机器学习:决策树和剪枝
本文目录:
- 一、决策树基本知识
- (一)概念
- (二)决策树建立过程
- 二、决策树生成
- (一)ID3决策树:基于信息增益构建的决策树。
- (二)C4.5决策树
- (三)CART决策树
- 1.CART分类决策树
- 2.CART回归决策树
- 三、决策树剪枝:防止过拟合
- (一)决策树剪枝的基本策略有"预剪枝" (pre-pruning)和"后剪枝"(post- pruning)
- 1.预剪枝(例):
- 2.后剪枝(例):
- (二) 剪枝方法对比
- 附赠1:ID3决策树、C4.5决策树、CART决策树对比(CART回归树采用平方损失,表中未说明)
- 附赠2:CART分类树与回归树对比
一、决策树基本知识
(一)概念
决策树(decision tree)是一种监督学习算法,是一种树形结构,树中每个内部节点表示一个特征上的判断,每个分支代表一个判断结果的输出,每个叶子节点代表一种分类结果。
(二)决策树建立过程
1.特征选择:选取有较强分类能力的特征;
2.决策树生成:根据选择的特征生成决策树;
3.决策树也易过拟合,采用剪枝的方法缓解过拟合。
二、决策树生成
(一)ID3决策树:基于信息增益构建的决策树。
信息熵:熵在信息论中代表随机变量不确定度的度量;熵越大,数据的不确定性度越高;熵越小,数据的不确定性越低。
公式:
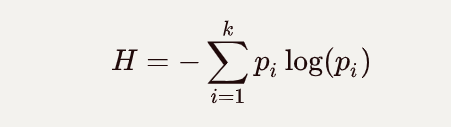
信息增益:集合 D D D的熵 H ( D ) H(D) H(D)与特征A给定条件下D的熵 H ( D ∣ A ) H(D|A) H(D∣A)之差。
公式:
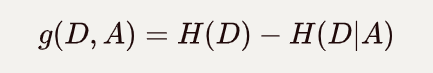
根据信息增益选择特征构建子树方法是:对训练数据集D,计算其每个特征的信息增益,并比较它们的大小,并选择信息增益最大的特征进行划分。
例:
已知6个样本,根据特征a:
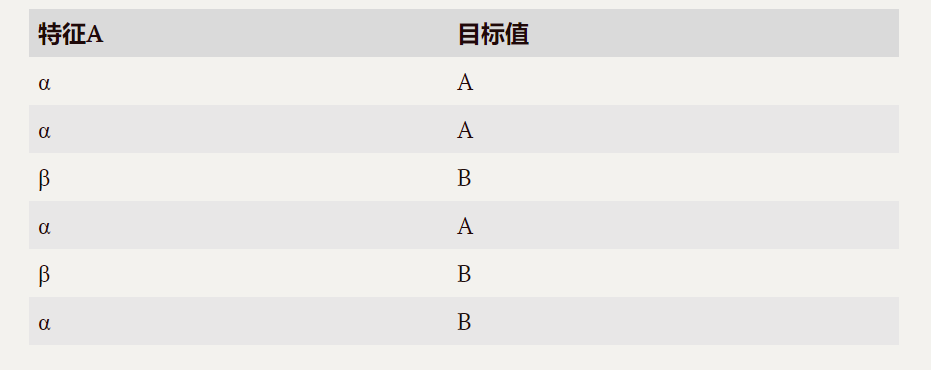
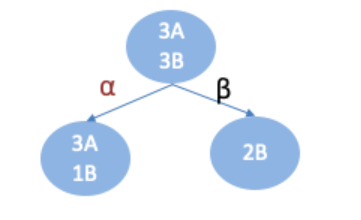

