基于功能基团的3D分子生成扩散模型 - D3FG 评测
D3FG 是一个在口袋中基于功能团的3D分子生成扩散模型。与通常分子生成模型直接生成分子坐标和原子类型不同,D3FG 将分子分解为两类组成部分:官能团和连接体,然后使用扩散生成模型学习这些组成部分的类型和几何分布。
一、背景介绍
D3FG 来源于西湖大学工学院计算机科学与技术系的李子青教授课题组的工作:《Functional-Group-Based Diffusion for Pocket-Specific Molecule Generation and Elaboration》。文章链接:https://arxiv.org/abs/2306.13769 。该文章于 2024 年 3 月 18 日发表在 Arxiv 上。

当前基于结构的分子生成方法大多数是基于原子层面的,将原子视为基本组成部分,生成原子的位置和类型。但这些方法很难生成具有复杂结构的分子。为解决这一问题,作者提出了基于功能基团扩散的 D3FG 模型,用于特定口袋的分子生成和扩展。
D3FG 将分子分解为两类组成部分:作为刚体的官能团和作为质量点的连接体。通过这两类组件可以形成复杂的片段,增强配体-蛋白相互作用。具体而言,在扩散过程中,D3FG 将组件的位置、方向和类型的数据分布扩散到先验分布中;在生成过程中,设计的等变图神经网络参数化的去噪器逐步去除这三个变量中的噪声。
实验评估结果显示,D3FG 可以生成具有更真实的 3D 结构、对蛋白质靶点有竞争性亲和力、并且具备更优药物性质的分子。此外,D3FG 还作为分子优化新任务的解决方案,能够根据现有配体和目标蛋白的热点生成具有高亲和力的分子。
二、模型介绍
相似的结构执行相似的功能是药物-靶标识别领域的公认理念之一。据此可以通过将蛋白-配体相互作用抽象为药效团,通过对齐相似的功能基团,从这些结构中提取药物信息。将合适的功能基团嵌入药效团可以增强配体-蛋白相互作用,从而提高药物的效率。
当前基于结构的分子生成方法存在两方面不足。一方面,它们很难生成能够为靶标贡献药理学效应的真实官能团,另一方面是难以在蛋白质上下文信息的效率和充分性之间做到很好的平衡。
为解决上述问题,作者提出了基于官能团的扩散模型 D3FG,主要有如下贡献:
(1)方法创新。作者将分子的官能团和蛋白质的氨基酸视为同一层次的片段,其中原子间的相对位置是固定的,如同刚体,并将单个原子表示为连接体。通过去噪过程逐步生成局部结构的位置、方向和原子类型变量。片段-连接体的设计使得结合系统成为异质图,并提出了两种解决方案,能够在分子结构、结合亲和力和药物性质方面实现竞争性性能,同时通过利用更多特征充分编码蛋白质上下文信息。
