
【TCP/IP和OSI模型以及区别——理论汇总】
参考小林code和卡尔哥,感恩! 网络基础篇 面试官您好!OSI和TCP/IP是网络通信中两个关键模型,本质都是分层处理数据传输,但设计理念和应用场景差异很大。 OSI模型是理论上的七层架构,从下到上依次是物理层…...

【HarmonyOS 5】生活与服务开发实践详解以及服务卡片案例
一、金融场景创新实践 智慧银行网点转型 通过统一设备方案整合国产芯片与鸿蒙系统,支持智能柜员机、移动展业终端等设备的弹性硬件组合,降低25%硬件成本。利用元服务框架实现卡片式交互(如客户画像、风险评估一键调取)&a…...

LEAP模型能源需求/供应预测、能源平衡表核算、空气污染物排放预测、碳排放建模预测、成本效益分析、电力系统优化
🌐 LEAP模型(Long-range Energy Alternatives Planning System),即长期能源替代规划系统,是由斯德哥尔摩环境研究所与美国波士顿大学共同开发的基于情景分析的自底向上的能源—环境核算工具。该模型采用自底向上的架构…...

STM32 I2C通信外设
1、外设简介 可变多主机 7位/10位寻址 10位寻址:起始之后的两个字节都作为寻址,第一个字节前5位是11110作为10位寻址的标志位 SMBus:系统管理总线,主要用于电源管理,与I2C类似 2、外设结构框图 比较器、自身地址寄…...

13. springCloud AlibabaSeata处理分布式事务
目录 一、分布式事务面试题 1.多个数据库之间如何处理分布式事务? 2.若拿出如下场景,阁下将如何应对? 3.阿里巴巴的Seata-AT模式如何做到对业务的无侵入? 4.对于分布式事务问题,你知道的解决方案有哪些?请你谈谈? 二、分布式事务问题…...
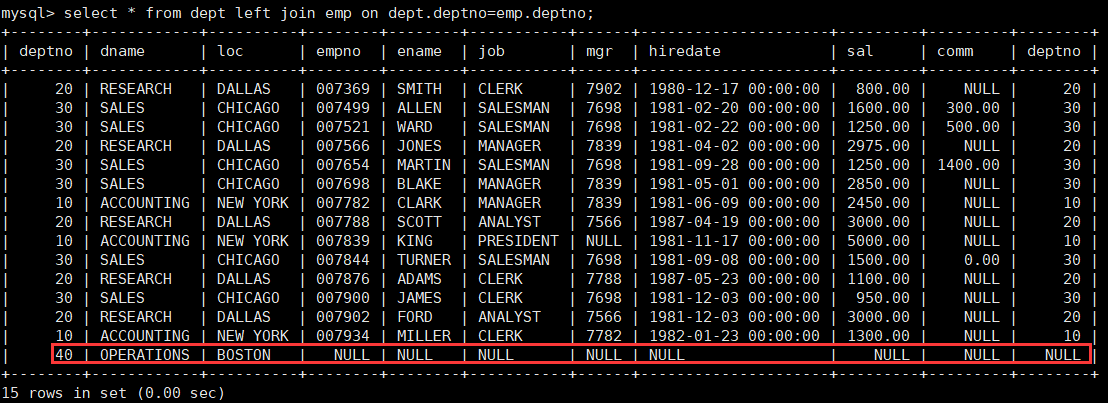
MySQL 表的内连和外连
一、内连接 内连接实际上就是利用 where 子句对两种表形成的笛卡儿积进行筛选,前面学习的查询都是内连接,也是在开发过程中使用的最多的连接查询。 select 字段 from 表1 inner join 表2 on 连接条件 and 其他条件; 注意:前面学习的都是内连…...

VR线上展厅特点分析与优势
VR线上展厅:特点、优势与实际应用 VR线上展厅,作为虚拟现实(VR)技术在展示行业的创新应用,正逐步改变着传统的展览方式。通过模拟真实的物理环境,为参观者提供身临其境的展览体验,成为展示行业…...

Python基于SVM技术的手写数字识别问题项目实战
说明:这是一个机器学习实战项目(附带数据代码文档),如需数据代码文档可以直接到文章最后关注获取。 1.项目背景 在当今数字化转型加速的时代,手写数字识别作为图像处理与机器学习领域的一个经典问题,具有广…...

Elasticsearch的写入性能优化
优化Elasticsearch的写入性能需要从多维度入手,包括集群配置、索引设计、数据处理流程和硬件资源等。以下是一些关键优化策略和最佳实践: 一、索引配置优化 合理设置分片数与副本数分片数(Shards):过少会导致写入瓶颈(无法并行),过多会增加集群管理开销。公式参考:分…...