RAG技术解析:实现高精度大语言模型知识增强
RAG技术解析:实现高精度大语言模型知识增强
RAG概述
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合检索系统和生成模型的技术架构,旨在提高大语言模型回答问题的准确性和相关性。当遇到如"如何退款"这类问题时,若没有提供标准答案,模型可能会产生"幻觉"(生成看似合理但实际不准确的信息)。而通过RAG提供标准答案参考,模型就能够输出准确且符合要求的回应。
RAG特别适用于企业私有化定制场景,处理那些不适合对外公开、需要模型学习的专有数据。其核心优势在于:不需要重新训练模型,而是通过检索相关信息来增强现有模型的输出。
RAG与模型微调的区别
| RAG(检索增强生成) | 模型微调 | |
|---|---|---|
| 本质区别 | “训练"模型的"四肢” | 训练模型的"大脑" |
| 成本 | 相对较低 | 极高(算力、费用) |
| 实现难度 | 中等 | 高 |
| 适用场景 | 需要参考特定知识库回答问题 | 需要模型从根本上学习新能力 |
| 可扩展性 | 高(知识库可动态更新) | 低(需重新训练) |
| 技术要求 | 向量检索、提示工程 | 深度学习、大规模算力 |
简单来说,微调是直接改变模型权重的过程,需要大量计算资源,一般企业难以承担。而RAG则是在不改变模型本身的情况下,通过检索相关信息来增强模型的回答能力,成本相对较小,更适合企业级应用。
RAG的两个核心阶段
1. 索引阶段(Indexing)
索引阶段主要完成以下工作:
- 读取文件内容:加载各种格式的文档(PDF、TXT、Word等)
- 文本分割:将长文本分割成适当大小的段落
- 向量化与存储:生成文本段落的向量表示并保存到向量数据库中
# 索引阶段示例代码
loader = TextLoader("documents.txt", encoding="utf-8")
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=50)
segments = text_splitter.split_documents(documents)
vector_store = RedisVectorStore(embedding_model, config=redis_config)
vector_store.add_documents(segments)
2. 检索增强阶段(Retrieval-Augmentation)
检索增强阶段执行以下流程:
- 读取用户查询并向量化
- 在向量库中检索相关文本段落
- 将检索结果作为上下文与用户问题一起提供给大模型
- 生成最终回答
# 检索增强阶段示例代码
retriever = vector_store.as_retriever(search_kwargs={"k": 5})
relevant_docs = retriever.invoke(user_query)
prompt = prompt_template.format(context=relevant_docs, question=user_query)
response = llm_model.invoke(prompt)
RAG效果评测
为了系统评估RAG系统的性能,通常需要构建自动化评测工具,结合RAGAs(RAG评估框架)进行全面评测。主要评测指标包括:
- 准确率(Accuracy):回答的正确程度
- 召回率(Recall):能够找回的相关信息比例
- 精确率(Precision):返回结果中相关信息的比例
- F1值:精确率和召回率的调和平均
- 回答时间:系统生成回答所需的时间
- 相关性(Relevance):回答与问题的相关程度
- 完整性(Completeness):回答包含所有必要信息的程度
RAG性能优化策略
要提升RAG系统的效能,可以从以下几个方面入手:
-
优化原始数据质量
- 确保文档内容准确、相关
- 预处理文本,去除噪音和冗余信息
- 结构化重要知识点
-
改进向量化方法
- 使用更先进的嵌入模型(如text-embedding-3等)
- 调整嵌入参数以适应特定领域
-
增强检索策略
- 实现混合检索(关键词+向量搜索)
- 调整检索参数(k值、相似度阈值等)
-
重排序机制
- 使用如通义千问的重排序模型对检索结果进行二次排序
- 基于相关性和信息丰富度重新评分
-
优化提示工程
- 设计更精确的提示模板
- 使用少样本示例引导模型输出
RAG应用场景
RAG技术在多种场景下表现出色:
-
问答系统
- 企业知识库问答
- 技术支持系统
- 产品常见问题解答
-
文档摘要与处理
- 长文档自动摘要
- 报告分析与重点提取
- 研究论文信息提取
-
客户服务
- 智能客服助手
- 工单自动分类与回复
- 个性化服务推荐
-
教育培训
- 智能教学助手
- 个性化学习内容推荐
- 自适应题目生成
-
决策支持
- 数据分析报告生成
- 市场趋势分析
- 风险评估与建议
结语
RAG技术为大语言模型注入了"外部记忆"能力,使其能够基于最新和专有知识提供准确回答,有效克服了大模型"幻觉"问题。相比传统的微调方法,RAG具有实现成本低、部署简单、知识可实时更新等优势,特别适合企业级应用场景。
随着向量数据库、嵌入模型和提示工程技术的不断进步,RAG系统的性能还将持续提升,为各领域的智能问答和知识服务带来更大价值。
相关文章:

RAG技术解析:实现高精度大语言模型知识增强
RAG技术解析:实现高精度大语言模型知识增强 RAG概述 RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合检索系统和生成模型的技术架构,旨在提高大语言模型回答问题的准确性和相关性。当遇到如"如何退…...

软件测评服务如何依据标准确保品质?涵盖哪些常见内容?
软件测评服务涉及对软件的功能和性能等多维度进行评估和检验,这一过程有助于确保软件的品质,降低故障发生率及维护费用,对于软件开发和维护环节具有至关重要的价值。 测评标准依据 GB/T 25000.51 - 2016是软件测评的核心依据。依照这一标准…...
-Hive数据分析函数总结)
大数据学习(131)-Hive数据分析函数总结
🍋🍋大数据学习🍋🍋 🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言Ǵ…...

SCAU数值计算OJ
18957.计算自然对数ln(x)的导数 Description 求自然对数ln(x)的导数,输入双精度实数x>1,输出自然对数ln(x)的导数(精确到小数点后2位有效数,小数点后第2位四舍五入所得)。输入格式 m(整数,实验数据总…...

c++ 基于openssl MD5用法
基于openssl MD5用法 #include <iostream> #include <openssl/md5.h> using namespace std; int main(int argc, char* argv[]) { cout << "Test Hash!" << endl; unsigned char data[] "测试md5数据"; unsigned char out[1024…...

