6.04打卡
@浙大疏锦行
DAY 43 复习日
作业:
kaggle找到一个图像数据集,用cnn网络进行训练并且用grad-cam做可视化
进阶:并拆分成多个文件
损失: 0.502 | 准确率: 75.53% 训练完成
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms, models
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
import torch.nn.functional as F
# 设置随机种子确保结果可复现
torch.manual_seed(42)
np.random.seed(42)
# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
# 1. 数据预处理
# 训练集:使用多种数据增强方法提高模型泛化能力
train_transform = transforms.Compose([# 新增:调整图像大小为统一尺寸transforms.Resize((32, 32)), # 确保所有图像都是32x32像素transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),transforms.RandomRotation(15),transforms.ToTensor(),transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))])
# 测试集:仅进行必要的标准化,保持数据原始特性
test_transform = transforms.Compose([# 新增:调整图像大小为统一尺寸transforms.Resize((32, 32)), # 确保所有图像都是32x32像素transforms.ToTensor(),transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
# 定义数据集根目录
root = r'day43'
train_dataset = datasets.ImageFolder(root=root + '/training_set', # 指向 train 子文件夹transform=train_transform
)
test_dataset = datasets.ImageFolder(root=root + '/test_set', # 指向 test 子文件夹transform=test_transform
)
# 打印类别信息,确认数据加载正确
print(f"训练集类别: {train_dataset.classes}")
print(f"测试集类别: {test_dataset.classes}")
# 3. 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# 定义一个简单的CNN模型
class SimpleCNN(nn.Module):def __init__(self):super(SimpleCNN, self).__init__()# 第一个卷积层,输入通道为3(彩色图像),输出通道为32,卷积核大小为3x3,填充为1以保持图像尺寸不变self.conv1 = nn.Conv2d(3, 32, kernel_size=3, padding=1)# 第二个卷积层,输入通道为32,输出通道为64,卷积核大小为3x3,填充为1self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)# 第三个卷积层,输入通道为64,输出通道为128,卷积核大小为3x3,填充为1self.conv3 = nn.Conv2d(64, 128, kernel_size=3, padding=1)# 最大池化层,池化核大小为2x2,步长为2,用于下采样,减少数据量并提取主要特征self.pool = nn.MaxPool2d(2, 2)# 第一个全连接层,输入特征数为128 * 4 * 4(经过前面卷积和池化后的特征维度),输出为512self.fc1 = nn.Linear(128 * 4 * 4, 512)# 第二个全连接层,输入为512,输出为2(对应猫和非猫两个类别)self.fc2 = nn.Linear(512, 2)def forward(self, x):# 第一个卷积层后接ReLU激活函数和最大池化操作,经过池化后图像尺寸变为原来的一半,这里输出尺寸变为16x16x = self.pool(F.relu(self.conv1(x)))# 第二个卷积层后接ReLU激活函数和最大池化操作,输出尺寸变为8x8x = self.pool(F.relu(self.conv2(x)))# 第三个卷积层后接ReLU激活函数和最大池化操作,输出尺寸变为4x4x = self.pool(F.relu(self.conv3(x)))# 将特征图展平为一维向量,以便输入到全连接层x = x.view(-1, 128 * 4 * 4)# 第一个全连接层后接ReLU激活函数x = F.relu(self.fc1(x))# 第二个全连接层输出分类结果x = self.fc2(x)return x
# 初始化模型
model = SimpleCNN()
print("模型已创建")
# 如果有GPU则使用GPU,将模型转移到对应的设备上
model = model.to(device)
# 训练模型
def train_model(model, train_loader, test_loader, epochs=20):# 定义损失函数为交叉熵损失,用于分类任务criterion = nn.CrossEntropyLoss()# 定义优化器为Adam,用于更新模型参数,学习率设置为0.001optimizer = torch.optim.Adam(model.parameters(), lr=0.001)for epoch in range(epochs):# 训练阶段model.train()running_loss = 0.0correct = 0total = 0for i, data in enumerate(train_loader, 0):# 从数据加载器中获取图像和标签inputs, labels = data# 将图像和标签转移到对应的设备(GPU或CPU)上inputs, labels = inputs.to(device), labels.to(device)# 清空梯度,避免梯度累加optimizer.zero_grad()# 模型前向传播得到输出outputs = model(inputs)# 计算损失loss = criterion(outputs, labels)# 反向传播计算梯度loss.backward()# 更新模型参数optimizer.step()running_loss += loss.item()_, predicted = outputs.max(1)total += labels.size(0)correct += predicted.eq(labels).sum().item()# 测试阶段model.eval()test_loss = 0correct = 0total = 0with torch.no_grad():for data in test_loader:images, labels = dataimages, labels = images.to(device), labels.to(device)outputs = model(images)test_loss += criterion(outputs, labels).item()_, predicted = outputs.max(1)total += labels.size(0)correct += predicted.eq(labels).sum().item()print(f'测试集 [{epoch + 1}] 损失: {test_loss/len(test_loader):.3f} | 准确率: {100.*correct/total:.2f}%')print("训练完成")return model
