基于BI PaaS架构的衡石HENGSHI SENSE平台技术解析:重塑企业级数据分析基座
在数据驱动决策的时代,传统BI工具日益显露出扩展性弱、灵活性差、资源利用率低等痛点。衡石科技推出的HENGSHI SENSE平台,创新性地采用BI PaaS(平台即服务)架构,为企业构建了一个强大、开放、可扩展的数据分析基础设施。本文将深入解析其核心技术架构与价值。
一、 为何需要BI PaaS?传统BI的瓶颈与突破
传统BI解决方案多为单体应用或SaaS模式,存在以下关键限制:
-
扩展性瓶颈: 用户量、数据量激增时,性能急剧下降,难以横向扩展。
-
定制化困难: 难以深度嵌入业务系统或满足高度个性化的分析需求。
-
集成成本高: 与企业现有数据栈(数仓、数据湖、业务系统)对接复杂。
-
资源隔离与效率: 多租户/多项目场景下,资源争抢严重,缺乏有效隔离与弹性伸缩。
-
开发运维负担: 安装、配置、升级、维护工作量大,占用IT团队大量精力。
BI PaaS应运而生,其核心思想是将BI能力平台化:
-
提供基础能力: 将数据连接、建模、计算、可视化、权限等核心BI功能封装为标准化服务。
-
开放API与SDK: 提供丰富的接口,供开发者灵活调用、集成和扩展。
-
弹性基础设施: 基于云原生技术,实现资源的动态分配与高效管理。
-
专注核心业务: 企业无需从零构建BI基础设施,聚焦于数据价值挖掘。
二、 衡石HENGSHI SENSE:BI PaaS架构的核心技术实现
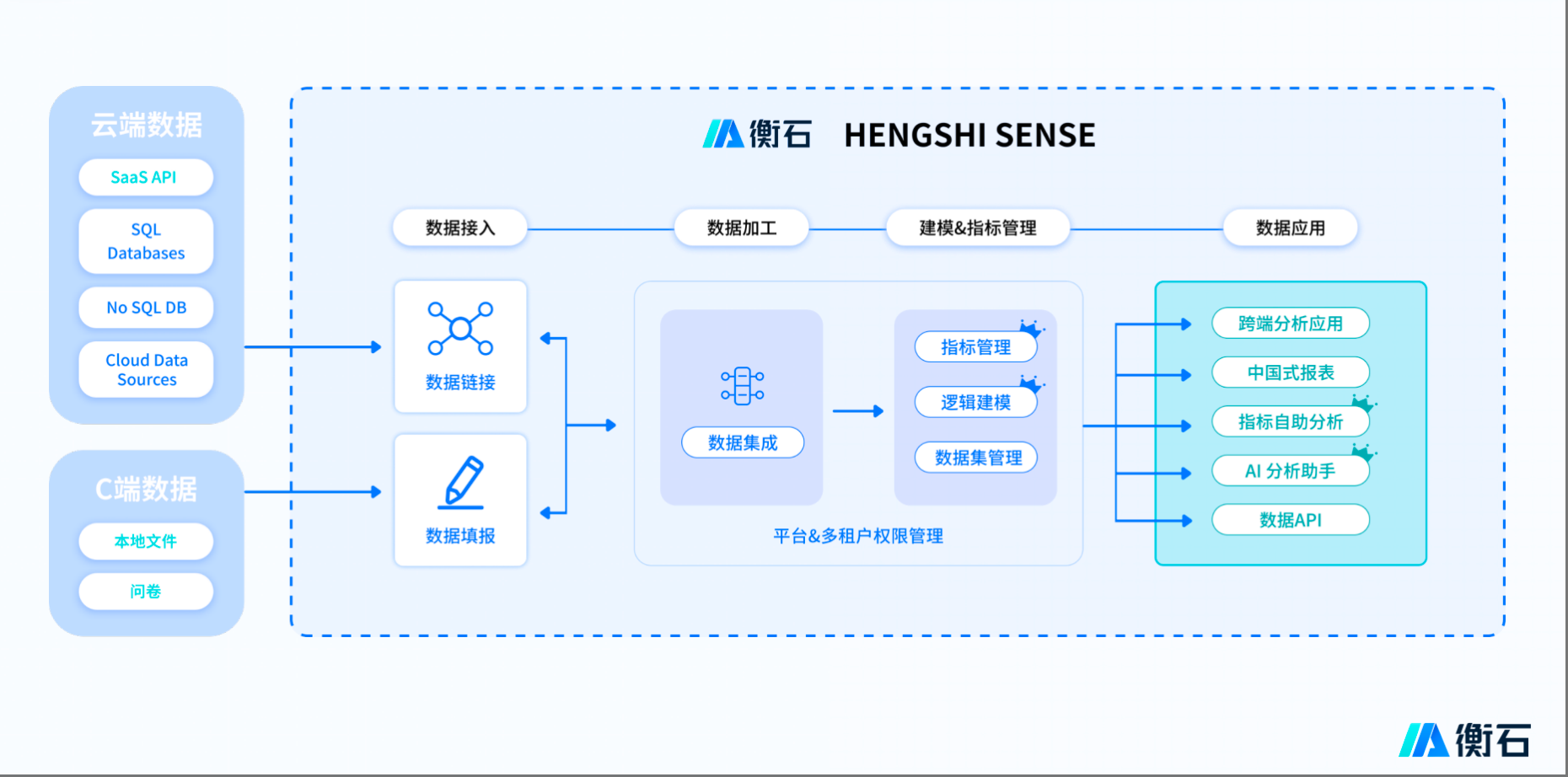
HENGSHI SENSE平台的设计哲学是构建一个“Analytics Infrastructure”(分析基础设施)。其技术架构的关键支柱包括:
-
云原生微服务架构:
-
解耦与弹性: 平台核心功能(如查询引擎、任务调度、元数据管理、渲染服务、权限服务等)被拆分为独立的微服务。
-
容器化部署: 基于Kubernetes等容器编排技术,实现服务的快速部署、滚动升级、故障自愈和水平扩展。用户量或计算负载增加时,可动态扩展相应服务实例。
-
高可用与容灾: 微服务架构和容器编排天然支持多副本部署,保障服务的高可用性。
-
-
统一数据建模层 (Semantic Layer):
-
核心枢纽: 这是SENSE平台的核心竞争力之一。它抽象了底层复杂的数据源(关系型数据库、数据仓库、数据湖、API、文件等),定义统一的业务指标(如“销售额”、“活跃用户数”)和维度(如“时间”、“地区”、“产品”)。
-
逻辑统一,物理分散: 业务人员和分析师在统一的语义层上进行拖拽式分析,无需关心底层物理数据存储位置和方言差异。平台自动将逻辑查询转换为对底层数据源的物理查询(如SQL)。
-
保障一致性: “Single Source of Truth”,确保不同分析报告中的指标定义和计算逻辑一致。
-
-
高性能分布式查询引擎:
-
智能下推: 引擎核心优化策略是将计算尽可能下推到数据源(如Pushdown到MPP数仓或Spark集群),仅拉取必要结果,最大化利用底层引擎的计算能力,减少网络传输。
-
多引擎适配: 内置或可扩展适配多种主流计算引擎(如Presto/Trino, Spark, Doris, ClickHouse等),根据数据源特性和查询复杂度选择最优执行路径。
-