Python打卡第46天
浙大疏锦行 注意力 注意力机制是一种让模型学会「选择性关注重要信息」的特征提取器,就像人类视觉会自动忽略背景,聚焦于图片中的主体(如猫、汽车)。 从数学角度看,注意力机制是对输入特征进行加权求和,…...
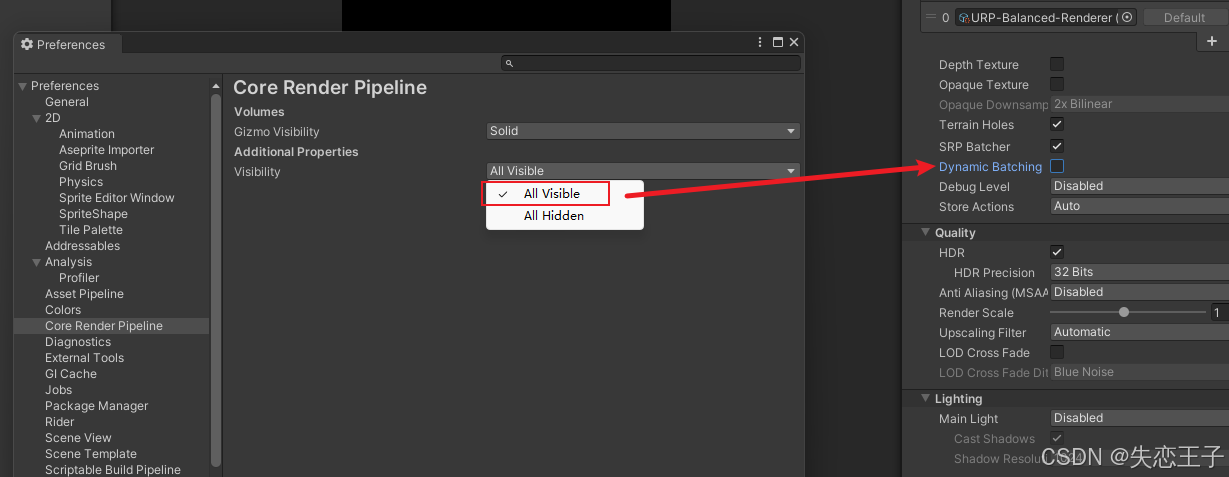
Unity优化篇之DrawCall
当然可以!以下是完整、详尽、可发布的博客文章,专注讲解 Unity 的静态合批与动态合批机制,并详细列出它们对 Shader 的要求和所有限制条件。文章结构清晰、技术深度足够,适合发布在 CSDN、掘金、知乎等技术平台。 urp默认隐藏动态…...
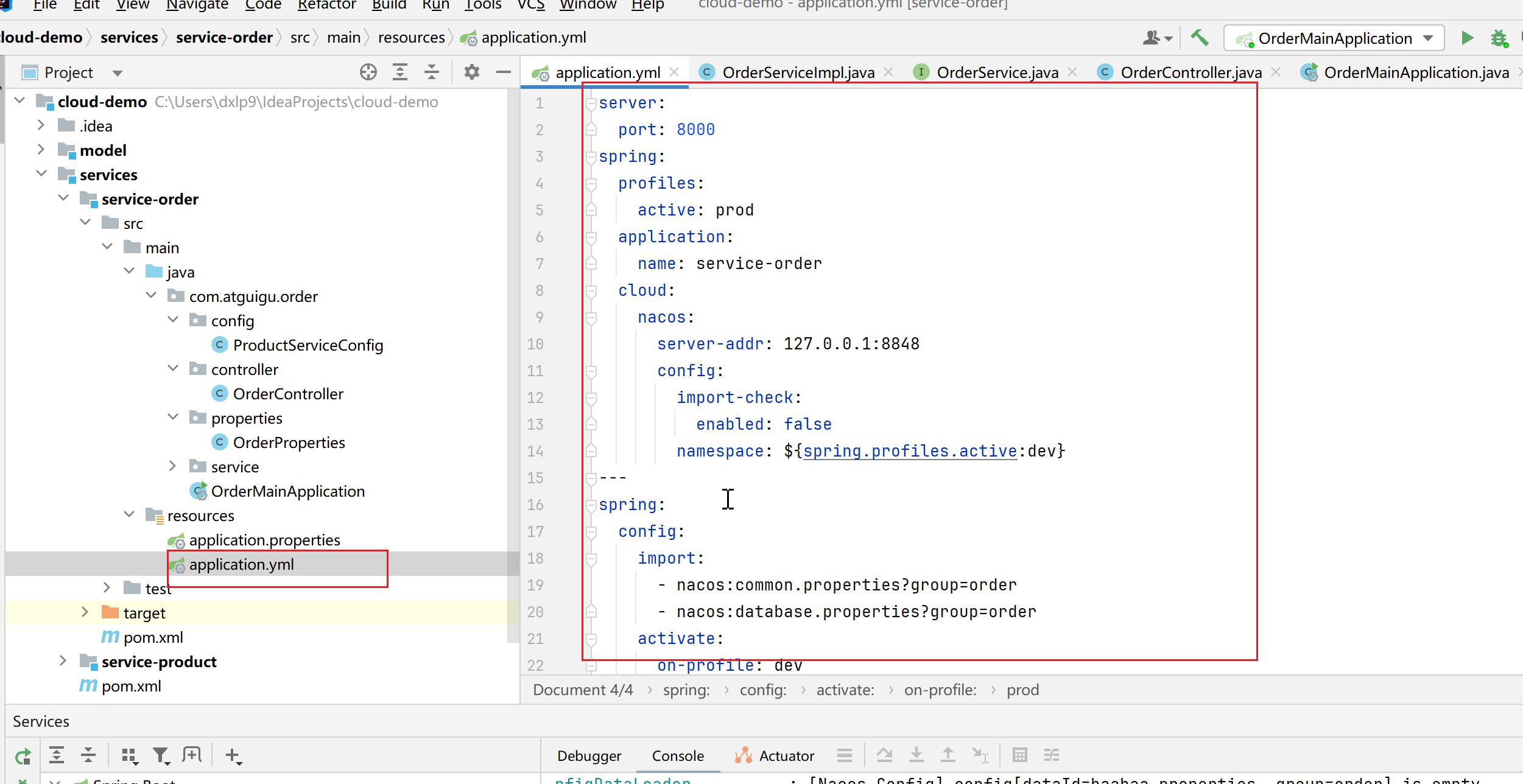
SpringCloud学习笔记-2
说明:来源于网络,如有侵权请联系我删除 1.提问:如果注册中心宕机,远程调用还能成功吗 答:当微服务发起请求时,会向注册中心请求所有的微服务地址,然后在向指定的微服务地址发起请求。在设计实…...
复习(Review))
C++.OpenGL (9/64)复习(Review)
复习(Review) 核心概念快速回顾 #mermaid-svg-MMSQf7gXQlHqiqfM {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-MMSQf7gXQlHqiqfM .error-icon{fill:#552222;}#mermaid-svg-MMSQf7gXQlHqiqfM .error-text{fill:#…...
)
Spring Boot-面试题(52)
摘要: 1、通俗易懂,适合小白 2、仅做面试复习用,部分来源网络,博文免费,知识无价,侵权请联系! 1. 什么是 Spring Boot 框架? Spring Boot 是基于 Spring 框架的快速开发框架&#…...
从混乱到秩序:探索管理系统如何彻底改变工作流程
内容摘要 在许多企业与组织中,工作流程混乱是阻碍发展的“绊脚石”。员工们常常被繁琐的步骤、模糊的职责和沟通不畅等问题搞得焦头烂额,工作效率低下,错误频发。而与之形成鲜明对比的是,一些引入了先进管理系统的团队࿰…...
最新研究揭示云端大语言模型防护机制的成效与缺陷
一项全面新研究揭露了主流云端大语言模型(LLM)平台安全机制存在重大漏洞与不一致性,对当前人工智能安全基础设施现状敲响警钟。该研究评估了三大领先生成式AI平台的内容过滤和提示注入防御效果,揭示了安全措施在阻止有害内容生成与…...
HTML5+CSS3+JS小实例:具有粘性重力的磨砂玻璃导航栏
实例:具有粘性重力的磨砂玻璃导航栏 技术栈:HTML+CSS+JS 效果: 源码: 【HTML】 <!DOCTYPE html> <html lang="zh-CN"><head><meta charset="UTF-8"><meta name="viewport" content="width=device-width…...

