day45python打卡
知识点回顾:
- tensorboard的发展历史和原理
- tensorboard的常见操作
- tensorboard在cifar上的实战:MLP和CNN模型
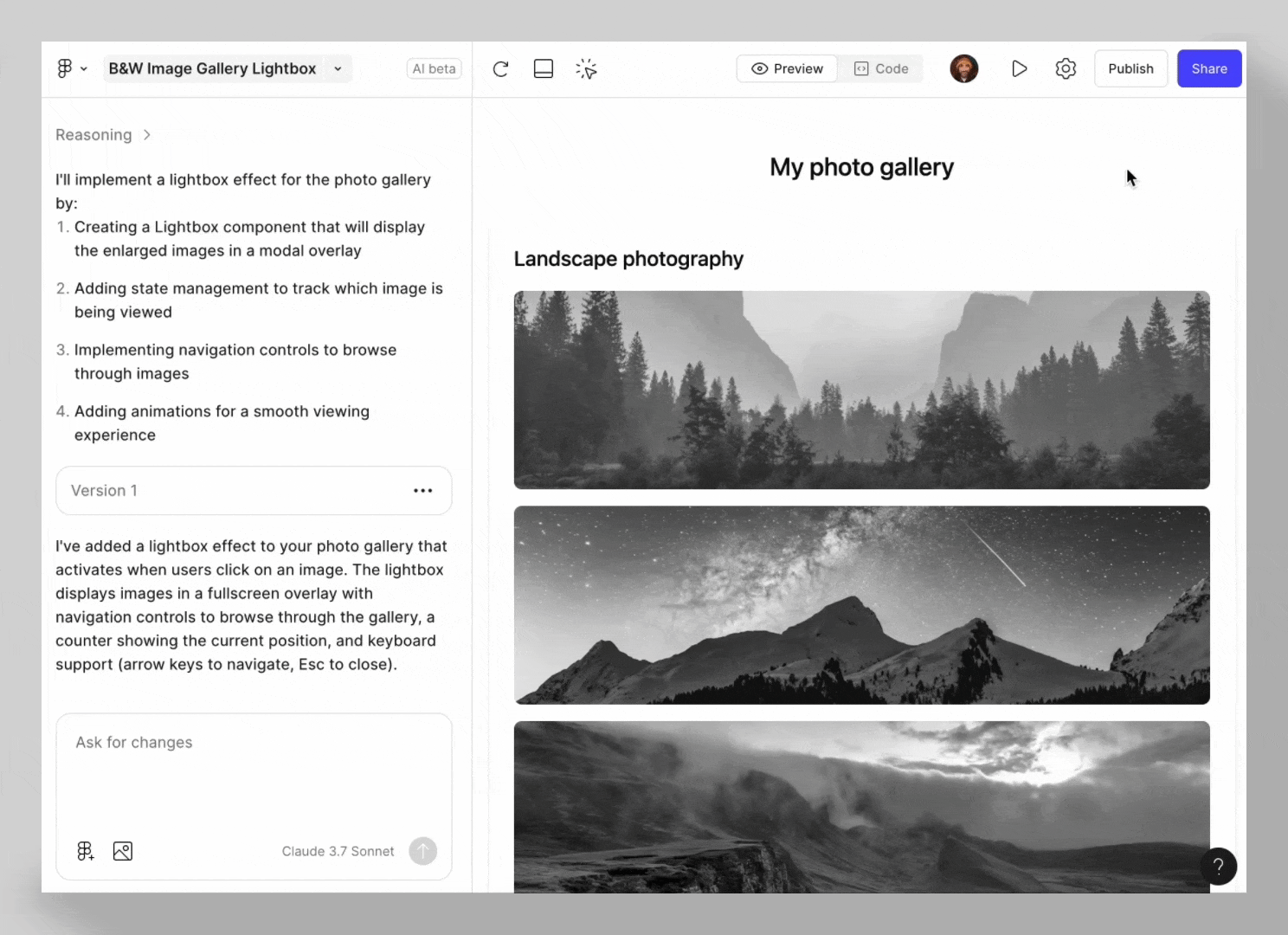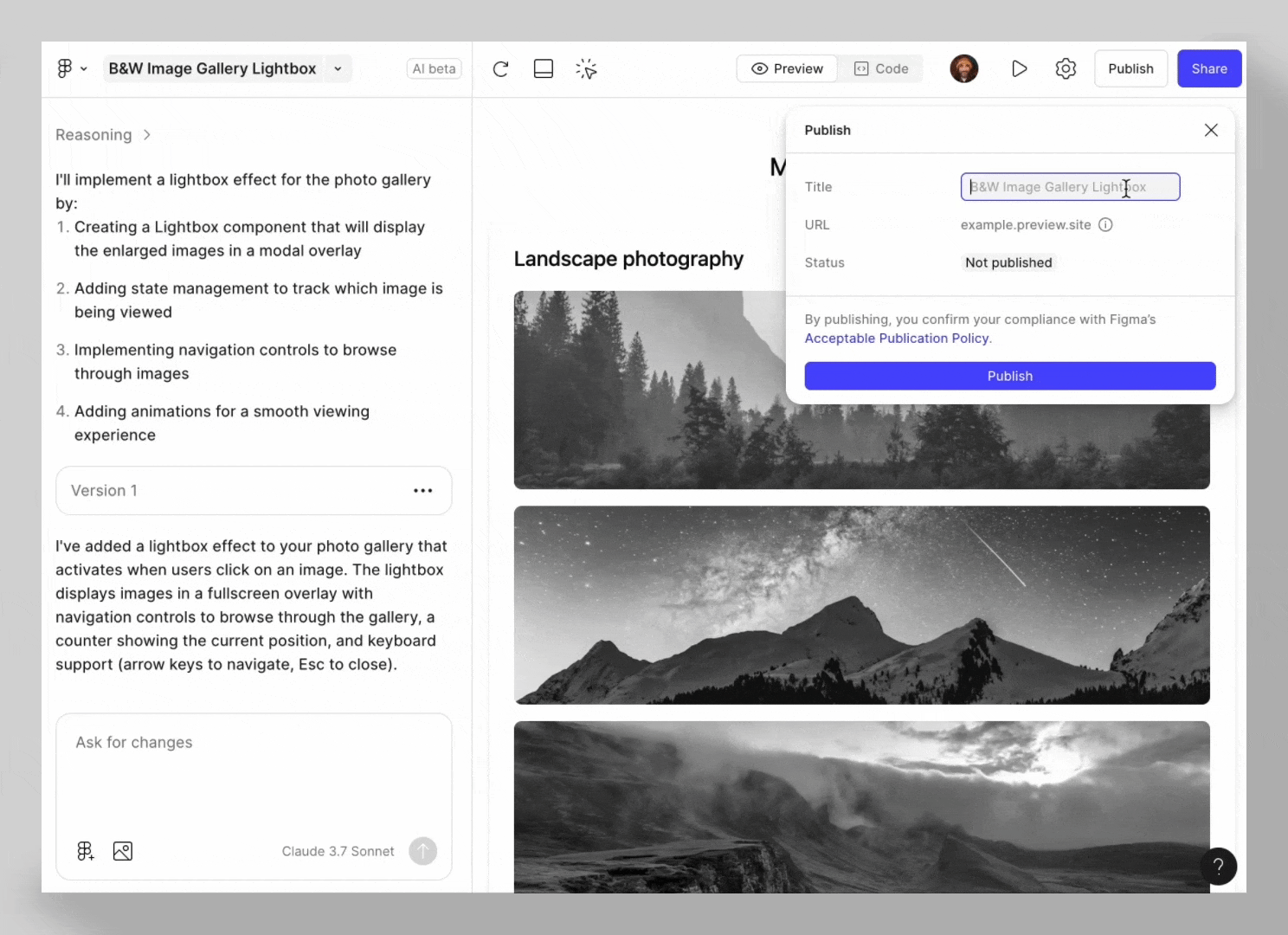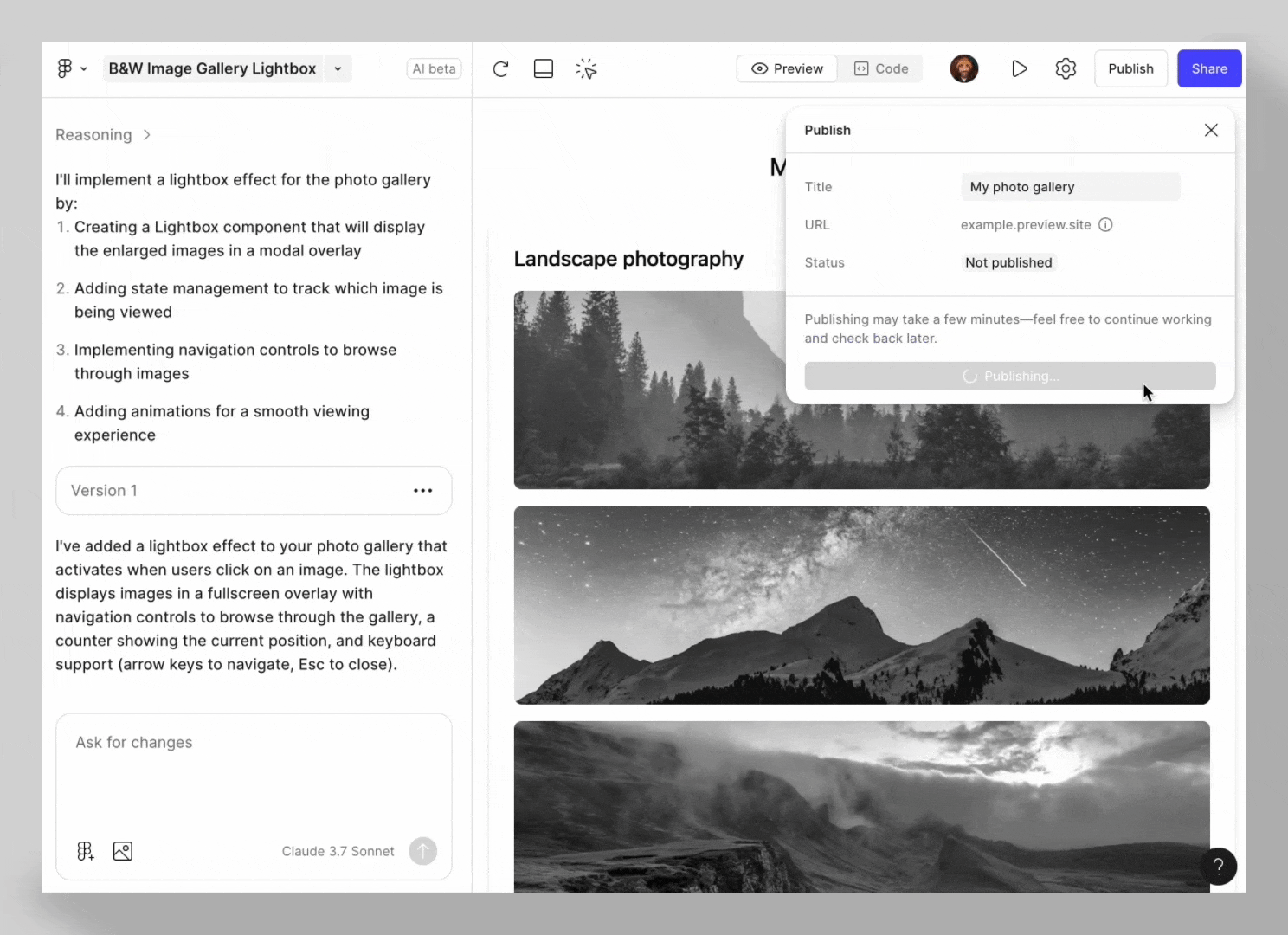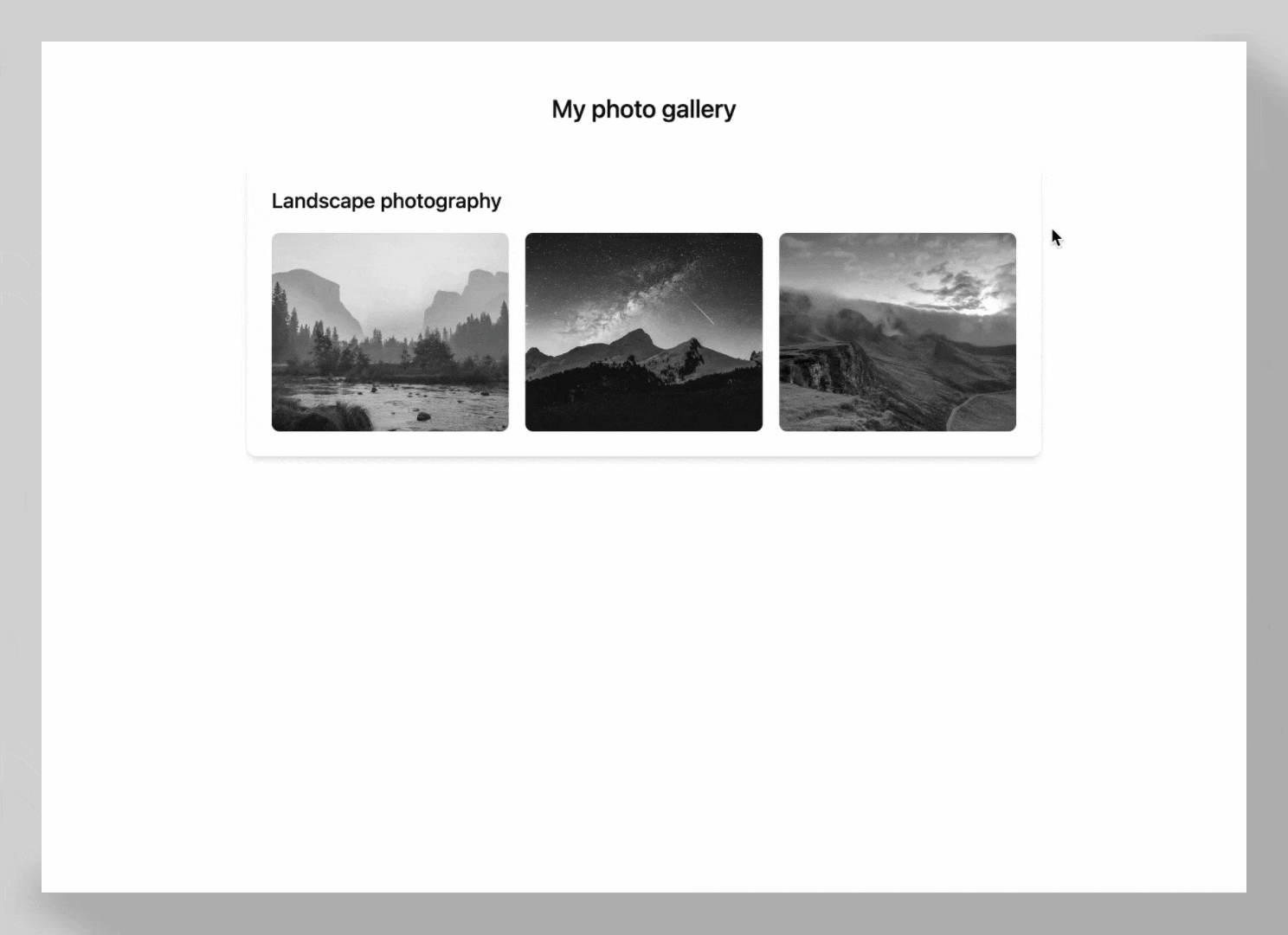
效果展示如下,很适合拿去组会汇报撑页数:
作业:对resnet18在cifar10上采用微调策略下,用tensorboard监控训练过程。
PS:
- tensorboard和torch版本存在一定的不兼容性,如果报错请新建环境尝试。启动tensorboard的时候需要先在cmd中进入对应的环境,conda activate xxx,再用cd命令进入环境(如果本来就是正确的则无需操作)。
- tensorboard的代码还有有一定的记忆量,实际上深度学习的经典代码都是类似于八股文,看多了就习惯了,难度远远小于考研数学等需要思考的内容
- 实际上对目前的ai而言,你只需要先完成最简单的demo,然后让他给你加上tensorboard需要打印的部分即可。---核心是弄懂tensorboard可以打印什么信息,以及如何看可视化后的结果,把ai当成记忆大师用到的时候通过它来调取对应的代码即可。
之前的内容中,我们在神经网络训练中,为了帮助自己理解,借用了很多的组件,比如训练进度条、可视化的loss下降曲线、权重分布图,运行结束后还可以查看单张图的推理效果。
如果现在有一个交互工具可以很简单的通过按钮完成这些辅助功能那就好了。所以我们现在介绍下tensorboard这个可视化工具,他可以很方便的很多可视化的功能,尤其是他可以在运行过程中实时渲染,方便我们根据图来动态调整训练策略,而不是训练完了才知道好不好。
一、tensorboard的基本操作
1.1 发展历史
TensorBoard 是 TensorFlow 生态中的官方可视化工具(也可无缝集成 PyTorch),用于实时监控训练过程、可视化模型结构、分析数据分布、对比实验结果等。它通过网页端交互界面,将枯燥的训练日志转化为直观的图表和图像,帮助开发者快速定位问题、优化模型。
简单来说,TensorBoard 是 TensorFlow 自带的一个「可视化工具」,就像给机器学习模型训练过程装了一个「监控屏幕」。你可以用它直观看到训练过程中的数据变化(比如损失值、准确率)、模型结构、数据分布等,不用盯着一堆枯燥的数字看,对新手非常友好。
TensorBoard 的发展历程如下:
-
2015 年随着 TensorFlow 框架一起发布,最初是为了满足深度学习研究者可视化复杂模型训练过程的需求。2016-2018 年新增了更多可视化功能,图像 / 音频可视化:可以直接看训练数据里的图片、听音频(比如在图像分类任务中,查看输入的图片是否正确)。 直方图:展示数据分布(比如权重参数的分布是否合理)。 多运行对比:同时对比多个训练任务的结果(比如不同学习率的效果对比)。
-
2019 年后与 PyTorch 兼容,变得更通用了。功能进一步丰富,比如支持3D 可视化、模型参数调试等。
目前这个工具还在不断发展,比如一些额外功能在tensorboardX上存在,但是我们目前只需要要用到最经典的几个功能即可
- 保存模型结构图
- 保存训练集和验证集的loss变化曲线,不需要手动打印了
- 保存每一个层结构权重分布
- 保存预测图片的预测信息
1.2 tensorboard的原理
TensorBoard 的核心原理就是在训练过程中,把训练过程中的数据(比如损失、准确率、图片等)先记录到日志文件里,再通过工具把这些日志文件可视化成图表,这样就不用自己手动打印数据或者用其他工具画图。
所以核心就是2个步骤:
- 数据怎么存?—— 先写日志文件
训练模型时,TensorBoard 会让程序把训练数据(比如损失值、准确率)和模型结构等信息,写入一个特殊的日志文件(.tfevents 文件)
- 数据怎么看?—— 用网页展示日志
写完日志后,TensorBoard 会启动一个本地网页服务,自动读取日志文件里的数据,用图表、图像、文本等形式展示出来。如果只用 print(损失值) 或者自己用 matplotlib 画图,不仅麻烦,还得手动保存数据、写代码,尤其训练几天几夜时,根本没法实时盯着看。而 TensorBoard 能自动把这些数据 “存下来 + 画出来”,还能生成网页版的可视化界面,随时刷新查看!
# pip install tensorboard -i https://pypi.tuna.tsinghua.edu.cn/simple下面是tensorboard的核心代码解析,无需运行 看懂大概在做什么即可
1.3 日志目录自动管理
log_dir = 'runs/cifar10_mlp_experiment'
if os.path.exists(log_dir):i = 1while os.path.exists(f"{log_dir}_{i}"):i += 1log_dir = f"{log_dir}_{i}"
writer = SummaryWriter(log_dir) #关键入口,用于写入数据到日志目录自动避免日志目录重复。若 runs/cifar10_mlp_experiment 已存在,会生成 runs/cifar10_mlp_experiment_1、_2 等新目录,确保每次训练的日志独立存储。
方便对比不同训练任务的结果(如不同超参数实验)
1.4 记录标量数据(Scalar)
# 记录每个 Batch 的损失和准确率
writer.add_scalar('Train/Batch_Loss', batch_loss, global_step)
writer.add_scalar('Train/Batch_Accuracy', batch_acc, global_step)# 记录每个 Epoch 的训练指标
writer.add_scalar('Train/Epoch_Loss', epoch_train_loss, epoch)
writer.add_scalar('Train/Epoch_Accuracy', epoch_train_acc, epoch)在 tensorboard的SCALARS 选项卡中查看曲线,支持多 run 对比。
1.5 可视化模型结构(Graph)
dataiter = iter(train_loader)
images, labels = next(dataiter)
images = images.to(device)
writer.add_graph(model, images) # 通过真实输入样本生成模型计算图TensorBoard 界面:在 GRAPHS 选项卡中查看模型层次结构(卷积层、全连接层等)。
1.6 可视化图像(Image)
# 可视化原始训练图像
img_grid = torchvision.utils.make_grid(images[:8].cpu()) # 将多张图像拼接成网格状(方便可视化),将前8张图像拼接成一个网格
writer.add_image('原始训练图像', img_grid)# 可视化错误预测样本(训练结束后)
wrong_img_grid = torchvision.utils.make_grid(wrong_images[:display_count])
writer.add_image('错误预测样本', wrong_img_grid)展示原始图像、数据增强效果、错误预测样本等。
1.7 记录权重和梯度直方图(Histogram)
if (batch_idx + 1) % 500 == 0:for name, param in model.named_parameters():writer.add_histogram(f'weights/{name}', param, global_step) # 权重分布if param.grad is not None:writer.add_histogram(f'grads/{name}', param.grad, global_step) # 梯度分布在 HISTOGRAMS 选项卡中查看不同层的参数分布随训练的变化。监控模型参数(如权重 weights)和梯度(grads)的分布变化,诊断训练问题(如梯度消失 / 爆炸)。
1.8 启动tensorboard
运行代码后,会在指定目录(如 runs/cifar10_mlp_experiment_1)生成 .tfevents 文件,存储所有 TensorBoard 数据。
在终端执行(需进入项目根目录):
tensorboard --logdir=runs # 假设日志目录在 runs/ 下
打开浏览器,输入终端提示的 URL(通常为 http://localhost:6006)。
二、tensorboard实战
2.1 cifar-10 MLP实战
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import numpy as np
import matplotlib.pyplot as plt
import os# 设置随机种子以确保结果可复现
torch.manual_seed(42)
np.random.seed(42)# 1. 数据预处理
transform = transforms.Compose([transforms.ToTensor(), # 转换为张量transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 标准化处理
])# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(root='./data',train=True,download=True,transform=transform
)test_dataset = datasets.CIFAR10(root='./data',train=False,transform=transform
)# 3. 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# CIFAR-10的类别名称
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')# 4. 定义MLP模型(适应CIFAR-10的输入尺寸)
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.flatten = nn.Flatten() # 将3x32x32的图像展平为3072维向量self.layer1 = nn.Linear(3072, 512) # 第一层:3072个输入,512个神经元self.relu1 = nn.ReLU()self.dropout1 = nn.Dropout(0.2) # 添加Dropout防止过拟合self.layer2 = nn.Linear(512, 256) # 第二层:512个输入,256个神经元self.relu2 = nn.ReLU()self.dropout2 = nn.Dropout(0.2)self.layer3 = nn.Linear(256, 10) # 输出层:10个类别def forward(self, x):# 第一步:将输入图像展平为一维向量x = self.flatten(x) # 输入尺寸: [batch_size, 3, 32, 32] → [batch_size, 3072]# 第一层全连接 + 激活 + Dropoutx = self.layer1(x) # 线性变换: [batch_size, 3072] → [batch_size, 512]x = self.relu1(x) # 应用ReLU激活函数x = self.dropout1(x) # 训练时随机丢弃部分神经元输出# 第二层全连接 + 激活 + Dropoutx = self.layer2(x) # 线性变换: [batch_size, 512] → [batch_size, 256]x = self.relu2(x) # 应用ReLU激活函数x = self.dropout2(x) # 训练时随机丢弃部分神经元输出# 第三层(输出层)全连接x = self.layer3(x) # 线性变换: [batch_size, 256] → [batch_size, 10]return x # 返回未经过Softmax的logits# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 初始化模型
model = MLP()
model = model.to(device) # 将模型移至GPU(如果可用)criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器# 创建TensorBoard的SummaryWriter,指定日志保存目录
log_dir = 'runs/cifar10_mlp_experiment'
# 如果目录已存在,添加后缀避免覆盖
if os.path.exists(log_dir):i = 1while os.path.exists(f"{log_dir}_{i}"):i += 1log_dir = f"{log_dir}_{i}"
writer = SummaryWriter(log_dir)# 5. 训练模型(使用TensorBoard记录各种信息)
def train(model, train_loader, test_loader, criterion, optimizer, device, epochs, writer):model.train() # 设置为训练模式# 记录训练开始时间,用于计算训练速度global_step = 0# 可视化模型结构dataiter = iter(train_loader)images, labels = next(dataiter)images = images.to(device)writer.add_graph(model, images) # 添加模型图# 可视化原始图像样本img_grid = torchvision.utils.make_grid(images[:8].cpu())writer.add_image('原始训练图像', img_grid)for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device) # 移至GPUoptimizer.zero_grad() # 梯度清零output = model(data) # 前向传播loss = criterion(output, target) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数# 统计准确率和损失running_loss += loss.item()_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()# 每100个批次记录一次信息到TensorBoardif (batch_idx + 1) % 100 == 0:batch_loss = loss.item()batch_acc = 100. * correct / total# 记录标量数据(损失、准确率)writer.add_scalar('Train/Batch_Loss', batch_loss, global_step)writer.add_scalar('Train/Batch_Accuracy', batch_acc, global_step)# 记录学习率writer.add_scalar('Train/Learning_Rate', optimizer.param_groups[0]['lr'], global_step)# 每500个批次记录一次直方图(权重和梯度)if (batch_idx + 1) % 500 == 0:for name, param in model.named_parameters():writer.add_histogram(f'weights/{name}', param, global_step)if param.grad is not None:writer.add_histogram(f'grads/{name}', param.grad, global_step)print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {batch_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')global_step += 1# 计算当前epoch的平均训练损失和准确率epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / total# 记录每个epoch的训练损失和准确率writer.add_scalar('Train/Epoch_Loss', epoch_train_loss, epoch)writer.add_scalar('Train/Epoch_Accuracy', epoch_train_acc, epoch)# 测试阶段model.eval() # 设置为评估模式test_loss = 0correct_test = 0total_test = 0# 用于存储预测错误的样本wrong_images = []wrong_labels = []wrong_preds = []with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()# 收集预测错误的样本wrong_mask = (predicted != target).cpu()if wrong_mask.sum() > 0:wrong_batch_images = data[wrong_mask].cpu()wrong_batch_labels = target[wrong_mask].cpu()wrong_batch_preds = predicted[wrong_mask].cpu()wrong_images.extend(wrong_batch_images)wrong_labels.extend(wrong_batch_labels)wrong_preds.extend(wrong_batch_preds)epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_test# 记录每个epoch的测试损失和准确率writer.add_scalar('Test/Loss', epoch_test_loss, epoch)writer.add_scalar('Test/Accuracy', epoch_test_acc, epoch)# 计算并记录训练速度(每秒处理的样本数)# 这里简化处理,假设每个epoch的时间相同samples_per_epoch = len(train_loader.dataset)# 实际应用中应该使用time.time()来计算真实时间print(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# 可视化预测错误的样本(只在最后一个epoch进行)if epoch == epochs - 1 and len(wrong_images) > 0:# 最多显示8个错误样本display_count = min(8, len(wrong_images))wrong_img_grid = torchvision.utils.make_grid(wrong_images[:display_count])# 创建错误预测的标签文本wrong_text = []for i in range(display_count):true_label = classes[wrong_labels[i]]pred_label = classes[wrong_preds[i]]wrong_text.append(f'True: {true_label}, Pred: {pred_label}')writer.add_image('错误预测样本', wrong_img_grid)writer.add_text('错误预测标签', '\n'.join(wrong_text), epoch)# 关闭TensorBoard写入器writer.close()return epoch_test_acc # 返回最终测试准确率# 6. 执行训练和测试
