vue+elementUI+springboot实现文件合并前端展示文件类型
项目场景:
element的table上传文件并渲染出文件名称点击所属行可以查看文件,并且可以导出合并文件,此文章是记录合并文档前端展示的帖子
解决方案:
后端定义三个工具类
分别是pdf,doc和word的excle的目前我没整
word的工具类
package com.sc.modules.biddinvestment.utils;import org.apache.poi.xwpf.usermodel.*;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.*;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.List;public class WordMerger {private static final Logger logger = LoggerFactory.getLogger(WordMerger.class);public String mergeWordDocuments(List<String> filePaths) throws IOException {validateFiles(filePaths);XWPFDocument mergedDoc = new XWPFDocument();try {for (String filePath : filePaths) {addFileToDocument(mergedDoc, filePath);}return saveMergedDocument(mergedDoc);} finally {mergedDoc.close();}}private void addFileToDocument(XWPFDocument mergedDoc, String filePath) throws IOException {File file = new File(filePath);addSectionTitle(mergedDoc, file.getName());if (filePath.toLowerCase().endsWith(".txt")) {addTxtContent(mergedDoc, file);} else if (filePath.toLowerCase().endsWith(".docx")) {addDocxContent(mergedDoc, file);} else {throw new IllegalArgumentException("暂不支持的文件格式: " + filePath);}}private void addSectionTitle(XWPFDocument doc, String fileName) {XWPFParagraph titlePara = doc.createParagraph();titlePara.setAlignment(ParagraphAlignment.CENTER);XWPFRun titleRun = titlePara.createRun();
// titleRun.setText("===== 文件: " + fileName + " ====="); //添加上之后文档名称会出现在合并后的文档里titleRun.setFontSize(14);titleRun.setBold(true);titleRun.addBreak();}private void addTxtContent(XWPFDocument doc, File txtFile) throws IOException {List<String> lines = Files.readAllLines(txtFile.toPath());XWPFParagraph para = doc.createParagraph();XWPFRun run = para.createRun();for (String line : lines) {run.setText(line);run.addBreak();}run.addBreak(); // 段落间隔}private void addDocxContent(XWPFDocument mergedDoc, File docxFile) throws IOException {try (XWPFDocument sourceDoc = new XWPFDocument(new FileInputStream(docxFile))) {for (XWPFParagraph para : sourceDoc.getParagraphs()) {XWPFParagraph newPara = mergedDoc.createParagraph();newPara.getCTP().set(para.getCTP()); // 复制段落格式}for (XWPFTable table : sourceDoc.getTables()) {mergedDoc.createTable().getCTTbl().set(table.getCTTbl()); // 复制表格}}}private String saveMergedDocument(XWPFDocument doc) throws IOException {Path desktopPath = Paths.get(System.getProperty("user.home"), "Desktop");if (!Files.exists(desktopPath)) Files.createDirectories(desktopPath);String timestamp = new SimpleDateFormat("yyyyMMdd_HHmmss").format(new Date());Path outputPath = desktopPath.resolve("merged_word_" + timestamp + ".docx");try (FileOutputStream fos = new FileOutputStream(outputPath.toFile())) {doc.write(fos);}logger.info("Word合并完成,输出路径: {}", outputPath);return outputPath.toString();}private void validateFiles(List<String> filePaths) {for (String path : filePaths) {File file = new File(path);if (!file.exists() || !file.canRead()) {throw new IllegalArgumentException("文件无效或不可读: " + path);}}}
}
doc的工具类
package com.sc.modules.biddinvestment.utils;import org.slf4j.Logger;
import org.slf4j.LoggerFactory;import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.BufferedWriter;
