【论文阅读笔记】万花筒:用于异构多智能体强化学习的可学习掩码
摘要
在多智能体强化学习(MARL)中,通常采用参数共享来提高样本效率。然而,全参数共享的流行方法通常会导致智能体之间的策略同质,这可能会限制从策略多样性中获得的性能优势。为了解决这一关键限制,我们提出了万花筒,一种新的自适应部分参数共享方案,在保持高样本效率的同时促进策略异质性。具体来说,万花筒为不同的智能体维护一组公共参数以及多组不同的、可学习的掩码,决定参数的共享。它通过鼓励这些掩码之间的差异来促进策略网络之间的多样性,而不会牺牲参数共享的效率。这种设计使万花筒能够动态平衡高样本效率和广泛的策略表示能力,有效地弥合了各种环境中全参数共享和非参数共享之间的差距。我们进一步将万花筒扩展到Actor-Critic算法背景下的批评器集合,这有助于提高价值估计。我们在广泛的环境中进行了实证评估,包括多智能体粒子环境,多智能体MuJoCo和星际争霸多智能体挑战v2,与现有的参数共享方法相比,万花筒的性能优越,展示了其在MARL中的性能增强潜力。该代码可在Github上访问。
1 引言
协作式多智能体强化学习(MARL)在解决各种领域复杂的现实世界决策问题方面表现出显著的有效性,例如资源分配、包裹递送、自动驾驶和机器人控制。为了缓解MARL典型的非平稳和部分可观察环境带来的挑战(Yuan等人,2023),集中式训练与分散执行(CTDE)范式已经变得普遍,激发了许多有影响力的MARL算法,如MADDPG 、COMA 、MATD3 、QMIX 和MAPPO 。
在CTDE范式下,智能体之间的参数共享是提高样本效率的常用方法。然而,跨智能体的相同网络参数往往导致同质策略,限制了行为的多样性和整体联合策略的表示能力。在某些情况下,这种限制会导致意想不到的结果,如图1所示,阻碍进一步的性能增加。另一种方法是无参数共享方案,其中每个智能体拥有自己的唯一参数。然而,尽管这种方法自然地支持异构策略,但它受到样本效率降低的影响,导致显著的训练成本。考虑到当前模型规模越来越大的趋势,其中一些扩展到数万亿个参数,这尤其成问题。因此,必须开发一种既具有高样本效率又具有广泛策略表征能力的参数共享策略,从而有可能显著提高性能。虽然一些努力已经探索了在训练开始时启动的部分参数共享,但是如果没有对智能体特定环境转换或奖励函数的详细了解,这种初始化设计可能具有挑战性。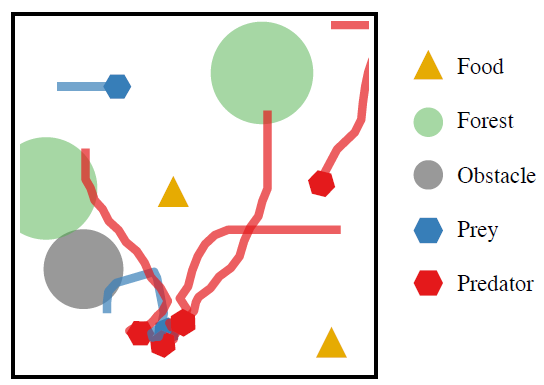
图1:全参数共享限制策略是同构的。在这个例子中,所有的捕食者都追逐同一个猎物,而忽略了游戏世界中的另一个猎物。更多游戏细节见附录A.2。
在这项工作中,我们建立在以前研究的见解基础上,提出了一种新的自适应部分参数共享方案万花筒。它维护一组策略参数,并使用多个可学习掩码来指定共享参数。与早期依赖于固定初始化的方法不同,Kaleidoscope在整个训练过程中动态地学习这些掩码以及MARL参数。这种端到端训练方法固有地集成了环境信息,其自适应特性使万花筒能够根据环境的需求和智能体的学习进度动态调整参数共享的水平。可学习掩码促进了全参数共享和非参数共享之间的动态平衡,通过增强异质性在样本效率和策略表征能力之间提供了灵活的权衡。首先,我们在智能体网络上构建万花筒,实现多种策略。在这一成功之后,我们将其扩展到多智能体Actor-Critic算法,以鼓励中心批评器集合之间的异质性,从而进一步提高性能。
【注】: 就像万花筒利用旋转镜子的反射特性将简单的形状转化为美丽的图案一样,我们提出的方法利用可学习的掩码将一组参数映射到不同的策略中,从而提高任务性能。
我们的贡献总结如下:
- 为了实现智能体之间策略的异构性以获得更好的训练灵活性,我们采用软阈值重参数化(STR)技术,在只保留一组公共参数的情况下,为不同的智能体网络学习不同的掩码,有效地平衡了全参数共享和非参数共享机制。
- 为了增强智能体之间的策略多样性,我们引入了一个新的正则化项来鼓励掩码之间的两两差异。此外,我们设计了重置机制,回收屏蔽参数以保持联合网络的表示能力。
- 通过在MARL基准上的大量实验,包括多智能体粒子环境(MPE),MAMuJoCo 和在《星际争霸》多智能体挑战v2 (SMACv2) ,我们展示了Kaleidoscope优于现有参数共享方法的性能。
2 背景
多智能体强化学习(MARL) 在MARL中,完全协作的部分可观察多智能体任务通常被表述为分散的部分可观察马尔可夫决策过程,由元组 M = ⟨ S , A , P , R , Ω , O , N , γ ⟩ \mathcal{M}=\langle\mathcal{S},A,P,R,\Omega,O,N,\gamma\rangle M=⟨S,A,P,R,Ω,O,N,γ⟩表示。其中,N为智能体的数量, γ ∈ ( 0 , 1 ] \gamma\in(0,1] γ∈(0,1]表示折现系数。在每个时间步t上,随着环境状态 s t ∈ S s^{t}\in\mathcal{S} st∈S,智能体 i i i从观测函数 O ( s t , i ) O(s^{t},i) O(st,i)接收局部观测 o i t ∈ Ω o_i^t\in\Omega oit∈Ω然后遵循本地策略 π i \pi_{i} πi选择动作 a i t ∈ A a_{i}^{t}\in A ait∈A。个体动作形成联合动作 a t ∈ A N a^{t}\in A^{N} at∈AN。导致状态转换到下一个状态 s t + 1 ∼ P ( s t + 1 ∣ s t , a t ) s^{t+1}\sim P(s^{t+1}|s^{t},\boldsymbol{a}^{t}) st+1∼P(st+1∣st,at)并包含一个全局奖励 r t = R ( s t , a t ) r^{t}=R(s^{t},\boldsymbol{a}^{t}) rt=R(st,at)。整个团队的目标是学习联合策略 π = ⟨ π 1 , … , π N ⟩ \boldsymbol{\pi}=\langle\pi_1,\ldots,\pi_N\rangle π=⟨π1,…,πN⟩从而最大化折现累计奖励的期望 G t = ∑ t γ t r t G^t=\sum_t{\gamma^t}r^t Gt=∑tγtrt。
为了学习策略 π θ \pi_{\theta} πθ,各种MARL算法被提出。例如,离线策略 Actor-Critic算法 MATD3作为示例方法。具体来说,通过最小化时间差(TD)误差损失来更新批评器网络
L c ( ϕ ) = E ( s t , o t , a t , r t , s t + 1 , o t + 1 ) ∼ D [ ( y t − Q ( s t , a t ; ϕ ) ) 2 ] , ( 1 ) \mathcal{L}_c(\phi)=\mathbb{E}_{(s^t,\boldsymbol{o}^t,\boldsymbol{a}^t,r^t,s^{t+1},\boldsymbol{o}^{t+1})\sim\mathcal{D}}\left[\left(y^t-Q(s^t,\boldsymbol{a}^t;\phi)\right)^2\right],\hspace{1cm} (1) Lc(ϕ)=E(st,ot,at,rt,st+1,ot+1)∼D[(yt−Q(st,at;ϕ))2],(1)
其中
y t = r t + γ min j = 1 , 2 Q ( s t + 1 , π 1 ( o 1 t + 1 ; θ 1 ′ ) + ϵ , … , π N ( o N t + 1 ; θ N ′ ) + ϵ ; ϕ j ) , ( 2 ) y^t=r^t+\gamma\min_{j=1,2}Q(s^{t+1},\pi_1(o_1^{t+1};\theta_1^{\prime})+\epsilon,\ldots,\pi_N(o_N^{t+1};\theta_N^{\prime})+\epsilon;\phi_j),\hspace{1cm} (2) yt=rt+γj=1,2minQ(st+1,π1(o1t+1;θ1′)+ϵ,…,πN(oNt+1;θN′)+ϵ;ϕj),(2)
