NLP学习路线图(二十六):自注意力机制
一、为何需要你?序列建模的困境
在你出现之前,循环神经网络(RNN)及其变种LSTM、GRU是处理序列数据(如文本、语音、时间序列)的主流工具。它们按顺序逐个处理输入元素,将历史信息压缩在一个隐藏状态向量中传递。
-
瓶颈显现:
-
长程依赖遗忘: 随着序列增长,早期信息在传递过程中极易被稀释或丢失。想象理解一段长文时,开篇的关键人物在结尾被提及,RNN可能已“忘记”其重要性。
-
并行化困难: 顺序处理特性严重阻碍了利用现代GPU/TPU强大并行计算能力,训练效率低下。
-
信息瓶颈: 无论序列多长,RNN都试图将所有历史信息塞进一个固定长度的隐藏向量中,导致信息损失。
-
这些限制呼唤着一种能直接建模序列元素间任意距离依赖关系,且高度并行的机制。你——自注意力机制,应运而生。
二、深入你的核心:工作原理与数学解析
你的核心思想直击要害:序列中的每个元素,都应该能直接关注到序列中所有其他元素(包括自己),并根据它们的重要性(相关性)动态地聚合信息。 让我们拆解这一过程:
-
输入表示:
-
假设我们有一个输入序列,包含
n个元素(如单词):X = [x₁, x₂, ..., xₙ],其中每个x_i是一个d_model维的向量(通常是词嵌入)。 -
将
X堆叠成矩阵:X ∈ ℝ^(n × d_model)。
-
-
线性投影:生成Q, K, V:
-
为每个输入元素
x_i创建三个不同的向量表示:-
查询向量 (Query, q_i): 表示当前元素“正在寻找什么”。它像一个问题:“哪些信息与我相关?”
-
键向量 (Key, k_i): 表示当前元素“能提供什么”。它像一个标识符,用于匹配查询。
-
值向量 (Value, v_i): 表示当前元素“实际包含的信息内容”。它是在匹配成功后将被提取的信息。
-
-
通过可学习的权重矩阵
W^Q,W^K,W^V(每个维度为d_model × d_k或d_model × d_v,通常d_k = d_v)进行线性投影:Q = X * W^Q # Q ∈ ℝ^(n × d_k) K = X * W^K # K ∈ ℝ^(n × d_k) V = X * W^V # V ∈ ℝ^(n × d_v)
-
-
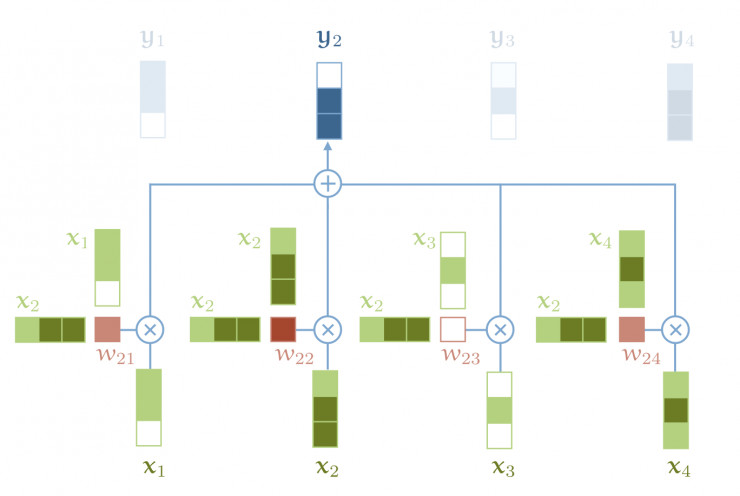
计算注意力分数:
-
目标:计算序列中 每个元素(作为查询) 对所有元素(包括自己,作为键)的“关注程度”(相关性分数)。
-
方法:计算查询向量
q_i与 所有 键向量k_j(j=1 to n) 的点积。点积衡量向量间的相似度(夹角越小,点积越大)。Score(q_i, k_j) = q_i · k_j^T -
将所有查询对所有键的分数组合起来,形成一个
n × n的注意力分数矩阵S:S = Q * K^T # S ∈ ℝ^(n × n) -
示例: 考虑句子 “The animal didn’t cross the street because it was too tired”。计算
it(作为Query) 的注意力分数时,理想情况下,it与animal和street的点积应较高(语义相关),而与didn’t、cross等的点积应较低。
-
-
缩放 (Scaling):
-
点积的值可能随着向量维度
d_k的增大而变得非常大(方差增大),导致Softmax后的梯度变得极小(梯度消失问题)。 -
解决方案:将分数除以
√d_k进行缩放,稳定梯度。S_scaled = S / √d_k
-
-
应用Softmax:获取注意力权重:
-
对
S_scaled矩阵的 每一行 应用Softmax函数。 -
作用: 将每个查询对应的那一行分数(与所有键的相关性)转换为概率分布(和为1)。
A = softmax(S_scaled, dim=-1) # A ∈ ℝ^(n × n) -
矩阵
A称为 注意力权重矩阵。元素A_ij表示当生成第i个位置的输出时,应该给予第j个输入位置多少关注度(权重)。 -
示例 (续): 对于
it对应的行,A_it, animal和A_it, street的权重会接近0.5(假设两者都相关),而其他位置的权重接近0。
-
-
加权求和:生成输出表示:
-
使用注意力权重矩阵
A对值向量矩阵V进行加权求和。 -
对于输出序列中的第
i个位置,其输出向量z_i是:z_i = Σ_j (A_ij * v_j) -
矩阵形式:
Z = A * V # Z ∈ ℝ^(n × d_v) -
输出矩阵
Z的每一行z_i是输入序列所有值向量的加权组合,权重由i位置对应的查询与所有键的匹配程度决定。 -
示例 (续):
z_it将是v_animal和v_street的加权组合(权重各约0.5),融合了这两个关键实体的信息,帮助模型正确理解it指代animal。
-
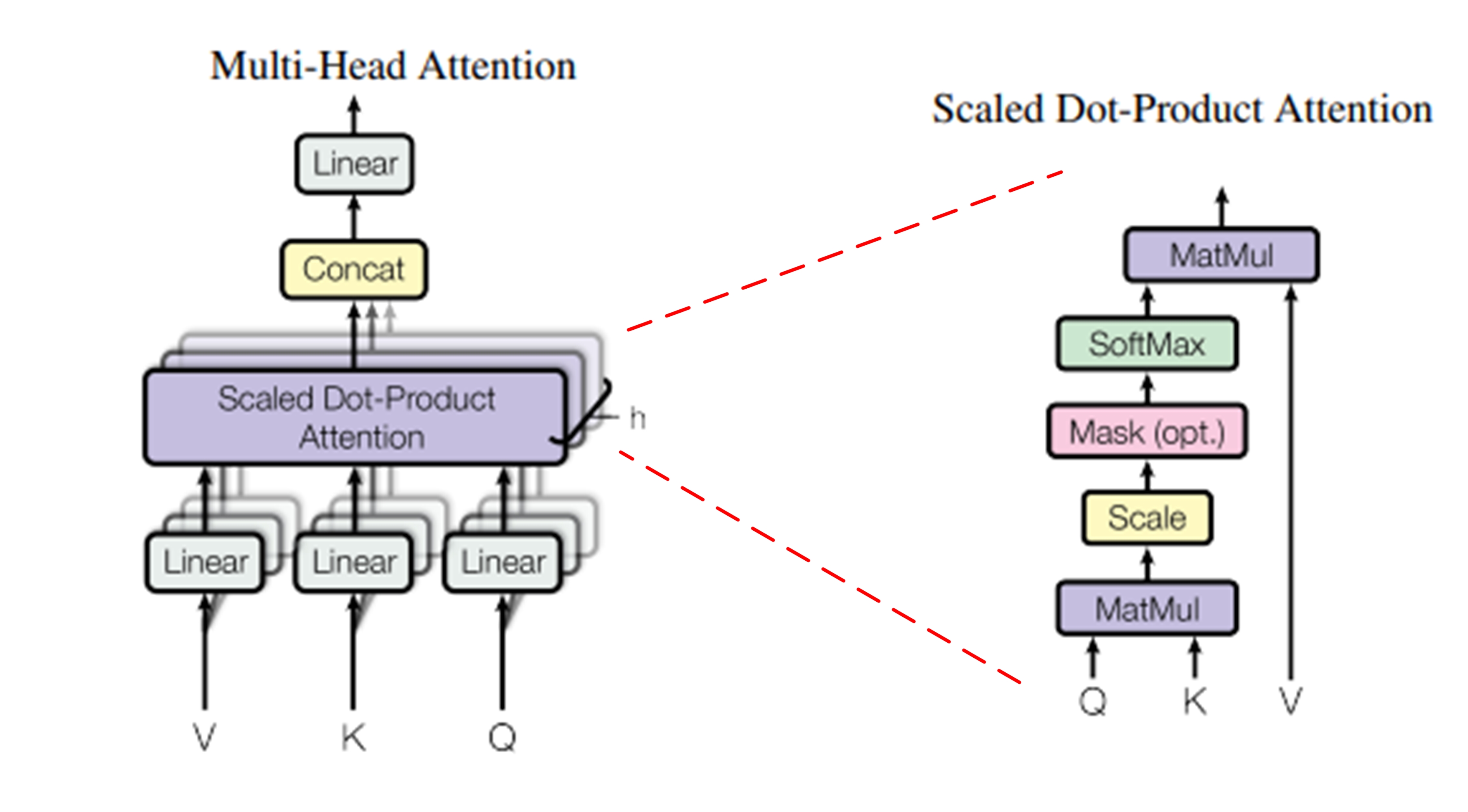
