[论文阅读] (38)基于大模型的威胁情报分析与知识图谱构建论文总结(读书笔记)
《娜璋带你读论文》系列主要是督促自己阅读优秀论文及听取学术讲座,并分享给大家,希望您喜欢。由于作者的英文水平和学术能力不高,需要不断提升,所以还请大家批评指正,非常欢迎大家给我留言评论,学术路上期待与您前行,加油。
忙碌的五月终于过去,忙到来不及分享技术,六月开启,继续更新博客,感谢大家的支持,久等了!
本文旨在系统梳理大语言模型(LLM)在网络安全与威胁情报分析中的最新研究进展,侧重知识图谱构建、攻击行为建模以及模型泛化与推理能力等关键技术维度。结合作者当前的研究方向与兴趣,本文挑选并归纳了多篇代表性论文,其中重点详述的为与团队工作紧密相关、具有实际借鉴价值的工作。这些大佬的文章真心值得我们学习,希望本文对您有所帮助,写得不足之处还请海涵。
在逐篇阅读过程中,笔者特别关注以下要素:论文所提出的系统框架图、大模型的技术创新点、与知识图谱的融合机制、以及所采用的实验验证方法和开源代码。这些内容不仅拓宽了对 LLM 能力边界的理解,也为我们后续在威胁情报建模与网络安全防御方面提供了一定的路径指引。
同时,欢迎各位老师和大佬补充相关高质量论文,后续笔者也将不断更新与精炼此系列内容。希望本读书笔记对从事大模型和网络安全结合的研究者与开发者提供有价值的参考。
- 欢迎关注作者新建的『网络攻防和AI安全之家』知识星球(文章末尾)
文章目录
- 一.威胁情报方向
- 1.RACONTEUR: A Knowledgeable, Insightful, and Portable LLM-Powered Shell Command Explainer (NDSS25)
- 2.LLM-TIKG: Threat intelligence knowledge graph construction utilizing large language model (C&S)
- 3.IntelEX: A LLM-driven Attack-level Threat Intelligence Extraction Framework
- 4.CTINEXUS: Automatic Cyber Threat Intelligence Knowledge Graph Construction Using Large Language Models(EuroS&P 2025)
- 5.基于大语言模型的网络威胁情报知识图谱构建技术研究
- 6.一种基于大语言模型的威胁情报信息抽取方法
- 7.面向威胁情报的大语言模型技术应用综述
- 二.网络安全相关方向
- 1.Attention-Based API Locating for Malware Techniques(TIFS24)
- 2.IDS-Agent: An LLM Agent for Explainable Intrusion Detection in IoT Networks(NeurIPS24)
- 3.Think-on-Graph: Deep and Responsible Reasoning of Large Language Model on Knowledge Graph(ICLR24)
- 4.KnowGraph: Knowledge-Enabled Anomaly Detection via Logical Reasoning on Graph Data(CCS24)
- 三.总结
一.威胁情报方向
1.RACONTEUR: A Knowledgeable, Insightful, and Portable LLM-Powered Shell Command Explainer (NDSS25)
- 期刊/会议:NDSS 2025
- 论文作者:Jiangyi Deng, Xinfeng Li, Yanjiao Chen, Yijie Bai, Haiqin Weng, Yan Liu, Tao Wei, Wenyuan Xu (浙江大学,蚂蚁集团)
- 论文地址:https://arxiv.org/pdf/2409.02074
本文来自浙大徐老师和蚂蚁兜哥他们的论文,提出了RACONTEUR系统。
(1) 摘要
恶意Shell命令是网络攻击的关键载体,但其复杂的语法和隐蔽性使得安全分析师难以快速理解其意图。现有通用大语言模型(LLM)如ChatGPT在解释Shell命令时存在两大问题:
- 缺乏专业知识:对恶意命令的行为和攻击技术(如MITRE ATT&CK框架中的技术分类)理解不足;
- 幻觉与泛化性差:对未见的私有命令(如企业内部工具)易生成错误或虚构的解释。
RACONTEUR旨在解决这些问题,提供知识驱动、深度洞察且可移植的Shell命令解释。

(2) 核心创新点
- 专业知识注入:通过微调LLM(如ChatGLM2-6B),结合恶意命令库(Atomic Red Team、Metta等)和良性命令库(NL2Bash、The Stack),生成高质量的行为解释。将自然语言解释映射到MITRE ATT&CK框架的技术(Technique) 和 战术(Tactic),帮助分析师快速关联攻击意图与防御措施。
- 意图识别技术:提出BD2Vec模型,将行为描述与MITRE ATT&CK标准描述映射到同一向量空间,通过语义相似度匹配技术标签(如“T1003 - OS 凭据转储”)。
- 文档增强的可移植性:设计CD2Vec模型,从私有文档中检索上下文信息,支持对未训练过的私有命令的解释(如企业内部工具的参数解析)。
(3) 核心框架
RACONTEUR核心框架图如下所示:

RACONTEUR包含三个核心模块:
- 行为解释器(Behavior Explainer):
– 输入:用户查询(如“解释命令bash -c '0<&137-...'”)。
– 处理:基于微调的LLM生成分步解释和整体行为总结(如“建立反向Shell连接”)。
– 数据增强:通过模板生成多样化提示,结合代码库知识生成专业回答。 - 意图识别器(Intent Identifier):
– 输入:行为解释的总结文本。
– 处理:使用BD2Vec模型将行为描述与MITRE ATT&CK技术描述对齐,通过相似度匹配确定攻击技术和战术(如“TA0006 - 凭据访问”)。 - 文档增强器(Doc-Augmented Enhancer):
– 输入:用户查询中的命令。
– 处理:利用CD2Vec模型从文档库(如Linux手册页或企业内部文档)检索相关上下文,增强LLM输入的提示信息。

(4) 实验分析
对比基线模型:
- 行为解释:GPT-3.5-Turbo、GPT-4、ChatGLM2-6B;
- 意图识别:GPT-3.5-Turbo、GPT-4;
- 文档检索:Sentence-T5、GTR-T5、SGPT、E5。


- 行为解释性能:
– RACONTEUR在恶意命令解释的ROUGE-1(68.9 vs. GPT-4的45.5)和BLEU-4(59.5 vs. GPT-4的40.5)上显著优于基线(表I)。
– 用户研究中,RACONTEUR的全面性(恶意命令评分4.2/5)和正确性(恶意命令评分4.5/5)均最高(图6)。 - 意图识别性能:
– 在MITRE ATT&CK技术匹配任务中,RACONTEUR的Top-1准确率达52.4%,远超基线(GPT-4为28.1%)(表V)。 - 文档检索性能:
– CD2Vec模型的AUC-ROC达0.981,优于所有基线(图5),表明其能有效区分相关与无关文档。

(5) 未来工作
- 混淆命令分析:扩展对Base64编码等混淆技术的支持;
- 会话级分析:从单条命令扩展到完整Shell会话的意图识别;
- 多模态日志处理:支持网络日志、数据库日志等其他安全日志分析;
- 更大基座模型:探索更大规模的开源模型(如LLaMA-2)以进一步提升性能。
2.LLM-TIKG: Threat intelligence knowledge graph construction utilizing large language model (C&S)
- 期刊/会议:Computers & Security
- 论文作者:Yuelin Hu, Futai Zou, Jiajia Han, Xin Sun, Yilei Wang(上海交通大学)
- 论文地址:https://www.sciencedirect.com/science/article/abs/pii/S0167404824003043
- 开源数据:https://github.com/Netsec-SJTU/LLM-TIKG-dataset
开源威胁情报(Open-source threat intelligence)通常表现为非结构化信息,难以直接应用于后续的威胁检测与防御。通过构建基于开源威胁情报的知识图谱,可以实现对安全信息的结构化整合,从而更有效地支撑入侵检测。然而,当前的知识图谱构建方法受到多个限制因素的制约,包括实体具有显著的领域特征、文本篇幅冗长难以处理,以及对大规模标注数据的高度依赖。此外,目前尚缺乏权威的开源威胁情报标注语料库,其构建过程往往需要大量人工投入。值得注意的是,现有研究普遍忽略了攻击行为的文本化描述,导致在理解复杂网络攻击行为时关键信息的丢失。
为应对上述挑战,本文提出 LLM-TIKG 方法,利用大型语言模型(LLM)从非结构化开源威胁情报中自动构建知识图谱。该方法充分发挥GPT的小样本学习能力(few-shot learning),实现数据的标注与扩充,从而生成用于微调中小规模语言模型(7B)的训练数据。在完成模型微调后,我们开展报告主题分类、实体及关系抽取,以及TTP(战术、技术与程序)信息识别,最终构建威胁情报知识图谱,实现对文本化威胁情报的自动化与通用化解析。实验结果表明,该方法在命名实体识别与TTP分类任务中表现优异,分别达到87.88%和96.53%的精度水平。
(1) 研究背景
① 威胁情报的挑战
- 非结构化文本:开源威胁情报(OSCTI)多呈非结构化文本形式(如安全报告、博客),难以直接应用于检测防御系统。
- 信息碎片化:传统方法聚焦于提取原子指标(IoCs,如IP、域名),但忽略高阶实体(攻击者、工具)及其关联关系,导致威胁狩猎和攻击归因困难。
- 领域特殊性:威胁情报实体存在边界模糊、多义性等问题,且长文本分析受模型序列长度限制,影响命名实体识别(NER)精度。
- 标注数据匮乏:缺乏权威的开源标注数据集,人工标注成本高昂。
② 知识图谱的价值
- 构建威胁情报知识图谱(KG)可整合多源情报,通过实体关系网络揭示攻击链路径(如TTPs:战术、技术与过程),提升威胁分析的深度和主动性。

