性能优化 - 案例篇:缓存_Guava#LoadingCache设计
文章目录
- Pre
- 引言
- 1. 缓存基本概念
- 2. Guava 的 LoadingCache
- 2.1 引入依赖与初始化
- 2.2 手动 put 与自动加载(CacheLoader)
- 2.2.1 示例代码
- 2.3 缓存移除与监听(invalidate + removalListener)
- 3. 缓存回收策略
- 3.1 基于容量的回收(LRU)
- 3.2 基于时间的回收
- 3.3 基于 JVM GC 的回收
- 3.3.1 GC 回收引发的缓存颠簸问题
- 4. 常见缓存算法简介
- 4.1 FIFO(先进先出)
- 4.2 LRU(最近最少使用)
- 4.3 LFU(最近最不常用)
- 5. 简易 LRU 实现——LinkedHashMap
- 5.1 功能局限与线程安全
- 6. 操作系统层面的预读与文件缓存
- 7. 缓存优化的一般思路
- 8. 缓存应用案例
- 9. 小结

Pre
性能优化 - 理论篇:常见指标及切入点
性能优化 - 理论篇:性能优化的七类技术手段
性能优化 - 理论篇:CPU、内存、I/O诊断手段
性能优化 - 工具篇:常用的性能测试工具
性能优化 - 工具篇:基准测试 JMH
性能优化 - 案例篇:缓冲区
- 引言:解释缓存与缓冲的区别及缓存在性能优化中的重要性;
- 缓存基本概念:缓存的本质、应用场景、进程内 vs 进程外缓存;
- Guava LoadingCache(LC)示例:
3.1 引入依赖与初始化配置;
3.2 手动 put 与自动加载(CacheLoader)模式;
3.3 缓存容量、初始大小与并发级别设置;
3.4 缓存移除与监听(invalidate + removalListener); - 缓存回收策略:
4.1 基于容量的回收(LRU);
4.2 基于时间的回收(expireAfterWrite / expireAfterAccess);
4.3 基于 JVM GC 的回收(weakKeys / weakValues / softValues);
4.4 GC 回收引发的缓存颠簸问题与解决思路; - 缓存算法简述:FIFO、LRU、LFU 三种常见策略;
- 用 LinkedHashMap 实现简易 LRU:
6.1 LinkedHashMap 构造参数与访问顺序;
6.2 覆盖 removeEldestEntry 实现容量控制;
6.3 线程安全与功能局限性说明; - 操作系统层面的预读与文件缓存:readahead 机制、完全加载策略;
- 缓存优化一般思路:何时用缓存、容量与命中率考量;
- 缓存的一些注意事项与示例:HTTP 304、CDN;
引言
在性能优化 - 案例篇:缓冲区中,介绍了“缓冲”这一优化手段——通过将数据暂存到内存缓冲区,批量顺序读写来缓解设备间的速度差异。与缓冲相伴随的“孪生兄弟”就是缓存(Cache)。缓存将常用数据放到相对高速的存储层(如内存)中,从而在后续访问时实现瞬时读取,显著提升性能。
举例而言:
- 浏览热门页面时,只要缓存中已有渲染结果,就可以实现“秒开”;
- 对数据库而言,引入缓存后,频繁查询热点记录可以直接命中缓存,数据库几乎无需负载。
缓存几乎是软件中最常见的优化技术。从 CPU L1/L2/L3 缓存到 Redis、Memcached 这样的分布式缓存,无不围绕“速度差异协调”这一核心展开。
接下来我们主要聚焦于进程内缓存——堆内缓存,以 Guava 的 LoadingCache 为示例讲解堆内缓存设计思路、常见回收策略和算法实现。
1. 缓存基本概念
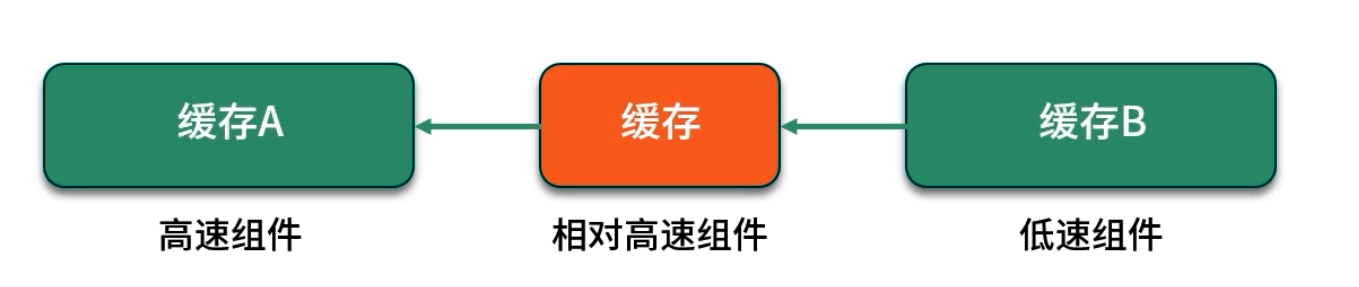
缓存的核心作用,是在两个速度差异巨大的组件之间增加一层高速存储:
- 速度慢组件:如数据库、文件存储,访问一次可能耗费几毫秒或更长;
- 速度快组件:如 CPU 寄存器、内存读写,只需几十纳秒;
- 缓存层(中间层):通常部署在内存中,通过哈希映射、LRU 回收等策略,只要缓存命中就能以几百纳秒返回结果。
根据缓存所在的物理位置,可将其分为:
- 进程内缓存(堆内缓存):直接存放在 JVM 堆里,访问速度最快,但容量受限于可用堆内存;
- 进程外缓存(进程间或分布式缓存):如 Redis、Memcached,通常运行在独立进程或集群里,通过网络访问,虽然速度比数据库快许多,但仍比堆内缓存慢一个数量级;
