吴恩达MCP课程(5):research_server_prompt_resource.py
代码
import arxiv
import json
import os
from typing import List
from mcp.server.fastmcp import FastMCPPAPER_DIR = "papers"# Initialize FastMCP server
mcp = FastMCP("research")@mcp.tool()
def search_papers(topic: str, max_results: int = 5) -> List[str]:"""Search for papers on arXiv based on a topic and store their information.Args:topic: The topic to search formax_results: Maximum number of results to retrieve (default: 5)Returns:List of paper IDs found in the search"""# Use arxiv to find the papers client = arxiv.Client()# Search for the most relevant articles matching the queried topicsearch = arxiv.Search(query = topic,max_results = max_results,sort_by = arxiv.SortCriterion.Relevance)papers = client.results(search)# Create directory for this topicpath = os.path.join(PAPER_DIR, topic.lower().replace(" ", "_"))os.makedirs(path, exist_ok=True)file_path = os.path.join(path, "papers_info.json")# Try to load existing papers infotry:with open(file_path, "r") as json_file:papers_info = json.load(json_file)except (FileNotFoundError, json.JSONDecodeError):papers_info = {}# Process each paper and add to papers_info paper_ids = []for paper in papers:paper_ids.append(paper.get_short_id())paper_info = {'title': paper.title,'authors': [author.name for author in paper.authors],'summary': paper.summary,'pdf_url': paper.pdf_url,'published': str(paper.published.date())}papers_info[paper.get_short_id()] = paper_info# Save updated papers_info to json filewith open(file_path, "w") as json_file:json.dump(papers_info, json_file, indent=2)print(f"Results are saved in: {file_path}")return paper_ids@mcp.tool()
def extract_info(paper_id: str) -> str:"""Search for information about a specific paper across all topic directories.Args:paper_id: The ID of the paper to look forReturns:JSON string with paper information if found, error message if not found"""for item in os.listdir(PAPER_DIR):item_path = os.path.join(PAPER_DIR, item)if os.path.isdir(item_path):file_path = os.path.join(item_path, "papers_info.json")if os.path.isfile(file_path):try:with open(file_path, "r") as json_file:papers_info = json.load(json_file)if paper_id in papers_info:return json.dumps(papers_info[paper_id], indent=2)except (FileNotFoundError, json.JSONDecodeError) as e:print(f"Error reading {file_path}: {str(e)}")continuereturn f"There's no saved information related to paper {paper_id}."@mcp.resource("papers://folders")
def get_available_folders() -> str:"""List all available topic folders in the papers directory.This resource provides a simple list of all available topic folders."""folders = []# Get all topic directoriesif os.path.exists(PAPER_DIR):for topic_dir in os.listdir(PAPER_DIR):topic_path = os.path.join(PAPER_DIR, topic_dir)if os.path.isdir(topic_path):papers_file = os.path.join(topic_path, "papers_info.json")if os.path.exists(papers_file):folders.append(topic_dir)# Create a simple markdown listcontent = "# Available Topics\n\n"if folders:for folder in folders:content += f"- {folder}\n"content += f"\nUse @{folder} to access papers in that topic.\n"else:content += "No topics found.\n"return content@mcp.resource("papers://{topic}")
def get_topic_papers(topic: str) -> str:"""Get detailed information about papers on a specific topic.Args:topic: The research topic to retrieve papers for"""topic_dir = topic.lower().replace(" ", "_")papers_file = os.path.join(PAPER_DIR, topic_dir, "papers_info.json")if not os.path.exists(papers_file):return f"# No papers found for topic: {topic}\n\nTry searching for papers on this topic first."try:with open(papers_file, 'r') as f:papers_data = json.load(f)# Create markdown content with paper detailscontent = f"# Papers on {topic.replace('_', ' ').title()}\n\n"content += f"Total papers: {len(papers_data)}\n\n"for paper_id, paper_info in papers_data.items():content += f"## {paper_info['title']}\n"content += f"- **Paper ID**: {paper_id}\n"content += f"- **Authors**: {', '.join(paper_info['authors'])}\n"content += f"- **Published**: {paper_info['published']}\n"content += f"- **PDF URL**: [{paper_info['pdf_url']}]({paper_info['pdf_url']})\n\n"content += f"### Summary\n{paper_info['summary'][:500]}...\n\n"content += "---\n\n"return contentexcept json.JSONDecodeError:return f"# Error reading papers data for {topic}\n\nThe papers data file is corrupted."@mcp.prompt()