CVAT标注服务
CVAT 是一个交互式的视频和图像标注工具,适用于计算机视觉,是一个典型的现代Web应用架构,可以实现大部分情况的标注工作,可以通过serveless CVAT-github cvat文档 下面将就其配置介绍一下几个服务: 1. 核心服务 (C…...
)
SpringBoot+Mybatisplus配置多数据源(超级简单!!!!)
今天分享配置多数据源的另外一种方式,SpringBoMybatisplus配置多数据源,此种方式配置相对简单,都是苞米豆封装好的,配置容易;此篇分享比较简单的方式配置数据源,多个固定的数据源,通过注解选择使…...

Git Svn
github一般需要科学上网,通过SourceTree通过URL克隆,会提示无效URL或者SLL Timeout之类,如果电脑开启了VPN,在系统设置-网络-DNS查看代理端口,如:127.0.0.1:7890 手动配置git代理 git config --global ht…...

Python爬虫伪装
一、网站防爬机制概述 在当今互联网环境中,具有一定规模或盈利性质的网站几乎都实施了各种防爬措施。这些措施主要分为两大类: 身份验证机制:直接将未经授权的爬虫阻挡在外反爬技术体系:通过各种技术手段增加爬虫获取数据的难度…...

Webpack的基本使用 - babel
Mode配置 Mode配置选项可以告知Webpack使用相应模式的内置优化 默认值是production(什么都不设置的情况下) 可选值有:none | development | production; 这几个选项有什么区别呢? 认识source-map 我们的代码通常运行在浏览器…...

LLaMA-Factory的5种推理方式总结
LLaMA-Factory 作为一款开源的大语言模型微调与推理框架,提供了 5 种核心推理方式,覆盖从本地调试到生产部署的全流程需求。以下是具体方式及示例: 1. 交互式命令行推理 适用场景:快速测试模型效果或进行简单对话。 示例命令&am…...

