CppCon 2015 学习:Functional Design Explained
这两个 C++ 程序 不完全相同。它们的差异在于对 std::cout 的使用和代码格式。
程序 1:
#include <iostream>
int main(int argc, char** argv)
{std::cout << "Hello World\n";
}
- 解释:这个程序是 正确的。
std::cout是 C++ 标准库中输出流对象,std是命名空间,cout是输出流对象。程序会正确地输出 “Hello World”。
程序 2:
#include <iostream>
int main(int argc, char** argv)
{std:: cout << "Hello World\n";
}
- 解释:虽然这个程序看起来像是没有语法错误,但它的写法存在问题。
std::和cout之间的空格并不会影响编译,C++ 编译器会尝试解析它为std::cout。所以,这段代码 仍然能编译通过,并且正常输出 “Hello World”。
关键点:
- 程序 1 是标准的正确写法。
- 程序 2 虽然有不必要的空格,但 依然可以正常工作,因为 C++ 允许在标识符和运算符之间有额外的空格。
总结:
- 这两个程序的功能上 是相同的,都会输出 “Hello World”。
- 但 程序 1 更符合 C++ 的标准格式,而程序 2 使用了不必要的空格,虽然在技术上没有错误,但并不推荐这种写法。
这两个程序 不相同,它们分别是用 C++ 和 Python 语言编写的,虽然它们的功能相似(都输出 “Hello World”),但它们的语法和执行方式完全不同。
程序 1:C++ 代码
#include <iostream>
int main(int argc, char** argv)
{std::cout << "Hello World\n";
}
- 解释:这是一个用 C++ 编写的程序,它会在控制台输出 “Hello World”。
- 特点:
- 需要使用
#include <iostream>来引入标准输入输出库。 - 使用
std::cout输出文本。 - 程序的入口点是
main()函数。 - 程序是静态编译的,运行前需要进行编译。
- 需要使用
程序 2:Python 代码
#!/usr/bin/env python
print("Hello World")
- 解释:这是一个用 Python 编写的程序,功能是输出 “Hello World”。
- 特点:
- 这行
#!/usr/bin/env python是一个 shebang,表示这个程序应该由 Python 解释器执行。 - 使用
print()函数来输出文本。 - 程序不需要显式地定义
main()函数,Python 程序会从顶部开始执行。 - Python 是一种动态解释型语言,不需要编译,直接运行源代码即可。
- 这行
关键区别:
- 编程语言不同:第一个程序是 C++,第二个程序是 Python。它们的语法和执行环境完全不同。
- 编译与解释:
- C++ 程序需要先 编译 成机器码,然后运行。
- Python 程序是 解释执行,不需要编译,直接通过 Python 解释器运行。
- 语法差异:C++ 使用
std::cout来输出,而 Python 使用print()。 - 结构:C++ 需要
main()函数作为入口,而 Python 不一定需要main()函数。
总结:
- 功能相同:两个程序的目标都是输出 “Hello World”。
- 语言和实现方式不同:一个是 C++,一个是 Python,因此它们的实现方式和执行方式完全不同。
关于“程序的本质”这个问题,目标是找到一种能够体现程序核心行为、具有通用性并可以应用于任何程序的语言。这种语言应该满足以下几个特点:
1. 强等价性质
- 理想情况下,程序具有等价性,即如果两个程序在功能上等价(即它们的输出相同),那么它们在本质上应该被认为是等价的。
- 这种语言应该能允许我们专注于程序的行为,而不是实现细节。举例来说,程序的重构不应该改变其行为,程序的“本质语言”应该支持这种等价性转换。
2. 可书面表达
- 本质语言应是可以形式化和书面表达的,这样我们就可以以标准化的方式描述程序的行为。通常这会是某种数学或形式化的语言,像是λ演算(Lambda Calculus)等。
3. 一套适用于任何程序的规则
- 本质语言应该附带一套能够应用于任何程序的变换规则(如类型系统、重写规则或等式推理),从而能够对程序进行逻辑推理和转换。
- 这使得我们能够证明程序的正确性、终止性、以及效率等性质,而这些证明不依赖于具体的实现细节,而是基于程序行为的本质特征。
可能的“本质语言”候选
- λ演算(Lambda Calculus)
- λ演算是最常被认为的“本质语言”,它是函数式编程的基础,具有以下特点:
- 图灵完备性:λ演算能够表示任何计算,具备强大的计算能力。
- 极简主义:它专注于函数及其应用,没有额外的语法,易于形式化和推理。
- 等价性质:λ演算中的两个表达式,如果它们在给定输入时输出相同的结果,那么它们被认为是等价的,并且可以通过β约简(即替换)等变换规则互相转换。
- 为什么适合:
- 强等价性质:λ演算通过约简规则(比如β约简)保证程序的等价性。
- 形式化系统:它有坚实的数学基础,广泛用于计算机科学的理论部分。
- 转换规则:λ演算有明确的规则,如α重命名、β约简、η转换等,这些规则可以用来对程序进行等价变换。
- λ演算是最常被认为的“本质语言”,它是函数式编程的基础,具有以下特点:
- 组合逻辑(Combinatory Logic)
- 组合逻辑是λ演算的一个替代,它使用组合子(没有自由变量的函数)而不是变量来表达计算。
- 它是一种极端抽象的计算模型,可以认为是函数式编程的另一种形式。
- 为什么适合:
- 等价性:组合子和λ演算一样,能够进行类似的变换,保留等价性。
- 极简性:它比λ演算更简洁,去除了变量的概念,可能更容易形式化和理解。
- 函数式编程语言(例如 Haskell)
- Haskell是一个纯粹的函数式编程语言,设计时就考虑了对程序进行形式化推理。
- 在Haskell中,引用透明性保证了相同输入下的函数总是返回相同结果,使得我们可以轻松地推理程序的等价性。
- 为什么适合:
- 强等价性质:Haskell支持等式推理,可以用等价的表达式替换程序中的部分而不改变程序行为。
- 形式化结构:Haskell的类型系统非常强大,可以用来推理程序的正确性、终止性等。
- 转换规则:Haskell程序可以通过技术如catamorphism、融合、惰性求值等方式进行转换,同时保持原有的行为不变。
- 进程演算(例如 Pi Calculus)
- 进程演算(如Pi演算)专注于系统中不同进程间的交互,特别适用于建模并发系统和分布式计算。
- 它提供了一种形式化的方式来描述进程间的通信和交互。
- 为什么适合:
- 它让我们能够推理程序间的交互行为,而不仅仅是程序内部的逻辑。
- 同样具有形式化的基础,能提供明确的规则来变换并发进程,并推理它们的等价性。
- 范畴理论(Category Theory,例:Monad, Functor)
- 范畴理论在函数式编程中得到广泛应用(特别是在Haskell中)。它提供了一种抽象的方式来处理映射(函数)及其关系,基于范畴的概念来进行推理。
- Monad是一种抽象计算效应(如状态或I/O)的方式,它允许保持核心计算的纯粹性。
- 为什么适合:
- 通过范畴和monads等概念,范畴理论提供了强大的等价性推理工具。
- 它提供了高层次的抽象,可以用来推理和构建复杂系统。
结论:什么是好的“本质语言”?
- 一个好的本质语言应当提供一个通用的框架,使我们能够推理和变换程序,同时保证其行为不变。λ演算被认为是最好的“本质语言”候选,因为它的简洁性、形式化基础和强大的计算能力。
- 范畴理论和组合逻辑等也可以作为高层次的抽象方法,适用于更复杂的程序建模和推理。
- 函数式编程语言(如Haskell)则是在这些理论基础上构建的实际编程语言,可以应用于实际系统的开发和推理。
理解问题:数学与意义的转换
提出的内容涉及到 Denotational Semantics(指称语义学),这是程序语言理论中的一个重要领域,旨在通过数学模型将程序语言的句法与其意义进行映射。我们在这方面的目标是通过定义一个数学函数,将程序的语法(syntax)转化为意义(meaning)。
数学等式:
你提到的:
- 3 + 2 = 5
- 5 = 3 + 2
这两个表达式在数学中是等价的,它们表明加法运算是交换律的,也就是a + b和b + a是一样的。
Denotational Semantics:指称语义学
Denotational Semantics(指称语义学)由 Dana Scott 和 Christopher Strachey 在1960年代末提出,其核心思想是通过数学函数来表示程序或语言的意义。这些数学函数将语言中的每个语法元素(如表达式、语句等)映射到一个数学对象(通常是一个值或状态),从而提供一个形式化的语义模型。
数学函数的定义
在指称语义学中,通常使用一个表示“语法元素”的映射来定义程序语言的语义。例如:
- μ⟦e₁ + e₂⟧ = μ⟦e₁⟧ + μ⟦e₂⟧
这里,μ是一个语义函数,它将程序语言的表达式(比如e₁ + e₂)映射到一个值。μ⟦e₁⟧是表达式e₁的语义值,μ⟦e₂⟧是表达式e₂的语义值,- 所以
μ⟦e₁ + e₂⟧表示将两个表达式的结果相加。
- μ⟦i⟧ = i
这里,i是一个整数,它的语义就是它本身,也就是μ⟦i⟧ = i。这意味着如果i是程序中的一个常量(整数),那么它的语义就是它自己。
对比数学公式
数学中,等式 3 + 2 = 5 和 5 = 3 + 2 表示的是加法的交换性和结合性。类似地,在指称语义学中:
- μ⟦e₁ + e₂⟧ = μ⟦e₂ + e₁⟧
这类似于加法的交换律,也就是说:将e₁和e₂的语义相加,结果是一样的,无论先加哪个表达式。
示例:指称语义学的应用
假设我们有一个简单的加法表达式 3 + 2,根据指称语义学的定义:
- 语法:
e = 3 + 2 - 语义函数:
μ⟦e⟧ = μ⟦3⟧ + μ⟦2⟧ - 值:
μ⟦3⟧ = 3和μ⟦2⟧ = 2
所以 μ⟦3 + 2⟧ = 3 + 2 = 5,即该表达式的“意义”是5。
总结
在指称语义学中,语法和意义是通过数学函数进行关联的。你提供的示例 3 + 2 = 5 和 5 = 3 + 2 本质上展示了加法的交换性,而指称语义学通过数学函数将这些表达式的语法映射为一个具体的数学值。最终,程序的每个语法单元都有对应的“意义”表示,它们通过相应的数学模型来定义和理解。
函数的含义
提到的代码和描述都涉及到函数的语义。让我们逐一理解并从不同角度分析它。
代码分析
首先,分析你给出的C++代码:
int f(int c)
{if (false)return 45;elsereturn c + 5;
}
- 这个函数
f接受一个整数参数c。 - 由于
if (false)永远为假,所以条件语句return 45;永远不会执行。 - 因此,程序总是执行
else部分,即return c + 5;。
从这个角度看,函数f的行为就是:返回参数c加 5 的结果。即:
f(c) = c + 5。
函数的不同表示方式
你还提到函数的表示方法,以下是几种常见的表示方式:
1. 集合表示法
你提到的集合表示法就是将函数定义为输入与输出值的配对集合。例如:
{ ..., (-1, 4), (0, 5), (1, 6), ... }
在这种表示法中,函数 f(c) 可以表示为输入值 c 与其对应输出 c + 5 的一对对,集合中的每一对表示一个输入值和对应的输出值。
例如:
- 输入
-1时,输出4(即:-1 + 5 = 4)。 - 输入
0时,输出5(即:0 + 5 = 5)。 - 输入
1时,输出6(即:1 + 5 = 6)。
所以,函数的集合可以表示为:
{ (-1, 4), (0, 5), (1, 6), ... }
2. λ演算表示法
函数还可以用 λ 演算(Lambda Calculus)表示。λ演算是一个形式化的方式,特别适用于函数的表示和运算。你提到的 λc. c + 5 表示一个接受输入 c 的函数,并返回 c + 5。这个表示法是非常简洁且直接的。
- λc. c + 5 表示一个输入
c并输出c + 5的函数。 - 这种表示方法通常用于描述函数式编程语言中的函数。
3. 常规的函数表示
通常情况下,函数可以用类似 f(c) = c + 5 的表达式来表示。这是一种非常直观的方式,表达了函数 f 对输入 c 执行的操作。
理解 f(c) 的意义
无论你选择哪种表示方法,它们都表达了相同的含义:给定一个输入 c,函数 f 返回 c + 5。
总结
- C++代码:这个函数的行为是返回输入
c加 5 的结果,即:f(c) = c + 5。 - 集合表示法:函数可以表示为一组输入输出对
{ (-1, 4), (0, 5), (1, 6), ... }。 - λ演算表示法:
λc. c + 5是该函数的 λ 演算表示,表示一个接收输入c并返回c + 5的函数。 - 标准函数表示:
f(c) = c + 5是一种简洁的数学表示。
因此,函数f(c)的意义可以通过这些不同的方式来表达,但核心含义都是返回c + 5。
解释问题:函数含义与“Bottom” (⊥)
代码和符号引出了一个非常重要的概念,特别是在程序语义学中的 “bottom”(⊥)状态。
代码分析
让我们先看看这段代码:
int f(int c)
{for(;;) ; // 无限循环return 45; // 这行永远不会被执行
}
- 这个函数
f会进入一个无限循环for(;;),这意味着程序会永远卡在这个循环中,无法退出。 - 因为
return 45这一行永远无法执行,程序会一直停留在无限循环中,因此这个函数实际上不会返回任何值。
语义学中的“Bottom” (⊥)
在程序语义学中,“bottom”(⊥)是一个特殊的符号,用来表示未定义的行为或程序的非正常终止,通常用来描述不会终止或进入死循环的程序状态。
- ⊥(Bottom) 通常表示一种“无意义”或“不确定的状态”。在函数语义中,它代表函数没有正常的输出,因为它在计算过程中卡住了或进入了无限循环,导致没有结果。
在这种情况下,函数f(c)在任何输入下都不会返回有效的值,而是停留在无限循环中,因此我们用 ⊥ 来表示它的意义。
函数的集合表示
你提到的 {…, (-1, ⊥), (0, ⊥), (1, ⊥), …} 是函数语义的一种表示方式,它表示对于每一个输入 c(无论是 -1、0、1 等),函数 f 都不会终止,结果是 ⊥。
这意味着:
- 对于输入
-1,函数会停在无限循环中,无法返回任何值,表示为(-1, ⊥)。 - 对于输入
0,函数同样会停在无限循环中,表示为(0, ⊥)。 - 对于输入
1,函数同样停在无限循环中,表示为(1, ⊥)。
因此,函数的意义是无法终止,它对于所有输入都返回⊥,即没有有效的输出。
解释符号“⊥”
⊥ 是表示 “程序没有返回值” 或 “程序没有终止” 的符号,常用来描述非终止的程序或计算出错的情况。
- ⊥ 表示程序的执行没有给出确定的结果,通常是因为程序进入了死循环、无限递归或者发生了错误(如除零错误、访问越界等)。
总结
在这个例子中,函数 f(c) 的定义进入了一个 无限循环,无法正常终止,因此它的返回值是 ⊥(表示无法终止或没有有效返回)。在语义学的表示中,这可以表示为:
- 对于所有输入值
c,函数的语义是 ⊥,即f(c) = ⊥,表示该函数无法给出有效的返回值。
函数的集合表示是:
{ ..., (-1, ⊥), (0, ⊥), (1, ⊥), ... }
这意味着对于任何输入,函数 f 都不会终止,它的结果是 未定义的,即 ⊥。
解析:ISWIM 编程语言与公式 f(b + 2c) + f(2b - c) 和 f(x) = x(x + a)
P. J. Landin 在 1966 年提出了关于编程语言的论文《The Next 700 Programming Languages》,并介绍了自己的编程语言 ISWIM。这篇论文讨论了编程语言设计的理念,并提出了对现有语言的批评以及对未来语言的展望。
1. ISWIM 编程语言
ISWIM(If You See What I Mean)是 P. J. Landin 提出的一个实验性编程语言,它是 Lambda Calculus(λ 演算)和 数学逻辑 的结合,具有强大的抽象功能。虽然 ISWIM 并未广泛应用,但它为后来的编程语言发展,特别是函数式编程语言,提供了重要的思想。
ISWIM 的特点包括:
- 表达式驱动:计算通过表达式进行,强调表达式求值,而不是命令执行。
- 函数应用:函数被看作一种应用关系,支持高阶函数。
- Lambda Calculus:ISWIM 强调使用 λ 演算形式的函数,尤其在函数式编程语言的设计中产生了深远影响。
ISWIM 的设计中,有着大量现代编程语言中我们所见的功能,如递归、抽象函数等。
2. 数学表达式解析:f(b + 2c) + f(2b - c) 和 f(x) = x(x + a)
你提到的表达式是:
- f(x) = x(x + a),这是一个函数定义。
- f(b + 2c) + f(2b - c) 是该函数应用的表达式。
2.1 函数定义:f(x) = x(x + a)
这个函数 f(x) 定义了对输入 x 的处理方式。具体来说,它计算 x 和 x + a 的乘积:
- f(x) = x(x + a)
表示函数 f 接受一个参数 x,并返回 x * (x + a)。
2.2 函数应用:f(b + 2c) + f(2b - c)
在此表达式中,我们使用 f(x) 来求两个不同表达式的值:
- f(b + 2c): 用 b + 2c 作为输入调用函数 f。代入函数定义后,我们得到:
f ( b + 2 c ) = ( b + 2 c ) ( ( b + 2 c ) + a ) = ( b + 2 c ) ( b + 2 c + a ) f(b + 2c) = (b + 2c)((b + 2c) + a) = (b + 2c)(b + 2c + a) f(b+2c)=(b+2c)((b+2c)+a)=(b+2c)(b+2c+a) - f(2b - c): 用 2b - c 作为输入调用函数 f。代入函数定义后,我们得到:
f ( 2 b − c ) = ( 2 b − c ) ( ( 2 b − c ) + a ) = ( 2 b − c ) ( 2 b − c + a ) f(2b - c) = (2b - c)((2b - c) + a) = (2b - c)(2b - c + a) f(2b−c)=(2b−c)((2b−c)+a)=(2b−c)(2b−c+a)
然后,我们将两个结果加起来,即:
f ( b + 2 c ) + f ( 2 b − c ) = ( b + 2 c ) ( b + 2 c + a ) + ( 2 b − c ) ( 2 b − c + a ) f(b + 2c) + f(2b - c) = (b + 2c)(b + 2c + a) + (2b - c)(2b - c + a) f(b+2c)+f(2b−c)=(b+2c)(b+2c+a)+(2b−c)(2b−c+a)
3. 函数式编程的启示
P. J. Landin 在他的论文中通过 ISWIM 提出了许多关于编程语言设计的思考,其中一个重要观点就是抽象与函数式编程。他通过函数的抽象(比如 f(x) = x(x + a))以及表达式的组合(比如 f(b + 2c) + f(2b - c))展示了程序设计如何从数学表达式中汲取灵感,构造出功能强大的语言。
在现代编程语言中,我们可以看到许多类似的特性,尤其是在 函数式编程语言(如 Haskell、Lisp)中,通过高阶函数、递归、不可变数据等概念,能够非常优雅地表示计算。
总结
- ISWIM 是 P. J. Landin 提出的编程语言,它通过引入函数和抽象表达式的方式,开创了许多现代编程语言的思想。
- 通过表达式 f(b + 2c) + f(2b - c) 和函数 f(x) = x(x + a),我们看到了如何通过函数抽象将计算转化为数学公式,而这些抽象也是现代编程语言中的核心思想。
理解 “Semantics Discovery”(语义发现)
你提到的 Semantics Discovery(语义发现)和 Conal Elliott 以及 Denotational design with type class morphisms 涉及到程序语言设计中的一个重要概念,即通过数学和抽象的方式发现问题的本质并推导出实现方法。我们可以从以下几个方面深入理解这个话题:
1. Semantics Discovery(语义发现)
语义发现的目标是通过数学化的方式理解和定义问题的本质,并基于此推导出合适的程序实现。在编程语言和软件开发中,这意味着从程序的数学意义入手,探讨其行为,并将其转换为具体的实现。这种方式是面向抽象的,强调对程序的“意义”(即语义)进行深入分析,以便更好地理解和构建程序。
1.1 数学本质与实现
- 在传统的软件工程中,我们通常会首先解决如何编码问题,然后在实现中找到有效的算法和数据结构。
- 而在语义发现的过程中,首先着眼于问题的数学模型,通过数学化的方式找到问题的本质,然后再基于此推导出具体的实现方案。
例如,如果问题可以用数学公式或者抽象模型来描述,那么程序设计的过程就可以通过将这些数学公式转换为代码来实现。这种方法强调了抽象和数学建模的重要性。
2. Conal Elliott 的贡献
Conal Elliott 是计算机科学,特别是函数式编程领域的知名学者,他在语义发现和程序设计方面做出了大量贡献。Elliott 提出了许多关于编程语言的深刻见解,并且在函数式编程语言的设计中,利用 Denotational Semantics(指称语义学) 和 类型系统 的数学模型,展示了如何通过理解问题的语义来设计优雅的程序。
2.1 Elliott 的应用实例
Conal Elliott 在职业生涯中,通过一系列研究,展示了如何通过语义分析来设计和实现各种系统:
- 函数式编程:他深入探讨了如何将抽象的数学模型(如 λ 演算)映射到程序语言中,进而实现高效且易于理解的编程语言。
- 图形和动画:Elliott 提出了动态编程语言的语义设计,并将其应用于图形和动画的生成,通过数学化的方式定义图像的动态行为。
2.2 Denotational Design with Type Class Morphisms
“Denotational design with type class morphisms” 是 Conal Elliott 及其合作者提出的一个概念,主要关注如何利用 Denotational Semantics(指称语义学)与 类型类(type classes)来设计程序的语义和抽象。
- Denotational Semantics:指称语义学是一种形式化的程序语言语义理论,它通过将程序语言中的每个构造映射到数学对象(如集合、函数等)来定义程序的意义。
- Type Class Morphisms:类型类是一种在许多编程语言中出现的抽象概念,尤其在 Haskell 等函数式编程语言中,类型类提供了对不同数据类型的抽象操作。类型类同态(morphisms)则是指从一种类型类结构到另一种类型类结构的转换方式,这种转换通常是通过数学的函数或映射来进行的。
通过结合 Denotational Semantics 和 类型类同态,可以将复杂的类型系统和抽象结构映射到数学模型中,从而为程序设计提供更加精确和灵活的工具。
3. 如何应用 Semantics Discovery
语义发现不仅仅是理论上的构建,它也对实践中的程序设计有重要的影响。在实际的编程语言设计和程序实现中,可以利用以下步骤:
- 抽象问题:首先,通过对问题的数学建模,找到该问题的本质,建立一个抽象的数学模型。
- 定义语义:根据数学模型定义程序的语义。通过 Denotational Semantics 或其他语义方法,明确每个语言构造的数学含义。
- 实现推导:从语义模型中推导出程序的实现,确定如何通过编程语言中的构造来实现该数学模型。
- 优化与调整:在实现过程中,根据实际需要对程序进行优化和调整,使其更高效、易用,同时保持与原始语义的一致性。
4. 总结
Semantics Discovery 是一种通过数学化的方式理解问题的本质,并基于此设计实现的过程。它强调了对程序语义的深入理解,旨在通过精确的数学模型来设计和实现程序。Conal Elliott 通过其研究展现了如何利用 Denotational Semantics 和 类型类同态 等工具来设计程序的语义,进而提高编程语言和程序设计的抽象能力和可维护性。
解析:数学与编程语言的结合
提到的几个观点涉及到将 数学 和 编程语言 有机结合,特别是在更高抽象层次的程序设计和语言实现中。以下是对这些观点的详细解析:
1. “Math augmented with some extra constructs can represent the essence of code”
这句话的核心思想是:数学 可以被增强和扩展,通过加入一些额外的构造,可以用来 表达代码的本质。
1.1 数学在程序设计中的作用
在许多编程语言(尤其是函数式编程语言)中,程序本质上是对 数学模型 的实现。例如,λ 演算(Lambda Calculus)为程序语言提供了一个强大的基础,程序的构造和运行可以通过数学化的表达式来理解。
通过引入数学的 集合论、图论、线性代数 等领域的概念,我们可以在更抽象的层面上理解程序的结构和行为,而不仅仅停留在具体的语法和实现细节上。
1.2 数学加上额外的构造
虽然数学本身有很强的表达能力,但通常程序设计需要一些额外的构造来处理现实世界中的问题。这些构造可能包括:
- 数据结构:如链表、树、图等。
- 并发和并行:如多线程、进程等。
- 错误处理和异常机制:如异常捕获、返回值、错误代码等。
这些“额外构造”让我们能够将数学模型扩展到更现实的编程问题中,从而能够 通过数学表达式来表达复杂的计算过程。
2. “Write programs in math”
这一观点意味着程序不仅仅是通过传统的编程语言(如 C++、Python 等)编写的代码,而是可以通过数学表达式直接来表示。
2.1 数学编程的体现
函数式编程语言尤其强调将 程序设计视作数学表达式。例如:
- Haskell 中的程序基本上是纯粹的函数应用,整个程序可以视为一系列函数的组合。
- λ 演算 是编程语言中的理论基础,函数应用和递归都可以用数学语言来表示。
