如何在IDE中通过Spark操作Hive
在IDE中通过Spark操作Hive是一项常见的任务,特别是在大数据处理和分析的场景中。本文将详细介绍如何在集成开发环境(IDE)中使用Apache Spark与Hive进行交互,包括必要的设置、代码示例以及详细解释。
环境准备
在开始之前,需要确保以下软件已安装并配置正确:
- Java Development Kit (JDK) :建议使用JDK 8或更高版本。
- Apache Spark:建议使用最新稳定版本。
- Apache Hive:建议使用最新稳定版本。
- IDE:推荐使用IntelliJ IDEA或Eclipse,本文以IntelliJ IDEA为例。
- Hadoop:Hive依赖Hadoop,确保Hadoop已经正确安装和配置。
- Maven:用于管理项目依赖。
步骤一:创建Maven项目
在IntelliJ IDEA中创建一个新的Maven项目,并添加以下依赖到 pom.xml文件中:
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.example</groupId><artifactId>spark-hive-example</artifactId><version>1.0-SNAPSHOT</version><properties><maven.compiler.source>1.8</maven.compiler.source><maven.compiler.target>1.8</maven.compiler.target></properties><dependencies><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><version>3.1.2</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.12</artifactId><version>3.1.2</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-hive_2.12</artifactId><version>3.1.2</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.2.2</version></dependency></dependencies>
</project>
步骤二:配置Spark和Hive
在项目根目录下创建 src/main/resources目录,并添加 hive-site.xml文件,用于配置Hive的相关信息。
<configuration><property><name>hive.metastore.uris</name><value>thrift://localhost:9083</value><description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description></property><property><name>hive.metastore.warehouse.dir</name><value>/user/hive/warehouse</value><description>location of default database for the warehouse</description></property><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value><description>JDBC connect string for a JDBC metastore</description></property><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.cj.jdbc.Driver</value><description>Driver class name for a JDBC metastore</description></property><property><name>javax.jdo.option.ConnectionUserName</name><value>hiveuser</value><description>username to use against metastore database</description></property><property><name>javax.jdo.option.ConnectionPassword</name><value>hivepassword</value><description>password to use against metastore database</description></property>
</configuration>
确保你的MySQL数据库已经创建并配置正确,并且Hive的MetaStore可以连接到该数据库。
步骤三:编写Spark代码
在 src/main/java/com/example目录下创建一个名为 SparkHiveExample.java的文件,并添加以下代码:
package com.example;import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;public class SparkHiveExample {public static void main(String[] args) {// 创建SparkSession,并启用Hive支持SparkSession spark = SparkSession.builder().appName("Spark Hive Example").config("spark.sql.warehouse.dir", "/user/hive/warehouse").enableHiveSupport().getOrCreate();// 显示SparkSession中的所有配置System.out.println(spark.conf().getAll());// 创建Hive数据库spark.sql("CREATE DATABASE IF NOT EXISTS example_db");// 使用创建的数据库spark.sql("USE example_db");// 创建Hive表spark.sql("CREATE TABLE IF NOT EXISTS example_table (id INT, name STRING)");// 加载数据到Hive表spark.sql("INSERT INTO example_table VALUES (1, 'Alice'), (2, 'Bob')");// 查询Hive表中的数据Dataset<Row> df = spark.sql("SELECT * FROM example_table");df.show();// 关闭SparkSessionspark.stop();}
}
代码解释
- 创建SparkSession:使用
SparkSession.builder()创建Spark会话,并启用Hive支持。 - 显示配置:通过
spark.conf().getAll()显示当前Spark会话的所有配置,便于调试。 - 创建数据库:通过SQL语句
CREATE DATABASE IF NOT EXISTS example_db创建名为example_db的数据库。 - 使用数据库:通过SQL语句
USE example_db切换到创建的数据库。 - 创建表:通过SQL语句
CREATE TABLE IF NOT EXISTS example_table (id INT, name STRING)创建名为example_table的表。 - 插入数据:通过SQL语句
INSERT INTO example_table VALUES (1, 'Alice'), (2, 'Bob')向表中插入数据。 - 查询数据:通过SQL语句
SELECT * FROM example_table查询表中的数据,并使用df.show()显示结果。 - 关闭SparkSession:通过
spark.stop()关闭Spark会话。
详细分析
在上述过程中,有几个关键点需要特别注意:
- 依赖管理:确保在
pom.xml中添加了正确的依赖,以便Spark能够正确使用Hive。 - 配置文件:正确配置
hive-site.xml文件,以确保Spark可以连接到Hive MetaStore。 - 代码逻辑:理解每一步操作的意义,确保操作顺序正确,从创建数据库、使用数据库到操作表数据。
实际应用
在实际应用中,Spark与Hive的结合可以用于大规模数据处理和分析。常见的应用场景包括:
- ETL(提取、转换、加载) :将数据从各种数据源提取出来,经过转换后加载到Hive中,便于后续分析。
- 数据仓库:使用Hive作为数据仓库,Spark进行复杂的数据分析和处理。
- 实时数据处理:结合Spark Streaming,实现对实时数据的处理,并将结果存储到Hive中。
通过以上方法和代码示例,你可以在IDE中成功通过Spark操作Hive,实现大规模数据处理和分析。
相关文章:

