第R9周:阿尔茨海默病诊断(优化特征选择版)
文章目录
- 1. 导入数据
- 2. 数据处理
- 2.1 患病占比
- 2.2 相关性分析
- 2.3 年龄与患病探究
- 3. 特征选择
- 4. 构建数据集
- 4.1 数据集划分与标准化
- 4.2 构建加载
- 5. 构建模型
- 6. 模型训练
- 6.1 构建训练函数
- 6.2 构建测试函数
- 6.3 设置超参数
- 7. 模型训练
- 8. 模型评估
- 8.1 结果图
- 8.2 混淆矩阵
- 9. 总结:
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
1. 导入数据
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, TensorDatasetplt.rcParams["font.sans-serif"] = ["Microsoft YaHei"] # 显示中文
plt.rcParams['axes.unicode_minus'] = False # 显示负号data_df = pd.read_csv("alzheimers_disease_data.csv")data_df.head()
| PatientID | Age | Gender | Ethnicity | EducationLevel | BMI | Smoking | AlcoholConsumption | PhysicalActivity | DietQuality | ... | MemoryComplaints | BehavioralProblems | ADL | Confusion | Disorientation | PersonalityChanges | DifficultyCompletingTasks | Forgetfulness | Diagnosis | DoctorInCharge | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 4751 | 73 | 0 | 0 | 2 | 22.927749 | 0 | 13.297218 | 6.327112 | 1.347214 | ... | 0 | 0 | 1.725883 | 0 | 0 | 0 | 1 | 0 | 0 | XXXConfid |
| 1 | 4752 | 89 | 0 | 0 | 0 | 26.827681 | 0 | 4.542524 | 7.619885 | 0.518767 | ... | 0 | 0 | 2.592424 | 0 | 0 | 0 | 0 | 1 | 0 | XXXConfid |
| 2 | 4753 | 73 | 0 | 3 | 1 | 17.795882 | 0 | 19.555085 | 7.844988 | 1.826335 | ... | 0 | 0 | 7.119548 | 0 | 1 | 0 | 1 | 0 | 0 | XXXConfid |
| 3 | 4754 | 74 | 1 | 0 | 1 | 33.800817 | 1 | 12.209266 | 8.428001 | 7.435604 | ... | 0 | 1 | 6.481226 | 0 | 0 | 0 | 0 | 0 | 0 | XXXConfid |
| 4 | 4755 | 89 | 0 | 0 | 0 | 20.716974 | 0 | 18.454356 | 6.310461 | 0.795498 | ... | 0 | 0 | 0.014691 | 0 | 0 | 1 | 1 | 0 | 0 | XXXConfid |
5 rows × 35 columns
# 标签中文化
data_df.rename(columns={ "Age": "年龄", "Gender": "性别", "Ethnicity": "种族", "EducationLevel": "教育水平", "BMI": "身体质量指数(BMI)", "Smoking": "吸烟状况", "AlcoholConsumption": "酒精摄入量", "PhysicalActivity": "体育活动时间", "DietQuality": "饮食质量评分", "SleepQuality": "睡眠质量评分", "FamilyHistoryAlzheimers": "家族阿尔茨海默病史", "CardiovascularDisease": "心血管疾病", "Diabetes": "糖尿病", "Depression": "抑郁症史", "HeadInjury": "头部受伤", "Hypertension": "高血压", "SystolicBP": "收缩压", "DiastolicBP": "舒张压", "CholesterolTotal": "胆固醇总量", "CholesterolLDL": "低密度脂蛋白胆固醇(LDL)", "CholesterolHDL": "高密度脂蛋白胆固醇(HDL)", "CholesterolTriglycerides": "甘油三酯", "MMSE": "简易精神状态检查(MMSE)得分", "FunctionalAssessment": "功能评估得分", "MemoryComplaints": "记忆抱怨", "BehavioralProblems": "行为问题", "ADL": "日常生活活动(ADL)得分", "Confusion": "混乱与定向障碍", "Disorientation": "迷失方向", "PersonalityChanges": "人格变化", "DifficultyCompletingTasks": "完成任务困难", "Forgetfulness": "健忘", "Diagnosis": "诊断状态", "DoctorInCharge": "主诊医生" },inplace=True)data_df.columns
Index(['PatientID', '年龄', '性别', '种族', '教育水平', '身体质量指数(BMI)', '吸烟状况', '酒精摄入量','体育活动时间', '饮食质量评分', '睡眠质量评分', '家族阿尔茨海默病史', '心血管疾病', '糖尿病', '抑郁症史','头部受伤', '高血压', '收缩压', '舒张压', '胆固醇总量', '低密度脂蛋白胆固醇(LDL)','高密度脂蛋白胆固醇(HDL)', '甘油三酯', '简易精神状态检查(MMSE)得分', '功能评估得分', '记忆抱怨', '行为问题','日常生活活动(ADL)得分', '混乱与定向障碍', '迷失方向', '人格变化', '完成任务困难', '健忘', '诊断状态','主诊医生'],dtype='object')
2. 数据处理
data_df.isnull().sum()
PatientID 0
年龄 0
性别 0
种族 0
教育水平 0
身体质量指数(BMI) 0
吸烟状况 0
酒精摄入量 0
体育活动时间 0
饮食质量评分 0
睡眠质量评分 0
家族阿尔茨海默病史 0
心血管疾病 0
糖尿病 0
抑郁症史 0
头部受伤 0
高血压 0
收缩压 0
舒张压 0
胆固醇总量 0
低密度脂蛋白胆固醇(LDL) 0
高密度脂蛋白胆固醇(HDL) 0
甘油三酯 0
简易精神状态检查(MMSE)得分 0
功能评估得分 0
记忆抱怨 0
行为问题 0
日常生活活动(ADL)得分 0
混乱与定向障碍 0
迷失方向 0
人格变化 0
完成任务困难 0
健忘 0
诊断状态 0
主诊医生 0
dtype: int64
from sklearn.preprocessing import LabelEncoder# 创建 LabelEncoder 实例
label_encoder = LabelEncoder()# 对非数值型列进行标签编码
data_df['主诊医生'] = label_encoder.fit_transform(data_df['主诊医生'])data_df.head()
| PatientID | 年龄 | 性别 | 种族 | 教育水平 | 身体质量指数(BMI) | 吸烟状况 | 酒精摄入量 | 体育活动时间 | 饮食质量评分 | ... | 记忆抱怨 | 行为问题 | 日常生活活动(ADL)得分 | 混乱与定向障碍 | 迷失方向 | 人格变化 | 完成任务困难 | 健忘 | 诊断状态 | 主诊医生 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 4751 | 73 | 0 | 0 | 2 | 22.927749 | 0 | 13.297218 | 6.327112 | 1.347214 | ... | 0 | 0 | 1.725883 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 1 | 4752 | 89 | 0 | 0 | 0 | 26.827681 | 0 | 4.542524 | 7.619885 | 0.518767 | ... | 0 | 0 | 2.592424 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 2 | 4753 | 73 | 0 | 3 | 1 | 17.795882 | 0 | 19.555085 | 7.844988 | 1.826335 | ... | 0 | 0 | 7.119548 | 0 | 1 | 0 | 1 | 0 | 0 | 0 |
| 3 | 4754 | 74 | 1 | 0 | 1 | 33.800817 | 1 | 12.209266 | 8.428001 | 7.435604 | ... | 0 | 1 | 6.481226 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 4755 | 89 | 0 | 0 | 0 | 20.716974 | 0 | 18.454356 | 6.310461 | 0.795498 | ... | 0 | 0 | 0.014691 | 0 | 0 | 1 | 1 | 0 | 0 | 0 |
5 rows × 35 columns
2.1 患病占比
# 计算是否患病, 人数
counts = data_df["诊断状态"].value_counts()# 计算百分比
sizes = counts / counts.sum() * 100# 绘制环形图
fig, ax = plt.subplots()
wedges, texts, autotexts = ax.pie(sizes, labels=sizes.index, autopct='%1.2ff%%', startangle=90, wedgeprops=dict(width=0.3))plt.title("患病占比(1患病,0没有患病)")
plt.show()

