SparkSQL 优化实操
一、基础优化配置
1. 资源配置优化
# 提交Spark作业时的资源配置示例
spark-submit \--master yarn \--executor-memory 8G \--executor-cores 4 \--num-executors 10 \--conf spark.sql.shuffle.partitions=200 \your_spark_app.py参数说明:
-
executor-memory: 每个Executor的内存 -
executor-cores: 每个Executor的CPU核心数 -
num-executors: Executor数量 -
spark.sql.shuffle.partitions: Shuffle操作的分区数(通常设为集群核心数的2-3倍)
2. 内存管理优化
// 在SparkSession初始化时设置
val spark = SparkSession.builder().appName("OptimizedSparkSQL").config("spark.memory.fraction", "0.8") // 执行和存储内存占总内存的比例.config("spark.memory.storageFraction", "0.3") // 存储内存占内存比例.getOrCreate()二、SQL查询优化技巧
1. 分区裁剪(Partition Pruning)
-- 原始查询(全表扫描)
SELECT * FROM sales WHERE dt = '2023-01-01';-- 优化后(确保表按dt分区)
SELECT * FROM sales WHERE dt = '2023-01-01'; -- 自动分区裁剪2. 谓词下推(Predicate Pushdown)
-- 原始查询(先JOIN后过滤)
SELECT a.*, b.name
FROM transactions a
JOIN users b ON a.user_id = b.id
WHERE a.dt = '2023-01-01' AND b.age > 18;-- 优化后(过滤条件下推)
SELECT /*+ MAPJOIN(b) */ a.*, b.name
FROM (SELECT * FROM transactions WHERE dt = '2023-01-01') a
JOIN (SELECT id, name FROM users WHERE age > 18) b
ON a.user_id = b.id;3. 广播小表(Broadcast Join)
// 方式1: 通过配置自动广播
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", "10485760") // 10MB// 方式2: 手动指定广播
val smallDF = spark.table("small_table")
val largeDF = spark.table("large_table")
largeDF.join(broadcast(smallDF), "key")三、数据存储优化
1. 文件格式选择
// 写入Parquet格式(列式存储,适合分析)
df.write.parquet("/path/to/parquet")// 写入Delta Lake(支持ACID)
df.write.format("delta").save("/path/to/delta")// 写入ORC(高度压缩)
df.write.orc("/path/to/orc")2. 分区与分桶
// 按日期分区
df.write.partitionBy("dt").parquet("/path/to/partitioned")// 分桶(适合大表JOIN)
df.write.bucketBy(50, "user_id").sortBy("user_id").saveAsTable("bucketed_table")四、执行计划分析与优化
1. 查看执行计划
val df = spark.sql("SELECT * FROM sales WHERE amount > 100")
df.explain(true) // 显示逻辑和物理计划// 更详细的执行计划
spark.sql("EXPLAIN EXTENDED SELECT * FROM sales WHERE amount > 100").show(false)2. 常见执行计划问题识别
-
数据倾斜:某个task执行时间远长于其他task
-
全表扫描:执行计划中出现
Scan操作没有过滤条件 -
非广播Join:出现
SortMergeJoin而不是BroadcastHashJoin -
数据重复计算:同一子查询被多次执行
3. 解决数据倾斜
