Python 训练营打卡 Day 33-神经网络
简单神经网络的流程
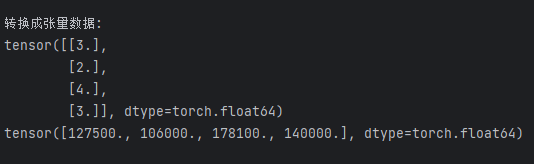
1.数据预处理(归一化、转换成张量)
2.模型的定义
继承nn.Module类
定义每一个层
定义前向传播流程
3.定义损失函数和优化器
4.定义训练过程
5.可视化loss过程
预处理补充:
分类任务中,若标签是整数(如 0/1/2 类别),需转为long类型(对应 PyTorch 的torch.long),否则交叉熵损失函数会报错
回归任务中,标签需转为float类型(如torch.float32)
数据的准备
以4特征,3分类的鸢尾花数据集作为我们今天的数据集
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import numpy as np# 加载鸢尾花数据集
iris = load_iris()
X = iris.data # 特征数据
y = iris.target # 标签数据
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 打印下尺寸
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)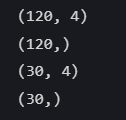
# 归一化数据,神经网络对于输入数据的尺寸敏感,归一化是最常见的处理方式
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test) #确保训练集和测试集是相同的缩放# 将数据转换为 PyTorch 张量,因为 PyTorch 使用张量进行训练
# y_train和y_test是整数,所以需要转化为long类型,如果是float32,会输出1.0 0.0
X_train = torch.FloatTensor(X_train)
y_train = torch.LongTensor(y_train)
X_test = torch.FloatTensor(X_test)
y_test = torch.LongTensor(y_test)模型架构定义
定义一个简单的全连接神经网络模型,包含一个输入层、一个隐藏层和一个输出层
定义层数+定义前向传播顺序
class MLP(nn.Module): # 定义一个多层感知机(MLP)模型,继承父类nn.Moduledef __init__(self): # 初始化函数super(MLP, self).__init__() # 调用父类的初始化函数# 前三行是八股文,后面的是自定义的self.fc1 = nn.Linear(4, 10) # 输入层到隐藏层self.relu = nn.ReLU()self.fc2 = nn.Linear(10, 3) # 隐藏层到输出层
# 输出层不需要激活函数,因为后面会用到交叉熵函数cross_entropy,交叉熵函数内部有softmax函数,会把输出转化为概率def forward(self, x):out = self.fc1(x)out = self.relu(out)out = self.fc2(out)return out# 实例化模型
model = MLP()这个网络结构非常简单:
输入层:4个特征
隐藏层:10个神经元,使用ReLU激活
输出层:3个神经元(适合3分类问题)
没有dropout或batch normalization等复杂结构,这是一个典型的前馈神经网络,适用于简单的分类或回归任务
模型训练
定义损失函数和优化器
# 分类问题使用交叉熵损失函数
criterion = nn.CrossEntropyLoss()# 使用随机梯度下降优化器