其中 ϕ \phi ϕ是批评器参数, θ \theta θ是执行策略参数, θ ′ \theta^{'} θ′是目标执行策略参数, ϵ \epsilon ϵ是截断高斯噪声,遵循分布 c l i p ( N ( 0 , σ ) , − c , c ) \mathsf{clip}(\mathcal{N}(0,\sigma),-c,c) clip(N(0,σ),−c,c)。
策略更新采用确定性策略梯度算法
∇ J ( θ i ) = E ( s t , o t , a t , r t , s t + 1 , o t + 1 ) ∼ D [ ∇ θ i π i ( o i t ; θ i ) ∇ a i Q ( s t , a 1 , … , a N ∣ a i = π i ( o i t ; θ i ) ; ϕ 1 ) ] . ( 3 ) \nabla\mathcal{J}(\theta_i)=\mathbb{E}_{(s^t,\boldsymbol{o}^t,\boldsymbol{a}^t,r^t,s^{t+1},\boldsymbol{o}^{t+1})\thicksim\mathcal{D}}\left[\nabla_{\theta_i}\pi_i(o_i^t;\theta_i)\nabla_{a_i}Q(s^t,a_1,\ldots,a_N|_{a_i=\pi_i(o_i^t;\theta_i)};\phi_1)\right].\hspace{1cm} (3) ∇J(θi)=E(st,ot,at,rt,st+1,ot+1)∼D[∇θiπi(oit;θi)∇aiQ(st,a1,…,aN∣ai=πi(oit;θi);ϕ1)].(3)
软阈值重参数化(STR) 最初是在模型稀疏化的背景下引入的,STR 是一种非结构化修剪方法,无需预先确定稀疏度水平即可实现显著性能。具体来说,STR对原始参数W进行如下变换
S g ( W , s ) = s i g n ( W ) ⋅ R e L U ( ∣ W ∣ − g ( s ) ) , ( 4 ) \mathcal{S}_g(W,s)=\mathrm{sign}(W)\cdot\mathrm{ReLU}\left(|W|-g(s)\right),\hspace{1cm} (4) Sg(W,s)=sign(W)⋅ReLU(∣W∣−g(s)),(4)
其中 s s s是可学习参数, α = g ( s ) \alpha=g(s) α=g(s)作为修剪阈值, R e L U ( ⋅ ) = max ( ⋅ , 0 ) \mathrm{ReLU}(\cdot)=\max(\cdot,0) ReLU(⋅)=max(⋅,0)。
最初的监督学习问题建模为
min W L ( W ; D ) ( 5 ) \min_{\boldsymbol{W}}\mathcal{L}(\boldsymbol{W};\mathcal{D})\hspace{1cm} (5) WminL(W;D)(5)
其中 ; D ;\mathcal{D} ;D作为数据现在转换为
min W , s L ( S g ( W , s ) ; D ) . ( 6 ) \min_{\boldsymbol{W},\boldsymbol{s}}\mathcal{L}(\mathcal{S}_g(\boldsymbol{W},s);\mathcal{D}).\hspace{1cm} (6) W,sminL(Sg(W,s);D).(6)
总体而言,该方法优化了可学习剪枝阈值和模型参数,便于在训练过程中动态调整到稀疏度水平。
3 用于异构多智能体强化学习的可学习掩码
在本节中,我们提出使用可学习掩码作为一种低成本的方法来实现MARL中的网络异构。如图2所示,其核心概念是学习一组由不同智能体的多个掩码补充的共享参数,并指定要共享哪些参数。
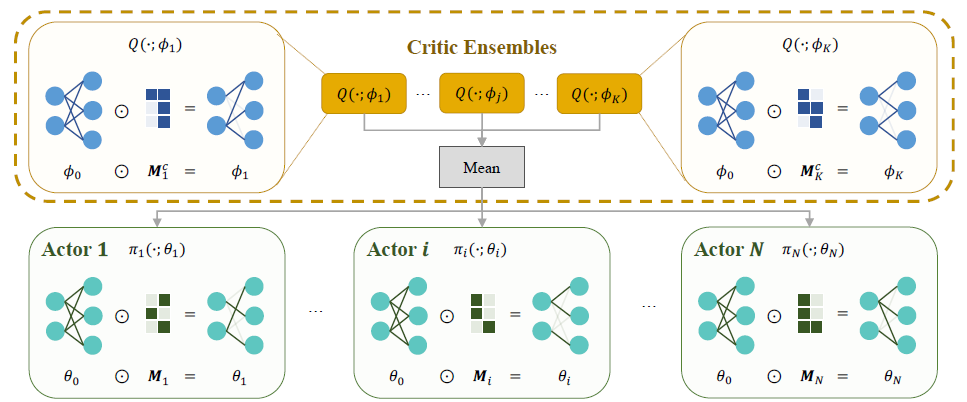
图2:万花筒的整体网络架构。它为Actor网络维护带有N组掩码 [ M i ] i = 1 N \left[M_{i}\right]_{i=1}^{N} [Mi]i=1N的一组参数 θ 0 \theta_0 θ0以及为集成Critic网络维护带有K组掩码 [ M j c ] j = 1 K \left[M_j^c\right]_{j=1}^K [Mjc]j=1K的一组参数 ϕ 0 \phi_{0} ϕ0,其中N是智能体的个数,K是集成网络中子网络的数量, ⊙ \odot ⊙是哈达玛积。
具体而言,在第3.1节中,我们首先将STR改进为动态部分参数共享方法,解锁联合策略网络在智能体之间表示多种策略的能力。在第3.2节中,我们通过基于掩码的新正则化项积极促进策略异质性。考虑到掩码技术可能会过度稀疏网络,潜在地降低其表示能力,在第3.3节中,我们提出了一种直接的补救措施,根据掩码的结果周期性地重置参数,这也减轻了首要偏差。最后,在第3.4节中,我们将探讨如何在Actor- Critic算法的Critic组件中进一步扩展这种方法,以改进MARL中的值估计并进一步提高性能。
为了清晰起见,我们将提出的万花筒与MATD3 算法集成在一起,以演示本节中的概念。然而,作为一种通用的部分参数共享技术,我们的方法可以很容易地适应其他MARL算法。我们将其与其他MARL框架的集成放到附录A.1.2,并将在第4节对它们进行实验评估。
3.1 自适应部分参数共享
这项工作的核心思想是为不同的智能体学习不同的二进制掩码 M i M_i Mi,以促进差异化策略,最终旨在提高MARL性能。为了实现这一目标,我们将STR技术应用于每个智能体专用的具有不同阈值的策略参数:
θ i = θ 0 ⊙ M i ( 7 ) \theta _{i}= \theta _{0}\odot M_{i}\hspace{1cm} (7) θi=θ0⊙Mi(7)
其中 θ i \theta _{i} θi表示智能体 i i i的策略参数, θ 0 \theta _{0} θ0表示所有智能体共享的一组可学习参数, M i M _{i} Mi为每个智能体的可学习掩码。具体来说,假设 θ 0 = [ θ 0 ( 1 ) , … , θ 0 ( N a ) ] \theta_0=\begin{bmatrix}\theta_0^{(1)},\ldots,\theta_0^{(N_a)}\end{bmatrix} θ0=[θ0(1),…,θ0(Na)], θ i = [ θ i ( 1 ) , … , θ i ( N a ) ] \theta_i=\left[\theta_i^{(1)},\ldots,\theta_i^{(N_a)}\right] θi=[θi(1),…,θi(Na)], M i = [ m i ( 1 ) , … , m i ( N a ) ] M_i=\left[m_i^{(1)},\ldots,m_i^{(N_a)}\right] Mi=[mi(1),…,mi(Na)],其中 N a N_a Na是一个智能体网络的总参数量。与STR保持一致,我们计算 M i M_i Mi中的每一个元素 m i ( k ) = 1 [ ∣ θ 0 ( k ) ∣ > σ ( s i ( k ) ) ] m_i^{(k)}=\mathbb{1}\left[|\theta_0^{(k)}|>\sigma(s_i^{(k)})\right] mi(k)=1[∣θ0(k)∣>σ(si(k))],其中 σ ( ⋅ ) \sigma(\cdot) σ(⋅)为Sigmoid函数。