- 类型理论(Type Theory)将程序的类型定义为数学对象,允许我们通过数学定理来推理程序的性质。
通过数学编程,我们可以更容易地验证程序的正确性、优化程序以及理解程序的底层结构。
2.2 数学表达式的优势
- 精确性:数学本身是一种精确的语言,能够清晰地表达程序的行为。
- 抽象性:数学具有高度的抽象性,使得我们可以从更高层次描述和推理程序。
- 可推理性:通过数学模型,程序的性质(如终止性、正确性等)可以通过形式化的方法进行验证。
3. “C++ straddles more levels of abstraction than any other language”
这句话的意思是:C++ 是一种多范式编程语言,它可以同时在多个层次的抽象上进行编程。与许多现代编程语言不同,C++ 既能进行高层次的抽象(如面向对象编程、模板编程等),又能进行底层的操作(如指针操作、内存管理等)。
3.1 C++ 的多重抽象层次
- 底层抽象:C++ 允许直接访问硬件资源,如内存管理(指针、引用)和低级操作(汇编语言级别的代码)。
- 中层抽象:C++ 提供了对象导向的编程特性(类、继承、多态等),使得可以对复杂系统进行建模。
- 高层抽象:C++ 中的模板编程、泛型编程、STL(标准模板库)使得开发者可以在较高层次上进行编程,抽象出数据结构和算法。
这种多重抽象层次的能力使得 C++ 在执行效率和灵活性之间达到了较好的平衡,特别适合需要高度优化和复杂设计的应用。
3.2 C++ 中的数学与抽象
C++ 中的 模板编程 和 元编程(template metaprogramming)可以看作是对 数学抽象 的一种实现,允许编写更高层次的、抽象的、在编译时求值的代码。例如,C++ 的模板编程实际上可以实现类似于数学中的函数抽象和递归推导。
4. “Discover essence of problem using math and derive implementation”
这一观点强调了通过数学的方式来发现问题的本质,并基于此推导出实现方法。
4.1 数学发现问题本质
通过数学建模和抽象,我们可以更清晰地理解问题的核心。例如,计算几何问题可以通过几何图形的数学模型来表达,图算法可以通过图论的方式来理解,排序算法可以通过排序理论来推导。
4.2 基于数学模型的实现
一旦我们用数学方式定义了问题,我们可以使用适当的编程语言和技术进行实现。比如:
- 使用 算法 来实现数学中的操作。
- 使用 数据结构 来表示数学中的对象。
- 使用 并行计算 来模拟数学中的并行操作。
例如,图的最短路径问题可以通过 Dijkstra 算法 在编程中实现,而这个算法本身就是通过图论的数学模型推导出来的。
5. 总结
- 数学增强的编程:通过结合数学和一些额外的构造,我们可以更好地表达代码的本质,将复杂的计算问题转化为清晰的数学问题,进而推导出具体的实现。
- C++ 的多重抽象:C++ 是一种多层次、多范式的语言,它可以在不同的抽象层次上进行编程,从底层硬件操作到高层抽象的模板编程,展现了数学建模与实现的灵活性。
- 数学与实现的关系:通过数学模型,我们可以发现问题的本质并找到有效的实现方法。在程序设计中,数学提供了清晰、精确的思维方式,帮助我们理解和优化程序的行为。
理解:函数式设计(Functional Design)
函数式设计(Functional Design)是指在程序开发过程中,从数学的本质出发,发现问题的根本结构,并基于此构建有效且高效的程序实现。这种方法强调在设计初期通过抽象的数学模型来明确问题的核心,从而能够推导出具有明确接口的高效实现。
1. 发现问题的数学本质并写出来
这一步骤的目标是将问题从高层次的数学角度进行抽象化和建模。通过数学建模,我们能够清晰地定义问题的输入、输出及其之间的关系。这一过程类似于定义问题的数学公式或模型,而这个模型成为后续编程实现的基础。
1.1 数学本质的抽象化
- 定义输入和输出:首先要明确程序的输入是什么,以及最终的输出是什么。例如,在一个排序问题中,输入可能是一个整数数组,输出是排序后的数组。
- 确定操作的关系:接着,定义输入与输出之间的关系。这些关系可以通过数学公式、关系或算法进行描述。例如,在排序算法中,关系是“数组元素的顺序被改变,使其按升序排列”。
- 简化问题:有时,我们会简化问题,将其转化为数学上的已知问题。例如,查找数组中的最大元素问题可以简化为“在给定数组中找到最大值”,它的数学描述就是一个函数问题:
max(array) = max(a_1, a_2, ..., a_n)。
1.2 数学模型的表达
- 公式:如上所述,数学模型通常通过公式来表示。例如,对于一个线性方程问题,可能表示为
Ax = b。 - 集合和映射:如果问题涉及集合和元素之间的映射,可能通过集合的定义和映射来表示。比如,计算图的最短路径可以通过图论中的顶点集合、边集合以及映射来表示。
- 关系和结构:在一些复杂问题中,可能需要通过关系、图、树等结构来建模。例如,构建一棵树的数据结构可以通过父子关系、节点等数学概念来定义。
2. 基于数学本质推导高效的 C++ 实现
一旦问题的数学本质得以定义,接下来的步骤就是推导高效的 C++ 实现。这要求我们将数学模型转化为程序代码,并根据实际需求优化性能。
2.1 设计接口
根据数学模型的抽象,我们需要设计程序的接口(即程序的输入、输出和功能)。接口是程序与外部交互的地方,因此设计时要确保其简洁、清晰且易于使用。
- 输入输出的接口设计:比如,在排序问题中,我们的接口可能是:
该函数接受一个整数向量作为输入,并对其进行排序。void sortArray(std::vector<int>& arr); - 函数式接口设计:通过数学模型确定接口的功能。例如,在图算法中,接口可能是:
这个函数返回从图的起点到终点的最短路径。std::vector<int> shortestPath(Graph g, int start, int end);
2.2 选择合适的数据结构和算法
根据问题的数学性质和实际需求,我们选择合适的数据结构和算法。
- 数据结构的选择:如果数学模型涉及某种数据结构(如树、图、堆等),我们就要在 C++ 中选择对应的实现方式。例如,二叉树可以使用 C++ 中的指针和类来实现,图可以通过邻接矩阵或邻接列表来表示。
- 算法的选择:基于数学模型,我们推导出合适的算法。例如,排序问题可能使用快速排序、归并排序等算法。对于图最短路径问题,可以使用 Dijkstra 算法或 Bellman-Ford 算法。
2.3 实现与优化
通过推导出的接口和选择的数据结构与算法,我们在 C++ 中实现程序。在实现过程中,关注以下几个方面:
- 代码结构清晰:确保代码的结构和接口设计清晰易懂,便于维护和扩展。
- 性能优化:根据问题的规模和性能需求,优化实现。例如,使用合适的算法减少时间复杂度,优化内存使用等。
- 错误处理:确保程序能够正确处理输入的异常情况,比如空数组、负数输入等。
示例:排序问题的实现
数学本质:
- 输入:一个整数数组
arr。 - 输出:排序后的数组
arr。 - 关系:将数组中的元素按照升序排列。
接口设计:
void sortArray(std::vector<int>& arr);
选择的算法:快速排序
C++ 实现:
#include <vector>
#include <algorithm>
void quickSort(std::vector<int>& arr, int low, int high) {if (low < high) {int pivot = arr[high];int i = low - 1;for (int j = low; j < high; j++) {if (arr[j] <= pivot) {i++;std::swap(arr[i], arr[j]);}}std::swap(arr[i + 1], arr[high]);quickSort(arr, low, i);quickSort(arr, i + 2, high);}
}
void sortArray(std::vector<int>& arr) {quickSort(arr, 0, arr.size() - 1);
}
优化:
- 使用递归和分治法优化排序。
- 对于小规模数组,可以选择其他更适合的算法(如插入排序)。
总结
函数式设计的核心是:
- 数学本质发现:通过数学建模和抽象,发现问题的核心。
- 推导实现:基于数学模型推导出合适的 C++ 实现,设计合理的接口,选择高效的算法和数据结构。
理解:代数数据类型(Algebraic Data Types,ADT)
代数数据类型(ADT)是函数式编程语言(如Haskell)中常见的概念,其数学基础源于集合论和代数结构。它们为我们提供了将类型构造组合在一起的方法,通过代数运算来定义复杂的数据结构。下面我们将逐步解释你提到的数学基础、两种基本类型和两个操作符的含义。
1. 代数数据类型的数学基础
代数数据类型(ADT)源于集合论和代数结构。ADT 的基本思想是通过组合简单类型来构建更复杂的类型。数学上,代数数据类型可以看作是一种集合的运算,通常通过加法(⊕)和乘法(⊗)来组合。
在代数数据类型中,类型构造通常是两种方式的组合:和类型(Sum Types)和积类型(Product Types)。这两种方式相当于你提到的“⨁” 和 “⊗” 两个运算符。
2. 两种基本类型:1 和 0
- 1:数学上,
1代表一个只有一个元素的集合,通常称为单位类型(Unit Type)。这个类型只有一个值,通常用来表示没有信息的类型。在 C++ 中,它可以类比为void,它不包含任何有效的数据。
示例:1类型可以代表一个空的状态或无返回值的函数。例如,void在 C++ 中表示一个没有返回值的函数。
- 0:数学上,
0代表一个没有元素的集合,通常称为空类型(Empty Type)。这个类型没有任何值,它用于表示程序中无法发生的状态。没有值可以属于这个类型,因此它的存在在程序设计中表示某些操作或状态不可能发生。
示例:0类型可以代表一个永远不会产生结果的操作。例如,在某些系统设计中,表示错误或失败的操作会返回一个空类型。
3. 两种操作符:⊕ 和 ⊗
这两个操作符分别表示代数数据类型中常见的和类型(Sum Types)和积类型(Product Types)构造。
3.1 和类型(⊕,Sum Types)
和类型表示多种选择的情况。它让我们能够将多个类型组合在一起,表示这几种类型中的一个。我们也可以称它为标签化联合(Tagged Union)。
- 数学上,和类型就是将几个集合的并集进行组合。
- 在编程语言中,和类型常常用来表示可能的多个不同类型中的一种。
C++ 示例:
#include <iostream>
#include <variant>
using MyType = std::variant<int, double, std::string>;
void printMyType(const MyType& v) {std::visit([](auto&& arg) { std::cout << arg << std::endl; }, v);
}
int main() {MyType x = 42; // 'int' typeprintMyType(x);x = 3.14; // 'double' typeprintMyType(x);x = "Hello, World!"; // 'string' typeprintMyType(x);
}
在这个例子中,std::variant 是 C++11 提供的一种类型,可以在多个类型之间进行选择,相当于数学中的和类型。
int ⊕ double ⊕ std::string表示一个可以是整数、浮点数或字符串的类型。
3.2 积类型(⊗,Product Types)
积类型表示多种值的组合。它可以表示一个类型包含多个字段,每个字段可以是不同类型的值。积类型的数学表示是将多个集合的笛卡尔积(Cartesian Product)组合起来。
- 数学上,积类型就是几个集合的笛卡尔积。例如,
A ⊗ B表示一个类型,它是由A类型和B类型的所有组合构成的。 - 在编程语言中,积类型通常对应于结构体(struct)或者元组(tuple)。
C++ 示例:
#include <iostream>
#include <tuple>
using MyType = std::tuple<int, double, std::string>;
void printMyType(const MyType& t) {std::cout << std::get<0>(t) << ", "<< std::get<1>(t) << ", "<< std::get<2>(t) << std::endl;
}
int main() {MyType x = std::make_tuple(42, 3.14, "Hello");printMyType(x);
}
在这个例子中,std::tuple 是 C++11 提供的一种类型,它允许将不同类型的数据组合在一起。就像数学中的积类型一样,它表示了一个包含多个字段的类型。
int ⊗ double ⊗ std::string表示一个包含整数、浮点数和字符串的元组类型。
4. 总结
- 代数数据类型(ADT)通过组合简单的类型来构造复杂的类型,它的基础在于集合论和代数结构中的加法和乘法运算。
- 1:表示只有一个元素的类型,通常作为“无信息”类型。
- 0:表示没有元素的类型,用来表示无法发生的状态。
- ⊕(和类型):表示多个类型中的一种,可以理解为联合类型。
- ⊗(积类型):表示多个类型的组合,可以理解为结构体或元组类型。
理解:0 类型(Empty Type)
0 类型是一个在数学和计算机科学中非常重要的概念,通常表示一个没有任何值的类型。它是一个空集合,即这个类型没有任何实例或值。因此,任何尝试创建该类型的实例都会导致程序出错或无法完成。
1. 0 类型的数学背景
在数学中,0(零)代表一个没有任何元素的集合。这意味着,无法从集合中选取任何元素。例如,假设我们定义一个集合 S = {},这个集合没有任何元素,因此它的大小是 0,表示这个集合的类型没有值。
0 类型(Empty Type)正是对应这种没有值的类型。在程序设计中,它常用于表示一个永远无法出现的状态,或者不可能发生的操作。
2. 0 类型在程序设计中的应用
在编程中,0 类型的存在通常用于标记某些操作或状态,在这些操作或状态中,没有任何有效值。这通常表示逻辑上的空结果,或者一个无法被实例化的类型。我们可以把它当作一个占位符,它代表一个永远不会存在的值。
2.1 C++ 中的 Zero 类型
在 C++ 中,你可以通过 删除构造函数 来实现一个 0 类型的类。这意味着你无法创建这个类的任何实例,从而实现了没有任何值的类型。来看以下示例:
struct Zero {Zero() = delete; // 删除默认构造函数
};
在这个例子中:
Zero类型是一个没有任何值的类型。- 删除构造函数
Zero() = delete;确保我们无法创建该类型的实例。任何试图创建Zero类型实例的操作都会导致编译错误。
2.2 为什么要使用 0 类型?
- 表示不可达的状态:0 类型经常用于表示程序中永远无法到达的状态。例如,你可以用它表示一个错误或不可能发生的情形。
- 类型系统的安全性:通过使用 0 类型,你可以在类型系统中明确表达某些操作或路径永远不会被执行。这种做法有助于增强程序的类型安全性。
- 表示不返回值的操作:某些情况下,特定的操作或函数可能不会返回任何有意义的值。比如在某些错误处理或异常情况下,可以使用 0 类型来表示没有返回值的函数。
3. C++ 中的 0 类型的另一个例子:
#include <iostream>
struct Zero {Zero() = delete; // 删除构造函数,无法实例化
};
int main() {// Zero z; // 编译错误:无法创建 Zero 类型的实例std::cout << "This program runs successfully, but we can't instantiate `Zero`!" << std::endl;
}
如果你尝试在 main 函数中创建 Zero 类型的实例,编译器会报错,因为 Zero 类型不能被实例化。
4. 0 类型的实际应用
- 错误处理:你可以使用 0 类型表示一个操作不能返回任何有效的值。例如,在一些错误处理机制中,
Zero类型可以用来表示一个错误路径,表明这条路径是无法执行的。 - 不可达状态:在状态机、控制流图或其他需要表示不可能状态的地方,0 类型也可以非常有用。例如,某个函数永远不会返回,可以将它的返回类型设为
Zero类型。
5. 总结
- 0 类型(Empty Type)表示一个没有任何值的类型,通常用于表示无法存在或永远不会发生的情况。
- 在 C++ 中,可以通过删除构造函数来实现一个 0 类型,它的实例无法被创建。
- 0 类型常用于表示不可达的状态、不可能发生的情况或没有返回值的操作。
理解:1 类型(Unit Type)
1 类型是另一种基本的类型,它代表的是一个只有单一值的类型。在数学中,1 类型表示一个包含一个元素的集合。这个元素是唯一的,因此没有其他选择。
1. 1 类型的数学背景
在数学中,1 类型表示一个只有一个元素的集合。这个集合的大小是 1,并且只有一个值存在。在集合论中,集合 S = {a} 就是一个 1 类型的集合,其中 a 是集合中的唯一元素。
1 类型在计算机科学中也类似,它表示一个没有可变性和唯一值的类型。这个类型通常用于表示完成或者无关紧要的状态,即不关心具体的值,只关心操作已经完成。
2. 1 类型在程序设计中的应用
在编程中,1 类型常常用来表示一种单一返回值或者无意义的类型。尽管该类型有一个值,但这个值本身并不携带有用的信息。
在 C++ 中,我们可以通过定义一个空结构体来模拟 1 类型。这意味着该类型只有一个唯一的值,而这个值并不需要额外的数据。
2.1 C++ 中的 One 类型
struct One {}; // 定义一个空结构体,表示 1 类型
在这个例子中:
One是一个空结构体,没有任何字段。- 唯一的值是该类型的唯一实例,尽管没有显式的值。
注意: - 我们不能将
One类型实例化为多个不同的值。该类型只能有一个值——它的实例就是唯一值。 One类型通常表示一种存在,但没有实际有效信息的状态。
2.2 1 类型的常见用途
1 类型在编程中常常用于表示操作完成或无返回值的操作。它的一个常见用途是表示某些操作执行成功后的状态,或者是一个占位符类型,表示“操作已经成功执行”,但不需要额外的数据。
示例:
- 空操作的返回类型:在某些情况下,函数需要完成某个操作,但没有返回有用的数据。你可以使用
One类型作为返回值,表示“操作已完成”但不关心具体的数据。
2.3 C++ 中的示例:
#include <iostream>
struct One {}; // 1 类型,只有一个实例
void doSomething() {// 执行一些操作,但不需要返回数据// 只需要表示操作完成One result; // 唯一值:唯一的 One 实例std::cout << "Operation completed successfully!" << std::endl;
}
int main() {doSomething(); // 调用函数return 0;
}
在这个例子中:
One是一个没有任何数据成员的结构体,表示 1 类型。doSomething函数表示完成某些操作,但不关心返回数据。因此,One类型在这里用作占位符,表明操作完成。result变量只是一个实例,表示操作已完成,但没有实际的数据。
2.4 其他常见用途
- 占位符类型:当你只关心操作是否完成,而不关心返回数据时,
One类型可以作为占位符使用。 - 返回类型的设计:比如设计 API 时,有些函数的返回类型可以是
One,表示这些函数成功执行但不需要返回其他数据。
3. 为什么要使用 1 类型?
- 表示“完成”:
One类型可以用来表示某个操作已成功完成,而无需关心返回的具体数据。例如,C++ 中的void就是一个类似的概念,用于表示没有返回值的函数。 - 类型安全:使用 1 类型可以提高程序的类型安全性,因为它明确表示函数或操作没有返回有意义的数据。这帮助程序员和编译器识别不需要值的情况。
- 表示无效信息:在一些情况下,程序不需要返回实际的值,
One类型作为返回值表明“没有其他数据”。
4. 总结
- 1 类型(Unit Type)是一个包含唯一值的类型。在数学上,它表示一个只有一个元素的集合,通常表示“完成”或者“无关紧要的值”。
- 在 C++ 中,
struct One {};可以用来实现 1 类型,它没有任何成员,表示只有一个唯一实例。 - 常见用途:
- 表示操作完成。
- 作为函数的返回类型,表示没有有效的返回数据。
- 作为占位符类型,表示某些特定状态。
理解:积类型(Product Types)
积类型(Product Types)是代数数据类型(ADT)中的一种重要类型,它用于表示多个值的组合。通过组合两个或多个类型,我们可以创建一个新的类型,它的值由这些组合的类型的值构成。
1. 积类型的数学背景
在数学中,积类型对应的是笛卡尔积(Cartesian Product),这是集合论中的一个概念。笛卡尔积表示两个集合中所有元素的有序对。对于两个集合 A 和 B,它们的笛卡尔积 A ⊗ B 是所有可能的 A 和 B 元素的有序组合,即:
A × B = { ( a , b ) ∣ a ∈ A , b ∈ B } A \times B = \{(a, b) \mid a \in A, b \in B \} A×B={(a,b)∣a∈A,b∈B}
在编程语言中,积类型的作用类似:它表示一个包含多个字段的复合类型,每个字段可以是不同的类型。
2. 积类型的含义
积类型就是通过组合多个类型,得到一个新的类型,该类型包含多个值。换句话说,积类型的值是由多个部分组成的,每一部分属于一个类型。常见的积类型包括元组(tuple)、结构体(struct) 和 pair(对)。
3. C++ 中的积类型实现
在 C++ 中,我们可以通过几种方式实现积类型:
- 使用
std::pair:这是一个标准库提供的类型,它表示一对值,值的类型可以不同。 - 使用
std::tuple:它是一个更通用的类型,可以表示多个值,类型可以不同。 - 使用自定义结构体:你可以通过定义结构体,将多个不同类型的字段组合起来,构成积类型。
3.1 使用 std::pair
std::pair 是 C++ 标准库中的一个类型模板,用于存储一对值。它的两个元素可以是不同类型。
#include <iostream>
#include <utility> // For std::pair
int main() {// 创建一个 std::pair 类型的变量,包含 int 和 double 类型的值std::pair<int, double> p = {10, 3.14};// 输出 pair 的值std::cout << "First: " << p.first << ", Second: " << p.second << std::endl;
}
这里,std::pair<int, double> 是一个积类型,包含两个值,一个是 int 类型,另一个是 double 类型。first 和 second 分别访问这两个值。
3.2 使用 std::tuple
std::tuple 是一个更为通用的类型,它可以存储多个不同类型的值,数量不限。与 std::pair 不同,std::tuple 可以包含任意数量的元素。
#include <iostream>
#include <tuple> // For std::tuple
int main() {// 创建一个 std::tuple 类型的变量,包含 int, double 和 string 类型的值std::tuple<int, double, std::string> t = {10, 3.14, "Hello"};// 获取 tuple 中的值std::cout << "First: " << std::get<0>(t) << ", "<< "Second: " << std::get<1>(t) << ", "<< "Third: " << std::get<2>(t) << std::endl;
}
在这个例子中,std::tuple<int, double, std::string> 表示一个包含 int、double 和 std::string 类型的积类型。
3.3 使用自定义结构体
你也可以使用自定义的结构体来实现积类型,这对于定义结构化数据非常有用。
#include <iostream>
struct AAndB {int a;double b;
};
int main() {// 创建一个 AAndB 类型的实例,包含 int 和 double 类型的值AAndB obj = {10, 3.14};// 输出 AAndB 类型的值std::cout << "a: " << obj.a << ", b: " << obj.b << std::endl;
}
在这个例子中,AAndB 结构体包含了 int 类型的字段 a 和 double 类型的字段 b,构成了一个积类型。
4. 积类型的应用
积类型在很多编程任务中非常有用,以下是一些常见的应用场景:
- 表示组合数据:当你需要表示多个属性或值时,积类型可以将它们组合在一起。例如,表示一个点
(x, y),可以用std::pair<int, int>来表示。 - 返回多个值:如果一个函数需要返回多个相关的值,积类型是一个理想选择。例如,函数可以返回一个元组,表示多个计算结果。
- 结构化数据:在结构体中,积类型经常被用来定义一个对象的属性。比如,一个
Person结构体可能包含姓名、年龄和地址等属性。
5. 总结
- **积类型(Product Types)**是通过将多个类型组合在一起,得到一个包含多个字段的复合类型。每个字段的类型可以不同。
- 笛卡尔积是积类型的数学基础,表示多个集合的有序组合。
- C++ 中实现积类型的方法:
std::pair<A, B>:用于表示一对值。std::tuple<A, B, C, ...>:用于表示多个值。- 自定义结构体:通过定义结构体,可以创建任意多个字段的复合类型。
- 积类型的常见应用:
- 表示多个值的组合。
- 返回多个值。
- 表示结构化数据。
理解:使用 std::unique_ptr 实现积类型(Product Type)
你提到的结构体:
struct AAndB {std::unique_ptr<A> a;std::unique_ptr<B> b;
};
这个结构体确实是**积类型(Product Type)**的一种实现,但它有一些特定的设计考虑。我们来分析它是如何工作的,以及它如何符合积类型的概念。
1. 积类型的复习
在之前的讨论中,我们了解到积类型表示一个包含多个字段(即不同类型)的类型,通常是将多个类型组合成一个新的类型。这种类型可以表示多个值的组合。
在数学中,积类型(笛卡尔积)表示将多个集合中的元素组合成一个有序对或有序组。例如:
A × B = { ( a , b ) ∣ a ∈ A , b ∈ B } A \times B = \{(a, b) | a \in A, b \in B\} A×B={(a,b)∣a∈A,b∈B}
这意味着你有一个类型 A 和一个类型 B,积类型将会是一个包含 A 和 B 两个元素的类型。
2. std::unique_ptr 和 产品类型
std::unique_ptr 是 C++11 引入的智能指针类型,它确保所指向的对象在 std::unique_ptr 被销毁时自动释放内存。这种设计使得内存管理更加安全,同时避免了许多常见的内存泄漏问题。
在你的结构体定义中:
struct AAndB {std::unique_ptr<A> a;std::unique_ptr<B> b;
};
这个结构体定义了两个指针:
a:指向类型A的unique_ptr。b:指向类型B的unique_ptr。
3. 这是否实现了积类型?
- 是的,它实现了积类型的基本概念。该结构体
AAndB表示了一个复合类型,它将类型A和B组合成一个新的类型。每个字段a和b分别保存了类型A和类型B的一个实例。由于是用std::unique_ptr来管理它们,确保了动态内存的正确管理和对象的生命周期控制。 - 这表示一个包含类型
A和类型B的组合,这与数学中的积类型概念一致。
4. 为什么使用 std::unique_ptr?
- 内存管理:
std::unique_ptr是一种智能指针,能自动管理资源,避免手动释放内存的问题。在 C++ 中,手动管理内存容易出错,而unique_ptr提供了安全、自动的内存管理。 - 动态分配内存:通过
std::unique_ptr,AAndB可以灵活地指向动态分配的A和B类型的对象。比如:
这样,我们可以在堆上动态创建AAndB obj; obj.a = std::make_unique<A>(); obj.b = std::make_unique<B>();A和B的实例,并将它们存储在std::unique_ptr中。 - 保证唯一性:
std::unique_ptr保证了对象的唯一所有权,因此避免了共享所有权可能带来的复杂性和潜在的资源管理问题。
5. 与简单的积类型结构体的比较
通常,积类型可以通过简单的结构体来表示:
struct AAndB {A a;B b;
};
这与使用 std::unique_ptr 的版本相比,主要有以下区别:
- 直接存储 vs 动态分配:没有
std::unique_ptr的版本将A和B直接作为成员存储,通常意味着它们是栈上分配的。使用std::unique_ptr则意味着这些对象可能在堆上分配。 - 内存管理:没有
std::unique_ptr的版本需要手动管理内存(如果是堆上分配),而std::unique_ptr会自动管理内存,防止内存泄漏。 - 所有权语义:
std::unique_ptr提供了更强的所有权语义,因为它不允许多个指针指向同一对象。它保证了资源的唯一所有权。
6. 总结
- 是的,这个结构体
AAndB使用了std::unique_ptr来实现积类型,它是 积类型的一种实现,但它是通过智能指针来确保动态分配内存和资源管理的安全性。 - 积类型的核心思想是将两个不同类型的值组合成一个新的类型。在这个结构体中,
AAndB组合了类型A和B,通过std::unique_ptr进行内存管理。 - 这个设计的优点在于它通过智能指针来确保对象的生命周期被正确管理,避免了手动内存管理可能带来的风险。
理解:和类型(Sum Types)
和类型(Sum Types)是代数数据类型(ADT)中的另一种重要类型,与积类型(Product Types)不同,它表示的是选择类型。和类型的值可以是多个类型中的一个,这些类型通常是互斥的。在数学上,和类型对应的是并集(Union)。
1. 和类型的数学背景
在数学中,和类型通常被表示为两个集合的并集(Union),即:
A ⊕ B = { a ∣ a ∈ A } ∪ { b ∣ b ∈ B } A \oplus B = \{a \mid a \in A\} \cup \{b \mid b \in B\} A⊕B={a∣a∈A}∪{b∣b∈B}
这意味着,和类型的值要么是类型 A 的一个值,要么是类型 B 的一个值,但不能同时是 A 和 B 的值。换句话说,和类型的值只能属于 A 或者 B 中的一个类型,而不是两者的组合。
2. 和类型的定义
在编程语言中,和类型通过标记来区分不同的类型。当你需要表示一个值可以是多个类型中的一个时,你就会使用和类型。
和类型有两个主要特点:
- 选择性:值只能是某一类型。
- 标记:通常会有一个标记,表示当前值属于哪个类型。
3. C++ 中的和类型实现
C++ 中有多种方式来实现和类型,下面展示了几种常见的实现方式。
3.1 使用 union 和 bool 标记
struct AOrB {bool hasA; // 标记值是否为 A 类型union {A a; // 存储 A 类型的值B b; // 存储 B 类型的值} contents;
};
这个结构体 AOrB 使用了一个 union 和一个 bool 类型的标记 hasA 来区分当前值是 A 类型还是 B 类型。具体的工作方式如下:
hasA:一个标记,指示当前存储的是A类型的值还是B类型的值。union:union允许在同一内存位置存储不同类型的数据。A和B类型的值将占用相同的内存空间。只有hasA标记为true时,a的内容有效,只有hasA为false时,b的内容有效。
这个实现的优点是:- 内存使用非常高效:
union只占用足够存储A或B类型的内存,不会浪费空间。 - 标记
hasA决定当前有效的数据是哪一个。
3.2 使用 std::variant
C++17 引入了 std::variant,这是一个更为现代和安全的方式来实现和类型。std::variant 允许你定义一个类型的集合,它可以存储这个集合中的任何一个类型的值。std::variant 还提供了类型安全的访问方式。
#include <iostream>
#include <variant>
using AOrB = std::variant<A, B>;
int main() {AOrB val1 = A(); // 存储一个 A 类型的值AOrB val2 = B(); // 存储一个 B 类型的值// 使用 std::get 来访问存储的值try {A a_val = std::get<A>(val1); // 获取 A 类型的值B b_val = std::get<B>(val2); // 获取 B 类型的值} catch (const std::bad_variant_access& e) {std::cout << "Error accessing variant value: " << e.what() << std::endl;}return 0;
}
在这个例子中:
std::variant<A, B>允许我们创建一个可以存储A或B类型的值。std::get<T>可以用来访问当前存储在std::variant中的值。如果类型不匹配,std::get会抛出一个std::bad_variant_access异常。
std::variant提供了很多方便的功能,比如:- 类型安全:访问存储的值时,你需要指定类型,如果类型不匹配,会抛出异常,防止了类型错误。
- 支持多种类型:
std::variant允许我们在一个类型中存储多种不同的类型,可以看作是一个强类型的联合体。
3.3 使用 boost::variant
在 C++17 之前,boost::variant 是一种常见的实现方式,提供了与 std::variant 类似的功能。boost::variant 的使用方式与 std::variant 类似,只是它是 Boost 库的一部分,需要额外的依赖。
#include <boost/variant.hpp>
using AOrB = boost::variant<A, B>;
int main() {AOrB val1 = A(); // 存储 A 类型的值AOrB val2 = B(); // 存储 B 类型的值// 使用 boost::get 来访问存储的值A a_val = boost::get<A>(val1); // 获取 A 类型的值B b_val = boost::get<B>(val2); // 获取 B 类型的值return 0;
}
3.4 比较这几种实现
- 使用
union和bool标记:- 优点:非常高效,内存开销较小。
- 缺点:需要手动管理标记(
hasA),容易出错;访问时没有类型安全。
- 使用
std::variant(C++17):- 优点:提供了类型安全的访问,现代 C++ 风格,易于使用。
- 缺点:相较于
union,它会有更高的内存开销和运行时开销,但通常足以接受。
- 使用
boost::variant:- 优点:与
std::variant类似,支持类型安全访问,但它是 Boost 库的一部分。 - 缺点:需要依赖 Boost 库,增加了额外的复杂度和依赖。
- 优点:与
4. 总结
- **和类型(Sum Types)**表示一个值可以是多个类型中的一个,类似于数学中的并集。
- C++ 中实现和类型的方法:
- 使用
union和标记(bool)来实现,能够高效地存储选择的数据,但没有类型安全。 - 使用
std::variant或boost::variant来实现,它们提供了类型安全的访问,能够避免类型错误。
- 使用
std::variant是现代 C++ 的推荐做法,因为它提供了类型安全的功能,并且是 C++17 标准的一部分。
理解:函数类型(Function Type)
在代数数据类型(ADT)中,函数类型表示的是一种从类型 A 到类型 B 的转换(即函数的输入类型是 A,输出类型是 B)。数学中,这种类型通常表示为:
A → B A \to B A→B
这意味着,函数类型是一个将 A 类型的输入映射到 B 类型输出的函数。
1. 函数类型的数学背景
函数类型的本质就是将一个类型 A 映射到另一个类型 B,因此它可以理解为一个 函数,其输入为类型 A 的值,输出为类型 B 的值。
在数学中,这个关系可以表示为:
f : A → B f : A \to B f:A→B
其中,f 是一个函数,它接受一个类型为 A 的输入,并返回一个类型为 B 的输出。
2. C++ 中的函数类型
在 C++ 中,函数类型可以通过几种方式来实现。最常见的方式之一是使用 std::function,它是 C++11 引入的一个标准库模板,用于表示任何可以调用的目标(例如普通函数、函数指针、函数对象、Lambda 表达式等)。
2.1 使用 std::function 表示函数类型
#include <iostream>
#include <functional>
using FunctionAB = std::function<int(int)>; // 表示一个从 int 到 int 的函数
int main() {FunctionAB f = [](int x) { return x + 5; }; // 定义一个 Lambda 表达式,接受 int 参数并返回 intstd::cout << "Result: " << f(10) << std::endl; // 调用 f(10),输出 15return 0;
}
在这个例子中:
std::function<int(int)>定义了一个函数类型,表示一个接受int类型参数并返回int类型的函数。f是一个std::function对象,可以绑定到任何匹配的函数、函数指针、Lambda 表达式等。f(10)调用了这个函数,并输出了计算结果。
2.2 std::function 的优势
std::function 提供了以下几个优点:
- 类型安全:它确保了你只能将符合指定签名的函数、Lambda 或者函数对象绑定到它。
- 灵活性:你可以将普通函数、Lambda 表达式、函数对象等作为回调函数传递给
std::function,使得函数调用更加灵活。 - 泛化:
std::function可以表示任何类型的可调用对象,支持多种调用方式,而不仅仅是单一的函数指针。
2.3 std::function 的开销
尽管 std::function 提供了极大的灵活性,但它也有一些开销:
- 内存开销:
std::function内部使用动态分配来管理存储,因此它比普通函数指针有更高的内存开销。 - 性能开销:由于
std::function支持多态,它在调用时需要间接调用,因此性能可能比直接函数调用稍低。
然而,在大多数应用场景中,这些开销是可以接受的,特别是在需要高灵活性的情况下。
3. 示例:如何使用函数类型
我们来看一个稍微复杂一点的示例,展示如何利用 std::function 来处理一个包含函数作为参数的场景。
#include <iostream>
#include <functional>
// 定义函数类型
using FunctionAB = std::function<int(int)>;
// 一个接受函数作为参数的函数
void applyFunction(FunctionAB func, int value) {std::cout << "Result: " << func(value) << std::endl;
}
int main() {// 定义一个 Lambda 表达式,接受 int 并返回 intFunctionAB addFive = [](int x) { return x + 5; };// 调用 applyFunction,将 addFive 作为参数传递applyFunction(addFive, 10); // 输出 Result: 15// 传递另一个函数FunctionAB multiplyByTwo = [](int x) { return x * 2; };applyFunction(multiplyByTwo, 10); // 输出 Result: 20return 0;
}
4. 总结
- 函数类型
A → B是指一个函数,它接受类型A的输入并返回类型B的输出。 - 在 C++ 中,
std::function是实现函数类型的标准工具,它允许你表示接受任意类型参数并返回某一类型结果的函数。 std::function提供了高度的灵活性,但也带来了一定的内存和性能开销。
这种方式不仅适用于普通函数,还能与 Lambda 表达式、函数对象、成员函数等配合使用,适合大多数现代 C++ 编程需求。
理解:语法和语义的映射
在计算机科学中,尤其是在编程语言的语义学中,语法(syntax)和语义(semantics)之间有着紧密的关系。你提到的公式描述了如何从编程语言的语法(即代码)映射到其语义(即数学表达式)。
让我们一步步解析这些公式。
1. 语法到语义的映射
μ⟦ syntax ⟧ = mathExpression
- 解释:这是一个常见的表示方法,表示“语法”的含义(或解释)是一个数学表达式。
- 语法:编程语言中的代码或表达式(例如:
3 + 4或者x = 5)。 - 数学表达式:表示程序运行时的“含义”,在数学中可以用某种表达式来表示。例如,
3 + 4在数学中表示加法操作。
这意味着,我们通过某种方式将程序语言的源代码转化为数学表示,以便我们能用更形式化的数学工具来分析它的行为。
2. 表达式的类型
μ⟦ expression ⟧ : mathExpression
- 解释:表示一个表达式的类型是某个数学表达式的类型。
- 这意味着,表达式(例如
3 + 4)不仅有一个“值”(例如它的结果7),还有一个“类型”(例如它属于整数类型)。
例如,在 C++ 中,int x = 5;中,x是一个整数类型的表达式,x = 5的“语法”在数学中对应的是一个整数的赋值操作。
3. 举例说明
μ⟦ int ⟧ = ℤ
- 解释:
int是编程语言中的一个类型,表示整数类型。在数学中,我们用符号ℤ来表示整数集合。 - 数学解释:程序语言中的
int类型相当于数学中的整数集合ℤ,即ℤ表示所有整数,包括负数、零和正数。
μ⟦ 3 ⟧ : ℤ
- 解释:
3是一个具体的表达式,它的类型是整数类型(ℤ)。 - 数学解释:在编程语言中,
3是一个整数常量,它属于整数类型ℤ,因此3的类型就是ℤ。
μ⟦ 3 ⟧ = 3
- 解释:这表示表达式
3的数学意义就是3本身。 - 数学解释:这个表达式直接表明了常量
3的值就是3,即它的数学值和语法值是相等的。
4. 从语法到语义的映射流程
根据你给出的公式,整个过程可以概括为以下步骤:
- 语法到数学表达式的映射:
- 编程语言中的每一个表达式(例如
3 + 4)可以映射到一个数学表达式(例如3 + 4这个加法运算)。 - 这种映射使得我们可以使用数学工具分析程序的行为,而不需要直接执行程序。
- 编程语言中的每一个表达式(例如
- 类型映射:
- 每个表达式不仅有值,还可以有类型。在数学中,类型可能是
ℤ(整数类型)、ℝ(实数类型)等。 - 例如,在 C++ 中,表达式
3是int类型的值,而在数学中它属于ℤ(整数集合)。
- 每个表达式不仅有值,还可以有类型。在数学中,类型可能是
5. 总结
- 语法(syntax):是编程语言中的代码部分,它定义了程序的结构。
- 语义(semantics):是编程语言中表达式的含义或值。通过将语法映射到数学表达式,我们能理解程序的数学意义。
- 类型:每个表达式都有类型,类型决定了表达式可以包含哪些值,并对程序行为的分析提供了重要的上下文。
例子: - 编程语言中的
int x = 3;,在数学中可以表示为x : ℤ和x = 3,其中ℤ表示整数类型。
这种形式化的映射方法(Denotational Semantics)常用于编译原理和程序语言的理论研究,通过数学表达式来准确地描述程序的行为。
理解:更多的例子与代数数据类型
在你给出的例子中,我们继续利用**代数数据类型(Algebraic Data Types,ADT)和语义学(Denotational Semantics)**来理解各种常见数据结构的数学意义。每个表达式的“语义”通过映射公式与数学结构连接。
1. boost::optional<e₁>
μ⟦ boost::optional<e₁> ⟧ = μ⟦ e₁ ⟧ ⊕ 1
- 解释:
boost::optional是一种类型,用于表示可能没有值的情况。它可以有两种状态:有值(类型e₁)或者没有值(通常表示为nullopt或None)。 - 数学表示:
boost::optional<e₁>可以映射为e₁ ⊕ 1,其中:e₁表示存在值的情况。1表示没有值的情况(通常为一个特殊的“无值”状态,类似于nullopt)。
- 总结:
boost::optional<e₁>在数学中可以表示为:一个e₁类型的值,或者是没有值的状态(可以使用⊕ 1来表示这种选择)。
2. std::pair<e₁, e₂>
μ⟦ std::pair<e₁,e₂> ⟧ = μ⟦ e₁ ⟧ ⊗ μ⟦ e₂ ⟧
- 解释:
std::pair<e₁, e₂>是一个包含两个元素的组合类型,元素类型分别为e₁和e₂。它允许我们存储两个不同类型的值。 - 数学表示:
std::pair<e₁, e₂>在数学中被表示为e₁ ⊗ e₂,这表示一个积类型(Product Type),即一个值包含了e₁类型的值和e₂类型的值。 - 总结:
std::pair<e₁, e₂>对应于数学中的直积(Cartesian Product),表示一个值由两个元素组成,分别来自类型e₁和类型e₂。
3. double 类型
μ⟦ double ⟧ = ℝ
- 解释:在数学中,
double类型通常表示一个实数。因此,我们将其映射到数学中的实数集合ℝ。 - 总结:
double类型的值在数学中对应于实数集合ℝ,因此μ⟦ double ⟧ = ℝ表示double类型的值是一个实数。
4. double 类型(扩展)
μ⟦ double ⟧ = ℝ ⊕ 1 ⊕ 1 ⊕ 1
- 解释:这个映射扩展了之前的实数类型
ℝ,加入了几个额外的状态:ℝ:表示正常的实数值。1 ⊕ 1 ⊕ 1:表示 特殊值,例如:-∞:负无穷大。+∞:正无穷大。NaN:Not a Number(非数字)。
- 数学表示:这个扩展表达了
double类型的更多可能值,包括实数值以及一些特殊状态。可以将其理解为:double类型不仅包含普通的实数,还可以包含无穷大和非数字值。 - 总结:
double类型的数学语义被扩展为实数集合ℝ,并且包括-∞、+∞和NaN这三种特殊的“状态”,可以用ℝ ⊕ 1 ⊕ 1 ⊕ 1来表示。
5. 总结
boost::optional<e₁>:表示一个可能有值,也可能没有值的类型。数学中可以表示为e₁ ⊕ 1,表示要么是e₁类型的值,要么是没有值。std::pair<e₁, e₂>:表示一个包含两个类型元素的组合,数学中表示为e₁ ⊗ e₂,对应于直积类型。double类型:表示实数集合ℝ,在实际应用中,double可能还包含一些额外的特殊值,如NaN、+∞和-∞,因此在扩展形式中可以表示为ℝ ⊕ 1 ⊕ 1 ⊕ 1。
通过这些数学映射,我们能够更准确地理解和分析编程语言中的数据类型和结构,尤其是涉及到缺失值、组合值、特殊值等复杂场景时,能够为程序提供更严格的形式化理解。
理解:电影(Movie)和其操作
在这里,我们探讨的是如何将**电影(Movie)**这一概念通过形式化的数学表示(特别是通过代数数据类型和函数类型)进行定义。接下来,我们一步步解析这些公式。
1. 电影类型的定义
μ⟦ Movie<e> ⟧ = ℝ → μ⟦ e ⟧
- 解释:
Movie<e>是一个泛型类型,表示一个与时间相关的电影。其中,e是电影中每一时刻的内容类型。ℝ → μ⟦ e ⟧表示一个函数,它接受一个实数(ℝ)作为输入(通常用来表示时间),并返回类型e的值(即某一时刻的内容)。
- 数学意义:一个电影的本质就是一个随时间变化的值。在每一个时刻,电影都会提供某种类型为
e的值。e可以代表电影中的任何内容,比如图像、声音或者任何其他的物理或抽象现象。
2. 电影的操作
接下来,我们定义了一些操作来处理电影类型:
always<e> 操作
μ⟦ always<e> ⟧ : μ⟦ e ⟧ → μ⟦ Movie<e> ⟧
μ⟦ always<e>(a) ⟧ = λ t. μ⟦ a ⟧
- 解释:
always<e>是一个操作,它接受一个类型为e的值(例如,某个电影帧),并返回一个电影类型Movie<e>。μ⟦ always<e>(a) ⟧表示将值a转化为一个“恒定的电影”。换句话说,无论时间t是什么,电影总是显示a这个值。λ t. μ⟦ a ⟧是一个 Lambda 表达式,它表示一个函数,接受时间t作为输入,但始终返回值a。这意味着这个电影是一个恒定的电影,内容不随时间变化。
- 数学意义:
always<e>表示创建一个永远显示同一个内容的电影。无论时间如何变化,电影的内容始终是a。
snapshot<e> 操作
μ⟦ snapshot<e> ⟧ : μ⟦ Movie<e> ⟧ → ℝ → A
μ⟦ snapshot<e>(movie, time) ⟧ = μ⟦ movie ⟧ ( μ⟦ time ⟧ )
- 解释:
snapshot<e>是一个操作,它接收一个电影movie和一个时间time,然后返回电影在给定时间time的内容。μ⟦ snapshot<e> ⟧的类型是:接受一个Movie<e>类型的电影,返回一个接受时间ℝ的函数,最终返回类型A的值。μ⟦ snapshot<e>(movie, time) ⟧ = μ⟦ movie ⟧ ( μ⟦ time ⟧ )表示在时间t处,电影movie显示的内容是μ⟦ movie ⟧ ( μ⟦ time ⟧ ),即我们通过时间time取得电影内容。
- 数学意义:
snapshot<e>操作表示从电影中获取某个特定时刻的内容。给定电影和时间,它返回该时刻的值。
transform<A, B> 操作
μ⟦ transform<A,B> ⟧ : (μ⟦A⟧ → μ⟦B⟧) → μ⟦Movie<A>⟧ → μ⟦Movie<B>⟧
- 解释:
transform<A,B>是一个操作,它接受一个函数,能将类型A的值转换为类型B的值,并且能够应用于电影Movie<A>。- 它返回一个新的电影
Movie<B>,这个电影的每一帧的内容都是通过转换函数将类型A的值转换为类型B。
- 数学意义:
transform<A, B>描述了一种操作,它对电影进行转换。给定一个转换函数,它将电影的每一帧内容从类型A转换为类型B。
timeMovie 操作
μ⟦ timeMovie ⟧ : μ⟦ Movie<double> ⟧
μ⟦ timeMovie ⟧ = λ t. t
- 解释:
timeMovie是一个电影,它显示的是时间本身。换句话说,电影中的每一帧就是当前的时间t。μ⟦ timeMovie ⟧ = λ t. t表示timeMovie是一个函数,它接受时间t,并且返回t,即在每一时刻,电影的内容就是当前时间。
- 数学意义:
timeMovie是一个时间的电影,它显示的是当前的时间。
3. 总结
- 电影类型(Movie) 是一个随时间变化的函数,接受时间作为输入,返回某个类型
e的值(如每一帧的图像或声音)。 always<e>创建一个永远显示同一内容的电影,不受时间变化的影响。snapshot<e>提供了获取电影在某个时间点内容的操作。transform<A,B>允许我们通过转换函数来改变电影的类型(如从类型A到类型B)。timeMovie是一个特殊的电影,其中的每一帧显示的是时间本身。
这些操作和类型提供了一种形式化的方式来处理电影类型和相关操作,借助数学语言和函数类型可以帮助我们更精确地理解和操作这类数据结构。
理解:Grey Flux Movie
你提供的代码段创建了一个灰度变化电影(Grey Flux Movie),其中随着时间的变化,图像的灰度值不断变化。让我们一步步解析这段代码及其背后的概念。
1. transform 操作