缓存优化: 智能缓存常用查询结果和中间数据,加速重复查询响应。
-
-
开放API与深度集成能力:
-
全方位API: 提供覆盖数据连接管理、模型构建、看板/报告创建、渲染、用户权限、任务调度等全生命周期的RESTful API。
-
SDK支持: 提供易用的SDK(如JavaScript SDK),方便将SENSE的分析能力(如可视化图表、仪表板)无缝嵌入到企业自有的业务系统、门户网站或移动应用中,实现深度集成。
-
嵌入式分析: 支持将分析模块作为组件嵌入第三方应用,提供沉浸式数据分析体验。
-
-
多租户与资源隔离:
-
精细管控: 平台层面支持多租户架构,可在组织、部门、项目等不同层级进行资源(计算、存储、并发)隔离和配额管理。
-
租户级定制: 不同租户可拥有独立的数据源连接、数据模型、分析内容、用户体系和权限配置,满足大型企业内不同业务单元的需求。
-
-
安全与治理:
-
细粒度权限: 提供从数据源、数据模型、行级、列级到看板/报告/图表的精细权限控制。
-
审计追踪: 记录关键操作日志,满足合规性要求。
-
数据加密: 支持数据传输和存储加密。
-
三、 BI PaaS架构带来的核心价值
基于以上技术实现,HENGSHI SENSE BI PaaS平台为企业带来显著价值:
-
敏捷交付与创新加速:
-
开发者和业务团队能基于平台能力,快速构建和迭代定制化的数据分析应用,无需从零开始。
-
嵌入式分析缩短了数据洞察融入业务流程的路径。
-
-
极致扩展性与弹性:
-
云原生架构轻松应对用户、数据量和并发查询的增长,按需伸缩资源,优化成本。
-
分布式查询引擎有效利用底层大数据基础设施。
-
-
降本增效:
-
集中化的平台管理大幅降低分散部署和运维的成本与复杂度。
-
资源池化和弹性伸缩提高基础设施利用率,避免资源浪费。
-
-
统一与一致的数据体验:
-
统一的语义层是构建企业级数据文化的基石,确保“说同一种数据语言”。
-
消除数据孤岛,提供跨数据源的统一分析视图。
-
-
生态构建与未来兼容:
-
开放API架构易于与企业现有IT生态(身份认证、流程引擎、监控系统等)集成。
-
平台的可扩展性便于未来接入新的数据源、计算引擎或分析算法。
-
四、 总结:构建面向未来的数据分析基础设施
衡石HENGSHI SENSE平台通过其先进的BI PaaS架构,成功将BI从孤立的应用工具升级为企业级的数据分析基础设施。其云原生微服务底座、强大的统一语义层、高性能分布式查询引擎、全面的开放API和精细的租户管理,共同支撑起一个高扩展、高灵活、深度集成、安全可控的现代化分析平台。
对于追求通过数据驱动实现业务增长、需要处理海量数据、拥有复杂IT环境、且需要深度定制和嵌入分析能力的企业而言,采用基于BI PaaS架构的衡石HENGSHI SENSE平台,无疑是构建坚实、灵活、面向未来的数据分析能力核心基座的战略性选择。它不仅仅是一个工具,更是企业释放数据潜能、加速数字化转型的引擎。
相关文章:
基于BI PaaS架构的衡石HENGSHI SENSE平台技术解析:重塑企业级数据分析基座
在数据驱动决策的时代,传统BI工具日益显露出扩展性弱、灵活性差、资源利用率低等痛点。衡石科技推出的HENGSHI SENSE平台,创新性地采用BI PaaS(平台即服务)架构,为企业构建了一个强大、开放、可扩展的数据分析基础设施…...