ID3决策树构建流程:
- 计算每个特征的信息增益
- 使用信息增益最大的特征将数据集 S 拆分为子集
- 使用该特征(信息增益最大的特征)作为决策树的一个节点
- 使用剩余特征对子集重复上述(1,2,3)过程
(二)C4.5决策树
信息增益率:
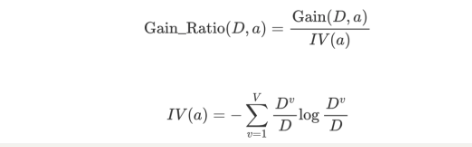
- Gain_Ratio 表示信息增益率;
- IV 表示分裂信息、内在信息;
- 信息增益率= 特征的信息增益 ➗ 内在信息。
特点:
- 如果某个特征的特征值种类较多,则其内在信息值就越大。即:特征值种类越多,除以的系数就越大。
- 如果某个特征的特征值种类较小,则其内在信息值就越小。即:特征值种类越小,除以的系数就越小。
信息增益率本质: 是在信息增益的基础之上乘上一个惩罚参数。特征个数较多时,惩罚参数较小;特征个数较少时,惩罚参数较大。惩罚参数:数据集D以特征A作为随机变量的熵的倒数。
根据信息增益率选择特征构建子树方法:对训练数据集D,计算其每个特征的信息增益率,并比较它们的大小,并选择信息增益率最大的特征进行划分。
例:
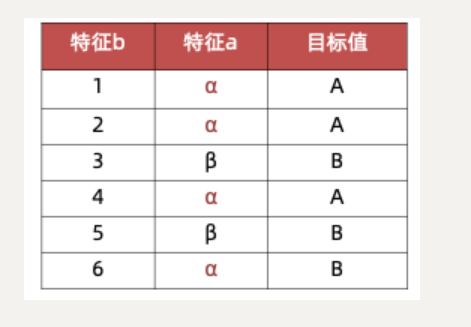
特征a的信息增益率:
- 信息增益:
1-0.5408520829727552=0.46 - 特征熵:
-4/6*math.log(4/6, 2) -2/6*math.log(2/6, 2)=0.9182958340544896 - 信息增益率:
信息增益/分裂信息=0.46/0.9182958340544896=0.5
特征b的信息增益率:
- 信息增益:1
- 特征熵:
-1/6*math.log(1/6, 2) * 6=2.584962500721156 - 信息增益率:
信息增益/信息熵=1/2.584962500721156=0.38685280723454163
由计算结果可见,特征1的信息增益率大于特征2的信息增益率,根据信息增益率,我们应该选择特征1作为分裂特征。
(三)CART决策树
Cart模型是一种决策树模型,它即可以用于分类,也可以用于回归。
分类和回归树模型采用不同的最优化策略。Cart回归树使用平方误差最小化策略,Cart分类生成树采用的基尼指数最小化策略。
基尼指数:
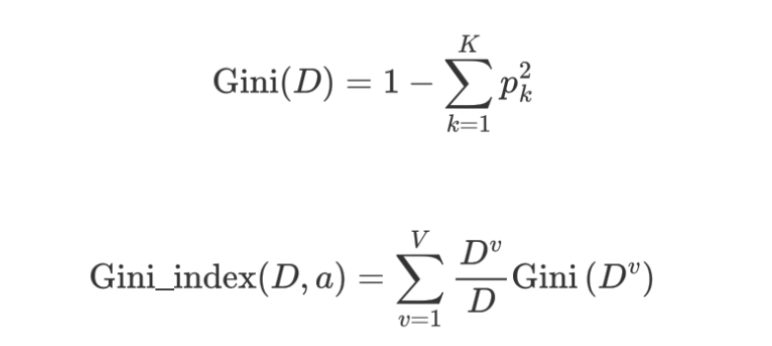
Gini为基尼值,Gini_index为基尼指数,基尼指数值越小(cart),则说明优先选择该特征。
平方损失:
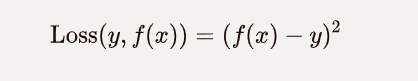
1.CART分类决策树
例:
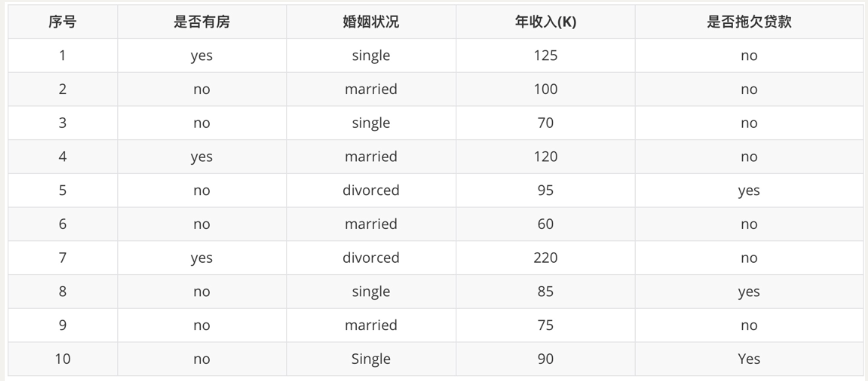
计算“是否有房”的基尼指数:
首先,根据是否有房将目标值划分为两部分:
-
计算有房子的基尼值: 有房子有 1、4、7 共计三个样本,对应:3个no、0个yes:
G i n i ( 是否有房,yes ) = 1 − ( 0 3 ) 2 − ( 3 3 ) 2 = 0 G i n i(\text {是否有房,yes })=1-\left(\frac{0}{3}\right)^{2}-\left(\frac{3}{3}\right)^{2}=0 Gini(是否有房,yes )=1−(30)2−(33)2=0
-
计算无房子的基尼值:无房子有 2、3、5、6、8、9、10 共七个样本,对应:4个no、3个yes:
Gini ( 是否有房,no ) = 1 − ( 3 7 ) 2 − ( 4 7 ) 2 = 0.4898 \operatorname{Gini}(\text {是否有房,no })=1-\left(\frac{3}{7}\right)^{2}-\left(\frac{4}{7}\right)^{2}=0.4898 Gini(是否有房,no )=1−(73)2−(74)2=0.4898
-
计算基尼指数:第一部分样本数量占了总样本的 3/10、第二部分样本数量占了总样本的 7/10:
G i n i − i n dex ( D , 是否有房 ) = 7 10 ∗ 0.4898 + 3 10 ∗ 0 = 0.343 \operatorname{Gini_{-}} i n \operatorname{dex}(D, \text { 是否有房 })=\frac{7}{10} * 0.4898+\frac{3}{10} * 0=0.343 Gini−index(D, 是否有房 )=107∗0.4898+103∗0=0.343
计算“婚姻状况”的基尼指数:
-
计算 {married} 和 {single,divorced} 情况下的基尼指数:
结婚的基尼值,有 2、4、6、9 共 4 个样本,并且对应目标值全部为 no:
Gini_index ( D , married ) = 0 \operatorname{Gini\_index}(D,\text{{married}})=0 Gini_index(D,married)=0
不结婚的基尼值,有 1、3、5、7、8、10 共 6 个样本,并且对应 3 个 no,3 个 yes:
Gini_index ( D , single,divorced ) = 1 − ( 3 6 ) 2 − ( 3 6 ) 2 = 0.5 \operatorname{Gini\_index}(D, \text { {single,divorced} })=1-\left(\frac{3}{6}\right)^{2}-\left(\frac{3}{6}\right)^{2}=0.5 Gini_index(D, single,divorced )=1−(63)2−(63)2=0.5
以 married 作为分裂点的基尼指数:
Gini_index ( D , married ) = 4 10 ∗ 0 + 6 10 ∗ [ 1 − ( 3 6 ) 2 − ( 3 6 ) 2 ] = 0.3 \operatorname{Gini\_index}(D, \text { married })=\frac{4}{10} * 0+\frac{6}{10} *\left[1-\left(\frac{3}{6}\right)^{2}-\left(\frac{3}{6}\right)^{2}\right]=0.3 Gini_index(D, married )=104∗0+106∗[1−(63)2−(63)2]=0.3
-
计算 {single} | {married,divorced} 情况下的基尼指数
Gini_index ( D , 婚姻状况 ) = 4 10 ∗ 0.5 + 6 10 ∗ [ 1 − ( 1 6 ) 2 − ( 5 6 ) 2 ] = 0.367 \operatorname{Gini\_index}(D,\text{婚姻状况})=\frac{4}{10} * 0.5+\frac{6}{10} *\left[1-\left(\frac{1}{6}\right)^{2}-\left(\frac{5}{6}\right)^{2}\right]=0.367 Gini_index(D,婚姻状况)=104∗0.5+106∗[1−(61)2−(65)2]=0.367
-
计算 {divorced} | {single,married} 情况下基尼指数
Gini_index ( D , 婚姻状况 ) = 2 10 ∗ 0.5 + 8 10 ∗ [ 1 − ( 2 8 ) 2 − ( 6 8 ) 2 ] = 0.4 \operatorname{Gini\_index}(D, \text { 婚姻状况 })=\frac{2}{10} * 0.5+\frac{8}{10} *\left[1-\left(\frac{2}{8}\right)^{2}-\left(\frac{6}{8}\right)^{2}\right]=0.4 Gini_index(D, 婚姻状况 )=102∗0.5+108∗[1−(82)2−(86)2]=0.4
-
最终:该特征的基尼值为 0.3,并且预选分裂点为:{married} 和 {single,divorced}
计算“年收入”的基尼指数:
先将数值型属性升序排列,以相邻中间值作为待确定分裂点:
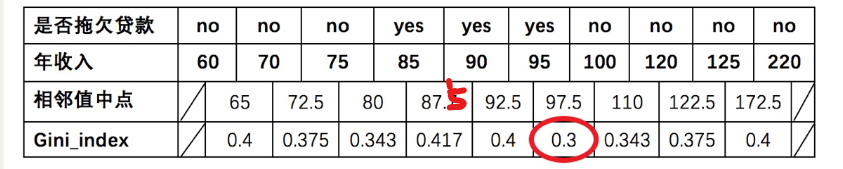
以年收入 65 将样本分为两部分,计算基尼指数:
节点为 65 时 : 年收入 = 1 10 ∗ 0 + 9 10 ∗ [ 1 − ( 6 9 ) 2 − ( 3 9 ) 2 ] = 0.4 节点为65时:{年收入}=\frac{1}{10} * 0 + \frac{9}{10} *\left[1-\left(\frac{6}{9}\right)^{2}-\left(\frac{3}{9}\right)^{2}\right]=0.4 节点为65时:年收入=101∗0+109∗[1−(96)2−(93)2]=0.4
以此类推计算所有分割点的基尼指数,我们发现最小的基尼指数为 0.3。
此时,我们发现:
- 以是否有房作为分裂点的基尼指数为:0.343
- 以婚姻状况为分裂特征、以 married 作为分裂点的基尼指数为:0.3
- 以年收入作为分裂特征、以 97.5 作为分裂点的的基尼指数为:0.3
最小基尼指数有两个分裂点,我们随机选择一个即可,假设婚姻状况,则可确定决策树如下:
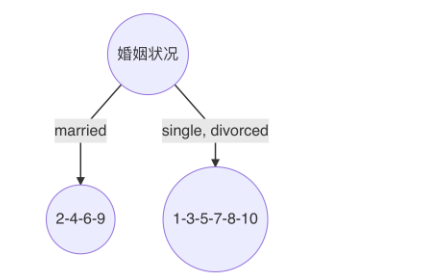
重复上面步骤,直到每个叶子结点纯度达到最高。
2.CART回归决策树
例:
假设:数据集只有 1 个特征 x, 目标值值为 y,如下图所示:

由于只有 1 个特征,所以只需要选择该特征的最优划分点,并不需要计算其他特征。
-
先将特征 x 的值排序,并取相邻元素均值作为待划分点,如下图所示:
s 1.5 2.5 3.5 4.5 5.5 6.5 7.5 8.5 9.5 -
计算每一个划分点的平方损失,例如:1.5 的平方损失计算过程为:
R1 为 小于 1.5 的样本个数,样本数量为:1,其输出值为:5.56
R 1 = 5.56 R_1 =5.56 R1=5.56
R2 为 大于 1.5 的样本个数,样本数量为:9 ,其输出值为:
R 2 = ( 5.7 + 5.91 + 6.4 + 6.8 + 7.05 + 8.9 + 8.7 + 9 + 9.05 ) / 9 = 7.50 R_2=(5.7+5.91+6.4+6.8+7.05+8.9+8.7+9+9.05) / 9=7.50 R2=(5.7+5.91+6.4+6.8+7.05+8.9+8.7+9+9.05)/9=7.50
该划分点的平方损失:
L ( 1.5 ) = ( 5.56 − 5.56 ) 2 + [ ( 5.7 − 7.5 ) 2 + ( 5.91 − 7.5 ) 2 + … + ( 9.05 − 7.5 ) 2 ] = 0 + 15.72 = 15.72 L(1.5)=(5.56-5.56)^{2}+\left[(5.7-7.5)^{2}+(5.91-7.5)^{2}+\ldots+(9.05-7.5)^{2}\right]=0+15.72=15.72 L(1.5)=(5.56−5.56)2+[(5.7−7.5)2+(5.91−7.5)2+…+(9.05−7.5)2]=0+15.72=15.72
-
以此方式计算 2.5、3.5… 等划分点的平方损失,结果如下所示:
s 1.5 2.5 3.5 4.5 5.5 6.5 7.5 8.5 9.5 m(s) 15.72 12.07 8.36 5.78 3.91 1.93 8.01 11.73 15.74 -
当划分点 s=6.5 时,m(s) 最小。因此,第一个划分变量:特征为 X, 切分点为 6.5,即:j=x, s=6.5**
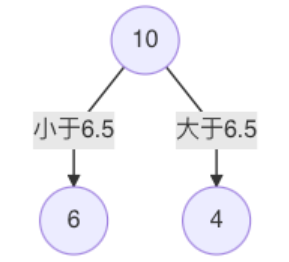
-
对左子树的 6 个结点计算每个划分点的平方式损失,找出最优划分点:
x 1 2 3 4 5 6 y 5.56 5.7 5.91 6.4 6.8 7.05 s 1.5 2.5 3.5 4.5 5.5 c1 5.56 5.63 5.72 5.89 6.07 c2 6.37 6.54 6.75 6.93 7.05 s 1.5 2.5 3.5 4.5 5.5 m(s) 1.3087 0.754 0.2771 0.4368 1.0644 -
s=3.5时,m(s) 最小,所以左子树继续以 3.5 进行分裂:
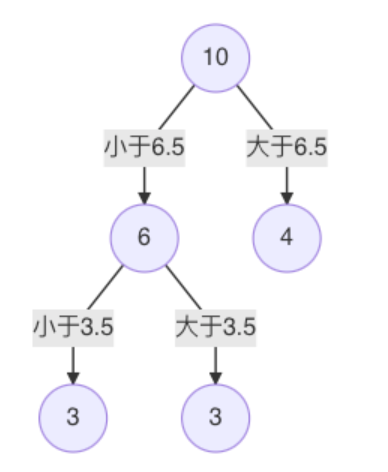
7. 假设在生成3个区域 之后停止划分,以上就是回归树。每一个叶子结点的输出为:挂在该结点上的所有样本均值。
| x | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| y | 5.56 | 5.7 | 5.91 | 6.4 | 6.8 | 7.05 | 8.9 | 8.7 | 9 | 9.05 |
1号样本真实值 5.56 预测结果:5.72
2号样本真实值是 5.7 预测结果:5.72
3 号样本真实值是 5.91 预测结果 5.72
三、决策树剪枝:防止过拟合
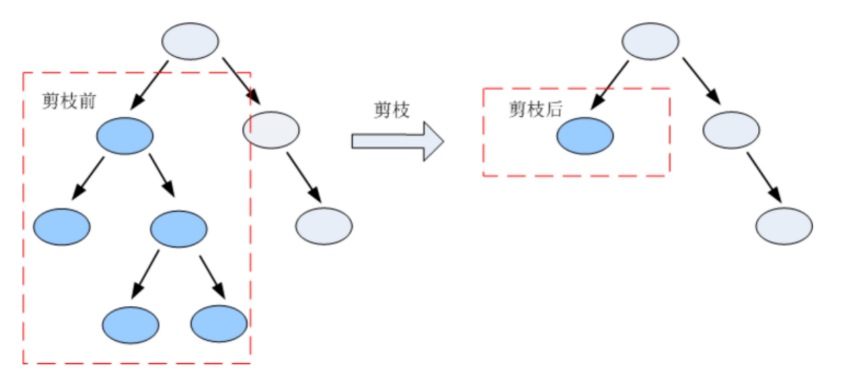
剪枝是指将一颗子树的子节点全部删掉,利用叶子节点替换子树(实质上是后剪枝技术),也可以(假定当前对以root为根的子树进行剪枝)只保留根节点本身而删除所有的叶子,以下图为例:
(一)决策树剪枝的基本策略有"预剪枝" (pre-pruning)和"后剪枝"(post- pruning)
- 预剪枝是指在决策树生成过程中,对每个结点在划分前先进行估计,若当前结点的划分不能带来决策树泛化性能提升,则停止划分并将当前结点标记为叶结点;
- 后剪枝则是先从训练集生成一棵完整的决策树,然后自底向上地对非叶结点进行考察,若将该结点对应的子树替换为叶结点能带来决策树泛化性能提升,则将该子树替换为叶结点。
1.预剪枝(例):
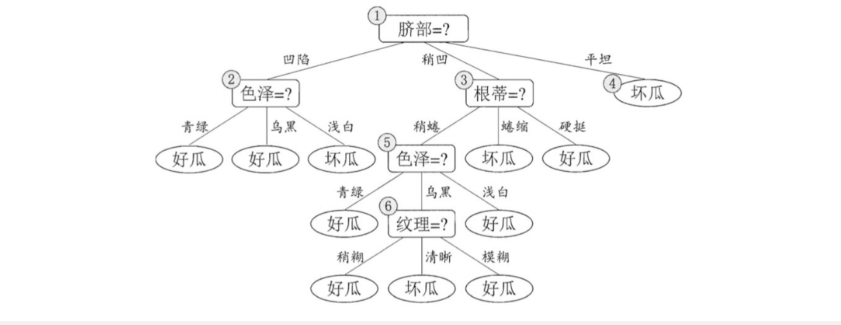
4. 假设: 当前树只有一个结点, 即编号为1的结点. 此时, 所有的样本预测类别为: 其类别标记为训练样例数最多的类别,假设我们将这个叶结点标记为 “好瓜”。此时, 在验证集上所有的样本都会被预测为 “好瓜”, 此时的准确率为: 3/7
-
如果进行此次分裂, 则树的深度为 2, 有三个分支. 在用属性"脐部"划分之后,上图中的结点2、3、4分别包含编号为 {1,2,3, 14}、 {6,7, 15, 17}、 {10, 16} 的训练样例,因此这 3 个结点分别被标记为叶结点"好瓜"、 “好瓜”、 “坏瓜”。此时, 在验证集上 4、5、8、11、12 样本预测正确,准确率为: 5/7。很显然, 通过此次分裂准确率有所提升, 值得分裂.
-
接下来,对结点2进行划分,基于信息增益准则将挑选出划分属性"色泽"。然而,在使用"色泽"划分后,编号为 {5} 的验证集样本分类结果会由正确转为错误,使得验证集精度下降为 57.1%。于是,预剪枝策略将禁止结点2被划分。
-
对结点3,最优划分属性为"根蒂",划分后验证集精度仍为 5/7. 这个 划分不能提升验证集精度,于是,预剪枝策略禁止结点3被划分。
-
对结点4,其所含训练样例己属于同一类,不再进行划分.
于是,基于预剪枝策略从上表数据所生成的决策树如上图所示,其验证集精度为 71.4%. 这是一棵仅有一层划分的决策树。
2.后剪枝(例):
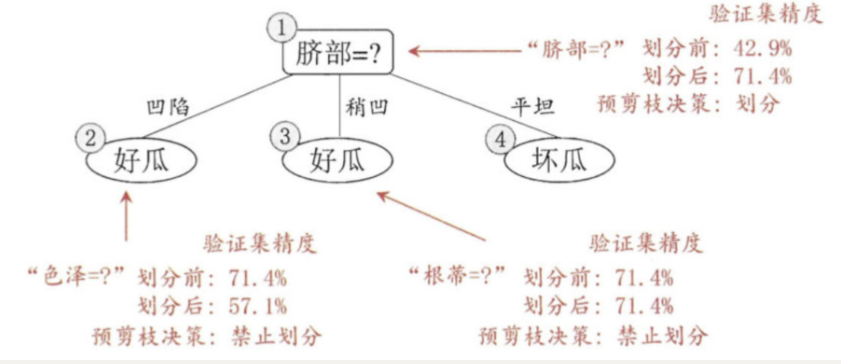
后剪枝先从训练集生成一棵完整决策树,继续使用上面的案例,从前面计算,我们知前面构造的决策树的验证集精度为42.9%。