2.2 相关性分析
plt.figure(figsize=(40, 35))
sns.heatmap(data_df.corr(), annot=True, fmt=".2f")
plt.show()

2.3 年龄与患病探究
data_df['年龄'].min(), data_df['年龄'].max()
(np.int64(60), np.int64(90))
# 计算每一个年龄段患病人数
age_bins = range(60, 91)
grouped = data_df.groupby('年龄').agg({'诊断状态': ['sum', 'size']}) # 分组、聚合函数: sum求和,size总大小
grouped.columns = ['患病', '总人数']
grouped['不患病'] = grouped['总人数'] - grouped['患病'] # 计算不患病的人数# 设置绘图风格
sns.set(style="whitegrid")plt.figure(figsize=(12, 5))# 获取x轴标签(即年龄)
x = grouped.index.astype(str) # 将年龄转换为字符串格式便于显示# 画图
plt.bar(x, grouped["不患病"], 0.35, label="不患病", color='skyblue')
plt.bar(x, grouped["患病"], 0.35, label="患病", color='salmon')# 设置标题
plt.title("患病年龄分布", fontproperties='Microsoft YaHei')
plt.xlabel("年龄", fontproperties='Microsoft YaHei')
plt.ylabel("人数", fontproperties='Microsoft YaHei')# 如果需要对图例也应用相同的字体
plt.legend(prop={'family': 'Microsoft YaHei'})# 展示
plt.tight_layout()
plt.show()

3. 特征选择
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import classification_reportdata = data_df.copy()X = data_df.iloc[:, 1:-2]
y = data_df.iloc[:, -2]X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 标准化
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)# 模型创建
tree = DecisionTreeClassifier()
tree.fit(X_train, y_train)
pred = tree.predict(X_test)reporter = classification_report(y_test, pred)
print(reporter)
precision recall f1-score support0 0.91 0.92 0.92 2771 0.85 0.84 0.85 153accuracy 0.89 430macro avg 0.88 0.88 0.88 430
weighted avg 0.89 0.89 0.89 430
# 特征展示
feature_importances = tree.feature_importances_
features_rf = pd.DataFrame({'特征': X.columns, '重要度': feature_importances})
features_rf.sort_values(by='重要度', ascending=False, inplace=True)
plt.figure(figsize=(20, 10))
sns.barplot(x='重要度', y='特征', data=features_rf)
plt.xlabel('重要度')
plt.ylabel('特征')
plt.title('随机森林特征图')
plt.show()

