算法篇 八大排序(冒泡 插入 选择 堆 希尔 快排 归并 计数)
目录
引言
1.冒泡排序
思路
代码实现
2.选择排序
思路
代码实现(存在易错点)
3.插入排序
思路
代码实现
4.希尔排序
思路
代码实现
5.堆排序
思路
代码实现
6.快速排序(快排)
一.三路划分
思路
代码实现
二.自省排序
思路
代码实现
7.归并排序
1.递归法
思路
代码实现
2.非递归法
思路
代码实现
8. 计数排序
思路
代码实现
总结(附排序训练OJ题)
引言
在计算机科学中,排序算法是非常基础且重要的内容。它可以将一组无序的数据按照特定的顺序(如升序或降序)进行排列。本文将详细介绍八大排序算法:冒泡排序、插入排序、选择排序、堆排序、希尔排序、快速排序、归并排序和计数排序,并结合代码进行分析。(本文展示代码均为升序)
先放一个前置的Swap交换函数方便函数调用:
//交换
void Swap(int* p1, int* p2)
{int tmp = *p1;*p1 = *p2;*p2 = tmp;
}1.冒泡排序
思路
冒泡排序是一种简单的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。每一趟交换的结果是把最大一个数放在最后。(以升序为例)走访数列的工作是重复地进行直到没有再需要交换,也就是说该数组已经排序完成。
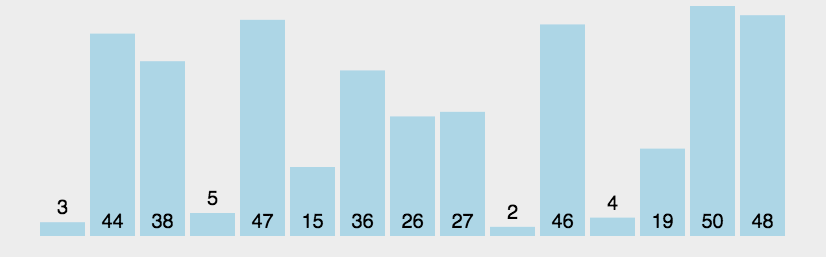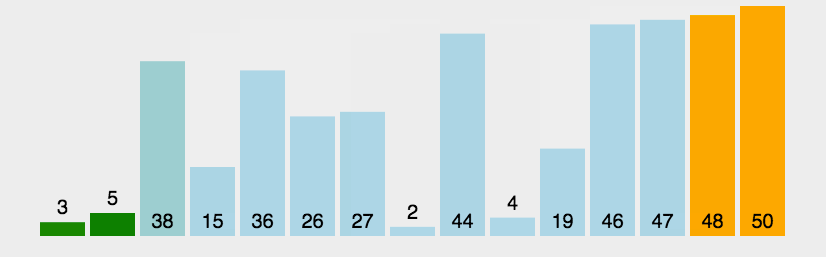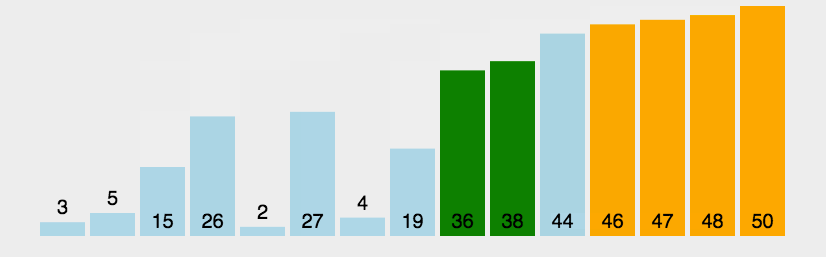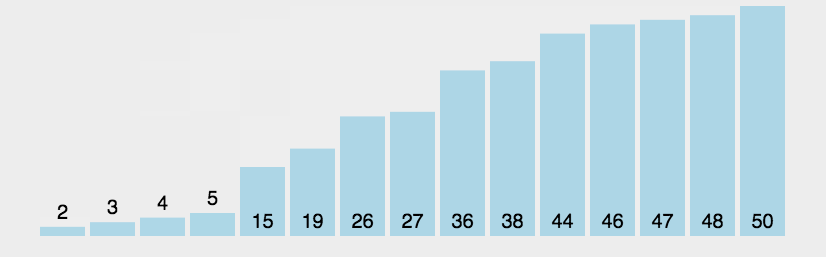
可定义一个flag变量,若第n(n>=0)次没有交换元素,则停止交换 。
时间复杂度:最好情况为 (O(N)),最坏情况为 (O(N^2))。
空间复杂度:(O(1))。
稳定性:稳定。
代码实现
//冒泡排序
void BubbleSort(int* a, int n)
{for(int i = 0; i < n; i++){int flag = 0;for(int j = 0; j < n - i; j++){if(a[j+1] > a[j]){Swap(&a[j+1], &a[j]);flag = 1;}}if(flag == 0){break;}}
}2.选择排序
思路
选择排序是一种简单直观的排序算法。它的工作原理是每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完。
但是实际操作的时候,每次排一个显得尤为繁琐,因此我们可以一趟选出最大值与最小值,以此将其放在开头与结尾,这样可以让效率得到大大提升。
时间复杂度:(O(N^2))。
空间复杂度:(O(1))。
稳定性:不稳定。(易错)
代码实现(存在易错点)
//选择排序
void SelectSort(int* a, int n)
{int begin = 0, end = n - 1;while(begin < end){int min = begin, max = begin;for(int i = begin + 1; i <= end; i++){if(a[i] < a[min]){min = i;}if(a[i] > a[max]){max = i;}}Swap(&a[begin], &a[min]);if(begin == max)max = min;Swap(&a[end], &a[max]);++begin;--end;}
}这里需要注意!如果max值出现在begin处,begin与min交换后需要把max 与min 的位置交换回来,以避免代码出现置换出错的问题。
3.插入排序
思路
插入排序是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
时间复杂度:最好情况为 (O(N)),最坏情况为 (O(N^2))。
空间复杂度:(O(1))。
稳定性:稳定。
代码实现
//插入排序 最好O(N) 最坏O(N ^ 2)
void InsertSort(int* a, int n)
