每日八股文6.3
每日八股-6.3
- Mysql
- 1.COUNT 作用于主键列和非主键列时,结果会有不同吗?
- 2.MySQL 中的内连接(INNER JOIN)和外连接(OUTER JOIN)有什么主要的区别?
- 3.能详细描述一下 MySQL 执行一条查询 SQL 语句的完整流程吗?
- 4.MySQL 中都有哪些常见的存储引擎?你能简单介绍一下吗?
- 5.MySQL 支持哪些常见的索引类型呢?
- 6.InnoDB 存储引擎的索引底层是基于什么数据结构实现的呢?
- 7.能详细说说 B+ 树这种数据结构都有哪些特点吗?
- 8.B+ 树和 B 树这两种数据结构有什么主要的区别呢?
- 9.你觉得为什么 MySQL 会选择使用 B+ 树作为其索引结构呢?
- 10.聚簇索引和非聚簇索引之间有什么主要的区别?
Mysql
1.COUNT 作用于主键列和非主键列时,结果会有不同吗?
在大多数情况下,COUNT() 作用于主键列和非主键列时,如果这些列中不包含 NULL 值,那么结果是相同的,都表示符合条件的行数。
然而,关键的区别在于 COUNT(column_name) 的行为:COUNT(column_name) 只计算指定列中非 NULL 值的数量。
-
主键列 (Primary Key Column): 根据定义,主键列的值不允许为 NULL。因此,COUNT(主键列) 实际上等同于 COUNT(*) 或者 COUNT(1),它会统计表中的总行数(或者符合 WHERE 子句条件的行数)。
-
非主键列 (Non-Primary Key Column):
- 如果该非主键列不允许为 NULL (定义了 NOT NULL 约束),那么 COUNT(非主键列) 的结果也会和 COUNT(*) 相同。
- 如果该非主键列允许为 NULL,并且该列中实际存在 NULL 值,那么 COUNT(非主键列) 的结果将会小于 COUNT(*),因为它只统计了该列中非 NULL 的行。
总结一下 COUNT 的几种常见用法:
- COUNT(*): 计算表中的总行数(或者符合 WHERE 子句条件的行数),包含 NULL 值的行。这是最常用的方式,通常效率也较好。
- COUNT(1): 效果和 COUNT() 类似,也是计算总行数。MySQL 对其进行了优化,效率与 COUNT() 相当。
- COUNT(column_name): 计算指定列 column_name 中非 NULL 值的行数。
- COUNT(DISTINCT column_name): 计算指定列 column_name 中不重复且非 NULL 值的行数。
-- 创建一个示例表
CREATE TABLE employees (id INT PRIMARY KEY, -- 主键列 (不允许 NULL)name VARCHAR(100) NOT NULL, -- 非主键列,不允许 NULLdepartment VARCHAR(50), -- 非主键列,允许 NULLsalary DECIMAL(10, 2)
);-- 插入一些数据
INSERT INTO employees (id, name, department, salary) VALUES
(1, 'Alice', 'HR', 50000.00),
(2, 'Bob', 'Engineering', 70000.00),
(3, 'Charlie', 'HR', 55000.00),
(4, 'David', NULL, 60000.00), -- department 是 NULL
(5, 'Eve', 'Engineering', NULL), -- salary 是 NULL
(6, 'Frank', NULL, 75000.00); -- department 是 NULL-- 查看表中的所有数据
SELECT * FROM employees;-- 1. COUNT(*) - 统计所有行
SELECT COUNT(*) AS total_rows FROM employees;
-- 预期结果: 6-- 2. COUNT(主键列) - 统计主键列 'id' (不允许 NULL)
SELECT COUNT(id) AS count_primary_key FROM employees;
-- 预期结果: 6 (与 COUNT(*) 相同,因为主键列不能为 NULL)-- 3. COUNT(非主键列,NOT NULL) - 统计非主键列 'name' (不允许 NULL)
SELECT COUNT(name) AS count_name_not_null FROM employees;