Hive中ORC存储格式的优化方法
优化Hive中的ORC(Optimized Row Columnar)存储格式可显著提升查询性能、降低存储成本。以下是详细的优化方法,涵盖参数配置、数据组织、写入优化及监控调优等维度: 一、ORC核心参数优化 1. 存储与压缩参数 SET orc.block.size=268435456; -- 块大小(默认256MB)…...
随机访问元素)
代码训练LeetCode(23)随机访问元素
代码训练(23)LeetCode之随机访问元素 Author: Once Day Date: 2025年6月5日 漫漫长路,才刚刚开始… 全系列文章可参考专栏: 十年代码训练_Once-Day的博客-CSDN博客 参考文章: 380. O(1) 时间插入、删除和获取随机元素 - 力扣(LeetCode)力…...

【R语言编程绘图-plotly】
安装与加载 在R中使用plotly库前需要安装并加载。安装可以通过CRAN进行,使用install.packages()函数。加载库使用library()函数。 install.packages("plotly") library(plotly)测试库文件安装情况 # 安装并加载必要的包 if (!requireNamespace("p…...

float、double 这类 浮点数 相比,DECIMAL 是另一种完全不同的数值类型
和 float、double 这类**“浮点数”**相比,DECIMAL 是另一种完全不同的数值类型,叫做: ✅ DECIMAL 是什么? DECIMAL 是“定点数”类型(fixed-point),用于存储精确的小数值,比如&…...

通信刚需,AI联手ethernet/ip转profinet网关打通工业技术难关
工业人工智能:食品和饮料制造商的实际用例通信刚需 了解食品饮料制造商如何利用人工智能克服业务挑战 食品和饮料制造商正面临劳动力短缺、需求快速变化、运营复杂性加剧以及通胀压力等挑战。如今,生产商比以往任何时候都更需要以更少的投入实现更高的…...

JavaEE->多线程:定时器
定时器 约定一个时间,时间到了,执行某个代码逻辑(进行网络通信时常见) 客户端给服务器发送请求 之后就需要等待 服务器的响应,客户端不可能无限的等,需要一个最大的期限。这里“等待的最大时间”可以用定时…...