from sklearn.feature_selection import RFE# 使用 RFE 来选择特征
rfe_selector = RFE(estimator=tree, n_features_to_select=20) # 选择前20个特征
rfe_selector.fit(X, y)
X_new = rfe_selector.transform(X)
feature_names = np.array(X.columns)
selected_feature_names = feature_names[rfe_selector.support_]
print(selected_feature_names)
[‘年龄’ ‘种族’ ‘教育水平’ ‘身体质量指数(BMI)’ ‘酒精摄入量’ ‘体育活动时间’ ‘饮食质量评分’ ‘睡眠质量评分’ ‘心血管疾病’
‘收缩压’ ‘舒张压’ ‘胆固醇总量’ ‘低密度脂蛋白胆固醇(LDL)’ ‘高密度脂蛋白胆固醇(HDL)’ ‘甘油三酯’
‘简易精神状态检查(MMSE)得分’ ‘功能评估得分’ ‘记忆抱怨’ ‘行为问题’ ‘日常生活活动(ADL)得分’]
4. 构建数据集
4.1 数据集划分与标准化
feature_selection = ['年龄', '种族','教育水平','身体质量指数(BMI)', '酒精摄入量', '体育活动时间', '饮食质量评分', '睡眠质量评分', '心血管疾病','收缩压', '舒张压', '胆固醇总量', '低密度脂蛋白胆固醇(LDL)', '高密度脂蛋白胆固醇(HDL)', '甘油三酯','简易精神状态检查(MMSE)得分', '功能评估得分', '记忆抱怨', '行为问题', '日常生活活动(ADL)得分']X = data_df[feature_selection]# 标准化, 标准化其实对应连续性数据,分类数据不适合,由于特征中只有种族是分类数据,这里我偷个“小懒”
sc = StandardScaler()
X = sc.fit_transform(X)X = torch.tensor(np.array(X), dtype=torch.float32)
y = torch.tensor(np.array(y), dtype=torch.long)# 再次进行特征选择
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)X_train.shape, y_train.shape
(torch.Size([1719, 20]), torch.Size([1719]))
4.2 构建加载
batch_size = 32train_dl = DataLoader(TensorDataset(X_train, y_train),batch_size=batch_size,shuffle=True
)test_dl = DataLoader(TensorDataset(X_test, y_test),batch_size=batch_size,shuffle=False
)
5. 构建模型
class Rnn_Model(nn.Module):def __init__(self):super().__init__()# 调用rnnself.rnn = nn.RNN(input_size=20, hidden_size=200, num_layers=1, batch_first=True)self.fc1 = nn.Linear(200, 50)self.fc2 = nn.Linear(50, 2)def forward(self, x):x, hidden1 = self.rnn(x)x = self.fc1(x)x = self.fc2(x)return x# 数据不大,cpu即可
device = "cpu"model = Rnn_Model().to(device)
model
Rnn_Model(
(rnn): RNN(20, 200, batch_first=True)
(fc1): Linear(in_features=200, out_features=50, bias=True)
(fc2): Linear(in_features=50, out_features=2, bias=True)
)
model(torch.randn(32, 20)).shape
torch.Size([32, 2])
6. 模型训练
6.1 构建训练函数
def train(data, model, loss_fn, opt):size = len(data.dataset)batch_num = len(data)train_loss, train_acc = 0.0, 0.0for X, y in data:X, y = X.to(device), y.to(device)pred = model(X)loss = loss_fn(pred, y)# 反向传播opt.zero_grad() # 梯度清零loss.backward() # 求导opt.step() # 设置梯度train_loss += loss.item()train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()train_loss /= batch_numtrain_acc /= size return train_acc, train_loss
6.2 构建测试函数
def test(data, model, loss_fn):size = len(data.dataset)batch_num = len(data)test_loss, test_acc = 0.0, 0.0 with torch.no_grad():for X, y in data: X, y = X.to(device), y.to(device)pred = model(X)loss = loss_fn(pred, y)test_loss += loss.item()test_acc += (pred.argmax(1) == y).type(torch.float).sum().item()test_loss /= batch_numtest_acc /= sizereturn test_acc, test_loss
6.3 设置超参数
loss_fn = nn.CrossEntropyLoss() # 损失函数
learn_lr = 1e-4 # 超参数
optimizer = torch.optim.Adam(model.parameters(), lr=learn_lr)
7. 模型训练
train_acc = []
train_loss = []
test_acc = []
test_loss = []epoches = 50for i in range(epoches):model.train()epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, optimizer)model.eval()epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)# 输出template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}')print(template.format(i + 1, epoch_train_acc*100, epoch_train_loss, epoch_test_acc*100, epoch_test_loss))print("Done")
Epoch: 1, Train_acc:57.9%, Train_loss:0.675, Test_acc:66.0%, Test_loss:0.608
Epoch: 2, Train_acc:67.2%, Train_loss:0.589, Test_acc:68.8%, Test_loss:0.556
Epoch: 3, Train_acc:75.1%, Train_loss:0.540, Test_acc:75.1%, Test_loss:0.506
Epoch: 4, Train_acc:79.1%, Train_loss:0.485, Test_acc:82.1%, Test_loss:0.460
Epoch: 5, Train_acc:83.0%, Train_loss:0.442, Test_acc:81.4%, Test_loss:0.427
Epoch: 6, Train_acc:83.5%, Train_loss:0.411, Test_acc:84.2%, Test_loss:0.407