-- 预期结果: 6 (与 COUNT(*) 相同,因为 'name' 列不允许 NULL)-- 4. COUNT(非主键列,允许 NULL) - 统计非主键列 'department' (允许 NULL)
SELECT COUNT(department) AS count_department_nullable FROM employees;
-- 预期结果: 4 (因为 'department' 列有两个 NULL 值,它们不被计算在内)-- 5. COUNT(非主键列,允许 NULL) - 统计非主键列 'salary' (允许 NULL)
SELECT COUNT(salary) AS count_salary_nullable FROM employees;
-- 预期结果: 5 (因为 'salary' 列有一个 NULL 值,它不被计算在内)
2.MySQL 中的内连接(INNER JOIN)和外连接(OUTER JOIN)有什么主要的区别?
- 内连接: 返回两个表中匹配的行(交集)。
- 外连接: 返回匹配的行加上驱动表中不匹配的行。
- 左外连接: 保留左表所有行,右表不匹配则填充 NULL。
- 右外连接: 保留右表所有行,左表不匹配则填充 NULL。
内连接(INNER JOIN):它会只返回两个表中连接条件相匹配的行。也就是说,只有当连接的两个表中都存在满足 ON 子句条件的记录时,这条记录才会被包含在结果集中。内连接关注的是两个表的交集部分。
外连接(OUTER JOIN):外连接则会返回两个表中匹配的行,并且还会包含某个表(或两个表)中不匹配的行。MySQL 外连接主要分为两种:
- 左外连接(LEFT JOIN 或 LEFT OUTER JOIN):它会返回左表中的所有行,以及右表中与左表匹配的行。如果右表中没有与左表某行匹配的记录,那么在结果集中,右表对应的列将会显示为 NULL。左连接适用于需要保留左表所有数据的场景。
- 右外连接(RIGHT JOIN 或 RIGHT OUTER JOIN):它会返回右表中的所有行,以及左表中与右表匹配的行。如果左表中没有与右表某行匹配的记录,那么在结果集中,左表对应的列将会显示为 NULL。右连接适用于需要保留右表所有数据的场景。
-- 创建顾客表
CREATE TABLE Customers (CustomerID INT PRIMARY KEY,CustomerName VARCHAR(100)
);-- 创建订单表
CREATE TABLE Orders (OrderID INT PRIMARY KEY,CustomerID INT, -- 外键,关联到 Customers 表的 CustomerIDOrderDate DATE,Amount DECIMAL(10, 2)
);-- 插入顾客数据
INSERT INTO Customers (CustomerID, CustomerName) VALUES
(1, 'Alice'),
(2, 'Bob'),
(3, 'Charlie'),
(4, 'Diana'); -- Diana 没有下过订单-- 插入订单数据
INSERT INTO Orders (OrderID, CustomerID, OrderDate, Amount) VALUES
(101, 1, '2024-01-15', 150.00), -- Alice的订单
(102, 2, '2024-01-20', 200.00), -- Bob的订单
(103, 1, '2024-02-10', 75.50), -- Alice的另一个订单
(104, 5, '2024-02-15', 300.00); -- 这个订单的CustomerID在Customers表中不存在-- 查看表数据 (可选)
SELECT * FROM Customers;
SELECT * FROM Orders;--内连接
SELECTc.CustomerName,o.OrderID,o.OrderDate,o.Amount
FROMCustomers c
INNER JOINOrders o ON c.CustomerID = o.CustomerID;--left join
SELECTc.CustomerName,o.OrderID,o.OrderDate,o.Amount
FROMCustomers c -- 左表
LEFT JOINOrders o ON c.CustomerID = o.CustomerID; -- 右表--right join
SELECTc.CustomerName,o.OrderID,o.OrderDate,o.Amount