{for(int i = 0; i < n - 1; i++){int end = i;int tmp = a[end + 1];while(end >= 0){if(tmp < a[end]){a[end + 1] = a[end];end--;}else{break;}}a[end + 1] = tmp;}
}4.希尔排序
思路
先给定一个小于n的整数gap,将所有距离为gap的元素分为一组,对每一组进行插入排序,再取比gap小的一个整数,重复上述操作,直到该整数取为1,即为插入排序,排序完成。
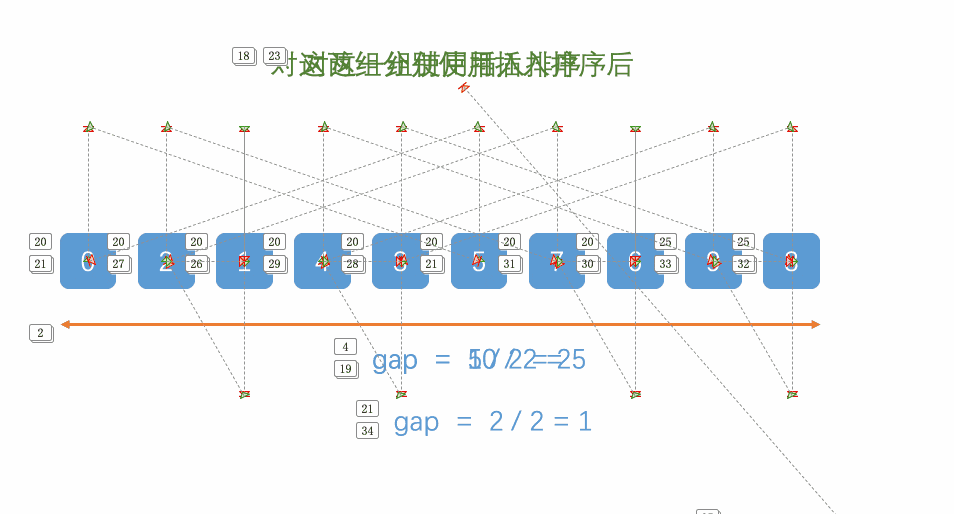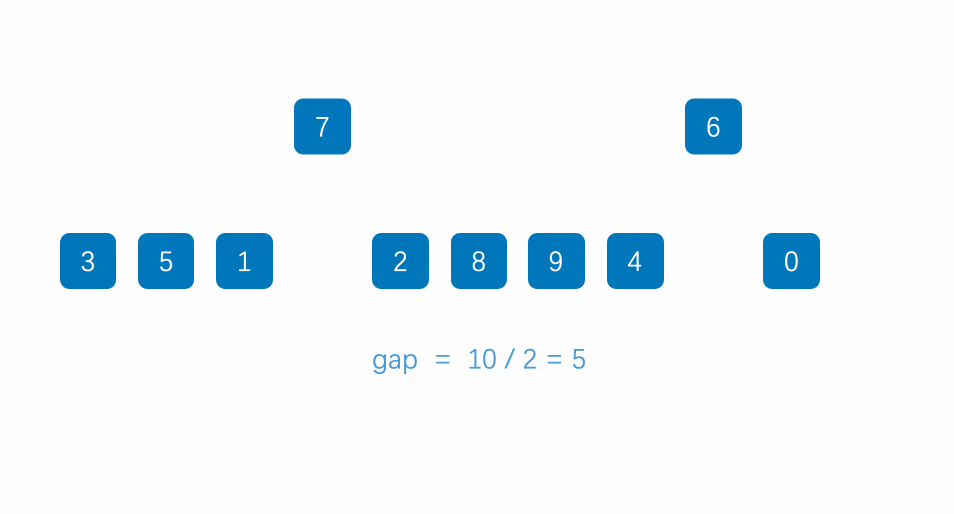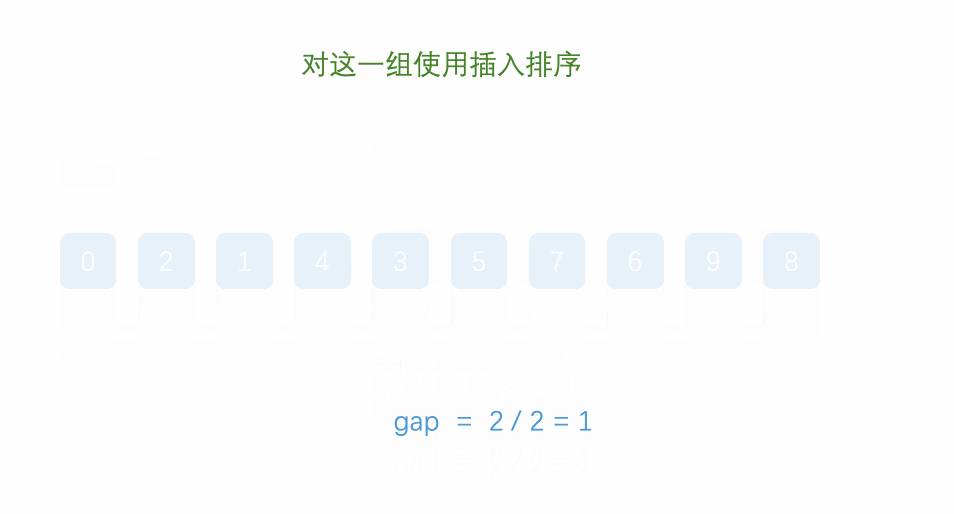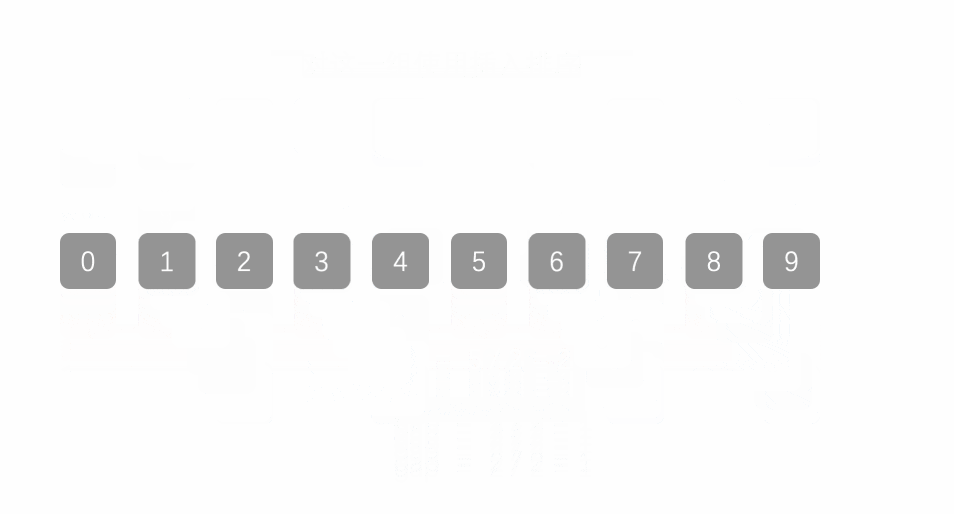
时间复杂度:(O(N^1.3))。
空间复杂度:(O(1))。
稳定性:不稳定。
代码实现
此处与图示取gap不同,取更为优化的循环gap = gap / 3 + 1,这样也能保证最后一次为1。
void ShellSort(int* a, int n)
{int gap = n;while(gap > 1){// +1保证最后一个gap一定是1// gap > 1时是预排序// gap == 1时是插入排序gap = gap / 3 + 1;for(int i = 0; i < n - gap; i++){int end = i;int tmp = a[end + gap];while (end >= 0){if (tmp < a[end]){a[end + gap] = a[end];end -= gap;}else{break;}}a[end + gap] = tmp;}}
}5.堆排序
思路
堆排序是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。
将数组通过向下调整算法建成一个堆,然后通过循环把堆顶元素与堆尾元素交换,再将堆用向下调整算法重新调整,重复调整成升序(降序)。
时间复杂度:(O(NlogN))。
空间复杂度:(O(1))。
稳定性:不稳定。
代码实现
//向下调整
void AdjustDown(int* a, int n, int parent)
{int child = parent * 2 + 1;while(child < n)//找不到孩子{//找出小的孩子if(child + 1 < n && a[child + 1] > a[child]){child = child + 1;}//调整if(a[child] > a[parent]){Swap(&a[child], &a[parent]);parent = child;child = parent * 2 + 1;}else{break;}}
}//堆排序(O(N*logN))
void HeapSort(int* a, int n)
{//降序,建小堆//升序,建大堆// for(int i = 1; i < n; i++)// {// AdjustUp(a, i);//向上调整建堆(O(N*logN))// }for(int i = (n-1-1)/2; i >= 0; i--){AdjustDown(a, n, i);//向下调整建堆(O(N))}int end = n - 1;//(O(N*logN))while(end > 0){Swap(&a[0], &a[end]);AdjustDown(a, end, 0);--end;}
}6.快速排序(快排)
时间复杂度:(O(NlogN)) 有序时退化成(O(N^2))。
空间复杂度:(O(logN))。(易错)
稳定性:不稳定。
快排里面的hoare法,双指针法以及一种非递归方法(还有三数取中,小区间优化两个优化策略)
可以看我这篇博文快速排序(Quick Sort)算法详解(递归与非递归)-CSDN博客
本文介绍两种快排优化:
一.三路划分
思路
三路划分问题主要来解决数组中存在大量重复数的问题,把所有重复数放在同一个区域可以大大提高效率,不过这样的代价也会牺牲一些其他无重复值时的效率。