auto greyFluxMovie = transform([](double timeInSeconds) -> Image {double dummy;double greyness = std::modf(timeInSeconds, &dummy);return greyImage(greyness);},time
);
transform:这里的transform操作接受一个函数(它将类型A的值转换为类型B)以及一个类型为Movie<A>的电影对象(在这个例子中,时间被视作电影的内容)。它返回一个新的类型为Movie<B>的电影对象,其中每一帧的内容是通过该转换函数生成的。- 传入的函数:这个函数定义了如何将时间(
timeInSeconds)映射为图像(Image)。它将时间(以秒为单位)转换为灰度图像。
2. std::modf 的使用
double greyness = std::modf(timeInSeconds, &dummy);
std::modf:这是 C++ 标准库中的一个数学函数,它将一个浮动数timeInSeconds分解为整数部分和小数部分。函数的返回值是小数部分,而整数部分被存储在dummy变量中。- 灰度计算:在这里,
std::modf的作用是提取出timeInSeconds的小数部分,它被用作图像的灰度值。通过这种方式,灰度值随时间变化,范围从0到1(假设timeInSeconds是正数)。
3. greyImage 函数
return greyImage(greyness);
greyImage:这是一个函数,假设它接受一个灰度值(如greyness),并返回一个相应的灰度图像。函数的细节可能是创建一个图像,其中每个像素的颜色由灰度值greyness决定,通常表示为一个黑白图像。
4. greyFluxMovie
- 定义:通过
transform,我们创建了一个新的电影对象greyFluxMovie,它是一个随时间变化的电影。电影的内容由timeInSeconds确定,每一时刻都会生成一个新的灰度图像(由greyness控制)。 - 电影内容:电影的内容是一个随着时间变化的灰度图像,每个时刻的图像根据
timeInSeconds生成,这意味着图像会根据时间的变化而变化。比如,时间流逝时,灰度值可能从0(完全黑)渐变到1(完全白)。
5. 数学表示
我们可以将这个过程的数学意义表达为:
μ⟦ greyFluxMovie ⟧ = λ t. greyImage( μ⟦ modf(t, dummy) ⟧ )
μ⟦ greyFluxMovie ⟧是一个电影类型,表示随着时间t变化的图像。λ t. greyImage( μ⟦ modf(t, dummy) ⟧ )是一个函数,接受时间t并通过std::modf(t, dummy)获取小数部分来生成相应的灰度值,然后调用greyImage来生成灰度图像。
6. 总结
greyFluxMovie是一个随着时间变化的电影,其中每一帧都是一个灰度图像,灰度值由时间的小数部分决定。transform操作将一个函数应用于每一时刻的时间,产生对应的图像(灰度图像)。每一帧的图像会随着时间而变化,从而形成动态的“灰度电影”。
通过这个例子,你可以看到如何将时间与图像内容结合起来,创建一个动态的电影对象。它体现了一个随时间变化的过程(例如灰度变化),并通过高阶函数(如transform)来表达这一过程。
理解:Stream 的定义
在这里,我们探讨的是如何用函数式编程的视角来定义和操作流(stream),特别是它与“动作”或者副作用(side-effecting operations)的关系。流是通过 source 和 sink 来建模的,分别表示数据流的输出和输入。
让我们一步步解析你提供的内容。
1. sink 的定义
μ⟦ sink<e> ⟧ = μ⟦ e ⟧ → Action
sink是一个接收端(sink),它接受一个类型为e的值并产生一个副作用(Action)。Action代表一个有副作用的操作,可能是打印、修改状态、写入文件等,而不仅仅是返回一个值。- 类型解释:
μ⟦ sink<e> ⟧是一个类型,表示将某个类型e的值作为输入,并触发副作用。- 换句话说,
sink<e>就是一个接受类型e的输入并执行某种操作(副作用)的函数。
代码表示:
template< typename T >
using sink = std::function<void ( const T & )>;
sink是一个模板类型别名,表示一个函数,它接受类型T的常量引用作为参数,并且没有返回值。这里的void代表的是一个副作用函数,而不是返回一个具体的值。
2. source 的定义
μ⟦ source<e> ⟧ = (μ⟦ e ⟧ → Action) → Action
source是源端(source),它表示从某个地方产生数据并执行副作用。一个source<e>期望接收一个函数,这个函数接受类型e的值并产生副作用。source<e>本身也会执行副作用。- 类型解释:
μ⟦ source<e> ⟧是一个类型,表示接收一个函数作为输入,函数类型为μ⟦ e ⟧ → Action,并返回一个Action(副作用)。- 可以理解为,
source<e>通过某种方式生成数据,然后将数据传递给一个sink进行处理。
代码表示:
template< typename T >
using source = std::function<void ( sink<T> ) >;
source是一个模板类型别名,表示一个函数,它接受一个sink<T>作为参数并执行副作用。这个sink函数会被调用以处理从源端生成的数据。
3. 总结
通过上述定义,我们可以看出,source 和 sink 是流(stream)的两个主要组成部分:
sink:它是一个接收端,表示你想要做某种操作的地方。例如,打印数据、更新 UI、修改数据库等。它接受某个类型的值并执行副作用。- 在代码中,
sink<T>是一个接受类型T的常量引用并返回void(没有返回值的副作用)的函数。
- 在代码中,
source:它是一个源端,表示数据的生成和传播。source通过传递一个sink函数来将数据传递给接收端,并在此过程中执行副作用。- 在代码中,
source<T>是一个接受sink<T>作为参数并执行副作用的函数。
- 在代码中,
4. 流的工作机制
假设有一个 source 生成数据,并且将数据传递给一个 sink,sink 接收到数据后就可以触发一些副作用(如打印数据、保存数据、执行其他操作)。
5. 流的应用
在实际应用中,流(stream)通常用于表示一种数据流动的模型。例如:
- 数据流:从源头生成数据并将其传递到接收端进行处理。
- 异步操作:
source可以异步地提供数据,sink可以异步地消费数据(例如:处理用户输入、处理网络请求等)。 - 事件驱动编程:
source产生事件,sink响应事件并做出相应的处理。
这种模式在很多应用场景中都非常有用,特别是在响应式编程和流式数据处理领域。
6. 示例
假设我们要使用 sink 和 source 来处理一个事件流:
- 创建一个事件源(source),比如从网络接收消息:
source<std::string> eventSource = [](sink<std::string> s) {// 模拟生成数据并传递给 sinks("Hello, world!"); }; - 创建一个处理事件的接收端(sink),比如打印收到的消息:
sink<std::string> printSink = [](const std::string& message) {std::cout << "Received message: " << message << std::endl; }; - 将事件源和接收端连接起来,通过
source来生成事件并传递给sink:eventSource(printSink); // 触发 source,并将事件传递给 sink
输出:
Received message: Hello, world!
7. 总结
sink是接收并处理数据的地方,通常伴随着副作用。source是数据的生成和传递者,通常会调用sink来将数据传递给接收端。- 通过这两个概念,我们可以构建灵活的流式处理模型,用于异步编程、事件驱动编程等领域。
理解:source 和 sink 示例 — 控制台输入输出
这个例子展示了如何使用 source 和 sink 模型来处理从控制台读取字符(输入)和将字符输出到控制台(输出)。在这个例子中,source 和 sink 被用来实现一个字符流的处理。
1. source<char> 示例:从控制台读取字符
source<char> consoleInput = [](sink<char> s) {int inputChar;while ((inputChar = std::cin.get()) != EOF) {s(static_cast<char>(inputChar));}
};
source<char>:这是一个源端,表示从控制台读取字符流,并将每个字符传递给下游的sink(接收端)。这个源端通过一个Lambda 函数来实现,其中s是一个sink<char>,它将被调用来处理每个读取到的字符。- 读取字符:
std::cin.get()用来从标准输入读取字符。当输入的字符不是EOF(文件结束符)时,它会继续读取字符。EOF是一个特殊的值,用于表示输入流的结束。 - 传递字符:每当读取到一个字符时,
sink<char>s被调用,并将字符传递给它。 - 工作流:这个
source是一个流,它从输入流中提取字符,并通过sink将字符传递给下游。这个过程在字符输入流没有结束时持续进行。
2. sink<char> 示例:将字符输出到控制台
sink<char> consoleOutput = [](char c) {std::cout.put(c);
};
sink<char>:这是一个接收端,它接受一个字符并将其输出到控制台。这里的sink使用std::cout.put(c)将字符打印到标准输出。- 打印字符:
std::cout.put(c)是一个标准的 C++ 输出函数,它将字符c输出到控制台。
3. 将 source 和 sink 结合
为了将这两个操作组合在一起,假设我们想要将从 consoleInput 读取的每个字符传递给 consoleOutput 来输出:
consoleInput(consoleOutput); // 从输入读取字符并传递到输出
- 工作流程:
consoleInput是一个source,它从控制台读取字符并传递给下游的sink。consoleOutput是一个sink,它接收字符并输出到控制台。- 调用
consoleInput(consoleOutput)会开始从控制台读取字符,并将每个字符传递给consoleOutput来显示。
4. 完整代码示例
#include <iostream>
#include <functional>
// Sink 接收并处理数据,执行副作用
template<typename T>
using sink = std::function<void(const T&)>;
// Source 生成数据,并通过 sink 传递
template<typename T>
using source = std::function<void(sink<T>)>;
int main() {// 1. Source:从控制台读取字符并通过 sink 传递source<char> consoleInput = [](sink<char> s) {int inputChar;while ((inputChar = std::cin.get()) != EOF) {s(static_cast<char>(inputChar)); // 将读取的字符传递给 sink}};// 2. Sink:将字符输出到控制台sink<char> consoleOutput = [](char c) {std::cout.put(c); // 输出字符};// 3. 连接 source 和 sink:从控制台读取字符并将其输出consoleInput(consoleOutput); // 读取并输出字符return 0;
}
5. 总结
source<char>:从控制台读取字符流(输入流),直到输入结束(EOF),并将每个字符传递给下游的sink。sink<char>:接收字符并将其输出到控制台(标准输出)。- 连接源和接收端:通过调用
consoleInput(consoleOutput),将从控制台读取的字符逐个传递到控制台输出。
这个模型使用了流(stream)的概念,利用 函数式编程 中的高阶函数来实现数据流的传递和副作用的执行。它展现了如何通过source和sink构建灵活的数据流动操作。
6. 流式处理的优点
这种流的模型可以应用到很多场景:
- 异步处理:可以用来处理异步事件流(例如:用户输入、网络请求等)。
- 响应式编程:源(
source)可以是外部事件的来源,接收端(sink)处理并响应这些事件。 - 可组合性:可以将多个
source和sink组合起来,形成复杂的数据流处理逻辑。
理解:连接 Source 和 Sink
在这里,我们讨论如何将一个 source(数据源)与 sink(接收端)连接起来,以便源端能够将数据流传递给接收端,执行一些副作用。connect 函数的作用就是将这些连接起来,让数据从源传递到接收端。
1. μ⟦ connect<e> ⟧ 类型签名
μ⟦ connect<e> ⟧ : μ⟦ source<e> ⟧ → μ⟦ sink<e> ⟧ → Action
μ⟦ connect<e> ⟧是一个函数类型,表示将一个source<e>与一个sink<e>连接起来。source<e>是一个生成数据的流,而sink<e>是一个接收并处理数据的流。- 通过
connect<e>(so, si),so作为 source,si作为 sink,函数执行时会将数据从source传递到sink,并触发副作用。
Action代表执行的副作用,因此connect的作用不仅仅是将数据传递,还包括触发接收端的副作用操作。
2. connect 函数实现
template< typename t >
void connect(source<t> so, sink<t> si) {so(si); // 将 sink 传递给 source,源端开始向接收端传递数据
}
connect函数:这是一个模板函数,接受两个参数:so:一个source<t>,即数据源。si:一个sink<t>,即数据的接收端。
- 执行逻辑:
so(si)表示将接收端si传递给源端so,使得源端开始产生数据,并将数据传递给接收端si。source会执行一些操作并将数据传递给sink,而sink执行对应的副作用。
3. main 函数示例
int main(int argc, char** argv) {connect(consoleInput, consoleOutput); // 将 consoleInput (source) 和 consoleOutput (sink) 连接
}
connect(consoleInput, consoleOutput):这里调用connect函数,将consoleInput和consoleOutput连接起来。consoleInput是一个source<char>,它从控制台读取字符。consoleOutput是一个sink<char>,它将字符输出到控制台。
4. 整个流程总结
source<char>(consoleInput):从标准输入读取字符流,每次读取一个字符。- 它会调用传递给它的
sink<char>,即consoleOutput,并将字符传递给它。
- 它会调用传递给它的
sink<char>(consoleOutput):接收来自source的字符并将其输出到控制台。connect函数:connect(consoleInput, consoleOutput)会连接源端(consoleInput)和接收端(consoleOutput),使得从控制台读取的每个字符都能通过sink被输出到控制台。
5. 扩展示例
我们可以进一步扩展这个概念,假设有一个从文件读取字符并输出到控制台的例子:
#include <iostream>
#include <fstream>
#include <functional>
// Sink 接收并处理数据
template<typename T>
using sink = std::function<void(const T&)>;
// Source 生成数据并通过 sink 传递
template<typename T>
using source = std::function<void(sink<T>)>;
// File Input Source
source<char> fileInput(const std::string& filename) {return [filename](sink<char> s) {std::ifstream file(filename);char ch;while (file.get(ch)) {s(ch); // 将读取的字符传递给 sink}};
}
// Console Output Sink
sink<char> consoleOutput = [](char c) {std::cout.put(c); // 将字符输出到控制台
};
// Connect Function
template< typename t >
void connect(source<t> so, sink<t> si) {so(si); // 将 sink 传递给 source
}
int main() {// 从文件中读取并将内容输出到控制台connect(fileInput("example.txt"), consoleOutput);return 0;
}
6. 总结
connect<e>:连接source和sink,使得数据流从源端传递到接收端,并触发副作用。source<t>:生成数据并传递给sink,通常用于输入流,如读取文件、控制台输入等。sink<t>:接收数据并执行副作用,通常用于输出流,如打印到控制台、写入文件等。
理解:转换流(Transforming Streams)
这段代码和数学表达式介绍了如何通过 转换器(transform)将一种类型的数据流 (sink<a>) 转换为另一种类型的数据流 (sink<b>),并执行相应的副作用。它展示了如何处理从类型 b 到类型 a 的流转换。
1. 数学定义
μ⟦ sink<e> ⟧ = μ⟦ e ⟧ → Action
μ⟦ transform<a,b> ⟧ = μ⟦ Sink<b> ⟧ → μ⟦ Sink<a> ⟧= μ⟦ Sink<b> ⟧ → (μ⟦ a ⟧ → Action)= μ⟦ Sink<b> ⟧ → μ⟦ a ⟧ → Action
解释:
sink<e>:一个接受类型e并执行副作用的操作(即产生副作用的接收端),它的类型是μ⟦ e ⟧ → Action,表示它会接收类型e的数据并执行副作用。transform<a, b>:是一个操作符,它接受一个sink<b>(接收类型b的流)并返回一个新的sink<a>(接收类型a的流)。具体来说,transform会将一个接收b类型的数据流转换成接收a类型的数据流的接收端。
2. transform 函数类型签名
template<typename a, typename b>
using transform = std::function<void(sink<b>, a)>;
transform是一个模板类型的 函数,它接受两个类型参数a和b。- 该函数接收两个参数:
sink<b>:一个接收类型b的流。a:数据的值类型,它会通过某些转换逻辑被转换成类型b。
transform函数会执行流的转换,并且对接收到的数据执行副作用。
3. 如何理解 transform:
假设你有一个 sink<char>,它接收字符类型的流,和一个 transform 函数,它将字符类型流转换成整数类型流(例如,将每个字符的 ASCII 值传递给 sink<int>)。那么,transform 会把一个 sink<char> 转换为一个接收 int 的 sink<int>。
4. transform 代码示例
假设我们有一个字符流 (source<char>) 和一个整数流 (sink<int>),我们可以通过 transform 函数将 char 类型的流转换为 int 类型的流。
#include <iostream>
#include <functional>
// Sink 接收并处理数据
template<typename T>
using sink = std::function<void(const T&)>;
// Source 生成数据并通过 sink 传递
template<typename T>
using source = std::function<void(sink<T>)>;
// Sink for integers
sink<int> consoleIntOutput = [](int value) {std::cout << "Integer value: " << value << std::endl;
};
// Transform function: transform from `char` to `int`
template <typename a, typename b>
using transform = std::function<void(sink<b>, a)>;
// Transform function: converts char to its ASCII integer value
transform<char, int> charToIntTransform = [](sink<int> si, char c) {si(static_cast<int>(c)); // 将字符转换为其 ASCII 值并传递给 sink
};
int main() {// 一个源端,读取字符source<char> consoleCharInput = [](sink<char> s) {for (char c : {'A', 'B', 'C'}) {s(c); // 每次传递一个字符}};// 连接 source 和 transformsource<char> transformedSource = [](sink<char> s) {consoleCharInput([&](char c) {// 使用 transform 将 char 转换为 int 并传递给 sinkcharToIntTransform(consoleIntOutput, c);});};transformedSource([](char c) {// 使用 transform 对字符流进行处理});return 0;
}
5. 解释:
transform<char, int>:定义了如何将char转换为int类型。具体实现就是将字符的 ASCII 值传递给sink<int>。consoleCharInput:一个简单的源端,模拟从控制台读取字符并传递给接收端。consoleIntOutput:接收转换后的整数,并打印到控制台。- 转换过程:每当字符从
source<char>被读取时,charToIntTransform将它们转换为 ASCII 值(int类型),然后通过consoleIntOutput输出。
6. 总结:
transform函数:将一个sink<b>(接收b类型数据的流)转换为一个sink<a>(接收a类型数据的流)。它允许你改变流的类型,将数据从一种类型转换为另一种类型。- 功能:它的主要功能是将源端的数据流经过转换后,传递给新的接收端,执行必要的副作用操作。
- 示例:
charToIntTransform是一个transform示例,它将字符流转换为整数流,处理每个字符的 ASCII 值。
理解:变换(Transform)在应用中的使用
这段代码和数学表达式扩展了 transform 函数的应用,展示了如何将它与数据流源(source)和接收端(sink)结合使用,以实现更复杂的数据处理。特别是如何通过 applyToSource 和 applyToSink 将变换应用于源端或接收端。
1. 数学定义
μ⟦ transform<a,b> ⟧ = μ⟦ sink<b> ⟧ → μ⟦ a ⟧ → Action
μ⟦ applyToSink<a,b> ⟧ : μ⟦ transform<a,b> ⟧ → μ⟦ sink<b> ⟧ → μ⟦ sink<a> ⟧
μ⟦ applyToSource<a,b> ⟧ : μ⟦ transform<a,b> ⟧ → μ⟦ source<a> ⟧ → μ⟦ source<b> ⟧
μ⟦ so >> t ⟧ = μ⟦ applyToSource<a,b> ⟧( t, so );
μ⟦ t >> si ⟧ = μ⟦ applyToSink<a,b> ⟧( t, si );
μ⟦ so >> si ⟧ = μ⟦ connect<t> ⟧( so, si );
解释:
μ⟦ transform<a,b> ⟧:表示一个转换函数,它接受一个sink<b>(接收b类型数据的流),并返回一个接受类型a的sink<a>。它的作用是将类型a转换为类型b。applyToSink:表示如何将transform<a,b>应用于一个sink<b>,并生成一个新的sink<a>。这让你可以对接收端的流进行变换。applyToSource:表示如何将transform<a,b>应用于一个source<a>,并生成一个新的source<b>。这让你可以对源端的数据流进行变换。so >> t:这是一个组合操作,它将so(源端)与t(变换)结合,最终返回一个新的source<b>。t >> si:将t(变换)应用于sink(si),返回一个新的sink<a>。so >> si:将so和si连接在一起,执行数据流的连接操作。
2. 实现说明
applyToSink和applyToSource的作用:
这两个函数的作用是分别将转换函数transform<a,b>应用到源端或接收端,使得源端和接收端的数据类型可以在处理过程中被转换。>>操作符:so >> t:它会将transform应用于源端,将source<a>转换为source<b>。换句话说,它会生成一个新的源端,它输出b类型的流。t >> si:它将变换应用于接收端,将sink<b>转换为sink<a>。so >> si:它连接源端和接收端,使得源端的数据流可以通过接收端进行处理。