optimizer = optim.SGD(model.parameters(), lr=0.01)# # 使用自适应学习率的化器
# optimizer = optim.Adam(model.parameters(), lr=0.001)使用交叉熵损失函数(CrossEntropyLoss),适用于多分类问题
会自动对输出进行softmax处理并计算损失
常用于分类任务,特别是当输出是类别概率时
使用随机梯度下降(SGD)优化器
优化对象是模型的所有可训练参数( model.parameters() )
学习率(lr)设置为0.01
这个配置是训练神经网络的标准设置:
交叉熵损失适用于分类任务
SGD是最基础的优化算法
学习率0.01是一个常用的初始值
循环训练
# 训练模型
num_epochs = 20000 # 训练的轮数# 用于存储每个 epoch 的损失值
losses = []for epoch in range(num_epochs): # range是从0开始,所以epoch是从0开始# 前向传播outputs = model.forward(X_train) # 显式调用forward函数# outputs = model(X_train) # 常见写法隐式调用forward函数,其实是用了model类的__call__方法loss = criterion(outputs, y_train) # output是模型预测值,y_train是真实标签# 反向传播和优化optimizer.zero_grad() #梯度清零,因为PyTorch会累积梯度,所以每次迭代需要清零,梯度累计是那种小的bitchsize模拟大的bitchsizeloss.backward() # 反向传播计算梯度optimizer.step() # 更新参数# 记录损失值losses.append(loss.item())# 打印训练信息if (epoch + 1) % 100 == 0: # range是从0开始,所以epoch+1是从当前epoch开始,每100个epoch打印一次print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')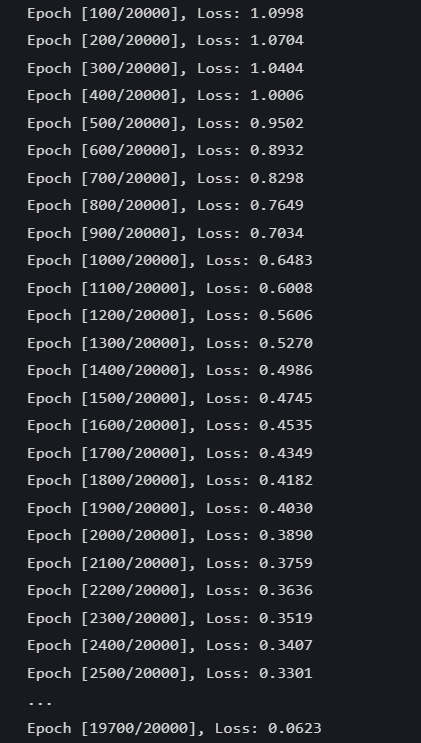
可视化结果
import matplotlib.pyplot as plt
# 可视化损失曲线
plt.plot(range(num_epochs), losses)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss over Epochs')
plt.show()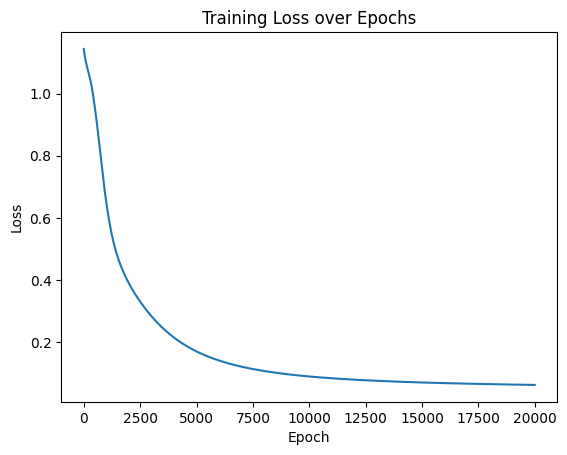
@浙大疏锦行
相关文章:
Python 训练营打卡 Day 33-神经网络
简单神经网络的流程 1.数据预处理(归一化、转换成张量) 2.模型的定义 继承nn.Module类 定义每一个层 定义前向传播流程 3.定义损失函数和优化器 4.定义训练过程 5.可视化loss过程 预处理补充: 分类任务中,若标签是整…...
] 有什么用?)
resolvers: [ElementPlusResolver()] 有什么用?
resolvers: [ElementPlusResolver()] 是配合特定自动化导入插件(如 unplugin-vue-components 和 unplugin-auto-import)使用的配置项,其核心作用是实现 Element Plus 组件库的按需自动导入。 具体来说: 自动导入组件 (对应 …...