def generate_search_prompt(topic: str, num_papers: int = 5) -> str:"""Generate a prompt for Claude to find and discuss academic papers on a specific topic."""return f"""Search for {num_papers} academic papers about '{topic}' using the search_papers tool. Follow these instructions:
1. First, search for papers using search_papers(topic='{topic}', max_results={num_papers})
2. For each paper found, extract and organize the following information:- Paper title- Authors- Publication date- Brief summary of the key findings- Main contributions or innovations- Methodologies used- Relevance to the topic '{topic}'3. Provide a comprehensive summary that includes:- Overview of the current state of research in '{topic}'- Common themes and trends across the papers- Key research gaps or areas for future investigation- Most impactful or influential papers in this area4. Organize your findings in a clear, structured format with headings and bullet points for easy readability.Please present both detailed information about each paper and a high-level synthesis of the research landscape in {topic}."""if __name__ == "__main__":# Initialize and run the servermcp.run(transport='stdio')
代码解释
这个research_server_prompt_resource.py文件实现了一个基于MCP(Model Context Protocol)的研究服务器,主要用于搜索、存储和检索arXiv上的学术论文。下面是对代码的详细解释:
1. 导入和初始化
import arxiv
import json
import os
from typing import List
from mcp.server.fastmcp import FastMCPPAPER_DIR = "papers"# Initialize FastMCP server
mcp = FastMCP("research")
- 导入必要的库:
arxiv用于访问arXiv API,json用于处理JSON数据,os用于文件操作 - 定义论文存储目录为
papers - 创建一个名为"research"的FastMCP服务器实例
2. 工具函数:搜索论文
@mcp.tool()
def search_papers(topic: str, max_results: int = 5) -> List[str]:
这个函数被注册为MCP工具,用于根据主题搜索arXiv上的论文:
- 功能:搜索arXiv上与指定主题相关的论文,并将结果保存到本地
- 参数:
topic:搜索主题max_results:最大结果数(默认5篇)
- 返回值:找到的论文ID列表
核心实现:
- 使用arxiv客户端搜索相关论文
- 为主题创建目录(如果不存在)
- 尝试加载现有的论文信息(如果有)
- 处理每篇论文,提取标题、作者、摘要等信息
- 将论文信息保存到JSON文件中
3. 工具函数:提取论文信息
@mcp.tool()
def extract_info(paper_id: str) -> str:
这个函数被注册为MCP工具,用于根据论文ID检索特定论文的详细信息:
- 功能:在所有主题目录中搜索指定ID的论文信息
- 参数:
paper_id:要查找的论文ID - 返回值:包含论文信息的JSON字符串,或未找到时的错误消息
实现逻辑:
- 遍历
papers目录下的所有主题文件夹 - 检查每个文件夹中的
papers_info.json文件 - 如果找到匹配的论文ID,返回其详细信息
4. 资源函数:获取可用文件夹
@mcp.resource("papers://folders")
def get_available_folders() -> str:
这个函数被注册为MCP资源,提供URI为papers://folders的访问点:
- 功能:列出
papers目录中所有可用的主题文件夹 - 返回值:包含所有主题列表的Markdown格式文本
实现方式:
- 扫描
papers目录,查找包含papers_info.json文件的子目录 - 将找到的主题列表格式化为Markdown文本
- 添加使用说明(如何访问特定主题)
5. 资源函数:获取主题论文
@mcp.resource("papers://{topic}")
def get_topic_papers(topic: str) -> str:
这个函数被注册为MCP资源,提供动态URI papers://{topic}的访问点:
- 功能:获取特定主题的所有论文详细信息
- 参数:
topic:要检索的研究主题 - 返回值:包含该主题所有论文详细信息的Markdown格式文本
实现细节:
- 根据主题名构建文件路径
- 检查并加载该主题的论文信息JSON文件
- 将论文信息格式化为结构化的Markdown文档
- 包含每篇论文的标题、ID、作者、发布日期、PDF链接和摘要
6. 提示函数:生成搜索提示
@mcp.prompt()
def generate_search_prompt(topic: str, num_papers: int = 5) -> str:
这个函数被注册为MCP提示,用于生成结构化的搜索指令:
- 功能:生成一个提示文本,指导AI如何搜索和讨论特定主题的学术论文
- 参数:
topic:要搜索的主题num_papers:要检索的论文数量(默认5篇)
- 返回值:格式化的提示文本
提示内容包括:
- 使用
search_papers工具搜索论文的指令 - 如何提取和组织每篇论文的信息(标题、作者、发布日期等)
- 如何提供综合摘要(研究现状、共同主题、研究空白等)
- 如何组织和呈现结果
7. 主程序
if __name__ == "__main__":# Initialize and run the servermcp.run(transport='stdio')
当脚本作为主程序运行时,启动MCP服务器,使用标准输入/输出(stdio)作为传输方式。
总结
这个服务器实现了以下核心功能:
- 论文搜索与存储:通过arXiv API搜索论文并将结果保存到本地JSON文件
- 论文信息检索:根据论文ID或主题检索论文详细信息
- 资源访问:提供URI访问点,用于获取可用主题列表和特定主题的论文信息
- 提示生成:生成结构化提示,指导AI如何搜索和分析学术论文
这个服务器设计为与MCP兼容的工具,可以被MCP客户端(如聊天机器人)调用,为用户提供学术论文搜索和分析功能。
相关文章:
:research_server_prompt_resource.py)
吴恩达MCP课程(5):research_server_prompt_resource.py
代码 import arxiv import json import os from typing import List from mcp.server.fastmcp import FastMCPPAPER_DIR "papers"# Initialize FastMCP server mcp FastMCP("research")mcp.tool() def search_papers(topic: str, max_results: int 5) …...

