.NET 原生驾驭 AI 新基建实战系列(三):Chroma ── 轻松构建智能应用的向量数据库
在人工智能AI和机器学习ML迅猛发展的今天,数据的存储和检索需求发生了巨大变化。传统的数据库擅长处理结构化数据,但在面对高维向量数据时往往力不从心。向量数据库作为一种新兴技术,专为AI应用设计,能够高效地存储和查询高维向量数据,成为现代智能应用的核心组件之一。
本文将详细介绍Chroma这一开源向量数据库,探讨其在.NET生态系统中的应用,包括安装步骤、代码示例以及实际应用场景,帮助.NET开发者充分利用这一工具构建智能应用。
一、Chroma简介
Chroma是一个开源的、AI原生的向量数据库,旨在为开发者提供简单、高效的方式来管理和查询高维向量数据。它特别适用于需要嵌入embeddings、向量搜索和多模态数据处理的AI应用场景。Chroma的设计目标是降低开发复杂性,同时保证高性能和灵活性,使其成为构建智能应用的理想选择。
1.1 Chroma 的特点
Chroma具备以下几个显著特点,使其在向量数据库领域脱颖而出:
- 开源和AI原生:
Chroma是完全开源的,遵循Apache 2.0许可,开发者可以自由使用、修改和分发。它专为AI应用设计,与现代机器学习工作流无缝衔接。 - 功能丰富:支持向量搜索、文档存储、全文搜索、元数据过滤和多模态检索等多种功能,满足多样化的应用需求。
- 易于使用:提供简洁的
RESTFul API接口,开发者无需深入了解底层实现即可快速上手。 - 高性能:针对高维向量数据的存储和检索进行了优化,支持大规模数据集的快速查询。
- 与.NET集成:通过官方提供的
C#客户端SDK,Chroma可以轻松集成到.NET应用中,为.NET开发者提供了强大的支持。 - 持久化
Chroma支持将数据持久化到磁盘,以便在重启后保留数据。用户可以选择将数据存储在内存中或持久化到磁盘。 - 可扩展性
Chroma设计为可扩展的系统,可以处理大规模的嵌入向量和文档集合。用户可以根据需要扩展Chroma的容量和性能。
1.2 Chroma 的核心概念
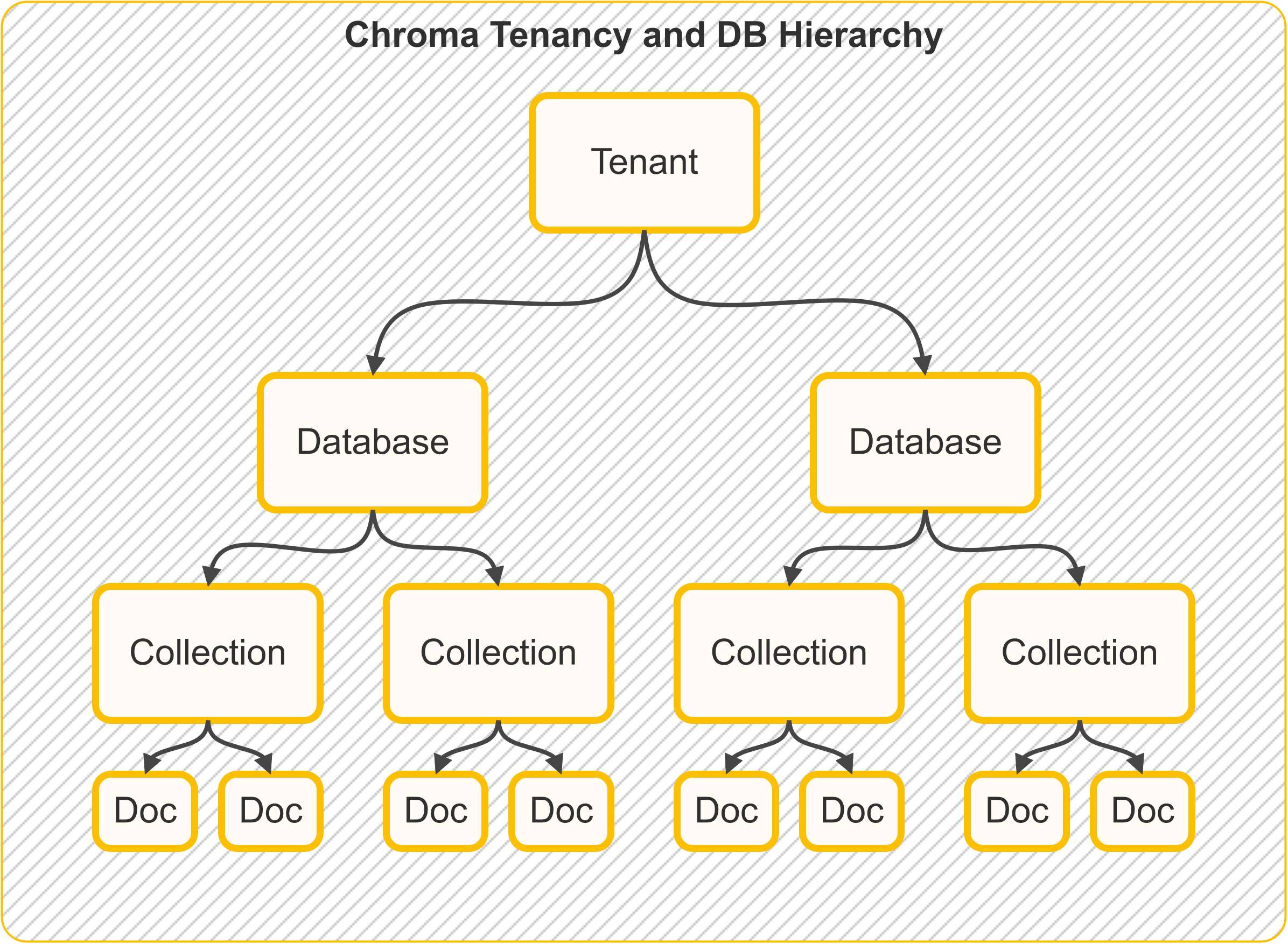
Chroma的核心概念主要围绕着高效存储、查询和管理嵌入向量(embeddings)以及相关数据。以下是Chroma的关键概念:
-
租户(Tenant):
Tenant 是一个逻辑分组,通常代表一个组织、用户或客户,用于组织一组数据库。 -
数据库(Database):
Database 是一个逻辑分组,通常代表一个应用程序或项目,用于组织一组 Collection(集合)。 -
集合(Collection):
集合是Chroma中存储嵌入向量、文档、ID和元数据的基本单元。每个集合通常代表一个特定的数据集或应用场景,类似于数据库中的“表”。
Database 与 Collection 的关系:
- Collection(集合) 是 ChromaDB 中存储实际数据的基本单元,比如嵌入向量、文> 档、ID 和元数据。Collection 隶属于某个 Database,而 Database 又隶属于某个 Ten> ant,形成了一个层次化的数据组织结构。
-
嵌入向量(Embeddings):
嵌入向量是文本、图像或其他数据的向量表示,用于捕捉其语义或特征。Chroma允许用户将这些嵌入向量与相应的文档和元数据一起存储。 -
文档(Documents):
文档是与嵌入向量相关联的原始数据,例如文本、图像或其他内容。文档可以与嵌入向量一起存储,以便在查询时提供上下文。 -
ID:
每个嵌入向量、文档和元数据都与一个唯一的ID相关联,用于标识和检索特定的条目。 -
元数据(Metadata):
元数据是与嵌入向量和文档相关的额外信息,例如作者、日期、类别等。元数据可以用于过滤和查询数据。 -
嵌入函数(Embedding Functions):
Chroma支持使用嵌入函数来自动生成嵌入向量。用户可以指定嵌入函数,以便在添加文档时自动生成嵌入向量。
这些核心概念共同构成了Chroma的功能和特性,使其成为一个高效的嵌入向量存储与查询工具。
1.3 Chroma 的工作原理
Chroma的核心功能基于高效的向量索引和搜索技术。它使用诸如HNSW(Hierarchical Navigable Small World)等先进的索引结构来存储高维向量数据,并支持多种距离度量(如欧几里得距离、余弦相似度)来计算向量之间的相似性。开发者可以将文本、图像或其他数据转换为嵌入向量,存储在Chroma中,并通过相似性搜索快速检索相关内容。这种设计特别适合语义搜索、推荐系统等需要理解数据深层含义的场景。
1.4 Chroma Embeddings算法简介