(2) 研究动机和主要贡献
现有KG构建方法存在三大局限:
- 信息提取精度低:领域特定实体识别困难,长文本处理效果差。
- 依赖标注数据:监督学习方法需大量标注样本,而权威数据集稀缺。
- 忽略攻击行为:文本中的行为描述(如“注入shellcode”)未被有效提取和映射到TTP框架,导致高阶情报丢失。
本文的核心目标:利用大语言模型(LLM)解决上述问题,实现非结构化OSCTI到KG的自动化、通用化转换。
本文主要主要贡献:
- 方法论贡献:提出首个端到端LLM驱动的威胁情报KG构建框架,实现非结构化文本到多层级情报(IoCs→TTPs)的自动化提取。
- 数据贡献:开源人工修正的数据集(https://github.com/Netsec-SJTU/LLM-TIKG-dataset),填补领域标注数据空白。
- 应用价值:构建的KG支持威胁狩猎(攻击链可视化)与攻击归因(恶意软件家族聚类)。
(3) 核心创新点
① LLM驱动的KG构建框架(LLM-TIKG)
- 少样本学习数据生成:利用GPT-3.5的少样本能力,通过指令设计(Instruction + Examples)自动生成标注数据,减少人工标注成本。
- 多任务微调模型:基于LoRA技术微调Llama2-7B模型,统一完成主题分类、实体关系抽取、TTP分类三类任务。
- TTP融合:首次将攻击行为描述映射至MITRE ATT&CK框架的TTP节点,关联低阶IoCs与高阶攻击模式。
② 领域自适应优化
- 指令工程:针对安全实体歧义问题,设计约束性指令(如“仅提取指定实体类型”)抑制LLM幻觉。
- 数据增强:采用多语言回译与语义改写(GPT指令:“保持原义重写句子”)提升TTP分类数据多样性。
(4) 方法逻辑框架
系统框架如下图所示,分四阶段:

① 数据获取
- 爬取12,545篇OSCTI报告(Symantec、CISA等平台),保留章节结构并清洗文本。
② 数据集构建(GPT驱动)
- 主题分类:过滤非威胁情报内容(如广告),保留恶意软件/攻击相关报告。
- 实体关系抽取:定义12类实体(攻击者、工具、漏洞等)及关系(use、aka等),通过指令模板生成标注数据。
- TTP分类:融合MITRE ATT&CK示例与TRAM数据集,经数据增强扩至38,946条。
③ 模型微调(Llama2-7B + LoRA)
- 参数高效训练:冻结原始权重,通过低秩矩阵 ΔW=BA 更新参数,降低计算成本。
- 输入格式:任务指令(Instruction) + 输入文本 + 输出示例(实体关系任务)。
④ 知识图谱构建
- 实体融合:规则融合是规范化同义恶意软件名称(如"Backdoor.Pterodo" → “Pterodo”);聚类融合是基于词嵌入余弦相似度,层次聚类生成代表实体。
- 关系优化:绑定攻击行为与主体,将"PowerShell执行文件"关联至具体恶意软件主体;冗余关系剔除:仅保留实体列表内的有效关系。
- 存储:输出至Neo4j图数据库,生成50,745实体、64,948关系。


(5) 实验效果对比
实体类别如表1所示。

命名实体识别(NER)结果如表3所示。

TTP分类结果如表4所示,其覆盖全部229种MITRE ATT&CK技术,准确率提升超70%,证明LLM对复杂攻击行为的语义理解能力。

生成的威胁知识图谱如下图所示:


(6) 结论与展望
LLM-TIKG显著提升威胁情报KG构建效率与精度,NER精确率87.88%、TTP分类96.53%,验证LLM在网络安全领域的泛化能力。该研究通过LLM技术解决了威胁情报KG构建中的领域适应性与数据依赖问题,为自动化威胁分析提供了新范式,其代码与数据开源进一步推动领域发展。
未来方向:
- 探索更长上下文处理技术(如RoPE扩展),优化长文本实体抽取。
- 融合多模态情报(如网络流量日志),增强KG的全面性。
- 研究LLM的推理能力,支持基于KG的自动化威胁推理。
3.IntelEX: A LLM-driven Attack-level Threat Intelligence Extraction Framework
- 期刊/会议:arXiv
- 论文作者:Ming Xu, Hongtai Wang, Jiahao Liu, Yun Lin, Chenyang Xu, Yingshi Liu, Hoon Wei Lim, Jin Song Dong(新加坡国立大学,上海交通大学)
- 论文地址:https://arxiv.org/abs/2412.10872
随着网络攻击的日益复杂化,企业面临的安全威胁不断增加。为了应对这些威胁,安全团队通常会将非结构化的网络威胁情报(CTI)报告转化为结构化的情报,以便于后续的安全任务,如生成检测规则或模拟攻击场景。然而,现有的威胁情报往往停留在技术层面,缺乏攻击级别的详细信息,例如攻击阶段的具体技术使用、实现步骤和上下文原因。这些信息对于快速调查和分析至关重要。
- IntelEX旨在填补这一空白,通过自动化工具提取结构化的攻击级情报,识别逻辑攻击序列(包括战术、技术和程序,TTPs),并提供上下文洞察。
(1) 研究背景
威胁情报分析的瓶颈:
- 非结构化数据主导:网络威胁情报(CTI)以非结构化文本形式存在(如安全报告、博客),难以直接应用于防御系统。
- 技术级情报的局限:现有方法(如STIX标准、AttackKG)主要提取原子指标(IoCs)或孤立技术(Techniques),缺乏攻击级情报(TTPs)——即战术逻辑序列(Tactics)、技术实现(Techniques)和具体步骤(Procedures)的整合。
- 下游任务依赖人工:规则生成(如Sigma规则)和攻击复现(红队演练)高度依赖安全专家,效率低且易出错。
LLM的机遇与挑战:
- 机遇:大语言模型(LLM)具备强大的上下文理解能力(如GPT-4o),可解析复杂攻击语义。
- 挑战:
– 幻觉问题:LLM易生成虚假技术描述。
– 动态知识滞后:MITRE ATT&CK框架持续更新,LLM预训练数据难以实时同步。
– 长文本处理:CTI报告平均长度408词,超出模型上下文窗口。


现有威胁情报提取方法存在三大缺陷:
- 逻辑缺失:忽略攻击阶段间的战术序列(如从"初始访问"到"横向移动"的链条)。
- 细节不足:缺乏具体实施步骤(如"通过钓鱼邮件投放Hikit恶意软件")。
- 应用脱节:提取的情报未有效支撑自动规则生成或攻击模拟。
目标:构建端到端框架,实现攻击级TTP情报的自动化提取与应用。

(2) 核心创新点
① 攻击级情报提取:
- IntelEX利用大语言模型(LLM)的上下文学习能力,结合外部情报向量数据库,精准提取攻击的战术、技术和程序(TTPs)。
- 通过引入LLM-as-a-judgment模块,减少LLM生成错误信息的可能性,降低误报率。
② 自动化检测规则生成:
- 基于提取的TTPs,IntelEX能够自动生成高保真的Sigma检测规则,并验证其在Splunk等SIEM平台上的有效性。
- 生成的规则在真实环境中表现出色,能够有效检测恶意事件。
③ 攻击模拟支持:
- IntelEX生成的攻击实现步骤(Procedures)能够帮助红队快速复现攻击环境,支持攻击模拟和防御演练。
- 生成的步骤包含完整的实体、关系和动作信息,83.48%的输出被安全分析师评为“极其有用”。

IntelEX基本流程如下图所示:

(3) 整体框架
IntelEX的框架分为以下几个核心模块:
① 威胁情报输入:
- 输入为非结构化的CTI报告(如博客、攻击文档)。
- 通过IDS系统或安全分析师手动输入可疑命令或攻击描述。
② 文档分块与IoC识别:
- 将长报告分块,识别每个块中的攻击指标(IoC),如IP地址、域名、文件哈希等。
- 分块机制确保LLM能够专注于每个块中的具体攻击行为。
③ 战术与技术分类:
- 使用LLM的上下文学习能力,结合MITRE ATT&CK框架,识别每个块中的战术和技术。
- 通过向量数据库增强检索,确保提取的技术与最新攻击技术保持一致。
④ LLM-as-a-judgment模块:
- 使用独立的LLM对提取的技术进行二次判断,过滤掉不相关的技术,减少误报。
- 该模块通过外部知识库(如MITRE ATT&CK描述)进行验证,确保提取结果的准确性。
⑤攻击步骤生成:
- 使用GraphRAG框架生成攻击实现步骤,确保步骤包含实体、关系和动作信息。
- 生成的步骤能够帮助红队快速复现攻击环境,支持攻击模拟。
⑥ 自动化检测规则生成:
- 基于提取的TTPs,生成Sigma规则,并通过Splunk验证其有效性。
- 生成的规则能够有效检测恶意事件,且在真实环境中表现优异。


下表为用于分类战术和技术的提示模板。详细的指南和示例分别列于附录B中,红色和绿色组件根据报告或识别的技术而变化。

(4) 实验分析
TTP提取精度分析,图6展示了AttackKG漏检如“T1059-命令脚本解释器”(假阴性),IntelEX凭借语义理解准确捕获。

下图是本文的规则生成和转换流程,我们将Sigma规则转换为Splunk规则。


其它实验结果如下所示,包括在野实测,IntelEX生成规则检测恶意事件的精确率/召回率(均值0.86/0.82)显著优于Sigma规则集(0.48/0.41)与Splunk规则集(0.52/0.45)(图10)。此外,本文方法能捕获API注入(如/phpunit/src/Util/PHP/eval-stdin.php)等新型攻击,覆盖开源规则盲区。