// 方法1: 加盐处理
import org.apache.spark.sql.functions._
val skewedKey = "user_id"// 为倾斜键添加随机前缀
val saltedDF = df.withColumn("salted_key", concat(col(skewedKey), lit("_"), floor(rand() * 10)))// 方法2: 单独处理倾斜键
val commonDF = df.filter($"user_id" =!= "skewed_value")
val skewedDF = df.filter($"user_id" === "skewed_value")// 分别处理后union
val result = commonDF.union(skewedDF)五、缓存策略优化
1. 缓存热数据
val hotDF = spark.sql("SELECT * FROM hot_table")
hotDF.persist(StorageLevel.MEMORY_AND_DISK) // 内存不足时溢写到磁盘// 检查缓存状态
spark.catalog.cacheTable("hot_table")
spark.catalog.isCached("hot_table")2. 缓存策略选择
| 存储级别 | 描述 | 适用场景 |
|---|---|---|
| MEMORY_ONLY | 仅内存 | 小数据集,频繁访问 |
| MEMORY_AND_DISK | 内存+磁盘 | 中等数据集 |
| MEMORY_ONLY_SER | 序列化存储 | 内存有限,减少内存占用 |
| DISK_ONLY | 仅磁盘 | 很少访问的大数据集 |
六、高级优化技巧
1. 动态资源分配
spark-submit \--conf spark.dynamicAllocation.enabled=true \--conf spark.dynamicAllocation.initialExecutors=5 \--conf spark.dynamicAllocation.minExecutors=2 \--conf spark.dynamicAllocation.maxExecutors=20 \your_app.py2. 自适应查询执行(AQE)
// Spark 3.0+ 启用AQE
spark.conf.set("spark.sql.adaptive.enabled", "true")
spark.conf.set("spark.sql.adaptive.coalescePartitions.enabled", "true")
spark.conf.set("spark.sql.adaptive.advisoryPartitionSizeInBytes", "128MB")3. 代码生成优化
// 启用全阶段代码生成(默认已启用)
spark.conf.set("spark.sql.codegen.wholeStage", "true")// 对于复杂表达式,可调优
spark.conf.set("spark.sql.codegen.maxFields", "100")七、监控与调优
1. Spark UI分析
-
Jobs页面:识别长任务
-
Stages页面:查看数据倾斜
-
Storage页面:检查缓存效率
-
SQL页面:分析查询执行计划
2. 日志分析
# 查看Executor日志中的GC情况
grep "GC" spark-executor-*.log# 检查是否有OOM错误
grep "OutOfMemory" spark-executor-*.log八、实战优化案例
案例:优化慢速JOIN查询
原始查询:
SELECT a.*, b.*
FROM large_table a
JOIN small_table b ON a.key = b.key
WHERE a.dt BETWEEN '2023-01-01' AND '2023-01-31'优化步骤:
-
确认执行计划:发现是SortMergeJoin
-
检查表大小:small_table < 10MB
-
应用广播Join:
SELECT /*+ BROADCAST(b) */ a.*, b.* FROM large_table a JOIN small_table b ON a.key = b.key WHERE a.dt BETWEEN '2023-01-01' AND '2023-01-31' -
添加分区过滤:确保large_table按dt分区
-
调整shuffle分区:
spark.conf.set("spark.sql.shuffle.partitions", "200")
通过以上优化,该查询性能提升了15倍。
相关文章:

SparkSQL 优化实操
一、基础优化配置 1. 资源配置优化 # 提交Spark作业时的资源配置示例 spark-submit \--master yarn \--executor-memory 8G \--executor-cores 4 \--num-executors 10 \--conf spark.sql.shuffle.partitions200 \your_spark_app.py 参数说明: executor-memory: 每…...

【vLLM 学习】Cpu Offload Lmcache
vLLM 是一款专为大语言模型推理加速而设计的框架,实现了 KV 缓存内存几乎零浪费,解决了内存管理瓶颈问题。 更多 vLLM 中文文档及教程可访问 →https://vllm.hyper.ai/ *在线运行 vLLM 入门教程:零基础分步指南 源码 examples/offline_inf…...
数据库同步是什么意思?数据库架构有哪些?
目录 一、数据库同步是什么 (一)基本概念 (二)数据库同步的类型 (三)数据库同步的实现方式 二、数据库架构的类型 (一)单机架构 (二)主从复制架构 &a…...

【数据结构】详解算法复杂度:时间复杂度和空间复杂度
🔥个人主页:艾莉丝努力练剑 ❄专栏传送门:《C语言》、《数据结构与算法》 🍉学习方向:C/C方向 ⭐️人生格言:为天地立心,为生民立命,为往圣继绝学,为万世开太平 前言&…...
Rest-Assured API 测试:基于 Java 和 TestNG 的接口自动化测试
1. 右键点击项目的文件夹,选择 New > File。 2. 输入文件名,例如 notes.md,然后点击 OK。 3. 选择项目类型 在左侧的 Generators 部分,选择 Maven Archetype,这将为你生成一个基于 Maven 的项目。 4. 配置项目基…...

多模型协同:基于 SAM 分割 + YOLO 检测 + ResNet 分类的工业开关状态实时监控方案
一、技术优势与适配性分析 1. 任务分工的合理性 YOLO(目标检测) 核心价值:快速定位工业开关在图像中的位置(边界框),为后续分割和分类提供ROI(感兴趣区域)。工业场景适配性…...

【分销系统商城】
分销商城系统是一种结合电商与社交裂变的多层级分销管理平台,通过佣金激励用户成为分销商,实现低成本快速拓客和销量增长。以下是其核心要点解析: 🛍️ 一、系统定义与核心价值 基本概念 核心模式&#…...

LangChainGo入门指南:Go语言实现与OpenAI/Qwen模型集成实战
目录 1、什么是langchainGo2、langchainGo的官方地址3、LangChainGo with OpenAI3-1、前置准备3-2、安装依赖库3-3、新建模型客户端3-4、使用模型进行对话 4、总结 1、什么是langchainGo langchaingo是langchain的go语言实现版本 2、langchainGo的官方地址 官网:…...

5.1 HarmonyOS NEXT系统级性能调优:内核调度、I/O优化与多线程管理实战
HarmonyOS NEXT系统级性能调优:内核调度、I/O优化与多线程管理实战 在HarmonyOS NEXT的全场景生态中,系统级性能调优是构建流畅、高效应用的关键。通过内核调度精细化控制、存储与网络I/O深度优化,以及多线程资源智能管理,开发者…...

react public/index.html文件使用env里面的变量
env文件 ENVdevelopment NODE_ENVdevelopment REACT_APP_URL#{REACT_APP_URL}# REACT_APP_CLIENTID#{REACT_APP_CLIENTID}# REACT_APP_TENANTID#{REACT_APP_TENANTID}# REACT_APP_REDIRECTURL#{REACT_APP_REDIRECTURL}# REACT_APP_DOMAIN_SCRIPT#{REACT_APP_DOMAIN_SCRIPT}#pu…...
chili3d 笔记17 c++ 编译hlr 带隐藏线工程图
这个要注册不然emscripten编译不起来 --------------- 行不通 ---------------- 结构体 using LineSegment std::pair<gp_Pnt, gp_Pnt>;using LineSegmentList std::vector<LineSegment>; EMSCRIPTEN_BINDINGS(Shape_Projection) {value_object<LineSegment&g…...

创建一个纯直线组成的字体库
纯直线组成的字体,一个“却”由五组坐标点组成,存储5个点共占21字节,使用简单,只要画直线即可, “微软雅黑”,2个轮廓,55坐标点,使用复杂,还填充。 自创直线字体 “微软…...