Chroma Embeddings算法是一种用于生成文本嵌入向量(text embeddings)的方法,主要在ChromaDB中应用。ChromaDB是一个专门设计用于存储和查询嵌入向量的数据库,支持多种嵌入模型,其中就包括Chroma Embeddings算法。
这种算法的核心目标是将文本转化为高维向量表示,从而捕捉文本的语义信息,并支持诸如相似性搜索、文本分类和聚类等自然语言处理任务。
算法原理
Chroma Embeddings算法通常基于Transformer模型,尤其是类似于**BERT(Bidirectional Encoder Representations from Transformers)**或其变体的预训练语言模型。BERT通过在大量文本数据上进行无监督学习,能够理解文本的上下文和深层语义。Chroma Embeddings算法利用这一特性,将输入文本转化为固定长度的嵌入向量。这些向量保留了文本的语义信息,使得相似的文本在向量空间中距离较近,而语义不同的文本则距离较远。
其工作流程大致如下:
- 文本输入:接收用户提供的文本数据。
- 嵌入生成:通过预训练的Transformer模型,将文本转换为嵌入向量。
- 存储与查询:在ChromaDB中存储这些向量,并支持基于向量的查询操作。
应用
- 生成嵌入向量:将文本数据转化为向量表示。
- 存储嵌入:将生成的向量高效存储在数据库中。
- 相似性搜索:通过比较向量之间的距离,找到与查询文本最相似的已有文本。
例如,用户可以输入一段查询文本,Chroma Embeddings算法会将其转化为嵌入向量,然后ChromaDB会返回数据库中最相似的文本结果。这种功能在信息检索、推荐系统等领域尤为实用。
优势
Chroma Embeddings算法具有以下优点:
- 语义捕捉能力强:基于Transformer模型,能够理解文本的深层含义,而不仅仅是表面词汇。
- 灵活性:ChromaDB支持多种嵌入模型,用户可以根据任务需求选择合适的模型。
- 高效性:生成的嵌入向量支持快速查询和相似性计算,适用于大规模数据场景。
实现细节
尽管具体实现可能因ChromaDB的版本和配置而有所不同,但Chroma Embeddings算法通常依赖于:
- 预训练模型:如BERT或其变体,这些模型已在大型语料库上训练完成。
- 微调(可选):根据特定任务对模型进行调整,以提升性能。
用户在使用时无需深入了解模型内部细节,只需通过ChromaDB的接口调用算法即可生成和查询嵌入向量。
Chroma Embeddings算法是一种基于Transformer模型的文本嵌入生成方法,广泛应用于ChromaDB中。它通过将文本转化为嵌入向量,捕捉深层语义信息,支持高效的存储和查询操作。这种算法在相似性搜索、文本分类等任务中表现出色,是自然语言处理领域的重要工具。
二、配置 Chroma 开发环境
目前在.NET中,想要完整的使用,还是比较困难的,最大的困难在于生成嵌入向量,虽然现在有很多的SDK,但这些这是对Chroma API的封装而已,还远没有达到可以实际应用的地步。
不过,好消息是,.NET官方正在Semantic Kernel中加入对Chroma的完整支持,目前尚不成熟,在这里,我简单的演示一下,大家也不用太深入的看代码,因为现在的代码都处于开发中,很多接口都会变化,而且已经实现的代码也有很多问题,我花了一下午的时间,才把这些问题清除掉,并运行起来。
2.1 安装 Chroma 服务
Chroma的客户端需要连接到一个运行中的Chroma服务器。开发者可以通过以下方式启动 Chroma服务:
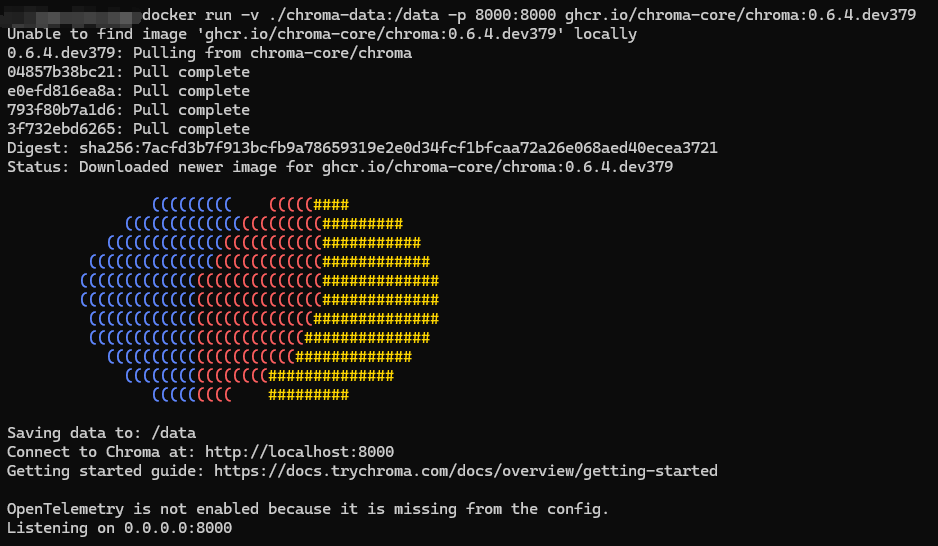
- 使用 Docker:
在本地运行以下命令以启动Chroma服务:
docker run -v ./chroma-data:/data -p 8000:8000 ghcr.io/chroma-core/chroma:0.6.4.dev379
- 使用 Python:
如果你更倾向于直接运行Chroma,可以通过Python安装并启动:
pip install chromadb
chromadb run --host localhost --port 8000
完成上述步骤后,Chroma服务将在本地运行,.NET客户端即可通过配置的URI进行连接。
Chroma 接口文档查看
接口地址:http://localhost:8000/docs
2.2 安装Ollama并配置相关模型
- 安装all-minilm用于对话功能
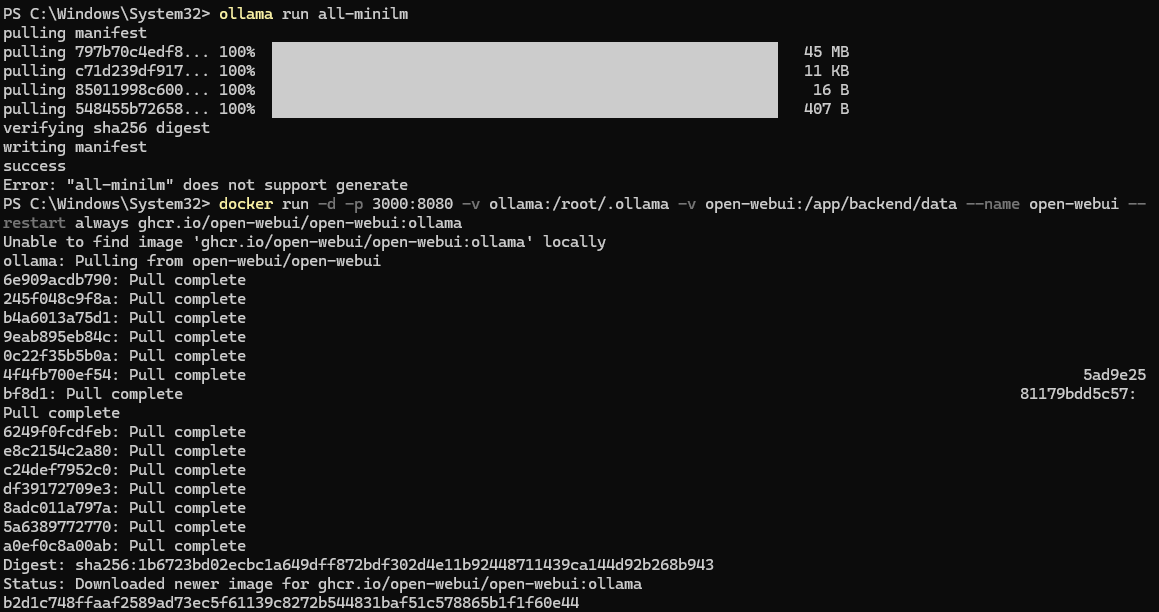
- 安装mxbai-embed-large用于生成嵌入向量