(5) 结论与展望
IntelEX首次实现攻击级威胁情报的自动化提取与应用,TTP提取F1达0.792,规则生成F1达0.929,显著提升防御效率。其轻量化设计(GPT-4o-mini)兼顾性能与成本,具备工业落地潜力。
本文主要贡献归纳如下:
- 理论创新:首创攻击级情报提取框架,统一战术序列、技术实现与操作步骤的自动化抽取。提出LLM-as-a-Judge机制,为LLM安全领域应用提供可解释性保障。
- 技术突破:RAG增强的动态知识融合,解决MITRE ATT&CK持续更新难题。端到端规则生成流水线,支持语法纠错与特异性过滤。
- 应用价值:开源校准数据集(171条标注技术)与代码,推动领域研究。在工业场景验证中,Splunk检测效率提升2倍,红队攻击复现效率提升5倍。

未来方向:
- 细粒度规则生成:支持SIEM定制化复杂规则(如Splunk ES)。
- 多模态扩展:融合网络流量、日志等多源数据,增强图谱完整性。
- 对抗性优化:研究攻击变体(Attack Variants)的自动生成与防御。
总之,该研究通过LLM与知识工程的协同创新,解决了攻击级情报提取与落地的核心难题,为自动化威胁防御提供了新范式。其技术路径(RAG+Judge)对安全领域的LLM应用具有普适参考价值。
4.CTINEXUS: Automatic Cyber Threat Intelligence Knowledge Graph Construction Using Large Language Models(EuroS&P 2025)
- 期刊/会议:EuroS&P 2025
- 论文作者:Yutong Cheng, Osama Bajaber, Saimon Amanuel Tsegai, Dawn Song, Peng Gao(Virginia Tech,UC Berkeley)
- 论文地址:https://arxiv.org/abs/2410.21060
- 开源地址:https://github.com/peng-gao-lab/CTINexus
网络威胁情报(Cyber Threat Intelligence, CTI)报告中的文本描述,如安全文章与新闻报道,是网络威胁知识的重要来源,对于组织掌握快速演化的威胁态势至关重要。然而,当前的CTI知识抽取方法在灵活性与通用性方面存在明显不足,常导致知识抽取结果不准确或不完整。语法解析方法依赖固定规则与词典,难以适应新的威胁类型和本体结构;而模型微调方法则依赖大量人工标注数据,限制了其在低资源场景下的可扩展性。
为弥合这一差距,本文提出了一种新型框架CTINexus,该框架基于大型语言模型(LLMs)的优化上下文学习(In-Context Learning, ICL)机制,实现在数据受限条件下的高效CTI知识抽取与高质量网络安全知识图谱(Cybersecurity Knowledge Graph, CSKG)构建。 与传统方法不同,CTINexus无需大量训练数据或复杂的参数调优,仅通过极少的标注示例即可适应多种本体体系。这一能力的实现依赖以下关键技术:
- (1)自动化构建提示词的策略,结合最优示例检索,支持多类别安全实体与关系的高效抽取;
- (2)分层实体对齐方法,对抽取得到的知识进行规范化与去冗余处理;
- (3)远距离关系预测机制,用于补全知识图谱中的缺失链接。
在150份来自10个平台的真实CTI报告上开展的大规模实证研究显示,CTINexus在构建准确、完整的CSKG方面显著优于现有方法,充分展示了其作为一种高效、可扩展的动态威胁分析解决方案的潜力。

(1) 研究背景
随着网络攻击日趋复杂和演化迅速,网络威胁情报(Cyber Threat Intelligence, CTI)已成为组织制定防御策略的关键依据。CTI文本(如安全博客、新闻报告)蕴含大量关于恶意软件、攻击者行为、漏洞利用等知识。然而,现有的CTI知识抽取方法主要基于:
- 语法解析(rule-based):依赖固定规则与词典,泛化能力弱;
- 模型微调(fine-tuning):需要大量标注数据,难以适应新兴威胁和本体结构变化。
这类方法导致生成的网络安全知识图谱(Cybersecurity Knowledge Graph, CSKG)不准确、不完整,难以支撑高质量威胁建模和响应。
(2) 研究动机
现有方法生成的网络安全知识图谱(CSKG)质量低下,如图1所示。
- 不完整:遗漏关键实体(如攻击链中的横向移动技术)。
- 不准确:实体边界错误(如"registry values and ransom note"被合并)。
- 碎片化:子图间缺乏关联(如"威胁组织"与"利用的漏洞"无显式关系)。
- 时效性差:无法快速适配新兴威胁(如零日漏洞术语)。
为突破上述瓶颈,本文旨在构建一个数据高效、可泛化、无需微调的新框架,借助大语言模型(Large Language Models, LLMs)的上下文学习能力(In-Context Learning, ICL),自动从CTI文本中抽取实体与关系,构建结构化的CSKG,从而支持安全分析与自动防御。

(3) 核心创新点
提出CTINexus框架,基于LLM上下文学习(ICL)实现数据高效的CSKG构建,主要创新如下:
- ICL优化的信息抽取机制
利用kNN检索选取与目标CTI报告相似的示例构造提示(prompt),结合本体知识,指导LLM抽取实体-关系三元组,避免冗长对话式提问,显著减少token消耗。 - 分层实体对齐机制(图4)
粗粒度对齐通过ICL对实体进行类型分类(如Threat Actor、Malware等);精细化对齐基于向量嵌入合并语义相似的实体,并设计IOC保护机制避免误合并(如IP地址与恶意软件名混淆)。 - 远程实体关系推理(图5)
基于子图中的度中心性选出核心实体,通过ICL推理这些中心节点与主题节点(topic entity)之间的隐式关系,连接原本离散的子图,提升CSKG的连通性。
(4) 方法逻辑框架
图2展示了CTINEXUS的整体流程,展示从CTI报告输入到三元组抽取、实体融合、远程推理的全流程。共分为三大阶段:
-
Phase 1: 安全三元组抽取(Cybersecurity Triplet Extraction)
输入为一篇CTI报告;通过kNN检索相似示例报告;构造统一ICL提示(instruction + examples + query),由LLM直接输出所有相关三元组;图3展示了与传统多轮提问相比,CTINEXUS的“单轮抽取”在效率与准确性上明显优越。 -
Phase 2: 分层实体对齐(Hierarchical Entity Alignment)
粗粒度使用ICL模板对triplet中主客体进行实体类型分类(如图4所示);细粒度使用text-embedding-3-large模型嵌入同类实体,合并相似度高于阈值(0.6)的实体。 -
Phase 3: 长距离关系推理(Long-Distance Relation Prediction)
图5中采用图结构分析选出各子图的中心实体;使用ICL模板构造问题推理这些中心实体与topic entity之间的关系,补全跨段落或跨句式的隐式链接。

图3是对比多轮问答与ICL方法,强调CTINEXUS在“Instruction + Examples + Query”结构中的信息浓缩能力,避免冗余问答与格式误差。

图4为实体对齐流程图,细化了从类型标注、聚类到安全过滤的步骤,IOC保护机制有效避免误合并关键实体(如CVE ID、IP地址等)。

图5展示的是CTINEXUS框架中第三阶段“长距离关系预测(Long-Distance Relation Prediction)”的完整流程设计,解决的是CTI文本中不同段落或句子中提及的实体之间缺乏显式关联的问题,确保最终构建的CSKG具有更好的连通性和完整性。
-
Phase 1:中心实体识别(Central Entity Identification)
对CSKG执行深度优先遍历,将其划分为多个连通子图。使用度中心性(Degree Centrality)指标,选出每个子图中边最多的实体作为“中心实体(Central Node)。在所有中心实体中,再选出度数最高者作为主题实体(Topic Node),即本报告最核心的威胁对象。 -
Phase 2:基于ICL的关系推理(ICL-Enhanced Relation Inference)
推断中心节点与主题节点之间可能存在但在原文本中未明确指出的“隐式关系”。构建一个ICL提示模板(prompt template),包含上下文、问题和示例。由大语言模型(如GPT-4)根据上述提示,生成预测三元组(predicted_triplet),完成关系推理。

(5) 对比实验结果
① 与主流方法对比
- 三元组抽取性能:CTINEXUS F1-score为87.65%,远超EXTRACTOR(62.29%);
- 实体识别性能:CTINEXUS F1-score为90.13%,领先LADDER(71.13%);
- 长距离关系推理:使用GPT-4模型下可达F1-score 90.99%,远高于GPT-3.5的76.87%。
② 各阶段优化分析
- 示例数量从1增至2显著提升准确性,进一步增加收益边际递减;
- kNN-ascend排序策略优于random与descending,验证“示例靠近查询越有效”;
- text-embedding-3-large在实体融合中F1达99.8%,优于SecureBERT等安全专用模型。


