【python深度学习】Day 45 Tensorboard使用介绍
- tensorboard的发展历史和原理
- tensorboard的常见操作
- tensorboard在cifar上的实战:MLP和CNN模型
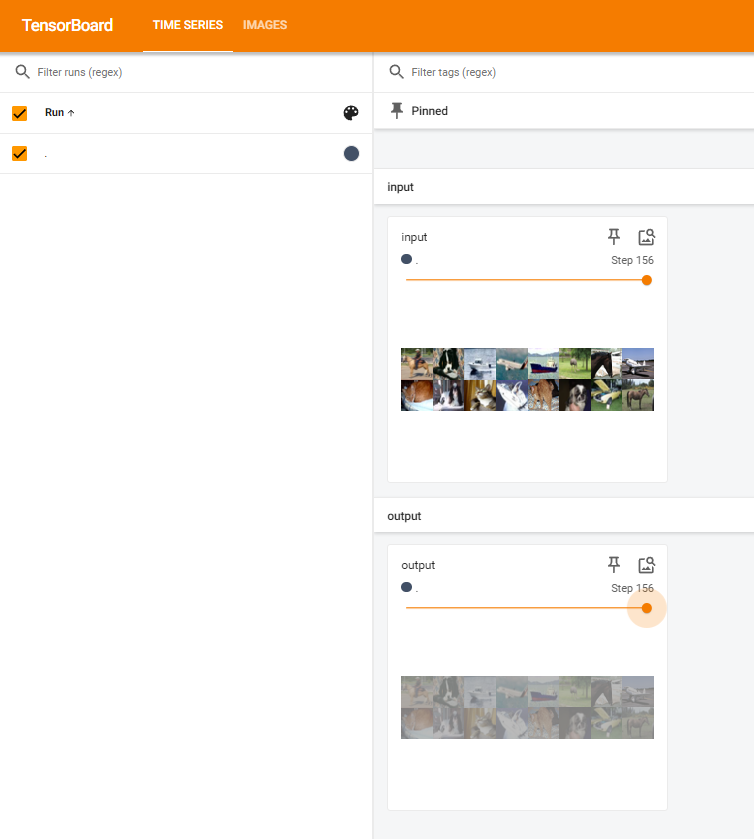
效果展示如下,很适合拿去组会汇报撑页数:
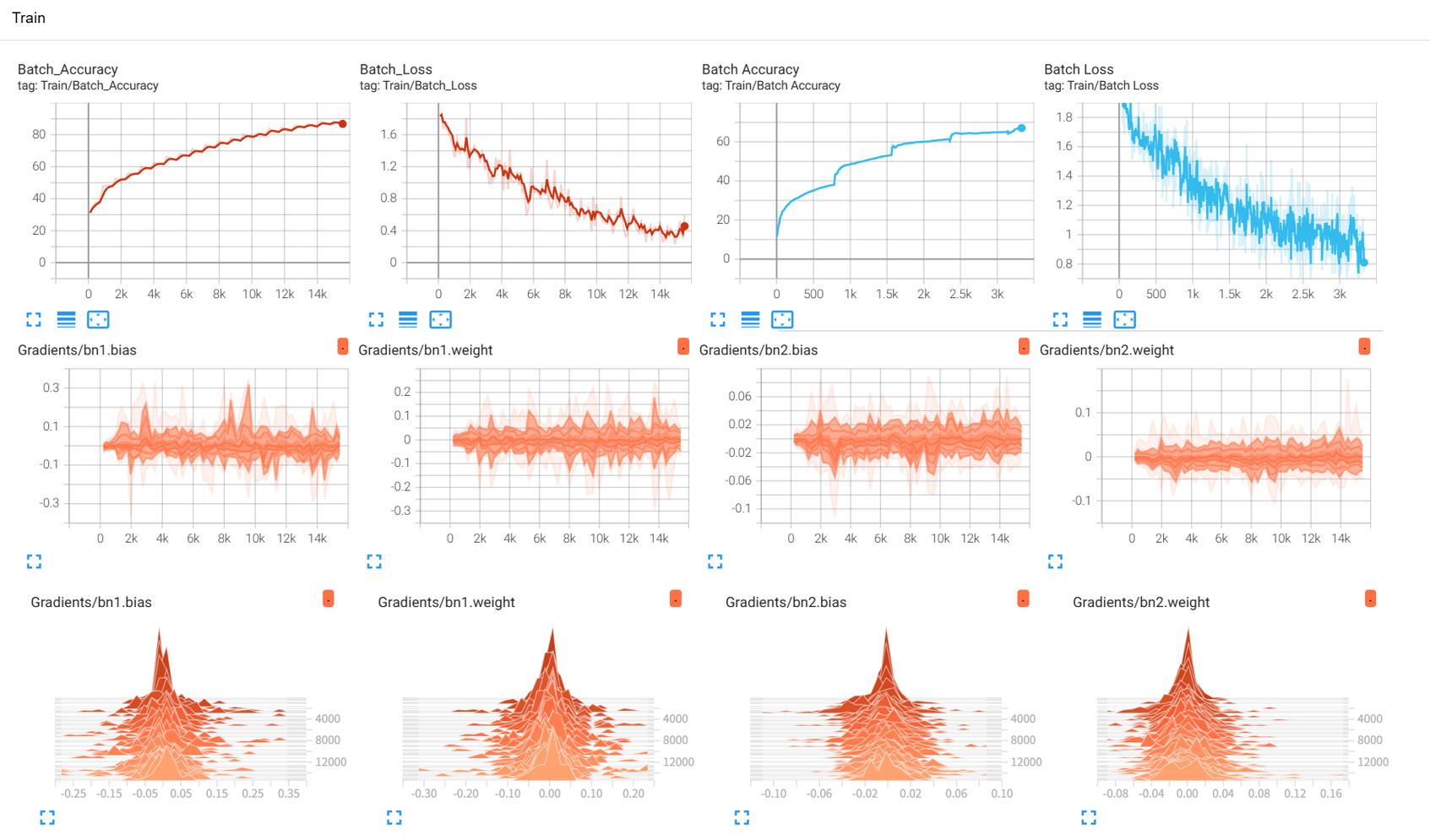
作业:对resnet18在cifar10上采用微调策略下,用tensorboard监控训练过程。
PS:
- tensorboard和torch版本存在一定的不兼容性,如果报错请新建环境尝试。
- tensorboard的代码还有有一定的记忆量,实际上深度学习的经典代码都是类似于八股文,看多了就习惯了,难度远远小于考研数学等需要思考的内容
- 实际上对目前的 AI 而言,你只需要先完成最简单的demo,然后让他给你加上tensorboard需要打印的部分即可。——核心是弄懂tensorboard可以打印什么信息,以及如何看可视化后的结果,把ai当成记忆大师用到的时候通过它来调取对应的代码即可。
一、介绍
之前在神经网络训练中,为了帮助自己理解,借用了很多的组件,比如训练进度条、可视化的loss下降曲线、权重分布图,运行结束后还可以查看单张图的推理效果。
tensorboard这个库,集成了以上所有可视化工具
二、代码实战
MLP
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import numpy as np
import matplotlib.pyplot as plt
import os# 设置随机种子以确保结果可复现
torch.manual_seed(42)
np.random.seed(42)# 1. 数据预处理
transform = transforms.Compose([transforms.ToTensor(), # 转换为张量transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 标准化处理
])# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(root='./data',train=True,download=True,transform=transform
)test_dataset = datasets.CIFAR10(root='./data',train=False,transform=transform
)# 3. 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# CIFAR-10的类别名称
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')# 4. 定义MLP模型(适应CIFAR-10的输入尺寸)
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.flatten = nn.Flatten() # 将3x32x32的图像展平为3072维向量self.layer1 = nn.Linear(3072, 512) # 第一层:3072个输入,512个神经元self.relu1 = nn.ReLU()self.dropout1 = nn.Dropout(0.2) # 添加Dropout防止过拟合self.layer2 = nn.Linear(512, 256) # 第二层:512个输入,256个神经元self.relu2 = nn.ReLU()self.dropout2 = nn.Dropout(0.2)self.layer3 = nn.Linear(256, 10) # 输出层:10个类别def forward(self, x):# 第一步:将输入图像展平为一维向量x = self.flatten(x) # 输入尺寸: [batch_size, 3, 32, 32] → [batch_size, 3072]# 第一层全连接 + 激活 + Dropoutx = self.layer1(x) # 线性变换: [batch_size, 3072] → [batch_size, 512]x = self.relu1(x) # 应用ReLU激活函数x = self.dropout1(x) # 训练时随机丢弃部分神经元输出# 第二层全连接 + 激活 + Dropoutx = self.layer2(x) # 线性变换: [batch_size, 512] → [batch_size, 256]x = self.relu2(x) # 应用ReLU激活函数x = self.dropout2(x) # 训练时随机丢弃部分神经元输出# 第三层(输出层)全连接x = self.layer3(x) # 线性变换: [batch_size, 256] → [batch_size, 10]return x # 返回未经过Softmax的logits# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 初始化模型
