大语言模型提示词(LLM Prompt)工程系统性学习指南:从理论基础到实战应用的完整体系

文章目录
- 前言:为什么提示词工程成为AI时代的核心技能
- 一、提示词的本质探源:认知科学与逻辑学的理论基础
- 1.1 认知科学视角下的提示词本质
- 信息处理理论的深层机制
- 图式理论的实际应用
- 认知负荷理论的优化策略
- 1.2 逻辑学框架下的提示词架构
- 形式逻辑的三段论结构
- 归纳与演绎推理的平衡
- 1.3 语用学与交流理论的指导原则
- Grice合作原则的现代应用
- 关联理论的优化启示
- 二、元提示工程:用AI优化AI的方法论与实践
- 2.1 元提示工程的理论基础与发展历程
- 从手工设计到自动优化的范式转变
- 类型理论与范畴理论的数学基础
- 2.2 核心技术框架与实现方法
- OPRO方法的深度剖析
- DSPy框架的系统化方法
- TextGrad的创新突破
- 2.3 实施策略与最佳实践
- 多层次优化架构
- 评估驱动的迭代改进
- 三、提示词框架技术体系:从基础到高级的完整架构
- 3.1 零样本与少样本学习:基础框架的原理与应用
- 零样本学习的理论机制
- 少样本学习的上下文机制
- 3.2 思维链技术的深度解析
- CoT的认知科学基础
- 高级CoT变体技术
- 3.3 树形思维:非线性推理的技术突破
- ToT的理论创新
- ToT的实现细节
- 3.4 ReAct框架:推理与行动的统一
- ReAct的理论基础
- 工具集成与外部知识访问
- 3.5 程序辅助语言模型:符号计算的融合
- PAL的混合范式
- 代码生成与执行策略
- 四、场景适配策略:严格性与灵活性的动态平衡
- 4.1 严格性输出场景的深度分析
- 关键业务场景的特征识别
- 严格性控制的技术实现
- 4.2 创造性与探索性场景的策略设计
- 创造性任务的认知机制
- 高级创造性提示技术
- 4.3 动态适配机制的设计与实现
- 智能场景识别系统
- 自适应参数调整系统
- 五、工具技术栈:从开发到部署的完整生态
- 5.1 核心开发框架的深度对比
- LangChain生态系统
- DSPy的编程范式革命
- 5.2 专业评估与监控工具
- Promptfoo:全面的测试框架
- LangSmith:企业级运营平台
- 5.3 高级优化与调试技术
- TextGrad的革命性方法
- 自动化A/B测试框架
- 5.4 部署与生产环境优化
- 缓存策略与性能优化
- 容错与降级策略
- 六、专业术语解释:理论概念与技术实现的桥梁
- 6.1 认知科学与心理学术语
- 认知负荷理论(Cognitive Load Theory)
- 图式理论(Schema Theory)
- 元认知(Metacognition)
- 6.2 计算语言学与自然语言处理术语
- 注意力机制(Attention Mechanism)
- 变换器架构(Transformer Architecture)
- 上下文窗口(Context Window)
- 6.3 机器学习与优化术语
- 梯度下降(Gradient Descent)
- 正则化(Regularization)
- 集成学习(Ensemble Learning)
- 6.4 软件工程与系统设计术语
- 微服务架构(Microservices Architecture)
- 容器化(Containerization)
- API网关(API Gateway)
- 6.5 评估与度量术语
- 语义相似度(Semantic Similarity)
- BLEU分数(Bilingual Evaluation Understudy)
- 困惑度(Perplexity)
- 七、实战案例分析:理论到应用的完整转化
- 7.1 金融风险评估系统的提示工程实践
- 业务需求与技术挑战
- 分层提示架构设计
- 多模型验证机制
- 7.2 多语言客户服务系统的适配策略
- 跨文化交流的提示设计
- 7.3 教育内容生成系统的个性化实现
- 认知水平适应性设计
- 多模态学习路径设计
- 八、未来趋势与发展方向
- 8.1 技术演进的关键趋势
- 8.2 应用模式的范式转变
- 8.3 伦理与安全的系统性考虑
- 8.4 人才培养与技能要求的演变
- 结语:迈向智能协作的新时代
前言:为什么提示词工程成为AI时代的核心技能
在人工智能快速发展的时代,大语言模型已从学术实验室走向产业应用的前沿。然而,模型能力的充分发挥并非自动实现,而需要精心设计的提示词作为桥梁。提示词工程正是这样一门艺术与科学并重的学科,它不仅决定了AI系统的输出质量,更影响着人机协作的效率和深度。
本指南基于最新的认知科学理论、逻辑学原理和工程实践,为读者构建从理论认知到实战应用的完整知识体系。通过系统性学习,读者将掌握提示词设计的底层逻辑、技术框架和优化策略,最终实现AI能力的最大化利用。
一、提示词的本质探源:认知科学与逻辑学的理论基础
1.1 认知科学视角下的提示词本质
信息处理理论的深层机制
提示词的工作原理植根于人类认知架构的基本特征。根据信息处理理论(Information Processing Theory),人类大脑通过三个核心组件处理信息:感觉寄存器、工作记忆和长期记忆。大语言模型的架构在很大程度上模仿了这一认知模式。
在这一框架下,提示词充当认知引导器的角色,类似于人类认知中的注意力机制。当我们向模型提供提示词时,实际上是在激活其训练数据中的特定知识模式,引导模型将"注意力"集中在与任务相关的信息表征上。这一过程的有效性直接取决于提示词设计的精确度和结构化程度。
图式理论的实际应用
图式理论(Schema Theory)由心理学家巴特利特提出,描述了人类如何组织和解释信息。在提示词工程中,每个有效的提示词实际上都在激活模型的特定"认知图式"。
例如,当我们使用"作为一名专业的金融分析师,请分析以下财务报表"这样的提示词时,我们正在激活模型中与金融分析相关的知识图式。这种激活不仅包括专业术语和分析方法,还包括金融分析师的思维模式、表达习惯和专业标准。
图式激活的关键在于语境一致性。提示词必须提供足够的语境信息,让模型能够准确识别和激活正确的知识图式。这解释了为什么详细的角色设定和任务描述通常比简单的指令更有效。
认知负荷理论的优化策略
认知负荷理论(Cognitive Load Theory)由约翰·斯威勒提出,将认知处理分为三种负荷类型:
内在负荷:处理任务本身所需的认知资源 外在负荷:由于信息呈现方式不当而产生的额外认知负担 生成负荷:构建新知识结构所需的认知投入
优秀的提示词设计应当最小化外在负荷,合理管理内在负荷,并为生成负荷预留充足空间。具体而言,这意味着提示词应当结构清晰、信息层次分明、避免冗余描述。
1.2 逻辑学框架下的提示词架构
形式逻辑的三段论结构
从形式逻辑角度,有效的提示词通常遵循三段论结构:
大前提设定:建立推理的基本框架和约束条件 小前提输入:提供具体的问题或数据 结论引导:明确期望的输出形式和质量标准
这一结构确保了推理过程的逻辑完整性。例如:
- 大前提:“你是一位具有20年经验的软件架构师”
- 小前提:“以下是一个电商系统的需求文档”
- 结论引导:“请设计系统架构并说明关键技术选型的理由”
归纳与演绎推理的平衡
提示词工程需要在归纳推理和演绎推理之间找到平衡点。归纳推理通过具体示例引导模型理解模式(如少样本学习),而演绎推理通过抽象规则指导具体应用(如零样本学习)。
归纳式提示设计适用于模式识别任务,通过提供多个相似示例让模型归纳出通用规律。演绎式提示设计适用于规则应用任务,通过明确的原则和步骤指导模型执行特定操作。
1.3 语用学与交流理论的指导原则
Grice合作原则的现代应用
语言哲学家保罗·格赖斯提出的合作原则为有效提示词设计提供了理论基础。该原则包含四个基本准则:
数量准则:信息应当充分但不冗余 质量准则:信息应当真实可靠 相关准则:信息应当与任务目标相关 方式准则:表达应当清晰、简洁、有序
在提示词工程中,违反这些准则会导致模型理解偏差或输出质量下降。例如,提供过多无关信息违反了数量准则,可能导致模型注意力分散;使用模糊或歧义的表达违反了方式准则,可能产生不确定的输出结果。
关联理论的优化启示
关联理论(Relevance Theory)由斯伯伯和威尔逊提出,强调最佳关联性原则:信息应当以最小的处理努力产生最大的认知效果。
这一理论指导我们设计提示词时应当:
- 优先提供与任务直接相关的信息
- 按照重要性递减的顺序组织信息
- 避免需要额外推理才能理解的复杂表达
- 确保每个信息元素都对任务完成有明确贡献
二、元提示工程:用AI优化AI的方法论与实践
2.1 元提示工程的理论基础与发展历程
从手工设计到自动优化的范式转变
传统提示工程依赖人工经验和试错迭代,这种方法不仅效率低下,而且难以应对大规模应用场景的复杂需求。元提示工程的出现标志着该领域从手工艺向工程化的重要转变。
元提示工程的核心思想是递归优化:使用AI系统的能力来改进AI系统的交互方式。这种方法的理论基础来自于元学习(Meta-Learning)和程序合成(Program Synthesis)领域的研究成果。
类型理论与范畴理论的数学基础
斯坦福大学的研究团队在Meta Prompting方法中引入了类型理论和范畴理论的数学框架。这些理论提供了形式化描述提示词结构和转换关系的工具。
在类型理论框架下,每个提示词可以被视为一个类型签名,定义了输入和输出之间的映射关系。范畴理论则提供了组合不同提示词的数学规则,确保复杂提示的逻辑一致性。
2.2 核心技术框架与实现方法
OPRO方法的深度剖析
OPRO(Optimization by PROmpting)方法由DeepMind团队于2023年提出,代表了元提示优化的重要突破。该方法的核心创新在于将优化问题转化为自然语言生成任务。
OPRO的工作流程包含以下关键步骤:
问题形式化:将优化目标转化为自然语言描述 历史信息整合:维护优化历史和性能反馈 候选解生成:利用LLM生成多个候选提示 性能评估:在验证集上测试候选提示的效果 迭代改进:根据评估结果更新优化策略
该方法在GSM8K数学推理任务上实现了显著改进,证明了自动化提示优化的可行性。更重要的是,OPRO发现了一些人类难以直觉想到的有效提示短语,如"深呼吸,逐步解决这个问题",这表明AI系统在探索提示空间方面具有独特优势。
DSPy框架的系统化方法
DSPy框架提出了"编程而非提示"的新理念,将提示工程转化为可编程的系统化过程。该框架的核心组件包括:
签名(Signatures):声明式地定义任务的输入输出规范 模块(Modules):实现特定策略的可复用组件 优化器(Optimizers):自动调整模块参数的算法
DSPy的优势在于将程序逻辑与提示参数分离,使得复杂AI应用的开发变得更加模块化和可维护。通过BootstrapFewShot、COPRO等优化器,DSPy能够自动寻找最佳的提示参数组合。
TextGrad的创新突破
TextGrad框架实现了"通过文本的自动微分",这是提示优化领域的重要理论突破。该框架将梯度下降的概念扩展到自然语言领域,使用LLM生成的反馈作为"文本梯度"来指导优化方向。
TextGrad的核心创新包括:
- 自然语言梯度计算:使用LLM分析当前输出的不足并生成改进建议
- 链式反向传播:在复杂的多步骤系统中传播梯度信息
- 损失函数设计:将任务目标转化为可优化的文本形式
该框架在多项任务上实现了显著改进,特别是在需要多步推理的复杂问题上表现出色。
2.3 实施策略与最佳实践
多层次优化架构
有效的元提示工程需要构建多层次优化架构,包括:
词汇层优化:优化关键词选择和表达方式 结构层优化:优化信息组织和逻辑流程 策略层优化:优化整体方法和技术路线 目标层优化:优化评估标准和成功指标
这种分层方法确保了优化过程的系统性和全面性,避免了局部优化导致的次优解。
评估驱动的迭代改进
元提示工程的成功关键在于建立闭环反馈机制。这要求我们:
- 定义明确的性能指标和评估标准
- 构建多样化的测试数据集
- 实施自动化的性能监控系统
- 建立快速迭代的开发流程
通过持续的评估和反馈,元提示系统能够不断学习和改进,适应新的任务需求和应用场景。
三、提示词框架技术体系:从基础到高级的完整架构
3.1 零样本与少样本学习:基础框架的原理与应用
零样本学习的理论机制
零样本学习(Zero-shot Learning)依赖于大语言模型在预训练过程中获得的泛化能力。这种能力的理论基础来自于迁移学习和表征学习的研究成果。
在零样本场景中,模型需要仅基于任务描述就理解并执行新任务。这一过程涉及以下认知机制:
- 概念抽象:从任务描述中提取抽象的任务特征
- 知识映射:将抽象特征映射到已学习的知识表征
- 模式匹配:在知识表征中找到最相关的处理模式
- 输出生成:基于匹配的模式生成相应输出
零样本学习的有效性很大程度上取决于任务描述的精确性和模型知识的丰富性。
少样本学习的上下文机制
少样本学习(Few-shot Learning)通过提供少量示例来增强模型对任务的理解。这种方法的理论基础是上下文学习(In-Context Learning),即模型在推理过程中从输入上下文中学习新模式的能力。
上下文学习的工作机制包括:
模式识别:从提供的示例中识别输入输出模式 规律抽象:从具体示例中抽象出一般规律 类比推理:将抽象规律应用到新的输入上 一致性维护:确保输出与示例风格保持一致
少样本学习的关键在于示例质量而非数量。高质量的示例应当:
- 代表性强,能够体现任务的核心特征
- 多样性足,覆盖任务的主要变化维度
- 难度适中,既不过于简单也不过于复杂
- 标注准确,提供正确的输入输出对应关系
3.2 思维链技术的深度解析
CoT的认知科学基础
思维链提示(Chain-of-Thought Prompting)的有效性根植于人类认知的序列推理特征。认知科学研究表明,人类在解决复杂问题时通常采用分解策略,将大问题拆分为可管理的子问题,然后逐步求解。
CoT技术模拟了这一认知过程,通过以下机制改善模型性能:
注意力聚焦:引导模型关注推理的每个步骤 中间监督:通过中间步骤提供额外的学习信号 错误检测:使推理过程可见,便于发现和纠正错误 知识激活:逐步激活相关知识,避免信息遗漏
高级CoT变体技术
自我一致性CoT通过生成多个推理路径并采用多数投票机制来提高结果可靠性。这种方法的理论依据是集成学习的基本原理:多个独立的弱学习器组合可以产生更强的整体性能。
实施自我一致性CoT的关键参数包括:
- 采样数量:通常设置为5-20个,平衡性能和计算成本
- 温度设置:使用较高温度(0.7-0.9)增加路径多样性
- 投票策略:可采用简单多数投票或加权投票
复合CoT技术将多种推理模式结合,例如:
- 演绎+归纳:先从一般原理演绎,再通过具体案例归纳
- 分析+综合:先分析问题的各个方面,再综合得出结论
- 正向+反向:从问题到结论的正向推理与从结论到问题的反向验证
3.3 树形思维:非线性推理的技术突破
ToT的理论创新
树形思维(Tree of Thoughts)代表了提示工程领域的重要理论突破。与传统的线性推理不同,ToT引入了搜索空间探索的概念,允许模型同时考虑多个推理路径。
ToT的核心创新包括:
状态空间建模:将问题求解过程建模为状态空间搜索 启发式评估:使用LLM评估中间状态的质量和前景 搜索策略选择:根据问题特征选择广度优先或深度优先搜索 回溯机制:当某个路径失败时能够回退到之前的状态
ToT的实现细节
ToT的实现需要定义以下关键组件:
思想生成器:负责从当前状态生成下一步可能的思想(思维步骤)。生成器需要平衡创造性和相关性,既要产生足够多样的候选,又要确保每个候选都是合理的。
状态评估器:评估每个中间状态的质量,判断其是否值得进一步探索。评估可以采用:
- 值函数评估:预测从当前状态到最终解决方案的预期价值
- 策略评估:评估当前状态下可采取行动的质量
- 启发式评估:基于领域知识的快速质量估计
搜索算法:控制探索过程的策略。常用算法包括:
- 广度优先搜索(BFS):适用于解空间较小的问题
- 深度优先搜索(DFS):适用于需要深度探索的问题
- 最优优先搜索:结合启发式信息的智能搜索
- 束搜索(Beam Search):在时间和质量之间找到平衡
3.4 ReAct框架:推理与行动的统一
ReAct的理论基础
ReAct框架(Reasoning and Acting)实现了推理和行动的有机统一,这一设计灵感来自认知科学中的具身认知理论。该理论认为,有效的问题解决需要将抽象推理与具体行动相结合。
ReAct的核心循环包括:
思考(Think):分析当前情况,制定行动计划 行动(Act):执行具体的工具调用或信息检索 观察(Observe):处理行动结果,更新知识状态 反思(Reflect):评估进展,调整策略
工具集成与外部知识访问
ReAct框架的一个重要特征是工具集成能力。这使得模型能够:
- 访问实时信息和数据库
- 执行计算和数据处理任务
- 与外部API和服务交互
- 调用专业软件和分析工具
工具集成的关键技术包括:
工具描述标准化:每个工具需要提供标准化的描述,包括功能说明、参数定义、返回格式等。
调用序列优化:优化工具调用的顺序和组合,最小化调用次数和计算开销。
错误处理机制:当工具调用失败时,能够识别错误类型并采取相应的恢复策略。
3.5 程序辅助语言模型:符号计算的融合
PAL的混合范式
程序辅助语言模型(Program-aided Language Models)代表了符号计算与神经计算的创新融合。这种方法将复杂的数学和逻辑推理任务转化为程序代码,利用传统计算机的精确计算能力。
