向 AI Search 迈进,腾讯云 ES 自研 v-pack 向量增强插件揭秘
作者:来自腾讯云刘忠奇
2025 年 1 月,腾讯云 ES 团队上线了 Elasticsearch 8.16.1 AI 搜索增强版,此发布版本重点提升了向量搜索、混合搜索的能力,为 RAG 类的 AI Search 场景保驾护航。除了紧跟 ES 官方在向量搜索上的大幅优化动作外,腾讯云 ES 还在此版本上默认内置了一个全新的插件 —— v-pack 插件。v-pack 名字里的 "v" 是 vector 的意思,旨在提供更加丰富、强大的向量、混合搜索能力。本文将对该版本 v-pack 插件所包含的功能做大体的介绍。
腾讯云 ES AI 搜索优化实践 刘忠奇 20250605
一、存储优化:突破向量搜索的存储瓶颈
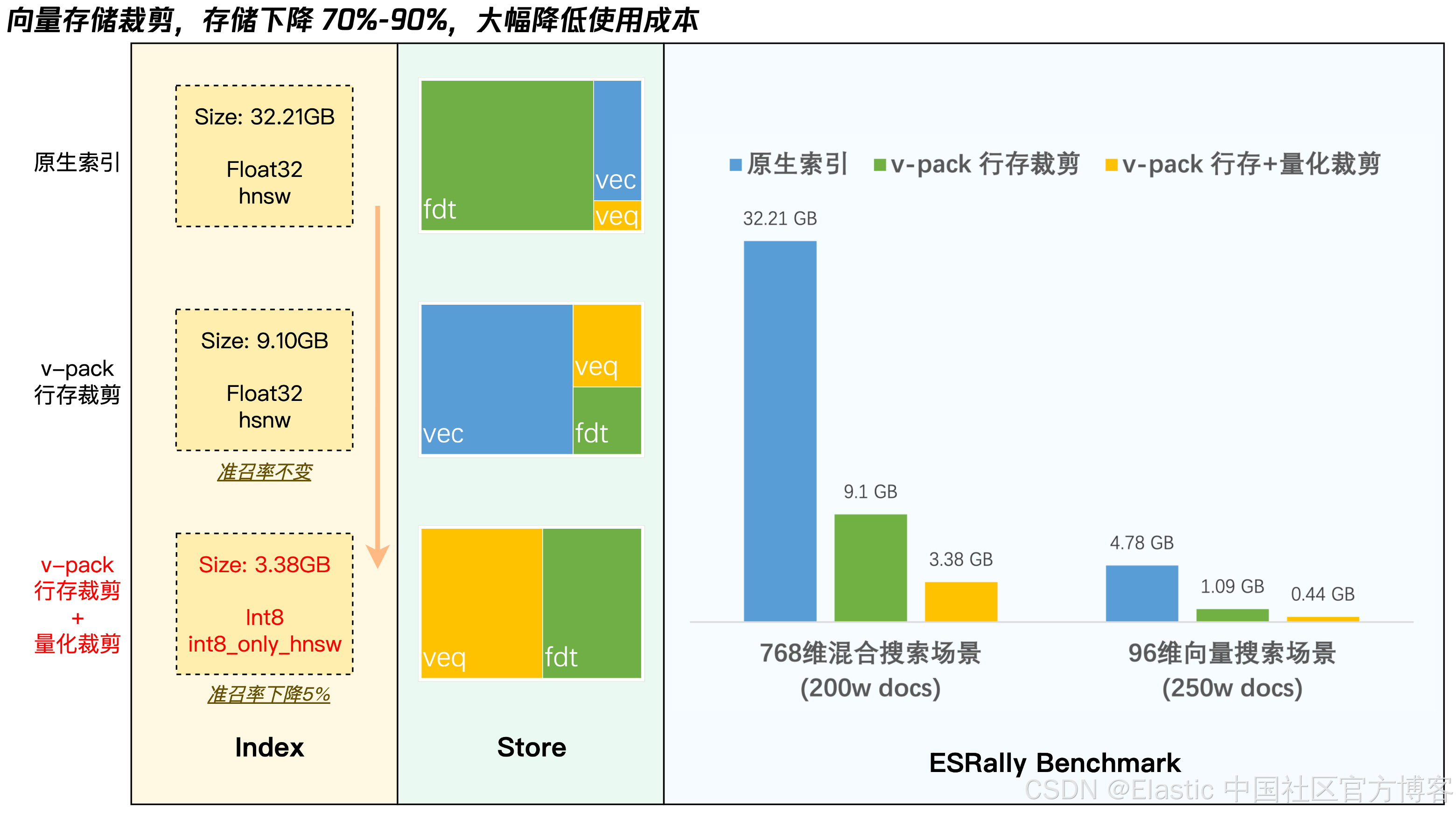
1.1 行存裁剪:无损瘦身节省 70% 存储
技术原理
传统 Elasticsearch 默认将向量数据同时存储在行存 _source(.fdt) 和列存 doc_value(.dvd/.vec) 中,造成冗余。利用腾讯云 ES 贡献给社区的向量列存读取能力(PR #114484),在安装了 v-pack 插件的集群上,默认无损排除 _source 中的向量(dense_vector)字段,实现存储空间的高效利用。
技术亮点
- 动态开关:通过集群级参数
vpack.auto_exclude_dense_vector控制(默认开启) - 无损兼容:通过
docvalue_fields语法仍可获取原始向量值(用于业务开发调试、reindex 等操作)
实测效果
| 场景 | 原始存储 | 优化后存储 | 节省比例 |
|---|---|---|---|
| 纯向量场景(250w条) | 4.78GB | 1.09GB | 77% |
| 混合场景(200w条) | 32.21GB | 9.10GB | 72% |
使用方法
无需手动启用,安装了 v-pack 插件的集群即生效。v-pack 会在创建新索引时,自动在索引 settings 中扩增 index.mapping.source.auto_exclude_types 参数来裁剪向量字段。
如需关闭,可关闭集群维度的动态开关,此后新创建的索引则不会做裁剪。
PUT _cluster/settings
{"persistent": {"vpack.auto_exclude_dense_vector": false}
}场景建议
所有生产场景
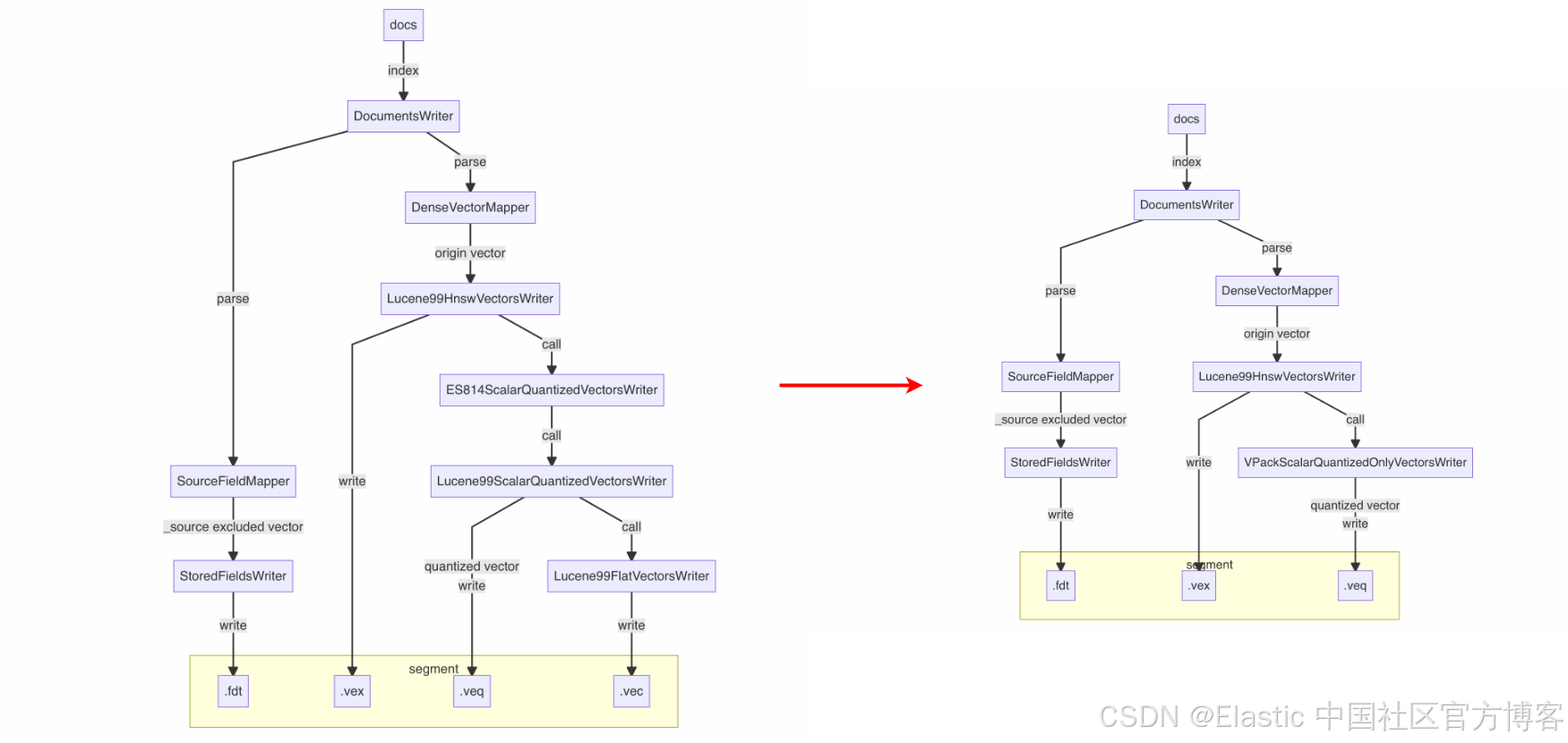
1.2 量化裁剪:极致瘦身节省 90% 存储
技术原理
量化实际是将原始高位向量压缩成低位向量的一种算法,如果把量化比作 “脱水”,那这类算法函数的逆运算,就可以实现反向 “复水” 得到原来的向量。当然由于低位不能完全表示高位,在精度上会有一定损失,但它带来的是磁盘存储的进一步下降,对于存储有强烈需求的客户仍然具有很高的实际意义。在上文行存裁剪的基础上,进一步节省存储到 90%。