如何在IDE中通过Spark操作Hive
在IDE中通过Spark操作Hive是一项常见的任务,特别是在大数据处理和分析的场景中。本文将详细介绍如何在集成开发环境(IDE)中使用Apache Spark与Hive进行交互,包括必要的设置、代码示例以及详细解释。 环境准备 在开始之前&#x…...
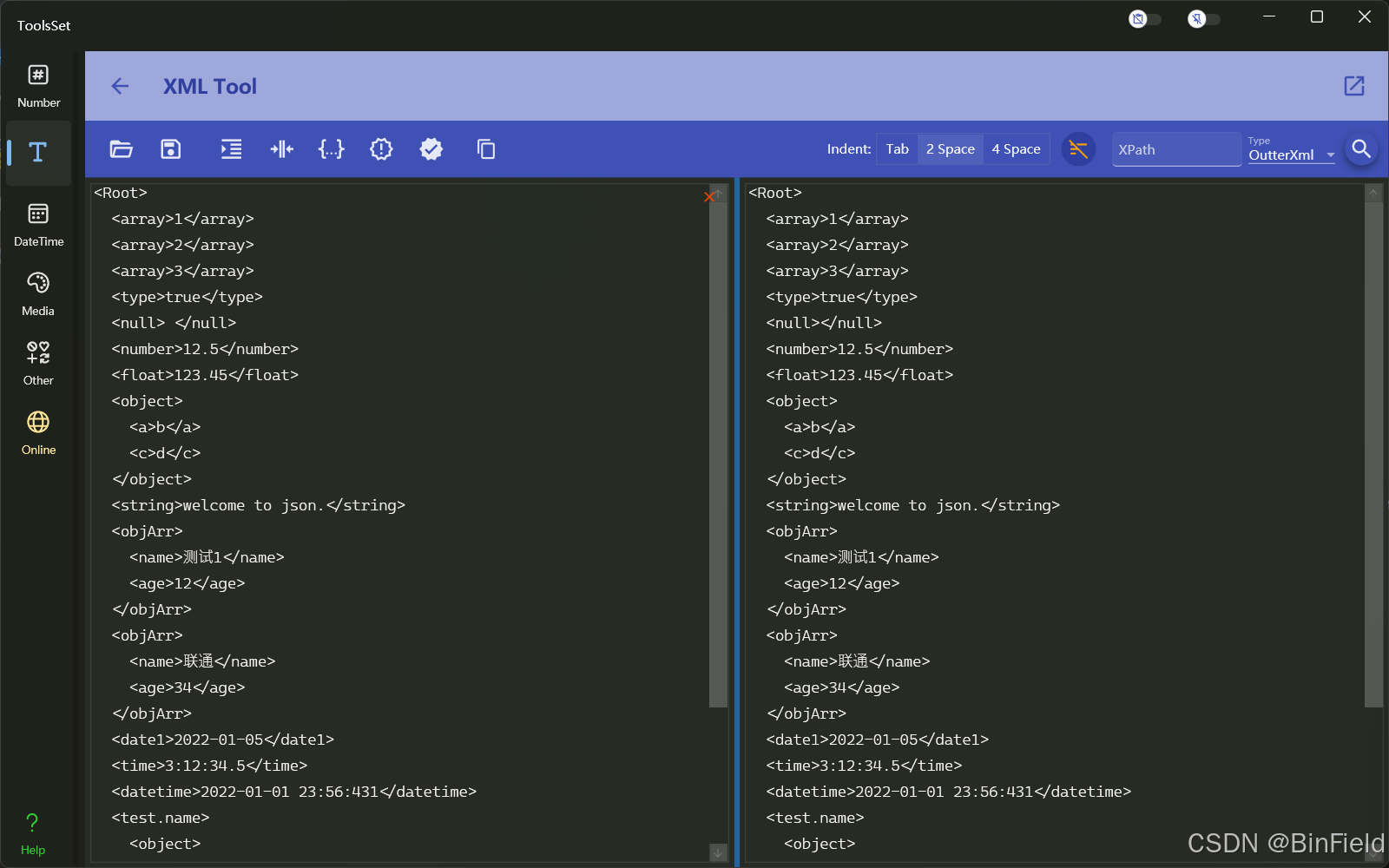
ToolsSet之:XML工具
ToolsSet是微软商店中的一款包含数十种实用工具数百种细分功能的工具集合应用,应用基本功能介绍可以查看以下文章: Windows应用ToolsSet介绍https://blog.csdn.net/BinField/article/details/145898264 ToolsSet中Text菜单下的XML Tool工具是一个Xml工…...
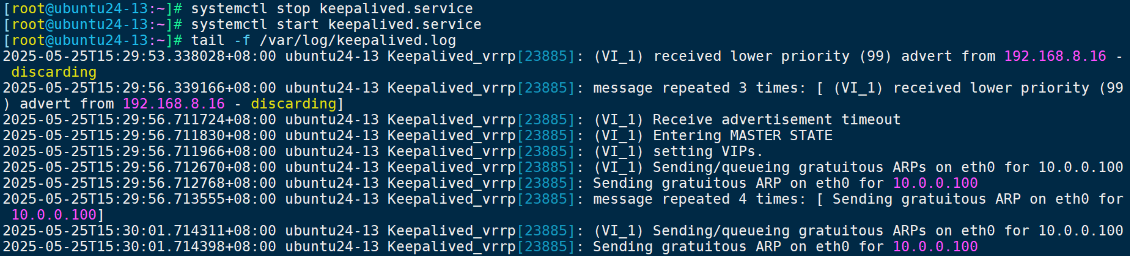
keepalived定制日志bug
keepalived定制日志bug 源码安装apt安装endl 源码安装 在/etc/rsyslog.d/目录下创建 keepalived的日志配置文件keepalived.conf [rootubuntu24-13:~]# vim /etc/rsyslog.d/keepalived.conf [rootubuntu24-13:~]# cat /etc/rsyslog.d/keepalived.conf local6.* /var/log/keepa…...

