Python训练营打卡Day46(2025.6.6)
知识点回顾:
- 不同CNN层的特征图:不同通道的特征图
- 什么是注意力:注意力家族,类似于动物园,都是不同的模块,好不好试了才知道。
- 通道注意力:模型的定义和插入的位置
- 通道注意力后的特征图和热力图
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 1. 数据预处理
# 训练集:使用多种数据增强方法提高模型泛化能力
train_transform = transforms.Compose([# 随机裁剪图像,从原图中随机截取32x32大小的区域transforms.RandomCrop(32, padding=4),# 随机水平翻转图像(概率0.5)transforms.RandomHorizontalFlip(),# 随机颜色抖动:亮度、对比度、饱和度和色调随机变化transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),# 随机旋转图像(最大角度15度)transforms.RandomRotation(15),# 将PIL图像或numpy数组转换为张量transforms.ToTensor(),# 标准化处理:每个通道的均值和标准差,使数据分布更合理transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])# 测试集:仅进行必要的标准化,保持数据原始特性,标准化不损失数据信息,可还原
test_transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(root='./data',train=True,download=True,transform=train_transform # 使用增强后的预处理
)test_dataset = datasets.CIFAR10(root='./data',train=False,transform=test_transform # 测试集不使用增强
)# 3. 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# 4. 定义CNN模型的定义(替代原MLP)
class CNN(nn.Module):def __init__(self):super(CNN, self).__init__() # 继承父类初始化# ---------------------- 第一个卷积块 ----------------------# 卷积层1:输入3通道(RGB),输出32个特征图,卷积核3x3,边缘填充1像素self.conv1 = nn.Conv2d(in_channels=3, # 输入通道数(图像的RGB通道)out_channels=32, # 输出通道数(生成32个新特征图)kernel_size=3, # 卷积核尺寸(3x3像素)padding=1 # 边缘填充1像素,保持输出尺寸与输入相同)# 批量归一化层:对32个输出通道进行归一化,加速训练self.bn1 = nn.BatchNorm2d(num_features=32)# ReLU激活函数:引入非线性,公式:max(0, x)self.relu1 = nn.ReLU()# 最大池化层:窗口2x2,步长2,特征图尺寸减半(32x32→16x16)self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2) # stride默认等于kernel_size# ---------------------- 第二个卷积块 ----------------------# 卷积层2:输入32通道(来自conv1的输出),输出64通道self.conv2 = nn.Conv2d(in_channels=32, # 输入通道数(前一层的输出通道数)out_channels=64, # 输出通道数(特征图数量翻倍)kernel_size=3, # 卷积核尺寸不变padding=1 # 保持尺寸:16x16→16x16(卷积后)→8x8(池化后))self.bn2 = nn.BatchNorm2d(num_features=64)self.relu2 = nn.ReLU()self.pool2 = nn.MaxPool2d(kernel_size=2) # 尺寸减半:16x16→8x8# ---------------------- 第三个卷积块 ----------------------# 卷积层3:输入64通道,输出128通道self.conv3 = nn.Conv2d(in_channels=64, # 输入通道数(前一层的输出通道数)out_channels=128, # 输出通道数(特征图数量再次翻倍)kernel_size=3,padding=1 # 保持尺寸:8x8→8x8(卷积后)→4x4(池化后))self.bn3 = nn.BatchNorm2d(num_features=128)self.relu3 = nn.ReLU() # 复用激活函数对象(节省内存)self.pool3 = nn.MaxPool2d(kernel_size=2) # 尺寸减半:8x8→4x4# ---------------------- 全连接层(分类器) ----------------------# 计算展平后的特征维度:128通道 × 4x4尺寸 = 128×16=2048维self.fc1 = nn.Linear(in_features=128 * 4 * 4, # 输入维度(卷积层输出的特征数)out_features=512 # 输出维度(隐藏层神经元数))# Dropout层:训练时随机丢弃50%神经元,防止过拟合self.dropout = nn.Dropout(p=0.5)# 输出层:将512维特征映射到10个类别(CIFAR-10的类别数)self.fc2 = nn.Linear(in_features=512, out_features=10)def forward(self, x):# 输入尺寸:[batch_size, 3, 32, 32](batch_size=批量大小,3=通道数,32x32=图像尺寸)# ---------- 卷积块1处理 ----------x = self.conv1(x) # 卷积后尺寸:[batch_size, 32, 32, 32](padding=1保持尺寸)x = self.bn1(x) # 批量归一化,不改变尺寸x = self.relu1(x) # 激活函数,不改变尺寸x = self.pool1(x) # 池化后尺寸:[batch_size, 32, 16, 16](32→16是因为池化窗口2x2)# ---------- 卷积块2处理 ----------x = self.conv2(x) # 卷积后尺寸:[batch_size, 64, 16, 16](padding=1保持尺寸)x = self.bn2(x)x = self.relu2(x)x = self.pool2(x) # 池化后尺寸:[batch_size, 64, 8, 8]# ---------- 卷积块3处理 ----------x = self.conv3(x) # 卷积后尺寸:[batch_size, 128, 8, 8](padding=1保持尺寸)x = self.bn3(x)x = self.relu3(x)x = self.pool3(x) # 池化后尺寸:[batch_size, 128, 4, 4]# ---------- 展平与全连接层 ----------# 将多维特征图展平为一维向量:[batch_size, 128*4*4] = [batch_size, 2048]x = x.view(-1, 128 * 4 * 4) # -1自动计算批量维度,保持批量大小不变x = self.fc1(x) # 全连接层:2048→512,尺寸变为[batch_size, 512]x = self.relu3(x) # 激活函数(复用relu3,与卷积块3共用)x = self.dropout(x) # Dropout随机丢弃神经元,不改变尺寸x = self.fc2(x) # 全连接层:512→10,尺寸变为[batch_size, 10](未激活,直接输出logits)return x # 输出未经过Softmax的logits,适用于交叉熵损失函数# 初始化模型
model = CNN()
model = model.to(device) # 将模型移至GPU(如果可用)criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器# 引入学习率调度器,在训练过程中动态调整学习率--训练初期使用较大的 LR 快速降低损失,训练后期使用较小的 LR 更精细地逼近全局最优解。
# 在每个 epoch 结束后,需要手动调用调度器来更新学习率,可以在训练过程中调用 scheduler.step()
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, # 指定要控制的优化器(这里是Adam)mode='min', # 监测的指标是"最小化"(如损失函数)patience=3, # 如果连续3个epoch指标没有改善,才降低LRfactor=0.5 # 降低LR的比例(新LR = 旧LR × 0.5)
)
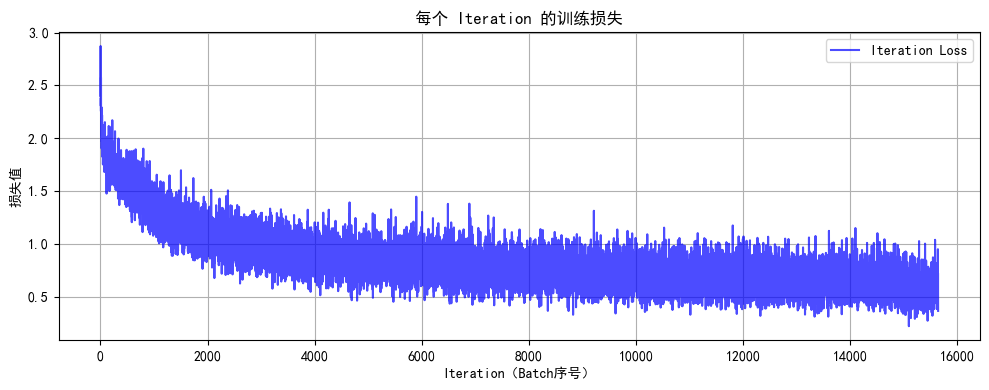
# 5. 训练模型(记录每个 iteration 的损失)
def train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs):model.train() # 设置为训练模式# 记录每个 iteration 的损失all_iter_losses = [] # 存储所有 batch 的损失iter_indices = [] # 存储 iteration 序号# 记录每个 epoch 的准确率和损失train_acc_history = []test_acc_history = []train_loss_history = []test_loss_history = []for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device) # 移至GPUoptimizer.zero_grad() # 梯度清零output = model(data) # 前向传播loss = criterion(output, target) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数# 记录当前 iteration 的损失iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1)# 统计准确率和损失running_loss += iter_loss_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()# 每100个批次打印一次训练信息if (batch_idx + 1) % 100 == 