TDengine 开发指南—— UDF函数

UDF 简介
在某些应用场景中,应用逻辑需要的查询功能无法直接使用内置函数来实现,TDengine 允许编写用户自定义函数(UDF),以便解决特殊应用场景中的使用需求。UDF 在集群中注册成功后,可以像系统内置函数一样在 SQL 中调用,就使用角度而言没有任何区别。UDF 分为标量函数和聚合函数。标量函数对每行数据输出一个值,如求绝对值(abs)、正弦函数(sin)、字符串拼接函数(concat)等。聚合函数对多行数据输出一个值,如求平均数(avg)、取最大值(max)等。
TDengine 支持用 C 和 Python 两种编程语言编写 UDF。C 语言编写的 UDF 与内置函数的性能几乎相同,Python 语言编写的 UDF 可以利用丰富的 Python 运算库。为了避免 UDF 执行中发生异常影响数据库服务,TDengine 使用了进程分离技术,把 UDF 的执行放到另一个进程中完成,即使用户编写的 UDF 崩溃,也不会影响 TDengine 的正常运行。
用 C 语言开发 UDF
使用 C 语言实现 UDF 时,需要实现规定的接口函数
- 标量函数需要实现标量接口函数 scalarfn。
- 聚合函数需要实现聚合接口函数 aggfn_start、aggfn、aggfn_finish。
- 如果需要初始化,实现 udf_init。
- 如果需要清理工作,实现 udf_destroy。
接口定义
接口函数的名称是 UDF 名称,或者是 UDF 名称和特定后缀(_start、_finish、_init、_destroy)的连接。后面内容中描述的函数名称,例如 scalarfn、aggfn,需要替换成 UDF 名称。
标量函数接口
标量函数是一种将输入数据转换为输出数据的函数,通常用于对单个数据值进行计算和转换。标量函数的接口函数原型如下。
int32_t scalarfn(SUdfDataBlock* inputDataBlock, SUdfColumn *resultColumn);
主要参数说明如下。
- inputDataBlock:输入的数据块。
- resultColumn:输出列。
聚合函数接口
聚合函数是一种特殊的函数,用于对数据进行分组和计算,从而生成汇总信息。聚合函数的工作原理如下。
- 初始化结果缓冲区:首先调用 aggfn_start 函数,生成一个结果缓冲区(result buffer),用于存储中间结果。
- 分组数据:相关数据会被分为多个行数据块(row data block),每个行数据块包含一组具有相同分组键(grouping key)的数据。
- 更新中间结果:对于每个数据块,调用 aggfn 函数更新中间结果。aggfn 函数会根据聚合函数的类型(如 sum、avg、count 等)对数据进行相应的计算,并将计算结
果存储在结果缓冲区中。 - 生成最终结果:在所有数据块的中间结果更新完成后,调用 aggfn_finish 函数从结果缓冲区中提取最终结果。最终结果只包含 0 条或 1 条数据,具体取决于聚
合函数的类型和输入数据。
聚合函数的接口函数原型如下。
int32_t aggfn_start(SUdfInterBuf *interBuf);
int32_t aggfn(SUdfDataBlock* inputBlock, SUdfInterBuf *interBuf, SUdfInterBuf *newInterBuf);
int32_t aggfn_finish(SUdfInterBuf* interBuf, SUdfInterBuf *result);
其中 aggfn 是函数名的占位符。首先调用 aggfn_start 生成结果 buffer,然后相关的数据会被分为多个行数据块,对每个数据块调用 aggfn 用数据块更新中间结果,最后再调用 aggfn_finish 从中间结果产生最终结果,最终结果只能含 0 或 1 条结果数据。
主要参数说明如下。
- interBuf:中间结果缓存区。
- inputBlock:输入的数据块。
- newInterBuf:新的中间结果缓冲区。
- result:最终结果。
初始化和销毁接口
初始化和销毁接口是标量函数和聚合函数共同使用的接口,相关 API 如下。
int32_t udf_init()
int32_t udf_destroy()
其中,udf_init 函数完成初始化工作,udf_destroy 函数完成清理工作。如果没有初始化工作,无须定义 udf_init 函数;如果没有清理工作,无须定义 udf_destroy 函数。
标量函数模板
用 C 语言开发标量函数的模板如下。
#include "taos.h"
#include "taoserror.h"
#include "taosudf.h"// Initialization function.
// If no initialization, we can skip definition of it.
// The initialization function shall be concatenation of the udf name and _init suffix.
// @return error number defined in taoserror.h
int32_t scalarfn_init() {// initialization.return TSDB_CODE_SUCCESS;
}// Scalar function main computation function.
// @param inputDataBlock, input data block composed of multiple columns with each column defined by SUdfColumn
// @param resultColumn, output column
// @return error number defined in taoserror.h
int32_t scalarfn(SUdfDataBlock* inputDataBlock, SUdfColumn* resultColumn) {// read data from inputDataBlock and process, then output to resultColumn.return TSDB_CODE_SUCCESS;
}// Cleanup function.
// If no cleanup related processing, we can skip definition of it.
// The destroy function shall be concatenation of the udf name and _destroy suffix.
// @return error number defined in taoserror.h
int32_t scalarfn_destroy() {// clean upreturn TSDB_CODE_SUCCESS;
}
聚合函数模板
用 C 语言开发聚合函数的模板如下。
#include "taos.h"
#include "taoserror.h"
#include "taosudf.h"// Initialization function.
// If no initialization, we can skip definition of it.
// The initialization function shall be concatenation of the udf name and _init suffix.
// @return error number defined in taoserror.h
int32_t aggfn_init() {// initialization.return TSDB_CODE_SUCCESS;
}// Aggregate start function.
// The intermediate value or the state(@interBuf) is initialized in this function.
// The function name shall be concatenation of udf name and _start suffix.
// @param interbuf intermediate value to initialize
// @return error number defined in taoserror.h
int32_t aggfn_start(SUdfInterBuf* interBuf) {// initialize intermediate value in interBufreturn TSDB_CODE_SUCCESS;
}// Aggregate reduce function.
// This function aggregate old state(@interbuf) and one data bock(inputBlock) and output a new state(@newInterBuf).
// @param inputBlock input data block
// @param interBuf old state
// @param newInterBuf new state
// @return error number defined in taoserror.h
int32_t aggfn(SUdfDataBlock* inputBlock, SUdfInterBuf *interBuf, SUdfInterBuf *newInterBuf) {// read from inputBlock and interBuf and output to newInterBufreturn TSDB_CODE_SUCCESS;
}// Aggregate function finish function.
// This function transforms the intermediate value(@interBuf) into the final output(@result).
// The function name must be concatenation of aggfn and _finish suffix.
// @interBuf : intermediate value
// @result: final result
// @return error number defined in taoserror.h
int32_t int32_t aggfn_finish(SUdfInterBuf* interBuf, SUdfInterBuf *result) {// read data from inputDataBlock and process, then output to resultreturn TSDB_CODE_SUCCESS;
}// Cleanup function.
// If no cleanup related processing, we can skip definition of it.
// The destroy function shall be concatenation of the udf name and _destroy suffix.
// @return error number defined in taoserror.h
int32_t aggfn_destroy() {// clean upreturn TSDB_CODE_SUCCESS;
}
编译
在 TDengine 中,为了实现 UDF,需要编写 C 语言源代码,并按照 TDengine 的规范编译为动态链接库文件。
按照前面描述的规则,准备 UDF 的源代码 bit_and.c。以 Linux 操作系统为例,执行如下指令,编译得到动态链接库文件。
gcc -g -O0 -fPIC -shared bit_and.c -o libbitand.so
为了保证可靠运行,推荐使用 7.5 及以上版本的 GCC。
C UDF 数据结构
typedef struct SUdfColumnMeta {int16_t type;int32_t bytes;uint8_t precision;uint8_t scale;
} SUdfColumnMeta;typedef struct SUdfColumnData {int32_t numOfRows;int32_t rowsAlloc;union {struct {int32_t nullBitmapLen;char *nullBitmap;int32_t dataLen;char *data;} fixLenCol;struct {int32_t varOffsetsLen;int32_t *varOffsets;int32_t payloadLen;char *payload;int32_t payloadAllocLen;} varLenCol;};
} SUdfColumnData;typedef struct SUdfColumn {SUdfColumnMeta colMeta;bool hasNull;SUdfColumnData colData;
} SUdfColumn;typedef struct SUdfDataBlock {int32_t numOfRows;int32_t numOfCols;SUdfColumn **udfCols;
} SUdfDataBlock;typedef struct SUdfInterBuf {int32_t bufLen;char *buf;int8_t numOfResult; //zero or one
} SUdfInterBuf;
数据结构说明如下:
- SUdfDataBlock 数据块包含行数 numOfRows 和列数 numCols。udfCols[i] (0 <= i <= numCols-1) 表示每一列数据,类型为 SUdfColumn*。
- SUdfColumn 包含列的数据类型定义 colMeta 和列的数据 colData。
- SUdfColumnMeta 成员定义同 taos.h 数据类型定义。
- SUdfColumnData 数据可以变长,varLenCol 定义变长数据,fixLenCol 定义定长数据。
- SUdfInterBuf 定义中间结构 buffer,以及 buffer 中结果个数 numOfResult
为了更好的操作以上数据结构,提供了一些便利函数,定义在 taosudf.h。
C UDF 示例代码
标量函数示例 bit_and