首先考察结点6,若将其领衔的分支剪除则相当于把6替换为叶结点。替换后的叶结点包含编号为 {7, 15} 的训练样本,于是该叶结点的类别标记为"好瓜", 此时决策树的验证集精度提高至 57.1%。
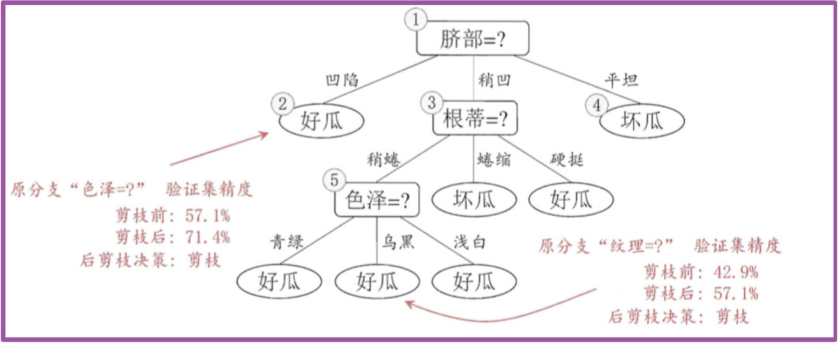
2. 然后考察结点5,若将其领衔的子树替换为叶结点,则替换后的叶结点包含编号为 {6,7,15}的训练样例,叶结点类别标记为"好瓜’;此时决策树验证集精度仍为 57.1%. 于是,可以不进行剪枝.
3. 对结点2,若将其领衔的子树替换为叶结点,则替换后的叶结点包含编号 为 {1, 2, 3, 14} 的训练样例,叶结点标记为"好瓜"此时决策树的验证集精度提高至 71.4%. 于是,后剪枝策略决定剪枝.
4. 对结点3和1,若将其领衔的子树替换为叶结点,则所得决策树的验证集 精度分别为 71.4% 与 42.9%,均未得到提高,于是它们被保留。
5. 最终, 基于后剪枝策略生成的决策树如上图所示, 其验证集精度为 71.4%。
(二) 剪枝方法对比
预剪枝优点:
- 预剪枝使决策树的很多分支没有展开,不单降低了过拟合风险,还显著减少了决策树的训练、测试时间开销
预剪枝缺点:
- 有些分支的当前划分虽不能提升泛化性能,甚至会导致泛化性能降低,但在其基础上进行的后续划分却有可能导致性能的显著提高
- 预剪枝决策树也带来了欠拟合的风险
后剪枝优点:
- 比预剪枝保留了更多的分支。一般情况下,后剪枝决策树的欠拟合风险很小,泛化性能往往优于预剪枝
后剪枝缺点:
- 但后剪枝过程是在生成完全决策树之后进行的,并且要自底向上地对树中所有非叶子节点进行逐一考察,因此在训练时间开销比未剪枝的决策树和预剪枝的决策树都要大得多。
附赠1:ID3决策树、C4.5决策树、CART决策树对比(CART回归树采用平方损失,表中未说明)