0:print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')# 计算当前epoch的平均训练损失和准确率epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / totaltrain_acc_history.append(epoch_train_acc)train_loss_history.append(epoch_train_loss)# 测试阶段model.eval() # 设置为评估模式test_loss = 0correct_test = 0total_test = 0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_testtest_acc_history.append(epoch_test_acc)test_loss_history.append(epoch_test_loss)# 更新学习率调度器scheduler.step(epoch_test_loss)print(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# 绘制所有 iteration 的损失曲线plot_iter_losses(all_iter_losses, iter_indices)# 绘制每个 epoch 的准确率和损失曲线plot_epoch_metrics(train_acc_history, test_acc_history, train_loss_history, test_loss_history)return epoch_test_acc # 返回最终测试准确率# 6. 绘制每个 iteration 的损失曲线
def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')plt.xlabel('Iteration(Batch序号)')plt.ylabel('损失值')plt.title('每个 Iteration 的训练损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# 7. 绘制每个 epoch 的准确率和损失曲线
def plot_epoch_metrics(train_acc, test_acc, train_loss, test_loss):epochs = range(1, len(train_acc) + 1)plt.figure(figsize=(12, 4))# 绘制准确率曲线plt.subplot(1, 2, 1)plt.plot(epochs, train_acc, 'b-', label='训练准确率')plt.plot(epochs, test_acc, 'r-', label='测试准确率')plt.xlabel('Epoch')plt.ylabel('准确率 (%)')plt.title('训练和测试准确率')plt.legend()plt.grid(True)# 绘制损失曲线plt.subplot(1, 2, 2)plt.plot(epochs, train_loss, 'b-', label='训练损失')plt.plot(epochs, test_loss, 'r-', label='测试损失')plt.xlabel('Epoch')plt.ylabel('损失值')plt.title('训练和测试损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# 8. 执行训练和测试
epochs = 50 # 增加训练轮次为了确保收敛
print("开始使用CNN训练模型...")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")# # 保存模型
# torch.save(model.state_dict(), 'cifar10_cnn_model.pth')
# print("模型已保存为: cifar10_cnn_model.pth")def visualize_feature_maps(model, test_loader, device, layer_names, num_images=3, num_channels=9):"""可视化指定层的特征图(修复循环冗余问题)参数:model: 模型test_loader: 测试数据加载器layer_names: 要可视化的层名称(如['conv1', 'conv2', 'conv3'])num_images: 可视化的图像总数num_channels: 每个图像显示的通道数(取前num_channels个通道)"""model.eval() # 设置为评估模式class_names = ['飞机', '汽车', '鸟', '猫', '鹿', '狗', '青蛙', '马', '船', '卡车']# 从测试集加载器中提取指定数量的图像(避免嵌套循环)images_list, labels_list = [], []for images, labels in test_loader:images_list.append(images)labels_list.append(labels)if len(images_list) * test_loader.batch_size >= num_images:break# 拼接并截取到目标数量images = torch.cat(images_list, dim=0)[:num_images].to(device)labels = torch.cat(labels_list, dim=0)[:num_images].to(device)with torch.no_grad():# 存储各层特征图feature_maps = {}# 保存钩子句柄hooks = []# 定义钩子函数,捕获指定层的输出def hook(module, input, output, name):feature_maps[name] = output.cpu() # 保存特征图到字典# 为每个目标层注册钩子,并保存钩子句柄for name in layer_names:module = getattr(model, name)hook_handle = module.register_forward_hook(lambda m, i, o, n=name: hook(m, i, o, n))hooks.append(hook_handle)# 前向传播触发钩子_ = model(images)# 正确移除钩子for hook_handle in hooks:hook_handle.remove()# 可视化每个图像的各层特征图(仅一层循环)for img_idx in range(num_images):img = images[img_idx].cpu().permute(1, 2, 0).numpy()# 反标准化处理(恢复原始像素值)img = img * np.array([0.2023, 0.1994, 0.2010]).reshape(1, 1, 3) + np.array([0.4914, 0.4822, 0.4465]).reshape(1, 1, 3)img = np.clip(img, 0, 1) # 确保像素值在[0,1]范围内# 创建子图num_layers = len(layer_names)fig, axes = plt.subplots(1, num_layers + 1, figsize=(4 * (num_layers + 1), 4))# 显示原始图像axes[0].imshow(img)axes[0].set_title(f'原始图像\n类别: {class_names[labels[img_idx]]}')axes[0].axis('off')# 显示各层特征图for layer_idx, layer_name in enumerate(layer_names):fm = feature_maps[layer_name][img_idx] # 取第img_idx张图像的特征图fm = fm[:num_channels] # 仅取前num_channels个通道num_rows = int(np.sqrt(num_channels))num_cols = num_channels // num_rows if num_rows != 0 else 1# 创建子图网格layer_ax = axes[layer_idx + 1]layer_ax.set_title(f'{layer_name}特征图 \n')# 加个换行让文字分离上去layer_ax.axis('off') # 关闭大子图的坐标轴# 在大子图内创建小网格for ch_idx, channel in enumerate(fm):ax = layer_ax.inset_axes([ch_idx % num_cols / num_cols, (num_rows - 1 - ch_idx // num_cols) / num_rows, 1/num_cols, 1/num_rows])ax.imshow(channel.numpy(), cmap='viridis')ax.set_title(f'通道 {ch_idx + 1}')ax.axis('off')plt.tight_layout()plt.show()# 调用示例(按需修改参数)
layer_names = ['conv1', 'conv2', 'conv3']
visualize_feature_maps(model=model,test_loader=test_loader,device=device,layer_names=layer_names,num_images=5, # 可视化5张测试图像 → 输出5张大图num_channels=9 # 每张图像显示前9个通道的特征图
)# ===================== 新增:通道注意力模块(SE模块) =====================