# 训练模型
try:# 尝试加载预训练模型(如果存在)model.load_state_dict(torch.load('cat_classifier.pth'))print("已加载预训练模型")
except:print("无法加载预训练模型,训练新模型")model = train_model(model, train_loader, test_loader, epochs=10)# 保存训练后的模型参数torch.save(model.state_dict(), 'cat_classifier.pth')
# 设置模型为评估模式
model.eval()
# Grad-CAM实现
class GradCAM:def __init__(self, model, target_layer):self.model = modelself.target_layer = target_layerself.gradients = Noneself.activations = None# 注册钩子,用于获取目标层的前向传播输出和反向传播梯度self.register_hooks()def register_hooks(self):# 前向钩子函数,在目标层前向传播后被调用,保存目标层的输出(激活值)def forward_hook(module, input, output):self.activations = output.detach()# 反向钩子函数,在目标层反向传播后被调用,保存目标层的梯度def backward_hook(module, grad_input, grad_output):self.gradients = grad_output[0].detach()# 在目标层注册前向钩子和反向钩子self.target_layer.register_forward_hook(forward_hook)self.target_layer.register_backward_hook(backward_hook)def generate_cam(self, input_image, target_class=None):# 前向传播,得到模型输出model_output = self.model(input_image)if target_class is None:# 如果未指定目标类别,则取模型预测概率最大的类别作为目标类别target_class = torch.argmax(model_output, dim=1).item()# 清除模型梯度,避免之前的梯度影响self.model.zero_grad()# 反向传播,构造one-hot向量,使得目标类别对应的梯度为1,其余为0,然后进行反向传播计算梯度one_hot = torch.zeros_like(model_output)one_hot[0, target_class] = 1model_output.backward(gradient=one_hot)# 获取之前保存的目标层的梯度和激活值gradients = self.gradientsactivations = self.activations# 对梯度进行全局平均池化,得到每个通道的权重,用于衡量每个通道的重要性weights = torch.mean(gradients, dim=(2, 3), keepdim=True)# 加权激活映射,将权重与激活值相乘并求和,得到类激活映射的初步结果cam = torch.sum(weights * activations, dim=1, keepdim=True)# ReLU激活,只保留对目标类别有正贡献的区域,去除负贡献的影响cam = F.relu(cam)# 调整大小并归一化,将类激活映射调整为与输入图像相同的尺寸(32x32),并归一化到[0, 1]范围cam = F.interpolate(cam, size=(32, 32), mode='bilinear', align_corners=False)cam = cam - cam.min()cam = cam / cam.max() if cam.max() > 0 else camreturn cam.cpu().squeeze().numpy(), target_class
# 可视化Grad-CAM结果的函数
import warnings
warnings.filterwarnings("ignore")
import matplotlib.pyplot as plt
# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 选择一个随机图像
# idx = np.random.randint(len(test_dataset))
idx = 50 # 选择测试集中的第49张图片 (索引从0开始)
image, label = test_dataset[idx]
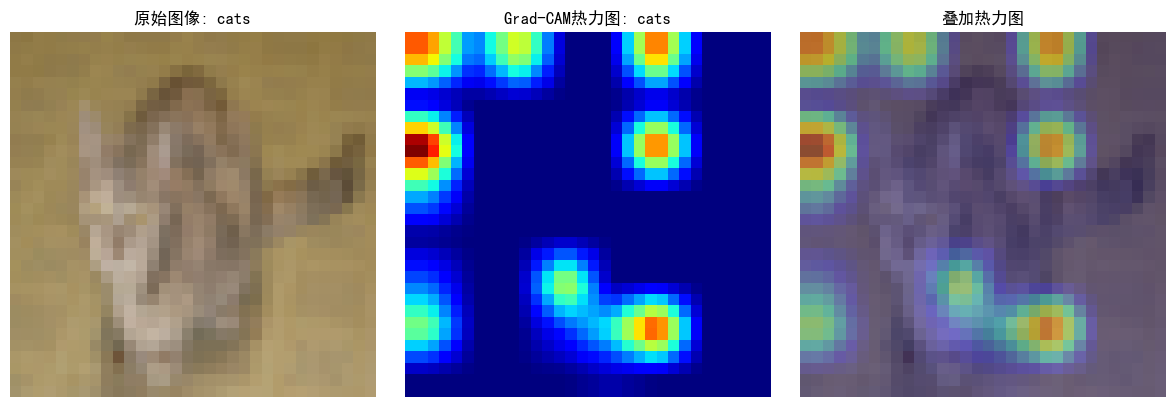
print(f"选择的图像类别: {test_dataset.classes[label]}")
# 转换图像以便可视化
def tensor_to_np(tensor):img = tensor.cpu().numpy().transpose(1, 2, 0)mean = np.array([0.485, 0.456, 0.406])std = np.array([0.229, 0.224, 0.225])img = std * img + meanimg = np.clip(img, 0, 1)return img
# 添加批次维度并移动到设备
input_tensor = image.unsqueeze(0).to(device)
# 初始化Grad-CAM(选择最后一个卷积层)
grad_cam = GradCAM(model, model.conv3)
# 生成热力图
heatmap, pred_class = grad_cam.generate_cam(input_tensor)
# 可视化
plt.figure(figsize=(12, 4))
# 原始图像
plt.subplot(1, 3, 1)
plt.imshow(tensor_to_np(image))
plt.title(f"原始图像: {test_dataset.classes[label]}")
plt.axis('off')
# 热力图
plt.subplot(1, 3, 2)
plt.imshow(heatmap, cmap='jet')
plt.title(f"Grad-CAM热力图: {test_dataset.classes[pred_class]}")
plt.axis('off')
# 叠加的图像
plt.subplot(1, 3, 3)
img = tensor_to_np(image)
heatmap_resized = np.uint8(255 * heatmap)
heatmap_colored = plt.cm.jet(heatmap_resized)[:, :, :3]
superimposed_img = heatmap_colored * 0.4 + img * 0.6
plt.imshow(superimposed_img)
plt.title("叠加热力图")
plt.axis('off')
plt.tight_layout()
plt.show()相关文章:
6.04打卡
浙大疏锦行 DAY 43 复习日 作业: kaggle找到一个图像数据集,用cnn网络进行训练并且用grad-cam做可视化 进阶:并拆分成多个文件 损失: 0.502 | 准确率: 75.53% 训练完成 import torch import torch.nn as nn import torch.optim as optim from…...
【基于SpringBoot的图书购买系统】操作Jedis对图书图书的增-删-改:从设计到实战的全栈开发指南
引言 在当今互联网应用开发中,缓存技术已成为提升系统性能和用户体验的关键组件。Redis作为一款高性能的键值存储数据库,以其丰富的数据结构、快速的读写能力和灵活的扩展性,被广泛应用于各类系统的缓存层设计。本文将围绕一个基于Redis的图…...