6个月Python学习计划 Day 15 - 函数式编程、高阶函数、生成器/迭代器
第三周 Day 1 🎯 今日目标 掌握 Python 中函数式编程的核心概念熟悉 map()、filter()、reduce() 等高阶函数结合 lambda 和 列表/字典 进行数据处理练习了解生成器与迭代器基础,初步掌握惰性计算概念 🧠 函数式编程基础 函数式编程是一种…...
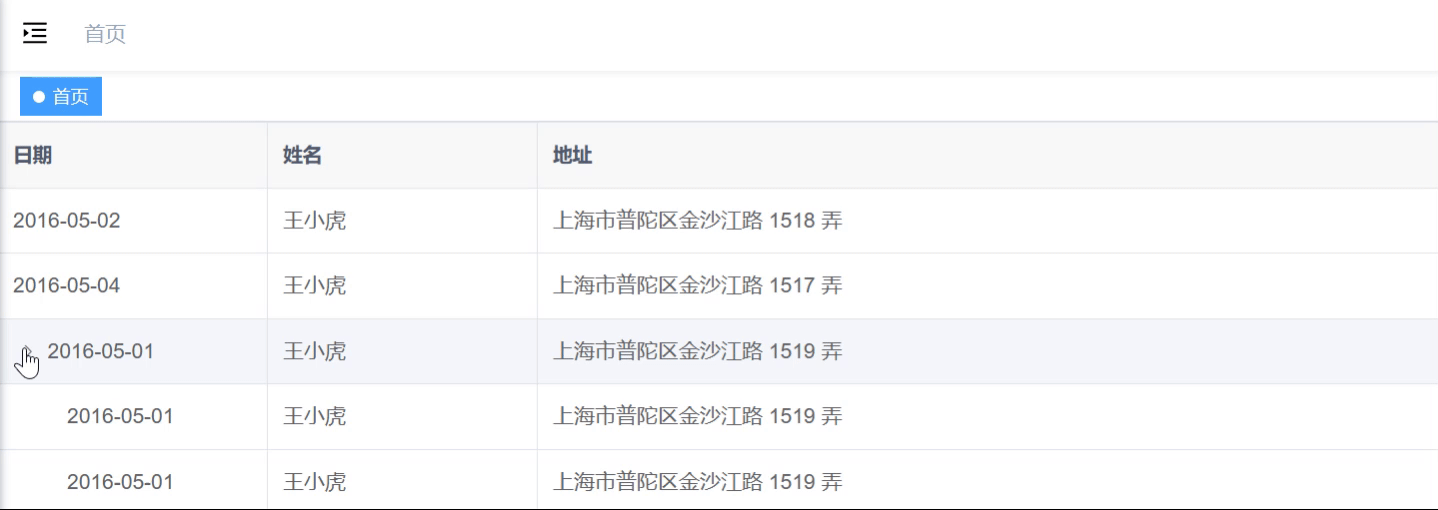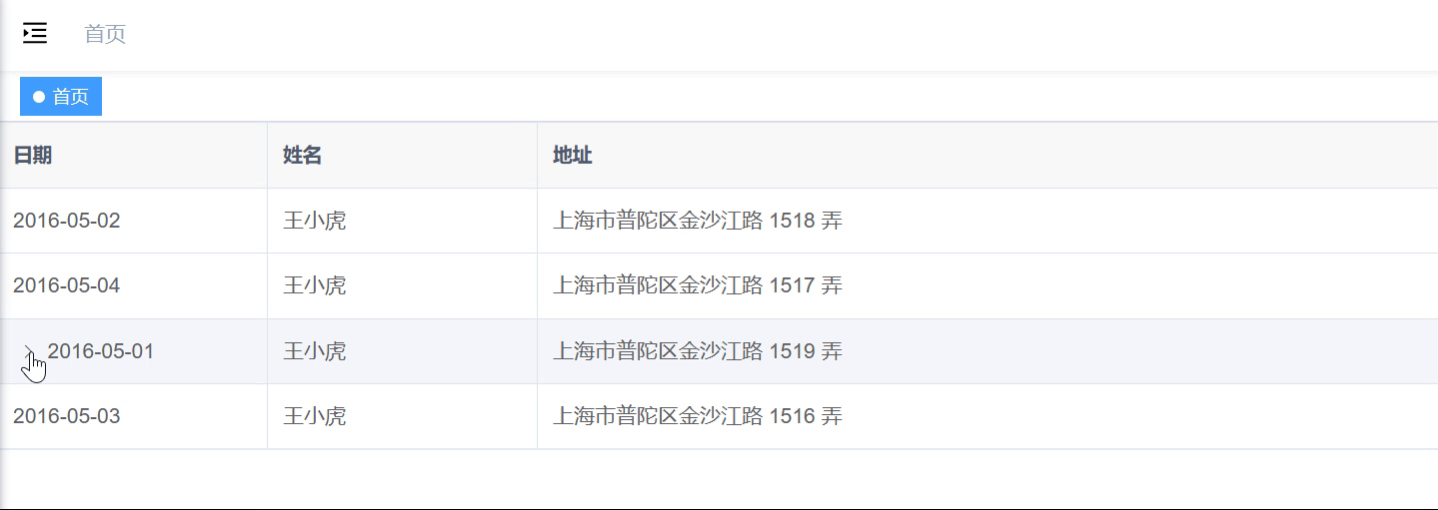