import java.io.File;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.List;public class DocMerger {private static final Logger logger = LoggerFactory.getLogger(DocMerger.class);// 保留原文本合并功能(可选)public String mergeTxtDocuments(List<String> filePaths) throws IOException {validateFiles(filePaths);Path desktopPath = Paths.get(System.getProperty("user.home"), "Desktop");if (!Files.exists(desktopPath)) Files.createDirectories(desktopPath);String timestamp = new SimpleDateFormat("yyyyMMdd_HHmmss").format(new Date());Path outputPath = desktopPath.resolve("merged_txt_" + timestamp + ".txt");try (BufferedWriter writer = Files.newBufferedWriter(outputPath, StandardCharsets.UTF_8)) {for (String path : filePaths) {File file = new File(path);writer.write("===== 文件: " + file.getName() + " =====\n");List<String> lines = Files.readAllLines(file.toPath(), StandardCharsets.UTF_8);for (String line : lines) {writer.write(line);writer.newLine();}writer.write("\n\n");}}logger.info("文本合并完成,输出路径: {}", outputPath);return outputPath.toString();}private void validateFiles(List<String> filePaths) {for (String path : filePaths) {File file = new File(path);if (!file.exists() || !file.canRead()) {throw new IllegalArgumentException("文件无效或不可读: " + path);}}}
}
pdf的
package com.sc.modules.biddinvestment.utils;
import org.apache.pdfbox.multipdf.PDFMergerUtility;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;import java.io.File;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.text.SimpleDateFormat;
import java.util.Arrays;
import java.util.Date;
import java.util.List;
import java.util.stream.Collectors;public class PdfMerger {private static final Logger logger = LoggerFactory.getLogger(PdfMerger.class);private static final String DEFAULT_OUTPUT_NAME = "merged";private static final String PDF_EXTENSION = ".pdf";/*** 合并多个PDF文件** @param filePaths 要合并的PDF文件路径列表* @return 合并后的文件绝对路径* @throws IOException 如果合并过程中发生错误*/public String mergePdfs(List<String> filePaths) throws IOException {validateInputFiles(filePaths);File outputFile = prepareOutputFile();mergeFiles(filePaths, outputFile);logger.info("成功合并 {} 个PDF文件到: {}", filePaths.size(), outputFile.getAbsolutePath());return outputFile.getAbsolutePath();}/*** 验证输入文件*/private void validateInputFiles(List<String> filePaths) {if (filePaths == null || filePaths.isEmpty()) {throw new IllegalArgumentException("文件路径列表不能为空");}for (String path : filePaths) {if (path == null || path.trim().isEmpty()) {throw new IllegalArgumentException("文件路径不能为空");}File file = new File(path);if (!file.exists()) {throw new IllegalArgumentException("文件不存在: " + path);}if (!file.isFile()) {throw new IllegalArgumentException("路径不是文件: " + path);}if (!file.canRead()) {throw new IllegalArgumentException("文件不可读: " + path);}if (!path.toLowerCase().endsWith(".pdf")) {throw new IllegalArgumentException("仅支持PDF文件: " + path);}}}/*** 准备输出文件*/private File prepareOutputFile() throws IOException {Path desktopPath = Paths.get(System.getProperty("user.home"), "Desktop");// 确保桌面目录存在if (!Files.exists(desktopPath)) {logger.warn("桌面目录不存在,尝试创建: {}", desktopPath);try {Files.createDirectories(desktopPath);} catch (IOException e) {throw new IOException("无法创建桌面目录: " + desktopPath, e);}}// 生成唯一文件名String timestamp = new SimpleDateFormat("yyyyMMdd_HHmmss").format(new Date());String baseName = DEFAULT_OUTPUT_NAME + "_" + timestamp + PDF_EXTENSION;Path outputPath = desktopPath.resolve(baseName);// 处理文件名冲突int counter = 1;while (Files.exists(outputPath)) {baseName = DEFAULT_OUTPUT_NAME + "_" + timestamp + "_" + counter + PDF_EXTENSION;outputPath = desktopPath.resolve(baseName);counter++;}return outputPath.toFile();}/*** 执行PDF合并*/private void mergeFiles(List<String> inputFilePaths, File outputFile) throws IOException {PDFMergerUtility merger = new PDFMergerUtility();try {// 添加所有源文件for (String filePath : inputFilePaths) {merger.addSource(new File(filePath));}// 设置输出文件merger.setDestinationFileName(outputFile.getAbsolutePath());// 执行合并merger.mergeDocuments(null);} catch (IOException e) {// 合并失败时删除可能已创建的部分输出文件if (outputFile.exists() && !outputFile.delete()) {logger.error("无法删除部分合并的文件: {}", outputFile.getAbsolutePath());}throw new IOException("PDF合并失败: " + e.getMessage(), e);}}// 重载方法,支持可变参数public String mergePdfs(String... filePaths) throws IOException {return mergePdfs(Arrays.asList(filePaths));}}调用方法
@PostMapping("/mergeDocuments")
public String mergeFiles(@RequestBody Map<String, List<String>> request) {try {List<String> filePaths = request.get("filePaths");if (filePaths == null || filePaths.isEmpty()) {return "错误:文件路径列表为空!";}boolean allPdf = filePaths.stream().allMatch(path -> path.toLowerCase().endsWith(".pdf"));String mergedFilePath;if (allPdf) {PdfMerger merger = new PdfMerger();mergedFilePath = merger.mergePdfs(filePaths);} else {WordMerger wordMerger = new WordMerger();mergedFilePath = wordMerger.mergeWordDocuments(filePaths);}return "文件合并成功,保存路径: " + mergedFilePath;} catch (Exception e) {return "文件合并失败:" + e.getMessage();}
}前端:
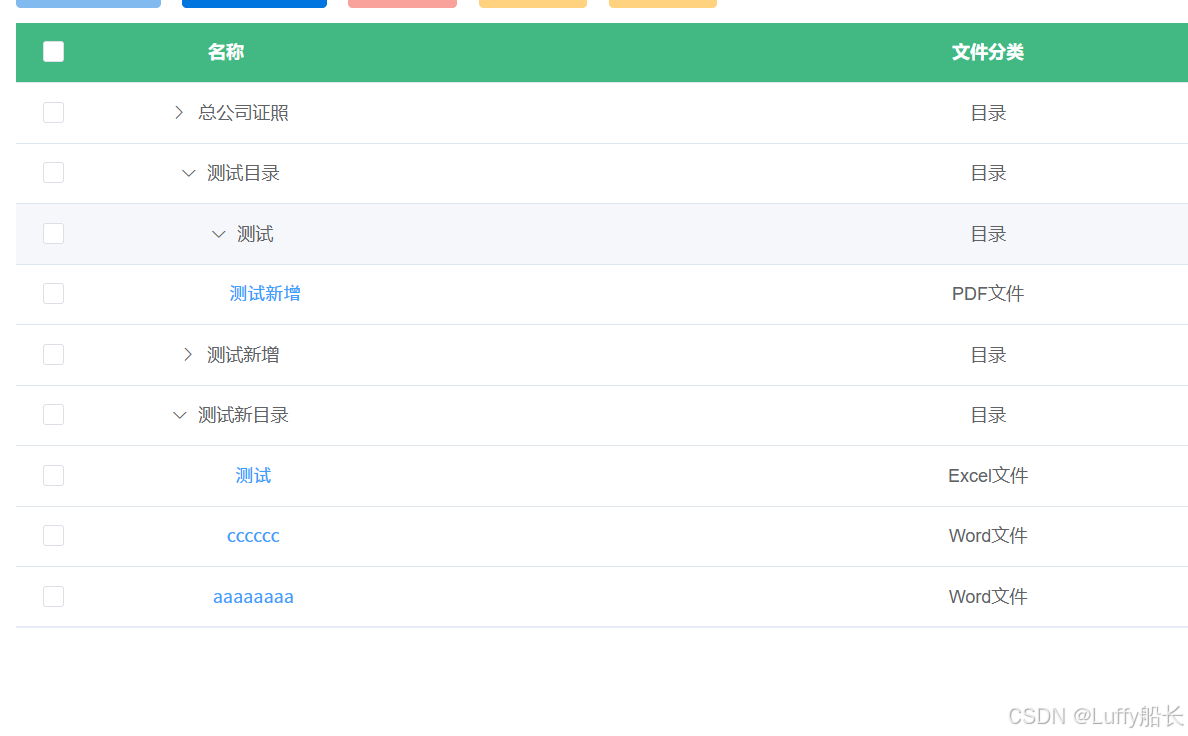
getMenuData() {setTimeout(() => {url.getMenusTree().then(res => {// 定义文件类型映射const fileTypeMap = {pdf: 'PDF文件',doc: 'Word文件',docx: 'Word文件',xls: 'Excel文件',xlsx: 'Excel文件'};// 提取文件后缀的工具函数const getFileType = (filepatch, filecode) => {if (filepatch) {const ext = filepatch.split('.').pop().toLowerCase();return fileTypeMap[ext] || '目录';}// fallback 用 filecode 判断return filecode === 0 ? '目录' : '目录';};// 定义递归处理函数const processTree = (nodes) => {return nodes.map(item => ({...item,filetype: getFileType(item.filepatch, item.filecode),children: item.children ? processTree(item.children) : []}));};// 处理后的树结构赋值this.biddData = processTree(res.data);});}, 100); },
前端定义递归方法遍历每条数据的filepatch 然后利用
filepatch.split('.').pop().toLowerCase();
获取名称的拓展名判断是哪一类
之后调用fileTypeMap将对应的文件名称写进去
就可以展示了
我这里是树形结构所以调用了processTree
相关文章:
vue+elementUI+springboot实现文件合并前端展示文件类型
项目场景: element的table上传文件并渲染出文件名称点击所属行可以查看文件,并且可以导出合并文件,此文章是记录合并文档前端展示的帖子 解决方案: 后端定义三个工具类 分别是pdf,doc和word的excle的目前我没整 word的工具类 package com.sc.modules…...
高效绘制业务流程图!专业模板免费下载
在复杂的业务流程管理中,可视化工具已成为提升效能的核心基础设施。为助力开发者、项目经理及业务架构师高效落地流程标准化,本文将为你精选5套开箱即用的专业流程图模板。这些模板覆盖跨部门协作、电商订单、客户服务等高频场景,具备以下核心…...
Spring Boot + Prometheus 实现应用监控(基于 Actuator 和 Micrometer)
文章目录 Spring Boot Prometheus 实现应用监控(基于 Actuator 和 Micrometer)环境准备示例结构启动和验证验证 Spring Boot 应用Prometheus 抓取配置(静态方式)Grafana 面板配置总结 Spring Boot Prometheus 实现应用监控&…...

