Transformer实战——词嵌入技术详解
Transformer实战——词嵌入技术详解
- 0. 前言
- 1. 词嵌入基础
- 2. 分布式表示
- 3. 静态嵌入
- 3.1 Word2Vec
- 3.2 GloVe
- 4. 使用 Gensim 构建词嵌入
- 5. 使用 Gensim 探索嵌入空间
- 6. 动态嵌入
- 小结
- 系列链接
0. 前言
在本节中,我们首先介绍词嵌入的概念,然后介绍两种实现词嵌入的方式:Word2Vec 和 GloVe,学习如何使用 Gensim 库从零开始构建语料库的词嵌入,并探索所创建的嵌入空间。
1. 词嵌入基础
词嵌入可以定义为自然语言处理 (natural language processing, NLP) 中的一组语言建模和特征学习技术,将词汇中的单词或短语映射为实数向量。
深度学习模型与其他机器学习模型一样,通常不直接处理文本,文本需要转换为数值,将文本转换为数值的过程称为向量化。早期的向量化通常使用独热编码,每个单词用一个长度等于词汇表总数的二进制向量表示,向量中只有一个位置是1,其余位置都是0。例如,如果词汇表种有三个单词 (A, B, C),则 A 编码为 [1, 0, 0],B 编码为 [0, 1, 0],C 编码为 [0, 0, 1],独热编码的主要问题是它将每个单词都视为完全独立的,因为任何两个单词之间的相似性(通过两个单词向量的点积衡量)始终为零。
点积是一种代数运算,作用于两个长度相同的向量 a = [ a 1 , … , a N ] a=[a_1, \ldots, a_N] a=[a1,…,aN] 和 b = [ b 1 , … , b N ] b=[b_1, \ldots, b_N] b=[b1,…,bN],得到一个数值,也称为内积或标量积:
a b = ∑ i = 1 N a i b i = a 1 b 1 + ⋯ + a N b N ab=\sum_{i=1}^Na_ib_i=a_1b_1+\cdots +a_Nb_N ab=i=1∑Naibi=a1b1+⋯+aNbN
接下来,我们分析为什么两个单词的独热向量的点积总是 0。假设存在两个单词 w i w_i wi 和 w j w_j wj,词汇表大小为 V V V,则它们对应的独热向量是一个大小为 V V V 的向量,除了 w i w_i wi 的位置 i i i 和 w j w_j wj 的位置 j j j 被设置为 1 外,其余元素均为零。通过使用点积操作这两个向量时, w i [ i ] w_i[i] wi[i] 中的 1 会乘以 w j [ i ] w_j[i] wj[i] 中的 0, w j [ j ] w_j[j] wj[j] 中的 1 会乘以 w i [ j ] w_i[j] wi[j] 中的 0,而两个向量中的所有其他元素均为 0,因此点积的结果也为 0。
为了克服独热编码的局限性,NLP 借鉴了信息检索 (Information Retrieval, IR) 中的技术,使用文档作为上下文对文本进行向量化。经典的技术包括词频-逆文档频率 (Term Frequency-Inverse Document Frequency, TF-IDF)、潜在语义分析 (Latent Semantic Analysis, LSA) 和主题建模。这些表示法试图捕捉基于文档的词汇之间的语义相似性。独热编码和 TF-IDF 是相对稀疏的嵌入,因为词汇量通常很大。
词嵌入技术与传统基于 IR 的技术不同,它们使用邻近单词作为上下文,提供了更自然的语义相似性。如今,词嵌入是各种 NLP 任务的基础技术,例如文本分类、文档聚类、词性标注、命名实体识别、情感分析等等,词嵌入产生稠密、低维度的向量,作为单词的潜在特征向量。
词嵌入基于分布假设,即出现在相似上下文中的单词往往具有相似的含义。因此,基于词嵌入的编码方法也被称为分布式表示。
2. 分布式表示
分布式表示试图通过考虑单词与其上下文中其他单词的关系来捕捉单词的含义。举例来说,考虑以下句子:
Paris is the capital of France.
Berlin is the capital of Germany.
以上句子表明巴黎、法国、柏林和德国之间存在某种关系,可以表示为:
"Paris" 之于 "France" 类似于 "Berlin" 之于 "Germany".
分布式表示的基础是存在某种转换,如下所示:
Paris : France :: Berlin : Germany
换句话说,分布式嵌入空间是一个单词在类似上下文中彼此接近的空间。因此,该空间中单词向量之间的相似性大致对应于单词之间的语义相似性。
下图展示了 TensorBoard 可视化中围绕 important 一词的单词嵌入空间,可以看到,该词的邻居往往与该词密切相关,或者可以在某些情况下互换使用。

例如,crucial 几乎是一个同义词,很容易看出 historical 或 valuable 这些词在某些情况下可以替代使用。
3. 静态嵌入
静态嵌入是早期的一种单词嵌入类型,这些嵌入根据大型语料库生成的,尽管词汇量很大,但却是有限的。可以把静态嵌入想象成一个字典,其中单词是键,对应的向量是值。如果你需要查找一个在原始语料库中不存在的词的嵌入,那么无论如何都不会成功。此外,一个单词不管如何使用,其嵌入始终相同,因此静态嵌入不能解决多义词的问题。
3.1 Word2Vec
Word2Vec 模型最早由 Google 团队于 2013 年提出,这类模型属于自监督模型,也就是说,它们是依赖自然语言结构提供标记训练数据的监督模型。Word2Vec 有两种架构:
- 连续词袋 (
Continuous Bag of Word,CBOW) Skip-gram
在 CBOW 架构中,模型基于周围一定窗口内的单词预测当前单词,上下文单词的顺序不影响预测(即单词袋假设)。而在 skip-gram 架构中,模型基于当前单词预测上下文单词。CBOW 速度更快,但 skip-gram 在预测罕见单词方面表现更好,CBOW 和 skip-gram 架构如下所示。