三、在.NET 中操作 Chroma
为了帮助开发者更好地理解Chroma在.NET中的使用方式,以下提供几个实用的代码示例,展示如何创建集合、添加文档、执行查询。
以下代码是使用官方代码库演示,而由于官方代码库尚未稳定,所以只是让大家先看看效果,但是暂时不需要对代码实现有太多的关注,建议把精力多放在 Chroma 的相关知识的学习中,静等微软发布正式版代码库。
3.1 连接与创建集合
参考代码:https://github.com/microsoft/semantic-kernel/blob/main/dotnet/samples/Concepts/Memory/TextMemoryPlugin_MultipleMemoryStore.cs
在Chroma中,集合Collection是存储向量数据的基本单元。以下代码演示如何创建一个名为products的集合:
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Connectors.Chroma;
using Microsoft.SemanticKernel.Connectors.Ollama;
using Microsoft.SemanticKernel.Embeddings;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Plugins.Memory;
using OllamaSharp;
#pragma warning disable SKEXP0070
#pragma warning disable SKEXP0050#pragma warning disable SKEXP0001
#pragma warning disable SKEXP0020const string MemoryCollectionName = "my-memory-collection";
IMemoryStore memoryStore = new ChromaMemoryStore("http://localhost:8000/api/v2/tenants/tenant_test/databases/db_test/");await memoryStore.CreateCollectionAsync(MemoryCollectionName);var kernel = Kernel.CreateBuilder().AddOllamaChatCompletion("phi3", new Uri("http://localhost:11434")).AddOllamaTextEmbeddingGeneration("mxbai-embed-large", new Uri("http://localhost:11434")).Build();// Create an embedding generator to use for semantic memory.// The combination of the text embedding generator and the memory store makes up the 'SemanticTextMemory' object used to
// store and retrieve memories.
SemanticTextMemory textMemory = new(memoryStore, new OllamaApiClient("http://localhost:11434", "mxbai-embed-large").AsTextEmbeddingGenerationService());
3.2 组建 SemanticTextMemory 对象并添加文档信息
SemanticTextMemory textMemory = new(memoryStore, new OllamaApiClient("http://localhost:11434", "mxbai-embed-large").AsTextEmbeddingGenerationService());Console.WriteLine("Saving memory with key 'info1': \"My name is Andrea\"");
await textMemory.SaveInformationAsync(MemoryCollectionName, id: "info1", text: "My name is Andrea");……
如果未提供嵌入,Chroma会使用内置的嵌入模型(如 all-MiniLM-L6-v2)自动生成向量。
3.3 执行向量查询
IAsyncEnumerable<MemoryQueryResult> answers = textMemory.SearchAsync(collection: MemoryCollectionName,query: "What's yous name?",limit: 2,minRelevanceScore: 0.4,withEmbeddings: true);
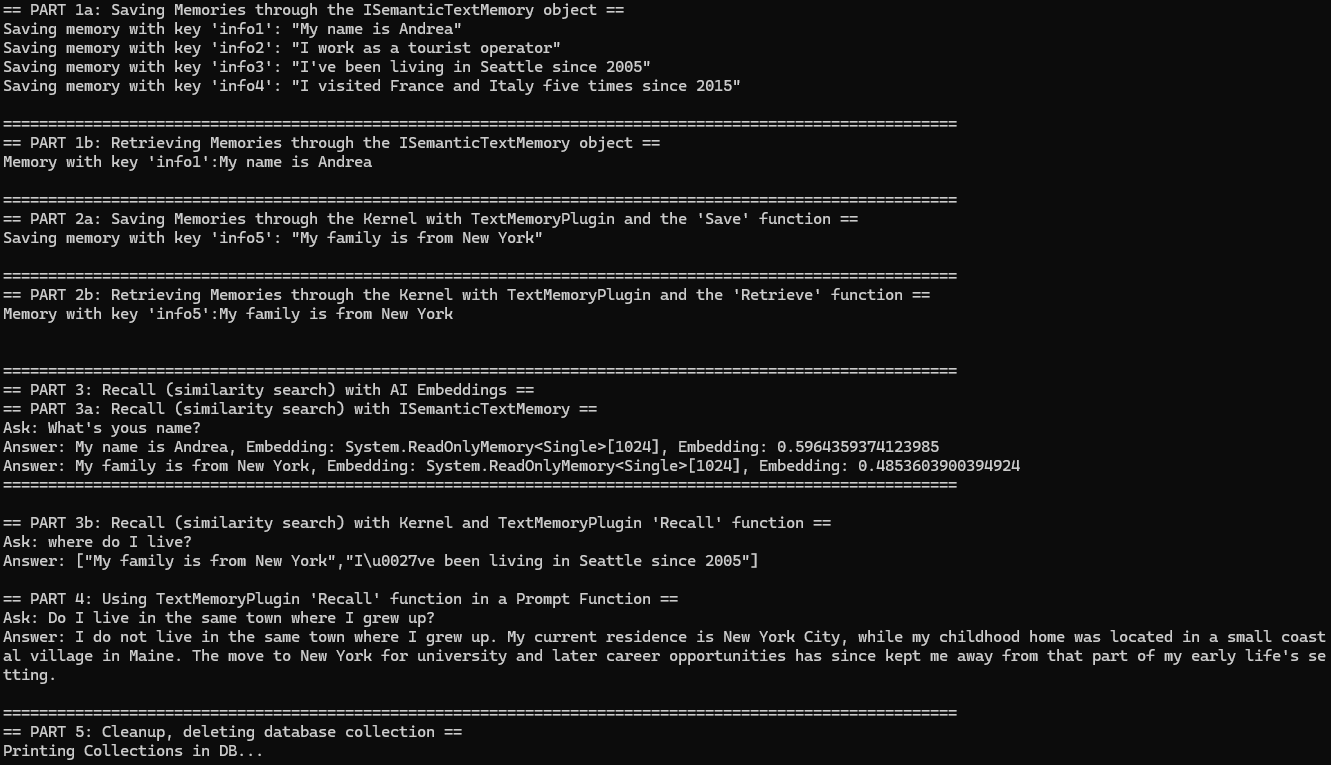
3.4 总的运行结果
四、Chroma 的实际应用场景
Chroma的强大功能使其在.NET应用中有着广泛的适用性。以下是几个典型的应用场景:
4.1 语义搜索
在企业文档管理系统中,传统的关键字搜索往往无法捕捉用户意图的深层含义。通过将文档转换为嵌入并存储在Chroma中,开发者可以实现语义搜索。例如,用户输入“如何提高团队效率”,系统能够返回与团队协作、时间管理相关的文档,而不仅仅是包含关键字的文档。
4.2 推荐系统
在电子商务平台中,可以使用Chroma存储商品和用户的向量表示。例如,将商品描述和用户浏览历史转换为嵌入,存储在Chroma中,通过相似性搜索为用户推荐相关商品。这种方法比传统基于规则的推荐系统更灵活、更智能。
4.3 多模态检索
在多媒体应用中,Chroma的多模态检索功能尤为强大。例如,可以将图像和文本描述的嵌入存储在同一个集合中,用户上传一张图片后,系统能够返回与之内容相似的图像和相关描述。
4.4 问答系统
在客户支持应用中,可以使用Chroma存储常见问题及其答案的向量表示。用户输入问题后,系统通过向量搜索返回最匹配的答案,提升响应速度和准确性。
五、Chroma 与.NET生态系统的集成
Chroma不仅可以通过C#客户端直接使用,还能与.NET生态系统中的其他组件深度集成,进一步提升开发效率:
- Semantic Kernel:这是
Microsoft推出的一款AI开发框架,支持与Chroma集成。开发者可以通过Semantic Kernel将Chroma作为向量存储,用于实现复杂的AI工作流。 - Microsoft.SemanticKernel.Connectors.Chroma:通过此扩展,
Chroma可以与.NET的依赖注入机制无缝协作,提供标准化的向量数据访问接口,简化应用程序架构。 - Microsoft.Extensions.VectorData:库的主要作用是为 .NET 应用程序提供与向量存储交互的统一抽象层。向量存储用于存储和管理高维嵌入向量,广泛应用于语义搜索和生成式 AI 等场景。
这些集成使得Chroma能够融入现有的.NET项目,与其他工具协同工作,加速智能应用的开发。
目前这些工作正在进行中,请大家静等.NET正式版的发布。
六、性能优化技巧
为了在.NET应用中充分发挥Chroma的性能,开发者可以采用以下优化策略:
- 索引调优:调整 HNSW 索引的参数,例如
efConstruction(构建时的搜索深度)和M(邻居数量),在搜索速度和精度之间找到平衡。 - 数据分片:对于超大规模数据集,可以将数据分散到多个集合或实例中,通过并行查询提高吞吐量。
- 缓存策略:对于频繁查询的热点数据,可以在
.NET应用层添加缓存,减少对Chroma的直接访问。
七、Chroma 的未来发展展望
随着AI技术的不断进步,向量数据库在软件开发中的重要性日益凸显。作为一款开源项目,Chroma在未来有很大的发展潜力,尤其是在.NET生态系统中:
- 功能扩展:支持更多类型的索引和距离度量,满足不同场景的需求。
- 性能提升:优化底层算法,进一步提高大规模数据集的处理能力。
- 云服务支持:推出官方托管版本,降低部署和维护的门槛,为
.NET开发者提供更便捷的接入方式。 - 与.NET深度融合:提供更多针对
.NET平台的专用工具和文档,提升开发效率。
八、总结
Chroma作为一个开源、易用且功能强大的向量数据库,为.NET开发者提供了一款构建智能应用的利器。通过简单的安装步骤和直观的API,开发者可以将Chroma集成到.NET项目中,实现高效的向量数据管理。无论是语义搜索、推荐系统还是多模态检索,Chroma都能为应用注入智能化能力。随着技术的不断演进,Chroma在.NET生态系统中的应用前景将更加广阔,为开发者开启更多创新可能。
相关文章:
.NET 原生驾驭 AI 新基建实战系列(三):Chroma ── 轻松构建智能应用的向量数据库
在人工智能AI和机器学习ML迅猛发展的今天,数据的存储和检索需求发生了巨大变化。传统的数据库擅长处理结构化数据,但在面对高维向量数据时往往力不从心。向量数据库作为一种新兴技术,专为AI应用设计,能够高效地存储和查询高维向量…...