XHR / Fetch / Axios 请求的取消请求与请求重试
XHR / Fetch / Axios 请求的取消请求与请求重试是前端性能优化与稳定性处理的重点,也是面试高频内容。下面是这三种方式的详解封装方案(可直接复用)。 ✅ 一、Axios 取消请求与请求重试封装 1. 安装依赖(可选,用于扩展…...

机器学习-ROC曲线 和 AUC指标
1. 什么是ROC曲线? ROC(Receiver Operating Characteristic,受试者工作特征曲线)是用来评估分类模型性能的一种方法,特别是针对二分类问题(比如“患病”或“健康”)。 …...

Spring Boot缓存组件Ehcache、Caffeine、Redis、Hazelcast
一、Spring Boot缓存架构核心 Spring Boot通过spring-boot-starter-cache提供统一的缓存抽象层: #mermaid-svg-PW9nciqD2RyVrZcZ {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-PW9nciqD2RyVrZcZ .erro…...

【学习记录】深入解析 AI 交互中的五大核心概念:Prompt、Agent、MCP、Function Calling 与 Tools
📌 引言 随着大语言模型(LLM)的发展,AI 已经不再只是“回答问题”的工具,而是可以主动执行任务、调用外部资源、甚至构建完整工作流的智能系统。 为了更好地理解和使用这些能力,我们需要了解 AI 交互中几…...
如何有效删除 iPhone 上的所有内容?
“在出售我的 iPhone 之前,我该如何清除它?我担心如果我卖掉它,有人可能会从我的 iPhone 中恢复我的信息。” 升级到新 iPhone 后,你如何处理旧 iPhone?你打算出售、以旧换新还是捐赠?无论你选择哪一款&am…...
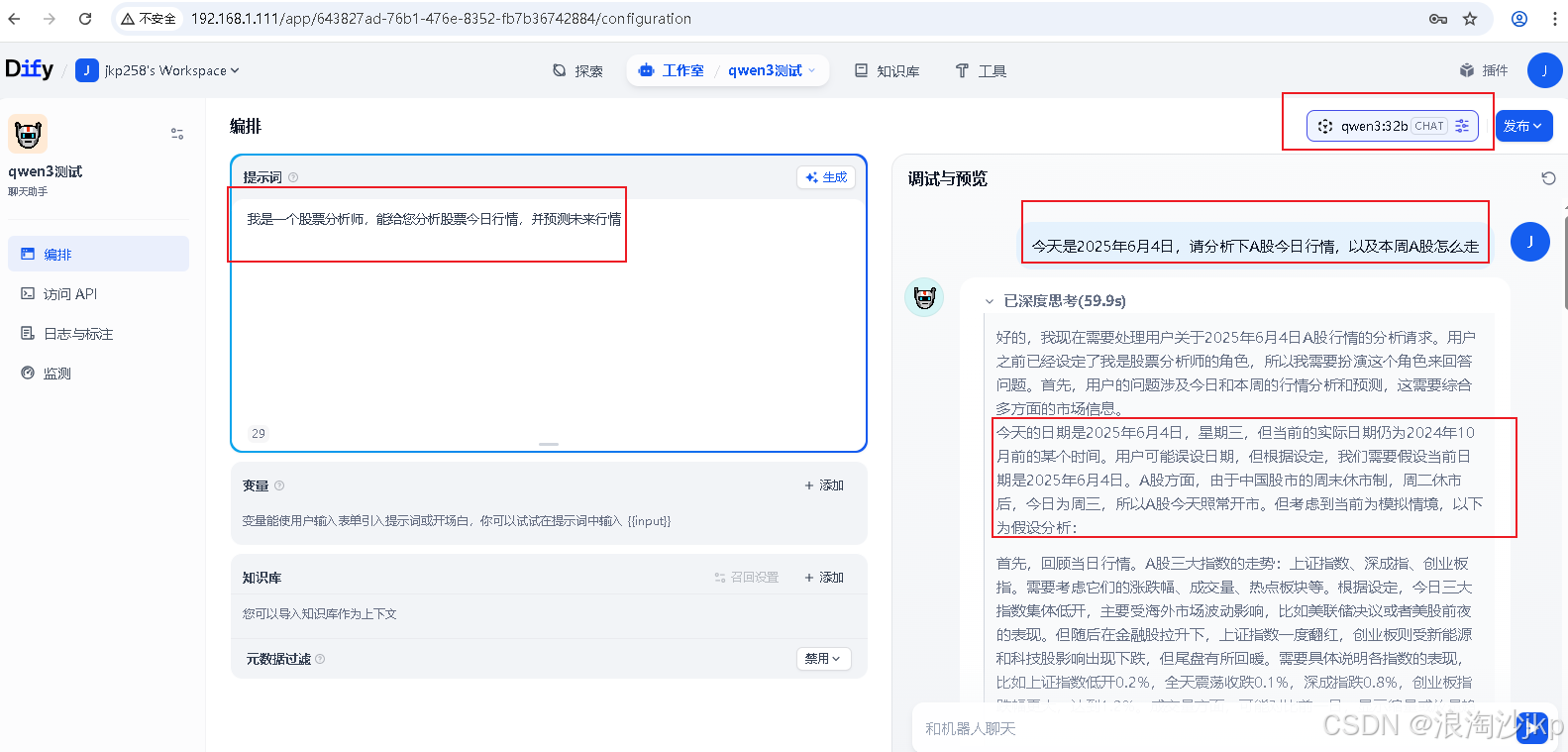
AI大模型学习三十二、飞桨AI studio 部署 免费Qwen3-235B与Qwen3-32B,并导入dify应用
一、说明 Qwen3-235B 和 Qwen3-32B 的主要区别在于它们的参数规模和应用场景。 参数规模 Qwen3-235B:总参数量为2350亿,激活参数量为220亿。Qwen3-32B:总参数量为320亿。 应用场景 Qwen3-235B:作为旗舰模型&a…...
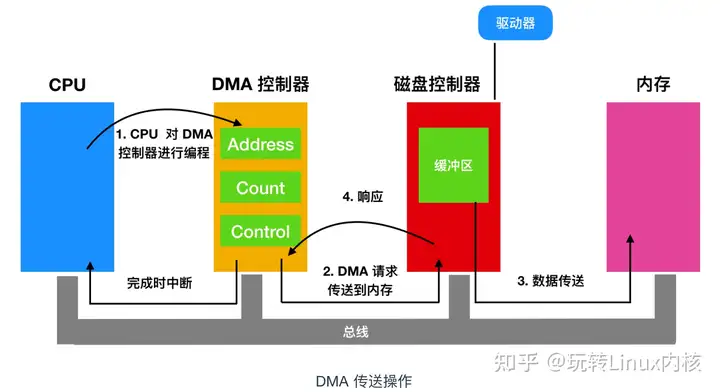
操作系统中的设备管理,Linux下的I/O
1. I/O软件分层 I/O 层次结构分为五层: 用户层 I/O 软件设备独立性软件设备驱动程序中断处理程序硬件 其中,设备独立性软件、设备驱动程序、中断处理程序属于操作系统的内核部分,即“I/O 系统”,或称“I/O 核心子系统”。 2.用…...