bit_and 实现多列的按位与功能。如果只有一列,返回这一列。bit_and 忽略空值。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include "taosudf.h"DLL_EXPORT int32_t bit_and_init() { return 0; }DLL_EXPORT int32_t bit_and_destroy() { return 0; }DLL_EXPORT int32_t bit_and(SUdfDataBlock* block, SUdfColumn* resultCol) {udfTrace("block:%p, processing begins, rows:%d cols:%d", block, block->numOfRows, block->numOfCols);if (block->numOfCols < 2) {udfError("block:%p, cols:%d needs to be greater than 2", block, block->numOfCols);return TSDB_CODE_UDF_INVALID_INPUT;}for (int32_t i = 0; i < block->numOfCols; ++i) {SUdfColumn* col = block->udfCols[i];if (col->colMeta.type != TSDB_DATA_TYPE_INT) {udfError("block:%p, col:%d type:%d should be int(%d)", block, i, col->colMeta.type, TSDB_DATA_TYPE_INT);return TSDB_CODE_UDF_INVALID_INPUT;}}SUdfColumnData* resultData = &resultCol->colData;for (int32_t i = 0; i < block->numOfRows; ++i) {if (udfColDataIsNull(block->udfCols[0], i)) {udfColDataSetNull(resultCol, i);udfTrace("block:%p, row:%d result is null since col:0 is null", block, i);continue;}int32_t result = *(int32_t*)udfColDataGetData(block->udfCols[0], i);udfTrace("block:%p, row:%d col:0 data:%d", block, i, result);int32_t j = 1;for (; j < block->numOfCols; ++j) {if (udfColDataIsNull(block->udfCols[j], i)) {udfColDataSetNull(resultCol, i);udfTrace("block:%p, row:%d result is null since col:%d is null", block, i, j);break;}char* colData = udfColDataGetData(block->udfCols[j], i);result &= *(int32_t*)colData;udfTrace("block:%p, row:%d col:%d data:%d", block, i, j, *(int32_t*)colData);}if (j == block->numOfCols) {udfColDataSet(resultCol, i, (char*)&result, false);udfTrace("block:%p, row:%d result is %d", block, i, result);}}resultData->numOfRows = block->numOfRows;udfTrace("block:%p, processing completed", block);return TSDB_CODE_SUCCESS;
}聚合函数示例 1 返回值为数值类型 l2norm
l2norm 实现了输入列的所有数据的二阶范数,即对每个数据先平方,再累加求和,最后开方。
#include <math.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include "taosudf.h"DLL_EXPORT int32_t l2norm_init() { return 0; }DLL_EXPORT int32_t l2norm_destroy() { return 0; }DLL_EXPORT int32_t l2norm_start(SUdfInterBuf* buf) {int32_t bufLen = sizeof(double);if (buf->bufLen < bufLen) {udfError("failed to execute udf since input buflen:%d < %d", buf->bufLen, bufLen);return TSDB_CODE_UDF_INVALID_BUFSIZE;}udfTrace("start aggregation, buflen:%d used:%d", buf->bufLen, bufLen);*(int64_t*)(buf->buf) = 0;buf->bufLen = bufLen;buf->numOfResult = 0;return 0;
}DLL_EXPORT int32_t l2norm(SUdfDataBlock* block, SUdfInterBuf* interBuf, SUdfInterBuf* newInterBuf) {udfTrace("block:%p, processing begins, cols:%d rows:%d", block, block->numOfCols, block->numOfRows);for (int32_t i = 0; i < block->numOfCols; ++i) {SUdfColumn* col = block->udfCols[i];if (col->colMeta.type != TSDB_DATA_TYPE_INT && col->colMeta.type != TSDB_DATA_TYPE_DOUBLE) {udfError("block:%p, col:%d type:%d should be int(%d) or double(%d)", block, i, col->colMeta.type,TSDB_DATA_TYPE_INT, TSDB_DATA_TYPE_DOUBLE);return TSDB_CODE_UDF_INVALID_INPUT;}}double sumSquares = *(double*)interBuf->buf;int8_t numNotNull = 0;for (int32_t i = 0; i < block->numOfCols; ++i) {for (int32_t j = 0; j < block->numOfRows; ++j) {SUdfColumn* col = block->udfCols[i];if (udfColDataIsNull(col, j)) {udfTrace("block:%p, col:%d row:%d is null", block, i, j);continue;}switch (col->colMeta.type) {case TSDB_DATA_TYPE_INT: {char* cell = udfColDataGetData(col, j);int32_t num = *(int32_t*)cell;sumSquares += (double)num * num;udfTrace("block:%p, col:%d row:%d data:%d", block, i, j, num);break;}case TSDB_DATA_TYPE_DOUBLE: {char* cell = udfColDataGetData(col, j);double num = *(double*)cell;sumSquares += num * num;udfTrace("block:%p, col:%d row:%d data:%f", block, i, j, num);break;}default:break;}++numNotNull;}udfTrace("block:%p, col:%d result is %f", block, i, sumSquares);}*(double*)(newInterBuf->buf) = sumSquares;newInterBuf->bufLen = sizeof(double);newInterBuf->numOfResult = 1;udfTrace("block:%p, result is %f", block, sumSquares);return 0;
}DLL_EXPORT int32_t l2norm_finish(SUdfInterBuf* buf, SUdfInterBuf* resultData) {double sumSquares = *(double*)(buf->buf);*(double*)(resultData->buf) = sqrt(sumSquares);resultData->bufLen = sizeof(double);resultData->numOfResult = 1;udfTrace("end aggregation, result is %f", *(double*)(resultData->buf));return 0;
}聚合函数示例 2 返回值为字符串类型 max_vol
max_vol 实现了从多个输入的电压列中找到最大电压,返回由设备 ID + 最大电压所在(行,列)+ 最大电压值 组成的组合字符串值
创建表:
create table battery(ts timestamp, vol1 float, vol2 float, vol3 float, deviceId varchar(16));
创建自定义函数:
create aggregate function max_vol as '/root/udf/libmaxvol.so' outputtype binary(64) bufsize 10240 language 'C';
使用自定义函数:
select max_vol(vol1, vol2, vol3, deviceid) from battery;
#include <math.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include "taosudf.h"#define STR_MAX_LEN 256 // inter buffer lengthDLL_EXPORT int32_t max_vol_init() { return 0; }DLL_EXPORT int32_t max_vol_destroy() { return 0; }DLL_EXPORT int32_t max_vol_start(SUdfInterBuf *buf) {int32_t bufLen = sizeof(float) + STR_MAX_LEN;if (buf->bufLen < bufLen) {udfError("failed to execute udf since input buflen:%d < %d", buf->bufLen, bufLen);return TSDB_CODE_UDF_INVALID_BUFSIZE;}udfTrace("start aggregation, buflen:%d used:%d", buf->bufLen, bufLen);memset(buf->buf, 0, sizeof(float) + STR_MAX_LEN);*((float *)buf->buf) = INT32_MIN;buf->bufLen = bufLen;buf->numOfResult = 0;return 0;
}DLL_EXPORT int32_t max_vol(SUdfDataBlock *block, SUdfInterBuf *interBuf, SUdfInterBuf *newInterBuf) {udfTrace("block:%p, processing begins, cols:%d rows:%d", block, block->numOfCols, block->numOfRows);float maxValue = *(float *)interBuf->buf;char strBuff[STR_MAX_LEN] = "inter1buf";if (block->numOfCols < 2) {udfError("block:%p, cols:%d needs to be greater than 2", block, block->numOfCols);return TSDB_CODE_UDF_INVALID_INPUT;}// check data typefor (int32_t i = 0; i < block->numOfCols; ++i) {SUdfColumn *col = block->udfCols[i];if (i == block->numOfCols - 1) {// last column is device id , must varcharif (col->colMeta.type != TSDB_DATA_TYPE_VARCHAR) {udfError("block:%p, col:%d type:%d should be varchar(%d)", block, i, col->colMeta.type, TSDB_DATA_TYPE_VARCHAR);return TSDB_CODE_UDF_INVALID_INPUT;}} else {if (col->colMeta.type != TSDB_DATA_TYPE_FLOAT) {udfError("block:%p, col:%d type:%d should be float(%d)", block, i, col->colMeta.type, TSDB_DATA_TYPE_FLOAT);return TSDB_CODE_UDF_INVALID_INPUT;}}}// calc max voltageSUdfColumn *lastCol = block->udfCols[block->numOfCols - 1];for (int32_t i = 0; i < block->numOfCols - 1; ++i) {for (int32_t j = 0; j < block->numOfRows; ++j) {SUdfColumn *col = block->udfCols[i];if (udfColDataIsNull(col, j)) {udfTrace("block:%p, col:%d row:%d is null", block, i, j);continue;}char *data = udfColDataGetData(col, j);float voltage = *(float *)data;if (voltage <= maxValue) {udfTrace("block:%p, col:%d row:%d data:%f", block, i, j, voltage);} else {maxValue = voltage;char *valData = udfColDataGetData(lastCol, j);int32_t valDataLen = udfColDataGetDataLen(lastCol, j);// get device idchar *deviceId = valData + sizeof(uint16_t);int32_t deviceIdLen = valDataLen < (STR_MAX_LEN - 1) ? valDataLen : (STR_MAX_LEN - 1);strncpy(strBuff, deviceId, deviceIdLen);snprintf(strBuff + deviceIdLen, STR_MAX_LEN - deviceIdLen, "_(%d,%d)_%f", j, i, maxValue);udfTrace("block:%p, col:%d row:%d data:%f, as max_val:%s", block, i, j, voltage, strBuff);}}}*(float *)newInterBuf->buf = maxValue;strncpy(newInterBuf->buf + sizeof(float), strBuff, STR_MAX_LEN);newInterBuf->bufLen = sizeof(float) + strlen(strBuff) + 1;newInterBuf->numOfResult = 1;udfTrace("block:%p, result is %s", block, strBuff);return 0;