ElasticSearch+Gin+Gorm简单示例
更多个人笔记见: (注意点击“继续”,而不是“发现新项目”) github个人笔记仓库 https://github.com/ZHLOVEYY/IT_note gitee 个人笔记仓库 https://gitee.com/harryhack/it_note 个人学习,学习过程中还会不断补充&…...

数据库系统概论(十三)详细讲解SQL中数据更新(插入,修改与更新)
数据库系统概论(十三)详细讲解SQL中数据更新 前言一、数据插入1. 插入数据是什么?2.插入单条数据(插入元组)场景 1:指定部分列插入场景 2:不指定列名(插入所有列)场景 3&…...

JVMTI 在安卓逆向工程中的应用
JVMTI 在安卓逆向工程中的应用 JVMTI 在安卓逆向工程中扮演着重要角色,尤其是在分析和修改 Java 层应用行为时。以下是其核心应用场景、实现方式及典型工具: 一、核心应用场景 1. 动态代码注入与 hook 通过 JVMTI 可以在运行时修改或拦截 Java 方法&…...
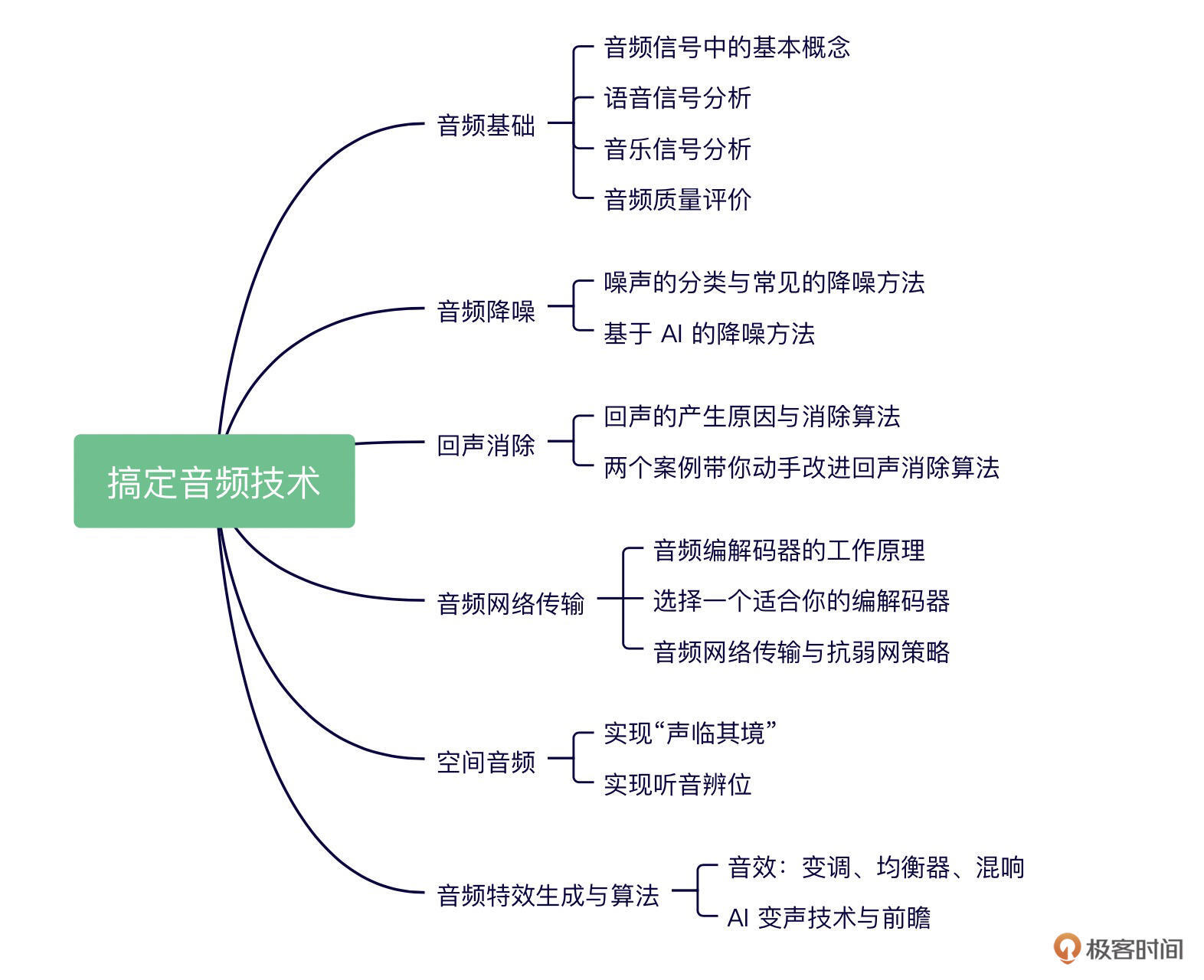
极客时间-《搞定音频技术》-学习笔记
极客时间-《搞定音频技术》-学习笔记 语音基础知识 https://www.zhangzhenhu.com/audio/feature.html 序章-0 作者说这个语音技术啊,未来肯定前景大好啊,大家都来学习,然后给出了课程的脑图 音频基础 什么是声音 声音的三要素是指响度、…...
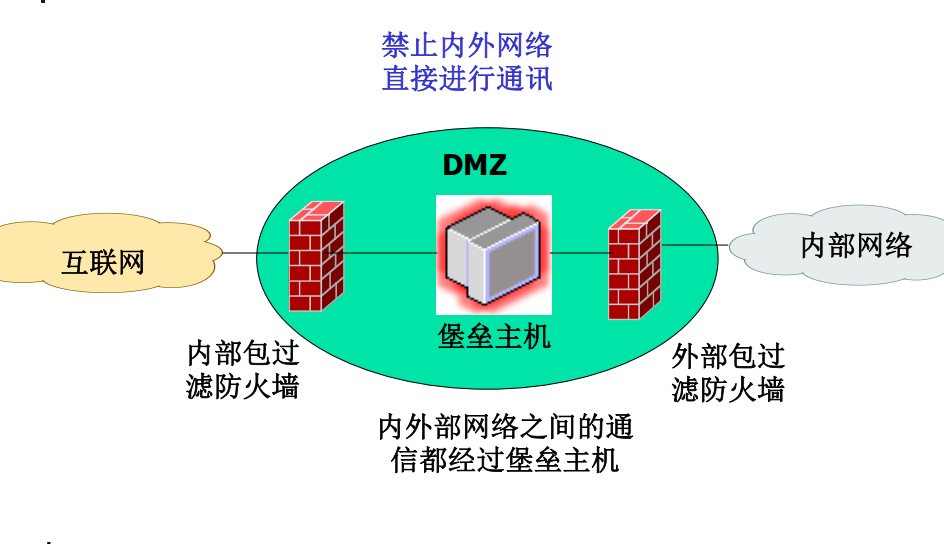
网络攻防技术十三:网络防火墙
文章目录 一、网络防火墙概述1、网络型防火墙(网络防火墙)2、Web应用防火墙3、数据库防火墙4、主机防火墙(个人防火墙)5、网络防火墙的功能 二、防火墙工作原理1、无状态包过滤防火墙2、有状态包过滤防火墙(状态检测/动…...

