基于本地LLM与MCP架构构建AI智能体全指南
一、AI智能体开发的新范式
随着人工智能技术的快速演进,AI智能体(AI Agents)正成为连接技术创新与实际应用的核心载体。从智能家居的温控系统到复杂的金融风控决策,AI智能体通过感知环境并执行目标导向的行为,正在重塑各行业的自动化与智能化水平。然而,传统依赖云端大语言模型(LLMs)的开发模式面临数据隐私风险、网络延迟以及高昂算力成本等挑战,而本地大语言模型(Local LLMs)与多上下文编程架构(MCP Architectures)的结合,为这些问题提供了创新性解决方案。
本文将深入探讨如何利用本地LLMs与MCP架构构建高性能AI智能体,涵盖核心概念解析、技术优势、开发工具链、架构设计、实施步骤及优化策略等关键环节,旨在为开发者提供从理论到实践的全流程指导。

二、核心概念:本地LLMs与MCP架构的技术基石
2.1 AI智能体的本质与分类
AI智能体是具备感知、决策与行动能力的软件实体,其核心特征包括:
- 环境感知
:通过传感器或数据接口获取外部信息(如用户输入、设备状态);
- 目标驱动
:基于预设目标或动态任务调整行为策略;
- 自主决策
:通过算法模型独立完成信息处理与行动选择;
- 持续学习
:从交互中积累经验以优化性能。
根据复杂度可分为三类:
- 反应式智能体
:仅依据当前状态触发固定响应(如恒温器调节温度);
- 基于模型的智能体
:通过环境建模预测行为后果(如自动驾驶路径规划);
- 基于目标的智能体
:结合目标优先级与资源约束动态调整策略(如智能客服多任务处理)。
2.2 本地大语言模型(Local LLMs)的技术突破
传统云端LLMs(如GPT-4)需将数据传输至远程服务器处理,而本地LLMs通过模型轻量化与硬件优化,实现了数据不出设备的本地化推理,其核心优势包括:
- 隐私增强
:敏感数据(如医疗记录、金融信息)无需联网,从源头规避数据泄露风险;
- 低延迟响应
:毫秒级推理速度适用于实时交互场景(如工业机器人控制、智能座舱语音助手);
- 成本优化
:减少对云端算力的依赖,降低长期运营成本(尤其适合边缘设备或离线环境);
- 定制化能力
:基于自有数据微调模型,提升垂直领域(如法律文书处理、企业知识库问答)的专业性。
2.3 MCP架构:多上下文管理的核心逻辑
多上下文编程(Multiple Context Programming, MCP)架构通过动态管理多个独立上下文,赋予AI智能体处理复杂场景的能力。其核心组件包括:
- 上下文管理器(Context Manager)
:创建、切换与销毁不同任务上下文(如用户购物场景中的“搜索-比价-下单”分段处理);
- 记忆模块(Memory Module)
:存储上下文相关数据(短期记忆用于当前交互,长期记忆用于历史行为分析);
- 状态机(State Machine)
:定义上下文转换规则(如客服智能体从“问题咨询”切换至“技术支持”的触发条件)。
典型应用场景:
- 多任务并行处理
:智能助手同时管理日程提醒、邮件筛选与新闻推送任务;
- 上下文敏感交互
:医疗问诊智能体根据患者病历(历史上下文)调整当前问诊流程;
- 跨模态协同
:教育智能体结合文本教材(文本上下文)与实验视频(视觉上下文)提供个性化学习路径。
三、技术优势:隐私、效率与定制化的三重提升
3.1 数据隐私与安全强化
- 本地化数据闭环
:敏感数据(如用户聊天记录、企业内部文档)仅在本地设备或私有服务器处理,符合GDPR、HIPAA等合规要求;
- 防逆向工程
:避免云端API接口被恶意攻击,降低模型被窃取或滥用的风险;
- 权限细粒度控制
:通过本地防火墙与访问策略限制模型调用权限,适合政府、金融等安全敏感领域。
3.2 实时响应与成本优化
- 延迟降低90%以上
