深度学习姿态估计实战:基于ONNX Runtime的YOLOv8 Pose部署全解析
本文将详细介绍如何脱离YOLO官方环境,使用ONNX Runtime部署YOLOv8姿态估计模型。内容包括模型加载、图像预处理(Letterbox缩放和填充)、推理执行、输出解码(边界框和关键点处理)、非极大值抑制(NMS)以及结果可视化。文章还将讨论部署中的性能优化和常见问题。
一,引言
姿态估计是计算机视觉中的一项重要任务,旨在检测图像或视频中人体关键点的位置。YOLOv8 Pose是Ultralytics公司推出的实时姿态估计模型,它将目标检测和关键点估计结合在一个端到端的网络中。为了在各种环境中高效部署该模型,选择使用ONNX Runtime(ORT),它支持跨平台(包括CPU和GPU)推理,且不依赖于原始训练框架。
二,模型加载与初始化
在YOLOv8Pose类的初始化方法中,加载ONNX模型并配置推理会话:
class YOLOv8Pose:def __init__(self, model_path, conf_thres=0.1, iou_thres=0.45):self.conf_thres = conf_thresself.iou_thres = iou_thres# 初始化ONNX Runtimeself.session = ort.InferenceSession(model_path)self.input_name = self.session.get_inputs()[0].nameself.output_name = self.session.get_outputs()[0].nameself.input_shape = self.session.get_inputs()[0].shape[2:] # (h, w)
注意:
model_path:ONNX模型文件的路径。
conf_thres:置信度阈值,用于过滤低置信度的检测框。
iou_thres:NMS中的IoU阈值。
从模型输入中获取输入形状(高度和宽度),通常为640x640。
三 . 图像预处理:Letterbox缩放与填充
由于模型输入尺寸固定,而输入图像尺寸各异,我们需要将图像调整为模型输入尺寸,同时保持长宽比,以避免扭曲。这通过Letterbox算法实现:
def preprocess(self, img):# 原始图像尺寸self.orig_h, self.orig_w = img.shape[:2]# 计算缩放比例(取最小比例,使长边缩放到模型输入尺寸,短边按比例缩放)scale = min(self.input_shape[0] / self.orig_h, self.input_shape[1] / self.orig_w)# 计算缩放后的新尺寸self.new_unpad = (int(self.orig_w * scale), int(self.orig_h * scale))# 计算填充(在缩放到模型尺寸后,需要在两侧添加的填充)self.dw = (self.input_shape[1] - self.new_unpad[0]) / 2 # 水平填充self.dh = (self.input_shape[0] - self.new_unpad[1]) / 2 # 垂直填充# 执行缩放if (self.new_unpad[0], self.new_unpad[1]) != (self.orig_w, self.orig_h):img = cv2.resize(img, self.new_unpad, interpolation=cv2.INTER_LINEAR)# 添加填充(上下左右)top, bottom = int(round(self.dh - 0.1)), int(round(self.dh + 0.1))left, right = int(round(self.dw - 0.1)), int(round(self.dw + 0.1))img = cv2.copyMakeBorder(img, top, bottom, left, right,cv2.BORDER_CONSTANT, value=(114, 114, 114))# 图像通道转换和归一化img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # BGR->RGBimg = img.transpose(2, 0, 1) # HWC->CHWimg = np.ascontiguousarray(img, dtype=np.float32) / 255.0 # 归一化到[0,1]return np.expand_dims(img, axis=0) # 添加batch维度
四,模型推理
推理过程非常简单,因为我们已经处理好了输入数据:
# 在main函数中:input_tensor = model.preprocess(img)outputs = model.session.run([model.output_name], {model.input_name: input_tensor})
注意:我们使用session.run进行推理,传入输入数据的字典(输入名称->输入张量)和输出名称列表(这里只需要一个输出)。
五,后处理:解析模型输出
模型输出是一个形状为[1, 11, 8400]的张量(以本文模型为例),其中:
1:批大小(batch size)。
11:每个预测框的维度(4个边界框坐标+1个置信度+6个关键点坐标,因为每个关键点有3个值:x,y,score,所以两个关键点就是6个值)。
8400:预测框的数量。
后处理步骤包括:
转置输出,得到形状为[8400, 11]的矩阵。
根据置信度阈值过滤掉低置信度的预测框。
将边界框格式从(cx, cy, w, h)转换为(x1, y1, x2, y2)。
解析关键点(重塑为[N, 2, 3],其中2是关键点的数量,每个关键点有x, y, score)。
将坐标从模型输入尺寸映射回原始图像尺寸(反转预处理中的缩放和填充)。
应用非极大值抑制(NMS)去除冗余检测框。
def postprocess(self, outputs):predictions = outputs[0][0].T # 转置为[8400, 11]# 1. 按置信度阈值过滤conf_mask = predictions[:, 4] > self.conf_threspredictions = predictions[conf_mask]if predictions.shape[0] == 0:return [], [], [] # 没有检测结果# 2. 边界框转换 (cx, cy, w, h) -> (x1, y1, x2, y2)boxes = predictions[:, :4].copy()boxes[:, 0] = boxes[:, 0] - boxes[:, 2] / 2 # x1 = cx - w/2boxes[:, 1] = boxes[:, 1] - boxes[:, 3] / 2 # y1 = cy - h/2boxes[:, 2] = boxes[:, 0] + boxes[:, 2] # x2 = x1 + wboxes[:, 3] = boxes[:, 1] + boxes[:, 3] # y2 = y1 + h# 3. 关键点:将6个值(2个关键点)重塑为[2, 3]keypoints = predictions[:, 5:].reshape(-1, 2, 3) # [n, 2, 3]# 4. 坐标转换(映射回原始图像尺寸)# 计算缩放比例scale = min(self.input_shape[0] / self.orig_h, self.input_shape[1] / self.orig_w)# 调整边界框boxes[:, [0, 2]] -= self.dw # 减去水平填充boxes[:, [1, 3]] -= self.dh # 减去垂直填充boxes[:, :4] /= scale # 缩放到原始图像尺寸# 调整关键点keypoints[:, :, 0] -= self.dw # 关键点x坐标减去水平填充keypoints[:, :, 1] -= self.dh # 关键点y坐标减去垂直填充keypoints[:, :, :2] /= scale # 缩放到原始图像尺寸# 取整boxes = boxes.round().astype(int)keypoints = keypoints.round().astype(int)# 5. NMSscores = predictions[:, 4]indices = cv2.dnn.NMSBoxes(boxes.tolist(), scores.tolist(), self.conf_thres, self.iou_thres)# 注意:如果indices为空,则返回空列表;否则使用索引获取元素if len(indices) > 0:indices = indices.flatten()return boxes[indices], scores[indices], keypoints[indices]else:return [], [], []
注意:
在坐标转换时,我们先减去填充(dw和dh),然后除以缩放比例scale。
使用round().astype(int)将坐标转为整数。
使用OpenCV的NMSBoxes函数进行非极大值抑制,该函数返回保留框的索引。
六,结果可视化
可视化函数在图像上绘制边界框和关键点:
def visualize(self, image, boxes, keypoints):# 绘制边界框for box in boxes:x1, y1, x2, y2 = boxcv2.rectangle(image, (x1, y1), (x2, y2), (0, 255, 0), 2)# 绘制关键点及连线for kpts in keypoints:# 绘制每个关键点(两个关键点,第一个为红色,第二个为蓝色)for i, (x, y, score) in enumerate(kpts):if score > 0.5: # 关键点置信度阈值color = (0, 0, 255) if i == 0 else (255, 0, 0)cv2.circle(image, (x, y), 5, color, -1)# 连接两个关键点(如果两个关键点都置信度高)if len(kpts) == 2 and all(kpts[:, 2] > 0.5):x1, y1, _ = kpts[0]x2, y2, _ = kpts[1]cv2.line(image, (x1, y1), (x2, y2), (0, 255, 255), 2)return image