PAL的优势在于:
计算精确性:避免了LLM在数值计算中的误差累积 逻辑可靠性:程序执行保证了逻辑推理的严密性 可验证性:生成的代码可以被独立验证和调试 可扩展性:能够处理任意复杂度的计算任务
代码生成与执行策略
PAL的实现涉及以下关键技术:
语义解析:将自然语言问题转化为程序逻辑。这一过程需要:
- 识别问题中的数量关系和约束条件
- 提取关键变量和操作
- 建立数学模型和算法流程
代码生成优化:生成高质量、可执行的代码。优化策略包括:
- 使用标准库和常见模式
- 添加适当的注释和文档
- 实施错误检查和异常处理
- 优化算法复杂度和执行效率
执行环境安全:确保代码执行的安全性。安全措施包括:
- 限制资源使用(CPU、内存、执行时间)
- 禁止危险操作(文件系统访问、网络连接)
- 沙箱隔离和权限控制
- 代码静态分析和动态监控
四、场景适配策略:严格性与灵活性的动态平衡
4.1 严格性输出场景的深度分析
关键业务场景的特征识别
严格性输出场景通常具有以下共同特征:
- 高风险决策:输出错误可能导致严重后果
- 规范化要求:需要遵循特定的行业标准和法规
- 一致性需求:要求输出保持高度一致的格式和质量
- 可审计性:输出需要能够被追踪、验证和解释
典型的严格性场景包括:
金融分析与风险评估:投资建议、信贷审批、风险报告 法律文档处理:合同审查、法律意见、合规检查 医疗诊断辅助:症状分析、用药建议、治疗方案 工程设计验证:安全评估、质量控制、标准符合性检查
严格性控制的技术实现
温度与随机性控制:严格性场景通常要求低温度设置(0.1-0.3),以最小化输出的随机性和不确定性。
约束条件明确化:通过详细的规则和约束条件限制模型的输出空间。约束可以包括:
- 格式约束:JSON结构、表格格式、特定模板
- 内容约束:词汇限制、长度要求、逻辑规则
- 质量约束:置信度阈值、验证标准、审核流程
多重验证机制:实施多层次的验证和检查:
- 语法验证:检查输出的格式和结构正确性
- 语义验证:验证内容的逻辑一致性和合理性
- 领域验证:使用专业知识检查领域特定的正确性
- 交叉验证:通过多个模型或方法验证结果一致性
审计跟踪系统:建立完整的审计跟踪机制:
- 记录输入输出的完整历史
- 保存推理过程的中间步骤
- 维护模型版本和配置信息
- 实现可追溯的决策链条
4.2 创造性与探索性场景的策略设计
创造性任务的认知机制
创造性场景需要模型展现发散性思维和原创性。认知科学研究表明,创造性过程涉及以下认知机制:
远程联想:在看似无关的概念间建立新颖连接 概念组合:将现有概念以新的方式组合 类比推理:从一个领域迁移洞察到另一个领域 打破常规:突破传统思维框架的限制
高级创造性提示技术
视角多样化技术:通过引入多个不同视角来增强创造性:
请从以下三个不同角度分析这个设计问题:
1. 用户体验设计师的角度
2. 技术工程师的角度
3. 商业策略分析师的角度
然后寻找这些视角的交集和创新机会
约束悖论技术:通过巧妙设置约束来激发创造性:
设计一个产品,要求:
1. 必须使用回收材料
2. 成本不能超过10美元
3. 能解决城市交通问题
4. 适用于所有年龄段
请提出三个完全不同的解决方案
时间维度探索:引入时间因素来扩展思考空间:
如果这个问题出现在:
- 100年前,人们会如何解决?
- 50年后,可能有什么新的解决方案?
- 外星文明会采用什么方法?
基于这些思考,提出一个融合传统智慧和未来技术的创新方案
4.3 动态适配机制的设计与实现
智能场景识别系统
多维度特征提取:构建智能系统自动识别任务类型和适配要求:
任务复杂度评估:
- 单步骤任务:直接问答、简单转换
- 多步骤任务:推理链、分析流程
- 开放性任务:创意生成、策略规划
风险等级分类:
- 低风险:娱乐、学习、创意
- 中风险:业务分析、技术咨询
- 高风险:医疗、法律、金融决策
输出要求分析:
- 精确性要求:严格格式 vs 灵活表达
- 创新性需求:标准答案 vs 原创内容
- 时效性约束:实时响应 vs 深度分析
自适应参数调整系统
动态温度控制:根据任务特征自动调整温度参数:
def adaptive_temperature(task_type, risk_level, creativity_need):base_temp = 0.5# 风险调整risk_adjustment = {'low': 0.2,'medium': 0.0,'high': -0.3}# 创造性调整creativity_adjustment = creativity_need * 0.3# 任务类型调整type_adjustment = {'analytical': -0.1,'creative': 0.2,'technical': -0.2}final_temp = max(0.1, min(1.0, base_temp + risk_adjustment[risk_level] + creativity_adjustment + type_adjustment.get(task_type, 0)))return final_temp
上下文长度优化:根据任务复杂度动态调整上下文窗口使用:
- 简单任务:短上下文,快速响应
- 复杂分析:长上下文,充分信息
- 迭代任务:渐进式上下文扩展
五、工具技术栈:从开发到部署的完整生态
5.1 核心开发框架的深度对比
LangChain生态系统
LangChain作为最成熟的LLM应用开发框架,提供了完整的工具链:
核心组件架构:
- Models:统一的模型接口,支持OpenAI、Anthropic、Hugging Face等
- Prompts:提示模板管理和版本控制
- Memory:对话历史和上下文管理
- Chains:复杂工作流的构建和编排
- Agents:自主决策和工具调用
- Callbacks:监控、日志和调试
高级特性:
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from langchain.memory import ConversationBufferWindowMemory# 创建具有记忆的对话链
memory = ConversationBufferWindowMemory(k=5)prompt = PromptTemplate(input_variables=["history", "human_input"],template="""你是一个专业的AI助手。基于以下对话历史,为用户提供准确和有帮助的回答。对话历史:{history}用户问题:{human_input}回答:"""
)chain = LLMChain(llm=llm,prompt=prompt,memory=memory,verbose=True
)
DSPy的编程范式革命
DSPy引入了全新的编程范式,将提示工程转化为模块化编程:
核心概念:
- Signatures:声明式任务定义
- Modules:可复用的功能组件
- Optimizers:自动参数优化
- Metrics:量化评估标准
实际应用示例:
import dspy# 定义任务签名
class GenerateAnswer(dspy.Signature):"""分析问题并生成准确答案"""context = dspy.InputField(desc="相关背景信息")question = dspy.InputField(desc="用户问题")answer = dspy.OutputField(desc="详细答案")# 创建模块
class RAGModule(dspy.Module):def __init__(self):super().__init__()self.retrieve = dspy.Retrieve(k=5)self.generate = dspy.ChainOfThought(GenerateAnswer)def forward(self, question):context = self.retrieve(question).passagesprediction = self.generate(context=context, question=question)return prediction# 自动优化
optimizer = dspy.BootstrapFewShot(metric=answer_accuracy)
optimized_module = optimizer.compile(RAGModule(), trainset=train_data)
5.2 专业评估与监控工具
Promptfoo:全面的测试框架
Promptfoo提供了业界最完整的LLM应用测试解决方案:
核心功能:
- 批量测试:大规模自动化测试
- 模型比较:多模型性能对比
- 安全测试:红队攻击模拟
- 回归测试:持续集成支持
配置示例:
# promptfoo.yaml
description: "客户服务聊天机器人测试"providers:- openai:gpt-4-turbo- anthropic:claude-3-opus- openai:gpt-3.5-turboprompts:- "你是专业的客户服务代表。请礼貌地回答客户问题:{{question}}"- "作为客服专家,请用友好的语调回应:{{question}}"tests:- vars:question: "我的订单什么时候能到?"assert:- type: containsvalue: "订单"- type: not-containsvalue: "不知道"- vars:question: "我想退货"assert:- type: llm-rubricvalue: "回答是否提供了退货流程信息?"defaultTest:assert:- type: latencythreshold: 5000- type: costthreshold: 0.01
LangSmith:企业级运营平台
LangSmith提供了生产环境的全方位支持:
核心能力:
- 实时监控:性能指标和系统健康状态
- 调试工具:详细的执行跟踪和错误分析
- A/B测试:多版本并行测试
- 用户反馈:收集和分析用户体验数据
监控仪表板配置:
from langsmith import trace, evaluate@trace
def customer_service_chain(question: str) -> str:"""客户服务主流程"""# 意图识别intent = classify_intent(question)# 知识检索knowledge = retrieve_knowledge(question, intent)# 答案生成answer = generate_answer(question, knowledge, intent)# 质量检查quality_score = evaluate_quality(answer)return {"answer": answer,"intent": intent,"quality": quality_score,"sources": knowledge["sources"]}# 自动评估配置
def accuracy_evaluator(run, example):"""评估答案准确性"""prediction = run.outputs["answer"]reference = example.outputs["expected_answer"]return {"score": calculate_similarity(prediction, reference)}evaluate(customer_service_chain,data=test_dataset,evaluators=[accuracy_evaluator],experiment_prefix="v2.1-"
)
5.3 高级优化与调试技术
TextGrad的革命性方法
TextGrad实现了文本领域的自动优化:
核心原理:
- 文本梯度:使用LLM生成的改进建议作为梯度
- 反向传播:在文本组件间传播优化信号
- 自动微分:计算文本变化对目标的影响
实现示例:
import textgrad as tg# 定义优化目标
def loss_function(prediction, target):"""计算预测与目标的差异"""evaluator = tg.LLMEvaluator("评估答案质量")return evaluator.evaluate(prediction, target)# 创建可优化的提示
prompt = tg.Variable("作为AI助手,请回答用户问题:{question}",requires_grad=True,role_description="系统提示"
)# 优化循环
optimizer = tg.Adam(learning_rate=0.1)for epoch in range(10):# 前向传播response = llm(prompt.value.format(question=user_question))# 计算损失loss = loss_function(response, target_answer)# 反向传播loss.backward()# 更新提示optimizer.step()optimizer.zero_grad()print(f"Epoch {epoch}: Loss = {loss.value}")
自动化A/B测试框架
实验设计与实施:
class PromptExperiment:def __init__(self, name, variants, traffic_split):self.name = nameself.variants = variants # 不同的提示版本self.traffic_split = traffic_split # 流量分配self.results = []def run_experiment(self, test_cases, metrics):"""执行A/B测试"""for case in test_cases:variant = self.select_variant(case["user_id"])# 执行测试result = self.execute_prompt(variant, case["input"])# 记录结果self.results.append({"variant": variant["name"],"input": case["input"],"output": result,"metrics": self.evaluate_metrics(result, case, metrics),"timestamp": datetime.now()})def analyze_results(self):"""统计分析结果"""df = pd.DataFrame(self.results)# 按变体分组分析analysis = df.groupby('variant').agg({'metrics.accuracy': ['mean', 'std'],'metrics.latency': ['mean', 'std'],'metrics.satisfaction': ['mean', 'std']})# 统计显著性检验variants = df['variant'].unique()for i, v1 in enumerate(variants):for v2 in variants[i+1:]:p_value = self.statistical_test(df[df['variant'] == v1]['metrics.accuracy'],df[df['variant'] == v2]['metrics.accuracy'])print(f"{v1} vs {v2}: p-value = {p_value}")return analysis
5.4 部署与生产环境优化
缓存策略与性能优化
多层缓存架构:
import redis
import hashlib
