Editing Language Model-based Knowledge Graph Embeddings
基于语言模型的知识图谱嵌入
原文链接:https://arxiv.org/abs/2301.10405
Comment: AAAI 2024.03
摘要
-
基于语言模型的KG嵌入通常部署为静态工件,这使得它们在部署后如果不重新训练就很难修改。在本文中提出了一个编辑基于语言模型的 KG 嵌入的新任务。
-
此任务旨在促进对 KG 嵌入进行快速、数据高效的更新,而不会影响其他方面的性能。
-
构建了四个新的数据集E-FB15k237、AFB15k237、E-WN18RR 和 A-WN18RR,并评估了几个知识编辑基线,这些基线表明以前的模型处理所提出的具有挑战性的任务的能力有限。我们进一步提出了一个简单而强大的基线,称为 KGEditor,它利用超网络(引入额外参数层)来编辑/添加事实。
引言
-
研究的背景与动机
-
KG的重要性:结构化知识的表示形式,广泛应用于信息检索、问答系统、推荐系统等任务,其质量直接影响下游应用的效果。
-
语言模型与KG嵌入的结合:近年来,预训练语言模型(BERT、GPT)被用于生成KG实体和关系的嵌入向量(KG embeddings),这类方法能够捕捉丰富的语义信息,优于传统基于规则或统计的方法。
-
静态模型的局限性:当前基于语言模型的KG嵌入通常是静态的(即训练后参数固定),无法动态适应KG的更新需求(如新增事实或修正错误)。这导致知识过时、模型与现实知识脱节等问题。
-
-
本文的核心任务与目标
-
提出新任务:定义“编辑KG嵌入”的任务,具体包括两种场景:
-
EDIT(编辑):修正KG中错误的事实(错误的实体关系)。
-
ADD(添加):向KG中新增知识(添加新的实体-关系对)。
-
-
目标:在不重新训练整个模型的前提下,通过局部调整实现对KG嵌入的高效编辑,同时保持其他知识的完整性。
-
-
方法和创新点
-
KGEditor 方法:提出一种基于超网络的轻量级编辑框架,通过引入额外参数层,仅修改与目标知识相关的嵌入,避免全局扰动。
-
数据集构建:为评估编辑效果,构建了四个新数据集(E-FB15k237、A-FB15k237、E-WN18RR、A-WN18RR),分别对应编辑和添加任务。
-
评价准则:
-
知识可靠性(Knowledge Correctness):编辑后的知识是否准确。
-
知识局部性(Knowledge Locality):编辑操作对其他知识的影响是否最小。
-
知识效率(Knowledge Efficiency):编辑过程是否资源友好(如计算和存储开销)。
-
-
-
主要贡献
-
任务定义与数据集:首次明确“编辑KG嵌入”的任务,并构建了标准化数据集,为后续研究提供基准。
-
KGEditor 方法:提出一种高效、灵活的编辑框架,能够快速更新KG嵌入,同时避免知识遗忘。
-
实证分析:通过对比实验验证了KGEditor在可靠性、局部性和效率上的优势,揭示了当前方法在编辑KG嵌入上的不足。
-
相关工作
传统的KG嵌入
-
基于结构的方法:
-
早期方法(TransE、TransR、DistMult、ComplEx)通过建模三元组(头实体-关系-尾实体)的几何关系,将实体和关系映射到低维向量空间。
-
优势:计算高效,适合大规模KG。
-
局限性:依赖KG的结构信息,难以捕捉语义信息(如实体描述、文本上下文)。
-
-
基于语义的方法:
-
方法(ConvE、R-GCN)结合图神经网络(GNN)或卷积操作,建模实体和关系的复杂交互。
-
优势:能捕捉更丰富的结构模式。
-
局限性:仍以结构信息为主,语义表示能力有限。
-
基于语言模型的KG嵌入
-
预训练语言模型的应用:
-
预训练语言模型(BERT、RoBERTa)用于生成KG嵌入,利用文本描述(如实体名称、属性值)增强语义表示。
-
典型方法:
-
K-BERT:结合KG结构和语言模型,通过掩码任务联合优化实体和关系的表示。
-
ERNIE:在文本中引入KG三元组作为额外监督信号,提升语义关联性。
-
-
优势:能捕捉实体的多义性和上下文依赖。
-
局限性:模型在训练后参数固定,无法动态更新嵌入(即“静态模型”问题)。
-
-
联合训练方法:
- 一些方法将KG结构与语言模型联合训练,但依然面临更新成本高、灵活性差的问题。
知识编辑与动态更新
-
KG的动态维护:
-
传统方法通过增量学习或迁移学习更新KG,但通常针对结构化数据(如三元组),难以直接应用于嵌入向量。
-
典型挑战:
-
知识冲突:新增或修改知识可能导致原有知识的“遗忘”。
-
局部性控制:如何仅修改目标知识而不影响其他部分。
-
-
-
基于嵌入的编辑方法:
-
参数微调:通过少量样本微调模型参数,但需重新训练整个模型,成本高。
-
向量覆盖:直接替换实体/关系的嵌入向量,但可能破坏语义一致性。
-
超网络:引入额外参数生成编辑后的嵌入,但早期方法缺乏系统性评估。
-
方法
任务定义
-
任务目标:在不重新训练整个语言模型的前提下,对基于语言模型生成的KG嵌入进行局部修改,以实现动态更新知识图谱中的实体或关系,同时保持其他知识的完整性。
-
任务分类
-
KG的知识定义(h,r,t)h头实体,r关系,t尾实体
-
EDIT
-
目标:修正知识图谱中已存在的错误事实
-
知识定义(h,r,y,a)或(y,r,t,a)其中y为错误/过时实体,a表示真确要替换y的实体
-
-
ADD
-
目标:向知识图谱中新增实体或关系。
-
同时需要维护模型的稳定性其中 x′ 和 y′ 分别表示模型中存储的事实知识的输入和标签
-
-
-
评估指标
-
知识可靠性(Knowledge Reliability)
-
编辑后的嵌入是否能正确预测目标事实
-
指标:Succ@k(Top-k的比例)
-
-
知识局部性(Knowledge Locality)
-
编辑KG嵌入后对原有知识的影响
-
其中 x′ 是从原始的预训练数据集中采样获取的, f(x′;W)≤k 代表的是由原始参数 W 的模型预测的rank值小于 k 的统计, W~ 表示的是更新后的参数。
-
其中 Redit 和 Rorigin 代表的模型编辑前后需要编辑数据集的平均rank值, Rs_edit 和 Rs_origin 表示的是模型编辑前后参考数据集的平均rank值。
-
-
知识效率(Knowledge Efficiency)
-
旨在评估编辑的效率
-
指标:编辑器的参数量和编辑时间
-
-
数据集构建
-
基础数据集
-
Freebase(FB15k237):一个大规模知识图谱,包含实体、关系和三元组,广泛用于KG嵌入研究。
-
WordNet(WN18RR):一个基于语义的词汇数据库,包含词与词之间的层次化关系。
-
-
衍生数据集
-
EDIT任务:E-FB15k237, E-WN18RR
-
ADD任务:A-FB15k237, A-WN18RR
-
-
关键构建步骤
-
排除简单样本(数据预处理)
-
问题:预训练语言模型(PLM)本身已包含大量事实知识,可能直接预测正确尾实体,干扰编辑效果评估。
-
解决方案:筛选 预测排名 > 2,500 的三元组作为候选集。将预测排名<2500的视为简单样本,剔除。
-
目的:数据过滤,为后续任务提供高质量评估集
-
-
EDIT 任务数据集构建
-
目标:训练和评估修正错误知识的能力
-
构造流程:
-
生成错误知识:从现有知识图谱中随机破坏三元组以生成损坏的数据集
-
训练需编辑的模型:用损坏数据集微调PLM,生成一个包含错误知识的待编辑模型。
-
过滤:
-
Edit Dataset:模型预测结果错误的三元组
-
参考集 (L-Test):模型依旧预测正确的(用于评估知识局部性)。
-
-
-
-
ADD任务数据集
-
目标:评估新增未见知识的能力
-
数据划分:
-
预训练集:原始训练集(不含新增三元组)。
-
新增集 (Train):完全独立的新三元组(从困难样本中选择)。
-
-
关键区别:
- 直接使用新增集作为测试集(因新增知识从未出现在预训练数据中)。
-
参考集 (L-Test):同EDIT任务,用于检验新增知识是否干扰原有知识。
-
-
基于语义模型的KGE
-
FT-KGE:微调方式
-
将三元组 (h, r, t) 转换为文本序列(例如:[CLS] + h描述 + [SEP] + r描述 + [SEP] + t描述)。
-
任务形式:二元分类(判断三元组是否有效):y∈{0,1} 表示三元组正确性。
-
-
PT-KGE:提示调优方式
-
将三元组转换为自然语言提示(例如:“h r [MASK]”),将链接预测转化为掩码预测任务。