说明:
边界框为绿色矩形。
第一个关键点(索引0)绘制为红色点,第二个关键点(索引1)为蓝色点。
如果两个关键点的置信度都大于0.5,则在它们之间绘制一条黄色连线。
七,主函数流程
if __name__ == "__main__":model_path = "./runs/pose/train16/weights/best.onnx"image_path = "./input/test.png"# 读取图像img = cv2.imread(image_path)if img is None:raise ValueError(f"Error: Unable to read image from {image_path}")# 创建模型实例model = YOLOv8Pose(model_path)# 预处理input_tensor = model.preprocess(img)# 推理outputs = model.session.run([model.output_name], {model.input_name: input_tensor})# 后处理boxes, scores, keypoints = model.postprocess(outputs)# 可视化result = model.visualize(img.copy(), boxes, keypoints)cv2.imshow("Result", result)cv2.waitKey(0)cv2.destroyAllWindows()
八,完整代码如下
import cv2
import numpy as np
import onnxruntime as ortclass YOLOv8Pose:def __init__(self, model_path, conf_thres=0.1, iou_thres=0.45):self.conf_thres = conf_thresself.iou_thres = iou_thres# 初始化ONNX Runtimeself.session = ort.InferenceSession(model_path)self.input_name = self.session.get_inputs()[0].nameself.output_name = self.session.get_outputs()[0].nameself.input_shape = self.session.get_inputs()[0].shape[2:] # (h, w)def preprocess(self, img):# Letterbox处理(保持宽高比)self.orig_h, self.orig_w = img.shape[:2]scale = min(self.input_shape[0] / self.orig_h, self.input_shape[1] / self.orig_w)# 计算新尺寸和填充self.new_unpad = (int(self.orig_w * scale), int(self.orig_h * scale))self.dw = (self.input_shape[1] - self.new_unpad[0]) / 2 # 水平填充self.dh = (self.input_shape[0] - self.new_unpad[1]) / 2 # 垂直填充# 执行缩放和填充if (self.new_unpad[0], self.new_unpad[1]) != (self.orig_w, self.orig_h):img = cv2.resize(img, self.new_unpad, interpolation=cv2.INTER_LINEAR)top, bottom = int(round(self.dh - 0.1)), int(round(self.dh + 0.1))left, right = int(round(self.dw - 0.1)), int(round(self.dw + 0.1))img = cv2.copyMakeBorder(img, top, bottom, left, right,cv2.BORDER_CONSTANT, value=(114, 114, 114))# 转换颜色通道和维度img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)img = img.transpose(2, 0, 1) # HWC -> CHWimg = np.ascontiguousarray(img, dtype=np.float32) / 255.0return np.expand_dims(img, axis=0)def postprocess(self, outputs):# 输出形状转换 [1, 11, 8400] -> [8400, 11] predictions = outputs[0][0].T# 过滤低置信度conf_mask = predictions[:, 4] > self.conf_threspredictions = predictions[conf_mask]if predictions.shape[0] == 0:return [], [], []# 转换边界框坐标 (cx, cy, w, h) -> (x1, y1, x2, y2)boxes = predictions[:, :4].copy()boxes[:, 0] = (boxes[:, 0] - boxes[:, 2] / 2) # x1boxes[:, 1] = (boxes[:, 1] - boxes[:, 3] / 2) # y1boxes[:, 2] += boxes[:, 0] # x2boxes[:, 3] += boxes[:, 1] # y2# 关键点处理 (每个目标有两个关键点,每个点含x,y,score)keypoints = predictions[:, 5:].reshape(-1, 2, 3) # [N, 2, 3]# 坐标转换到原始图像空间scale = min(self.input_shape[0] / self.orig_h, self.input_shape[1] / self.orig_w)# 调整边界框boxes[:, [0, 2]] -= self.dw # 减去水平填充boxes[:, [1, 3]] -= self.dh # 减去垂直填充boxes /= scaleboxes = boxes.round().astype(int)# 调整关键点keypoints[:, :, 0] -= self.dwkeypoints[:, :, 1] -= self.dhkeypoints[:, :, :2] /= scalekeypoints = keypoints.round().astype(int)# 应用NMSscores = predictions[:, 4]indices = self.nms(boxes, scores)return boxes[indices], scores[indices], keypoints[indices]def nms(self, boxes, scores):# OpenCV实现的高效NMSreturn cv2.dnn.NMSBoxes(boxes.tolist(),scores.tolist(),self.conf_thres,self.iou_thres)def visualize(self, image, boxes, keypoints):# 绘制边界框for box in boxes:x1, y1, x2, y2 = boxcv2.rectangle(image, (x1, y1), (x2, y2), (0, 255, 0), 2)# 绘制关键点及连线for kpts in keypoints:# 绘制关键点for i, (x, y, score) in enumerate(kpts):if score > 0.5:color = (0, 0, 255) if i == 0 else (255, 0, 0)cv2.circle(image, (x, y), 5, color, -1)# 绘制两个关键点之间的连线if len(kpts) == 2 and all(kpts[:, 2] > 0.5):x1, y1 = kpts[0][:2]x2, y2 = kpts[1][:2]cv2.line(image, (x1, y1), (x2, y2), (0, 255, 255), 2)return imageif __name__ == "__main__":model_path = "./runs/pose/train16/weights/best.onnx"image_path = "./input/test.png"# 读取图像img = cv2.imread(image_path)if img is None:raise ValueError(f"Error: Unable to read image from {image_path}")# 创建YOLOv8Pose实例model = YOLOv8Pose(model_path)# 预处理input_tensor = model.preprocess(img)# 推理outputs = model.session.run([model.output_name], {model.input_name: input_tensor})# 后处理boxes, scores, keypoints = model.postprocess(outputs)# 可视化result = model.visualize(img.copy(), boxes, keypoints)cv2.imshow("Result", result)cv2.waitKey(0)cv2.destroyAllWindows()
相关文章:

深度学习姿态估计实战:基于ONNX Runtime的YOLOv8 Pose部署全解析
本文将详细介绍如何脱离YOLO官方环境,使用ONNX Runtime部署YOLOv8姿态估计模型。内容包括模型加载、图像预处理(Letterbox缩放和填充)、推理执行、输出解码(边界框和关键点处理)、非极大值抑制(NMS…...

深度探索:如何用DeepSeek重构你的工作流
前言:AI时代的工作革命 在人工智能浪潮席卷的今天,DeepSeek作为国产大模型的代表之一,正以其强大的自然语言处理能力、代码生成能力和多模态交互特性,重新定义着人类的工作方式。根据IDC报告显示,2024年企业级AI应用市场规模已突破800亿美元,其中智能办公场景占比达32%,…...
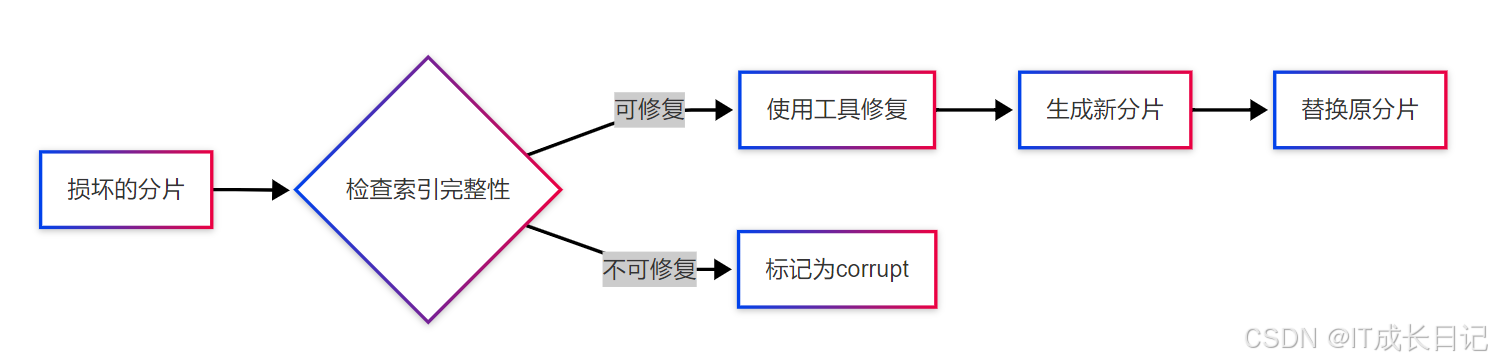
深入解析与解决方案:处理Elasticsearch中all found copies are either stale or corrupt未分配分片问题
目录 引言 1 问题诊断深入分析 1.1 错误含义深度解析 1.2 获取详细的诊断信息 2 解决方案选择与决策流程 2.1 可用选项全面对比 2.2 推荐处理流程与决策树 3 具体操作步骤详解 3.1 优先尝试 - 分配最新副本(最低风险) 3.2 中等风险方案 - 分配…...
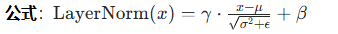
【NLP 78、手搓Transformer模型结构】
你以为走不出的淤泥,也迟早会云淡风轻 —— 25.5.31 引言 ——《Attention is all you need》 《Attention is all you need》这篇论文可以说是自然语言处理领域的一座里程碑,它提出的 Transformer 结构带来了一场技术革命。 研究背景与目标 在 Transfo…...