epochs = 20 # 训练轮次
print("开始训练模型...")
print(f"TensorBoard日志保存在: {log_dir}")
print("训练完成后,使用命令 `tensorboard --logdir=runs` 启动TensorBoard查看可视化结果")final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, device, epochs, writer)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")Files already downloaded and verified 开始训练模型... TensorBoard日志保存在: runs/cifar10_mlp_experiment_1 训练完成后,使用命令 `tensorboard --logdir=runs` 启动TensorBoard查看可视化结果 Epoch: 1/20 | Batch: 100/782 | 单Batch损失: 1.8327 | 累计平均损失: 1.9410 Epoch: 1/20 | Batch: 200/782 | 单Batch损失: 1.8588 | 累计平均损失: 1.8519 Epoch: 1/20 | Batch: 300/782 | 单Batch损失: 1.6719 | 累计平均损失: 1.8029 Epoch: 1/20 | Batch: 400/782 | 单Batch损失: 1.7609 | 累计平均损失: 1.7754 Epoch: 1/20 | Batch: 500/782 | 单Batch损失: 1.6642 | 累计平均损失: 1.7508 Epoch: 1/20 | Batch: 600/782 | 单Batch损失: 1.6564 | 累计平均损失: 1.7330 Epoch: 1/20 | Batch: 700/782 | 单Batch损失: 1.5870 | 累计平均损失: 1.7199 Epoch 1/20 完成 | 训练准确率: 39.23% | 测试准确率: 45.11% Epoch: 2/20 | Batch: 100/782 | 单Batch损失: 1.4987 | 累计平均损失: 1.5227 Epoch: 2/20 | Batch: 200/782 | 单Batch损失: 1.3297 | 累计平均损失: 1.4918 Epoch: 2/20 | Batch: 300/782 | 单Batch损失: 1.3329 | 累计平均损失: 1.4820 Epoch: 2/20 | Batch: 400/782 | 单Batch损失: 1.5894 | 累计平均损失: 1.4701 Epoch: 2/20 | Batch: 500/782 | 单Batch损失: 1.3843 | 累计平均损失: 1.4710 Epoch: 2/20 | Batch: 600/782 | 单Batch损失: 1.3671 | 累计平均损失: 1.4662 Epoch: 2/20 | Batch: 700/782 | 单Batch损失: 1.4408 | 累计平均损失: 1.4614 Epoch 2/20 完成 | 训练准确率: 48.51% | 测试准确率: 49.87% Epoch: 3/20 | Batch: 100/782 | 单Batch损失: 1.3722 | 累计平均损失: 1.3401 Epoch: 3/20 | Batch: 200/782 | 单Batch损失: 1.8139 | 累计平均损失: 1.3486 Epoch: 3/20 | Batch: 300/782 | 单Batch损失: 1.1994 | 累计平均损失: 1.3457 Epoch: 3/20 | Batch: 400/782 | 单Batch损失: 1.1896 | 累计平均损失: 1.3403 Epoch: 3/20 | Batch: 500/782 | 单Batch损失: 1.4191 | 累计平均损失: 1.3419 Epoch: 3/20 | Batch: 600/782 | 单Batch损失: 1.4218 | 累计平均损失: 1.3475 Epoch: 3/20 | Batch: 700/782 | 单Batch损失: 1.4627 | 累计平均损失: 1.3441 Epoch 3/20 完成 | 训练准确率: 52.43% | 测试准确率: 51.27% Epoch: 4/20 | Batch: 100/782 | 单Batch损失: 1.3596 | 累计平均损失: 1.2346 Epoch: 4/20 | Batch: 200/782 | 单Batch损失: 1.3270 | 累计平均损失: 1.2381 Epoch: 4/20 | Batch: 300/782 | 单Batch损失: 1.2478 | 累计平均损失: 1.2434 Epoch: 4/20 | Batch: 400/782 | 单Batch损失: 1.3861 | 累计平均损失: 1.2422 Epoch: 4/20 | Batch: 500/782 | 单Batch损失: 1.3478 | 累计平均损失: 1.2422 Epoch: 4/20 | Batch: 600/782 | 单Batch损失: 1.1521 | 累计平均损失: 1.2447 Epoch: 4/20 | Batch: 700/782 | 单Batch损失: 1.2833 | 累计平均损失: 1.2469 Epoch 4/20 完成 | 训练准确率: 55.63% | 测试准确率: 51.32% Epoch: 5/20 | Batch: 100/782 | 单Batch损失: 0.9809 | 累计平均损失: 1.1235 Epoch: 5/20 | Batch: 200/782 | 单Batch损失: 1.0800 | 累计平均损失: 1.1295 Epoch: 5/20 | Batch: 300/782 | 单Batch损失: 1.0129 | 累计平均损失: 1.1372 Epoch: 5/20 | Batch: 400/782 | 单Batch损失: 1.0918 | 累计平均损失: 1.1459 Epoch: 5/20 | Batch: 500/782 | 单Batch损失: 1.3155 | 累计平均损失: 1.1532 Epoch: 5/20 | Batch: 600/782 | 单Batch损失: 1.1727 | 累计平均损失: 1.1588 Epoch: 5/20 | Batch: 700/782 | 单Batch损失: 1.2888 | 累计平均损失: 1.1649 Epoch 5/20 完成 | 训练准确率: 58.74% | 测试准确率: 52.74% Epoch: 6/20 | Batch: 100/782 | 单Batch损失: 1.1855 | 累计平均损失: 1.0499 Epoch: 6/20 | Batch: 200/782 | 单Batch损失: 0.8994 | 累计平均损失: 1.0567 Epoch: 6/20 | Batch: 300/782 | 单Batch损失: 1.2460 | 累计平均损失: 1.0602 Epoch: 6/20 | Batch: 400/782 | 单Batch损失: 1.1033 | 累计平均损失: 1.0660 Epoch: 6/20 | Batch: 500/782 | 单Batch损失: 0.9182 | 累计平均损失: 1.0679 Epoch: 6/20 | Batch: 600/782 | 单Batch损失: 1.4116 | 累计平均损失: 1.0745 Epoch: 6/20 | Batch: 700/782 | 单Batch损失: 1.0211 | 累计平均损失: 1.0814 Epoch 6/20 完成 | 训练准确率: 61.37% | 测试准确率: 52.98% Epoch: 7/20 | Batch: 100/782 | 单Batch损失: 1.0082 | 累计平均损失: 0.9592 Epoch: 7/20 | Batch: 200/782 | 单Batch损失: 1.0255 | 累计平均损失: 0.9742 Epoch: 7/20 | Batch: 300/782 | 单Batch损失: 1.1416 | 累计平均损失: 0.9837 Epoch: 7/20 | Batch: 400/782 | 单Batch损失: 0.9732 | 累计平均损失: 0.9875 Epoch: 7/20 | Batch: 500/782 | 单Batch损失: 1.1387 | 累计平均损失: 0.9947 Epoch: 7/20 | Batch: 600/782 | 单Batch损失: 0.8657 | 累计平均损失: 0.9994 Epoch: 7/20 | Batch: 700/782 | 单Batch损失: 0.9666 | 累计平均损失: 1.0046 Epoch 7/20 完成 | 训练准确率: 64.09% | 测试准确率: 52.69% Epoch: 8/20 | Batch: 100/782 | 单Batch损失: 0.6081 | 累计平均损失: 0.8927 Epoch: 8/20 | Batch: 200/782 | 单Batch损失: 0.6484 | 累计平均损失: 0.8922 Epoch: 8/20 | Batch: 300/782 | 单Batch损失: 0.8360 | 累计平均损失: 0.9001 Epoch: 8/20 | Batch: 400/782 | 单Batch损失: 1.1883 | 累计平均损失: 0.9150 Epoch: 8/20 | Batch: 500/782 | 单Batch损失: 0.9597 | 累计平均损失: 0.9244 Epoch: 8/20 | Batch: 600/782 | 单Batch损失: 0.8802 | 累计平均损失: 0.9273 Epoch: 8/20 | Batch: 700/782 | 单Batch损失: 0.9168 | 累计平均损失: 0.9295 Epoch 8/20 完成 | 训练准确率: 66.68% | 测试准确率: 52.01% Epoch: 9/20 | Batch: 100/782 | 单Batch损失: 0.8491 | 累计平均损失: 0.7973 Epoch: 9/20 | Batch: 200/782 | 单Batch损失: 0.8207 | 累计平均损失: 0.8219 Epoch: 9/20 | Batch: 300/782 | 单Batch损失: 0.9952 | 累计平均损失: 0.8260 Epoch: 9/20 | Batch: 400/782 | 单Batch损失: 0.8664 | 累计平均损失: 0.8395 Epoch: 9/20 | Batch: 500/782 | 单Batch损失: 0.8573 | 累计平均损失: 0.8478 Epoch: 9/20 | Batch: 600/782 | 单Batch损失: 1.2844 | 累计平均损失: 0.8503 Epoch: 9/20 | Batch: 700/782 | 单Batch损失: 0.7931 | 累计平均损失: 0.8556 Epoch 9/20 完成 | 训练准确率: 69.11% | 测试准确率: 53.24% Epoch: 10/20 | Batch: 100/782 | 单Batch损失: 0.6661 | 累计平均损失: 0.7471 Epoch: 10/20 | Batch: 200/782 | 单Batch损失: 0.7758 | 累计平均损失: 0.7521 Epoch: 10/20 | Batch: 300/782 | 单Batch损失: 1.1638 | 累计平均损失: 0.7680 Epoch: 10/20 | Batch: 400/782 | 单Batch损失: 0.7825 | 累计平均损失: 0.7754 Epoch: 10/20 | Batch: 500/782 | 单Batch损失: 0.6984 | 累计平均损失: 0.7834 Epoch: 10/20 | Batch: 600/782 | 单Batch损失: 0.7199 | 累计平均损失: 0.7880 Epoch: 10/20 | Batch: 700/782 | 单Batch损失: 0.9765 | 累计平均损失: 0.7918 Epoch 10/20 完成 | 训练准确率: 71.70% | 测试准确率: 53.59% Epoch: 11/20 | Batch: 100/782 | 单Batch损失: 0.7485 | 累计平均损失: 0.6873 Epoch: 11/20 | Batch: 200/782 | 单Batch损失: 0.6853 | 累计平均损失: 0.6817 Epoch: 11/20 | Batch: 300/782 | 单Batch损失: 0.7594 | 累计平均损失: 0.6880 Epoch: 11/20 | Batch: 400/782 | 单Batch损失: 0.9249 | 累计平均损失: 0.7001 Epoch: 11/20 | Batch: 500/782 | 单Batch损失: 0.5742 | 累计平均损失: 0.7060 Epoch: 11/20 | Batch: 600/782 | 单Batch损失: 0.7716 | 累计平均损失: 0.7190 Epoch: 11/20 | Batch: 700/782 | 单Batch损失: 0.6123 | 累计平均损失: 0.7273 Epoch 11/20 完成 | 训练准确率: 73.83% | 测试准确率: 52.58% Epoch: 12/20 | Batch: 100/782 | 单Batch损失: 0.6315 | 累计平均损失: 0.6275 Epoch: 12/20 | Batch: 200/782 | 单Batch损失: 0.5326 | 累计平均损失: 0.6286 Epoch: 12/20 | Batch: 300/782 | 单Batch损失: 0.5623 | 累计平均损失: 0.6369 Epoch: 12/20 | Batch: 400/782 | 单Batch损失: 0.7911 | 累计平均损失: 0.6473 Epoch: 12/20 | Batch: 500/782 | 单Batch损失: 0.6620 | 累计平均损失: 0.6545 Epoch: 12/20 | Batch: 600/782 | 单Batch损失: 0.5583 | 累计平均损失: 0.6637 Epoch: 12/20 | Batch: 700/782 | 单Batch损失: 0.6010 | 累计平均损失: 0.6709 Epoch 12/20 完成 | 训练准确率: 75.82% | 测试准确率: 52.88% Epoch: 13/20 | Batch: 100/782 | 单Batch损失: 0.7061 | 累计平均损失: 0.5733 Epoch: 13/20 | Batch: 200/782 | 单Batch损失: 0.5555 | 累计平均损失: 0.5713 Epoch: 13/20 | Batch: 300/782 | 单Batch损失: 0.3972 | 累计平均损失: 0.5712 Epoch: 13/20 | Batch: 400/782 | 单Batch损失: 0.8246 | 累计平均损失: 0.5824 Epoch: 13/20 | Batch: 500/782 | 单Batch损失: 0.4577 | 累计平均损失: 0.5935 Epoch: 13/20 | Batch: 600/782 | 单Batch损失: 0.7397 | 累计平均损失: 0.5992 Epoch: 13/20 | Batch: 700/782 | 单Batch损失: 0.6297 | 累计平均损失: 0.6090 Epoch 13/20 完成 | 训练准确率: 78.18% | 测试准确率: 53.19% Epoch: 14/20 | Batch: 100/782 | 单Batch损失: 0.5944 | 累计平均损失: 0.5333 Epoch: 14/20 | Batch: 200/782 | 单Batch损失: 0.5172 | 累计平均损失: 0.5252 Epoch: 14/20 | Batch: 300/782 | 单Batch损失: 0.5107 | 累计平均损失: 0.5313 Epoch: 14/20 | Batch: 400/782 | 单Batch损失: 0.4882 | 累计平均损失: 0.5414 Epoch: 14/20 | Batch: 500/782 | 单Batch损失: 0.4880 | 累计平均损失: 0.5560 Epoch: 14/20 | Batch: 600/782 | 单Batch损失: 0.6760 | 累计平均损失: 0.5617 Epoch: 14/20 | Batch: 700/782 | 单Batch损失: 0.5190 | 累计平均损失: 0.5651 Epoch 14/20 完成 | 训练准确率: 79.50% | 测试准确率: 53.00% Epoch: 15/20 | Batch: 100/782 | 单Batch损失: 0.3614 | 累计平均损失: 0.4667 Epoch: 15/20 | Batch: 200/782 | 单Batch损失: 0.5322 | 累计平均损失: 0.4657 Epoch: 15/20 | Batch: 300/782 | 单Batch损失: 0.5792 | 累计平均损失: 0.4838 Epoch: 15/20 | Batch: 400/782 | 单Batch损失: 0.6562 | 累计平均损失: 0.4975 Epoch: 15/20 | Batch: 500/782 | 单Batch损失: 0.5755 | 累计平均损失: 0.5062 Epoch: 15/20 | Batch: 600/782 | 单Batch损失: 0.8258 | 累计平均损失: 0.5142 Epoch: 15/20 | Batch: 700/782 | 单Batch损失: 0.4823 | 累计平均损失: 0.5194 Epoch 15/20 完成 | 训练准确率: 81.21% | 测试准确率: 52.39% Epoch: 16/20 | Batch: 100/782 | 单Batch损失: 0.3308 | 累计平均损失: 0.4314 Epoch: 