这种结合的好处总结如下:
- 保留原MARL学习目标:与剪枝相关文献中的大多数方法不同,它们主要目的是尽量减少剪枝和未剪枝网络在权重,损失或激活方面的差异,STR保持最小化特定任务损失的原始目标,与我们提高MARL性能的目标直接一致。
- 稀疏的灵活性:许多经典的剪枝方法需要预定义每层的稀疏度水平。这样的需求会使我们的设计复杂化,我们的目标不是获得极端的稀疏性,而是通过掩码来促进异构性。STR技术在我们的案例中是理想的,因为它不需要预定义稀疏度水平,允许掩码的自适应学习。
- 增强网络表征能力:利用可学习掩码进行自适应部分参数共享,提高了网络的表征能力,超越了传统的全参数共享。在全参数共享中,智能体的联合策略参数化表示为 π p s ( ⋅ ∣ θ 0 ) = ⟨ π 1 ( ⋅ ∣ θ 0 ) , … , π N ( ⋅ ∣ θ 0 ) ⟩ \pi^{\mathrm{ps}}(\cdot|\theta_{0})\quad=\quad\langle\pi_{1}(\cdot|\theta_{0}),\ldots,\pi_{N}(\cdot|\theta_{0})\rangle πps(⋅∣θ0)=⟨π1(⋅∣θ0),…,πN(⋅∣θ0)⟩相比之下,我们提出的自适应部分参数共享机制将联合策略参数化表示为 π Kaleidoscope ( ⋅ ∣ θ 0 , M ) = ⟨ π 1 ( ⋅ ∣ θ 0 ⊙ M 1 ) , … , π n ( ⋅ ∣ θ 0 ⊙ M N ) ⟩ \pi^\text{Kaleidoscope}{(\cdot|\theta_0,M)}=\langle\pi_1(\cdot|\theta_0\odot M_1),\ldots,\pi_n(\cdot|\theta_0\odot M_N)\rangle πKaleidoscope(⋅∣θ0,M)=⟨π1(⋅∣θ0⊙M1),…,πn(⋅∣θ0⊙MN)⟩。在极端情况下, M i M_i Mi中所有的值都为1s,函数集表示为 π Kaleidoscope ( ⋅ ∣ θ 0 , M ) \pi^{\text{Kaleidoscope}}(\cdot|\theta_{0},M) πKaleidoscope(⋅∣θ0,M)退化为 π p s ( ⋅ ∣ θ 0 ) \pi^{\mathrm{ps}}(\cdot|\theta_{0}) πps(⋅∣θ0)。其他情况下,它是由 π p s ( ⋅ ∣ θ 0 ) \pi^{\mathrm{ps}}(\cdot|\theta_{0}) πps(⋅∣θ0)表示的集合的超集。
3.2 策略异质性正则化
虽然独立学习的掩码使智能体能够制定不同的策略,但在没有特定激励的情况下,这些策略仍然可能收敛到同质。为此,我们建议通过引入多样性正则化项来最大化网络掩码之间的加权两两距离,从而明确鼓励智能体策略的异质性,该正则化项定义为
J d i v ( s ) = ∑ i = 1 , … , n ∑ j = 1 , … , n ∥ θ 0 ⊙ ( M i − M j ) ∥ 1 . ( 8 ) \mathcal{J}^{\mathrm{div}}(s)=\sum_{i=1,\ldots,n}\sum_{j=1,\ldots,n}\|\theta_0\odot(M_i-M_j)\|_1.\hspace{1cm} (8) Jdiv(s)=i=1,…,n∑j=1,…,n∑∥θ0⊙(Mi−Mj)∥1.(8)
由于M中的指示函数 1 [ ⋅ ] \mathbb{1}[\cdot] 1[⋅],这一项本质上不可微。为了克服这一困难,遵循文献中的既定做法,我们利用代理函数进行梯度近似:
∂ J d i v ∂ g ( s i ) = − tanh [ ∂ J d i v ∂ M i ] . ( 9 ) \frac{\partial\mathcal{J}^\mathrm{div}}{\partial g(s_i)}=-\tanh\left[\frac{\partial\mathcal{J}^\mathrm{div}}{\partial M_i}\right].\hspace{1cm} (9) ∂g(si)∂Jdiv=−tanh[∂Mi∂Jdiv].(9)
我们在附录A.1.1中正式提供了Actor的总体训练目标。
3.3 定期重置
随着掩码训练的进行,我们观察到每个智能体网络的稀疏度越来越大,这可能会降低整个网络的容量。为了解决这个问题,我们提出了一种简单的方法,以一定的概率ρ周期性地重置在所有 M i M_i Mi上一致屏蔽的参数,如图3a所示。在由t定义的区间内修改reset_interval==0,如果参数索引k满足 ∀ i , m i ( k ) = = 0 \forall i,m_i^{(k)}==0 ∀i,mi(k)==0我们应用以下重置规则
θ 0 ( k ) , s 1 ( k ) , … , s N ( k ) ← { Reinitialize [ θ 0 ( k ) , s 1 ( k ) , … , s N ( k ) ] with probability ρ θ 0 ( k ) , s 1 ( k ) , … , s N ( k ) with probability 1 − ρ . ( 10 ) \theta_0^{(k)},s_1^{(k)},\ldots,s_N^{(k)}\leftarrow \begin{cases} \text{Reinitialize}[\theta_0^{(k)},s_1^{(k)},\ldots,s_N^{(k)}] & \text{with probability }\rho \\ \theta_0^{(k)},s_1^{(k)},\ldots,s_N^{(k)} & \text{with probability }1-\rho & \end{cases}.\hspace{1cm} (10) θ0(k),s1(k),…,sN(k)←{Reinitialize[θ0(k),s1(k),…,sN(k)]θ0(k),s1(k),…,sN(k)with probability ρwith probability 1−ρ.(10)
这种重置机制回收被所有掩码屏蔽为零的权重,从而防止网络变得过于稀疏。这种重置机制的一个附带好处是增强神经可塑性,这有助于缓解强化学习中的首因偏差。与重新初始化整个层导致性能突然下降的方法不同,我们的重置方法选择性地针对可学习掩模所指示的权重,从而避免了显著的性能中断,如第4节所示。
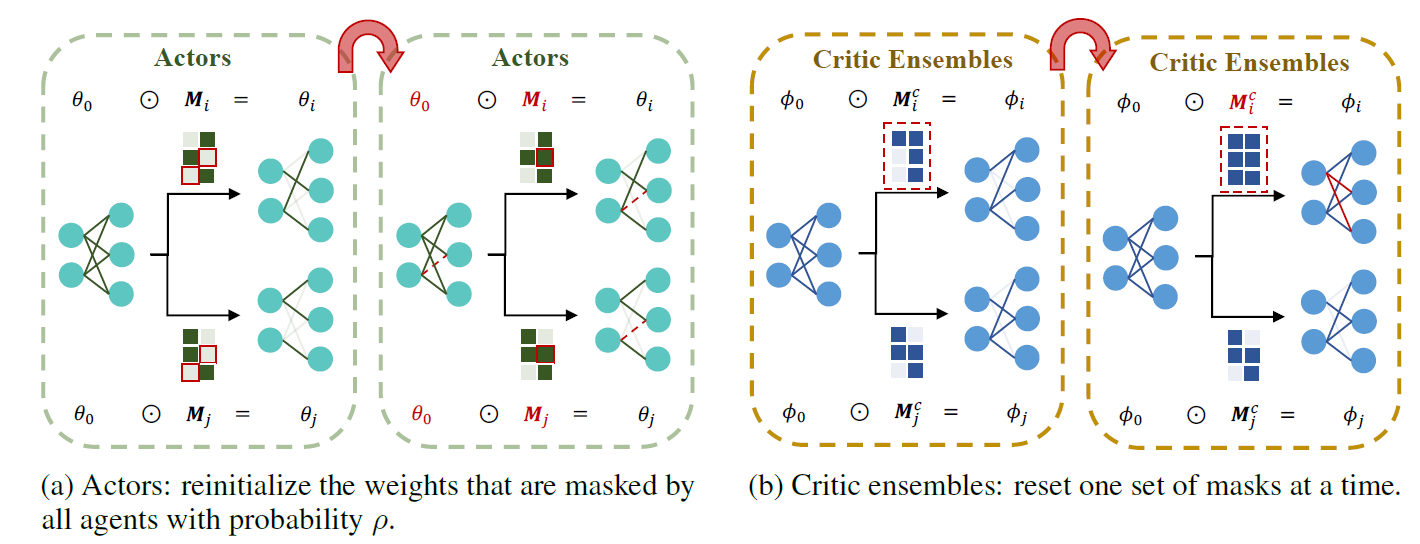
图3:重置机制的说明
3.4 带有可学习掩码的批评器集成
在Actor-Critic算法框架中,我们进一步将万花筒应用于中心批评器,作为实现集成式批评器的有效方法。通过促进动态部分参数共享,万花筒实现了批评器集合之间的异质性。此外,通过规范批评器函数之间的异质性,我们可以控制集成方差。这一方法将在以后各段加以阐述。
- 批评器集成的自适应部分参数共享 在标准的MATD3算法中,维护两个具有独立参数的批评器以减轻过估计风险。但是,使用单独的参数通常会导致对数据的利用效率较低。为了解决这个问题,我们提出通过在批评器集合中使用万花筒参数共享来提高数据利用效率。具体来说,我们维护一组参数 ϕ 0 \phi_{0} ϕ0和K个掩码 [ M j c ] j = 1 K \begin{bmatrix}M_j^c\end{bmatrix}_{j=1}^K [Mjc]j=1K以区分批评函数,从而产生由K个批评器组成的集成批评器 [ Q ( ⋅ ; ϕ j ) ] j = 1 K [Q(\cdot;\phi_j)]_{j=1}^K [Q(⋅;ϕj)]j=1K,其中 ϕ j = ϕ 0 ⊙ M j c \phi_j=\phi_0\odot M_j^c ϕj=ϕ0⊙Mjc。