PowerBI企业运营分析—列互换式中国式报表分析
PowerBI企业运营分析—列互换式中国式报表分析 欢迎来到Powerbi小课堂,在竞争激烈的市场环境中,企业运营分析平台成为提升竞争力的核心工具。 该平台通过高效整合多源数据,并实时监控关键指标,能够迅速揭示业务表现的全貌&#…...
BugKu Web渗透之需要管理员
启动场景,打开网页,显示如下: 一般没有上面头绪的时候,就是两步:右键查看源代码 和 扫描网站目录。 步骤一: 右键查看源代码 和 扫描网站目录。 右键查看源代码没有发现异常。 于是扫描网站目录&…...
)
Java集合初始化:Lists.newArrayList vs new ArrayList()
文章目录 前言一、核心区别全景图二、代码实现深度对比1. 初始化方式对比2. 容量预分配机制 三、性能与底层原理1. 内存分配策略2. 基准测试数据(JMH) 四、Guava的进阶功能生态1. 集合转换2. 集合分片3. 不可变集合创建 五、最佳实践指南六、源码级实现解…...

VBA清空数据
列数转字母 Function CNtoW(ByVal num As Long) As String CNtoW Replace(Cells(1, num).Address(False, False), "1", "") End Function 字母转列数 Function CWtoN(ByVal AB As String) As Long CWtoN Range("a1:" & AB & &…...
综合知识答案和详解(回忆版))
【信息系统项目管理师-选择真题】2025上半年(第二批)综合知识答案和详解(回忆版)
更多内容请见: 备考信息系统项目管理师-专栏介绍和目录 文章目录 【第1题】【第2题】【第3题】【第4题】【第5题】【第6题】【第7题】【第8题】【第9题】【第10题】【第11题】【第12题】【第13题】【第14题】【第15题】【第16题】【第17题】【第18题】【第19题】【第20题】【第…...