from functools import wrapsclass PromptCacheManager:def __init__(self):self.redis_client = redis.Redis(host='localhost', port=6379, db=0)self.local_cache = {}self.cache_ttl = 3600 # 1小时def cache_key(self, prompt, model, parameters):"""生成缓存键"""content = f"{prompt}:{model}:{str(sorted(parameters.items()))}"return hashlib.md5(content.encode()).hexdigest()def get_cached_response(self, prompt, model, parameters):"""获取缓存响应"""key = self.cache_key(prompt, model, parameters)# 检查本地缓存if key in self.local_cache:return self.local_cache[key]# 检查Redis缓存cached = self.redis_client.get(key)if cached:response = json.loads(cached)self.local_cache[key] = response # 更新本地缓存return responsereturn Nonedef cache_response(self, prompt, model, parameters, response):"""缓存响应"""key = self.cache_key(prompt, model, parameters)# 存储到Redisself.redis_client.setex(key, self.cache_ttl, json.dumps(response))# 存储到本地缓存self.local_cache[key] = responsedef cached_llm_call(cache_manager):"""装饰器:为LLM调用添加缓存"""def decorator(func):@wraps(func)def wrapper(prompt, model="gpt-4", **kwargs):# 尝试获取缓存cached = cache_manager.get_cached_response(prompt, model, kwargs)if cached:return cached# 执行实际调用response = func(prompt, model, **kwargs)# 缓存结果cache_manager.cache_response(prompt, model, kwargs, response)return responsereturn wrapperreturn decorator
容错与降级策略
多模型故障转移:
class RobustLLMService:def __init__(self, model_configs):self.models = []for config in model_configs:self.models.append({"name": config["name"],"client": self.create_client(config),"priority": config["priority"],"max_retries": config.get("max_retries", 3),"timeout": config.get("timeout", 30),"fallback_conditions": config.get("fallback_conditions", [])})# 按优先级排序self.models.sort(key=lambda x: x["priority"])async def generate_response(self, prompt, **kwargs):"""生成响应,具有故障转移功能"""last_error = Nonefor model in self.models:try:# 健康检查if not await self.health_check(model):continue# 尝试生成响应response = await self.call_model(model, prompt, **kwargs)# 质量检查if self.validate_response(response):return {"content": response,"model": model["name"],"status": "success"}else:raise ValueError("Response quality check failed")except Exception as e:last_error = eawait self.log_failure(model, prompt, e)# 检查是否应该故障转移if self.should_fallback(model, e):continueelse:# 重试当前模型for retry in range(model["max_retries"]):try:response = await self.call_model(model, prompt, **kwargs)if self.validate_response(response):return {"content": response,"model": model["name"],"status": "success_after_retry"}except Exception:if retry == model["max_retries"] - 1:breakawait asyncio.sleep(2 ** retry) # 指数退避# 所有模型都失败,返回降级响应return await self.fallback_response(prompt, last_error)async def fallback_response(self, prompt, error):"""降级响应策略"""return {"content": "抱歉,服务暂时不可用,请稍后重试。","model": "fallback","status": "fallback","error": str(error)}
六、专业术语解释:理论概念与技术实现的桥梁
6.1 认知科学与心理学术语
认知负荷理论(Cognitive Load Theory)
定义:由约翰·斯威勒(John Sweller)提出的学习理论,描述了人类工作记忆在处理信息时的限制和优化策略。
三种负荷类型:
- 内在负荷(Intrinsic Load):任务本身的固有复杂性,取决于学习材料的基本特征和学习者的先验知识
- 外在负荷(Extraneous Load):由于不当的信息呈现方式而产生的额外认知负担
- 生成负荷(Germane Load):用于图式构建和知识整合的认知投入
在提示工程中的应用:优秀的提示设计应当最小化外在负荷(避免冗余信息、歧义表达),合理管理内在负荷(将复杂任务分解为子任务),并为生成负荷预留空间(促进深度理解和创新思维)。
图式理论(Schema Theory)
定义:认知心理学理论,描述了人类如何组织、存储和检索知识的心理结构。图式是对概念、事件或对象的抽象知识结构。
核心机制:
- 同化(Assimilation):将新信息整合到现有图式中
- 调节(Accommodation):修改现有图式以适应新信息
- 平衡(Equilibration):在同化和调节之间寻找认知平衡
提示工程应用:有效的提示词通过激活特定的知识图式来引导模型行为。例如,"作为资深数据科学家"这样的角色设定会激活与数据分析相关的专业图式。
元认知(Metacognition)
定义:对自己认知过程的认知,即"对思维的思维"。包括元认知知识(关于认知过程的知识)和元认知调节(对认知过程的控制)。
组成要素:
- 计划(Planning):制定认知策略
- 监控(Monitoring):跟踪认知进展
- 评估(Evaluation):评价认知效果
技术实现:自我反思提示、思维链技术和自我一致性方法都体现了元认知原理的应用。
6.2 计算语言学与自然语言处理术语
注意力机制(Attention Mechanism)
定义:神经网络中的一种机制,允许模型在处理序列数据时动态地关注输入的不同部分。
核心原理:
- 查询(Query):当前处理位置的表征
- 键(Key):输入序列中各位置的表征
- 值(Value):与键对应的信息内容
- 注意力权重:查询与键的相似度计算结果
在LLM中的作用:注意力机制使模型能够建立输入序列中远距离元素之间的关联,这是理解复杂语言结构和上下文关系的基础。
变换器架构(Transformer Architecture)
定义:基于注意力机制的神经网络架构,是当前大语言模型的核心技术基础。
关键组件:
- 多头自注意力(Multi-Head Self-Attention):并行计算多个注意力表征
- 位置编码(Positional Encoding):为序列添加位置信息
- 前馈网络(Feed-Forward Network):非线性变换层
- 残差连接(Residual Connection):缓解梯度消失问题
- 层归一化(Layer Normalization):稳定训练过程
上下文窗口(Context Window)
定义:模型能够同时处理的最大输入长度,以令牌(token)为单位。
技术挑战:
- 计算复杂度:注意力机制的计算复杂度为O(n²),其中n是序列长度
- 内存消耗:长序列需要大量内存存储注意力矩阵
- 位置编码:超出训练长度的位置编码可能导致性能下降
最新发展:
- 稀疏注意力:只计算部分位置对之间的注意力
- 滑动窗口:维护固定大小的注意力窗口
- 分层注意力:在不同层使用不同的注意力模式
6.3 机器学习与优化术语
梯度下降(Gradient Descent)
定义:通过迭代地沿着目标函数梯度的反方向更新参数来最小化损失函数的优化算法。
核心概念:
- 梯度(Gradient):多变量函数在某点的偏导数向量,指示函数增长最快的方向
- 学习率(Learning Rate):控制参数更新步长的超参数
- 收敛(Convergence):算法达到最优解或接近最优解的状态
变体算法:
- SGD(随机梯度下降):使用小批量数据估计梯度
- Adam:结合动量和自适应学习率的优化器
- AdaGrad:根据历史梯度自适应调整学习率
正则化(Regularization)
定义:通过在损失函数中添加惩罚项或采用其他技术来防止模型过拟合的方法。
常见技术:
- L1正则化:添加参数绝对值的和作为惩罚项
- L2正则化:添加参数平方和作为惩罚项
- Dropout:随机将神经元输出设为零
- Early Stopping:在验证误差开始增加时停止训练
集成学习(Ensemble Learning)
定义:通过组合多个学习算法来提高预测性能的机器学习技术。
核心原理:
- 偏差-方差权衡:集成方法通过减少方差来提高性能
- 多样性:基学习器之间的差异是集成效果的关键
- 投票机制:通过投票或加权平均组合预测结果
提示工程应用:自我一致性技术本质上是集成学习在提示工程中的应用,通过生成多个推理路径并投票选择最终答案。
6.4 软件工程与系统设计术语
微服务架构(Microservices Architecture)
定义:将大型应用程序拆分为多个小型、独立的服务,每个服务负责特定的业务功能。
核心特征:
- 服务独立性:每个服务可以独立开发、部署和扩展
- 通信机制:服务间通过轻量级协议(如HTTP/REST或消息队列)通信
- 数据去中心化:每个服务管理自己的数据
- 故障隔离:单个服务的故障不会影响整个系统
在LLM应用中的应用:将不同的AI功能(如文本生成、图像分析、语音识别)拆分为独立的微服务,提高系统的可维护性和可扩展性。
容器化(Containerization)
定义:使用容器技术将应用程序及其依赖项打包在一起,确保在不同环境中的一致性运行。
核心概念:
- 镜像(Image):包含应用程序和依赖项的只读模板
- 容器(Container):镜像的运行实例
- 编排(Orchestration):自动化容器的部署、扩展和管理
Docker示例:
FROM python:3.9-slimWORKDIR /appCOPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txtCOPY . .EXPOSE 8000CMD ["gunicorn", "--bind", "0.0.0.0:8000", "app:create_app()"]
API网关(API Gateway)
定义:作为客户端和后端服务之间的中介,统一管理API请求的路由、认证、限流等功能。
核心功能:
- 请求路由:将请求转发到相应的后端服务
- 认证授权:统一处理用户身份验证和权限控制
- 限流熔断:防止系统过载和级联故障
- 监控日志:收集API调用的度量数据和日志
6.5 评估与度量术语
语义相似度(Semantic Similarity)
定义:衡量两个文本在语义层面相似程度的指标。
计算方法:
- 词嵌入相似度:使用Word2Vec、GloVe等词向量计算余弦相似度
- 句子嵌入相似度:使用BERT、Sentence-BERT等模型生成句子向量
- 语义角色标注:比较文本的语义结构和角色关系
评估应用:在提示工程中,语义相似度用于评估生成的答案与期望答案的匹配程度。
BLEU分数(Bilingual Evaluation Understudy)
定义:评估机器翻译质量的指标,通过比较生成文本与参考文本的n-gram重叠度计算。
计算公式:
BLEU = BP × exp(∑(w_n × log(p_n)))
其中:
- BP是短句惩罚因子(Brevity Penalty)
- p_n是n-gram精确度
- w_n是n-gram权重
局限性:
- 只考虑精确匹配,忽略语义相似性
- 对词序敏感,可能低估合理的改写
- 无法评估创造性和原创性
困惑度(Perplexity)
定义:语言模型对文本预测不确定性的度量,数值越低表示模型对文本的预测能力越强。
数学定义:
PPL(W) = 2^(-1/N × ∑log₂P(w_i|context))
其中W是词序列,N是词数,P(w_i|context)是给定上下文条件下词w_i的预测概率。
实际意义:困惑度为N意味着模型在每个位置平均"困惑"于N个等概率的选择之间。
七、实战案例分析:理论到应用的完整转化
7.1 金融风险评估系统的提示工程实践
业务需求与技术挑战
业务背景:某大型银行需要构建AI驱动的信贷风险评估系统,要求在保证高准确性的同时,提供可解释的决策依据。
核心挑战:
- 监管合规:需要满足银行业监管要求的可解释性和可审计性
- 准确性要求:误判可能导致重大财务损失
- 实时性需求:支持在线信贷审批的时效要求
- 多维度分析:整合财务数据、行为数据、市场数据等多源信息
分层提示架构设计
第一层:数据理解与预处理
data_analysis_prompt = """
你是专业的金融数据分析师。请按以下结构分析客户数据:1. 基本信息概览- 年龄、收入、职业稳定性- 婚姻状况、教育背景2. 财务状况分析- 资产负债比例- 收入支出结构- 现金流状况3. 信用历史评估- 历史违约记录- 信用卡使用模式- 贷款偿还历史4. 风险信号识别- 异常交易模式- 收入波动性- 债务集中度请以JSON格式输出分析结果,确保每个判断都有具体数据支撑。客户数据:{customer_data}
"""
第二层:风险评估与决策建议
risk_assessment_prompt = """
基于以下数据分析结果,请作为高级风险管理专家进行信贷风险评估:数据分析:{analysis_result}请按以下框架进行评估:1. 风险等级判定(1-10分,10分最高风险)- 违约概率预估- 置信区间范围- 关键风险因素2. 决策建议- 是否批准贷款- 建议贷款额度- 风险缓释措施3. 监控建议- 重点关注指标- 预警阈值设定- 复评周期建议4. 合规性说明- 决策依据梳理- 监管要求符合性- 文档化建议要求:
- 每个判断必须有明确的数据支撑
- 提供量化的风险指标
- 确保决策过程可追溯
- 考虑监管合规要求输出格式:结构化JSON,包含所有评估要素和置信度。
"""
多模型验证机制
交叉验证架构:
class RiskAssessmentValidator:def __init__(self):self.models = {'primary': 'gpt-4-turbo','secondary': 'claude-3-opus','tertiary': 'qwen-72b'}self.consistency_threshold = 0.8async def validate_assessment(self, customer_data):"""多模型交叉验证风险评估"""results = {}# 并行调用多个模型tasks = []for model_name, model_id in self.models.items():task = self.single_model_assessment(model_id, customer_data)tasks.append((model_name, task))# 收集结果for model_name, task in tasks:try:result = await taskresults[model_name] = resultexcept Exception as e:logger.error(f"Model {model_name} failed: {e}")results[model_name] = None# 一致性检查consistency_score = self.calculate_consistency(results)if consistency_score >= self.consistency_threshold:return self.synthesize_results(results)else:# 一致性不足,触发人工审核return await self.escalate_to_human_review(customer_data, results, consistency_score)def calculate_consistency(self, results):"""计算模型间一致性"""valid_results = [r for r in results.values() if r is not None]if len(valid_results) < 2:return 0.0# 比较风险评分scores = [r['risk_score'] for r in valid_results]score_std = np.std(scores)score_consistency = max(0, 1 - (score_std / 10)) # 标准化到0-1# 比较决策建议decisions = [r['decision'] for r in valid_results]decision_consistency = len(set(decisions)) == 1return (score_consistency + decision_consistency) / 2