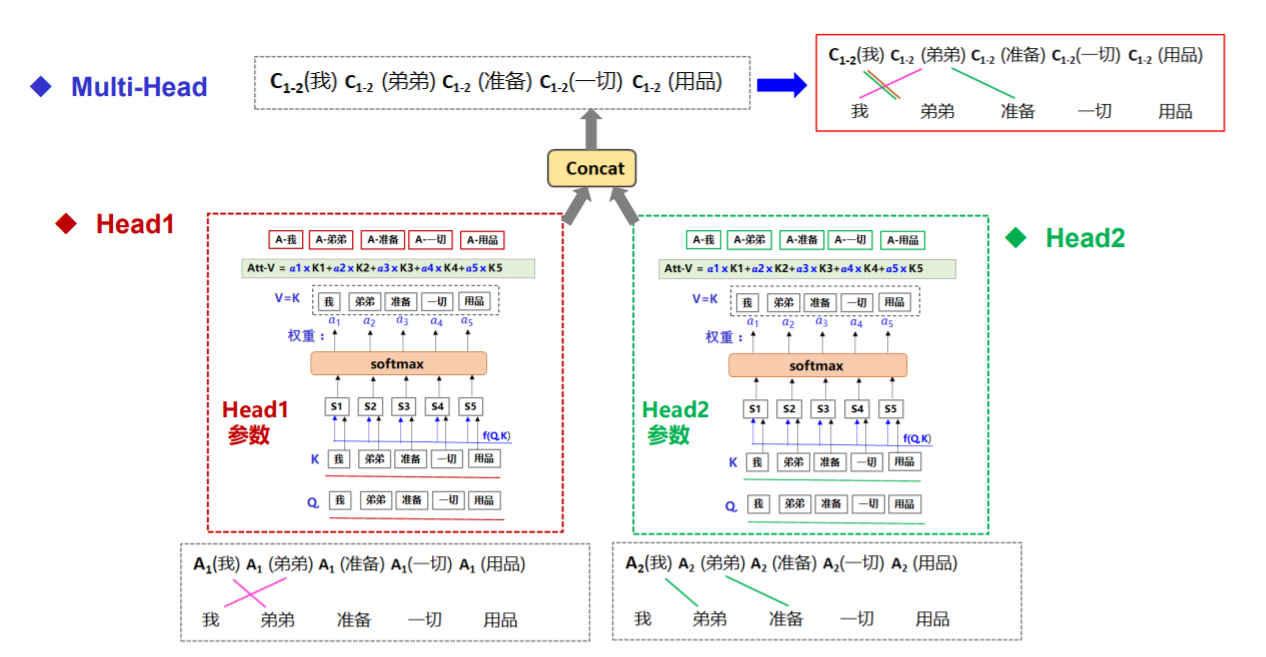
三、你的超能力:多头注意力 (Multi-Head Attention)
单一的自注意力机制捕捉到的关系模式可能有限。你进化出了更强大的形态——多头注意力:
-
并行化投影:
-
不再只使用一组
W^Q, W^K, W^V,而是使用h组不同的投影矩阵{W^Q_l, W^K_l, W^V_l} for l=1 to h。 -
将输入
X分别投影到h组不同的Q_l, K_l, V_l子空间。每组投影将输入向量映射到较低的维度(d_k' = d_k / h,d_v' = d_v / h)。
-
-
并行计算:
-
在每组投影后的
(Q_l, K_l, V_l)上 独立并行地 执行前面描述的缩放点积注意力计算,得到h个输出矩阵Z_l ∈ ℝ^(n × d_v')。
-
-
拼接与线性变换:
-
将所有
h个头的输出Z_l拼接 (Concatenate) 起来:Concat(Z_1, Z_2, ..., Z_h) ∈ ℝ^(n × (h * d_v'))。 -
通过一个可学习的线性投影矩阵
W^O ∈ ℝ^(h*d_v' × d_model)将拼接后的结果映射回原始的d_model维度:MultiHead(Q, K, V) = Concat(head_1, ..., head_h) * W^O where head_l = Attention(Q * W^Q_l, K * W^K_l, V * W^V_l)
-
-
为何强大?
-
捕捉不同关系模式: 不同的投影子空间允许每个“头”关注输入序列的不同方面或关系类型(例如,一个头关注句法依赖,一个头关注语义角色,一个头关注局部共现)。
-
增强表示能力: 相当于将模型的表征空间分解为多个子空间,并在这些子空间中学习不同的交互模式,最后再融合,极大地增强了模型的表达能力。
-
并行效率: 多个头的计算是完全独立的,可以高效并行。
-
四、位置信息的融入:位置编码 (Positional Encoding)
你有一个关键的特性:置换不变性 (Permutation Invariance)。输入序列的顺序改变(单词位置互换),只要内容相同,计算出的 Q, K, V 矩阵以及注意力权重矩阵 A 在行/列置换的意义下是相同的。这意味着你本身 无法感知元素的顺序信息!这对于理解语言(依赖词序)是灾难性的。
解决方案:位置编码 (Positional Encoding, PE)
-
思想: 为输入序列中每个元素的嵌入向量
x_i显式地注入其位置i的信息。 -
方法: 生成一个与输入嵌入
x_i维度相同 (d_model) 的位置向量p_i,然后将其加到x_i上:x'_i = x_i + p_i -
经典实现 (正弦/余弦波):
-
使用不同频率的正弦和余弦函数:
PE(pos, 2i) = sin(pos / 10000^(2i / d_model)) PE(pos, 2i+1) = cos(pos / 10000^(2i / d_model))-
pos:单词在序列中的位置(0, 1, 2, ...)。 -
i:维度索引(0 ≤ i < d_model/2)。
-
-
优点:
-
能唯一编码任意位置。
-
能相对轻松地学习到位置间的相对关系(
PE_pos + PE_offset可以表示为PE_pos的线性函数)。 -
值域有界([-1, 1]),适合模型处理。
-
-
-
可学习的位置嵌入 (Learned Positional Embeddings): 将位置
pos也视为一个需要学习的嵌入向量(类似词嵌入)。BERT等模型常用此方法。 -
作用: 通过
x'_i = x_i + p_i,你处理的实际输入就包含了“我是谁”(词义)和“我在哪”(位置)的信息,从而能够建模序列的顺序结构。
五、你在Transformer架构中的核心地位
你(通常以多头形式)是Transformer编码器和解码器层中无可替代的核心组件:
-
编码器 (Encoder):
-
输入:源序列(例如待翻译的句子)。
-
结构:由
N个相同的层堆叠而成。 -
每层核心子层:
-
多头自注意力层 (Multi-Head Self-Attention): 让序列中的每个单词关注源序列中所有单词(包括自身),学习源句内部的依赖关系。
-
前馈神经网络层 (Position-wise Feed-Forward Network): 对每个位置的表示进行独立变换(通常包含非线性激活)。
-
-
每个子层周围有:残差连接 (Residual Connection) + 层归一化 (Layer Normalization)。这是稳定深层训练的关键 (
SubLayerOutput = LayerNorm(x + SubLayer(x)))。 -
作用: 为源序列生成富含上下文信息的表示。
-
-
解码器 (Decoder):
-
输入:目标序列(例如正在生成的翻译句子),通常右移一位(Teacher Forcing训练)。