接下来重点讲解 进程内缓存,常见实现包括 Guava Cache、Caffeine、Ehcache、JCache 等。它们都提供了基于内存分片、高并发访问、灵活回收策略和统计监控的堆内缓存解决方案。
2. Guava 的 LoadingCache
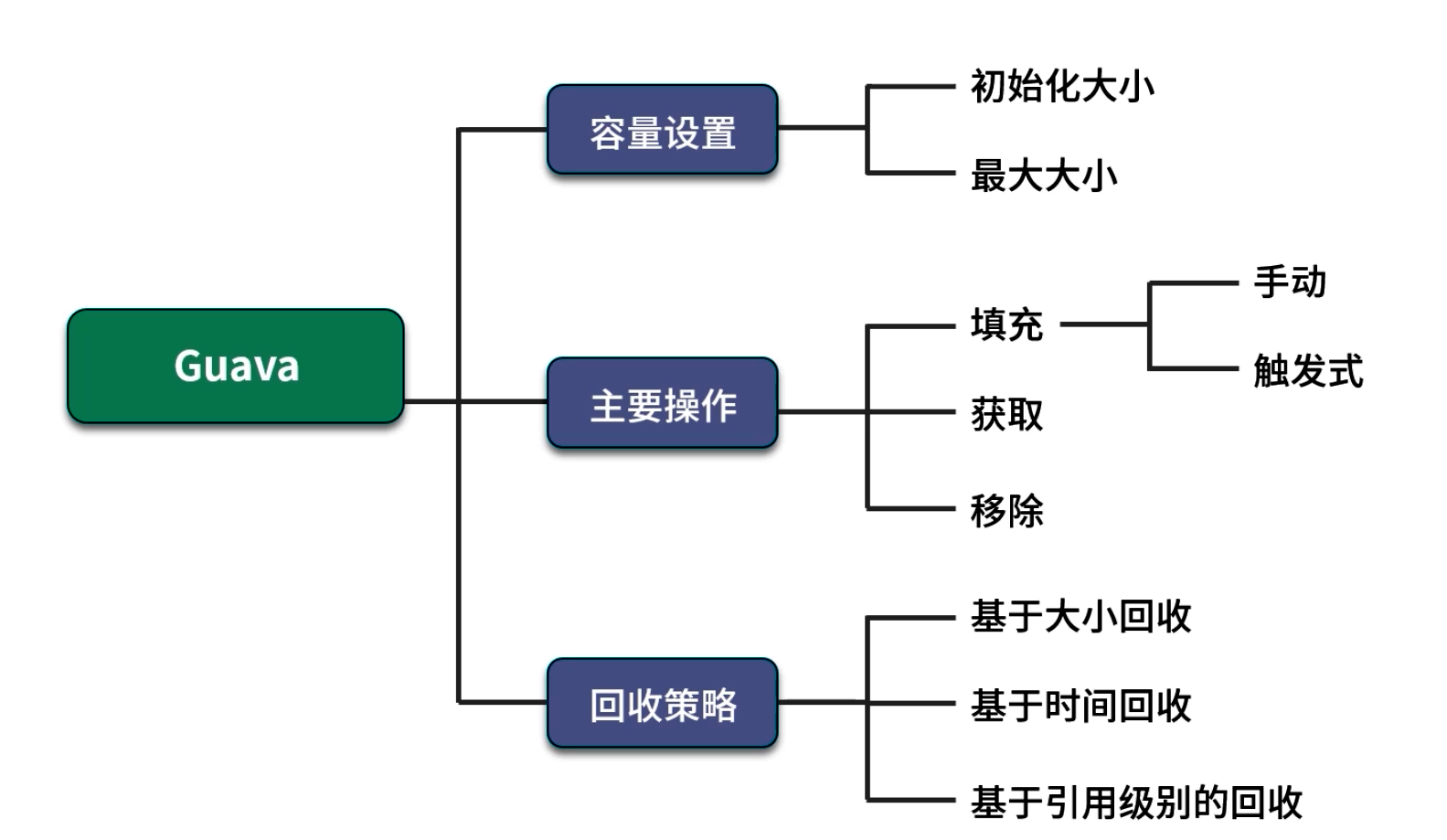
Guava 提供了功能强大的 Cache 接口和 LoadingCache 实现,既支持手动存入(put()),也支持在缓存未命中时“自动加载”(CacheLoader)。下面通过示例逐步介绍其用法与内部配置要点。
2.1 引入依赖与初始化
首先,通过 Maven 将 Guava 库加入项目:
<dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>29.0-jre</version>
</dependency>
然后,使用 CacheBuilder 来创建一个 LoadingCache:
LoadingCache<String, String> lc = CacheBuilder.newBuilder()// 设置最大缓存容量:达到上限后回收其他元素.maximumSize(1000)// 设置初始容量:底层 Hash 表的初始大小为 16(默认).initialCapacity(16)// 设置并发级别:将缓存分片成 4 个 segment,提升并发读写性能.concurrencyLevel(4).build(new CacheLoader<String, String>() {@Overridepublic String load(String key) throws Exception {// 缓存未命中时,自动调用 slowMethod 从外部数据源加载return slowMethod(key);}});
maximumSize(int):指定 缓存中可保留条目的最大数量,一旦超过,将根据回收策略(默认 LRU)移除旧元素;initialCapacity(int):指定底层哈希表初始大小(bucket 数量),避免在缓存初始化时反复扩容;concurrencyLevel(int):指定并发写的“分段”数,Guava 会将内部数据结构拆分为concurrencyLevel个部分,以减少并发冲突;
2.2 手动 put 与自动加载(CacheLoader)
LoadingCache 支持两种获取方式:
-
手动
put():lc.put("key1", "value1"); String v = lc.getIfPresent("key1"); // 立即返回 "value1"在这种模式下,开发者负责将外部数据同步写入缓存。
-
自动加载
get():
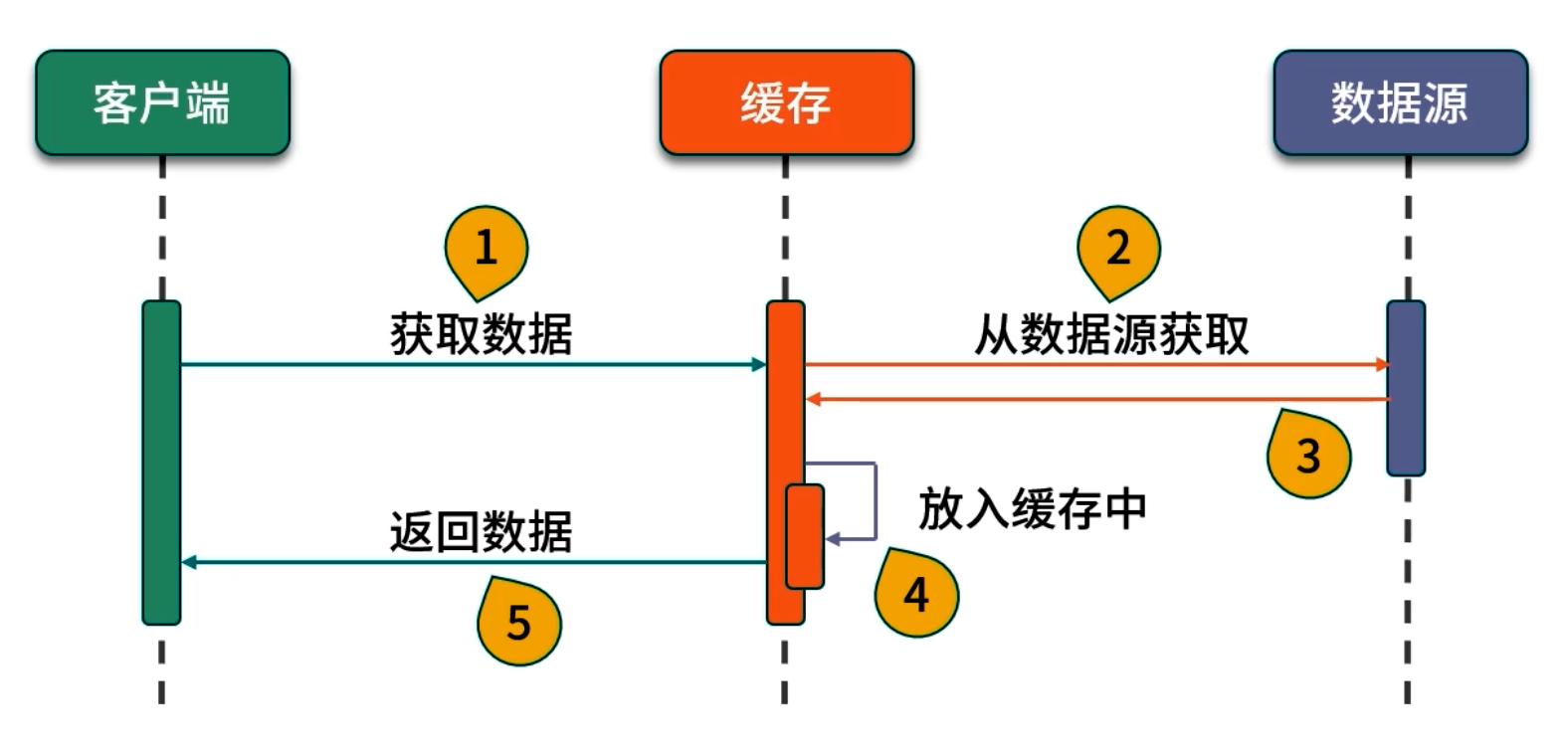
// 第一次调用:缓存中无 key "a",触发 CacheLoader.load("a")
long start = System.nanoTime();
String result1 = lc.get("a"); // slowMethod("a") 需 1s
System.out.println("第一次调用耗时: " + (System.nanoTime() - start));
// 第二次调用:缓存命中,迅速返回
long start2 = System.nanoTime();
String result2 = lc.get("a");
System.out.println("第二次调用耗时: " + (System.nanoTime() - start2));
其中 load(String key) 方法可同步加载所需数据(如从数据库或外部 API 拉取),并在返回值后自动存入缓存。
2.2.1 示例代码
public class GuavaCacheDemo {// 模拟一个缓慢方法:睡眠 1 秒后返回结果static String slowMethod(String key) throws Exception {Thread.sleep(1000);return key + ".result";}public static void main(String[] args) throws Exception {LoadingCache<String, String> lc = CacheBuilder.newBuilder().maximumSize(1000).initialCapacity(16).concurrencyLevel(4).recordStats() // 开启统计信息收集.build(new