:对比云端调用的百毫秒级延迟,本地推理可实现10ms以内响应(如自动驾驶避障决策);
- 算力成本节省
:减少对高带宽网络与云端GPU的依赖,边缘设备单机即可支撑简单智能体运行;
- 离线可用性
:在无网络环境(如地下矿井、偏远地区)仍能保持完整功能,提升系统鲁棒性。
3.3 深度定制化与领域适配
- 数据闭环微调
:利用企业私有数据(如客服对话日志、生产流程数据)对基础模型进行微调,提升专业任务准确率(如法律文书生成的条款引用正确率提升40%);
- 动态架构调整
:通过MCP架构灵活添加领域特定模块(如医疗智能体的药物相互作用查询工具),无需重构整体框架;
- 小样本学习能力
:结合提示工程(Prompt Engineering)与少量标注数据,快速适配新业务场景(如新品类电商推荐系统)。
四、开发全流程:从环境搭建到智能体落地
4.1 开发准备:硬件与软件基础
4.1.1 硬件配置建议
| 组件 | 基础配置(中小型模型) | 进阶配置(大型模型) |
|---|---|---|
| CPU | Intel i7/AMD Ryzen 7 及以上 | Intel Xeon/AMD EPYC 服务器级 |
| GPU | NVIDIA RTX 3060(8GB VRAM) | NVIDIA A100/H100(40GB+ VRAM) |
| 内存 | 16GB DDR4 | 64GB+ DDR5 |
| 存储 | 512GB SSD(NVMe协议) | 2TB+ NVMe SSD |
关键说明:
-
GPU加速:本地LLMs推理依赖CUDA或ROCM加速,NVIDIA显卡兼容性最佳;
-
边缘设备:树莓派4(8GB版)可运行轻量级模型(如DistilBERT),适合原型开发。
4.1.2 软件工具链
- 编程语言
:Python 3.8+(主流AI开发语言);
- 深度学习框架
:PyTorch 2.0+(动态图灵活调试)或TensorFlow 2.12+(静态图生产部署);
- 模型工具
:Hugging Face Transformers(预训练模型库)、AutoGPTQ(模型量化工具);
- MCP框架
:LangChain(上下文管理与工具集成)、Microsoft Semantic Kernel(语义内核开发);
- 开发环境
:Anaconda(环境隔离)、Jupyter Notebook(交互式调试)。
4.2 环境搭建:从框架安装到模型部署
4.2.1 框架安装步骤(以PyTorch为例)
# 创建虚拟环境
conda create -n ai_agent python=3.10
conda activate ai_agent# 安装PyTorch(GPU版本)
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118# 安装Hugging Face库
pip install transformers datasets accelerate
4.2.2 本地LLMs部署流程
- 模型下载
:从Hugging Face Hub获取开源模型(如
facebook/llama-2-7b-chat); - 模型量化:使用AutoGPTQ将32位浮点模型转换为4/8位整型,压缩模型体积并提升推理速度:
from auto_gptq import AutoGPTQForCausalLM model = AutoGPTQForCausalLM.from_quantized("model_path",quantize_config=QuantizeConfig(bits=4, # 量化位数group_size=128, # 分组大小优化desc_act=True) ) - 模型加载优化:利用TensorRT-LLM或GGML库进一步加速推理,如:
# 使用GGML加载LLaMA模型 import llama_cpp model = llama_cpp.Llama(model_path="llama-2-7b.ggmlv3.q4_0.bin",n_ctx=2048 # 上下文窗口大小 )
4.3 智能体架构设计:基于MCP的分层建模
4.3.1 三层架构模型
AI智能体架构
├─ 感知层(Perception Layer)
│ ├─ 数据接口:API调用、文件解析、传感器数据采集
│ └─ 预处理模块:文本清洗、图像特征提取、语音转文字
├─ 决策层(Decision Layer)
│ ├─ 本地LLMs引擎:负责自然语言理解与生成
│ ├─ MCP管理器:上下文创建(如用户身份识别)、切换(如从购物车管理到订单支付)、销毁
│ └─ 工具调用模块:数据库查询、计算器、外部API(如天气查询)
└─ 执行层(Execution Layer)├─ 动作引擎:指令解析(如生成SQL语句、控制硬件设备)└─ 反馈模块:用户响应生成、日志记录、性能监控
4.3.2 上下文管理核心实现
-
上下文数据结构:
class Context:def __init__(self, context_id: str, metadata: dict, memory: list):self.context_id = context_id # 唯一标识self.metadata = metadata # 上下文元数据(如用户ID、任务类型)self.memory = memory # 对话历史或任务状态列表def add_memory(self, message: dict):self.memory.append(message) # 添加对话记录或事件日志 -
上下文切换逻辑:
class ContextManager:def __init__(self):self.contexts = {} # 存储所有活跃上下文self.current_context = None # 当前激活上下文def create_context(self, context_id: str, **kwargs):new_context = Context(context_id, kwargs.get("metadata", {}), [])self.contexts[context_id] = new_contextself.current_context = new_contextdef switch_context(self, context_id: str):if context_id in self.contexts:self.current_context = self.contexts[context_id]else:raise ValueError("Context not found")
4.4 功能集成:工具调用与知识检索
4.4.1 工具调用机制
通过LangChain的Tool类定义可调用工具,示例如下:
from langchain.tools import Tool
from datetime import datetime# 定义获取当前时间的工具
def get_current_time():return datetime.now().strftime("%Y-%m-%d %H:%M:%S")tool = Tool(name="GetCurrentTime",func=get_current_time,description="Use this tool to get the current date and time."
)# 在LLMs中启用工具调用
from langchain.agents import initialize_agent