7.2 多语言客户服务系统的适配策略
跨文化交流的提示设计
文化适配性考虑:
cultural_adaptation_template = """
你是{language}地区的专业客服代表,需要考虑以下文化特点:{language}客户服务文化特点:
{cultural_context}沟通风格要求:
- 敬语使用:{honorific_usage}
- 直接性程度:{directness_level}
- 情感表达:{emotional_expression}
- 问题解决方式:{problem_solving_style}客户问题:{customer_query}
客户情绪状态:{customer_emotion}
历史交互记录:{interaction_history}请提供适合的回复,确保:
1. 符合当地文化礼仪
2. 准确理解客户需求
3. 提供有效解决方案
4. 维护良好客户关系回复格式:
- 情感回应:[表达理解和关心]
- 问题确认:[确认理解客户问题]
- 解决方案:[提供具体解决步骤]
- 后续安排:[说明后续跟进计划]
"""
动态语言模型选择:
class MultilingualServiceRouter:def __init__(self):self.language_models = {'zh-CN': {'primary': 'qwen-turbo', 'fallback': 'gpt-4'},'zh-TW': {'primary': 'claude-3-haiku', 'fallback': 'gpt-4'},'en': {'primary': 'gpt-4-turbo', 'fallback': 'claude-3-opus'},'ja': {'primary': 'gpt-4', 'fallback': 'claude-3-sonnet'},'ko': {'primary': 'gpt-4', 'fallback': 'claude-3-haiku'}}self.cultural_contexts = {'zh-CN': {'honorific_usage': '适度使用敬语,体现专业性','directness_level': '相对直接,但保持礼貌','emotional_expression': '温和表达,避免过度情绪化','problem_solving_style': '系统性分析,提供详细步骤'},'ja': {'honorific_usage': '严格使用敬语系统(尊敬语、谦让语)','directness_level': '间接表达,避免直接拒绝','emotional_expression': '克制表达,重视和谐','problem_solving_style': '细致入微,关注每个细节'}}async def route_and_respond(self, query, language, customer_profile):"""根据语言和文化背景路由请求"""# 选择合适的模型model_config = self.language_models.get(language)if not model_config:model_config = self.language_models['en'] # 默认英文# 构建文化适配的提示cultural_context = self.cultural_contexts.get(language, {})prompt = cultural_adaptation_template.format(language=language,cultural_context=cultural_context,honorific_usage=cultural_context.get('honorific_usage', '标准礼貌用语'),directness_level=cultural_context.get('directness_level', '适度直接'),emotional_expression=cultural_context.get('emotional_expression', '专业友好'),problem_solving_style=cultural_context.get('problem_solving_style', '系统化解决'),customer_query=query,customer_emotion=self.detect_emotion(query),interaction_history=customer_profile.get('history', []))# 尝试主要模型try:response = await self.call_model(model_config['primary'], prompt)return await self.post_process_response(response, language)except Exception as e:# 降级到备用模型logger.warning(f"Primary model failed: {e}")response = await self.call_model(model_config['fallback'], prompt)return await self.post_process_response(response, language)
7.3 教育内容生成系统的个性化实现
认知水平适应性设计
布鲁姆分类法的提示应用:
bloom_taxonomy_prompts = {'remember': """作为教育专家,请为{grade_level}学生设计{subject}的记忆练习:学习目标:{learning_objective}认知层次:记忆(Bloom分类法第1层)请创建以下类型的练习:1. 关键概念识别2. 重要事实回忆3. 术语定义匹配4. 时间线排序要求:- 难度适合{grade_level}学生- 提供即时反馈- 包含记忆策略提示- 设计5-10个练习题""",'analyze': """作为高级教育设计师,请为{grade_level}学生创建{subject}的分析任务:学习目标:{learning_objective}认知层次:分析(Bloom分类法第4层)请设计包含以下要素的分析任务:1. 问题分解练习2. 模式识别活动3. 因果关系分析4. 比较对比任务设计原则:- 激发批判性思维- 提供分析框架- 鼓励多角度思考- 包含自我评估标准""",'create': """请设计{subject}创造性学习任务,培养{grade_level}学生的创新能力:学习目标:{learning_objective}认知层次:创造(Bloom分类法第6层)创造性任务类型:1. 原创作品设计2. 解决方案生成3. 概念重组应用4. 未来情境预测评估框架:- 原创性(25%)- 实用性(25%)- 完整性(25%)- 表达质量(25%)"""
}
多模态学习路径设计
学习风格适应系统:
class AdaptiveLearningPathGenerator:def __init__(self):self.learning_styles = {'visual': {'content_types': ['图表', '思维导图', '流程图', '信息图'],'prompt_modifiers': ['请用视觉化的方式展示','创建相关的图表说明','提供空间组织的信息']},'auditory': {'content_types': ['讲解脚本', '对话练习', '音频内容', '讨论问题'],'prompt_modifiers': ['设计适合朗读的内容','包含对话和讨论环节','提供韵律和节奏变化']},'kinesthetic': {'content_types': ['实践活动', '动手实验', '角色扮演', '游戏化学习'],'prompt_modifiers': ['设计动手操作活动','创建体验式学习场景','包含身体参与的元素']}}async def generate_personalized_content(self, student_profile, lesson_topic):"""生成个性化学习内容"""# 分析学生特征learning_style = student_profile['learning_style']cognitive_level = student_profile['cognitive_level']interests = student_profile['interests']prior_knowledge = student_profile['prior_knowledge']# 构建适应性提示base_prompt = f"""为学生创建关于{lesson_topic}的个性化学习内容:学生档案:- 学习风格:{learning_style}- 认知水平:{cognitive_level}- 兴趣爱好:{', '.join(interests)}- 先验知识:{prior_knowledge}内容要求:"""# 添加学习风格特定的修饰style_config = self.learning_styles[learning_style]for modifier in style_config['prompt_modifiers']:base_prompt += f"\n- {modifier}"# 添加认知水平适应if cognitive_level == 'beginner':base_prompt += "\n- 从基础概念开始,逐步深入"base_prompt += "\n- 提供大量具体例子"base_prompt += "\n- 使用简单明了的语言"elif cognitive_level == 'advanced':base_prompt += "\n- 快速回顾基础,重点讲解高级概念"base_prompt += "\n- 提供挑战性的思考问题"base_prompt += "\n- 鼓励独立探索和研究"# 兴趣整合base_prompt += f"\n- 结合学生的兴趣({', '.join(interests)})设计相关案例"# 生成内容content = await self.llm_call(base_prompt)# 后处理和质量检查return await self.post_process_educational_content(content, student_profile)async def assess_learning_progress(self, student_id, content_id, interaction_data):"""评估学习进展并调整内容"""assessment_prompt = f"""分析学生的学习交互数据并提供个性化反馈:交互数据:{interaction_data}请评估:1. 理解程度(1-10分)2. 参与度(1-10分)3. 困难点识别4. 学习偏好分析基于评估结果,请提供:1. 个性化反馈2. 学习建议3. 下一步学习内容推荐4. 学习策略调整建议"""assessment = await self.llm_call(assessment_prompt)# 更新学生档案await self.update_student_profile(student_id, assessment)return assessment
八、未来趋势与发展方向
8.1 技术演进的关键趋势
多模态融合的深度发展
视觉-语言-音频的统一处理将成为下一代AI系统的标志性特征。这种融合不仅体现在输入层面,更重要的是在推理和生成过程中实现真正的多模态理解。
未来的提示工程将需要考虑:
- 跨模态的语义对齐:确保不同模态信息的一致性解释
- 模态特定的提示设计:针对视觉、听觉、触觉等不同感官通道的优化
- 多模态推理链:在包含多种信息类型的复杂推理中维护逻辑一致性
神经符号计算的成熟应用
神经符号AI(Neuro-Symbolic AI)代表了连接主义和符号主义的融合趋势。这种方法将神经网络的学习能力与符号推理的精确性相结合。
在提示工程中,这意味着:
- 逻辑约束的嵌入:在生成过程中强制执行逻辑规则和约束
- 可验证的推理过程:生成可以被形式化验证的推理步骤
- 知识图谱的深度整合:将结构化知识无缝集成到语言生成中
8.2 应用模式的范式转变
从工具使用到认知伙伴
AI系统正从被动的工具转变为主动的认知伙伴。这种转变将重新定义人机交互的本质:
协作式问题解决:
- AI主动提出问题和假设
- 人类和AI共同构建解决方案
- 动态角色分配和任务协调
持续学习和适应:
- 系统从每次交互中学习用户偏好
- 自动调整交流风格和内容深度
- 预测用户需求并主动提供支持
领域专业化的深度发展
垂直领域的AI专家将成为主流应用模式。这些系统不仅理解领域知识,更重要的是掌握领域特定的思维方式和问题解决策略。
专业化特征:
- 领域语言的精确掌握:理解专业术语的细微差别和语境
- 行业标准的自动遵循:内化行业规范和最佳实践
- 专家级判断的模拟:在复杂情况下做出专业水准的决策
8.3 伦理与安全的系统性考虑
可解释AI的标准化
可解释性将从技术特性转变为基本要求。未来的AI系统必须能够:
- 决策过程的透明化:清晰展示推理的每个步骤
- 不确定性的量化表达:准确传达置信度和风险
- 偏见的主动识别:检测和缓解各种形式的偏见
隐私保护的技术创新
联邦学习和差分隐私等技术将成为AI应用的标准配置:
- 去中心化的模型训练:在不共享原始数据的情况下改进模型
- 隐私保护的个性化:在保护用户隐私的前提下提供个性化服务
- 数据最小化原则:只收集和使用完成任务所必需的最少数据
8.4 人才培养与技能要求的演变
跨学科能力的重要性
未来的提示工程师需要具备:
技术基础:
- 深度学习和自然语言处理的扎实理论基础
- 软件工程和系统设计的实践能力
- 数据科学和统计分析的专业技能
领域专业知识:
- 目标应用领域的深入理解
- 行业标准和最佳实践的熟悉
- 用户需求和痛点的敏锐洞察
人文社科素养:
- 认知科学和心理学的理论基础
- 语言学和交流理论的应用能力
- 伦理学和社会责任的价值判断
持续学习的重要性
AI技术的快速发展要求从业者具备终身学习的能力:
- 技术更新的快速适应:跟上新模型、新方法的发展节奏
- 应用场景的敏锐洞察:识别新的应用机会和商业价值
- 跨界合作的开放心态:与不同背景的专家有效协作
结语:迈向智能协作的新时代
提示词工程作为人工智能时代的核心技能,其重要性将随着AI系统的普及而不断提升。本指南从认知科学的理论基础出发,通过逻辑学的严密框架,结合工程实践的具体方法,为读者构建了完整的知识体系。
我们正站在人机协作的新时代门槛上。在这个时代,成功不再仅仅取决于技术的掌握,更在于理解AI的本质、洞察人类需求的深层逻辑,以及设计有效交互方式的艺术。提示词工程正是这种艺术与科学结合的典型体现。
掌握提示词工程的精髓,需要我们既要有工程师的严谨思维,又要有艺术家的创造灵感;既要深入技术细节,又要保持战略高度;既要追求效率优化,又要坚持伦理原则。只有在这种平衡中,我们才能真正发挥AI的潜力,创造出既强大又负责任的智能系统。
未来属于那些能够与AI有效协作的个人和组织。而提示词工程,正是开启这种协作的钥匙。让我们以开放的心态、严谨的方法和创新的精神,共同探索人机协作的无限可能。
相关文章:
大语言模型提示词(LLM Prompt)工程系统性学习指南:从理论基础到实战应用的完整体系
文章目录 前言:为什么提示词工程成为AI时代的核心技能一、提示词的本质探源:认知科学与逻辑学的理论基础1.1 认知科学视角下的提示词本质信息处理理论的深层机制图式理论的实际应用认知负荷理论的优化策略 1.2 逻辑学框架下的提示词架构形式逻辑的三段论…...
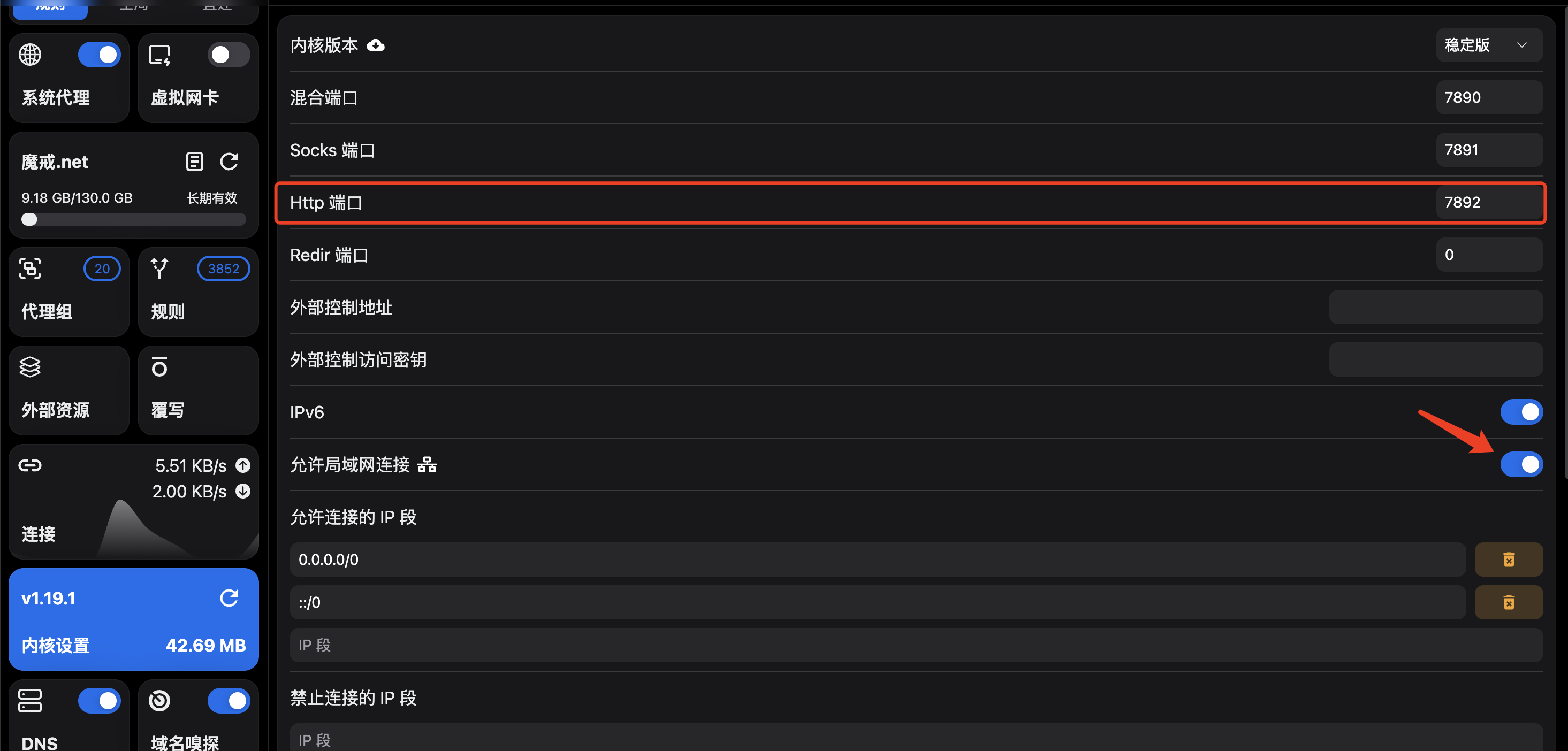
如何基于Mihomo Party http端口配置git与bash命令行代理
如何基于Mihomo Party http端口配置git与bash命令行代理 1. 确定Mihomo Party http端口配置 点击内核设置后即可查看 默认7892端口,开启允许局域网连接 2. 配置git代理 配置本机代理可以使用 127.0.0.1 配置局域网内其它机代理需要使用本机的非回环地址 IP&am…...

