Go语言爬虫系列教程5:HTML解析技术以及第三方库选择
Go语言爬虫系列教程5:HTML解析技术以及第三方库选择
在上一章中,我们使用正则表达式提取网页内容,但这种方法有局限性。对于复杂的HTML结构,我们需要使用专门的HTML解析库。在这一章中,我们将介绍HTML解析技术以及如何选择合适的第三方库。
一、HTML DOM树结构介绍
1.1 什么是DOM
在学习HTML解析之前,我们需要了解HTML的DOM树结构。DOM(Document Object Model)是HTML文档的树形结构表示,它将HTML文档中的每个元素、属性和文本都表示为一个节点。
1.2 DOM树的基本组成
DOM树由多种类型的节点组成:
- 元素节点:对应HTML标签,如
<div>、<p>等 - 文本节点:包含文本内容
- 属性节点:元素的属性,如
class="container" - 注释节点:HTML注释
<!-- 注释 -->
1.3 节点关系
DOM树中的节点具有以下关系:
- 父子关系:包含其他元素的节点是父节点,被包含的是子节点
- 兄弟关系:共享同一父节点的节点互为兄弟节点
- 祖先和后代关系:间接的父子关系
1.4 DOM树示例
以下是一个简单HTML文档及其DOM树结构:
<!DOCTYPE html>
<html>
<head><title>示例页面</title>
</head>
<body><div class="container"><h1>标题</h1><p>这是<a href="https://example.com">一个</a>段落。</p></div>
</body>
</html>
其树状结构可以表示为:
html
├── head
│ └── title
│ └── "示例页面"
└── body└── div.container├── h1│ └── "标题"└── p├── "这是"├── a[href="https://example.com"]│ └── "一个"└── "段落。"
1.5 HTML解析的重要性
理解DOM树结构对于HTML解析至关重要,因为它是我们进行网页数据提取的基础。
- 从网页中提取结构化数据
- 查找特定的元素和属性
- 分析网页结构
- 数据清洗和处理
二、CSS选择器详解
CSS选择器是一种用于选择HTML元素的语法。它不仅在CSS样式中使用,也是HTML解析库中定位元素的重要工具。
2.1 基础选择器
元素选择器
选择指定标签的所有元素:
p /* 选择所有<p>元素 */
div /* 选择所有<div>元素 */
h1 /* 选择所有<h1>元素 */
类选择器
选择具有指定class的元素,以.开头:
.quote /* 选择所有class="quote"的元素 */
.container /* 选择所有class="container"的元素 */
ID选择器
选择具有指定id的元素,以#开头:
#header /* 选择id="header"的元素 */
#main /* 选择id="main"的元素 */
2.2 组合选择器
后代选择器(空格)
选择某元素内部的所有指定元素:
.quote .text /* 选择class="quote"元素内的class="text"元素 */
div p /* 选择div内的所有p元素 */
子元素选择器(>)
选择某元素的直接子元素:
.quote > .text /* 选择class="quote"元素的直接子元素中class="text"的元素 */
ul > li /* 选择ul的直接子元素li */
相邻兄弟选择器(+)
选择紧接在指定元素后的兄弟元素:
h1 + p /* 选择紧跟在h1后的p元素 */
.title + .author /* 选择紧跟在class="title"后的class="author"元素 */
通用兄弟选择器(~)
选择指定元素后的所有兄弟元素:
h1 ~ p /* 选择h1后的所有兄弟p元素 */
.title ~ .info /* 选择class="title"后的所有class="info"兄弟元素 */
2.3 属性选择器
| 选择器 | 说明 | 示例 |
|---|---|---|
[attr] | 选择具有指定属性的元素 | a[href] |
[attr=value] | 选择属性值完全匹配的元素 | input[type="text"] |
[attr!=value] | 选择属性值不等于指定值的元素 | input[type!="hidden"] |
[attr^=value] | 选择属性值以指定值开头的元素 | a[href^="https"] |
[attr$=value] | 选择属性值以指定值结尾的元素 | img[src$=".jpg"] |
[attr*=value] | 选择属性值包含指定值的元素 | class[*="nav"] |
[attr~=value] | 选择属性值包含指定单词的元素 | class[~="active"] |
| `[attr | =value]` | 选择属性值等于指定值或以指定值开头后跟连字符的元素 |
2.4 伪类选择器
结构伪类
:first-child /* 选择作为第一个子元素的元素 */
:last-child /* 选择作为最后一个子元素的元素 */
:nth-child(n) /* 选择作为第n个子元素的元素 */
:nth-last-child(n) /* 选择作为倒数第n个子元素的元素 */
:only-child /* 选择作为唯一子元素的元素 */:first-of-type /* 选择同类型中的第一个元素 */
:last-of-type /* 选择同类型中的最后一个元素 */
:nth-of-type(n) /* 选择同类型中的第n个元素 */
:nth-last-of-type(n) /* 选择同类型中的倒数第n个元素 */
:only-of-type /* 选择同类型中的唯一元素 */
内容伪类
:empty /* 选择没有子元素和文本内容的元素 */
:contains(text) /* 选择包含指定文本的元素(goquery特有) */
:has(selector) /* 选择包含匹配选择器的子元素的元素 */
2.5 选择器优先级
当多个选择器作用于同一元素时,优先级规则如下(从高到低):
- 内联样式:
style="..." - ID选择器:
#id - 类选择器、属性选择器、伪类:
.class、[attr]、:hover - 元素选择器、伪元素:
div、::before
三、Go中的HTML解析库:goquery
3.1 goquery简介
goquery是Go语言的一个强大HTML解析库,灵感来自jQuery。它基于Go标准库中的net/html包,并提供了类似jQuery的链式API,使HTML文档的遍历和操作变得简单。
goquery的主要特点包括:
- 简单易用的API
- 高效的解析性能
- 支持CSS选择器
3.2 安装goquery
使用以下命令安装goquery:
go get github.com/PuerkitoBio/goquery
3.3 创建文档
在使用goquery之前,首先需要创建一个文档对象。这相当于将HTML转换成可以用代码操作的结构。
3.3.1 从字符串创建文档
package mainimport ("fmt""github.com/PuerkitoBio/goquery""strings"
)func main() {html := `<html><body><div class="content"><h1>标题</h1><p>这是段落</p></div></body></html>`// 将HTML字符串转换为可读取的对象reader := strings.NewReader(html)doc, err := goquery.NewDocumentFromReader(reader)if err != nil {fmt.Println("加载HTML出错:", err)return}// 现在我们有了一个doc对象,可以用它来查找元素title := doc.Find("h1").Text()content := doc.Find("p").Text()fmt.Println("标题:", title)fmt.Println("内容:", content)
}得到的结果:
标题: 标题
内容: 这是段落
NewDocumentFromReader()从字符串创建一个新的文档, 返回了一个*Document和error。Document代表一个将要被操作的HTML文档。
Find() 主要是用来查找元素, Find("h1") 即代表获取html中h1标签的元素,包括它的子元素。如果有多个h1标签,默认获取的是最后一个。
Text() 获取元素的纯文本内容
3.3.2 从网络加载文档
如果你还记得上一章的内容,我们使用 https://quotes.toscrape.com/ 作为演示,使用正则表达式获取了引言和作者,现在我们使用goquery代替
package mainimport ("fmt""github.com/PuerkitoBio/goquery""net/http"
)func main() {// 发送HTTP请求获取网页resp, err := http.Get("https://quotes.toscrape.com/")if err != nil {fmt.Println("请求网页失败:", err)return}defer resp.Body.Close() // 记得关闭连接// 检查HTTP状态码if resp.StatusCode != 200 {fmt.Printf("状态码不对: %d %s\n", resp.StatusCode, resp.Status)return}// 从响应创建文档doc, err := goquery.NewDocumentFromReader(resp.Body)if err != nil {fmt.Println("解析HTML失败:", err)return}// 使用文档quote := doc.Find(".text").Text()author := doc.Find(".author").Text()fmt.Println("引言:", quote)fmt.Println("作者:", author)