技术亮点
在社区标量量化技术int8_hnsw基础上,首创int8_only_hnsw索引类型:
- “脱水”存储:仅保留量化后的 int8 向量(
.veq文件) - 动态“复水”:merge 时通过量化参数还原近似原始向量
实测效果
| 场景 | 原始存储 | 优化后存储 | 节省比例 |
|---|---|---|---|
| 纯向量场景(250w条) | 4.78GB | 0.44GB | 90% |
| 混合场景(200w条) | 32.21GB | 1.09GB | 91% |
技术对比
使用方法
在安装了 v-pack 插件的集群,创建索引时,将 index_options.type 设置为 int8_only_hnsw 索引类型
PUT product_vector_index
{"mappings": {"properties": {"embedding": {"type": "dense_vector","dims": 768,"index_options": {"type": "int8_only_hnsw","m": 32,"ef_construction": 100}}}}
}场景建议
- 搜推系统:对存储敏感的场景
- RAG 应用:海量的知识库数据
1.3 小结
下图展示了 v-pack 的两种向量存储裁剪的效果。详细的技术方案解析详见:《ES8向量功能窥探系列(二):向量数据的存储与优化》
二、排序优化:多策略融合的灵活组合
2.1 权重可调 RRF 融合:
算法演进
在标准 RRF(Reciprocal Rank Fusion)公式中引入权重因子:
加权得分 = Σ( weight_i / (k + rank_i) )突破传统多路召回等权融合的限制,支持业务自定义权重策略。
混合排序示例
GET news/_search
{"retriever": {"rank_fusion": {"retrievers": [{"standard": {"query": {"match": {"title": "人工智能"}}}},{"knn": {"field": "vector","query_vector": [...],"k": 50}}],"weights": [2, 1],"rank_constant": 20}}
}适用场景
- 电商搜索:提升关键词权重(权重比 3:1 或更大)
- 内容推荐:增强语义相关性(权重比 1:2 或更大)
- 知识库检索:平衡语义与关键词(权重比 1:1 微调)
2.2 归一化 Score 融合
算法原理
通过动态归一化将不同评分体系统一到 0,1 区间:
- BM25 归一化:
(score - min_score)/(max_score - min_score) - 向量相似度归一化:
cosine_similarity + 1 / 2
混合排序示例
{"retriever": {"score_fusion": {"retrievers": [...],"weights": [1.5, 1]}}
}适用场景
- 结果可解释性强
- 多维度加权评分的精排搜索
