CppCon 2015 学习:CLANG/C2 for Windows
Visual Studio 2015 引入了基于 CLANG/LLVM 的新代码生成器,及其背景和意义。简单理解如下:
理解要点:
- VS2015 中引入了全新的代码生成技术,性能和质量都很棒。
- 这套新技术基于 Clang,微软展示了相关新工具。
- Clang 和 LLVM 背后有庞大且活跃的开源社区,技术领先且更新迅速。
- LLVM 官方网站,开源项目的主站。
- 新代码生成器的使命和目标:
- VS2015 中采用了新的代码生成框架。
- 微软内部所有 C/C++ 代码都用这个新生成器编译。
- 所有应用商店里的通用应用程序(Universal Apps)用 C# 写,也借助这个编译架构。
- 这技术最终整合进 VS2015 的正式零售版里。
- 同时支持基于 Clang/LLVM 的 Windows 平台编译器。
总结
微软在 VS2015 里引入了基于开源 Clang/LLVM 技术的新编译器后端,用来提升代码生成质量,同时支持公司内部代码及应用商店的普遍应用,体现了微软向开源和跨平台技术靠拢的趋势。
代码生成(Code Generation)变得越来越重要且复杂,因为现代计算环境越来越多样化,涉及多种计算平台和加速技术。具体包括:
- FPGA acceleration(FPGA 加速)
使用现场可编程门阵列来加速特定任务,代码生成需要支持针对 FPGA 的优化和硬件描述语言。 - Distributed Compute (MPI)(分布式计算,使用消息传递接口)
多台机器协同计算,代码生成要考虑多进程、多节点间通信与同步。 - GPU(图形处理单元)
利用 GPU 进行并行计算,代码生成需要生成针对 GPU 架构的代码(如 CUDA、OpenCL)。 - Heterogeneous Compute(异构计算)
多种计算设备(CPU、GPU、FPGA等)混合使用,代码生成要兼顾不同硬件的特性,实现协同优化。
总结:
随着硬件平台变得多样且复杂,代码生成不仅要生成正确的代码,还要智能地适配各种加速器和分布式环境,从而提高程序性能和效率。这使得代码生成成为编译器设计中非常关键且挑战大的部分。
编译器的重要性(Compiler matters!),并且列出了编译器在软件开发和运行中几个关键的考量点:
理解要点:
- $87.7B 和 $100.0B+
这可能指的是软件行业或某些大型软件项目的市场规模或投入资金,表明编译器技术背后涉及巨大的经济价值。 - 1. Absolute Correctness(绝对正确性)
编译器必须确保生成的代码是正确无误的,程序行为符合预期,没有bug。 - 2. Compiler throughput(编译器吞吐量)
编译器的编译速度要快,能够高效处理大规模代码,减少开发等待时间。 - 3. Code size(代码体积)
生成的二进制代码体积要尽可能小,这对嵌入式、移动设备等资源受限平台尤为重要。 - 4. Code quality(代码质量)
生成代码的执行效率高、性能好,充分利用硬件资源。 - Built with C+
这里可能是“Built with C++”的缩写或口误,意思是很多优秀的编译器都是用 C++ 写的,体现 C++ 在系统软件领域的地位。
总结
编译器不仅是程序正确运行的基础,其性能和生成代码的质量直接影响软件的效率和用户体验,甚至涉及巨大经济价值。高质量的编译器设计需要平衡正确性、速度、代码大小和质量等多个方面。
这段代码和描述讲的是 IE Aurora 漏洞(Dangling pointer,悬挂指针漏洞),具体是如何利用 JavaScript 事件处理机制导致内存错误(Use-After-Free)从而被攻击者利用的过程。(看不懂)
漏洞代码简要说明
<html>
<head>
<script>var e1;function f1(evt){e1 = document.createEventObject(evt); // 复制事件对象 evt,但未对内部指针做引用计数增加(AddRef)document.getElementById("sp").innerHTML = ""; // 清空 span 内部内容,导致 img 标签被销毁(释放内存)window.setInterval(f2, 50); // 定时调用 f2,异步访问事件对象 e1}function f2(){var t = e1.srcElement; // 访问事件对象的成员,但 e1 已经指向被释放的内存 -> 悬挂指针}
</script>
</head>
<body><span id="sp"><img src="any.gif" onload="f1(evt)"> <!-- 图片加载完成时触发 f1,传入事件 evt --></span>
</body>
</html>
漏洞流程及分析
| 步骤 | 描述 | 详细解释 |
|---|---|---|
| 1 | 传入 onload 事件对象 evt 给 f1 | JavaScript 触发 img 加载事件,evt 包含事件相关信息 |
| 2 | f1 中复制事件对象(createEventObject(evt)),但没有对内部的 C++ 对象 CTreeNode 调用 AddRef | 这里 CTreeNode 是 IE 内部用来管理 DOM 事件树节点的 C++对象,引用计数未增加导致后续可能被释放 |
| 3 | 通过 innerHTML="" 清空 span,销毁 img 标签,从而释放了事件对象的内部 C++ 资源 CTreeNode | DOM 树节点被删除,释放内存,导致事件对象内部指针悬空 |
| 4 | 异步调用 f2,访问事件对象 e1 的 srcElement 成员 | 此时 e1 指向已被释放的内存,产生悬挂指针,导致内存错误或劫持控制流(通过虚函数表调用) |
漏洞的关键点总结
- 事件对象复制没有正确增加引用计数(AddRef),导致内部资源被提前释放。
- 异步访问悬挂指针,导致 Use-After-Free(UAF)漏洞。
- 攻击者可以利用悬挂指针劫持虚函数表(vtable hijack),执行任意代码。
图示(简化ASCII)
事件触发 ---> 传入 evt|Vf1(evt) ---复制evt,e1指向复制对象(未AddRef)| || 内部CTreeNode指针(悬空风险)|清空 span 内容 ---> img 标签销毁,释放 CTreeNode|V
异步执行 f2() ---> 访问 e1.srcElement (悬挂指针)|VUse-After-Free,攻击发生
这段汇编代码实现的逻辑大致是:
代码解读
mov eax, ecx ; 将 ecx 的值复制到 eax
shr eax, 9 ; eax 右移9位,相当于除以512
mov eax, dword ptr [0x20000000 + eax*4] ; 以 eax 作为索引,访问基地址0x20000000的数组元素(4字节*eax偏移)
shr ecx, 4 ; ecx 右移4位,相当于除以16
bt eax, ecx ; 测试 eax 寄存器中第 ecx 位的值(bit test指令)
jb ok_to_call ; 如果该位是0,则跳转到 ok_to_call(jb: jump if below,表示cf=0)
int 3 ; 否则触发断点异常(int 3是调试中断,通常用于触发调试器)
逻辑分析
ecx作为输入寄存器,经过两次位移:- 先右移9位(
eax=ecx>>9)用作索引数组,说明可能是对某个大数据结构的查找或哈希。 - 再右移4位(
ecx=ecx>>4),用于后面bt指令测试位。
- 先右移9位(
[0x20000000 + eax*4]:访问一个以0x20000000为基址的32位整型数组,索引为ecx>>9,取得一个32位整数。bt eax, ecx:检查这个整数的某个位(由ecx>>4确定)是否被设置。jb ok_to_call:如果该位为0,跳转继续执行。int 3:如果该位为1,则触发中断,通常表示这里禁止继续,可能是做权限检查或防止某些操作。
总结
这段代码是一个 位图(bitmask)检查 的例子:
- 先通过
ecx的高位确定应该检查哪个32位块, - 再检查该块内的具体位是否被置位。
- 如果相应的位是0,则继续执行(跳转ok_to_call)
- 如果是1,则触发断点中断,阻止后续操作。
这通常用于: - 权限控制(检查是否有权限位)
- 功能开关(检查某功能是否启用)
- 内存或资源使用标记
Instrumentation(插装)相关的数据结构设计,主要针对内存中的调用点检查,特别是间接调用(icall)的检测机制。
理解分析
1. 数据结构(Data structures)
- memory callable
表示在内存中,用来存放“是否可调用”信息的数据结构。 - 8 bytes
大小为8字节,这里应该是指用来存放相关信息的内存块大小。 - 接下来8个“0”和“1”的位,构成了一个Bitmap(位图)。
2. Bitmap 的作用
- 这个位图用来快速判断某个地址或某个内存区域是否是合法的间接调用(indirect call)目标。
- icall–Windows modified–Loader modified
说明这个机制是Windows系统定制的,在Loader(加载器)和编译器、链接器协同修改二进制格式时加入的。 - Linker and compiler paired
编译器和链接器配合生成带有这种位图的二进制。 - Small binary format changes
引入这种位图只是做了很小的二进制格式调整。 - Binary static analysis (cracking binaries) changed
因为位图的存在,针对二进制的静态分析(比如破解、反汇编)工具的行为也会被改变,增加了破解难度。
总结
这段描述讲的是一种通过位图进行安全检查的插装技术,用于保护间接调用:
- 通过维护一个位图来快速判断某个代码位置是否是安全可调用的地方。
- 这种机制是在Windows的Loader、编译器和链接器共同支持下实现的。
- 对二进制文件的格式做了轻量级修改,给攻击者静态分析带来困难,提高了安全性。
/Guard 这个新的编译器开关,它的作用和特点:
理解
- /Guard – new compiler switch
/Guard是一个新的编译器参数选项(开关),用来开启某种安全防护机制。 - Performance – required close OS integration
为了保证性能,这个功能需要和操作系统(OS)紧密集成。
换句话说,防护机制不是单纯靠编译器实现,而是编译器和操作系统协同工作,才能做到既安全又高效。 - Interoperation – required massive testing
这个机制需要大量的兼容性和互操作性测试,确保和现有代码、库、系统功能无缝配合,不引入错误。 - Stopping zero day exploits today
这个功能的目标是“阻止零日漏洞攻击”,即防止未被发现或尚无补丁的安全漏洞被利用。
总结