model = MLP()
model = model.to(device) # 将模型移至GPU(如果可用)criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器# 创建TensorBoard的SummaryWriter,指定日志保存目录
log_dir = 'runs/cifar10_mlp_experiment'
# 如果目录已存在,添加后缀避免覆盖
if os.path.exists(log_dir):i = 1while os.path.exists(f"{log_dir}_{i}"):i += 1log_dir = f"{log_dir}_{i}"
writer = SummaryWriter(log_dir)# 5. 训练模型(使用TensorBoard记录各种信息)
def train(model, train_loader, test_loader, criterion, optimizer, device, epochs, writer):model.train() # 设置为训练模式# 记录训练开始时间,用于计算训练速度global_step = 0# 可视化模型结构dataiter = iter(train_loader)images, labels = next(dataiter)images = images.to(device)writer.add_graph(model, images) # 添加模型图# 可视化原始图像样本img_grid = torchvision.utils.make_grid(images[:8].cpu())writer.add_image('原始训练图像', img_grid)for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device) # 移至GPUoptimizer.zero_grad() # 梯度清零output = model(data) # 前向传播loss = criterion(output, target) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数# 统计准确率和损失running_loss += loss.item()_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()# 每100个批次记录一次信息到TensorBoardif (batch_idx + 1) % 100 == 0:batch_loss = loss.item()batch_acc = 100. * correct / total# 记录标量数据(损失、准确率)writer.add_scalar('Train/Batch_Loss', batch_loss, global_step)writer.add_scalar('Train/Batch_Accuracy', batch_acc, global_step)# 记录学习率writer.add_scalar('Train/Learning_Rate', optimizer.param_groups[0]['lr'], global_step)# 每500个批次记录一次直方图(权重和梯度)if (batch_idx + 1) % 500 == 0:for name, param in model.named_parameters():writer.add_histogram(f'weights/{name}', param, global_step)if param.grad is not None:writer.add_histogram(f'grads/{name}', param.grad, global_step)print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {batch_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')global_step += 1# 计算当前epoch的平均训练损失和准确率epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / total# 记录每个epoch的训练损失和准确率writer.add_scalar('Train/Epoch_Loss', epoch_train_loss, epoch)writer.add_scalar('Train/Epoch_Accuracy', epoch_train_acc, epoch)# 测试阶段model.eval() # 设置为评估模式test_loss = 0correct_test = 0total_test = 0# 用于存储预测错误的样本wrong_images = []wrong_labels = []wrong_preds = []with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()# 收集预测错误的样本wrong_mask = (predicted != target).cpu()if wrong_mask.sum() > 0:wrong_batch_images = data[wrong_mask].cpu()wrong_batch_labels = target[wrong_mask].cpu()wrong_batch_preds = predicted[wrong_mask].cpu()wrong_images.extend(wrong_batch_images)wrong_labels.extend(wrong_batch_labels)wrong_preds.extend(wrong_batch_preds)epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_test# 记录每个epoch的测试损失和准确率writer.add_scalar('Test/Loss', epoch_test_loss, epoch)writer.add_scalar('Test/Accuracy', epoch_test_acc, epoch)# 计算并记录训练速度(每秒处理的样本数)# 这里简化处理,假设每个epoch的时间相同samples_per_epoch = len(train_loader.dataset)# 实际应用中应该使用time.time()来计算真实时间print(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# 可视化预测错误的样本(只在最后一个epoch进行)if epoch == epochs - 1 and len(wrong_images) > 0:# 最多显示8个错误样本display_count = min(8, len(wrong_images))wrong_img_grid = torchvision.utils.make_grid(wrong_images[:display_count])# 创建错误预测的标签文本wrong_text = []for i in range(display_count):true_label = classes[wrong_labels[i]]pred_label = classes[wrong_preds[i]]wrong_text.append(f'True: {true_label}, Pred: {pred_label}')writer.add_image('错误预测样本', wrong_img_grid)writer.add_text('错误预测标签', '\n'.join(wrong_text), epoch)# 关闭TensorBoard写入器writer.close()return epoch_test_acc # 返回最终测试准确率# 6. 执行训练和测试
epochs = 20 # 训练轮次
print("开始训练模型...")
print(f"TensorBoard日志保存在: {log_dir}")
print("训练完成后,使用命令 `tensorboard --logdir=runs` 启动TensorBoard查看可视化结果")final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, device, epochs, writer)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")相关文章:
【python深度学习】Day 45 Tensorboard使用介绍
知识点: tensorboard的发展历史和原理tensorboard的常见操作tensorboard在cifar上的实战:MLP和CNN模型 效果展示如下,很适合拿去组会汇报撑页数: 作业:对resnet18在cifar10上采用微调策略下,用tensorboard监…...