具体来说,我们通过最小化时间差(TD)误差损失来更新批评器网络
L c ( ϕ j ) = E ( s t , a t , s t + 1 ) ∼ D [ ( y t − Q ( s t , a t ; ϕ j ) ) 2 ] , ( 11 ) \mathcal{L}_c(\phi_j)=\mathbb{E}_{(s^t,\boldsymbol{a}^t,s_{t+1})\sim\mathcal{D}}\left[\left(y^t-Q(s^t,\boldsymbol{a}^t;\phi_j)\right)^2\right],\hspace{1cm} (11) Lc(ϕj)=E(st,at,st+1)∼D[(yt−Q(st,at;ϕj))2],(11)
其中
y t = r t + γ min j = 1 , . . . , K Q ( s t + 1 , π 1 ( o 1 t + 1 ; θ 1 ′ ) + ϵ , . . . , π n ( o N t + 1 ; θ N ′ ) + ϵ ; ϕ j ) . ( 12 ) y^t=r^t+\gamma\min_{j=1,...,K}Q(s^{t+1},\pi_1(o_1^{t+1};\theta_1^{\prime})+\epsilon,...,\pi_n(o_N^{t+1};\theta_N^{\prime})+\epsilon;\phi_j).\hspace{1cm} (12) yt=rt+γj=1,...,KminQ(st+1,π1(o1t+1;θ1′)+ϵ,...,πn(oNt+1;θN′)+ϵ;ϕj).(12)
并根据批评器集合的均值估计来更新策略
∇ J ( θ i ) = E s t ∼ D [ ∇ θ i π i ( o i t ; θ i ) ∇ a i 1 K ∑ j = 1 K [ Q ( s t , a 1 , … , a N ∣ a i = π i ( o i t ; θ i ) ; ϕ j ) ] ] . ( 13 ) \nabla\mathcal{J}(\theta_i)=\mathbb{E}_{s^t\sim\mathcal{D}}\left[\nabla_{\theta_i}\pi_i(o_i^t;\theta_i)\nabla_{a_i}\frac{1}{K}\sum_{j=1}^K\left[Q(s^t,a_1,\ldots,a_N|_{a_i=\pi_i(o_i^t;\theta_i)};\phi_j)\right]\right].\hspace{1cm} (13) ∇J(θi)=Est∼D[∇θiπi(oit;θi)∇aiK1j=1∑K[Q(st,a1,…,aN∣ai=πi(oit;θi);ϕj)]].(13)
批评器集合的多样性正则化 如第3.2节所述,我们还将多样性正则化应用于批评器掩码,以防止批评函数崩溃为相同的函数。最大化批评器集合的多样性正则化表示为
J c d i v ( s c ) = ∑ i = 1 , … , K ∑ j = 1 , … , K ∥ ϕ 0 ⊙ ( M i c − M j c ) ∥ 1 . ( 14 ) \mathcal{J}_c^{\mathrm{div}}(s^c)=\sum_{i=1,\ldots,K}\sum_{j=1,\ldots,K}\|\phi_0\odot(M_i^c-M_j^c)\|_1.\hspace{1cm} (14) Jcdiv(sc)=i=1,…,K∑j=1,…,K∑∥ϕ0⊙(Mic−Mjc)∥1.(14)
直观地说,随着训练的进展,这个正则项鼓励了批评掩码之间的差异性,导致模型估计的不确定性增加。这个过程促进了从过估计到欠估计的逐渐转变。正如之前的研究所讨论的那样,过估计可以鼓励探索,在早期训练阶段是有益的,而欠估计可以减轻误差积累,这在训练后期是首选的。我们在附录A.1.1中正式提供了批评器集合的总体训练目标。
定期重置 为了进一步促进批评器集合之间的多样性,并抵消掩码导致的网络容量减少,我们实现了类似于第3.3节所述的重置机制。特别是,我们按照循环模式依次重新初始化掩码 M j c M_{j}^{c} Mjc,如图3b所示。通过这种方式,每个批评函数的掩码在不同的数据段上进行训练,从而导致不同的偏差。综上所述,通过采用万花筒参数共享和可学习掩码,我们为实现具有高数据利用效率的批评器集合建立了一种经济有效的方法。通过增强掩码之间的区分度,我们巧妙地控制了批评函数之间的差异,从而改善了MARL中的价值估计。
4.实验结果
在本节中,我们将万花筒与基于价值的MARL算法QMIX和Actor-Critic MARL算法MATD3集成,并在三个基准任务中的11个场景中对它们进行评估。
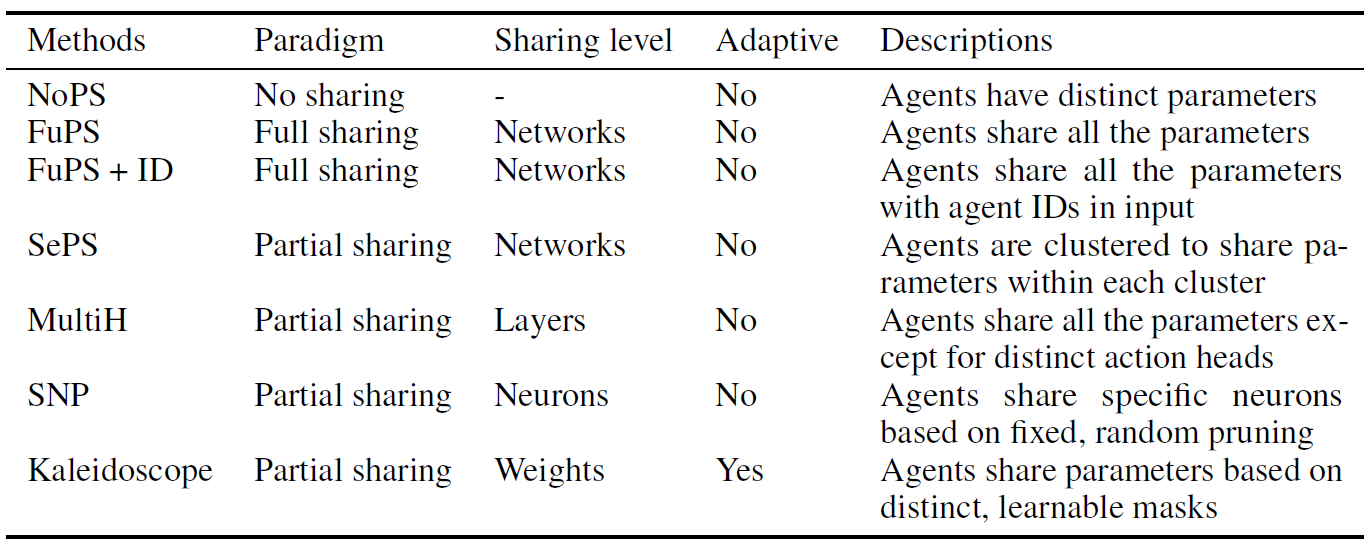
表1 在实验中进行比较的方法。这里的“adaptive”表示共享方案在训练过程中是否进化。
4.1 实验设置
环境描述 我们在三个基准任务上测试了我们提出的万花筒:MPE、MaMuJoCo和SMACv2。对于离散任务MPE和SMACv2,我们将万花筒和基线与QMIX集成并评估性能。对于连续任务MaMuJoCo,我们采用MATD3 。我们对MPE和MaMuJoCo使用了5个随机种子,对SMACv2使用了3个随机种子,报告了平均结果,并用阴影区域显示了95%的置信区间。所选择的基准任务反映了离散和连续动作空间以及同构和异构智能体类型的混合,详见附录A .2。
基线在下文中,我们将我们提出的万花筒与基线进行比较,如表1所示。对于万花筒和基线,在具有固定智能体类型(MPE和MaMuJoCo)的场景中,我们为每个智能体分配一个掩码。对于智能体类型不同的SMACv2,我们为每个智能体类型分配一个掩码。在可用的情况下,我们使用基线的官方实现;否则,我们将密切关注他们各自论文中的描述,将其集成到QMIX或MATD3中。附录A.1.3中提供了超参数和进一步的细节。
4.2 结果
性能 我们在图4和图5中展示了万花筒和基线的比较性能。总的来说,Kaleidoscope表现出了优越的性能,这归功于可学习掩码的灵活性和多样性正则化的有效性。此外,我们观察到,除了Ant-v2-4x2场景外,FuPS + ID通常优于NoPS(图4c)。这种优势很大程度上是由于FuPS更高的样本利用效率;单个转换数据样本在FuPS + ID中更新模型参数N次,每个智能体一次,而在NoPS中只更新一次。因此,FuPS + ID模型从相同数量的转换中学习得更快。同样的, Kaleidoscope受益于这种机制,因为它在智能体之间共享权重,允许一次转换多次更新模型参数。此外,通过可学习掩码集成策略异质性,Kaleidoscope实现了不同的智能体行为,如图8所示的可视化结果。最终,万花筒有效地平衡了参数共享和多样性,优于全参数共享和非参数共享方法。
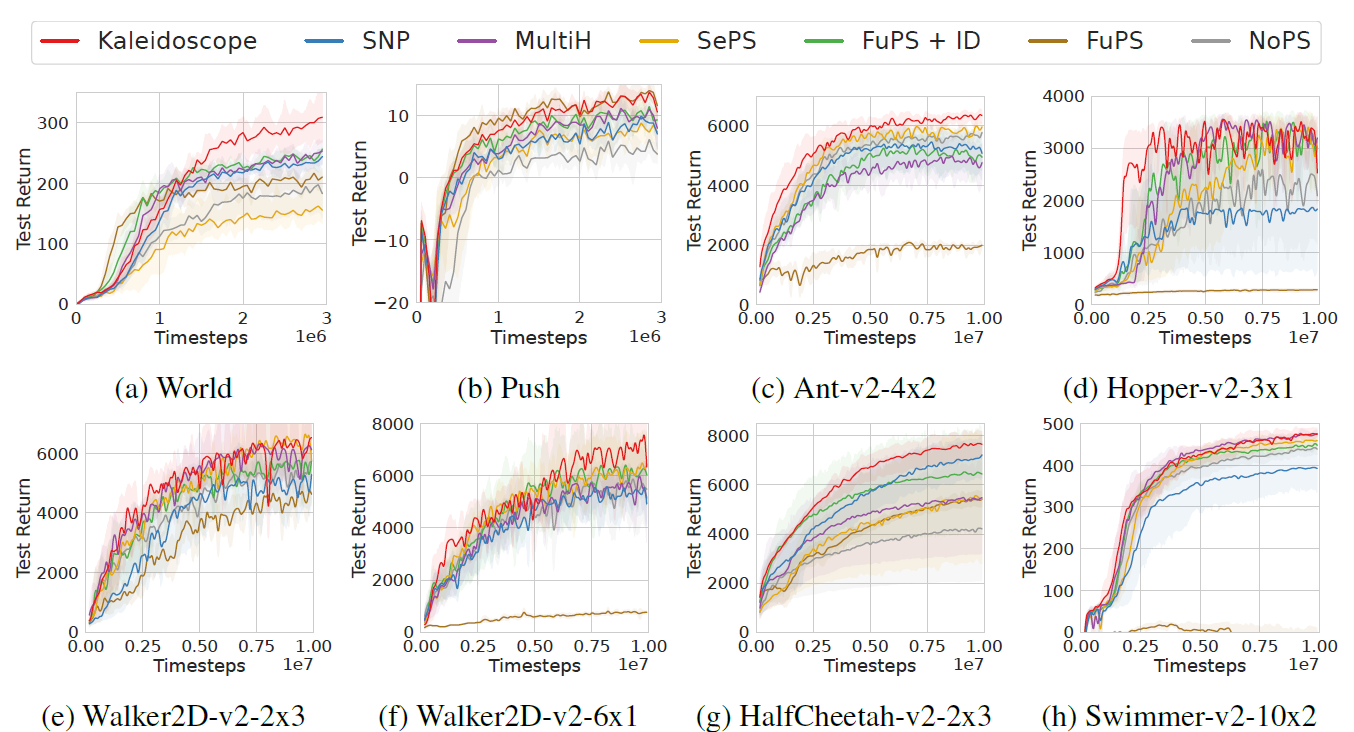
图4:MPE和MaMuJoCo基准任务上与基线的性能比较
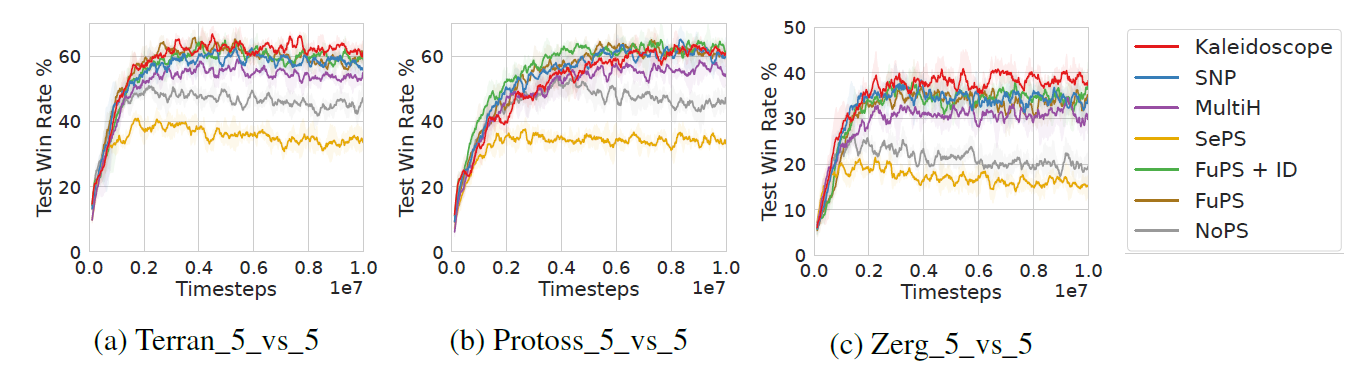
图5:SMACv2基准任务上与基线的性能比较。
成本分析 尽管Kaleidoscope具有优越的性能,但与基线相比,它在测试时并没有增加计算复杂度。我们报告了万花筒和表2中基线方法测试时间平均FLOPs的比较。我们看到,由于掩码技术,万花筒与基线相比具有更低的FLOPs,因此在部署时具有更快的推理速度。
表2:不同方法的平均FLOPs。此外,我们还进行了实验来研究口罩设计的影响。首先根据每个场景的FuPS + ID模型对结果进行归一化,然后对每个环境中的各个场景进行平均。最低成本以粗体突出显示。