yum更换阿里云的镜像源
步骤 1:备份原有源配置(重要!) sudo mkdir /etc/yum.repos.d/backup sudo mv /etc/yum.repos.d/CentOS-* /etc/yum.repos.d/backup/步骤 2:下载阿里云源配置 sudo curl -o /etc/yum.repos.d/CentOS-Base.repo https:…...
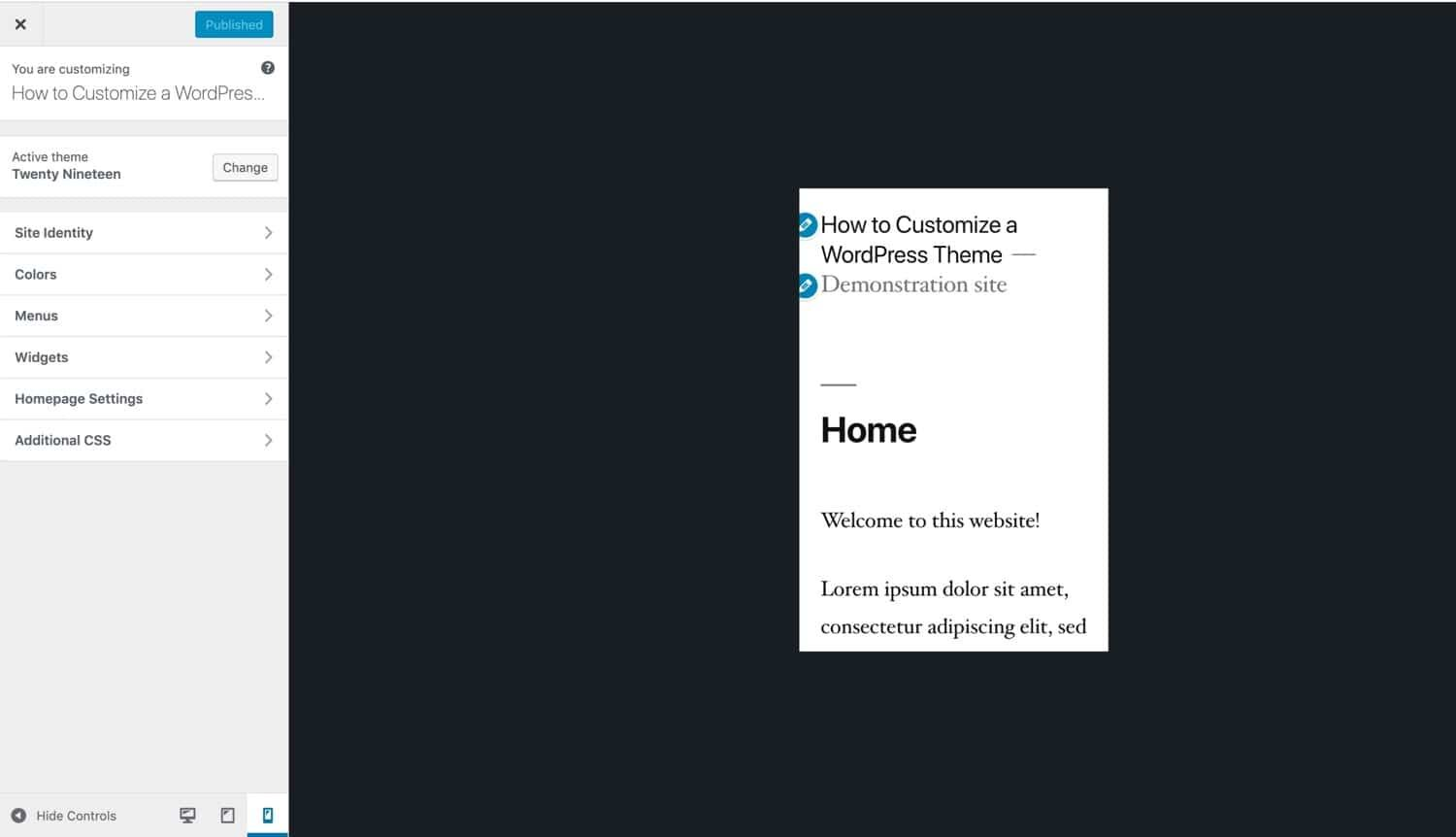
如何自定义WordPress主题(5个分步教程)
如果您已经安装了一个 WordPress 主题,但它不太适合您,您可能会感到沮丧。在定制 WordPress 主题方面,您有很多选择。 挑战在于找到正确的方法。 在本篇文章中,我将引导您了解自定义 WordPress 主题的各种选项,帮助您…...