-
实体扩展:将 KG 中所有实体视为语言模型的特殊 token,扩展词汇表。
-
任务形式:预测掩码位置的实体:
-
-
KGEditor 编辑框架独立于 KGE 构建方法,可同时应用于 FT-KGE 和 PT-KGE 生成的嵌入。
编辑KGE的基线模型
-
外部模型编辑器
-
利用超外部网络来获取参数的偏移并添加到原始模型参数中进行编辑(将原始实体 y 替换为实体 a)修改的保持全局的一致性
-
核心思想:通过外部超网络生成参数更新量(ΔW),间接修改原模型参数。
-
代表方法:
-
**KE:**使用双向LSTM作为超网络,学习参数更新量 ΔW。
-
MEND:用MLP预测微调梯度的低秩分解,生成轻量级参数更新。适用于大模型(如BART、GPT-3)的高效编辑。
-
-
优势:灵活性强,不直接改动原模型结构。
-
局限:需额外训练超网络,参数量较大。
-
-
附加参数编辑器
-
核心思想:在模型内部添加可训练参数层,调整输出分布以实现编辑。
-
代表方法:CALINET
-
假设FFN存储事实知识,通过添加带“校准记忆槽”的小型FFN层调整原FFN输出。
-
参数量小,但编辑能力有限。
-
-
优势:参数量少,计算高效。
-
局限:依赖FFN存储知识的假设,对复杂编辑任务效果不佳。
-
KGEditor
利用超外部网络来更新 FFN 中的知识(上:EDIT,下:ADD)。
-
KGEditor融合外部模型编辑器和附加参数编辑器的优势,提出一个简单健壮的基线模型。
-
使用双向LSTM构建超网络。对 ⟨x、y、a⟩ 进行编码,用特殊的分隔符将它们连接起来,给LSTM。然后双向 LSTM 的最后的输出送到 FNN 中,以生成用于知识编辑的单个向量H。
-
低秩梯度变换
评估
实验设置
-
数据集:使用构建的数据集E-FB15k237、AFB15k237、E-WN18RR 和 A-WN18RR
-
模型初始化:使用预训练数据集(EDIT任务用被破坏的训练集,ADD任务用原始训练集),基于BERT初始化KG Embedding
-
训练与评估:
-
编辑器(Editor)使用训练集训练,测试集评估
-
ADD任务直接使用训练集评估(因新知识未出现在预训练中)
-
-
微调方式:采用PT-KGE作文默认设置
主要结果
-
EDIT任务:
-
KGE_FT:直接微调所有参数;KGE_ZSL:不调整任何参数;K-Adapter:使用适配器微调参数。CALINET:扩展FNN;KE和MEND:使用外部编辑器
-
知识可靠性:KGEditor在
Succ@1和Succ@3上显著优于基线。 -
知识局部性:KGEditor的
RK@3最高,表明其最小化对原有知识的干扰。 -
效率:KGEditor参数量(38.9M)远低于KE(88.9M)和MEND(59.1M),且推理时间更短。
-
-
ADD任务:
-
可靠性:KGEditor在
Succ@1接近全参数微调(KGE_FT),且显著优于其他编辑器。 -
局部性:KGEditor的
RK@3最高,且RKroc(稳定性变化率)最低。
-
-
KG初始化方法对比:PT-KGE在知识可靠性(
ERroc)和局部性(RKroc)上均优于FT-KGE,表明Prompt更适合编辑任务。 -
编辑知识数量的影响:
-
单次编辑中修改的三元组数量
-
所有模型的
Succ@1下降,但KGEditor和KE的局部性(RK@3)更稳定,MEND则显著下降。
-
-
可视化案例:编辑后目标实体(如"Marc Shaiman")进入预测中心,其他实体位置基本不变,直观验证了知识可靠性和局部性。
结论
-
提出KGE模型的任务允许直接修改三元组以适应特定任务,从而提高编辑过程的效率和准确性。
-
与早期的预训练语言模型编辑任务相反,该方法依赖于KG事实来修改知识,而不使用预训练模型知识。
-
这些方法提高了性能,并为知识表示和推理的研究提供了重要的见解。
未来工作
-
编辑KGE模型会带来持续存在的问题,特别是处理复杂的知识和多对多关系。由此类关系产生的已编辑事实可能会使模型偏向于已编辑的实体,从而忽略其他有效实体。
-
实验KGE模型很小,都利用了标准 BERT。未来,目标是设计模型来编辑具有多对多关系的知识,并集成 LLM 编辑技术。
相关文章:

Editing Language Model-based Knowledge Graph Embeddings
基于语言模型的知识图谱嵌入 原文链接:https://arxiv.org/abs/2301.10405 Comment: AAAI 2024.03 摘要 基于语言模型的KG嵌入通常部署为静态工件,这使得它们在部署后如果不重新训练就很难修改。在本文中提出了一个编辑基于语言模型的 KG 嵌入的新任务。…...

深入了解linux系统—— 进程池
前言: 本篇博客所涉及到的代码以同步到本人gitee:进程池 迟来的grown/linux - 码云 - 开源中国 一、池化技术 在之前的学习中,多多少少都听说过池,例如内存池,线程池等等。 那这些池到底是干什么的呢?池…...

JavaScript 原型与原型链:深入理解 __proto__ 和 prototype 的由来与关系
引言 在 JavaScript 的世界中,原型和原型链是理解这门语言面向对象编程(OOP)机制的核心。不同于传统的基于类的语言如 Java,JavaScript 采用了一种独特的原型继承机制。本文将深入探讨 __proto__ 和 prototype 的由来、关系以及它…...

逻辑回归与Softmax
Softmax函数是一种将一个含任意实数的K维向量转化为另一个K维向量的函数,这个输出向量的每个元素都在(0, 1)区间内,并且所有元素之和等于1。 因此,它可以被看作是某种概率分布,常用于多分类问题中作为输出层的激活函数。这里我们以拓展逻辑回归解决多分类的角度对Softmax函…...

vscode .husky/pre-commit: line 4: npx: command not found
目录 1. 修复 npx 路径问题(90% 的解决方案)2. 显式加载环境变量(nvm 用户必选)3. 修复全局 PATH 配置4. 重装 Husky 与钩子5. 使用 HUSKY_DEBUG 调试执行流程 🔧 核心解决方法(按优先级排序) …...

光电耦合器:数字时代的隐形守护者
在数字化、自动化高速发展的今天,光电耦合器正以一种低调却不可或缺的方式,悄然改变着我们的生活。它不仅是电子电路中的“安全卫士”,更是连接信号世界的“桥梁”,凭借出色的电气隔离能力,为各类设备提供稳定可靠的信…...

FPGA没有使用的IO悬空对漏电流有没有影响
结论: 1.在FPGA中,没有使用的IO悬空确实是可能对漏电流和功耗产生一定的影响。 2.这种影响特别是在低功耗设计中或者电流敏感的应用中需要注意。 问题一:未连接 IO(Floating IO)会不会产生漏电流? 1.会有影…...

11. vue pinia 和react redux、jotai对比
对比 Vue 的 Pinia,和 React 的 Redux、Jotai,分中英文简要介绍、特性、底层原理、使用场景。 简单介绍 1.1 Pinia(Vue) • 英文:Pinia is the official state management library for Vue 3, designed to be simple…...