有声书画本
有声书画本服务标准 有声喵连接 一、基础服务(5r/w字) 核心: 基础删(快捷键AltD)调,优化播讲流畅度 执行: 删除冗余旁白 删除角色动作/心理的重复描述(例:小明冷笑道…...

StarRocks与Apache Iceberg:构建高效湖仓一体的实时分析平台
## 引言:数据湖的挑战与演进 在数据驱动的时代,企业数据湖需要同时满足海量存储、高性能查询、多引擎协作和实时更新等复杂需求。传统基于 Hive 的数据湖方案面临元数据管理低效、缺乏 ACID 事务支持、查询性能瓶颈等问题。在此背景下,**Sta…...

WebRTC 与 WebSocket 的关联关系
WebRTC(Web Real-Time Communication)与 WebSocket 作为重要技术,被广泛应用于各类实时交互场景。虽然它们在功能和特性上存在明显差异,但在实际应用中也有着紧密的关联,共同为用户提供流畅的实时交互体验。 一、WebR…...

8.RV1126-OPENCV 视频中添加LOGO
一.视频中添加 LOGO 图像大体流程 首先初始化VI,VENC模块并使能,然后创建两个线程:1.把LOGO灰度化,然后获取VI原始数据,其次把VI数据Mat化并创建一个感兴趣区域,最后把LOGO放感兴趣区域里并把数据发送给VENC。2.专门获…...
API管理是什么?API自动化测试怎么搭建?
目录 一、API管理是什么 (一)API管理的定义 (二)API管理的重要性 二、API管理的主要内容 (一)API设计 1. 遵循标准规范 2. 考虑可扩展性 3. 保证接口的易用性 (二)API开发 …...

Next.js+prisma开发一
1.初始化Next.js项目 #按版本安装 npx create-next-app13.4.5 如果最新版本 执行:npx create-next-applatest2. 安装Prima和客户端 npm install prisma --save-dev npm install prisma/client3.初始化Prisma,以SQLit举例 # 初始化 Prisma 并配置 SQLi…...
GIC v3 v4 虚拟化架构
ARMV8-A架构中包含了对虚拟化的支持。为了与架构保持匹配,GICV3也对虚拟化做了支持。新增了以下特性: 对CPU interface的硬件虚拟化虚拟中断maintenance 中断:用于通知监管程序(例如hypervisor)一些特定的虚拟机事件 …...