为了理解输入和输出,考虑以下例句:
The Earth travels around the Sun once per year.
假设窗口大小为 5,即内容单词左右各两个上下文单词,则产生的上下文窗口如下所示。黑体字为当前考虑的单词,其他单词为窗口内的上下文单词:

对于 CBOW 模型,前三个上下文窗口的输入和标签元组如下。例如,在第一个例子中,CBOW 模型将学习在给定单词 Earth 和 travels 的情况下预测单词 The。更准确地说,是根据单词 Earth 和 travels 的稀疏向量输入,模型预测向量中最高值对应于单词 The:

对于 skip-gram 模型,前三个上下文窗口的输入和标签元组如下。我们可以简化 skip-gram 模型的目标,即给定目标单词预测上下文单词,实际上就是预测一对单词是否在上下文上相关。上下文相关意味着在上下文窗口内的一对单词在某种程度上相关。也就是说,对于第一个例子,skip-gram 模型的输入是单词 The 和 Earth 的稀疏向量,输出值为 1:

还需要负样本来训练模型,因此通过将每个输入单词与词汇表中的一些随机单词配对来生成负样本,此过程称为负采样,例如,生成以下输入:

使用负样本输入训练的模型称为带负采样的 Skip-Gram (Skip-Gram with Negative Sampling, SGNS) 模型。需要注意的是,我们并不关注这些模型的分类能力,相反,关键在于学习到的模型权重,这些学习到的权重就是嵌入。
使用 TensorFlow 从零开始实现 CBOW 模型:
import tensorflow as tfclass CBOWModel(tf.keras.Model):def __init__(self, vocab_sz, emb_sz, window_sz, **kwargs):super(CBOWModel, self).__init__(**kwargs)self.embedding = tf.keras.layers.Embedding(input_dim=vocab_sz,output_dim=emb_sz,embeddings_initializer="glorot_uniform",input_length=window_sz*2)self.dense = tf.keras.layers.Dense(vocab_sz,kernel_initializer="glorot_uniform",activation="softmax")def call(self, x):x = self.embedding(x)x = tf.reduce_mean(x, axis=1)x = self.dense(x)return xVOCAB_SIZE = 5000
EMBED_SIZE = 300
WINDOW_SIZE = 1 # 3 word window, 1 on left, 1 on rightmodel = CBOWModel(VOCAB_SIZE, EMBED_SIZE, WINDOW_SIZE)
model.build(input_shape=(None, VOCAB_SIZE))
model.compile(optimizer=tf.optimizers.Adam(),loss="categorical_crossentropy",metrics=["accuracy"])model.summary()# train the model
# retrieve embeddings from trained model
emb_layer = [layer for layer in model.layers if layer.name.startswith("embedding")][0]
emb_weight = [weight.numpy() for weight in emb_layer.weightsif weight.name.endswith("/embeddings:0")][0]
print(emb_weight, emb_weight.shape)
接下来,使用 TensorFlow 从零开始实现 skip-gram 模型:
import tensorflow as tfclass SkipgramModel(tf.keras.Model):def __init__(self, vocab_sz, embed_sz, **kwargs):super(SkipgramModel, self).__init__(**kwargs)embedding = tf.keras.layers.Embedding(input_dim=vocab_sz,output_dim=embed_sz,embeddings_initializer="glorot_uniform",input_length=1)self.word_model = tf.keras.Sequential([embedding,tf.keras.layers.Flatten()])self.context_model = tf.keras.Sequential([embedding,tf.keras.layers.Flatten()])self.merge = tf.keras.layers.Dot(axes=1)self.dense = tf.keras.layers.Dense(1,kernel_initializer="glorot_uniform",activation="sigmoid")def call(self, input):word, context = inputword_emb = self.word_model(word)context_emb = self.context_model(context)x = self.merge([word_emb, context_emb])x = self.dense(x)return xVOCAB_SIZE = 5000
EMBED_SIZE = 300model = SkipgramModel(VOCAB_SIZE, EMBED_SIZE)
model.build(input_shape=[(None, VOCAB_SIZE), (None, VOCAB_SIZE)])
model.compile(optimizer=tf.optimizers.Adam(),loss="categorical_crossentropy",metrics=["accuracy"])model.summary()# train the model# retrieve embeddings from trained model
word_model = model.layers[0]
word_emb_layer = word_model.layers[0]
emb_weights = None
for weight in word_emb_layer.weights:if weight.name == "embedding/embeddings:0":emb_weights = weight.numpy()
print(emb_weights, emb_weights.shape)
虽然我们可以从零开始实现这些模型,但由于 Word2Vec 已被大量使用,因此也可以使用预训练嵌入。
原始 Word2Vec 模型是由 Google 在 Google News 数据集的大约 1000 亿个词上进行自监督训练的,并使用包含 300 万个单词的词汇表。随后,Google 发布了预训练的 Word2Vec 模型供下载和使用。输出向量的维度为 300,以 BIN 文件的形式提供,可以使用 Gensim 的 gensim.models.Word2Vec.load_word2vec_format() 方法或 gensim() 数据下载器打开。
3.2 GloVe
GloVe (Global vectors for word representation) 是一种用于获取单词向量表示的无监督学习算法。训练是在来自语料库的全局单词对共现统计数据上进行的,生成的表示表现出类似于 Word2Vec 中相似单词的聚类行为。
GloVe 与 Word2Vec 的不同之处在于,Word2Vec 是一种预测模型,而 GloVe 是一种基于计数的模型。第一步是构建一个大的 (单词, 上下文) 对矩阵,该矩阵统计了每对词在上下文中共同出现的频率。行对应于单词,列对应于上下文,通常是一个或多个单词的序列。矩阵的每个元素表示单词在上下文中的共现频率。
GloVe 使用矩阵分解将该共现矩阵分解为 (单词, 特征) 和 (特征, 上下文) 矩阵。这个过程称为矩阵因式分解,使用随机梯度下降 (Stochastic Gradient Descent, SGD)进行,这是一种迭代的数值方法。举例来说,如果我们想要将一个矩阵 R R R 因式分解为其因子 P P P 和 Q Q Q:
R = P ∗ Q ≈ R ′ R=P*Q\approx R' R=P∗Q≈R′
SGD 过程将从包含随机值的 P P P 和 Q Q Q 开始,尝试通过将它们相乘来重建矩阵 R ′ R' R′。矩阵 R R R 与 R ′ R' R′ 之间的差异代表损失,通常计算为两个矩阵之间的均方误差。损失决定了 P P P 和 Q Q Q 的值需要如何改变,以使 R ′ R' R′ 更接近 R R R,从而最小化重建损失。重复此过程,直到损失降到某个可接受的阈值,此时,(单词, 特征)矩阵 P P P 就是 GloVe 嵌入。
GloVe 过程比 Word2Vec 需要更多计算资源。这是因为 Word2Vec 通过对单词向量进行批训练来学习嵌入,而 GloVe 一次性因式分解整个共现矩阵。为了使过程具有可扩展性,通常使用 SGD 并行模式。
研究表明 Word2Vec 和 GloVe 方法之间存在等价性,Word2Vec SGNS 模型隐含地因式分解了一个词-上下文矩阵。使用 TensorFlow 从零开始实现 GloVe 模型:
import numpy as np
import tensorflow as tfclass MatrixFactorizationLayer(tf.keras.layers.Layer):def __init__(self, emb_sz, **kwargs):super(MatrixFactorizationLayer, self).__init__(**kwargs)self.emb_sz = emb_szdef build(self, input_shape):num_rows, num_cols = input_shapeself.P = self.add_variable("P", shape=[num_rows, self.emb_sz], dtype=tf.float32,initializer=tf.initializers.GlorotUniform)self.Q = self.add_variable("Q", shape=[num_cols, self.emb_sz],dtype=tf.float32, initializer=tf.initializers.GlorotUniform)def call(self, input):return tf.matmul(self.P, tf.transpose(self.Q))class MatrixFactorizationModel(tf.keras.Model):def __init__(self, embedding_size):super(MatrixFactorizationModel, self).__init__()self.mfl = MatrixFactorizationLayer(embedding_size)self.sigmoid = tf.keras.layers.Activation("sigmoid")def call(self, x):x = self.mfl(x)x = self.sigmoid(x)return xdef loss_fn(source, target):mse = tf.keras.losses.MeanSquaredError()loss = mse(source, target)return lossEMBEDDING_SIZE = 15
NUM_ROWS = 1000
NUM_COLS = 5000# this is the input matrix R, which we are currently spoofing
# with a random matrix (this should be sparse)
R = np.random.random((NUM_ROWS, NUM_COLS))model = MatrixFactorizationModel(EMBEDDING_SIZE)
model.build(input_shape=R.shape)
model.summary()optimizer = tf.optimizers.RMSprop(learning_rate=1e-3, momentum=0.9)# train model
losses, steps = [], []
for i in range(5000):with tf.GradientTape() as tape:Rprime = model(R)loss = loss_fn(R, Rprime)if i % 100 == 0:loss_value = loss.numpy()losses.append(loss_value)steps.append(i)print("step: {:d}, loss: {:.3f}".format(i, loss_value))variables = model.trainable_variablesgradients = tape.gradient(loss, variables)optimizer.apply_gradients(zip(gradients, variables))# after training, retrieve P and Q
mf_layer = model.layers[0]
P, Q = [weight.numpy() for weight in mf_layer.weights]
print(P.shape, Q.shape)
和 Word2Vec 一样,通常并不需要从零开始生成 GloVe 嵌入,我们可以使用预先生成的针对大型语料库的嵌入。
GloVe 项目下载页面提供了在各种大型语料库(从 60 亿到 840 亿标记,词汇量从 40 万到 220 万)上训练的 GloVe 向量,并且有多种维度 (50、100、200、300) 可供选择,可以直接从 GloVe 项目下载页面获取,也可以使用 Gensim 或 spaCy 的数据下载器下载。
4. 使用 Gensim 构建词嵌入
在本节中,我们将使用 Gensim 和小文本语料库 text8 构建词嵌入。Gensim 是一个开源的 Python 库,旨在从文本文档中提取语义信息。其包含优秀的 Word2Vec 算法实现,提供了易于使用的 API,可以训练自定义 Word2Vec 模型。
text8 数据集是 Large Text Compression Benchmark 的前 10 8 10^8 108 字节,text8 数据集可以作为一个可迭代的词元 (tokens) 序列在 Gensim API 中访问,实质上是一个词元化句子的列表。下载 text8 语料库,创建一个 Word2Vec 模型,并将其保存以供后续使用:
import gensim.downloader as api
from gensim.models import Word2Vecinfo = api.info("text8")
assert(len(info) > 0)dataset = api.load("text8")
model = Word2Vec(dataset)model.save("data/text8-word2vec.bin")
在 text8 数据集上训练 Word2Vec 模型,并将其保存为一个二进制文件。Word2Vec 模型包含多个参数,本节中我们使用默认值,这种情况下,训练了一个 CBOW 模型 (sg=0),窗口大小为 5 (window=5),并生成 100 维的嵌入 (size=100)。在命令行中执行以下命令,以运行代码:
$ mkdir data
$ python create_embedding_with_text8.py
代码运行完成后,会将训练好的模型写入到 data 文件夹中。下一小节中,我们将检查训练好的模型。
5. 使用 Gensim 探索嵌入空间
重新加载上一小节构建的 Word2Vec 模型,并使用 Gensim API 进行探索。
(1) 实际的词向量可以通过模型的 wv 属性作为自定义的 Gensim 类访问:
from gensim.models import KeyedVectors
model = KeyedVectors.load("data/text8-word2vec.bin")
word_vectors = model.wv
(2) 查看词汇表中的前几个词,并检查特定词是否可用:
words = word_vectors.key_to_index.keys()
print([x for i, x in enumerate(words) if i < 10])
assert("king" in words)
输出如下所示:
['the', 'of', 'and', 'one', 'in', 'a', 'to', 'zero', 'nine', 'two']
(3) 查找给定词 (king) 的相似词:
def print_most_similar(word_conf_pairs, k):for i, (word, conf) in enumerate(word_conf_pairs):print("{:.3f} {:s}".format(conf, word))if i >= k-1:breakif k < len(word_conf_pairs):print("...")
print_most_similar(word_vectors.most_similar("king"), 5)
使用 most_similar() 方法输出如下。其中,浮点分数是相似性的度量,较高的值表示相似度较高,可以看到,大多数相似的词是准确的:
0.746 prince
0.727 queen
0.712 throne
0.705 emperor
0.687 kings
...
(4) 也可以进行向量运算,查看 Paris:France :: Berlin:Germany 的关系是否成立。这相当于说在嵌入空间中,Paris 和 France 之间的距离应该与 Berlin 和 Germany 之间的距离相同。换句话说,France - Paris + Berlin 应该等于 Germany:
print_most_similar(word_vectors.most_similar(positive=["france", "berlin"], negative=["paris"]), 1
)
输出结果如下所示:
0.785 germany
以上相似度值使用余弦相似度进行度量,但 Levy 和 Goldberg 提出了一种更好的相似度度量,这种度量也包含在 Gensim API 中,这种度量方法本质上是在对数尺度上计算距离,从而放大短距离之间的差异,并缩小长距离之间的差异:
print_most_similar(word_vectors.most_similar_cosmul(positive=["france", "berlin"], negative=["paris"]), 1
)
# 0.951 germany
(5) Gensim 还提供了 doesnt_match() 函数,可以用来检测一组单词中的离群词:
print(word_vectors.doesnt_match(["hindus", "parsis", "singapore", "christians"]))
输出结果与预取一致,即 singapore,因为它是在给定的一组词中唯一代表国家的词汇。
(6) 还可以计算两个单词之间的相似度,相关单词之间的距离小于不相关单词之间的距离:
for word in ["woman", "dog", "whale", "tree"]:print("similarity({:s}, {:s}) = {:.3f}".format("man", word,word_vectors.similarity("man", word)))
结果如下所示:
similarity(man, woman) = 0.738
similarity(man, dog) = 0.427
similarity(man, whale) = 0.274
similarity(man, tree) = 0.268
similar_by_word() 函数在功能上等同于 similar(),只是默认情况下后者在比较前会对向量进行归一化。similar_by_vector() 函数通过指定向量来查找相似的单词。尝试找到与 singapore 相似的单词:
print(print_most_similar(word_vectors.similar_by_word("singapore"), 5)
)
输出结果如下,从地理角度来看,大多数结果是正确的:
0.870 malaysia
0.850 indonesia
0.812 zambia
0.810 thailand
0.807 uganda
...
(7) 还可以使用 distance() 函数计算嵌入空间中两个单词之间的距离,实质上就是 1 - similarity():
print("distance(singapore, malaysia) = {:.3f}".format(word_vectors.distance("singapore", "malaysia")
))
(8) 还可以直接从 word_vectors 对象查找单词的向量,或者使用 word_vec() 包装器:
vec_song = word_vectors["song"]
vec_song_2 = word_vectors.get_vector("song", norm=True)
6. 动态嵌入
在静态嵌入中,嵌入部署为将单词(或子词)映射到固定维度向量的字典。在这些嵌入中,一个词对应的向量在句子中无论是作为名词还是动词使用,都是相同的,如 ensure 作为名词表示一种健康补充剂,作为动词则表示确保。静态嵌入还会为多义词(有多种含义的词)提供相同的向量,如 bank,根据它与 money 或 river 一词的共现情况,它的含义可能不同。在以上两种情况下,单词的含义会根据上下文、即句子中的信息而改变。动态嵌入试图利用这些信息,根据它们的上下文为单词提供不同的向量。
动态嵌入部署为经过训练的网络,通过观察整个序列(而不仅仅是单个词),将输入(通常是一个热编码向量的序列)转换为低维的密集固定大小的嵌入。可以选择将输入预处理为密集嵌入,然后将其作为任务特定网络的输入,或者将网络封装起来,类似于静态嵌入的 tf.keras.layers.Embedding 层,以这种方式使用动态嵌入网络通常比提前生成嵌入(第一种方式)或使用传统嵌入的计算代价更加高昂。
动态嵌入最早由 McCann 等人提出,称为上下文向量 (Contextualized Word Vectors, CoVe),使用机器翻译网络的编码器-解码器对的编码器输出,并将其与相同单词的词向量拼接起来。
语言模型嵌入 (Embeddings from Language Model, ELMo) 是由 Peters 等人提出的动态嵌入技术。ELMo 使用基于字符的词表示和双向长短期记忆 (Long Short-Term Memory, LSTM) 来计算上下文化的单词表示。预训练的 ELMo 网络可以在 TensorFlow 的模型库 TensorFlow Hub 中找到,通过以下方式访问并生成 ELMo 嵌入,使用一组句子,模型通过基于空格的分词策略来识别词语:
import tensorflow as tf
import tensorflow_hub as hubelmo = hub.load("https://tfhub.dev/google/elmo/3")
embeddings = elmo.signatures["default"](tf.constant(["I like watching movie","I do not like eating apple"]))["elmo"]
print(embeddings.shape)
输出结果为 (2, 7, 1024)。第一个索引表示输入包含 2 个句子,第二个索引是指所有句子的最大单词数(模型会自动填充输出句子为最大长度),第三个索引给出了由 ELMo 创建的上下文化词嵌入的大小,每个词转换为一个大小为 1024 的向量。
还可以通过将 ELMo 嵌入层包装在 tf.keras.KerasLayer 适配器中,将 ELMo 嵌入层集成到 TensorFlow 模型中。在以下模型中,模型将返回整个字符串的嵌入:
embed = hub.KerasLayer("https://tfhub.dev/google/elmo/3",input_shape=[],
dtype=tf.string)
model = tf.keras.Sequential([embed])
embeddings = model.predict(["I like watching movie","I do not like eating apple"])
print(embeddings.shape)
动态嵌入(如 ELMo )能够在不同的上下文中为相同的单词提供不同的嵌入,相较于静态嵌入(如 Word2Vec 或 GloVe )进一步进行了改进。
小结
词嵌入的核心思想是,通过将词语表示为稠密的向量,使得计算机可以更有效地处理和理解文本中的语义关系。在本节中,我们学习了单词分布式表示的概念及其实现,包括静态嵌入和动态嵌入,实现了 Word2Vec 和 GloVe 模型,并介绍了如何使用 Gensim API 探索嵌入空间。
系列链接
Transformer实战——循环神经网络详解
相关文章:
Transformer实战——词嵌入技术详解
Transformer实战——词嵌入技术详解 0. 前言1. 词嵌入基础2. 分布式表示3. 静态嵌入3.1 Word2Vec3.2 GloVe 4. 使用 Gensim 构建词嵌入5. 使用 Gensim 探索嵌入空间6. 动态嵌入小结系列链接 0. 前言 在本节中,我们首先介绍词嵌入的概念,然后介绍两种实现…...