Ubuntu中TFTP服务器安装使用
TFTP服务器 在 Ubuntu 下使用 TFTP(Trivial File Transfer Protocol) 服务,通常用于简单的文件传输(如网络设备固件更新、嵌入式开发等)。 1 TFTP服务器安装 sudo apt-get install tftp-hpa sudo apt-get install…...
Spring Boot微服务架构(十):Docker与K8S部署的区别
Spring Boot微服务在Docker与Kubernetes(K8S)中的部署存在显著差异,主要体现在技术定位、管理能力、扩展性及适用场景等方面。以下是两者的核心区别及实践对比: 一、技术定位与核心功能 Docker 功能:专注于单节点容器化…...

接口重试的7种常用方案!
前言 记得五年前的一个深夜,某个电商平台的订单退款接口突发异常,因为银行系统网络抖动,退款请求连续失败。 原本技术团队只是想“好心重试几次”,结果开发小哥写的重试代码竟疯狂调用了银行的退款接口 82次! 最终导致…...
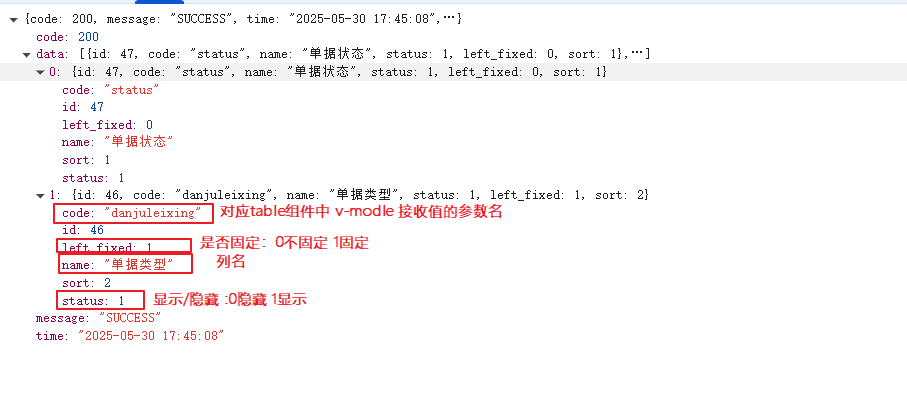
vue3:Table组件动态的字段(列)权限、显示隐藏和左侧固定
效果展示 根据后端接口返回,当前登录用户详情中的页面中el-table组件的显示隐藏等功能。根据菜单id查询该菜单下能后显示的列。 后端返回的数据类型: 接收到后端返回的数据后处理数据结构. Table组件文件 <!-- 自己封装的Table组件文件 --> onMounted(()>…...
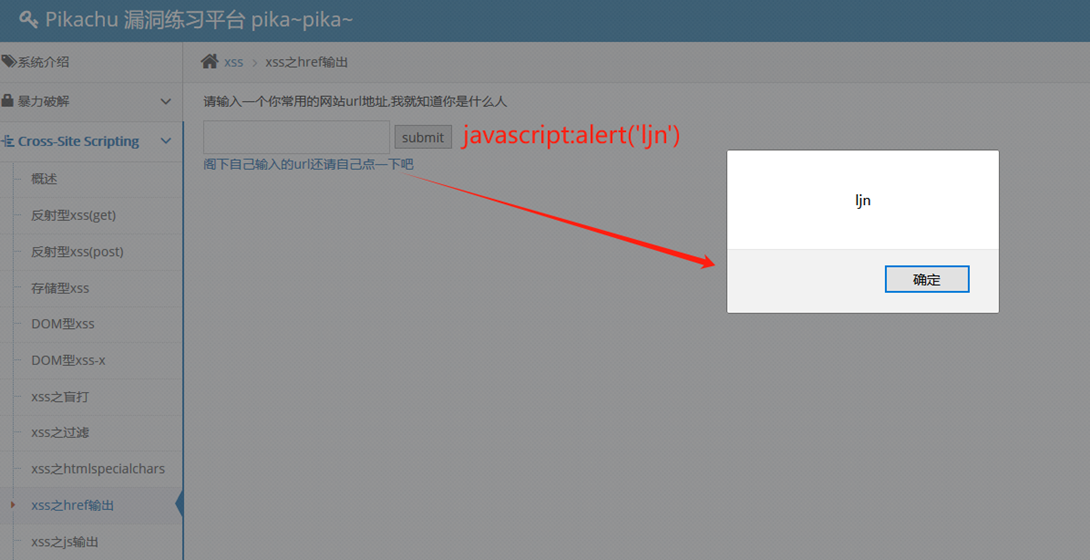