手机如何防止ip关联?3种低成本方案
在当今数字化时代,手机已成为人们日常生活中不可或缺的工具,无论是社交、购物、支付还是工作,都离不开手机。然而,随着网络技术的不断发展,网络安全问题也日益突出,其中IP关联问题尤为常见。那么࿰…...
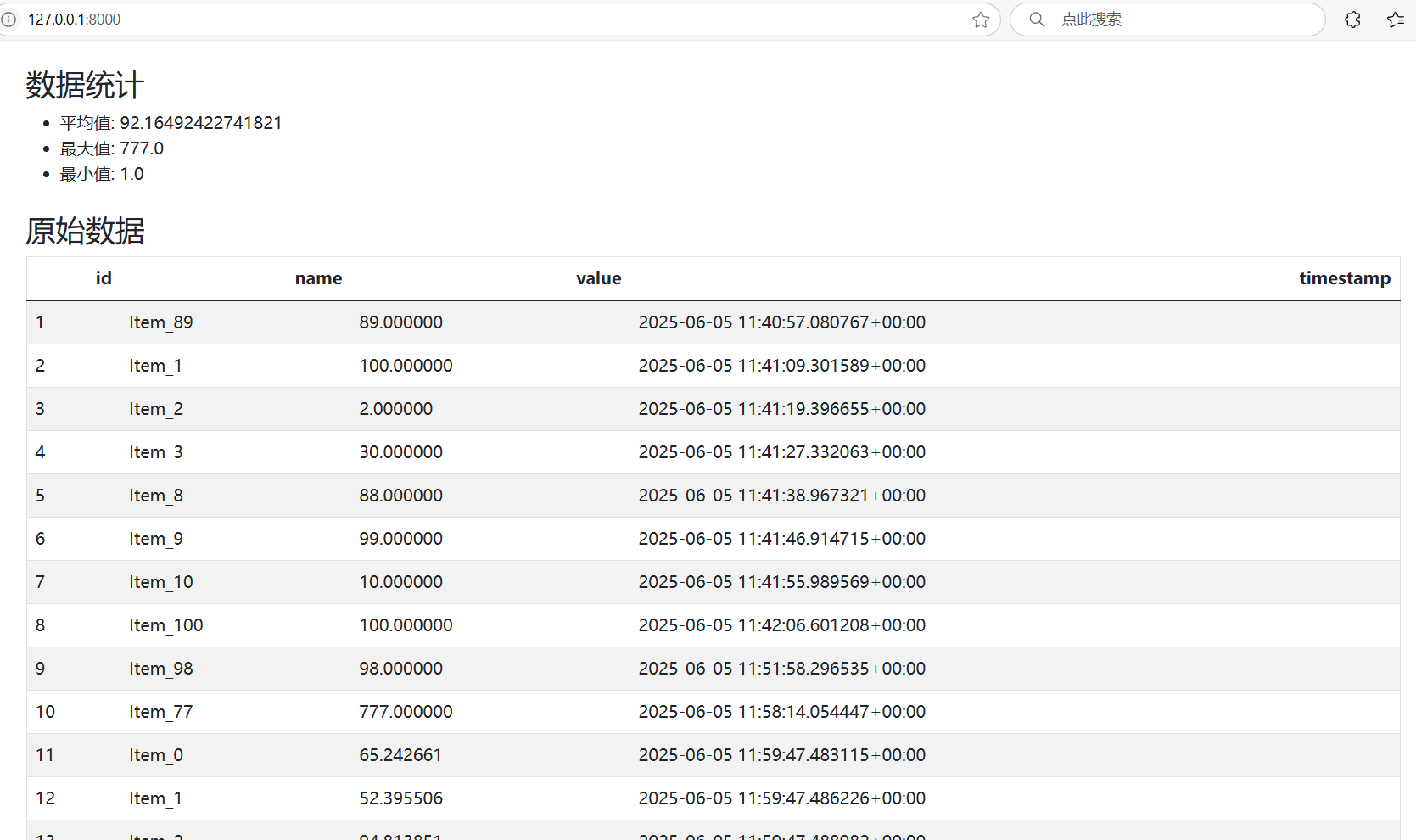
Pandas和Django的示例Demo
以下是一个结合Pandas和Django的示例Demo,展示如何在Django项目中读取、处理和展示Pandas数据。 Pandas和Django的示例Demo 前置条件: 安装python 基础设置 确保已安装Django和Pandas: pip install django pandasInstalling collected p…...
)
护网行动面试试题(1)
文章目录 1、描述外网打点的流程?2、举几个 FOFA 在外网打点过程中的使用小技巧?3、如何识别 CDN?4、判断出靶标的 CMS,对外网打点有什么意义?5、Apache Log4j2 的漏洞原理是什么?6、如何判断靶标站点是 wi…...