这里的key可以使用随机数选key的策略以提高效率。
代码实现
/快速排序(递归) 三路划分 适用于多个相同值的情况
void QuickSort1(int* a, int left, int right)
{if(left >= right)return;//小区间优化if((right - left + 1) < 10){InsertSort(a + left, right - left + 1);}else{随机数选key可以自行实现.int key = a[left];int cur = left + 1;int begin = left;int end = right;while(cur <= end){if(a[cur] < key){Swap(&a[begin], &a[cur]);begin++;cur++;}else if(a[cur] > key){Swap(&a[cur], &a[end]);end--;}else{cur++;}}QuickSort1(a, left , begin - 1);QuickSort1(a, end + 1 , right);}
}二.自省排序
思路
这是快排在数据库中的基本代码,拥有足够的优化策略。
这里基本快排代码依旧使用hoare法的找小与找大与小区间优化(具体思路可看上述文章)。
这里要讲的是防止选key时出现二叉树(递归)层数过深的情况下引起的效率降低。
此处定义一个logn用于记录最佳情况下选key的递归深度。当函数递归深度大于两倍logn时使用其他排序方案来提高排序效率,这里使用n*logn的堆排序。
代码实现
//自省排序
void IntroSort(int* a, int left, int right, int depth, int defaultDepth)
{if(left >= right)return;if(right - left + 1 < 16){InsertSort(a + left, right - left + 1);return;} if(depth > defaultDepth){HeapSort(a + left, right - left + 1);return;}depth++;//随机数取keyint tmp = left + (rand() % (right - left + 1));Swap(&a[left], &a[tmp]);int key = left;int begin = left;int end = right;while(begin < end){while(begin < end && a[end] > a[key]){end--;}while(begin < end && a[begin] <= a[key]){begin++;}Swap(&a[end], &a[begin]);}Swap(&a[key], &a[begin]);key = begin;IntroSort(a, left, key - 1, depth, defaultDepth);IntroSort(a, key + 1, right, depth, defaultDepth);
}//快排升级版- 自省排序
void QuickSortPlus(int* a, int left, int right)
{int depth = 0;int logn = 0;int n = right - left + 1;for(int i = 1; i < n; i *= 2){logn++;}// introspective sort -- ⾃省排序
IntroSort(a, left, right, depth, logn*2);
}7.归并排序
时间复杂度:(O(NlogN))。
空间复杂度:(O(N))。
稳定性:稳定。
1.递归法
思路
归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。
将一个数组先通过取中递归的方式拆分成1个单元,再通过归并来使各个分序列有序。如图示
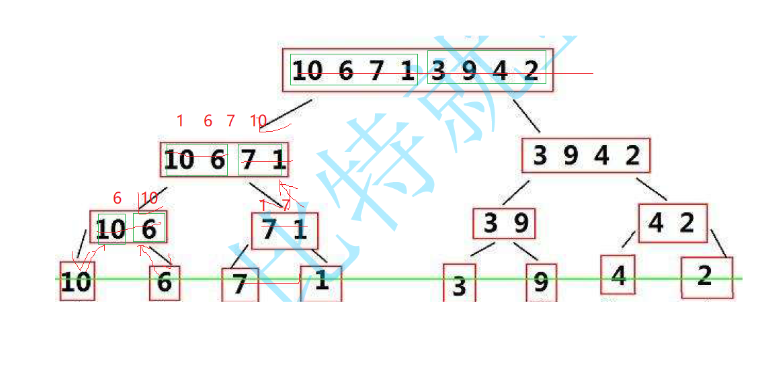
代码实现
//归并子函数
void _MergeSort(int* a, int* tmp, int left, int right)
{if(left >= right)return; int mid = (left + right) / 2;_MergeSort(a, tmp, left, mid);_MergeSort(a, tmp, mid + 1, right);//归并int begin1 = left, end1 = mid;int begin2 = mid + 1, end2 = right;int count = left;while(begin1 <= end1 && begin2 <= end2){if(a[begin1] <= a[begin2])tmp[count++] = a[begin1++];elsetmp[count++] = a[begin2++];}while(begin1 <= end1)tmp[count++] = a[begin1++];while(begin2 <= end2)tmp[count++] = a[begin2++];memcpy(a + left, tmp + left, (right - left + 1) * sizeof(int));}//归并排序(递归)