[pdf、epub]300道《软件方法》强化自测题业务建模需求分析共257页(202505更新)
DDD领域驱动设计批评文集 做强化自测题获得“软件方法建模师”称号 《软件方法》各章合集 在本账号CSDN资源下载,或者访问链接: http://www.umlchina.com/url/quizad.html 如果需要提取码:umlc 文件夹中的“300道软件方法强化自测题2025…...
Vue3入门指南:从零到精通的快速上手
齐爷学vue3 一、Vue3入门 vite:前端构架工具,构建速度快于webpack。轻量快速、对TS,JSX,CSS开箱即用、按需编译。 创建Vue3工程 1.在想要创建Vue3的位置打开cmd,执行如下命令。 npm create vuelatest 2.功能只选择…...

前端常见错误
1. TypeError: Cannot read property xxx of undefined 错误原因:尝试访问一个 undefined 或 null 对象的属性 / 方法。 示例代码: const user { name: "John" }; console.log(user.address.street); // user.address 为 undefined 解决方…...
吴恩达MCP课程(5):mcp_chatbot_prompt_resource.py
前提条件: 1、吴恩达MCP课程(5):research_server_prompt_resource.py 2、server_config_prompt_resource.json文件 {"mcpServers": {"filesystem": {"command": "npx","args"…...

关于DDOS
DDOS是一门没什么技术含量的东西,其本质而言是通过大量数据报文,发送到目标受害主机IP地址上,导致目标主机无法继续服务(俗称:拒绝服务) DDOS灰产人期望达成的预期目标,几乎都是只要把对面打到 …...

云服务器自带的防御可靠吗
最近有不少朋友问我,云服务器自带的防御靠不靠谱。就拿大厂的云服务器来说,很多都自带5G防御。但这5G防御能力,在如今的网络攻击环境下,真的有些不够看。 如今,网络攻击手段层出不穷,攻击流量更是越来越大。…...
:LeetCode 21. 合并两个有序链表(Merge Two Sorted Lists)详解)
Java详解LeetCode 热题 100(27):LeetCode 21. 合并两个有序链表(Merge Two Sorted Lists)详解
文章目录 1. 题目描述1.1 链表节点定义 2. 理解题目2.1 问题可视化2.2 核心挑战 3. 解法一:迭代法(哨兵节点)3.1 算法思路3.2 Java代码实现3.3 详细执行过程演示3.4 执行结果示例3.5 复杂度分析3.6 优缺点分析 4. 解法二:递归法4.…...
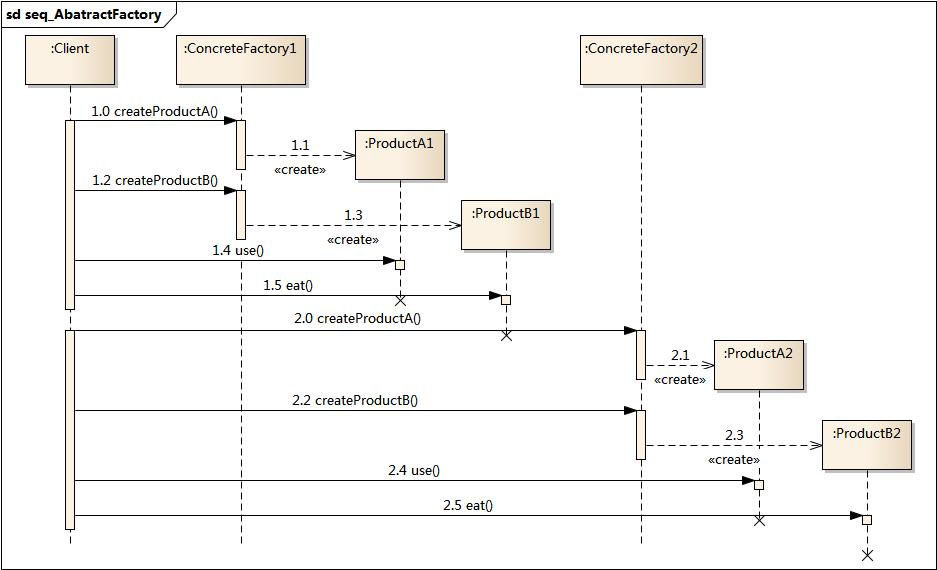
设计模式——抽象工厂设计模式(创建型)
摘要 抽象工厂设计模式是一种创建型设计模式,旨在提供一个接口,用于创建一系列相关或依赖的对象,无需指定具体类。它通过抽象工厂、具体工厂、抽象产品和具体产品等组件构建,相比工厂方法模式,能创建一个产品族。该模…...
基于LocalAI与cpolar技术协同的本地化AI模型部署与远程访问方案解析
文章目录 前言1. Docker部署2. 简单使用演示3. 安装cpolar内网穿透4. 配置公网地址5. 配置固定公网地址前言 各位极客朋友们!今天要向大家推荐一套创新性的本地部署方案——LocalAI技术架构。这款开源工具包能够将普通配置的笔记本电脑转化为具备强大算力的AI工作站,轻松实现…...
)
Linux 云服务器部署 Flask 项目(含后台运行与 systemd 开机自启)
一、准备工作 在开始正式部署之前,请确认以下前提条件已经准备好: 你有一台运行 Linux 系统(CentOS 或 Ubuntu)的服务器; 服务器有公网 IP,本例中使用:111.229.204.102; 你拥有该服务器的管理员权限(可以使用 sudo); 打算使用 Flask 构建一个简单的 Web 接口; 服务…...