16/20 | Batch: 200/782 | 单Batch损失: 0.3376 | 累计平均损失: 0.4463 Epoch: 16/20 | Batch: 300/782 | 单Batch损失: 0.5752 | 累计平均损失: 0.4539 Epoch: 16/20 | Batch: 400/782 | 单Batch损失: 0.4853 | 累计平均损失: 0.4700 Epoch: 16/20 | Batch: 500/782 | 单Batch损失: 0.5356 | 累计平均损失: 0.4794 Epoch: 16/20 | Batch: 600/782 | 单Batch损失: 0.6754 | 累计平均损失: 0.4817 Epoch: 16/20 | Batch: 700/782 | 单Batch损失: 0.4735 | 累计平均损失: 0.4875 Epoch 16/20 完成 | 训练准确率: 82.41% | 测试准确率: 53.40% Epoch: 17/20 | Batch: 100/782 | 单Batch损失: 0.3944 | 累计平均损失: 0.4055 Epoch: 17/20 | Batch: 200/782 | 单Batch损失: 0.3707 | 累计平均损失: 0.4074 Epoch: 17/20 | Batch: 300/782 | 单Batch损失: 0.5363 | 累计平均损失: 0.4122 Epoch: 17/20 | Batch: 400/782 | 单Batch损失: 0.3647 | 累计平均损失: 0.4147 Epoch: 17/20 | Batch: 500/782 | 单Batch损失: 0.4949 | 累计平均损失: 0.4241 Epoch: 17/20 | Batch: 600/782 | 单Batch损失: 0.2563 | 累计平均损失: 0.4316 Epoch: 17/20 | Batch: 700/782 | 单Batch损失: 0.3814 | 累计平均损失: 0.4394 Epoch 17/20 完成 | 训练准确率: 84.10% | 测试准确率: 51.73% Epoch: 18/20 | Batch: 100/782 | 单Batch损失: 0.4645 | 累计平均损失: 0.3851 Epoch: 18/20 | Batch: 200/782 | 单Batch损失: 0.2752 | 累计平均损失: 0.3906 Epoch: 18/20 | Batch: 300/782 | 单Batch损失: 0.4404 | 累计平均损失: 0.3927 Epoch: 18/20 | Batch: 400/782 | 单Batch损失: 0.4450 | 累计平均损失: 0.4015 Epoch: 18/20 | Batch: 500/782 | 单Batch损失: 0.4082 | 累计平均损失: 0.4158 Epoch: 18/20 | Batch: 600/782 | 单Batch损失: 0.3982 | 累计平均损失: 0.4203 Epoch: 18/20 | Batch: 700/782 | 单Batch损失: 0.5168 | 累计平均损失: 0.4263 Epoch 18/20 完成 | 训练准确率: 84.83% | 测试准确率: 51.31% Epoch: 19/20 | Batch: 100/782 | 单Batch损失: 0.2534 | 累计平均损失: 0.3471 Epoch: 19/20 | Batch: 200/782 | 单Batch损失: 0.3286 | 累计平均损失: 0.3488 Epoch: 19/20 | Batch: 300/782 | 单Batch损失: 0.2713 | 累计平均损失: 0.3563 Epoch: 19/20 | Batch: 400/782 | 单Batch损失: 0.4733 | 累计平均损失: 0.3728 Epoch: 19/20 | Batch: 500/782 | 单Batch损失: 0.3166 | 累计平均损失: 0.3756 Epoch: 19/20 | Batch: 600/782 | 单Batch损失: 0.4382 | 累计平均损失: 0.3798 Epoch: 19/20 | Batch: 700/782 | 单Batch损失: 0.3680 | 累计平均损失: 0.3888 Epoch 19/20 完成 | 训练准确率: 86.05% | 测试准确率: 52.17% Epoch: 20/20 | Batch: 100/782 | 单Batch损失: 0.2334 | 累计平均损失: 0.3316 Epoch: 20/20 | Batch: 200/782 | 单Batch损失: 0.3335 | 累计平均损失: 0.3274 Epoch: 20/20 | Batch: 300/782 | 单Batch损失: 0.4049 | 累计平均损失: 0.3455 Epoch: 20/20 | Batch: 400/782 | 单Batch损失: 0.5196 | 累计平均损失: 0.3514 Epoch: 20/20 | Batch: 500/782 | 单Batch损失: 0.3912 | 累计平均损失: 0.3619 Epoch: 20/20 | Batch: 600/782 | 单Batch损失: 0.2988 | 累计平均损失: 0.3776 Epoch: 20/20 | Batch: 700/782 | 单Batch损失: 0.5925 | 累计平均损失: 0.3867 Epoch 20/20 完成 | 训练准确率: 86.26% | 测试准确率: 51.46% 训练完成!最终测试准确率: 51.46%
TensorBoard日志保存在: runs/cifar10_mlp_experiment_1 可以在命令行中进入目前的环境,然后通过tensorboard --logdir=xxxx(目录)即可调出本地链接,点进去就是目前的训练信息,可以不断F5刷新来查看变化。
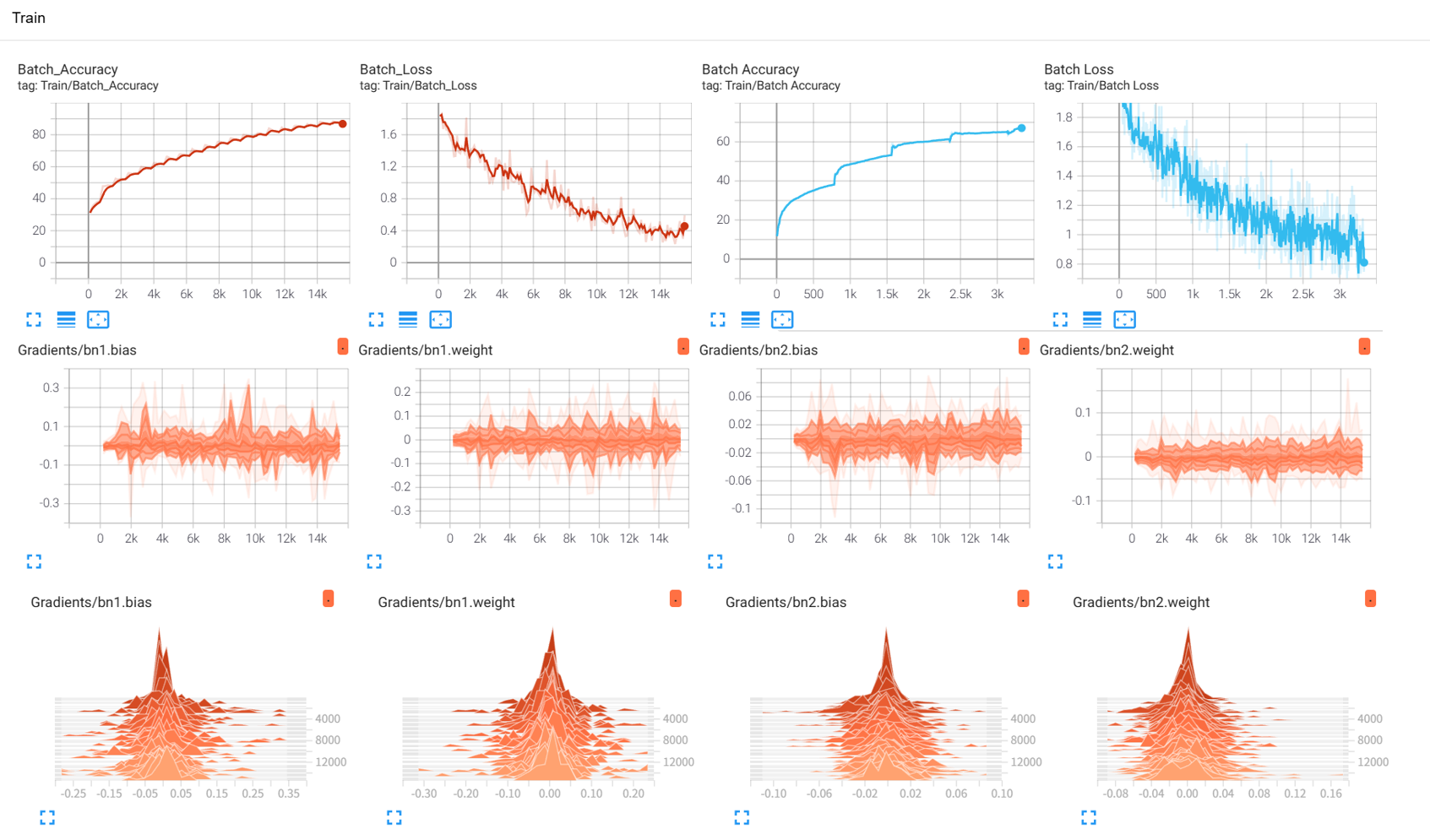
在TensorBoard界面中,你可以看到:
-
SCALARS 选项卡:展示损失曲线、准确率变化、学习率等标量数据----Scalar意思是标量,指只有大小、没有方向的量。
-
IMAGES 选项卡:展示原始训练图像和错误预测的样本
-
GRAPHS 选项卡:展示模型的计算图结构
-
HISTOGRAMS 选项卡:展示模型参数和梯度的分布直方图
2.2 cifar-10 CNN实战
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import matplotlib.pyplot as plt
import numpy as np
import os
import torchvision # 记得导入 torchvision,之前代码里用到了其功能但没导入# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 1. 数据预处理
train_transform = transforms.Compose([transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),transforms.RandomRotation(15),transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])test_transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(root='./data',train=True,download=True,transform=train_transform
)test_dataset = datasets.CIFAR10(root='./data',train=False,transform=test_transform
)# 3. 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# 4. 定义CNN模型的定义(替代原MLP)
class CNN(nn.Module):def __init__(self):super(CNN, self).__init__() # 继承父类初始化# ---------------------- 第一个卷积块 ----------------------# 卷积层1:输入3通道(RGB),输出32个特征图,卷积核3x3,边缘填充1像素self.conv1 = nn.Conv2d(in_channels=3, # 输入通道数(图像的RGB通道)out_channels=32, # 输出通道数(生成32个新特征图)kernel_size=3, # 卷积核尺寸(3x3像素)padding=1 # 边缘填充1像素,保持输出尺寸与输入相同)# 批量归一化层:对32个输出通道进行归一化,加速训练self.bn1 = nn.BatchNorm2d(num_features=32)# ReLU激活函数:引入非线性,公式:max(0, x)self.relu1 = nn.ReLU()# 最大池化层:窗口2x2,步长2,特征图尺寸减半(32x32→16x16)self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2) # stride默认等于kernel_size# ---------------------- 第二个卷积块 ----------------------# 卷积层2:输入32通道(来自conv1的输出),输出64通道self.conv2 = nn.Conv2d(in_channels=32, # 输入通道数(前一层的输出通道数)out_channels=64, # 输出通道数(特征图数量翻倍)kernel_size=3, # 卷积核尺寸不变padding=1 # 保持尺寸:16x16→16x16(卷积后)→8x8(池化后))self.bn2 = nn.BatchNorm2d(num_features=64)self.relu2 = nn.ReLU()self.pool2 = nn.MaxPool2d(kernel_size=2) # 尺寸减半:16x16→8x8# ---------------------- 第三个卷积块 ----------------------# 卷积层3:输入64通道,输出128通道self.conv3 = nn.Conv2d(in_channels=64, # 输入通道数(前一层的输出通道数)out_channels=128, # 输出通道数(特征图数量再次翻倍)kernel_size=3,padding=1 # 保持尺寸:8x8→8x8(卷积后)→4x4(池化后))self.bn3 = nn.BatchNorm2d(num_features=128)self.relu3 = nn.ReLU() # 复用激活函数对象(节省内存)self.pool3 = nn.MaxPool2d(kernel_size=2) # 尺寸减半:8x8→4x4# ---------------------- 全连接层(分类器) ----------------------# 计算展平后的特征维度:128通道 × 4x4尺寸 = 128×16=2048维self.fc1 = nn.Linear(in_features=128 * 4 * 4, # 输入维度(卷积层输出的特征数)out_features=512 # 输出维度(隐藏层神经元数))# Dropout层:训练时随机丢弃50%神经元,防止过拟合self.dropout = nn.Dropout(p=0.5)# 输出层:将512维特征映射到10个类别(CIFAR-10的类别数)self.fc2 = nn.Linear(in_features=512, out_features=10)def forward(self, x):# 输入尺寸:[batch_size, 3, 32, 32](batch_size=批量大小,3=通道数,32x32=图像尺寸)# ---------- 卷积块1处理 ----------x = self.conv1(x) # 卷积后尺寸:[batch_size, 32, 32, 32](padding=1保持尺寸)x = self.bn1(x) # 批量归一化,不改变尺寸x = self.relu1(x) # 激活函数,不改变尺寸x = self.pool1(x) # 池化后尺寸:[batch_size, 32, 16, 16](32→16是因为池化窗口2x2)# ---------- 卷积块2处理 ----------x = self.conv2(x) # 卷积后尺寸:[batch_size, 64, 16, 16](padding=1保持尺寸)x = self.bn2(x)x = self.relu2(x)x = self.pool2(x) # 池化后尺寸:[batch_size, 64, 8, 8]# ---------- 卷积块3处理 ----------x = self.conv3(x) # 卷积后尺寸:[batch_size, 128, 8, 8](padding=1保持尺寸)x = self.bn3(x)x = self.relu3(x)x = self.pool3(x) # 池化后尺寸:[batch_size, 128, 4, 4]# ---------- 展平与全连接层 ----------# 将多维特征图展平为一维向量:[batch_size, 128*4*4] = [batch_size, 2048]x = x.view(-1, 128 * 4 * 4) # -1自动计算批量维度,保持批量大小不变x = self.fc1(x) # 全连接层:2048→512,尺寸变为[batch_size, 512]x = self.relu3(x) # 激活函数(复用relu3,与卷积块3共用)x = self.dropout(x) # Dropout随机丢弃神经元,不改变尺寸x = self.fc2(x) # 全连接层:512→10,尺寸变为[batch_size, 10](未激活,直接输出logits)return x # 输出未经过Softmax的logits,适用于交叉熵损失函数# 初始化模型
model = CNN()
model = model.to(device) # 将模型移至GPU(如果可用)criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, # 指定要控制的优化器(这里是Adam)mode='min', # 监测的指标是"最小化"(如损失函数)patience=3, # 如果连续3个epoch指标没有改善,才降低LRfactor=0.5, # 降低LR的比例(新LR = 旧LR × 0.5)verbose=True # 打印学习率调整信息
)# ======================== TensorBoard 核心配置 ========================
# 创建 TensorBoard 日志目录(自动避免重复)
log_dir = "runs/cifar10_cnn_exp"
if os.path.exists(log_dir):version = 1while os.path.exists(f"{log_dir}_v{version}"):version += 1log_dir = f"{log_dir}_v{version}"
writer = SummaryWriter(log_dir) # 初始化 SummaryWriter# 5. 训练模型(整合 TensorBoard 记录)
def train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs, writer):model.train()all_iter_losses = [] iter_indices = [] global_step = 0 # 全局步骤,用于 TensorBoard 标量记录# (可选)记录模型结构:用一个真实样本走一遍前向传播,让 TensorBoard 解析计算图dataiter = iter(train_loader)images, labels = next(dataiter)images = images.to(device)writer.add_graph(model, images) # 写入模型结构到 TensorBoard# (可选)记录原始训练图像:可视化数据增强前/后效果img_grid = torchvision.utils.make_grid(images[:8].cpu()) # 取前8张writer.add_image('原始训练图像(增强前)', img_grid, global_step=0)for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()# 记录迭代级损失iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(global_step + 1) # 用 global_step 对齐# 统计准确率running_loss += iter_loss_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()# ======================== TensorBoard 标量记录 ========================# 记录每个 batch 的损失、准确率batch_acc = 100. * correct / totalwriter.add_scalar('Train/Batch Loss', iter_loss, global_step)writer.add_scalar('Train/Batch Accuracy', batch_acc, global_step)# 记录学习率(可选)writer.add_scalar('Train/Learning Rate', optimizer.param_groups[0]['lr'], global_step)# 每 200 个 batch 记录一次参数直方图(可选,耗时稍高)if (batch_idx + 1) % 200 == 0:for name, param in model.named_parameters():writer.add_histogram(f'Weights/{name}', param, global_step)if param.grad is not None:writer.add_histogram(f'Gradients/{name}', param.grad, global_step)# 每 100 个 batch 打印控制台日志(同原代码)if (batch_idx + 1) % 100 == 0:print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')global_step += 1 # 全局步骤递增# 计算 epoch 级训练指标epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / total# ======================== TensorBoard epoch 标量记录 ========================writer.add_scalar('Train/Epoch