}.text 和.author 都是类选择器,代表class="quote"和class="author" 类名前加.表示类
3.4 goquery常用方法介绍
3.4.1 Find方法 - 查找所有匹配元素
Find方法是最基础也是最常用的方法,它可以查找符合CSS选择器的所有元素。
// 查找所有段落
paragraphs := doc.Find("p")// 获取找到的元素数量
count := paragraphs.Length()
fmt.Printf("找到了%d个段落\n", count)// 获取第一个段落的文本
firstParagraph := paragraphs.First().Text()
fmt.Printf("第一个段落内容: %s\n", firstParagraph)
Length()告诉我们找到了多少个元素First()取出第一个找到的元素
3.4.2 Text方法 - 获取文本内容
// 获取h1标签的文本
title := doc.Find("h1").Text()
fmt.Println("标题文本:", title)
// 输出: 标题文本: 欢迎来到我的网站Text()方法提取元素内的所有文本,包括子元素的文本- 它会自动去除HTML标签,只保留纯文本
- 它会合并所有文本节点,中间可能有空格
3.4.3 Html方法 - 获取HTML内容
// 获取元素的HTML
contentHtml, err := doc.Find(".content").Html()
if err == nil {fmt.Println("内容区HTML:")fmt.Println(contentHtml)// 输出会包含所有HTML标签和内容
}Html()方法获取元素的完整HTML代码,包括所有标签- 如果你需要保留原始格式,比如需要分析HTML结构,这很有用
3.4.4 Attr方法 - 获取属性
// 获取链接的href属性
doc.Find("a").Each(func(i int, s *goquery.Selection) {// Attr返回两个值:属性值和是否存在该属性href, exists := s.Attr("href")if exists {fmt.Printf("链接 #%d 指向: %s\n", i+1, href)// 获取链接文本text := s.Text()fmt.Printf("链接文本: %s\n", text)}
})
s.Attr("href")尝试获取元素的href属性- 它返回两个值:属性的值和一个布尔值表示属性是否存在
exists告诉我们属性是否存在,防止我们使用不存在的属性
3.4.5 Each方法 - 遍历所有元素
刚刚我们获取quotes的例子中,我们想要获取到页面所有的.text 和.author 元素,Each是一个不二的选择,简单的修改下代码:
// 从响应创建文档doc, err := goquery.NewDocumentFromReader(resp.Body)if err != nil {fmt.Println("解析HTML失败:", err)return}// 使用文档doc.Find(`.quote`).Each(func(i int, s *goquery.Selection) {quote := s.Find(".text").Text()author := s.Find(".author").Text()fmt.Printf("第%d个: \n", i)fmt.Println("引言:", quote)fmt.Println("作者:", author)fmt.Println()})Each方法就像是一个循环,会依次处理每个找到的元素,- 函数
func(i int, s *goquery.Selection)中:i是当前处理的是第几个元素(从0开始计数)s就是当前正在处理的元素, 示例代码中s代表.quote及下面的子元素
3.4.6 筛选元素方法**
筛选元素的方法有很多个,我一起介绍
items := doc.Find("li")// 获取第一个元素
first := items.First()
fmt.Println("第一个菜单项:", first.Text())// 获取最后一个元素
last := items.Last()
fmt.Println("最后一个菜单项:", last.Text())// 获取特定索引的元素(从0开始)
second := items.Eq(1) // 第二个元素
fmt.Println("第二个菜单项:", second.Text())// 过滤有特定类的元素
selected := items.Filter(".selected")
fmt.Println("选中的菜单项:", selected.Text())// 排除特定元素
notSelected := items.Not(".selected")
fmt.Printf("未选中的菜单项有%d个\n", notSelected.Length())First():拿出第一个元素Last():拿出最后一个元素Eq(1):拿出索引为1的元素(实际上是第2个,因为索引从0开始)Filter(".selected"):只保留有class="selected"的元素Not(".selected"):排除有class="selected"的元素,只留下其他的
3.5 完整实例:图书信息提取
我们来写一个完整的实例,从一个包含图书信息的HTML页面中提取图书名称、作者、出版年份、简介、评分和链接。
package mainimport ("fmt""github.com/PuerkitoBio/goquery""strings"
)func main() {// 一个包含各种元素的HTML示例html := `<!DOCTYPE html><html><head><title>我的图书列表</title></head><body><div id="header"><h1>我收藏的图书</h1><p>这是我最喜欢的一些书籍</p></div><div class="book-list"><div class="book"><h2 class="title">Go语言编程</h2><p class="author">作者: 张三</p><p class="year">出版年份: 2022</p><p class="description">这是一本关于<b>Go语言</b>的入门书籍</p><span class="rating">评分: 4.5/5</span><a href="https://example.com/go-book" class="link">查看详情</a></div><div class="book"><h2 class="title">Python数据分析</h2><p class="author">作者: 李四</p><p class="year">出版年份: 2021</p><p class="description">这本书讲解了Python在<b>数据分析</b>中的应用</p><span class="rating">评分: 4.8/5</span><a href="https://example.com/python-book" class="link">查看详情</a></div><div class="book"><h2 class="title">JavaScript高级编程</h2><p class="author">作者: 王五</p><p class="year">出版年份: 2023</p><p class="description">深入讲解<b>JavaScript</b>的高级特性</p><span class="rating">评分: 4.2/5</span><a href="https://example.com/js-book" class="link">查看详情</a></div><div class="book"><h2 class="title">Python入门</h2><p class="author"></p><p class="year">出版年份: 2023</p><p class="description">深入讲解<b>Python</b>的高级特性</p><span class="rating">评分: 4.3/5</span><a href="https://example.com/js-book" class="link">查看详情</a></div></div><div id="footer"><p>更新时间: 2025年3月15日</p></div></body></html>`// 创建goquery文档reader := strings.NewReader(html)doc, err := goquery.NewDocumentFromReader(reader)if err != nil {fmt.Println("解析HTML失败:", err)return}// 1. 提取页面标题fmt.Println("=== 页面信息 ===")pageTitle := doc.Find("title").Text()headerTitle := doc.Find("#header h1").Text()fmt.Printf("页面标题: %s\n", pageTitle)fmt.Printf("主标题: %s\n", headerTitle)// 2. 