Express 集成Sequelize+Sqlite3 默认开启WAL 进程间通信 Conf 打包成可执行 exe 文件
代码:express-exe: 将Express开发的js打包成exe服务丢给客户端使用 实现目标 Express 集成 Sequelize 操作 Sqlite3 数据库; 启动 Sqlite3 时默认开启 WAL 模式,避免读写互锁,支持并发读; 利用 Conf 实现主进程与 Ex…...

CppCon 2015 学习:A C++14 Approach to Dates and Times
Big Picture — 日期库简介 扩展 标准库 这个库是对 C 标准库中 <chrono> 的自然延伸,专注于处理“日历”相关的功能(比如年月日、闰年、节假日等),而不仅仅是时间点和时长。极简设计 它是**单头文件(header-on…...

基于CNN的OFDM-IM信号检测系统设计与实现
基于CNN的OFDM-IM信号检测系统设计与实现 摘要 本文详细研究了基于卷积神经网络(CNN)的正交频分复用索引调制(OFDM-IM)信号检测方法。通过在不同信噪比(SNR)和信道条件下进行系统仿真,对比分析了CNN检测器与传统最大似然(ML)检测器的误码率(BER)性能和计算复杂度。实验结果表…...
)
macos常见且应该避免被覆盖的系统环境变量(避免用 USERNAME 作为你的自定义变量名)
文章目录 macos避免用 USERNAME 作为你的自定义变量名macos常见且应该避免被覆盖的系统环境变量 macos避免用 USERNAME 作为你的自定义变量名 问题: 你执行了:export USERNAME“admin” 然后执行:echo ${USERNAME} 输出却是:xxx …...

2024年认证杯SPSSPRO杯数学建模D题(第二阶段)AI绘画带来的挑战解题全过程文档及程序
2024年认证杯SPSSPRO杯数学建模 D题 AI绘画带来的挑战 原题再现: 2023 年开年,ChatGPT 作为一款聊天型AI工具,成为了超越疫情的热门词条;而在AI的另一个分支——绘图领域,一款名为Midjourney(MJÿ…...