2.3 基于模型的 Rerank 融合
算法原理
借助腾讯云智能搜索的原子能力,腾讯云 ES 8.16.1 搜索增强版,已支持调用第三方 rerank 模型对混合搜索的结果进行重排。当前已支持内置下列重排序模型,这些模型都部署在 GPU 上,性能有极大提升。
| 原子服务 | token限制 | 维度 | 语言 | 备注 |
|---|---|---|---|---|
| bge-reranker-large | 514 | 1024 | 中文、英文 | bge经典模型 |
| bge-reranker-v2-m3 | 8194 | 1024 | 多语言 | bge经典模型 |
| bge-reranker-v2-minicpm-layerwise | 2048 | 2304 | 多语言 | 在英语和中文水平上均表现良好,可以自由选择输出层,有助于加速推理 |
使用示例
PUT _inference/rerank/tencentcloudapi_bge-reranker-large
{"service": "tencent_cloud_ai_search","service_settings": {"secret_id": "xxx","secret_key": "xxx","url": "https://aisearch.internal.tencentcloudapi.com","model_id": "bge-reranker-large","region": "ap-beijing","language": "zh-CN","version": "2024-09-24"}
}POST _inference/rerank/tencentcloudapi_bge-reranker-large
{"query": "中国","input": ["美国","中国","英国"]
}{"rerank": [{"index": 1,"relevance_score": 0.99990976,"text": "中国"},{"index": 0,"relevance_score": 0.013636836,"text": "美国"},{"index": 2,"relevance_score": 0.00941259,"text": "英国"}]
}混合排序示例
{"retriever": {"tencent_cloud_ai_reranker": {"retrievers": [...],"model_id": "tencentcloudapi_bge-reranker-large", "rank_field": "content","rank_text": "nice day","rank_window_size": 10, "min_score": 0.6}}
}适用场景
- 对语义相关性有更高需求的场景
- 对准召率有更高需求的场景
2.4 小结
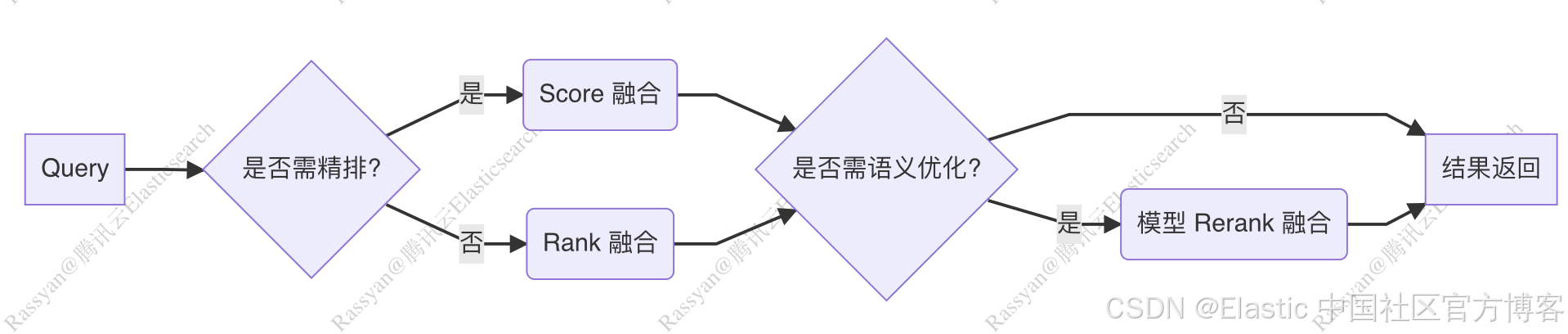
下图展示了 v-pack 提供的多种融合排序算法,所带来的更丰富的准召率提升手段。

