【论文阅读】DanceGRPO: Unleashing GRPO on Visual Generation
DanceGRPO: Unleashing GRPO on Visual Generation
-
原文摘要
-
研究背景与问题
- 生成模型的突破:扩散模型和整流流等生成模型在视觉内容生成领域取得了显著进展。
- 核心挑战:如何让模型的输出更好地符合人类偏好仍是一个关键问题。
- 现有方法的局限性:
- 兼容性问题:传统的基于强化学习(RL)的方法无法与现代基于常微分方程(ODE)的采样范式兼容。
- 训练不稳定:在大规模训练中容易出现不稳定性。
- 缺乏验证:现有方法在视频生成任务上缺乏验证。
-
提出的解决方案:DanceGRPO
-
DanceGRPO 是第一个将 GRPO 应用于视觉生成的统一框架
-
统一性:支持多种生成范式(扩散模型、整流流)、任务(文本生成图像/视频、图像生成视频)、基础模型(如 Stable Diffusion、HunyuanVideo 等)和奖励模型(如美学评分、文本对齐、视频运动质量等)。
-
-
技术优势
- 稳定性:在复杂的视频生成任务中稳定策略优化。
- 轨迹学习:帮助生成策略更好地捕捉去噪轨迹(denoising trajectories),从而支持 Best-of-N 推理(即从多个生成结果中选择最优输出)。
- 稀疏反馈学习:能够从稀疏的二元反馈中学习。
-
实验结果
- 性能提升:在多个基准测试上显著超过基线方法,最高提升达 181%。
- 广泛验证:覆盖了多种任务、模型和奖励机制,证明了其鲁棒性和通用性。
-
研究意义
- 为 RLHF 提供新思路:DanceGRPO 为视觉生成领域的 RLHF 提供了可扩展且通用的解决方案。
- 调和 RL 与视觉生成:揭示了强化学习与视觉合成之间的协同潜力,为未来研究提供了新方向。
-
1. Introduction
-
研究背景与现状
-
生成模型的进展
- 扩散模型 和 整流流取得突破性进展,显著提升了图像/视频生成的质量和多样性。
- 预训练虽能建立基础数据分布,但人类反馈的整合对对齐生成结果与人类偏好至关重要。
-
现有方法的局限性
-
ReFL方法:依赖可微奖励模型,导致视频生成中显存(VRAM)效率低下,且工程实现复杂。
-
DPO系列方法:仅能带来边际视觉质量提升。
-
基于RL的方法虽具潜力,但存在三大挑战:
- 整流流的ODE采样与马尔可夫决策过程(MDP)的数学形式冲突;
- 现有策略梯度方法在小规模数据集(<100 prompts)外表现不稳定;
- 现有方法未在视频生成任务中得到验证。
-
-
-
解决方案
-
技术路径
-
通过随机微分方程(SDEs)重新形式化扩散模型和整流流的采样过程。
-
引入GRPO稳定训练——GRPO原是提升大语言模型(LLMs)在数学/代码等复杂任务性能的技术,本文首次将其适配到视觉生成任务,提出DanceGRPO框架,实现GRPO与视觉生成的“和谐协同”。
-
-
-
贡献总结
-
统一性与首创性
- 首次将GRPO扩展到扩散模型和整流流,在统一RL框架下支持多视觉生成任务。
- 关键实现:SDE重构、优化时间步选择、噪声初始化与尺度调整。
-
泛化性与可扩展性
-
DanceGRPO是首个支持多生成范式、任务、基础模型和奖励模型的RL框架。
-
突破此前RL方法仅在小规模文本→图像任务验证的局限,证明其在大规模数据集的实用价值。
-
-
高效性
-
实验显示:在HPSv2.1、CLIP score等基准上,性能最高提升181%。
-
额外能力:
- 支持Best-of-N推理中的去噪轨迹学习;
- 初步验证对稀疏二元奖励(0/1反馈)分布的捕捉能力。
-
-
2. Approach
2.1 Preliminary
-
Diffusion Model
-
前向过程
- 核心公式: z t = α t x + σ t ϵ z_t = \alpha_t x + \sigma_t \epsilon zt=αtx+σtϵ, 其中 ϵ ∼ N ( 0 , I ) \epsilon \sim \mathcal{N}(0, I) ϵ∼N(0,I)
- 变量说明:
- x x x:原始数据。
- z t z_t zt:第 t t t 步加噪后的数据。
- α t , σ t \alpha_t, \sigma_t αt,σt:噪声调度系数(控制噪声混合比例)。
- ϵ \epsilon ϵ:标准高斯噪声(均值为0,方差为1)。
- 意义: 通过线性混合原始数据 x x x 和噪声 ϵ \epsilon ϵ,逐步破坏数据。噪声调度设计需满足:
- t = 0 t=0 t=0 时 z 0 ≈ x z_0 \approx x z0≈x(接近干净数据)。
- t = 1 t=1 t=1 时 z 1 ≈ ϵ z_1 \approx \epsilon z1≈ϵ(接近纯噪声)。
- 变量说明:
- 核心公式: z t = α t x + σ t ϵ z_t = \alpha_t x + \sigma_t \epsilon zt=αtx+σtϵ, 其中 ϵ ∼ N ( 0 , I ) \epsilon \sim \mathcal{N}(0, I) ϵ∼N(0,I)
-
反向去噪
-
生成初始化: 从纯噪声 z 1 ∼ N ( 0 , I ) z_1 \sim \mathcal{N}(0, I) z1∼N(0,I) 开始,逐步去噪生成样本。
-
关键公式: z s = α s x ^ + σ s ϵ ^ z_s = \alpha_s \hat{x} + \sigma_s \hat{\epsilon} zs=αsx^+σsϵ^
- 变量说明:
- ϵ ^ \hat{\epsilon} ϵ^:去噪模型预测的噪声。
- x ^ \hat{x} x^:去噪模型预测的原始数据
- s s s:比当前步 t t t 更低的噪声级别。
- 意义: 通过去噪模型预测噪声 ϵ ^ \hat{\epsilon} ϵ^,结合噪声调度系数 α s , σ s \alpha_s, \sigma_s αs,σs,生成更低噪声级别的数据 z s z_s zs。
- 变量说明:
-
-
-
Rectified Flow
-
前向过程
- 核心公式: z t = ( 1 − t ) x + t ϵ , ϵ ∼ N ( 0 , I ) z_t = (1 - t)x + t \epsilon, \quad \epsilon \sim \mathcal{N}(0, I) zt=(1−t)x+tϵ,ϵ∼N(0,I)
- t t t :时间步( t ∈ [ 0 , 1 ] t \in [0, 1] t∈[0,1]),控制插值比例。
- 核心公式: z t = ( 1 − t ) x + t ϵ , ϵ ∼ N ( 0 , I ) z_t = (1 - t)x + t \epsilon, \quad \epsilon \sim \mathcal{N}(0, I) zt=(1−t)x+tϵ,ϵ∼N(0,I)
-
速度场(Velocity Field)
- 定义: u = ϵ − x u = \epsilon - x u=ϵ−x
- 解释:
- u u u 表示从数据 x x x 到噪声 ϵ \epsilon ϵ 的方向向量(即“速度场”)。
- 前向过程可重写为 z t = x + t ⋅ u z_t = x + t \cdot u zt=x+t⋅u,即沿速度场线性移动。
- 解释:
- 定义: u = ϵ − x u = \epsilon - x u=ϵ−x
-
反向过程
-
核心公式: z s = z t + u ^ ⋅ ( s − t ) , s < t z_s = z_t + \hat{u} \cdot (s - t), \quad s < t zs=zt+u^⋅(s−t),s<t
-
u ^ \hat{u} u^:模型预测的速度场。
-
意义: 通过模型预测 u ^ \hat{u} u^,从当前状态 z t z_t zt 反向沿速度场移动,生成更低噪声的 z s z_s zs。
- 若 u ^ = u \hat{u} = u u^=u,则完美逆转前向过程(即 z s = x + s ⋅ u z_s = x + s \cdot u zs=x+s⋅u)。
-
-
-
-
分析:两种方法具有统一的形式
-
数学表达 z ~ s = z ~ t + Network output ⋅ ( η s − η t ) \tilde{z}_s = \tilde{z}_t + \text{Network output} \cdot (\eta_s - \eta_t) z~s=z~t+Network output⋅(ηs−ηt)
- z ~ s , z ~ t \tilde{z}_s, \tilde{z}_t z~s,z~t:变换后的状态变量。
-
Network output \text{Network output} Network output:模型输出(噪声预测或速度场预测)。
-
η s , η t \eta_s, \eta_t ηs,ηt:与时间步相关的缩放系数。
-
2.2 DanceGRPO
2.2.1 去噪过程建模为MDP
-
MDP的要素定义
-
状态(State): s t ≜ ( c , t , z t ) s_t \triangleq (c, t, z_t) st≜(c,t,zt)
- c c c:条件提示