void MergeSort(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);if(tmp == NULL){perror("malloc fail!");exit(1);}_MergeSort(a, tmp, 0, n - 1);free(tmp);tmp = NULL;
}
2.非递归法
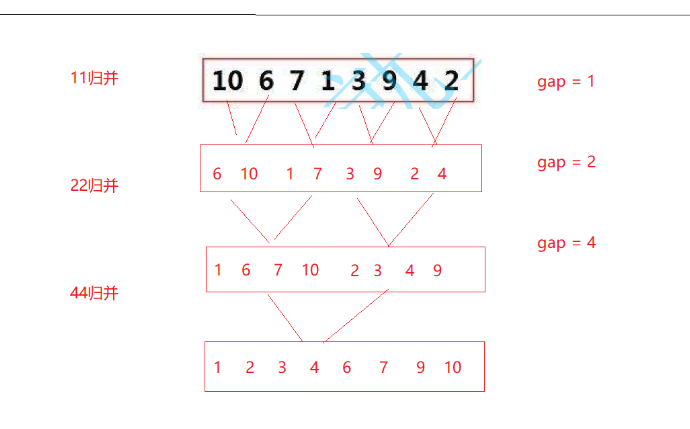
思路
定义一个gap来定义每组归并数据的数据个数,gap每次取二的倍数,再通过归并来实现排序 如图:
可能你会发现:如果数据个数不是二的倍数,那是不是会存在越界访问的风险?
举十个数据为例如图: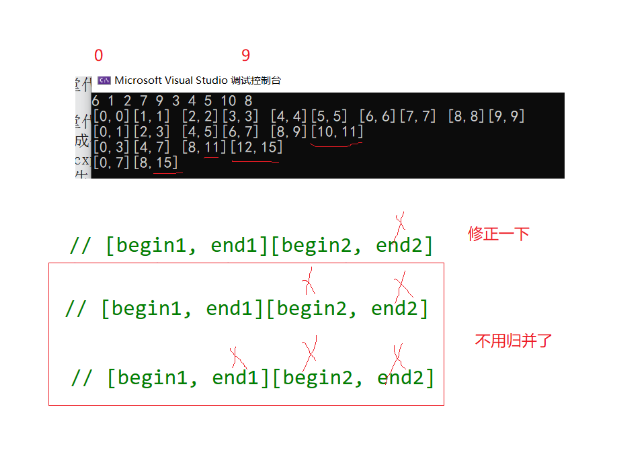
可见后几位似乎都出现了越界,那么共会出现三种情况,可以把后两种归为一类,让最后一组数据不再归并,最后必然出现两组数归并的情况,并且最后一次归并begin2必然不越界,此时修正end2即可形成8.2归并,实现归并排序。
代码实现
//归并排序(非递归)
void MergeSortNonR(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);if(tmp == NULL){perror("malloc fail!");exit(1);}//归并int gap = 1;while(gap < n){for(int i = 0; i < n; i += gap * 2){int begin1 = i, end1 = i + gap - 1;int begin2 = i + gap, end2 = i + gap * 2 - 1;//两个修正的解释:举10个数为例依次进行11.22.44归并,最后两个数不纳入归并,//最后一次归并begin2必然不越界,此时修正end2即可形成8.2归并,实现归并排序//第二组都越界不存在,这一组就不需要归并if(begin2 > n){break;}//第二组的begin2没越界,end2越界,需要修正end2取值,重新归并if(end2 > n){end2 = n - 1;}int count = i;while(begin1 <= end1 && begin2 <= end2){if(a[begin1] <= a[begin2])tmp[count++] = a[begin1++];elsetmp[count++] = a[begin2++];}while(begin1 <= end1)tmp[count++] = a[begin1++];while(begin2 <= end2)tmp[count++] = a[begin2++];memcpy(a + i, tmp + i, (end2 - i + 1) * sizeof(int));}gap *= 2;}free(tmp);tmp = NULL;
}8. 计数排序
思路
计数排序是一种非比较排序算法。它的核心在于将输入的数据值转化为键存储在额外开辟的数组空间中 该被开辟的数组空间大小为原数组max - min + 1。以该数组下标为数值,原数组有这个数则a[i]++。
时间复杂度:(O(N + range))。(range为开辟的数组空间大小)
空间复杂度:(O(range))。
代码实现
//计数排序
// 时间复杂度:O(N+range)
// 只适合整数/适合范围集中
// 空间复杂度:O(range)
void CountSort(int* a, int n)
{int min = 0, max = 0;for(int i = 1; i < n; i++){if(a[i] > a[max])max = i;if(a[i] < a[min])min = i;}int range = a[max] - a[min] + 1;int* count = (int*)calloc(range, sizeof(int));if(count == NULL){perror("calloc fail!");exit(1);}for(int i = 0; i < n; i++){count[a[i] - a[min]]++; // 计数}//排序int j = 0;for(int i = 0; i < range; i++){while(count[i]--)a[j++] = i + a[min];}free(count);count = NULL;
}总结(附排序训练OJ题)
读完本文,你可以在该OJ题上进行实操来加深印象:912. 排序数组 - 力扣(LeetCode)
不同的排序算法有不同的时间复杂度和空间复杂度,适用于不同的场景。在实际应用中,我们需要根据数据的特点和需求选择合适的排序算法。例如,当数据量较小且基本有序时,插入排序可能是一个不错的选择;而当数据量较大时,快速排序、归并排序和堆排序通常表现更好。计数排序则适用于数据范围较小且为整数的情况。
通过本文的介绍和代码实现,相信你对八大排序算法有了更深入的理解。希望这些知识能帮助你在实际编程中更好地处理排序问题。
相关文章:
算法篇 八大排序(冒泡 插入 选择 堆 希尔 快排 归并 计数)
目录 引言 1.冒泡排序 思路 代码实现 2.选择排序 思路 代码实现(存在易错点) 3.插入排序 思路 代码实现 4.希尔排序 思路 代码实现 5.堆排序 思路 代码实现 6.快速排序(快排) 一.三路划分 思路 代码实现 二.自…...