-
结构:也由
N个相同的层堆叠而成。 -
每层核心子层:
-
带掩码的多头自注意力层 (Masked Multi-Head Self-Attention): 让目标序列中的每个单词只能关注它自身及之前的位置(防止信息泄露,保证自回归生成)。这是通过在计算注意力分数时,将“未来”位置的分数设置为负无穷大(经Softmax后变为0)来实现的。
-
多头编码器-解码器注意力层 (Multi-Head Encoder-Decoder Attention): 这一层的
Q来自解码器上一层的输出,而K和V来自编码器最终的输出。这允许解码器中的每个位置关注源序列中的所有位置,获取与当前生成目标词最相关的源信息。 -
前馈神经网络层 (Position-wise Feed-Forward Network)。
-
-
同样,每个子层周围有残差连接和层归一化。
-
作用: 基于编码器提供的源信息以及已生成的目标序列,自回归地预测下一个目标词。
-
六、你带来的革命与深远影响
自注意力机制,你赋予了Transformer模型一系列颠覆性的优势:
-
无与伦比的长程依赖建模: 序列中任意两个元素间的依赖关系,无论距离多远,都只需一步计算即可建立联系。彻底解决了RNN的长程依赖难题。
-
极致并行计算: 矩阵乘法 (
Q*K^T,A*V) 是现代硬件加速(GPU/TPU)的绝佳搭档。训练速度比RNN快几个数量级。 -
强大的表征学习能力: 通过动态加权聚合全局信息,为序列中的每个元素生成高度上下文化的表示。多头机制进一步增强了捕捉复杂模式的能力。
-
架构简洁优雅: 核心计算基于线性变换和矩阵乘法,结构清晰,易于理解和扩展。
七、你的辉煌舞台:现代大模型的基石
你的思想已成为当今几乎所有最先进NLP模型的基石:
-
BERT (Bidirectional Encoder Representations from Transformers):
-
本质:仅使用Transformer编码器堆叠。
-
预训练任务:
-
Masked Language Model (MLM): 随机掩盖输入句子中的部分单词,让模型基于上下文预测被掩盖的词。这迫使模型学习强大的双向上下文表示。
-
Next Sentence Prediction (NSP): 判断两个句子是否是连续的上下文关系。
-
-
影响: 开创了“预训练+微调”范式。其强大的上下文表示能力在众多下游任务(文本分类、问答、NER等)上取得突破性进展。
-
-
GPT (Generative Pre-trained Transformer) 系列:
-
本质:仅使用Transformer解码器堆叠(注意:GPT的解码器块去除了编码器-解码器注意力层,只保留带掩码的自注意力和前馈层)。
-
预训练任务:自回归语言建模。 根据上文预测下一个词。强大的生成能力是其核心。
-
演进:
-
GPT-1:证明仅解码器架构的有效性。
-
GPT-2:更大规模,展示零样本/少样本学习潜力。
-
GPT-3:庞大规模(1750亿参数),强大的上下文学习 (In-Context Learning) 和提示 (Prompting) 能力震惊世界。
-
GPT-4 / ChatGPT:多模态、对话能力、指令遵循能力达到新高度。
-
-
影响: 引领了大语言模型 (LLM) 和生成式AI的浪潮。
-
-
其他闪耀明星:
-
T5 (Text-to-Text Transfer Transformer): 将所有NLP任务统一转换为“文本到文本”的格式(如输入
"translate English to German: ..."),使用标准的编码器-解码器Transformer架构处理。 -
RoBERTa, ALBERT, DistilBERT 等: 对BERT的优化(如动态掩码、移除NSP、参数共享、模型蒸馏),追求更高效或更强大的表示。
-
Transformer-XL, Longformer, BigBird: 致力于克服Transformer在超长序列上计算复杂度高 (
O(n²)) 和内存消耗大的问题,引入分块、稀疏注意力(局部+全局)、随机注意力等机制。 -
ViT (Vision Transformer): 开创性地将Transformer应用于计算机视觉。将图像分割成块 (Patches),视为序列输入Transformer编码器处理,在图像分类等任务上媲美甚至超越CNN。证明了你的通用性。
-
多模态模型 (CLIP, DALL·E, Flamingo): 利用Transformer架构处理文本、图像、音频等多种模态信息,学习它们之间的对齐和联合表示。
-
相关文章:
NLP学习路线图(二十六):自注意力机制
一、为何需要你?序列建模的困境 在你出现之前,循环神经网络(RNN)及其变种LSTM、GRU是处理序列数据(如文本、语音、时间序列)的主流工具。它们按顺序逐个处理输入元素,将历史信息压缩在一个隐藏…...