v-pack 提供的融合算法,支持自定义的灵活组合,可以参考如下的做法来组合使用。
三、推理飞跃:无缝连接最强模型
3.1 对话推理:一键接入满血 Deepseek 大模型
借助腾讯云智能搜索的 LLM 生成服务,腾讯云 ES 8.16.1 搜索增强版亦可以一键接入 DeepSeek 以及混元系列大模型进行推理。
| 模型类型 | 模型名称(model) | Tokens | 特性 |
|---|---|---|---|
| deepseek-r1 | 最大输入128k | 最大输出8k | 擅长复杂需求拆解、技术方案直译,提供精准结构化分析及可落地方案,实现了与GPT-4o和Claude Sonnet 3.5等顶尖模型相媲美的性能 |
| deepseek-v3 | 最大输入128k | 最大输出8k | 通用型AI模型,拥有庞大参数规模及强大多任务泛化能力,擅长开放域对话、知识问答、创意生成等多样化需求 |
| deepseek-r1-distill-qwen-32b | 最大输入128k | 最大输出8k | r1-36b参数蒸馏版,效果没有r1好,但响应速度更快,资源成本更低 |
| hunyuan-turbo | 最大输入28k | 最大输出4k | 腾讯新一代旗舰大模型,混元Turbo模型,在语言理解、文本创作、数学、推理和代码等领域都有较大提升,具备强大的知识问答能力 |
| ... |
使用示例
PUT _inference/completion/deepseek
{"service": "tencent_cloud_ai_search","service_settings": {"secret_id": "xxx","secret_key": "xxx","url": "https://aisearch.internal.tencentcloudapi.com","model_id": "deepseek-v3","region": "ap-beijing","language": "zh-CN","version": "2024-09-24"}
}POST _inference/completion/deepseek
{"input": "你是谁?"
}{"completion": [{"result": "我是DeepSeek Chat,一个由深度求索公司开发的智能助手,旨在通过自然语言处理和机器学习技术来提供信息查询、对话交流和解答问题等服务。"}]
}我们可以借助该能力,使用 Deepseek 代替 OpenAI 实现官方最佳实践中的相关功能:https://www.elastic.co/search-labs/blog/elasticsearch-openai-completion-support
3.2 嵌入推理:接入 GPU embedding 消除推理高延迟
借助腾讯云智能搜索的 LLM 生成服务,腾讯云 ES 8.16.1 搜索增强版支持内网无缝推理,目前支持以下主流的 embedding 模型。
| 原子服务 | token限制 | 维度 | 语言 | 备注 |
|---|---|---|---|---|
| bge-base-zh-v1.5 | 512 | 768 | 中文 | bge经典模型 |
| bge-m3 | 8194 | 1024 | 多语言 | bge经典模型 |
| conan-embedding-v1 | 512 | 1792 | 中文 | 腾讯自研,在MTEB榜单一度综合排第一 |
使用示例
PUT _inference/text_embedding/tencentcloudapi_bge_base_zh-v1.5
{"service": "tencent_cloud_ai_search","service_settings": {"secret_id": "xxx","secret_key": "xxx","url": "https://aisearch.internal.tencentcloudapi.com","model_id": "bge-base-zh-v1.5","region": "ap-beijing", "language": "zh-CN","version": "2024-09-24"}
}PUT semantic_text_index
{"mappings": {"properties": {"content": {"type": "semantic_text","inference_id": "tencentcloudapi_bge_base_zh-v1.5"}}}
}3.3 小结
借助腾讯云智能搜索的原子服务,腾讯云 ES 允许用户将 ES 作为 AI Search 的服务中枢,成为向量、文本、模型的统一引擎,all in one 一站式地完成整套 RAG 场景的搜索和推理需求。
四、持续进化:社区贡献与自研特性齐头并进
腾讯云 ES 团队持续投入开源生态建设,覆盖最新的向量场景:
- 核心贡献:累计提交 200+ 社区PR,向量相关 10+
让技术回归本质,用创新驱动价值
腾讯云 ES 将持续深耕 AI Search 基础设施,致力服务好当今日益增长的 RAG 与多模态搜索需求,与开发者共同探索搜索技术的无限可能。
相关文章:
向 AI Search 迈进,腾讯云 ES 自研 v-pack 向量增强插件揭秘
作者:来自腾讯云刘忠奇 2025 年 1 月,腾讯云 ES 团队上线了 Elasticsearch 8.16.1 AI 搜索增强版,此发布版本重点提升了向量搜索、混合搜索的能力,为 RAG 类的 AI Search 场景保驾护航。除了紧跟 ES 官方在向量搜索上的大幅优化动…...
、业务架构设计、投标任务)
接IT方案编写(PPT/WORD)、业务架构设计、投标任务
1、IT 方案编写(PPT/WORD) 定制化方案:根据客户需求,提供涵盖云计算、大数据、人工智能等前沿技术领域的 PPT/WORD 方案编写服务,精准提炼核心价值,呈现专业技术内容。 逻辑清晰架构:采用…...