提取所有图书信息fmt.Println("\n=== 图书列表 ===")doc.Find(".book").Each(func(i int, book *goquery.Selection) {// 提取图书标题title := book.Find(".title").Text()// 提取作者(使用替代方法)authorElem := book.Find(".author")author := authorElem.Text()// 清理"作者: "前缀author = strings.TrimPrefix(author, "作者: ")// 提取评分(使用属性选择器)ratingText := book.Find(".rating").Text()// 使用strings包处理字符串rating := strings.TrimPrefix(ratingText, "评分: ")// 提取链接URL和文本linkElem := book.Find(".link")linkText := linkElem.Text()linkHref, _ := linkElem.Attr("href")// 输出图书信息fmt.Printf("图书 #%d:\n", i+1)fmt.Printf(" 标题: %s\n", title)fmt.Printf(" 作者: %s\n", author)fmt.Printf(" 评分: %s\n", rating)fmt.Printf(" 链接: %s (%s)\n", linkText, linkHref)// 检查描述中是否有强调内容desc := book.Find(".description")boldText := desc.Find("b").Text()if boldText != "" {fmt.Printf(" 重点内容: %s\n", boldText)}fmt.Println() // 添加空行分隔不同图书})// 3. 统计信息fmt.Println("=== 统计信息 ===")bookCount := doc.Find(".book").Length()fmt.Printf("图书总数: %d本\n", bookCount)// 统计高评分(>4.5)的书籍highRatedBooks := 0doc.Find(".book").Each(func(i int, s *goquery.Selection) {ratingText := s.Find(".rating").Text()// 提取评分数字ratingStr := strings.TrimPrefix(ratingText, "评分: ")ratingStr = strings.TrimSuffix(ratingStr, "/5")// 简单转换为浮点数进行比较var rating float64fmt.Sscanf(ratingStr, "%f", &rating)if rating > 4.5 {highRatedBooks++}})fmt.Printf("高评分图书(>4.5): %d本\n", highRatedBooks)// 获取页脚信息footerText := doc.Find("#footer").Text()fmt.Printf("页脚信息: %s\n", strings.TrimSpace(footerText))fmt.Println("=== 分隔符 ===")// 4. 查找并修改元素 ,查找作者为空的元素,填充作者doc.Find(".author:empty").SetHtml(`老六`)//查找.book ,第四个元素newSelection := doc.Find(".book").Eq(3)title := newSelection.Find(".title").Text()// 提取作者(使用替代方法)authorElem := newSelection.Find(".author")author := authorElem.Text()// 清理"作者: "前缀author = strings.TrimPrefix(author, "作者: ")// 提取评分(使用属性选择器)ratingText := newSelection.Find(".rating").Text()// 使用strings包处理字符串rating := strings.TrimPrefix(ratingText, "评分: ")// 提取链接URL和文本linkElem := newSelection.Find(".link")linkText := linkElem.Text()linkHref, _ := linkElem.Attr("href")// 输出图书信息fmt.Printf(" 标题: %s\n", title)fmt.Printf(" 作者: %s\n", author)fmt.Printf(" 评分: %s\n", rating)fmt.Printf(" 链接: %s (%s)\n", linkText, linkHref)
}3.6 性能优化
- 使用具体的选择器:避免使用过于宽泛的选择器
- 缓存选择结果:如果需要多次使用同一选择器,先保存结果
- 避免深层嵌套:尽量使用直接的选择器路径
四、XPath查询
XPath(XML Path Language)是一种用于在 XML 和 HTML 文档中定位特定节点的查询语言。它最初设计用于 XML 文档,但由于 HTML 可以视为 XML 的一种变体,因此 XPath 也广泛应用于 HTML 解析场景,尤其是在网络爬虫中用于提取特定数据。
XPath 使用类似文件系统路径的语法来描述节点在文档中的位置,支持从根节点开始的绝对路径查询,也支持从当前节点开始的相对路径查询。在爬虫领域,XPath 常用于从 HTML 页面中提取结构化数据,如新闻标题、商品价格、评论内容等。
4.1 XPath 核心语法规则
4.1.1 基本路径表达式
XPath 使用以下符号构建路径表达式:
/- 从根节点选择//- 从当前节点选择文档中符合条件的所有节点.- 选择当前节点..- 选择当前节点的父节点@- 选择属性
4.1.2 节点选择器
XPath 提供多种节点选择器用于定位特定节点:
- 标签名选择:直接使用标签名选择节点,如
div、a - 通配符选择:
*表示选择所有节点,@*表示选择所有属性 - 节点索引:使用方括号
[]指定节点索引,如div[1]表示第一个 div 节点 - 属性选择:通过属性名和值选择节点,如
a[@href]表示有 href 属性的 a 节点,a[@class='link']表示 class 属性为 ‘link’ 的 a 节点
4.1.3 常用操作符
XPath 支持多种操作符用于构建复杂查询:
- 逻辑操作符:
and、or、not() - 比较操作符:
=、!=、<、>、<=、>= - 算术操作符:
+、-、*、div - 位置操作符:
start-with()、contains()、text()
4.1.4 XPath常用表达式示例
- 谓语(筛选条件)
//li[1]- 选择第一个li元素//li[last()]- 选择最后一个li元素//div[count(p) > 2]- 选择包含超过2个段落的div元素
- 轴(指定节点关系方向)
//h1/following-sibling::p- 选择h1后的所有兄弟段落//li/ancestor::div- 选择li的所有div祖先元素//a/parent::div- 选择a的父元素中的div
- 函数
string(//h1)- 获取第一个h1元素的文本contains(//p, '文本')- 检查段落是否包含"文本"count(//li)- 计算li元素的数量
五、在Go中使用XPath:htmlquery
goquery也是支持xpath的,但是为了让大家了解更多的库,这里我们使用htmlquery库来解析,htmlquery更专注于xpath的解析
5.1 安装htmlquery
go get github.com/antchfx/htmlquery
5.2 简单示例
package mainimport ("fmt""log""strings""github.com/antchfx/htmlquery""golang.org/x/net/html"
)func xpathExamples() {htmlStr := `<books><book id="1" category="fiction"><title>Go编程</title><author>作者1</author><price>59.90</price></book><book id="2" category="technical"><title>数据结构</title><author>作者2</author><price>79.90</price></book><book id="3" category="fiction"><title>算法导论</title><author>作者3</author><price>99.90</price></book></books>`doc, err := html.Parse(strings.NewReader(htmlStr))if err != nil {log.Fatal(err)}// 1. 基本路径表达式fmt.Println("=== 基本XPath ===")// 选择所有书的标题titles := htmlquery.Find(doc, "//title")for _, title := range titles {fmt.Printf("Title: %s\n", htmlquery.InnerText(title))}// 2. 属性选择fmt.Println("\n=== 属性选择 ===")// 选择category为fiction的书fictionBooks := htmlquery.Find(doc, "//book[@category='fiction']/title")for _, book := range fictionBooks {fmt.Printf("Fiction book: %s\n", htmlquery.InnerText(book))}// 3. 