Unity3D仿星露谷物语开发60之定制角色其他部位
1、目标 上一篇中定制了角色的衬衫、手臂。 本篇中将定制角色其他部位的图形,包括:裤子、发型、皮肤、帽子等。 2、定制裤子 (1)修改ApplyCharacterCustomisation.cs脚本 我们需要设置一个输入框选择裤子的颜色。 // Select …...
)
C++动态链接库封装,供C#/C++ 等编程语言使用——C++动态链接库概述(总)
目录: 一、前言及背景1.1需求描述1.2常见编程语言对比1.3应用背景 二、C对外接口2.1C对外封装2.2基于目标平台封装接口形式 三、系列文章汇总 一、前言及背景 1.1需求描述 不同的编程语言,具有不同的编程生态环境,对于项目应用来说ÿ…...
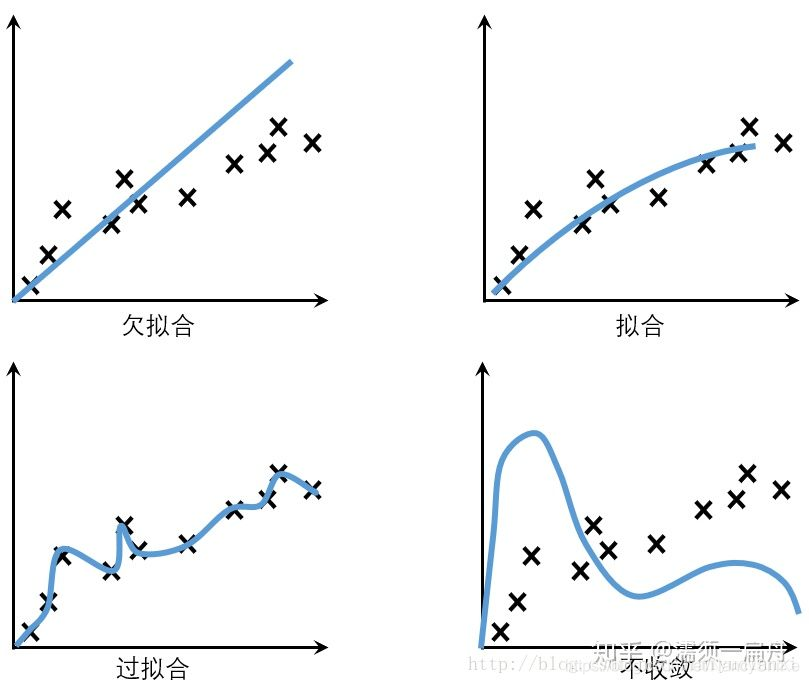
Google机器学习实践指南(机器学习模型泛化能力)
🔥 Google机器学习(14)-机器学习模型泛化能力解析 Google机器学习(14)-机器学习模型泛化原理与优化(约10分钟) 一、泛化问题引入 ▲ 模型表现对比: 假设森林中树木健康状况预测模型: 图1:初始模型表现 …...