}DLL_EXPORT int32_t max_vol_finish(SUdfInterBuf *buf, SUdfInterBuf *resultData) {char *str = buf->buf + sizeof(float);// copy to deschar *des = resultData->buf + sizeof(uint16_t);strcpy(des, str);// set binary type lenuint16_t len = strlen(str);*((uint16_t *)resultData->buf) = len;// set buf lenresultData->bufLen = len + sizeof(uint16_t);// set row countresultData->numOfResult = 1;udfTrace("end aggregation, result is %s", str);return 0;
}聚合函数示例 3 切分字符串求平均值 extract_avg
extract_avg 函数是将一个逗号分隔的字符串数列转为一组数值,统计所有行的结果,计算最终平均值。实现时需注意:
interBuf->numOfResult需要返回 1 或者 0,不能用于 count 计数。- count 计数可使用额外的缓存,例如
SumCount结构体。 - 字符串的获取需使用
varDataVal。
创建表:
create table scores(ts timestamp, varStr varchar(128));
创建自定义函数:
create aggregate function extract_avg as '/root/udf/libextract_avg.so' outputtype double bufsize 16 language 'C';
使用自定义函数:
select extract_avg(valStr) from scores;
生成 .so 文件
gcc -g -O0 -fPIC -shared extract_vag.c -o libextract_avg.so
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include "taos.h"
#include "taoserror.h"
#include "taosudf.h"// Define a structure to store sum and count
typedef struct {double sum;int count;
} SumCount;// initialization function
DLL_EXPORT int32_t extract_avg_init() {udfTrace("extract_avg_init: Initializing UDF");return TSDB_CODE_SUCCESS;
}DLL_EXPORT int32_t extract_avg_start(SUdfInterBuf *interBuf) {int32_t bufLen = sizeof(SumCount);if (interBuf->bufLen < bufLen) {udfError("extract_avg_start: Failed to execute UDF since input buflen:%d < %d", interBuf->bufLen, bufLen);return TSDB_CODE_UDF_INVALID_BUFSIZE;}// Initialize sum and countSumCount *sumCount = (SumCount *)interBuf->buf;sumCount->sum = 0.0;sumCount->count = 0;interBuf->numOfResult = 0;udfTrace("extract_avg_start: Initialized sum=0.0, count=0");return TSDB_CODE_SUCCESS;
}DLL_EXPORT int32_t extract_avg(SUdfDataBlock *inputBlock, SUdfInterBuf *interBuf, SUdfInterBuf *newInterBuf) {udfTrace("extract_avg: Processing data block with %d rows", inputBlock->numOfRows);// Check the number of columns in the input data blockif (inputBlock->numOfCols != 1) {udfError("extract_avg: Invalid number of columns. Expected 1, got %d", inputBlock->numOfCols);return TSDB_CODE_UDF_INVALID_INPUT;}// Get the input columnSUdfColumn *inputCol = inputBlock->udfCols[0];if (inputCol->colMeta.type != TSDB_DATA_TYPE_VARCHAR) {udfError("extract_avg: Invalid data type. Expected VARCHAR, got %d", inputCol->colMeta.type);return TSDB_CODE_UDF_INVALID_INPUT;}// Read the current sum and count from interBufSumCount *sumCount = (SumCount *)interBuf->buf;udfTrace("extract_avg: Starting with sum=%f, count=%d", sumCount->sum, sumCount->count);for (int i = 0; i < inputBlock->numOfRows; i++) {if (udfColDataIsNull(inputCol, i)) {udfTrace("extract_avg: Skipping NULL value at row %d", i);continue;}char *buf = (char *)udfColDataGetData(inputCol, i);char data[64];memset(data, 0, 64);memcpy(data, varDataVal(buf), varDataLen(buf));udfTrace("extract_avg: Processing row %d, data='%s'", i, data);char *rest = data;char *token;while ((token = strtok_r(rest, ",", &rest))) {while (*token == ' ') token++;int tokenLen = strlen(token);while (tokenLen > 0 && token[tokenLen - 1] == ' ') token[--tokenLen] = '\0';if (tokenLen == 0) {udfTrace("extract_avg: Empty string encountered at row %d", i);continue;}char *endPtr;double value = strtod(token, &endPtr);if (endPtr == token || *endPtr != '\0') {udfError("extract_avg: Failed to convert string '%s' to double at row %d", token, i);continue;}sumCount->sum += value;sumCount->count++;udfTrace("extract_avg: Updated sum=%f, count=%d", sumCount->sum, sumCount->count);}}newInterBuf->bufLen = sizeof(SumCount);newInterBuf->buf = (char *)malloc(newInterBuf->bufLen);if (newInterBuf->buf == NULL) {udfError("extract_avg: Failed to allocate memory for newInterBuf");return TSDB_CODE_UDF_INTERNAL_ERROR;}memcpy(newInterBuf->buf, sumCount, newInterBuf->bufLen);newInterBuf->numOfResult = 0;udfTrace("extract_avg: Final sum=%f, count=%d", sumCount->sum, sumCount->count);return TSDB_CODE_SUCCESS;
}DLL_EXPORT int32_t extract_avg_finish(SUdfInterBuf *interBuf, SUdfInterBuf *result) {SumCount *sumCount = (SumCount *)interBuf->buf;double avg = (sumCount->count > 0) ? (sumCount->sum / sumCount->count) : 0.0;*(double *)result->buf = avg;result->bufLen = sizeof(double);result->numOfResult = sumCount->count > 0 ? 1 : 0;udfTrace("extract_avg_finish: Final result=%f (sum=%f, count=%d)", avg, sumCount->sum, sumCount->count);return TSDB_CODE_SUCCESS;
}DLL_EXPORT int32_t extract_avg_destroy() {udfTrace("extract_avg_destroy: Cleaning up UDF");return TSDB_CODE_SUCCESS;
}用 Python 语言开发 UDF
准备环境
准备环境的具体步骤如下:
- 第 1 步,准备好 Python 运行环境。本地编译安装 python 注意打开
--enable-shared选项,不然后续安装 taospyudf 会因无法生成共享库而导致失败。 - 第 2 步,安装 Python 包 taospyudf。命令如下。
pip3 install taospyudf - 第 3 步,执行命令 ldconfig。
- 第 4 步,启动 taosd 服务。
安装过程中会编译 C++ 源码,因此系统上要有 cmake 和 gcc。编译生成的 libtaospyudf.so 文件自动会被复制到 /usr/local/lib/ 目录,因此如果是非 root 用户,安装时需加 sudo。安装完可以检查这个目录是否有了这个文件:
root@slave11 ~/udf $ ls -l /usr/local/lib/libtaos*
-rw-r--r-- 1 root root 671344 May 24 22:54 /usr/local/lib/libtaospyudf.so
接口定义
当使用 Python 语言开发 UDF 时,需要实现规定的接口函数。具体要求如下。
- 标量函数需要实现标量接口函数 process。
- 聚合函数需要实现聚合接口函数 start、reduce、finish。
- 如果需要初始化,则应实现函数 init。
- 如果需要清理工作,则实现函数 destroy。
标量函数接口
标量函数的接口如下。
def process(input: datablock) -> tuple[output_type]:
主要参数说明如下:
- input:datablock 类似二维矩阵,通过成员方法 data(row, col) 读取位于 row 行、col 列的 Python 对象
- 返回值是一个 Python 对象元组,每个元素类型为输出类型。
聚合函数接口
聚合函数的接口如下。
def start() -> bytes:
def reduce(inputs: datablock, buf: bytes) -> bytes
def finish(buf: bytes) -> output_type:
上述代码定义了 3 个函数,分别用于实现一个自定义的聚合函数。具体过程如下。
首先,调用 start 函数生成最初的结果缓冲区。这个结果缓冲区用于存储聚合函数的内部状态,随着输入数据的处理而不断更新。
然后,输入数据会被分为多个行数据块。对于每个行数据块,调用 reduce 函数,并将当前行数据块(inputs)和当前的中间结果(buf)作为参数传递。reduce 函数会根据输入数据和当前状态来更新聚合函数的内部状态,并返回新的中间结果。
最后,当所有行数据块都处理完毕后,调用 finish 函数。这个函数接收最终的中间结果(buf)作为参数,并从中生成最终的输出。由于聚合函数的特性,最终输出只能包含 0 条或 1 条数据。这个输出结果将作为聚合函数的计算结果返回给调用者。
