Doris Catalog 联邦分析查询性能优化:从排查到优化的完整指南

在大数据分析中,Doris 的 Catalog 联邦分析功能为整合多源数据提供了有力支持。然而,在实际应用中,可能会遇到各种问题影响其正常运行。本文将详细剖析这些问题并提供解决方案。
一、联邦分析查询慢:内外表通用排查逻辑
当遇到 Doris Catalog 联邦分析查询慢的问题时,无论操作的是内表还是外表,都可以遵循以下通用逻辑进行排查:
1. 统计信息准确性验证
-
核心作用:统计信息(如行数、列分布)是查询优化器生成执行计划的关键依据。若统计信息缺失或过时,可能导致优化器误判数据量,选择低效的执行路径(如全表扫描而非索引扫描)。
-
排查方法
-
通过
SHOW STATS命令查看表的统计信息是否存在,以及更新时间是否合理。 -
对于外表,需注意其统计信息默认关闭,需手动开启(参考 Doris 文档)。
-
2. 执行计划合理性分析
-
核心工具:使用
EXPLAIN VERBOSE + SQL命令查看执行计划,重点关注以下部分:-
SCAN NODE:是否触发全表扫描?是否命中索引?对于外表,是否应用了分区裁剪? -
JOIN顺序与方法:优化器是否选择了合理的表连接顺序?是否使用了高效的连接算法(如哈希连接、嵌套循环连接)?
-
-
典型问题
- 谓词条件未下推至外表,导致从源端读取大量冗余数据。
- 多表关联时连接条件错误,引发笛卡尔积,数据量爆炸式增长。
注意: 目前JDBC 的下推能力是有限的,所以对于复杂SQL,可以考虑使用 SQL 透传功能 来直接把完整的 SQL 发到源端。
3. 并发度配置检查
-
核心参数:Doris 的并发度(如
parallel_fragment_exec_instance_num)会影响查询并行处理能力。 -
问题表现
- 并发度过低:无法充分利用集群资源,查询耗时延长。
- 并发度过高:可能导致资源竞争(如内存、网络带宽),反而降低性能。
二、外表查询慢:特有瓶颈与排查重点
外表查询(如 JDBC、Hive、Iceberg 等)因涉及跨网络数据交互和外部系统访问,存在特有的性能瓶颈,需从以下维度深入排查:
1. FE 端:元数据访问与查询规划
-
网络开销
-
FE 在解析查询时,需访问外部数据源的元数据(如 Hive 的分区信息、JDBC 的表结构),若网络延迟高或元数据量庞大(如百万级分区),会导致
Plan Time显著增加。 -
排查方法:单独执行
EXPLAIN SQL,观察Plan Time是否异常(正常情况下应在毫秒级,复杂元数据可能达秒级)。
-
-
元数据缓存
- 若未开启元数据缓存(参考 Doris 元数据缓存文档),每次查询都需重新拉取元数据,导致重复开销。
注意:数据缓存仅用于缓存parquet/orc/text 等文件格式。对于jdbc、jni 部分的数据,没有缓存效果。
2. BE 端:数据扫描与读取
-
FILE_SCAN** 耗时分析**-
通过
PROFILE查看SCAN_OPERATOR部分的ExecTime,若该值占总查询时间的 70% 以上,说明瓶颈在数据扫描阶段。 -
关键指标
-
FileNumber:扫描的文件数量,小文件过多(如数万级)会导致高 IOPS 和元数据开销。 -
FileReadBytes:实际读取的数据量,若远大于预期,可能是谓词条件未下推或分区裁剪失败。 -
MergedSmallIO:合并小 IO 的情况,若MergedBytes远大于RequestBytes,说明存在读放大,需调整合并策略(如merged_oss_min_io_size参数)。
-
-
-
文件格式与分片优化
-
格式影响:Parquet/Orc 格式支持列式存储和谓词下推,性能优于 Text 格式;Text 格式需全量读取,仅适用于小数据量。(text比较吃磁盘IO 或网络带宽。也无法进行列式读取。一般text 格式不保证性能)
-
分片策略:
-
分片数过多(如
InputSplitNum达百万级)会导致 BE 节点任务调度开销增大,可通过调整变量file_split_size(默认 64MB)合并分片。explain 的 verbose 方式会打印出具体文件分片。如:
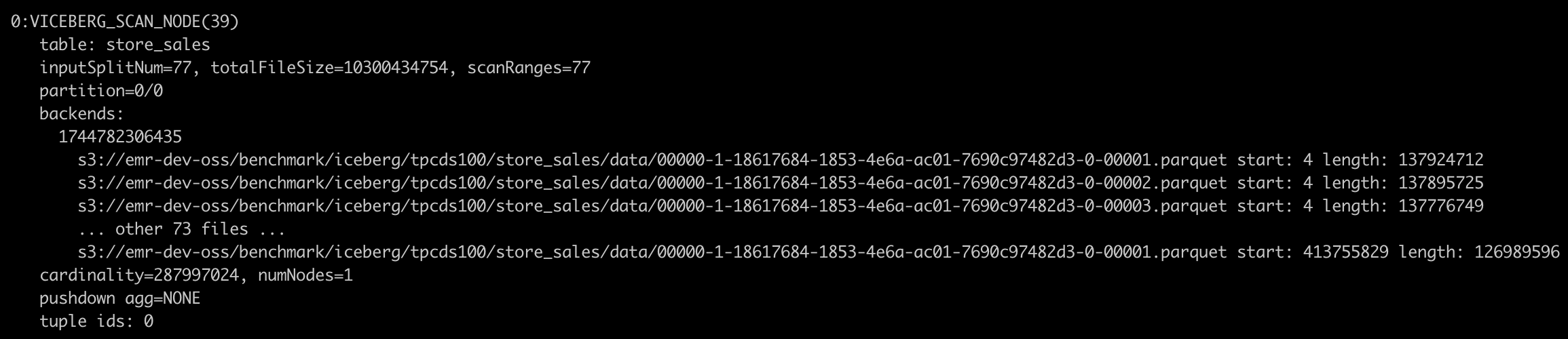
-
对于 Hive/Iceberg 表,若分区裁剪失败(如时间字段存储为字符串类型,导致隐式转换),需修正表结构或查询条件。
-
-
3. 网络与磁盘 IO 影响
-
网络延迟
-
BE 节点访问外部数据源(如 HDFS、对象存储)时,若使用公网 IP 或跨 VPC 访问,网络延迟可能高达数百毫秒,导致
FileReadTime激增。 -
排查方法:通过
ping或curl测试 BE 节点与数据源的网络连通性,确保延迟在可接受范围内(如 < 10ms)。
-
-
磁盘性能
- 若数据存储在机械硬盘或高负载磁盘上,
FileScannerOpenReaderTime和ParseFooterTime可能长达秒级,可通过更换 SSD 或优化磁盘队列提升性能。
- 若数据存储在机械硬盘或高负载磁盘上,
三、典型外表类型的针对性优化
1. JDBC 外表:下推逻辑与连接优化