3. 代码实现
假设我们有一个源端 source<char> 和一个接收端 sink<int>,我们可以通过 transform 将源端的字符流转换为整数流,然后将其传递给接收端。
示例:将 source<char> 转换为 source<int>,并通过 sink<int> 处理
#include <iostream>
#include <functional>
// Sink 接收并处理数据
template<typename T>
using sink = std::function<void(const T&)>;
// Source 生成数据并通过 sink 传递
template<typename T>
using source = std::function<void(sink<T>)>;
// Transform function: converts char to its ASCII integer value
template <typename a, typename b>
using transform = std::function<void(sink<b>, a)>;
// Apply transformation to sink (char -> int)
template <typename a, typename b>
using applyToSink = std::function<sink<a>(transform<a,b>, sink<b>)>;
template <typename a, typename b>
sink<a> applyToSinkFunc(transform<a,b> t, sink<b> si) {return [t, si](const a& value) {t(si, value);};
}
// Apply transformation to source (char -> int)
template <typename a, typename b>
using applyToSource = std::function<source<b>(transform<a,b>, source<a>)>;
template <typename a, typename b>
source<b> applyToSourceFunc(transform<a,b> t, source<a> so) {return [t, so](sink<b> si) {so([&](const a& value) {t(si, value);});};
}
int main() {// Example: transform from char to int (ASCII value)transform<char, int> charToIntTransform = [](sink<int> si, char c) {si(static_cast<int>(c)); // Convert char to its ASCII value and pass to sink};// Define a source that generates characterssource<char> consoleInput = [](sink<char> s) {for (char c : {'A', 'B', 'C'}) {s(c); // Pass characters to sink}};// Define a sink that receives and prints integerssink<int> consoleOutput = [](int value) {std::cout << "Received integer: " << value << std::endl;};// Apply the transformation to the source (char to int)auto transformedSource = applyToSourceFunc(charToIntTransform, consoleInput);transformedSource(consoleOutput); // Output the converted values to consolereturn 0;
}
4. 代码解析
transform<char, int>:这个transform函数将字符(char)转换为整数(int)——这里是字符的 ASCII 值。consoleInput:一个源端,模拟从控制台读取字符并传递给接收端。consoleOutput:一个接收端,接收整数并打印它们。applyToSourceFunc:将char到int的变换应用到源端consoleInput,生成一个新的source<int>,它将字符转换为整数后传递。- 执行:
transformedSource(consoleOutput)会执行源端到接收端的连接,并打印每个字符的 ASCII 值。
5. 总结
applyToSource:将变换应用于源端,生成一个新的源端,处理不同类型的数据流。applyToSink:将变换应用于接收端,生成一个新的接收端,处理不同类型的数据流。>>操作符:它是应用变换并连接源端和接收端的操作符,通过连接流式数据和副作用操作,使得我们可以更加灵活地构建数据流处理系统。
继续理解:Transformers (转换器)
在这一部分,我们继续探讨如何使用变换器(transformers)来转换和处理不同类型的数据流。通过组合不同的转换器(transformer),我们可以实现更复杂的流式数据处理。
1. 理解变换器(Transformers)
transformer<char, std::string> getLines
这代表一个转换器,它将字符流(char)转换为字符串流(std::string)。通常,我们可能希望将来自输入流(比如文件或控制台)的字符按行分组,形成字符串表示。
transformer<std::string, char> unWords
这是另一个转换器,它将字符串流(std::string)转换为字符流(char)。它可以将一行字符串拆分成字符流,通常用于逐字处理。
source<string> inputLines = consoleInput >> getLines
这里的 inputLines 是一个新的源端,表示从 consoleInput(输入流)中获取字符流并将其通过 getLines 转换器处理,生成按行拆分的字符串流。
sink<string> wordOutput = unWords >> consoleOutput
wordOutput 是一个接收端,它从 unWords(转换器)接收字符串流并将其转换为字符流,然后将字符流传递给 consoleOutput 进行输出。也就是说,这个接收端将字符串拆分成字符并输出。
InputLines >> wordOutput
这表示将 inputLines(从控制台输入的按行字符串流)与 wordOutput(将字符串转为字符并输出的接收端)连接起来。它实现了一个从输入到输出的完整数据流。
transformer<char,char> linesToSpaces = getLines >> unwords
这里通过使用组合操作符 >> 将 getLines 和 unWords 两个转换器连接成一个新的转换器 linesToSpaces。它首先将字符流转换为按行分隔的字符串流,然后将每个字符串转换为字符流。这样的组合可以灵活地处理更复杂的数据转换任务。
2. 代码实现
为了更好地理解这些转换器的使用,我们可以尝试在代码中模拟这些变换。
示例代码:转换字符流为按行的字符串流,拆分字符串为字符流,并连接输入和输出
#include <iostream>
#include <string>
#include <functional>
#include <sstream>
#include <vector>
// Sink 接收并处理数据
template<typename T>
using sink = std::function<void(const T&)>;
// Source 生成数据并通过 sink 传递
template<typename T>
using source = std::function<void(sink<T>)>;
// Transformer function 类型:将 'a' 类型转换为 'b' 类型
template <typename a, typename b>
using transformer = std::function<void(sink<b>, a)>;
// 示例:将字符流转换为按行的字符串流
transformer<char, std::string> getLines = [](sink<std::string> s, char inputChar) {static std::string currentLine;if (inputChar == '\n') {s(currentLine); // 一行结束,传递当前行currentLine.clear();} else {currentLine.push_back(inputChar); // 累积字符}
};
// 示例:将字符串拆分为字符流
transformer<std::string, char> unWords = [](sink<char> s, const std::string& line) {for (char c : line) {s(c); // 逐字符输出}
};
// 源端:从控制台输入字符流
source<char> consoleInput = [](sink<char> s) {char inputChar;while (std::cin.get(inputChar)) {s(inputChar); // 读取并传递字符}
};
// 接收端:将字符输出到控制台
sink<char> consoleOutput = [](const char& c) {std::cout.put(c); // 输出字符到控制台
};
int main() {// 连接并应用变换// 从输入字符流转换为按行的字符串流source<std::string> inputLines = [](sink<std::string> s) {consoleInput([&](char inputChar) {getLines(s, inputChar);});};// 将每行的字符串转换为字符流并输出sink<char> wordOutput = [&](const char& c) {unWords(consoleOutput, std::string(1, c));};// 将输入流与输出流连接inputLines(wordOutput);return 0;
}
3. 解析
getLines(字符流转换为按行的字符串流):
getLines会将字符逐个接收并拼接成字符串,当遇到换行符\n时,表示一行结束,调用sink将完整的一行(字符串)传递出去。
unWords(字符串拆分为字符流):
unWords会将接收到的字符串拆分为单个字符,并通过sink将字符逐个传递到下游。
数据流的连接:
inputLines:从控制台读取字符流,并通过getLines转换为按行的字符串流。wordOutput:接收unWords输出的字符流,并将其输出到控制台。
变换器的组合:
linesToSpaces:通过getLines和unWords组合,我们实现了一个新的转换器,先将字符流转换为按行的字符串流,再将每行字符串拆分为字符流。
4. 总结
在流式编程中,变换器(transformer)可以被组合和链式应用,以实现更复杂的转换操作。通过将 source(源端)与 sink(接收端)进行组合,我们能够灵活地处理数据流的输入、转换和输出。具体的操作包括:
>>操作符:用于将变换器链式连接,以便多个变换操作按顺序应用于数据流。transformer类型:定义了数据从一种类型到另一种类型的转换。source和sink:分别代表数据的生产和消费端。
命令行处理的理解
在编程和软件系统的上下文中,命令行处理指的是处理用户通过命令行界面(CLI)输入的命令。CLI 允许用户通过文本命令与系统进行交互。命令行处理的过程包括解析这些输入命令,并将其转换为系统可以理解和执行的操作。
让我们分解一下给出的符号和解释:
符号和它们的含义
- μ⟦ CommandLineProcessor ⟧ = ListOf String → μ⟦ a ⟧
- 这表示一个命令行处理器,其输入类型为
a。 - ListOf String:表示命令行参数的字符串列表(用户输入的内容)。
- μ⟦ a ⟧:表示命令行处理的输出类型。这个输出类型可以是任何类型,取决于命令行参数的处理结果。它可能是整数、布尔值、字符串,甚至是更复杂的数据结构。
CommandLineProcessor 处理一个字符串列表(命令行输入),然后将其转换为类型a的结果。
- 这表示一个命令行处理器,其输入类型为
- μ⟦ Parser<a,b> ⟧ = ListOf μ⟦ a ⟧ → μ⟦ b ⟧
- Parser 代表一个函数,它接受一系列类型
a的值(这些可以是单独的元素或标记),并将其转换为类型b的值。 - 这个符号展示了一个解析器是如何工作的:它处理一个类型
a的值列表,并返回一个类型b的转换结果。
在命令行处理中,这表示通常需要将字符串(命令行参数)解析成某种结构化的类型(如整数、布尔值或对象),以便程序可以理解和操作。
- Parser 代表一个函数,它接受一系列类型
- μ⟦ CommandLineProcessor ⟧ = μ⟦ Parser<String,b>
- 这表示 CommandLineProcessor 实际上是一个 解析器,它处理字符串类型的输入,并返回类型
b的值。 - Parser 负责解析字符串列表(命令行参数),并将其处理成程序可以使用的输出类型。
简而言之,CommandLineProcessor 就是一个解析器,它处理字符串并返回有意义的结果。
- 这表示 CommandLineProcessor 实际上是一个 解析器,它处理字符串类型的输入,并返回类型
命令行处理器的示例
假设我们有一个简单的命令行输入:
输入:
./program --add 5 10
这个命令表示用户希望将 5 和 10 相加。命令行处理器的作用是:
- 解析命令(
--add 5 10)。 - 提取相关参数(
5和10)。 - 执行操作(加法)。
- 返回结果(
15)。
步骤解析:
- μ⟦ CommandLineProcessor ⟧ 会接受像
["--add", "5", "10"]这样的字符串列表作为输入。 - Parser:解析器会识别出
--add表示加法操作,5和10是操作数。 - CommandLineProcessor 会计算并返回结果(
15),即两个数的和。
代码实现(使用概念性解析器):
#include <iostream>
#include <string>
#include <vector>
#include <functional>
using namespace std;
using CommandLineProcessor = function<int(vector<string>)>;
int addNumbers(vector<string> args) {if (args.size() != 3) {throw invalid_argument("Invalid number of arguments for add");}int a = stoi(args[1]);int b = stoi(args[2]);return a + b;
}
int main(int argc, char** argv) {vector<string> args(argv, argv + argc);CommandLineProcessor processor = addNumbers; // 命令处理函数try {int result = processor(args); // 执行处理器cout << "Result: " << result << endl; // 输出结果} catch (const exception& e) {cout << "Error: " << e.what() << endl;}return 0;
}
命令行输入: ./program --add 5 10
- CommandLineProcessor (
addNumbers) 会处理输入["--add", "5", "10"]。 addNumbers函数提取数字5和10,将其相加并返回15。
总结
- 命令行处理 涉及解析来自命令行的输入,将其转换为程序可以理解的形式,并根据这些输入执行操作。
- CommandLineProcessor:表示一个处理命令行输入的逻辑,它将字符串参数转换为有意义的输出。
- Parser:将命令行字符串转换为更结构化的类型,通常是程序可以进一步操作的类型。
命令行解析 (Command Line Parsing)
命令行解析是指解析从命令行输入的参数,以便根据它们的含义执行相应的操作。在 C++ 中,命令行参数通常是字符串,而解析的任务是将这些字符串转换为结构化的数据,例如标志(flags)或特定参数。我们可以使用一些技术来解析这些输入,通常包括正则表达式、递归下降解析、状态机等。
你给出的代码看起来是使用了一个命令行解析库来解析输入。我们来逐步解释它。
代码分解
struct HelpFlag {};
struct UserFlag {std::string user;
};
auto flagP = mix(args("--help", HelpFlag()), // 帮助标志处理args("--user" >> stringP, // 用户标志处理[](std::string username) { return UserFlag{username}; })
);
1. struct HelpFlag {}
HelpFlag是一个结构体,没有任何成员。它用于表示一个标志,可能在命令行中作为帮助信息标志(--help)使用。- 通过这种方式,我们创建了一个占位符类型
HelpFlag来代表该标志。实际上,HelpFlag结构体的存在只是为了在命令行解析过程中占据一个位置。
2. struct UserFlag { std::string user; };
UserFlag是一个包含std::string的结构体,用来存储与--user标志相关的数据。在命令行中,--user后面跟着一个用户名,该用户名将存储在user字段中。
3. auto flagP = mix(...)
flagP是一个通过调用mix函数构造的解析器。mix函数用来组合多个命令行参数的解析逻辑。它接受多个解析规则,并根据给定的输入(命令行参数)将它们组合成一个统一的解析规则。
4. args("--help", HelpFlag())
- 这是一个匹配
--help标志的解析规则。如果命令行中包含--help参数,args("--help", HelpFlag())就会匹配,并返回一个HelpFlag类型的结果,表示该标志被激活。
5. args("--user" >> stringP, [](std::string username) { return UserFlag{username}; })
- 这是一个匹配
--user参数并提取用户名的规则。--user后面跟着一个字符串(用户名)。这里stringP是用来解析用户名的解析器,它会解析字符串部分,并将结果传递给 lambda 函数。 >>操作符表示将--user参数和接下来的字符串解析器stringP连接起来。如果--user后面有一个字符串,那么stringP会解析它并将其传递给 lambda 函数。[](std::string username) { return UserFlag{username}; }是一个 lambda 函数,它接收解析到的用户名(username)并创建一个UserFlag类型的对象,包含该用户名。
如何工作
- 命令行输入:
假设我们运行以下命令:--user john - 命令行解析:
args("--user" >> stringP)会匹配--user参数,并将接下来的字符串john传递给stringP解析器。stringP会提取john,并将它传递给 lambda 函数:[](std::string username) { return UserFlag{username}; }。- 这个 lambda 函数将创建一个
UserFlag类型的对象,其中user字段为"john"。
- 输出:
- 最终,
flagP会返回一个UserFlag对象,包含解析到的user值。
- 最终,
总结
这段代码演示了如何使用一种声明式的方式来解析命令行参数。它通过定义结构体和组合解析器来简化命令行参数的解析过程。在这个例子中,--help 和 --user 参数分别对应 HelpFlag 和 UserFlag 类型。--user 参数后面的用户名被提取出来并保存在 UserFlag 的 user 字段中。
命令行解析(Command Line Parsing)
这个代码展示了如何使用一种结构化方式来解析命令行参数,并将它们映射到特定的 C++ 类型。它使用了 boost::variant 来表示不同类型的命令行参数和模式。我们来逐步解析这个代码。
代码分解
struct ListAccounts {};
struct ListJob {int jobId;
};
struct CommandLineParse {std::vector<boost::variant<HelpFlag, UserFlag>> globalFlags;boost::variant<ListAccounts, ListJob> mode;
};
1. 结构体定义
ListAccounts和ListJob:ListAccounts是一个空的结构体,表示一个命令模式(例如:列出所有账户)。这个结构体不包含任何数据。ListJob包含一个jobId,表示列出某个具体作业的命令,需要提供一个jobId。
CommandLineParse:- 这个结构体表示命令行解析的结果。它包含两个字段:
globalFlags:一个包含HelpFlag或UserFlag的std::vector,用于表示全局的命令标志(例如:--help或--user)。mode:一个boost::variant<ListAccounts, ListJob>,表示解析出的命令模式,它可以是ListAccounts或ListJob,具体取决于用户输入的命令。
- 这个结构体表示命令行解析的结果。它包含两个字段:
命令行解析器
auto parser = flagP>> (args(“listAccounts”, ListAccounts()) ||(args(“listJob”) >> “--jobId” >> intP([](int id) { return ListJob{id}; })));
这部分代码是定义了一个命令行解析器 parser。它使用 >> 操作符来组合多个解析器,从而处理不同类型的命令行输入。
2. 解析规则
flagP:之前定义的命令行标志解析器,它处理全局标志(如--help或--user),并将结果存储在CommandLineParse::globalFlags中。args("listAccounts", ListAccounts()):- 这个解析器匹配命令行输入中的
"listAccounts"参数,并将其解析为一个ListAccounts类型的值。这个表示了一个列出账户的命令模式。
- 这个解析器匹配命令行输入中的
args("listJob") >> "--jobId" >> intP([](int id) { return ListJob{id}; }):- 这个解析器首先匹配命令行中的
"listJob"参数,接着要求提供一个--jobId参数。解析器intP将--jobId后面的值解析为整数(jobId)。 - 使用
lambda函数将解析到的jobId值封装到ListJob结构体中。
这种方式允许我们使用listJob --jobId 123来表示列出jobId为123的作业。
- 这个解析器首先匹配命令行中的
3. ||(OR)操作符
||操作符用于将两个解析器组合成一个“或”关系:如果命令行输入是"listAccounts",那么它将匹配第一个解析器(并返回一个ListAccounts);如果命令行输入是"listJob"且有一个--jobId参数,它将匹配第二个解析器(并返回一个ListJob)。
如何工作
示例 1:listAccounts
如果命令行输入如下:
listAccounts
- 解析器首先匹配
args("listAccounts", ListAccounts())。 listAccounts匹配成功,并将ListAccounts类型的结构体返回。mode字段被设置为ListAccounts,而globalFlags字段根据flagP解析的结果来填充(例如,可能包含HelpFlag或UserFlag)。
示例 2:listJob --jobId 123
如果命令行输入如下:
listJob --jobId 123
- 解析器首先匹配
args("listJob")。 - 然后,
--jobId参数被解析为123。 intP解析123并将其传递给 lambda 函数:[](int id) { return ListJob{id}; },这将创建一个ListJob类型的结构体,jobId为123。mode字段被设置为ListJob{123},而globalFlags字段根据flagP解析的结果填充。
总结
- 该代码实现了一个命令行解析器,能够解析具有不同模式的命令行输入。它通过组合多个解析器(使用
>>和||)来处理不同类型的命令行参数。 - 使用
boost::variant来表示不同类型的命令(例如:ListAccounts或ListJob),这使得命令行解析的结果可以灵活地表示为不同的模式。 - 解析器会根据命令行参数(如
listAccounts或listJob --jobId 123)解析并返回相应的结构体,帮助后续的程序执行。
相关文章:

CppCon 2015 学习:Functional Design Explained
这两个 C 程序 不完全相同。它们的差异在于对 std::cout 的使用和代码格式。 程序 1: #include <iostream> int main(int argc, char** argv) {std::cout << "Hello World\n"; }解释:这个程序是 正确的。std::cout 是 C 标准库中…...

基于3D对象体积与直径特征的筛选
1,目的 筛选出目标3D对象。 效果如下: 2,原理 使用3D对象的体积与直径特征进行筛选。 3,代码解析 3.1,预处理2.5D深度图。 * 参考案例库:select_object_model_3d.hdev * ****************************…...

GIT - 如何从某个分支的 commit创建一个新的分支?
如果上一个Release 分支被污染了,想要还原这个分支最原始的样子,有什么办法或者说该怎么办呢?简单来说,就是如何从某个指定的 commit 创建一个新的 Git 分支? 操作非常简单! 命令格式 git branch <ne…...

Claude vs ChatGPT vs Gemini:功能对比、使用体验、适合人群
随着AI应用全面进入生产力场景,市面上的主流AI对话工具也进入“三国杀”时代: Claude(Anthropic):新锐崛起,语言逻辑惊艳,Opus 模型被称为 GPT-4 杀手ChatGPT(OpenAI)&a…...

线程基础编程
早期的计算机只能执行一个任务,一旦任务完成,计算机就会等待下一个任务。这种模型效率低下,无 法充分利用计算机的性能。 随着计算机技术的发展,操作系统开始支持多进程模型,即同时执行多个任务。每个任务被称为一个进…...