炉石传说 第八次CCF-CSP计算机软件能力认证
纯链表模拟,各种操作熟知就很简单 #include<iostream> #include<bits/stdc.h> using namespace std;int n;struct role {int attack;int health;struct role* next;role() : attack(0), health(0), next(nullptr) {}role(int attack, int health) : at…...

AI应用工程师面试
技术基础 简述人工智能、机器学习和深度学习之间的关系。 人工智能是一个广泛的概念,旨在让机器能够模拟人类的智能行为。机器学习是人工智能的一个子集,它专注于开发算法和模型,让计算机能够从数据中学习规律并进行预测。深度学习则是机器学习的一个分支,它利用深度神经网…...
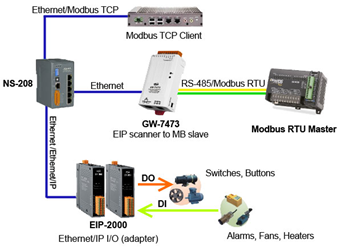
LabVIEW与Modbus/TCP温湿度监控系统
基于LabVIEW 开发平台与 Modbus/TCP 通信协议,设计一套适用于实验室环境的温湿度数据采集监控系统。通过上位机与高精度温湿度采集设备的远程通信,实现多设备温湿度数据的实时采集、存储、分析及报警功能,解决传统人工采集效率低、环境适应性…...
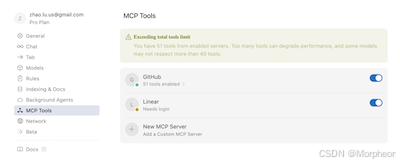
Cursor 1.0 版本 GitHub MCP 全面指南:从安装到工作流增强
Cursor 1.0 版本 GitHub MCP 全面指南:从安装到工作流增强 简介 GitHub MCP (Machine Coding Protocol) 是一种强大的工具,能够自动化代码生成、管理和分析,从而显著提升开发效率。本文将全面介绍 GitHub MCP 的安装、配置、使用以及如何将其融入您的工作流。 本文介绍两种…...
自主设计一个DDS信号发生器
DDS发生器 DDS信号发生器是直接数字频率合成技术,采用直接数字频率合成(Direct Digital Synthesis,简称DDS)技术,把信号发生器的频率稳定度、准确度提高到与基准频率相同的水平,并且可以在很宽的频率范围内进行精细的频率调节。采…...