接口不是json的内容能用Jsonpath获取吗,如果不能,我们选用什么方法处理呢?
JsonPath 是一种专门用于查询和提取 JSON 数据的查询语言(类似 XPath 用于 XML)。以下是详细解答: JsonPath 的应用场景 API 响应处理:从 REST API 返回的 JSON 数据中提取特定字段。配置文件解析:读取 J…...
)
使用 Docker Compose 从零部署 TeamCity + PostgreSQL(详细新手教程)
JetBrains TeamCity 是一款专业的持续集成(CI)服务器工具,支持各种编程语言和构建流程。本文将一步一步带你用 Docker 和 Docker Compose 快速部署 TeamCity,搭配 PostgreSQL 数据库,并确保 所有操作新手可跟着做。 一…...
)
Go 语言实现高性能 EventBus 事件总线系统(含网络通信、微服务、并发异步实战)
前言 在现代微服务与事件驱动架构(EDA)中,事件总线(EventBus) 是实现模块解耦与系统异步处理的关键机制。 本文将以 Go 语言为基础,从零构建一个高性能、可扩展的事件总线系统,深入讲解&#…...
Linux进程(中)
目录 进程等待 为什么有进程等待 什么是进程等待 怎么做到进程等待 wait waitpid 进程等待 为什么有进程等待 僵尸进程无法杀死,需要进程等待来消灭他,进而解决内存泄漏问题--必须解决的 我们要通过进程等待,获得子进程退出情况--知…...
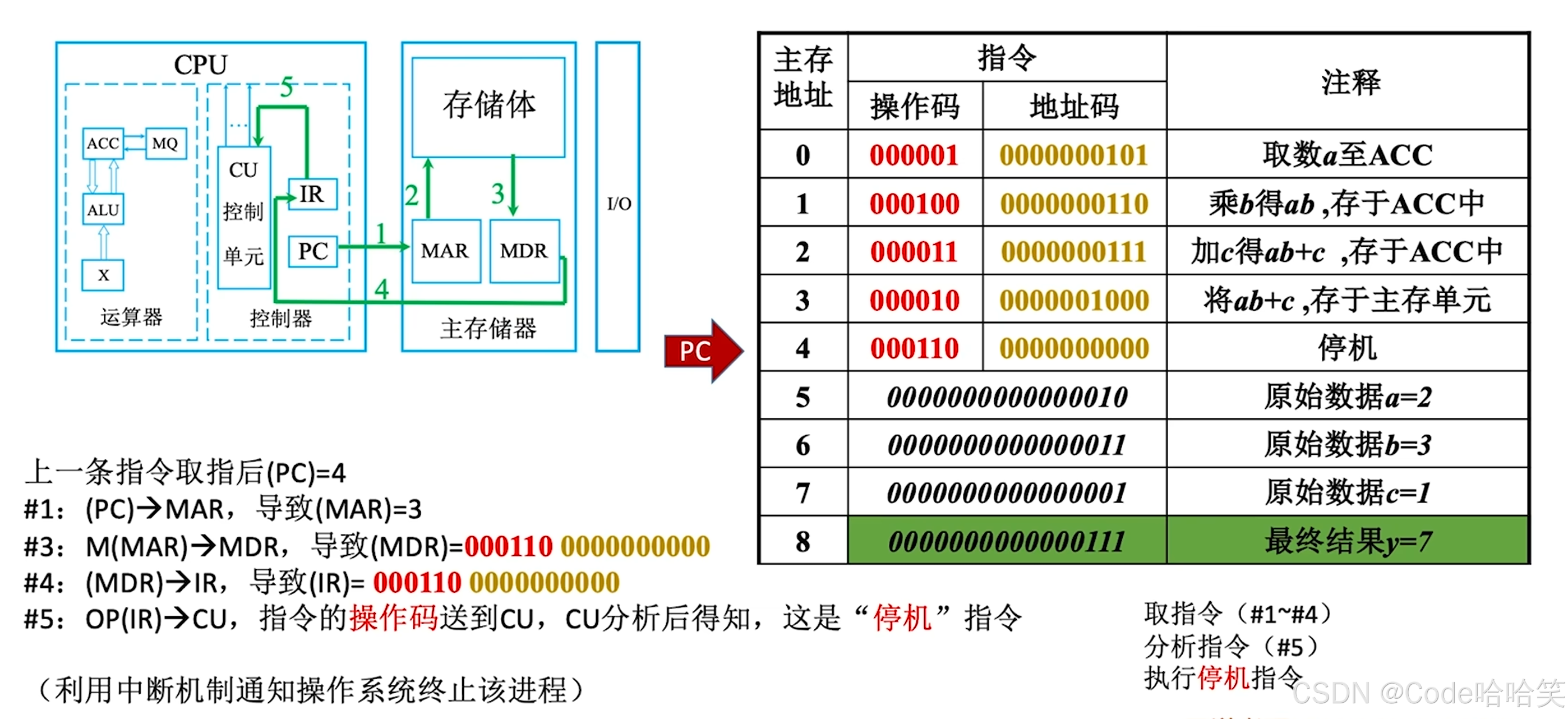
【计算机组成原理】计算机硬件的基本组成、详细结构、工作原理
引言 计算机如同现代科技的“大脑”,其硬件结构的设计逻辑承载着信息处理的核心奥秘。从早期程序员手动输入指令的低效操作,到冯诺依曼提出“存储程序”概念引发的革命性突破,计算机硬件经历了从机械操控到自动化逻辑的蜕变。本文将深入拆解…...
)
npm error Cannot read properties of null (reading ‘matches‘)
当在使用 npm 命令时遇到 Cannot read properties of null (reading matches) 错误,这通常表示代码尝试访问一个 null 对象的 matches 属性。以下是综合多个来源的解决策略,按优先级排列: 一、核心解决方法 1. 清理缓存与重新安装依赖&…...