-
SQL 下推限制
- JDBC 的谓词下推能力有限(如仅支持简单的
WHERE条件),复杂逻辑(如ORDER BY、LIMIT)需手动通过 SQL 透传功能 推至源端执行(参考 Doris JDBC 透传文档)。
- JDBC 的谓词下推能力有限(如仅支持简单的
-
内存问题定位
- 确保 BE 节点与源数据库的连接参数正确(如端口、用户名、密码),可以通过
jstack或async-profiler排查 JNI 调用或 JVM 内存问题(如连接泄漏)。
- 确保 BE 节点与源数据库的连接参数正确(如端口、用户名、密码),可以通过
2. Hive/Iceberg 外表:分区与文件管理
-
分区裁剪优化
-
确保分区字段类型与查询条件一致(如日期字段存储为
DATE而非STRING),避免隐式转换导致裁剪失败。 -
通过
EXPLAIN VERBOSE确认Partition部分是否显示有效裁剪,若未裁剪,需调整查询条件或表结构。
-
-
小文件与 Delete 文件处理
-
Iceberg 表若存在大量
Equality Delete或Position Delete文件,需定期执行COMPACT操作合并数据(参考 Iceberg 维护文档)。 -
对于 Flink 写入的 Iceberg 表,建议开启自动合并策略,避免小文件堆积。
-
3. Paimon/Hudi 外表:Native Reader 与 JNI 优化
-
优先使用 Native Reader
- Paimon/Hudi 的
Native Reader(C++ 实现)性能优于JNI Reader,通过EXPLAIN查看scan node是否包含paimonNativeReadSplits,若JNI Reader占比过高,需引导用户对表进行COMPACTION,减少增量数据。
- Paimon/Hudi 的
-
JVM 性能调优
- 若
JNI Reader内存占用过高,可通过调整 BE 的 JVM 参数(如be.conf中的java_opts)或使用jstat监控 GC 情况,避免频繁 Full GC 影响性能。
- 若
四、实战优化步骤与工具链
1. 快速定位瓶颈的 3 步流程
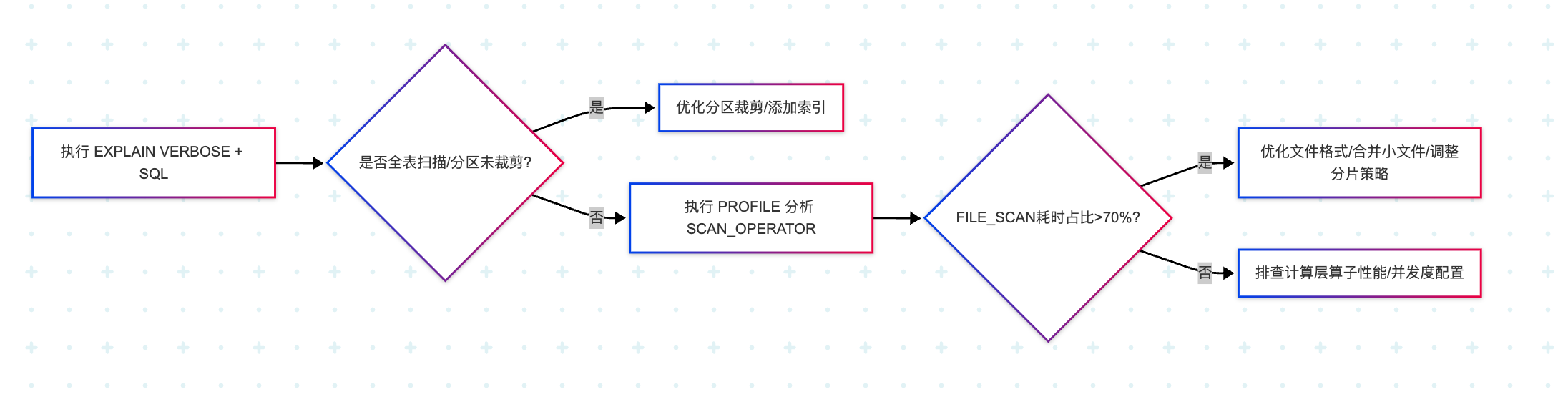
2. 关键工具与命令
-
执行计划分析:
EXPLAIN VERBOSE + SQL,重点关注SCAN NODE和JOIN节点。 -
性能 profiling:通过
PROFILE来分析Plan Time、Scan Time、Compute Time等指标。 -
Java 诊断工具:
jstack(线程栈分析)、jstat(JVM 内存监控)、async-profiler(火焰图生成),用于排查 JNI 或 JVM 相关性能问题。 -
系统表查询:通过
information_schema.file_cache_statistics查看数据缓存命中率,system.runtime.metrics监控集群资源使用情况。
五、优化方案总结
1. 数据层优化
-
文件格式:优先使用 Parquet/Orc,避免 Text 格式;对 Iceberg/Paimon/Hudi 表定期执行
COMPACTION合并小文件。 -
分区策略:基于时间、地域等高频查询维度创建分区,确保分区字段类型与查询条件匹配。
-
统计信息:开启外表统计信息收集(
SET enable_external_table_stats_collect = true),定期更新统计信息(ANALYZE TABLE)。
2. 查询层优化
-
下推逻辑:对 JDBC 外表使用 SQL 透传,将复杂逻辑推至源端;对 Hive/Iceberg 外表确保谓词下推和分区裁剪生效。
-
并发度调整:根据集群资源设置合理并发度(如
SET parallel_fragment_exec_instance_num = 16),避免资源竞争。
3. 基础设施优化
-
网络连通性:确保 FE/BE 节点与外部数据源在同一 VPC 内,关闭不必要的防火墙规则,降低网络延迟。
-
硬件升级:将机械硬盘替换为 SSD,提升磁盘 IO 性能;为高负载节点增加内存或 CPU 资源。
-
缓存配置:开启元数据缓存(
metastore_cache.ttl)和数据缓存(enable_file_cache = true),减少重复访问开销。
六、总结
Doris Catalog 联邦分析的查询性能优化是一个系统性工程,需结合执行计划分析、外表特性、基础设施等多维度排查。通过本文提供的通用逻辑和针对性方案,可快速定位瓶颈并实施优化,充分发挥 Doris 在多源数据联邦分析中的性能优势。实际操作中建议先从小规模数据测试优化效果,再逐步应用于生产环境,确保稳定性与效率的平衡。
相关文章:
Doris Catalog 联邦分析查询性能优化:从排查到优化的完整指南
在大数据分析中,Doris 的 Catalog 联邦分析功能为整合多源数据提供了有力支持。然而,在实际应用中,可能会遇到各种问题影响其正常运行。本文将详细剖析这些问题并提供解决方案。 一、联邦分析查询慢:内外表通用排查逻辑 当遇到 …...