鸿蒙UI(ArkUI-方舟UI框架)- 使用弹框
返回主章节 → 鸿蒙UI(ArkUI-方舟UI框架) 文章目录 弹框概述使用弹出框(Dialog)弹出框概述不依赖UI组件的全局自定义弹出框(openCustomDialog)(推荐)生命周期自定义弹出框的打开与关闭更新自定义弹出框内容更新自定义弹出框的属性完整示例 基础自定义弹…...
学习笔记(24): 机器学习之数据预处理Pandas和转换成张量格式[2]
学习笔记(24): 机器学习之数据预处理Pandas和转换成张量格式[2] 学习机器学习,需要学习如何预处理原始数据,这里用到pandas,将原始数据转换为张量格式的数据。 学习笔记(23): 机器学习之数据预处理Pandas和转换成张量格式[1]-CSDN博客 下面…...

在不同型号的手机或平板上后台运行Aidlux
在不同型号的手机或平板上后台运行Aidlux 一、鸿蒙/HarmonyOS手机与平板 二、小米手机与平板 三、OPPO手机与平板 四、vivo手机与平板 一、鸿蒙/HarmonyOS手机与平板 (系统版本有差异,但操作原理相通) 第一步:点击设置——应用和…...

【SSM】SpringBoot学习笔记1:SpringBoot快速入门
前言: 文章是系列学习笔记第9篇。基于黑马程序员课程完成,是笔者的学习笔记与心得总结,供自己和他人参考。笔记大部分是对黑马视频的归纳,少部分自己的理解,微量ai解释的内容(ai部分会标出)。 …...

1.企业可观测性监控三大支柱及开源方案的横评对比
[ 知识是人生的灯塔,只有不断学习,才能照亮前行的道路 ] 📢 大家好,我是 WeiyiGeek,一名深耕安全运维开发(SecOpsDev)领域的技术从业者,致力于探索DevOps与安全的融合(De…...

Neo4j图数据库管理:原理、技术与最佳实践
Neo4j作为领先的图数据库,其高效管理是发挥图计算潜力的关键。本文基于官方技术文档,深入探讨其管理原理、核心操作及生产环境最佳实践。 一、 管理架构与核心原理 多数据库架构 系统数据库 (system):管理元数据(用户、角色、权限、其他数据库信息)。标准数据库:存储实际…...
数据类型介绍)
Elasticsearch中的地理空间(Geo)数据类型介绍
在Elasticsearch中,地理空间(Geo)数据类型用于存储和处理与地理位置相关的数据,支持基于地理坐标的查询、过滤和分析。这类数据类型允许用户在分布式环境中高效地处理地理空间相关的搜索、聚合和可视化需求,广泛应用于地图应用、物流追踪、位置服务(LBS)等场景。 一、核…...