技术文档写作全攻略
一、引言 在快速迭代的软件开发中,技术文档早已不只是附属品,而是与代码同等重要的交付物: 帮助新成员 T0 → T1 学习曲线指数下降;降低支持成本,将重复性问答前移到自助文档;为合规审计、知识传承及商业…...

网络安全全景解析
引言 在数字化时代,网络已深度融入社会生产生活的各个领域,成为推动经济发展和社会进步的关键力量。然而,随着网络应用的日益复杂,网络安全问题也呈现出多样化、复杂化的趋势。从个人隐私泄露到企业核心数据被盗,从基础…...
音视频之视频压缩编码的基本原理
系列文章: 1、音视频之视频压缩技术及数字视频综述 2、音视频之视频压缩编码的基本原理 一、预测编码: 1、预测编码的基本概念: 预测法是最简单、实用的视频压缩编码方法,经过压缩编码后传输的并不是像素本身的取样值࿰…...
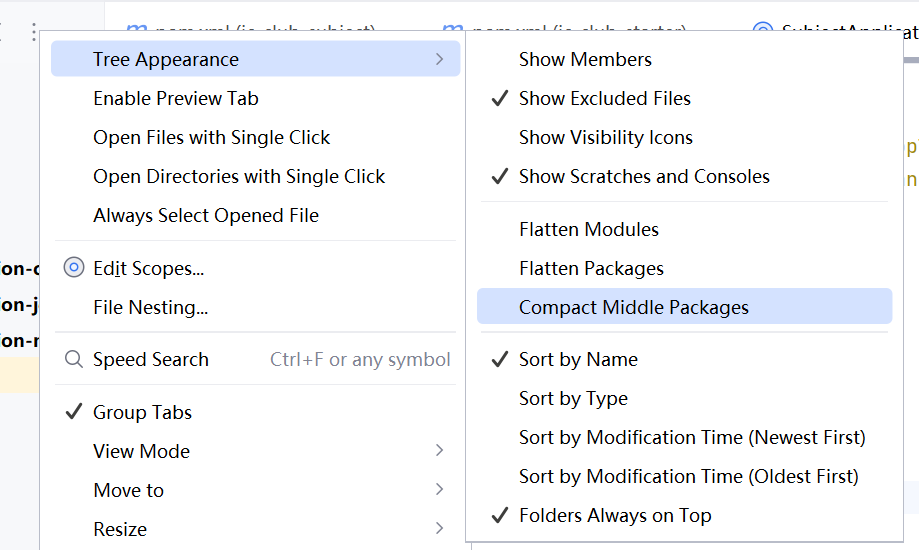
IDEA 包分层显示设置
方法一(用的IntelliJ IDEA 2024.1.4版本): 找到项目视图设置入口:在左侧Project(项目)面板的顶部,有个三个点...的按钮 ,点击它。 进入树形外观配置:在弹出的菜单中&…...
0605)
书籍将正方形矩阵顺时针转动90°(8)0605
题目 给定一个N x N的矩阵matrix,把这个矩阵调整成顺时针转动90后的形式。 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 顺时针转动90后为: 13 9 5 1 14 …...