2025远离Deno和Fresh
原创作者:庄晓立(LIIGO) 原创时间:2025年6月6日 原创链接:https://blog.csdn.net/liigo/article/details/148479884 版权所有,转载请注明出处! 相识 Deno,是Nodejs原开发者Ryan Da…...

相机camera开发之差异对比核查一:测试机和对比机的硬件配置差异对比
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了: 这一篇我们开始讲: 目录 一、背景 二、:Camera硬件配置差异 2.1:硬件配置差异核查项 2.2 :核查方式 2.3 :高通camx平台核查 2.4 :MTK平台核查...
Flask+LayUI开发手记(七):头像的上传及突破static目录限制
看了看,上篇开发手记是去年8月份写的,到现在差2个月整一年了。停更这么长时间,第一个原因是中间帮朋友忙一个活,那个技术架构是用springboot的,虽然前端也用layUI,但和Flask-python完全不搭界,所…...

uv管理spaCy语言模型
本文记录如何在使用uv管理python项目dependencies时,把spaCy的模型也纳入其中. spaCy 一、spaCy简介 spaCy是一个开源的自然语言处理(NLP)库,它主要用于处理文本数据。它支持多种语言,包括英语、中文等。它是由Expl…...

MiniExcel模板填充Excel导出
目录 1.官方文档 2. 把要导出的数据new一个匿名对象 3.导出 4.注意事项 5.模板制作 6.结果 1.官方文档 https://gitee.com/dotnetchina/MiniExcel/#%E6%A8%A1%E6%9D%BF%E5%A1%AB%E5%85%85-excel // 1. By POCO var value new {Name "Jack",CreateDate n…...