CMake 为 Debug 版本的库或可执行文件添加 d 后缀
在使用 CMake 构建项目时,我们经常需要区分 Debug 和 Release 构建版本。一个常见的做法是为 Debug 版本的库或可执行文件添加后缀(如 d),例如 libmylibd.so 或 myappd.exe。 本文将介绍几种在 CMake 中实现为 Debug 版本自动添加 d 后缀的方法。 方法一:使用 CMAKE_DEBU…...

Linux 特殊权限位详解:SetUID, SetGID, Sticky Bit
Linux 特殊权限位详解:SetUID, SetGID, Sticky Bit 在Linux权限系统中,除了基本的读、写(w)、执行(x)权限外,还有三个特殊权限位:SetUID、SetGID和Sticky Bit。这些权限位提供了更精细的权限控制机制,尤其在需要临时提升权限或管理共享资源时非常有用。 一、SetUID (s位…...
埃文科技智能数据引擎产品入选《中国网络安全细分领域产品名录》
嘶吼安全产业研究院发布《中国网络安全细分领域产品名录》,埃文科技智能数据引擎产品成功入选数据分级分类产品名录。 在数字化转型加速的今天,网络安全已成为企业生存与发展的核心基石,为了解这一蓬勃发展的产业格局,嘶吼安全产业…...