- ≜ \triangleq ≜:定义为
-
动作(Action): a t ≜ z t − 1 , π ( a t ∣ s t ) ≜ p ( z t − 1 ∣ z t , c ) a_t \triangleq z_{t-1}, \quad \pi(a_t | s_t) \triangleq p(z_{t-1} | z_t, c) at≜zt−1,π(at∣st)≜p(zt−1∣zt,c)
-
动作 a t a_t at 是下一步的状态 z t − 1 z_{t-1} zt−1。
-
策略 π ( a t ∣ s t ) \pi(a_t | s_t) π(at∣st) 即去噪模型,对应 z t z_{t} zt 到 z t − 1 z_{t-1} zt−1的概率。
-
-
状态转移(Transition): P ( s t + 1 ∣ s t , a t ) ≜ ( δ c , δ t − 1 , δ z t − 1 ) P(s_{t+1} | s_t, a_t) \triangleq (\delta_c , \delta_{t-1} , \delta_{z_{t-1}}) P(st+1∣st,at)≜(δc,δt−1,δzt−1)
-
解释
- δ y \delta_y δy 是Dirac delta函数(仅在 y y y 处非零),表示确定性转移。
- 也就是下一个状态 s t + 1 s_{t+1} st+1 一定为 ( c , t − 1 , z t − 1 ) (c,t-1,z_{t-1}) (c,t−1,zt−1)
- δ y \delta_y δy 是Dirac delta函数(仅在 y y y 处非零),表示确定性转移。
-
意义: 去噪过程的每一步严格按时间倒序执行,无随机性(与DDIM的确定性采样一致)。
-
-
奖励(Reward): R ( s t , a t ) ≜ { r ( z 0 , c ) , if t = 0 0 , otherwise R(s_t, a_t) \triangleq \begin{cases} r(z_0, c), & \text{if } t=0 \\0, & \text{otherwise}\end{cases} R(st,at)≜{r(z0,c),0,if t=0otherwise
-
设计逻辑:
- 仅在终止状态计算奖励。
- 中间步骤奖励为0,因无法直接评估部分去噪结果的质量。
-
奖励模型: r ( z 0 , c ) r(z_0, c) r(z0,c) 通常基于视觉-语言模型(如CLIP、Qwen-VL)
-
-
-
轨迹(Trajectory)
-
长度:固定为 T T T 步。
-
终止:到达 t = 0 t=0 t=0 后进入终止状态,不再转移。
-
2.2.2 SDE的采样形式化
-
核心动机
-
GRPO的需求: GRPO依赖随机探索(通过多轨迹采样)和轨迹概率分布来更新策略。
-
问题: 扩散模型和整流流的原始采样过程是确定性或部分确定性的,无法提供足够的随机性。
-
解决方案: 将两者的采样过程统一为随机微分方程(SDE)形式,通过引入噪声项 ϵ t \epsilon_t ϵt 实现随机探索。
-
-
扩散模型的SDE形式化
-
前向SDE(加噪过程): d z t = f t z t d t + g t d w dz_t = f_t z_t dt + g_t dw dzt=ftztdt+gtdw
-
f t , g t f_t, g_t ft,gt:与噪声调度相关的系数(控制噪声注入速度)。
-
d w dw dw:布朗运动(标准Wiener过程),表示随机噪声。
-
-
反向SDE(去噪过程)为支持随机探索,反向SDE需引入额外噪声项 ϵ t \epsilon_t ϵt:
d z t = [ f t z t − ( 1 + ϵ t 2 2 ) g t 2 ∇ log p t ( z t ) ] d t + ϵ t g t d w dz_t = \left[ f_t z_t - \left(1 + \frac{\epsilon_t^2}{2}\right) g_t^2 \nabla \log p_t(z_t) \right] dt + \epsilon_t g_t dw dzt=[ftzt−(1+2ϵt2)gt2∇logpt(zt)]dt+ϵtgtdw- ϵ t g t d w \epsilon_t g_t dw ϵtgtdw:新增的随机噪声项,为GRPO提供探索能力。
-
-
整流流的SDE形式化
-
原始ODE形式 :前向过程是线性ODE-- d z t = u t d t dz_t = u_t dt dzt=utdt
-
反向SDE
d z t = ( u t − 1 2 ϵ t 2 ∇ log p t ( z t ) ) d t + ϵ t d w dz_t = \left( u_t - \frac{1}{2} \epsilon_t^2 \nabla \log p_t(z_t) \right) dt + \epsilon_t dw dzt=(ut−21ϵt2∇logpt(zt))dt+ϵtdw -
关键修改:
- 添加得分函数修正项 − 1 2 ϵ t 2 ∇ log p t ( z t ) -\frac{1}{2} \epsilon_t^2 \nabla \log p_t(z_t) −21ϵt2∇logpt(zt) ,确保路径收敛性。
- 新增噪声项 ϵ t d w \epsilon_t dw ϵtdw 实现随机探索。
-
-
策略获得
- 假设 p t ( z t ) = N ( z t ∣ α t x , σ t 2 I ) p_t(z_t) = \mathcal{N}(z_t | \alpha_t x, \sigma_t^2 I) pt(zt)=N(zt∣αtx,σt2I)(高斯分布),则:
∇ log p t ( z t ) = − z t − α t x σ t 2 \nabla \log p_t(z_t) = -\frac{z_t - \alpha_t x}{\sigma_t^2} ∇logpt(zt)=−σt2zt−αtx
- 这个式子可以回带入上面两个SDE公式,来获得策略 π ( a t ∣ s t ) \pi(a_t|s_t) π(at∣st)
2.2.3 算法
-
核心目标函数
-
给定提示词 c c c,生成模型会从旧策略 π θ o l d π_{θ_{old}} πθold 采样一组输出 o 1 , o 2 , . . . , o G {o₁, o₂,..., o_G} o1,o2,...,oG,通过最大化以下目标函数优化新策略 π θ π_θ πθ :
J ( θ ) = E { o i } i = 1 G ∼ π θ o l d ( ⋅ ∣ c ) a t , i ∼ π θ o l d ( ⋅ ∣ s t , i ) [ [ 1 G ∑ i = 1 G 1 T ∑ t = 1 T min ( ρ t , i A i , clip ( ρ t , i , 1 − ϵ , 1 + ϵ ) A i ) ] J(\theta) = {\mathbb{E}_{\substack{\{o_i\}_{i=1}^G \sim \pi_{\theta_{old}}(\cdot|c) \\ a_{t,i} \sim \pi_{\theta_{old}}(\cdot|s_{t,i})}}} [\left[ \frac{1}{G} \sum_{i=1}^G \frac{1}{T} \sum_{t=1}^T \min\left( \rho_{t,i}A_i, \text{clip}(\rho_{t,i}, 1-\epsilon, 1+\epsilon)A_i \right) \right] J(θ)=E{oi}i=1G∼πθold(⋅∣c)at,i∼πθold(⋅∣st,i)[[G1i=1∑GT1t=1∑Tmin(ρt,iAi,clip(ρt,i,1−ϵ,1+ϵ)Ai)]-
ρ t , i = π θ ( a t , i ∣ s t , i ) π θ o l d ( a t , i ∣ s t , i ) \rho_{t,i} = \frac{\pi_\theta(a_{t,i}|s_{t,i})}{\pi_{\theta_{old}}(a_{t,i}|s_{t,i})} ρt,i=πθold(at,i∣st,i)πθ(at,i∣st,i) 是新旧策略的概率比
-
A i A_i Ai 是标准化优势函数(计算见下文)
-
ϵ \epsilon ϵ 是控制策略更新幅度的超参数
-
-
-
优势函数计算
A i = r i − mean ( { r 1 , r 2 , ⋯ , r G } ) std ( { r 1 , r 2 , ⋯ , r G } ) A_i = \frac{r_i - \text{mean}(\{r_1,r_2,\cdots,r_G\})}{\text{std}(\{r_1,r_2,\cdots,r_G\})} Ai=std({r1,r2,⋯,rG})ri−mean({r1,r2,⋯,rG})-
其中 r 1 , . . . , r G {r₁,...,r_G} r1,...,rG是对应输出的奖励值
-
由于实际奖励稀疏性,优化时对所有时间步使用相同的奖励信号
-
传统GRPO方法使用KL正则化防止奖励过优化,但实验显示省略该组件对性能影响很小,因此默认不包含KL正则项
-
-
-
完整算法流程