CacheLoader<String, String>() {@Overridepublic String load(String key) throws Exception {return slowMethod(key);}});// 第一次 get,会调用 slowMethodlong t1 = System.nanoTime();String v1 = lc.get("a");long elapsed1 = System.nanoTime() - t1;System.out.println("第一次 get 用时: " + elapsed1 + " ns");// 第二次 get,立即返回long t2 = System.nanoTime();String v2 = lc.get("a");long elapsed2 = System.nanoTime() - t2;System.out.println("第二次 get 用时: " + elapsed2 + " ns");// 输出命中率与加载次数等统计System.out.println("Cache Stats: " + lc.stats());}
}
recordStats():开启缓存统计功能,可用于后续分析hitRate()、loadSuccessCount()等指标;CacheLoader.load():当 key 未命中时,自动调用并将结果写回缓存;
2.3 缓存移除与监听(invalidate + removalListener)
-
手动删除:
lc.invalidate("a"); // 移除 key "a" 对应的缓存项 -
监听删除事件:
LoadingCache<String, String> lc2 = CacheBuilder.newBuilder().removalListener(notification -> {System.out.println("移除: " + notification.getKey() + " 因为 " + notification.getCause());}).maximumSize(100).build(new CacheLoader<>() {@Overridepublic String load(String key) { return slowMethod(key); }});当缓存项因为容量、过期、显式
invalidate()等原因被移除时,监听器会收到回调,可用于日志、监控或二次清理。
3. 缓存回收策略
在缓存容量有限的前提下,需设计合适的回收策略来剔除“冷”或不再需要的数据,以保证“热点”数据得到优先保留。Guava 原生支持多种回收方式:
3.1 基于容量的回收(LRU)
maximumSize(long):当超过指定数量时,按照“最近最少使用(LRU)”策略移除最旧项;- LRU 意味着:每次缓存命中(
get())或写入(put())时,该条目被标记为“最近被使用”;容量满时,优先移除最久未被访问的条目; - 这是默认的回收策略,适合大多数“热点覆盖度有限”的场景。
3.2 基于时间的回收
expireAfterWrite(long duration, TimeUnit unit):在缓存项被写入后,若在duration时间内未被访问,自动过期移除;expireAfterAccess(long duration, TimeUnit unit):在缓存项最后一次访问后,若超过duration,自动过期移除;- 这两种策略可以组合使用,用于场景如“用户会话缓存”、“短期热点数据”。
3.3 基于 JVM GC 的回收
-
Guava 提供了
weakKeys(),weakValues(),softValues()等方法,利用不同强度的引用进行回收:weakKeys():将缓存 key 按弱引用存放,若 key 对象仅被缓存引用,则可随时被 GC 回收,相应条目自动失效;weakValues():将缓存 value 按弱引用存放,若 value 对象不再被强引用,则可被 GC 回收;softValues():将 value 以软引用存放,当 JVM 内存不足时,GC 会优先回收这些软引用对象;
-
典型语法:
Cache<String, byte[]> cache = CacheBuilder.newBuilder().maximumSize(1000).weakValues().build(); -
面试高频:若同时设置