深入理解CSS常规流布局
引言 在网页设计中,理解元素如何排列和相互作用至关重要。CSS提供了三种主要的布局方式:常规流、浮动和定位。本文将重点探讨最基础也是最常用的常规流布局(Normal Flow),帮助开发者掌握页面布局的核心机制。 什么是…...

DOCKER使用记录
1、拉取镜像 直接使用docker pull <image>,大概率会出现下面的报错信息: (base) jetsonyahboom:~$ docker pull ubuntu:18.04 Error response from daemon: Get "https://registry-1.docker.io/v2/": net/http: request canceled while …...

MYSQL中常见的函数和使用
字符串函数 CONCAT(str1,str2,...,strN) :用于将多个字符串连接成一个字符串。例如,SELECT CONCAT(SQL, , 函数) ,结果为 “SQL 函数”。 LOWER(str) :将字符串中的所有字母转换为小写。例如,SELECT LOWER(MySQL Fun…...
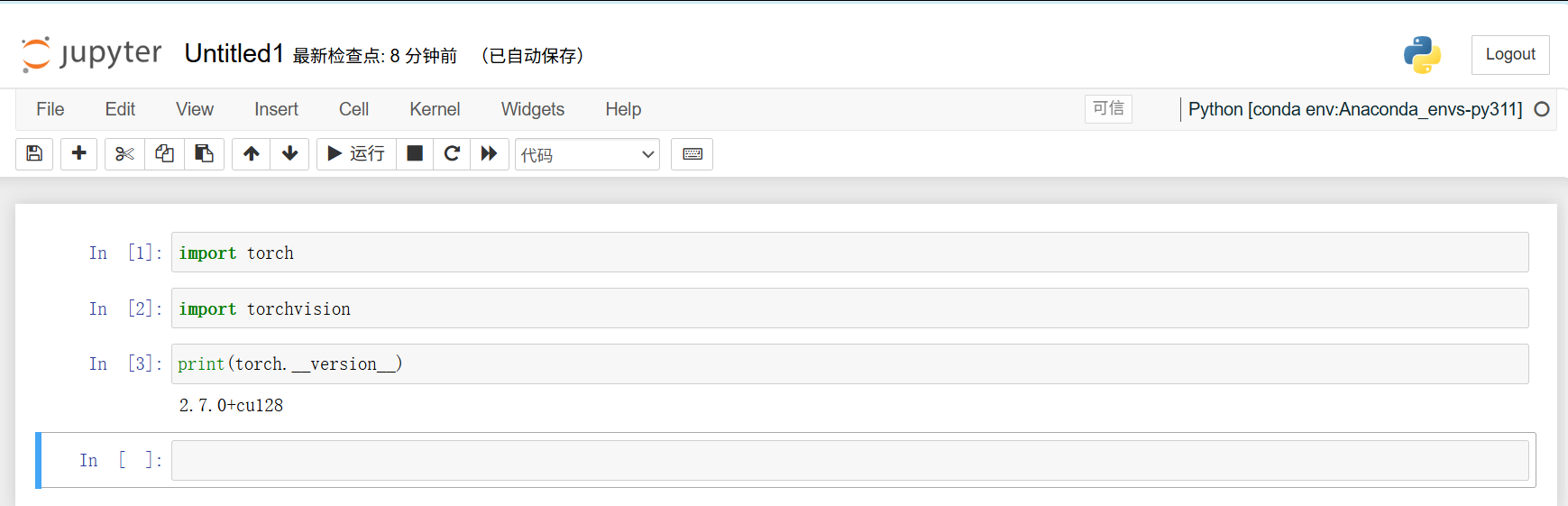