01 Deep learning神经网络的编程基础 二分类--吴恩达
二分类 1. 核心定义 二分类任务是监督学习中最基础的问题类型,其目标是将样本划分为两个互斥类别。设样本特征空间为 X ⊆ R n \mathcal{X} \subseteq \mathbb{R}^n X⊆Rn,输出空间为 Y { 0 , 1 } \mathcal{Y} \{0,1\} Y{0,1},学习目标为…...
视频自动化分割方案:支持按时间与段数拆分
在日常视频处理任务中,如何快速将一个较长的视频文件按照指定规则拆分为多个片段,是许多用户都会遇到的问题。尤其对于需要批量处理视频的开发者、自媒体运营者或内容创作者来说,手动剪辑不仅效率低下,还容易出错。这是一款绿色免…...

Open SSL 3.0相关知识以及源码流程分析
Open SSL 3.0相关知识以及源码流程分析 编译 windows环境编译1、工具安装 安装安装perl脚本解释器、安装nasm汇编器(添加到环境变量)、Visual Studio编译工具 安装dmake ppm install dmake # 需要过墙2、开始编译 # 1、找到Visual Studio命令行编译工具目录 或者菜单栏直接…...

股指期货合约价值怎么算?
股指期货合约价值就是你买一手股指期货合约,理论上值多少钱。这个价值是根据期货的价格和合约乘数来计算的。就好比你买了一斤苹果,价格是5块钱一斤,那你买一斤就得付5块钱。股指期货也是一样,只不过它的计算稍微复杂一点点。 一…...
【QT】使用QT帮助手册找控件样式
选择帮助—》输入stylesheet(小写)—》选择stylesheet—》右侧选择Qt Style Sheets Reference 2.使用CtrlF—》输入要搜索的控件—》点击Customizing QScrollBar 3.显示参考样式表–》即可放入QT-designer的样式表中...