【p2p、分布式,区块链笔记 MESH】Bluetooth蓝牙通信拓扑与操作 BR/EDR(经典蓝牙)和 BLE
目录 1. BR/EDR(经典蓝牙)网络结构微微网(Piconet)散射网(Scatternet)蓝牙 BR/EDR 拓扑结构示意图 2. BLE(低功耗蓝牙)网络结构广播器与观察者(Broadcaster and Observer…...
航道无人机巡检系统
随着长江干线、京杭运河等航道智慧化升级提速,传统人工巡检模式已难以满足高频次、大范围、高精度的航道管理需求。无人机凭借其灵活机动、多源感知、高效覆盖等优势,正成为航道巡检的“空中卫士”。本文将结合多地成功案例,从选型标准、技术…...
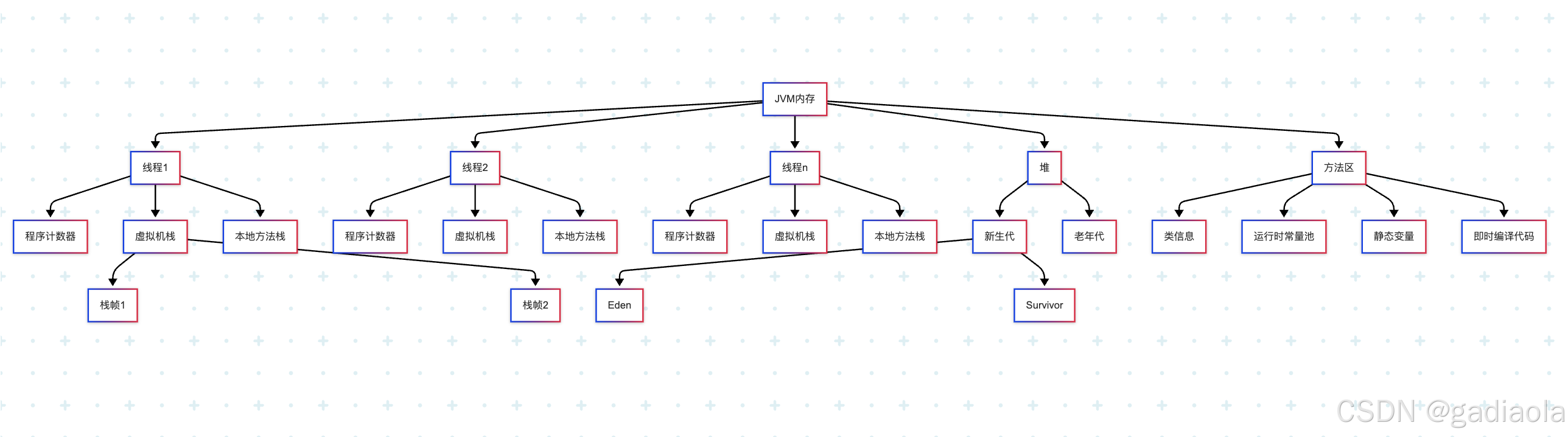
【JVM】Java虚拟机(一)——内存结构
目录 一、简介 二、程序计数器 三、虚拟机栈 栈帧结构: 特点: 四、本地方法栈 特点: 五、堆 堆结构: 特点: 对象分配过程: 六、方法区 方法区结构: 特点: 运行时常量池…...
从微积分到集合论(1630-1910)(历史简介)——第4章——现代积分理论的起源(Thomas Hawkins)
第 4 章 现代积分理论的起源 (The Origins of Modern Theories of Integration) Thomas Hawkins 目录 4.1 引言(Introduction) 4.2 Fourier分析与任意函数(Fourier analysis and arbitrary functions) 4.3 对Fourier问题的回应(Responses to Fourier)(1821-1854)…...

《Linux运维总结:宝德服务器RAID开启(方式一)》
总结:整理不易,如果对你有帮助,可否点赞关注一下? 更多详细内容请参考:Linux运维实战总结 一、背景信息 说明:从客户那里退回来的一台宝德服务器,硬盘不见了,现在需要用两个2T的硬盘…...

NY118NY120美光固态闪存NY124NY129
NY118NY120美光固态闪存NY124NY129 美光NY系列固态闪存深度解析:技术、性能与行业洞察 技术架构与核心创新 美光NY系列(包括NY118、NY120、NY124、NY129等型号)作为企业级存储解决方案的代表作,延续了品牌在3D NAND技术上的深厚…...