【图像处理入门】5. 形态学处理:腐蚀、膨胀与图像的形状雕琢
摘要 形态学处理是基于图像形状特征的处理技术,在图像分析中扮演着关键角色。本文将深入讲解腐蚀、膨胀、开闭运算等形态学操作的原理,结合OpenCV代码展示其在去除噪声、提取边缘、分割图像等场景的应用,带你掌握通过结构元素雕琢图像形状的核心技巧。 一、形态学处理:基…...
并行智算MaaS云平台:打造你的专属AI助手,开启智能生活新纪元
目录 引言:AI助手,未来生活的必备伙伴 并行智算云:大模型API的卓越平台 实战指南:调用并行智算云API打造个人AI助手 3.1 准备工作 3.2 API调用示例 3.3 本地智能AI系统搭建 3.4 高级功能实现 并行智算云的优势 4.1 性能卓越…...

在 SpringBoot+Tomcat 环境中 线程安全问题的根本原因以及哪些变量会存在线程安全的问题。
文章目录 前言Tomcat SpringBoot单例加载结果分析多例加载:结果分析: 哪些变量存在线程安全的问题?线程不安全线程安全 总结 前言 本文带你去深入理解为什么在web环境中(Tomcat SpringBoot)会存在多线程的问题以及哪些变量会存在线程安全的…...
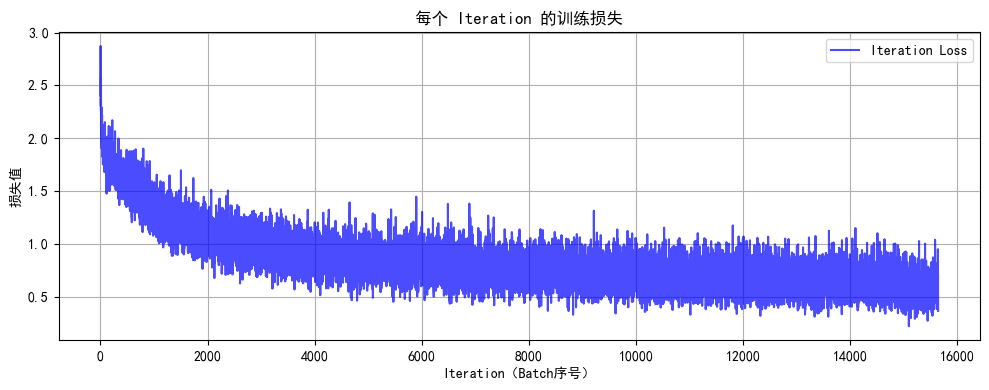
Day45 Python打卡训练营