(2)建立数据集。基于 CrossDocked 2020 数据集,深入探索了分子官能团的相对位置和类型的细节,建立了一个可扩展的常见官能团数据库。
(3)提出新任务。除了分子生成外,作者还提出了分子优化作为模型可以完成的另一个任务。作者使用片段热点图(FHM)对 CrossDocked 2020 中的蛋白-分子对进行预处理,以完成该任务。结果表明,D3FG 能够基于参考分子生成具有高结合亲和力的分子。
2.1 模型框架
D3FG 首先将分子分解为两类组成部分:官能团和连接体,然后使用扩散生成模型学习这些组成部分的类型和几何分布。
扩散模型通过构建两个马尔可夫过程来学习数据分布。第一个过程是前向扩散过程,逐渐添加噪音,直到噪音数据的分布接近先验分布。另一个过程是生成去噪过程,逐步从采样自先验分布的数据中去除噪音,直到它们恢复到目标数据分布。
在前向过程中,单个官能团或连接体表示成独热编码被随机转移到吸收状态。在生成过程中,首先从吸收状态中采样出连接体和官能团,它们的类型均处于吸收状态,然后从中按照一定的比例吧部分样本的类型从吸收状态转化为预测状态。
为了降低计算复杂度,作者将蛋白质上下文编码到氨基酸级别。除了氨基酸类型之外,还使用了 C_{α}原子坐标和方向、每个原子在局部系统中的坐标以及三个扭转角作为氨基酸内部特征。这些特征通过多层感知机(MLP)进行拼接和嵌入,形成氨基酸内嵌入向量。这些嵌入向量都是平移和旋转不变的。
如下表所示,在采样过程中,作者将蛋白质的位置信息和原子信息特征处理成模型输入的形式,并从两个训练集获得的经验分布中采样连接原子数和官能团数。从采样的初始状态逐步更新官能团和原子的状态,进而更新生成的分子状态。经过 T-1 个时间步后,确定生成分子官能团和原子的最终位置、类型及其旋转矩阵。

氨基酸和功能基团都是由蛋白质和分子中的原子组成的片段,被视为刚体,而连接器是单个原子,被视为质点。因此,在结合图中,节点处于不同的层次,连接也是不同种类的,从而导致图的异构性。为此,作者提出了两种生成方案:联合生成方案和两阶段生成方案,如下图所示。
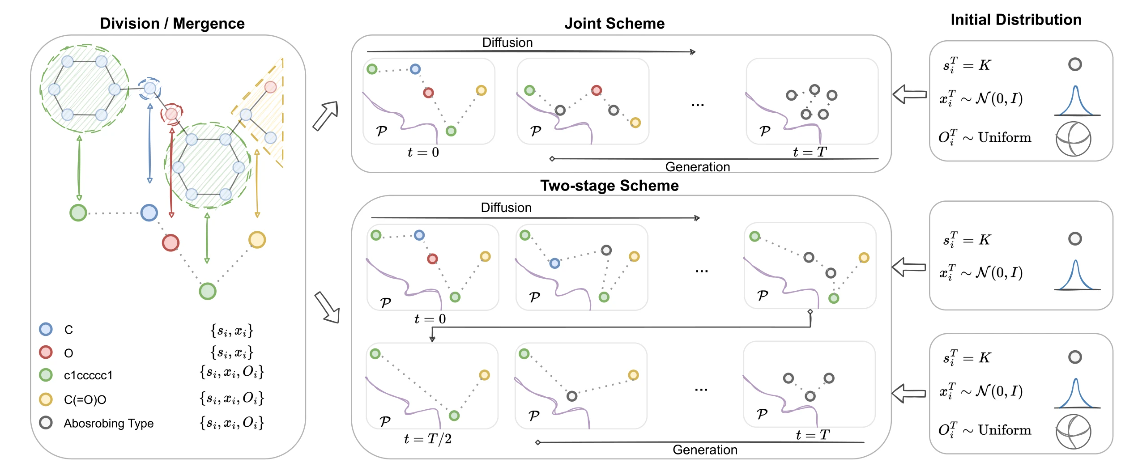
在联合生成方案中,作者将氨基酸、官能团和连接体视为同一层次,并使用单个神经网络来预测和更新这三种变量。