[论文阅读] 人工智能+项目管理 | 当 PMBOK 遇见 AI:传统项目管理框架的破局之路
当PMBOK遇见AI:传统项目管理框架的“AI适配指南” 论文信息 arXiv:2506.02214 Is PMBOK Guide the Right Fit for AI? Re-evaluating Project Management in the Face of Artificial Intelligence Projects Alexey Burdakov, Max Jaihyun Ahn Subjects: Software …...
Gateway 搭建
1.创建 moudle 命名为 gateway 2,pom中引入依赖 网关依赖;注册中心依赖等 <!-- 网关依赖--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-gateway</artifactId></d…...
pytorch基本运算-导数和f-string
引言 在前序对机器学习的探究过程中,我们已经深刻体会到人工智能到处都有微分求导运算,相关文章链接包括且不限于: BP神经网络 逻辑回归 对于pytorch张量,求导运算必不可少,所以本次就专门来学习一下。 f-string的用…...

impala中更改公网ip为内网ip
实际有时候需求中需要将公网的impala监听ip改为内网的ip 步骤 1,更改配置文件中的ip 1,更改/etc/default/impala中的ip配置重启服务即可在hive元数据同一个节点上要启动sudo service impala-state-store restartsudo service impala-catalog restart所有…...
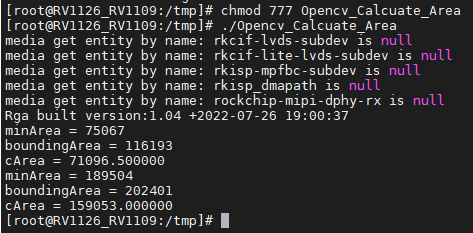
5.RV1126-OPENCV 图形计算面积
一.图形面积、弧长计算介绍 前面我们已经把图形轮廓的检测、画框等功能讲解了一遍。这次主要结合轮廓检测的 API 去计算图形的面积,这些面积可以是矩形、圆形等等。图形面积计算和弧长计算常用于车辆识别、桥梁识别等重要功能,常用的 API 如 contourArea…...