/Guard 是微软新推出的编译器安全开关,它通过紧密结合操作系统,经过大量测试,能够有效防止当下流行且危险的零日攻击,同时保证程序性能和兼容性。
微软(MSFT)C++引入的新异步编程模型,重点是基于**协程(coroutine)**的机制:
1. 新的 C++ 异步模型
- 微软C++引入了两个新关键字:_yield 和 _await,用于支持协程的语法和行为。
- 协程是真正的用户态轻量线程,支持函数中断和恢复执行。
2. 协程示例代码 — 斐波那契数列生成器
generator<int> fib(int n)
{int a = 0;int b = 1;while (n-- > 0){yield a; // 生成一个值,挂起执行点auto next = a + b;a = b;b = next;}
}
int main() {for (auto v : fib(35)) {printf("%d\n", v);if (v > 10)break; // 中途可以退出协程遍历}
}
yield用来从协程生成一个值并挂起,等待下一次恢复。- 这种协程可以像普通容器那样,用
for循环遍历生成的序列,且可中途打断。
3. 协程执行的底层结构(Call Stack 和寄存器状态)
- 协程调用时,函数栈上保存了调用现场(寄存器状态、返回地址等)。
- 协程挂起时会保存当前状态到堆上(heap),包括:
- 各种寄存器的值(RDI, RSI, RDX, RIP等)
- 局部变量的状态
- 协程“promise”对象(协程的状态和结果容器)
- 恢复协程时,从堆中恢复这些保存的状态,再继续执行。
4. 协程的优势
- 支持异步操作,避免回调地狱(callback hell)。
- 内存和性能开销比传统线程低很多。
- 使异步代码像同步代码一样易读、易写。
总结
微软新引入的 C++ 协程模型:
- 用
_yield和_await关键字实现。 - 底层通过保存和恢复寄存器与调用现场实现函数的挂起与继续。
- 让异步流(如生成器)像普通序列一样方便使用。
基于协程的异步编程在效率和可扩展性上的优势,并配了一个实际的异步 TCP 读取示例。下面是详细理解:
1. Efficient and Scalable(高效且可扩展)
- 支持上百万个协程同时运行
由于协程的轻量级和低资源消耗,系统可以创建和管理非常多的协程,远超传统线程。 - 恢复和挂起协程的开销接近函数调用开销
协程切换不涉及上下文切换到内核线程,开销非常小,性能优异。 - 支持零开销抽象
通过协程,可以在已有异步机制上构建抽象,几乎不增加额外的运行时成本。
2. 示例代码:异步 TCP 读取
std::future<void> tcp_reader(int total) {char buf[64 * 1024];auto conn = await Tcp::Dial("127.0.0.1", 1337); // 异步建立连接do {auto bytesRead = await conn.read(buf, sizeof(buf)); // 异步读取数据total -= bytesRead;} while (total > 0);
}
int main() {tcp_reader(1000 * 1000 * 1000).get(); // 等待协程完成
}
await关键字挂起协程,等待异步操作完成而不阻塞线程。- 该例子展示了一个异步 TCP 连接的读取过程,持续读取数据直到达到目标字节数。
- 整个过程只进行一次内存分配,大幅降低内存管理开销。
3. 性能表现
- 在一台普通笔记本的环回接口上,达到了大约15GB/s的数据传输速率,体现了协程模型的高效。
总结
- 这个异步协程模型不仅高效(接近函数调用开销),还极其可扩展(百万级协程)。
- 使异步网络编程更自然、简洁,同时性能媲美传统同步代码。
如何用**矢量化(vectorization)**来优化带复杂控制流的循环,尤其是包含条件判断的代码。下面是详细解析:
代码背景
原始代码是一个常见的条件赋值:
for (…) {if (cond) {LHS1 = RHS1;} else {LHS2 = RHS2;}
}
这段代码在循环体中有分支(if-else),在 SIMD(单指令多数据)矢量化时,分支会阻碍指令的并行执行。
矢量化改写示例
改写为矢量化操作,处理4个元素(假设一次处理4个数据):
for (i = 0; i < N; i += 4) {mask = {cond[i], cond[i+1], cond[i+2], cond[i+3]}; // 4个条件构成的掩码v1 = RHS1 & mask; // 只在mask为真位置取RHS1的值v2 = LHS1 & !mask; // 在mask为假位置保留原LHS1的值LHS1 = v1 | v2; // 合并,更新LHS1v3 = RHS2 & !mask; // 在mask为假位置取RHS2v4 = LHS2 & mask; // 在mask为真位置保留原LHS2LHS2 = v3 | v4; // 合并,更新LHS2
}
理解点
- mask 是一个布尔向量,长度等于处理的并行元素数(这里是4)。
- 使用位操作(
&,|)模拟条件赋值,避免了分支判断。 - 通过矢量操作同时处理多个元素,提升性能。
总结
- 通过掩码(mask)实现条件的“选择”,使得分支代码能在 SIMD 指令下并行执行。
- 这种做法是现代编译器向量化复杂控制流的经典技术。
- 避免分支跳转,提高流水线利用率和指令并行度。
如何将Black-Scholes定价模型中的复杂条件分支用SIMD指令矢量化,用“位掩码(bit mask)”技术替代传统的if分支,提升性能。以下是详细的理解与分析:
一、标量控制流代码片段对应的含义
for (j = 0; j < NUM_RUNS; j++) {for (i = start; i < end; i++) {// ...if (InputX < 0.0) { // control flow 1InputX = -InputX;sign = 1;} elsesign = 0;if (sign) { // control flow 2OutputX = 1.0 - OutputX;}// 类似的又出现了control flow 3和4,重复前面两步if (otype == 0) { // control flow 5OptionPrice = (sptprice * NofXd1) - (FutureValueX * NofXd2);} else {NegNofXd1 = (1.0 - NofXd1);NegNofXd2 = (1.0 - NofXd2);OptionPrice = (FutureValueX * NegNofXd2) - (sptprice * NegNofXd1);}// ...}
}
二、对应的矢量化关键点(汇编指令)
- 生成掩码:
cmpltps xmm1, xmm2 ; xmm1 = (xmm2 < xmm1) ? 0xFFFFFFFF : 0
cmpltps指令对4个float并行比较,生成对应的掩码(true为全1,false为全0)- 这对应标量
if (InputX < 0.0)的判断
- 利用掩码进行条件赋值:
movaps xmm0, xmm2 ; xmm0 = InputX
subps xmm0, xmm3 ; xmm0 = InputX - 参考值(如0或常量)
andnps xmm4, xmm0 ; xmm4 = (~掩码) & xmm0 (false分支的值)
andps xmm0, xmm2 ; xmm0 = 掩码 & xmm2 (true分支的值)
orps xmm4, xmm0 ; 合并两部分得到结果
- 通过位操作
andps,andnps,orps实现掩码控制流:andps选择掩码为真的分支值andnps选择掩码为假的分支值orps合并结果
- 类似的掩码控制流用来处理
sign标志和基于otype的两个分支
pcmpeqd xmm1, xmm3 ; 生成掩码 (掩码为 true/false)
pcmpeqd生成等于比较掩码,用于判断otype == 0
三、矢量化的核心思想
- 传统分支(
if语句)导致CPU流水线停顿,分支预测失败,降低性能。 - 掩码控制流用向量指令对数据进行并行比较生成掩码,
- 通过掩码选择性地操作数据,不跳转,不分支,利用SIMD并行提高吞吐率。
- 可以同时处理4个及以上数据元素(取决于寄存器宽度),非常适合金融数值计算中的批量处理。
四、整体流程总结
| 标量代码控制流 | 矢量化实现方法 | 使用的SIMD指令 |
|---|---|---|
if (InputX < 0) | cmpltps生成掩码,掩码控制赋值 | cmpltps, andps, andnps, orps |
if (sign) | 用掩码控制是否执行操作 | 同上 |
if (otype == 0) | pcmpeqd生成掩码选择不同结果 | pcmpeqd, 位操作合并结果 |
五、代码分析总结
- 代码利用SIMD浮点比较指令生成掩码,代替if判断。
- 使用位运算指令根据掩码选择性地赋值和更新变量。
- 整体实现了无分支的条件控制流,极大减少流水线停顿。
- 适合处理批量数据的数值模型,如Black-Scholes期权定价。
- 这是现代高性能计算中重要的矢量化编程技巧。
这段内容总结了几个著名计算密集型程序或算法在通过矢量化(vectorization)优化后取得的性能提升,重点在于对控制流的矢量化处理,利用现代SIMD指令集(如SSE2、AVX2)实现加速。
理解与分析
| 程序/算法 | 矢量化后性能提升 | SIMD指令集 |
|---|---|---|
| PARSEC\blackscholes | 600%加速 | AVX2 |
| 388%加速 | SSE2 | |
| Numerical Recipe\ks2d1s | 476%加速 | AVX2 |
| 309%加速 | SSE2 | |
| Geekbench_mini\sobel | 231%加速 | SSE2 |
| Eigen\quatmul (四元数乘法) | 229%加速 | SSE2 |
关键点
- Vectorizing control flow:对代码中的控制流(if、循环中的分支等)进行矢量化处理,利用SIMD指令批量并行处理数据,避免分支预测失败和流水线停顿。
- 显著的性能提升:在AVX2和SSE2指令集上的多倍加速,表明矢量化对数值计算的巨大影响。
- 涉及多个领域:
- 金融计算(Black-Scholes)
- 数值分析(Numerical Recipes中的ks2d1s)
- 图像处理(Sobel算子)
- 数学库(Eigen四元数乘法)
总结
这显示了现代CPU SIMD指令对复杂控制流和数值密集计算的强大加速能力。针对具体应用,合理设计矢量化算法,可以带来几倍甚至数十倍的性能提升,是性能优化的关键技术之一。
这是两个典型的软件开发场景,区别在于开发周期和工作负载:
#1 Developer Scenario(开发者场景)
- 操作流程:编辑(EDIT)→ 编译(BUILD)→ 调试(DEBUG)
- 频率:开发者一天大约做40次
- 特点:
- 关注快速编译和反馈