计算机网络(5)——数据链路层
1.概述 数据链路层负责一套链路上从一个节点向另一个物理链路直接相连的相邻节点传输数据报。换言之,主要解决相邻节点间的可靠数据传输 节点(nodes):路由器和主机 链路(links):连接相邻节点的通信信道 2.数据链路层服务 2.1 组帧 组帧(fra…...
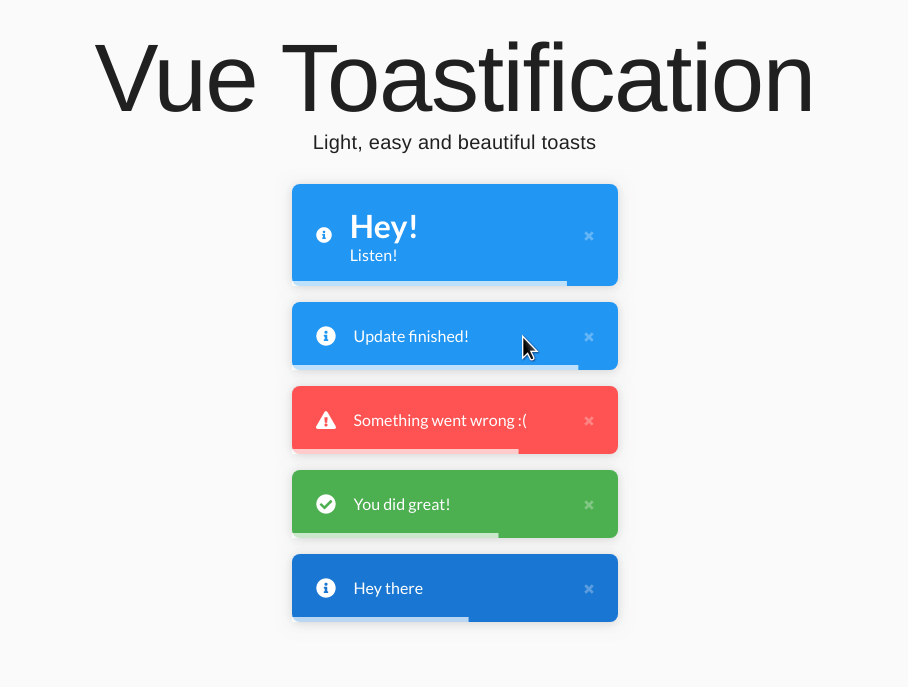
VuePress完美整合Toast消息提示
VuePress 整合 Vue-Toastification 插件笔记 记录如何在 VuePress 项目中整合使用 vue-toastification 插件,实现优雅的消息提示。 一、安装依赖 npm install vue-toastification或者使用 yarn: yarn add vue-toastification二、配置 VuePress 客户端增…...

JVM 调优参数详解与实践
JVM 是 Java 程序性能的关键,合理的调优可以显著提升系统稳定性和吞吐量。本文将从基础参数出发,结合线上生产实践,对常用调优参数进行深入剖析与实战分享。 一、JVM内存结构概览 在进行JVM参数调优前,了解JVM内存结构非常关键 堆内存(Heap):用于存储对象,是GC主要处理…...
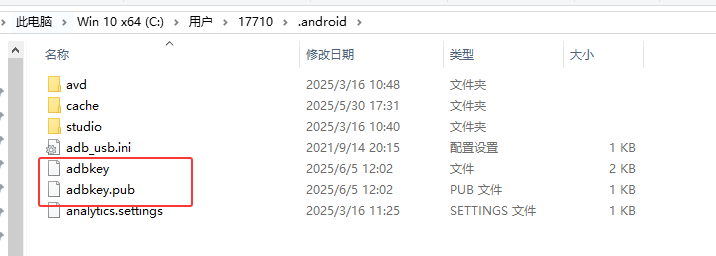
adb 连不上真机设备问题汇总
问题一、无法弹出 adb 调试授权弹窗 详细描述: 开发者选项中已打开 usb 调试,仅充电模式下 usb 调试也已打开,电脑通过 usb 连上手机后,一直弹出 adb 调试授权弹窗,尝试取消授权再次连接,还是无法弹出问题…...
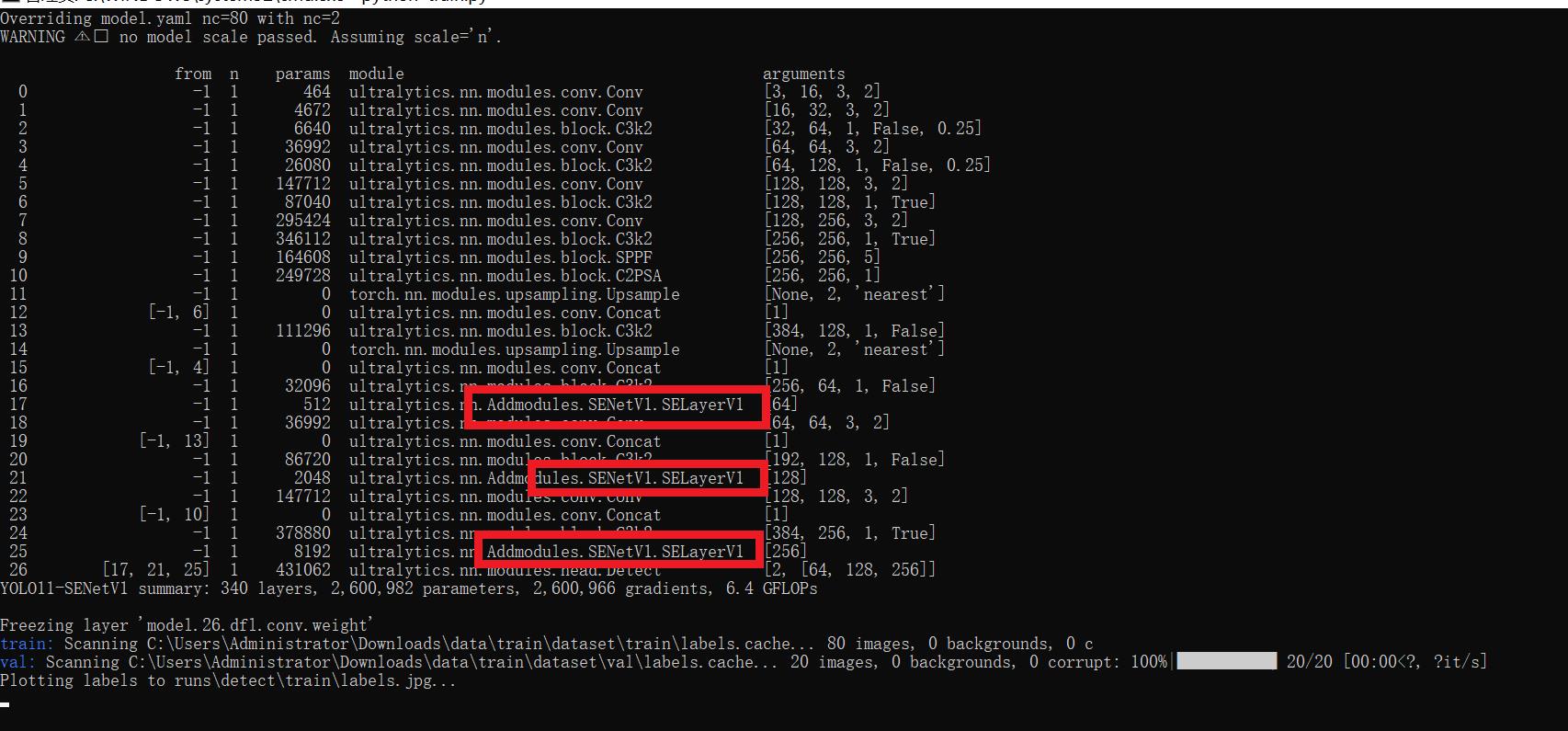
[yolov11改进系列]基于yolov11引入注意力机制SENetV1或者SENetV2的python源码+训练源码
本文给大家带来的改进机制是SENet(Squeeze-and-Excitation Networks)其是一种通过调整卷积网络中的通道关系来提升性能的网络结构。SENet并不是一个独立的网络模型Q,而是一个可以和现有的任何一个模型相结合的模块(可以看作是一种…...