MySQL性能调优:Mysql8高频面试题汇总
1,主键和唯一键有什么区别? 主键不能重复,不能为空,唯一键不能重复,可以为空。 建立主键的目的是让外键来引用。 一个表最多只有一个主键,但可以有很多唯一键 2,MySQL常用的存储引擎有哪些&…...

Neo4j 数据建模:原理、技术与实践指南
Neo4j 作为领先的图数据库,其核心优势在于利用图结构直观地表达和高效地查询复杂关系。其数据建模理念与传统关系型数据库截然不同,专注于实体(节点)及其连接(关系)。以下基于官方文档,系统阐述其建模原理、关键技术、实用技巧及最佳实践: 一、 核心原理:以关系为中心…...

【数据结构知识分享】顺序表详解
一、存储结构 物理相邻性: 若元素 a 和 b 逻辑相邻,则它们在内存中的地址也连续(如 &a[i1] &a[i] sizeof(ElemType))。 内存布局x: 基地址 索引 元素大小,通过首地址直接计算任意位置地址。 …...
vue+elementUI+springboot实现文件合并前端展示文件类型
项目场景: element的table上传文件并渲染出文件名称点击所属行可以查看文件,并且可以导出合并文件,此文章是记录合并文档前端展示的帖子 解决方案: 后端定义三个工具类 分别是pdf,doc和word的excle的目前我没整 word的工具类 package com.sc.modules…...
高效绘制业务流程图!专业模板免费下载
在复杂的业务流程管理中,可视化工具已成为提升效能的核心基础设施。为助力开发者、项目经理及业务架构师高效落地流程标准化,本文将为你精选5套开箱即用的专业流程图模板。这些模板覆盖跨部门协作、电商订单、客户服务等高频场景,具备以下核心…...
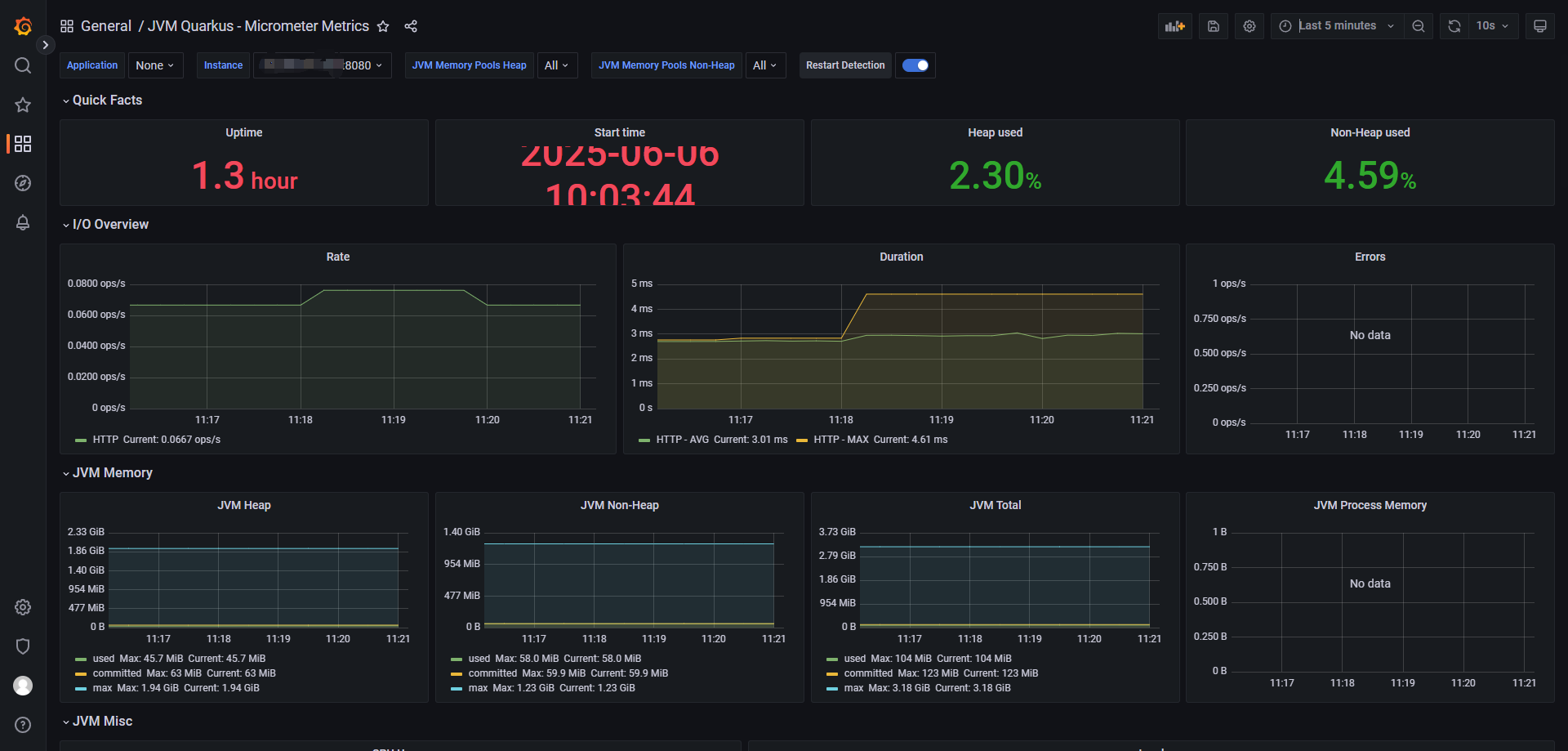
Spring Boot + Prometheus 实现应用监控(基于 Actuator 和 Micrometer)
文章目录 Spring Boot Prometheus 实现应用监控(基于 Actuator 和 Micrometer)环境准备示例结构启动和验证验证 Spring Boot 应用Prometheus 抓取配置(静态方式)Grafana 面板配置总结 Spring Boot Prometheus 实现应用监控&…...