ios版本的Tiktok二次安装不上,提示:Unable to Install “TikTok”
问题:Domain: IXUserPresentableErrorDomain Code: 1 Recovery Suggestion: Failed to load Info.plist from bundle at path /private/var/containers/Bundle/Application/E99D86D4-F96E-48F9-86C5-FE095A22E13A/DouyinDev.app/PlugIns/AwemeNotificationService.a…...
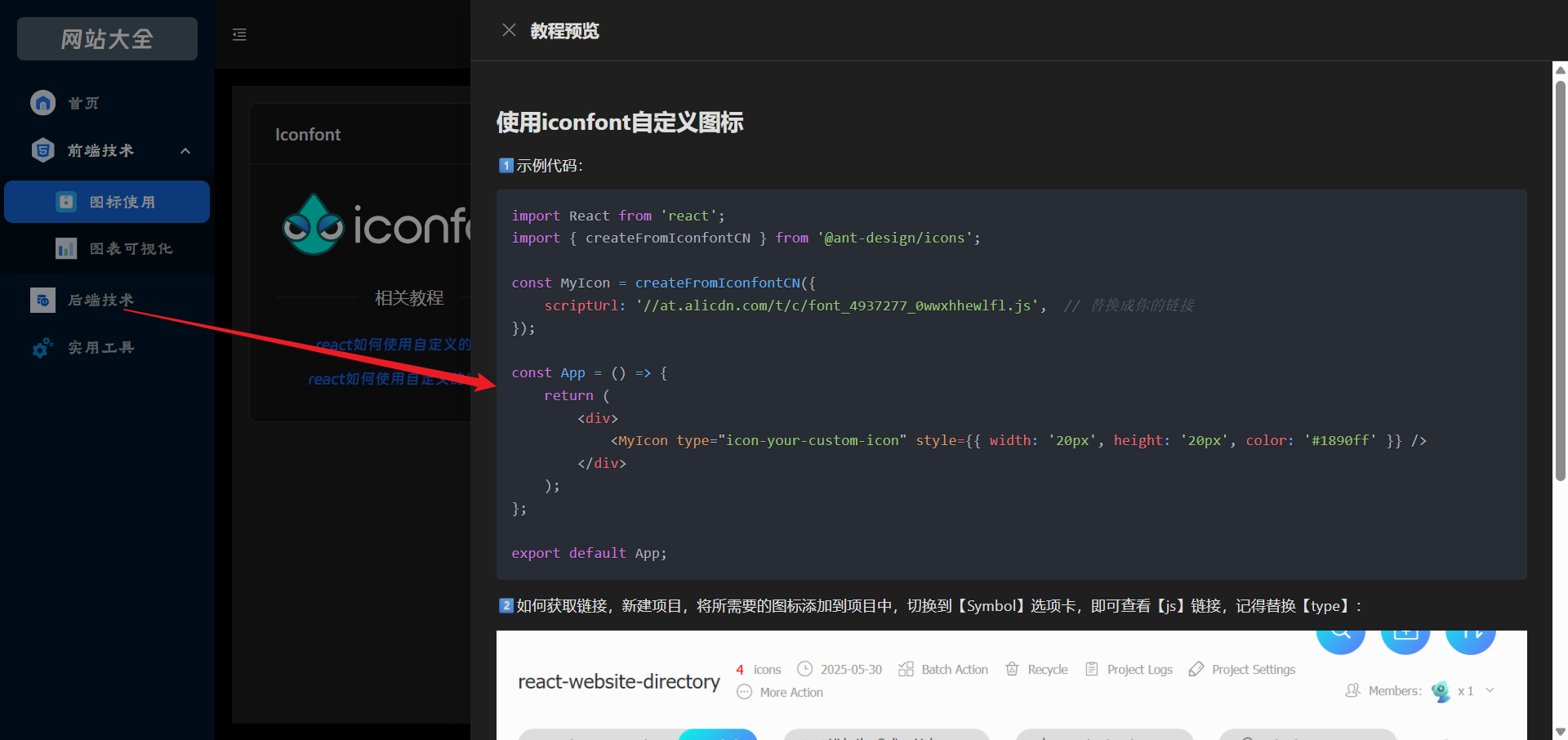
react实现markdown文件预览
文章目录 react实现markdown文件预览1、实现md文件预览2、解决图片不显示3、实现效果 react实现markdown文件预览 1、实现md文件预览 1️⃣第一步:安装依赖: npm install react-markdown remark-gfmreact-markdown:将 Markdown 渲染为 Rea…...

Neo4j 认证与授权:原理、技术与最佳实践深度解析
Neo4j 作为领先的图数据库,其安全机制——认证(Authentication)与授权(Authorization)——是保障数据资产的核心防线。本文将深入剖析其工作原理、关键技术、实用技巧及行业最佳实践,助您构建坚不可摧的图数据安全体系。 Neo4j 提供了强大且灵活的认证授权框架,涵盖从基…...

Android Studio 配置之gitignore
1.创建或编辑.gitignore文件 在项目根目录下检查是否已有.gitignore文件。如果没有,创建一个新文件,命名为.gitignore(注意文件名前有个点)。 添加忽略规则:在.gitignore中添加以下内容: 忽略整个 .idea …...

PDF处理控件Aspose.PDF教程:在 C# 中更改 PDF 页面大小
PDF 的页面大小决定了其内容的显示、打印或处理方式。我们通常在准备打印、转换格式或标准化布局时需要更改 PDF 页面大小。在本文中,您将学习如何使用 C# 更改任何 PDF 文件的页面大小。我们将通过完整的代码示例,逐步指导您完成操作。 Aspose.PDF最新…...

Perl One-liner 数据处理——基础语法篇【匠心】
Perl(Practical Extraction and Report Language)是一种功能强大且灵活的脚本语言,因其强大的文本处理能力和简洁的语法而广受开发者和系统管理员的喜爱。特别是在命令行环境下,Perl 的 one-liner(单行脚本)以其高效、简洁的特点,成为数据处理、文本转换和快速原型设计的…...