【docker】容器技术如何改变软件开发与部署格局
在当今数字化时代,软件开发与部署的效率和灵活性至关重要。就像古人云:“工欲善其事,必先利其器。”Docker 作为一款强大的容器技术,正如同软件开发领域的一把利器,极大地改变了应用的开发、交付和运行方式。本文将深入…...

C#抽象类深度解析 _ 核心特性与实战指南
—— 面向对象设计的基石 🔍抽象类核心定义 abstract class AbClass { ... } // abstract修饰符声明 不可实例化:new AbClass() 将触发编译错误继承专用:仅能作为其他类的基类存在混合成员组合:可同时包含抽象方法和已实现方法…...

时序数据库IoTDB的UDF Sample算法在数据监控、故障预防的应用
一、数据监控在工业物联网中的重要性 设备数据监控是工业物联网(IoT)中最为广泛应用的领域之一。通过实时监控工厂机械设备的运行状态,企业能够提前发现设备的潜在故障,从而实现预防性维护与可预测性维护。这一做法不仅能有效提升…...

Flask-SQLAlchemy使用小结
链表查询 join方法允许你指定两个或多个表之间的连接条件,并返回一个新的查询对象,该对象包含了连接后的结果。 内连接 from sqlalchemy import join # 使用join函数 query db.session.query(User, Order).join(Order, User.id Order.user_id) res…...
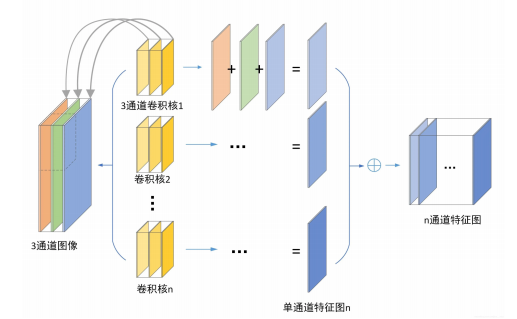
深度学习和神经网络 卷积神经网络CNN
1.什么是卷积神经网络 一种前馈神经网络;受生物学感受野的机制提出专门处理网格结构数据的深度学习模型 核心特点:通过卷积操作自动提取空间局部特征(如纹理、边缘),显著降低参数量 2.CNN的三个结构特征 局部连接&a…...

用 NGINX 构建高效 POP3 代理`ngx_mail_pop3_module`
一、模块定位与作用 协议代理 ngx_mail_pop3_module 让 NGINX 能够充当 POP3 代理:客户端与后端 POP3 服务器之间的所有请求均转发到 NGINX,由 NGINX 负责与后端会话逻辑。认证方式控制 通过 pop3_auth 指令指定允许客户端使用的 POP3 认证方法…...

解决:如何在Windows adb使用dmesg | grep检查内核日志
首先: C:\Users\TF> adb shell 再 rk3568_r:/ $ dmesg | grep -i “goodix” 显示 130|rk3568_r:/ $ dmesg | grep -i “goodix” [ 0.764071] goodix_ts_probe() start111 [ 0.764108] goodix_ts_probe() start222 [ 0.764181] Goodix-TS 1-0014: Linked as a c…...
PlayWright | 初识微软出品的 WEB 应用自动化测试框架
Playwright是微软大厂背书的跨平台 WEB 应用自动化测试框架,支持多开发语言(TypeScript、JavaScript、.Net、Python、Java)及多浏览器(Chromium、WebKit、Firefox),同时支持移动端测试。 安装 playwright …...
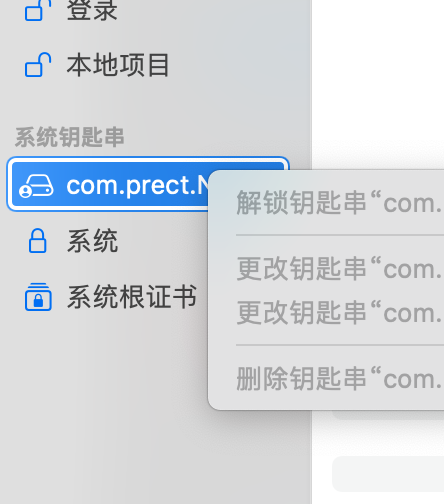
Mac电脑_钥匙串操作选项变灰的情况下如何删除?
Mac电脑_钥匙串操作选项变灰的情况下如何删除? 这时候 可以使用相关的终端命令进行操作。 下面附加文章《Mac电脑_钥匙串操作的终端命令》。 《Mac电脑_钥匙串操作的终端命令》 (来源:百度~百度AI 发布时间:2025-06)…...

Git Patch 使用详解:生成、应用与多提交合并导出
在多人协作、代码审查、离线提交或跨仓库迁移的场景中,git patch 是非常实用的技术。本文将系统地介绍如何使用 Git 的补丁机制导出和应用修改内容。 📖 什么是 Git Patch? 严格来说,git patch 并不是一个 Git 命令,而…...

2025前端微服务 - 无界 的实战应用
遇饮酒时须饮酒,得高歌处且高歌 文章目录 什么是前端微服务主流框架概述无界 - 腾讯乾坤 - 阿里Micro-app Vue3项目引用⑴. 项目依赖安装⑵. main.ts 文件配置⑶. 路由配置⑷. 页面设置 隐藏子应用菜单及顶部信息栏子应用样式冲突问题虚拟路由⑴. 路由⑵. 页面 跨域…...
)
Spring Boot 缓存注解详解:@Cacheable、@CachePut、@CacheEvict(超详细实战版)
💡 前言 在高并发、高性能的系统开发中,缓存是提升接口响应速度和降低数据库压力的重要手段。Spring Boot 提供了强大的缓存抽象层 —— spring-context-support,并结合 JSR-107 标准,提供了多个缓存注解,如ÿ…...
【设计模式-4.8】行为型——中介者模式
说明:本文介绍行为型设计模式之一的中介者模式 定义 中介者模式(Mediator Pattern)又叫作调节者模式或调停者模式。用一个中介对象封装一系列对象交互,中介者使各对象不需要显式地互相作用,从而使其耦合松散…...

SpringCloud-基于SpringAMQP实现消息队列
在微服务架构中,使用消息队列进行异步通信是一种常见而有效的方法。Spring Cloud提供了一个强大的工具集,用于构建分布式系统,而Spring AMQP是其支持高级消息队列协议(AMQP)的组件,广泛应用于消息队列的场景中,尤其是与…...