Java Lambda 表达式的缺点和替代方案
Java 8 引入的 Lambda 表达式曾被誉为编写简洁、函数式代码的革命性工具。但说实话,它们并不是万能钥匙。它有不少问题,比如它没有宣传的那么易读,在某些场景下还带来性能开销。 作为一名多年与 Java 冗长语法搏斗的开发者,我找到了更注重清晰、可维护性和性能的替代方案。…...

TDengine 开发指南—— UDF函数
UDF 简介 在某些应用场景中,应用逻辑需要的查询功能无法直接使用内置函数来实现,TDengine 允许编写用户自定义函数(UDF),以便解决特殊应用场景中的使用需求。UDF 在集群中注册成功后,可以像系统内置函数一…...
使用vsftpd搭建FTP服务器(TLS/SSL显式加密)
安装vsftpd服务 使用vsftpd RPM安装包安装即可,如果可以访问YUM镜像源,通过dnf或者yum工具更加方便。 yum -y install vsftpd 启动vsftpd、查看服务状态 systemctl enable vsftpd systemctl start vsftpd systemctl status vsftpd 备份配置文件并进…...
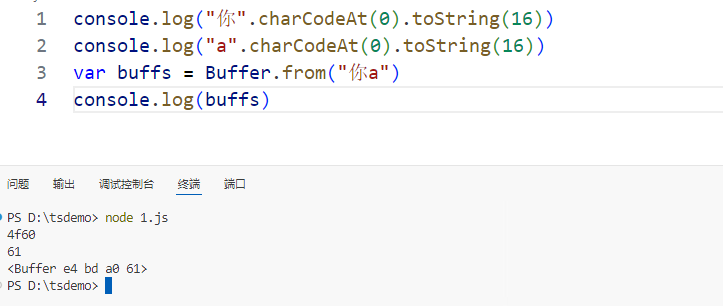
1.1Nodejs和浏览器中的二进制处理
Buffer 在 Node.js 中,Buffer 类用于处理二进制数据。由于 JavaScript 在浏览器环境中主要用于处理字符串和数字等类型的数据,对二进制数据的处理能力较弱,因此 Node.js 引入了 Buffer 类来弥补这一不足,特别是在处理文件系统操作…...
入门AJAX——XMLHttpRequest(Post)
一、前言 在上篇文章中,我们已经介绍了 HMLHttpRequest 的GET 请求的基本用法,并基于我提供的接口练习了两个简单的例子。如果你还没有看过第一篇文章,强烈建议你在学习完上篇文章后再学习本篇文章: 🔗入门AJAX——XM…...

Qt(part1)Qpushbutton,信号与槽,对象树,自定义信号与槽,lamda表达式。
1、创建Qt程序 2、命名规范及快捷键 3、Qpushbutton按钮创建 4、对象树概念 5、信号与槽 6、自定义信号与槽 7、当自定义信号和槽发生重载时 8、信号可以连接信号,信号也可以断开。 9、lamda表达式...

西北某省级联通公司:3D动环模块如何实现机房“一屏统管”?
一、运营商机房监控痛点凸显 在通信行业快速发展的当下,西北某省级联通公司肩负着保障区域通信畅通的重任。然而,公司分布广泛的机房面临着诸多监控难题,尤其是偏远机房环境风险无法实时感知这一痛点,严重影响了机房的稳定运行和通…...

【WPF】从普通 ItemsControl 到支持筛选的 ItemsControl:深入掌握 CollectionViewSource 用法
✨ 从普通 ItemsControl 到支持筛选的 ItemsControl:深入掌握 CollectionViewSource 用法 在日常 WPF 开发中,我们经常需要对数据进行筛选、排序、分组等操作,而原生的 ItemsControl 并不直接支持这些功能。本文将介绍如何通过 CollectionVi…...