在两阶段方案中,作者将氨基酸、官能团视为片段层次,而连接体视为原子层次,并使用两个不同的神经网络对转移分布进行参数化。在第一阶段,生成官能团,然后在第二阶段生成单个原子作为连接体,将已经生成的官能团连接成一个完整分子。该方案类似于计算机辅助药物设计过程(CADD),首先确定针对目标蛋白质的药效团,将具有高活性的官能团嵌入其中,然后搜索含有这些官能团的潜在分子。
2.2 数据集、评价指标和基线模型
在实验中,作者使用 CrossDocked 2020 进行评估。在现有的工作大多专注于原子级别的分子生成,而 D3FG 基于官能团生成,因此需要将分子划分为官能团和连接体。作者选择了 25 种最常见且结构稳定的官能团,它们部分展示于下图。对于一些官能团,它们的结构中存在手性,作者将它们视为两种不同的官能团。最终,为 CrossDocked 2020 构建了包含 27 种官能团(25 种中有两种具有手性)的数据集,且这些官能团的内部结构被固定为刚体,确保大多数分子可以分解为数据集中的子结构。对于连接基体,选择 {B, C, N, O, F, P, S, Cl, Br, I} 作为代表性的重原子。经过处理后,在实验中,M_fg = 27 和 M_at = 10,对应 27 种官能团和 10 种原子的连接体。此外,通过结合图中的片段-连接体划分,图神经网络的消息传递节点数量平均减少至 53.62 个。
对于分子生成任务,训练和评估的数据集按照 Pocket2Mol 和 TargetDiff 划分。选择了 2250 万个低 RMSD(< 1Å)且序列同一性小于 30% 的对接蛋白质结合复合物,最终选出 10 万个口袋-配体复合物对,以 100 个新的复合物作为评估参考。
对于分子优化任务,药效团信息通过计算目标蛋白的片段热点图(FHM)来提取。具体而言,FHM 描述了结合口袋中可能对结合亲和力产生积极贡献的区域。通过将分子放置在结合口袋中,可以根据结合复合物获得每个官能团的热点评分。官能团的热点评分越高,对结合亲和力的贡献就越大。基于 Cross Docked 2020 中的 100,000 对口袋-配体复合物,作者计算了每个配体的官能团热点评分,并根据这些评分选择官能团。最终,基于 FHM 建立了新的分子优化数据集。
评价指标主要包括结构分析、结合亲和力和药物属性三个方面。在结构分析方面,统计了生成分子种包含官能团的比例和频率。其中,比例表示每个分子平均包含的指定官能团数量,频率表示生成分子中指定官能团出现的统计频率。均方误差(MAE)作为整体指标,依据参考比例和生成比例计算;Jensen-Shannon散度(JSD)则依据参考频率和生成频率计算。MAE 和 JSD 越小,表明该方法的性能越好。