消融实验 我们进行了消融研究,以评估万花筒中关键部件的影响,结果如图6所示。具体来说,我们比较万花筒及其三种消融:1)万花筒 w/o reg,缺少式(8)中使得掩码可以区分的正则化项。2)万花筒 w/o reset,不重置参数。3)万花筒w/o ce ,它不使用万花筒参数共享在批评器集合中,而是为批评器保留两个独立的参数集。结果表明,多样性正则化对万花筒的性能贡献最大。如果没有正则化,由于每个策略网络中的参数数量减少,掩码会降低性能。在需要时,重置主要有助于训练后期阶段的学习,这与先前研究工作的观察一致。值得注意的是,即使重置,由于掩码提供的关于重置位置的指导,性能也不会突然下降。当对具有万花筒参数共享的批评器集合进行消融时,我们观察到从训练开始就表现较差。这是因为与万花筒参数共享的批评器集合使批评器具有更高的数据利用效率,如3.4节所述。
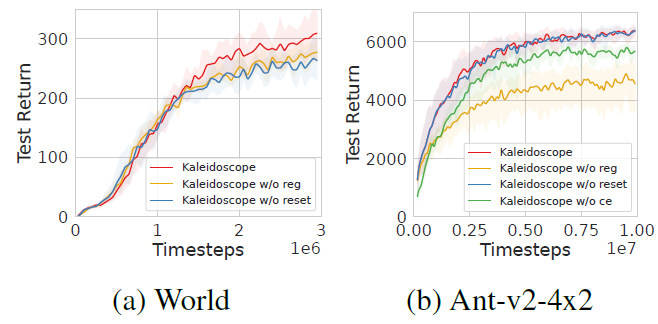
图6:消融实验
此外,我们还进行了实验来研究掩码设计的影响。结果如图7所示。具体来说,我们比较了原来的万花筒与两种不同的掩码设计选择:1)万花筒/神经元掩码,其中自适应掩码技术应用于神经元而不是权重。2)带有固定掩码的万花筒,其中掩码在训练开始时初始化,并在整个学习过程中保持固定。结果表明,在任何一种设计选择下,性能都会下降,这表明万花筒的优越性能源于可学习掩码对权重的灵活性。
关于超参数分析的更多结果见附录B.2。
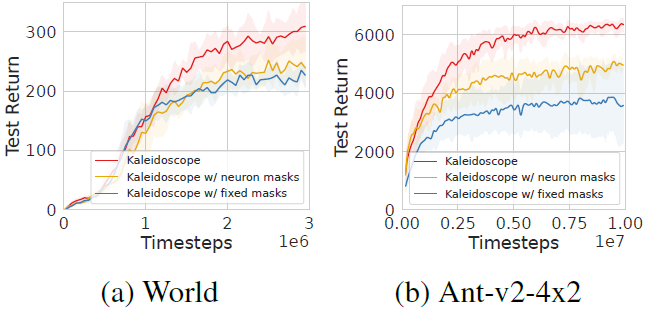
图7:掩码设计比较
可视化 我们将Kaleidoscope在World上的训练策略可视化,如图8a所示。智能体表现出合作的分而治之策略(四个红色智能体分成两个团队并包围猎物),与图1中描述的同质策略形成对比。我们进一步检查了智能体掩码的区别,并在图8b中给出了结果。首先,我们观察到,在训练结束时,每个智能体都开发了一个独特的掩码,这表明不同的掩码通过选择性地激活神经网络权重的不同部分来促进不同的策略。其次,在整个训练过程中,我们注意到智能体掩码之间的差异是动态演变的。这一观察结果证实了万花筒有效地实现了基于学习进度的智能体之间的动态参数共享,这是由可学习掩模的适应性赋予的。更多的可视化结果见附录B.3。
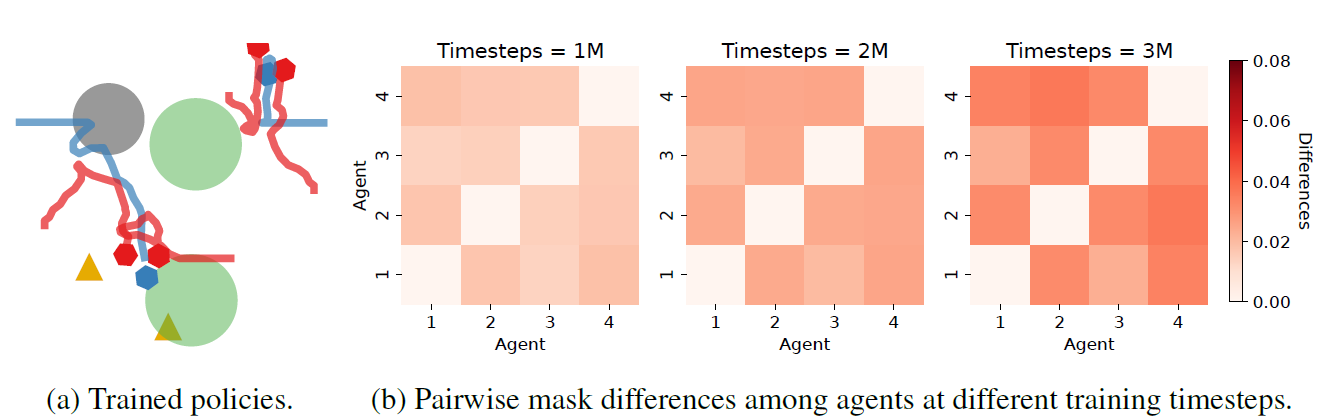
图8:World的可视化结果
5.相关工作
参数共享 首先由Tan(1993)提出,参数共享(Foerster et al., 2018;Rashid et al., 2020;Yu et al., 2022)由于其简单和高样本效率(Grammel et al., 2020)在MARL算法得到广泛应用。然而,没有参数共享的方案通常为策略表示提供更大的灵活性。为了平衡样本效率和策略表征能力,一些研究致力于寻找有效的部分参数共享方案。值得注意的是,SePS (Christianos et al., 2021)首先根据训练开始时的转换对智能体进行聚类,并限制这些聚类内的参数共享。随后,SNP(Kim and Sung, 2023)利用彩票假设(Su et al., 2020)初始化异构网络结构,实现部分参数共享。与我们的工作同步,AdaPS (Li et al., 2024)通过提出基于簇的部分参数共享方案将SNP和SePS结合起来。虽然这些方法在某些领域显示出希望,但它们的性能潜力往往受到训练早期设置的参数共享方案的静态性质的限制。我们提出的万花筒通过动态学习特定的参数共享配置以及MARL策略的开发来区分自己,从而提供增强的训练灵活性。
MARL中智能体的异构性 为了将智能体异构性纳入MARL中,并使智能体之间的行为多样化,以前的方法已经探索了多样性和角色等概念。具体来说,基于多样性的方法旨在通过对比学习技术,增强基于身份、轨迹或信用分配的智能体之间的成对可区分性。同时,基于角色的策略,有时被称为技能或子任务,采用条件策略通过分配不同的条件来区分智能体。这些条件可能基于智能体身份、局部观察、局部历史或联合历史。这条线的研究主要集中在模块设计上,与参数级调整分开进行,与我们的方法是正交的。然而,将这些方法与我们的工作相结合可能会进一步提高性能。
深度强化学习(RL)中的稀疏网络虽然相对较少,但最近有一些值得注意的尝试为深度强化学习寻找稀疏网络。特别是PoPS(Livne和
Cohen, 2020)在训练后对密集网络进行修剪,显著降低了执行时间复杂度。此外,(Yu et al., 2020)在RL领域验证了彩票假设,即使在极端修剪率下也能产生高性能模型。随后的研究包括DST (Sokar et al., 2022)、TE-RL* (Graesser et al., 2022)和RLx2 (Tan et al.,2023)采用拓扑进化(TE)技术进一步降低训练成本。虽然这些开发利用了稀疏训练技术,这与我们使用的方法类似,但它们的主要重点是减少单智能体设置中的训练和执行成本。相比之下,我们的工作利用稀疏网络策略作为增强参数共享技术的手段,旨在提高MARL性能。
6 结论和未来工作
本文提出了一种用于MARL新的自适应部分参数共享机制万花筒。它利用不同的可学习掩码来促进网络异质性,适用于智能体策略和批评器集合。具体来说,万花筒是建立在三个技术组成部分:STR驱动的可学习掩码,网络多样性正则化和周期性重置机制。当应用于智能体策略网络时,万花筒平衡了样本效率和网络表示能力。在评论家集合的背景下,它提高了价值估计。通过将我们提出的万花筒与QMIX和MATD3相结合,我们已经从经验上证明了它在各种MARL基准测试中的有效性。该研究为开发自适应部分参数共享机制以提高MARL的性能提供了广阔的前景。对于未来的工作,将万花筒进一步扩展到其他领域,如离线MARL或元RL,是一个有趣的研究方向。
原文链接:https://proceedings.neurips.cc/paper_files/paper/2024/hash/274d0146144643ee2459a602123c60ff-Abstract-Conference.html
(学习笔记,侵权立删)
相关文章:
【论文阅读笔记】万花筒:用于异构多智能体强化学习的可学习掩码
摘要 在多智能体强化学习(MARL)中,通常采用参数共享来提高样本效率。然而,全参数共享的流行方法通常会导致智能体之间的策略同质,这可能会限制从策略多样性中获得的性能优势。为了解决这一关键限制,我们提出…...
负载均衡LB》》HAproxy
Ubuntu 22.04 安装HA-proxy 官网 资料 # 更新系统包列表: sudo apt update # 安装 HAproxy sudo apt install haproxy -y # 验证安装 haproxy -v # 如下图配置 Haproxy 在这里插入代码片》》》配置完之后 重启 Haproxy sudo systemctl restart haproxy 补充几…...