- 代码修改频繁
- 需要快速发现和修复bug
- 编译时间和调试效率对开发效率影响大
#2 Build Lab Scenario(构建实验室场景)
- 操作流程:完全清理后进行全量编译(CLEAN BUILD)
- 频率:通常每天晚上进行一次(nightly build)
- 特点:
- 关注生成完整、干净、可靠的产品版本
- 编译时间较长,但对开发者实时反馈不敏感
- 强调构建的一致性和完整性,避免累积错误
总结:
- 开发者场景强调快速迭代和频繁构建,优化编译速度和调试体验非常关键。
- 构建实验室场景则侧重于稳定性和完整性,通常用来生成可发布的产品版本。
编译器的增量编译和别名分析优化的一个示例。
代码解析与关键点:
// 第一次 foo 函数定义
void foo(int * a, int * b, int * c, int count) {for (int i = 0; i < count; i++) {c[i] = a[i] * b[i];}
}
// 大量未改动的代码(100,000 个函数,500个文件)
int bar() {__declspec(align(16)) int a[128], b[128], c[128];foo(a, b, c, 128);// 其他操作
}
// 第二次 foo 函数修改
void foo(int * a, int * b, int * c, int count) {for (int i = 0; i < count; i++) {c[i] = c[i] + a[i] * b[i];}
}
关键点解释:
- WPA (Whole Program Analysis,整个程序分析) 证明了指针
a,b,c不会别名(alias),即它们指向的内存区域不重叠。 - 当
foo函数被修改时,只有foo这一函数被重新编译,而其它近10万函数和500个文件都不用重新编译。 - 这是增量编译的典型优势:只重新编译受影响的代码,极大缩短构建时间。
- 由于
a,b,c不别名,编译器可以做更积极的优化(比如向量化、内存访问重排),因为可以安全地假设它们不会相互影响。
重要意义:
- 别名分析的结果直接影响优化能力和增量编译效率。
- WPA帮助编译器证明更多优化前提,避免不必要的保守假设。
- 在实际大型项目中,利用WPA和增量编译,可以大大提高开发效率,缩短构建时间。
这是增量构建(Incremental Build)工作流程的简要描述,重点在于编译器和链接器如何配合来快速完成构建。
逐步解析:
- CIL
- Common Intermediate Language(公共中间语言),这里泛指中间编译结果。
- 第一次全量构建时生成。
- Full Build(全量构建)流程
- 编译器核心模块
c2.dll负责编译源代码生成目标文件.obj。 - 生成的
.obj文件交给链接器link.exe,生成最终的可执行文件或 DLL。
- 编译器核心模块
- Edited(代码修改后)
- 只对修改过的文件重新触发编译过程。
- Incremental Build(增量构建)流程
- 使用
IPDB(Incremental Program Database)来追踪代码的变更和依赖关系。 - 只重新编译修改了的部分,更新对应的
.obj文件。 IPDB和c2.dll配合,使得编译器能快速定位变化,避免全量编译。- 然后通过
link.exe链接,生成新的可执行文件或 DLL。
- 使用
- IPDB的作用
- 维护编译中间状态和符号信息。
- 跟踪哪些文件和函数发生了变化。
- 确保增量编译的正确性和效率。
总结:
- 增量构建极大节省了编译时间。
- IPDB是实现增量编译的关键技术。
- 只重新编译必要代码,配合高效链接,提升开发体验。
这段信息涉及了两个重要的链接器选项和一个优化技术的对比:
/debug 与 /debug:fastlink 比较:
/debug:生成完整的调试信息,链接时间较长。/debug:fastlink:微软 Visual Studio 提供的一种快速生成调试信息的方式,极大减少链接时间,但生成的调试信息仍可用。
你给出的时间数据(单位:秒)示例:
| 项目 | 链接时间(/debug) | 链接时间(/debug:fastlink) |
|---|---|---|
| Destiny | 85 | (未列出) |
| Chrome | 471 | (未列出) |
| Kinect Sports | 338 | (未列出) |
| Rival | 11 | (未列出) |
| 280 | (不清楚具体含义) | |
| 124 | ||
(看上去这只是部分数据,但主要是说明 /debug:fastlink 链接时间远短于传统 /debug) |
Profile Guided Optimization (PGO)
- PGO 是一种通过采集程序运行时行为的优化技术,帮助编译器生成更优代码。
- PGO结合上述快速链接选项可进一步优化最终程序性能和构建效率。
总结:
- 使用
/debug:fastlink,链接时间大幅缩短,尤其对大型项目影响明显。 - 配合 PGO,可以在保持调试能力的同时,显著提升程序性能和开发效率。
Profile Guided Optimization (PGO) 在 Xbox One 上的应用
- PGO 已经支持 Xbox One 平台,从2014年6月发布的 XDK(Xbox Development Kit)版本开始。
- 很多大型 Xbox One 游戏(比如 Forza、Kinect Sports Rival、Fable Legends 等)通过 PGO 获得了显著性能提升,提升幅度在 10% 到 20% 之间。
PGO 在 Forza 游戏中的表现
- 游戏主线程(Game thread)性能提升了 14%。
- 渲染线程(Render thread)性能提升了 4%。
- 这还是在已经开启了 LTCG(Link Time Code Generation,链接时代码生成优化)的基础上进一步提升。
小结
PGO 是一种基于实际运行时数据来指导编译器优化的技术,Xbox One 游戏利用它可以获得显著的性能提升,特别是在游戏主线程和渲染线程上。
1. VS2015 中的代码生成器(Code Generators)
- 不仅用来构建 Windows 操作系统,同时也用于编译:
- SQL Server
- Office 套件
- .NET 框架
- Visual Studio 自身
- Windows 的未来版本和特性
2. 代码生成器的重要职责
代码生成在整个软件开发和运行过程中扮演关键角色,负责以下方面:
- **指令集架构(ISA)**的选择和实现
- 性能优化,生成高效的机器代码
- 应用二进制接口(ABI),确保不同模块之间的兼容
- 安全性,防止安全漏洞和攻击
- 互操作性(Interop),让不同语言、模块协同工作
- 运行时语义,保证程序行为符合预期
- 调试,生成便于调试的代码和符号信息
- 垃圾回收和自动引用计数(GC & AutoRefCounting)支持
- 错误和警告报告,提升开发质量
3. 硬件背景
- Ivy Bridge 微架构处理器,拥有 14亿个晶体管,这是支撑上述复杂编译器和代码生成技术的硬件基础。
总结来说,这强调了 VS2015 的代码生成器不仅是 Windows 的构建基石,也支撑了微软全线重要产品的高效、可靠、安全的运行。
1. API + ABI 体系结构
- API(应用程序接口):程序员与系统交互的接口,比如 C#, C++ 函数等。
- ABI(应用二进制接口):定义了二进制层面的调用约定、数据布局、链接规则,确保不同模块编译后能正确协作。
2. 编译流程及组件关系
C# (MSIL) <-- 编译为 --> 中间语言 (MSIL)
C/C++ <-- 通过代码生成器 (C2.dll) --> 目标机器码 (.EXE/.DLL)
- C2.dll:VS2015 中 C++ 的代码生成器,负责把 C++ 代码编译成机器代码。
- linker / binder:将目标文件链接生成最终可执行文件或库。
- 运行时库和框架:
- CRT140.dll(C运行时)
- Ntdll.dll(Windows内核模式和用户模式接口)
- .Net Native Framework
- MRT100.dll(Windows Runtime Library)
3. 运行环境层级
Windows Executive Layer (内核层)|+-- API + ABI (应用层)| - Framework-1、Runtime-1(如.NET运行时)| - STL、BOOST(C++标准库和第三方库)| - WinRT(Windows Runtime)| - .NET Native Framework|+-- 硬件层(如 ARM 32位4核 CPU)
4. 多语言示例代码说明
C++ 例子
#include <vector>
#include <atlbase.h>
#include "MyATLObj.h"
extern int bar();
void DoWork() {std::CComPtr<MyATLObj> myObj;myObj.CoCreateInstance(CLSID_MyATLOBj);int value;myObj->getValue(&value);std::vector<int> v{ bar(), bar(), value };
}
int main() {__try {DoWork();}__except(EXCEPTION_EXECUTE_HANDLER) {__fastfail(1);}
}
- 使用了 ATL (Active Template Library) 的智能指针
CComPtr管理 COM 对象。 DoWork创建 COM 对象,调用成员,保存结果到std::vector。- 通过
__try/__except做结构化异常处理,确保异常安全。
C++/CX 例子(用于 WinRT 编程)
#include <future>
#using "MyWinRTNS.winmd"
using namespace MyWinRTNS;
using namespace std;
using namespace std::chrono;
future<int> DoWork() {MyWinRTObj^ myObj = ref new MyWinRTObj();return __await async([=]() {return myObj->baz()->GetResults();});
}
int bar() {try {return DoWork().get() + 5;} catch (Platform::Exception^ e) {return -1;}
}
- 使用 WinRT 的
ref new和托管指针^。 - 异步调用
baz(),使用future和async处理异步操作。 - 捕获
Platform::Exception异常,保证异常安全。
C# 例子(WinRT接口实现)
using System;
using System.Threading.Tasks;