pikachu靶场通关笔记13 XSS关卡09-XSS之href输出
目录 一、href 1、常见取值类型 2、使用示例 3、安全风险 二、源码分析 1、进入靶场 2、代码审计 3、渗透思路 三、渗透实战 1、注入payload1 2、注入payload2 3、注入payload3 本系列为通过《pikachu靶场通关笔记》的XSS关卡(共10关)渗透集合ÿ…...
MCP客户端Client开发流程
1. uv工具入门使用指南 1.1 uv入门介绍 MCP开发要求借助uv进行虚拟环境创建和依赖管理。 uv 是一个Python 依赖管理工具,类似于pip 和 conda ,但它更快、更高效,并且可以更好地管理 Python 虚拟环境和依赖项。它的核心目标是 替代 pip 、…...
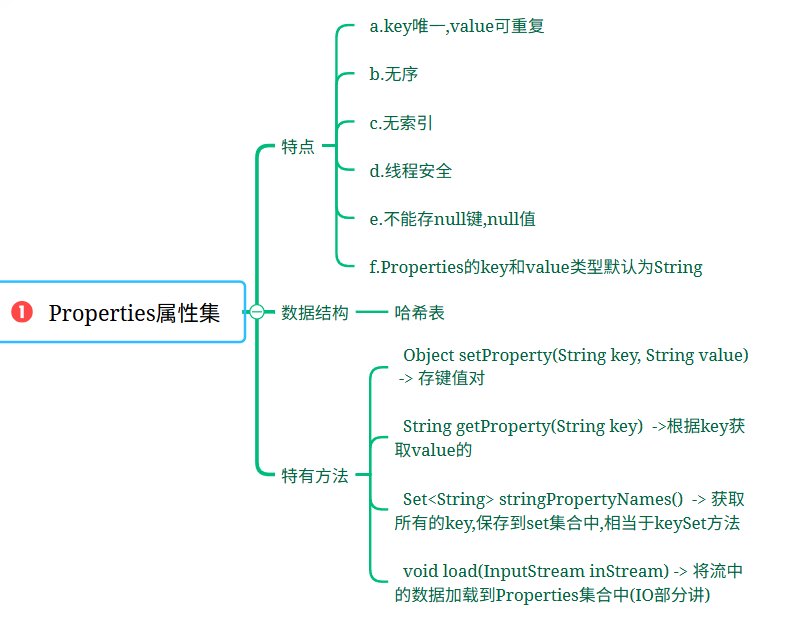
学习日记-day21-6.3
完成目标: 目录 知识点: 1.集合_哈希表存储过程说明 2.集合_哈希表源码查看 3.集合_哈希表无索引&哈希表有序无序详解 4.集合_TreeSet和TreeMap 5.集合_Hashtable和Vector&Vector源码分析 6.集合_Properties属性集 7.集合_集合嵌套 8.…...
C语言探索之旅:深入理解结构体的奥秘
目录 引言 一、什么是结构体? 二、结构体类型的声明和初始化 1、结构体的声明 2、结构体的初始化 3、结构体的特殊声明 4、结构体的自引用 5、结构体的重命名 三、结构体的内存对齐 1、对齐规则 2、为什么存在内存对齐? 3、修改默认对齐数 三…...