鸿蒙仓颉语言开发实战教程:商城搜索页
大家好,今天要分享的是仓颉语言商城应用的搜索页。 搜索页的内容比较多,都有点密集恐惧症了,不过我们可以从上至下将它拆分开来,逐一击破。 导航栏 搜索页的的最顶部是导航栏,由返回按钮和搜索框两部分组成,比较简单…...

上门服务小程序会员系统框架设计
逻辑分析 会员注册与登录:用户需要能够通过小程序进行会员注册,提供必要信息如手机号码、密码等,注册成功后可登录系统。会员信息管理:包括会员基本信息(姓名、联系方式等)的修改、查看,同时可能…...

图像去雾数据集总汇
自然去雾数据集 部分的数据清洗可以看这里:图像去雾数据集的下载和预处理操作 RESIDE-IN 将ITS作为训练集,SOTSindoor作为测试集。训练集13990对,验证集500对。 目前室内sota常用,最高已经卷到PSNR-42.72 最初应该是dehazefo…...

小程序引入deepseek
首先需要申请key: 地址 deepseek文档地址 使用wx.request获取数据 const task wx.request({url: https://api.deepseek.com/chat/completions,method: POST,responseType: text,headers: {Content-Type: application/json,Authorization: Bearer YOUR_API_KEY},dataType: te…...