using Windows.Web;
using Windows.Web.Http;
using Windows.Foundation;
namespace MyWinRTNS {public interface IMyWinRTObj {IAsyncOperation<int> baz();}public sealed class MyWinRTObj : IMyWinRTObj {private async Task<int> DoWork() {HttpClient client = new HttpClient();try {string str = await client.GetStringAsync(new Uri("http://msdn.microsoft.com"));return str.Length;} catch (Exception e) {if (WebError.GetStatus(e.HResult) == WebErrorStatus.BadGateway) {return -1;}throw e;}}public IAsyncOperation<int> baz() {return DoWork().AsAsyncOperation<int>();}}
}
- 定义 WinRT 接口
IMyWinRTObj和实现类MyWinRTObj。 - 异步方法通过
async/await获取网页字符串长度。 - 捕获网络异常,处理特定错误码。
- 将
Task<int>转换为IAsyncOperation<int>,以便 WinRT 兼容。
总结
- 代码示例演示了如何用多语言(C++、C++/CX、C#)访问和实现 WinRT 异步接口。
- 体现了 API 和 ABI 之间的桥梁,通过编译、代码生成、运行时组件协同工作,支持复杂异步操作和安全异常处理。
- 反映了现代 Windows 平台上,跨语言、跨运行时的系统集成和互操作设计。
这段内容描述了微软在Windows平台上引入Clang/LLVM技术支持C++跨平台编译的整体架构和流程,结合了微软自家的C2编译后端。
逐条分析:
1. Top Down - 跨平台的C++支持架构
- Windows 平台上,微软支持多语言混合开发:
- C#、C++/CX 用于Windows Runtime层
- C++作为核心系统编程语言,同时支持iOS、Android(通过Objective-C, Swift, Java)
- 编译链:
- 使用 Clang 作为前端解析器,生成抽象语法树(AST)
- AST 转换成 LLVM IR(中间表示)
- 通过微软自家的 c2.dll 编译器后端,将 LLVM IR 转成机器码,支持微软4种ABI(应用二进制接口)
2. 跨架构支持
- 支持多架构:
- ARM 32位
- x64(64位Intel架构)
- x86(32位Intel架构)
- 新功能如
fall(可能指控制流相关的新指令或特性)
3. Clang/C2的结合
- Clang负责前端解析和LLVM IR生成
- C2负责LLVM IR到Windows目标机器代码的生成(后端)
- 支持微软特有的ABI(如微软的异常处理、调用约定等)
4. 测试和优化
- 99%的内部C++测试覆盖了四个架构
- 支持多种编译选项:
/O2完全优化/Od全调试信息支持
- 许多大型应用测试通过,保证稳定性
5. 版本迭代
- V1 (11月):大量本地改动,包含调试信息、结构化异常处理和桥接代码(约3行)
- V2 (2月):几乎没有本地改动,继续贡献给社区
6. Clang工具链整合Windows的关键代码路径
driver.cpp:加载微软后端 c2.dllcc1_main.cpp:初始化c2后端编译器执行CodeGenAction.cpp:LLVM IR转微软C2的代码生成调用
7. 合作与未来
- 微软不打算分叉Clang/LLVM源码,保持与开源社区同步
- Clang/C2代码库保持只读,仅有极少数本地改动(约3行)
- 致力于帮助Clang/LLVM更好地支持Windows和微软ABI
- 使用LLVM Bitcode作为通用输入格式,以便多平台工具链和Windows ABI兼容
总结
- 微软将Clang作为前端,结合自有C2后端,实现跨架构高性能的Windows C++编译支持。
- 通过社区协作和极小的本地改动,实现了与LLVM生态的紧密集成。
- 支持多语言、多平台、多ABI环境,满足微软及跨平台开发需求。
- 体现了微软在现代C++编译器生态中的开放与合作态度。
这段内容主要讲述了在跨平台C++开发中,如何通过条件编译(#ifdef)来处理不同编译器和平台的实现差异,尤其是微软编译器(C1xx/C2)与Clang/LLVM的兼容性问题,以及逐步摆脱一些历史遗留的兼容性hack。
代码分析和理解:
1. 跨平台通用C++的条件编译(#ifdef)
- 代码中会根据编译器或平台定义条件编译宏,如:
#ifdef _MSC_VER // Windows/MSVC专用代码 #endif - 这允许同一份代码支持多个平台和编译器,保证:
- Windows用C1xx/C2编译器编译,调用Windows特有代码。
- Android用Clang/LLVM编译器,性能和代码质量达到同等水平。
- 共享的C++库中通过
#ifdef区分平台特定代码。
2. 缺失的C++标准支持、错误和兼容问题
- 通过
#ifdef (conformance)来开启或关闭某些新标准特性,保证不同编译器的兼容性:struct limits {template<typename T>static const T min; }; template<typename T> const T limits::min = { }; - 代码中提到支持变量模板、聚合初始化中非静态成员初始化、嵌套命名空间等现代C++特性。
3. 逐步去除历史兼容性hack
- 过去为了兼容MSVC和GCC的差异,常用这些hack:
或者#ifndef _MSC_VER #pragma GCC diagnostic push #pragma GCC diagnostic ignored "-Wall" #endif#ifdef _MSC_VER #pragma warning(disable : 4127) #endif - 这些hack现在“goes away”(去除),说明环境或编译器更现代化,或者C++标准支持更完善,不再需要特别针对某些编译器抑制警告。
4. 示例:模板bug的临时解决方案
- 示例代码中有一个针对打印不同整数类型的函数重载:
template <typename T> void print(T t) { cout << "Unknown: " << t << endl; } void print(long long n) { cout << "long long: " << n << endl; } void print(unsigned long n) { cout << "unsigned long: " << n << endl; } void print(unsigned long long n) { cout << "unsigned long long: " << n << endl; } - 主函数中根据不同编译器有不同的写法:
#if defined(_MSC_VER) print(-(long long)4000000000); #else print(-4000000000); #endif - 这是为了处理不同编译器对整数字面量和类型转换的解析差异,避免编译错误或运行时错误。
总结
- 利用
#ifdef控制编译,针对平台和编译器差异写不同代码分支。 - 逐渐采用现代C++标准,减少编译器特定的hack和警告抑制。
- 保持代码库的跨平台可维护性。
- 对复杂类型转换和重载存在兼容性处理。
- 目标是统一代码,最终能在Windows和Android上都使用现代编译器构建,且性能和质量保持一致。
关于不同编译器(MSVC的c1/c2编译器和Clang/c2编译器)在编译不同语言和代码复杂度时的性能比较,特别关注在Windows平台下,使用不同编译器及其优化选项的表现,以及对向量化和语言特性支持的进展:
代码编译性能与对比
1. 编译时间(Compile Time)对比
- C语言编译 (Spec2k6 gcc /O2 优化)
- c1/c2 编译器总耗时 28秒(7.8秒前端 + 20秒后端)
- clang/c2 编译器总耗时 38秒(不分具体前后端时间)
- MSVC编译器在C语言上更快。
- C++无模板代码编译 (Spec2k6\xalancbmk)
- 单一最大文件,/O2 优化
- c1/c2 总耗时 2.65秒(24.3秒前端 + 1.5秒后端)
- clang/c2 总耗时 13.4秒(1.14秒前端 + 2.67秒后端)
- 这里可能数据有误,前端时间差异大,可能表示不同测试内容。
- C++含模板代码编译 (Eigen\benchmarks.cpp,重模板,/O2)
- c1/c2 总耗时 16.8秒(3.1秒前端 + 13.8秒后端)
- clang/c2 总耗时 14.3秒(1.4秒前端 + 2.7秒后端)
- clang/c2在模板代码前端解析上非常快,后端略慢。
2. LLVM-C2 Bridge性能影响
- VTune性能分析显示LLVM-C2桥接层开销小于1%,几乎可忽略不计,说明MSVC和LLVM的整合高效。
编译器选项和性能
- c1/c2 使用
/O2 /fp:fast(全优化,快速浮点) - clang/c2 使用
/O2 -Xclang -ffast-math(全优化,快速数学运算)
基准测试性能对比
- c1/c2 在一些基准测试(如bzip2, mcf, milc等)中比clang/c2快,提升幅度从1%到52%不等。
- 具体示例:
- bzip2快7%
- gobmk快13%
- libquantum快52%
- h264ref慢4%
向量化与代码重写
- 完整重写了整数向量化代码,支持回退(undo)。
- 90%功能完成,示例函数:
void test16(int *x, int *a, int *b) {while (a < b)*a++ += 2 + *x++; } - 向量化对提升性能关键,尤其是在数据密集型代码中。
语言特性和其他支持
- C99支持: 用户投票最高的需求之一,显示微软对现代C语言标准的支持。
- 结构化异常处理(SEH): 完全支持,重要的Windows平台特性。
- 跨平台示例: iOS的Objective-C也可在Windows上使用。
- 应用示例: Bing Maps的Jason库使用这些技术。
总结
- MSVC的c1/c2编译器在传统C/C++代码(尤其无模板或轻模板代码)编译上表现较好,整体更快。
- Clang/c2在模板代码的前端解析上表现优异,后端优化略慢。
- LLVM和MSVC整合良好,桥接成本极低。
- 向量化代码重写提升性能,接近完备。
- 微软正努力支持现代C99标准和结构化异常处理,满足开发者需求。
- 目标是提升跨平台编译性能和代码质量,支持更多语言和平台。
相关文章:

CppCon 2015 学习:CLANG/C2 for Windows
Visual Studio 2015 引入了基于 CLANG/LLVM 的新代码生成器,及其背景和意义。简单理解如下: 理解要点: VS2015 中引入了全新的代码生成技术,性能和质量都很棒。这套新技术基于 Clang,微软展示了相关新工具。Clang 和…...

Spring中@Primary注解的作用与使用
在 Spring 框架中,Primary 注解用于解决依赖注入时的歧义性(Ambiguity)问题。当 Spring 容器中存在多个相同类型的 Bean 时,通过 Primary 标记其中一个 Bean 作为默认的首选注入对象。 核心作用: 解决多个同类型 Bean …...

Spring Boot + Elasticsearch + HBase 构建海量数据搜索系统
Spring Boot Elasticsearch HBase 构建海量数据搜索系统 📖 目录 1. 系统需求分析2. 系统架构设计3. Elasticsearch 与 HBase 集成方案4. Spring Boot 项目实现5. 大规模搜索系统最佳实践 项目概述 本文档提供了基于 Spring Boot、Elasticsearch 和 HBase 构建…...
)
[zynq] Zynq Linux 环境下 AXI BRAM 控制器驱动方法详解(代码示例)
Zynq Linux 环境下 AXI BRAM 控制器驱动方法详解 文章目录 Zynq Linux 环境下 AXI BRAM 控制器驱动方法详解1. UIO (Userspace I/O) 驱动方法完整示例代码 2. /dev/mem 直接内存映射方法完整示例代码 3. 自定义字符设备驱动方法完整示例代码 4. 方法对比总结5. 实战建议 在 Zyn…...
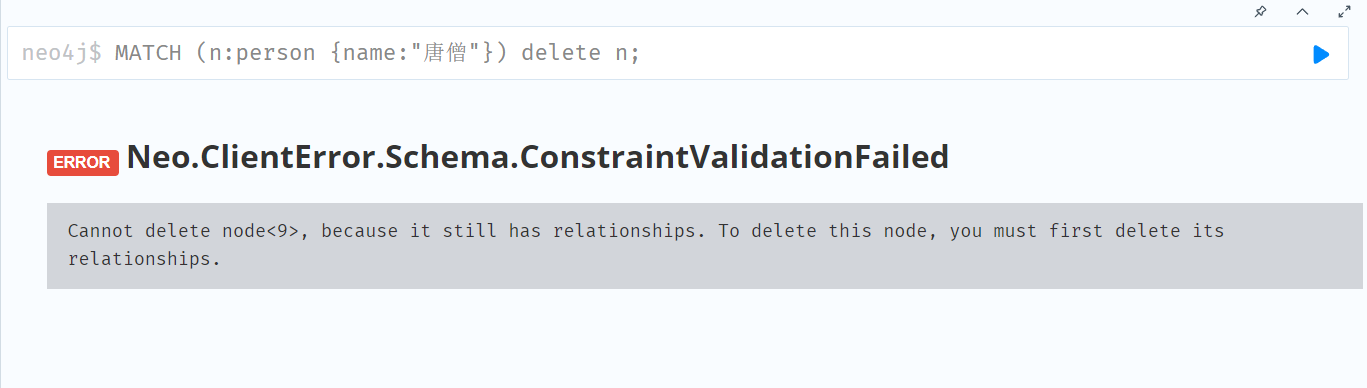
【大模型:知识图谱】--5.neo4j数据库管理(cypher语法2)
目录 1.节点语法 1.1.CREATE--创建节点 1.2.MATCH--查询节点 1.3.RETURN--返回节点 1.4.WHERE--过滤节点 2.关系语法 2.1.创建关系 2.2.查询关系 3.删除语法 3.1.DELETE 删除 3.2.REMOVE 删除 4.功能补充 4.1.SET (添加属性) 4.2.NULL 值 …...