-
策略更新(第10-13行)
-
时间步子采样:
- 从T个时间步中选择⌈τT⌉个步(τ∈(0,1]),仅在这些步上计算梯度。
-
梯度上升更新:
-
对选中的时间步 t ∈ T s u b t ∈ T_{sub} t∈Tsub,计算目标函数 J ( θ ) J(θ) J(θ) 的梯度并更新参数 θ θ θ:
θ ← θ + η ∇ θ J \theta \leftarrow \theta + \eta \nabla_\theta J θ←θ+η∇θJ -
因为每一个时间步采取特定动作的概率不同,所以需要在不同时间步上做梯度更新
-
我觉得可以加上一个权重参数来优化梯度更新函数,因为不同的时间步会对生成结果产生不同大小的影响
-
-
-
2.2.4 噪声初始化
-
传统方法初始化噪声(如DDPO):
-
对同一提示词(prompt)生成的多个样本(如视频或图像),使用不同的随机噪声向量初始化。
-
问题:
- Reward Hacking:模型通过利用噪声的随机性,生成某些“幸运”样本(恰好匹配奖励函数偏好),而非真正学习提升整体质量。
- 训练不稳定:噪声差异导致梯度更新方向不一致,难以收敛。
-
-
DanceGRPO初始化
- 核心设计:对同一提示词 c 生成的 G 个样本,共享相同的初始化噪声。
2.2.5 时间步选择
- 在去噪轨迹中省略部分时间步的子集并不会影响模型性能。
- 这种减少计算步骤的方法在保持输出质量的同时显著提升了效率。
2.2.6 整合多个奖励模型
- 在实际应用中,我们采用多个奖励模型以确保训练过程更稳定、视觉输出质量更高。
- 仅使用HPS-v2.1奖励训练的模型易生成不自然(“油润感”)的输出
- 引入CLIP评分则有助于保持更真实的图像特征。
- 作者没有直接合并各奖励值,而是通过聚合优势函数来实现多模型协同。
- 该方法既能稳定优化过程,又能产生更均衡的生成结果。
2.2.7 基于Best-of-N推理扩展
- 本方法优先利用高效样本–通过Best-of-N采样筛选出的前k名与末k名候选样本。
- 这种选择性采样策略通过聚焦解空间中的高奖励区域与关键低奖励区域,显著提升训练效能。
- 当前采用暴力搜索生成这些样本。
- 树搜索或贪婪搜索等替代方法同样具有研究潜力
2.3 Different Rewards
-
实验验证范围
-
两种生成范式:扩散模型 / rectified flow
-
三种任务:文本→图像、文本→视频、图像→视频
-
四个基础模型:
-
Stable Diffusion
-
HunyuanVideo
-
FLUX
-
SkyReels-I2V
-
-
-
五类奖励模型设计
奖励模型 作用 技术实现 1. 图像美学评分 量化生成图像的视觉吸引力 基于人类评分数据微调的预训练模型 2. 文本-图像对齐(CLIP) 确保生成内容与输入提示词语义一致 CLIP模型计算图文跨模态相似度 3. 视频美学质量 评估视频帧质量及时序连贯性 视觉语言模型(VLM)扩展至时序域 4. 视频运动质量 分析运动轨迹和形变的物理合理性 物理感知VLM对运动轨迹建模 5. 阈值二值奖励 测试模型在阈值优化下的学习能力 基于固定阈值离散化奖励(超过阈值=1,否则=0)
2.4 Comparisons
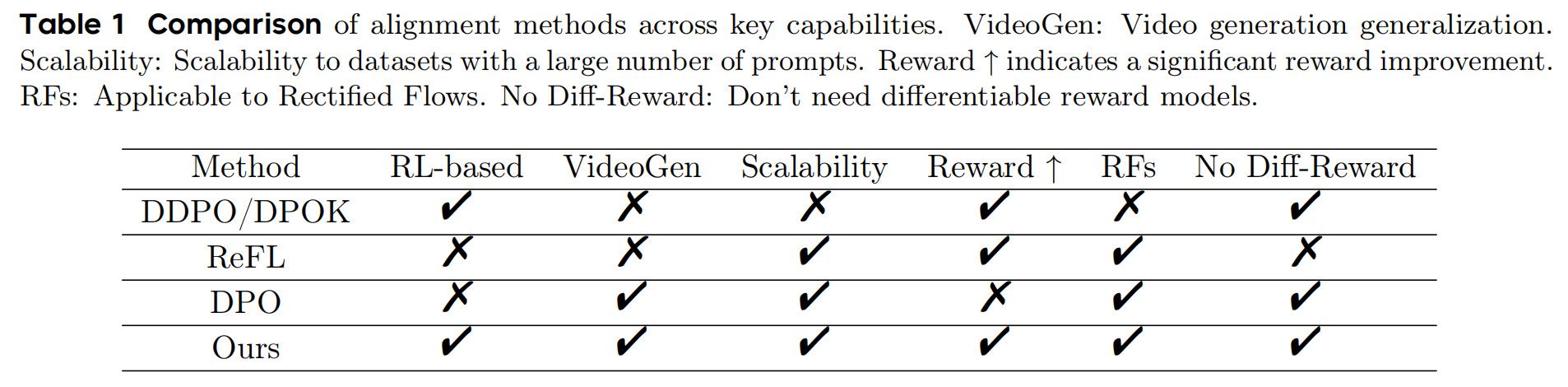
3. Experiments
-
文本到图像生成(Text-to-Image Generation)
-
基础模型: Stable Diffusion v1.4、FLUX、HunyuanVideo-T2I
-
奖励模型: HPS-v2.1、CLIP Score、二值化奖励
-
训练数据: 精选提示词数据集(平衡多样性与复杂性)
-
测试评估:
- 1,000条测试提示词,用于计算CLIP分数和Pick-a-Pic性能
- GenEval和HPS-v2.1官方基准
-
-
文本到视频生成(Text-to-Video Generation)
-
基础模型:HunyuanVideo
-
奖励模型:VideoAlign
-
训练数据: VidProM数据
-
测试评估: 额外1,000条测试提示词,用于VideoAlign评分
-
-
图像到视频生成(Image-to-Video Generation)
-
基础模型:SkyReels-I2V
-
奖励模型:VideoAlign
-
训练数据:
- 提示词来自VidProM数据集
- 参考图像由HunyuanVideo-T2I生成
-
测试评估:1,000条测试提示词,计算VideoAlign分数
-
相关文章:
【论文阅读】DanceGRPO: Unleashing GRPO on Visual Generation
DanceGRPO: Unleashing GRPO on Visual Generation 原文摘要 研究背景与问题 生成模型的突破:扩散模型和整流流等生成模型在视觉内容生成领域取得了显著进展。核心挑战:如何让模型的输出更好地符合人类偏好仍是一个关键问题。现有方法的局限性࿱…...
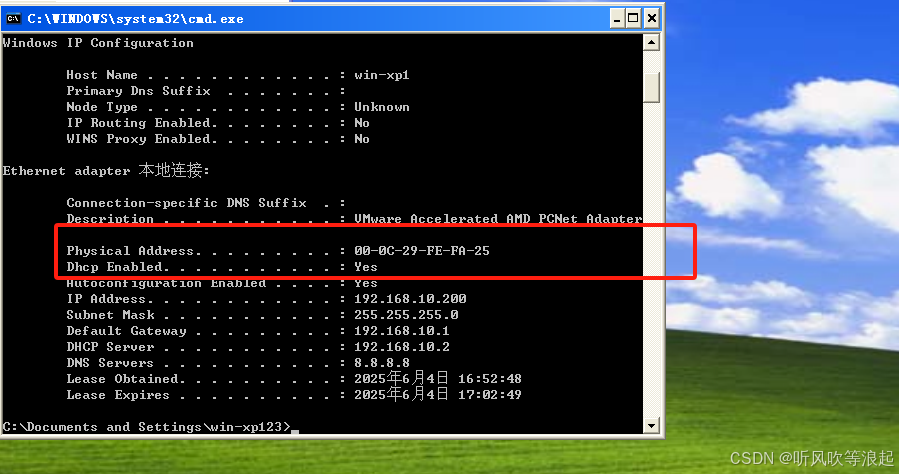
CentOS在vmware局域网内搭建DHCP服务器【踩坑记录】
1. 重新设置环境 配置dhcp服务踩了不少坑,这里重头搭建记录一下: 1.1 centos 网卡还原 如果之前搭了乱七八糟的环境,导致NAT模式也没法上网,这里重新还原 我们需要在NAT模式下联网,下载DHCP服务 先把centos的网卡还…...