uniapp 开发企业微信小程序,如何区别生产环境和测试环境?来处理不同的服务请求
在 uniapp 开发企业微信小程序时,区分生产环境和测试环境是常见需求。以下是几种可靠的方法,帮助你根据环境处理不同的服务请求: 一、通过条件编译区分(推荐) 使用 uniapp 的 条件编译 语法,在代码中标记…...

Dockerfile常用指令介绍
Dockerfile常用指令介绍 Dockerfile是一个文本文件,用于定义Docker镜像的构建过程。下面介绍一些最常用的Dockerfile指令及其用法: 基础指令 FROM - 指定基础镜像 FROM python:3.9-slim这是Dockerfile的第一个指令,用于指定构建镜像的基础镜…...

Docker 容器化:核心技术原理与实践
哈喽,大家好,我是左手python! Docker 的基本概念与核心组件 Docker 是一个开源的容器化平台,能够将应用程序及其依赖项打包成一个容器,确保在任何环境中都能一致运行。Docker 的核心在于其容器化技术,这种…...

不确定性分析在LEAP能源-环境系统建模中的整合与应用
本内容突出与实例结合,紧密结合国家能源统计制度及《省级温室气体排放编制指南》,深入浅出地介绍针对不同级别研究对象时如何根据数据结构、可获取性、研究目的,构建合适的能源生产、转换、消费、温室气体排放(以碳排放为主&#…...