Odoo 19 路线图(新功能)
Odoo 19 路线图(新功能) Odoo 19 路线图是Odoo官方针对下一版本的发布计划,将在自动化、合规性、用户体验、碳排放报告及本地化等领域推出超过16项新功能。本路线图详细阐述了Odoo 19如何在过往版本基础上进一步提升,助力企业优化销售、财务、运营及客户…...

基于NXP例程学习CAN UDS刷写流程
文章目录 前言1.概述1.1 诊断报文 2.协议数据单元(N_PDU)2.1 寻址信息(N_AI)2.1.1 物理寻址2.1.2 功能寻址2.1.3 常规寻址(Normal addressing)2.1.4 常规固定寻址(Normal fixed addressing)2.1.5 扩展寻址&…...
)
RNN循环网络:给AI装上“记忆“(superior哥AI系列第5期)
🔄 RNN循环网络:给AI装上"记忆"(superior哥AI系列第5期) 嘿!小伙伴们,又见面啦!👋 上期我们学会了让AI"看懂"图片,今天要给AI装上一个更酷的技能——…...

Python训练第四十三天
DAY 43 复习日 作业: kaggle找到一个图像数据集,用cnn网络进行训练并且用grad-cam做可视化 进阶:并拆分成多个文件 import torch import torch.nn as nn import torch.optim as optim from torchvision import datasets, transforms, models …...

基于有效集MPC控制算法的直线同步电机simulink建模与仿真,MPC使用S函数实现
目录 1.课题概述 2.系统仿真结果 3.核心程序 4.系统仿真参数 5.系统原理简介 6.参考文献 7.完整工程文件 1.课题概述 有效集算法通过迭代地选择一组 "有效" 约束,将约束优化问题转化为一系列无约束或等式约束优化问题。直线同步电机 (Linear Synch…...

让敏感数据在流转与存储中始终守护在安全范围
在企业数字化运营浪潮中,企业内部应用服务器面临着非法访问、数据泄露等风险,如何全面守护应用服务器文件安全,让敏感数据在流转与存储中始终守护在安全范围? 服务器白名单让数据流转安全又高效 天 锐 蓝盾的服务器白名单功能既…...

【Linux】find 命令详解及使用示例:递归查找文件和目录
【Linux】find 命令详解及使用示例:递归查找文件和目录 引言 find 是 Linux/Unix 系统中强大的文件搜索工具,用于在目录层次结构中递归查找文件和目录。它提供了丰富的搜索条件和灵活的操作选项,可以满足从简单到复杂的各种文件查找需求。 …...
:参数验证)
Java转Go日记(五十九):参数验证
1. 结构体验证 用gin框架的数据验证,可以不用解析数据,减少if else,会简洁许多。 package mainimport ("fmt""time""github.com/gin-gonic/gin" )//Person .. type Person struct {//不能为空并且大于10Age …...

机器学习与深度学习14-集成学习
目录 前文回顾1.集成学习的定义2.集成学习中的多样性3.集成学习中的Bagging和Boosting4.集成学习中常见的基本算法5.什么是随机森林6.AdaBoost算法的工作原理7.如何选择集成学习中的基础学习器或弱分类器8.集成学习中常见的组合策略9.集成学习中袋外误差和交叉验证的作用10.集成…...