知识点回顾: 1. tensorboard的发展历史和原理 2. tensorboard的常见操作 3. tensorboard在cifar上的实战:MLP和CNN模型 一、tensorboard的基本操作 1.1 发展历史 TensorBoard 是 TensorFlow 生态中的官方可视化工具(也可无缝集成 PyTorch&…...
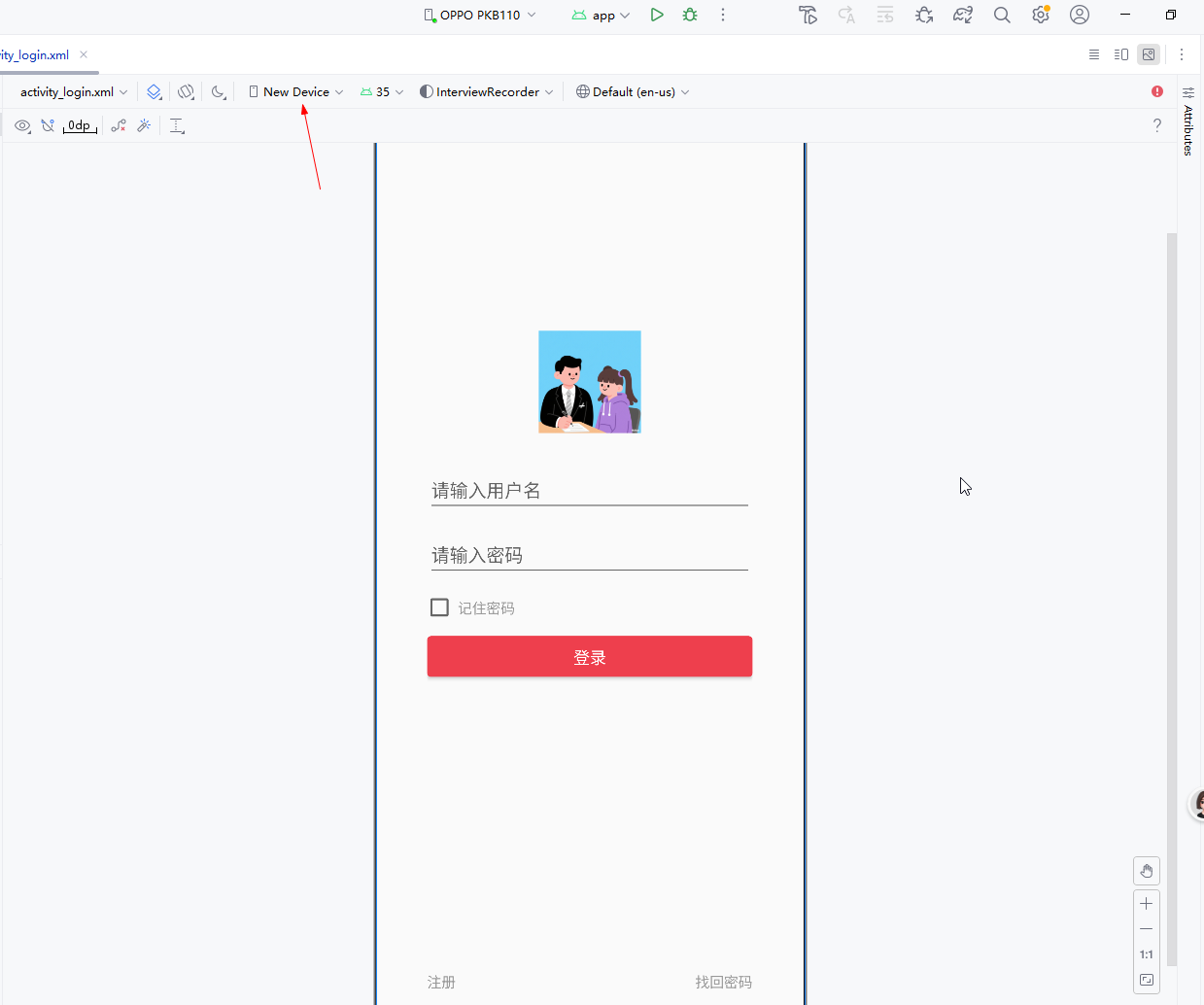
2025年目前最新版本Android Studio自定义xml预览的屏幕分辨率
一、前言 在实际开发项目当中,我们的设备的分辨率可能会比较特殊,AS并没有自带这种屏幕分辨率的设备,但是我们又想一边编写XML界面,一边实时看到较为真实的预览效果,该怎么办呢?在早期的AS版本中ÿ…...
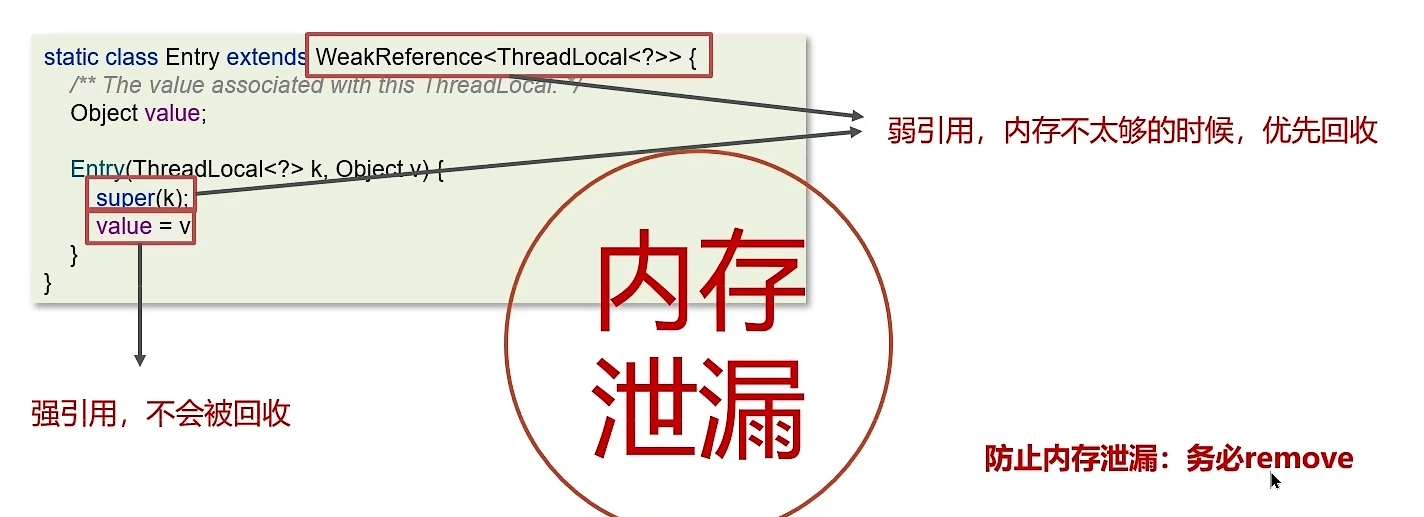
黑马Java面试笔记之 并发编程篇(线程池+使用场景)
一. 线程池的核心参数(线程池的执行原理) 线程池核心参数主要参考ThreadPoolExecutor这个类的7个参数的构造函数 corePoolSize 核心线程数目 maximumPoolSize 最大线程数目 (核心线程救急线程的最大数目) keepAliveTime 生存时间 - 救急线程的生存时…...