【深度学习相关安装及配环境】Anaconda搭建虚拟环境并安装CUDA、cuDVV和对应版本的Pytorch,并在jupyter notebook上部署
目录 1. 查看自己电脑的cuda版本2.安装cuda关于环境变量的配置测试一下,安装完成 3.安装cuDVV环境变量的配置测试一下,安装完成 4.创建虚拟环境先安装镜像源下载3.11版本py 5.在虚拟环境下,下载pytorch6.验证是否安装成功7.在jupyter noteboo…...
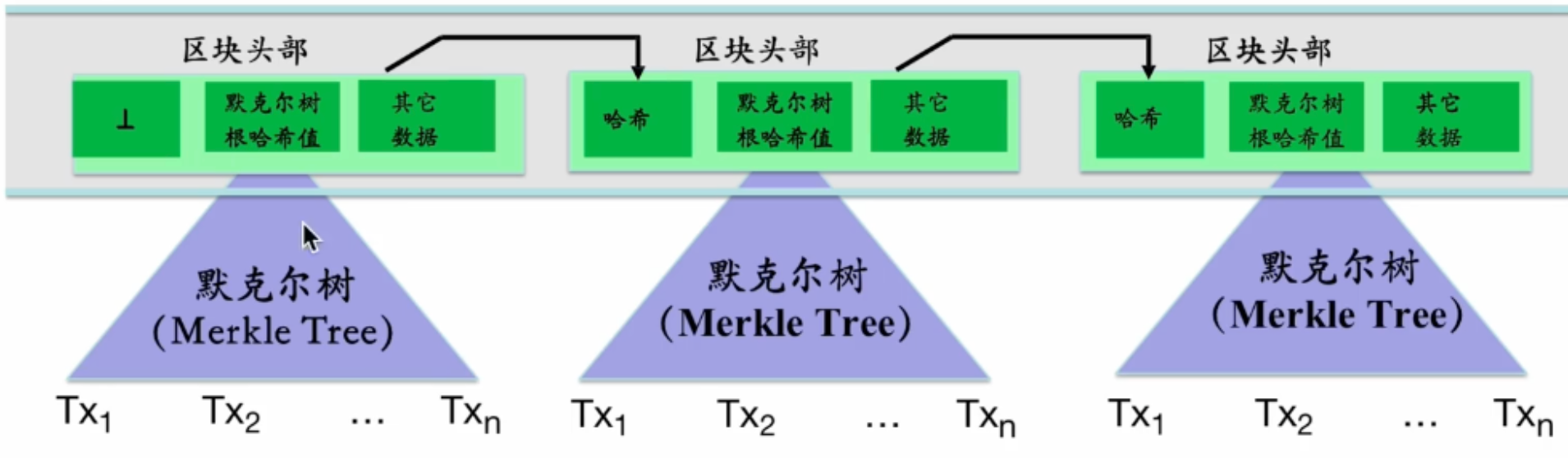
web3-区块链基础:从区块添加机制到哈希加密与默克尔树结构
区块链基础:从区块添加机制到哈希加密与默克尔树结构 什么是区块链 抽象的回答: 区块链提供了一种让多个参与方在没有一个唯一可信方的情况下达成合作 若有可信第三方 > 不需要区块链 [金融系统中常常没有可信的参与方] 像股票市场,或者一个国家的…...
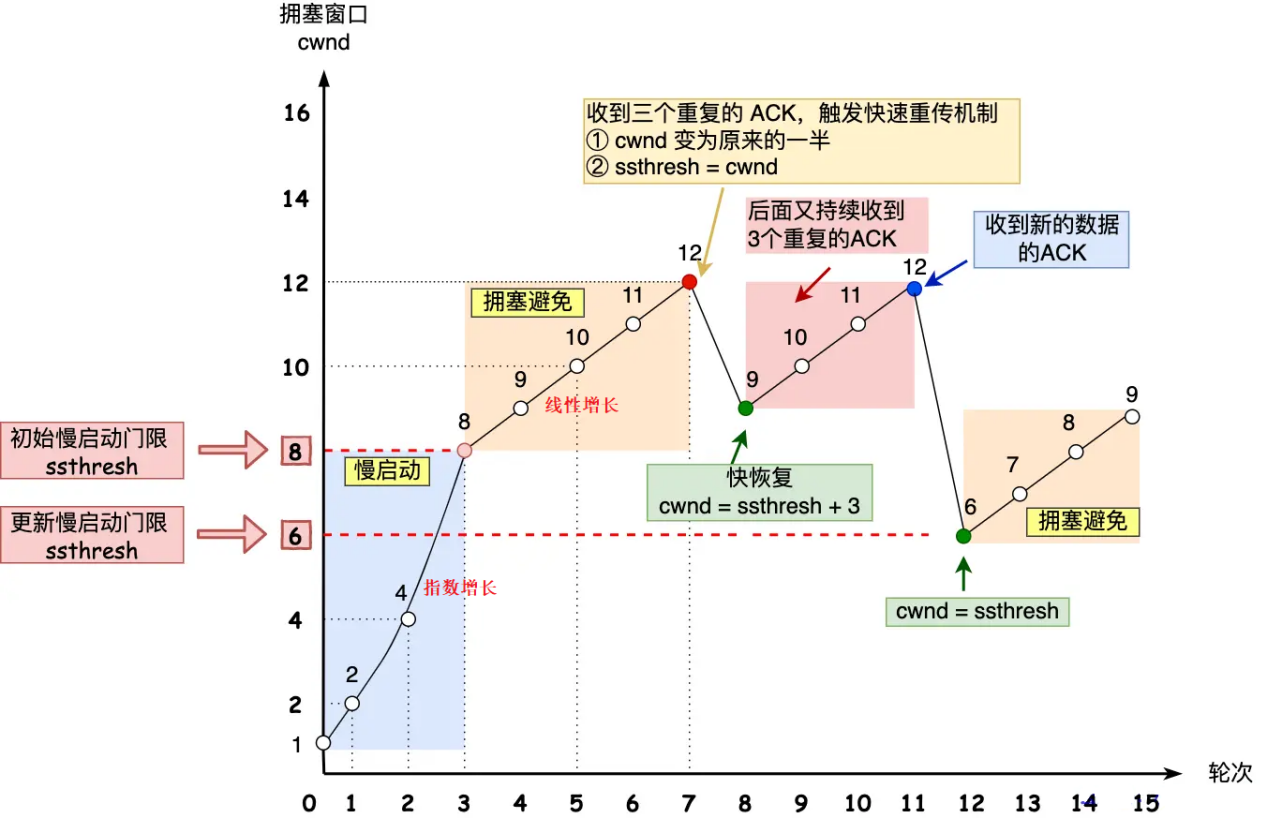
TCP小结
1. 核心特性 面向连接:通过三次握手建立连接,四次挥手终止连接,确保通信双方状态同步。 TCP连接建立的3次握手 抓包: client发出连接请求; server回应client请求,并且同步发送syn连接; clien…...