经典算法回顾之最小生成树
最小生成树(Minimum Spanning Tree,简称MST)是图论中的一个重要概念,主要用于解决加权无向图中连接所有顶点且总权重最小的树结构问题。本文对两种经典的算法即Prim算法和Kruskal算法进行回顾,并对后者的正确性给出简单…...
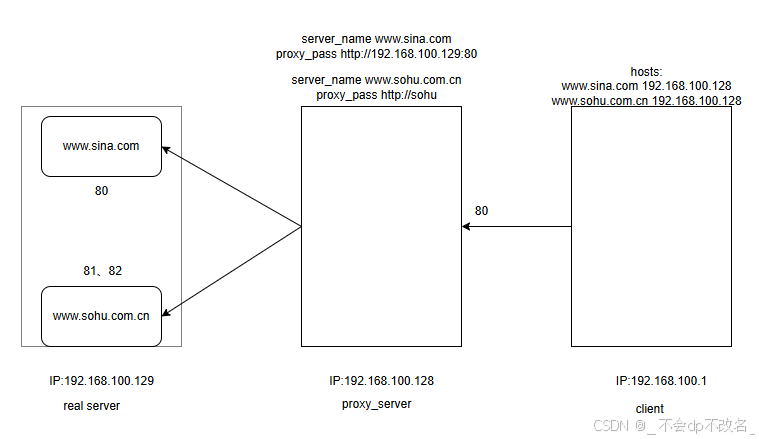
Ubuntu下实现nginx反向代理
1. 多个ngx实例安装 脚本已经在deepseek的指导下完成啦! deepseek写的脚本支持ubuntu/centos两种系统。 ins_prefix"/usr/local/" makefile_gen() {ngx$1 ngx_log_dir"/var/log/"$ngx"/"ngx_temp_path"/var/temp/"${ngx}…...
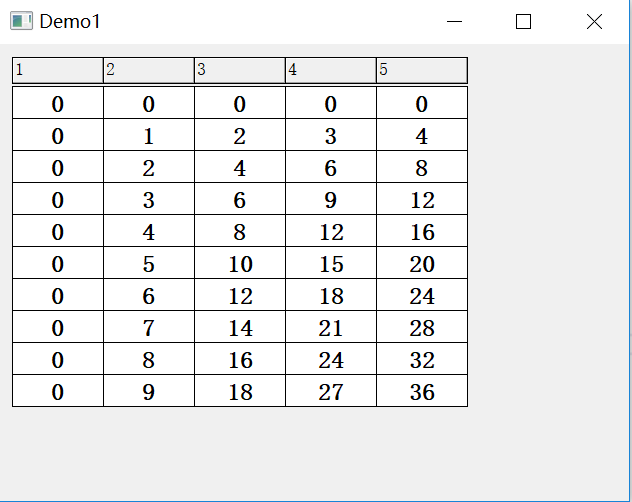
c++ QicsTable使用实例
效果图: #include <QicsTable.h> #include <QicsDataModelDefault.h> #include <QVBoxLayout> Demo1::Demo1(QWidget *parent) : QWidget(parent) { ui.setupUi(this); const int numRows 10; const int numCols 5; // create th…...

在WordPress上添加隐私政策页面
在如今的互联网时代,保护用户隐私已经成为每个网站管理员的责任。隐私政策不仅是法律要求,还能提高用户对网站的信任。本文将介绍两种常用方法,帮助你在WordPress上轻松创建并发布隐私政策页面。这些方法简单易行,符合中国用户的阅…...

二维 根据矩阵变换计算镜像旋转角度
在二维变换中,镜像(Reflection) 是一种特殊的线性变换,它会将图形对称地翻转到某个轴线或点。镜像的存在会显著影响圆弧变换后的参数(圆心、半径、起始角度),尤其是在角度方向和旋转方向的处理上…...

你工作中涉及的安全方面的测试有哪些怎么回答
在面试或工作总结中,回答 **“工作中涉及的安全测试”** 时,可以结合具体场景、测试方法和工具,突出你的技术广度和深度。以下是结构化回答建议: --- ### **1. 分类说明安全测试范围** #### **(1) Web 应用安全测试** - **OWASP…...