Zookeeper 和 Kafka 版本与 JDK 要求
Apache Zookeeper 和 Apache Kafka 在不同版本中对 JDK 的要求如下表所示(基于官方文档和历史版本记录整理): 1. Zookeeper 版本与 JDK 要求 Zookeeper 版本要求的最低 JDK 版本说明3.4.x 系列JDK 6生产环境建议用 JDK 8(旧版兼容性强)。3.5.x 系列(3.5.5+)JDK 83.5.0 …...

3步布局关键词让流量更精准
其实流量不精准,90% 是关键词没布局好! 掌握这 3 个超实用技巧,让你的内容精准推给目标人群! 第一步:深挖高潜力关键词 别再一股脑用 “好看”“好用” 这些泛词啦!打开平台搜索框,输入核心词…...
视觉分析在人员行为属性检测中的应用
基于视觉分析的人员行为属性检测方案 一、背景与需求分析 在工业生产、建筑施工、公共安全等领域,人员行为属性的合规性检测是保障安全生产的关键环节。例如,工地工人未佩戴安全帽、厨房人员未佩戴手套、作业现场人员使用手机等行为,均可能…...

学习 React【Plan - June - Week 1】
一、使用 JSX 书写标签语言 JSX 是一种 JavaScript 的语法扩展,React 使用它来描述用户界面。 什么是 JSX? JSX 是 JavaScript 的一种语法扩展。看起来像 HTML,但它实际上是在 JavaScript 代码中写 XML/HTML。浏览器并不能直接运行 JSX&…...

电子行业AI赋能软件开发经典案例——某金融软件公司
01.案例标题 金融行业某金融软件公司通过StarShip CodeSouler达成效率突破性增长,零流程侵入验证AI代码高度可行性 02.执行摘要 某金融软件公司在核心产品研发中引入开放传神(OpenCSG)的StarShip CodeSouler AI代码生成平台,在无…...

【前端】js如何处理计算精度问题
JavaScript 的精度问题源于其遵循 IEEE 754 标准的 64 位双精度浮点数表示法,导致 0.1 0.2 ! 0.3 等经典问题。以下是系统化的解决方案及适用场景: ⚙️ 一、整数转换法(适合简单运算) 将小数转换为整数运算后再还原࿰…...

使用 Python 自动化 Word 文档样式复制与内容生成
在办公自动化领域,如何高效地处理 Word 文档的样式和内容复制是一个常见需求。本文将通过一个完整的代码示例,展示如何利用 Python 的 python-docx 库实现 Word 文档样式的深度复制 和 动态内容生成,并结合知识库中的最佳实践优化文档处理流程…...
)
Kafka 核心架构与消息模型深度解析(二)
案例实战:Kafka 在实际场景中的应用 (一)案例背景与需求介绍 假设我们正在为一个大型电商平台构建数据处理系统。该电商平台拥有庞大的用户群体,每天会产生海量的订单数据、用户行为数据(如浏览、点击、收藏等&#…...

4G网络中频段的分配
国内三大运营商使用的4G网络频段及对应关系如下: 📶 一、中国移动(以TD-LTE为主) 主力频段 Band 38(2570-2620MHz):室内覆盖Band 39(1880-1920MHz):广覆盖&am…...

SQL进阶之旅 Day 19:统计信息与优化器提示
【SQL进阶之旅 Day 19】统计信息与优化器提示 文章简述 在数据库性能调优中,统计信息和优化器提示是两个至关重要的工具。统计信息帮助数据库优化器评估查询成本并选择最佳执行计划,而优化器提示则允许开发人员对优化器的行为进行微调。本文深入探讨了…...