django ssh登录 并执行命令
在Django开发环境中,通常不推荐直接通过SSH登录到服务器并执行命令,因为这违背了Django的架构设计原则,即前端与后端分离。Django主要负责处理Web请求、逻辑处理和数据库交互,而不直接执行系统级命令。然而,在某些情况…...

unix/linux,sudo,其高级使用
掌握了sudo的基石,现在是时候向更高阶的技巧和应用进发了!sudo的强大远不止于简单的sudo <command>。它的高级用法能让你在复杂的系统管理和安全场景中游刃有余,如同经验丰富的物理学家巧妙运用各种定律解决棘手问题。 sudo 的高级使用技巧与场景 精细化命令控制与参…...

Python 打包指南:setup.py 与 pyproject.toml 的全面对比与实战
在 Python 开发中,创建可安装的包是分享代码的重要方式。本文将深入解析两种主流打包方法——setup.py 和 pyproject.toml,并通过一个实际项目示例,展示如何使用现代的 pyproject.toml 方法构建、测试和发布 Python 包。 一、setup.py 与 pyp…...

计算机视觉与深度学习 | 基于OpenCV的实时睡意检测系统
基于OpenCV的实时睡意检测系统 下面是一个完整的基于OpenCV的睡意检测系统实现,该系统使用眼睛纵横比(EAR)算法检测用户是否疲劳或瞌睡。 import cv2 import numpy as np import dlib from scipy.spatial import distance as dist import pygame import time# 初始化pygame用…...

python打卡day44@浙大疏锦行
知识点回顾: 预训练的概念常见的分类预训练模型图像预训练模型的发展史预训练的策略预训练代码实战:resnet18 作业: 尝试在cifar10对比如下其他的预训练模型,观察差异,尽可能和他人选择的不同尝试通过ctrl进入resnet的…...

性能优化 - 案例篇:缓存_Guava#LoadingCache设计
文章目录 Pre引言1. 缓存基本概念2. Guava 的 LoadingCache2.1 引入依赖与初始化2.2 手动 put 与自动加载(CacheLoader)2.2.1 示例代码 2.3 缓存移除与监听(invalidate removalListener) 3. 缓存回收策略3.1 基于容量的回收&…...

NiceGUI 是一个基于 Python 的现代 Web 应用框架
NiceGUI 是一个基于 Python 的现代 Web 应用框架,它允许开发者直接使用 Python 构建交互式 Web 界面,而无需编写前端代码。以下是 NiceGUI 的主要功能和特点: 核心功能 1.简单易用的 UI 组件 提供按钮、文本框、下拉菜单、滑块、图表等常见…...