agent = initialize_agent([tool],model,agent="zero-shot-react-description",verbose=True
)# 调用示例:用户询问“现在几点了?”
response = agent.run("现在几点了?") # 自动触发工具调用并返回结果
4.4.2 知识检索系统
结合FAISS向量数据库构建实时知识库,流程如下:
- 数据预处理
:将文档分割为500字左右的文本块,使用BERT模型生成句向量;
- 向量存储
:将向量存入FAISS索引库,支持快速最近邻搜索;
-
检索增强生成(RAG):在LLMs生成响应前,先检索相关文档片段作为上下文:
from langchain.retrievers import FAISSDatabaseRetriever from langchain.chains import RetrievalQAretriever = FAISSDatabaseRetriever.from_index(faiss_index, embeddings) qa_chain = RetrievalQA.from_chain_type(model,chain_type="stuff",retriever=retriever,verbose=True )# 查询示例:“如何配置PyTorch环境?” result = qa_chain.run("如何配置PyTorch环境?") # 结合知识库内容生成回答
五、优化与调试:提升智能体性能的关键环节
5.1 性能基准测试
- 响应时间
:使用
timeit模块测量从输入到输出的端到端延迟,目标控制在50ms以内(对话场景); - 吞吐量
:模拟多用户并发请求,测试智能体每秒处理请求数(QPS),通过模型量化与异步推理提升性能;
- 资源占用
:监控CPU/GPU利用率、内存占用,使用
nvidia-smi或psutil库定位内存泄漏问题。
5.2 记忆优化策略
- 滑动窗口机制
:限制对话历史长度(如保留最近20轮交互),避免上下文膨胀导致推理速度下降;
- 语义压缩
:使用Sentence-BERT对长文本记忆进行摘要,减少存储体积与计算负载;
- 分层存储
:将高频访问的短期记忆存于内存,低频长期记忆存于磁盘数据库(如SQLite)。
5.3 常见问题与解决方案
| 问题类型 | 典型现象 | 解决方法 |
|---|---|---|
| 上下文丢失 | 智能体忽略历史对话信息 | 检查上下文管理器是否正确保存记忆,增加记忆持久化机制(如Redis缓存) |
| 模型加载失败 | 启动时提示文件不存在或格式错误 | 验证模型路径正确性,使用官方提供的转换工具(如LLaMA模型转换脚本) |
| 工具调用错误 | 返回“未知工具”或参数错误 | 确保工具注册到智能体架构,使用JSON Schema验证输入参数格式 |
| 生成内容偏离主题 | 响应与问题无关或逻辑混乱 | 调整提示词引导(如添加“请围绕‘XXX’主题回答”),启用输出格式约束(如JSON) |
相关文章:
基于本地LLM与MCP架构构建AI智能体全指南
一、AI智能体开发的新范式 随着人工智能技术的快速演进,AI智能体(AI Agents)正成为连接技术创新与实际应用的核心载体。从智能家居的温控系统到复杂的金融风控决策,AI智能体通过感知环境并执行目标导向的行为,正在重塑…...
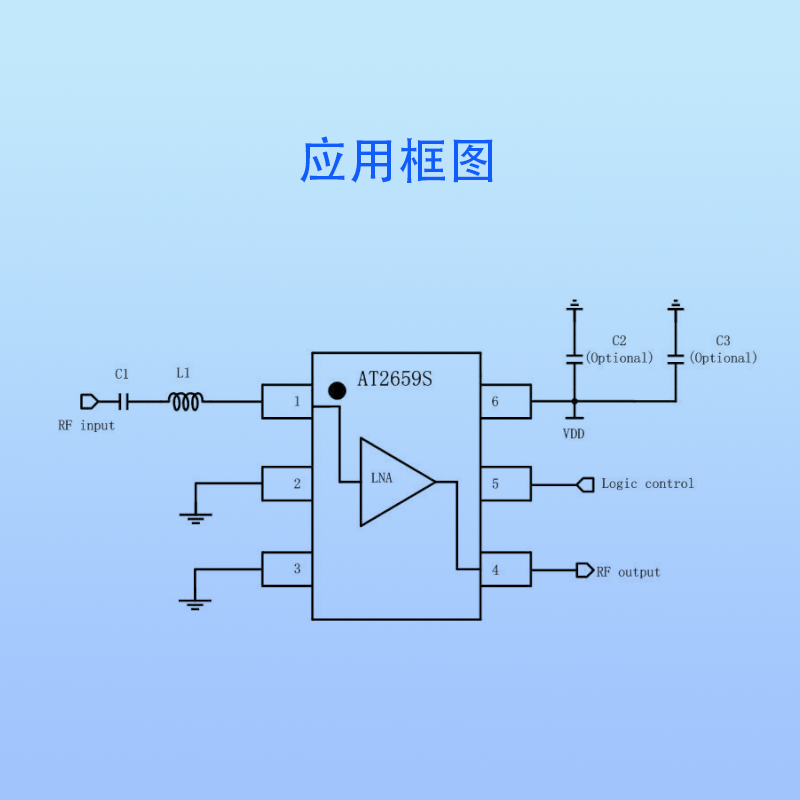
AT2659_GNSS低噪声放大器芯片
AT2659 射频放大器在SiGe工艺平台上实现23dB增益与0.71dB噪声系数的优异组合,专为BDS/GPS/GLONASS/GALILEO多模导航系统优化设计。其宽电压适应能力(1.4-3.6V)与低至4.4mA的功耗特性,配合1.5mm1mm0.55mm的6脚DFN封装(R…...