PHP 打印扩展开发:从易联云到小鹅通的多驱动集成实践
目前已有易联云WIFI打印机扩展 扩展入口文件 文件目录 crmeb\services\printer\Printer.php namespace crmeb\services\printer;use crmeb\basic\BaseManager; use think\facade\Config; use think\Container;/*** Class Printer* package crmeb\services\auth* mixin \crme…...
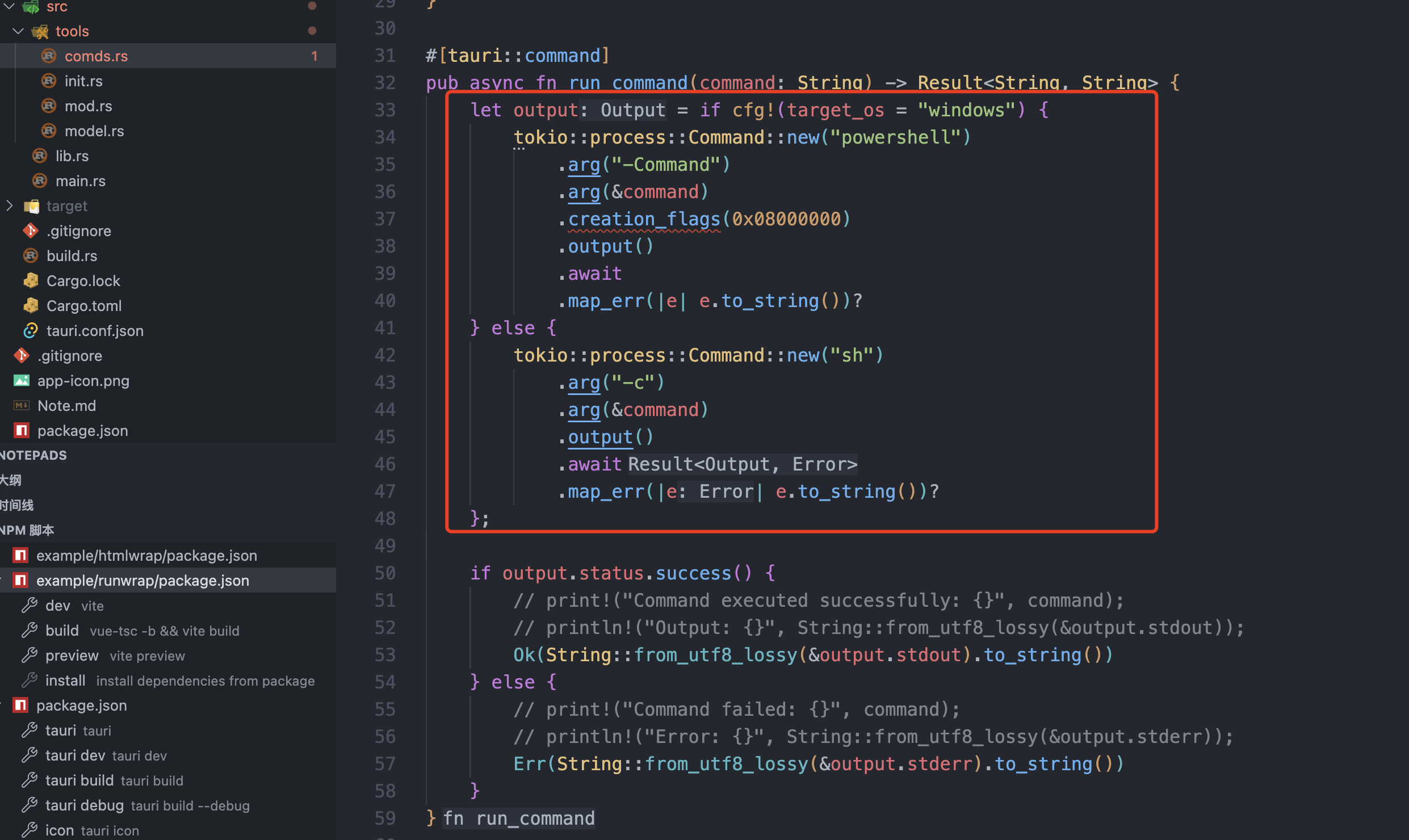
rust或tauri项目执行命令的时候,cmd窗口也会弹出显示解决方法
阻止 Tauri 执行命令时弹出 CMD 窗口 当你在 Tauri 中使用 tokio::process::Command 执行命令时弹出 CMD 窗口,这是因为 Windows 默认会为控制台程序创建可见窗口。以下是几种解决方法: 1. 使用 Windows 特有的创建标志 (推荐) #[tauri::command] pub…...

[软件工程] 文档 | 技术文档撰写全流程指南
技术文档撰写全流程指南 一份优秀的技术文档需平衡 “技术严谨性” 与 “用户友好性”,其本质是降低信息传递成本,让读者能快速获取所需信息,减少沟通与试错成本。在实际操作中,从明确目标、结构化内容、可视化表达,到…...

使用Python进行函数作画
前言 因为之前通过deepseek绘制一下卡通的人物根本就不像,又想起来之前又大佬通过函数绘制了一些图像,想着能不能用Python来实现,结果发现可以,不过一些细节还是需要自己调整,deepseek整体的框架是没有问题࿰…...

Python应用continue关键字初解
大家好!对于刚接触编程的初学者来说,理解循环控制语句是掌握编程语言的重要一步。在Python中,continue关键字是一个非常实用的循环控制工具,本文将通过简易示例帮助大家理解它的作用。 基本概念: continue关键字用于中断本次循环,…...