FROMCustomers c -- 左表
RIGHT JOINOrders o ON c.CustomerID = o.CustomerID; -- 右表
3.能详细描述一下 MySQL 执行一条查询 SQL 语句的完整流程吗?
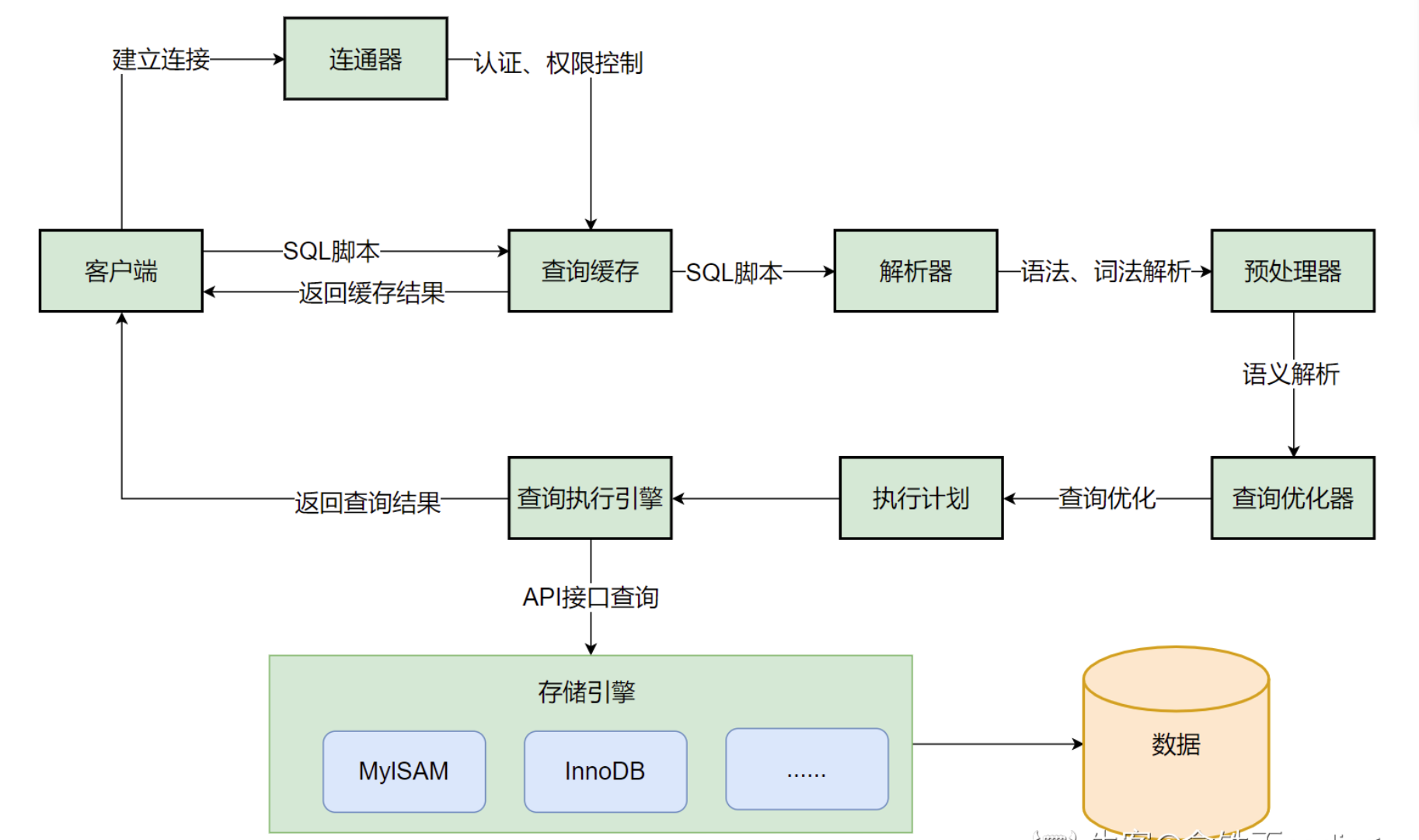
首先,客户端会通过连接器与 MySQL 服务器建立连接。连接器负责处理 TCP 连接、用户身份验证和权限校验。
连接成功后,MySQL 会先检查查询缓存(在 MySQL 8.0 版本之前)。如果查询的 SQL 语句和查询条件与缓存中的记录完全一致,并且查询结果未过期,则会直接从缓存中返回结果,避免了后续的执行过程。但由于查询缓存的命中率不高,MySQL 8.0 已经移除了这个功能。
如果查询缓存没有命中或者版本在 8.0 之后,SQL 语句会被发送到解析器。解析器会对 SQL 语句进行词法分析和语法分析,识别出语句的类型、表名、字段名等,并构建一个抽象语法树(AST)。
接下来是优化器的阶段。优化器会根据一定的规则和成本模型,对语法树进行优化,生成最优的执行计划。这包括选择合适的索引、决定表的连接顺序等。优化器的目标是找到执行成本最低的方案。
优化完成后,执行器会根据优化器生成的执行计划,调用存储引擎(如 InnoDB、MyISAM 等)提供的接口来执行实际的数据查询操作。执行器会负责控制数据的读取和返回,它就像一个调度员,指挥存储引擎完成任务。查询结果返回给执行器后,由执行器最终返回给客户端。
4.MySQL 中都有哪些常见的存储引擎?你能简单介绍一下吗?
MySQL 中常见的存储引擎主要有 InnoDB、MyISAM 和 Memory。
我比较熟悉的是 InnoDB 引擎,它也是 MySQL 的默认存储引擎。InnoDB 支持事务,具有事务的提交、回滚和崩溃恢复功能,这保证了数据的完整性和一致性。此外,InnoDB 还支持行级锁,这使得在并发环境下可以有更好的性能。
MyISAM 引擎是我在学习过程中了解到的,它不支持事务,只支持表级锁。这意味着当一个会话正在写入 MyISAM 表时,其他会话都无法读取或写入该表,并发性能相对较差。但 MyISAM 在某些只读或者读多写少的场景下,可能会有更高的性能,因为它维护了一个表的行数,执行 COUNT(*) 操作会非常快。
Memory 引擎正如其名,它将数据存储在内存中,因此读写速度非常快。但是,Memory 引擎不支持持久化存储,一旦服务器发生故障或者重启,数据就会丢失。它通常用于临时存储对性能要求较高的中间结果或者作为缓存。
当然,MySQL 还支持其他的存储引擎,比如 Archive、CSV、NDB Cluster 等
5.MySQL 支持哪些常见的索引类型呢?
MySQL 支持多种索引类型,这主要取决于存储引擎的实现。不同的存储引擎支持的索引类型可能会有所不同。
从存储结构上来看,主要的索引类型有:
- B+ 树索引:这是 MySQL 中最常见和最广泛使用的索引类型,尤其是在 InnoDB 和 MyISAM 存储引擎中。它是一种平衡树结构,非常适合范围查询、排序查询和等值查询。
- 哈希索引:这种索引类型主要由 Memory 存储引擎实现。它的特点是查找速度非常快,时间复杂度可以达到 O(1),但它不支持范围查询、排序等操作。
- 全文索引:全文索引用于在文本类型的数据中进行关键词搜索,可以支持模糊匹配等功能。它主要用于解决 LIKE ‘%keyword%’ 这类查询效率低下的问题。
此外,我们还可以从其他角度对索引进行分类:
- 按存储方式(针对 InnoDB 引擎):可以分为聚簇索引和非聚簇索引。
- 按字段特性:可以分为主键索引、唯一索引、普通索引和前缀索引。
- 按索引列数:可以分为单列索引和联合索引。
我个人比较常用的是 B+ 树索引,因为它是 InnoDB 引擎默认使用的索引类型,而且功能非常全面,支持各种常见的查询场景。
顺便提一下,MySQL 选择使用树结构(特别是 B+ 树)作为索引,主要是因为树结构能够很好地支持范围查询,并且在磁盘 I/O 方面做了优化,更适合数据库这种需要频繁进行磁盘操作的场景。像哈希索引虽然查找快,但不支持范围查询,而跳表在磁盘场景下的适应性不如树结构。
6.InnoDB 存储引擎的索引底层是基于什么数据结构实现的呢?
InnoDB 存储引擎主要采用 B+ 树作为其索引的数据结构。
B+ 树是一种自平衡的多路查找树。对于一个度数为 m 的 B+ 树,它的每个节点最多可以有 m 个子节点,并且所有的数据都存储在叶子节点上。叶子节点之间通常会通过指针连接起来,形成一个有序链表(在 InnoDB 中,这个链表是双向的)。