(6) 结论与前景
CTINEXUS展示了LLM+ICL在CTI知识抽取与CSKG构建中的显著优势,具备高准确率、高适应性、低数据依赖;对本体切换(如MALOnt到STIX)的出色兼容性,支持实时威胁图谱构建(如STIX格式输出),赋能入侵检测系统(如AlienVault OTX集成);高计算效率。
未来工作将探索降低LLM幻觉影响、图谱增强生成(KG-augmented Generation)、安全可视化分析与问答系统集成,使CSKG成为安全LLM的动态记忆与防御基础设施。
5.基于大语言模型的网络威胁情报知识图谱构建技术研究
- 期刊/会议:通信学报 2024
- 论文作者:赖清楠,金建栋,周昌令(北京大学)
随着网络威胁的复杂性和精细度不断增加,将网络威胁情报整合到网络安全措施中变得至关重要。设计了一个基于大语言模型的网络威胁情报知识图谱构建框架AutoCTI2KG,通过指令提示和上下文学习,自动从网络威胁情报中生成网络安全知识图谱和攻击知识图谱,并提供可操作的防护建议。
实验结果表明,所提出的框架在网络安全知识图谱和攻击知识图谱构建方面表现出色,F1值在0.90左右,展示了大语言模型在网络安全领域知识图谱构建的潜力。所提出的框架不仅推进了网络安全知识图谱构建的前沿技术,还为网络安全专业人员提供了一个实用工具,以更好地理解和降低网络风险。
本文设计了一个基于大语言模型的全自动框架AutoCTI2KG,通过调用大语言模型的接口,利用指令提示和上下文学习来实现,该框架的整体设计如图1所示,由5个模块组成。
- 重写模块、网络安全知识图谱生成模块、攻击知识图谱生成模块、防护建议生成模块和总结输出模块

随着大语言模型对长文本的理解和处理能力的逐步增强,可以将网络威胁情报、输出模板和企业 ATT&CK框架等背景知识作为输入,通过给定的提示词,让大语言模型处理后按照模板进行输出。

实验结果如下所示:

攻击知识图谱生成如下所示:


6.一种基于大语言模型的威胁情报信息抽取方法
- 期刊/会议:网络空间安全科学学报 2024
- 论文作者:马冰琦,周盈海,王梓宇,田志宏(广州大学)
随着网络攻防对抗日益激烈,威胁情报的深度挖掘与有效利用成为提升网络安全防御策略的关键。针对传统信息抽取技术在训练数据构建和模型泛化能力方面的局限性,提出了一种基于大语言模型(Large Language Models,LLMs)的威胁情报实体及其相互关系抽取框架。借助 LLMs 的深度语义理解能力,通过提示工程技术准确抽取威胁实体及其相互关系,同时辅以 LangChain 扩展抽取广度。此外,通过搜索引擎集成提高情报挖掘的时效性和准确性。
实验结果显示,该框架在少样本或零样本情境下表现出色,有效减少了误导信息的生成,实现了实时高效的情报知识提取。总体而言,引入一种灵活高效的威胁情报智能化挖掘方法,优化了威胁情报的知识融合过程,提升了网络防御的主动性与先进性。
LLMs 能够捕捉文本中的细微语义区别并挖掘隐含语义信息,实现对语言内容的深层分析。因此,LLMs 适应性极强,可通过少量样本学习(Few-Shot Learning)和零样本学习(Zero-Shot Learning)技术,就能在少数样本或无样本的情况下迅速适应新型威胁知识的语义模式。
- 增强威胁信息时效性,并减轻 LLMs 的“幻觉”问题
常见实体类型如下:

(1) 提示工程
根据威胁实体模型及关系类型的详细定义,并遵循“清晰度”“特异性”和 “迭代”prompt 设计原则,鉴于中英文语法习惯的区别,针对中英文威胁情报分别构建了一套完整规范的 prompt 文本。
- 首先,明确阐述了模型需要执行的任务,确保了prompt的清晰性。
- 其次,通过提供详尽的细节描述,显著消除了歧义,增强了特异性 。
- 最后,基于AI反馈,不断对prompt进行优化迭代,以提升其准确性和适用性。
具体的prompt文本如图1和图2所示。


(2) 文档分析
威胁情报通常以PDF文档形式发布,威胁情报文档详细记录了安全威胁的全面信息,包括攻击方法的具体细节、受影响的系统与应用以及相应的解决策略和缓解措施。
PDF文档将文本、图表和布局等元素以复杂方式结合,这给基于纯文本的 LLMs 带来挑战。特别地,像GPT-3这样的模型面临输入长度的限制,通常在2048个token左右,在处理长文档时无法全面考虑文档内容,影响对文档结构和内容的整体理解。针对这 一问题,采用结合LLMs和LangChain技术的方法来处理威胁情报的PDF文档,旨在通过问答形式更高效地抽取文档中的关键信息,具体分析流程如图3所示。
- 输入问题处理
- 文档内容向量化
- 基于问答对文档内容进行解析

(3) 搜索引擎
威胁情报实体关系抽取领域面临着诸多挑战,如信息的海量性和分布的广泛性、威胁情报的专业深度与结构复杂性、实体间多样且动态变化的关系以及表达形式的多样性。为应对这些难题,结合LLMs 与 Web 搜索引擎提出了一种有效的解决方案。利用 Web 搜索引擎的广泛检索功能,全面收集相关的威胁情报,保障信息的完整性和实时性。同时,借助LLMs卓越的自然语言处理技术,深度解析这些信息,包括精准辨识复杂术语、捕捉实体间细微的关系变化以及理解不同表述间的语义差异。这一集成方法不仅提高了实体关系抽取的精确度和效率,也为威胁情报的进一步分析与应用奠定了坚实的基础。
本文提出的 LLMs 与 Web 搜索引擎集成的方法如图 4 所示。在 LLMs 与搜索引擎结合进行网络安全领域的威胁实体问答任务时,流程始于用户提出的针对特定网络安全威胁或具体威胁实体的查询,比如询问某种恶意软件的特性或是某个攻击者的历史行 为。

提示工程实例分析结果如下:

文档实例分析结果如下:

搜索引擎实例分析结果如下,图 9 展示了在 ChatGPT 3.5 与 Web 搜索引擎集成的情况下,ChatGPT 3.5 的回答示例。LLMs 如 GPT 系列,在生成文本时偶尔会产生一种被称为“幻觉”的现象,即产生不准确或与现实不符的信息。将搜索引擎的结果作为输入提供给LLMs 是一种有效的解决策略,该策略能够利用搜索引擎检索到的实时和准确的外部信息来提高 LLMs 回答的质量,确保生成的内容更加贴近数据和事实真相。
如图 9 所示,通过将 ChatGPT 3.5 和 Web 搜索引擎集成进行问答,可以直观明确地获得关于恶意软件 ShadowPad 的详细属性信息。这种集成方法显著减少了 LLMs 可能出现的“幻觉”(生成与事实不符的信息),提高了生成答案的内容丰富度、准确性、客观性和可靠性。

7.面向威胁情报的大语言模型技术应用综述
- 期刊/会议:信息安全学报 2024
- 论文作者:崔孟娇, 姜政伟, 陈奕任, 江钧, 张开, 凌志婷, 封化民, 杨沛安 (中国科学院信息工程研究所)
随着计算机与网络技术的不断发展, 网络空间面临着日益复杂的安全威胁。为了有效防御网络攻击, 网络威胁情报应运而生。然而当前网络威胁如零日漏洞、高级可持续性威胁(Advanced Persistent Threat, APT)等, 具有形式复杂、针对性强、危害性高、隐蔽性强, 时间跨度长等特征, 传统的威胁情报技术难以有效应对。近年来, 大语言模型(Large Language Models, LLM)的兴起不仅降低了攻击成本, 还促进了网络攻击技术的普及化。因此, 本文旨在通过探讨大语言模型在威胁情报领域的技术应用现状, 利用大语言模型的潜能提高对威胁情报聚合, 分析及应用的能力, 从而更为精准地识别、分析和应对网络威胁。
本文首先概述了网络威胁情报背景知识, 接着介绍大语言模型的概念、发展历程和研究现状, 以发掘大语言模型在威胁情报领域应用的可能。然后深入分析了威胁情报与大语言模型结合的相关文献, 围绕威胁情报生命周期系统地梳理了大语言模型在增强威胁情报聚合、驱动威胁情报分析以及赋能威胁情报应用方面的成果, 并从技术应用场景和主要方法等角度对其进行分类归纳。此外, 针对这三个方面分别总结了研究现状、技术特点和潜在发展方向。最后本文讨论了大语言模型应用于威胁情报和网络安全领域所面临的挑战, 并给出了未来研究方向, 进一步推动网络威胁情报的发展。
(1) LLM 增强威胁情报聚合
- 威胁情报自动采集
- 威胁情报预处理
- 威胁情报评估融合


LLM 增强威胁情报聚合技术汇总如下:

(2) LLM 驱动威胁情报分析
- 威胁情报信息提取识别:实体识别、关系提取、TTPs 提取、漏洞描述映射
- 威胁情报自动生成
- 知识图谱构建

(3) LLM 赋能威胁情报应用
- 网络攻击威胁预测
- 网络攻击威胁检测
- 网络攻击威胁溯源

四个未来可能热门的研究方向:
- 通过大语言模型降低威胁情报生产成本, 提高威胁情报输出质量。
- 通过大语言模型推动威胁情报更好地完成威胁检测、威胁溯源等应用层级工作。
- 将大语言模型融入威胁情报平台、网络威胁分析平台等安全产品的生态体系中。
- 通过解决模型自身问题, 设计新应用场景来促进大语言模型更好地应用于威胁情报工作。
思考以下四组问题:
- 大语言模型技术的安全效益问题。
- 新的攻防辩证关系。
- 大语言模型和网络安全的关系。
- 技术应用过程存在的一些挑战。
二.网络安全相关方向
该部分内容是作者最近阅读网络安全相关的四篇不错论文,其框架图和创新性较好,仅作在线笔记分享。
1.Attention-Based API Locating for Malware Techniques(TIFS24)
- 论文地址:https://ieeexplore.ieee.org/document/10309174
本研究提出了一种创新的恶意软件行为分析方法——APILI(API-Level Inference for Low-level Identification),该方法基于深度学习技术,能够在动态执行轨迹中精准定位与已识别恶意行为技术相关联的API调用。APILI通过构建API调用、资源实体与攻击技术之间的多重注意力机制,融合MITRE ATT&CK框架中的对抗者策略、技术与程序信息,以神经网络形式实现对恶意行为的语义关联建模。
具体而言,APILI采用微调后的BERT模型对参数与资源进行嵌入表示,引入奇异值分解(SVD)方法表征技术向量,并通过网络层结构优化与噪声增强策略进一步提升定位性能。据我们所知,这是首次实现从高层恶意行为技术向低层API调用的精确映射与定位。实验评估结果显示,APILI在恶意技术识别与API调用定位两个任务中,均显著优于传统方法与其他机器学习技术,有效提升了恶意软件行为分析的自动化水平。该方法具有良好的实用性与推广价值,有助于显著降低分析人员的工作负担。