一键净化Excel数据:高性能Python脚本实现多核并行清理
摘要 本文分享两个基于Python的Excel数据净化脚本,通过多进程并行技术清除工作表内不可见字符、批注、单元格样式等冗余内容,利用OpenPyXL实现底层操作,结合tqdm进度条和进程级任务分配,可快速处理百万级单元格数据。适用于数据分…...
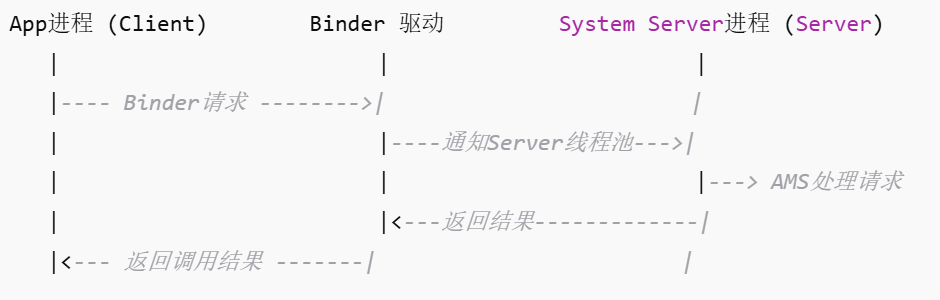
【Android基础回顾】一:Binder机制是什么?有什么用?
Android中的Binder机制是Android系统中最核心和最基础的进程间通讯机制。 1 什么是进程间通讯机制(IPC)? 众所周知,Android系统基于Linux开发,Linux系统里面本来就有进程间通讯机制。 1.1 Linux的IPC(Inter-Process Communication)概览 它…...

LeetCode 高频 SQL 50 题(基础版) 之 【高级查询和连接】· 上
题目:1731. 每位经理的下属员工数量 题解: select employee_id,name,reports_count,average_age from Employees t1,(select reports_to,count(*) reports_count,round(avg(age)) average_agefrom Employeeswhere reports_to is not nullgroup by repor…...
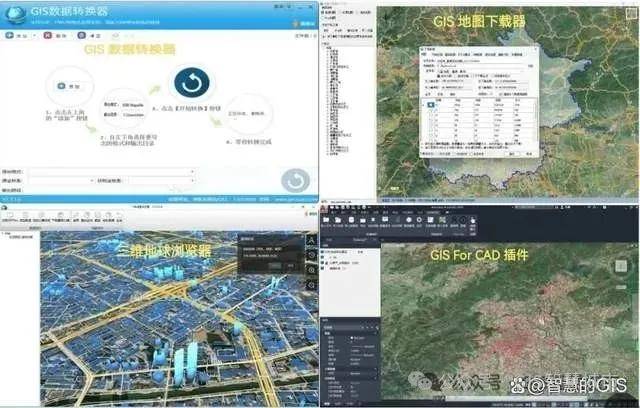
资产智慧管理安全监测中心
在数字经济高速发展的今天,资产管理的智能化已成为企业降本增效的核心竞争力。从智慧园区到古建筑群,从交通枢纽到城市电网,资产智慧管理安全监测中心正以物联网、人工智能、数字孪生等技术为支撑,构建起资产全生命周期的“智慧大…...

从零开始的云计算——番外实战,iptables防火墙项目
目录 一网络规划 二项目要求 三环境准备 1防火墙设置 2PC1设置 3PC2设置 4服务器S1设置 四环境检测 1内网链接 2外网连接 五防火墙配置及测试 1内部网络中的pc1采用SNAT访问外部互联网,但是无法ping到内部网关。 编辑编辑 2内部网络服务器s1通过DN…...