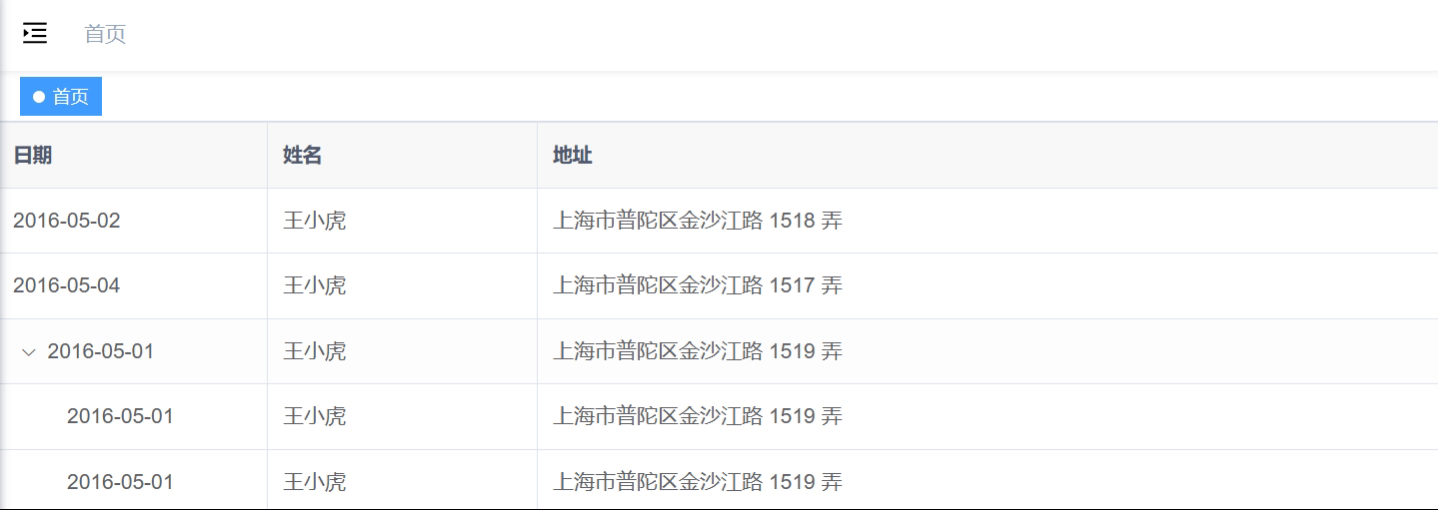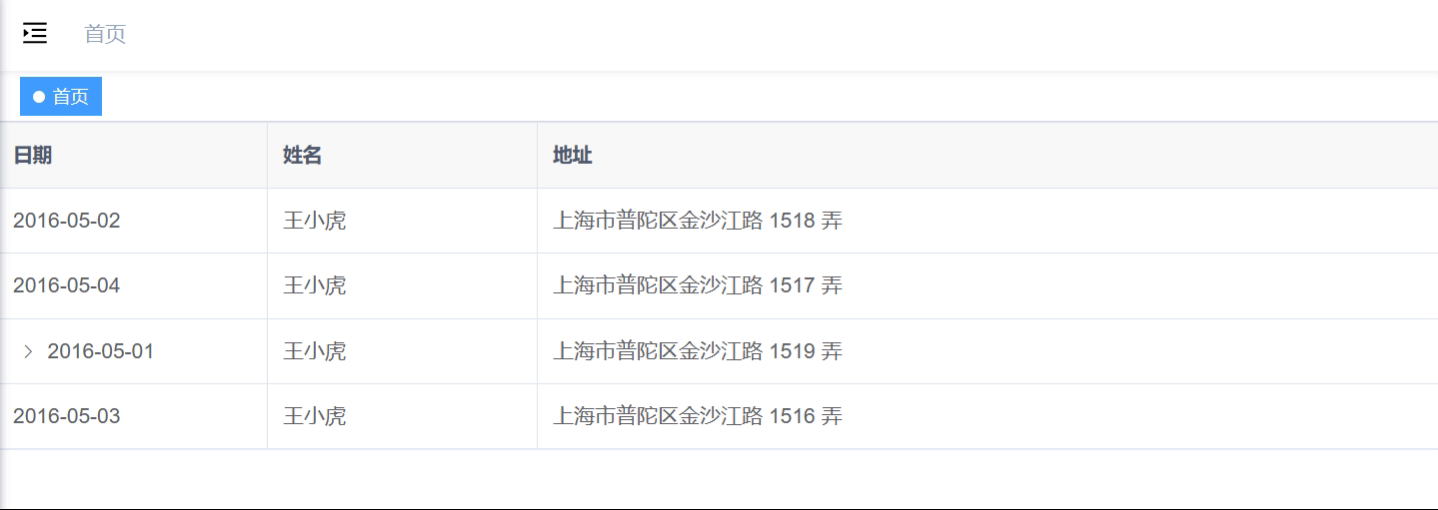
<el-table>构建树形结构
最佳实践 el-table实现树形结构主要依靠row-key和tree-props来实现的。 💫 无论是el-table实现的树形结构还是el-tree组件都是绑定的树形结构的数据,因此如果数据是扁平的话,需要进行树化。 代码 <template><div><el-table:d…...