weakKeys()与weakValues(),则当 key 或 value 都失去任何强引用后,该条目会被 GC 回收。
3.3.1 GC 回收引发的缓存颠簸问题
当缓存条目使用弱引用或软引用,一旦 JVM 触发 GC,就可能一次性清空大批缓存数据。若该缓存频繁被访问,缓存将被迅速重新加载,导致连续触发多次 GC 和缓存“哗啦啦回补”的现象——CPU 消耗骤增,却无法留住数据。
解决思路:
- 仅对内存占用较大的非热点对象使用
softValues(),而不是对所有缓存。一旦发现缓存颠簸,可考虑放宽 GC 压力或降低缓存容量; - 尽量使用基于容量+时间的回收,避免过度依赖 JVM GC;
- 在缓存加载逻辑中加入适当延迟,防止短时间内同一批 key 被重复加载。
4. 常见缓存算法简介
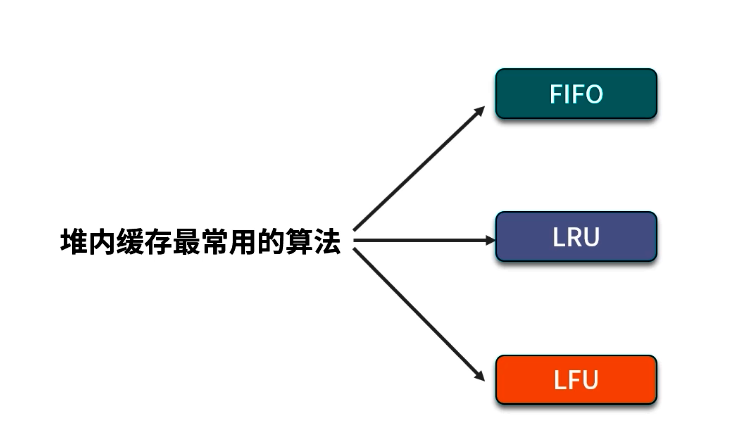
除了 Guava 提供的默认 LRU,缓存领域常见还有两种算法:
4.1 FIFO(先进先出)
-
按“插入顺序”回收:
- 缓存满时,移除最早插入的条目;
- 结构简单,但不考虑条目热度;
- 适用于“日志队列”、“任务处理队列”这类只关心先来先服务的场景。
4.2 LRU(最近最少使用)
-
按“访问顺序”回收:
- 每次
get()或put()时,将条目移至最近位置; - 满载时移除最久未被访问的条目;
- 适用于“热点数据需长时间保留”的场景,是一般缓存中最为常见的策略。
- 每次
4.3 LFU(最近最不常用)
-
按“访问频率”回收:
- 维护每个条目的访问计数;
- 缓存满时,移除访问计数最少的条目;若存在多项访问计数相同,则移除“最久未使用”者;
- 适用于需要保留“高访问频次”数据的场景,但实现较复杂,需要额外维护计数与优先级队列。
5. 简易 LRU 实现——LinkedHashMap
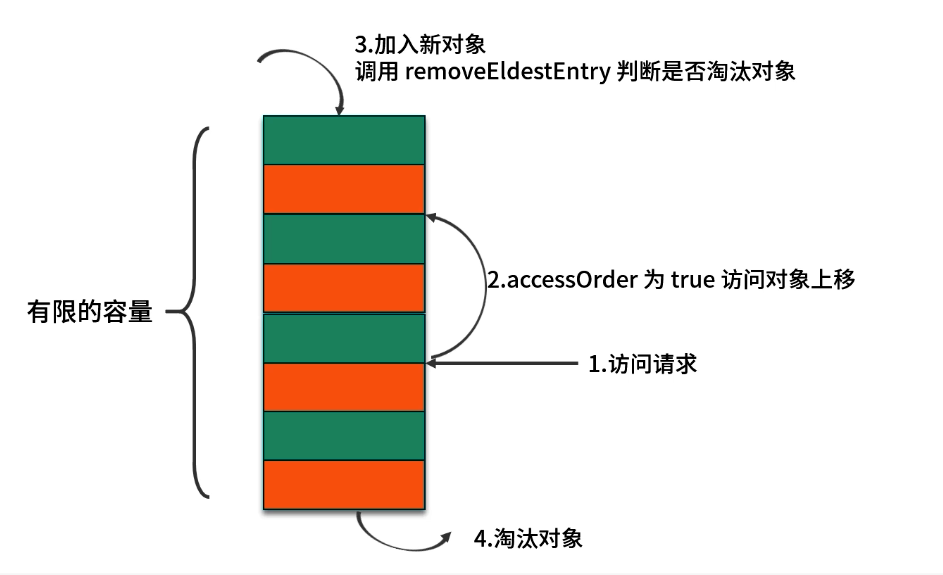
在 Java 中,要实现一个轻量级的 LRU 缓存,最便捷的方式是利用 LinkedHashMap 提供的“访问顺序”功能:
public class LRUCache<K, V> extends LinkedHashMap<K, V> {private final int capacity;public LRUCache(int capacity) {// 初始容量 16,负载因子 0.75,accessOrder=true 表示按访问顺序排列super(16, 0.75f, true);this.capacity = capacity;}// 当 put 后,自动调用此方法判断是否需要移除最老条目@Overrideprotected boolean removeEldestEntry(Map.Entry<K, V> eldest) {return size() > capacity;}
}
-
构造参数说明:
initialCapacity:初始哈希表桶数,默认 16;loadFactor:负载因子(0.75f);accessOrder=true:按照“访问顺序”保持双向链表;
-
removeEldestEntry:在每次put()后自动调用,若返回true,则移除“最久未访问”者,即 LRU 算法的核心。
5.1 功能局限与线程安全
-
优势:代码简洁,无需自行维护优先级队列或计数器;
-
局限:
- 仅基于“条目数量”控制容量,不能指定基于“内存占用大小”回收;
- 无法设置“基于时间过期”或“基于访问次数”回收;
-
线程安全:
LinkedHashMap本身并非线程安全,如需并发访问,应加锁或改用ConcurrentLinkedHashMap/ Guava Cache / Caffeine。
6. 操作系统层面的预读与文件缓存
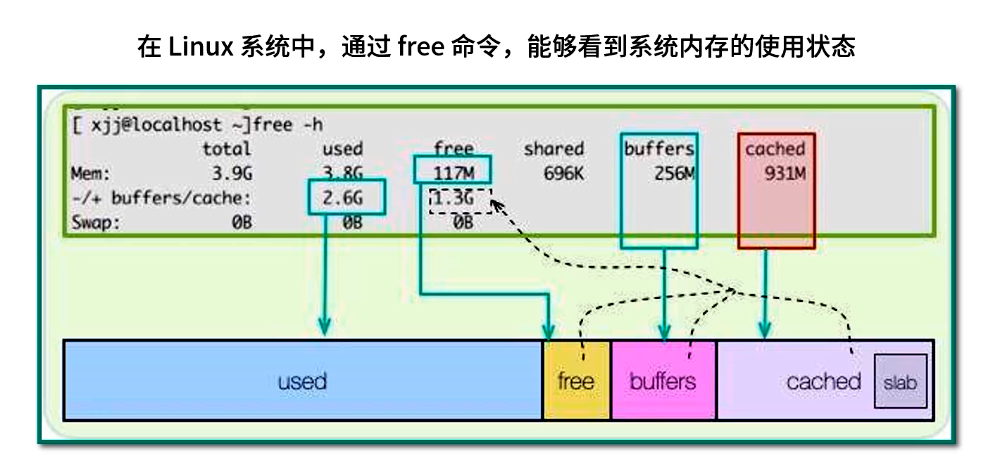
在操作系统层面,对文件 I/O 缓存设计也非常智能,进一步支撑了高性能缓存架构。Linux 下可以通过 free 命令查看内存状态,其中 cached 区域往往十分庞大:
$ free -htotal used free shared buff/cache available
Mem: 16Gi 4.2Gi 2.5Gi 128Mi 9.4Gi 11Gi
Swap: 2.0Gi 512Mi 1.5Gi
buff/cache:表示操作系统将磁盘块缓存在内存中的容量,包括文件系统页缓存、目录缓存等;- Readahead(预读):当进程顺序读取文件时,内核会自动尝试以“页面”为单位预读后续若干页面,以减少随机读时的磁盘寻道开销。