Epoch: 7, Train_acc:83.3%, Train_loss:0.395, Test_acc:82.8%, Test_loss:0.400
Epoch: 8, Train_acc:84.1%, Train_loss:0.383, Test_acc:84.0%, Test_loss:0.396
Epoch: 9, Train_acc:84.1%, Train_loss:0.380, Test_acc:84.0%, Test_loss:0.394
Epoch:10, Train_acc:83.9%, Train_loss:0.375, Test_acc:84.0%, Test_loss:0.395
Epoch:11, Train_acc:84.5%, Train_loss:0.375, Test_acc:84.4%, Test_loss:0.396
Epoch:12, Train_acc:84.5%, Train_loss:0.374, Test_acc:83.5%, Test_loss:0.399
Epoch:13, Train_acc:83.7%, Train_loss:0.373, Test_acc:83.0%, Test_loss:0.401
Epoch:14, Train_acc:84.3%, Train_loss:0.372, Test_acc:84.0%, Test_loss:0.402
Epoch:15, Train_acc:84.1%, Train_loss:0.375, Test_acc:83.3%, Test_loss:0.400
Epoch:16, Train_acc:84.6%, Train_loss:0.370, Test_acc:83.0%, Test_loss:0.404
Epoch:17, Train_acc:84.2%, Train_loss:0.371, Test_acc:83.0%, Test_loss:0.406
Epoch:18, Train_acc:84.3%, Train_loss:0.377, Test_acc:83.3%, Test_loss:0.401
Epoch:19, Train_acc:84.8%, Train_loss:0.371, Test_acc:83.0%, Test_loss:0.402
Epoch:20, Train_acc:84.8%, Train_loss:0.372, Test_acc:83.5%, Test_loss:0.402
Epoch:21, Train_acc:84.9%, Train_loss:0.374, Test_acc:83.7%, Test_loss:0.399
Epoch:22, Train_acc:85.2%, Train_loss:0.369, Test_acc:83.7%, Test_loss:0.401
Epoch:23, Train_acc:84.7%, Train_loss:0.374, Test_acc:84.4%, Test_loss:0.401
Epoch:24, Train_acc:84.2%, Train_loss:0.371, Test_acc:84.2%, Test_loss:0.398
Epoch:25, Train_acc:84.3%, Train_loss:0.370, Test_acc:83.7%, Test_loss:0.399
Epoch:26, Train_acc:84.8%, Train_loss:0.373, Test_acc:83.7%, Test_loss:0.398
Epoch:27, Train_acc:84.6%, Train_loss:0.373, Test_acc:83.7%, Test_loss:0.395
Epoch:28, Train_acc:85.1%, Train_loss:0.372, Test_acc:83.5%, Test_loss:0.397
Epoch:29, Train_acc:84.4%, Train_loss:0.373, Test_acc:84.4%, Test_loss:0.399
Epoch:30, Train_acc:85.0%, Train_loss:0.371, Test_acc:83.7%, Test_loss:0.401
Epoch:31, Train_acc:84.7%, Train_loss:0.372, Test_acc:83.7%, Test_loss:0.401
Epoch:32, Train_acc:84.5%, Train_loss:0.372, Test_acc:84.0%, Test_loss:0.400
Epoch:33, Train_acc:84.4%, Train_loss:0.369, Test_acc:83.5%, Test_loss:0.397
Epoch:34, Train_acc:84.7%, Train_loss:0.369, Test_acc:83.7%, Test_loss:0.401
Epoch:35, Train_acc:84.6%, Train_loss:0.372, Test_acc:83.3%, Test_loss:0.396
Epoch:36, Train_acc:84.8%, Train_loss:0.370, Test_acc:83.3%, Test_loss:0.396
Epoch:37, Train_acc:84.8%, Train_loss:0.371, Test_acc:83.5%, Test_loss:0.399
Epoch:38, Train_acc:84.9%, Train_loss:0.369, Test_acc:83.5%, Test_loss:0.398
Epoch:39, Train_acc:85.0%, Train_loss:0.370, Test_acc:83.0%, Test_loss:0.395
Epoch:40, Train_acc:83.8%, Train_loss:0.371, Test_acc:83.7%, Test_loss:0.394
Epoch:41, Train_acc:84.6%, Train_loss:0.370, Test_acc:83.7%, Test_loss:0.394
Epoch:42, Train_acc:85.1%, Train_loss:0.370, Test_acc:84.2%, Test_loss:0.392
Epoch:43, Train_acc:84.4%, Train_loss:0.371, Test_acc:84.0%, Test_loss:0.393
Epoch:44, Train_acc:84.5%, Train_loss:0.372, Test_acc:84.7%, Test_loss:0.396
Epoch:45, Train_acc:85.3%, Train_loss:0.372, Test_acc:84.2%, Test_loss:0.396
Epoch:46, Train_acc:85.0%, Train_loss:0.368, Test_acc:84.4%, Test_loss:0.397
Epoch:47, Train_acc:85.0%, Train_loss:0.372, Test_acc:84.0%, Test_loss:0.395
Epoch:48, Train_acc:84.5%, Train_loss:0.370, Test_acc:84.4%, Test_loss:0.394
Epoch:49, Train_acc:85.1%, Train_loss:0.368, Test_acc:84.2%, Test_loss:0.400
Epoch:50, Train_acc:84.9%, Train_loss:0.370, Test_acc:84.2%, Test_loss:0.397
Done
8. 模型评估
8.1 结果图
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
from datetime import datetime
current_time = datetime.now() # 获取当前时间epochs_range = range(epoches)plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training Accuracy')
plt.xlabel(current_time) # 打卡请带上时间戳,否则代码截图无效plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training= Loss')
plt.show()