NoSQL之redis哨兵
一、哨兵的核心功能 监控(Monitoring) 持续检查主节点和从节点的运行状态(是否存活、延迟等)。 自动故障转移(Automatic Failover) 当主节点不可用时,自动选举一个从节点升级为主节点。 更新…...
MCP协议重构AI Agent生态:万能插槽如何终结工具孤岛?
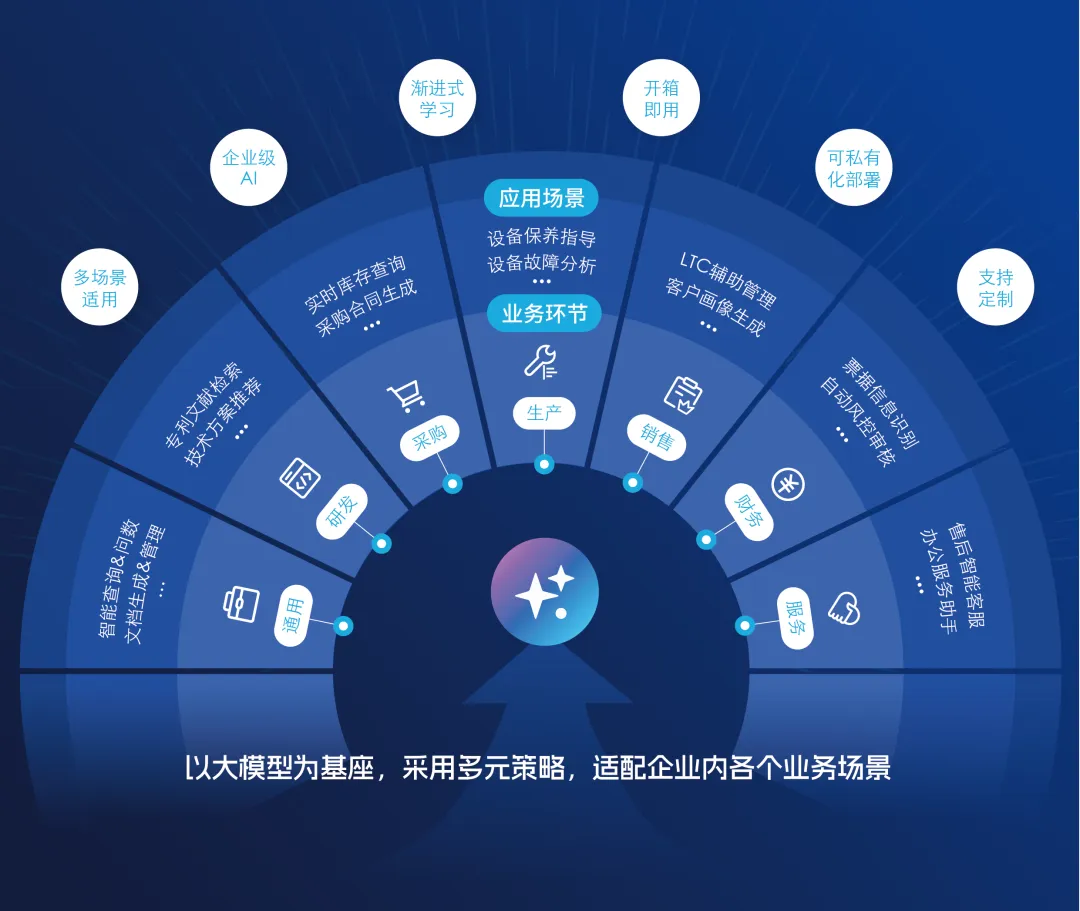
前言 在人工智能技术快速发展的2025年,MCP(Model Context Protocol,模型上下文协议)正逐渐成为AI Agent生态系统的关键基础设施。这一由Anthropic主导的开放协议,旨在解决AI模型与外部工具和数据源之间的连接难题,被业界形象地称…...
阿里云事件总线 EventBridge 正式商业化,构建智能化时代的企业级云上事件枢纽
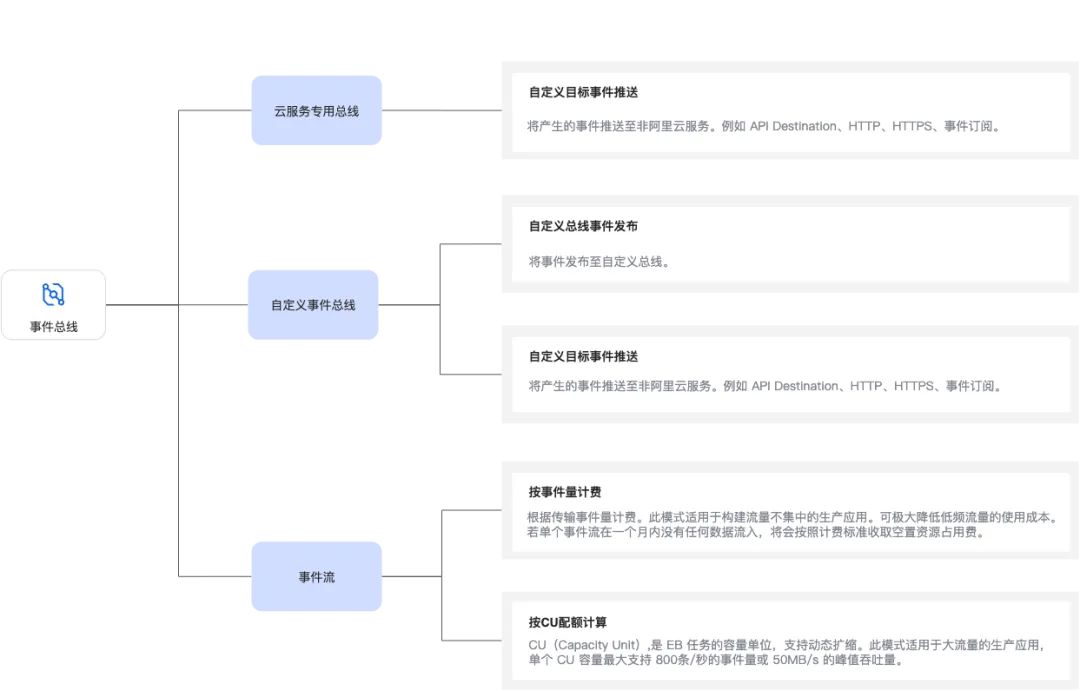
作者:肯梦、稚柳 产品演进历程:在技术浪潮中的成长之路 早在 2018 年,Gartner 评估报告便将事件驱动模型(Event-Driven Model)列为十大战略技术趋势之一,指出事件驱动架构(EDA,Eve…...
CentOS8.3+Kubernetes1.32.5+Docker28.2.2高可用集群二进制部署
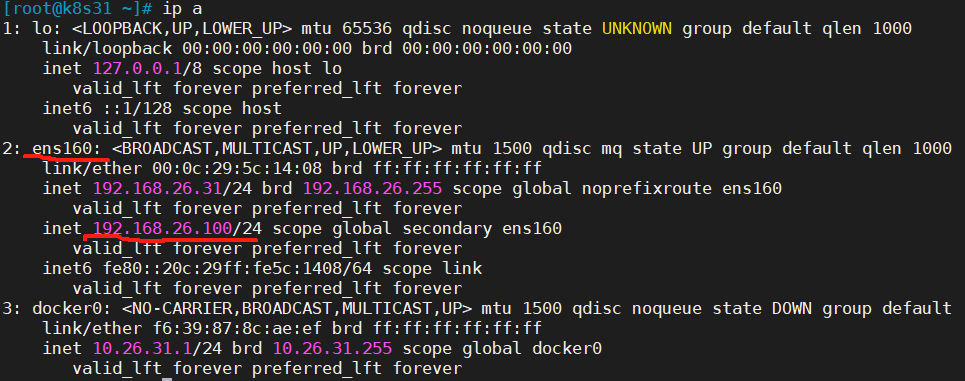