阿里云ACP云计算备考笔记 (3)——云服务器ECS
目录 第一章 整体概览 第二章 ECS简介 1、产品概念 2、ECS对比本地IDC 3、BGP机房优势 第三章 ECS实例 1、实例规格族 2、实例系列 3、应用场景推荐选型 4、实例状态 5、创建实例 ① 完成基础配置 ② 完成网络和安全组配置 ③ 完成管理配置和高级选项 ④ 确认下单…...

Eigen实现非线性最小二乘拟合 + Gauss-Newton算法
下面是使用 Eigen 实现的 非线性最小二乘拟合 Gauss-Newton 算法 的完整示例,拟合模型为: 拟合目标模型: y exp ( a x 2 b x c ) y \exp(a x^2 b x c) yexp(ax2bxc) 已知一组带噪声数据点 ( x i , y i ) (x_i, y_i) (xi,yi)&…...

区块链技术:原理、应用与发展趋势
区块链技术:原理、应用与发展趋势 引言 区块链作为一种去中心化的分布式账本技术,自2008年比特币白皮书发布以来,已经从简单的加密货币底层技术发展成为具有广泛应用前景的创新技术。区块链通过独特的数据结构和加密机制,实现了…...

从零开始:用Tkinter打造你的第一个Python桌面应用
目录 一、界面搭建:像搭积木一样组合控件 二、菜单系统:给应用装上“控制中枢” 三、事件驱动:让界面“活”起来 四、进阶技巧:打造专业级体验 五、部署发布:让作品触手可及 六、学习路径建议 在Python生态中&am…...

Web开发主流前后端框架总结
🖥 一、前端主流框架 前端框架的核心是提升用户界面开发效率,实现高交互性应用。当前三大主流框架各有侧重: React (Meta/Facebook) 核心特点:采用组件化架构与虚拟DOM技术(减少真实DOM操作,优化渲染性能&…...

Java Spring Boot 自定义注解详解与实践
目录 一、自定义注解的场景与优势1.1 场景1.2 优势 二、创建自定义注解2.1 定义注解2.2 创建注解处理器 三、使用自定义注解3.1 在业务方法上使用注解3.2 配置类加载注解 四、总结 在 Spring Boot 中,自定义注解为我们提供了一种灵活且强大的方式来简化开发、增强代…...