初始化和销毁接口
初始化和销毁的接口如下。
def init()
def destroy()
参数说明:
- init 完成初始化工作
- destroy 完成清理工作
注意 用 Python 开发 UDF 时必须定义 init 函数和 destroy 函数
标量函数模板
用 Python 语言开发标量函数的模板如下。
def init():# initialization
def destroy():# destroy
def process(input: datablock) -> tuple[output_type]:
聚合函数模板
用 Python 语言开发聚合函数的模板如下。
def init():#initialization
def destroy():#destroy
def start() -> bytes:#return serialize(init_state)
def reduce(inputs: datablock, buf: bytes) -> bytes# deserialize buf to state# reduce the inputs and state into new_state. # use inputs.data(i, j) to access python object of location(i, j)# serialize new_state into new_state_bytesreturn new_state_bytes
def finish(buf: bytes) -> output_type:#return obj of type outputtype
数据类型映射
下表描述了 TDengine SQL 数据类型和 Python 数据类型的映射。任何类型的 NULL 值都映射成 Python 的 None 值。
| TDengine SQL 数据类型 | Python 数据类型 |
|---|---|
| TINYINT / SMALLINT / INT / BIGINT | int |
| TINYINT UNSIGNED / SMALLINT UNSIGNED / INT UNSIGNED / BIGINT UNSIGNED | int |
| FLOAT / DOUBLE | float |
| BOOL | bool |
| BINARY / VARCHAR / NCHAR | bytes |
| TIMESTAMP | int |
| JSON and other types | 不支持 |
开发示例
本文内容由浅入深包括 5 个示例程序,同时也包含大量实用的 debug 技巧。
注意:UDF 内无法通过 print 函数输出日志,需要自己写文件或用 Python 内置的 logging 库写文件。
示例一
编写一个只接收一个整数的 UDF 函数:输入 n,输出 ln(n^2 + 1)。
首先编写一个 Python 文件,存在系统某个目录,比如 /root/udf/myfun.py 内容如下。
from math import logdef init():passdef destroy():passdef process(block):rows, _ = block.shape()return [log(block.data(i, 0) ** 2 + 1) for i in range(rows)]
这个文件包含 3 个函数,init 和 destroy 都是空函数,它们是 UDF 的生命周期函数,即使什么都不做也要定义。最关键的是 process 函数,它接受一个数据块,这个数据块对象有两个方法。
- shape() 返回数据块的行数和列数
- data(i, j) 返回 i 行 j 列的数据
标量函数的 process 方法传入的数据块有多少行,就需要返回多少行数据。上述代码忽略列数,因为只需对每行的第一列做计算。
接下来创建对应的 UDF 函数,在 TDengine CLI 中执行下面语句。
create function myfun as '/root/udf/myfun.py' outputtype double language 'Python'
其输出如下。
taos> create function myfun as '/root/udf/myfun.py' outputtype double language 'Python';
Create OK, 0 row(s) affected (0.005202s)
看起来很顺利,接下来查看系统中所有的自定义函数,确认创建成功。
taos> show functions;name |
=================================myfun |
Query OK, 1 row(s) in set (0.005767s)
生成测试数据,可以在 TDengine CLI 中执行下述命令。
create database test;
create table t(ts timestamp, v1 int, v2 int, v3 int);
insert into t values('2023-05-01 12:13:14', 1, 2, 3);
insert into t values('2023-05-03 08:09:10', 2, 3, 4);
insert into t values('2023-05-10 07:06:05', 3, 4, 5);
测试 myfun 函数。
taos> select myfun(v1, v2) from t;DB error: udf function execution failure (0.011088s)
不幸的是执行失败了,什么原因呢?查看 taosudf 进程的日志。
tail -10 /var/log/taos/taosudf.log
发现以下错误信息。
05/24 22:46:28.733545 01665799 UDF ERROR can not load library libtaospyudf.so. error: operation not permitted
05/24 22:46:28.733561 01665799 UDF ERROR can not load python plugin. lib path libtaospyudf.so
错误很明确:没有加载到 Python 插件 libtaospyudf.so,如果遇到此错误,请参考前面的准备环境一节。
修复环境错误后再次执行,如下。
taos> select myfun(v1) from t;myfun(v1) |
============================0.693147181 |1.609437912 |2.302585093 |
至此,我们完成了第一个 UDF 😊,并学会了简单的 debug 方法。
示例二
上面的 myfun 虽然测试测试通过了,但是有两个缺点。
- 这个标量函数只接受 1 列数据作为输入,如果用户传入了多列也不会抛异常。
taos> select myfun(v1, v2) from t;myfun(v1, v2) |
============================0.693147181 |1.609437912 |2.302585093 |
- 没有处理 null 值。我们期望如果输入有 null,则会抛异常终止执行。因此 process 函数改进如下。
def process(block):rows, cols = block.shape()if cols > 1:raise Exception(f"require 1 parameter but given {cols}")return [ None if block.data(i, 0) is None else log(block.data(i, 0) ** 2 + 1) for i in range(rows)]
执行如下语句更新已有的 UDF。
create or replace function myfun as '/root/udf/myfun.py' outputtype double language 'Python';
再传入 myfun 两个参数,就会执行失败了。
taos> select myfun(v1, v2) from t;DB error: udf function execution failure (0.014643s)
自定义的异常信息打印在插件的日志文件 /var/log/taos/taospyudf.log 中。
2023-05-24 23:21:06.790 ERROR [1666188] [doPyUdfScalarProc@507] call pyUdfScalar proc function. context 0x7faade26d180. error: Exception: require 1 parameter but given 2At:/var/lib/taos//.udf/myfun_3_1884e1281d9.py(12): process至此,我们学会了如何更新 UDF,并查看 UDF 输出的错误日志。
(注:如果 UDF 更新后未生效,在 TDengine 3.0.5.0 以前(不含)的版本中需要重启 taosd,在 3.0.5.0 及之后的版本中不需要重启 taosd 即可生效。)
示例三
输入(x1, x2, …, xn), 输出每个值和它们的序号的乘积的和:1 * x1 + 2 * x2 + … + n * xn。如果 x1 至 xn 中包含 null,则结果为 null。
本例与示例一的区别是,可以接受任意多列作为输入,且要处理每一列的值。编写 UDF 文件 /root/udf/nsum.py。
def init():passdef destroy():passdef process(block):rows, cols = block.shape()result = []for i in range(rows):total = 0for j in range(cols):v = block.data(i, j)if v is None:total = Nonebreaktotal += (j + 1) * block.data(i, j)result.append(total)return result
创建 UDF。
create function nsum as '/root/udf/nsum.py' outputtype double language 'Python';
测试 UDF。
taos> insert into t values('2023-05-25 09:09:15', 6, null, 8);
Insert OK, 1 row(s) affected (0.003675s)taos> select ts, v1, v2, v3, nsum(v1, v2, v3) from t;ts | v1 | v2 | v3 | nsum(v1, v2, v3) |
================================================================================================2023-05-01 12:13:14.000 | 1 | 2 | 3 | 14.000000000 |2023-05-03 08:09:10.000 | 2 | 3 | 4 | 20.000000000 |2023-05-10 07:06:05.000 | 3 | 4 | 5 | 26.000000000 |2023-05-25 09:09:15.000 | 6 | NULL | 8 | NULL |
Query OK, 4 row(s) in set (0.010653s)
示例四
编写一个 UDF,输入一个时间戳,输出距离这个时间最近的下一个周日。比如今天是 2023-05-25,则下一个周日是 2023-05-28。
完成这个函数要用到第三方库 moment。先安装这个库。
pip3 install moment
然后编写 UDF 文件 /root/udf/nextsunday.py。
import momentdef init():passdef destroy():passdef process(block):rows, cols = block.shape()if cols > 1:raise Exception("require only 1 parameter")if not type(block.data(0, 0)) is int:raise Exception("type error")return [moment.unix(block.data(i, 0)).replace(weekday=7).format('YYYY-MM-DD')for i in range(rows)]
UDF 框架会将 TDengine 的 timestamp 类型映射为 Python 的 int 类型,所以这个函数只接受一个表示毫秒数的整数。process 方法先做参数检查,然后用 moment 包替换时间的星期为星期日,最后格式化输出。输出的字符串长度是固定的 10 个字符长,因此可以这样创建 UDF 函数。
create function nextsunday as '/root/udf/nextsunday.py' outputtype binary(10) language 'Python';
此时测试函数,如果你是用 systemctl 启动的 taosd,肯定会遇到错误。
taos> select ts, nextsunday(ts) from t;DB error: udf function execution failure (1.123615s)
tail -20 taospyudf.log
2023-05-25 11:42:34.541 ERROR [1679419] [PyUdf::PyUdf@217] py udf load module failure. error ModuleNotFoundError: No module named 'moment'
这是因为“moment”所在位置不在 Python udf 插件默认的库搜索路径中。怎么确认这一点呢?通过以下命令搜索 taospyudf.log。
grep 'sys path' taospyudf.log | tail -1
输出如下
2023-05-25 10:58:48.554 INFO [1679419] [doPyOpen@592] python sys path: ['', '/lib/python38.zip', '/lib/python3.8', '/lib/python3.8/lib-dynload', '/lib/python3/dist-packages', '/var/lib/taos//.udf']
发现 Python udf 插件默认搜索的第三方库安装路径是: /lib/python3/dist-packages,而 moment 默认安装到了 /usr/local/lib/python3.8/dist-packages。下面我们修改 Python udf 插件默认的库搜索路径。