霍尔效应传感器的革新突破:铟化铟晶体与结构演进驱动汽车点火系统升级
一、半导体材料革新:铟化铟晶体的电压放大机制 铟化铟(InSb)晶体因其独特的能带结构,成为提升霍尔电压的关键材料。相较于传统硅基材料,其载流子迁移率高出3-5倍,在相同磁场强度下可显著放大霍尔电压。其作…...
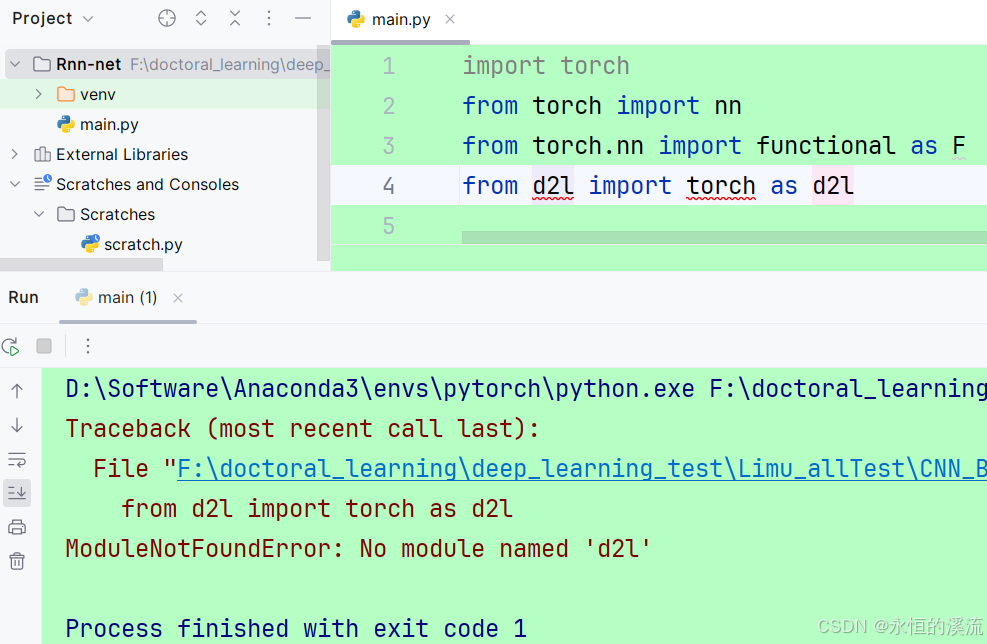
无法运用pytorch环境、改环境路径、隔离环境
一.未建虚拟环境时 1.创建新项目后,直接运行是这样的。 2.设置中Virtualenv找不到pytorch环境?因为此时没有创建新虚拟环境。 3.选择conda环境(全局环境)时,是可以下载环境的。 运行结果如下: 是全局环境…...

从0开始学vue:pnpm怎么安装
一、什么是 pnpm? pnpm(Performant npm)是新一代 JavaScript 包管理器,优势包括: 节省磁盘空间:通过硬链接和符号链接实现高效存储安装速度更快:比 npm/yarn 快 2-3 倍内置工作区支持…...

React从基础入门到高级实战:React 实战项目 - 项目二:电商平台前端
React 实战项目:电商平台前端 欢迎来到本 React 开发教程专栏的第 27 篇!在前 26 篇文章中,我们从 React 的基础概念逐步深入到高级技巧,涵盖了组件、状态、路由、性能优化和设计模式等核心知识。这一次,我们将通过一…...
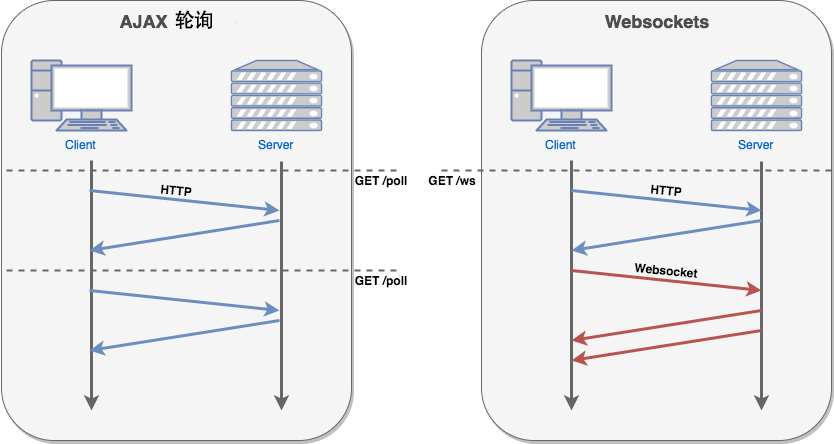
Python 网络编程 -- WebSocket编程
作者主要是为了用python构建实时网络通信程序。 概念性的东西越简单越好理解,因此,下面我从晚上摘抄的概念 我的理解。 什么是网络通信? 更确切地说,网络通信是两台计算机上的两个进程之间的通信。比如,浏览器进程和新浪服务器上的某个Web服务进程在通…...