B+ 树的一些关键特性使得它非常适合作为数据库索引的底层结构,比如它的平衡性减少了磁盘的IO次数,保证了查询效率,数据只存储在叶子节点的特性以及叶子节点之间的链表结构都为范围查询提供了便利。
7.能详细说说 B+ 树这种数据结构都有哪些特点吗?
B+ 树作为一种常用的索引结构,它有几个非常重要的特性:
- 首先,B+ 树的中间节点(也就是非叶子节点)不会存储实际的数据,它们只存储索引信息(也就是键值)以及指向子节点的指针。这样做的好处是,在相同的磁盘页大小下,中间节点可以存储更多的索引,从而使得 B+ 树更加“矮胖”,降低了树的高度。更低的树高度意味着查询时需要访问的磁盘 I/O 次数更少,提高了查询效率。
- 其次,B+ 树的所有实际数据都存储在叶子节点上。每个叶子节点包含了索引的键值以及对应的数据记录。
- 第三个重要的特性是,B+ 树的所有叶子节点之间会通过双向指针(在 InnoDB 中)串联在一起,形成一个双向链表。这个特性对于进行范围查询(例如查找某个区间内的数据)非常高效。我们只需要找到范围的起始叶子节点,然后沿着链表顺序遍历即可,不需要再回到上层节点进行搜索。同时,这个链表也方便进行全表扫描。
- 最后,B+ 树的查询性能非常稳定。因为所有的数据都存储在叶子节点,所以每次查询都需要从根节点遍历到叶子节点,查询路径的长度是相同的,这确保了所有数据项的检索都具有相同的 I/O 延迟。而且,由于 B+ 树通常能够保持很低的树高度(例如,3-4 层的 B+ 树可以存储千万级别的数据),因此查询效率非常高。
8.B+ 树和 B 树这两种数据结构有什么主要的区别呢?
B+ 树和 B 树都是常用的多路平衡查找树,它们之间主要的区别可以从以下几个方面来说明:
- 数据存储的区别:B 树的所有节点(包括中间节点和叶子节点)都会存储索引和实际的数据,而 B+ 树只有叶子节点才会存储实际的数据,中间节点只存储索引信息和指向子节点的指针。这意味着在存储相同数据量的情况下,B+ 树的中间节点可以存储更多的索引,因此 B+ 树通常会比 B 树更加“矮胖”,树的高度更低,从而减少了查询叶子节点所需的磁盘 I/O 次数。
- 范围查询的区别:B+ 树的所有叶子节点之间会通过双向指针串联在一起,形成一个有序链表。这种结构使得 B+ 树在进行范围查询时非常高效。我们只需要找到范围的起始点,然后沿着链表顺序遍历即可。而 B 树并没有将叶子节点用链表连接起来,进行范围查询时可能需要通过中序遍历,这可能会涉及更多节点的磁盘 I/O 操作,因此在范围查询方面,B+ 树通常比 B 树更高效。
- 查询效率的区别:在 B 树中,如果我们要查找的值恰好在某个非叶子节点上,那么在查找到该节点后就可以直接结束查询,B 树的优点在于其查找速度可能更快,尤其是在要查找的数据位于靠近根节点的非叶子节点时。然而,B+ 树由于数据只存储在叶子节点,所以每次查询都必须从根节点搜索到叶子节点,查询路径的长度是固定的。从平均时间代价来看,B 树可能在某些情况下会比 B+ 树稍快一些,但是 B+ 树的查询性能更加稳定,因为每一次成功的查询都需要访问到叶子节点,具有相同的 I/O 延迟。
9.你觉得为什么 MySQL 会选择使用 B+ 树作为其索引结构呢?
MySQL 选择使用 B+ 树作为其索引结构,我认为主要有以下几个重要的原因:
- 首先,B+ 树是一种多路平衡查找树,这种结构非常适合磁盘 I/O 操作。数据库的数据通常存储在磁盘上,而每次磁盘 I/O 的成本是比较高的。B+ 树的非叶子节点只存储索引键值和子节点指针,而不存储实际的数据,这使得每个节点能够存储更多的索引,从而显著降低了树的高度。例如,一个 3-4 层的 B+ 树就可以存储千万级别的数据,这意味着查询一条数据只需要 3-4 次磁盘 I/O 操作,大大提高了查找效率。相比之下,像二叉搜索树(包括平衡树和红黑树),在存储大量数据时树的高度会很高,导致更多的磁盘 I/O。
- 其次,B+ 树通过自平衡的机制(节点的分裂和合并)来保持树的平衡,这确保了查询路径的长度是相对稳定的,从而保证了查询、插入和删除操作的时间复杂度都是 O(log n),具有较好的性能稳定性。对于频繁进行增删改操作的数据库来说,这一点非常重要。
- 第三,B+ 树特别适合范围查询。这是因为 B+ 树的所有叶子节点都通过链表连接在一起,形成一个有序链表。在进行范围查询时,我们只需要找到范围的起始叶子节点,然后沿着链表顺序扫描即可,非常高效。而像 B 树在进行范围查询时可能需要进行多次中序遍历。