网络攻防技术十四:入侵检测与网络欺骗
文章目录 一、入侵检测概述二、入侵系统的分类三、入侵检测的分析方法1、特征检测(滥用检测、误用检测)2、异常检测 四、Snort入侵检测系统五、网络欺诈技术1、蜜罐2、蜜网3、网络欺骗防御 六、简答题1. 入侵检测系统对防火墙的安全弥补作用主要体现在哪…...
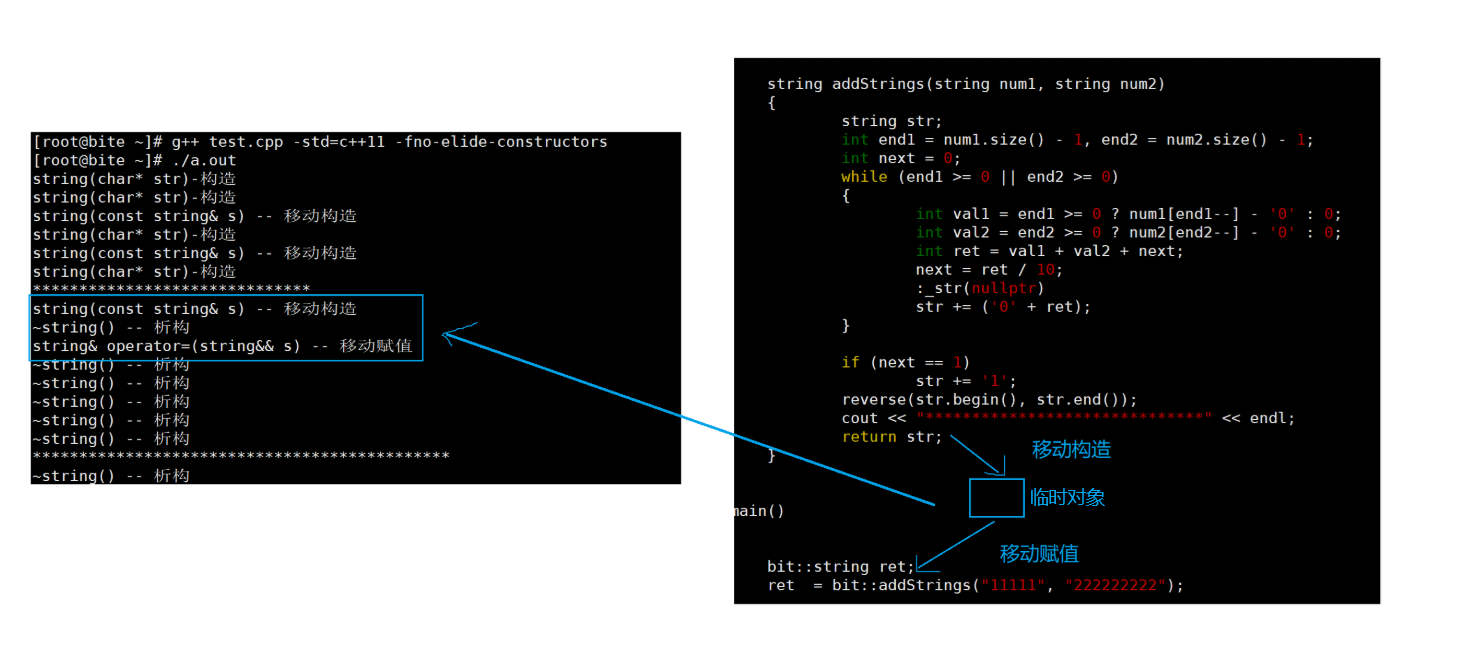
C++笔记-C++11(一)
1.C11的发展历史 C11 是 C 的第⼆个主要版本,并且是从 C98 起的最重要更新。它引⼊了⼤量更改,标准化了既有实践,并改进了对 C 程序员可⽤的抽象。在它最终由 ISO 在 2011 年 8 ⽉ 12 ⽇采纳前,⼈们曾使⽤名称“C0x”,…...
JVM 类初始化和类加载 详解
类初始化和类加载 类加载的时机 加载、验证、准备、初始化和卸载这五个阶段的顺序是确定的,类型的加载过程必须按照这种顺序按部就班地开始,而解析阶段则不一定:它在某些情况下可以在初始化阶段之后再开始(懒解析)&am…...
B站缓存视频数据m4s转mp4
B站缓存视频数据m4s转mp4 结构分析 结构分析 在没有改变数据存储目录的情况下,b站默认数据保存目录为: Android->data->tv.danmaku.bili->download每个文件夹代表一个集合的视频,比如,我下载的”java从入门到精通“&…...

DeepSeek 助力 Vue3 开发:打造丝滑的日历(Calendar),日历_天气预报日历示例(CalendarView01_18)
前言:哈喽,大家好,今天给大家分享一篇文章!并提供具体代码帮助大家深入理解,彻底掌握!创作不易,如果能帮助到大家或者给大家一些灵感和启发,欢迎收藏关注哦 💕 目录 Deep…...

【机器学习】主成分分析 (PCA)
目录 一、基本概念 二、数学推导 2.1 问题设定:寻炸最大方差的投影方向 2.2 数据中心化 2.3 目标函数:最大化投影后的方差 2.4 约束条件 2.5 拉格朗日乘子法 编辑 2.6 主成分提取 2.7 降维公式 三、SVD 四、实际案例分析 一、基本概念 主…...
二叉树-104.二叉树的最大深度-力扣(LeetCode)
一、题目解析 这里需要注意根节点的深度是1,也就是说计算深度的是从1开始计算的 二、算法原理 解法1:广度搜索,使用队列 解法2:深度搜索,使用递归 当计算出左子树的深度l,与右子树的深度r时,…...

物料转运人形机器人适合应用于那些行业?解锁千行百业的智慧物流革命
当传统物流设备困于固定轨道,当人力搬运遭遇效率与安全的天花板,物料转运人形机器人正以颠覆性姿态重塑产业边界。富唯智能凭借GRID大模型驱动的"感知-决策-执行"闭环系统,让物料流转从机械输送升级为智慧调度——这不仅是工具的革…...