核心创新为提出APILI系统,首创"技术-资源-API"三层注意力机制。
- 双阶段注意力架构。微调BERT嵌入API参数(如文件路径C:\Startup\Enc.exe)→ 生成768维语义向量。SVD分解技术共现矩阵压缩为25维特征向量,融合资源向量与噪声扰动生成技术-资源权重。
- 联合优化损失函数。二元交叉熵优化F1-score,资源距离函数最大化关键资源注意力值(如勒索软件的.enc文件路径)。
- API定位算法。对识别的技术(如T1129),按技术注意力降序取TOP-K资源(如tasksche.exe);检索资源注意力峰值对应的API(如NtOpenFile/CreateFile/WriteFile);通过查找表映射至原始调用序列(图3)。


2.IDS-Agent: An LLM Agent for Explainable Intrusion Detection in IoT Networks(NeurIPS24)
- 论文地址:https://neurips.cc/virtual/2024/100920
物联网(IoT)网络面临的新型威胁正在加速入侵检测系统(IDS)的发展,其特点是从依赖攻击特征或异常检测的传统方法,逐步转向以机器学习(ML)为基础的检测手段。然而,现有基于机器学习的IDS在多个方面仍存在局限:一是未能显式融合领域知识,二是缺乏可解释性,三是难以有效应对零日攻击。
为解决上述问题,本文提出了IDS-Agent,这是一种由大语言模型(LLMs)驱动的首个智能体型入侵检测系统。 IDS-Agent不仅能够判断输入的网络流量是否为恶意,还能生成基于推理过程的解释性结果。其检测流程由核心LLM在状态观测基础上推理生成一系列操作指令。IDS-Agent的操作空间涵盖数据提取与预处理、分类判断、知识与记忆检索以及结果聚合等多个任务,这些操作通过一系列IDS专用工具进行执行。此外,IDS-Agent集成了记忆模块与知识库,可保留当前与历史会话的信息,并引入IDS相关文档支持推理和行动生成能力。该系统的提示词机制具有高度可定制性,可根据需求调整检测灵敏度,或识别新型未知攻击类型。
实验结果表明,IDS-Agent在ACI-IoT与CIC-IoT两个基准数据集上分别取得了0.97与0.75的F1检测得分,显著优于传统机器学习IDS与基于提示工程的LLM-IDS基线模型。同时,其在零日攻击检测任务中达到了0.61的召回率,优于现有专门面向该任务的模型,显示出良好的通用性与前瞻性检测能力。

核心创新点是IDS-Agent框架是首个基于LLM的入侵检测智能体,融合推理-执行管道与多工具协同。
-
推理-执行管道
– 迭代式工作流:观察→推理→生成动作→执行→更新观察(灵感源于ReAct)。
– 结构化动作生成:动作以JSON格式输出(如{“action”: “Classification”, “input”: {“model”: “RF”}})。 -
专用工具链设计
– 六类核心工具:数据提取(结构化流量解析)、预处理(特征选择+F-test标准化)、分类(集成RF/SVM/MLP等6模型,输出Top-3预测及置信度)、知识检索(RAG检索50+安全博客/论文)、长期记忆(LTM存储历史会话决策)、结果聚合(LLM综合模型输出与知识生成最终判断)。 -
动态知识增强
– 长期记忆(LTM):存储历史正确决策案例,检索公式为:
– 外部知识库:ChromaDB向量数据库存储攻击特征文档,支持语义检索。

实验结果如表1所示,大家可以重点关注开源的数据集。

0-Day攻击分析结果如下:


3.Think-on-Graph: Deep and Responsible Reasoning of Large Language Model on Knowledge Graph(ICLR24)
- 论文地址:https://arxiv.org/pdf/2307.07697
- 参考文章:https://mp.weixin.qq.com/s/6rKzeBfUgShWJnHGSx4SyA
尽管大语言模型(Large Language Models, LLMs)在多种任务中取得了显著成功,但在需要深层次与责任性推理的情境下,仍常面临“幻觉”(hallucination)问题。引入外部知识图谱(Knowledge Graph, KG)以辅助LLM进行推理,是缓解此类问题的一种可行途径。
本文提出一种新的LLM与KG集成范式——“LLM ⊗ KG”,将大语言模型视为智能体,通过交互方式主动检索KG中相关的实体与关系,并基于检索知识开展推理。 在此基础上,我们具体实现该范式,提出Think-on-Graph(ToG)方法。该方法允许LLM代理以束搜索(beam search)的方式迭代式探索知识图谱,定位最具潜力的推理路径,并输出最优的推理结论。
一系列精心设计的实验验证了ToG方法的四项核心优势:
- (1)与传统LLM相比,ToG展现出更强的深度推理能力;
- (2)借助LLM的推理能力与专家反馈机制,ToG具备知识可追溯性与可校正性;
- (3)ToG框架具有高度灵活性,可作为“即插即用”模块适配不同LLMs、KGs及提示策略,无需额外训练开销;
- (4)ToG结合小规模LLMs在部分任务中表现优于GPT-4等大型模型,从而显著降低部署与应用成本。
作为一种训练无关、计算代价低、适应性强的推理范式,ToG在9个评估数据集中有6个任务中达到当前最优水平(SOTA),而大多数已有SOTA方法依赖额外训练。相关代码已开源,地址为:
- https://github.com/IDEA-FinAI/ToG

对于大模型在面对需要深度和负责任推理的复杂知识推理任务时存在显著的局限性,一个有效的解决方案就是整合外部知识(如知识图谱),以帮助改进LLM的推理。KGs提供了结构化、明确且可编辑的知识表示,呈现出一种补充策略,以减轻LLMs的局限性。
- 研究人员已经探索了将KGs作为外部知识源来减轻LLMs中的幻觉。而这些方法遵循一种常规:从KGs中检索信息,相应地增强提示,并输入增强后的提示到LLMs(如上图b所示),在本文中,我们将这种范式称为“LLM⊕KG”。
- LLM推理缺陷:LLM在知识密集型任务(如多跳推理)中存在幻觉问题(图1a),尤其涉及专业领域或动态知识(如网络安全漏洞库更新)。现有方法(如Chain-of-Thought)依赖训练数据内的知识,缺乏外部知识验证机制,导致可解释性差和知识追溯困难。

尽管此方法整合LLM和KG的力量,在这个范式中,LLM扮演翻译者的角色,将输入问题转换为机器可理解的命令,用于KG搜索和推理,但它不直接参与图推理过程。同时,松耦合的LLM ⊕ KG范式有其自身的局限性,其成功在很大程度上取决于KG的完整性和高质量。例如,在上图b中,尽管LLM成功识别了回答问题所需的必要关系类型,但由于缺少“多数党”这一关系,导致无法检索到正确答案。
因此,本文提出了一个算法框架**“Think-on-Graph”**即LLMs在知识“图”上逐步“思考”推理路径,用于进行深入、负责任和高效的LLM推理。
- LLM⊗KG范式。LLM代理通过Beam Search在KG上迭代探索,动态补全缺失知识(如通过实体"Anthony Albanese"补全"majority party"关系)。对比传统LLM⊕KG范式,KG仅提供静态检索,LLM不参与路径推理。本文范式,LLM驱动路径探索,结合自身知识修正KG信息(如知识注入)。
- Think-on-Graph (ToG) 框架。推理流程包括初始化、迭代探索(关系探索、实体探索)、优化变体ToG-R。
- 责任性设计。知识追溯:显式推理路径支持结果审计(图4)。知识修正:当检测到错误(如过时三元组"Bright House Field"),结合专家反馈更新KG。

总之,ToG通过LLM⊗KG紧密耦合范式,将LLM作为推理代理在KG上执行定向搜索。首先,ToG解决幻觉问题,KG提供结构化知识锚点,实验显示深层推理准确率提升最高达51.8%(GrailQA)。其次,实现责任性,路径可追溯、知识可修正,为高风险领域(如网络安全)提供可靠推理框架。最后,ToG高效部署,小模型+ToG超越GPT-4,降低LLM应用成本。
4.KnowGraph: Knowledge-Enabled Anomaly Detection via Logical Reasoning on Graph Data(CCS24)
- 论文地址:https://arxiv.org/pdf/2410.08390
基于图的异常检测在多种安全场景中发挥着关键作用,如交易网络中的欺诈检测以及网络流量的入侵识别。然而,标准方法(包括图神经网络 Graph Neural Networks, GNNs)常常难以应对数据分布的动态变化,从而影响模型的泛化能力。以eBay的真实交易数据集为例,仅引入一天的新数据就使欺诈检测的准确率下降超过50%,凸显了纯粹依赖数据驱动方法的脆弱性。相较之下,现实场景中存在大量稳定而通用的领域知识(如“同一账户在两个地点同时交易可能为异常”),这些规则已广泛应用于现有的检测策略中。