Loss', epoch_train_loss, epoch)writer.add_scalar('Train/Epoch Accuracy', epoch_train_acc, epoch)# 测试阶段model.eval()test_loss = 0correct_test = 0total_test = 0wrong_images = [] # 存储错误预测样本(用于可视化)wrong_labels = []wrong_preds = []with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()# 收集错误预测样本(用于可视化)wrong_mask = (predicted != target)if wrong_mask.sum() > 0:wrong_batch_images = data[wrong_mask][:8].cpu() # 最多存8张wrong_batch_labels = target[wrong_mask][:8].cpu()wrong_batch_preds = predicted[wrong_mask][:8].cpu()wrong_images.extend(wrong_batch_images)wrong_labels.extend(wrong_batch_labels)wrong_preds.extend(wrong_batch_preds)# 计算 epoch 级测试指标epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_test# ======================== TensorBoard 测试集记录 ========================writer.add_scalar('Test/Epoch Loss', epoch_test_loss, epoch)writer.add_scalar('Test/Epoch Accuracy', epoch_test_acc, epoch)# (可选)可视化错误预测样本if wrong_images:wrong_img_grid = torchvision.utils.make_grid(wrong_images)writer.add_image('错误预测样本', wrong_img_grid, epoch)# 写入错误标签文本(可选)wrong_text = [f"真实: {classes[wl]}, 预测: {classes[wp]}" for wl, wp in zip(wrong_labels, wrong_preds)]writer.add_text('错误预测标签', '\n'.join(wrong_text), epoch)# 更新学习率调度器scheduler.step(epoch_test_loss)print(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# 关闭 TensorBoard 写入器writer.close()# 绘制迭代级损失曲线(同原代码)plot_iter_losses(all_iter_losses, iter_indices)return epoch_test_acc# 6. 绘制迭代级损失曲线(同原代码,略)
def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')plt.xlabel('Iteration(Batch序号)')plt.ylabel('损失值')plt.title('每个 Iteration 的训练损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# (可选)CIFAR-10 类别名
classes = ('plane', 'car', 'bird', 'cat','deer', 'dog', 'frog', 'horse', 'ship', 'truck')# 7. 执行训练(传入 TensorBoard writer)
epochs = 20
print("开始使用CNN训练模型...")
print(f"TensorBoard 日志目录: {log_dir}")
print("训练后执行: tensorboard --logdir=runs 查看可视化")final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs, writer)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")使用设备: cuda Files already downloaded and verified 开始使用CNN训练模型... TensorBoard 日志目录: runs/cifar10_cnn_exp 训练后执行: tensorboard --logdir=runs 查看可视化 Epoch: 1/20 | Batch: 100/782 | 单Batch损失: 1.8809 | 累计平均损失: 2.0134 Epoch: 1/20 | Batch: 200/782 | 单Batch损失: 1.7645 | 累计平均损失: 1.8838 Epoch: 1/20 | Batch: 300/782 | 单Batch损失: 1.6334 | 累计平均损失: 1.8246 Epoch: 1/20 | Batch: 400/782 | 单Batch损失: 1.6380 | 累计平均损失: 1.7784 Epoch: 1/20 | Batch: 500/782 | 单Batch损失: 1.5500 | 累计平均损失: 1.7435 Epoch: 1/20 | Batch: 600/782 | 单Batch损失: 1.5527 | 累计平均损失: 1.7107 Epoch: 1/20 | Batch: 700/782 | 单Batch损失: 1.4984 | 累计平均损失: 1.6852 Epoch 1/20 完成 | 训练准确率: 38.11% | 测试准确率: 52.47% Epoch: 2/20 | Batch: 100/782 | 单Batch损失: 1.3814 | 累计平均损失: 1.4373 Epoch: 2/20 | Batch: 200/782 | 单Batch损失: 1.2911 | 累计平均损失: 1.3985 Epoch: 2/20 | Batch: 300/782 | 单Batch损失: 1.1904 | 累计平均损失: 1.3747 Epoch: 2/20 | Batch: 400/782 | 单Batch损失: 1.4026 | 累计平均损失: 1.3556 Epoch: 2/20 | Batch: 500/782 | 单Batch损失: 1.0859 | 累计平均损失: 1.3323 Epoch: 2/20 | Batch: 600/782 | 单Batch损失: 1.0579 | 累计平均损失: 1.3118 Epoch: 2/20 | Batch: 700/782 | 单Batch损失: 1.0614 | 累计平均损失: 1.2968 Epoch 2/20 完成 | 训练准确率: 53.28% | 测试准确率: 64.18% Epoch: 3/20 | Batch: 100/782 | 单Batch损失: 1.2669 | 累计平均损失: 1.1595 Epoch: 3/20 | Batch: 200/782 | 单Batch损失: 1.1426 | 累计平均损失: 1.1423 Epoch: 3/20 | Batch: 300/782 | 单Batch损失: 0.9215 | 累计平均损失: 1.1318 Epoch: 3/20 | Batch: 400/782 | 单Batch损失: 0.9795 | 累计平均损失: 1.1233 Epoch: 3/20 | Batch: 500/782 | 单Batch损失: 1.2100 | 累计平均损失: 1.1204 Epoch: 3/20 | Batch: 600/782 | 单Batch损失: 1.1693 | 累计平均损失: 1.1098 Epoch: 3/20 | Batch: 700/782 | 单Batch损失: 1.0973 | 累计平均损失: 1.1007 Epoch 3/20 完成 | 训练准确率: 61.37% | 测试准确率: 67.55% Epoch: 4/20 | Batch: 100/782 | 单Batch损失: 0.8795 | 累计平均损失: 1.0080 Epoch: 4/20 | Batch: 200/782 | 单Batch损失: 1.0070 | 累计平均损失: 1.0122 Epoch: 4/20 | Batch: 300/782 | 单Batch损失: 1.1206 | 累计平均损失: 1.0071 Epoch: 4/20 | Batch: 400/782 | 单Batch损失: 1.0918 | 累计平均损失: 1.0017 Epoch: 4/20 | Batch: 500/782 | 单Batch损失: 0.8132 | 累计平均损失: 0.9982 Epoch: 4/20 | Batch: 600/782 | 单Batch损失: 1.1464 | 累计平均损失: 0.9895 Epoch: 4/20 | Batch: 700/782 | 单Batch损失: 0.9950 | 累计平均损失: 0.9883 Epoch 4/20 完成 | 训练准确率: 65.12% | 测试准确率: 70.56% Epoch: 5/20 | Batch: 100/782 | 单Batch损失: 0.9320 | 累计平均损失: 0.9707 Epoch: 5/20 | Batch: 200/782 | 单Batch损失: 0.9041 | 累计平均损失: 0.9490 Epoch: 5/20 | Batch: 300/782 | 单Batch损失: 0.7707 | 累计平均损失: 0.9494 Epoch: 5/20 | Batch: 400/782 | 单Batch损失: 0.8947 | 累计平均损失: 0.9423 Epoch: 5/20 | Batch: 500/782 | 单Batch损失: 0.8728 | 累计平均损失: 0.9352 Epoch: 5/20 | Batch: 600/782 | 单Batch损失: 0.9779 | 累计平均损失: 0.9290 Epoch: 5/20 | Batch: 700/782 | 单Batch损失: 0.9652 | 累计平均损失: 0.9266 Epoch 5/20 完成 | 训练准确率: 67.76% | 测试准确率: 74.09% Epoch: 6/20 | Batch: 100/782 | 单Batch损失: 0.8804 | 累计平均损失: 0.8748 Epoch: 6/20 | Batch: 200/782 | 单Batch损失: 0.9413 | 累计平均损失: 0.8779 Epoch: 6/20 | Batch: 300/782 | 单Batch损失: 0.9451 | 累计平均损失: 0.8813 Epoch: 6/20 | Batch: 400/782 | 单Batch损失: 0.9844 | 累计平均损失: 0.8811 Epoch: 6/20 | Batch: 500/782 | 单Batch损失: 0.9123 | 累计平均损失: 0.8804 Epoch: 6/20 | Batch: 600/782 | 单Batch损失: 0.7724 | 累计平均损失: 0.8747 Epoch: 6/20 | Batch: 700/782 | 单Batch损失: 0.9191 | 累计平均损失: 0.8738 Epoch 6/20 完成 | 训练准确率: 69.24% | 测试准确率: 74.44% Epoch: 7/20 | Batch: 100/782 | 单Batch损失: 0.4618 | 累计平均损失: 0.8522 Epoch: 7/20 | Batch: 200/782 | 单Batch损失: 1.0956 | 累计平均损失: 0.8398 Epoch: 7/20 | Batch: 300/782 | 单Batch损失: 0.7080 | 累计平均损失: 0.8442 Epoch: 7/20 | Batch: 400/782 | 单Batch损失: 0.8755 | 累计平均损失: 0.8423 Epoch: 7/20 | Batch: 500/782 | 单Batch损失: 1.0161 | 累计平均损失: 0.8451 Epoch: 7/20 | Batch: 600/782 | 单Batch损失: 0.9611 | 累计平均损失: 0.8436 Epoch: 7/20 | Batch: 700/782 | 单Batch损失: 0.9344 | 累计平均损失: 0.8433 Epoch 7/20 完成 | 训练准确率: 70.60% | 测试准确率: 75.97% Epoch: 8/20 | Batch: 100/782 | 单Batch损失: 0.5846 | 累计平均损失: 0.7982 Epoch: 8/20 | Batch: 200/782 | 单Batch损失: 1.1336 | 累计平均损失: 0.8046 Epoch: 8/20 | Batch: 300/782 | 单Batch损失: 0.7393 | 累计平均损失: 0.8122 Epoch: 8/20 | Batch: 400/782 | 单Batch损失: 0.8892 | 累计平均损失: 0.8108 Epoch: 8/20 | Batch: 500/782 | 单Batch损失: 0.9932 | 累计平均损失: 0.8128 Epoch: 8/20 | Batch: 600/782 | 单Batch损失: 0.8610 | 累计平均损失: 0.8154 Epoch: 8/20 | Batch: 700/782 | 单Batch损失: 1.0081 | 累计平均损失: 0.8130 Epoch 8/20 完成 | 训练准确率: 71.44% | 测试准确率: 76.04% Epoch: 9/20 | Batch: 100/782 | 单Batch损失: 0.8448 | 累计平均损失: 0.8206 Epoch: 9/20 | Batch: 200/782 | 单Batch损失: 0.6494 | 累计平均损失: 0.8086 Epoch: 9/20 | Batch: 300/782 | 单Batch损失: 0.8203 | 累计平均损失: 0.8021 Epoch: 9/20 | Batch: 400/782 | 单Batch损失: 0.6053 | 累计平均损失: 0.7929 Epoch: 9/20 | Batch: 500/782 | 单Batch损失: 0.8298 | 累计平均损失: 0.7890 Epoch: 9/20 | Batch: 600/782 | 单Batch损失: 0.9492 | 累计平均损失: 0.7873 Epoch: 9/20 | Batch: 700/782 | 单Batch损失: 0.7991 | 累计平均损失: 0.7889 Epoch 9/20 完成 | 训练准确率: 72.75% | 测试准确率: 77.43% Epoch: 10/20 | Batch: 100/782 | 单Batch损失: 0.7773 | 累计平均损失: 0.7684 Epoch: 10/20 | Batch: 200/782 | 单Batch损失: 0.7030 | 累计平均损失: 0.7681 Epoch: 10/20 | Batch: 300/782 | 单Batch损失: 0.7726 | 累计平均损失: 0.7708 Epoch: 10/20 | Batch: 400/782 | 单Batch损失: 0.7785 | 累计平均损失: 0.7681 Epoch: 10/20 | Batch: 500/782 | 单Batch损失: 0.8096 | 累计平均损失: 0.7653 Epoch: 10/20 | Batch: 600/782 | 单Batch损失: 0.6069 | 累计平均损失: 0.7635 Epoch: 10/20 | Batch: 700/782 | 单Batch损失: 0.5608 | 累计平均损失: 0.7630 Epoch 10/20 完成 | 训练准确率: 73.20% | 测试准确率: 76.64% Epoch: 11/20 | Batch: 100/782 | 单Batch损失: 0.7491 | 累计平均损失: 0.7709 Epoch: 11/20 | Batch: 200/782 | 单Batch损失: 0.8199 | 累计平均损失: 0.7523 Epoch: 11/20 | Batch: 300/782 | 单Batch损失: 1.0428 | 累计平均损失: 0.7427 Epoch: 11/20 | Batch: 400/782 | 单Batch损失: 0.7862 | 累计平均损失: 0.7416 Epoch: 11/20 | Batch: 500/782 | 单Batch损失: 0.7416 | 累计平均损失: 0.7450 Epoch: 11/20 | Batch: 600/782 | 单Batch损失: 0.8239 | 累计平均损失: 0.7390 Epoch: 11/20 | Batch: 700/782 | 单Batch损失: 0.5744 | 累计平均损失: 0.7427 Epoch 11/20 完成 | 训练准确率: 74.04% | 测试准确率: 77.92% Epoch: 12/20 | Batch: 100/782 | 单Batch损失: 0.7772 | 累计平均损失: 0.7281 Epoch: 12/20 | Batch: 200/782 | 单Batch损失: 0.6939 | 累计平均损失: 0.7296 Epoch: 12/20 | Batch: 300/782 | 单Batch损失: 0.6478 | 累计平均损失: 0.7348 Epoch: 12/20 | Batch: 400/782 | 单Batch损失: 0.6809 | 累计平均损失: 0.7306 Epoch: 12/20 | Batch: 500/782 | 单Batch损失: 0.7887 | 累计平均损失: 0.7308 Epoch: 12/20 | Batch: 600/782 | 单Batch损失: 0.9312 | 累计平均损失: 0.7293 Epoch: 12/20 | Batch: 700/782 | 单Batch损失: 0.8912 | 累计平均损失: 0.7249 Epoch 12/20 完成 | 训练准确率: 74.57% | 测试准确率: 78.34% Epoch: 13/20 | Batch: 100/782 | 单Batch损失: 0.7660 | 累计平均损失: 0.7202 Epoch: 13/20 | Batch: 200/782 | 单Batch损失: 0.8096 | 累计平均损失: 0.7066 Epoch: 13/20 | Batch: 300/782 | 单Batch损失: 0.6760 | 累计平均损失: 0.7041 Epoch: 13/20 | Batch: 400/782 | 单Batch损失: 0.9175 | 累计平均损失: 0.7036 Epoch: 13/20 | Batch: 500/782 | 单Batch损失: 0.7499 | 累计平均损失: 0.7067 Epoch: 13/20 | Batch: 600/782 | 单Batch损失: 0.5950 | 累计平均损失: 0.7061 Epoch: 13/20 | Batch: 700/782 | 单Batch损失: 0.5243 | 累计平均损失: 0.7101 Epoch 13/20 完成 | 训练准确率: 75.14% | 测试准确率: 78.82% Epoch: 14/20 | Batch: 100/782 | 单Batch损失: 0.4825 | 累计平均损失: 0.6837 Epoch: 14/20 | Batch: 200/782 | 单Batch损失: 0.6175 | 累计平均损失: 0.6888 Epoch: 14/20 | Batch: 300/782 | 单Batch损失: 0.7952 | 累计平均损失: 0.6866 Epoch: 14/20 | Batch: 400/782 | 单Batch损失: 0.5896 | 累计平均损失: 0.6942 Epoch: 14/20 | Batch: 500/782 | 单Batch损失: 0.6090 | 累计平均损失: 0.6938 Epoch: 14/20 | Batch: 600/782 | 单Batch损失: 0.7104 | 累计平均损失: 0.6953 Epoch: 14/20 | Batch: 700/782 | 单Batch损失: 0.4085 | 累计平均损失: 0.6972 Epoch 14/20 完成 | 训练准确率: 75.52% | 测试准确率: 78.96% Epoch: 15/20 | Batch: 100/782 | 单Batch损失: 0.6176 | 累计平均损失: 0.6590 Epoch: 15/20 | Batch: 200/782 | 单Batch损失: 0.4711 | 累计平均损失: 0.6702 Epoch: 15/20 | Batch: 300/782 | 单Batch损失: 0.6192 | 累计平均损失: 0.6718 Epoch: 15/20 | Batch: 400/782 | 单Batch损失: 0.9684 | 累计平均损失: 0.6750 Epoch: 15/20 | Batch: 500/782 | 单Batch损失: 0.5928 | 累计平均损失: 0.6773 Epoch: 15/20 | Batch: 600/782 | 单Batch损失: 0.7290 | 累计平均损失: 0.6795 Epoch: 15/20 | Batch: 700/782 | 单Batch损失: 0.6996 | 累计平均损失: 0.6792 Epoch 15/20 完成 | 训练准确率: 76.17% | 测试准确率: 79.87% Epoch: 16/20 | Batch: 100/782 | 单Batch损失: 0.4865 | 累计平均损失: 0.6782 Epoch: 16/20 | Batch: 200/782 | 单Batch损失: 0.5581 | 累计平均损失: 0.6671 Epoch: 16/20 | Batch: 300/782 | 单Batch损失: 0.6508 | 累计平均损失: 0.6648 Epoch: 16/20 | Batch: 400/782 | 单Batch损失: 0.8125 | 累计平均损失: 0.6715 Epoch: 16/20 | Batch: 500/782 | 单Batch损失: 0.5303 | 累计平均损失: 0.6735 Epoch: 16/20 | Batch: 600/782 | 单Batch损失: 0.6881 | 累计平均损失: 0.6737 Epoch: 16/20 | Batch: 700/782 | 单Batch损失: 0.9869 | 累计平均损失: 0.6726 Epoch 16/20 完成 | 训练准确率: 76.63% | 测试准确率: 79.73% Epoch: 17/20 | Batch: 100/782 | 单Batch损失: 0.5943 | 累计平均损失: 0.6603 Epoch: 17/20 | Batch: 200/782 | 单Batch损失: 0.8486 | 累计平均损失: 0.6590 Epoch: 17/20 | Batch: 300/782 | 单Batch损失: 0.5727 | 累计平均损失: 0.6586 Epoch: 17/20 | Batch: 400/782 | 单Batch损失: 0.6489 | 累计平均损失: 0.6592 Epoch: 17/20 | Batch: 500/782 | 单Batch损失: 0.7211 | 累计平均损失: 0.6612 Epoch: 17/20 | Batch: 600/782 | 单Batch损失: 0.5552 | 累计平均损失: 0.6615 Epoch: 17/20 | Batch: 700/782 | 单Batch损失: 0.5500 | 累计平均损失: 0.6617 Epoch 17/20 完成 | 训练准确率: 76.85% | 测试准确率: 80.07% Epoch: 18/20 | Batch: 100/782 | 单Batch损失: 0.6643 | 累计平均损失: 0.6195 Epoch: 18/20 | Batch: 200/782 | 单Batch损失: 0.5175 | 累计平均损失: 0.6383 Epoch: 18/20 | Batch: 300/782 | 单Batch损失: 0.8941 | 累计平均损失: 0.6423 Epoch: 18/20 | Batch: 400/782 | 单Batch损失: 0.5957 | 累计平均损失: 0.6494 Epoch: 18/20 | Batch: 500/782 | 单Batch损失: 0.6997 | 累计平均损失: 0.6515 Epoch: 18/20 | Batch: 600/782 | 单Batch损失: 0.8387 | 累计平均损失: 0.6526 Epoch: 18/20 | Batch: 700/782 | 单Batch损失: 0.6168 | 累计平均损失: 0.6502 Epoch 18/20 完成 | 训练准确率: 77.20% | 测试准确率: 80.18% Epoch: 19/20 | Batch: 100/782 | 单Batch损失: 0.5368 | 累计平均损失: 0.6308 Epoch: 19/20 | Batch: 200/782 | 单Batch损失: 0.4568 | 累计平均损失: 0.6476 Epoch: 19/20 | Batch: 300/782 | 单Batch损失: 0.4435 | 累计平均损失: 0.6396 Epoch: 19/20 | Batch: 400/782 | 单Batch损失: 0.5895 | 累计平均损失: 0.6407 Epoch: 19/20 | Batch: 500/782 | 单Batch损失: 0.9253 | 累计平均损失: 0.6424 Epoch: 19/20 | Batch: 600/782 | 单Batch损失: 0.5735 | 累计平均损失: 0.6417 Epoch: 19/20 | Batch: 700/782 | 单Batch损失: 0.6145 | 累计平均损失: 0.6418 Epoch 19: reducing learning rate of group 0 to 5.0000e-04. Epoch 19/20 完成 | 训练准确率: 77.65% | 测试准确率: 79.72% Epoch: 20/20 | Batch: 100/782 | 单Batch损失: 0.5315 | 累计平均损失: 0.5793 Epoch: 20/20 | Batch: 200/782 | 单Batch损失: 0.5769 | 累计平均损失: 0.5837 Epoch: 20/20 | Batch: 300/782 | 单Batch损失: 0.4930 | 累计平均损失: 0.5806 Epoch: 20/20 | Batch: 400/782 | 单Batch损失: 0.5806 | 累计平均损失: 0.5821 Epoch: 20/20 | Batch: 500/782 | 单Batch损失: 0.8352 | 累计平均损失: 0.5847 Epoch: 20/20 | Batch: 600/782 | 单Batch损失: 0.5066 | 累计平均损失: 0.5831 Epoch: 20/20 | Batch: 700/782 | 单Batch损失: 0.5890 | 累计平均损失: 0.5816 Epoch 20/20 完成 | 训练准确率: 79.72% | 测试准确率: 81.85%
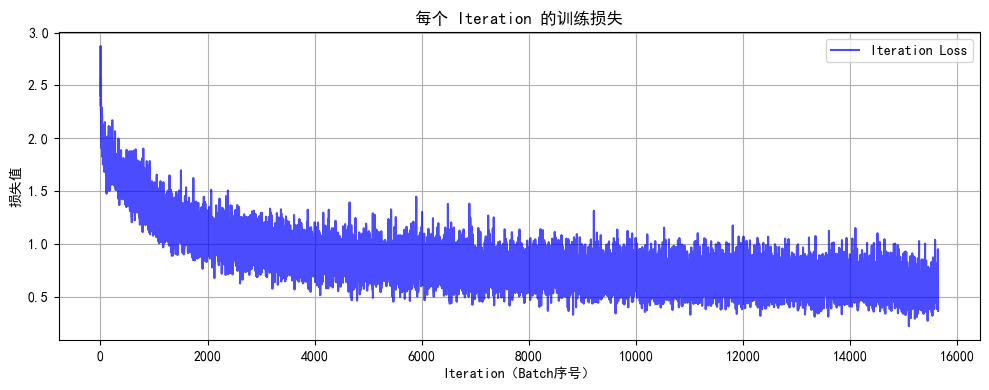
训练完成!最终测试准确率: 81.85%
由于已近搭载了tensorboard,上述代码中一些之前可视化的冗余部分可以删除了
# 省略预处理、模型定义代码# ======================== TensorBoard 核心配置 ========================
# 在使用tensorboard前需要先指定日志保存路径
log_dir = "runs/cifar10_cnn_exp" # 指定日志保存路径
if os.path.exists(log_dir): #检查刚才定义的路径是否存在version = 1 while os.path.exists(f"{log_dir}_v{version}"): # 如果路径存在且版本号一致version += 1 # 版本号加1log_dir = f"{log_dir}_v{version}" # 如果路径存在,则创建一个新版本
writer = SummaryWriter(log_dir) # 初始化SummaryWriter
print(f"TensorBoard 日志目录: {log_dir}") # 所以第一次是cifar10_cnn_exp、第二次是cifar10_cnn_exp_v1# 5. 训练模型(整合 TensorBoard 记录)
def train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs, writer):model.train()global_step = 0 # 全局步骤,用于 TensorBoard 标量记录# 记录模型结构和训练图像dataiter = iter(train_loader)images, labels = next(dataiter)images = images.to(device)writer.add_graph(model, images)img_grid = torchvision.utils.make_grid(images[:8].cpu())writer.add_image('原始训练图像(增强前)', img_grid, global_step=0)for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()# 统计准确率running_loss += loss.item()_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()# 记录每个 batch 的损失、准确率和学习率batch_acc = 100. * correct / totalwriter.add_scalar('Train/Batch Loss', loss.item(), global_step)writer.add_scalar('Train/Batch Accuracy', batch_acc, global_step)writer.add_scalar('Train/Learning Rate', optimizer.param_groups[0]['lr'], global_step)# 每 200 个 batch 记录一次参数直方图if (batch_idx + 1) % 200 == 0:for name, param in model.named_parameters():writer.add_histogram(f'Weights/{name}', param, global_step)if param.grad is not None:writer.add_histogram(f'Gradients/{name}', param.grad, global_step)global_step += 1# 计算 epoch 级训练指标epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / totalwriter.add_scalar('Train/Epoch Loss', epoch_train_loss, epoch)writer.add_scalar('Train/Epoch Accuracy', epoch_train_acc, epoch)# 测试阶段model.eval()test_loss = 0correct_test = 0total_test = 0wrong_images = []wrong_labels = []wrong_preds = []with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()# 收集错误预测样本wrong_mask = (predicted != target)if wrong_mask.sum() > 0:wrong_batch_images = data[wrong_mask][:8].cpu()wrong_batch_labels = target[wrong_mask][:8].cpu()wrong_batch_preds = predicted[wrong_mask][:8].cpu()wrong_images.extend(wrong_batch_images)wrong_labels.extend(wrong_batch_labels)wrong_preds.extend(wrong_batch_preds)# 计算 epoch 级测试指标epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_testwriter.add_scalar('Test/Epoch Loss', epoch_test_loss, epoch)writer.add_scalar('Test/Epoch Accuracy', epoch_test_acc, epoch)# 可视化错误预测样本if wrong_images:wrong_img_grid = torchvision.utils.make_grid(wrong_images)writer.add_image('错误预测样本', wrong_img_grid, epoch)wrong_text = [f"真实: {classes[wl]}, 预测: {classes[wp]}" for wl, wp in zip(wrong_labels, wrong_preds)]writer.add_text('错误预测标签', '\n'.join(wrong_text), epoch)# 更新学习率调度器scheduler.step(epoch_test_loss)print(f'Epoch {epoch+1}/{epochs} 完成 | 测试准确率: {epoch_test_acc:.2f}%')writer.close()return epoch_test_acc# (可选)CIFAR-10 类别名
classes = ('plane', 'car', 'bird', 'cat','deer', 'dog', 'frog', 'horse', 'ship', 'truck')# 执行训练
epochs = 20
print("开始使用CNN训练模型...")
print("训练后执行: tensorboard --logdir=runs 查看可视化")final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs, writer)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")TensorBoard 日志目录: runs/cifar10_cnn_exp_v2 开始使用CNN训练模型... 训练后执行: tensorboard --logdir=runs 查看可视化 Epoch 21: reducing learning rate of group 0 to 5.0000e-04. Epoch 1/20 完成 | 测试准确率: 75.81% Epoch 2/20 完成 | 测试准确率: 80.88% Epoch 3/20 完成 | 测试准确率: 80.36% Epoch 4/20 完成 | 测试准确率: 82.32% Epoch 5/20 完成 | 测试准确率: 80.98% Epoch 6/20 完成 | 测试准确率: 81.43% Epoch 7/20 完成 | 测试准确率: 81.86% Epoch 28: reducing learning rate of group 0 to 2.5000e-04. Epoch 8/20 完成 | 测试准确率: 81.89% Epoch 9/20 完成 | 测试准确率: 82.69% Epoch 10/20 完成 | 测试准确率: 83.66% Epoch 11/20 完成 | 测试准确率: 83.29% Epoch 12/20 完成 | 测试准确率: 82.99% Epoch 13/20 完成 | 测试准确率: 83.11% Epoch 34: reducing learning rate of group 0 to 1.2500e-04. Epoch 14/20 完成 | 测试准确率: 83.58% Epoch 15/20 完成 | 测试准确率: 83.79% Epoch 16/20 完成 | 测试准确率: 83.88% Epoch 17/20 完成 | 测试准确率: 83.89% Epoch 18/20 完成 | 测试准确率: 84.08% Epoch 19/20 完成 | 测试准确率: 84.25% Epoch 20/20 完成 | 测试准确率: 84.21% 训练完成!最终测试准确率: 84.21%
上述这段代码,由于我单独拎出来了,没有重新初始化cnn,如果二次运行就会创建一个新的目录,并且接着之前的运行
tensorboard的代码还有有一定的记忆量,实际上深度学习的经典代码都是类似于八股文,看多了就习惯了,难度远远小于考研数学等需要思考的内容
实际上对目前的ai而言,你只需要先完成最简单的demo,然后让他给你加上tensorboard需要打印的部分即可。---核心是弄懂tensorboard可以打印什么信息,以及如何看可视化后的结果,把ai当成记忆大师用到的时候通过它来调取对应的代码即可。浙大疏锦行
相关文章:
day45python打卡
知识点回顾: tensorboard的发展历史和原理tensorboard的常见操作tensorboard在cifar上的实战:MLP和CNN模型 效果展示如下,很适合拿去组会汇报撑页数: 作业:对resnet18在cifar10上采用微调策略下,用tensorbo…...
AIGC赋能前端开发
一、引言:AIGC对前端开发的影响 1. AIGC与前端开发的关系 从“写代码”到“生成代码”传统开发痛点:重复性编码工作、UI 设计稿还原、问题定位与调试...核心场景的AI化:需求转代码(P2C)、设计稿转代码(D2…...