PowerBI企业运营分析—列互换式中国式报表分析
PowerBI企业运营分析—列互换式中国式报表分析 欢迎来到Powerbi小课堂,在竞争激烈的市场环境中,企业运营分析平台成为提升竞争力的核心工具。 该平台通过高效整合多源数据,并实时监控关键指标,能够迅速揭示业务表现的全貌&#…...
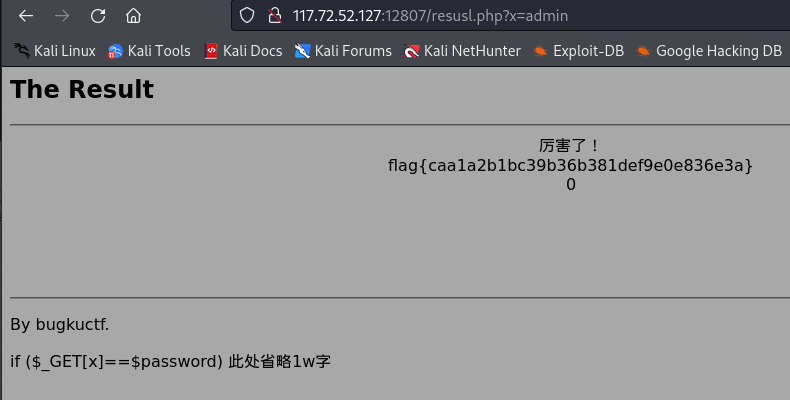
BugKu Web渗透之需要管理员
启动场景,打开网页,显示如下: 一般没有上面头绪的时候,就是两步:右键查看源代码 和 扫描网站目录。 步骤一: 右键查看源代码 和 扫描网站目录。 右键查看源代码没有发现异常。 于是扫描网站目录&…...
)
Java集合初始化:Lists.newArrayList vs new ArrayList()
文章目录 前言一、核心区别全景图二、代码实现深度对比1. 初始化方式对比2. 容量预分配机制 三、性能与底层原理1. 内存分配策略2. 基准测试数据(JMH) 四、Guava的进阶功能生态1. 集合转换2. 集合分片3. 不可变集合创建 五、最佳实践指南六、源码级实现解…...

VBA清空数据
列数转字母 Function CNtoW(ByVal num As Long) As String CNtoW Replace(Cells(1, num).Address(False, False), "1", "") End Function 字母转列数 Function CWtoN(ByVal AB As String) As Long CWtoN Range("a1:" & AB & &…...
综合知识答案和详解(回忆版))
【信息系统项目管理师-选择真题】2025上半年(第二批)综合知识答案和详解(回忆版)
更多内容请见: 备考信息系统项目管理师-专栏介绍和目录 文章目录 【第1题】【第2题】【第3题】【第4题】【第5题】【第6题】【第7题】【第8题】【第9题】【第10题】【第11题】【第12题】【第13题】【第14题】【第15题】【第16题】【第17题】【第18题】【第19题】【第20题】【第…...

Java Lambda 表达式的缺点和替代方案
Java 8 引入的 Lambda 表达式曾被誉为编写简洁、函数式代码的革命性工具。但说实话,它们并不是万能钥匙。它有不少问题,比如它没有宣传的那么易读,在某些场景下还带来性能开销。 作为一名多年与 Java 冗长语法搏斗的开发者,我找到了更注重清晰、可维护性和性能的替代方案。…...