微信小程序动态组件加载的应用场景与实现方式
动态组件加载的应用场景与实现方式 你提供的代码展示了微信小程序中动态加载组件的方法,但这种方式在实际开发中需要注意使用场景和实现细节。下面我来详细说明如何应用: 应用场景 按需加载组件:在某些条件满足时才加载组件动态配置组件&a…...

人工智能在智能教育中的创新应用与未来趋势
随着人工智能(AI)技术的飞速发展,教育领域正经历着一场深刻的变革。智能教育通过引入AI、物联网(IoT)、大数据和云计算等前沿技术,正在实现教育的个性化、智能化和高效化。本文将探讨人工智能在智能教育中的…...

边缘计算应用实践心得
当数据中心的光纤开始承载不了爆炸式增长的物联网数据流时,边缘计算就像毛细血管般渗透进现代数字肌理的末梢。这种将算力下沉到数据源头的技术范式,本质上是对传统云计算中心化架构的叛逆与补充——在智能制造车间里,实时质检算法直接在工业…...

EXCEL如何快速批量给两字姓名中间加空格
EXCEL如何快速批量给姓名中间加空格 优点:不会导致排版混乱 缺点:无法输出在原有单元格上,若需要保留原始数据,可将公式结果复制后“选择性粘贴为值” 使用场景:在EXCEL中想要快速批量给两字姓名中间加入空格使姓名对…...

OD 算法题 B卷【BOSS的收入】
文章目录 BOSS的收入 BOSS的收入 一个公司只有一个boss,其有若干一级分销,一级分销又有若干二级分销,每个分销只有唯一的上级;每个月,下级分销需要将自己的总收入(自己的下级上交的)࿰…...

Linux共享内存原理及系统调用分析
shmget 是 System V 共享内存的核心系统调用之一,其权限位(shmflg 参数)决定了共享内存段的访问控制和创建行为。以下是权限位的详细解析: 权限位的组成 shmflg 参数由两部分组成: 权限标志(低 9 位&…...
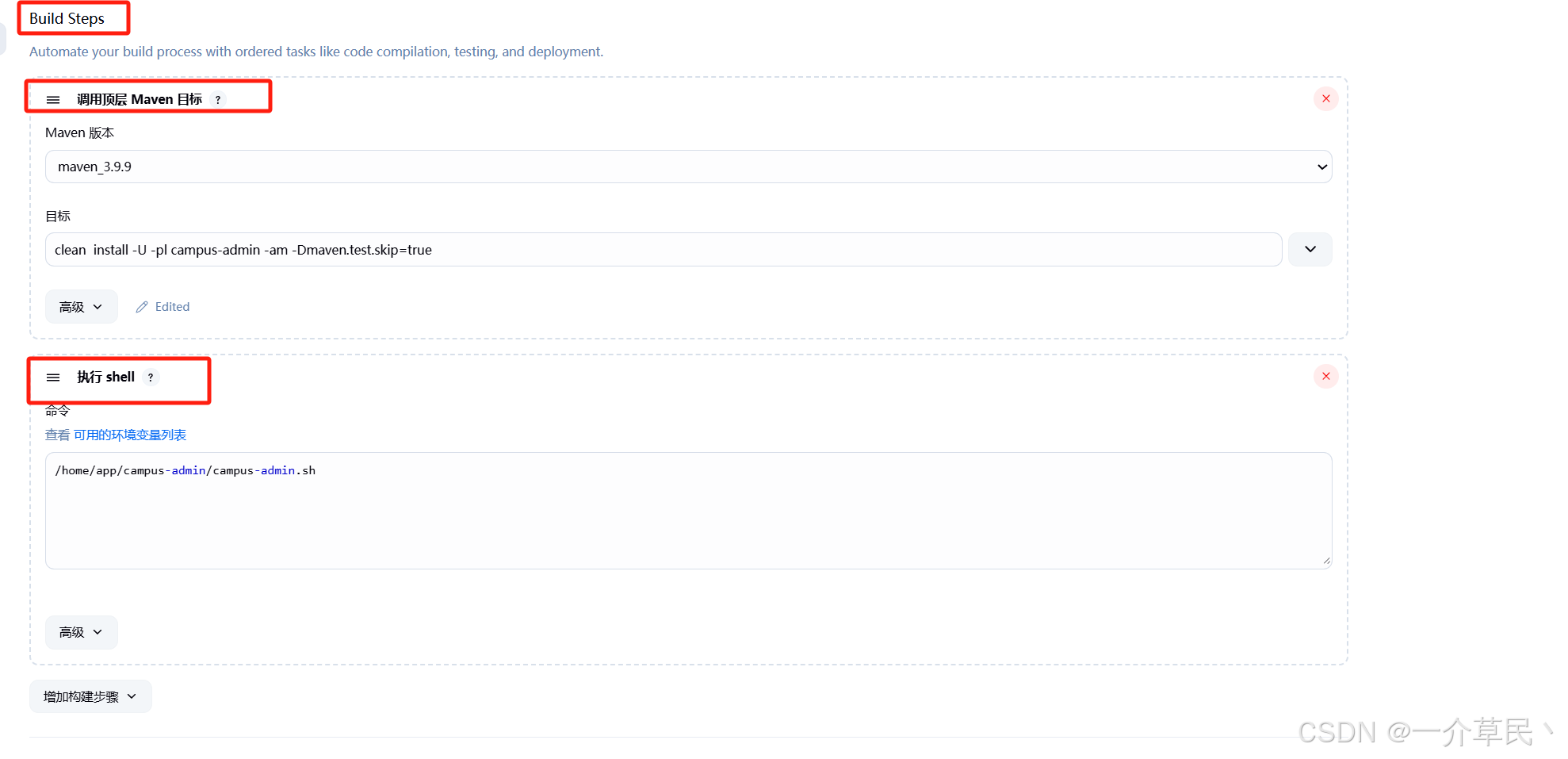
Jenkins | Linux环境部署Jenkins与部署java项目
1. 部署jenkins 1.1 下载war包 依赖环境 jdk 11 下载地址: https://www.jenkins.io/ 依赖环境 1.2 启动服务 启动命令 需要注意使用jdk11以上的版本 直接启动 # httpPort 指定端口 #-Xms2048m -Xmx4096m 指定java 堆内存初始大小 与最大大小 /usr/java/jdk17/bin/java…...
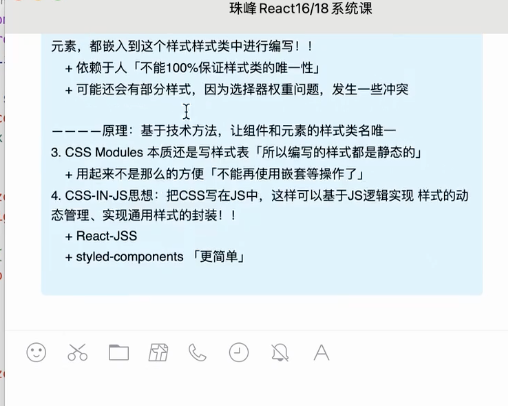
react私有样式处理
react私有样式处理 Nav.jsx Menu.jsx vue中通过scoped来实现样式私有化。加上scoped,就属于当前组件的私有样式。 给视图中的元素都加了一个属性data-v-xxx,然后给这些样式都加上属性选择器。(deep就是不加属性也不加属性选择器) …...
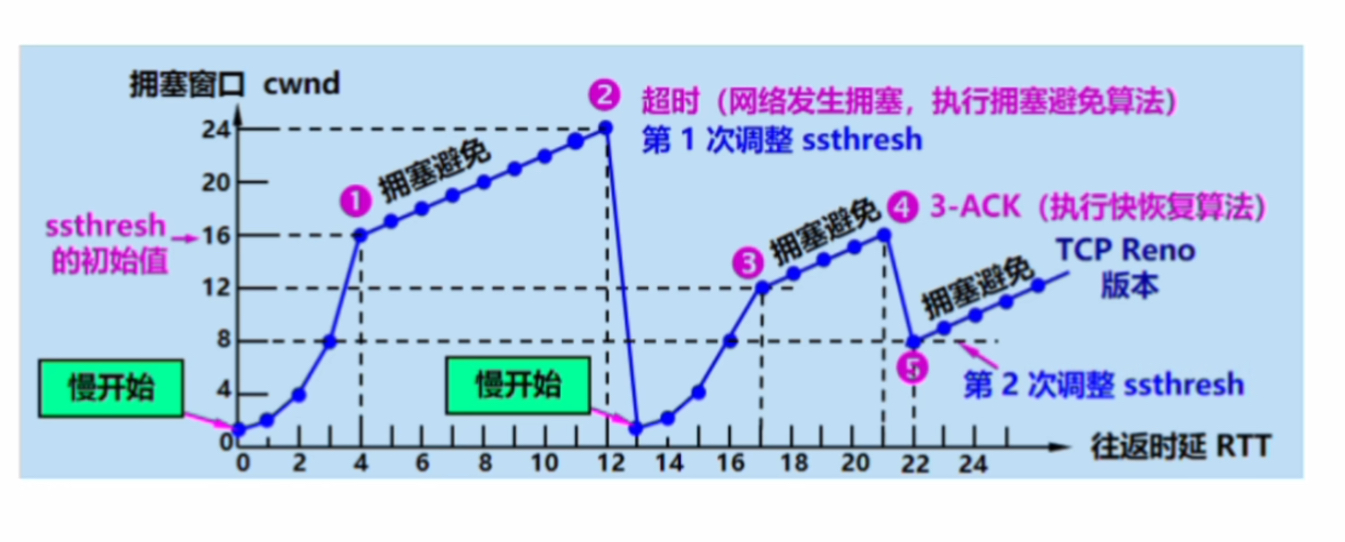
UDP/TCP协议全解
目录 一. UDP协议 1.UDP协议概念 2.UDP数据报格式 3.UDP协议差错控制 二. TCP协议 1.TCP协议概念 2.三次握手与四次挥手 3.TCP报文段格式(重点) 4.流量控制 5.拥塞控制 一. UDP协议 1.UDP协议概念 当应用层的进程1要向进程2传输报文ÿ…...