AI炼丹日志-28 - Audiblez 将你的电子书epub转换为音频mp3 做有声书
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 大模型与Java双线更新中! 目前《大语言模型实战》已连载至第22篇,探索 MCP 自动操作 FigmaCursor 实…...

图像处理篇---face_recognition库实现人脸检测
以下是使用face_recognition库实现人脸检测的详细步骤、实例代码及解释: 一、环境准备 1. 安装依赖库 pip install face_recognition opencv-python # 核心库 pip install matplotlib # 用于显示图像(可选)2. 依赖说明 face_recognitio…...
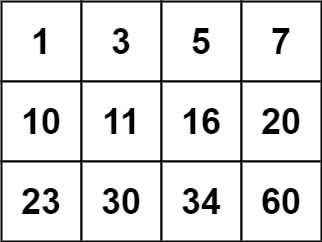
74. 搜索二维矩阵 (力扣)
给你一个满足下述两条属性的 m x n 整数矩阵: 每行中的整数从左到右按非严格递增顺序排列。每行的第一个整数大于前一行的最后一个整数。 给你一个整数 target ,如果 target 在矩阵中,返回 true ;否则,返回 false 。…...
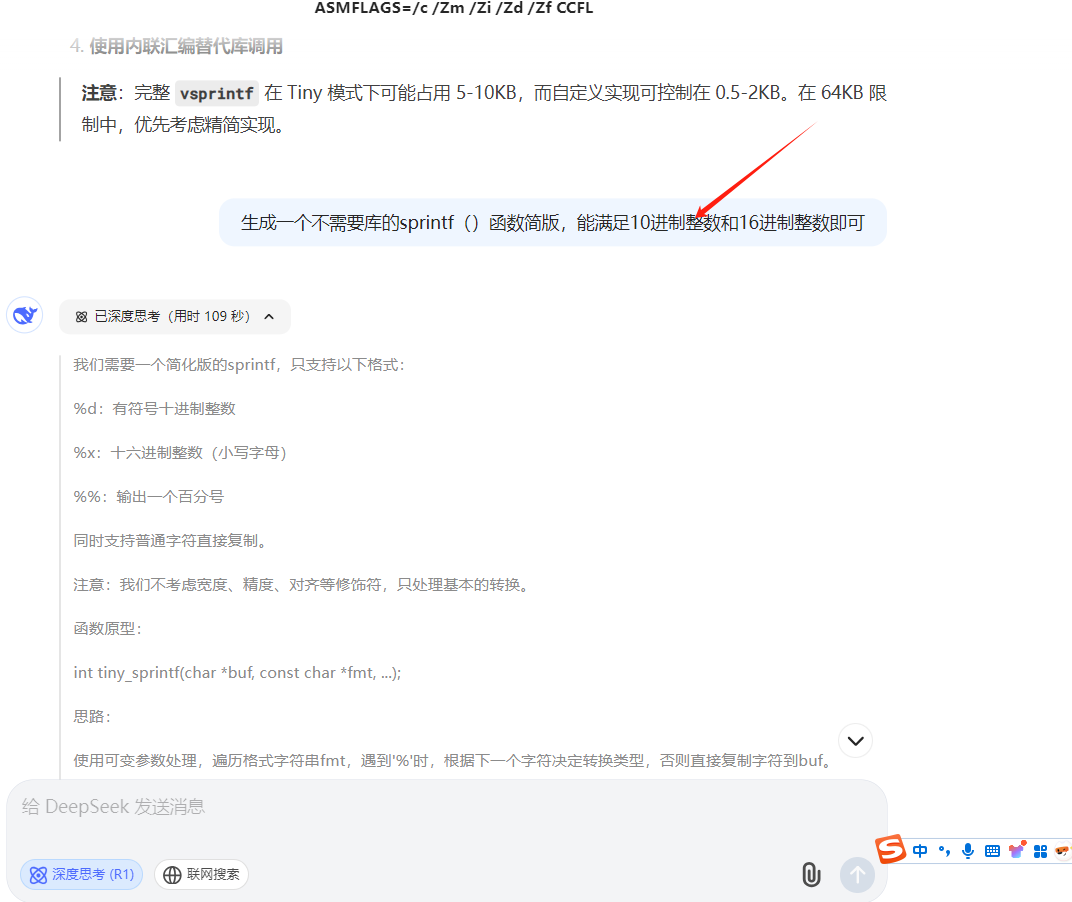
8088单板机C语言sprintf()格式化串口输出---Prj04
#include "tiny_stdarg.h" // 使用自定义可变参数实现#define ADR_273 0x0200 #define ADR_244 0x0400 #define LED_PORT 0x800 #define PC16550_THR 0x1f0 #define PC16550_LSR 0x1f5 / //基本的IO操作函数 / char str[]"Hello World! 20250531 Ve…...