使用VTK还是OpenGL集成到qt程序里哪个好?
在Qt程序中集成VTK与OpenGL:选择哪个更好? 在Qt程序中实现三维可视化时,开发者常常面临一个选择:是使用VTK(Visualization Toolkit)还是OpenGL(Open Graphics Library)。这两种技术…...

Java-IO流之打印流详解
Java-IO流之打印流详解 一、打印流概述1.1 什么是打印流1.2 打印流的特点1.3 打印流的应用场景 二、PrintStream详解2.1 基本概念2.2 构造函数2.3 核心方法2.4 使用示例 三、PrintWriter详解3.1 基本概念3.2 构造函数3.3 核心方法3.4 使用示例 四、PrintStream与PrintWriter的比…...

高效图像处理:使用 Pillow 进行格式转换与优化
高效图像处理:使用 Pillow 进行格式转换与优化 1. 背景引入 在图像处理应用中,格式转换、裁剪、压缩等操作是常见需求。Python 的 Pillow 库基于 PIL(Python Imaging Library),提供 轻量、强大 的图像处理能力,广泛用于 Web 开发、数据分析、机器学习 等领域。 本文将…...

Github 2025-06-06 Java开源项目日报Top10
根据Github Trendings的统计,今日(2025-06-06统计)共有10个项目上榜。根据开发语言中项目的数量,汇总情况如下: 开发语言项目数量Java项目10TypeScript项目1Java实现的算法集合:使用Gitpod.io进行编辑和贡献 创建周期:2883 天开发语言:Java协议类型:MIT LicenseStar数量…...

使用 Ansible 在 Windows 服务器上安装 SSL 证书
在本教程中,我将向您展示如何使用 Ansible 在 Windows 服务器上安装 SSL 证书。使用 Ansible 自动化 SSL 证书安装过程可以提高 IT 运营的效率、一致性和协作性。我将介绍以下步骤: 将 SSL 证书文件复制到服务器将 PFX 证书导入指定的存储区获取导入的证…...