linux——磁盘和文件系统管理
1、磁盘基础简述 1.1 硬盘基础知识 硬盘(Hard Disk Drive,简称 HDD)是计算机常用的存储设备之一. p如果从存储数据的介质上来区分,硬盘可分为机械硬盘(Hard Disk Drive, HDD)和固态硬盘(Soli…...

云原生 DevOps 实践路线:构建敏捷、高效、可观测的交付体系
📝个人主页🌹:一ge科研小菜鸡-CSDN博客 🌹🌹期待您的关注 🌹🌹 一、引言:DevOps 与云原生的深度融合 在传统软件工程范式下,开发与运维之间存在天然的壁垒。开发希望尽快…...
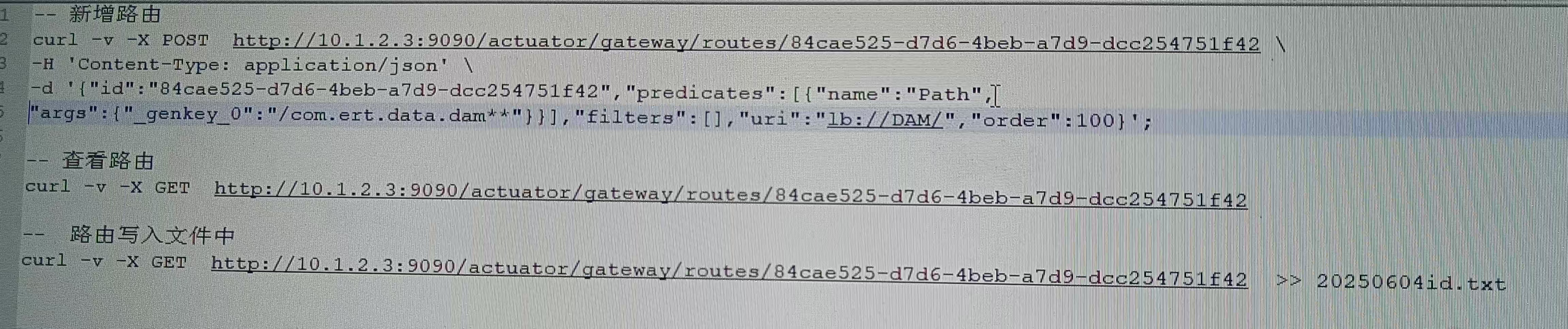
gateway 网关 路由新增 (已亲测)
问题: 前端通过gateway调用后端接口,路由转发失败,提示404 not found 排查: 使用 { "href":"/actuator/gateway/routes", "methods":[ "POST", "GET" ] } 命令查看路由列表&a…...

ArcGIS Pro 3.4 二次开发 - 共享
环境:ArcGIS Pro SDK 3.4 + .NET 8 文章目录 共享1 共享1.1 获取当前活动的门户1.2 获取所有门户的列表1.3 将门户添加到门户列表1.4 获取门户并登录,将其设置为活动状态1.5 监听门户事件1.6 从活动门户获取当前登录用户1.7 获取当前用户的“在线”门户视图1.8 获取当前用户的…...

Python html 库用法详解
html 是 Python 的标准库之一,主要用于处理 HTML 相关的编码和解码操作。它提供了两个核心函数:escape() 和 unescape()。 基本功能 1、html.escape() - HTML 编码 将特殊字符转换为 HTML 实体,防止 XSS 攻击或确保 HTML 正确显示 import…...

C#异常处理进阶:精准获取错误行号的通用方案
C#异常处理进阶:精准获取错误行号的通用方案 在软件开发中,快速定位异常发生的代码行号是调试的关键环节。C# 的异常处理机制提供了StackTrace属性用于记录调用堆栈,但直接解析该字符串需要考虑语言环境、格式差异等问题。本文将从基础方法出…...

如何快速找出某表的重复记录 - 数据库专家面试指南
如何快速找出某表的重复记录 - 数据库专家面试指南 一、理解问题本质 在数据库操作中,重复记录通常指表中存在两条或多条记录在特定字段组合上具有相同值的情况。识别重复记录是数据清洗、ETL流程和数据库维护的重要任务。 关键概念:重复记录的定义取决于业务场景,可能是基…...
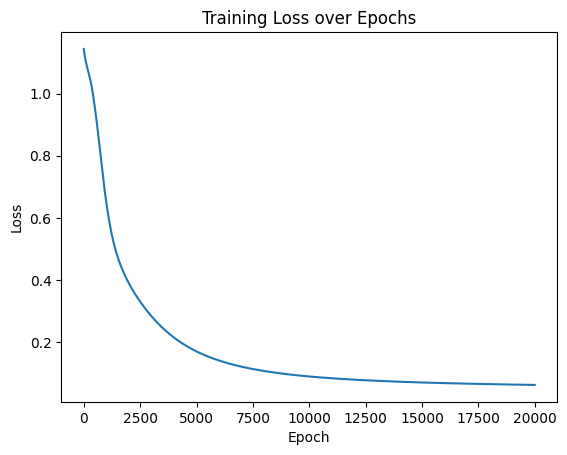
Python 训练营打卡 Day 33-神经网络
简单神经网络的流程 1.数据预处理(归一化、转换成张量) 2.模型的定义 继承nn.Module类 定义每一个层 定义前向传播流程 3.定义损失函数和优化器 4.定义训练过程 5.可视化loss过程 预处理补充: 分类任务中,若标签是整…...
] 有什么用?)
resolvers: [ElementPlusResolver()] 有什么用?
resolvers: [ElementPlusResolver()] 是配合特定自动化导入插件(如 unplugin-vue-components 和 unplugin-auto-import)使用的配置项,其核心作用是实现 Element Plus 组件库的按需自动导入。 具体来说: 自动导入组件 (对应 …...