Vue 中组件命名与引用
Vue 中组件命名与引用 前言 在 vue 项目中,我们会发现在代码中,import 组件 和 components 组件注册中得命名方式与组件引用时的命名方式不一样,这种现象是由组件名的大小写转换规则造成的。如下示例: 组件引入与注册ÿ…...

UE 5 和simulink联合仿真,如果先在UE5这一端结束Play,过一段时间以后**Unreal Engine 5** 中会出现显存不足错误
提问 UE5报错如图。解析原因 回答 你遇到的这个错误提示是: “Out of video memory trying to allocate a rendering resource. Make sure your video card has the minimum required memory, try lowering the resolution and/or closing other applications tha…...

在uni-app中如何从Options API迁移到Composition API?
uni-app 从 Options API 迁移到 Composition API 的详细指南 一、迁移前的准备 升级环境: 确保 HBuilderX 版本 ≥ 3.2.0项目 uni-app 版本 ≥ 3.0.0 了解 Composition API 基础: 响应式系统:ref、reactive生命周期钩子:onMount…...

Rust 控制流
文章目录 Rust 控制流if 表达式循环实现重复用 loop 重复代码从循环返回值循环标签用于区分多层循环while 条件循环用 for 循环遍历集合 Rust 控制流 在大多数编程语言中,根据条件是否为真来运行某些代码,以及在条件为真时重复运行某些代码,是…...

【Linux基础知识系列】第十三篇-Cron与定时任务管理
在Linux系统中,任务自动化是提高效率和确保服务连续性的关键。Cron是一个强大的定时任务管理工具,它允许用户设置定期执行的命令或脚本。通过Cron,用户可以自动化系统维护、备份、报告生成等多种任务。本文将详细介绍如何使用Cron工具创建和管…...