位置选择fmt.Println("\n=== 位置选择 ===")// 选择第一本书firstBook := htmlquery.FindOne(doc, "//book[1]/title")if firstBook != nil {fmt.Printf("First book: %s\n", htmlquery.InnerText(firstBook))}// 选择最后一本书lastBook := htmlquery.FindOne(doc, "//book[last()]/title")if lastBook != nil {fmt.Printf("Last book: %s\n", htmlquery.InnerText(lastBook))}// 4. 条件表达式fmt.Println("\n=== 条件表达式 ===")// 价格大于60的书expensiveBooks := htmlquery.Find(doc, "//book[price>60]/title")for _, book := range expensiveBooks {fmt.Printf("Expensive book: %s\n", htmlquery.InnerText(book))}// 5. 轴运算fmt.Println("\n=== 轴运算 ===")// 选择作者为"作者2"的书的下一个兄弟节点nextBook := htmlquery.FindOne(doc, "//author[text()='作者2']/parent::book/following-sibling::book[1]/title")if nextBook != nil {fmt.Printf("Next book after 作者2's book: %s\n", htmlquery.InnerText(nextBook))}
}
六、goquery与htmlquery比较
6.1基本实现对比
goquery:
- 灵感来源:基于jQuery的API设计
- 查询语法:主要使用CSS选择器
- 底层实现:基于Go标准库的
net/html包 - 链式操作:支持jQuery风格的链式调用
htmlquery:
- 灵感来源:专注于XPath查询
- 查询语法:主要使用XPath表达式
- 底层实现:同样基于
net/html包,但专门优化了XPath支持 - 函数式操作:提供函数式的查询API
6.2 查询语法对比
| 功能 | goquery (CSS选择器) | htmlquery (XPath) |
|---|---|---|
| 选择所有div | doc.Find("div") | htmlquery.Find(doc, "//div") |
| 按class选择 | doc.Find(".content") | htmlquery.Find(doc, "//[@class='content']") |
| 按ID选择 | doc.Find("#title") | htmlquery.Find(doc, "//*[@id='title']") |
| 选择第一个元素 | doc.Find("p").First() | htmlquery.FindOne(doc, "//p[1]") |
| 选择最后一个元素 | doc.Find("p").Last() | htmlquery.FindOne(doc, "//p[last()]") |
| 包含文本 | doc.Find("p:contains('文本')") | htmlquery.Find(doc, "//p[contains(text(),'文本')]") |
| 父子关系 | doc.Find("div > p") | htmlquery.Find(doc, "//div/p") |
| 祖先后代 | doc.Find("div p") | htmlquery.Find(doc, "//div//p") |
6.3 性能对比
goquery:
- 优势:CSS选择器解析较快,链式操作减少重复查询
- 劣势:复杂查询可能需要多次调用
htmlquery:
- 优势:XPath查询功能强大,一次查询可以完成复杂条件
- 劣势:XPath解析相对较慢
6.4 适用场景
使用goquery的场景:
- 前端开发背景:熟悉jQuery或CSS选择器
- 简单到中等复杂度的查询:大部分网页爬虫需求
- 需要DOM操作:修改、添加、删除元素
- 链式操作偏好:喜欢流畅的API调用
- 快速原型开发:语法简洁,开发效率高
使用htmlquery的场景:
- 复杂查询需求:需要使用XPath的高级功能
- XML处理经验:熟悉XPath语法
- 精确节点定位:需要基于位置、文本内容等复杂条件查询
- 性能敏感:单次复杂查询比多次简单查询更高效
- 数据提取为主:主要用于读取,不需要修改DOM
实际项目建议:对于大多数网页爬虫项目,建议优先选择goquery,只有在遇到goquery无法高效解决的复杂查询时,再考虑使用htmlquery作为补充。
七、处理中文编码问题
7.1 编码类型
在网络传输中,数据通常以二进制形式进行编码,而不同的编码方式会导致数据的显示或处理方式不同。在爬取中文网站时,经常会遇到编码问题。常见的中文编码包括:
- UTF-8:Unicode的一种编码方式,支持全球几乎所有字符,是最常用的编码方式。
- GBK/GB2312:中国的编码方式,主要用于简体中文,兼容ASCII字符集。
- BIG5:台湾的编码方式,主要用于繁体中文。
7.2 编码检测
在爬取网页时,我们通常无法确定网页的编码类型,因此需要进行编码检测。以下是一些常用的编码检测方法:
-
HTTP头信息:大多数网页会在HTTP头信息中包含
Content-Type字段,其中包含了网页的编码类型。 -
HTML文档:可以通过查看HTML文档的头部部分,查找
<meta>标签中charset属性的值。 -
字符识别:可以使用一些字符识别工具,如
chardet库,自动检测网页的编码类型。
7.3 处理中文编码
下面使用一个姓名评分的网站来演示,网站的编码是GBK,我们来演示下编码处理:
package mainimport ("bytes""fmt""golang.org/x/text/encoding/simplifiedchinese""golang.org/x/text/transform""io""net/http""strings""github.com/PuerkitoBio/goquery"
)// 处理中文编码的HTTP客户端
func fetchWithEncoding(url string) (*goquery.Document, error) {resp, err := http.Get(url)if err != nil {return nil, err}defer resp.Body.Close()// 读取响应内容body, err := io.ReadAll(resp.Body)if err != nil {return nil, err}// 检测编码类型// bodyStr := string(body)var reader io.Reader// 检查是否是GB2312/GBK编码if detectEncoding(body) == "gbk" {reader = transform.NewReader(bytes.NewReader(body), simplifiedchinese.GBK.NewDecoder())} else {reader = bytes.NewReader(body)}/*if strings.Contains(strings.ToLower(resp.Header.Get("Content-Type")), "gb2312") ||strings.Contains(strings.ToLower(resp.Header.Get("Content-Type")), "gbk") ||strings.Contains(strings.ToLower(bodyStr), "gb2312") ||strings.Contains(strings.ToLower(bodyStr), "gbk") {// 转换GBK到UTF-8reader = transform.NewReader(bytes.NewReader(body), simplifiedchinese.GBK.NewDecoder())} else {// 默认使用UTF-8reader = bytes.NewReader(body)}*/// 解析HTMLdoc, err := goquery.NewDocumentFromReader(reader)if err != nil {return nil, err}return doc, nil
}// 自动检测编码
func detectEncoding(body []byte) string {bodyStr := strings.ToLower(string(body))// 检查HTML中的编码声明if strings.Contains(bodyStr, "charset=gb2312") || strings.Contains(bodyStr, "charset=gbk") {return "gbk"}if strings.Contains(bodyStr, "charset=utf-8") {return "utf-8"}// 默认返回UTF-8return "utf-8"
}func main() {// 使用示例doc, err := fetchWithEncoding("http://www.8882088.com/ceming/result.php?firstname=%C1%FA&lastname=%B0%C1%CC%EC&xb=0&bir_year=2025&bir_month=5&bir_day=28&bir_hour=5")if err != nil {fmt.Printf("获取页面失败: %v\n", err)return}// 正常使用goquery处理中文内容title := doc.Find("title").Text()fmt.Printf("页面标题: %s\n", title)
}相关文章:

Go语言爬虫系列教程5:HTML解析技术以及第三方库选择
Go语言爬虫系列教程5:HTML解析技术以及第三方库选择 在上一章中,我们使用正则表达式提取网页内容,但这种方法有局限性。对于复杂的HTML结构,我们需要使用专门的HTML解析库。在这一章中,我们将介绍HTML解析技术以及如何…...

理解JavaScript中map和parseInt的陷阱:一个常见的面试题解析
前言 在JavaScript面试中,map和parseInt的组合常常被用作考察候选人对这两个方法理解深度的题目。让我们通过一个简单的例子来深入探讨其中的原理。 问题现象 [1, 2, 3].map(parseInt) // 输出结果是什么?很多人可能会预期输出[1, 2, 3],但…...

文件上传漏洞深度解析:检测与绕过技术矩阵
文件上传漏洞深度解析:检测与绕过技术矩阵 引言:无处不在的文件上传风险 在当今的Web应用生态系统中,文件上传功能几乎无处不在。从社交媒体分享图片到企业文档管理系统,用户上传文件已成为现代Web应用的核心功能之一。然而&…...

3.2 HarmonyOS NEXT跨设备任务调度与协同实战:算力分配、音视频协同与智能家居联动
HarmonyOS NEXT跨设备任务调度与协同实战:算力分配、音视频协同与智能家居联动 在万物互联的全场景时代,设备间的高效协同是释放分布式系统潜力的关键。HarmonyOS NEXT通过分布式任务调度技术,实现了跨设备算力动态分配与任务无缝流转&#…...