为将此类稳定知识显式集成进数据驱动的图模型中,本文提出 KnowGraph 框架,一种融合领域知识与图神经网络的增强型异常检测方法。
KnowGraph 包含两个主要模块:
- (1)统计学习模块:构建以主检测模型为核心,并辅以多个预测特定语义实体的知识子模型;
- (2)推理模块:采用概率图模型对前述模型输出进行逻辑推理,利用加权一阶逻辑公式表达并执行领域知识。
此外,KnowGraph 融合了 可预测性-可计算性-稳定性(Predictability-Computability-Stability, PCS) 框架,以估计并缓解预测中的不确定性。

核心贡献如下:
- 提出了KnowGraph框架,该框架结合了领域知识和数据驱动学习,用于增强基于图的异常检测。
- KnowGraph包含两个主要组件:统计学习组件和推理组件。统计学习组件利用主模型进行整体检测任务,并辅以多个专门的知识模型预测领域特定的语义实体;推理组件使用概率图模型执行基于模型输出的逻辑推理,通过加权一阶逻辑公式编码领域知识。

本文在eBay平台的合谋欺诈检测与企业网络入侵检测两大实际场景中,KnowGraph 均展现出卓越性能。大量实验结果表明,KnowGraph 在传导式与归纳式设置下均显著优于现有先进模型,在泛化至全新测试图数据时平均准确率提升显著。消融实验进一步验证了推理模块对处理类别严重不平衡情况下的检测效果具有明显增益。综上所述,KnowGraph 成功证明了在高风险安全应用中,将领域知识有机整合进数据驱动模型可显著提升基于图的异常检测能力。

三.总结
写到这里,这篇文章介绍完毕,希望对您有所帮助。学术或许是需要天赋的,这些大佬真值得我们学习,同时自己会继续努力的,学会思考和探索,争取靠后天努力来弥补这些鸿沟,更重要的是享受这种奋斗的过程,加油!
2024年4月28日是Eastmount的安全星球——『网络攻防和AI安全之家』正式创建和运营的日子,该星球目前主营业务为 安全零基础答疑、安全技术分享、AI安全技术分享、AI安全论文交流、威胁情报每日推送、网络攻防技术总结、系统安全技术实战、面试求职、安全考研考博、简历修改及润色、学术交流及答疑、人脉触达、认知提升等。下面是星球的新人券,欢迎新老博友和朋友加入,一起分享更多安全知识,比较良心的星球,非常适合初学者和换安全专业的读者学习。
目前收到了很多博友、朋友和老师的支持和点赞,尤其是一些看了我文章多年的老粉,购买来感谢,真的很感动,类目。未来,我将分享更多高质量文章,更多安全干货,真心帮助到大家。虽然起步晚,但贵在坚持,像十多年如一日的博客分享那样,脚踏实地,只争朝夕。继续加油,再次感谢!
(By:Eastmount 2025-06-03 周二夜于贵阳 http://blog.csdn.net/eastmount/ )
前文赏析:
- [论文阅读] (01)拿什么来拯救我的拖延症?初学者如何提升编程兴趣及LATEX入门详解
- [论文阅读] (02)SP2019-Neural Cleanse: Identifying and Mitigating Backdoor Attacks in DNN
- [论文阅读] (03)清华张超老师 - GreyOne: Discover Vulnerabilities with Data Flow Sensitive Fuzzing
- [论文阅读] (04)人工智能真的安全吗?浙大团队外滩大会分享AI对抗样本技术
- [论文阅读] (05)NLP知识总结及NLP论文撰写之道——Pvop老师
- [论文阅读] (06)万字详解什么是生成对抗网络GAN?经典论文及案例普及
- [论文阅读] (07)RAID2020 Cyber Threat Intelligence Modeling Based on Heterogeneous GCN
- [论文阅读] (08)NDSS2020 UNICORN: Runtime Provenance-Based Detector for Advanced Persistent Threats
- [论文阅读] (09)S&P2019 HOLMES Real-time APT Detection through Correlation of Suspicious Information Flow
- [论文阅读] (10)基于溯源图的APT攻击检测安全顶会总结
- [论文阅读] (11)ACE算法和暗通道先验图像去雾算法(Rizzi | 何恺明老师)
- [论文阅读] (12)英文论文引言introduction如何撰写及精句摘抄——以入侵检测系统(IDS)为例
- [论文阅读] (13)英文论文模型设计(Model Design)如何撰写及精句摘抄——以入侵检测系统(IDS)为例
- [论文阅读] (14)英文论文实验评估(Evaluation)如何撰写及精句摘抄(上)——以入侵检测系统(IDS)为例
- [论文阅读] (15)英文SCI论文审稿意见及应对策略学习笔记总结
- [论文阅读] (16)Powershell恶意代码检测论文总结及抽象语法树(AST)提取
- [论文阅读] (17)CCS2019 针对PowerShell脚本的轻量级去混淆和语义感知攻击检测
- [论文阅读] (18)英文论文Model Design和Overview如何撰写及精句摘抄——以系统AI安全顶会为例
- [论文阅读] (19)英文论文Evaluation(实验数据集、指标和环境)如何描述及精句摘抄——以系统AI安全顶会为例
- [论文阅读] (20)USENIXSec21 DeepReflect:通过二进制重构发现恶意功能(恶意代码ROI分析经典)
- [论文阅读] (21)S&P21 Survivalism: Systematic Analysis of Windows Malware Living-Off-The-Land (经典离地攻击)
- [论文阅读] (22)图神经网络及认知推理总结和普及-清华唐杰老师
- [论文阅读] (23)恶意代码作者溯源(去匿名化)经典论文阅读:二进制和源代码对比
- [论文阅读] (24)向量表征:从Word2vec和Doc2vec到Deepwalk和Graph2vec,再到Asm2vec和Log2vec(一)
- [论文阅读] (25)向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)
- [论文阅读] (26)基于Excel可视化分析的论文实验图表绘制总结——以电影市场为例
- [论文阅读] (27)AAAI20 Order Matters: 二进制代码相似性检测(腾讯科恩实验室)
- [论文阅读] (28)李沐老师视频学习——1.研究的艺术·跟读者建立联系
- [论文阅读] (29)李沐老师视频学习——2.研究的艺术·明白问题的重要性
- [论文阅读] (30)李沐老师视频学习——3.研究的艺术·讲好故事和论点
- [论文阅读] (31)李沐老师视频学习——4.研究的艺术·理由、论据和担保
- [论文阅读] (32)南洋理工大学刘杨教授——网络空间安全和AIGC整合之道学习笔记及强推(InForSec)
- [论文阅读] (33)NDSS2024 Summer系统安全和恶意代码分析方向相关论文汇总
- [论文阅读] (34)EWAS2024 基于SGDC的轻量级入侵检测系统
- [论文阅读] (35)TIFS24 MEGR-APT:基于攻击表示学习的高效内存APT猎杀系统
- [论文阅读] (36)C&S22 MPSAutodetect:基于自编码器的恶意Powershell脚本检测模型
- [论文阅读] (37)CCS21 DeepAID:基于深度学习的异常检测(解释)
相关文章:
[论文阅读] (38)基于大模型的威胁情报分析与知识图谱构建论文总结(读书笔记)
《娜璋带你读论文》系列主要是督促自己阅读优秀论文及听取学术讲座,并分享给大家,希望您喜欢。由于作者的英文水平和学术能力不高,需要不断提升,所以还请大家批评指正,非常欢迎大家给我留言评论,学术路上期…...

SpringBoot EhCache 缓存
一、EhCache核心原理 层级存储 堆内缓存(Heap):高速访问,受JVM内存限制堆外缓存(Off-Heap):突破JVM堆大小限制(直接内存)磁盘存储(Disk)ÿ…...