链游技术破壁:NFT资产确权与Play-to-Earn经济模型实战
链游技术破壁:NFT资产确权与Play-to-Earn经济模型实战 ——从「投机泡沫」到「可持续生态」的技术重构 一、NFT确权技术革新:从链上存证到动态赋权 跨链确权架构 全链互操作协议:采用LayerZero协议实现以太坊装备与Solana土地的跨链组合&…...
为什么HDI叠孔比错孔设计难生产
摘要:本文深入探讨了HDI(高密度互连)技术中叠孔与错孔设计在生产难度上的差异。通过对两种设计在对位精度、制程复杂性、可靠性挑战等方面进行详细分析,阐述了叠孔设计在生产过程中面临的一系列难题,旨在为HDI产品的设…...
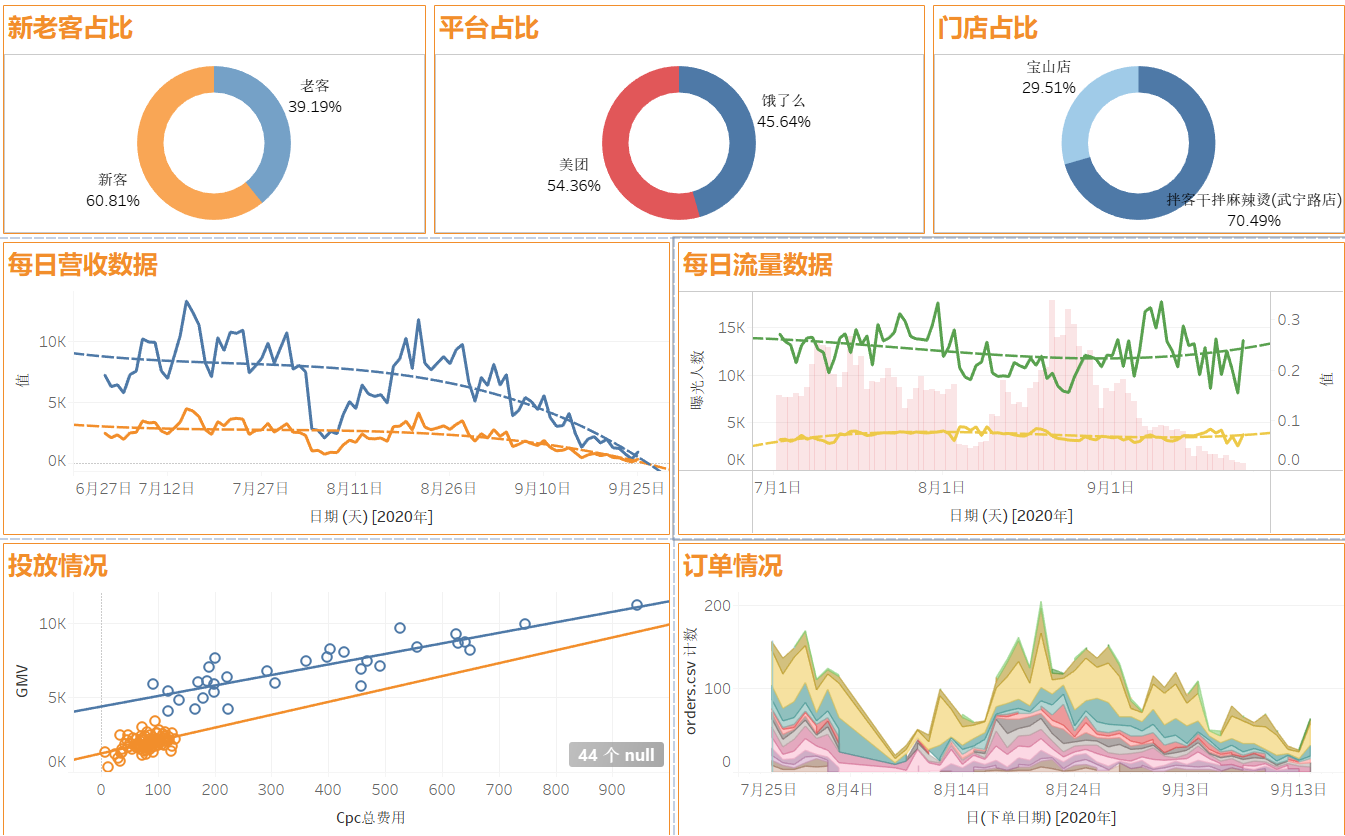
数据分析实战2(Tableau)