六、数据库的安全性
六、数据库的安全性 数据库的安全问题 数据库中的数据是可以共享的数据共享必然带来数据库的安全性问题 数据库系统中的数据共享不能是无条件的共享数据库中数据的共享是在 DBMS 统一的严格控制之下的共享,即:只允许有合法使用权限的用户访其被授权的数…...

贪心算法应用:装箱问题(BFD算法)详解
贪心算法应用:装箱问题(BFD算法)详解 1. 装箱问题与BFD算法概述 1.1 装箱问题定义 装箱问题(Bin Packing Problem)是组合优化中的经典问题,其定义为: 给定n个物品,每个物品有大小wᵢ (0 < wᵢ ≤ C)无限数量的箱子…...

C#学习第27天:时间和日期的处理
时间和日期的核心概念 1. UTC 和 本地时间 UTC(Coordinated Universal Time): 是一种不受时区影响的世界标准时间。在网络通信和全球协作中,用于统一时间度量 本地时间(Local Time): 是根据所…...
编程技能:格式化打印05,格式控制符
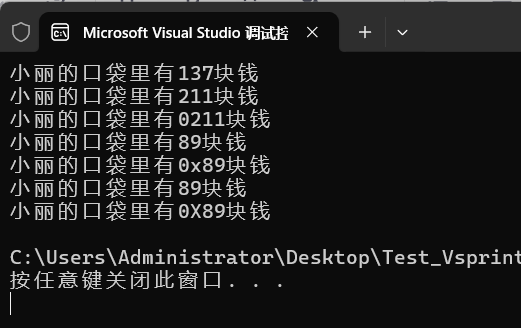
专栏导航 本节文章分别属于《Win32 学习笔记》和《MFC 学习笔记》两个专栏,故划分为两个专栏导航。读者可以自行选择前往哪个专栏。 (一)WIn32 专栏导航 上一篇:编程技能:格式化打印04,sprintf 回到目录…...
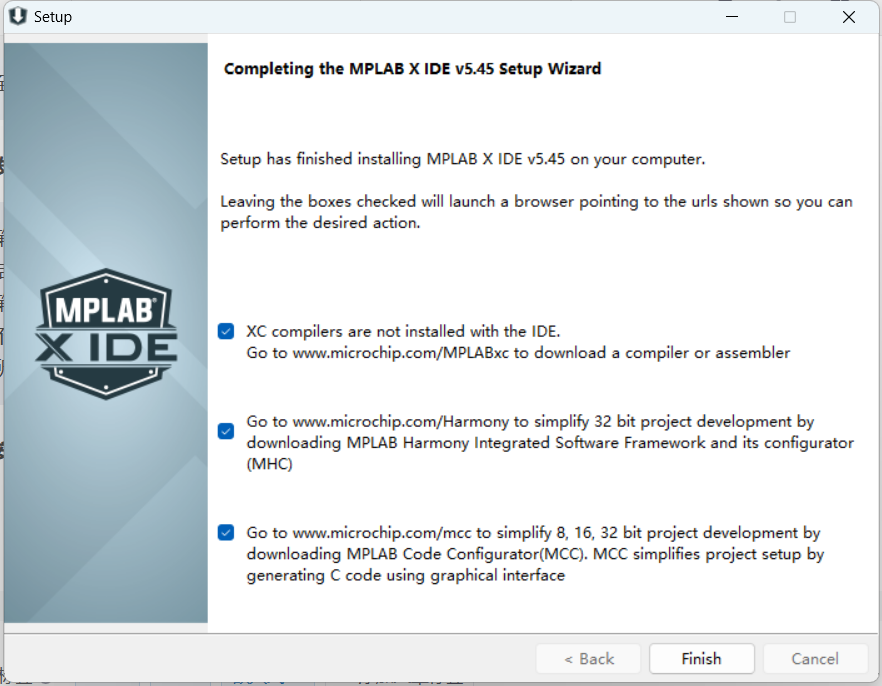
MPLAB X IDE 软件安装与卸载
1、下载MPLAB X IDE V6.25 MPLAB X IDE | Microchip Technology 正常选Windows,点击Download,等待自动下载完成; MPLAB X IDE 一台电脑上可以安装多个版本; 2、安装MPLAB X IDE V6.25 右键以管理员运行;next; 勾选 I a…...

windows编程实现文件拷贝
项目源码链接: 实现文件拷贝功能(限制5GB大小) 81c57de 周不才/cpp_linux study - Gitee.com 知识准备: 1.句柄 句柄是一个用于标识和引用系统资源(如文件、窗口、进程、线程、位图等)的值。它不是资…...
[6-01-01].第12节:字节码文件内容 - 属性表集合
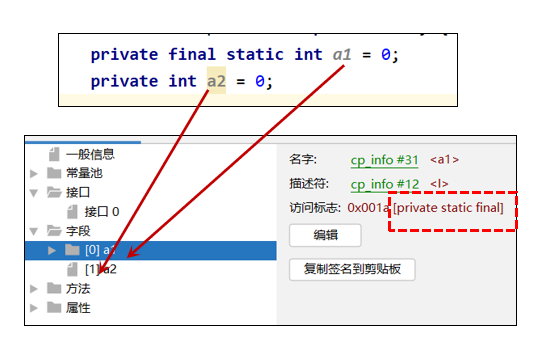
JVM学习大纲 二、属性表集合: 2.1.属性计数器: 2.2.属性表: 2.3.字节码文件组成5 -> 属性: 1.属性主要指的是类的属性,比如源码的文件名、内部类的列表等 2.4.字节码文件组成3 -> 字段: 1.字段中…...
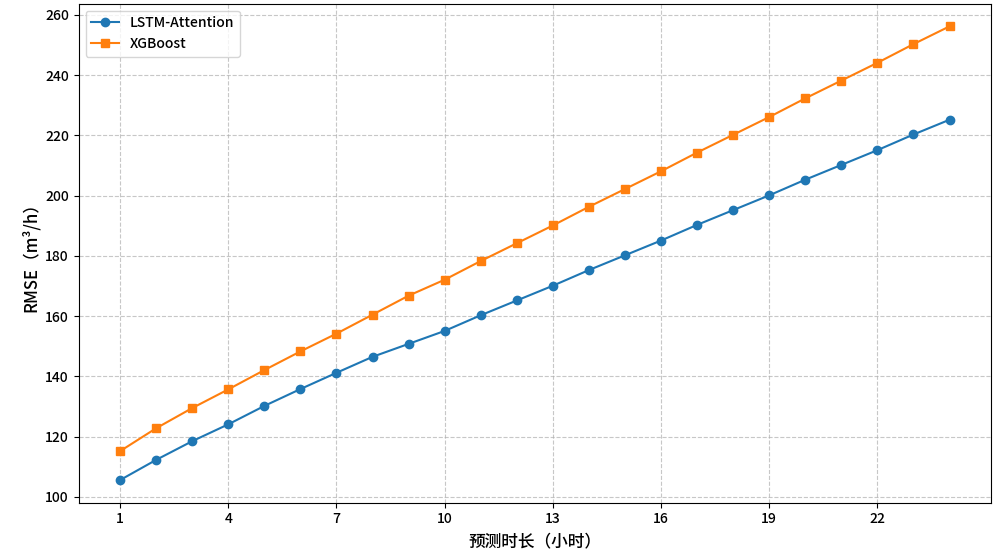
基于机器学习的水量智能调度研究
摘要:随着城市化进程的加速和水资源供需矛盾的日益突出,传统的水量调度模式因缺乏精准预测和动态调控能力,难以满足现代供水系统对高效性、稳定性和节能性的要求。本文针对供水系统中用水峰谷预测不准确、能耗高、供需失衡等核心问题…...

深度解码:我如何用“结构进化型交互学习方法”与AI共舞,从学习小白到构建复杂认知体系
嗨,亲爱的学习者们,思考者们,以及所有渴望在知识海洋中自由翱行却时常感到迷茫的朋友们: 你是否也曾有过这样的深夜,面对堆积如山的学习资料,眼神迷离,内心却一片荒芜?明明每个字都…...
深入浅出 Scrapy:打造高效、强大的 Python 网络爬虫
在数据为王的时代,高效获取网络信息是开发者必备的技能。今天我将为大家介绍 Python 爬虫领域的王者框架——Scrapy。无论你是数据工程师、分析师还是开发者,掌握 Scrapy 都能让你的数据采集效率提升数倍! 项目地址:https://github.com/scrapy/scrapy 官方文档:https://do…...

ES6 Promise 状态机
状态机:抽象的计算模型,根据特定的条件或者信号切换不同的状态 一、Promise 是什么? 简单来说,Promise 就是一个“承诺对象”。在ES6 里,有些代码执行起来需要点时间,比如加载文件、等待网络请求或者设置…...