8.2 混淆矩阵
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay pred = model(X_test.to(device)).argmax(1).cpu().numpy()# 计算混淆矩阵
cm = confusion_matrix(y_test, pred)# 计算
plt.figure(figsize=(6, 5))
sns.heatmap(cm, annot=True, fmt="d", cmap="Blues")
# 标题
plt.title("混淆矩阵")
plt.xlabel("Predicted Label")
plt.ylabel("True Label")plt.tight_layout() # 自适应
plt.show()

9. 总结:
本周在上周的基础上更加完善了阿尔茨海默病诊断模型,加入了REF(递归特征消除)特征选择方法。并且通过实践更好的理解了模型以及该如何使用这种特征选择方法。
相关文章:
第R9周:阿尔茨海默病诊断(优化特征选择版)
文章目录 1. 导入数据2. 数据处理2.1 患病占比2.2 相关性分析2.3 年龄与患病探究 3. 特征选择4. 构建数据集4.1 数据集划分与标准化4.2 构建加载 5. 构建模型6. 模型训练6.1 构建训练函数6.2 构建测试函数6.3 设置超参数 7. 模型训练8. 模型评估8.1 结果图 8.2 混淆矩阵9. 总结…...
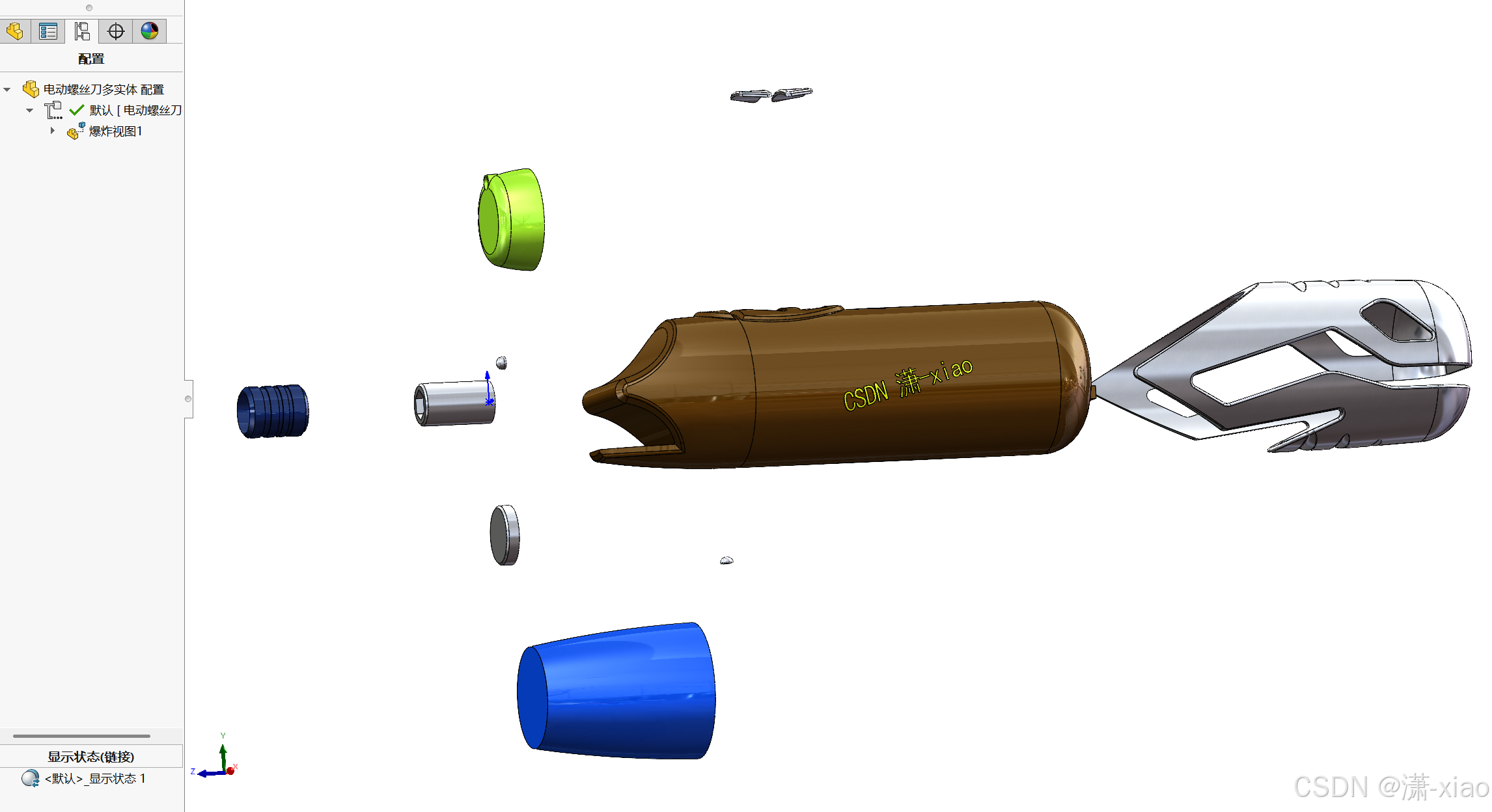
电动螺丝刀-多实体拆图建模案例
多实体建模要注意下面两点: 多实体建模的合并结果一定要谨慎在实际工作中多实体建模是一个非常好的思路,先做产品的整体设计,再将个体零件导出去做局部细节设计 电动螺丝刀模型动图展示 爆炸视图动图展示 案例素材点击此处获取 建模步骤 1. …...

当丰收季遇上超导磁测量:粮食产业的科技新征程
麦浪藏光阴,心田种丰年!又到了一年中最令人心潮澎湃的粮食丰收季。金色的麦浪随风翻滚,沉甸甸的稻穗谦逊地低垂着,处处洋溢着丰收的喜悦。粮食产业,无疑是国家发展的根基与命脉,是民生稳定的压舱石。在现代…...

电子电气架构 --- 什么是功能架构?
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 做到欲望极简,了解自己的真实欲望,不受外在潮流的影响,不盲从,不跟风。把自己的精力全部用在自己。一是去掉多余,凡事找规律,基础是诚信;二是…...