float和float32有什么区别
这是一个非常重要但容易混淆的问题。我们来一步一步讲清楚: ✅ 简答:float 和 float32 的区别 项目float(通用名称)float32(精确定义)含义通常指“浮点数”,具体精度由语言/平台决定明确指 32 …...
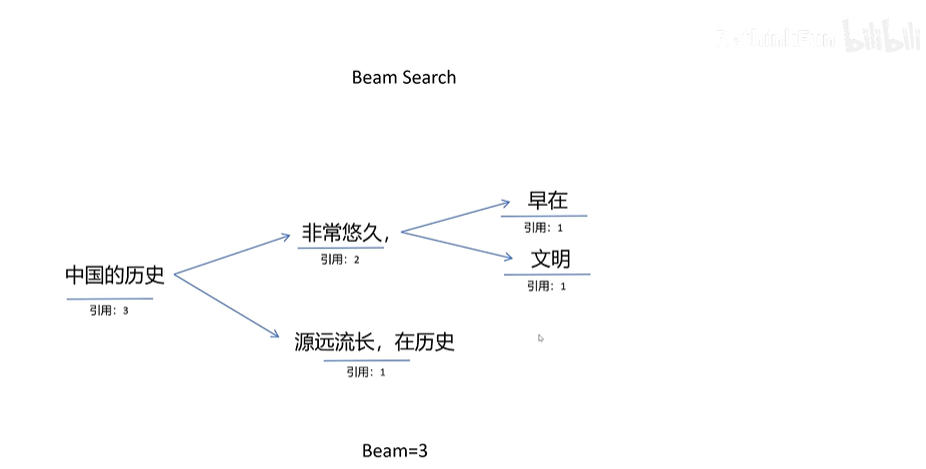
【AI学习】KV-cache和page attention
目录 带着问题学AI KV-cache KV-cache是什么? 之前每个token生成的K V矩阵给缓存起来有什么用? 为啥缓存K、V,没有缓存Q? KV-cache为啥在训练阶段不需要,只在推理阶段需要? KV cache的过程图解 阶段一:KV cac…...
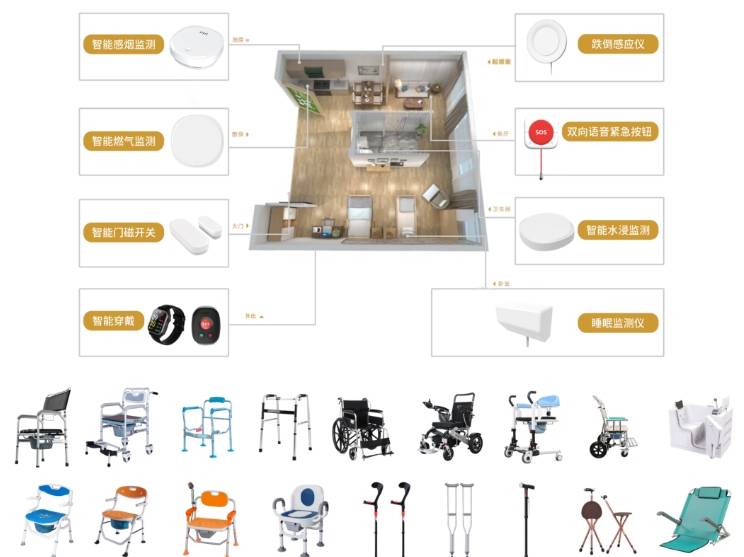
七彩喜智慧养老平台:科技赋能下的市场蓝海,满足多样化养老服务需求
在人口老龄化加速与科技快速发展的双重驱动下,七彩喜智慧养老平台正成为破解养老服务供需矛盾、激活银发经济的核心引擎。 这一领域依托物联网、人工智能、大数据等技术,构建起覆盖居家、社区、机构的多层次服务体系。 既满足老年人多样化需求…...
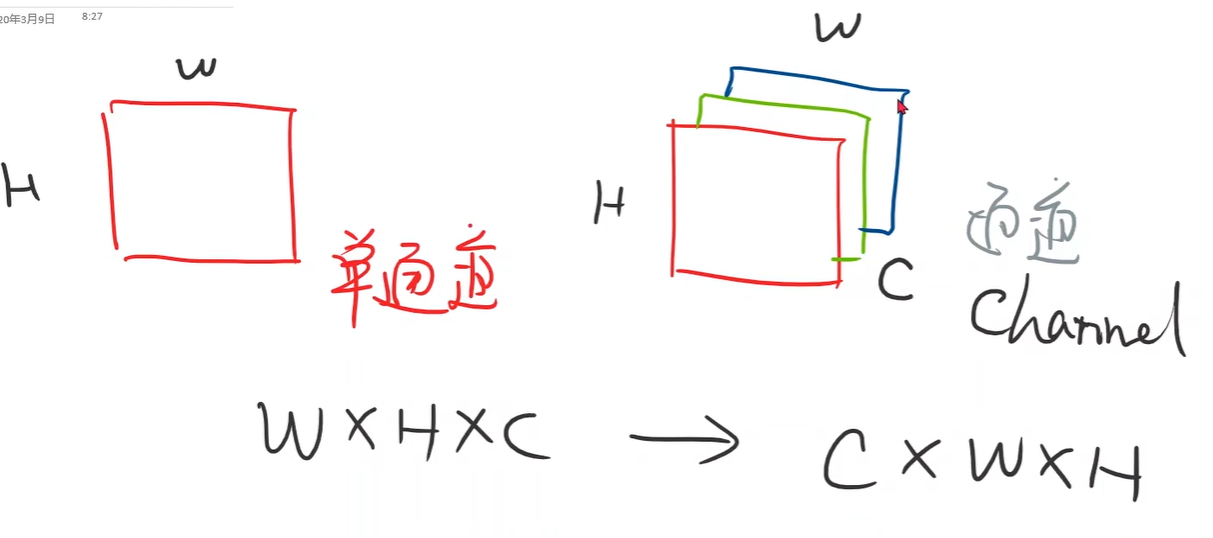
《Pytorch深度学习实践》ch8-多分类
------B站《刘二大人》 1.Softmax Layer 在多分类问题中,输出的是每类的概率: 计算公式:保证了每类概率大于 0 ,又由保证了概率之和为 1; 举例如下: 2.Cross Entropy 计算损失: y np.array…...