板凳-------Mysql cookbook学习 (九)
第4章:表管理 4.0 引言 MySQL :: 员工样例数据库 :: 3 安装 https://dev.mysql.com/doc/employee/en/employees-installation.html Employees 数据库与几种不同的 存储引擎,默认情况下启用 InnoDB 引擎。编…...

深入解析 Flask 命令行工具与 flask run命令的使用
Flask 是一个轻量级的 Python Web 应用框架,其内置的命令行工具(CLI)基于 Click 库,提供了方便的命令行接口,用于管理和运行 Flask 应用程序。本文将详细介绍 Flask 命令行工具的功能,以及如何使用 flask r…...

第6篇:中间件 SQL 重写与语义分析引擎实现原理
6.1 章节导读 SQL 是数据库中间件的“输入语言”。 在一个真正强大的中间件系统中,SQL 语句的执行通常不再是“原封不动”地传递给数据库,而是需要先经过: 语义分析:解析 SQL 的结构和含义。 SQL 重写:根据中间件逻辑…...

基于SpringBoot的“嗨玩旅游”网站设计与实现(源码+定制+开发)嗨玩旅游平台开发:景点展示与个性化推荐系统(SpringBoot)
博主介绍: ✌我是阿龙,一名专注于Java技术领域的程序员,全网拥有10W粉丝。作为CSDN特邀作者、博客专家、新星计划导师,我在计算机毕业设计开发方面积累了丰富的经验。同时,我也是掘金、华为云、阿里云、InfoQ等平台…...
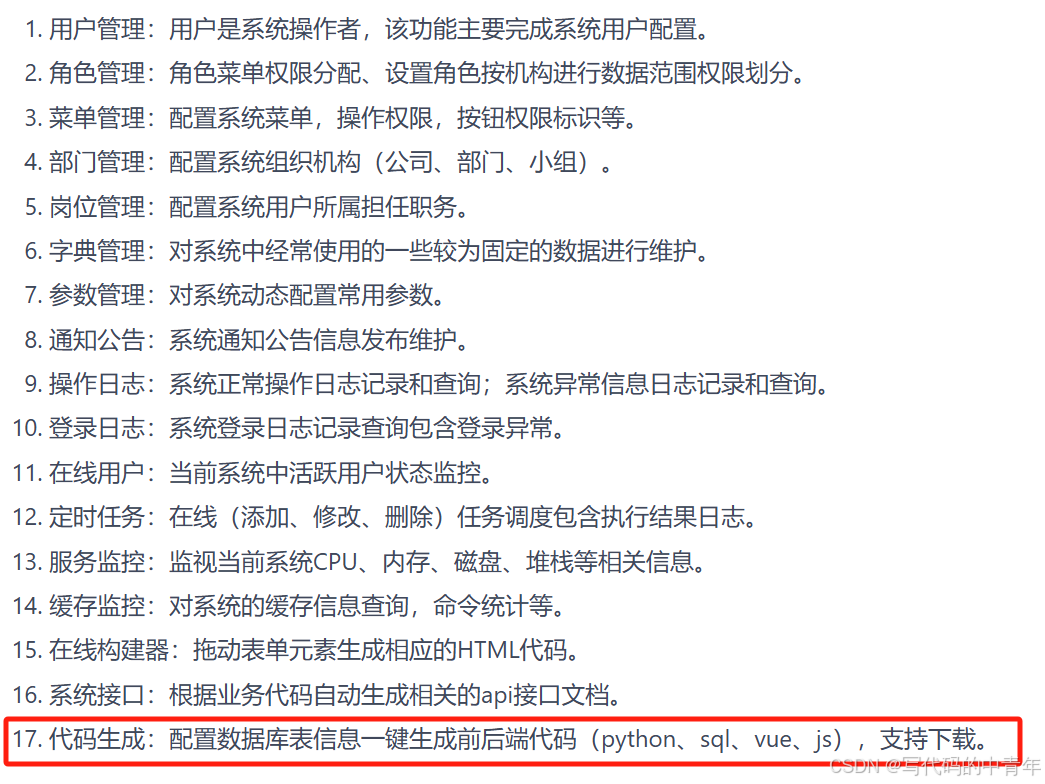
python版若依框架开发:python版若依部署
python版若依框架开发 从0起步,扬帆起航。 python版若依部署文章目录 python版若依框架开发1.源码2.概述3.部署1.源码 https://gitee.com/insistence2022/RuoYi-Vue-FastAPI 请诸君移步上述链接,即可对python版若依项目进行初步了解。 2.概述 若依框架本身基于java,可以快…...