移动网页调试的多元路径:WebDebugX 与其他调试工具的组合使用策略
在移动端网页开发中,仅靠一款工具很难覆盖所有调试场景。不同问题类型需要不同的调试维度——有时是网络请求,有时是 DOM 样式,有时是 JS 状态,有时是性能瓶颈。 本文以“多工具协作”为核心思想,结合多个项目经验&am…...
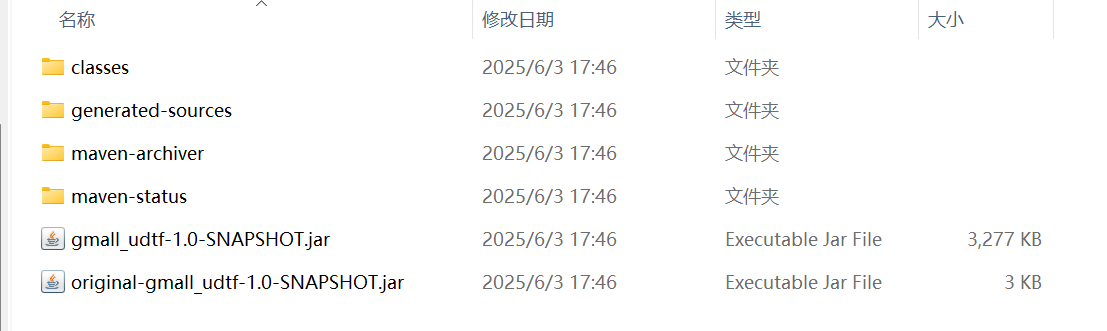
【基于阿里云搭建数据仓库(离线)】IDEA导出Jar包(包括第三方依赖)
目录 方法一: 方法二 1.双击"package”即可进行打包呈jar 2.双击后就会自动打包生成jar了, 生成的jar在这个目录下 3.右击,点击“复制路径/引用”,即可获得“绝对路径”、“根路径”等相关信息 前提: 在pop.…...
研发方案详解)
【HarmonyOS 5】鸿蒙HarmonyOS —(cordova)研发方案详解
Android、Ios 和 HarmonyOS APP研发分析 Android研发语言Java、Ios研发语言objective-c, HarmonOS研发语言ArkTs和C/C,写了第一句,就会有人反驳,Android和Ios也支持C/C语言,封装成动态库so,然后调用就可以了࿰…...

Linux程序运行日志总结
在Linux系统中,程序运行时产生的日志记录主要通过以下几种方式实现,这些日志有助于排查问题、监控系统行为或审计安全事件: 1. 系统日志(System Logs) 存放路径:通常位于 /var/log/ 目录下。常见日志文件: /var/log/syslog 或 /var/log/messages:通用系统日志(取决于发…...
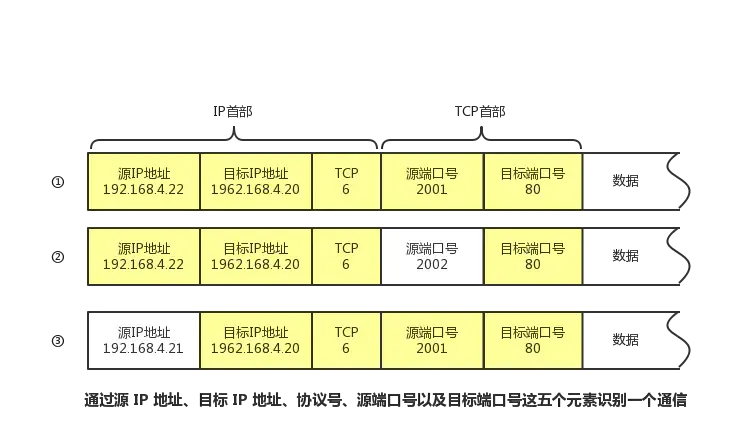
【物联网-TCP/IP】
物联网-TCP/IP ■ TCP/IP■■■ 添加链接描述 ■ TCP/IP ■ ■ ■...

SAP ECC 与 SAP S/4HANA 技术架构全面对比
SAP ECC 是过去几十年众多企业核心业务系统的基石,涵盖财务、物流、制造等关键领域。然而,随着数字化转型的加速和企业需求的增长,其架构日益显现局限。因此,SAP 推出了新一代 ERP 解决方案——SAP S/4HANA。它不仅在功能上做出优…...