国产录播一体机:科技赋能智慧教育信息化
在数字化时代,教育正经历着前所未有的变革。国产工控机作为信息化教育的核心载体,正在重新定义学习方式,赋能教师与学生,打造高效、互动、智能的教学环境,让我们一起感受科技与教育的深度融合!高能计算机推…...

关于逻辑回归的见解
逻辑回归通过将线性回归的输出映射到 [ 0 , 1 ] \left[0,1\right] [0,1]区间,来表示某个类别的概率。也就是其本质是先通过线性回归的预测值 y \boldsymbol{y} y输入到映射函数,既将线性回归的输出通过映射函数映射到 [ 0 , 1 ] \left[0,1\right] [0,1].常用的映射函数是sigm…...
Amazon Augmented AI:人类智慧与AI协作,破解机器学习审核难题
在人工智能日益渗透业务核心的今天,你是否遭遇过这样的困境:自动化AI处理海量数据时,面对模糊、复杂或高风险的场景频频“卡壳”?人工审核团队则被低效、重复的任务压得喘不过气?Amazon Augmented AI (A2I) 的诞生&…...

CMake入门:3、变量操作 set 和 list
在 CMake 中,set 和 list 是两个核心命令,用于变量管理和列表操作。理解它们的用法对于编写高效的 CMakeLists.txt 文件至关重要。下面详细介绍这两个命令的功能和常见用法: 一、set 命令:变量定义与赋值 set 命令用于创建、修改…...

聊聊FlaUI:让Windows UI自动化测试优雅起飞!
你还在为手动点点点测试Windows应用而感到膝盖疼?更愁于自动化测试工具价格贵得让钱包瑟瑟发抖?今天,我要给你安利一款“野路子有余,正经事儿也能干”的.NET UI自动化神器——FlaUI!别眨眼,看完你能少加三个…...
VIN码车辆识别码解析接口如何用C#进行调用?
一、什么是VIN码车辆识别码解析接口 输入17位vin码,获取到车辆的品牌、型号、出厂日期、发动机类型、驱动类型、车型、年份等信息。无论是汽车电商平台、二手车商、维修厂,还是保险公司、金融机构,都能通过接入该API实现信息自动化、决策智能…...