例如,若应用以 4KB 为单位读取大型文件,内核可能在后台提前载入 128KB 或更多连续页面,由此实现“顺序读取性能≈内存读取性能”的效果。
- 完全加载策略:若某一小文件(如几 MB)访问频率极高,可在应用启动时一次将整个文件
mmap()或read()到内存(posix_fadvise(..., POSIX_FADV_WILLNEED)),确保后续访问都命中内核缓存;
7. 缓存优化的一般思路
在实际项目中,引入进程内缓存时,可根据以下几个准则:
-
缓存目标场景:
- 存在稳定的数据热点(某些 key 会被反复访问);
- 读操作远多于写操作;
- 下游服务(数据库、远程接口)性能低,成为瓶颈;
- 缓存一致性要求相对宽松,偶尔允许短暂的“陈旧”数据。
-
缓存大小与容量:
- 缓存容量过小,会导致“热点”数据被频繁淘汰,命中率低,性能提升有限;
- 缓存容量过大,会占用大量堆空间,增加 GC 频率与时长;
- 通常通过监控缓存命中率(
cache.stats().hitRate())来调整容量,推荐至少达到 50% 的命中率,若低于 10% 就要重新评估是否需要缓存。
-
回收策略选择:
- 默认使用 LRU,即
maximumSize(...); - 对于需要“短期热点”或“超时失效”的数据,可结合
expireAfterWrite(...)与expireAfterAccess(...); - 若缓存数据对象非常大,且不想占用堆内存,可考虑
weakValues()或softValues(),但要避免“缓存颠簸”现象。
- 默认使用 LRU,即
-
监控与统计:
- 开启
recordStats(),收集命中、加载、移除次数等数据; - 定期导出或打印
cache.stats(),分析缓存命中率(hitRate)与平均加载时间(averageLoadPenalty); - 若发现加载成本过高,可考虑加大缓存容量或优化加载算法;
- 开启
-
缓存失效与一致性:
- 当缓存中数据与源数据库数据不一致时,需要设计缓存更新/清理策略(如主动失效、定时刷新或消息通知触发刷新);
- 对于对一致性要求极高场景,可使用“双写+事务+消息队列+双删失效”等方案,见后续“缓存一致性”课时。
-
预加载 vs 惰性加载:
- 惰性加载(Lazy Loading):在第一次访问时加载到缓存,常见于
LoadingCache; - 预加载(Preloading):在应用启动时或定时调度时一次性加载所有热点数据,减少首次访问延迟;
- 若热点集合较小且可预见,可采用预加载;若热点动态且数据量大,优先使用惰性加载。
- 惰性加载(Lazy Loading):在第一次访问时加载到缓存,常见于
8. 缓存应用案例
-
HTTP 304(Not Modified)缓存
- 浏览器发送条件性请求:带上
If-Modified-Since或ETag; - 服务端判断资源是否自上次修改以来未发生变化,若无改动则直接返回
304,让浏览器使用本地缓存;否则返回200并携带新的资源与缓存头; - 这样可以在浏览器端节省一次完整的资源下载,并允许操作系统与浏览器在内存/硬盘层面做更深层次的缓存。
- 浏览器发送条件性请求:带上
-
CDN(内容分发网络)缓存
- 用户访问某个静态资源时,会首先到就近的 CDN 节点请求;
- 若该节点已有缓存,直接返回给用户;否则节点会向**源站(Origin)**拉取一份并缓存在本地;
- CDN 缓存策略包括 TTL(Time-To-Live)、LRU 或 LFU,来自不同运营商或网络环境下的缓存命中率优化直接影响用户体验与带宽成本。
-
数据库二级缓存
- ORM 框架(如 Hibernate)常集成二级缓存,将热点实体缓存在本地 heap 或分布式缓存中;
- 在事务提交或数据更新时,需要将对应缓存项失效或更新;
- 缓存失效策略与事务边界息息相关,需要设计清晰的缓存注解或 AOP 拦截器。
9. 小结
进程内缓存(堆内缓存) 的设计思路与常见实现:
-
缓存本质与应用场景
- 缓存用于调和下游“慢”与上游“快”之间的速度差异;
- 典型场景包括:热点数据查询、配置读取、会话管理、短期临时数据。
-
Guava LoadingCache
CacheBuilder提供灵活配置:maximumSize、initialCapacity、concurrencyLevel;- 支持手动
put()与自动加载(CacheLoader)两种模式; - 可通过
invalidate()手动移除,并通过removalListener监听删除事件; - 回收策略包括基于容量(LRU)、基于时间(
expireAfterWrite/Access)与 JVM 引用回收(weakKeys/weakValues/softValues); - 避免“软引用缓存颠簸”带来的频繁 GC 问题。
-
常见缓存算法
- FIFO:先进先出,简单但不考虑热点;
- LRU:最近最少使用,当前最流行,保留热点;
- LFU:最近最不常用,保留高频访问数据,支持频次计数;
-
简易 LRU 实现
- 利用
LinkedHashMap构造参数accessOrder=true,覆写removeEldestEntry; - 整体逻辑简单,但不支持过期时间与并发安全,需要在生产环境中慎用或加锁。
- 利用
-
操作系统缓存与预读
- Linux 内核会自动执行 readahead,预读后续页面到
cached区域; - 可手动使用
mmap()、posix_fadvise()等方式实现“完全加载”,适用于小文件的高频访问。
- Linux 内核会自动执行 readahead,预读后续页面到
-
缓存优化一般思路
- 在缓存容量、命中率与 JVM GC 之间做折中;
- CDC(缓存、数据库、集群)技术栈常见组合;
- 监控
cache.stats()指标,命中率需 ≥ 50% 才有较好收益;若 < 10% 则应卸载或重构缓存策略。
-
示例应用
- HTTP 304、CDN 缓存;
- 数据库二级缓存;
- Redis 作为分布式缓存,面向更大规模数据。