Elasticsearch 海量数据写入与高效文本检索实践指南
Elasticsearch 海量数据写入与高效文本检索实践指南 一、引言 在大数据时代,企业和组织面临着海量数据的存储与检索需求。Elasticsearch(以下简称 ES)作为一款基于 Lucene 的分布式搜索和分析引擎,凭借其高可扩展性、实时搜索和…...
jenkins集成gitlab发布到远程服务器
jenkins集成gitlab发布到远程服务器 前面我们讲了通过创建maven项目部署在jenkins本地服务器,这次实验我们将部署在远程服务器,再以nginx作为前端项目做一个小小的举例 1、部署nginx服务 [rootweb ~]# docker pull nginx [rootweb ~]# docker images …...

AI问答-vue3+ts+vite:http://www.abc.com:3022/m-abc-pc/#/snow 这样的项目 在服务器怎么部署
为什么记录有子路径项目的部署,因为,通过子路径可以区分项目,那么也就可以实现微前端架构,并且具有独特优势,每个项目都是绝对隔离的。 要将 Vue3 项目(如路径为 http://www.abc.com:3022/m-saas-pc/#/sno…...
当主观认知遇上机器逻辑:减少大模型工程化中的“主观性”模糊
一、人类与机器的认知差异 当自动驾驶汽车遇到紧急情况需要做出选择时,人类的决策往往充满矛盾:有人会优先保护儿童和老人,有人坚持"不主动变道"的操作原则。这种差异背后,体现着人类特有的情感判断与价值选择。而机器的…...