TDengine 开发指南—— UDF函数
UDF 简介 在某些应用场景中,应用逻辑需要的查询功能无法直接使用内置函数来实现,TDengine 允许编写用户自定义函数(UDF),以便解决特殊应用场景中的使用需求。UDF 在集群中注册成功后,可以像系统内置函数一…...
使用vsftpd搭建FTP服务器(TLS/SSL显式加密)
安装vsftpd服务 使用vsftpd RPM安装包安装即可,如果可以访问YUM镜像源,通过dnf或者yum工具更加方便。 yum -y install vsftpd 启动vsftpd、查看服务状态 systemctl enable vsftpd systemctl start vsftpd systemctl status vsftpd 备份配置文件并进…...
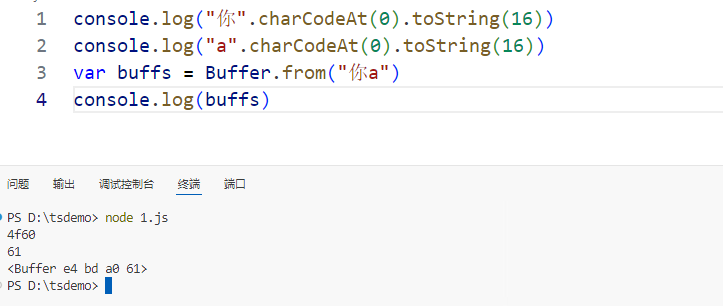
1.1Nodejs和浏览器中的二进制处理
Buffer 在 Node.js 中,Buffer 类用于处理二进制数据。由于 JavaScript 在浏览器环境中主要用于处理字符串和数字等类型的数据,对二进制数据的处理能力较弱,因此 Node.js 引入了 Buffer 类来弥补这一不足,特别是在处理文件系统操作…...
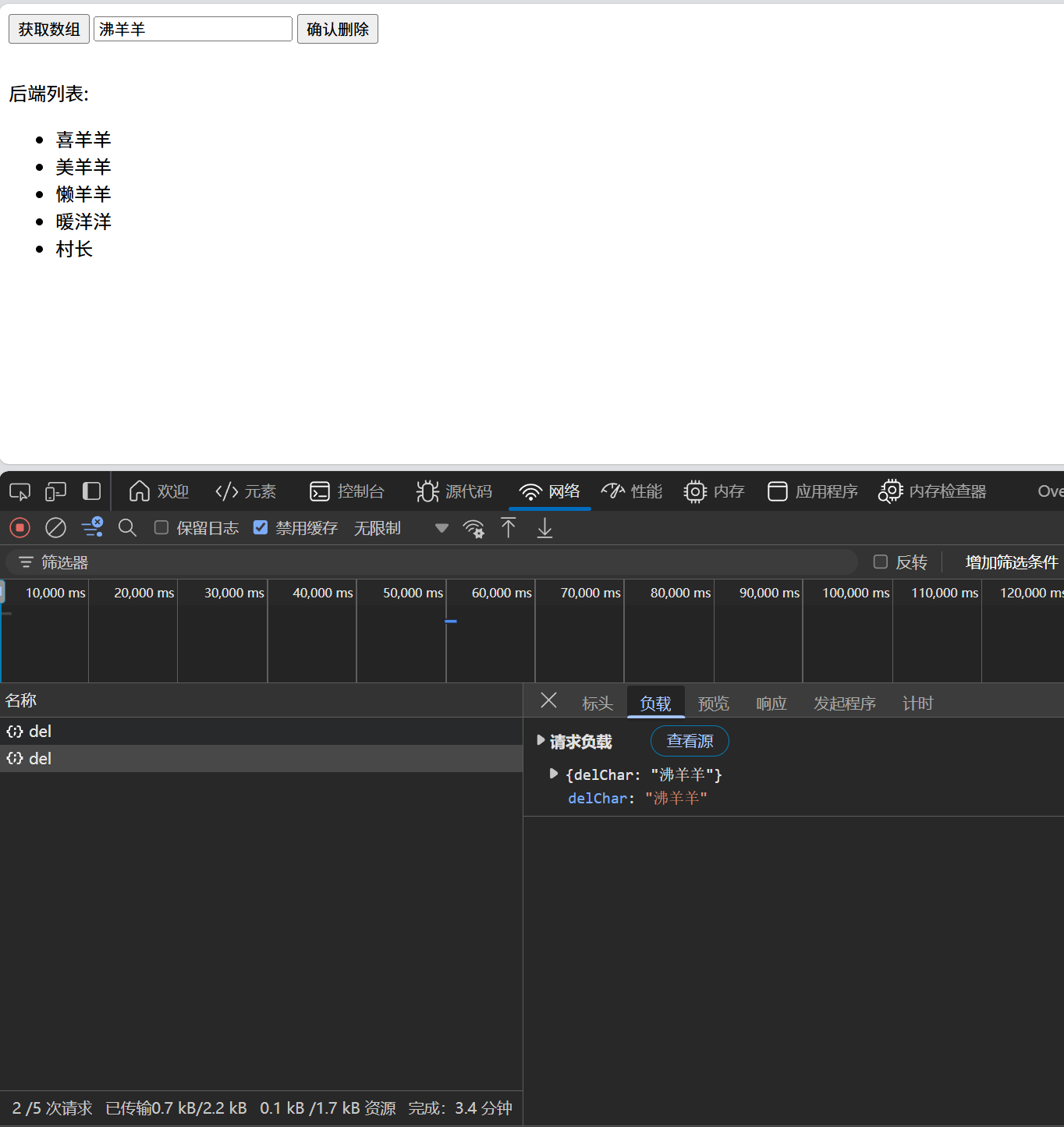
入门AJAX——XMLHttpRequest(Post)
一、前言 在上篇文章中,我们已经介绍了 HMLHttpRequest 的GET 请求的基本用法,并基于我提供的接口练习了两个简单的例子。如果你还没有看过第一篇文章,强烈建议你在学习完上篇文章后再学习本篇文章: 🔗入门AJAX——XM…...