MVC分层架构模式深入剖析
🔄 MVC 交互流程 #mermaid-svg-5xGt0Ka13DviDk15 {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-5xGt0Ka13DviDk15 .error-icon{fill:#552222;}#mermaid-svg-5xGt0Ka13DviDk15 .error-text{fill:#552222…...
【方案分享】蓝牙Beacon定位精度优化(包含KF、EKF与UKF卡尔曼滤波算法详解)
蓝牙Beacon定位精度优化:KF、EKF与UKF卡尔曼滤波算法详解 标签:蓝牙定位|Beacon|卡尔曼滤波|UKF|EKF|RSSI|室内定位|滤波算法|精度优化 相关分享:…...

新能源汽车热管理核心技术解析:冬季续航提升40%的行业方案
新能源汽车热管理核心技术解析:冬季续航提升40%的行业方案 摘要:突破续航焦虑的关键在热能循环! 👉 本文耗时72小时梳理行业前沿方案,含特斯拉/比亚迪等8家车企热管理系统原理图 一、热管理为何成新能源车决胜关键&am…...
)
LeetCode 239. 滑动窗口最大值(单调队列)
题目传送门:239. 滑动窗口最大值 - 力扣(LeetCode) 题意就是求每个窗口内的最大值,返回一个最大值的数组,滑动窗口的最值问题。 做法:维护一个单调递减队列,队头为当前窗口的最大值。 设计的…...
华为云Flexus+DeepSeek征文|DeepSeek-V3/R1开通指南及使用心得
🏆作者简介,黑夜开发者,CSDN领军人物,全栈领域优质创作者✌,CSDN博客专家,阿里云社区专家博主,2023年CSDN全站排名top 28。 🏆数年电商行业从业经验,AWS/阿里云资深使用用…...
)
鸿蒙图片缓存(一)
移动端开发过程中图片缓存功能是必备,iOS和安卓都有相关工具库,鸿蒙系统组件本身也自带缓存功能,但是遇到复杂得逻辑功能还是需要封装图片缓存工具。 系统组件Image 1. Image的缓存策略 Image模块提供了三级Cache机制,解码后内…...
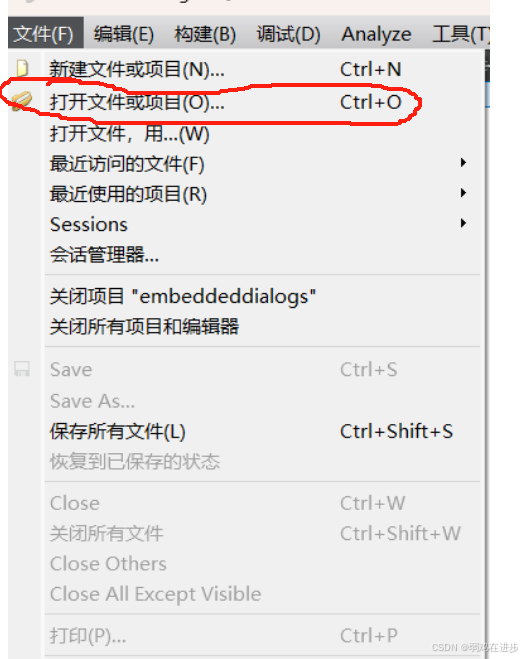
运行示例程序和一些基本操作
欢迎 ----> 示例 --> 选择sample CTRL B 编译代码 CTRL R 运行exe 项目 中 Shadow build 表示是否 编译生成文件和 源码是否放一块 勾上不在同一个地方 已有项目情况下怎么打开项目 方法一: 左键双击 xxx.pro 方法二: 文件菜单里面 选择打开项目...