厂区能源监控系统:网关赋能下的高效能源管理与环保监测
在现代工业生产领域,能源的有效利用与环境保护是企业实现可持续发展的两大关键要素。厂区能源监控系统借助先进的信息技术与自动化控制手段,对厂区内能源消耗及污水处理等核心环节展开实时监控与精细化管理。其中,御控网关作为系统关键枢纽&a…...

CentOS 7 如何安装llvm-project-10.0.0?
CentOS 7 如何安装llvm-project-10.0.0? 需要先升级gcc至7.5版本,详见CentOS 7如何编译安装升级gcc版本?一文 # 备份之前的yum .repo文件至 /tmp/repo_bak 目录 mkdir -p /tmp/repo_bak && cd /etc/yum.repo.d && /bin/mv ./*.repo …...

Cursor 1.0 的核心功能亮点及技术价值分析
Cursor 1.0 的核心功能亮点及技术价值分析 结合官方更新和开发者实测整理: 🛠️ 一、BugBot:智能自动化代码审查 功能亮点:深度集成 GitHub,自动扫描 Pull Request(PR)中的潜在 Bug(…...
)
软考 系统架构设计师系列知识点之杂项集萃(83)
接前一篇文章:软考 系统架构设计师系列知识点之杂项集萃(82) 第150题 体系结构权衡分析方法(Architecture Tradeoff Analysis Method,ATAM)是一种常见的系统架构评估框架,该框架主要关注系统的…...
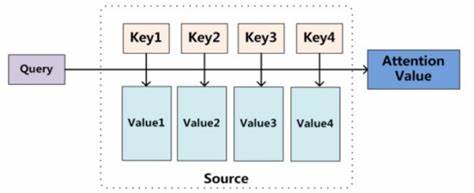
NLP学习路线图(二十六):自注意力机制
一、为何需要你?序列建模的困境 在你出现之前,循环神经网络(RNN)及其变种LSTM、GRU是处理序列数据(如文本、语音、时间序列)的主流工具。它们按顺序逐个处理输入元素,将历史信息压缩在一个隐藏…...

Unity3D仿星露谷物语开发60之定制角色其他部位
1、目标 上一篇中定制了角色的衬衫、手臂。 本篇中将定制角色其他部位的图形,包括:裤子、发型、皮肤、帽子等。 2、定制裤子 (1)修改ApplyCharacterCustomisation.cs脚本 我们需要设置一个输入框选择裤子的颜色。 // Select …...
)
C++动态链接库封装,供C#/C++ 等编程语言使用——C++动态链接库概述(总)
目录: 一、前言及背景1.1需求描述1.2常见编程语言对比1.3应用背景 二、C对外接口2.1C对外封装2.2基于目标平台封装接口形式 三、系列文章汇总 一、前言及背景 1.1需求描述 不同的编程语言,具有不同的编程生态环境,对于项目应用来说ÿ…...
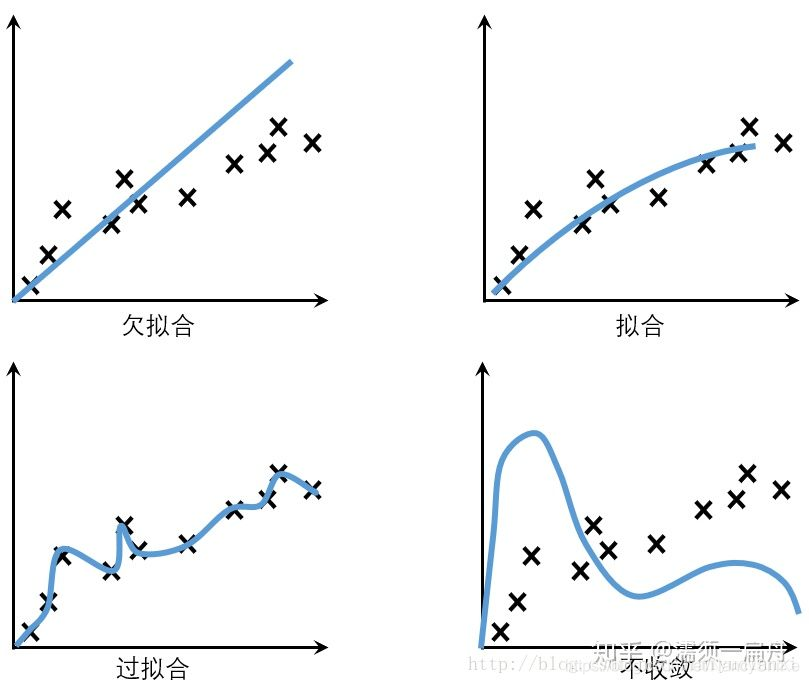
Google机器学习实践指南(机器学习模型泛化能力)
🔥 Google机器学习(14)-机器学习模型泛化能力解析 Google机器学习(14)-机器学习模型泛化原理与优化(约10分钟) 一、泛化问题引入 ▲ 模型表现对比: 假设森林中树木健康状况预测模型: 图1:初始模型表现 …...

MySQL性能调优:Mysql8高频面试题汇总
1,主键和唯一键有什么区别? 主键不能重复,不能为空,唯一键不能重复,可以为空。 建立主键的目的是让外键来引用。 一个表最多只有一个主键,但可以有很多唯一键 2,MySQL常用的存储引擎有哪些&…...

Neo4j 数据建模:原理、技术与实践指南
Neo4j 作为领先的图数据库,其核心优势在于利用图结构直观地表达和高效地查询复杂关系。其数据建模理念与传统关系型数据库截然不同,专注于实体(节点)及其连接(关系)。以下基于官方文档,系统阐述其建模原理、关键技术、实用技巧及最佳实践: 一、 核心原理:以关系为中心…...