[论文阅读] 人工智能 | 用大语言模型解决软件元数据“身份谜题”:科研软件的“认脸”新方案
用大语言模型解决软件元数据“身份谜题”:科研软件的“认脸”新方案 论文信息 作者: Eva Martn del Pico, Josep Llus Gelp, Salvador Capella-Gutirrez 标题: Identity resolution of software metadata using Large Language Models 年份: 2025 来源: arX…...

gorm多租户插件的使用
一、关于gorm多租户插件的使用 1、安装依赖 go get -u github.com/kuangshp/gorm-tenant2、创建一个mysql数据表 DROP TABLE IF EXISTS user; CREATE TABLE user (id int(11) NOT NULL AUTO_INCREMENT primary key COMMENT 主键id,name varchar(50) not null comment 名称,ten…...

Playwright 测试框架 - Java
🚀【Playwright + Java 实战教程】从零到一掌握自动化测试利器! 🔧 本文专为 Java 开发者量身打造,通过详尽示例带你快速掌握 Playwright 自动化测试。涵盖基础操作、表单交互、测试框架集成、高阶功能及常见实战技巧,适用于企业 UI 测试与 CI/CD 场景。 🛠️ 一、环境…...

力扣100题之128. 最长连续序列
方法1 使用了hash 方法思路 使用哈希集合:首先将数组中的所有数字存入一个哈希集合中,这样可以在 O(1) 时间内检查某个数字是否存在。 寻找连续序列:遍历数组中的每一个数字,对于每一个数字, 检查它是否是某个连续序列…...
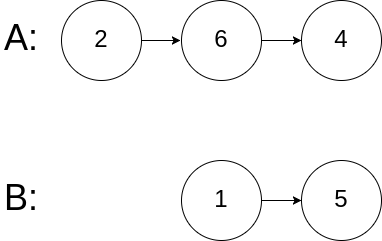
算法打卡12天
19.链表相交 (力扣面试题 02.07. 链表相交) 给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表没有交点,返回 null 。 图示两个链表在节点 c1 开始相交**:** 题目数据…...
:图像/视频的输入输出(highgui模块 高层GUI和媒体I/O))
OpenCV C++ 学习笔记(四):图像/视频的输入输出(highgui模块 高层GUI和媒体I/O)
文章目录 图片读取创建窗口图片显示图片保存视频输入输出 图片读取 cv::Mat imread( const String& filename, int flags IMREAD_COLOR );enum ImreadModes {IMREAD_UNCHANGED -1, //!< If set, return the loaded image as is (with alpha channel, othe…...

我的创作纪念日——聊聊我想成为一个创作者的动机
2025年6月4日,是我在CSDN写下第一篇技术博客的第1024天。 1024,这个数字对于程序员来说意义非凡,它不仅是内存单位的基础,更是我们这群“码农”的节日符号。而对我来说,它更像是一段旅程的里程碑:从一个曾想…...
蓝桥杯国赛训练 day1 Java大学B组
目录 k倍区间 舞狮 交换瓶子 k倍区间 取模后算组合数就行 import java.util.HashMap; import java.util.Map; import java.util.Scanner;public class Main {static Scanner sc new Scanner(System.in);public static void main(String[] args) {solve();}public static vo…...
PyTorch——非线性激活(5)
非线性激活函数的作用是让神经网络能够理解更复杂的模式和规律。如果没有非线性激活函数,神经网络就只能进行简单的加法和乘法运算,没法处理复杂的问题。 非线性变化的目的就是给我们的网络当中引入一些非线性特征 Relu 激活函数 Relu处理图像 # 导入必…...

OPenCV CUDA模块目标检测----- HOG 特征提取和目标检测类cv::cuda::HOG
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 cv::cuda::HOG 是 OpenCV 的 CUDA 模块中对 HOG 特征提取和目标检测 提供的 GPU 实现。它与 CPU 版本的 cv::HOGDescriptor 类似,但利…...

MATLAB读取文件内容:Excel、CSV和TXT文件解析
MATLAB读取文件内容:Excel、CSV和TXT文件解析 MATLAB 是一款强大的数学与工程计算工具,广泛应用于数据分析、模型构建和图像处理等领域。在处理实际问题时,我们常常需要从文件中读取数据进行分析。本文将介绍如何使用 MATLAB 读取常见的文件…...
Spring MVC 之 异常处理
使用Spring MVC可以很灵活地完成数据的绑定和响应,极大的简化了Java Web的开发。但Spring MVC提供的便利不仅仅如此,使用Spring MVC还可以很便捷地完成项目中的异常处理、自定义拦截器以及文件上传和下载等高级功能。本章将对Spring MVC提供的这些高级功…...

缓存控制HTTP标头设置为“无缓存、无存储、必须重新验证”
文章目录 说明示例核心响应头设置实现原理代码实现1. 原生 Node.js (使用 http 模块)2. Express 框架3. 针对特定路由设置 (Express) 验证方法(使用 cURL)关键注意事项 说明 日期:2025年6月4日。 对于安全内容,请确保缓存控制HT…...