会计 - 金融负债和权益工具
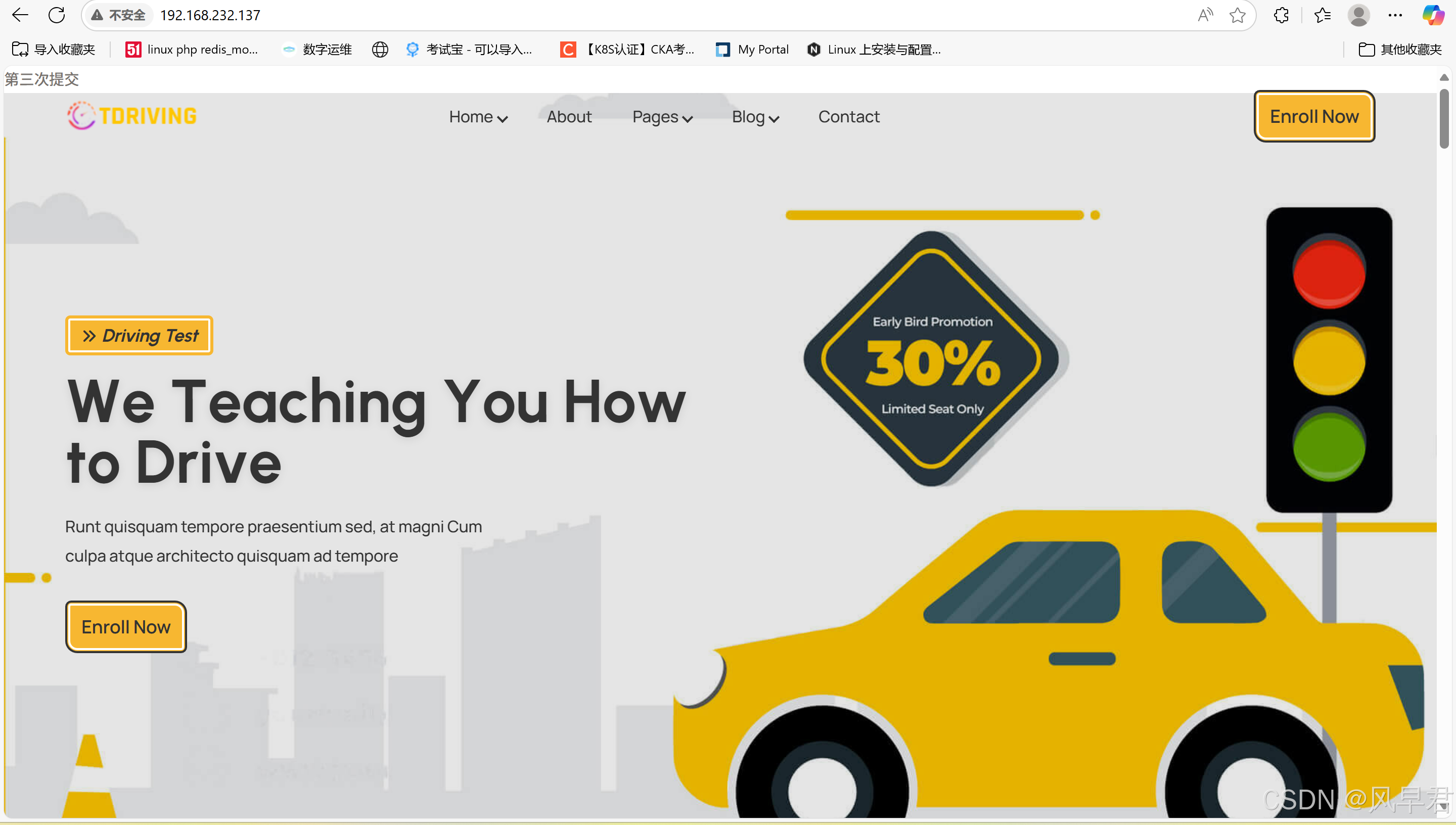
一、金融负债和权益工具区分的基本原则 (1)是否存在无条件地避免交付现金或其他金融资产的合同义务 如果企业不能无条件地避免以交付现金或其他金融资产来履行一项合同义务,则该合同义务符合金融负债的义务。 常见的该类合同义务情形包括:- 不能无条件避免的赎回; -强制…...

.net Span类型和Memory类型
.NET 中 Span 类型和 Memory 类型的深度剖析 在 .NET 编程的世界里,高效处理内存是提升程序性能的关键。Span<T> 和 Memory<T> 类型的出现,为开发者提供了强大而灵活的工具,用于高效地访问和操作连续内存区域。今天,…...

Dify工具插件开发和智能体开发全流程
想象一下,你正在开发一个 AI 聊天机器人,想让它能实时搜索 Google、生成图像,甚至自动规划任务,但手动集成这些功能耗时又复杂。Dify 来了!这个开源的 AI 应用平台让你轻松开发工具插件和智能体策略插件,快…...

ES6——对象扩展之Set对象
在ES6(ECMAScript 2015)中,Set 对象允许存储任何类型的唯一值,无论是原始值还是对象引用。Set 对象有一些有用的方法,可以操作集合中的数据。以下是一些常用的 Set 对象方法: 方法描述 add 向 Set 对象添加…...
AI书签管理工具开发全记录(十三):TUI基本框架搭建
文章目录 AI书签管理工具开发全记录(十三):TUI基本框架搭建前言 📝1.TUI介绍 🔍2. 框架选择 ⚙️3. 功能梳理 🎯4. 基础框架搭建⚙️4.1 安装4.2 参数设计4.3 绘制ui4.3.1 设计结构体4.3.2 创建头部4.3.3 创…...

<2>-MySQL库的操作
目录 一,创建数据库 二,查看字符集和校验规则 三,修改数据库 四,删除数据库 五,备份和恢复数据库 六,查看连接 一,创建数据库 创建一个名为bin_db的数据库,并设置字符集为utf8…...