Android四大组件通讯指南:Kotlin版组件茶话会
某日,Android王国举办Kotlin主题派对。Activity穿着Jetpack Compose定制礼服,Service戴着协程手表,BroadcastReceiver拿着Flow喇叭,ContentProvider抱着Room数据库入场。它们正愁如何交流,Intent举着"邮差"牌…...
材质(Materials))
C++.OpenGL (11/64)材质(Materials)
材质(Materials) 真实感材质系统 #mermaid-svg-NjBjrmlcpHupHCFQ {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-NjBjrmlcpHupHCFQ .error-icon{fill:#552222;}#mermaid-svg-NjBjrmlcpHupHCFQ .error-text{fill:…...

AudioRelay 0.27.5 手机充当电脑音响
—————【下 载 地 址】——————— 【本章下载一】:https://pan.xunlei.com/s/VOS4MvfPxrnfS2Zu_YS4egykA1?pwdi2we# 【本章下载二】:https://pan.xunlei.com/s/VOS4MvfPxrnfS2Zu_YS4egykA1?pwdi2we# 【百款黑科技】:https://uc…...

会计 - 合并1- 业务、控制、合并日
一、业务 1.1 业务的定义以及构成要素 业务,是指企业内部某些生产经营活动或资产的组合,该组合一般具有投入、加工处理过程和产出能力,能够独立计算其成本费用或所产生的收入。 (1)投入,指原材料、人工、必要的生产技术等无形资产以及构成产出能力的机器设备等其他长期资…...

前端项目eslint配置选项详细解析
文章目录 1. 前言2、错误级别3、常用规则4、目前项目使用的.eslintrc.js 1. 前言 ESLint 是一个可配置的 JavaScript 代码检查工具,旨在帮助开发者发现并修复代码中的潜在问题,包括语法错误、逻辑错误以及风格不一致等问题。以下是其核心功能和特点…...

NVIDIA Dynamo:数据中心规模的分布式推理服务框架深度解析
NVIDIA Dynamo:数据中心规模的分布式推理服务框架深度解析 摘要 NVIDIA Dynamo是一个革命性的高吞吐量、低延迟推理框架,专为在多节点分布式环境中服务生成式AI和推理模型而设计。本文将深入分析Dynamo的架构设计、核心特性、代码实现以及实际应用示例&…...

第十三节:第四部分:集合框架:HashMap、LinkedHashMap、TreeMap
Map集合体系 HashMap集合的底层原理 HashMap集合底层是基于哈希表实现的 LinkedHashMap集合的底层原理 TreeMap集合的底层原理 代码: Student类 package com.itheima.day26_Map_impl;import java.util.Objects;public class Student implements Comparable<Stu…...
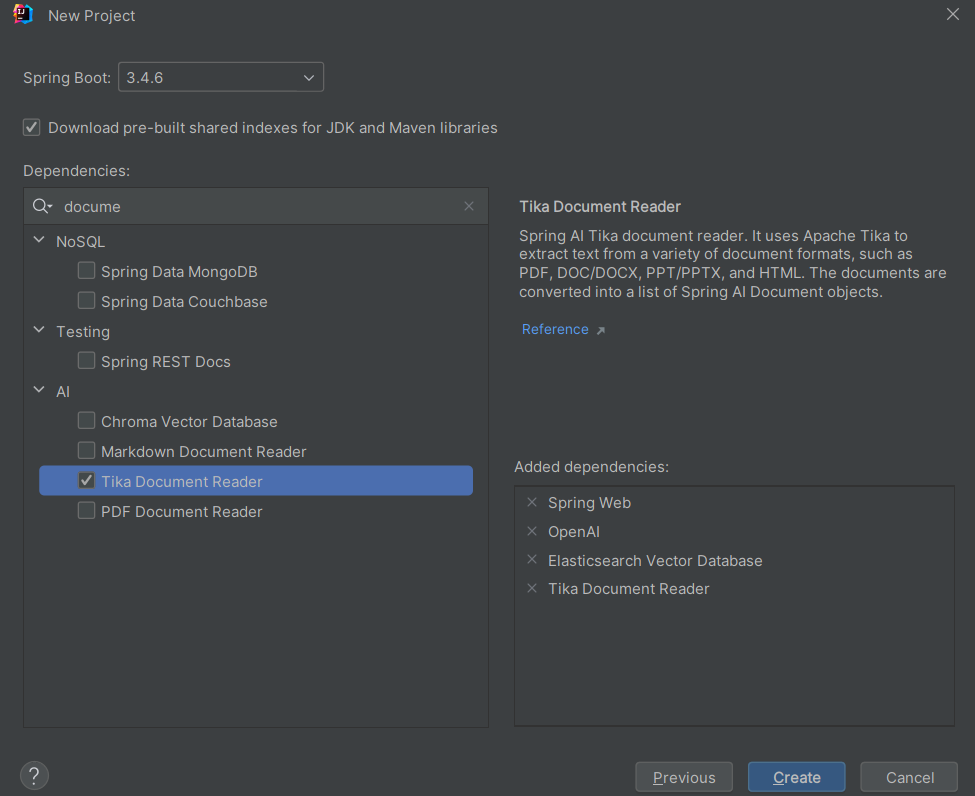
Spring AI之RAG入门
目录 1. 什么是RAG 2. RAG典型应用场景 3. RAG核心流程 3.1. 检索阶段 3.2. 生成阶段 4. 使用Spring AI实现RAG 4.1. 创建项目 4.2. 配置application.yml 4.3. 安装ElasticSearch和Kibana 4.3.1. 安装并启动ElasticSearch 4.3.2. 验证ElasticSearch是否启动成功 …...
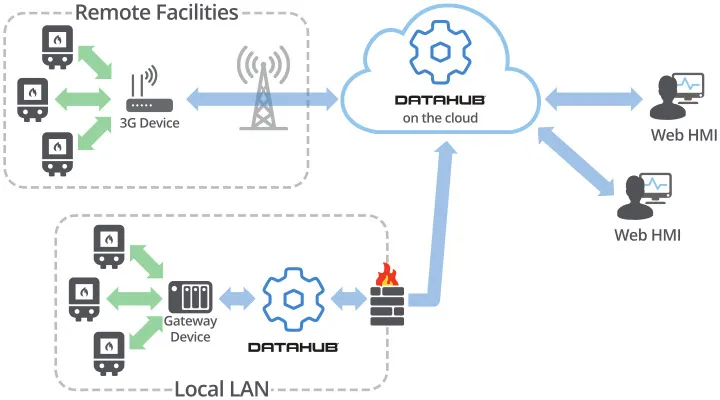
应用案例 | 设备分布广, 现场维护难? 宏集Cogent DataHub助力分布式锅炉远程运维, 让现场变“透明”
在日本,能源利用与环保问题再次成为社会关注的焦点。越来越多的工业用户开始寻求更高效、可持续的方式来运营设备、管理能源。而作为一家专注于节能与自动化系统集成的企业,日本大阪的TESS工程公司给出了一个值得借鉴的答案。 01 锅炉远程监控难题如何破…...