class ChannelAttention(nn.Module):"""通道注意力模块(Squeeze-and-Excitation)"""def __init__(self, in_channels, reduction_ratio=16):"""参数:in_channels: 输入特征图的通道数reduction_ratio: 降维比例,用于减少参数量"""super(ChannelAttention, self).__init__()# 全局平均池化 - 将空间维度压缩为1x1,保留通道信息self.avg_pool = nn.AdaptiveAvgPool2d(1)# 全连接层 + 激活函数,用于学习通道间的依赖关系self.fc = nn.Sequential(# 降维:压缩通道数,减少计算量nn.Linear(in_channels, in_channels // reduction_ratio, bias=False),nn.ReLU(inplace=True),# 升维:恢复原始通道数nn.Linear(in_channels // reduction_ratio, in_channels, bias=False),# Sigmoid将输出值归一化到[0,1],表示通道重要性权重nn.Sigmoid())def forward(self, x):"""参数:x: 输入特征图,形状为 [batch_size, channels, height, width]返回:加权后的特征图,形状不变"""batch_size, channels, height, width = x.size()# 1. 全局平均池化:[batch_size, channels, height, width] → [batch_size, channels, 1, 1]avg_pool_output = self.avg_pool(x)# 2. 展平为一维向量:[batch_size, channels, 1, 1] → [batch_size, channels]avg_pool_output = avg_pool_output.view(batch_size, channels)# 3. 通过全连接层学习通道权重:[batch_size, channels] → [batch_size, channels]channel_weights = self.fc(avg_pool_output)# 4. 重塑为二维张量:[batch_size, channels] → [batch_size, channels, 1, 1]channel_weights = channel_weights.view(batch_size, channels, 1, 1)# 5. 将权重应用到原始特征图上(逐通道相乘)return x * channel_weights # 输出形状:[batch_size, channels, height, width]class CNN(nn.Module):def __init__(self):super(CNN, self).__init__() # ---------------------- 第一个卷积块 ----------------------self.conv1 = nn.Conv2d(3, 32, 3, padding=1)self.bn1 = nn.BatchNorm2d(32)self.relu1 = nn.ReLU()# 新增:插入通道注意力模块(SE模块)self.ca1 = ChannelAttention(in_channels=32, reduction_ratio=16) self.pool1 = nn.MaxPool2d(2, 2) # ---------------------- 第二个卷积块 ----------------------self.conv2 = nn.Conv2d(32, 64, 3, padding=1)self.bn2 = nn.BatchNorm2d(64)self.relu2 = nn.ReLU()# 新增:插入通道注意力模块(SE模块)self.ca2 = ChannelAttention(in_channels=64, reduction_ratio=16) self.pool2 = nn.MaxPool2d(2) # ---------------------- 第三个卷积块 ----------------------self.conv3 = nn.Conv2d(64, 128, 3, padding=1)self.bn3 = nn.BatchNorm2d(128)self.relu3 = nn.ReLU()# 新增:插入通道注意力模块(SE模块)self.ca3 = ChannelAttention(in_channels=128, reduction_ratio=16) self.pool3 = nn.MaxPool2d(2) # ---------------------- 全连接层(分类器) ----------------------self.fc1 = nn.Linear(128 * 4 * 4, 512)self.dropout = nn.Dropout(p=0.5)self.fc2 = nn.Linear(512, 10)def forward(self, x):# ---------- 卷积块1处理 ----------x = self.conv1(x) x = self.bn1(x) x = self.relu1(x) x = self.ca1(x) # 应用通道注意力x = self.pool1(x) # ---------- 卷积块2处理 ----------x = self.conv2(x) x = self.bn2(x) x = self.relu2(x) x = self.ca2(x) # 应用通道注意力x = self.pool2(x) # ---------- 卷积块3处理 ----------x = self.conv3(x) x = self.bn3(x) x = self.relu3(x) x = self.ca3(x) # 应用通道注意力x = self.pool3(x) # ---------- 展平与全连接层 ----------x = x.view(-1, 128 * 4 * 4) x = self.fc1(x) x = self.relu3(x) x = self.dropout(x) x = self.fc2(x) return x # 重新初始化模型,包含通道注意力模块
model = CNN()
model = model.to(device) # 将模型移至GPU(如果可用)criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器# 引入学习率调度器,在训练过程中动态调整学习率--训练初期使用较大的 LR 快速降低损失,训练后期使用较小的 LR 更精细地逼近全局最优解。
# 在每个 epoch 结束后,需要手动调用调度器来更新学习率,可以在训练过程中调用 scheduler.step()
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, # 指定要控制的优化器(这里是Adam)mode='min', # 监测的指标是"最小化"(如损失函数)patience=3, # 如果连续3个epoch指标没有改善,才降低LRfactor=0.5 # 降低LR的比例(新LR = 旧LR × 0.5)
)# 训练模型(复用原有的train函数)
print("开始训练带通道注意力的CNN模型...")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs=50)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")# 可视化空间注意力热力图(显示模型关注的图像区域)
def visualize_attention_map(model, test_loader, device, class_names, num_samples=3):"""可视化模型的注意力热力图,展示模型关注的图像区域"""model.eval() # 设置为评估模式with torch.no_grad():for i, (images, labels) in enumerate(test_loader):if i >= num_samples: # 只可视化前几个样本breakimages, labels = images.to(device), labels.to(device)# 创建一个钩子,捕获中间特征图activation_maps = []def hook(module, input, output):activation_maps.append(output.cpu())# 为最后一个卷积层注册钩子(获取特征图)hook_handle = model.conv3.register_forward_hook(hook)# 前向传播,触发钩子outputs = model(images)# 移除钩子hook_handle.remove()# 获取预测结果_, predicted = torch.max(outputs, 1)# 获取原始图像img = images[0].cpu().permute(1, 2, 0).numpy()# 反标准化处理img = img * np.array([0.2023, 0.1994, 0.2010]).reshape(1, 1, 3) + np.array([0.4914, 0.4822, 0.4465]).reshape(1, 1, 3)img = np.clip(img, 0, 1)# 获取激活图(最后一个卷积层的输出)feature_map = activation_maps[0][0].cpu() # 取第一个样本# 计算通道注意力权重(使用SE模块的全局平均池化)channel_weights = torch.mean(feature_map, dim=(1, 2)) # [C]# 按权重对通道排序sorted_indices = torch.argsort(channel_weights, descending=True)# 创建子图fig, axes = plt.subplots(1, 4, figsize=(16, 4))# 显示原始图像axes[0].imshow(img)axes[0].set_title(f'原始图像\n真实: {class_names[labels[0]]}\n预测: {class_names[predicted[0]]}')axes[0].axis('off')# 显示前3个最活跃通道的热力图for j in range(3):channel_idx = sorted_indices[j]# 获取对应通道的特征图channel_map = feature_map[channel_idx].numpy()# 归一化到[0,1]channel_map = (channel_map - channel_map.min()) / (channel_map.max() - channel_map.min() + 1e-8)# 调整热力图大小以匹配原始图像from scipy.ndimage import zoomheatmap = zoom(channel_map, (32/feature_map.shape[1], 32/feature_map.shape[2]))# 显示热力图axes[j+1].imshow(img)axes[j+1].imshow(heatmap, alpha=0.5, cmap='jet')axes[j+1].set_title(f'注意力热力图 - 通道 {channel_idx}')axes[j+1].axis('off')plt.tight_layout()plt.show()# 调用可视化函数
visualize_attention_map(model, test_loader, device, class_names, num_samples=3)@浙大疏锦行
相关文章:
)
Python训练营打卡Day46(2025.6.6)
知识点回顾: 不同CNN层的特征图:不同通道的特征图什么是注意力:注意力家族,类似于动物园,都是不同的模块,好不好试了才知道。通道注意力:模型的定义和插入的位置通道注意力后的特征图和热力图 i…...