Axure 与 Cursor 集成实现方案
Axure 与 Cursor 集成实现方案 以下是一个完整的 Axure 与 Cursor AI 集成的原型实现方案,通过自定义 JavaScript 代码实现无缝对接: 一、整体架构设计 #mermaid-svg-f9hQDSN4hijU3mJY {font-family:"trebuchet ms",verdana,arial,sans-seri…...

汽车加气站操作工证考试重点
汽车加气站操作工证考试重点 一、汽车加气站操作工证考试主要内容 汽车加气站操作工证是从事CNG(压缩天然气)和LNG(液化天然气)加气站作业人员的必备资格证书。随着新能源汽车的快速发展,该证书的市场需求持续增长&a…...
贪心算法应用:带权任务间隔调度问题详解
贪心算法应用:带权任务间隔调度问题详解 贪心算法是一种在每一步选择中都采取在当前状态下最好或最优(即最有利)的选择,从而希望导致结果是全局最好或最优的算法。带权任务间隔调度问题是贪心算法的一个经典应用场景。 问题定义…...
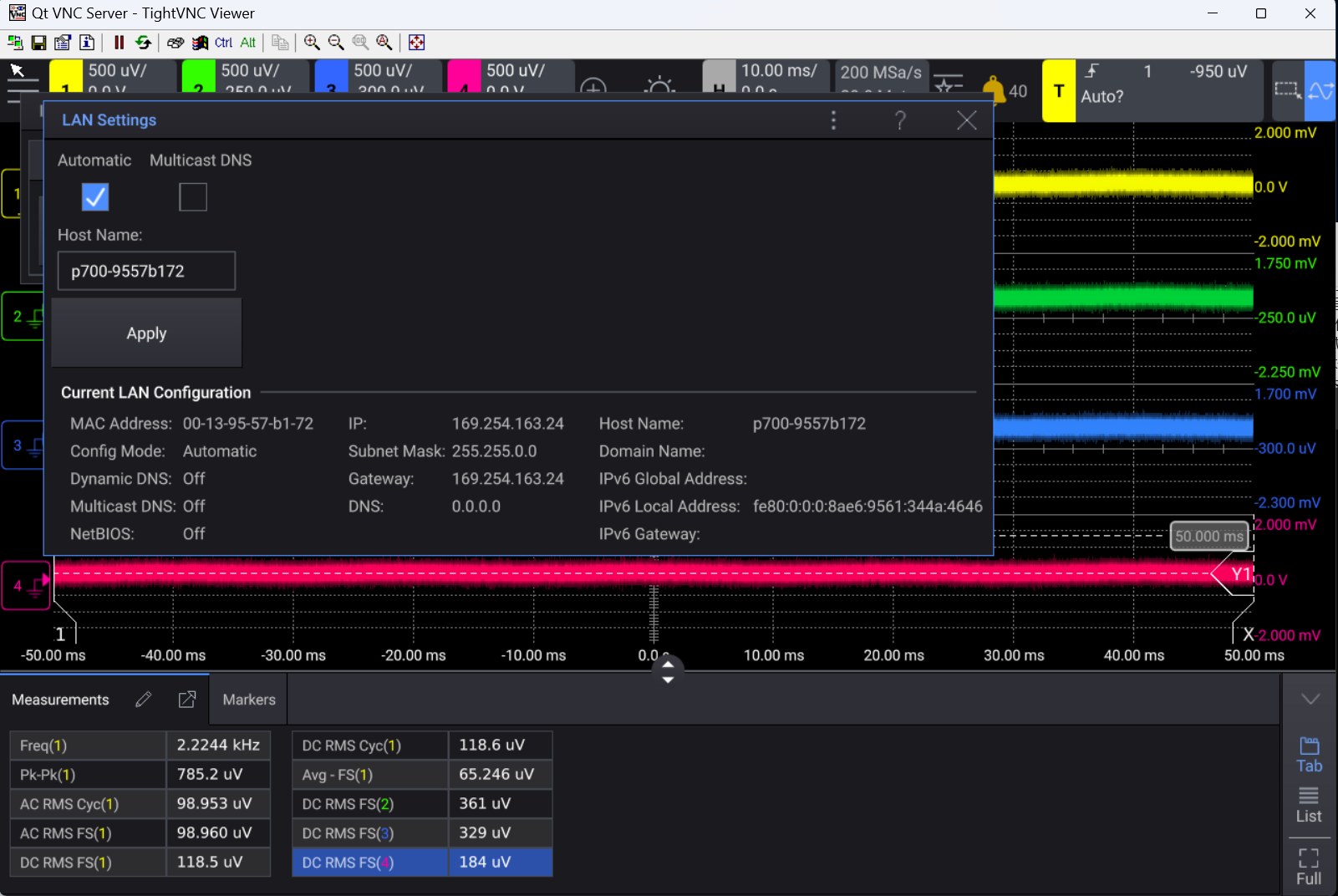
用电脑控制keysight示波器
KEYSIGHT示波器HD304MSO性能 亮点: 体验 200 MHz 至 1 GHz 的带宽和 4 个模拟通道。与 12 位 ADC 相比,使用 14 位模数转换器 (ADC) 将垂直分辨率提高四倍。使用 10.1 英寸电容式触摸屏轻松查看和分析您的信号。捕获 50 μVRMS …...
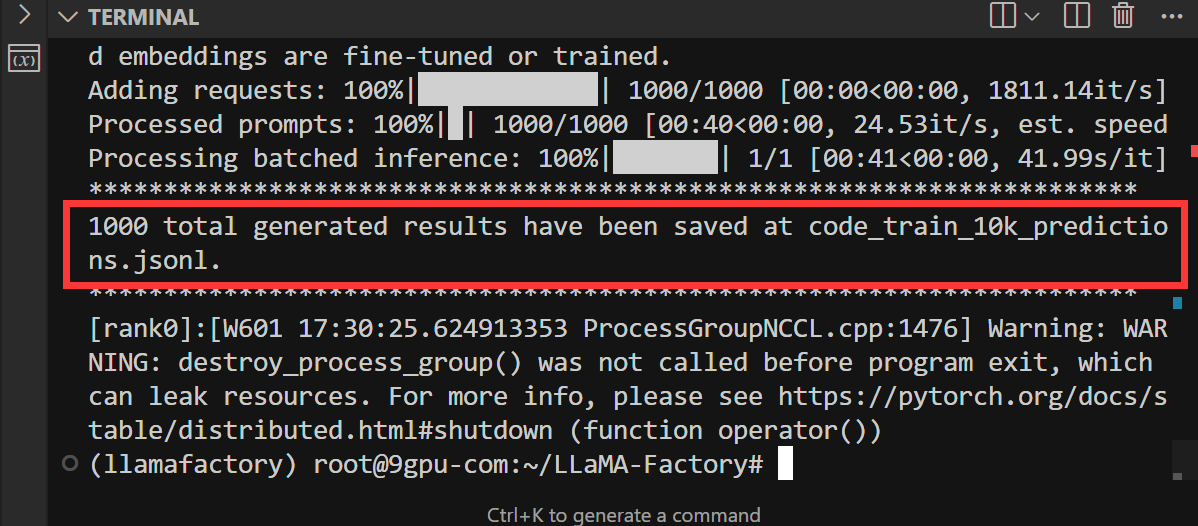
LLaMA-Factory - 批量推理(inference)的脚本
scripts/vllm_infer.py 是 LLaMA-Factory 团队用于批量推理(inference)的脚本,基于 vLLM 引擎,支持高效的并行推理。它可以对一个数据集批量生成模型输出,并保存为 JSONL 文件,适合大规模评测和自动化测试。…...

React从基础入门到高级实战:React 高级主题 - 测试进阶:从单元测试到端到端测试的全面指南
React 测试进阶:从单元测试到端到端测试的全面指南 引言 在2025年的React开发环境中,测试不仅是代码质量的保障,更是提升开发效率和用户体验的关键支柱。随着React应用的复杂性不断增加,高级测试技术——如端到端(E2…...