k8s开发webhook使用certmanager生成证书
1.创建 Issuer apiVersion: cert-manager.io/v1 kind: Issuer metadata:name: selfsigned-issuernamespace: default spec:selfSigned: {}2.Certificate(自动生成 TLS 证书) apiVersion: cert-manager.io/v1 kind: Certificate metadata:name: webhook…...
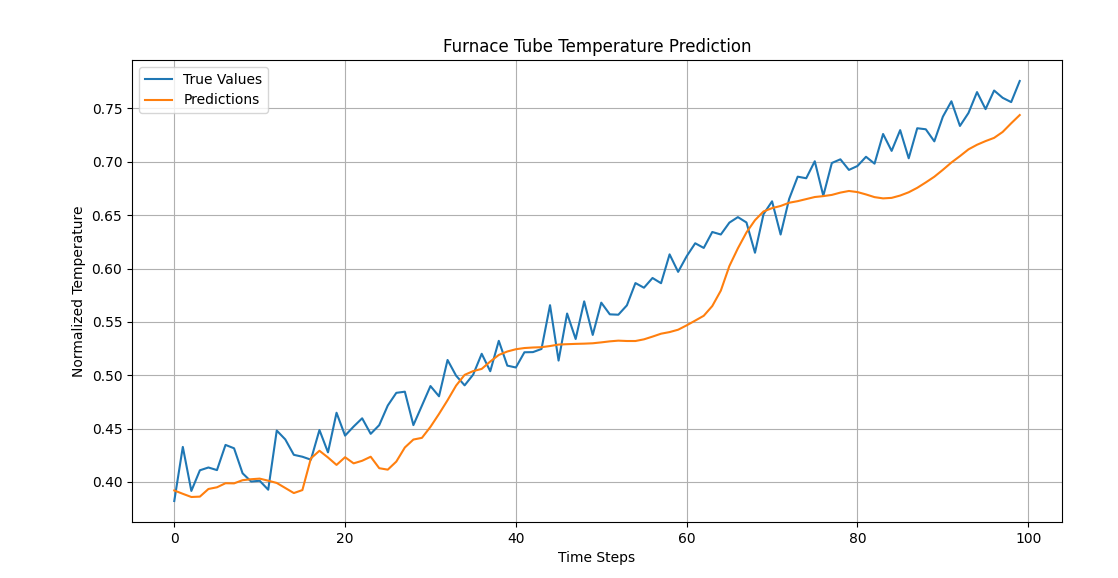
时序预测模型测试总结
0.背景描述 公司最近需要在仿真平台上增加一些AI功能,针对于时序数据,想到的肯定是时序数据处理模型,典型的就两大类:LSTM 和 tranformer 。查阅文献,找到一篇中石化安全工程研究院有限公司的文章,题目为《…...
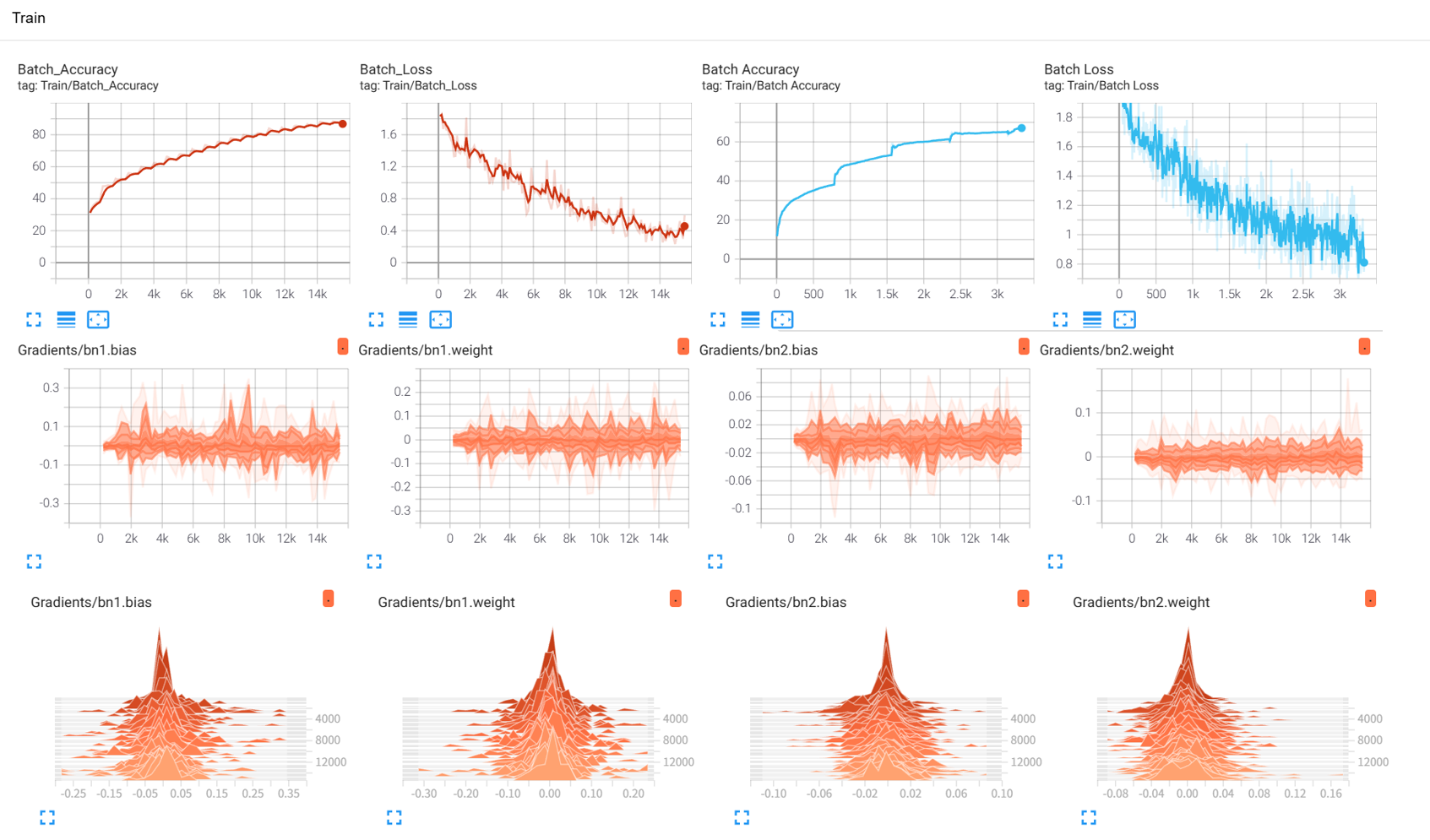
第四十五天打卡
知识点回顾: tensorboard的发展历史和原理 tensorboard的常见操作 tensorboard在cifar上的实战:MLP和CNN模型 效果展示如下,很适合拿去组会汇报撑页数: 作业:对resnet18在cifar10上采用微调策略下,用tensor…...
springboot mysql/mariadb迁移成oceanbase
前言:项目架构为 springbootmybatis-plusmysql 1.部署oceanbase服务 2.springboot项目引入oceanbase依赖(即ob驱动) ps:删除原有的mysql/mariadb依赖 <dependency> <groupId>com.oceanbase</groupId> …...