C# Wkhtmltopdf HTML转PDF碰到的问题
最近碰到一个Html转PDF的需求,看了一下基本上都是需要依赖Wkhtmltopdf,需要在Windows或者linux安装这个可以后使用。找了一下选择了HtmlToPDFCore,这个库是对Wkhtmltopdf.NetCore简单二次封装,这个库的好处就是通过NuGet安装HtmlT…...
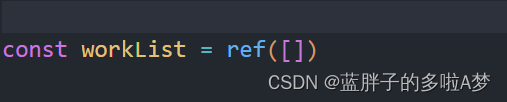
Vue3 (数组push数据报错) 解决Cannot read property ‘push‘ of null报错问题
解决Cannot read property ‘push‘ of null报错问题 错误写法 定义变量 <script setup>const workList ref([{name:,value:}])</script>正确定义变量 <script setup>const workList ref([]) </script>解决咯~...

Lifecycle 核心原理面试回答
1. 核心目标与设计思想 解耦生命周期管理: 将 Activity/Fragment 的生命周期回调逻辑从视图控制器中剥离,让业务组件(如 Presenter, Repository 封装)能独立感知生命周期。 状态驱动: 将离散的生命周期事件 (ON_CREAT…...

PHP:Web 开发的强大基石与未来展望
在当今数字化时代,Web 开发技术日新月异,各种编程语言和框架层出不穷。然而,PHP 作为一种历史悠久且广泛应用的服务器端脚本语言,依然在 Web 开发领域占据着重要地位。 PHP 的历史与现状 PHP(Hypertext Preprocessor…...
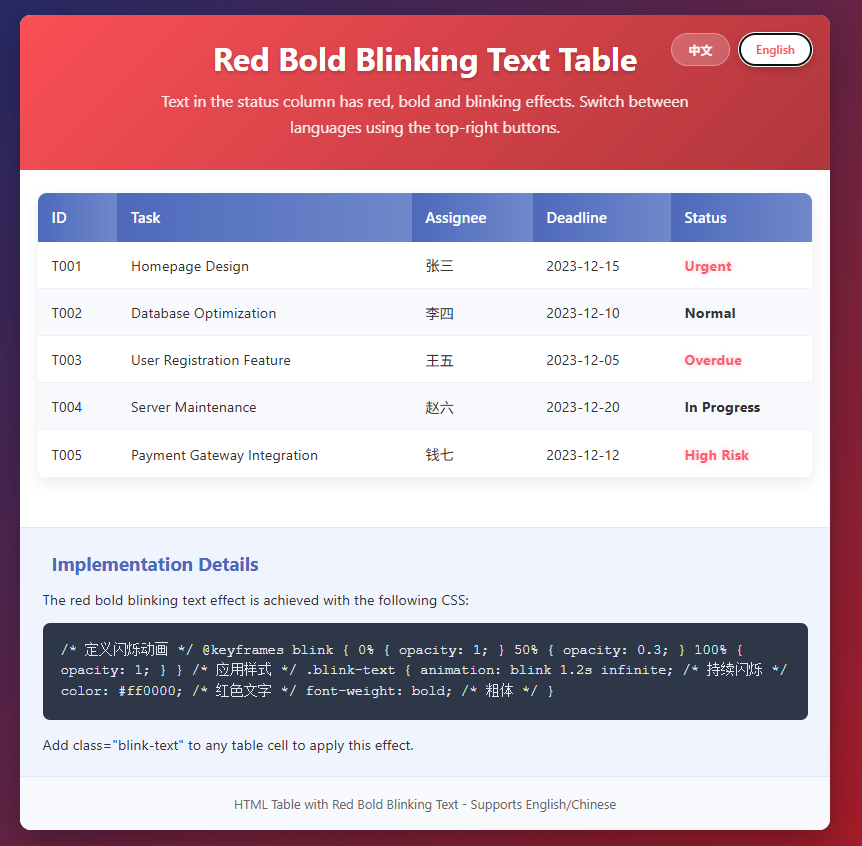
html文字红色粗体,闪烁渐变动画效果,中英文切换版本
1. 代码 <!DOCTYPE html> <html lang"zh"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>红色粗体闪烁文字表格 - 中英文切换</t…...