Halcon光度立体法
1、光度立体法,可用于将对象的三维形状与其二维纹理(例如打印图像)分离。需要用不同方向而且已知照明方向的多个光源,拍摄同一物体的至少三张图像。请注意,所有图像的相机视角必须相同。 物体的三维形状主要被计算为三…...
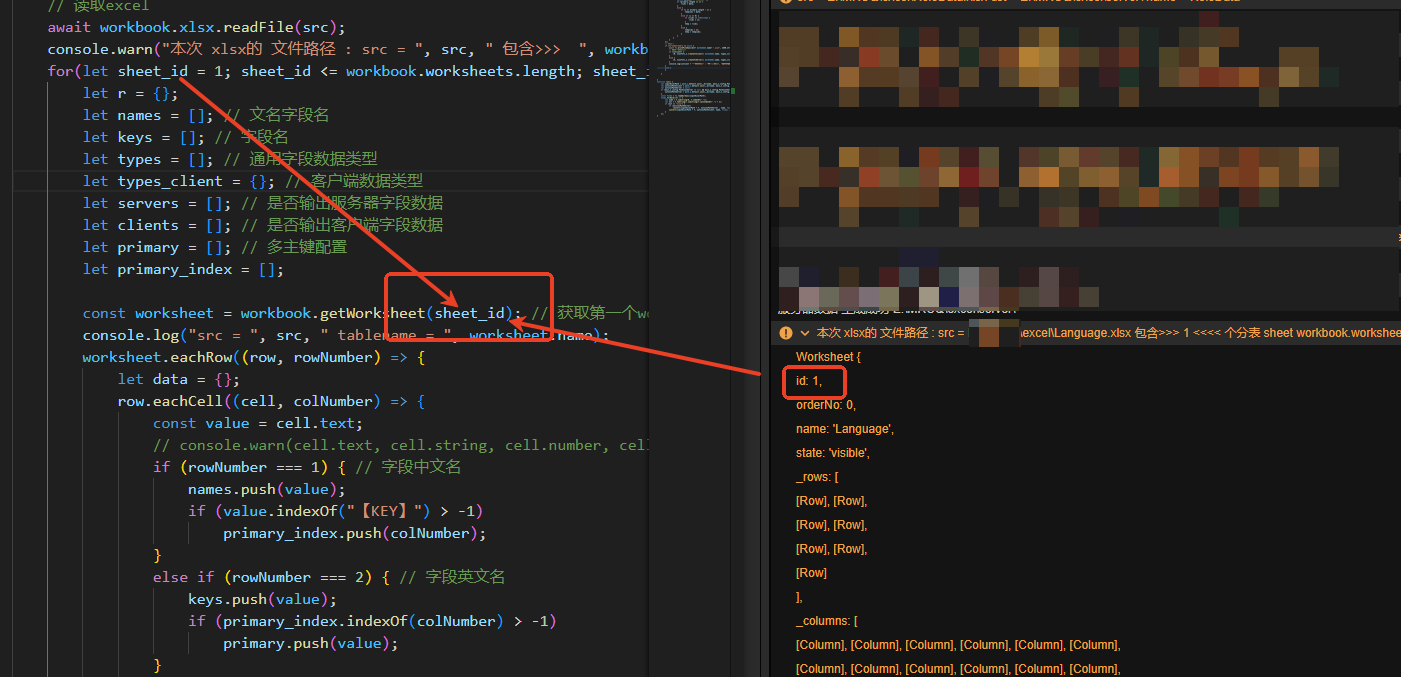
cocos3.X的oops框架oops-plugin-excel-to-json改进兼容多表单导出功能
在使用oops框架的过程中,它的导出数据并生成数据结构的插件oops-plugin-excel-to-json有些小的坑点,为满足我个人习惯,对此部分进行了一个小的修改,有需要的拿去用,记录下供大家参考; 一、配置:…...

Spring Boot + OpenAI 构建基于RAG的智能问答系统
一、技术架构设计 1.1 系统架构图 [前端]│▼ (HTTP/REST) [Spring Boot Controller]│▼ (Service Call) [问答处理服务层]├─▶ [知识库检索模块] ──▶ [向量数据库]└─▶ [OpenAI集成模块] ──▶ [OpenAI API]│▼ [结果组装与返回] 1.2 技术选型 组件技术栈版本要求…...

开源量子模拟引擎:Quantum ESPRESSO本地部署教程,第一性原理计算轻松入门!
一、介绍 Quantum ESPRESSO 是一个用于电子结构计算和纳米尺度材料建模的开源计算机代码集成套件,专门用于进行第一性原理(第一性原理)计算,涵盖了电子结构、晶体学和材料性能的模拟。 Quantum ESPRESSO GPU 版本支持GPU加速&am…...