React进阶:状态管理选择题
React进阶:状态管理选择题 引言 随着React应用复杂度增加,选择合适的状态管理方案成为我们面临的关键决策。 状态管理本质上是解决"谁来存储数据"以及"如何更新和分发这些数据"的问题。在React生态中,随着应用规模扩大…...
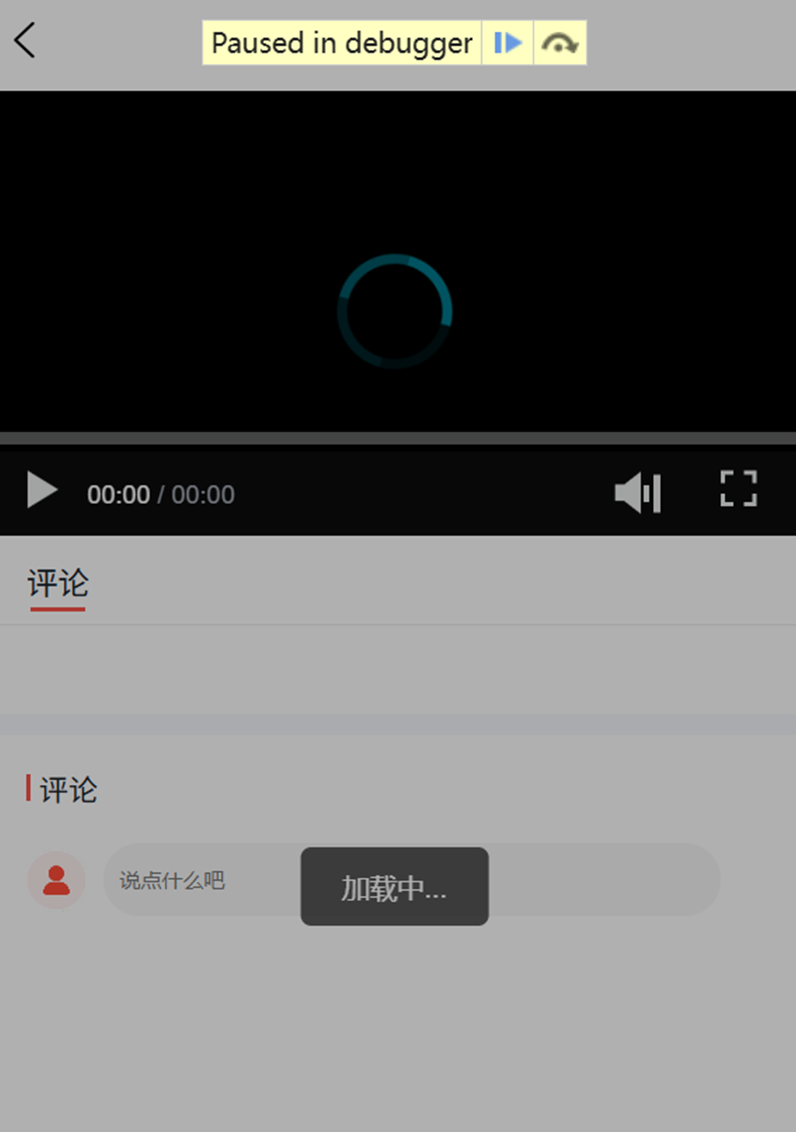
h5的aliplayer-min.js 加密视频会走到debugger
h5的aliplayer-min.js 如果 https://g.alicdn.com/apsara-media-box/imp-web-player/2.19.0/aliplayer-min.js走加密视频的话会有debugger 更换aliplayer-min.js版本解决了 https://g.alicdn.com/apsara-media-box/imp-web-player/2.25.1/aliplayer-min.js 对应css:…...

第5篇《中间件负载均衡与连接池管理机制设计》
5.1 章节导读 在数据库中间件中,如何高效地管理数据库连接与请求调度至关重要。 本节围绕两个核心模块展开: 连接池管理:提升连接复用能力,避免频繁建立/断开连接。 负载均衡策略:合理调度 SQL 请求,提升…...
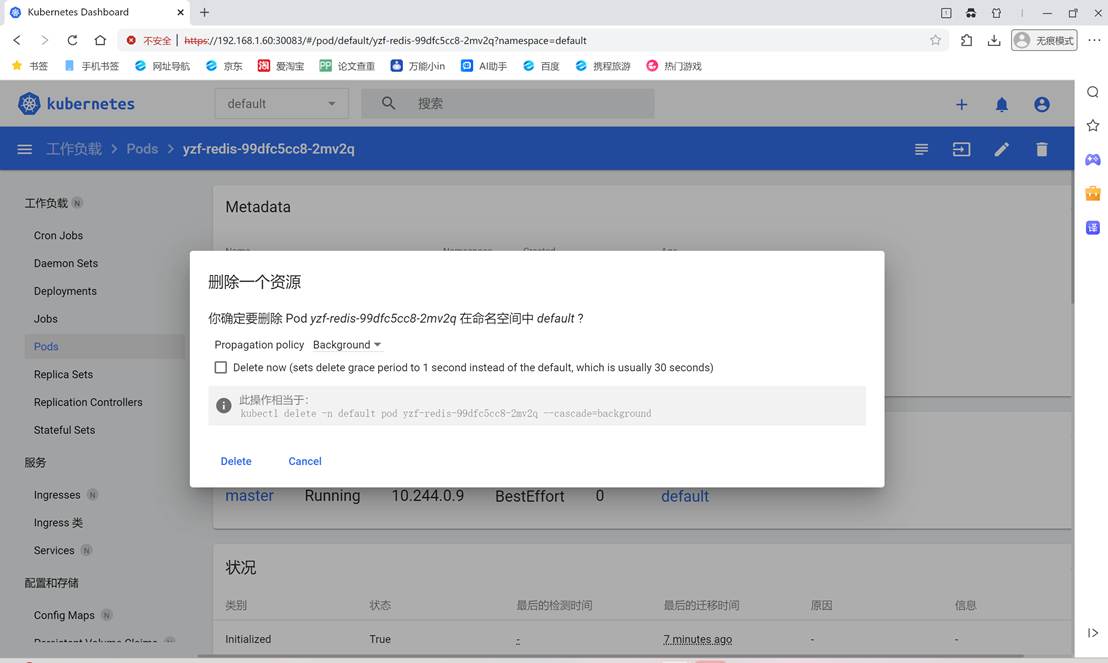
DashBoard安装使用
DashBoard安装使用 一、实验目的 1、掌握dashboard 的安装部署 2、熟悉图像化部署任务:产生pod---定义服务--验证访问 二、实验内容: 1、配置步骤 1.1、Helm安装 离线安装(适用于内网/离线环境) # 根据系统架构选择版本&am…...
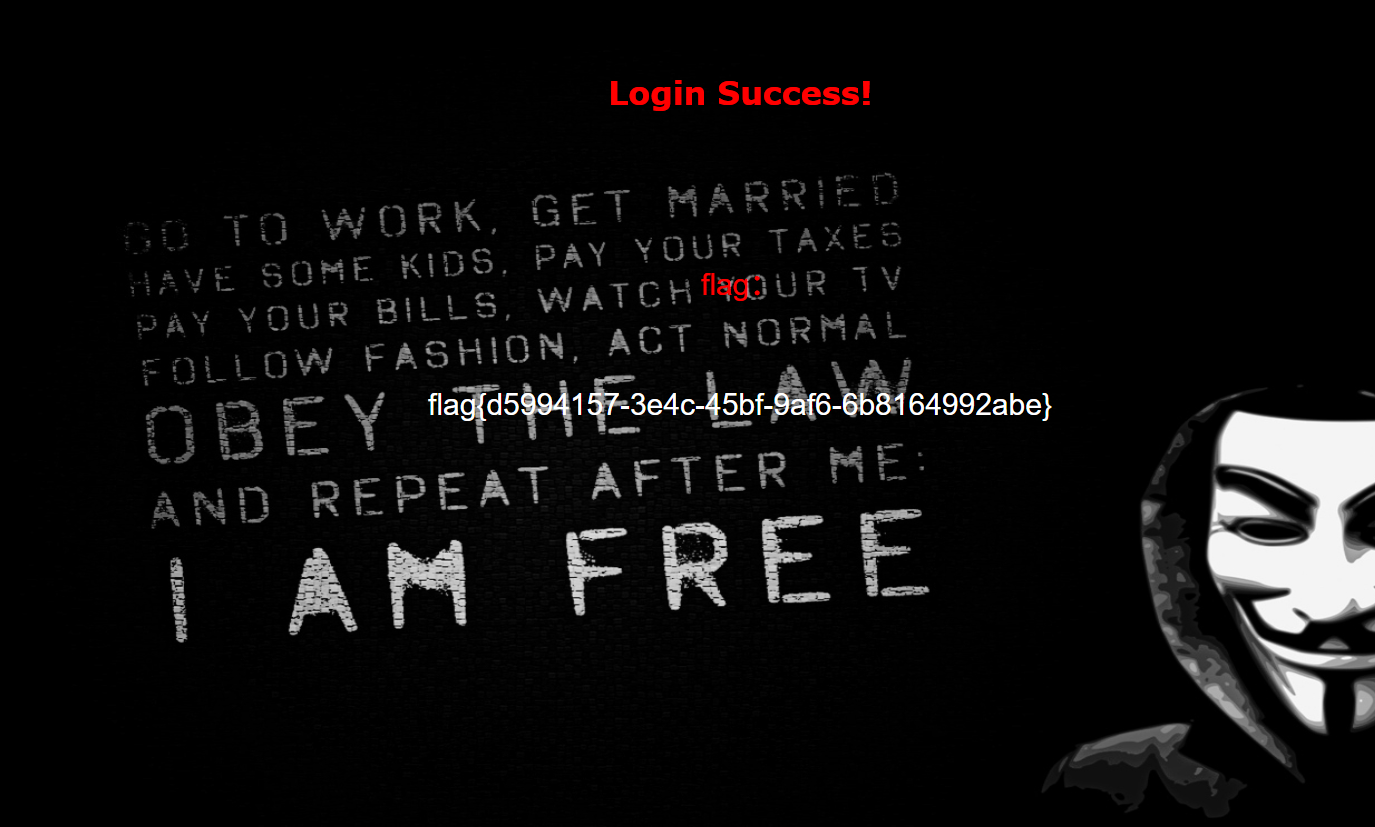
极客大挑战 2019 EasySQL 1(万能账号密码,SQL注入,HackBar)
题目 做法 启动靶机,打开给出的网址 随便输点东西进去,测试一下 输入1、1’、1"判断SQL语句闭合方式 输入以上两个都是以下结果 但是,输入1’时,出现的是另外结果 输入1,1"时,SQL语句没有…...