数据结构之LinkedList
系列文章目录 数据结构之ArrayList-CSDN博客 目录 系列文章目录 前言 一、模拟实现链表 1. 遍历链表 2. 插入节点 3. 删除节点 4. 清空链表 二、链表的常见操作 1. 反转链表 2. 返回链表的中间节点 3. 链表倒数第 k 个节点 4. 合并两个有序链表 5. 分割链表 6. 判…...
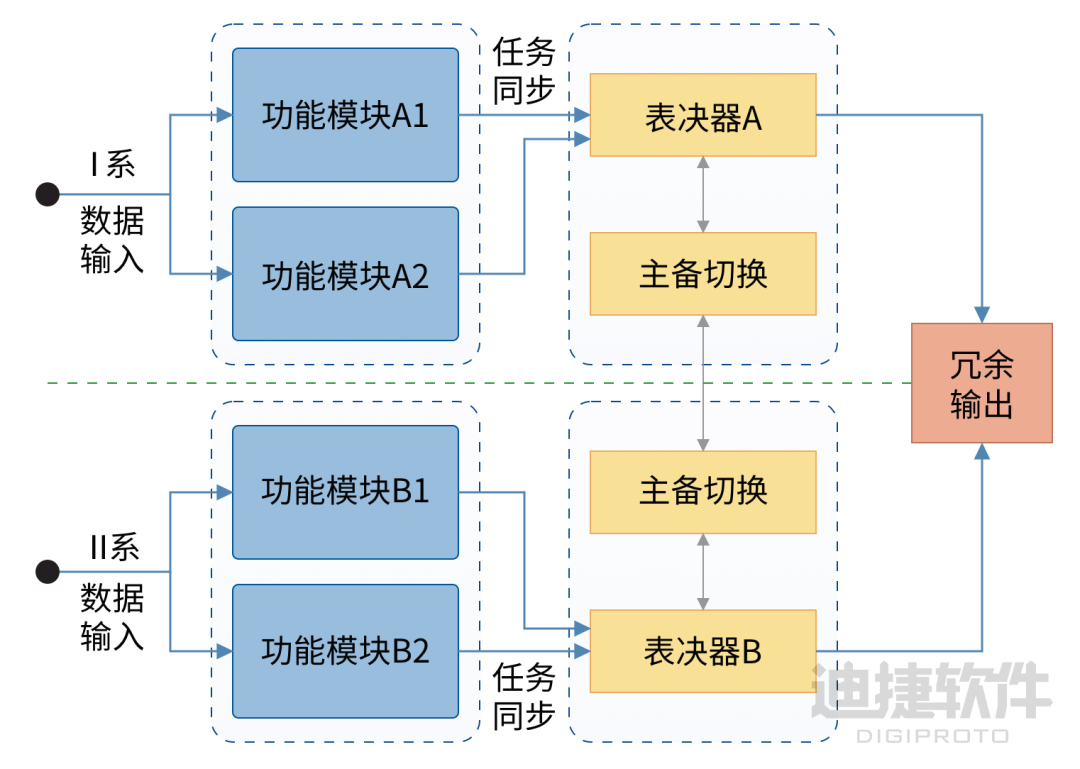
摆脱硬件依赖:SkyEye在轨道交通中的仿真应用
在城市轨道交通系统中,信号系统承担着确保列车安全、高效运行的关键任务。从排列进路、信号开放,到终点折返与接发车,几乎每一个调度动作背后都依赖于信号系统的精密控制与实时响应。作为信号系统的重要组成部分,目标控制器&#…...
使用变异系数增强 CFD 收敛标准
将描述性统计整合到 CFD 中,以评估可变性和收敛性。 挑战 在工程设计中,尤其是在进行仿真时,我们经常处理描述流体、温度、应力或浓度行为的大型数据集。以有意义的方式解释这些值需要的不仅仅是原始数字;它需要对统计的理解。 统计学在工程…...

解决获取视频第一帧黑屏问题
文章目录 解决获取视频第一帧黑屏问题核心代码 解决获取视频第一帧黑屏问题 废话不多说,直接上代码: <script setup> const status ref(请点击“添加视频”按钮添加视频) const videoElement ref(document.createElement(video)) const curren…...