算法blog合集
https://zhuanlan.zhihu.com/p/600245782 https://zhuanlan.zhihu.com/p/696212679 https://zhuanlan.zhihu.com/p/291406172 【推荐系统】DSSM双塔召回2_pair-wise训练和推理-CSDN博客 精通推荐算法1:为什么需要推荐系统(系列文章,建议收…...
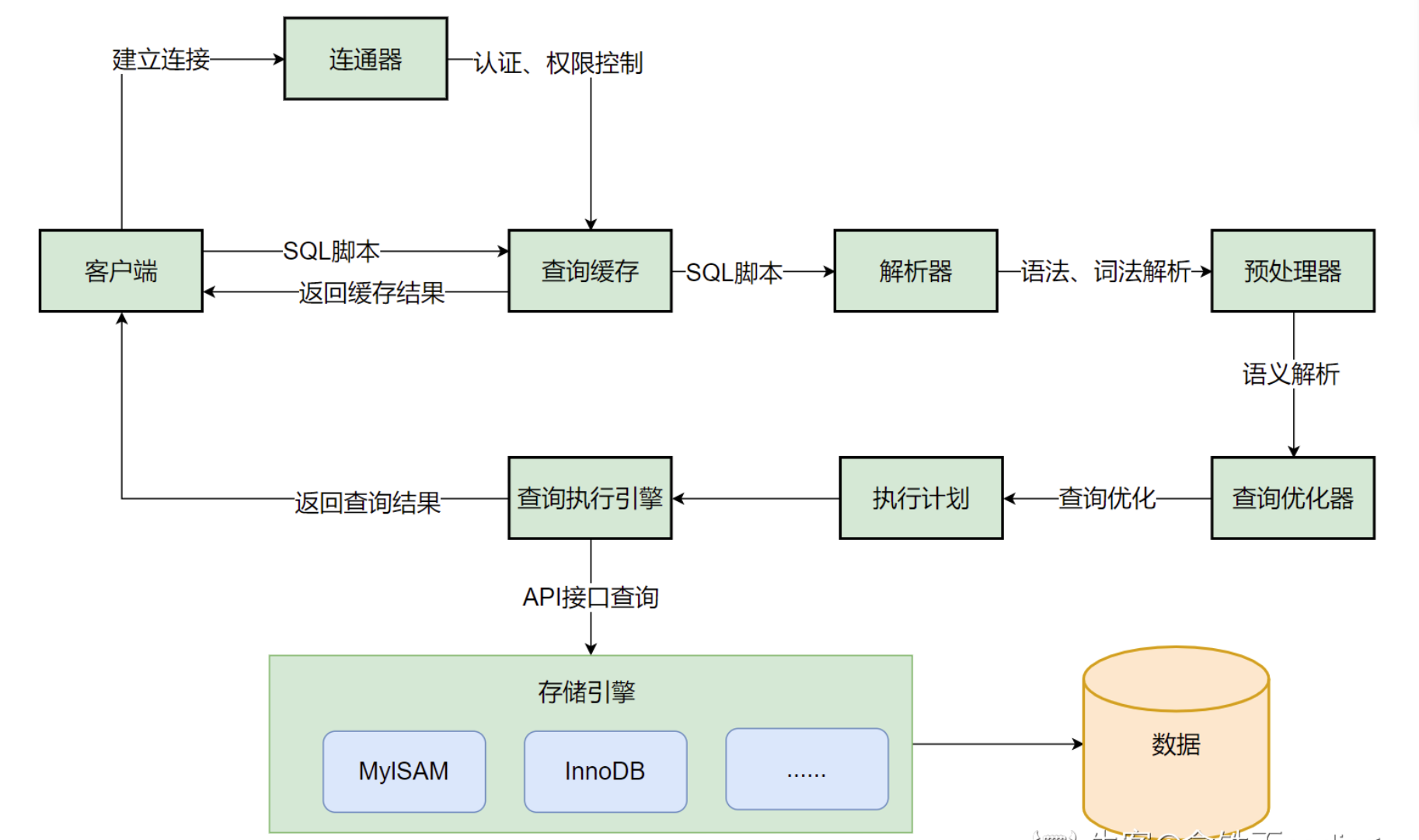
每日八股文6.3
每日八股-6.3 Mysql1.COUNT 作用于主键列和非主键列时,结果会有不同吗?2.MySQL 中的内连接(INNER JOIN)和外连接(OUTER JOIN)有什么主要的区别?3.能详细描述一下 MySQL 执行一条查询 SQL 语句的…...
Kubernetes (k8s)版本发布情况
Kubernetes (k8s)版本发布情况 代码放在 GitHub - kubernetes/kubernetes: Production-Grade Container Scheduling and Management https://github.com/kubernetes/kubernetes/releases 文档放在 kubernetes.io各个版本变更等: https://github.com/kubernetes/kubernet…...
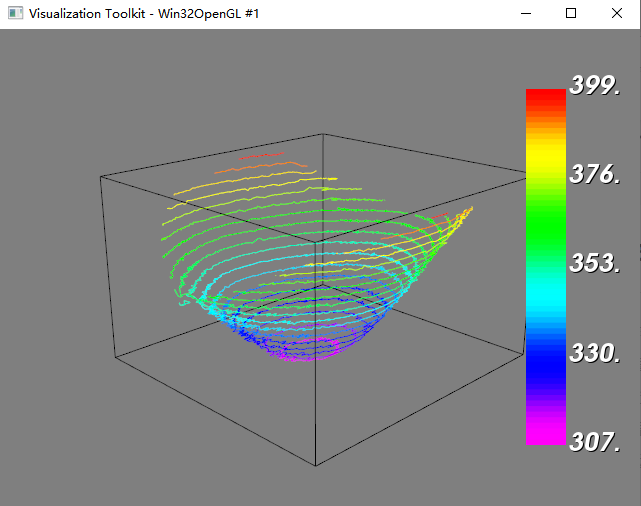
QT 5.9.2+VTK8.0实现等高线绘制
项目下载链接:QT5.9.2VTK8.0实现等高线绘制资源-CSDN文库 示例如下: 主要代码如下: #include "vtkRenderer.h" #include "vtkRenderWindow.h" #include "vtkRenderWindowInteractor.h" #include "vtkPo…...
CppCon 2015 学习:3D Face Tracking and Reconstruction using Modern C++
1. 3D面部追踪和重建是什么? 3D面部追踪(3D Face Tracking): 实时检测并追踪人脸在三维空间中的位置和姿态(如转头、点头、表情变化等),通常基于摄像头捕获的视频帧。3D面部重建(3D…...