1、Tableau功能 数据赋能(让业务一线也可以轻松使用最新数据) 分析师可以直接将数据看板发布到线上自动更新看板自由下载数据线上修改图表邮箱发送数据设置数据预警 数据探索(通过统计分析和数据可视化,从数据发现问题…...
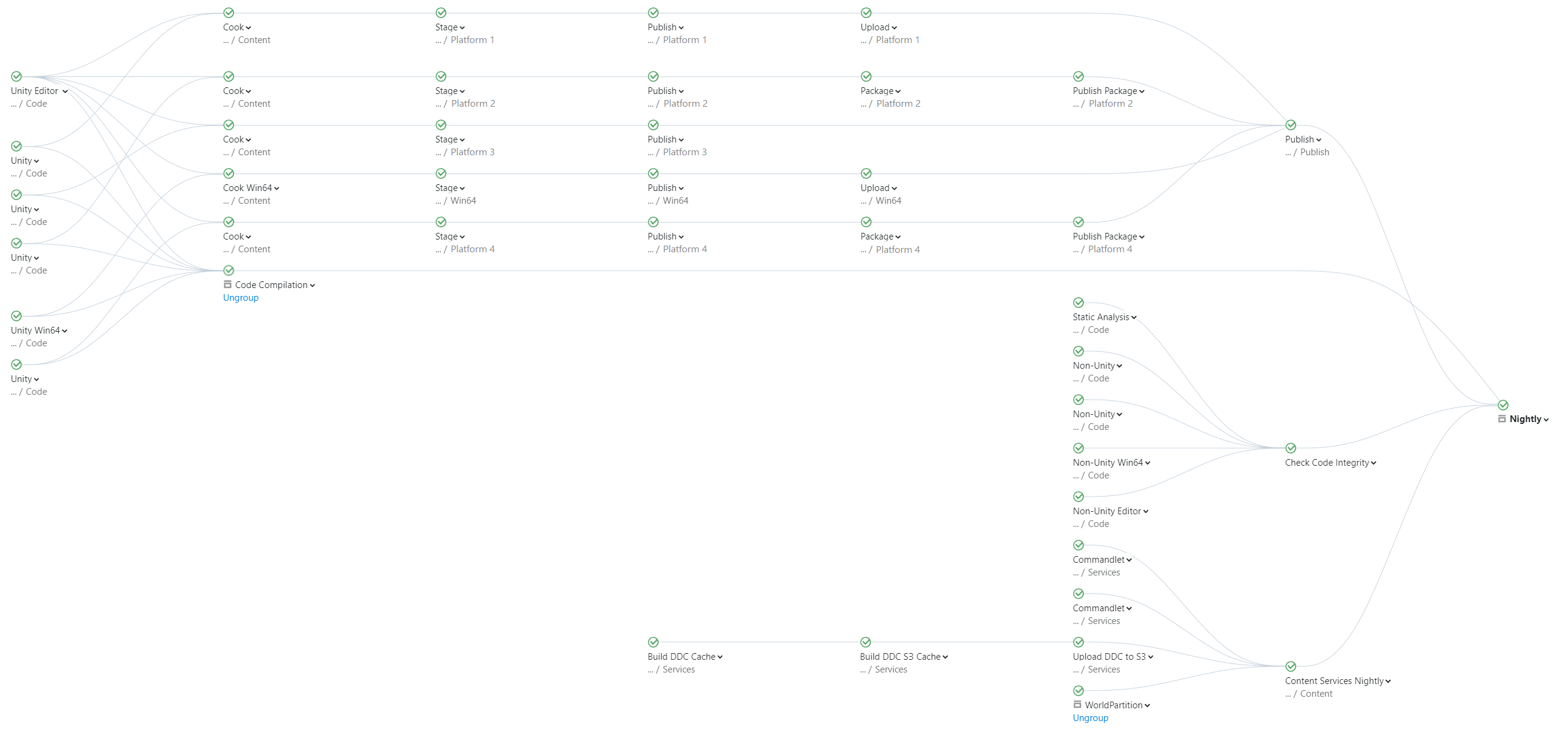
游戏开发中的CI/CD优化案例:知名游戏公司Gearbox使用TeamCity简化CI/CD流程
案例背景 关于Gearbox: Gearbox 是一家美国电子游戏公司,总部位于德克萨斯州弗里斯科,靠近达拉斯。Gearbox 成立于1999年,推出过多款史上最具代表性的视频游戏,包括《半衰期》、《战火兄弟连》以及《无主之地》。 团队…...