Web 3D协作平台开发案例:构建制造业远程设计与可视化协作
HOOPS Communicator为开发者提供了丰富的定制化能力,助力他们在实现强大 Web 3D 可视化功能的同时,灵活构建符合特定业务需求的工程应用。对于希望构建在线协同设计工具的企业而言,如何在保障性能与用户体验的前提下实现高效开发,…...

AI Agent开发第78课-大模型结合Flink构建政务类长公文、长文件、OA应用Agent
开篇 AI Agent2025确定是进入了爆发期,到处都在冒出各种各样的实用AI Agent。很多人、组织都投身于开发AI Agent。 但是从3月份开始业界开始出现了一种这样的声音: AI开发入门并不难,一旦开发完后没法用! 经历过至少一个AI Agent从开发到上线的小伙伴们其实都听到过这种…...

极空间z4pro配置gitea mysql,内网穿透
极空间z4pro配置gitea mysql等记录,内网穿透 1、mysql、gitea镜像下载,极空间不成功,先用自己电脑科学后下载镜像,拉取代码: docker pull --platform linux/amd64 gitea/gitea:1.23 docker pull --platform linux/amd64 mysql:5.…...

第三方测试机构进行科技成果鉴定测试有什么价值
在当今科技创新的浪潮中,科技成果的鉴定测试至关重要,而第三方测试机构凭借其独特优势,在这一领域发挥着不可替代的作用。那么,第三方测试机构进行科技成果鉴定测试究竟有什么价值呢? 一、第三方测试机构能提供独立、公…...
华为云Flexus+DeepSeek征文|基于华为云Flexus X和DeepSeek-R1打造个人知识库问答系统
目录 前言 1 快速部署:一键搭建Dify平台 1.1 部署流程详解 1.2 初始配置与登录 2 构建专属知识库 2.1 进入知识库模块并创建新库 2.2 选择数据源导入内容 2.3 上传并识别多种文档格式 2.4 文本处理与索引构建 2.5 保存并完成知识库创建 3接入ModelArts S…...