先打开 python3 命令行,查看当前的 sys.path。
>>> import sys
>>> ":".join(sys.path)
'/usr/lib/python3.8:/usr/lib/python3.8/lib-dynload:/usr/local/lib/python3.8/dist-packages:/usr/lib/python3/dist-packages'
复制上面脚本的输出的字符串,然后编辑 /var/taos/taos.cfg 加入以下配置。
UdfdLdLibPath /usr/lib/python3.8:/usr/lib/python3.8/lib-dynload:/usr/local/lib/python3.8/dist-packages:/usr/lib/python3/dist-packages
保存后执行 systemctl restart taosd, 再测试就不报错了。
taos> select ts, nextsunday(ts) from t;ts | nextsunday(ts) |
===========================================2023-05-01 12:13:14.000 | 2023-05-07 |2023-05-03 08:09:10.000 | 2023-05-07 |2023-05-10 07:06:05.000 | 2023-05-14 |2023-05-25 09:09:15.000 | 2023-05-28 |
Query OK, 4 row(s) in set (1.011474s)
示例五
编写一个聚合函数,计算某一列最大值和最小值的差。
聚合函数与标量函数的区别是:标量函数是多行输入对应多个输出,聚合函数是多行输入对应一个输出。聚合函数的执行过程有点像经典的 map-reduce 框架的执行过程,框架把数据分成若干块,每个 mapper 处理一个块,reducer 再把 mapper 的结果做聚合。不一样的地方在于,对于 TDengine Python UDF 中的 reduce 函数既有 map 的功能又有 reduce 的功能。reduce 函数接受两个参数:一个是自己要处理的数据,一个是别的任务执行 reduce 函数的处理结果。如下面的示例 /root/udf/myspread.py。
import io
import math
import pickleLOG_FILE: io.TextIOBase = Nonedef init():global LOG_FILELOG_FILE = open("/var/log/taos/spread.log", "wt")log("init function myspead success")def log(o):LOG_FILE.write(str(o) + '\n')def destroy():log("close log file: spread.log")LOG_FILE.close()def start():return pickle.dumps((-math.inf, math.inf))def reduce(block, buf):max_number, min_number = pickle.loads(buf)log(f"initial max_number={max_number}, min_number={min_number}")rows, _ = block.shape()for i in range(rows):v = block.data(i, 0)if v > max_number:log(f"max_number={v}")max_number = vif v < min_number:log(f"min_number={v}")min_number = vreturn pickle.dumps((max_number, min_number))def finish(buf):max_number, min_number = pickle.loads(buf)return max_number - min_number
在这个示例中,我们不但定义了一个聚合函数,还增加了记录执行日志的功能。
- init 函数打开一个文件用于记录日志
- log 函数记录日志,自动将传入的对象转成字符串,加换行符输出
- destroy 函数在执行结束后关闭日志文件
- start 函数返回初始的 buffer,用来存聚合函数的中间结果,把最大值初始化为负无穷大,最小值初始化为正无穷大
- reduce 函数处理每个数据块并聚合结果
- finish 函数将 buffer 转换成最终的输出
执行下面 SQL 语句创建对应的 UDF。
create or replace aggregate function myspread as '/root/udf/myspread.py' outputtype double bufsize 128 language 'Python';
这个 SQL 语句与创建标量函数的 SQL 语句有两个重要区别。
- 增加了 aggregate 关键字
- 增加了 bufsize 关键字,用来指定存储中间结果的内存大小,这个数值可以大于实际使用的数值。本例中间结果是两个浮点数组成的 tuple,序列化后实际占用大小只有 32 个字节,但指定的 bufsize 是 128,可以用 Python 命令行打印实际占用的字节数
>>> len(pickle.dumps((12345.6789, 23456789.9877)))
32
测试这个函数,可以看到 myspread 的输出结果和内置的 spread 函数的输出结果是一致的。
taos> select myspread(v1) from t;myspread(v1) |
============================5.000000000 |
Query OK, 1 row(s) in set (0.013486s)taos> select spread(v1) from t;spread(v1) |
============================5.000000000 |
Query OK, 1 row(s) in set (0.005501s)
最后,查看执行日志,可以看到 reduce 函数被执行了 3 次,执行过程中 max 值被更新了 4 次,min 值只被更新 1 次。
root@slave11 /var/log/taos $ cat spread.log
init function myspead success
initial max_number=-inf, min_number=inf
max_number=1
min_number=1
initial max_number=1, min_number=1
max_number=2
max_number=3
initial max_number=3, min_number=1
max_number=6
close log file: spread.log
通过这个示例,我们学会了如何定义聚合函数,并打印自定义的日志信息。
更多 Python UDF 示例代码
标量函数示例 pybitand
pybitand 实现多列的按位与功能。如果只有一列,返回这一列。pybitand 忽略空值。
pybitand.pydef init():passdef process(block):(rows, cols) = block.shape()result = []for i in range(rows):r = 2 ** 32 - 1for j in range(cols):cell = block.data(i,j)if cell is None:result.append(None)breakelse:r = r & cellelse:result.append(r)return resultdef destroy():pass聚合函数示例 pyl2norm
pyl2norm 实现了输入列的所有数据的二阶范数,即对每个数据先平方,再累加求和,最后开方。
pyl2norm.pyimport json
import mathdef init():passdef destroy():passdef start():return json.dumps(0.0).encode('utf-8')def finish(buf):sum_squares = json.loads(buf)result = math.sqrt(sum_squares)return resultdef reduce(datablock, buf):(rows, cols) = datablock.shape()sum_squares = json.loads(buf)for i in range(rows):for j in range(cols):cell = datablock.data(i,j)if cell is not None:sum_squares += cell * cellreturn json.dumps(sum_squares).encode('utf-8') 聚合函数示例 pycumsum
pycumsum 使用 numpy 计算输入列所有数据的累积和。
pycumsum.pyimport pickle
import numpy as npdef init():passdef destroy():passdef start():return pickle.dumps(0.0)def finish(buf):return pickle.loads(buf)def reduce(datablock, buf):(rows, cols) = datablock.shape()state = pickle.loads(buf)row = []for i in range(rows):for j in range(cols):cell = datablock.data(i, j)if cell is not None:row.append(datablock.data(i, j))if len(row) > 1:new_state = np.cumsum(row)[-1]else:new_state = statereturn pickle.dumps(new_state)管理 UDF
在集群中管理 UDF 的过程涉及创建、使用和维护这些函数。用户可以通过 SQL 在集群中创建和管理 UDF,一旦创建成功,集群的所有用户都可以在 SQL 中使用这些函数。由于 UDF 存储在集群的 mnode 上,因此即使重启集群,已经创建的 UDF 也仍然可用。
在创建 UDF 时,需要区分标量函数和聚合函数。标量函数接受零个或多个输入参数,并返回一个单一的值。聚合函数接受一组输入值,并通过对这些值进行某种计算(如求和、计数等)来返回一个单一的值。如果创建时声明了错误的函数类别,则通过 SQL 调用函数时会报错。
此外,用户需要确保输入数据类型与 UDF 程序匹配,UDF 输出的数据类型与 outputtype 匹配。这意味着在创建 UDF 时,需要为输入参数和输出值指定正确的数据类型。这有助于确保在调用 UDF 时,输入数据能够正确地传递给 UDF,并且 UDF 的输出值与预期的数据类型相匹配。
创建标量函数
创建标量函数的 SQL 语法如下。
CREATE [OR REPLACE] FUNCTION function_name AS library_path OUTPUTTYPE output_type LANGUAGE 'Python';
各参数说明如下。
- or replace:如果函数已经存在,则会修改已有的函数属性。
- function_name:标量函数在 SQL 中被调用时的函数名。
- language:支持 C 语言和 Python 语言(3.7 及以上版本),默认为 C。
- library_path:如果编程语言是 C,则路径是包含 UDF 实现的动态链接库的库文件绝对路径,通常指向一个 so 文件。如果编程语言是 Python,则路径是包含 UDF
实现的 Python 文件路径。路径需要用英文单引号或英文双引号括起来。 - output_type:函数计算结果的数据类型名称。
创建聚合函数
创建聚合函数的 SQL 语法如下。
CREATE [OR REPLACE] AGGREGATE FUNCTION function_name library_path OUTPUTTYPE output_type BUFSIZE buffer_size LANGUAGE 'Python';
其中,buffer_size 表示中间计算结果的缓冲区大小,单位是字节。其他参数的含义与标量函数相同。
如下 SQL 创建一个名为 l2norm 的 UDF。
CREATE AGGREGATE FUNCTION l2norm AS "/home/taos/udf_example/libl2norm.so" OUTPUTTYPE DOUBLE bufsize 8;
删除 UDF
删除指定名称的 UDF 的 SQL 语法如下。
DROP FUNCTION function_name;
查看 UDF
显示集群中当前可用的所有 UDF 的 SQL 如下。
show functions;
查看函数信息
同名的 UDF 每更新一次,版本号会增加 1。
select * from ins_functions \G;
访问官网
更多内容欢迎访问 TDengine 官网
相关文章:
- 使用 Python 开发 TDengine UDF 函数全攻略
相关文章:
TDengine 开发指南—— UDF函数
UDF 简介 在某些应用场景中,应用逻辑需要的查询功能无法直接使用内置函数来实现,TDengine 允许编写用户自定义函数(UDF),以便解决特殊应用场景中的使用需求。UDF 在集群中注册成功后,可以像系统内置函数一…...
使用vsftpd搭建FTP服务器(TLS/SSL显式加密)
安装vsftpd服务 使用vsftpd RPM安装包安装即可,如果可以访问YUM镜像源,通过dnf或者yum工具更加方便。 yum -y install vsftpd 启动vsftpd、查看服务状态 systemctl enable vsftpd systemctl start vsftpd systemctl status vsftpd 备份配置文件并进…...
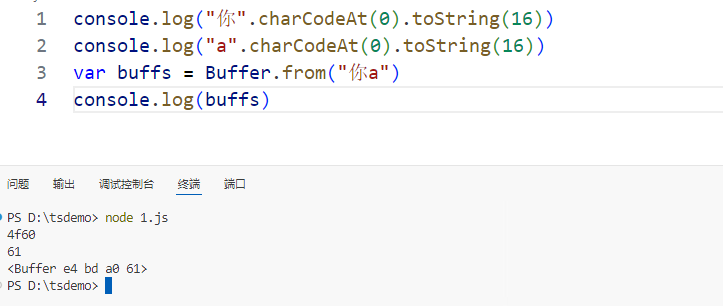
1.1Nodejs和浏览器中的二进制处理
Buffer 在 Node.js 中,Buffer 类用于处理二进制数据。由于 JavaScript 在浏览器环境中主要用于处理字符串和数字等类型的数据,对二进制数据的处理能力较弱,因此 Node.js 引入了 Buffer 类来弥补这一不足,特别是在处理文件系统操作…...
入门AJAX——XMLHttpRequest(Post)
一、前言 在上篇文章中,我们已经介绍了 HMLHttpRequest 的GET 请求的基本用法,并基于我提供的接口练习了两个简单的例子。如果你还没有看过第一篇文章,强烈建议你在学习完上篇文章后再学习本篇文章: 🔗入门AJAX——XM…...