六、【ESP32开发全栈指南:深入解析ESP32 IDF中的WiFi AP模式开发】
1. 引言:AP模式的核心价值 ESP32的AP(Access Point)模式使设备成为独立无线热点,适用于: 设备配网(SmartConfig)无路由器场景的本地组网数据直采终端(传感器集中器)临时…...
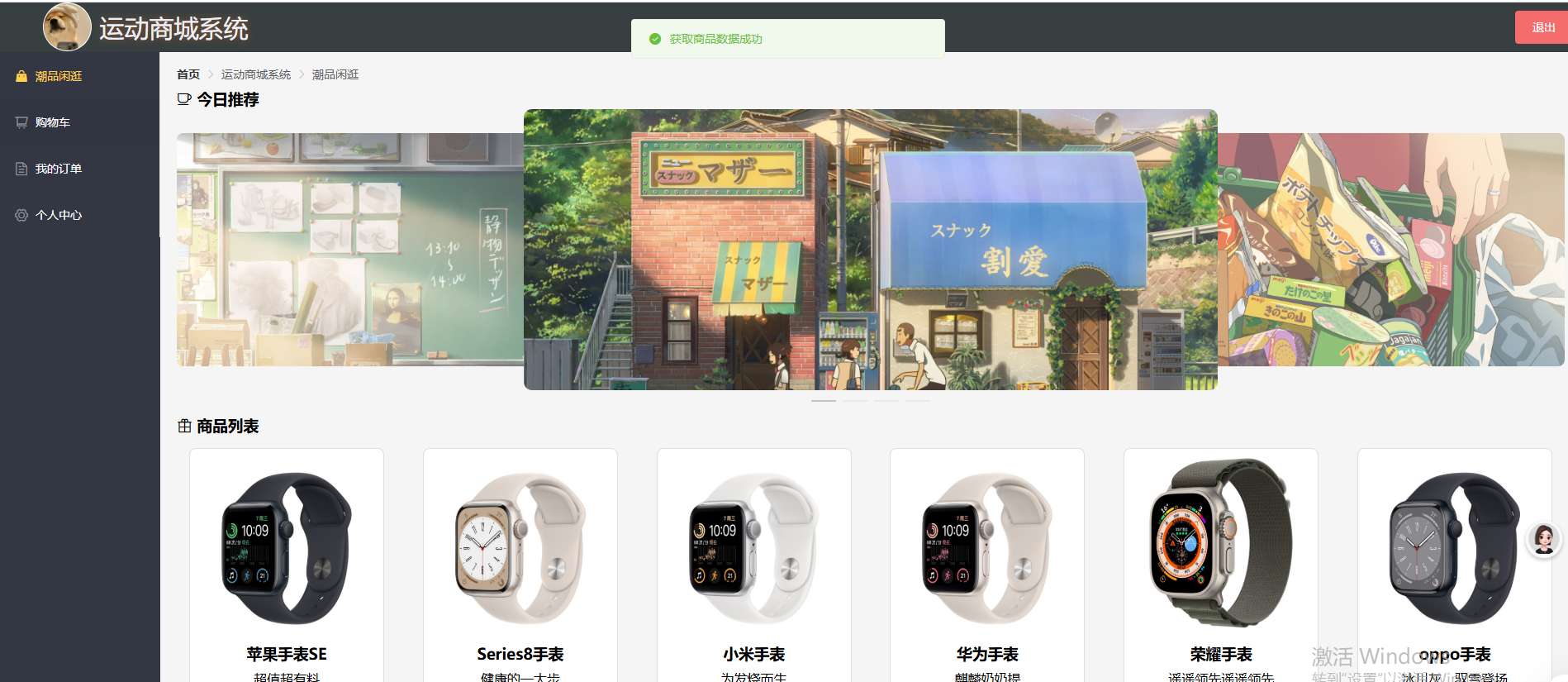
基于Django开发的运动商城系统项目
运动商城系统项目描述 运动商城系统是一个基于现代Web技术构建的电子商务平台,专注于运动类商品的在线销售与管理。该系统采用前后端分离架构,前端使用Vue.js实现动态交互界面,后端基于Django框架提供RESTful API支持,数据库采用…...