【数据结构】_排序
【本节目标】 排序的概念及其运用常见排序算法的实现排序算法复杂度及稳定性分析 1.排序的概念及其运用 1.1排序的概念 排序:所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作。 1.2特性…...

《前端面试题:JS数据类型》
JavaScript 数据类型指南:从基础到高级全解析 一、JavaScript 数据类型概述 JavaScript 作为一门动态类型语言,其数据类型系统是理解这门语言的核心基础。在 ECMAScript 标准中,数据类型分为两大类: 1. 原始类型(Pr…...
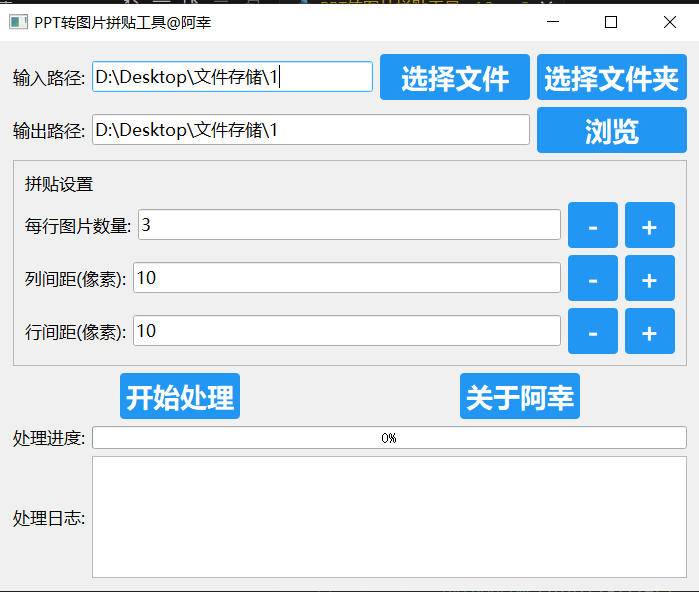
PPT转图片拼贴工具 v4.3
软件介绍 这个软件就是将PPT文件转换为图片并且拼接起来。 效果展示 支持导入文件和支持导入文件夹,也支持手动输入文件/文件夹路径 软件界面 这一次提供了源码和开箱即用版本,exe就是直接用就可以了。 软件源码 import os import re import sys …...
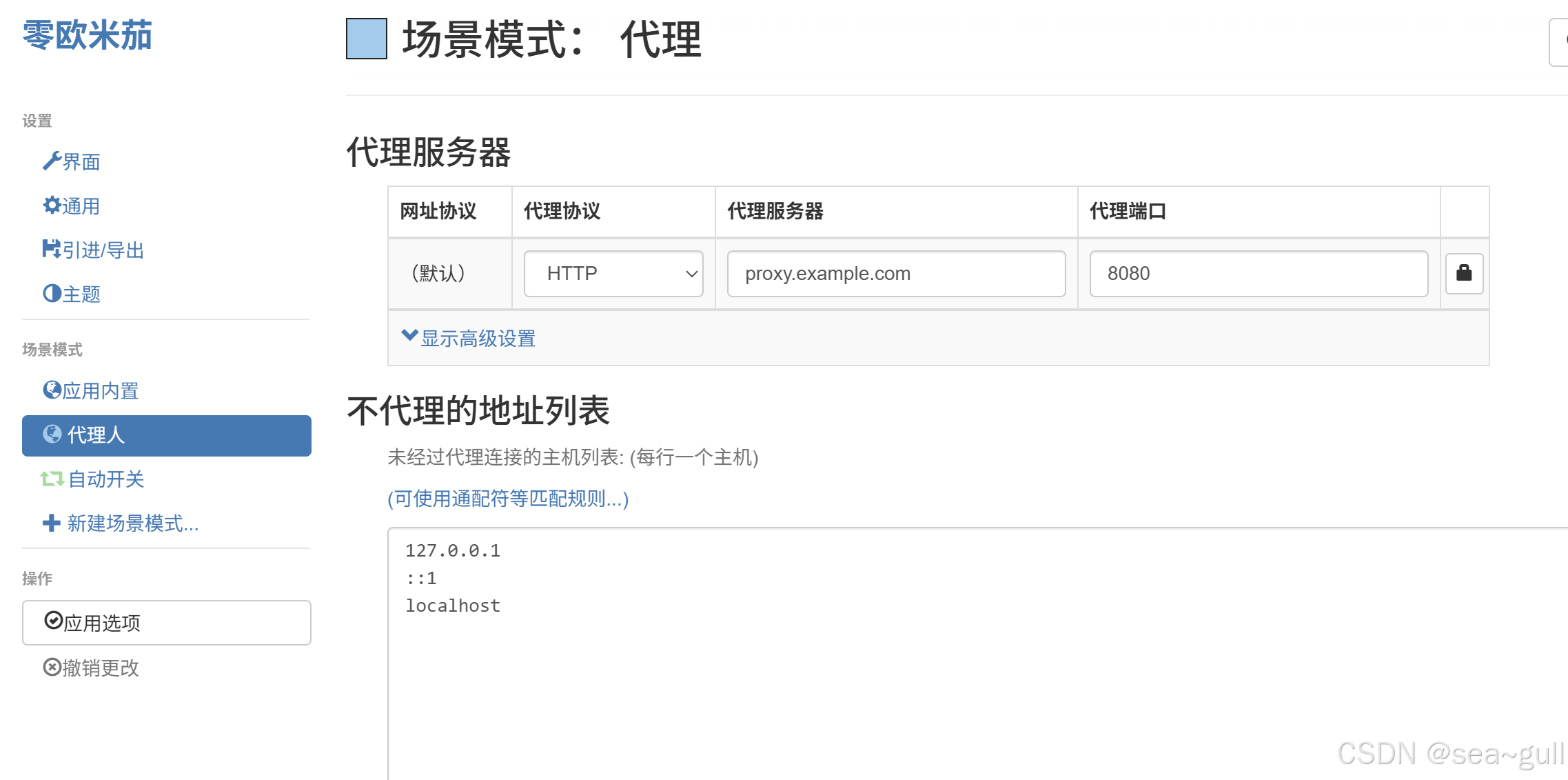
Chrome安装代理插件ZeroOmega(保姆级别)
目录 本文直接讲解一下怎么本地安装ZeroOmega一、下载文件在GitHub直接下ZeroOmega 的文件(下最新版即可) 二、安装插件打开 Chrome 浏览器,访问 chrome://extensions/ 页面(扩展程序管理页面),并打开开发者…...
Transformer-BiGRU多变量时序预测(Matlab完整源码和数据)
Transformer-BiGRU多变量时序预测(Matlab完整源码和数据) 目录 Transformer-BiGRU多变量时序预测(Matlab完整源码和数据)效果一览基本介绍程序设计参考资料 效果一览 基本介绍 1.Matlab实现Transformer-BiGRU多变量时间序列预测&…...

新华三H3CNE网络工程师认证—Easy IP
Easy IP 就是“用路由器自己的公网IP,给全家所有设备当共享门牌号”的技术!(省掉额外公网IP,省钱又省配置!) 生活场景对比,想象你住在一个小区:普通动态NAT:物业申请了 …...