Qt(part1)Qpushbutton,信号与槽,对象树,自定义信号与槽,lamda表达式。
1、创建Qt程序 2、命名规范及快捷键 3、Qpushbutton按钮创建 4、对象树概念 5、信号与槽 6、自定义信号与槽 7、当自定义信号和槽发生重载时 8、信号可以连接信号,信号也可以断开。 9、lamda表达式...

西北某省级联通公司:3D动环模块如何实现机房“一屏统管”?
一、运营商机房监控痛点凸显 在通信行业快速发展的当下,西北某省级联通公司肩负着保障区域通信畅通的重任。然而,公司分布广泛的机房面临着诸多监控难题,尤其是偏远机房环境风险无法实时感知这一痛点,严重影响了机房的稳定运行和通…...

【WPF】从普通 ItemsControl 到支持筛选的 ItemsControl:深入掌握 CollectionViewSource 用法
✨ 从普通 ItemsControl 到支持筛选的 ItemsControl:深入掌握 CollectionViewSource 用法 在日常 WPF 开发中,我们经常需要对数据进行筛选、排序、分组等操作,而原生的 ItemsControl 并不直接支持这些功能。本文将介绍如何通过 CollectionVi…...

Zookeeper 和 Kafka 版本与 JDK 要求
Apache Zookeeper 和 Apache Kafka 在不同版本中对 JDK 的要求如下表所示(基于官方文档和历史版本记录整理): 1. Zookeeper 版本与 JDK 要求 Zookeeper 版本要求的最低 JDK 版本说明3.4.x 系列JDK 6生产环境建议用 JDK 8(旧版兼容性强)。3.5.x 系列(3.5.5+)JDK 83.5.0 …...

3步布局关键词让流量更精准
其实流量不精准,90% 是关键词没布局好! 掌握这 3 个超实用技巧,让你的内容精准推给目标人群! 第一步:深挖高潜力关键词 别再一股脑用 “好看”“好用” 这些泛词啦!打开平台搜索框,输入核心词…...
视觉分析在人员行为属性检测中的应用
基于视觉分析的人员行为属性检测方案 一、背景与需求分析 在工业生产、建筑施工、公共安全等领域,人员行为属性的合规性检测是保障安全生产的关键环节。例如,工地工人未佩戴安全帽、厨房人员未佩戴手套、作业现场人员使用手机等行为,均可能…...