- 此外,对比其他数据结构,例如哈希表虽然等值查询很快,但是不支持范围查询;跳表在内存中表现良好,但在磁盘场景下不如 B+ 树;B 树虽然所有节点都存储数据,可能在某些情况下等值查询更快,但其范围查询性能不如 B+ 树,且查询性能不如 B+ 树稳定。
综上所述,B+ 树在平衡性、查询效率(特别是范围查询)、以及对磁盘 I/O 的优化等方面都非常适合数据库索引的需求,因此成为了 MySQL 等主流数据库系统的首选索引结构。
10.聚簇索引和非聚簇索引之间有什么主要的区别?
聚簇索引和非聚簇索引是 MySQL 中两种主要的索引类型,它们最主要的区别在于 B+ 树的叶子节点所存储的内容不同:
- 聚簇索引:在 InnoDB 存储引擎中,主键索引就是聚簇索引。聚簇索引的 B+ 树的叶子节点存储的是完整的行数据,包含了该行所有列的值。由于数据和索引是存储在一起的,所以通过聚簇索引查找数据时,可以直接获取到整行数据,不需要进行额外的查找。一个表只能有一个聚簇索引,通常是表的主键。
- 非聚簇索引(也叫二级索引或辅助索引):非聚簇索引的 B+ 树的叶子节点存储的不是完整的行数据,而是索引列的值以及对应行的主键 ID。如果我们需要查询的数据列不是索引列本身,也不是主键,那么在使用非聚簇索引查询到主键 ID 后,通常还需要回到聚簇索引中再进行一次查找,才能获取到完整的行数据,这个过程被称为“回表”。一个表可以有多个非聚簇索引。
因此,从查询效率上来说,通常情况下,通过聚簇索引查询数据的速度会更快,因为只需要扫描一次 B+ 树就可以获取到所需的数据。而通过非聚簇索引查询时,可能需要扫描两次 B+ 树(一次非聚簇索引,一次聚簇索引,即回表)。
另外,需要补充一点的是,如果一个表没有显式地定义主键,InnoDB 会默认选择一个唯一的非空索引作为聚簇索引。
CREATE TABLE users (id INT PRIMARY KEY, -- 聚簇索引 (主键)name VARCHAR(100),email VARCHAR(100),age INT
);-- 在 email 列上创建非聚簇索引
CREATE INDEX idx_email ON users (email);-- 由于 name 和 age 列不在 idx_email 的叶子节点中,数据库必须使用 id = 10 这个主键值去聚簇索引中查找完整的行数据,然后取出 name 和 age。这就是“回表”
SELECT name, age FROM users WHERE email = 'test@example.com';-- 查询所需的所有信息都在索引的叶子节点中找到了,无需回表。 这个查询就是使用了覆盖索引
SELECT email, id FROM users WHERE email = 'test@example.com';-- 即使只查询 email 字段,也构成覆盖索引
SELECT email FROM users WHERE email = 'test@example.com';
相关文章:
每日八股文6.3
每日八股-6.3 Mysql1.COUNT 作用于主键列和非主键列时,结果会有不同吗?2.MySQL 中的内连接(INNER JOIN)和外连接(OUTER JOIN)有什么主要的区别?3.能详细描述一下 MySQL 执行一条查询 SQL 语句的…...
Kubernetes (k8s)版本发布情况
Kubernetes (k8s)版本发布情况 代码放在 GitHub - kubernetes/kubernetes: Production-Grade Container Scheduling and Management https://github.com/kubernetes/kubernetes/releases 文档放在 kubernetes.io各个版本变更等: https://github.com/kubernetes/kubernet…...
QT 5.9.2+VTK8.0实现等高线绘制
项目下载链接:QT5.9.2VTK8.0实现等高线绘制资源-CSDN文库 示例如下: 主要代码如下: #include "vtkRenderer.h" #include "vtkRenderWindow.h" #include "vtkRenderWindowInteractor.h" #include "vtkPo…...
CppCon 2015 学习:3D Face Tracking and Reconstruction using Modern C++
1. 3D面部追踪和重建是什么? 3D面部追踪(3D Face Tracking): 实时检测并追踪人脸在三维空间中的位置和姿态(如转头、点头、表情变化等),通常基于摄像头捕获的视频帧。3D面部重建(3D…...