学习数字孪生,为你的职业发展开辟新赛道
你有没有想过,未来十年哪些技能最吃香? AI、大数据、智能制造、元宇宙……这些词频繁出现在招聘市场和行业报告中。而在它们背后,隐藏着一个“看不见但无处不在”的关键技术——数字孪生(Digital Twin)。 它不仅在制造…...
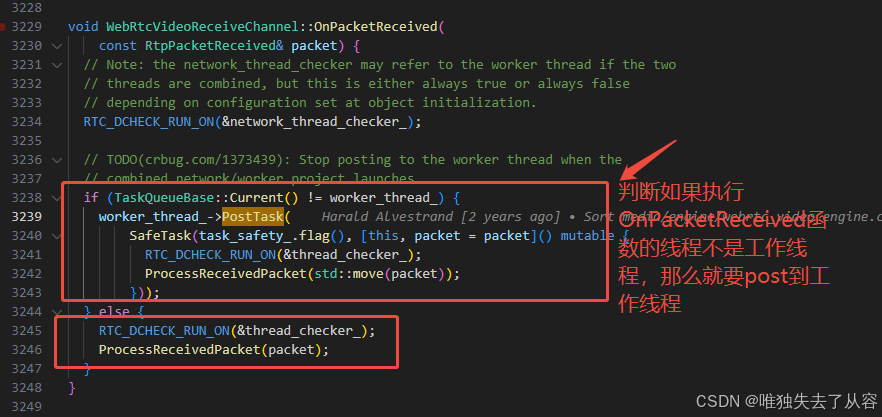
WebRTC源码线程-1
1、概述 本篇主要是简单介绍WebRTC中的线程,WebRTC源码对线程做了很多的封装。 1.1 WebRTC中线程的种类 1.1.1 信令线程 用于与应用层的交互,比如创建offer,answer,candidate等绝大多数的操作 1.1.2 工作线程 负责内部的处理逻辑&…...

python学习打卡day47
DAY 47 注意力热图可视化 昨天代码中注意力热图的部分顺移至今天 知识点回顾: 热力图 作业:对比不同卷积层热图可视化的结果 # 可视化空间注意力热力图(显示模型关注的图像区域) def visualize_attention_map(model, test_loader,…...
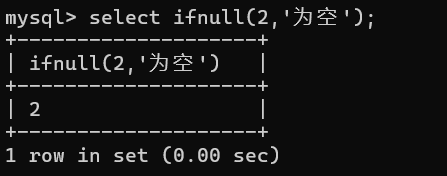
MySQL中的内置函数
文章目录 一、日期函数1.1 获取当前的日期1.2 获取当前时间1.3 获取当前日期和时间1.4 提取时间日期1.5 添加日期1.6 减少日期1.7 两个日期的差值 二、字符串处理函数2.1 获取字符串的长度2.2 获取字符串的字节数2.3 字符串拼接2.4 转小写2.5 转大写2.6 子字符串第⼀次出现的索…...

Ansible自动化运维全解析:从设计哲学到实战演进
一、Ansible的设计哲学:简单即正义 在DevOps工具链中,Ansible以其"无代理架构(Agentless)"设计独树一帜。这个用Python编写的自动化引擎,通过SSH协议与目标主机通信,彻底摒弃了传统配置管理工具…...