PostgreSQL 的扩展pageinspect
PostgreSQL 的扩展pageinspect pageinspect 是 PostgreSQL 提供的一个强大的底层扩展,允许数据库管理员和开发者直接检查数据库页面的内部结构。这个扩展对于数据库调试、性能优化和深入学习 PostgreSQL 存储机制非常有价值。 一、扩展概述 功能:提供…...

Unity——QFramework框架 内置工具
QFramework 除了提供了一套架构之外,QFramework 还提供了可以脱离架构使用的工具 TypeEventSystem、EasyEvent、BindableProperty、IOCContainer。 这些工具并不是有意提供,而是 QFramework 的架构在设计之初是通过这几个工具组合使用而成的。 内置工具…...
【win | docker开启远程配置】使用 SSH 隧道访问 Docker的前操作
在主机A pycharm如何连接远程主机B win docker? 需要win docker配置什么? 快捷配置-主机B win OpenSSH SSH Server https://blog.csdn.net/z164470/article/details/121683333 winR,打开命令行,输入net start sshd,启动SSH。 或者右击我的电脑&#…...

股指期货波动一个点多少钱?
很多朋友在交易股指期货时,都会好奇一个问题:股指期货波动一个点,我的账户里到底是赚了还是亏了多少钱?要搞清楚这个问题,其实很简单,只需要了解两个关键信息:股指期货的“交易单位”࿰…...
)
Kafka 快速上手:安装部署与 HelloWorld 实践(一)
一、Kafka 是什么?为什么要学? ** 在大数据和分布式系统的领域中,Kafka 是一个如雷贯耳的名字。Kafka 是一种分布式的、基于发布 / 订阅的消息系统,由 LinkedIn 公司开发,后成为 Apache 基金会的顶级开源项目 。它以…...

NGINX `ngx_stream_core_module` 模块概览
一、模块定位与功能 通用 TCP/UDP 代理 支持同时处理 TCP 和 UDP 流量,透明转发请求到后端服务器组(upstream)。可作为四层负载均衡,根据客户端 IP、权重、最少连接等策略将连接分发给后端。 预读(preread)…...
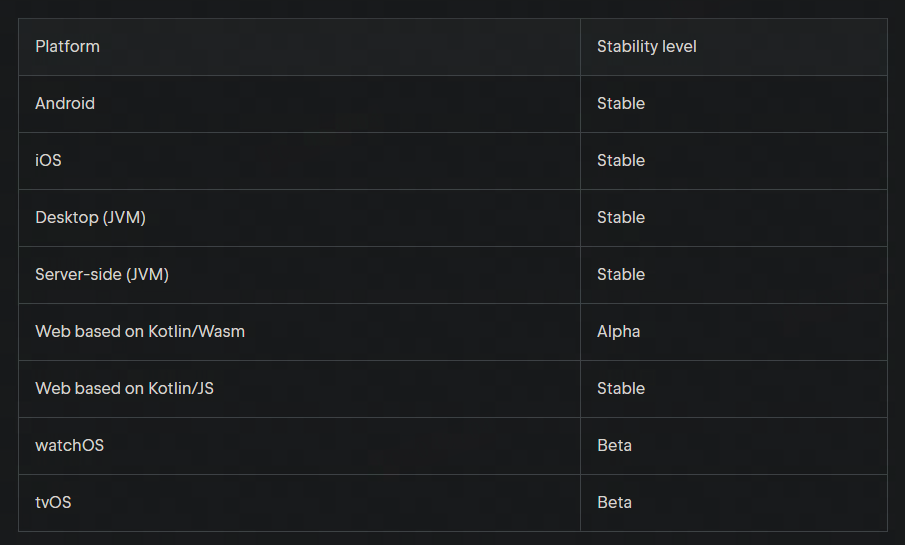
iOS、Android、鸿蒙、Web、桌面 多端开发框架Kotlin Multiplatform
Kotlin Multiplatform(简称 KMP)是 JetBrains 推出的开源跨平台开发框架 Kuikly 是腾讯开源的跨端开发框架,基于 Kotlin Multiplatform 技术构建,为开发者提供了技术栈更统一的跨端开发体验 KMP 不仅局限于移动端,它…...

探索C++标准模板库(STL):String接口的底层实现(下篇)
前引:在C的面向对象编程中,对象模型是理解语言行为的核心。无论是类的成员函数如何访问数据,还是资源管理如何自动化,其底层机制均围绕两个关键概念展开:this指针与六大默认成员函数。它们如同对象的“隐形守护者”&am…...
Flutter知识点汇总
Flutter架构解析 1. Flutter 是什么?它与其他移动开发框架有什么不同? Flutter 是 Google 开发的开源移动应用开发框架,可用于快速构建高性能、高保真的移动应用(iOS 和 Android),也支持 Web、桌面和嵌入式设备。。它与其他移动开发框架(如 React Native、Xamarin、原…...

vue组件的data为什么是函数?
vue组件的data为什么是函数? 在JS中,实例是通过构造函数创建的,每个构造函数可以new出多个实例,每个实例都会继承原型上的方法和属性。 在vue中,一个vue组件就是一个实例,当一个组件被复用多次࿰…...