跨平台游戏引擎 Axmol-2.6.1 发布
Axmol 2.6.1 版本是一个以错误修复和功能改进为主的次要LTS长期支持版本 🙏感谢所有贡献者及财务赞助者:scorewarrior、peterkharitonov、duong、thienphuoc、bingsoo、asnagni、paulocoutinhox、DelinWorks 错误修复 修复Android armv7架构崩溃问题&…...
MADlib —— 基于 SQL 的数据挖掘解决方案(4)—— 数据类型之矩阵
目录 一、矩阵定义 二、MADlib 中的矩阵表示 1. 稠密 2. 稀疏 三、MADlib 中的矩阵运算函数 1. 矩阵操作函数分类 (1)表示函数 (2)计算函数 (3)提取函数 (4)归约函数&…...

ServBay 1.13.0 更新,新增第三方反向代理/内网穿透
ServBay 作为一款简化本地开发环境搭建与管理的强大工具,致力于打造一个开箱即用、稳定可靠的本地开发平台,让用户专注于代码编写,提升开发效率。 ServBay 1.13.0 正式发布!本次更新聚焦于提升本地开发项目的外部可访问性、增强国…...

C#对象扩展方法:提升对象操作的灵活性与效率
C#对象扩展方法:提升对象操作的灵活性与效率 在C#编程中,我们经常需要对对象进行各种操作,如获取对象属性信息、转换对象格式、复制对象等。通过扩展方法,我们可以为现有类型添加新的功能,而无需修改原始类型的代码。…...

Python爬虫爬取天猫商品数据,详细教程【Python经典实战项目】
Python爬取天猫商品数据详细教程 一、前期准备 1. 环境配置 Python环境:确保已安装Python 3.x版本,建议使用Anaconda或直接从Python官网下载安装。第三方库: requests:用于发送HTTP请求。BeautifulSoup:用于解析HTM…...

Oracle 的 SEC_CASE_SENSITIVE_LOGON 参数
Oracle 的SEC_CASE_SENSITIVE_LOGON 参数 关键版本信息 SEC_CASE_SENSITIVE_LOGON 参数在以下版本中被弃用: Oracle 12c Release 1 (12.1): 该参数首次被标记为"过时"(obsolete)但依然保持功能有效 Oracle 18c/19c 及更高版本: …...

Docker构建自定义的镜像
构建自定义的 Docker 镜像是 Docker 使用中的核心操作之一。通过自定义镜像,你可以将应用程序及其依赖环境打包成一个可移植的容器化镜像。以下是详细的步骤和注意事项: 1. 准备工作 在构建自定义镜像之前,你需要准备以下内容: D…...
【SSM】SpringMVC学习笔记8:拦截器
这篇学习笔记是Spring系列笔记的第8篇,该笔记是笔者在学习黑马程序员SSM框架教程课程期间的笔记,供自己和他人参考。 Spring学习笔记目录 笔记1:【SSM】Spring基础: IoC配置学习笔记-CSDN博客 对应黑马课程P1~P20的内容。 笔记2…...
井川里予瓜pdf完整版
井川里予瓜pdf完整版 下载链接: 链接:https://pan.quark.cn/s/c75455d6be60 在网红文化盛行的当下,井川里予无疑是一位备受瞩目的人物。这位2001年出生于广东湛江的姑娘,凭借独特风格在网络世界掀起波澜,其发展轨迹…...