DJango项目
一.项目创建 在想要将项目创键的目录下,输入cmd (进入命令提示符)在cmd中输入:Django-admin startproject 项目名称 (创建项目)cd 项目名称 (进入项目)Django-admin startapp 程序名称 (创建程序)python manage.py runserver 8080 (运行程序)将弹出的网址复制到浏览器中…...

深入了解JavaScript当中如何确定值的类型
JavaScript是一种弱类型语言,当你给一个变量赋了一个值,该值是什么类型的,那么该变量就是什么类型的,并且你还可以给一个变量赋多种类型的值,也不会报错,这就是JavaScript的内部机制所决定的,那…...
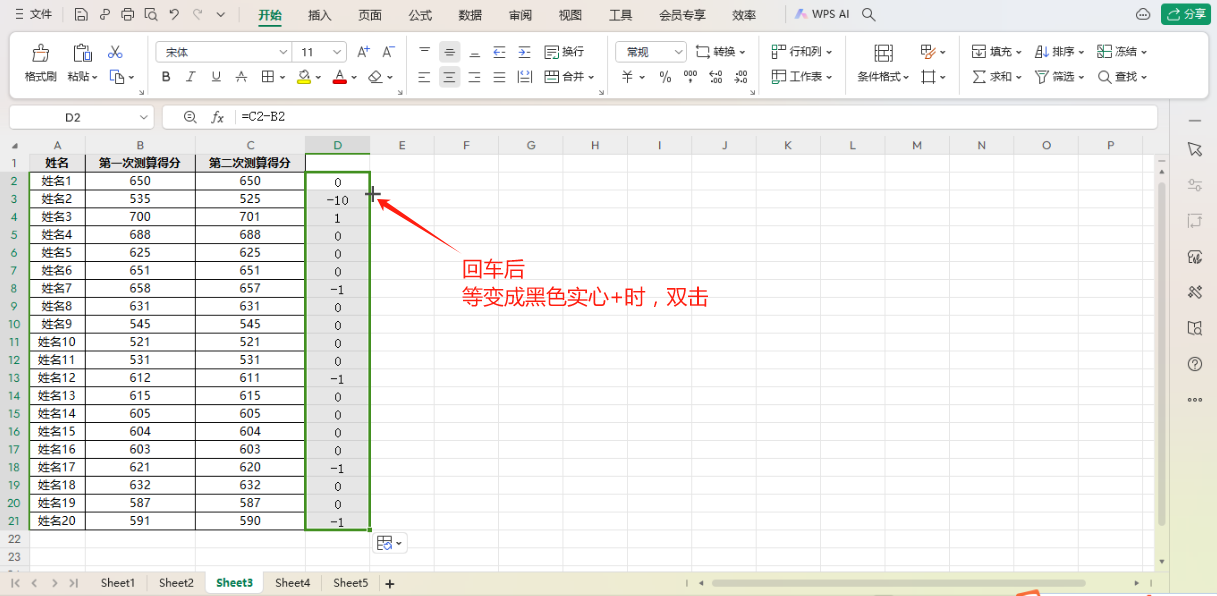
excel数据对比找不同:6种方法核对两列数据差异
工作中,有时需要核对两列数据的差异,用于对比、复核等。数据较少的情况下差异肉眼可见,数据量较大时用什么方法比较好呢?从个人习惯出发,我整理了6种方法供参考。 6种方法核对两列数据差异: 1、Ctrl G定位…...
基于智能代理人工智能(Agentic AI)对冲基金模拟系统:模范巴菲特、凯西·伍德的投资策略
股票市场涉及众多统计数据和模式。股票交易基于研究和数据驱动的决策。人工智能的使用可以实现流程自动化,让投资者在研究上花费更少的时间,同时提高准确性。这使他们能够更加专注于监督实际交易和服务客户。 顶尖对冲基金经理发挥着至关重要的作用&…...
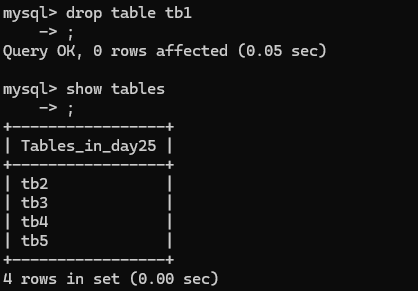
MySQL数据库基础(二)———数据表管理
前言 上篇文章介绍了MySQL数据库以即数据库的管理 这篇文章将给大家讲解数据表的管理 一、数据表常见操作 数据表常见操作的指令 进入数据库use数据库; 查看当前所有表:show tables; 创建表结构 1.创建表操作 1.1创建表 create table 表名(列名 …...

如何在Lyra中创建一个新的Game Feature Plugin和Experience游戏体验
目录 -1.前言0.预备知识1.创建一个新的Game Feature Plugin插件2.创建Lyra Pawn Data Asset3. 创建Lyra Experience Definition4. 创建自定义关卡5. 设置资产管理器Asset Manager引用6. 创建Lyra User Facing Experience Definition7. 在编辑器中运行测试后记-1.前言 由于转职…...

RDMA简介5之RoCE v2队列
在RoCE v2协议中,RoCE v2队列是数据传输的最底层控制机制,其由工作队列(WQ)和完成队列(CQ)共同组成。其中工作队列采用双向通道设计,包含用于存储即将发送数据的发送队列(SQ…...
SAFe/LeSS/DAD等框架的核心适用场景如何选择?
在敏捷开发的规模化实践中,SAFe(Scaled Agile Framework)、LeSS(Large Scale Scrum)和DAD(Disciplined Agile Delivery)是三大主流框架。它们分别以不同的哲学和方法论应对复杂性、协作与交付的…...

鸿蒙应用开发之uni-app x实践
鸿蒙应用开发之uni-app x实践 前言 最近在开发鸿蒙应用时,发现uni-app x从4.61版本开始支持纯血鸿蒙(Harmony next),可以直接编译成ArkTS原生应用。这里记录一下开发过程中的一些经验和踩过的坑。 一、环境搭建 1.1 开发工具 …...
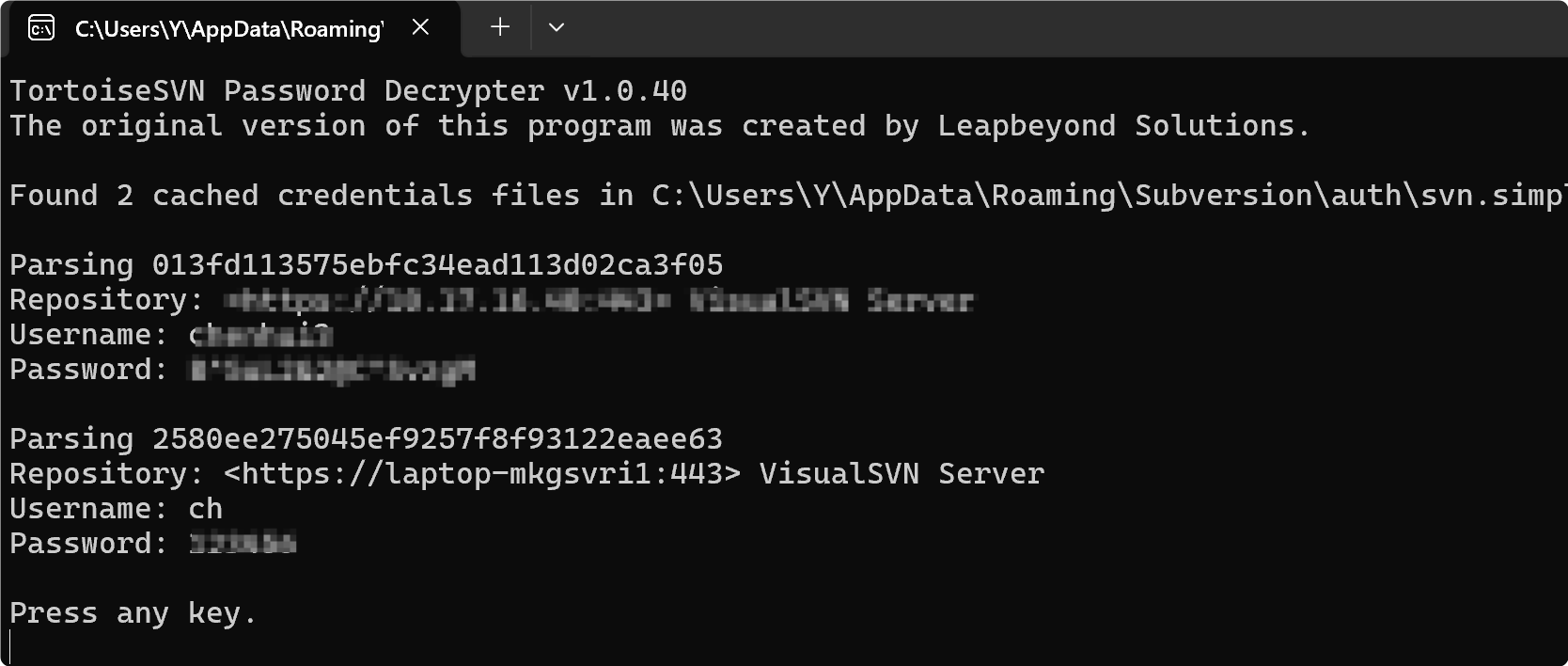
window查看SVN账号密码
背景 公司的SVN地址发生迁移,想迁移一下本地SVN地址,后来发现SVN账号密码忘记了。写此文章纯记录。 迁移SVN地址: 找到svn目录点击relocate,输入新的svn地址,如需输入账号密码,输入账号密码即完成svn地址…...