Three.js进阶之音频处理与展示
引擎在对音频处理提供了丰富的接口,本文展示两个音频处理示例。 一、声音可视化 Three.js中的声音可视化是以视觉为核心,以音乐为载体,为音乐提供直观的视觉呈现。通过对音乐数据的分析并结合开发需求,能实现酷炫的视觉效果。在…...

4.2 HarmonyOS NEXT分布式AI应用实践:联邦学习、跨设备协作与个性化推荐实战
HarmonyOS NEXT分布式AI应用实践:联邦学习、跨设备协作与个性化推荐实战 在HarmonyOS NEXT的全场景分布式架构下,AI能力突破设备边界,通过联邦学习保护数据隐私、跨设备任务协作释放算力潜能、个性化推荐实现服务主动化。本文结合华为分布式…...

兼容老设备!EtherNet/IP转DeviceNet网关解决储能产线通讯难题
在新能源行业飞速发展的当下,工业自动化水平的高低直接影响着企业的生产效率与产品质量。JH-EIP-DVN疆鸿智能ETHERNET/IP和DEVICENET作为工业领域常用的通信协议,它们之间的转换应用在新能源生产线上发挥着关键作用。本文重点探讨ETHERNETIP从站转DEVICE…...

健康检查:在 .NET 微服务模板中优雅配置 Health Checks
🚀 健康检查:在 .NET 微服务模板中优雅配置 Health Checks 📚 目录 🚀 健康检查:在 .NET 微服务模板中优雅配置 Health Checks一、背景与意义 🔍二、核心配置 🔧2.1 引入必要的 NuGet 依赖 &…...