AI图片售卖:是暴利新风口还是虚幻泡沫?哪些平台适合售卖AI图片
还记得去年大火的Midjourney吗?今年4月,Midjourney又发布了备受期待的V7版本,带来了更高的图像质量和创新功能。使用Midjourney、Stable Diffusion、DALLE等AI图片生成工具,创作者只需输入关键词即可获得高质量的原创图片。这一变…...
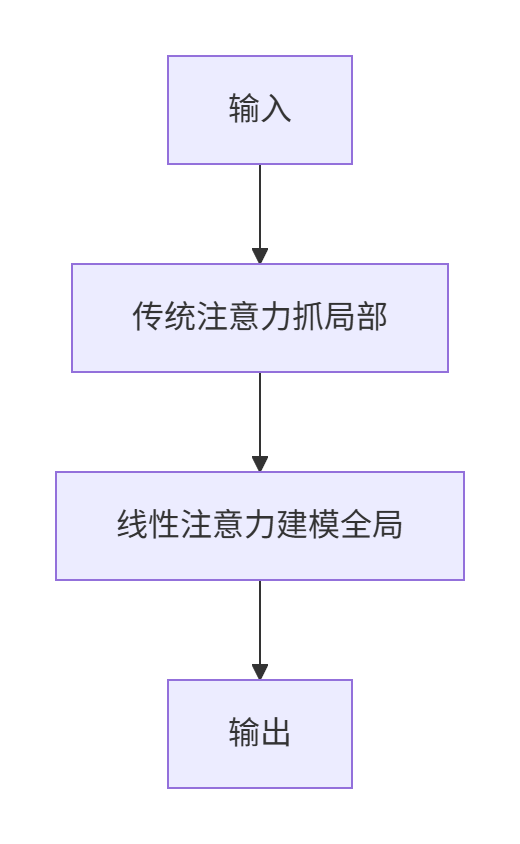
线性注意力 vs. 传统注意力:效率与表达的博弈新解
核心结论:线性注意力用计算复杂度降维换取全局建模能力,通过核函数和结构优化补足表达缺陷 一、本质差异:两种注意力如何工作? 特性传统注意力(Softmax Attention)线性注意力(Linear At…...

YOLO在QT中的完整训练、验证与部署方案
以下是YOLO在QT中的完整训练、验证与部署方案: 训练方案 准备数据集: 收集数据:收集与目标检测任务相关的图像数据集,可以是公开数据集如COCO、Pascal VOC,也可以是自定义数据集。标注数据:使用标注工具如…...

Vue在线预览excel、word、ppt等格式数据。
目录 前言 1.安装库 2.预览文件子组件代码 3、新建store/system.ts 4、父页面进行使用 总结 前言 纯前端处理文件预览,包含excel、word、ppt、txt等格式,不需要后端服务器进行部署,并且内网也可以使用。 1.安装库 npm install vue-offi…...