MySQL数据库表设计与索引优化终极指南
MySQL数据库表设计与索引优化终极指南 标签:MySQL 数据库设计 索引优化 性能调优 一、前言:为什么表设计和索引如此重要? 在数据库系统中,良好的表设计和高效的索引策略是保证系统性能的关键。据统计,约70%的数据库性…...
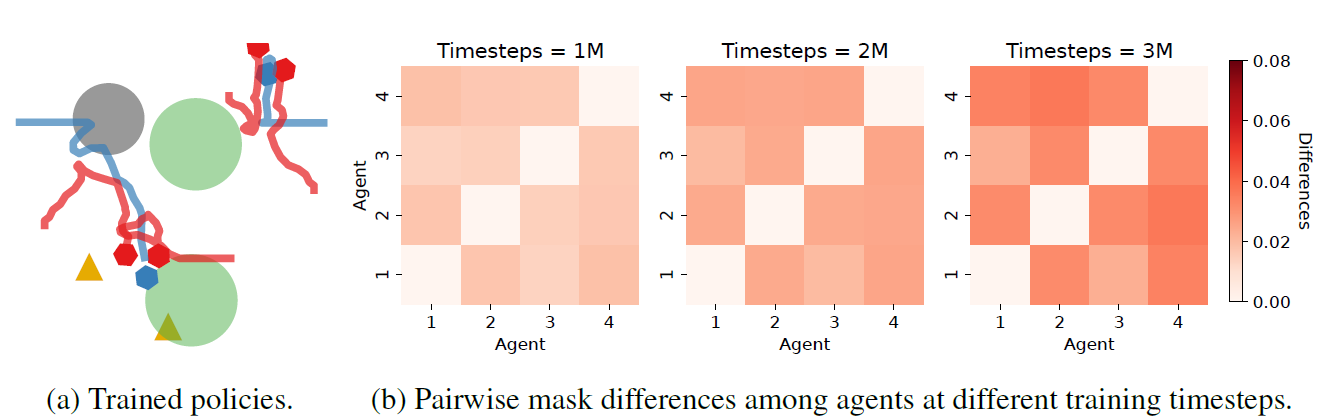
【论文阅读笔记】万花筒:用于异构多智能体强化学习的可学习掩码
摘要 在多智能体强化学习(MARL)中,通常采用参数共享来提高样本效率。然而,全参数共享的流行方法通常会导致智能体之间的策略同质,这可能会限制从策略多样性中获得的性能优势。为了解决这一关键限制,我们提出…...
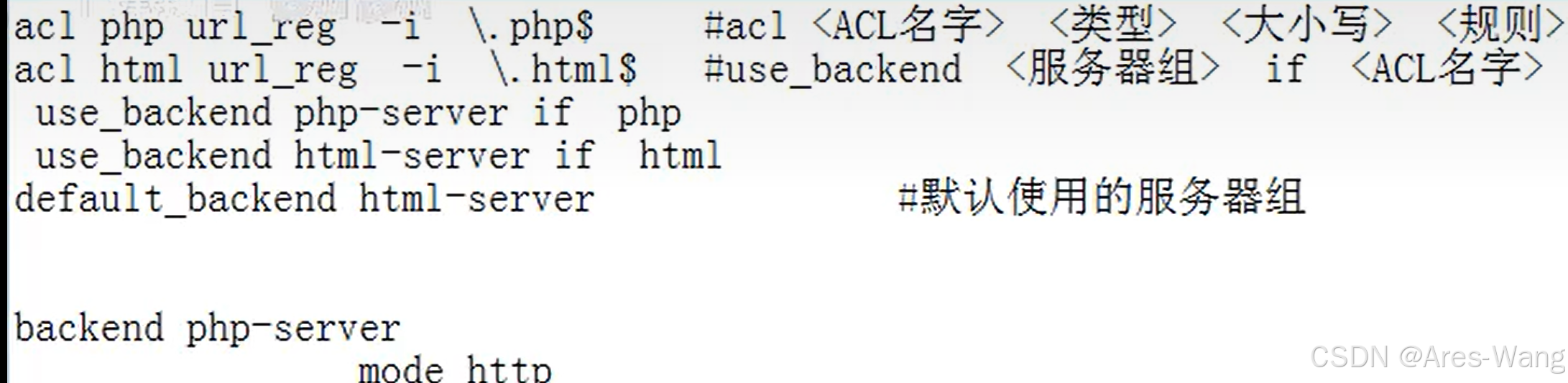
负载均衡LB》》HAproxy
Ubuntu 22.04 安装HA-proxy 官网 资料 # 更新系统包列表: sudo apt update # 安装 HAproxy sudo apt install haproxy -y # 验证安装 haproxy -v # 如下图配置 Haproxy 在这里插入代码片》》》配置完之后 重启 Haproxy sudo systemctl restart haproxy 补充几…...

Vue 中组件命名与引用
Vue 中组件命名与引用 前言 在 vue 项目中,我们会发现在代码中,import 组件 和 components 组件注册中得命名方式与组件引用时的命名方式不一样,这种现象是由组件名的大小写转换规则造成的。如下示例: 组件引入与注册ÿ…...