生动形象理解CNN
好的!我们把卷积神经网络(CNN)想象成一个专门识别图像的“侦探小队”,用破案过程来生动解释它的工作原理: 🕵️♂️ 案件:识别一张“猫片” 侦探小队(CNN)的破案流程&am…...
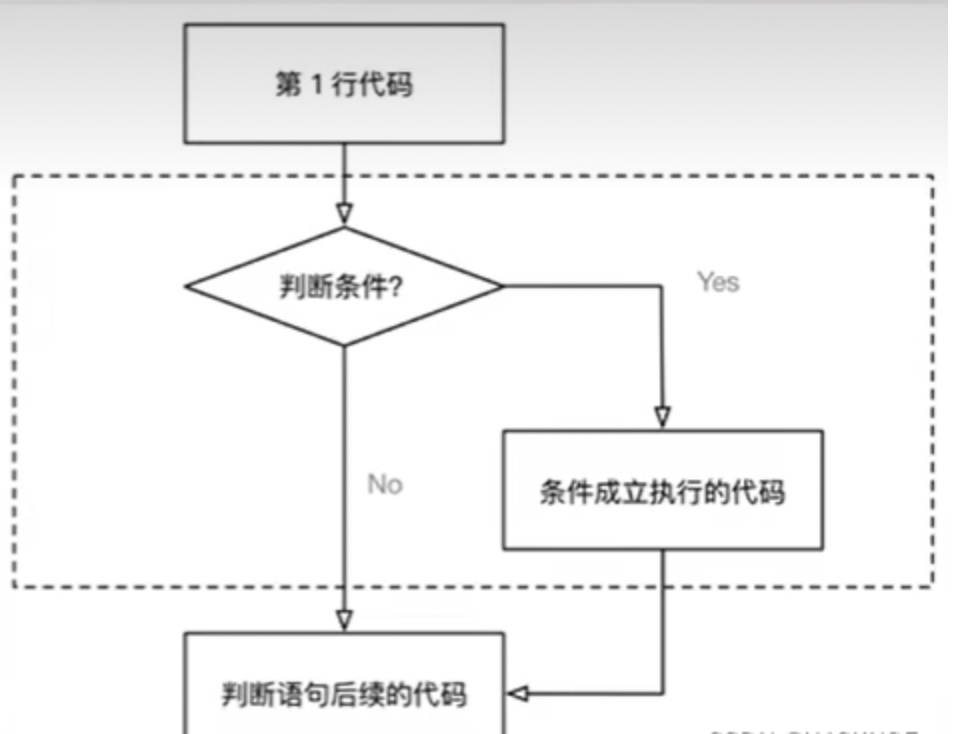
python入门(1)
第一章 第一个python程序 1.1 print函数 print方法的作用 : 把想要输出的内容打印在屏幕上 print("Hello World") 1.2 输出中文 在Python 2.x版本中,默认的编码方式是ASCII编码方式,如果程序中用到了中文,直接输出结果很可能会…...
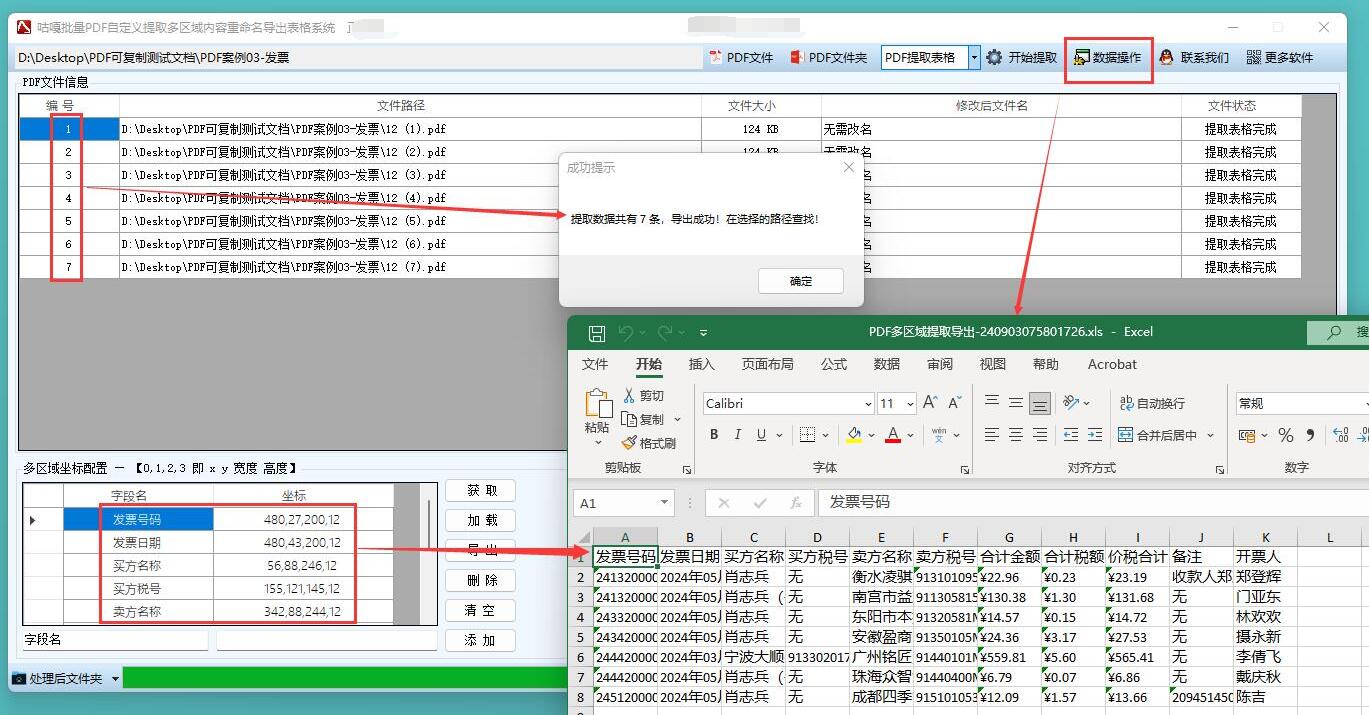
【PDF提取表格】如何提取发票内容文字并导出到Excel表格,并将发票用发票号改名,基于pdf电子发票的应用实现
应用场景 该应用主要用于企业财务部门或个人处理大量电子发票,实现以下功能: 自动从 PDF 电子发票中提取关键信息(如发票号码、日期、金额、销售方等)将提取的信息整理并导出到 Excel 表格,方便进行财务统计和报销使…...

Hugging Face 最新开源 SmolVLA 小模型入门教程(一)
系列文章目录 目录 系列文章目录 前言 一、引言 二、认识 SmolVLA! 三、如何使用SmolVLA? 3.1 安装 3.2 微调预训练模型 3.3 从头开始训练 四、方法 五、主要架构 5.1 视觉语言模型(VLM) 5.2 动作专家:流匹…...