增量式网络爬虫通用模板
之前做过一个项目,他要求是只爬取新产生的或者已经更新的页面,避免重复爬取未变化的页面,从而节省资源和时间。这里我需要设计一个增量式网络爬虫的通用模板。可以继承该类并重写部分方法以实现特定的解析和数据处理逻辑。这样可以更好的节约…...
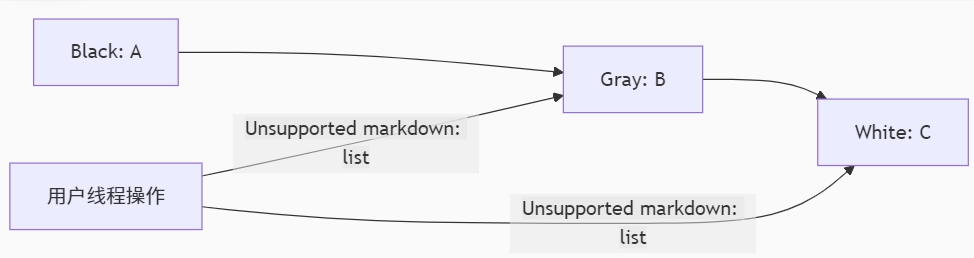
【JVM】三色标记法原理
在JVM中,三色标记法是GC过程中对象状态的判断依据,回收前给对象设置上不同的三种颜色,三色分为白色、灰色、黑色。根据颜色的不同,决定对象是否要被回收。 白色表示: 初始状态:所有对象未被 GC 访问。含义…...
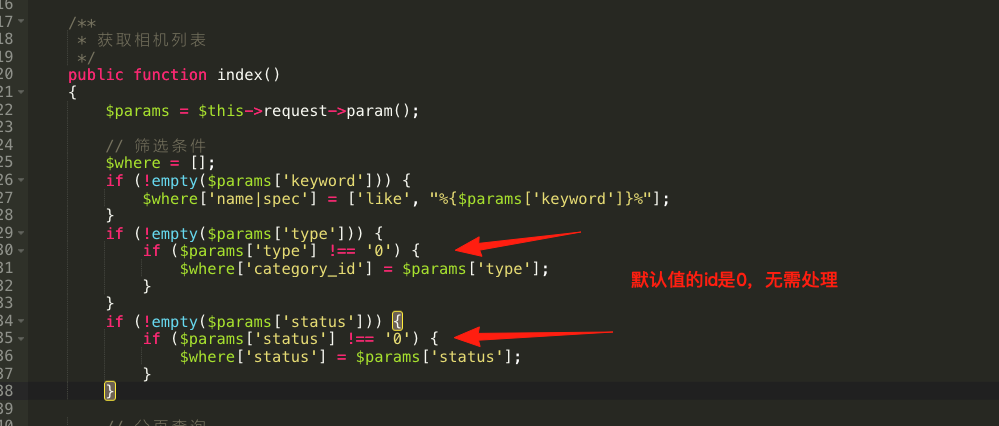
【uniapp开发】picker组件的使用
项目uniapp,结合fastadmin后端开发 picker组件的官方文档说明 https://en.uniapp.dcloud.io/component/picker.html#普通选择器 先看效果: 1、实现设备类型的筛选;2、实现设备状态的筛选; 前端代码(节选࿰…...
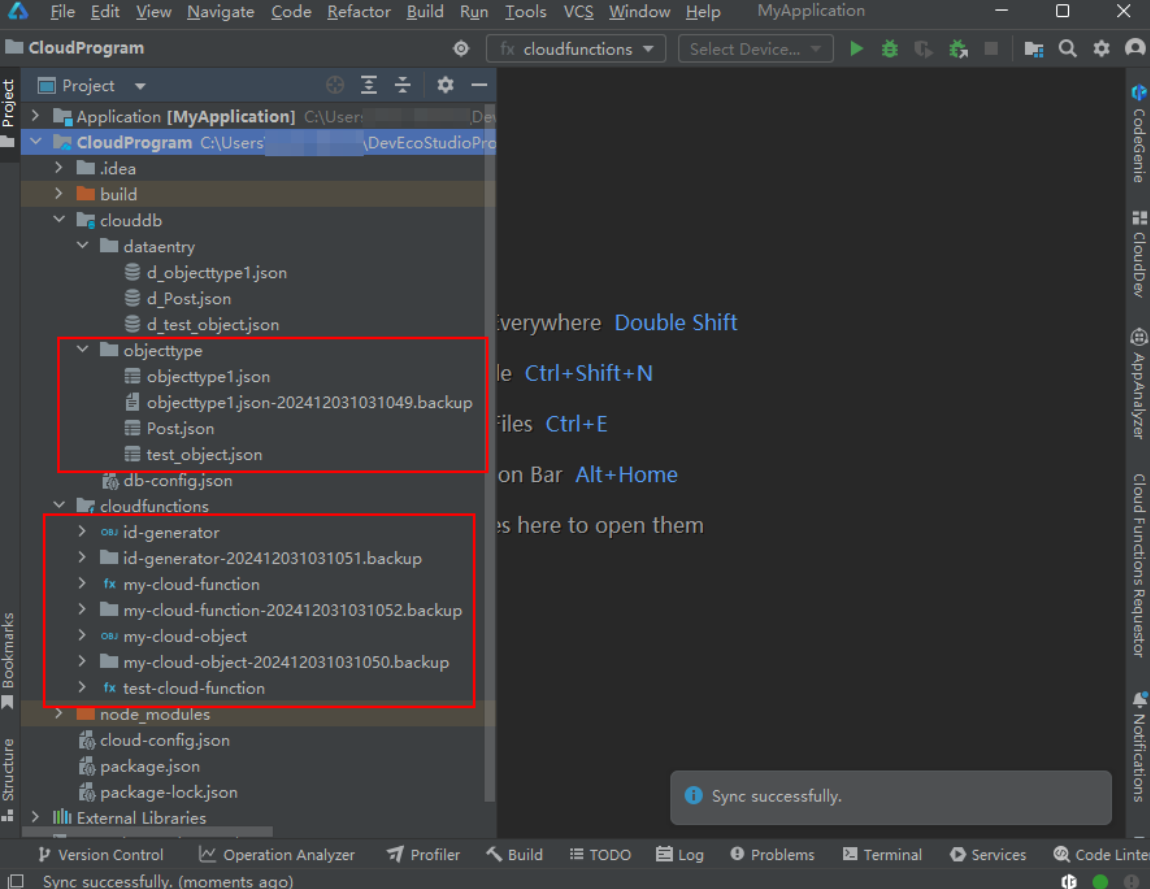
【HarmonyOS Next之旅】DevEco Studio使用指南(三十一) -> 同步云端代码至DevEco Studio工程
目录 1 -> 同步云函数/云对象 1.1 -> 同步单个云函数/云对象 1.2 -> 批量同步云函数/云对象 2 -> 同步云数据库 2.1 -> 同步单个对象类型 2.2 -> 批量同步对象类型 3 -> 一键同步云侧代码 1 -> 同步云函数/云对象 说明 对于使用DevEco Studio…...

如何评估大语言模型效果
评估大模型微调后的效果是一个系统化的过程,需要结合客观指标和主观评估,并根据任务类型(分类、生成、回归等)选择合适的评估方法。 一、评估前的准备工作 数据集划分: 将数据分为 训练集、验证集 和 测试集ÿ…...

go-zero微服务入门案例
一、go-zero微服务环境安装 1、go-zero脚手架的安装 go install github.com/zeromicro/go-zero/tools/goctllatest2、etcd的安装下载地址根据自己电脑操作系统下载对应的版本,具体的使用自己查阅文章 二、创建一个user-rpc服务 1、定义user.proto文件 syntax &qu…...

Python控制台输出彩色字体指南
在Python开发中,有时我们需要在控制台输出彩色文本以提高可读性或创建更友好的用户界面。本文将介绍如何使用colorama库来实现这一功能。 为什么需要彩色输出? 提高可读性:重要信息可以用不同颜色突出显示更好的用户体验:错误信息…...
)
零基础在实践中学习网络安全-皮卡丘靶场(第十六期-SSRF模块)
最后一期了,感谢大家一直以来的关注,如果您对本系列文章内容有问题或者有更好的方法,请在评论区发送。 介绍 其形成的原因大都是由于服务端提供了从其他服务器应用获取数据的功能,但又没有对目标地址做严格过滤与限制导致攻击者可以传入任意…...