GlobalSign、DigiCert、Sectigo三种SSL安全证书有什么区别?
GlobalSign、DigiCert和Sectigo是三家知名的SSL证书颁发机构,其产品在安全性、功能、价格和适用场景上存在一定差异。选择SSL证书就像为你的网站挑选最合身的“安全盔甲”,核心是匹配你的实际需求,避免过度配置或防护不足。 一、核心特点对…...
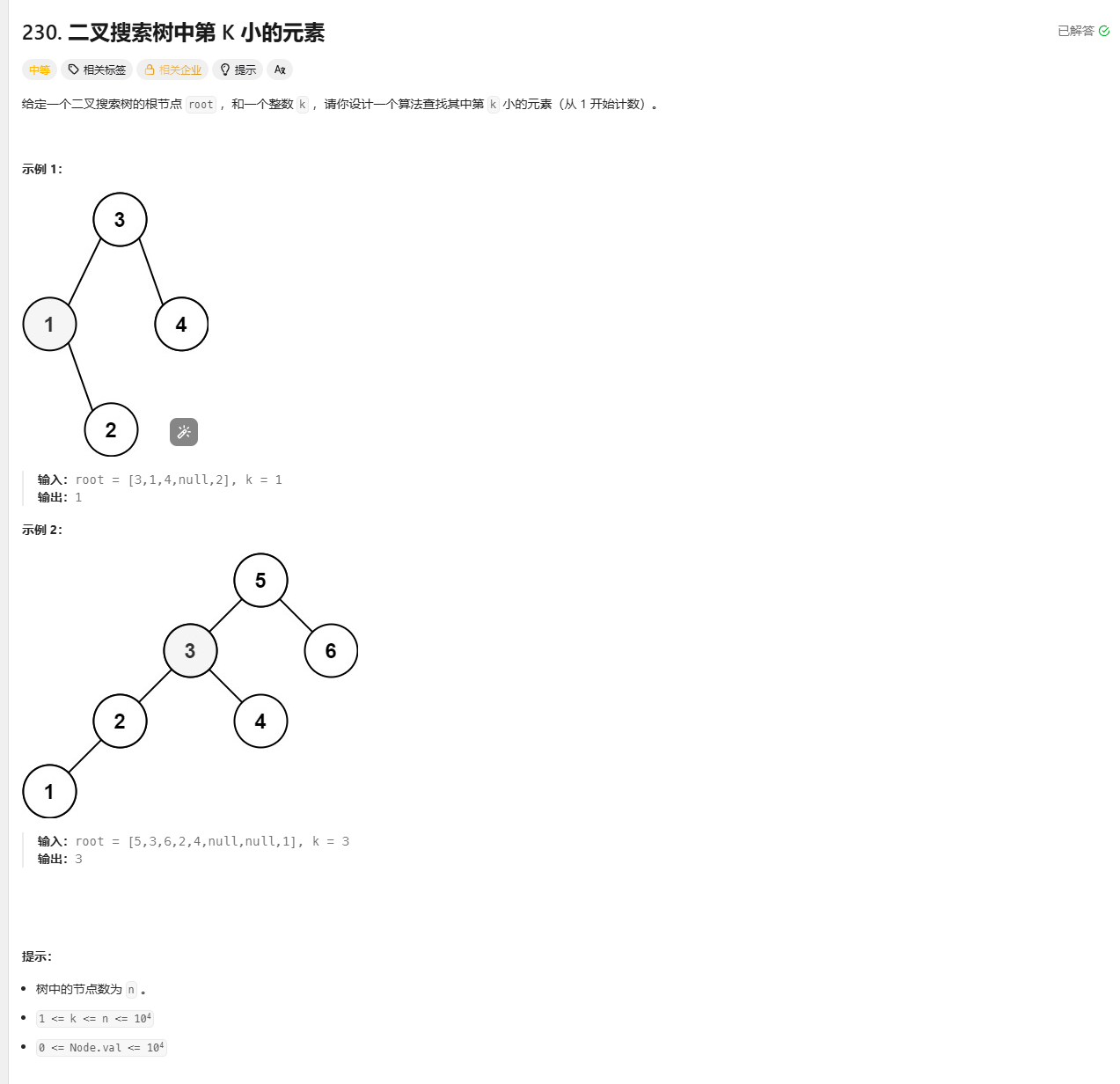
力扣面试150题--二叉搜索树中第k小的元素
Day 58 题目描述 思路 直接采取中序遍历,不过我们将k参与到中序遍历中,遍历到第k个元素就结束 /*** Definition for a binary tree node.* public class TreeNode {* int val;* TreeNode left;* TreeNode right;* TreeNode() {}* …...

SQL Server Agent 不可用怎么办?
在 SQL Server Management Studio (SSMS) 中,SQL Server Agent 通常位于对象资源管理器(Object Explorer)的树形结构中,作为 SQL Server 实例的子节点。以下是详细说明和可能的原因: 1. SQL Server Agent 的位置 默认路…...
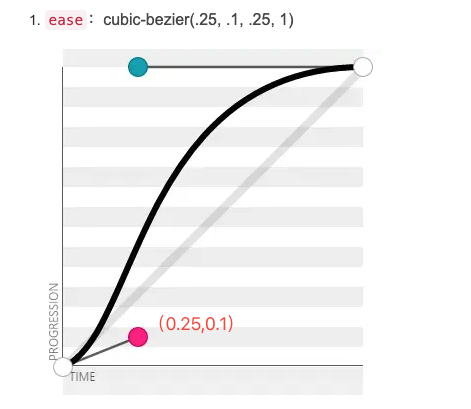
css-塞贝尔曲线
文章目录 1、定义2、使用和解释 1、定义 cubic-bezier() 函数定义了一个贝塞尔曲线(Cubic Bezier)语法:cubic-bezier(x1,y1,x2,y2) 2、使用和解释 x1,y1,x2,y2,表示两个点的坐标P1(x1,y1),P2(x2,y2)将以一条直线放在范围只有 1 的坐标轴中,并…...