Python训练营---Day44
DAY 44 预训练模型 知识点回顾: 预训练的概念常见的分类预训练模型图像预训练模型的发展史预训练的策略预训练代码实战:resnet18 作业: 尝试在cifar10对比如下其他的预训练模型,观察差异,尽可能和他人选择的不同尝试通…...

前端项目初始化
目录 1. 安装 nvm 2. 配置 nvm 并切换到 Node.js 16.15.0 3. 安装 LightProxy 代理 4. GIT安装 1. 配置用户名和邮箱(这些信息将用于您在提交代码时的标识): 2. 生成SSH密钥(用于将本地代码仓库与远程存储库连…...

USB扩展器与USB服务器的2个主要区别
在现代办公和IT环境中,连接和管理USB设备是常见需求。USB扩展器(常称USB集线器)与USB服务器(如朝天椒USB服务器)是两类功能定位截然不同的解决方案。前者主要解决物理接口数量不足的“近身”连接扩展问题,而…...
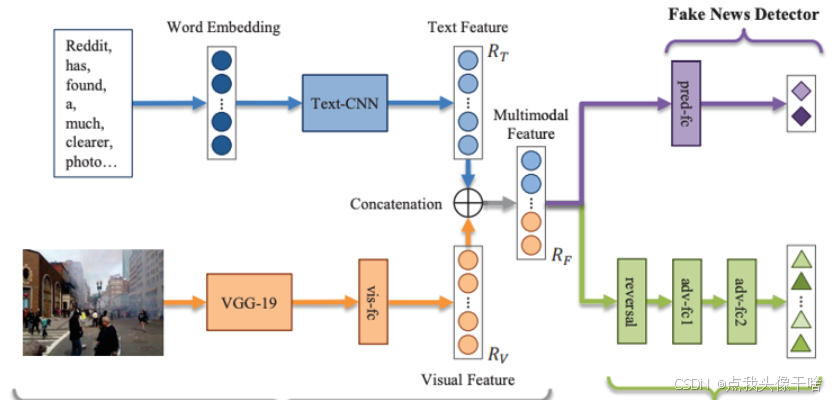
第46节:多模态分类(图像+文本)
一、多模态分类概述 多模态分类是指利用来自不同模态(如图像、文本、音频等)的数据进行联合分析和分类的任务。 在当今大数据时代,信息往往以多种形式存在,例如社交媒体上的图片配文字、视频附带字幕、医疗检查中的影像与报告等。单一模态的数据往往只能提供有限的信息,…...

spring获取注册的bean并注册到自定义工厂中管理
背景 在开发的时候,对于同一个对象的按照某个字段的不同有很多的处理方式。想着开发一个类似于工厂模式,由上层工厂统一分配。 由于是基于springboot开发,所以有很多自动注入的对象,如果由工厂统一创建new对象的方式,那…...

IDEA 中 Maven Dependencies 出现红色波浪线的原因及解决方法
在使用 IntelliJ IDEA 开发 Java 项目时,尤其是基于 Maven 的项目,开发者可能会遇到 Maven Dependencies 中出现红色波浪线的问题。这种现象通常表示项目依赖未能正确解析或下载,导致代码提示错误、编译失败等问题。本文将详细分析该问题的常…...
springMVC-10验证及国际化
验证 概述 ● 概述 1. 对输入的数据(比如表单数据),进行必要的验证,并给出相应的提示信息。 2. 对于验证表单数据,springMVC提供了很多实用的注解, 这些注解由JSR303 验证框架提供. ●JSR 303 验证框架 1. JSR 303 的含义 JSR࿰…...

使用Python和TensorFlow实现图像分类
最近研学过程中发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击链接跳转到网站人工智能及编程语言学习教程。读者们可以通过里面的文章详细了解一下人工智能及其编程等教程和学习方法。下面开始对正文内容的…...
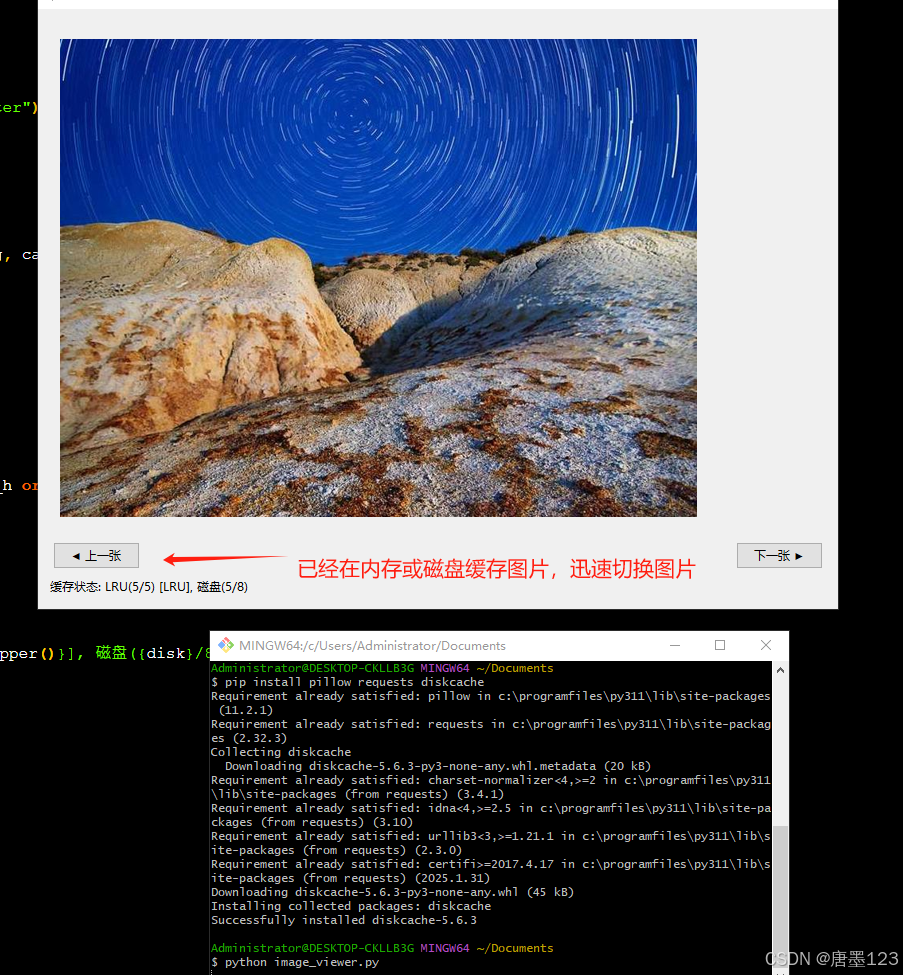
LRU 和 DiskLRU实现相册缓存器
我是写Linux后端的(golang、c、py),后端缓存算法通常是指的是内存里面的lru、或diskqueue,都是独立使用。 很少有用内存lru与disklru结合的场景需求。近段时间研究android开发,里面有一些设计思想值得后端学习。 写这…...
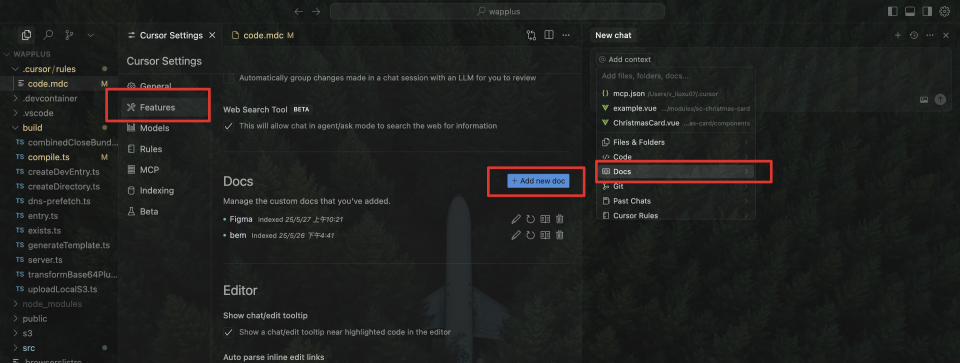
figma MCP + cursor如何将设计稿生成前端页面
一、准备工作 figma MCP需要通过figma key来获取设计稿权限,key的生成步骤如下 1. 打开figma网页版/APP,进入账户设定 2. 点击生成token 3. 填写内容生成token(一定要确认复制了,不然关闭弹窗后就不会显示了) 二、配置MCP 4. 进入到cursor…...
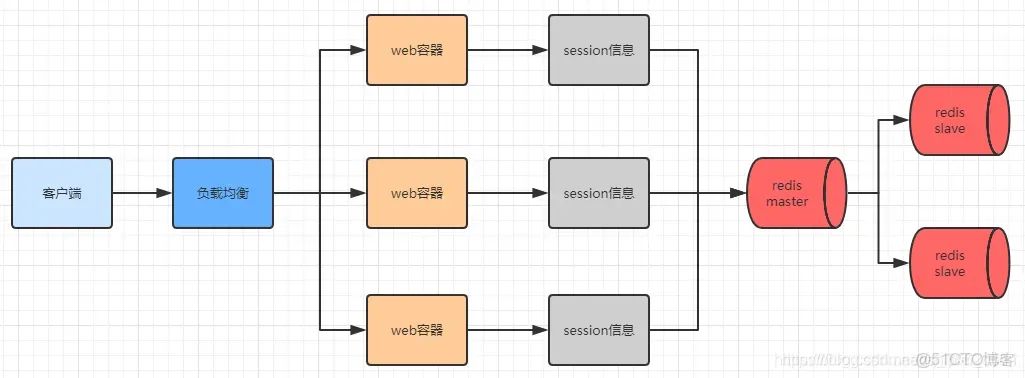
如何理解OSI七层模型和TCP/IP四层模型?HTTP作为如何保存用户状态?多服务器节点下 Session方案怎么做
本篇概览: OSI 七层模型是什么?每一层的作用是什么?TCP/IP四层模型和OSI七层模型的区别是什么? HTTP 本身是无状态协议,HTTP如何保存用户状态? 能不能具体说一下Cookie的工作原理、生命周期、作用域?使用…...

Flask 核心概念速览:路由、请求、响应与蓝图
一、路由参数与请求方法 Flask 路由允许定义多种参数类型,并通过 methods 属性限制请求方法。 1. 路由参数类型: 除了默认的 string,Flask 还支持: int: 匹配整数,自动转换为 Python int 类型。非数字输入会返回 404。 float: 匹配浮点数,自动转换为 Python float 类型…...

Spring Boot消息系统开发指南
消息系统基础概念 消息系统作为分布式架构的核心组件,实现了不同系统模块间的高效通信机制。其应用场景从即时通讯软件延伸至企业级应用集成,形成了现代软件架构中不可或缺的基础设施。 通信模式本质特征 同步通信要求收发双方必须同时在线交互&#…...
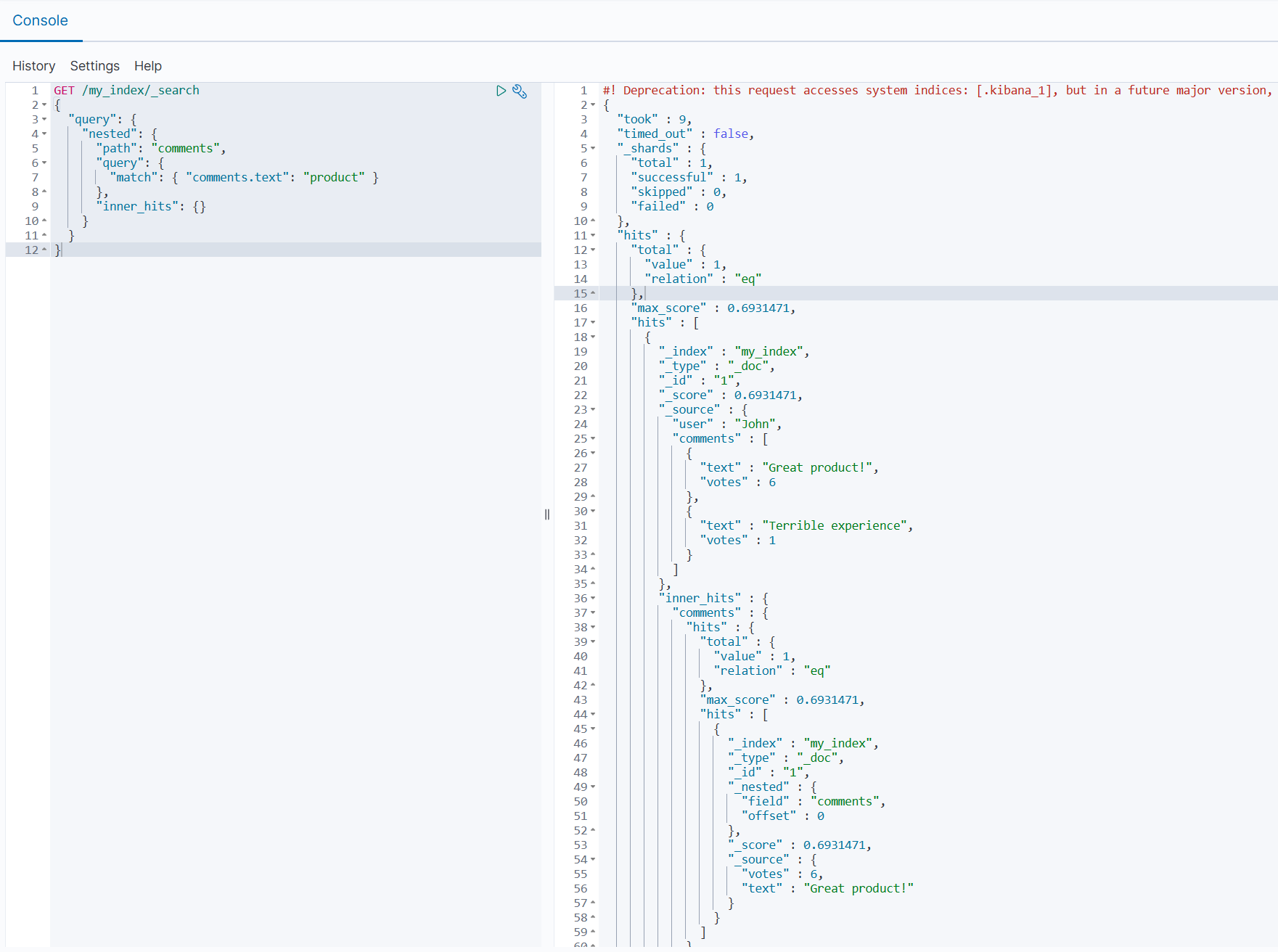
【Elasticsearch】映射:Nested 类型
映射:Nested 类型 1.为什么需要 Nested 类型2.如何定义 Nested 类型3.相关操作3.1 索引包含 Nested 数据的文档3.2 查询 Nested 数据3.3 聚合 Nested 数据3.4 排序 Nested 数据3.5 更新 Nested 文档中的特定元素 4.Nested 类型的高级操作4.1 内嵌 inner hits4.2 多级…...
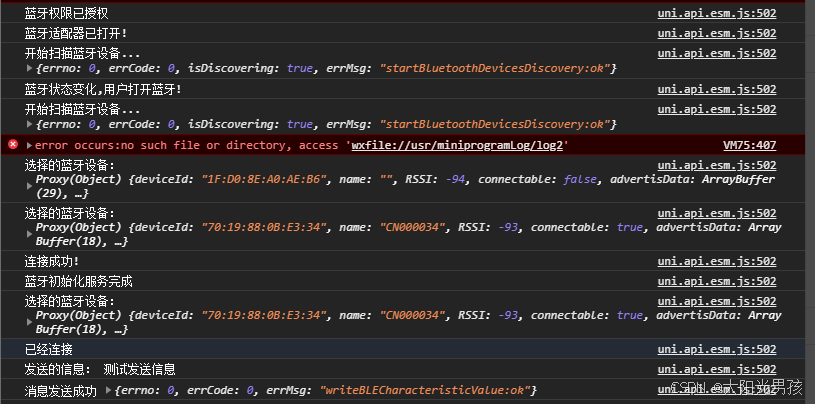
Vue3 + UniApp 蓝牙连接与数据发送(稳定版)
本教程适用于使用 uni-app Vue3 (script setup) 开发的跨平台 App(支持微信小程序、H5、Android/iOS 等) 🎯 功能目标 ✅ 获取蓝牙权限✅ 扫描周围蓝牙设备✅ 连接指定蓝牙设备✅ 获取服务和特征值✅ 向设备发送数据包(ArrayBu…...