C# CallerMemberName特性
当你在一个方法运用了CallerMemberName特性,编译器会自动将调用该方法的方法或属性的名称作为该参数的默认值,可应用于MVVM框架。 代码: using System.ComponentModel; using System.Runtime.CompilerServices;public class Person : INoti…...
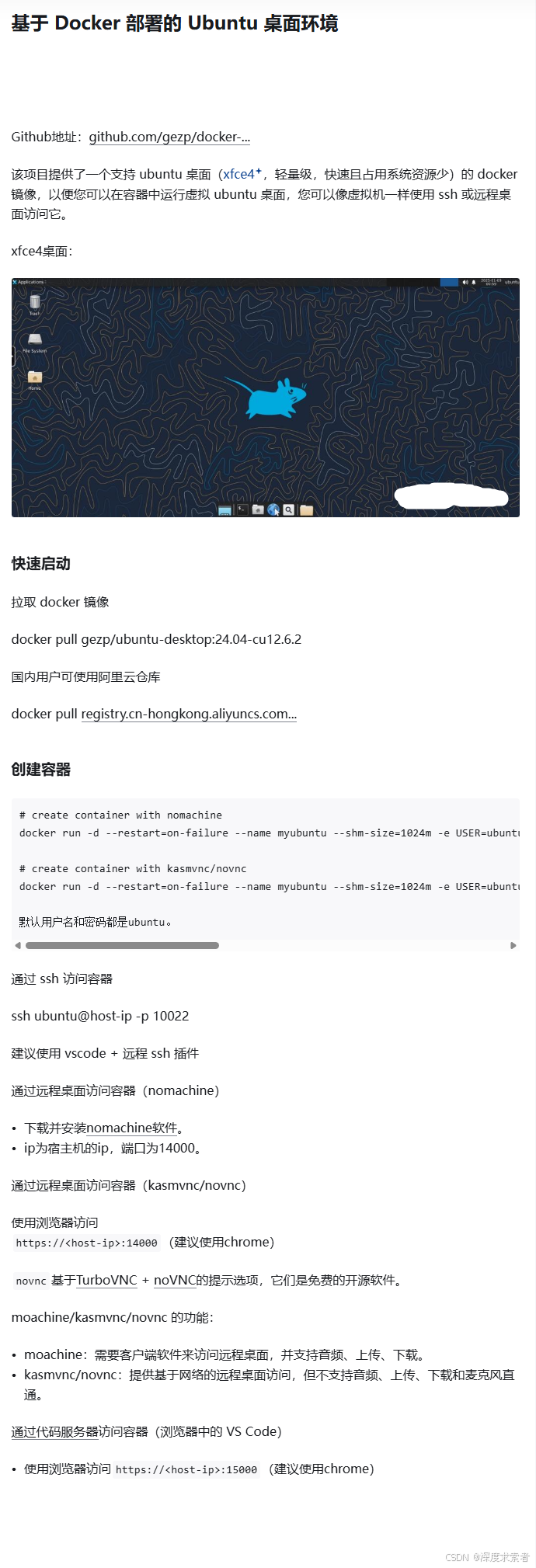
采用 Docker GPU 部署的 Ubuntu 或者 windows 桌面环境
# 国内下载不了 docker pull gezp/ubuntu-desktop:24.04-cu12.6.2# 阿里云镜像 docker pull registry.cn-hongkong.aliyuncs.com/gezp/ubuntu-desktop:24.04-cu12.6.2# create container with nomachine docker run -d --restarton-failure --name myubuntu --shm-size1024m -e…...

关于面试找工作的总结(四)
不同情况下收到offer后的处理方法 1.不会去的,只是面试练手2.还有疑问,考虑中3.offer/职位不满足期望的4.已确认,但又收到更好的5.还想挽回之前的offer6.确认,准备入职7.还想拖一下的1.不会去的,只是面试练手 HR您好,非常荣幸收到贵司的offer,非常感谢一直以来您的帮助,…...