Apache DolphinScheduler 和 Apache Airflow 对比
Apache DolphinScheduler 和 Apache Airflow 都是开源的工作流调度平台,用于管理和编排复杂的数据处理任务和管道。以下是对两者在功能、架构、使用场景等方面的对比,用中文清晰说明: 1. 概述 Apache DolphinScheduler: 一个分布…...
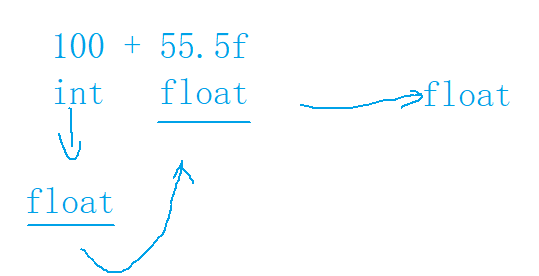
初识结构体,整型提升及操作符的属性
目录 一、结构体成员访问操作符1.1 结构体二、操作符的属性:优先级、结合性2.1 优先级2.2 结合性C 运算符优先级 三、表达式求值3.1 整型提升3.2 算数转化 总结 一、结构体成员访问操作符 1.1 结构体 C语言已经提供了内置类型,如:char,shor…...
检测到 #include 错误。请更新 includePath。已为此翻译单元(D:\软件\vscode\test.c)禁用波形曲线
原文链接:【VScodeMinGw】安装配置教程 下载mingw64 打开可以看到bin文件夹下是多个.exe文件,gcc.exe地址在环境配置中要用到 原文链接:VSCode中出现“#include错误,请更新includePath“问题,解决方法 重新VScode后…...
)
python --导出数据库表结构(pymysql)
import pymysql from pymysql.cursors import DictCursor from typing import Optional, Dict, List, Anyclass DBSchemaExporter:"""MySQL数据库表结构导出工具,支持提取表和字段注释使用示例:>>> exporter DBSchemaExporter("local…...

如何自动部署GitLab项目
如何自动部署 原理 GitLab有预制的钩子, 在代码提交/合并等事件中,会自动调用WebHoos, 即向该URL发送POST请求在布署服务器上监听该POST, 验证通过后执行相关的布置Shell脚本, 即可完成自动布署 配置环境 安装Python和Pip 2.如果需要, 安装python的requests模块和argparse模…...

在 Windows 系统上运行 Docker 容器中的 Ubuntu 镜像并显示 GUI
在 Windows 上安装一个 X Server(如 VcXsrv 或 X410),Ubuntu 容器通过网络将图形界面转发到 Windows。 步骤: 安装 X Server: 推荐使用VcXsrv,免费开源。 安装后运行 XLaunch,选择࿱…...
 的总结)
基于 COM 的 XML 解析技术(MSXML) 的总结
✅ 一、COM 与 MSXML 简要说明 🔷 什么是 COM? COM(Component Object Model)是一种 Windows 平台下的组件技术,可以实现在不重新编译代码的前提下复用组件。 特点: 用 接口调用方式 解耦依赖;…...

多分辨率 LCD 的 GUI 架构设计与实现
1.1多分辨率显示系统的挑战与解决方案 1.1.1 分辨率适配的核心问题 在嵌入式系统中,同时支持不同分辨率的 LCD(如 240160、320480 等)面临以下挑战: 布局适配:同一界面元素在不同分辨率下需要调整大小和位置 字体显示:小分辨率屏幕需要更小的字体,而大分辨率需要更清…...
2025年,百度智能云打响AI落地升维战
如果说从AI到Agent是对于产品落地形态的共识,那么如今百度智能云打响的恰是一个基于Agent进行TO B行业表达的AI生产力升维战。 在这个新的工程体系能力里,除了之前百度Create大会上提出的面向Agent的RAG能力等通用能力模块,对更为专业、个性…...

Seed1.5-VL登顶,国产闭源模型弯道超车丨多模态模型5月最新榜单揭晓
随着图像、文本、语音、视频等多模态信息融合能力的持续增强,多模态大模型在感知理解、逻辑推理和内容生成等任务中的综合表现不断提升,正在展现出愈发接近人类的智能水平。多模态能力也正在从底层的感知理解,迈向具备认知、推理、决策能力的…...
和JSON.parse()之间的转换)
SON.stringify()和JSON.parse()之间的转换
1.JSON.stringify() 作用:将对象、数组转换成字符串 const obj {code: "500",message: "出错了", }; const jsonString JSON.stringify(obj); console.log(jsonString);//"{"code":"Mark Lee","message"…...

【学习笔记】构造函数+重载相关
【学习笔记】构造函数重载相关 一、构造函数 构造函数在创建对象的过程就会执行,带参数与不带参数,带参数的构造函数会默认将成员变量赋值传进去的参数。 class Layer { private:int layer_id; // 层IDstd::string layer_json; // 层的JSON配置…...

JVM——打开JVM后门的钥匙:反射机制
引入 在Java的世界里,反射机制(Reflection)就像一把万能钥匙,能够打开JVM的“后门”,让开发者在运行时突破静态类型的限制,动态操控类的内部结构。想象一下,传统的Java程序如同按菜单点菜的食客…...
第3章——SSM整合
一、整合持久层框架MyBatis 1.准备数据库表及数据 创建数据库:springboot 使用IDEA工具自带的mysql插件来完成表的创建和数据的准备: 创建表 表创建成功后,为表准备数据,如下: 2.创建SpringBoot项目 使用脚手架创建…...
VTK 显示文字、图片及2D/3D图
1. 基本环境设置 首先确保你已经安装了VTK库,并配置好了C开发环境。 #include <vtkSmartPointer.h> #include <vtkRenderWindow.h> #include <vtkRenderWindowInteractor.h> #include <vtkRenderer.h> 2. 显示文字 2D文字 #include &l…...

小白如何在cursor中使用mcp服务——以使用notion的api为例
1. 首先安装node.js,在这一步的时候不要勾选不要勾选 2. 安装完之后,前往notion页面 我的创作者个人资料 | Notion 前往集成页面,添加新集成,自己输入名字,选择内部 新建完之后,进入选择只读 复制密匙 然后前往cursor页面 新建…...