微型导轨在手术机器人领域中有哪些关键操作?
在微创手术领域,手术机器人凭借其高精度、高稳定性和远程操控能力,正逐步成为现代外科手术的重要工具。微型导轨作为一种专为高精度运动设计的线性导向系统,凭借其亚微米级定位精度、低摩擦运动特性及紧凑结构设计,已成为手术机器…...
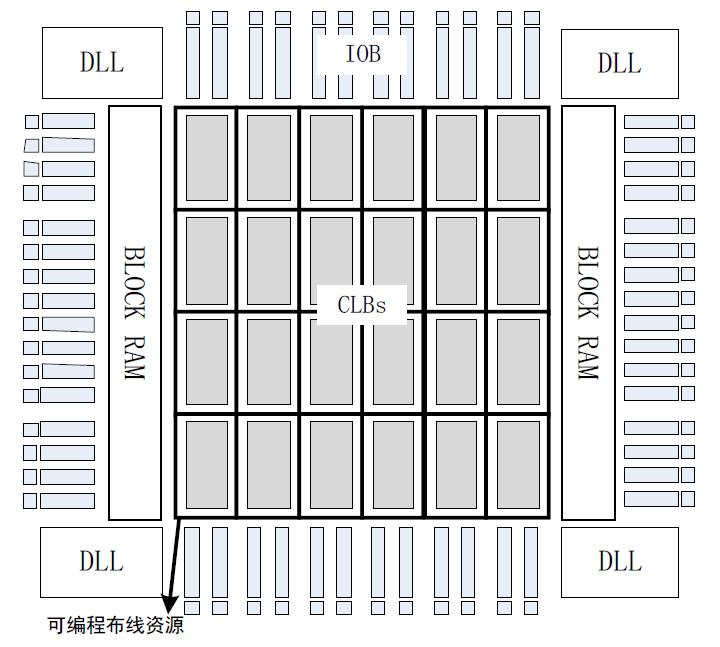
FPGA 的硬件结构
FPGA 的基本结构分为5 部分:可编程逻辑块(CLB)、输入/输出块(IOB)、逻辑块之间的布线资源、内嵌RAM 和内嵌的功能单元。 (1)可编程逻辑块(CLB) 一个基本的可编程逻辑块由…...
EasyRTC音视频实时通话助力新一代WebP2P视频物联网应用解决方案
一、方案背景 物联网技术深刻变革各行业,视频物联在智慧城市、工业监控等场景广泛应用。传统方案依赖中心服务器中转,存在传输效率低、网络负载大的问题。新一代WebP2P视频物联技术实现设备直连,降低网络压力并提升传输效率,成…...
QT开发技术【ffmpeg + QAudioOutput】音乐播放器 完善
一、完善上章的功能,形成一个小工具 QT开发技术【ffmpeg QAudioOutput】音乐播放器 二、增加歌曲保存类 #include "../Include/MusicListManager.h" #include "QtGui/Include/Conversion.h" #include <QFile> #include <QXmlStream…...

vscode 离线安装第三方库跳转库
我安装的是C/C的函数跳转 下载的离线库: 项目首页 - vscode代码自动补全跳转插件离线安装包:cpptools-win32.vsix是一款专为VSCode设计的离线安装插件,特别适合无法连接网络的电脑环境。通过安装此插件,您的VSCode将获得强大的代码自动跳转…...
DevExpress WinForms v24.2 - 新增日程组件、电子表格组件功能扩展
DevExpress WinForms拥有180组件和UI库,能为Windows Forms平台创建具有影响力的业务解决方案。DevExpress WinForms能完美构建流畅、美观且易于使用的应用程序,无论是Office风格的界面,还是分析处理大批量的业务数据,它都能轻松胜…...
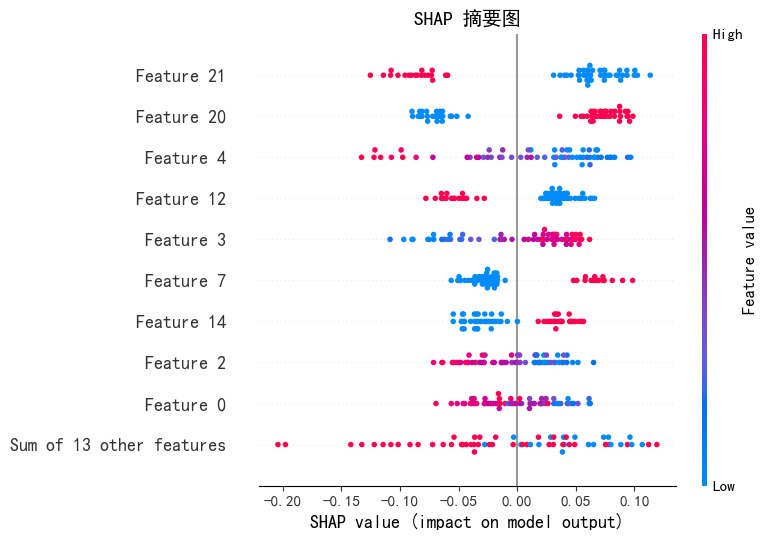
基于机器学习的心脏病预测模型构建与可解释性分析
一、引言 心脏病是威胁人类健康的重要疾病之一,早期预测和诊断对防治心脏病具有重要意义。本文利用公开的心脏病数据集,通过机器学习算法构建预测模型,并使用 SHAP 值进行模型可解释性分析,旨在为心脏病的辅助诊断提供参考。 二、…...

VisDrone无人机视觉挑战赛观察解析2025.6.5
VisDrone无人机视觉挑战赛观察解析 历史沿革与发展进程 VisDrone无人机视觉挑战赛由天津大学联合国内外多所高校及科研机构发起,自2018年起依托ECCV、ICCV等顶级计算机视觉会议连续举办,已成为全球无人机视觉领域最具影响力的学术竞赛之一。赛事以推动无人机平台视觉算法创…...