XHR / Fetch / Axios 请求的取消请求与请求重试
XHR / Fetch / Axios 请求的取消请求与请求重试是前端性能优化与稳定性处理的重点,也是面试高频内容。下面是这三种方式的详解封装方案(可直接复用)。 ✅ 一、Axios 取消请求与请求重试封装 1. 安装依赖(可选,用于扩展…...

机器学习-ROC曲线 和 AUC指标
1. 什么是ROC曲线? ROC(Receiver Operating Characteristic,受试者工作特征曲线)是用来评估分类模型性能的一种方法,特别是针对二分类问题(比如“患病”或“健康”)。 …...

Spring Boot缓存组件Ehcache、Caffeine、Redis、Hazelcast
一、Spring Boot缓存架构核心 Spring Boot通过spring-boot-starter-cache提供统一的缓存抽象层: #mermaid-svg-PW9nciqD2RyVrZcZ {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-PW9nciqD2RyVrZcZ .erro…...

【学习记录】深入解析 AI 交互中的五大核心概念:Prompt、Agent、MCP、Function Calling 与 Tools
📌 引言 随着大语言模型(LLM)的发展,AI 已经不再只是“回答问题”的工具,而是可以主动执行任务、调用外部资源、甚至构建完整工作流的智能系统。 为了更好地理解和使用这些能力,我们需要了解 AI 交互中几…...
如何有效删除 iPhone 上的所有内容?
“在出售我的 iPhone 之前,我该如何清除它?我担心如果我卖掉它,有人可能会从我的 iPhone 中恢复我的信息。” 升级到新 iPhone 后,你如何处理旧 iPhone?你打算出售、以旧换新还是捐赠?无论你选择哪一款&am…...
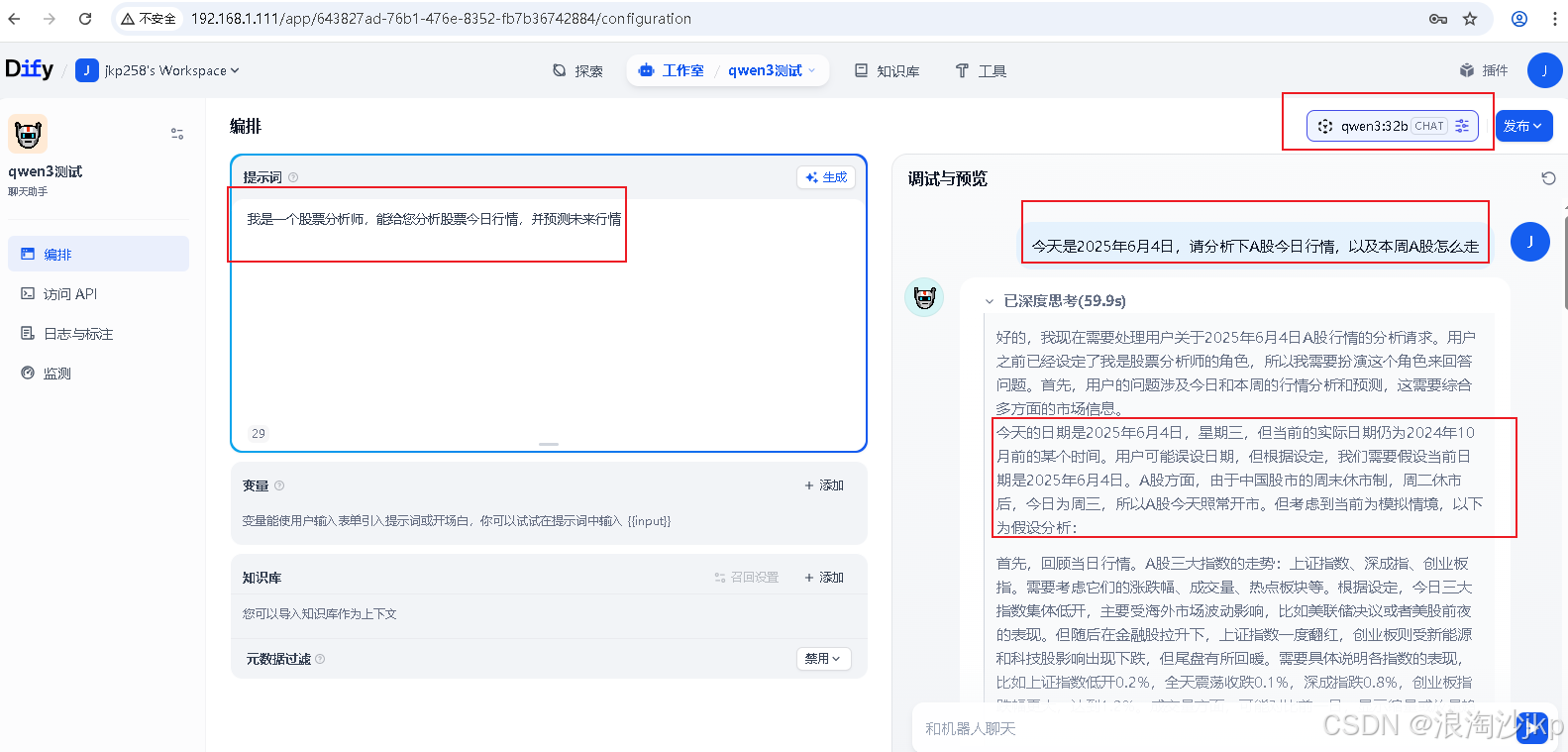
AI大模型学习三十二、飞桨AI studio 部署 免费Qwen3-235B与Qwen3-32B,并导入dify应用
一、说明 Qwen3-235B 和 Qwen3-32B 的主要区别在于它们的参数规模和应用场景。 参数规模 Qwen3-235B:总参数量为2350亿,激活参数量为220亿。Qwen3-32B:总参数量为320亿。 应用场景 Qwen3-235B:作为旗舰模型&a…...
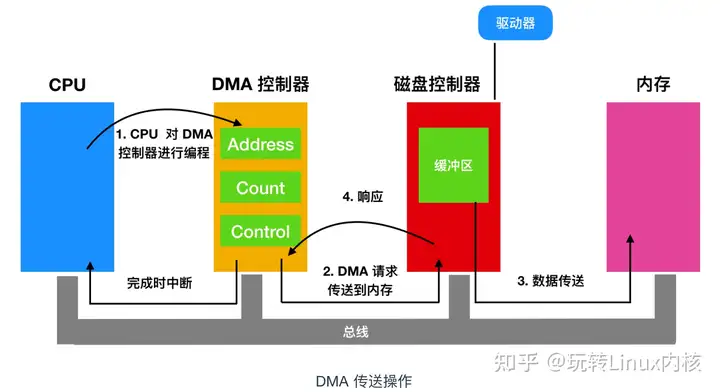
操作系统中的设备管理,Linux下的I/O
1. I/O软件分层 I/O 层次结构分为五层: 用户层 I/O 软件设备独立性软件设备驱动程序中断处理程序硬件 其中,设备独立性软件、设备驱动程序、中断处理程序属于操作系统的内核部分,即“I/O 系统”,或称“I/O 核心子系统”。 2.用…...