Python训练营打卡Day42
知识点回顾 回调函数lambda函数hook函数的模块钩子和张量钩子Grad-CAM的示例 1. 回调函数(Callback Function) 回调函数是作为参数传递给另一个函数的函数,目的是在某个事件发生后执行。 def fetch_data(callback):# 模拟数据获取data {&quo…...

https相比http的区别
https相比http的区别 https相比http的区别在于:https使用了SSL/TLS加密协议,确保数据传输的安全性和完整性,通信时需要证书验证。 https相比于http的区别主要在于安全性。https使用SSL/TLS加密传输数据,确保数据在客户端和服务器之间的通信…...

【Linux】为 Git 设置 Commit 提交模板方法,可统一个人或者项目的提交风格
为 Git 设置 Commit 提交模板 新建模板文件。注意之后不能删除该文件。 gedit ~/.gitmessage.txt粘贴自己的模板。可以给 AI 提自己的需求,定制一个模板,例如 # <type>(<scope>): <description> # # [optional body] # # [optional…...

caliper config.yaml 文件配置,解释了每个配置项的作用和注意事项
以下是添加了详细备注的 config.yaml 文件配置,解释了每个配置项的作用和注意事项: # Caliper 性能测试主配置文件 # 文档参考: https://hyperledger.github.io/caliper/# 测试轮次配置 - 可以定义多个测试轮次,每个轮次测试不同的合约或场景 rounds:# 第一个测试轮次 - 测试…...

结构体和指针1
#include <iostream> using namespace std; #include <string> struct Student{ int age; string name; double score; }; int main() { //静态分配 Student s1 {18,"小明",88.5}; //cout << s1.name<<"的成绩为…...
Python60日基础学习打卡Day45
之前的神经网络训练中,为了帮助理解借用了很多的组件,比如训练进度条、可视化的loss下降曲线、权重分布图,运行结束后还可以查看单张图的推理效果。 如果现在有一个交互工具可以很简单的通过按钮完成这些辅助功能那就好了,他就是…...