学习 React【Plan - June - Week 1】
一、使用 JSX 书写标签语言 JSX 是一种 JavaScript 的语法扩展,React 使用它来描述用户界面。 什么是 JSX? JSX 是 JavaScript 的一种语法扩展。看起来像 HTML,但它实际上是在 JavaScript 代码中写 XML/HTML。浏览器并不能直接运行 JSX&…...

电子行业AI赋能软件开发经典案例——某金融软件公司
01.案例标题 金融行业某金融软件公司通过StarShip CodeSouler达成效率突破性增长,零流程侵入验证AI代码高度可行性 02.执行摘要 某金融软件公司在核心产品研发中引入开放传神(OpenCSG)的StarShip CodeSouler AI代码生成平台,在无…...

【前端】js如何处理计算精度问题
JavaScript 的精度问题源于其遵循 IEEE 754 标准的 64 位双精度浮点数表示法,导致 0.1 0.2 ! 0.3 等经典问题。以下是系统化的解决方案及适用场景: ⚙️ 一、整数转换法(适合简单运算) 将小数转换为整数运算后再还原࿰…...

使用 Python 自动化 Word 文档样式复制与内容生成
在办公自动化领域,如何高效地处理 Word 文档的样式和内容复制是一个常见需求。本文将通过一个完整的代码示例,展示如何利用 Python 的 python-docx 库实现 Word 文档样式的深度复制 和 动态内容生成,并结合知识库中的最佳实践优化文档处理流程…...
)
Kafka 核心架构与消息模型深度解析(二)
案例实战:Kafka 在实际场景中的应用 (一)案例背景与需求介绍 假设我们正在为一个大型电商平台构建数据处理系统。该电商平台拥有庞大的用户群体,每天会产生海量的订单数据、用户行为数据(如浏览、点击、收藏等&#…...

4G网络中频段的分配
国内三大运营商使用的4G网络频段及对应关系如下: 📶 一、中国移动(以TD-LTE为主) 主力频段 Band 38(2570-2620MHz):室内覆盖Band 39(1880-1920MHz):广覆盖&am…...

SQL进阶之旅 Day 19:统计信息与优化器提示
【SQL进阶之旅 Day 19】统计信息与优化器提示 文章简述 在数据库性能调优中,统计信息和优化器提示是两个至关重要的工具。统计信息帮助数据库优化器评估查询成本并选择最佳执行计划,而优化器提示则允许开发人员对优化器的行为进行微调。本文深入探讨了…...

数据结构之LinkedList
系列文章目录 数据结构之ArrayList-CSDN博客 目录 系列文章目录 前言 一、模拟实现链表 1. 遍历链表 2. 插入节点 3. 删除节点 4. 清空链表 二、链表的常见操作 1. 反转链表 2. 返回链表的中间节点 3. 链表倒数第 k 个节点 4. 合并两个有序链表 5. 分割链表 6. 判…...
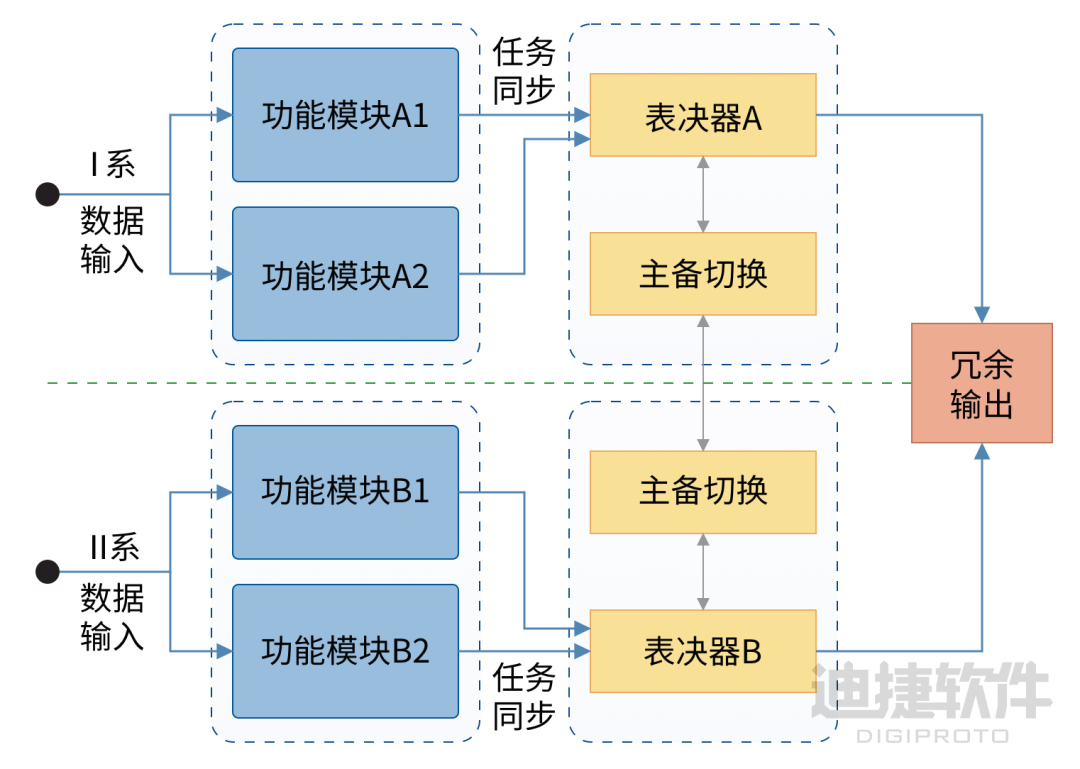
摆脱硬件依赖:SkyEye在轨道交通中的仿真应用
在城市轨道交通系统中,信号系统承担着确保列车安全、高效运行的关键任务。从排列进路、信号开放,到终点折返与接发车,几乎每一个调度动作背后都依赖于信号系统的精密控制与实时响应。作为信号系统的重要组成部分,目标控制器&#…...
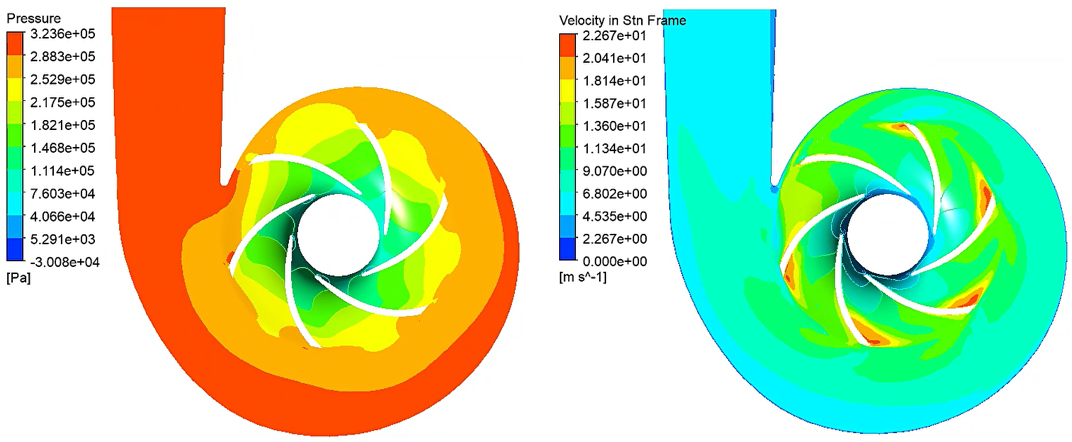
使用变异系数增强 CFD 收敛标准
将描述性统计整合到 CFD 中,以评估可变性和收敛性。 挑战 在工程设计中,尤其是在进行仿真时,我们经常处理描述流体、温度、应力或浓度行为的大型数据集。以有意义的方式解释这些值需要的不仅仅是原始数字;它需要对统计的理解。 统计学在工程…...