ObjectMapper 在 Spring 统一响应处理中的作用详解
ObjectMapper 是 Jackson 库的核心类,专门用于处理 JSON 数据的序列化(Java 对象 → JSON)和反序列化(JSON → Java 对象)。在你提供的代码中,它解决了字符串响应特殊处理的关键问题。 一、为什么需要 Obj…...
)
H5移动端性能优化策略(渲染优化+弱网优化+WebView优化)
一、渲染优化:首屏速度提升的核心 1. 关键页面采用SSR或Native渲染 适用场景:首页、列表页、详情页等强内容展示页面 优化原理: SSR(服务端渲染):在服务端生成完整…...

【汇编逆向系列】二、函数调用包含单个参数之整型-ECX寄存器,LEA指令
目录 一. 汇编源码 二. 汇编分析 1. ECX寄存器 2. 栈位置计算 3. 特殊指令深度解析 三、 汇编转化 一. 汇编源码 single_int_param:0000000000000040: 89 4C 24 08 mov dword ptr [rsp8],ecx0000000000000044: 57 push rdi0000…...
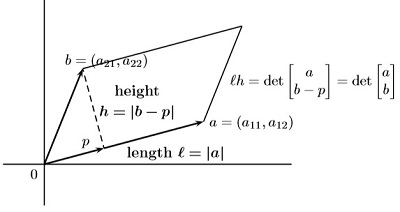
行列式的性质
1 行列式使用如下性质定义 1)单位矩阵行列式值为 1, ,对于任意单位矩阵均成立; 2)当矩阵交换一行后,行列式值改变符号,如置换矩阵的行列式值为 (根据行交换次数决定)&…...
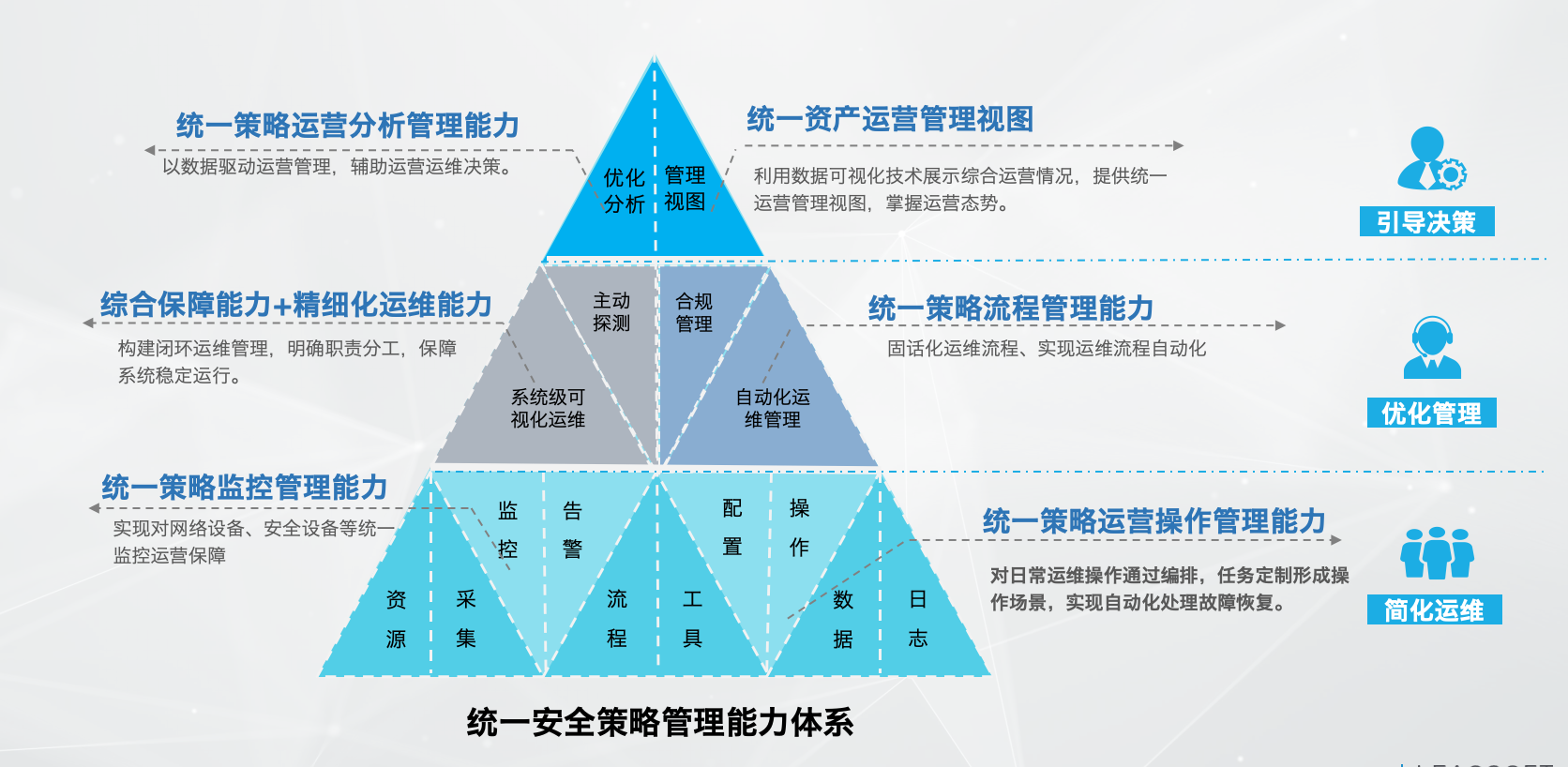
联软NSPM自动化策略管理 助力上交所加速国产化替代提升运维效率
在金融行业核心基础设施国产化浪潮与网络安全强监管的双重背景下,上海证券交易所(以下简称“上交所”)积极拥抱变革,携手长期合作伙伴联软科技,成功部署了联软安全策略管理系统(NSPM)。该项目不…...
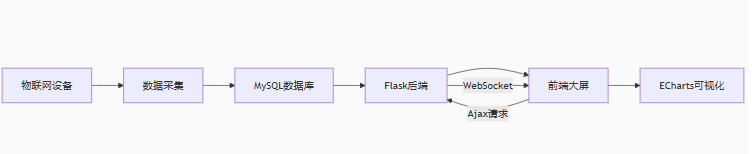
Flask + ECharts+MYSQL物联网数字化大屏
基于Flask+ECharts的物联网数字化大屏系统,包含中国地图实时数据更新功能。这个系统模拟了物联网设备在全国范围内的分布和运行状况,并实时更新数据。 一、系统架构设计 技术栈 后端:Flask(轻量级路由+API支持) 前端:ECharts(地图+动态图表)、WebSocket(实时更新)…...