《Java 并发神器:深入理解CompletableFuture.supplyAsync与线程池实战优化》
一、背景介绍 在 Java 后端开发中,我们经常会遇到以下问题: 需要并行执行多个数据库查询或远程调用;单线程执行多个 .list() 方法时耗时过长;希望提升系统响应速度,但又不想引入过多框架。 这时,Java 8 …...
【Visual Studio 2022】卸载安装,ASP.NET
Visual Studio 2022 彻底卸载教程 手动清理残留文件夹 删除C:\Program Files\Microsoft Visual Studio 是旧版本 Visual Studio 的残留安装目录 文件夹名对应的 Visual Studio 版本Microsoft Visual Studio 9.0Visual Studio 2008Microsoft Visual Studio 10.0Visual Studio…...

JVM中的各类引用
JVM中的各类引用 欢迎来到我的博客:TWind的博客 我的CSDN::Thanwind-CSDN博客 我的掘金:Thanwinde 的个人主页 对象 众所不周知,Java中基本所有的对象都是分配在堆内存之中的,除开基本数据类型在栈帧中以外…...
thinkphp-queue队列随笔
安装 # 创建项目 composer create-project topthink/think 5.0.*# 安装队列扩展 composer require topthink/think-queue 配置 // application/extra/queue.php<?php return [connector > Redis, // Redis 驱动expire > 0, // 任务的过期时间…...
STM32标准库-TIM输出比较
文章目录 一、输出比较二、PWM2.1简介2.2输出比较通道(高级)2.3 输出比较通道(通用)2.4输出比较模式2.5 PWM基本结构1、时基单元2、输出比较单元3、输出控制(绿色右侧)4、右上波形图(以绿色脉冲…...

科技创新驱动人工智能,计算中心建设加速产业腾飞
在科技飞速发展的当下,人工智能正以前所未有的速度融入我们的生活。一辆辆无人驾驶的车辆在道路上自如地躲避车辆和行人,行驶平稳且操作熟练;刷脸支付让购物变得安全快捷,一秒即可通行。这些曾经只存在于想象中的场景,…...

figma 和蓝湖 有什么区别
以下是 Figma 和蓝湖的详细对比分析: 核心定位区别 维度Figma蓝湖本质全功能云端设计工具设计协作与交付平台核心功能设计原型协作开发交付设计稿交付标注切图协作设计能力✅ 完整矢量设计工具❌ 无设计功能(需导入其他工具文件)适用阶段全流…...

SQLServer中的存储过程与事务
一、存储过程的概念 1. 定义 存储过程(Stored Procedure)是一组预编译的 SQL 语句的集合,它们被存储在数据库中,可以通过指定存储过程的名称并执行来调用它们。存储过程可以接受输入参数、输出参数,并且可以返回执行…...