Three.js进阶之音频处理与展示
引擎在对音频处理提供了丰富的接口,本文展示两个音频处理示例。 一、声音可视化 Three.js中的声音可视化是以视觉为核心,以音乐为载体,为音乐提供直观的视觉呈现。通过对音乐数据的分析并结合开发需求,能实现酷炫的视觉效果。在…...

4.2 HarmonyOS NEXT分布式AI应用实践:联邦学习、跨设备协作与个性化推荐实战
HarmonyOS NEXT分布式AI应用实践:联邦学习、跨设备协作与个性化推荐实战 在HarmonyOS NEXT的全场景分布式架构下,AI能力突破设备边界,通过联邦学习保护数据隐私、跨设备任务协作释放算力潜能、个性化推荐实现服务主动化。本文结合华为分布式…...

兼容老设备!EtherNet/IP转DeviceNet网关解决储能产线通讯难题
在新能源行业飞速发展的当下,工业自动化水平的高低直接影响着企业的生产效率与产品质量。JH-EIP-DVN疆鸿智能ETHERNET/IP和DEVICENET作为工业领域常用的通信协议,它们之间的转换应用在新能源生产线上发挥着关键作用。本文重点探讨ETHERNETIP从站转DEVICE…...

健康检查:在 .NET 微服务模板中优雅配置 Health Checks
🚀 健康检查:在 .NET 微服务模板中优雅配置 Health Checks 📚 目录 🚀 健康检查:在 .NET 微服务模板中优雅配置 Health Checks一、背景与意义 🔍二、核心配置 🔧2.1 引入必要的 NuGet 依赖 &…...