flutter 中Stack 使用clipBehavior: Clip.none, 超出的部分无法响应所有事件
原因 在 Flutter 中,当 Stack 使用 clipBehavior: Clip.none 时,子 Widget 可以超出 Stack 的边界,但默认情况下,超出部分无法响应触摸事件(如点击、拖动等)。这是因为 Flutter 的 HitTest 机制默认会裁剪…...
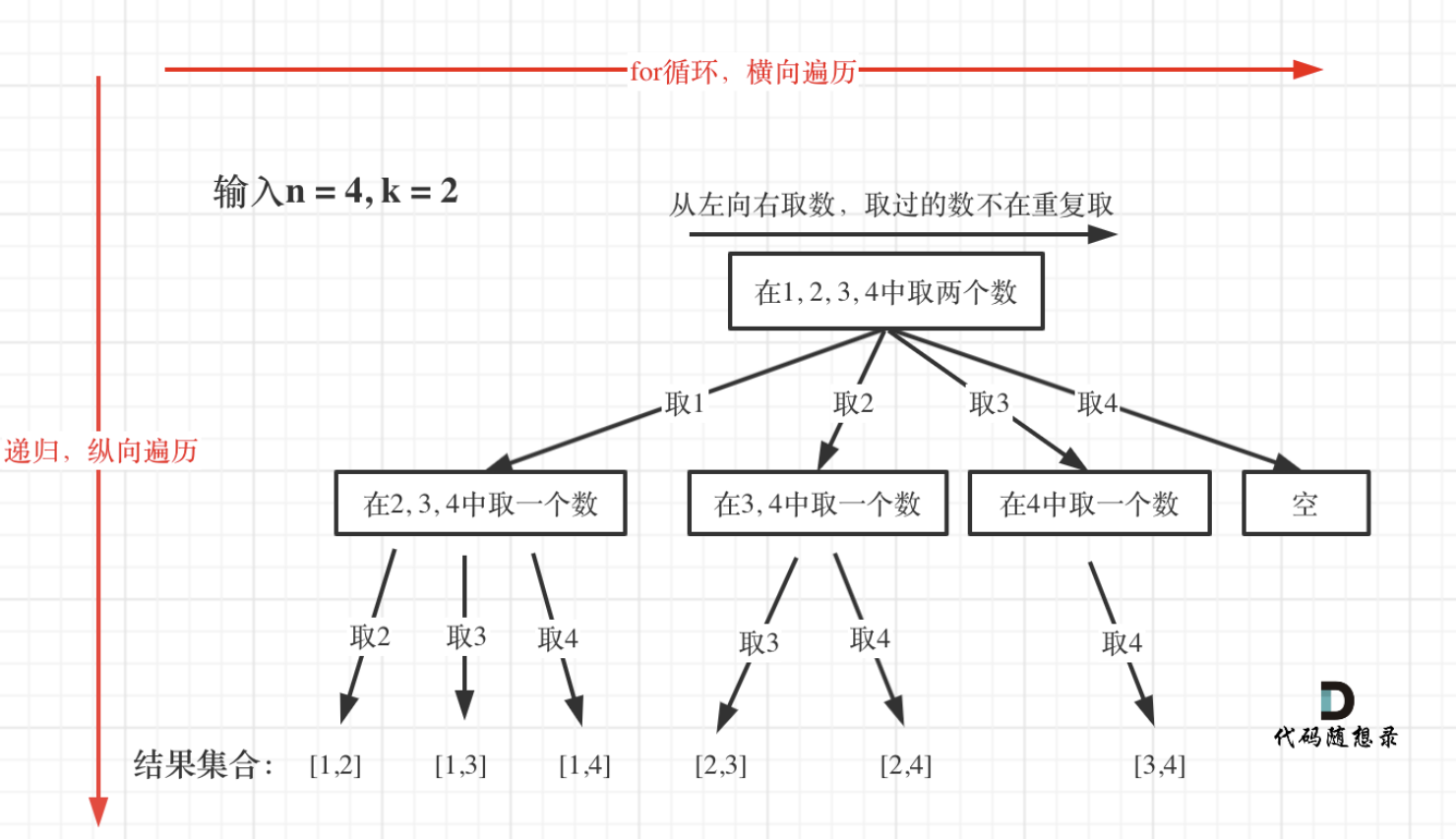
回溯算法复习(1)
1.回溯的定义(ai) 回溯(Backtracking) 是一种通过搜索所有可能的解空间来求解问题的算法思想,属于试探性求解方法。其核心是在搜索过程中逐步构建解,并在发现当前路径无法得到有效解时,主动回退…...

瀚文机械键盘固件开发详解:HWKeyboard.h文件解析与应用
【手把手教程】从零开始的机械键盘固件开发:HWKeyboard.h详解 前言 大家好,我是键盘DIY爱好者Despacito0o!今天想和大家分享我开发的机械键盘固件核心头文件HWKeyboard.h的设计思路和技术要点。这个项目是我多年来对键盘固件研究的心血结晶…...

学习路之PHP--webman安装及使用、webman/admin安装
学习路之PHP--webman安装及使用 一、安装webman二、运行三、安装webman/admin四、效果五、配置Nginx反向代理(生产环境:可选)六、使用 一、安装webman 准备: PHP > 8.1 Composer > 2.0 启用函数: putenv proc_o…...

Python打卡训练营day45——2025.06.05
作业:对resnet18在cifar10上采用微调策略下,用tensorboard监控训练过程。 import torch import torch.nn as nn import torch.optim as optim from torchvision import datasets, transforms, models from torch.utils.data import DataLoader import m…...

益莱储参加 Keysight World 2025,助力科技加速创新
全球领先的测试和测量技术解决方案提供商益莱储 / Electro Rent 再次受邀参加2025 年 6 月 26 日将于在 上海浦东嘉里大酒店隆重举行的 Keysight World Tech Day 2025 年度盛会,与是德科技深度合作,助力行业科技创新,为客户提供更经济、更灵活…...
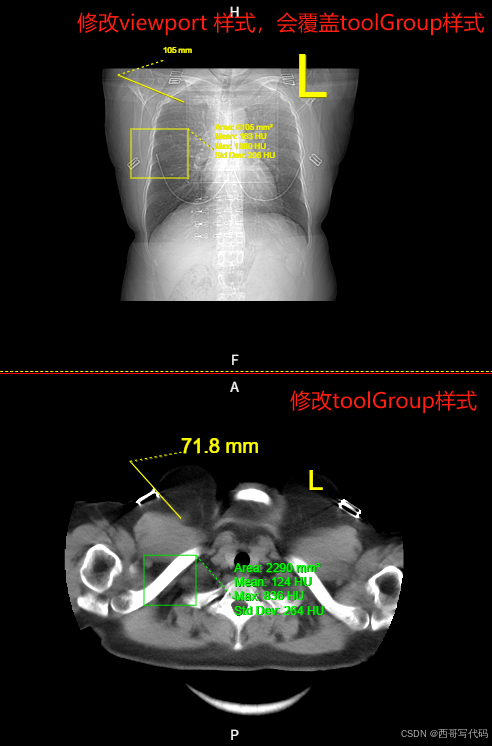
基于cornerstone3D的dicom影像浏览器 第二十八章 LabelTool文字标记,L标记,R标记及标记样式设置
文章目录 前言一、L标记、R标记二、修改工具样式1. 样式的四种级别2. 导入annotation3. 示例1 - 修改toolGroup中的样式4. 示例2 - 修改viewport中的样式 三、可配置样式 前言 cornerstone3D 中的文字标记工具LabelTool,在添加文字标记时会弹出对话框让用户输入文字…...

基于责任链模式进行订单参数的校验
目录 概念 总体分为三步 我们定义责任链模式接口 各个节点的具体逻辑 用户校验器 库存校验器 商品校验器 把责任链编排在一起 概念 责任链模式 是一种行为设计模式 可以通过将一系列处理器按照顺序连接起来 使每个处理器都有机会处理请求 我理解的责任链的实现类似于…...
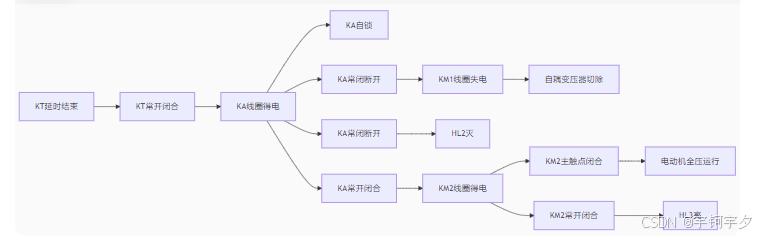
电路图识图基础知识-自耦变压器降压启动电动机控制电路(十六)
自耦变压器降压启动电动机控制电路 自耦变压器降压启动电动机控制电路是将自耦变压器的原边绕组接于电源侧,副边绕组接 于电机侧。电动机定子绕组启动时的电压为自耦变压器降压后得到的电压,这样可以减少电动 机的启动电流和启动力矩,当电动…...
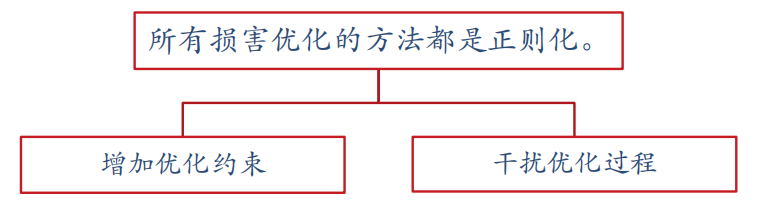
神经网络与深度学习 网络优化与正则化
1.网络优化存在的难点 (1)结构差异大:没有通用的优化算法;超参数多 (2)非凸优化问题:参数初始化,逃离局部最优 (3)梯度消失(爆炸) …...

【Git系列】如何同步原始仓库的更新到你的fork仓库?
🎉🎉🎉欢迎来到我们的博客!无论您是第一次访问,还是我们的老朋友,我们都由衷地感谢您的到来。无论您是来寻找灵感、获取知识,还是单纯地享受阅读的乐趣,我们都希望您能在这里找到属于…...

PDF.js无法显示数字签名
问题 pdfjs加载pdf文件时无法显示数字签名 PDF.js 从 v2.9.359 版本开始正式支持数字签名的渲染与显示,此前版本需通过修改源代码实现基础兼容。 建议升级pdfjs组件大于等于v2.9.359 pdfjs历史版本:https://github.com/mozilla/pdf.js/releases pdfjs…...

spel 多层list嵌套表达式踩坑记
场景 Expression exp spelParser.parseExpression("#{#avgTable?.get(2)?.get(0)}", new TemplateParserContext()); String _result exp.getValue(evalContext, String.class);当avgTable?.get(2)为空时,Method threw java.lang.IndexO…...

深度强化学习驱动的智能爬取策略优化:基于网页结构特征的状态表示方法
传统网络爬虫依赖静态规则(如广度优先搜索)或启发式策略,在面对动态网页(如SPA单页应用)、复杂层级结构(如多层嵌套导航)及反爬机制时,常表现出爬取效率低下、覆盖率不足等问题。本文…...

【网络安全】XSS攻击
如果文章不足还请各位师傅批评指正! XSS攻击是什么? XSS全称是“Cross Site Scripting”,也就是跨站脚本攻击。想象一下,你正在吃一碗美味的面条,突然发现里面有一只小强!恶心不?XSS攻击就是这么…...