Monorepo架构: Lerna、NX、Turbo等对比与应用分析
概述 对于大型的 Monorepo 项目来说,Nx 绝对算是神器,在包管理和版本控制部分有优势对于大型 Monorepo 项目,Nx 是非常实用的工具,在包管理、版本控制以及构建、测试优化等方面都有一定作用下面我们来对比一下这几种工具 NPM 包…...

redis进入后台操作、查看key、删除key
cmd进入 redis后台 避免报错NOAUTH Authentication required 第一步 ./redis-cli -h 127.0.0.1 -p 6379第二步 AUTH YourPassword通过key删除redis缓存 进了后台之后输入 keys * 删除key del key1...
谷粒商城-分布式微服务项目-高级篇[三]
十五、商城业务-支付 15.1 支付宝支付 15.1.1 进入“蚂蚁金服开放平台” 支付宝开放 平台地址: 支付宝开放平台 15.1.2 下载支付宝官方 demo,进行配置和测试 开发者文档:支付宝开放平台文档中心 电脑网站支付文档:小程序文…...
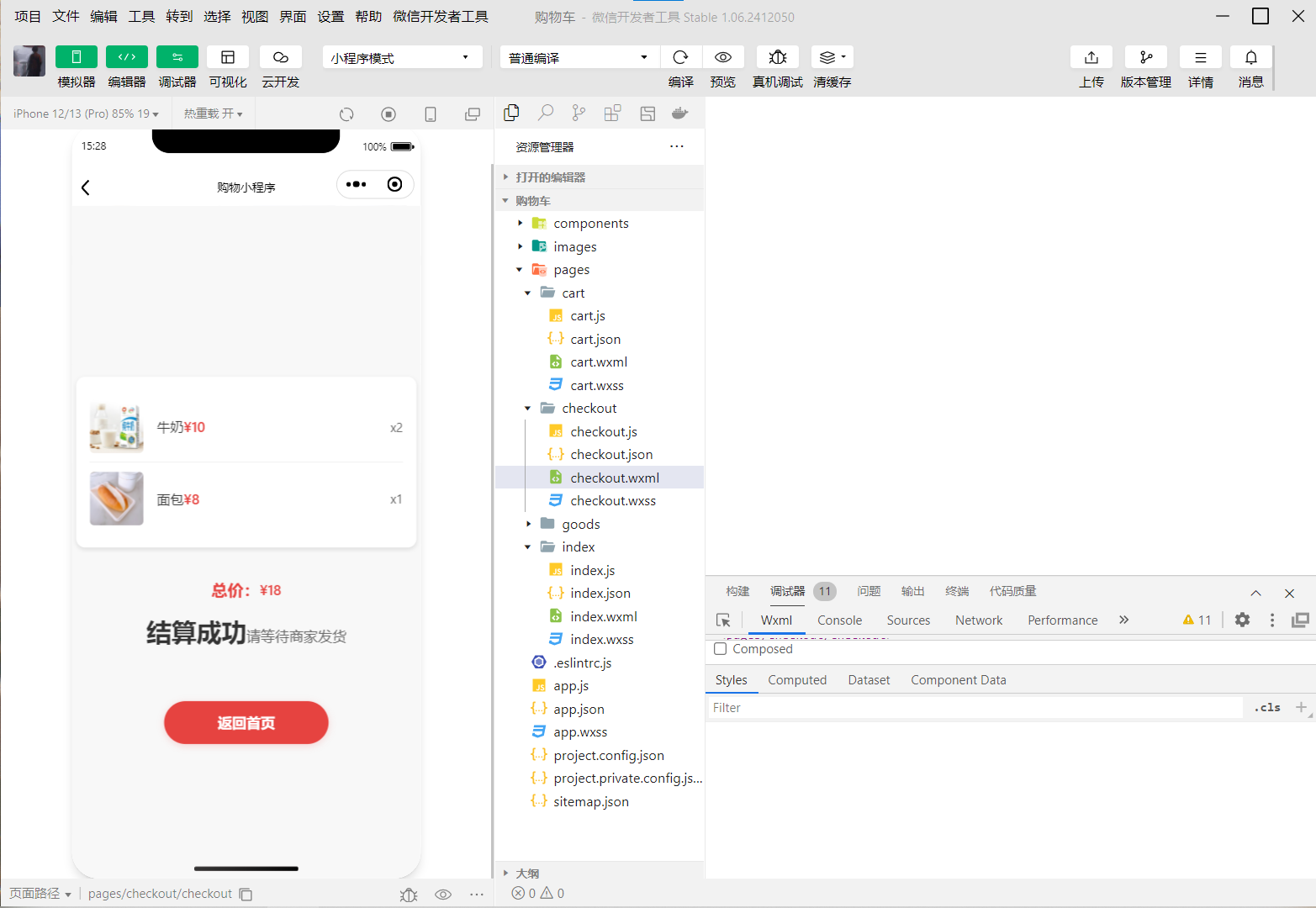
实现购物车微信小程序
实现一个微信小程序购物车页面,包含以下功能: 需求说明: 商品列表:显示商品名称、价格、数量加减按钮,支持修改商品数量(数量≥1)。 全选 / 反选功能:顶部 “全选” 复选框&#…...

26考研 | 王道 | 计算机组成原理 | 四、指令系统
26考研 | 王道 | 计算机组成原理 | 四、指令系统 文章目录 26考研 | 王道 | 计算机组成原理 | 四、指令系统1.指令系统0.指令集体系结构1. 指令格式1.按地址码数目不同来分2.指令-按指令长度分类3.指令-按操作码长度分类4.指令-按操作类型分类 2. 扩展操作码指令格式 2.指令的寻…...