分布式拜占庭容错算法——实现工作量证明(PoW)算法详解
Java 实现工作量证明(PoW)算法详解 一、PoW 核心原理 #mermaid-svg-AAj0Pvst1PVcVy5v {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-AAj0Pvst1PVcVy5v .error-icon{fill:#552222;}#mermaid…...
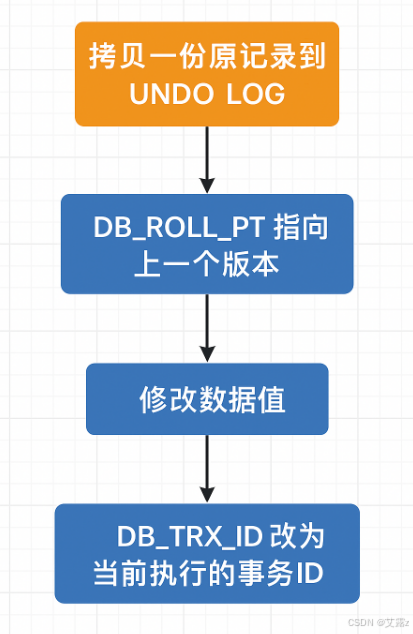
深度解析Mysql中MVCC的工作机制
MVCC,多版本并发控制 定义:维护一个数据的多个版本,使读写操作没有冲突,依赖于:隐藏字段,undo log日志,readView MVCC会为每条版本记录保存三个隐藏字段 DB_TRX_ID: 记录最近插入或修改该记录的事务IDDB_R…...
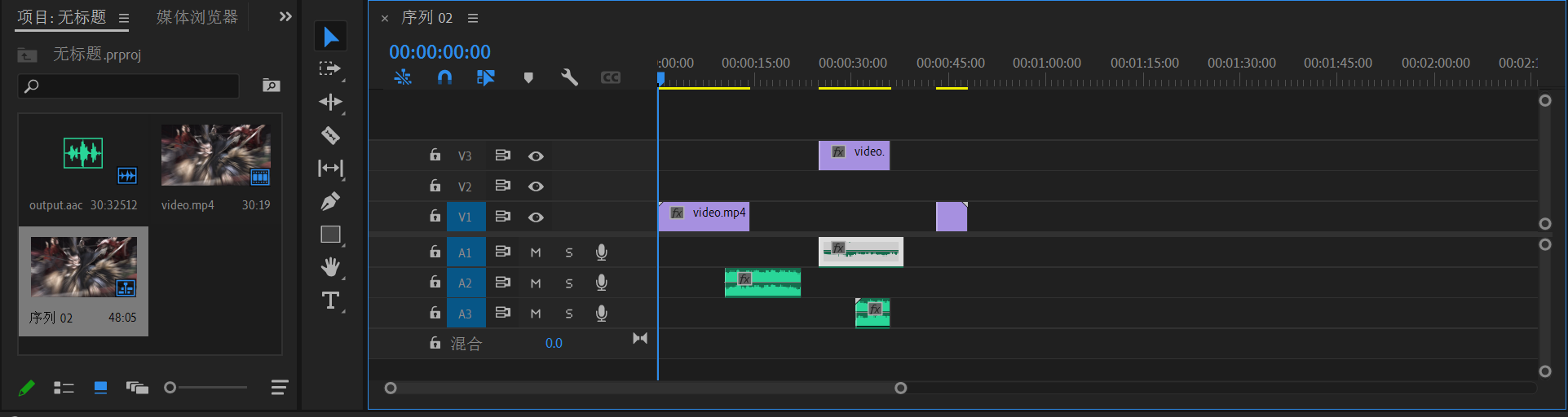
MP4文件声音与视频分离
最近学习PR剪辑 要添加视频文件和音频文件 但是直接给MP4文件 得到的是一个整体 不管怎么切分 都是无法得到单独的整体 这就需要将视频文件和音频文件分离 我推荐使用ffmpeg工具进行分离 迅雷链接:https://pan.xunlei.com/s/VORu5x64jjL-gXFd_VTpYjRPA1?pwd8wec#…...

接口自动化测试之pytest 运行方式及前置后置封装
🍅 点击文末小卡片,免费获取软件测试全套资料,资料在手,涨薪更快 一、Pytest 优点认知 1.可以结合所有的自动化测试工具 2.跳过失败用例以及失败重跑 3.结合allure生产美观报告 4.和Jenkins持续集成 5.很多强大的插件 pytest-htm…...

服务器被攻击了怎么办
可以上一个高防IP或者AI云防护都是可以的。(有效防御CC、APl接口、http、tcp、WEB应用扫描/爬虫、SYN、WAF、DDOS、UDP、入侵、渗透、SQL注入、XSS跨站脚本攻击、远程恶意代码执行、session fixation、Webshell攻击、恶意请求,恶意扫描、暴力破解、CSRF等…...

06-排序
排序 1. 排序的概念及其应用 1.1 排序的概念 排序:所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作。 稳定性:假定在待排序的记录序列中,存在多个具有相同的关键…...

python,shell,linux,bash概念的不同和对比联系
一、基本概念理解 1. Linux 是一个 操作系统内核,常与 GNU 工具集成组成完整的 Linux 操作系统。 提供对硬件的管理能力与系统调用接口。 用户通过 Shell 或 GUI 与 Linux 交互。 2. Shell 是用户与 Linux 内核之间的 命令行解释器(CLI)…...
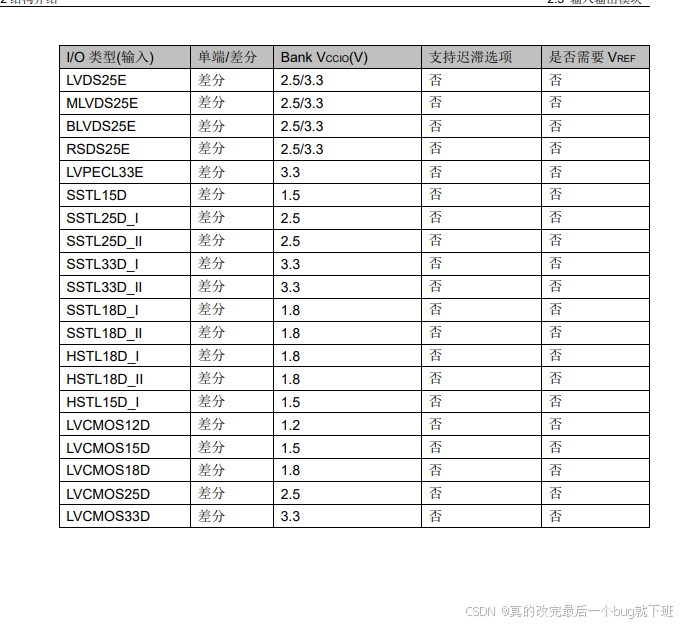
FPGA管脚类型,及选择
fpga的IO Type选择,如下: 具体的定义:...
如何在 Ubuntu22.04 上安装并开始使用 RabbitMQ
单体架构学的差不多了,可以朝着微服务进军了,笔者打算实操一下 RabbitMQ(这个和 Redis 一样重要的组件) 笔者这里采用的是本地 wsl2 的 Ubuntu22.04 先按指定的博客进行前置操作 Ubuntu22.04 安装 RabbitMQ 解决 ARM Ubuntu 22.04 缺少 libs…...
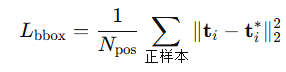
R-CNN 模型算法流程梳理
目录 一、R-CNN整体流程 二、需要注意的地方 论文连接:[1311.2524] Rich feature hierarchies for accurate object detection and semantic segmentation 如果你之前了解过RNN,很容易混淆认为R-CNN也具有RNN的时序循环功能,这种理解是错误…...

细说C语言将格式化输出到FILE *stream流的函数fprintf、_fprintf_I、fwprintf、_fwprintf_I
目录 1、将格式化数据输出到FILE *stream流基本型 (1)语法 (2)参数 (3)示例 2、将格式化数据输出到FILE *stream流并启用并启用在格式字符串中使用参数的顺序的规范 (1)语法 …...