nginx 服务启动失败问题记录
背景和问题 systemctl status nginx.service 查看报错信息,显示如下: nginx: [emerg] socket() [::]:80 failed (97: Address family not supported by protocol) nginx: configuration file /etc/nginx/nginx.conf test failed问题分析 这个错误通常…...
Duix.HeyGem:以“离线+开源”重构数字人创作生态
在AI技术快速演进的今天,虚拟数字人正从高成本、高门槛的专业领域走向大众化应用。Duix.HeyGem 数字人项目正是这一趋势下的杰出代表。该项目由一支拥有七年AI研发经验的团队打造,通过放弃传统3D建模路径,转向真人视频驱动的AI训练模型,成功实现了低成本、高质量、本地化的…...

ubuntu22.04安装megaton
前置 sudo apt-get install git cmake ninja-build generate-ninja安装devkitPro https://blog.csdn.net/qq_39942341/article/details/148388639?spm1001.2014.3001.5502 安装cargo https://blog.csdn.net/qq_39942341/article/details/148387783?spm1001.2014.3001.5501 …...

风机下引线断点检测算法实现
风机下引线断点检测算法实现 1. 算法原理 该检测系统基于时域反射法(TDR)原理: 在引线起点注入高压纳秒级脉冲脉冲沿引线传播,遇到阻抗不连续点(断点)产生反射采集反射信号并计算时间差通过小波变换进行信号去噪和特征提取根据传播速度计算断点位置:距离 = (传播速度 时间…...

Windows应用-GUID工具
下载本应用 我们在DirectShow和媒体基础程序的调试中,将会遇到大量的GUID,调试窗口大部分情况下只给出GUID字符串,此GUID代表什么,我们无从得知。这时,就需要此“GUID工具”,将GUID字符串翻译为GUID定义&am…...