Qt(part1)Qpushbutton,信号与槽,对象树,自定义信号与槽,lamda表达式。
1、创建Qt程序 2、命名规范及快捷键 3、Qpushbutton按钮创建 4、对象树概念 5、信号与槽 6、自定义信号与槽 7、当自定义信号和槽发生重载时 8、信号可以连接信号,信号也可以断开。 9、lamda表达式...

西北某省级联通公司:3D动环模块如何实现机房“一屏统管”?
一、运营商机房监控痛点凸显 在通信行业快速发展的当下,西北某省级联通公司肩负着保障区域通信畅通的重任。然而,公司分布广泛的机房面临着诸多监控难题,尤其是偏远机房环境风险无法实时感知这一痛点,严重影响了机房的稳定运行和通…...

【WPF】从普通 ItemsControl 到支持筛选的 ItemsControl:深入掌握 CollectionViewSource 用法
✨ 从普通 ItemsControl 到支持筛选的 ItemsControl:深入掌握 CollectionViewSource 用法 在日常 WPF 开发中,我们经常需要对数据进行筛选、排序、分组等操作,而原生的 ItemsControl 并不直接支持这些功能。本文将介绍如何通过 CollectionVi…...

Zookeeper 和 Kafka 版本与 JDK 要求
Apache Zookeeper 和 Apache Kafka 在不同版本中对 JDK 的要求如下表所示(基于官方文档和历史版本记录整理): 1. Zookeeper 版本与 JDK 要求 Zookeeper 版本要求的最低 JDK 版本说明3.4.x 系列JDK 6生产环境建议用 JDK 8(旧版兼容性强)。3.5.x 系列(3.5.5+)JDK 83.5.0 …...

3步布局关键词让流量更精准
其实流量不精准,90% 是关键词没布局好! 掌握这 3 个超实用技巧,让你的内容精准推给目标人群! 第一步:深挖高潜力关键词 别再一股脑用 “好看”“好用” 这些泛词啦!打开平台搜索框,输入核心词…...
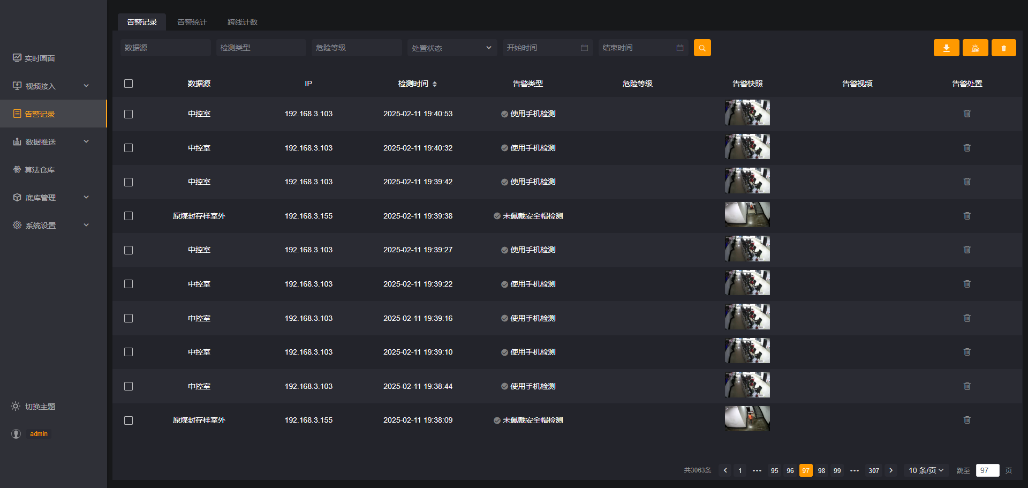
视觉分析在人员行为属性检测中的应用
基于视觉分析的人员行为属性检测方案 一、背景与需求分析 在工业生产、建筑施工、公共安全等领域,人员行为属性的合规性检测是保障安全生产的关键环节。例如,工地工人未佩戴安全帽、厨房人员未佩戴手套、作业现场人员使用手机等行为,均可能…...

学习 React【Plan - June - Week 1】
一、使用 JSX 书写标签语言 JSX 是一种 JavaScript 的语法扩展,React 使用它来描述用户界面。 什么是 JSX? JSX 是 JavaScript 的一种语法扩展。看起来像 HTML,但它实际上是在 JavaScript 代码中写 XML/HTML。浏览器并不能直接运行 JSX&…...

电子行业AI赋能软件开发经典案例——某金融软件公司
01.案例标题 金融行业某金融软件公司通过StarShip CodeSouler达成效率突破性增长,零流程侵入验证AI代码高度可行性 02.执行摘要 某金融软件公司在核心产品研发中引入开放传神(OpenCSG)的StarShip CodeSouler AI代码生成平台,在无…...

【前端】js如何处理计算精度问题
JavaScript 的精度问题源于其遵循 IEEE 754 标准的 64 位双精度浮点数表示法,导致 0.1 0.2 ! 0.3 等经典问题。以下是系统化的解决方案及适用场景: ⚙️ 一、整数转换法(适合简单运算) 将小数转换为整数运算后再还原࿰…...

使用 Python 自动化 Word 文档样式复制与内容生成
在办公自动化领域,如何高效地处理 Word 文档的样式和内容复制是一个常见需求。本文将通过一个完整的代码示例,展示如何利用 Python 的 python-docx 库实现 Word 文档样式的深度复制 和 动态内容生成,并结合知识库中的最佳实践优化文档处理流程…...