UI自动化常见的一些问题解决方式
1、遇到元素无法定位的情况 解决方法:(1)手写css 先找到父级的唯一元素 (2)手写xpath、 (3)js在浏览器控制台去定位 控制台定位样例:(1)…...
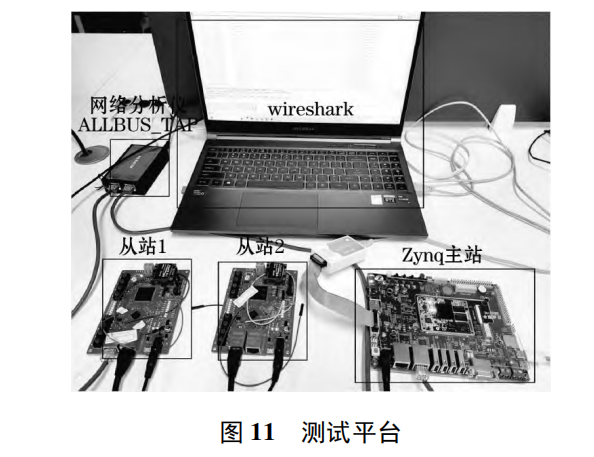
基于 Zynq 平台的 EtherCAT 主站的软硬件协同设计
摘要: 针对工业自动化对控制能力和强实时性的需求,提出了一种基于 FPGA 的改进型 EtherCAT 硬件主站方案 。 该方案利用 Zynq-7000 平台,在 PL 端实现 FPGA 协议栈,以保证核心功能的高效执 行 。 基于 AXI4 总线设计…...
聊一聊 .NET在Linux下的IO多路复用select和epoll
一:背景 1. 讲故事 在windows平台上,相信很多人都知道.NET异步机制是借助了Windows自带的 IO完成端口 实现的异步交互,那在 Linux 下.NET 又是怎么玩的呢?主要还是传统的 select,poll,epoll 的IO多路复用…...
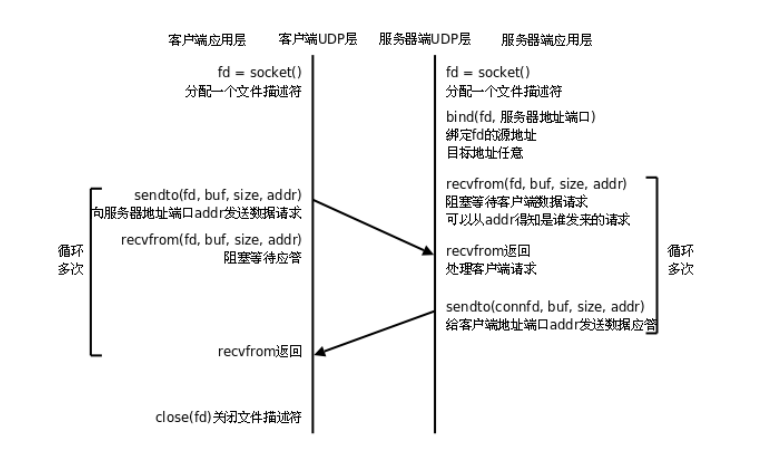
从零开始的嵌入式学习day33
网络编程及相关概念 UDP网络通信程序 UDP网络通信操作 一、网络编程及相关概念 1. 网络编程概念: 指通过计算机网络实现程序间通信的技术,涉及协议、套接字、数据传输等核心概念。常见的应用场景包括客户端-服务器模型、分布式系统、实时通信等。…...

ArcGIS Pro 3.4 二次开发 - 宗地
环境:ArcGIS Pro SDK 3.4 + .NET 8 文章目录 宗地1 宗地1.1 向地图添加宗地图层1.2 获取活动记录1.3 设置活动记录1.4 创建新记录1.5 将标准线要素复制到宗地类型1.6 将宗地线复制到宗地类型1.7 将要素分配给活动记录1.8 创建宗地种子1.9 构建地块1.10 重复地块1.11 设置地块为…...

前端面试准备-7
1.定义class的实现 //定义class class Person{//公有属性nameage 18//构造函数constructor(name){//构造函数内部的this实例化对象this.name name//动态添加属性(不推荐)this.food [🐂,🐎,🐏]}//公有方法sayHi(){c…...