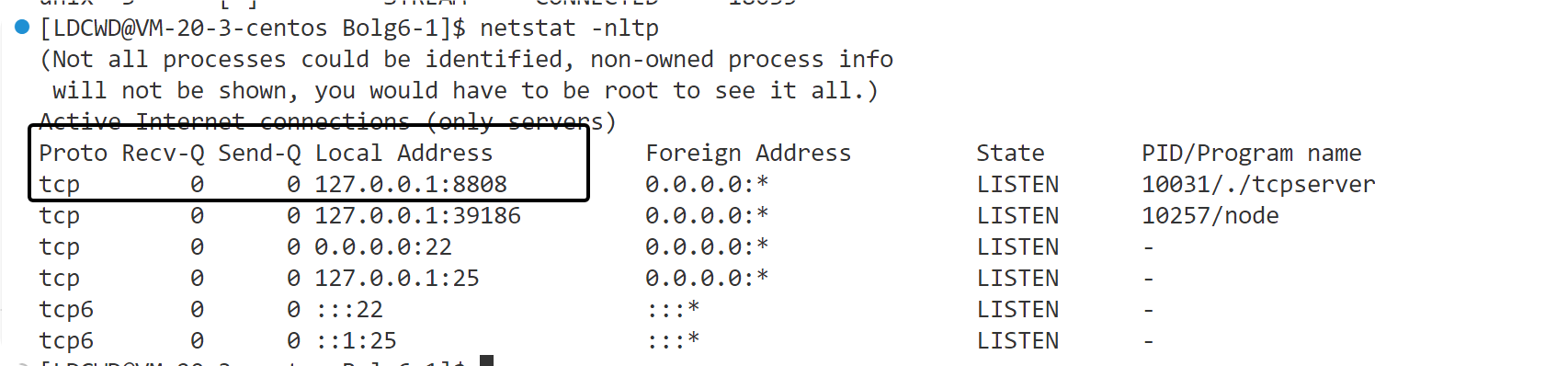
Linux --TCP协议实现简单的网络通信(中英翻译)
一、什么是TCP协议 1.1 、TCP是传输层的协议,TCP需要连接,TCP是一种可靠性传输协议,TCP是面向字节流的传输协议; 二、TCPserver端的搭建 2.1、我们最终好实现的效果是 客户端在任何时候都能连接到服务端,然后向服务…...
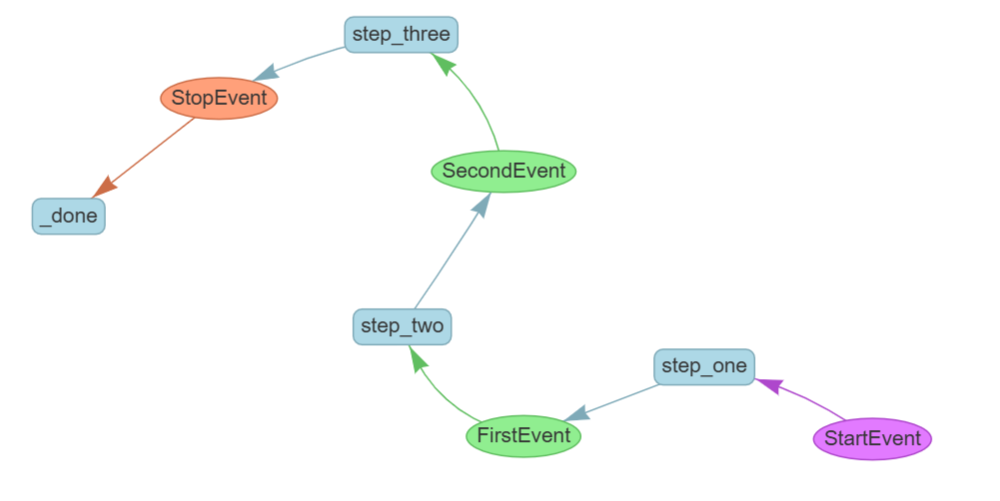
LlamaIndex 工作流简介以及基础工作流
什么是工作流? 工作流是一种由事件驱动、基于步骤的应用程序执行流程控制方式。 你的应用程序被划分为多个称为“步骤(Steps)”的部分,这些步骤由“事件(Events)”触发,并且它们自身也会发出事…...