【Pytorch学习笔记】模型模块08——AlexNet模型详解
AlexNet模型详解:结构、算法与PyTorch实现 一、AlexNet模型结构 AlexNet是2012年ImageNet竞赛冠军模型,由Alex Krizhevsky等人提出,标志着深度学习在计算机视觉领域的突破。 网络结构(5卷积层 3全连接层)ÿ…...
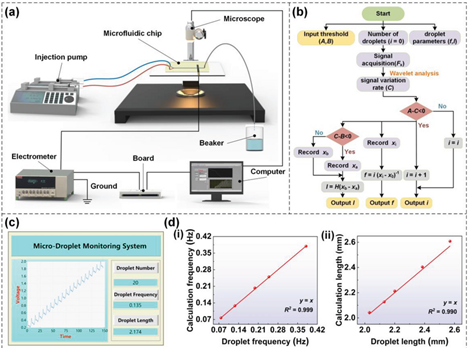
LabVIEW自感现象远程实验平台
LabVIEW开发自感现象远程实验平台,通过整合 NI数据采集设备、菲尼克斯(Phoenix Contact)继电器模块及罗技(Logitech)高清摄像头,实现远程数据采集、仪器控制与实时监控三大核心功能。平台突破传统实验装置局…...

AppTrace 视角下 App 一键拉起:提升应用转化率的高效方案
官网地址:AppTrace - 专业的移动应用推广追踪平台 在大规模开展 App 推广、用户召回、广告投放、邀请传播等活动时,高效的深度链接方案至关重要。它不仅能缩短用户路径,带来无缝、流畅的跳转体验,更核心的是通过参数传递打通 web…...

梯度下降:机器学习优化的核心算法
梯度下降算法原理及其在机器学习中的实践应用 引言 在机器学习领域,优化算法扮演着核心角色。其中梯度下降法作为最基础的优化方法,为神经网络、支持向量机等模型提供了参数优化解决方案。本文将深入解析梯度下降的数学原理,探讨其多种变体实现,并通过Python代码演示具体…...

Vue-6-前端框架Vue之基于Plotly.js绘制曲线
文章目录 1 安装Plotly.js2 折线图2.1 创建一个Vue组件来绘制图表2.1.1 Vue模板部分template2.1.2 Vue脚本部分script2.1.3 Vue样式部分style2.2 使用这个组件APP.vue3 动态更新图表3.1 创建一个Vue组件来绘制图表3.1.1 Vue模板部分template3.1.2 Vue脚本部分script3.1.3 Vue样…...

Python----目标检测(《YOLOv3:AnIncrementalImprovement》和YOLO-V3的原理与网络结构)
一、《YOLOv3:AnIncrementalImprovement》 1.1、基本信息 标题:YOLOv3: An Incremental Improvement 作者:Joseph Redmon, Ali Farhadi 机构:华盛顿大学(University of Washington) 发表时间:2018年 代…...

Redux:不可变数据与纯函数的艺术
Redux:不可变数据与纯函数的艺术 状态管理的困境 随着现代 Web 应用功能的不断扩展,前端开发者面临着日益复杂的状态管理挑战。当应用从简单的表单交互发展到复杂的单页应用时,组件间共享状态的问题变得尤为突出。想象一个电商平台…...
算法篇 八大排序(冒泡 插入 选择 堆 希尔 快排 归并 计数)
目录 引言 1.冒泡排序 思路 代码实现 2.选择排序 思路 代码实现(存在易错点) 3.插入排序 思路 代码实现 4.希尔排序 思路 代码实现 5.堆排序 思路 代码实现 6.快速排序(快排) 一.三路划分 思路 代码实现 二.自…...

技术文档写作全攻略
一、引言 在快速迭代的软件开发中,技术文档早已不只是附属品,而是与代码同等重要的交付物: 帮助新成员 T0 → T1 学习曲线指数下降;降低支持成本,将重复性问答前移到自助文档;为合规审计、知识传承及商业…...

网络安全全景解析
引言 在数字化时代,网络已深度融入社会生产生活的各个领域,成为推动经济发展和社会进步的关键力量。然而,随着网络应用的日益复杂,网络安全问题也呈现出多样化、复杂化的趋势。从个人隐私泄露到企业核心数据被盗,从基础…...
音视频之视频压缩编码的基本原理
系列文章: 1、音视频之视频压缩技术及数字视频综述 2、音视频之视频压缩编码的基本原理 一、预测编码: 1、预测编码的基本概念: 预测法是最简单、实用的视频压缩编码方法,经过压缩编码后传输的并不是像素本身的取样值࿰…...
IDEA 包分层显示设置
方法一(用的IntelliJ IDEA 2024.1.4版本): 找到项目视图设置入口:在左侧Project(项目)面板的顶部,有个三个点...的按钮 ,点击它。 进入树形外观配置:在弹出的菜单中&…...
0605)
书籍将正方形矩阵顺时针转动90°(8)0605
题目 给定一个N x N的矩阵matrix,把这个矩阵调整成顺时针转动90后的形式。 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 顺时针转动90后为: 13 9 5 1 14 …...