一、准备工作 1.1 主机列表 HostnameHost IPDocker IPRolek8s31.vm.com192.168.26.3110.26.31.1/24master&worker、etcd、dockerk8s32.vm.com192.168.26.3210.26.32.1/24master&worker、etcd、dockerk8s33.vm.com192.168.26.3310.26.33.1/24master&worker、etcd、…...
学习日记-day23-6.6
完成目标: 知识点: 1.IO流_转换流使用 ## 转换流_InputStreamReader1.字节流读取中文在编码一致的情况,也不要边读边看,因为如果字节读不准,读不全,输出的内容有可能会出现乱码 2.所以,我们学了字符流,字符流读取文本文档中的内容如果编码一致,就不会出…...
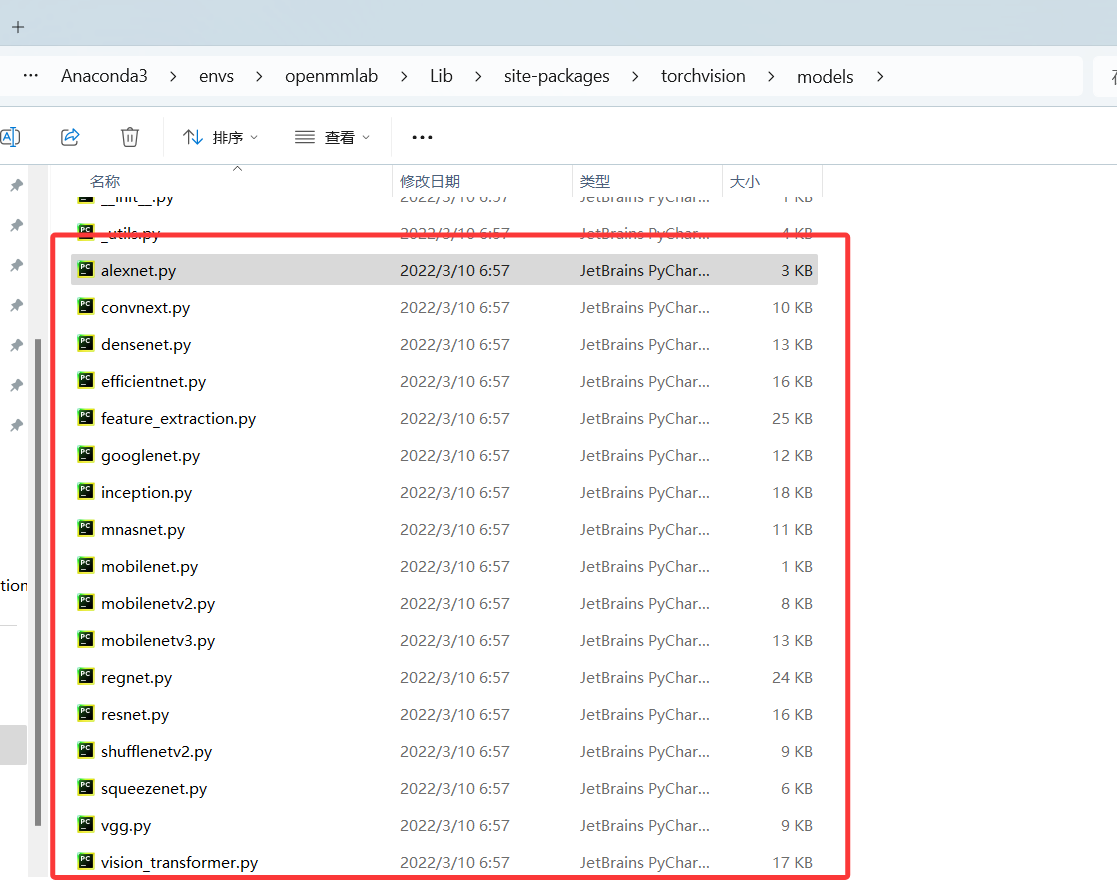
Pytorch安装后 如何快速查看经典的网络模型.py文件(例如Alexnet,VGG)(已解决)
当你用conda 安装好虚拟环境后, 找到你的Anaconda 的安装位置。 我的在D盘下; 然后 从Anaconda3文件夹开始:一级一级的查看,一直到models Anaconda3\envs\openmmlab\Lib\site-packages\torchvision\models 在models下面&#x…...