【数据结构知识分享】顺序表详解
一、存储结构 物理相邻性: 若元素 a 和 b 逻辑相邻,则它们在内存中的地址也连续(如 &a[i1] &a[i] sizeof(ElemType))。 内存布局x: 基地址 索引 元素大小,通过首地址直接计算任意位置地址。 …...
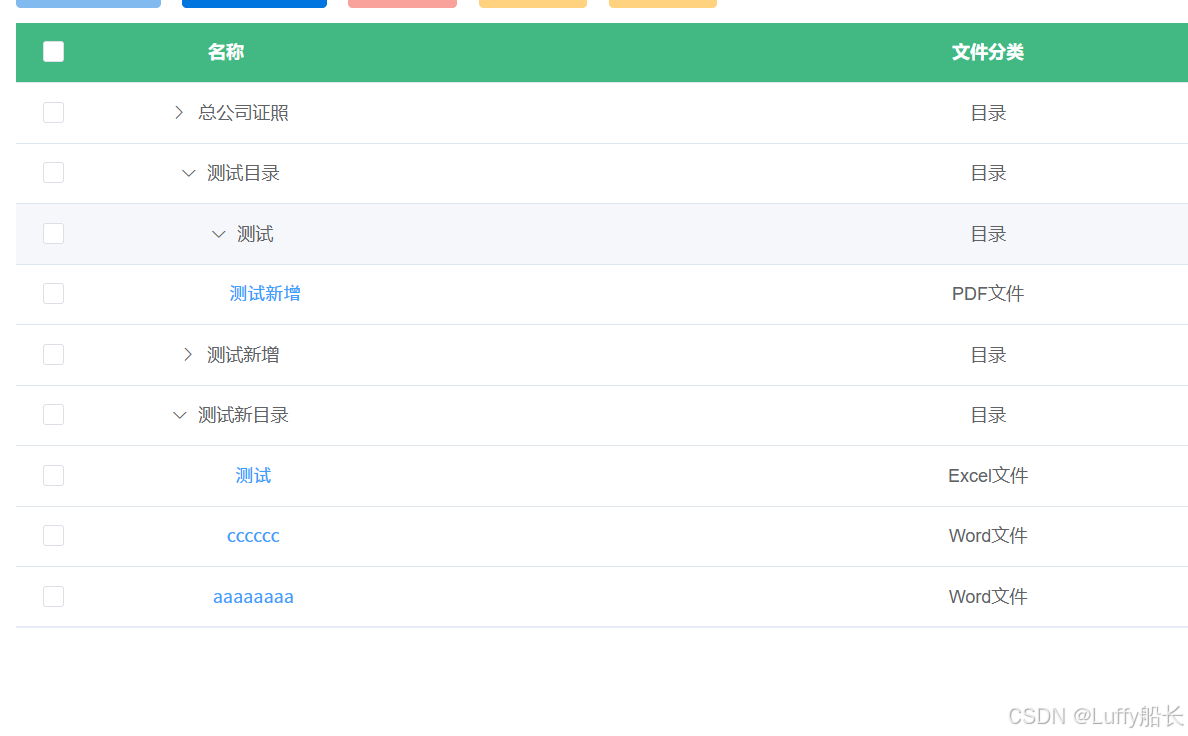
vue+elementUI+springboot实现文件合并前端展示文件类型
项目场景: element的table上传文件并渲染出文件名称点击所属行可以查看文件,并且可以导出合并文件,此文章是记录合并文档前端展示的帖子 解决方案: 后端定义三个工具类 分别是pdf,doc和word的excle的目前我没整 word的工具类 package com.sc.modules…...
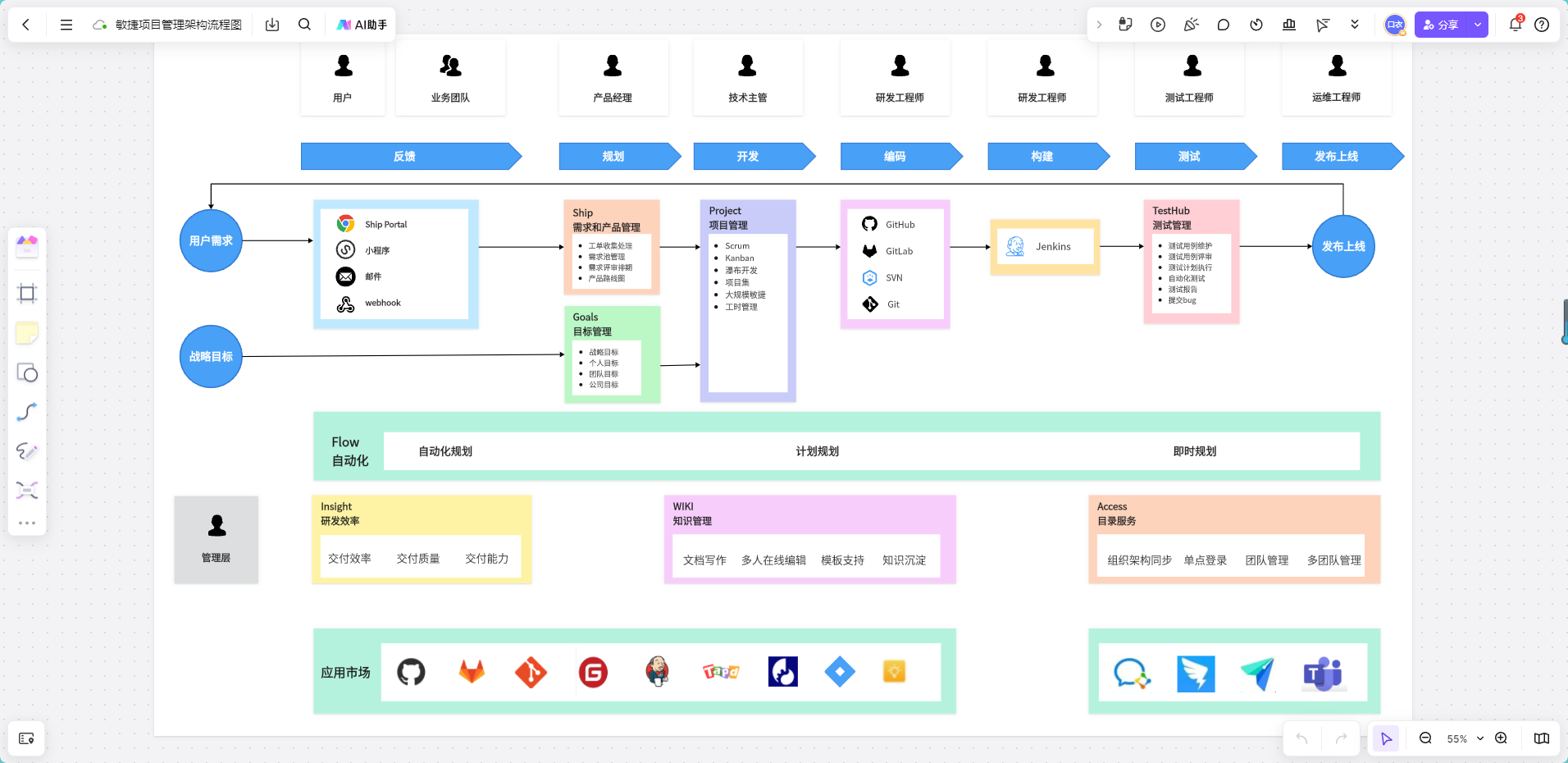
高效绘制业务流程图!专业模板免费下载
在复杂的业务流程管理中,可视化工具已成为提升效能的核心基础设施。为助力开发者、项目经理及业务架构师高效落地流程标准化,本文将为你精选5套开箱即用的专业流程图模板。这些模板覆盖跨部门协作、电商订单、客户服务等高频场景,具备以下核心…...
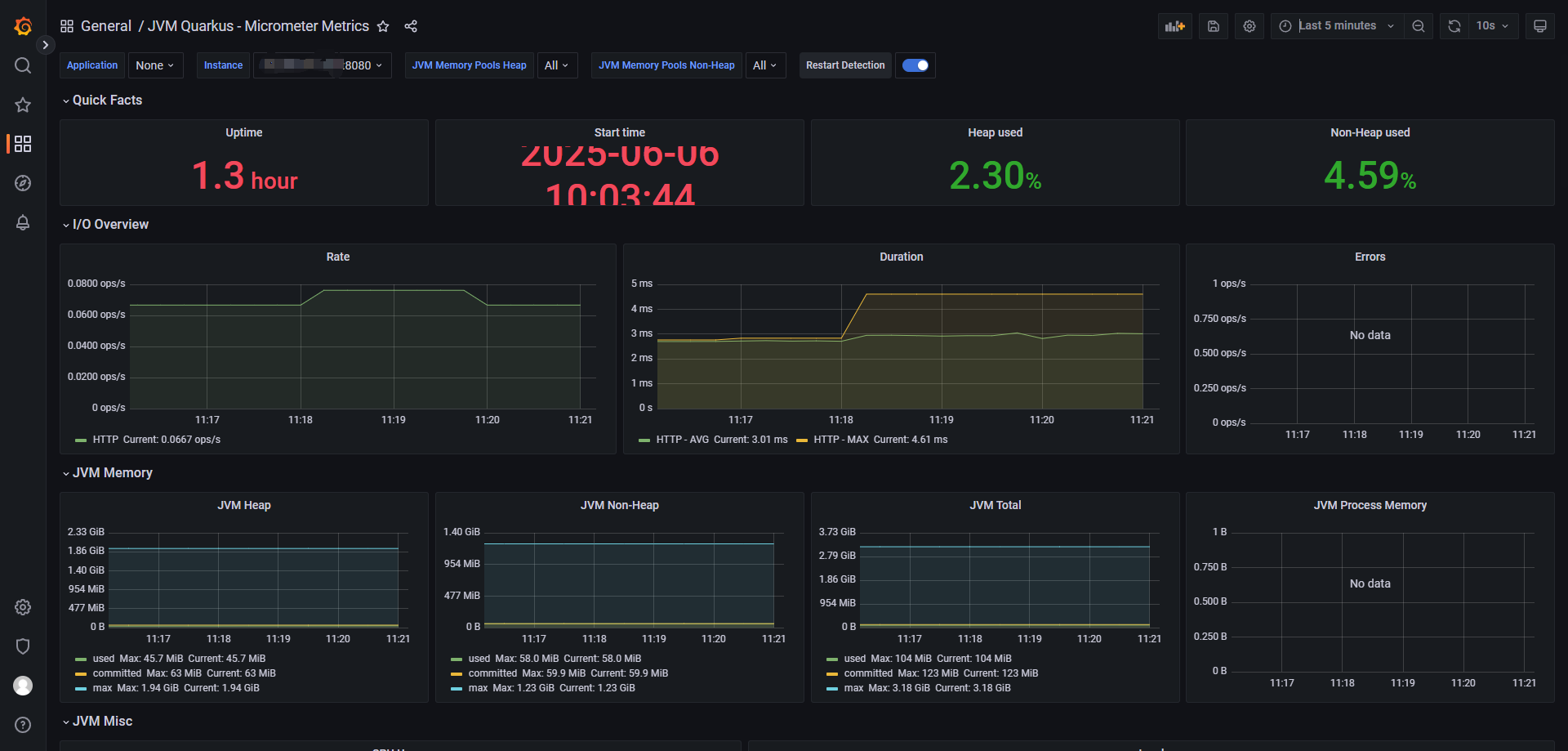
Spring Boot + Prometheus 实现应用监控(基于 Actuator 和 Micrometer)
文章目录 Spring Boot Prometheus 实现应用监控(基于 Actuator 和 Micrometer)环境准备示例结构启动和验证验证 Spring Boot 应用Prometheus 抓取配置(静态方式)Grafana 面板配置总结 Spring Boot Prometheus 实现应用监控&…...

PowerBI企业运营分析—列互换式中国式报表分析
PowerBI企业运营分析—列互换式中国式报表分析 欢迎来到Powerbi小课堂,在竞争激烈的市场环境中,企业运营分析平台成为提升竞争力的核心工具。 该平台通过高效整合多源数据,并实时监控关键指标,能够迅速揭示业务表现的全貌&#…...
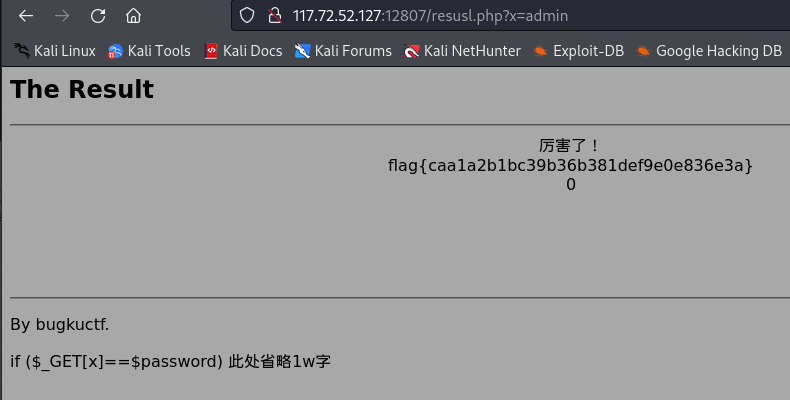
BugKu Web渗透之需要管理员
启动场景,打开网页,显示如下: 一般没有上面头绪的时候,就是两步:右键查看源代码 和 扫描网站目录。 步骤一: 右键查看源代码 和 扫描网站目录。 右键查看源代码没有发现异常。 于是扫描网站目录&…...
)
Java集合初始化:Lists.newArrayList vs new ArrayList()
文章目录 前言一、核心区别全景图二、代码实现深度对比1. 初始化方式对比2. 容量预分配机制 三、性能与底层原理1. 内存分配策略2. 基准测试数据(JMH) 四、Guava的进阶功能生态1. 集合转换2. 集合分片3. 不可变集合创建 五、最佳实践指南六、源码级实现解…...

VBA清空数据
列数转字母 Function CNtoW(ByVal num As Long) As String CNtoW Replace(Cells(1, num).Address(False, False), "1", "") End Function 字母转列数 Function CWtoN(ByVal AB As String) As Long CWtoN Range("a1:" & AB & &…...
综合知识答案和详解(回忆版))
【信息系统项目管理师-选择真题】2025上半年(第二批)综合知识答案和详解(回忆版)
更多内容请见: 备考信息系统项目管理师-专栏介绍和目录 文章目录 【第1题】【第2题】【第3题】【第4题】【第5题】【第6题】【第7题】【第8题】【第9题】【第10题】【第11题】【第12题】【第13题】【第14题】【第15题】【第16题】【第17题】【第18题】【第19题】【第20题】【第…...

Java Lambda 表达式的缺点和替代方案
Java 8 引入的 Lambda 表达式曾被誉为编写简洁、函数式代码的革命性工具。但说实话,它们并不是万能钥匙。它有不少问题,比如它没有宣传的那么易读,在某些场景下还带来性能开销。 作为一名多年与 Java 冗长语法搏斗的开发者,我找到了更注重清晰、可维护性和性能的替代方案。…...