解决获取视频第一帧黑屏问题
文章目录 解决获取视频第一帧黑屏问题核心代码 解决获取视频第一帧黑屏问题 废话不多说,直接上代码: <script setup> const status ref(请点击“添加视频”按钮添加视频) const videoElement ref(document.createElement(video)) const curren…...
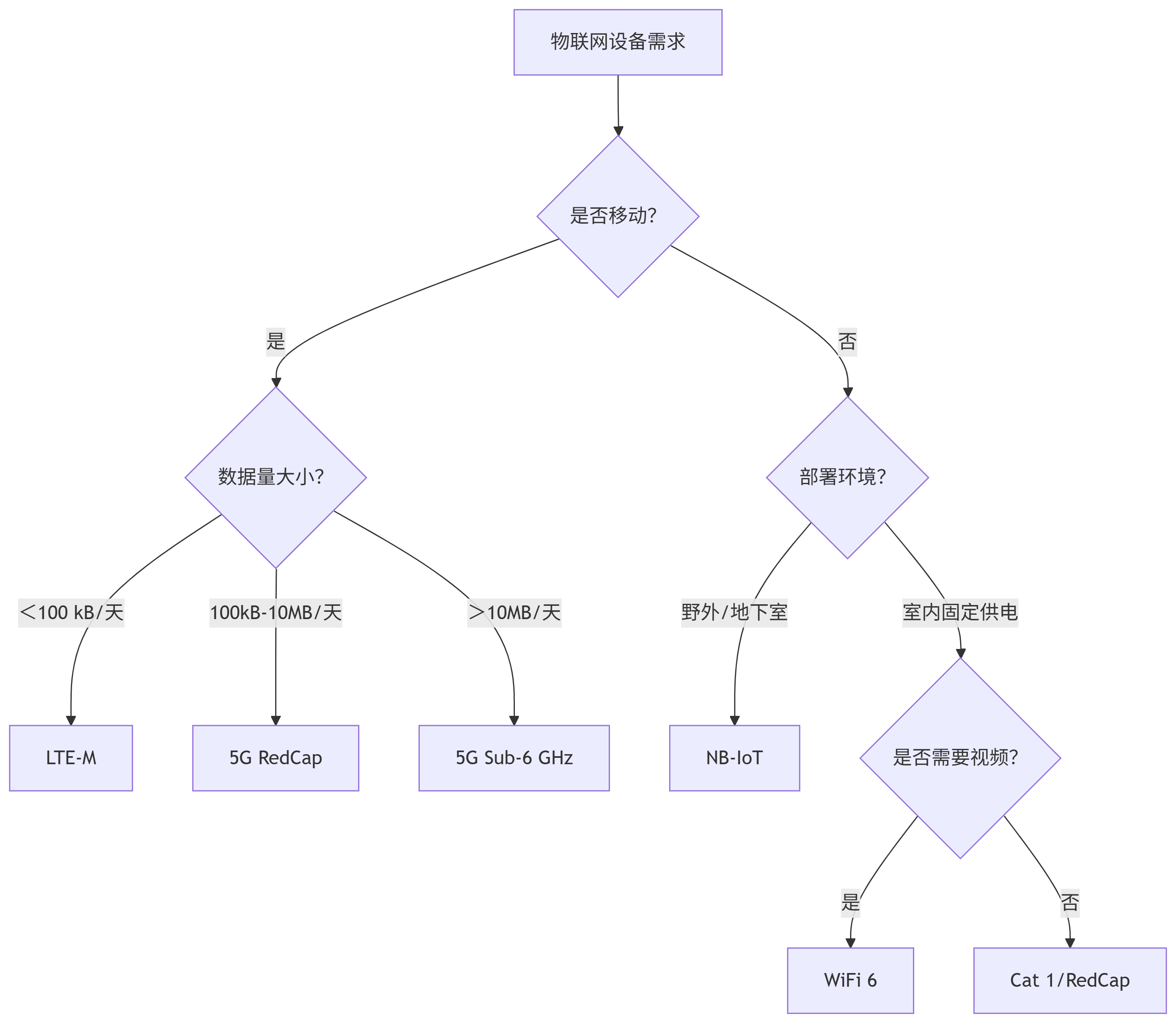
物联网通信技术全景指南(2025)之如何挑选合适的物联网模块
物联网通信技术全景指南(2025)之 如何挑选合适的物联网模块 物联网通信技术全景指南(2025)一、技术代际演进与退网背景二、5G 物联网技术体系(Sub-6 GHz 核心)1. 技术分层架构2. 蜂窝技术性能矩阵3. Sub-6 …...

影楼精修-AI衣服祛褶皱算法解析
注:为避免侵权,本文所用图像均为AIGC生成或无版权网站提供; 衣服祛褶皱功能,目前在像素蛋糕、美图云修、百度网盘AI修图、阿里云都有相关的功能支持,它的价值就是将不平整的衣服图像,变得整齐平整…...
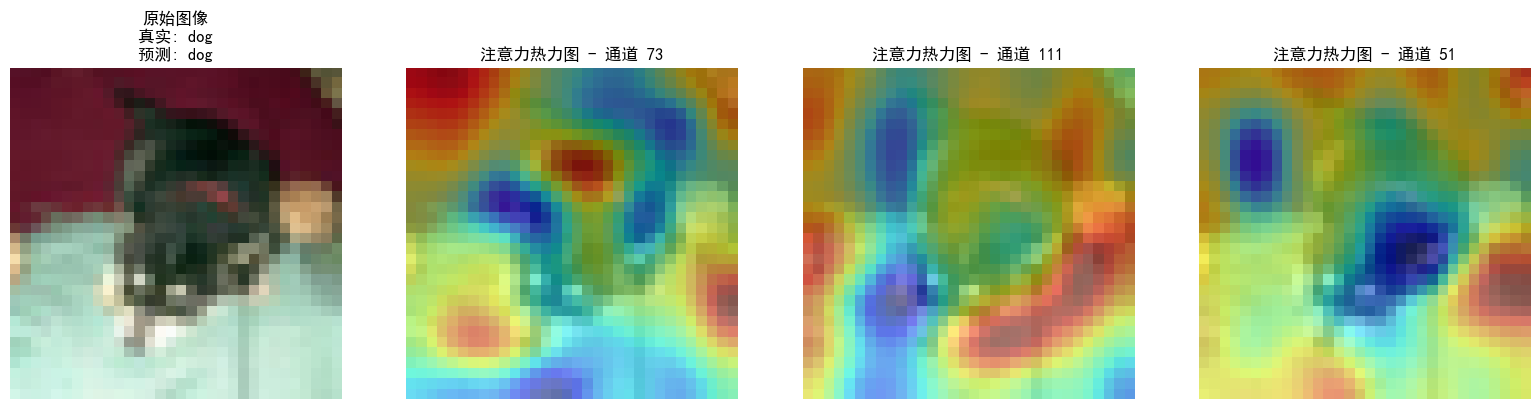
Day46 Python打卡训练营
知识点回顾: 1. 不同CNN层的特征图:不同通道的特征图 2. 什么是注意力:注意力家族,类似于动物园,都是不同的模块,好不好试了才知道。 3. 通道注意力:模型的定义和插入的位置 4. 通道注意力后…...

信号电压高,传输稳定性变强,但是传输速率下降?
信号电压高,传输稳定性变强,但是传输速率下降? 一、信号电压升高,传输稳定性变强 1.信号幅度更大,抗噪声能力增强 2.噪声,比如干扰电磁波,串扰等相对于信号幅度比例变小,误码率降低 …...

linux安全加固(非常详细)
安全加固方案原则 1.版本升级 对于系统和应用在使用过程中暴露的安全缺陷,系统或应用厂商会及时发布解决问题的升级补丁包。升级系统或应用版本,可有效解决旧版本存在的安全风险。2.关闭端口服务 在不影响业务系统正常运行情况下,停止或禁用承…...

关于事务的简介
一、引言 在数据处理与存储的领域中,事务(Transaction)是确保数据完整性和一致性的关键概念。无论是金融系统的资金转账、电商平台的订单处理,还是企业资源规划(ERP)系统的业务流程操作,事务都…...

qt控制台程序与qt窗口程序在读取数据库中文字段的差异!!巨坑
问题:最近在自己编写一个类,这个类需要对mysql数据库进行插入和查询。因为最后是以一个类文件的形式拿来单独使用,所以在创建项目的时候就创建了一个qt的控制台程序。但是在对数据库的内容进行查询时,出现了中文乱码。参考了之前的…...
动手学深度学习12.7. 参数服务器-笔记练习(PyTorch)
以下内容为结合李沐老师的课程和教材补充的学习笔记,以及对课后练习的一些思考,自留回顾,也供同学之人交流参考。 本节课程地址:35 分布式训练【动手学深度学习v2】_哔哩哔哩_bilibili 本节教材地址:12.7. 参数服务器…...

告别数据泥沼,拥抱智能中枢:King’s四位一体重塑科研生产力
在现代科研的战场上,数据堪称科研人员手中的“弹药”。然而,许多实验室却深陷数据管理的泥沼:硬盘里堆满了不同年份的实验记录,U盘里塞着各种格式的谱图,Excel表格里还留着手动计算的痕迹……,当科研人员想…...