Visual Studio 中的 MD、MTD、MDD、MT 选项详解
在Visual Studio中开发C++项目时,正确选择运行时库(runtime library)对于确保应用程序的性能、稳定性和兼容性至关重要。本文将详细介绍/MD, /MT, /MDd, 和 /MTd这些编译器选项的意义、应用场景及其区别。 MSVCRT.dll MSVCRT.dll 是 Microsoft Visual C++ Runtime Library …...
Python 3.11.9 安装教程
前言 记录一下Windows环境下Python解释器的安装过程。 安装过程 1、安装程序下载 打开Python官网: 点击Downloads,选择Windows: 页面中找到需要的3.11.9版本,点击Download Windows installer (64-bit)下载: 2、…...
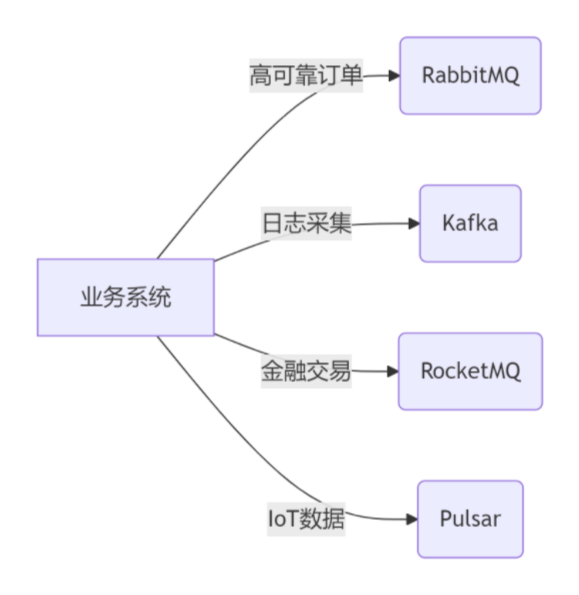
【各种主流消息队列(MQ)对比指南】
主流消息队列对比分析 一、核心指标对比 特性/消息队列RabbitMQKafkaRocketMQActiveMQPulsar协议支持AMQP, MQTT, STOMP自定义协议JMS/自定义协议JMS, AMQP, MQTT, STOMPMQTT, AMQP, STOMP单机吞吐量万级百万级十万级万级百万级延迟微秒级(低吞吐)毫秒…...

PySpark、Plotly全球重大地震数据挖掘交互式分析及动态可视化研究
全文链接:https://tecdat.cn/?p42455 分析师:Yapeng Zhao 在数字化防灾减灾的时代背景下,地震数据的深度解析成为公共安全领域的关键议题。作为数据科学工作者,我们始终致力于通过技术整合提升灾害数据的应用价值(点击…...
数组乘积)
代码训练LeetCode(24)数组乘积
代码训练(24)LeetCode之数组乘积 Author: Once Day Date: 2025年6月5日 漫漫长路,才刚刚开始… 全系列文章可参考专栏: 十年代码训练_Once-Day的博客-CSDN博客 参考文章: 238. 除自身以外数组的乘积 - 力扣(LeetCode)力扣 (LeetCode) 全…...

如何让AI自己检查全文?使用OCR和LLM实现自动“全文校订”(可DIY校订规则)
详细流程及描述参见仓库(如果有用的话,请给个收藏): GitHub - xurongtang/DocRevision_Proj: A simple project about how to revist docment (such as your academic paper) in a automatic way with the help of OCR and LLM.A…...

volka 25个短语动词
以下是分句分段后的内容: 3,000. Thats 95% of spoken English. And I am teaching you all of these words. First, Ill teach you todays words. And then youll hear them in real conversations. With my brother. Stick around until the end, because witho…...

Java观察者模式深度解析:构建松耦合事件驱动系统的艺术
目录 观察者模式基础解析核心结构与实现原理Java内置观察者实现Spring框架中的高级应用典型应用场景与实战案例观察者模式变体与优化常见问题与最佳实践总结与未来展望1. 观察者模式基础解析 1.1 模式定义与核心思想 观察者模式(Observer Pattern)是一种行为型设计模式,它…...
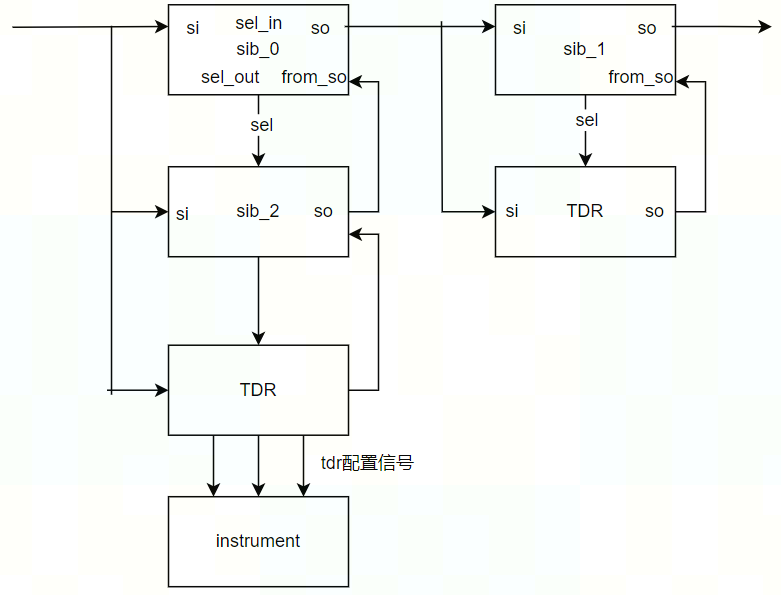
DFT测试之TAP/SIB/TDR
TAP的作用 tap全称是test access port,是将jtag接口转为reset、sel、ce、ue、se、si、tck和so这一系列测试组件接口的模块。 jtag的接口主要是下面几个信号: 信号名称信号方向信号描述TCK(测试时钟)输入测试时钟,同…...
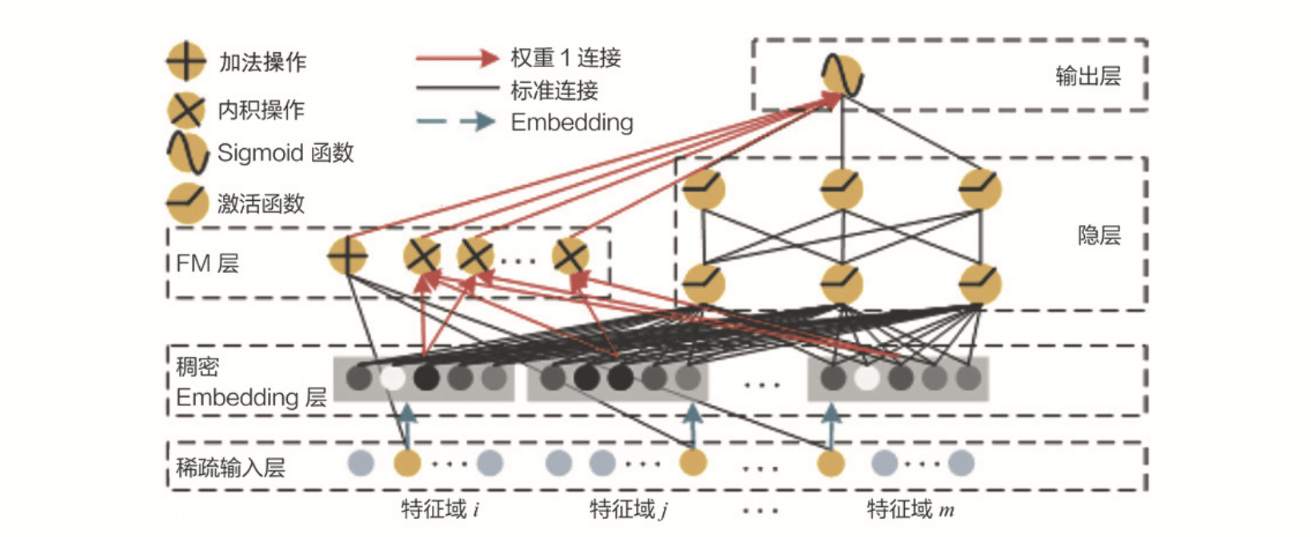
【推荐算法】DeepFM:特征交叉建模的革命性架构
DeepFM:特征交叉建模的革命性架构 一、算法背景知识:特征交叉的演进困境1.1 特征交叉的核心价值1.2 传统方法的局限性 二、算法理论/结构:双路并行架构2.1 FM组件:显式特征交叉专家2.2 Deep组件:隐式高阶交叉挖掘机2.3…...