STM32H562----------ADC外设详解
1、ADC 简介 STM32H5xx 系列有 2 个 ADC,都可以独立工作,其中 ADC1 和 ADC2 还可以组成双模式(提高采样率)。每个 ADC 最多可以有 20 个复用通道。这些 ADC 外设与 AHB 总线相连。 STM32H5xx 的 ADC 模块主要有如下几个特性: 1、可配置 12 位、10 位、8 位、6 位分辨率,…...
uniapp 安卓 APP 后台持续运行(保活)的尝试办法
在移动应用开发领域,安卓系统的后台管理机制较为复杂,应用在后台容易被系统回收,导致无法持续运行。对于使用 Uniapp 开发的安卓 APP 来说,实现后台持续运行(保活)是很多开发者面临的重要需求,比…...
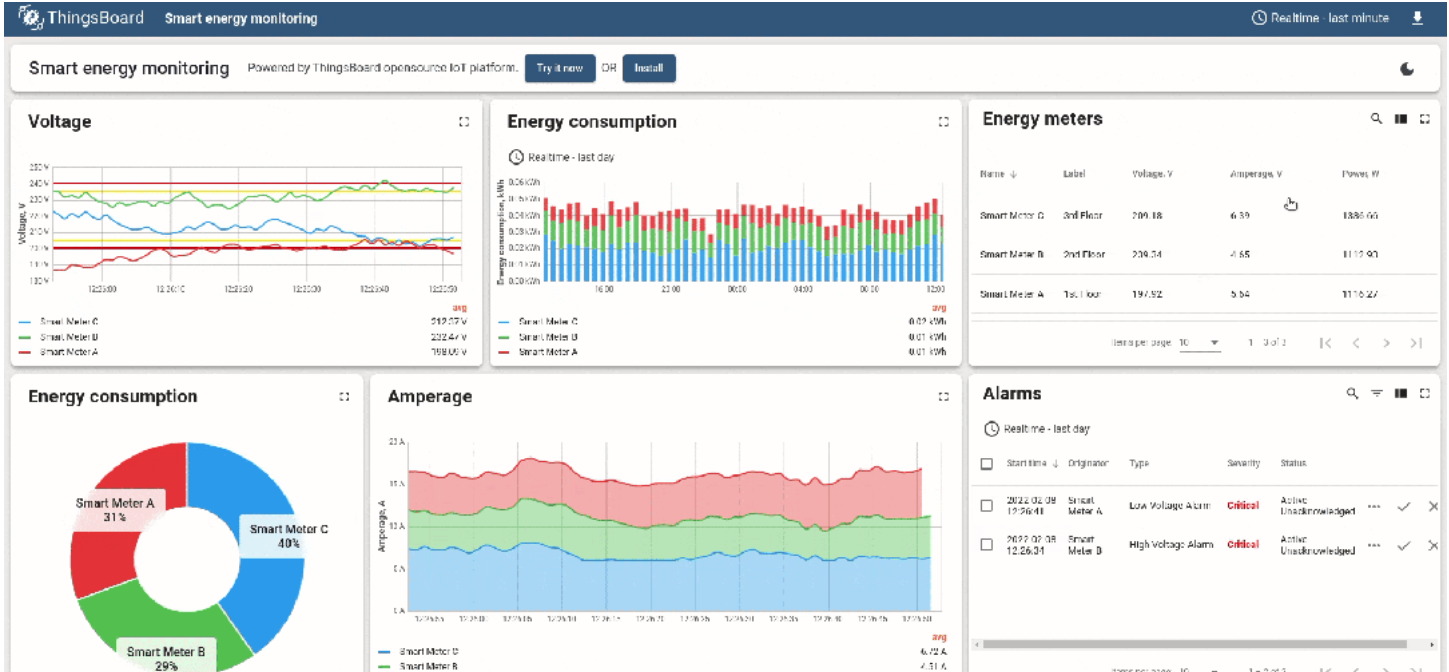
AI大数据模型如何与thingsboard物联网结合
一、 AI大数据与ThingsBoard物联网的结合可以从以下几个方面实现: 1. 数据采集与集成 设备接入:ThingsBoard支持多种通信协议(如MQTT、CoAP、HTTP、Modbus、OPC-UA等),可以方便地接入各种物联网设备。通过这些协议&am…...
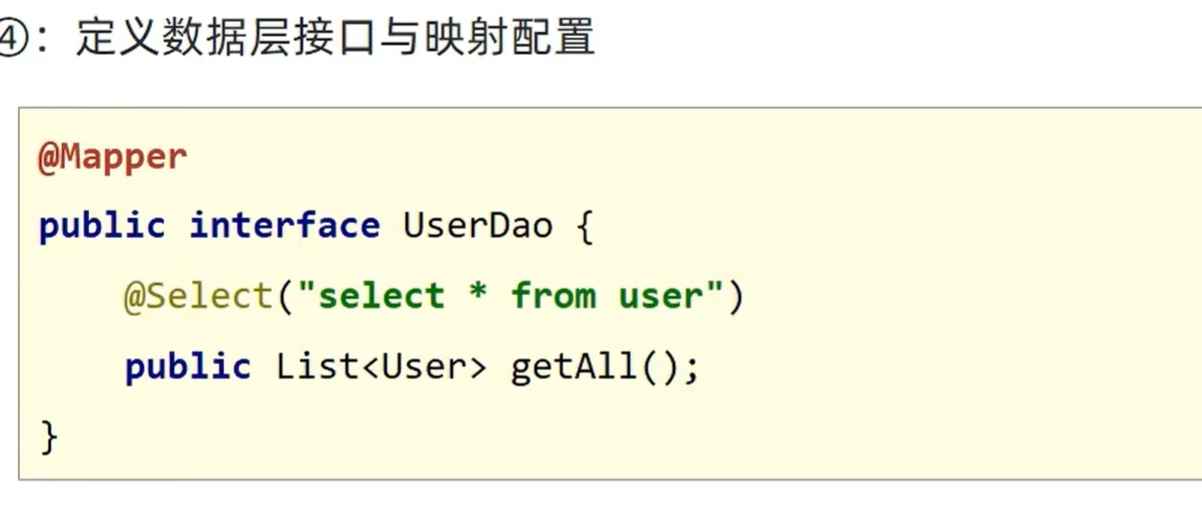
【SSM】SpringBoot笔记2:整合Junit、MyBatis
前言: 文章是系列学习笔记第9篇。基于黑马程序员课程完成,是笔者的学习笔记与心得总结,供自己和他人参考。笔记大部分是对黑马视频的归纳,少部分自己的理解,微量ai解释的内容(ai部分会标出)。 …...

STM32——CAN总线
STM32——CAN总线 1. CAN总线基础概念 1.1 CAN总线简介 控制器局域网(Controller Area Network, CAN)是由Bosch公司开发的串行通信协议,专为汽车电子和工业控制设计,具有以下核心特性: 多主控制架构:所有…...
嵌入式面试高频!!!C语言(四)(嵌入式八股文,嵌入式面经)
更多嵌入式面试文章见下面连接,会不断更新哦!!关注一下谢谢!!!! https://blog.csdn.net/qq_61574541/category_12976911.html?fromshareblogcolumn&sharetypeblogcolumn&…...

数据治理在制造业的实践案例
一、数据治理在制造业的重要性 随着工业4.0的到来,制造业正经历着前所未有的变革。数据治理作为制造业数字化转型的关键组成部分,对提升企业竞争力、优化生产流程、提高产品质量和客户满意度等方面起着至关重要的作用。在制造业中,数据治理不仅涉及到数据的收集、存…...

【强化学习】——03 Model-Free RL之基于价值的强化学习
【强化学习】——03 Model-Free RL之基于价值的强化学习 \quad\quad \quad\quad 动态规划算法是基于模型的算法,要求已知状态转移概率和奖励函数。但很多实际问题中环境 可能是未知的,这就需要不基于模型(Model-Free)的RL方法。 \quad\quad 其又分为: 基于价值(Valu…...