附赠2:CART分类树与回归树对比

今天的分享到此结束。
相关文章:
机器学习:决策树和剪枝
本文目录: 一、决策树基本知识(一)概念(二)决策树建立过程 二、决策树生成(一)ID3决策树:基于信息增益构建的决策树。(二)C4.5决策树(三ÿ…...
vscode自定义主题语法及流程
vscode c/c 主题 DIY 启用自己的主题(最后步骤) 重启生效 手把手教你制作 在C:\Users\jlh.vscode\extensions下自己创建一个文件夹 里面有两个文件一个文件夹 package.json: {"name":"theme-jlh","displayName":"%displayName%&qu…...

vue中加载Cesium地图(天地图、高德地图)
目录 1、将下载的Cesium包移动至public下 2、首先需要将Cesium.js和widgets.css文件引入到 3、 新建Cesium.js文件,方便在全局使用 4、新建cesium.vue文件,展示三维地图 1、将下载的Cesium包移动至public下 npm install cesium后 2、…...
SpringBoot整合RocketMQ与客户端注意事项
SpringBoot整合RocketMQ 引入依赖(5.3.0比较稳定) <dependencies><dependency><groupId>org.apache.rocketmq</groupId><artifactId>rocketmq-spring-boot-starter</artifactId><version>2.3.1</version&…...

Github 2025-06-04 C开源项目日报 Top7
根据Github Trendings的统计,今日(2025-06-04统计)共有7个项目上榜。根据开发语言中项目的数量,汇总情况如下: 开发语言项目数量C项目7C++项目1Assembly项目1jq:轻量灵活的命令行JSON处理器 创建周期:4207 天开发语言:C协议类型:OtherStar数量:27698 个Fork数量:1538 …...

大二下期末
一.Numpy(Numerical Python) Numpy库是Python用于科学计算的基础包,也是大量Python数学和科学计算包的基础。不少数据处理和分析包都是在Numpy的基础上开发的,如后面介绍的Pandas包。 Numpy的核心基础是ndarray(N-di…...

LeetCode 热题 100 74. 搜索二维矩阵
LeetCode 热题 100 | 74. 搜索二维矩阵 大家好,今天我们来解决一道经典的算法题——搜索二维矩阵。这道题在 LeetCode 上被标记为中等难度,要求我们在一个满足特定条件的二维矩阵中查找一个目标值。如果目标值在矩阵中,返回 true;…...

解决 VSCode 中无法识别 Node.js 的问题
当 VSCode 无法识别 Node.js 时,通常会出现以下症状: 代码提示缺失require 等 Node.js API 被标记为错误调试功能无法正常工作终端无法运行 Node.js 命令 常见原因及解决方案 1. Node.js 未安装或未正确配置 解决方法: 确保已安…...
Mysql的卸载与安装
确保卸载干净mysql 不然在进行mysal安装时候会出现不一的页面和问题 1、卸载 在应用页面将查询到的mysql相关应用卸载 2、到c盘下将残留的软件包进行数据删除 3、删除programData下的mysql数据 4、检查系统中的mysql是否存在 cmd中执行 sc deleted mysql80 5、删除注册表中的…...

ES101系列09 | 运维、监控与性能优化
本篇文章主要讲解 ElasticSearch 中 DevOps 与性能优化的内容,包括集群部署最佳实践、容量规划、读写性能优化和缓存、熔断器等。 集群部署最佳实践 在生产环境中建议设置单一角色的节点。 Dedicated master eligible nodes:负责集群状态的管理。使用…...

Java常用的判空方法
文章目录 Java常用的判空方法JDK 自带的判空方法1. 使用 或 ! 运算符2. 使用 equals 方法3. Objects.isNull / Objects.nonNull4. Objects.equals4. JDK8 中的 Optional 第三方工具包1. Apache Commons Lang32. Google Guava3. Lombok 注解4. Vavr(函数式风格&…...
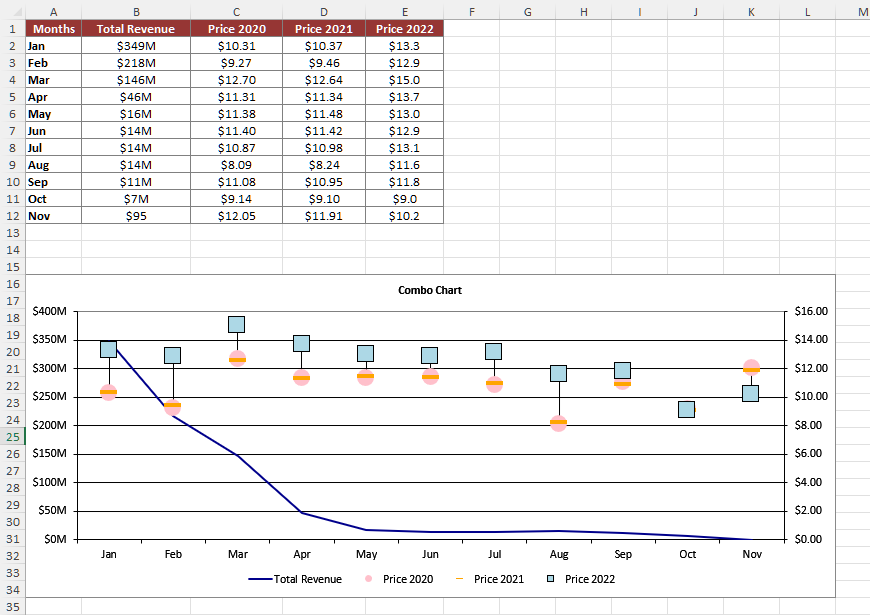
Excel处理控件Aspose.Cells教程:使用 C# 在 Excel 中创建组合图表
可视化项目时间线对于有效规划和跟踪至关重要。在本篇教程中,您将学习如何使用 C# 在 Excel 中创建组合图。只需几行代码,即可自动生成动态、美观的组合图。无论您是在构建项目管理工具还是处理内部报告,本指南都将向您展示如何将任务数据转换…...