如何利用Elastic Stack(ELK)进行安全日志分析
在以下文章中,我将解释如何使用Elastic Stack(ELK)进行安全日志分析,以提高安全性和监控网络活动。ELK是一个功能强大的开源日志管理和分析平台,由Elasticsearch、Logstash和Kibana组成,适用于各种用例&…...

创客匠人:以 AI 利器赋能创始人 IP 打造,加速知识变现新路径
在知识付费与个人 IP 崛起的时代,创客匠人作为行业领先的技术服务商,正通过 AI 工具重构创始人 IP 打造与知识变现的生态。其推出的三大 AI 利器 ——AI 销售信、免训数字人、AI 智能客服,精准解决 IP 运营中的核心痛点。 以 AI 销售信为例&…...

Opencv中的copyto函数
一.OpenCV中copyto函数详解 copyto()是 OpenCV 中用于图像复制和融合的核心函数,支持灵活的数据复制和掩模(Mask)操作,其功能和使用方法如下: 1. 核心功能 基础复制:将源图像&…...
)
TeamCity Agent 配置完整教程(配合 Docker Compose 快速部署)
在《使用 Docker Compose 从零部署 TeamCity PostgreSQL(详细新手教程)》中,我们成功部署了 TeamCity Server 和数据库服务。但要真正运行构建任务,还需要至少一个 Build Agent(构建代理)。 本教程将继续…...

基于深度强化学习的Scrapy-Redis分布式爬虫动态调度策略研究
在大数据时代,网络数据的采集与分析变得至关重要,分布式爬虫作为高效获取海量数据的工具,被广泛应用于各类场景。然而,传统的爬虫调度策略在面对复杂多变的网络环境和动态的抓取需求时,往往存在效率低下、资源浪费等问…...