结合亲和力方面使用了两个评估指标:Vina 对接评分和 Gnina 对接评分。较低的 Vina 能量评分表明分子具有更好的结合亲和力。Gnina 对接是一种基于深度学习的对接工具,会对结合亲和力高的分子给出较高的评分。∆ Affinity 衡量的是生成的分子中结合亲和力优于相应参考分子的百分比。
药物属性方面的评估指标包括 QED、SA、LogP 和 Lipinski 五规则的遵循情况。QED、SA 和 Lipinski 是三个偏好原子数量的指标。
为了性能比较,作者选择了当前的 6 种基线模型和 D3FG 进行对比。LIGAN 作为基于 3D CNN 的方法,在规则网格上生成原子,并使用 VAE 作为其生成模型。3DSBDD、GraphBP 和 Pocket2Mol 都是基于 GNN 的方法,以自回归的方式生成原子。DiffSBDD 和 TargetDiff 是基于扩散的两种方法,在全原子级别生成分子,并使用等变 GNN 作为去噪器。提供了两种生成方案,官能团和连接体联合生成方案和两阶段生成方案,分别记作 D3FG(Joint) 和 D3FG(Stage)。作者选择 Pocket2Mol 作为自回归方法的代表,并选择 DiffSBDD 和 TargetDiff 作为使用扩散模型的基准,因为这三种基线方法是最新的,并显示出良好的经验性能。
2.3 模型性能
D3FG 模型可以应用到基于口袋从头生成分子和对参考分子优化两个任务上,下面针对这两个任务的性能分别展示评估结果。针对该任务,作者设置每种方法采样 100 个分子,在 100 个测试蛋白体系上共生成 10000 对复合物。
2.3.1 分子生成任务
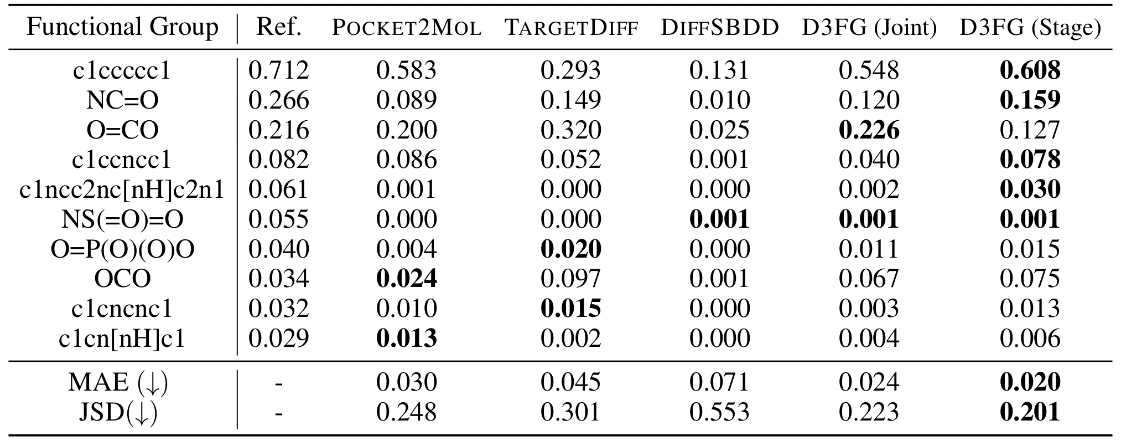
下表展示了在 Crossdocked 2020 数据集中频率最高的前十个官能团的比例。Ref 是在训练集中计算的结果。MAE(平均绝对误差)是在 Ref. 和不同方法的比例之间计算得出。JSD(杰森-香农散度)是根据“频率”计算的。相较于基线模型,D3FG 生成分子中的官能团分布与真实药物分子更为相似,表明 D3FG 在生成具有真实药物结构的分子方面表现出色。
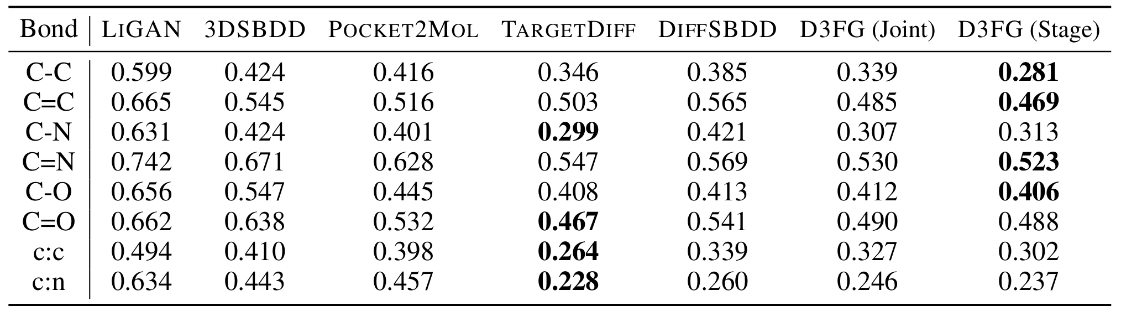
接着,作者计算了键长分布的 JSD,以参考分子为基准与生成分子进行对比。符号 ‘-’、‘=’、‘:’ 分别代表单键、双键和芳香键。JSD 的数值越小越好。从下表可以看出,D3FG(Stage) 和 TargetDiff 是最具有竞争力的方法。