【多线程初阶】阻塞队列 生产者消费者模型
文章目录 一、阻塞队列二、生产者消费者模型(一)概念(二)生产者消费者的两个重要优势(阻塞队列的运用)1) 解耦合(不一定是两个线程之间,也可以是两个服务器之间)2) 削峰填谷 (三)生产者消费者模型付出的代价 三、标准库中的阻塞队列(一)观察模型的运行效果(二)观察阻塞效果1) 队…...

《100天精通Python——基础篇 2025 第5天:巩固核心知识,选择题实战演练基础语法》
目录 一、踏上Python之旅二、Python输入与输出三、变量与基本数据类型四、运算符五、流程控制 一、踏上Python之旅 1.想要输出 I Love Python,应该使用()函数。 A.printf() B.print() C.println() D.Print() 在Python中想要在屏幕中输出内容,应该使用print()函数…...

机器人夹爪的选型与ROS通讯——机器人抓取系统基础系列(六)
文章目录 前言一、夹爪的选型1.1 任务需求分析1.2 软体夹爪的选型 二、夹爪的ROS通讯2.1 夹爪的通信方式介绍2.2 串口助手测试2.3 ROS通讯节点实现 总结Reference: 前言 本文将介绍夹爪的选型方法和通讯方式。以鞋子这类操作对象为例,将详细阐述了对应的夹爪选型过…...
第二十八章 RTC——实时时钟
第二十八章 RTC——实时时钟 目录 第二十八章 RTC——实时时钟 1 RTC实时时钟简介 2 RTC外设框图剖析 3 UNIX时间戳 4 与RTC控制相关的库函数 4.1 等待时钟同步和操作完成 4.2 使能备份域涉及RTC配置 4.3 设置RTC时钟分频 4.4 设置、获取RTC计数器及闹钟 5 实时时…...

使用 DuckLake 和 DuckDB 构建 S3 数据湖实战指南
本文介绍了由 DuckDB 和 DuckLake 组成的轻量级数据湖方案,旨在解决传统数据湖(如HadoopHive)元数据管理复杂、查询性能低及厂商锁定等问题。该方案为中小规模数据湖场景提供了简单、高性能且无厂商锁定的替代选择。 1. 什么是 DuckLake 和 D…...

大语言模型提示词(LLM Prompt)工程系统性学习指南:从理论基础到实战应用的完整体系
文章目录 前言:为什么提示词工程成为AI时代的核心技能一、提示词的本质探源:认知科学与逻辑学的理论基础1.1 认知科学视角下的提示词本质信息处理理论的深层机制图式理论的实际应用认知负荷理论的优化策略 1.2 逻辑学框架下的提示词架构形式逻辑的三段论…...
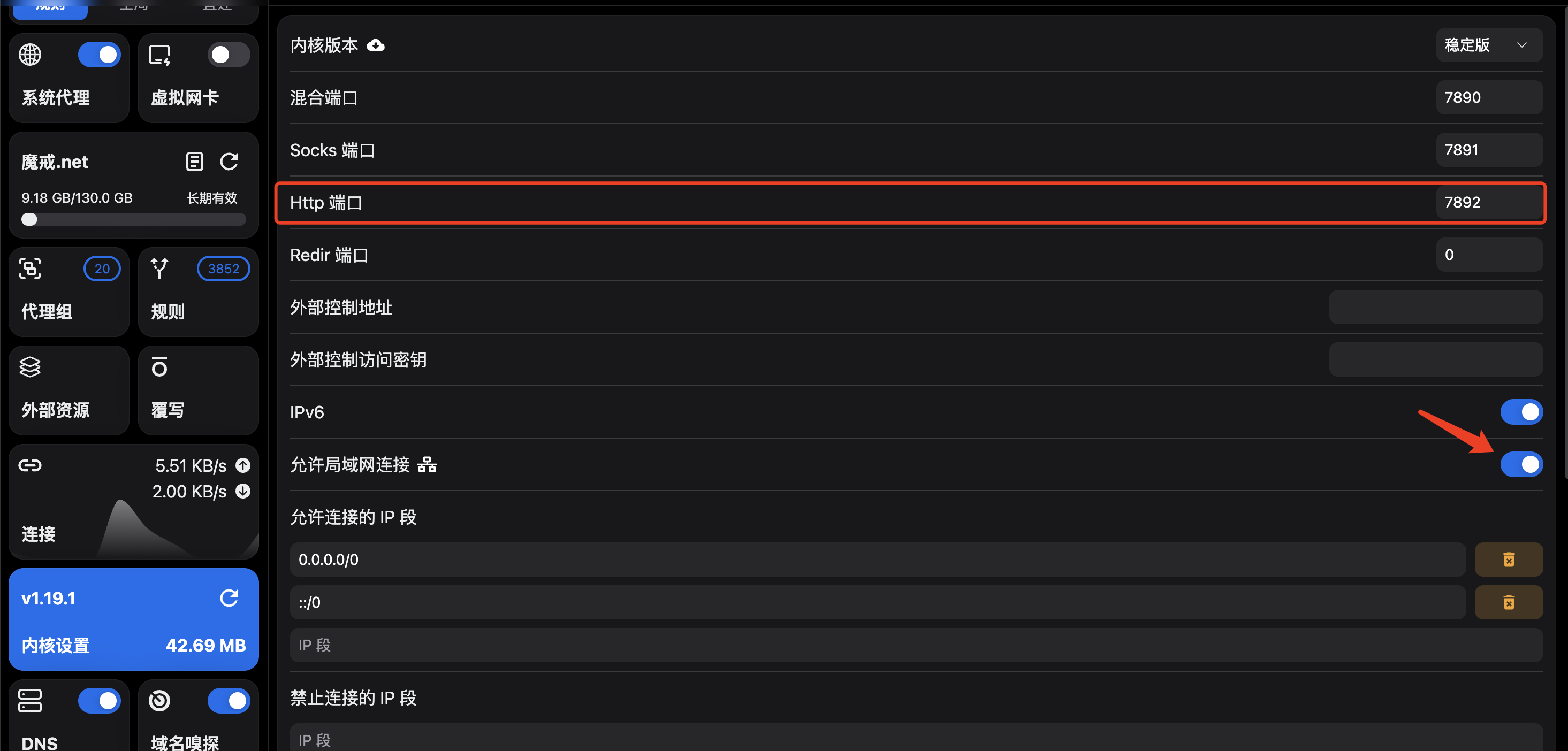
如何基于Mihomo Party http端口配置git与bash命令行代理
如何基于Mihomo Party http端口配置git与bash命令行代理 1. 确定Mihomo Party http端口配置 点击内核设置后即可查看 默认7892端口,开启允许局域网连接 2. 配置git代理 配置本机代理可以使用 127.0.0.1 配置局域网内其它机代理需要使用本机的非回环地址 IP&am…...