如何轻松将视频从安卓设备传输到电脑?
现在,我们可以轻松地使用安卓手机拍摄高分辨率视频。然而,这些视频会占用大量的存储空间。如果您想将视频从安卓设备传输到电脑以释放存储空间、编辑素材或只是备份记忆,可以使用本文介绍的 8 种实用方法来完成视频传输。 第 1 部分ÿ…...

时代星光推出战狼W60智能运载无人机,主要性能超市场同类产品一倍!
在刚刚结束的第九届世界无人机大会上,时代星光科技发布了其全新产品战狼W60智能运载无人机,并展示了基于战狼W60无人机平台的多种应用场景解决方案。据了解,该产品作为一款多旋翼无人机,主要性能参数均远超市场同类产品࿰…...
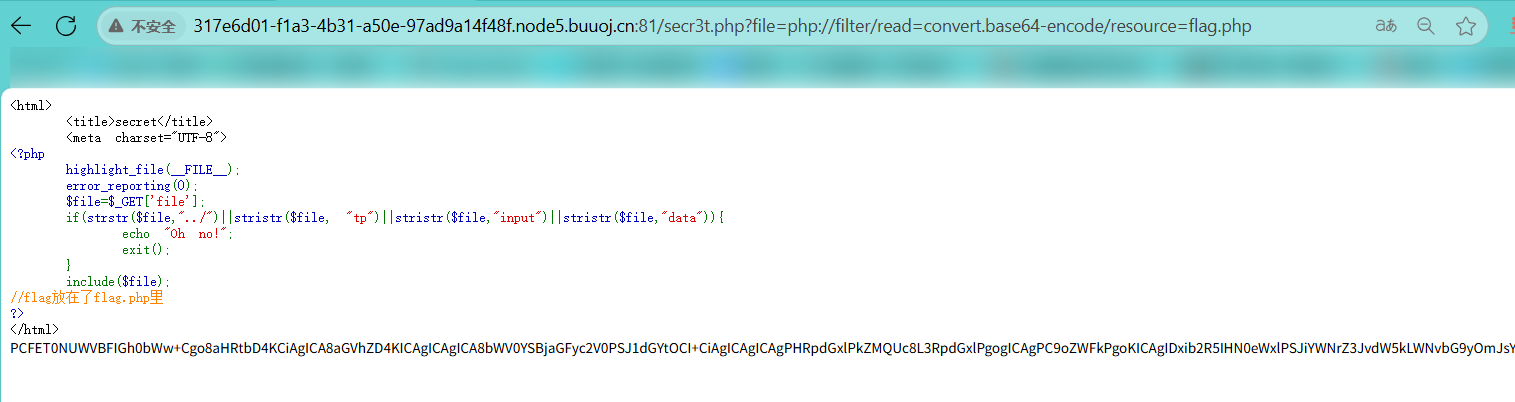
BUUCTF[极客大挑战 2019]Secret File 1题解
[极客大挑战 2019]Secret File 1 分析:解题界面1:界面二:界面3: 总结: 分析: 事后来看,这道题主打一个走一步看一步。我们只能从题目的标题中猜到,这道题与文件有关。 解题 界面1:…...
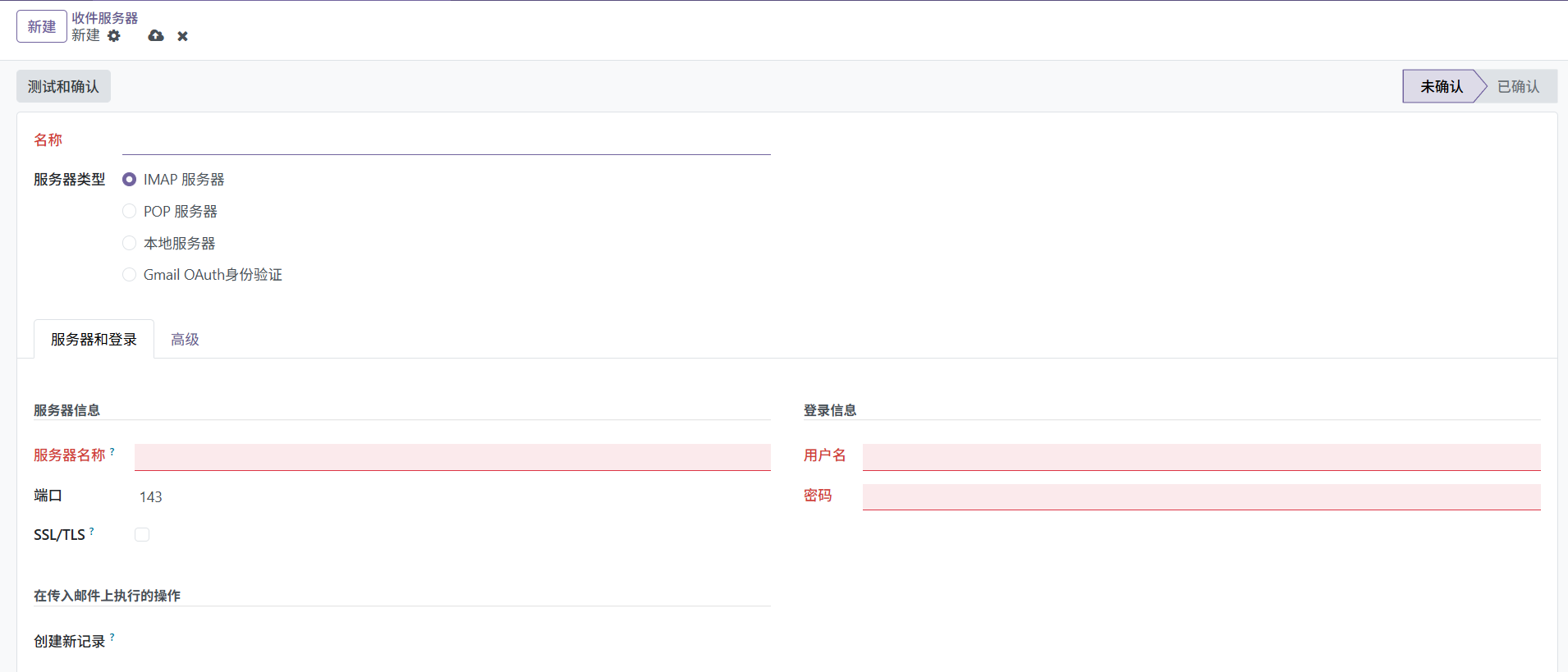
Odoo电子邮件使用配置指南
在Odoo中配置邮件收发功能需要设置SMTP发件服务器和IMAP/POP3收件服务器,并确保DNS记录(如SPF、DKIM)正确,以避免邮件被标记为垃圾邮件。以下指南是详细配置步骤: 1. 配置出站邮件(SMTP) 1.1 使…...

自定义Spring Boot Starter的全面指南
自定义Starter的核心优势 开发效率提升 通过将通用依赖和配置封装至Starter中,开发者可显著减少重复性工作: 消除样板代码:自动包含基础依赖(如Web、JPA等),无需在每个项目中手动添加 // build.gradle配…...

Spring Security中的认证实现
Spring Security认证架构概述 Spring Security的认证流程建立在精心设计的组件协作体系之上。图3.1展示了该框架实现认证过程的核心架构,这个架构由多个关键组件构成,理解这些组件的交互关系对于任何Spring Security实现都至关重要。 认证流程核心组件…...

MacOS解决局域网“没有到达主机的路由 no route to host“
可能原因:MacOS 15新增了"本地网络"访问权限,在 APP 第一次尝试访问本地网络的时候会请求权限,可能顺手选择了关闭。 解决办法:给想要访问本地网络的 APP (例如 terminal、Navicat、Ftp)添加访问…...

找到每一个单词+模拟的思路和算法
如大家所知,我们可以对给定的字符串 sentence 进行一次遍历,找出其中的每一个单词,并根据题目的要求进行操作。 在寻找单词时,我们可以使用语言自带的 split() 函数,将空格作为分割字符,得到所有的单词。为…...

澄清 STM32 NVIC 中断优先级
我们来澄清一下 STM32 NVIC 中断优先级的行为,特别是在抢占优先级和响应优先级(子优先级)都相同的情况下: 核心规则回顾: 抢占优先级 (Preemption Priority): 决定了中断是否可以打断另一个正在执行的中断。 高抢占优…...

2025东南亚跨境选择:Lazada VS. Shopee深度对比
东南亚电商市场持续爆发,2025年预计规模突破2000亿美元。对跨境卖家而言,Lazada与Shopee仍是两大核心战场,但平台生态与竞争格局已悄然变化。深入对比,方能制胜未来。 一、平台基因与核心优势对比 维度 Lazada (阿里系) Shopee …...
)
如何做好一份技术文档?(上篇)
如何做好一份技术文档?(上篇) 上篇:技术文档的基石设计 ——构建可持续迭代的文档体系 文档金字塔模型 [概念层] 为什么 —— 设计理念/适用场景 ▲ [指南层] 怎么做 —— 任务教程/最佳实践 ▲ [参考层] 是什么 ——…...

StarRocks
StarRocks 是一款由中国公司 北京快立方科技有限公司(Fenruilab)开发的 高性能分析型数据库,专注于解决大规模数据分析和实时查询场景的需求。它基于 MPP(大规模并行处理)架构设计,具备高并发、低延迟、易扩…...
Java-39 深入浅出 Spring - AOP切面增强 核心概念 通知类型 XML+注解方式 附代码
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...