《视觉SLAM十四讲》自用笔记 第二讲:SLAM系统概述
在rm队伍里作为算法组梯队队员度过了一个赛季,为了促进和负责其他工作的算法组成员的交流,我决定在接下来的半个学期里(可能更快)读完这本书,并将其中的部分理论应用于我自制的雷达导航小车上。 以下为第二讲的部分笔记…...

vscode 插件 eslint, 检查 js 语法
1. 起因, 目的: 我的需求 vscode 写js代码, 有什么插件能进行语法检查。 比如某个函数没有定义,getName(), 但是却调用了。 那么这个插件会给出警告,在 getName() 给出红色波浪线。类似这种效果的插件, 有吗…...
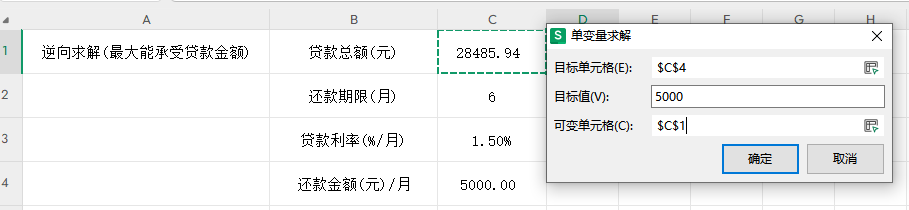
Excel 模拟分析之单变量求解简单应用
正向求解 利用公式根据贷款总额、还款期限、贷款利率,求每月还款金额 反向求解 根据每月还款能力,求最大能承受贷款金额 参数: 目标单元格:求的值所在的单元格 目标值:想要达到的预期值 可变单元格:变…...

装备制造项目管理具备什么特征?如何选择适配的项目管理软件系统进行项目管控?
国内某大型半导体装备制造企业与奥博思软件达成战略合作,全面引入奥博思 PowerProject 打造企业专属项目管理平台,进一步提升智能制造领域的项目管理效率与协同能力。 该项目管理平台聚焦半导体装备研发与制造的业务特性,实现了从项目立项、…...
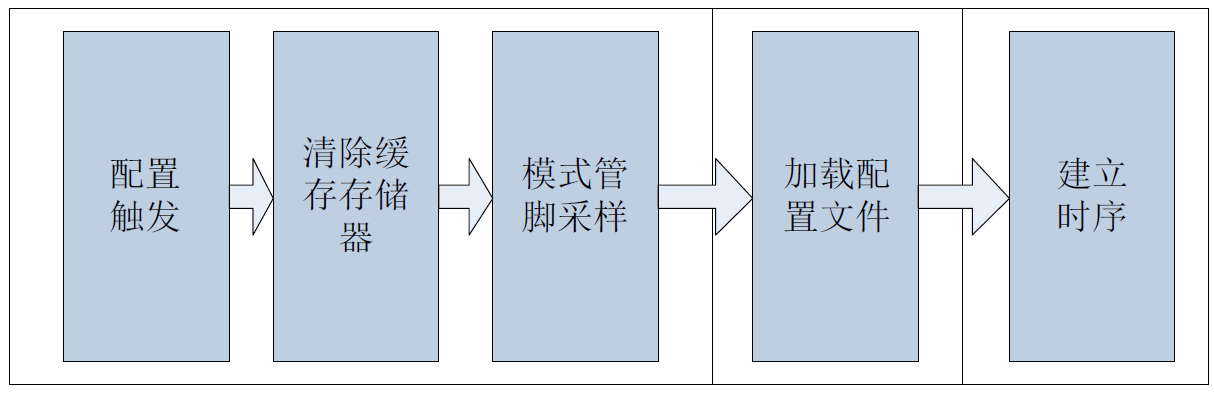
FPGA 动态重构配置流程
触发FPGA 进行配置的方式有两种,一种是断电后上电,另一种是在FPGA运行过程中,将PROGRAM 管脚拉低。将PROGRAM 管脚拉低500ns 以上就可以触发FPGA 进行重构。 FPGA 的配置过程大致可以分为:配置的触发和建立阶段、加载配置文件和建…...
介绍)
Elasticsearch的审计日志(Audit Logging)介绍
Elasticsearch 的审计日志(Audit Logging)是一种记录与安全相关事件的功能,用于监控和追踪对集群的访问行为。通过审计日志,管理员可以了解谁在何时对哪些资源执行了什么操作,从而满足合规性要求、进行安全分析和排查异常行为。 一、审计日志的核心功能 记录安全事件捕获…...

软件测试:质量保障的基石与未来趋势
软件测试作为软件开发生命周期中的关键环节,不仅是发现和修复缺陷的手段,更是确保产品质量、提升用户体验和降低开发成本的重要保障。在当今快速迭代的互联网时代,测试已从单纯的验证活动演变为贯穿整个开发过程的质量管理体系。本文将系统阐…...

网络安全逆向分析之rust逆向技巧
rust逆向技巧 rust逆向三板斧: 快速定位关键函数 (真正的main函数):观察输出、输入,字符串搜索,断点等方法。定位关键 加密区 :根据输入的flag,打硬件断点,快速捕获程序中对flag访问的位置&am…...

Docker容器化技术概述与实践
哈喽,大家好,我是左手python! Docker 容器化的基本概念 Docker 容器化是一种轻量级的虚拟化技术,通过将应用程序及其依赖项打包到一个可移植的容器中,使其在任何兼容 Docker 的环境中都能运行。与传统的虚拟机技术不同…...

win中将pdf转为图片
0 资料 博客 1 正文 直接使用这个软件即可https://sourceforge.net/projects/pkpdfconverter/...
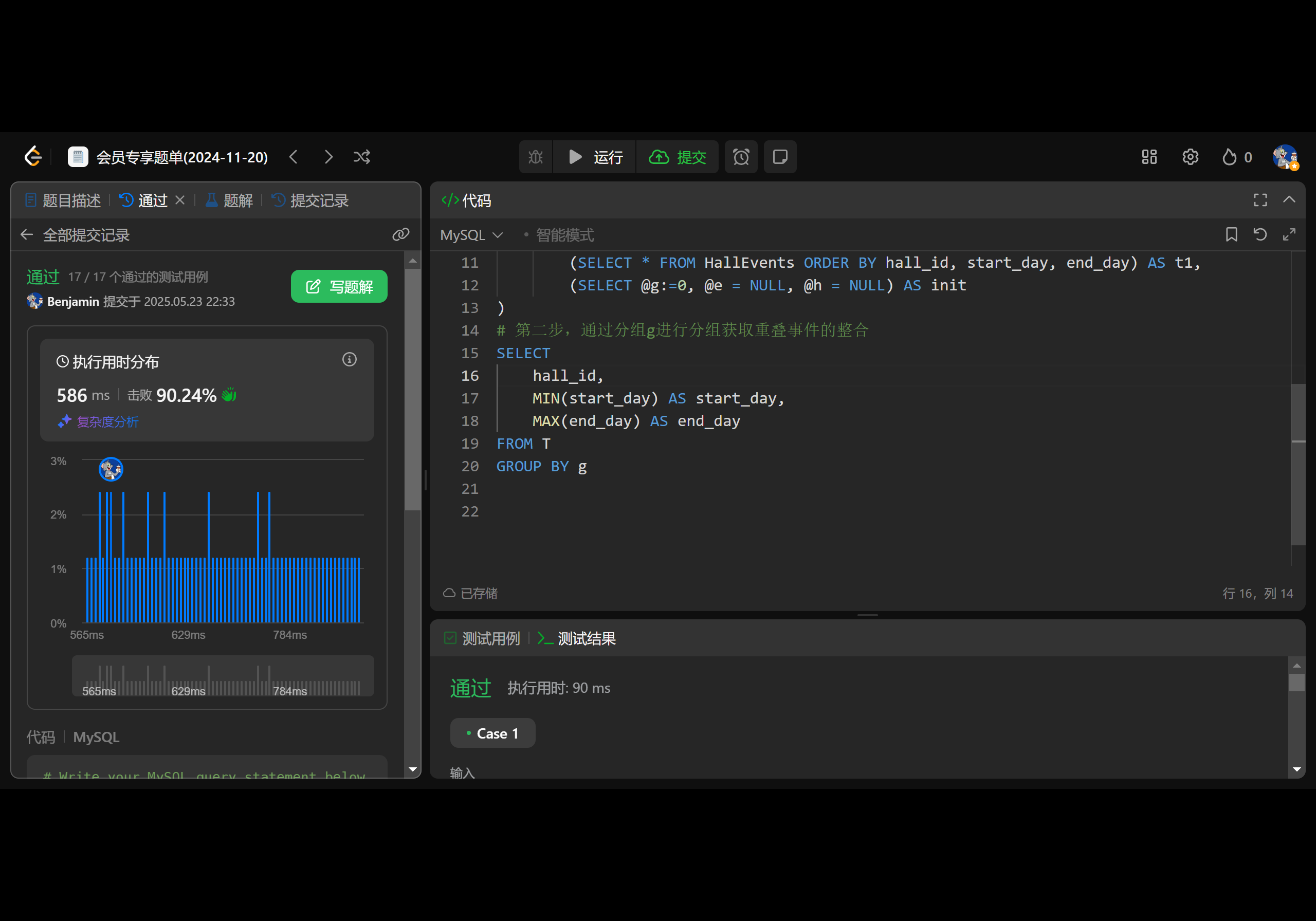
Leetcode 2494. 合并在同一个大厅重叠的活动
1.题目基本信息 1.1.题目描述 表: HallEvents ----------------- | Column Name | Type | ----------------- | hall_id | int | | start_day | date | | end_day | date | ----------------- 该表可能包含重复字段。 该表的每一行表示活动的开始日期和结束日期&…...
vue+elementui 网站首页顶部菜单上下布局
菜单集合后台接口动态获取,保存到store vuex状态管理器 <template><div id"app"><el-menu:default-active"activeIndex2"class"el-menu-demo"mode"horizontal"select"handleSelect"background-…...
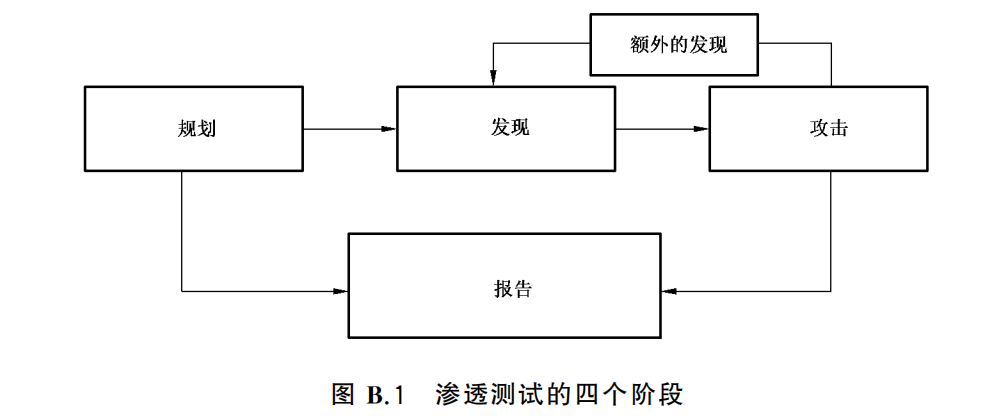
网络安全-等级保护(等保) 3-3-1 GB/T 36627-2018 附录A (资料性附录) 测评后活动、附 录 B (资料性附录)渗透测试的有关概念说明
################################################################################ GB/T 36627-2018 《信息安全技术 网络安全等级保护测试评估技术指南》对网络安全等级保护测评中的相关测评技术进行明确的分类和定义,系统地归纳并阐述测评的技术方法,概述技术性安全测试和…...

pytorch3d+pytorch1.10+MinkowskiEngine安装
1、配置pytorch1.10cuda11.0 pip install torch1.10.1cu111 torchvision0.11.2cu111 torchaudio0.10.1 -f https://download.pytorch.org/whl/cu111/torch_stable.html 2、配置 MinkowskiEngine库 不按下面步骤,出现错误 1、下载MinkowskiEngine0.5.4到本地 2、查看…...
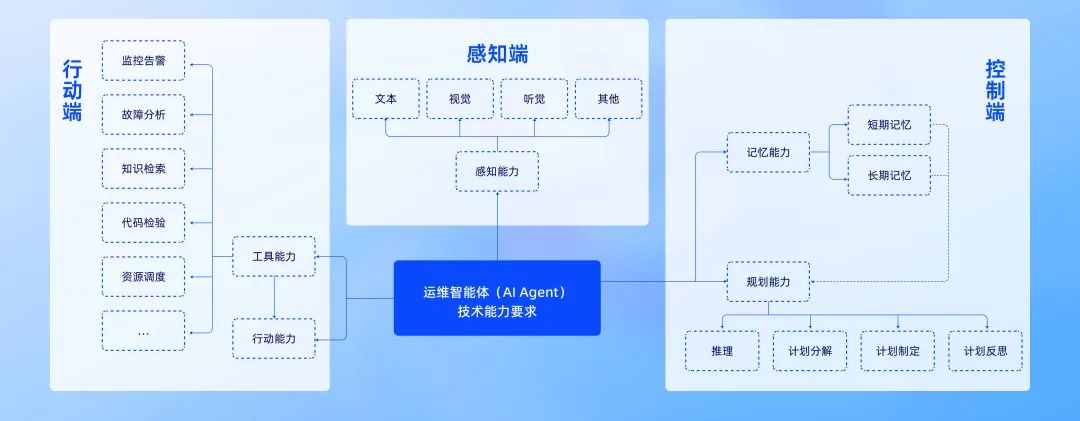
AI Infra运维实践:DeepSeek部署运维中的软硬结合
发布会资料 《AI Infra运维实践:DeepSeek部署运维中的软硬结合》 袋鼠云运维服务 1、行业痛点 随着数字化转型的深入,企业面临的运维挑战日益复杂,所依托的平台在长期使用的过程中积累了各式各样的问题或者难点。这些问题不仅影响效率&…...

MySQL体系架构解析(二):MySQL目录与启动配置全解析
MySQL中的目录和文件 bin目录 在 MySQL 的安装目录下有一个特别重要的 bin 目录,这个目录下存放着许多可执行文件。与其他系统的可执行文件类似,这些可执行文件都是与服务器和客户端程序相关的。 启动MySQL服务器程序 在 UNIX 系统中,用…...

深度学习在RNA分子动力学中的特征提取与应用指南
深度学习在RNA分子动力学中的特征提取与应用指南 引言:RNA结构动力学与AI的融合 RNA作为生命活动的核心分子,其动态构象变化直接影响基因调控、蛋白合成等关键生物过程。分子动力学(Molecular Dynamics, MD)模拟通过求解牛顿运动方程,可获取RNA原子级运动轨迹(时间尺度…...