C#报错 iText.Kernel.Exceptions.PdfException: ‘Unknown PdfException
【问题】 直接new一个PdfWriter的对象直接会报错: iText.Kernel.Exceptions.PdfException: Unknown PdfException. NotSupportedException: Either com.itextpdf:bouncy-castle-adapter or com.itextpdf:bouncy-castle-fips-adapter dependency must be added in…...
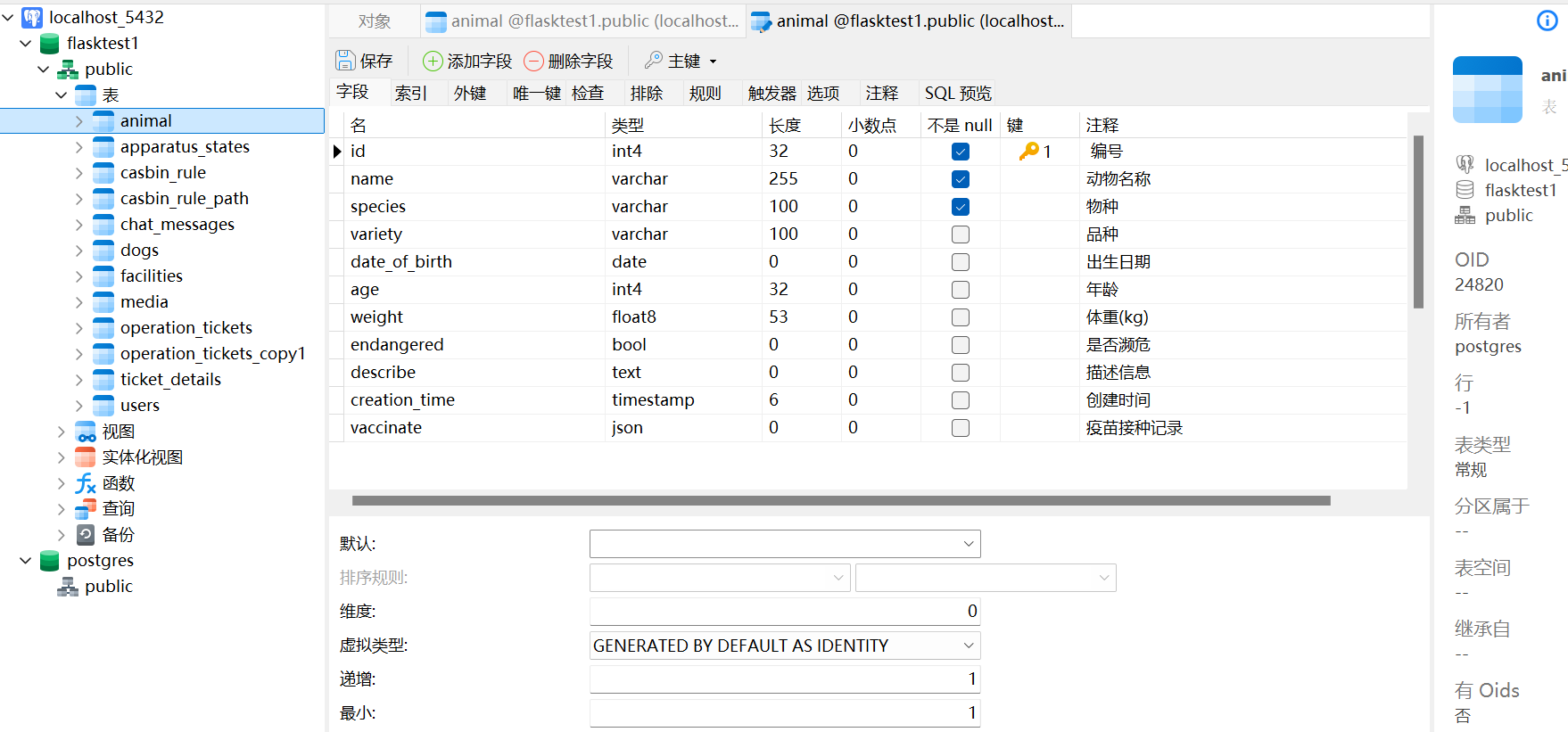
数据库表中「不是 null」的含义
例图: 1.勾选了「不是 null」(NOT NULL): 这个字段在数据库中必须有值,不能为空。也就是说,你插入数据的时候,必须给它赋值,否则插入会报错。 2.没有勾选「不是 null」ÿ…...

Elasticsearch的搜索流程描述
Elasticsearch 的搜索流程是一个结合 分布式查询、分片协同、结果聚合和排序 的复杂过程,其设计目标是在海量数据中实现快速检索和精准结果返回。以下是搜索流程的详细解析: 一、搜索流程总览 Elasticsearch 搜索流程示意图 (图源:Elastic 官方文档) 二、详细步骤解析 …...

Visual Studio问题记录
程序"xxx dotnet.exe"已退出,返回值为-2147450730 问deepseek:visual studio输出程序dotnet.exe已退出,返回值为-2147450730 dotnet.exe 编译时退出并返回错误代码 **-2147450730**(十六进制 0x80008076)&…...

GNSS终端授时方式-合集:PPS、B码、NTP、PTP、单站授时,共视授时
GNSS接收机具备授时功能,能够对外输出高精度的时间信息,并通过多种接口、多种形式进行时间信息的传递。 step by step介绍GNSS卫星导航定位基本原理,为什么定位需要至少4个卫星?这个文章的最后,我们介绍了为什么GNSS接…...

5.2 HarmonyOS NEXT应用性能诊断与优化:工具链、启动速度与功耗管理实战
HarmonyOS NEXT应用性能诊断与优化:工具链、启动速度与功耗管理实战 在HarmonyOS NEXT的全场景生态中,应用性能直接影响用户体验。通过专业的性能分析工具链、针对性的启动速度优化,以及精细化的功耗管理,开发者能够构建"秒…...

从EDR到XDR:终端安全防御体系演进实践指南
在数字化浪潮中,企业的终端安全面临着前所未有的挑战。从早期单纯的病毒威胁,到如今复杂多变的高级持续性威胁(APT)、零日漏洞攻击等,安全形势日益严峻。为应对这些挑战,终端安全防御技术不断演进ÿ…...

重启路由器ip不变怎么回事?原因分析与解决方法
在日常生活中,我们经常会遇到网络问题,而重启路由器是解决网络故障的常用方法之一。然而,有些用户发现,即使重启了路由器,自己的IP地址却没有变化,这让他们感到困惑。那么,重启路由器IP不变是怎…...
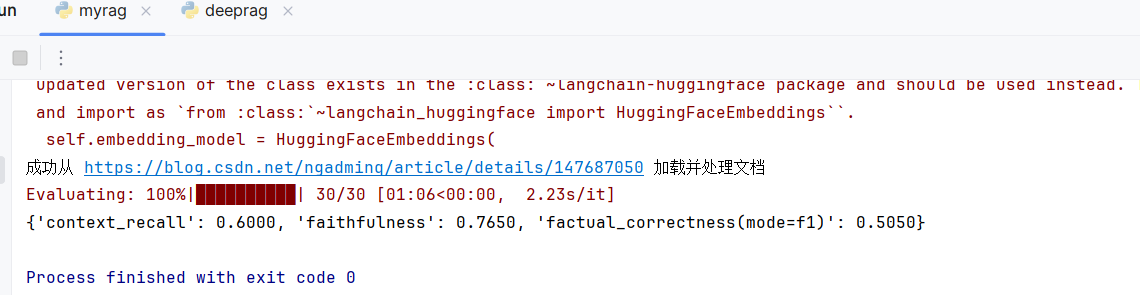
实践篇:利用ragas在自己RAG上实现LLM评估②
文章目录 使用ragas做评估在自己的数据集上评估完整代码代码讲解1. RAG系统构建核心组件初始化文档处理流程 2. 评估数据集构建3. RAGAS评估实现1. 评估数据集创建2. 评估器配置3. 执行评估 本系列阅读: 理论篇:RAG评估指标,检索指标与生成指…...

【CVE-2025-4123】Grafana完整分析SSRF和从xss到帐户接管
摘要 当Web应用程序使用URL参数并将用户重定向到指定的URL而不对其进行验证时,就会发生开放重定向。 /redirect?url=https://evil.com`–>(302重定向)–>`https://evil.com这本身可能看起来并不危险,但这种类型的错误是发现两个独立漏洞的起点:全读SSRF和帐户接管…...

高精度滚珠导轨在医疗设备中的多元应用场景
在医疗行业不断追求高效、精准与安全的今天,医疗设备的性能优化至关重要。每一个精密部件都像是设备这个庞大“生命体”中的细胞,共同维持着设备的稳定运行。滚珠导轨,这一看似不起眼却功能强大的传动元件,正悄然在医疗设备领域发…...

深入理解Java单例模式:确保类只有一个实例
文章目录 什么是单例模式?为什么我们需要单例模式?单例模式的常见实现方式1. 饿汉式(Eager Initialization)2. 懒汉式(Lazy Initialization)3. 双重检查锁定(Double-Checked Locking - DCL&…...

JavaScript性能优化实战:从核心原理到工程实践的全流程解析
下面我给出一个较为系统和深入的解析,帮助你理解和实践“JavaScript 性能优化实战:从核心原理到工程实践的全流程解析”。下面的内容不仅解释了底层原理,也结合实际工程中的最佳模式和工具,帮助你在项目中贯彻性能优化理念&#x…...