CMake 为 Debug 版本的库或可执行文件添加 d 后缀
在使用 CMake 构建项目时,我们经常需要区分 Debug 和 Release 构建版本。一个常见的做法是为 Debug 版本的库或可执行文件添加后缀(如 d),例如 libmylibd.so 或 myappd.exe。 本文将介绍几种在 CMake 中实现为 Debug 版本自动添加 d 后缀的方法。 方法一:使用 CMAKE_DEBU…...

Linux 特殊权限位详解:SetUID, SetGID, Sticky Bit
Linux 特殊权限位详解:SetUID, SetGID, Sticky Bit 在Linux权限系统中,除了基本的读、写(w)、执行(x)权限外,还有三个特殊权限位:SetUID、SetGID和Sticky Bit。这些权限位提供了更精细的权限控制机制,尤其在需要临时提升权限或管理共享资源时非常有用。 一、SetUID (s位…...
埃文科技智能数据引擎产品入选《中国网络安全细分领域产品名录》
嘶吼安全产业研究院发布《中国网络安全细分领域产品名录》,埃文科技智能数据引擎产品成功入选数据分级分类产品名录。 在数字化转型加速的今天,网络安全已成为企业生存与发展的核心基石,为了解这一蓬勃发展的产业格局,嘶吼安全产业…...

使用VTK还是OpenGL集成到qt程序里哪个好?
在Qt程序中集成VTK与OpenGL:选择哪个更好? 在Qt程序中实现三维可视化时,开发者常常面临一个选择:是使用VTK(Visualization Toolkit)还是OpenGL(Open Graphics Library)。这两种技术…...

Java-IO流之打印流详解
Java-IO流之打印流详解 一、打印流概述1.1 什么是打印流1.2 打印流的特点1.3 打印流的应用场景 二、PrintStream详解2.1 基本概念2.2 构造函数2.3 核心方法2.4 使用示例 三、PrintWriter详解3.1 基本概念3.2 构造函数3.3 核心方法3.4 使用示例 四、PrintStream与PrintWriter的比…...

高效图像处理:使用 Pillow 进行格式转换与优化
高效图像处理:使用 Pillow 进行格式转换与优化 1. 背景引入 在图像处理应用中,格式转换、裁剪、压缩等操作是常见需求。Python 的 Pillow 库基于 PIL(Python Imaging Library),提供 轻量、强大 的图像处理能力,广泛用于 Web 开发、数据分析、机器学习 等领域。 本文将…...

Github 2025-06-06 Java开源项目日报Top10
根据Github Trendings的统计,今日(2025-06-06统计)共有10个项目上榜。根据开发语言中项目的数量,汇总情况如下: 开发语言项目数量Java项目10TypeScript项目1Java实现的算法集合:使用Gitpod.io进行编辑和贡献 创建周期:2883 天开发语言:Java协议类型:MIT LicenseStar数量…...

使用 Ansible 在 Windows 服务器上安装 SSL 证书
在本教程中,我将向您展示如何使用 Ansible 在 Windows 服务器上安装 SSL 证书。使用 Ansible 自动化 SSL 证书安装过程可以提高 IT 运营的效率、一致性和协作性。我将介绍以下步骤: 将 SSL 证书文件复制到服务器将 PFX 证书导入指定的存储区获取导入的证…...

厂区能源监控系统:网关赋能下的高效能源管理与环保监测
在现代工业生产领域,能源的有效利用与环境保护是企业实现可持续发展的两大关键要素。厂区能源监控系统借助先进的信息技术与自动化控制手段,对厂区内能源消耗及污水处理等核心环节展开实时监控与精细化管理。其中,御控网关作为系统关键枢纽&a…...

CentOS 7 如何安装llvm-project-10.0.0?
CentOS 7 如何安装llvm-project-10.0.0? 需要先升级gcc至7.5版本,详见CentOS 7如何编译安装升级gcc版本?一文 # 备份之前的yum .repo文件至 /tmp/repo_bak 目录 mkdir -p /tmp/repo_bak && cd /etc/yum.repo.d && /bin/mv ./*.repo …...

Cursor 1.0 的核心功能亮点及技术价值分析
Cursor 1.0 的核心功能亮点及技术价值分析 结合官方更新和开发者实测整理: 🛠️ 一、BugBot:智能自动化代码审查 功能亮点:深度集成 GitHub,自动扫描 Pull Request(PR)中的潜在 Bug(…...