相关文章:
性能优化 - 案例篇:缓存_Guava#LoadingCache设计
文章目录 Pre引言1. 缓存基本概念2. Guava 的 LoadingCache2.1 引入依赖与初始化2.2 手动 put 与自动加载(CacheLoader)2.2.1 示例代码 2.3 缓存移除与监听(invalidate removalListener) 3. 缓存回收策略3.1 基于容量的回收&…...

NiceGUI 是一个基于 Python 的现代 Web 应用框架
NiceGUI 是一个基于 Python 的现代 Web 应用框架,它允许开发者直接使用 Python 构建交互式 Web 界面,而无需编写前端代码。以下是 NiceGUI 的主要功能和特点: 核心功能 1.简单易用的 UI 组件 提供按钮、文本框、下拉菜单、滑块、图表等常见…...

生动形象理解CNN
好的!我们把卷积神经网络(CNN)想象成一个专门识别图像的“侦探小队”,用破案过程来生动解释它的工作原理: 🕵️♂️ 案件:识别一张“猫片” 侦探小队(CNN)的破案流程&am…...
python入门(1)
第一章 第一个python程序 1.1 print函数 print方法的作用 : 把想要输出的内容打印在屏幕上 print("Hello World") 1.2 输出中文 在Python 2.x版本中,默认的编码方式是ASCII编码方式,如果程序中用到了中文,直接输出结果很可能会…...
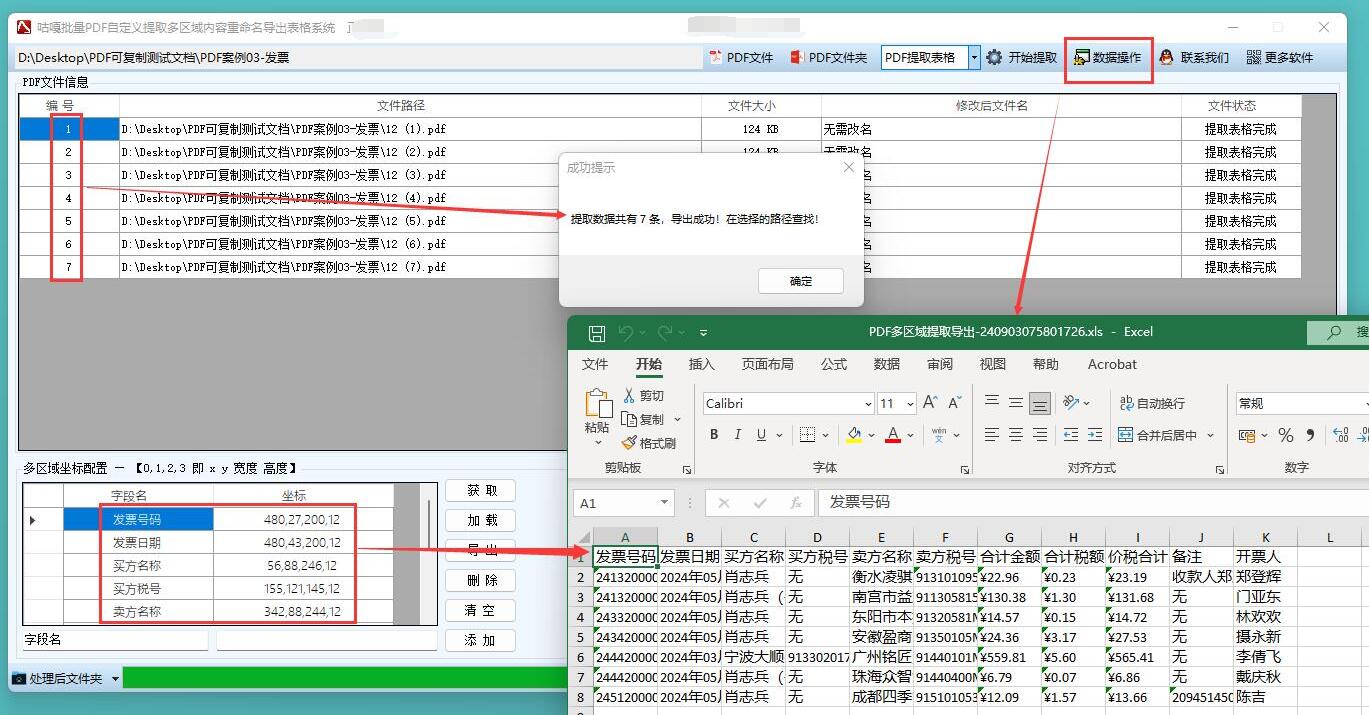
【PDF提取表格】如何提取发票内容文字并导出到Excel表格,并将发票用发票号改名,基于pdf电子发票的应用实现
应用场景 该应用主要用于企业财务部门或个人处理大量电子发票,实现以下功能: 自动从 PDF 电子发票中提取关键信息(如发票号码、日期、金额、销售方等)将提取的信息整理并导出到 Excel 表格,方便进行财务统计和报销使…...