【docker】容器技术如何改变软件开发与部署格局
在当今数字化时代,软件开发与部署的效率和灵活性至关重要。就像古人云:“工欲善其事,必先利其器。”Docker 作为一款强大的容器技术,正如同软件开发领域的一把利器,极大地改变了应用的开发、交付和运行方式。本文将深入…...

C#抽象类深度解析 _ 核心特性与实战指南
—— 面向对象设计的基石 🔍抽象类核心定义 abstract class AbClass { ... } // abstract修饰符声明 不可实例化:new AbClass() 将触发编译错误继承专用:仅能作为其他类的基类存在混合成员组合:可同时包含抽象方法和已实现方法…...

时序数据库IoTDB的UDF Sample算法在数据监控、故障预防的应用
一、数据监控在工业物联网中的重要性 设备数据监控是工业物联网(IoT)中最为广泛应用的领域之一。通过实时监控工厂机械设备的运行状态,企业能够提前发现设备的潜在故障,从而实现预防性维护与可预测性维护。这一做法不仅能有效提升…...

Flask-SQLAlchemy使用小结
链表查询 join方法允许你指定两个或多个表之间的连接条件,并返回一个新的查询对象,该对象包含了连接后的结果。 内连接 from sqlalchemy import join # 使用join函数 query db.session.query(User, Order).join(Order, User.id Order.user_id) res…...
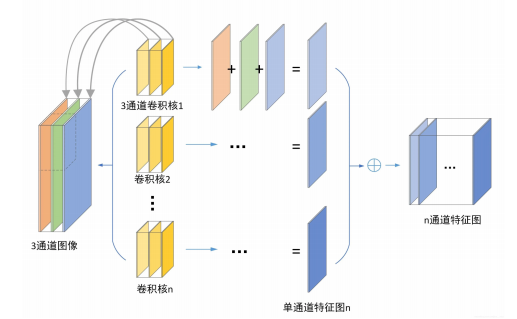
深度学习和神经网络 卷积神经网络CNN
1.什么是卷积神经网络 一种前馈神经网络;受生物学感受野的机制提出专门处理网格结构数据的深度学习模型 核心特点:通过卷积操作自动提取空间局部特征(如纹理、边缘),显著降低参数量 2.CNN的三个结构特征 局部连接&a…...

用 NGINX 构建高效 POP3 代理`ngx_mail_pop3_module`
一、模块定位与作用 协议代理 ngx_mail_pop3_module 让 NGINX 能够充当 POP3 代理:客户端与后端 POP3 服务器之间的所有请求均转发到 NGINX,由 NGINX 负责与后端会话逻辑。认证方式控制 通过 pop3_auth 指令指定允许客户端使用的 POP3 认证方法…...

解决:如何在Windows adb使用dmesg | grep检查内核日志
首先: C:\Users\TF> adb shell 再 rk3568_r:/ $ dmesg | grep -i “goodix” 显示 130|rk3568_r:/ $ dmesg | grep -i “goodix” [ 0.764071] goodix_ts_probe() start111 [ 0.764108] goodix_ts_probe() start222 [ 0.764181] Goodix-TS 1-0014: Linked as a c…...
PlayWright | 初识微软出品的 WEB 应用自动化测试框架
Playwright是微软大厂背书的跨平台 WEB 应用自动化测试框架,支持多开发语言(TypeScript、JavaScript、.Net、Python、Java)及多浏览器(Chromium、WebKit、Firefox),同时支持移动端测试。 安装 playwright …...
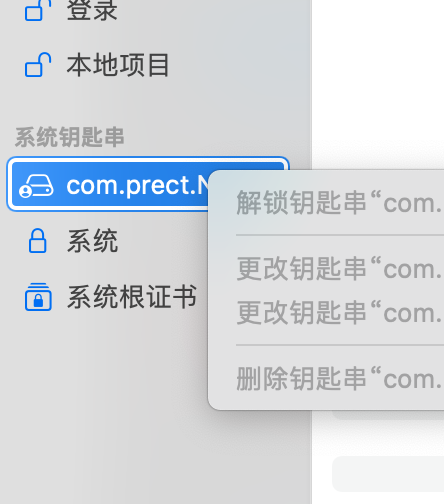
Mac电脑_钥匙串操作选项变灰的情况下如何删除?
Mac电脑_钥匙串操作选项变灰的情况下如何删除? 这时候 可以使用相关的终端命令进行操作。 下面附加文章《Mac电脑_钥匙串操作的终端命令》。 《Mac电脑_钥匙串操作的终端命令》 (来源:百度~百度AI 发布时间:2025-06)…...