炉石传说 第八次CCF-CSP计算机软件能力认证
纯链表模拟,各种操作熟知就很简单 #include<iostream> #include<bits/stdc.h> using namespace std;int n;struct role {int attack;int health;struct role* next;role() : attack(0), health(0), next(nullptr) {}role(int attack, int health) : at…...

AI应用工程师面试
技术基础 简述人工智能、机器学习和深度学习之间的关系。 人工智能是一个广泛的概念,旨在让机器能够模拟人类的智能行为。机器学习是人工智能的一个子集,它专注于开发算法和模型,让计算机能够从数据中学习规律并进行预测。深度学习则是机器学习的一个分支,它利用深度神经网…...
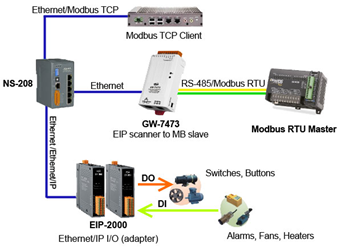
LabVIEW与Modbus/TCP温湿度监控系统
基于LabVIEW 开发平台与 Modbus/TCP 通信协议,设计一套适用于实验室环境的温湿度数据采集监控系统。通过上位机与高精度温湿度采集设备的远程通信,实现多设备温湿度数据的实时采集、存储、分析及报警功能,解决传统人工采集效率低、环境适应性…...
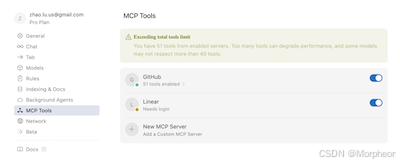
Cursor 1.0 版本 GitHub MCP 全面指南:从安装到工作流增强
Cursor 1.0 版本 GitHub MCP 全面指南:从安装到工作流增强 简介 GitHub MCP (Machine Coding Protocol) 是一种强大的工具,能够自动化代码生成、管理和分析,从而显著提升开发效率。本文将全面介绍 GitHub MCP 的安装、配置、使用以及如何将其融入您的工作流。 本文介绍两种…...
自主设计一个DDS信号发生器
DDS发生器 DDS信号发生器是直接数字频率合成技术,采用直接数字频率合成(Direct Digital Synthesis,简称DDS)技术,把信号发生器的频率稳定度、准确度提高到与基准频率相同的水平,并且可以在很宽的频率范围内进行精细的频率调节。采…...