Hugging Face 最新开源 SmolVLA 小模型入门教程(一)
系列文章目录 目录 系列文章目录 前言 一、引言 二、认识 SmolVLA! 三、如何使用SmolVLA? 3.1 安装 3.2 微调预训练模型 3.3 从头开始训练 四、方法 五、主要架构 5.1 视觉语言模型(VLM) 5.2 动作专家:流匹…...
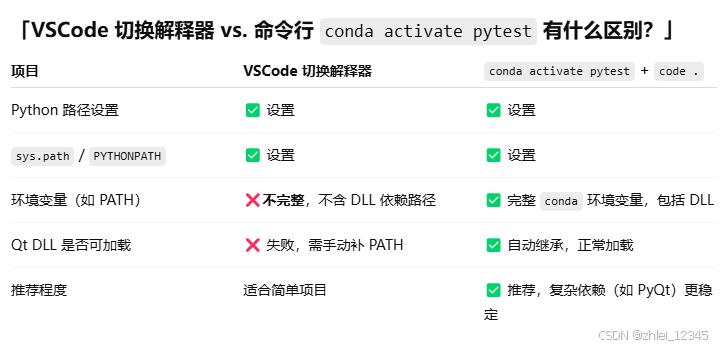
封闭内网安装配置VSCode Anconda3 并配置 PyQt5开发
封闭内网安装配置VSCode Anconda3 并配置 PyQt5开发 零一 vscode1.1 下载 vscode1.2 下载插件1.3 安装 二 anaconda 32.1 下载2.2 新建虚拟环境1 新建快捷方式,启动base2 新建虚拟环境 3 配置Qt designer3.1 designer.exe和uic.exe3.2 设置插件,3.4 ui文件转为py文件 4使用4.1 …...

大话软工笔记—组合要素2之逻辑
1. 逻辑的概念 逻辑,指的是思维的规律和规则,是对思维过程的抽象。 结合逻辑的一般定义以及信息系统的设计方法,对逻辑的概念进行抽提、定义为三个核心内涵,即:规律、顺序、规则。 (1)规律&a…...

浅谈边缘计算
(꒪ꇴ꒪ ),Hello我是祐言QAQ我的博客主页:C/C语言,数据结构,Linux基础,ARM开发板,网络编程等领域UP🌍快上🚘,一起学习,让我们成为一个强大的攻城狮࿰…...
)
宝塔专属清理区域,宝塔清理MySQL日志(高效释放空间)
1. 删除超过 365 天的积分变更记录 宝塔面板 → 数据库 → 选择数据库 → 点击 管理 进入 phpMyAdmin 后: 选择在用的数据库名 看到顶部的 SQL 点击 输入命令 然后点击执行 DELETE FROM pre_common_credit_log WHERE dateline < UNIX_TIMESTAMP(DATE_SUB(NO…...

7.Demo Js执行同步任务,微任务,宏任务的顺序(3)
一个包含 同步任务、微任务(Promise)、宏任务(setTimeout) 的例子,JS 是怎么调度这些任务的。 🎯 例子代码(建议复制到浏览器控制台运行) console.log(‘同步任务 1’); setTimeo…...

边缘计算网关赋能沸石转轮运行故障智能诊断的配置实例
一、项目背景 在环保行业,随着国家对大气污染治理要求的不断提高,VOCs废气处理成为了众多企业的重要任务。沸石转轮作为一种高效的VOCs治理设备,被广泛应用于石油化工、汽车制造、印刷包装等主流行业。这些行业生产规模大、废气排放量多&…...

机器学习之深入理解机器学习常见算法:原理、公式与应用
机器学习之深入理解机器学习常见算法:原理、公式与应用 机器学习是一门让计算机自动从数据中学习规律的技术体系。常见的机器学习算法可以分为监督学习、无监督学习和深度学习三大类。本文将系统介绍每类中具有代表性的算法,并深入剖析其核心原理与数学基础。 一、监督学习(…...

Python实例题: Python 的简单电影信息
目录 Python实例题 题目 代码实现 实现原理 网页请求: 内容解析: 数据存储: 反爬策略: 关键代码解析 1. 网页请求处理 2. 电影列表解析 3. 电影详情解析 4. 爬虫主逻辑 使用说明 安装依赖: 修改配置&a…...

MyBatis 的动态 SQL
1. 动态 SQL 的定义 动态 SQL 是 MyBatis 的核心特性之一,它允许开发者根据运行时条件动态生成 SQL 语句。通过特殊的 XML 标签或注解语法,实现 SQL 的灵活拼接,避免在 Java 代码中手动拼接 SQL 字符串的复杂性和安全风险。 2. 核心作用 条…...

Redis中的setIfAbsent方法和execute
Redis中的setIfAbsent方法 Redis中的setIfAbsent方法是一种原子操作,它的作用是只有在指定的键不存在时才会设置值。这个方法在并发环境下非常有用,因为它可以避免多个客户端同时尝试设置相同键而导致的冲突。 代码示例 在Java中使用setIfAbsent方法通…...

高考数学易错考点02 | 临阵磨枪
文章目录 前言解析几何立体几何排列组合概率导数及应用前言 本篇内容下载于网络,网络上的都是以 WORD 版本呈现,缺字缺图很不完整,没法使用,我只是做了补充和完善。有空准备进行第二次完善,添加问题解释的链接。 ##平面向量 40.向量 0 ⃗ \vec{0} 0 与数 0 0 0 有区别…...

国产高性能pSRAM选型指南:CSS6404LS-LI 64Mb QSPI伪静态存储器
一、芯片基础特性 核心参数 容量 :64Mb(8M 8bit)电压 :单电源供电 2.7-3.6V (兼容3.3V系统)接口 :Quad-SPI(QPI/SPI)同步模式封装 : SOP-8L (150mil) &#…...