C#中的密封类与静态类:特性、区别与应用实例
深入解析两类特殊类的设计哲学与实战应用 在面向对象编程领域中,C#提供了多种特殊的类类型以满足不同设计需求。其中密封类(sealed class)和静态类(static class)是最常用的两种特殊类类型。本文将从设计理念、应用场…...
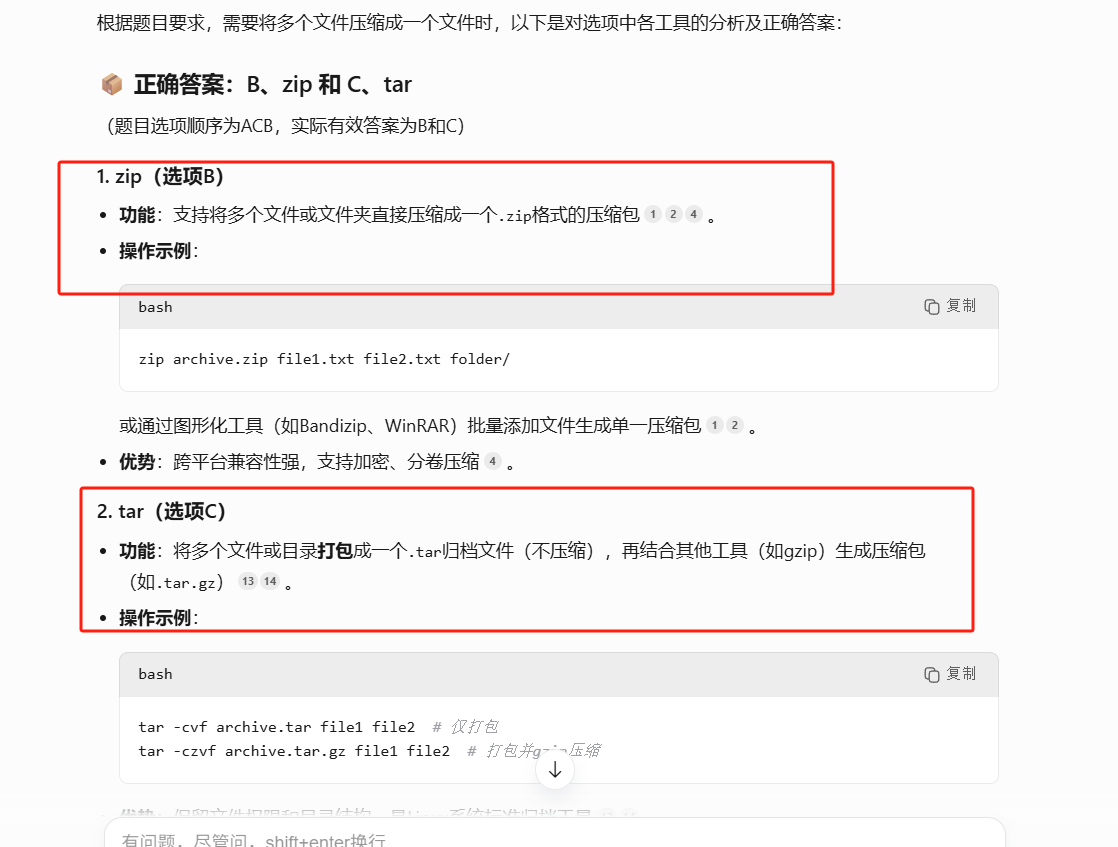
LINUX 66 FTP 2 ;FTP被动模式;FTP客户服务系统
19. 在vim中将所有 abc 替换为 def,在底行模式下执行©?D A、s/abc/def B、s/abc/def/g C、%s/abc/def D、%s/abc/def/g FTP连接 用户名应该填什么 [rootcode ~]# grep -v ^# /etc/vsftpd/vsftpd.conf anonymous_enableNO local_enab…...