开源之夏·西安电子科技大学站精彩回顾:OpenTiny开源技术下沉校园,点燃高校开发者技术热情
开源之夏2025编程活动正在如火如荼的进行中,当前也迎来了报名的倒计时阶段,开源之夏组织方也通过高校行系列活动进入各大高校,帮助高校开发者科普开源文化、开源活动、开源技术。 6月4日 开源之夏携手多位开源技术大咖、经验型选手走进西安电…...
)
html、css(javaweb第一天)
HTML: 文字、图片、视频组成 由标签组成的语言 行内标签span//无语意 <img src"url">//图片 <a herf"url" target"是否开新页面">点击谁</a>//超链接 <video src"url" controls></video>//controls播放…...
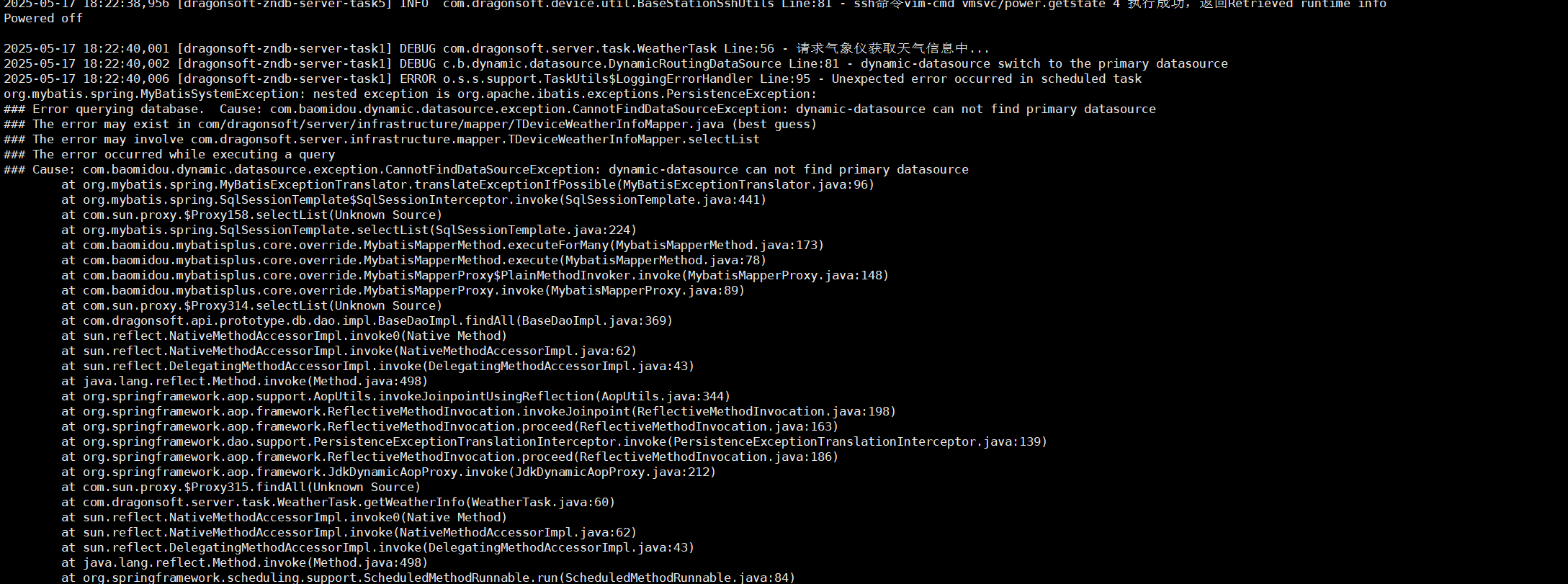
解决数据库重启问题
最近部署软件时,发现mysql会一直在重启,记录下解决办法: 1.删除/home/dataexa/install/docker/datas/mysql路径下的data文件夹 2.重新构建mysql docker-compose up -d --build mysql 3.停掉所有应用,在全部重启: do…...
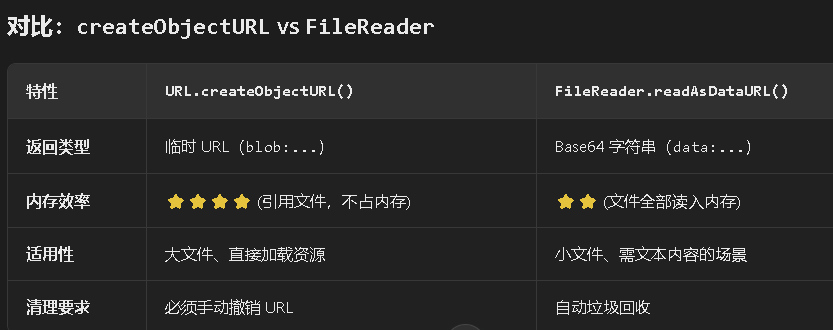
前后端交互过程中—各类文件/图片的上传、下载、显示转换
前后端交互过程中—各类文件/图片的上传、下载、显示转换 图片补充:new Blob()URL.createObjectURL()替代方案:FileReader.readAsDataURL()对比: tiff文件TIFF库TIFF转换通过url转换tiff文件为png通过文件选择的方式转换tiff文件为png 下…...

SparkSQL 优化实操
一、基础优化配置 1. 资源配置优化 # 提交Spark作业时的资源配置示例 spark-submit \--master yarn \--executor-memory 8G \--executor-cores 4 \--num-executors 10 \--conf spark.sql.shuffle.partitions200 \your_spark_app.py 参数说明: executor-memory: 每…...

【vLLM 学习】Cpu Offload Lmcache
vLLM 是一款专为大语言模型推理加速而设计的框架,实现了 KV 缓存内存几乎零浪费,解决了内存管理瓶颈问题。 更多 vLLM 中文文档及教程可访问 →https://vllm.hyper.ai/ *在线运行 vLLM 入门教程:零基础分步指南 源码 examples/offline_inf…...