npm install 报错:npm error: ...node_modules\deasync npm error command failed
npm install 时报错如下: 首先尝试更换node版本,当前node版本20.15.0,更换node版本为16.17.0。再次执行npm install安装成功...
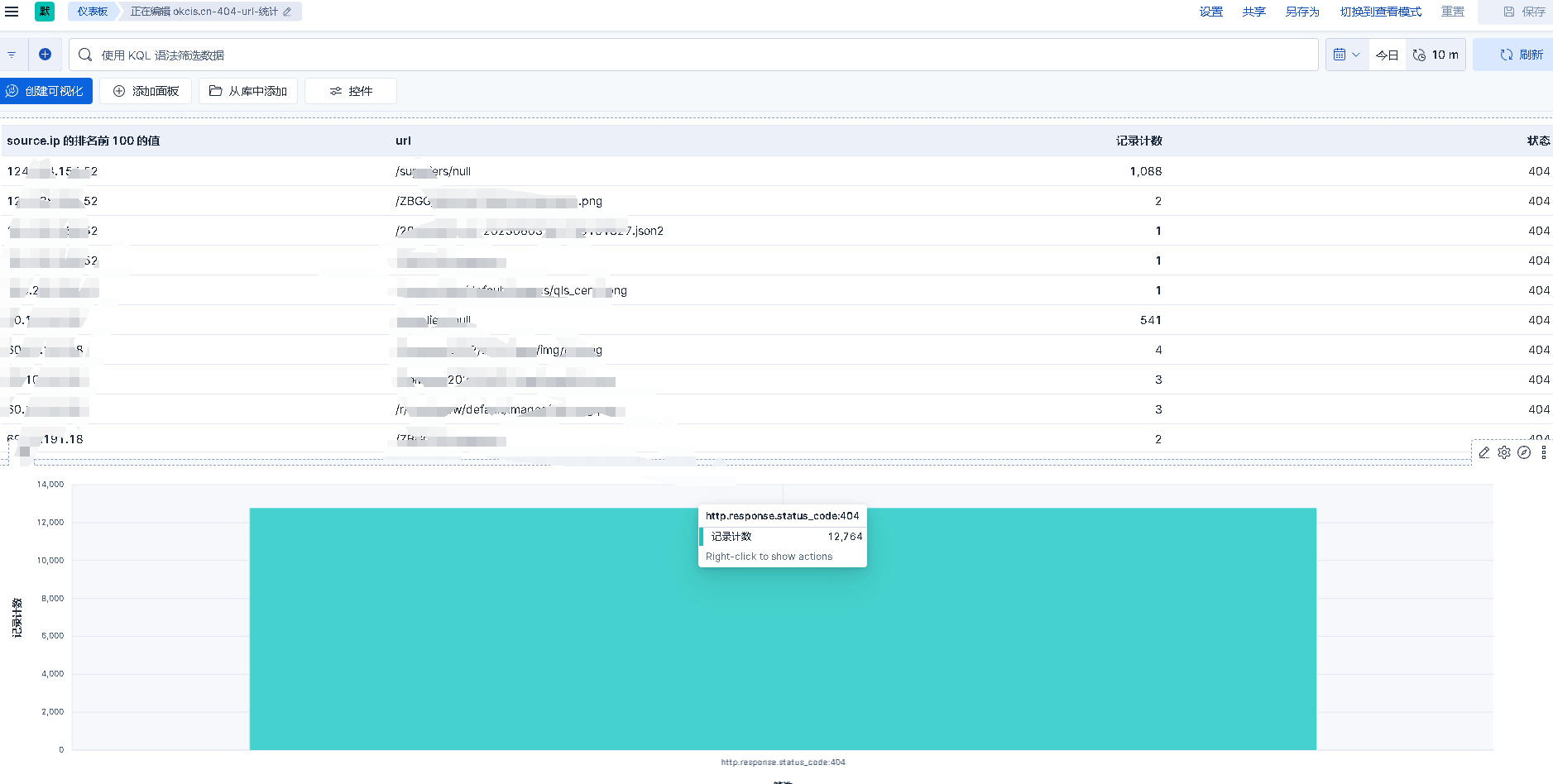
Filebeat收集nginx日志到elasticsearch,最终在kibana做展示(二)
EFK 项目需求是要将 一天或15分钟内 搜索引擎抓取网站次数做个统计,并且 如 200 301 404 状态码 也要区分出来, 访问 404 报错的 url 也要截取出来 前期 收集数据 看这篇文章,点击跳转 收集数据完成之后,使用下面方法做展示 创建一个 仪表…...

halcon c# 自带examples报错 Matching
最近开始学习halcon与C#的联合编程,打开Matching例程时遇到了下面的问题 “System.TypeInitializationException”类型的未经处理的异常在 halcondotnet.dll 中发生 “HalconDotNet.HHandleBase”的类型初始值设定项引发异常。 System.TypeInitializationExceptio…...