网心云 OEC/OECT 笔记(2) 运行RKNN程序
目录 网心云 OEC/OECT 笔记(1) 拆机刷入Armbian固件网心云 OEC/OECT 笔记(2) 运行RKNN程序 RKNN OEC/OEC-Turbo 使用的芯片是 RK3566/RK3568, 这个系列是内建神经网络处理器 NPU 的, 利用 RKNN 可以部署运行 AI 模型利用 NPU 硬件加速模型推理. 要使用 NPU, 首先需要在电脑使…...
)
vue-21 (使用 Vuex 模块和异步操作构建复杂应用)
实践练习:使用 Vuex 模块和异步操作构建复杂应用 Vuex 模块提供了一种结构化的方式来组织你的应用程序状态,特别是当应用程序变得复杂时。命名空间模块通过防止命名冲突和提高代码可维护性来增强这种组织。异步操作对于处理从 API 获取数据等操作至关重要,这些操作在现代 W…...

#开发环境篇:postMan可以正常调通,但是浏览器里面一直报403
本地header代理下面内容即可 headers: { // 添加必要的请求头 ‘Host’: ‘服务端域名’, ‘Origin’: https://服务端域名, ‘Referer’: https://服务端域名 }, devServer: {// 本地开发代理API地址proxy: {^/file: {target: https://服务端域名,changeOrigin: true, // 是否…...

将word文件转为kindle可识别的azw3文件的方法
亚马逊在中国停服后,要将word文件传送到kindle设备上进行阅读就不能通过电子邮件的方式了,只能通过将word文件进行转换后通过数据线传到kindle的方式来实现,通过线上或线下的转换工具可将word文件转化为azw文件,但通过数据线将转换…...

动态规划之01背包
首要 由于自己的个人原因(说白了就是懒),忙于各种事情,实在忙不过来(哭),只能把发文分享的事情一推再推,直到某天良心发现产生了想发文的想法,于是就写下了这篇文章,请各位大佬轻喷 背包问题 背包问题是一…...

Lua和JS的继承原理
JavaScript 和 Lua 都是动态语言,支持面向对象编程(OOP),但它们的 继承机制 实现方式不一样。下面分别介绍它们的继承实现原理和方式: 🔶 JavaScript 的继承机制 JavaScript 使用的是 基于原型(…...
灵活控制,modbus tcp转ethernetip的 多功能水处理方案
油田自动化和先进的油气行业软件为油气公司带来了诸多益处。其中包括: 1.自动化可以消除多余的步骤、减少人为错误并降低运行设备所需的能量,从而降低成本。 2.油天然气行业不断追求高水平生产。自动化可以更轻松地减少计划外停机时间,从而…...

boost::qvm 使用示例
boost::qvm 使用示例 boost::qvm (Quaternions, Vectors and Matrices) 是 Boost 库中的一个组件,专门用于处理向量、矩阵和四元数运算。以下是几个常见的使用示例: 基本向量操作 #include <boost/qvm/vec.hpp> #include <boost/qvm/vec_ope…...

go语言学习 第6章:错误处理
第6章:错误处理 在任何编程语言中,错误处理都是一个至关重要的环节。Go语言以其简洁而强大的错误处理机制而闻名,这使得开发者能够以一种优雅且高效的方式处理程序中可能出现的错误情况。本章将深入探讨Go语言中的错误处理机制,包…...
附连接公网、虚拟机yum源等系统配置)
VMware 安装 CentOS8详细教程 (附步骤截图)附连接公网、虚拟机yum源等系统配置
1 下载安装镜像 centos8官方源已下线,旧的下载地址已不可用,需要切换centos-vault源 华为云CentOS8镜像下载地址 阿里云CentOS8镜像下载地址 中科大CentOS8镜像下载地址 2 安装CentOS8 2.1 创建虚拟机 打开VMware Workstation 左上角 文件-新建虚拟机...

Editing Language Model-based Knowledge Graph Embeddings
基于语言模型的知识图谱嵌入 原文链接:https://arxiv.org/abs/2301.10405 Comment: AAAI 2024.03 摘要 基于语言模型的KG嵌入通常部署为静态工件,这使得它们在部署后如果不重新训练就很难修改。在本文中提出了一个编辑基于语言模型的 KG 嵌入的新任务。…...

深入了解linux系统—— 进程池
前言: 本篇博客所涉及到的代码以同步到本人gitee:进程池 迟来的grown/linux - 码云 - 开源中国 一、池化技术 在之前的学习中,多多少少都听说过池,例如内存池,线程池等等。 那这些池到底是干什么的呢?池…...

JavaScript 原型与原型链:深入理解 __proto__ 和 prototype 的由来与关系
引言 在 JavaScript 的世界中,原型和原型链是理解这门语言面向对象编程(OOP)机制的核心。不同于传统的基于类的语言如 Java,JavaScript 采用了一种独特的原型继承机制。本文将深入探讨 __proto__ 和 prototype 的由来、关系以及它…...

逻辑回归与Softmax
Softmax函数是一种将一个含任意实数的K维向量转化为另一个K维向量的函数,这个输出向量的每个元素都在(0, 1)区间内,并且所有元素之和等于1。 因此,它可以被看作是某种概率分布,常用于多分类问题中作为输出层的激活函数。这里我们以拓展逻辑回归解决多分类的角度对Softmax函…...

vscode .husky/pre-commit: line 4: npx: command not found
目录 1. 修复 npx 路径问题(90% 的解决方案)2. 显式加载环境变量(nvm 用户必选)3. 修复全局 PATH 配置4. 重装 Husky 与钩子5. 使用 HUSKY_DEBUG 调试执行流程 🔧 核心解决方法(按优先级排序) …...