黑马Java面试笔记之框架篇(Spring、SpringMvc、Springboot)
一. 单例bean Spring框架中的单例bean是线程安全的吗? Spring框架中的bean是单例的,可以在注解Scope()进行设置 singleton:bean在每一个Spring IOC容器中只有一个实例。prototype:一个bean的定义可以有多个实例 总结 二. AOP AOP称…...
全球IP归属地查询接口如何用C#进行调用?
一、什么是全球IP归属地查询接口 在全球化互联网时代,IP地址作为网络世界的地理位置标识,扮演着至关重要的角色。全球IP归属地查询接口通过解析IP地址,提供包括国家、省、市、区县和运营商在内的详细信息。 二、应用场景 1. 访问识别 全球…...
NumPy 比较、掩码与布尔逻辑
文章目录 比较、掩码与布尔逻辑示例:统计下雨天数作为通用函数(Ufuncs)的比较运算符使用布尔数组计数条目布尔运算符 布尔数组作为掩码使用关键字 and/or 与运算符 &/| 的区别 比较、掩码与布尔逻辑 本文介绍如何使用布尔掩码来检查和操…...
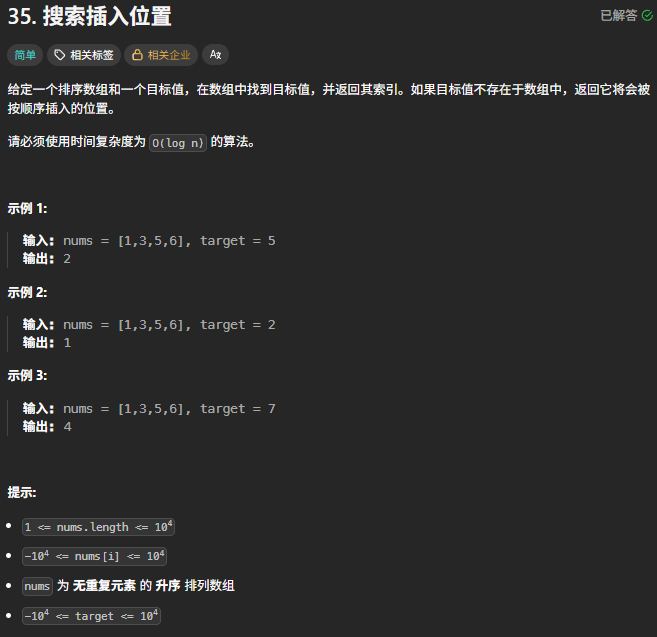
力扣HOT100之二分查找:35. 搜索插入位置
这道题属于是二分查找的入门题了,我依稀记得一些二分查找的编码要点,但是最后还是写出了一个死循环,无语(ˉ▽ˉ;)…又回去看了下自己当时的博客和卡哥的视频,这才发现自己分情况只分了两种,最后导致死循环…...
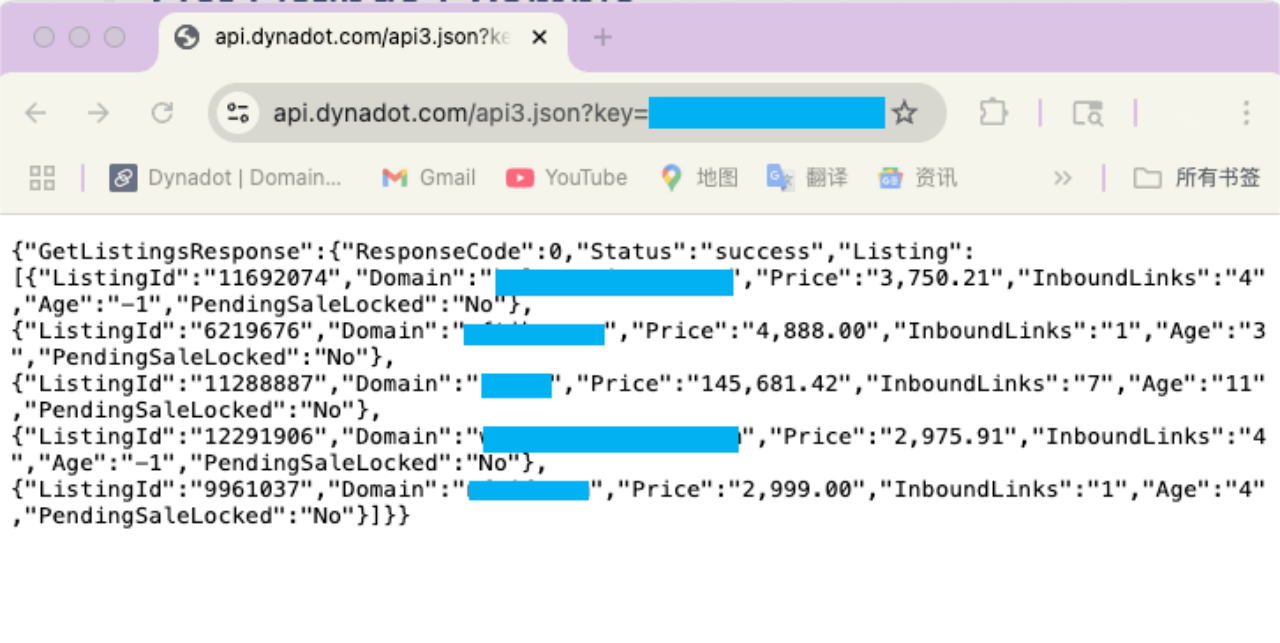
使用API有效率地管理Dynadot域名,查看域名市场中所售域名的详细信息
关于Dynadot Dynadot是通过ICANN认证的域名注册商,自2002年成立以来,服务于全球108个国家和地区的客户,为数以万计的客户提供简洁,优惠,安全的域名注册以及管理服务。 Dynadot平台操作教程索引(包括域名邮…...