[论文阅读] 软件工程 | 如何挖掘可解释性需求?三种方法的深度对比研究
如何挖掘可解释性需求?三种方法的深度对比研究 研究背景:当软件变复杂,我们需要“说明书” 想象你买了一台智能家电,却发现它的运行逻辑完全看不懂,按钮按下后毫无反应,故障时也不提示原因——这就是现代…...
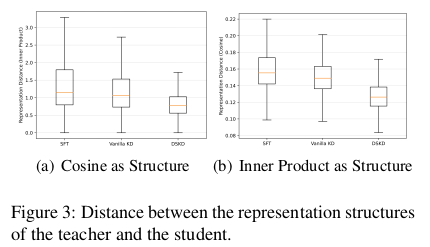
双空间知识蒸馏用于大语言模型
Dual-Space Knowledge Distillation for Large Language Models 发表:EMNLP 2024 机构:Beijing Key Lab of Traffic Data Analysis and Mining 连接:https://aclanthology.org/2024.emnlp-main.1010.pdf 代码:GitHub - songmz…...
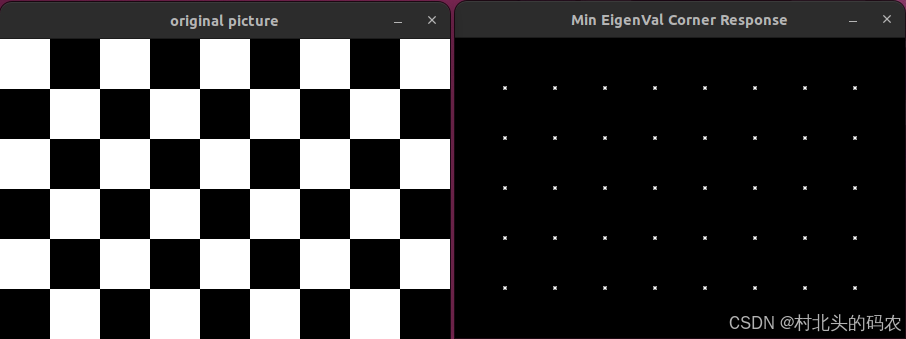
OpenCV CUDA模块特征检测------角点检测的接口createMinEigenValCorner()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 该函数创建一个 基于最小特征值(Minimum Eigenvalue)的角点响应计算对象,这是另一种经典的角点检测方法&…...

Git 提交备注应该如何规范
Git 提交备注应该如何规范 在软件开发过程中,Git 作为版本控制系统被广泛使用,而规范的提交备注对于代码的可维护性、团队协作以及项目的长期发展都有着至关重要的意义。良好的提交备注能够清晰地记录代码变更的原因、范围和影响,方便团队成…...

青少年编程与数学 02-020 C#程序设计基础 17课题、WEB与移动开发
青少年编程与数学 02-020 C#程序设计基础 17课题、WEB与移动开发 一、C#语言Web和移动项目开发1. Web项目开发2. 移动项目开发 二、ASP.NET Core1. ASP.NET Core 基础架构1.1 请求处理管道1.2 主机模型1.3 服务器选项 2. 核心新特性2.1 NativeAOT 支持2.2 增强的身份验证方案2.…...
)
Qt OpenGL 实现交互功能(如鼠标、键盘操作)
一、基本概念 1. Qt 事件系统与 OpenGL 渲染的协同 Qt 提供了完善的事件处理机制,而 OpenGL 负责图形渲染。交互的实现本质上是: 事件捕获:通过 Qt 的事件系统(如 mousePressEvent、keyPressEvent)捕获用户输入。 状态更新:根据输入事件更新场景状态(如相机位置、模型…...

【Go语言基础【3】】变量、常量、值类型与引用类型
文章目录 一、值(Value)与字面量(Literal)1. 值2. 字面量 二、变量(Variable)1. 声明方式2. 赋值方式3. 变量默认值4. 类型与值的匹配 三、常量(Constant)1. 声明方式2. 常量的特性3…...

8天Python从入门到精通【itheima】-69~70(字符串的常见定义和操作+案例练习)
目录 69节-字符串的定义和操作 1.学习目标 2.数据容器视角下的字符串 3.字符串的下标索引 4.字符串是一个无法修改的数据容器 5.字符串的常用操作 【1】index方法 【2】replace方法:进过替换,得到一个新的字符串 【3】split方法:将字…...

在 Linux 中查看文件并过滤空行
在 Linux 中查看文件并过滤空行 在 Linux 中查看文件内容时过滤掉空行有多种方法,以下是几种常用的方法: 方法 1:使用 grep grep -v ^$ filename-v:反转匹配,只显示不匹配的行^$:表示空行的正则表达式&a…...