《ERP原理与应用教程》第3版习题和答案
ERP原理与应用教程是一门系统介绍企业资源计划(Enterprise Resource Planning, ERP)系统核心理论、技术架构及实施应用的综合性课程。它主要面向管理类、信息类、工程类等专业学生及企业管理者,旨在培养对现代企业信息化管理的理解与实践能力。以下是该课程的详细解析: 一…...

JavaScript中的正则表达式:文本处理的瑞士军刀
JavaScript中的正则表达式:文本处理的瑞士军刀 在编程世界中,正则表达式(Regular Expression,简称RegExp)被誉为“文本处理的瑞士军刀”。它能够高效地完成字符串匹配、替换、提取和验证等任务。无论是前端开发中的表…...

vue对axios的封装和使用
在 Vue 项目中,使用 axios 进行 HTTP 请求是非常常见的做法。为了提高代码的可维护性、统一错误处理和请求拦截/响应拦截逻辑,对axios进行封装使用。 一、基础封装(适用于 Vue 2 / Vue 3) 1. 安装 axios npm install axios2. 创…...
)
软考 系统架构设计师系列知识点之杂项集萃(82)
接前一篇文章:软考 系统架构设计师系列知识点之杂项集萃(81) 第148题 “41”视图主要用于描述系统逻辑架构,最早由Philippe Kruchten于1995年提出。其中( )视图用于描述对象模型,并说明系统应该…...

DrissionPage调试工具:网页自动化与数据采集的革新利器
在网页自动化测试与数据采集领域,开发者长期面临两难选择:使用Selenium等工具操作浏览器时效率不足,而直接调用Requests库又难以应对复杂动态页面。DrissionPage的出现完美解决了这一矛盾,这款基于Python开发的工具创新性地将浏览…...

有人-无人(人机)交互记忆、共享心智模型与AI准确率的边际提升
有人-无人(人机)交互记忆、共享心智模型与AI准确率的边际提升是人工智能发展中相互关联且各有侧重的三个方面。人机交互记忆通过记录和理解用户与机器之间的交互历史,增强机器对用户需求的个性化响应能力,从而提升用户体验和协作效…...

如何使用k8s安装redis呢
在Kubernetes (k8s) 上安装Redis 在Kubernetes上安装Redis有几种方法,下面我将介绍两种常见的方式:使用StatefulSet直接部署和使用Helm chart部署。 一、安装redis 1.1 拉去ARM镜像(7.4.2) docker pull registry.cn-hangzhou.ali…...

AI对测试行业的应用
AI对测试行业的应用 AI技术在软件测试领域的应用已从概念验证全面迈向工程化落地,正在重构测试流程、提升效率边界,并为质量保障体系带来范式级变革。以下从技术突破、行业实践与未来趋势三个维度展开深度解析: ⚙️ 一、核心技术突破&#…...
【OpenGL学习】(五)自定义着色器类
文章目录 【OpenGL学习】(五)自定义着色器类着色器类插值着色统一着色 【OpenGL学习】(五)自定义着色器类 项目结构: 着色器类 // shader_s.h #ifndef SHADER_H #define SHADER_H#include <glad/glad.h>#inc…...
408第一季 - 数据结构 - 栈与队列的应用
括号匹配 用瞪眼法就可以知道的东西 栈在表达式求值运用 先简单看看就行,题目做了就理解了 AB是操作符,也是被狠狠加入后缀表达式了,然后后面就是*,只要优先级比栈顶运算符牛逼就放里面,很显然,*比牛逼 继续前进&#…...

超声波清洗设备的清洗效果如何?
超声波清洗设备是一种常用于清洗各种物体的技术,它通过超声波振荡产生的微小气泡在液体中破裂的过程来产生高能量的冲击波,这些冲击波可以有效地去除表面和细微裂缝中的污垢、油脂、污染物和杂质。超声波清洗设备在多个领域得到广泛应用,包括…...