Go 中 `json.NewEncoder/Decoder` 与 `json.Marshal/Unmarshal` 的区别与实践
Go 中 json.NewEncoder/Decoder 与 json.Marshal/Unmarshal 的区别与实践(HTTP 示例) 在 Go 中处理 JSON 有两种主要方式:使用 json.Marshal/Unmarshal 和使用 json.NewEncoder/Decoder。它们都能完成 JSON 的序列化与反序列化,但…...
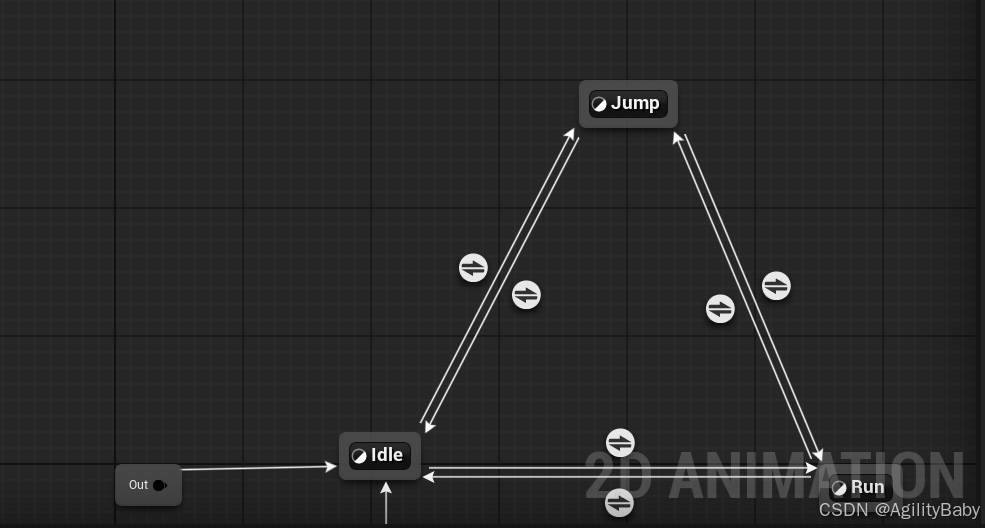
UE5 2D角色PaperZD插件动画状态机学习笔记
UE5 2D角色PaperZD插件动画状态机学习笔记 0.安装PaperZD插件 这是插件下载安装地址 https://www.fab.com/zh-cn/listings/6664e3b5-e376-47aa-a0dd-f7bbbd5b93c0 1.右键创建PaperZD 动画序列 2.添加动画序列 3,右键创建PaperZD AnimBP (动画蓝图&am…...
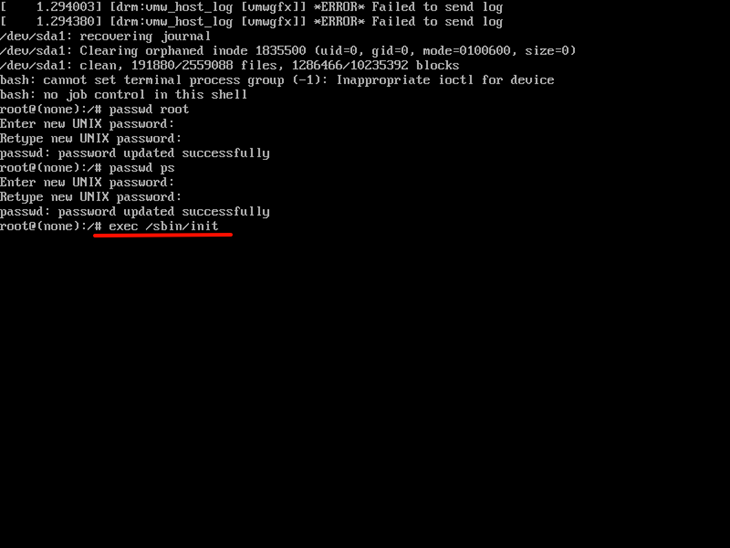
Ubuntu 16.04 密码找回
同事整理的供参考: 进入GRUB菜单 重启系统,在启动过程中长按Shift键(或Esc键)进入GRUB引导菜单。 若未显示GRUB菜单,可尝试在启动时连续按多次Shift/Esc键。 在GRUB菜单中选择默认的Ubuntu启动项(第一…...
【论文阅读】DanceGRPO: Unleashing GRPO on Visual Generation
DanceGRPO: Unleashing GRPO on Visual Generation 原文摘要 研究背景与问题 生成模型的突破:扩散模型和整流流等生成模型在视觉内容生成领域取得了显著进展。核心挑战:如何让模型的输出更好地符合人类偏好仍是一个关键问题。现有方法的局限性࿱…...
CentOS在vmware局域网内搭建DHCP服务器【踩坑记录】
1. 重新设置环境 配置dhcp服务踩了不少坑,这里重头搭建记录一下: 1.1 centos 网卡还原 如果之前搭了乱七八糟的环境,导致NAT模式也没法上网,这里重新还原 我们需要在NAT模式下联网,下载DHCP服务 先把centos的网卡还…...

AI炼丹日志-28 - Audiblez 将你的电子书epub转换为音频mp3 做有声书
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 大模型与Java双线更新中! 目前《大语言模型实战》已连载至第22篇,探索 MCP 自动操作 FigmaCursor 实…...

图像处理篇---face_recognition库实现人脸检测
以下是使用face_recognition库实现人脸检测的详细步骤、实例代码及解释: 一、环境准备 1. 安装依赖库 pip install face_recognition opencv-python # 核心库 pip install matplotlib # 用于显示图像(可选)2. 依赖说明 face_recognitio…...
74. 搜索二维矩阵 (力扣)
给你一个满足下述两条属性的 m x n 整数矩阵: 每行中的整数从左到右按非严格递增顺序排列。每行的第一个整数大于前一行的最后一个整数。 给你一个整数 target ,如果 target 在矩阵中,返回 true ;否则,返回 false 。…...
8088单板机C语言sprintf()格式化串口输出---Prj04
#include "tiny_stdarg.h" // 使用自定义可变参数实现#define ADR_273 0x0200 #define ADR_244 0x0400 #define LED_PORT 0x800 #define PC16550_THR 0x1f0 #define PC16550_LSR 0x1f5 / //基本的IO操作函数 / char str[]"Hello World! 20250531 Ve…...

板凳-------Mysql cookbook学习 (九)
第4章:表管理 4.0 引言 MySQL :: 员工样例数据库 :: 3 安装 https://dev.mysql.com/doc/employee/en/employees-installation.html Employees 数据库与几种不同的 存储引擎,默认情况下启用 InnoDB 引擎。编…...

深入解析 Flask 命令行工具与 flask run命令的使用
Flask 是一个轻量级的 Python Web 应用框架,其内置的命令行工具(CLI)基于 Click 库,提供了方便的命令行接口,用于管理和运行 Flask 应用程序。本文将详细介绍 Flask 命令行工具的功能,以及如何使用 flask r…...

第6篇:中间件 SQL 重写与语义分析引擎实现原理
6.1 章节导读 SQL 是数据库中间件的“输入语言”。 在一个真正强大的中间件系统中,SQL 语句的执行通常不再是“原封不动”地传递给数据库,而是需要先经过: 语义分析:解析 SQL 的结构和含义。 SQL 重写:根据中间件逻辑…...