IM即时通讯软件,构建企业局域网内安全协作
安全与权限:协同办公的企业级保障 在协同办公场景中,BeeWorks 将安全机制贯穿全流程。文件在局域网内传输与存储时均采用加密处理,企业网盘支持水印预览、离线文档权限回收等功能,防止敏感资料外泄;多人在线编辑文档时…...
VueScan:全能扫描,高清输出
在数字化办公和图像处理的领域,扫描仪扮演着不可或缺的角色。无论是文档的数字化存档、照片的高清复制,还是创意项目的素材采集,一款性能卓越、操作便捷的扫描软件能大幅提升工作效率和成果质量。VueScan正是这样一款集多功能于一身的扫描仪软…...

PyCharm项目和文件运行时使用conda环境的教程
打开【文件】—【新建项目】 按照下图配置环境 可以看到我这个项目里,报错“No module named modelscope” 点击终端,输入命令 #显示所有的conda环境 conda env list #选择需要激活的conda环境 conda activate XXX在终端中,执行pip install …...
:组件的幕后工作)
第八部分:第五节 - 生命周期与副作用 (`useEffect` Hook):组件的幕后工作
知识点: 组件生命周期(挂载 Mounting, 更新 Updating, 卸载 Unmounting - 高级概念),副作用 (Side Effects),useEffect Hook (用于处理副作用,如数据获取、订阅、DOM 操作),useEffect 的依赖数组…...
)
docker 搭建php 开发环境 添加扩展redis、swoole、xdebug(2)
3、创建compose 的yml文件 version: "3.9" services:#配置nginxnginx:#镜像名称 nginx:latestimage: nginx#自定义容器的名称#container_name: c_nginxports:- "80:80"#lnmp目录和容器的/usr/share/nginx/html目录进行绑定,设置rw权限#将宿主机的~/lnmp/…...

DeepSwiftSeek 开源软件 |用于 DeepSeek LLM 模型的 Swift 客户端 |轻量级和高效的 DeepSeek 核心功能通信
一、软件介绍 文末提供程序和源码下载 DeepSeek Swift SDK 是一个轻量级且高效的基于 Swift 的客户端,用于与 DeepSeek API 进行交互。它支持聊天消息完成、流式处理、错误处理以及使用高级参数配置 DeepSeekLLM。 二、Features 特征 Supports chat completion …...
Flask-Login使用示例
项目结构 首先创建以下文件结构: flask_login_use/ ├── app.py ├── models.py ├── requirements.txt └── templates/├── base.html├── index.html├── login.html├── register.html└── profile.html1. requirements.txt Flask2.3.3 Fl…...

React Hooks 基础指南
React Hooks 是 React 16.8 引入的重要特性,它允许开发者在函数组件中使用状态和其他 React 特性。本文将详细介绍 6 个最常用的 React Hooks。 1. useState useState 是最常用的 Hook,用于在函数组件中添加 state。 import React, { useState } from…...