Ansible 剧本精粹 - 编写你的第一个 Playbook
Ansible 剧本精粹 - 编写你的第一个 Playbook 如果说 Ansible Ad-Hoc 命令像是你对厨房里的助手发出的零散口头指令(“切个洋葱”、“烧开水”),那么 Playbook 就是一份完整、详细、写在纸上的菜谱。它列明了所有需要的“食材”(变量),详细的“烹饪步骤”(任务),甚至还…...
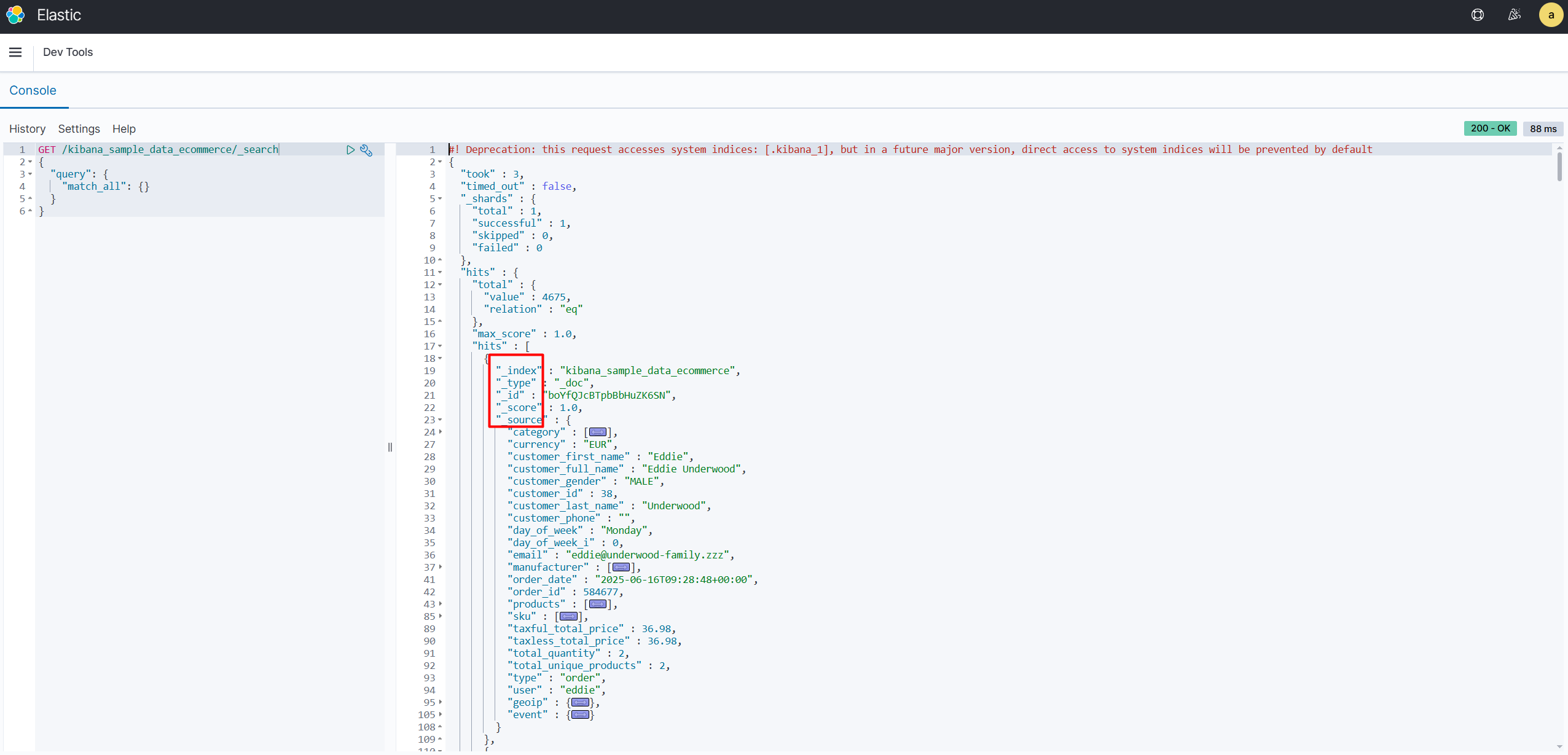
【Elasticsearch】Elasticsearch 核心技术(二):映射
Elasticsearch 核心技术(二):映射 1.什么是映射(Mapping)1.1 元字段(Meta-Fields)1.2 数据类型 vs 映射类型1.2.1 数据类型1.2.2 映射类型 2.实际运用案例案例 1:电商产品索引映射案…...
【计算机网络】网络层协议
1. ICMP协议的介绍及应用 IP协议的助手 —— ICMP 协议 ping 是基于 ICMP 协议工作的,所以要明白 ping 的工作,首先我们先来熟悉 ICMP 协议。 ICMP 全称是 Internet Control Message Protocol,也就是互联网控制报文协议。 里面有个关键词 …...

.NET Core接口IServiceProvider
.NET Core 接口 IServiceProvider 深度剖析 在 .NET Core 和 .NET 5 的世界里,依赖注入(Dependency Injection,简称 DI)是构建可维护、可测试应用程序的关键技术。而 IServiceProvider 接口,正是依赖注入机制中的核心…...
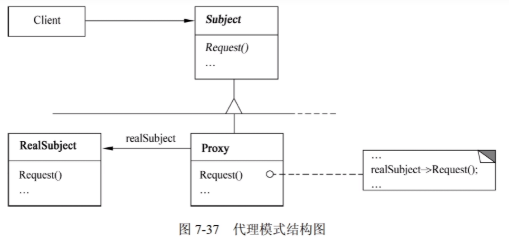
结构型设计模式之Proxy(代理)
结构型设计模式之Proxy(代理) 前言: 代理模式,aop环绕通知,动态代理,静态代理 都是代理的一种,这次主要是记录设计模式的代理demo案例,详情请看其他笔记。 1)意图 为其…...

案例分享--汽车制动卡钳DIC测量
制动系统是汽车的主要组成部分,是汽车的主要安全部件之一。随着车辆性能的不断提高,车速不断提升,对车辆的制动系统也随之提出了更高要求,因此了解车辆制动系统中每个部件的动态行为成为了制动系统优化的主要途径,同时…...
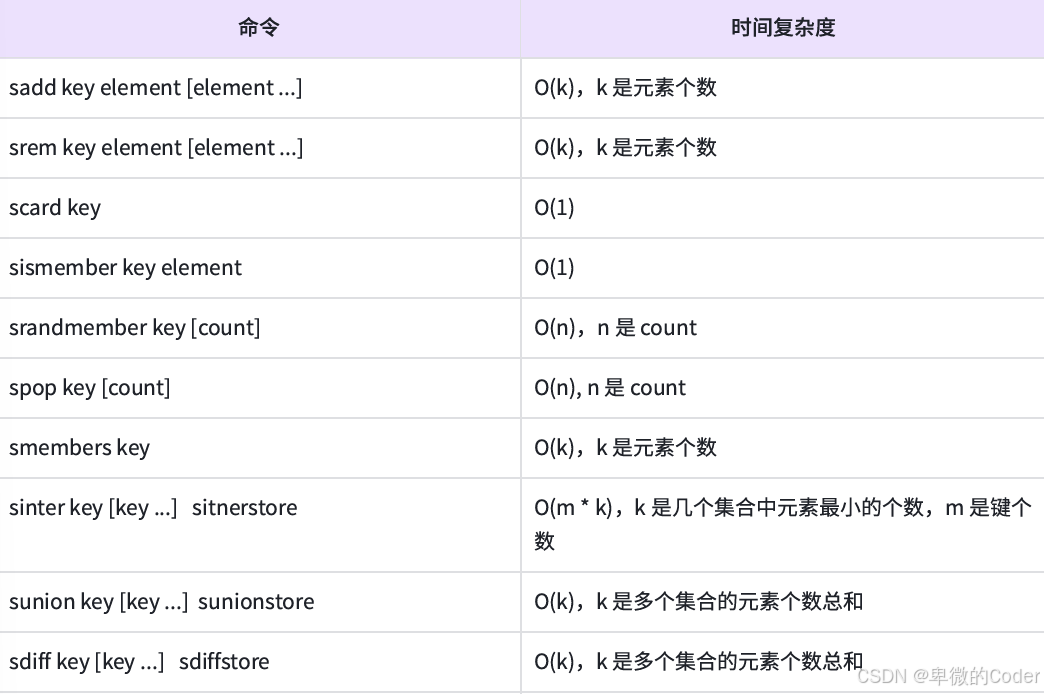
Redis Set集合命令、内部编码及应用场景(详细)
文章目录 前言普通命令SADDSMEMBERSSISMEMBERSCARDSPOPSMOVESREM 集合间操作SINTERSINTERSTORESUNIONSUNIONSTORESDIFFSDIFFSTORE 命令小结内部编码使用场景 前言 集合类型也是保存多个字符串类型的元素的,但和列表类型不同的是,集合中 1)元…...

C++算法动态规划1
DP定义: 动态规划是分治思想的延申,通俗一点来说就是大事化小,小事化无的艺术。 在将大问题化解为小问题的分治过程中,保存对这些小问题已经处理好的结果,并供后面处理更大规模的问题时直接使用这些结果。 动态规划具…...