业务到解决方案构想
解决方案构想的核心理解 解决方案构想是连接业务需求与技术实现的关键桥梁,从您描述的内容和我的理解,这个阶段的核心点包括: 核心要点解读 转化视角:将业务视角的需求转变为解决方案视角 业务能力探索阶段识别了"做什么&q…...

数据库系统概论(十六)数据库安全性(安全标准,控制,视图机制,审计与数据加密)
数据库系统概论(十六)数据库安全性 前言一、数据库安全性1. 什么是数据库安全性?2. 为何会存在安全问题? 二、安全标准的发展1. 早期的“开拓者”:TCSEC标准2. 走向国际统一:CC标准3. TCSEC和CC标准有什么不…...
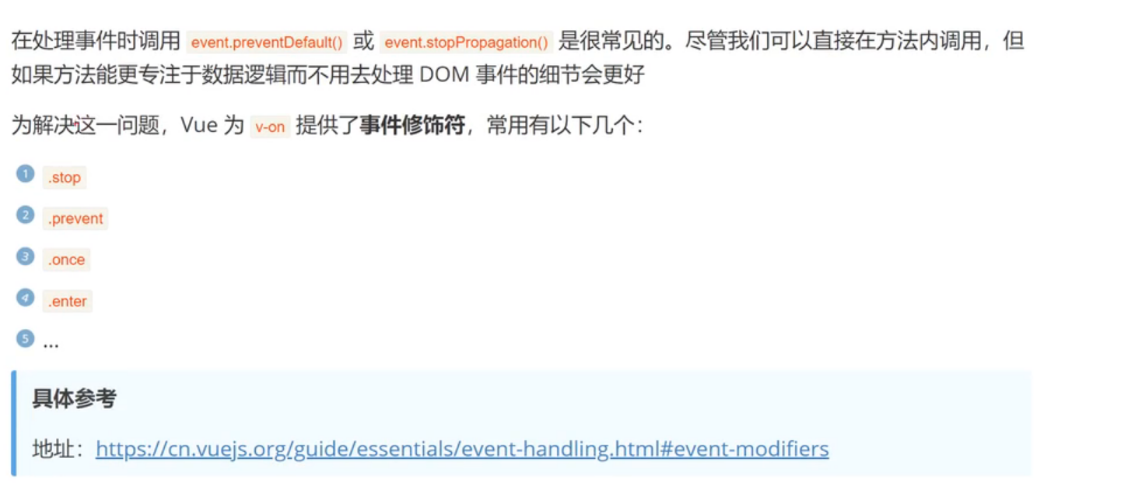
vue3从入门到精通(基础+进阶+案例)
Vue是什么? 渐进式JavaScript框架,易学易用,性能出色,适用场景丰富的Web前端框架 为什么要学习Vue Vue是目前前端最火的框架之一 Vue是目前企业技术栈中要求的知识点 Vue可以提升开发体验 。。。 Vue简介 Vue(发音为/vju/,…...
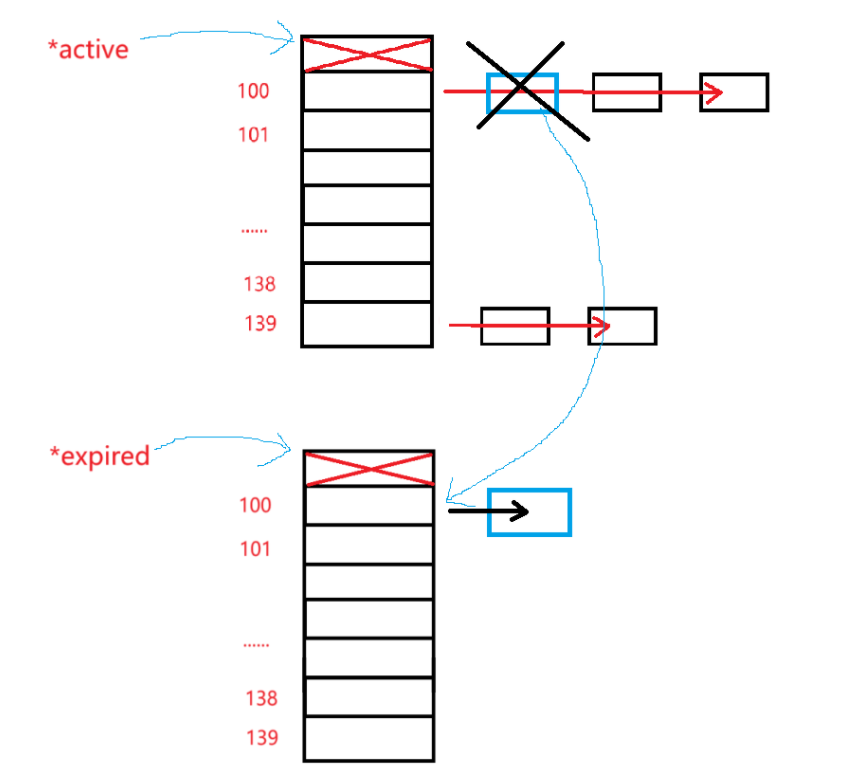
【Linux 学习计划】-- 系统中进程是如何调度的(内核进程调度队列)
目录 回顾进程优先级与进程调度的引入 内核runqueue图例 关于queue[140]前100个位置 | 实时进程与分时进程 遍历需要调度的进程与bitmap的引入 active、expired指针 结语 回顾进程优先级与进程调度的引入 在我们之前的学习中,我们是有学习过进程优先级这个概…...