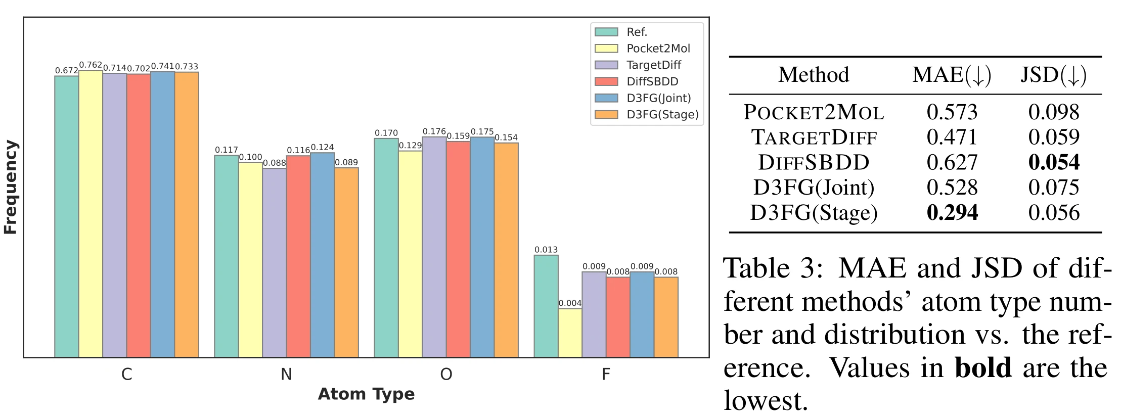
下图给出了详细的原子类型频率,下表展示了不同方法生成分子和参考分子原子类型的比较。综合来看,D3FG(Stage) 在生成更具现实性的分子方面优于 D3FG(joint) ,并且其性能与 TargetDiff 具有竞争力。
2.3.2 分子优化任务
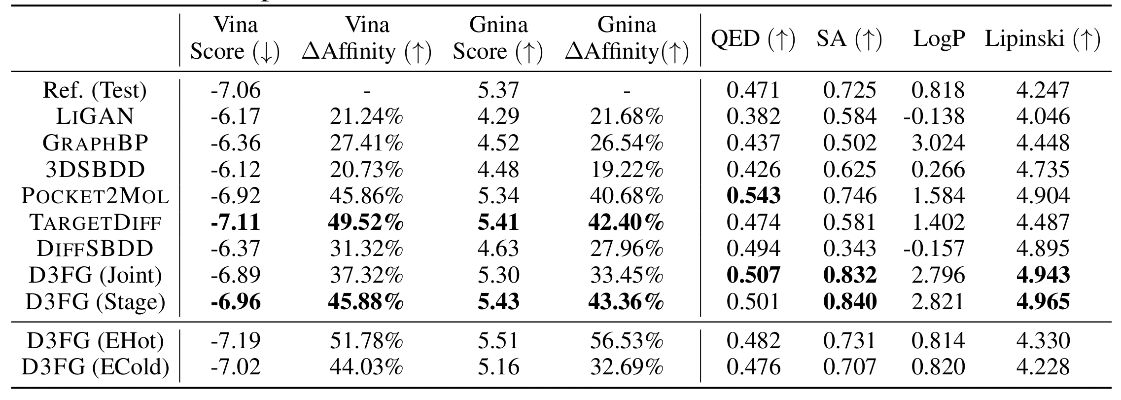
在分子优化中,考虑了两种方案。第一种是移除具有最高热点评分的官能团,并通过 D3FG 生成的官能团替换剩余的片段,将其表示为 D3FG(EHot)。第二种方案 D3FG(ECold) 则是替换具有最低热点评分的官能团。下表中展示了 D3FG 通过这两种方案优化后的分子指标。结果显示,D3FG(EHot) 倾向于生成更多具有更高亲和力的分子,而 D3FG(ECold) 优化的分子在结合亲和力上与原始参考分子相比几乎没有差异。此外,在其他化学性质方面,优化后的分子与原始参考分子非常接近,因为两者的差异仅在于一个官能团,而主要的分子骨架几乎保持不变。
三、D3FG 评测
3.1 安装环境
复制代码项目:
git clone https://github.com/EDAPINENUT/CBGBench.git使用项目提供的 environment.yml 创建 D3FG 环境并安装基础依赖库(将yml文件中的名字手动改为 D3FG),命令如下:
conda env create -f environment.yml
conda activate D3FG安装 pytorch 和 torch_geometric:
conda install pytorch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 pytorch-cuda=11.8 -c pytorch -c nvidia
conda install pyg pytorch-scatter pytorch-cluster -c pyg安装化学处理相关的依赖库:
# install rdkit, efgs, obabel, etc.
pip install --use-pep517 EFGs
pip install biopython
pip install lxml
conda install rdkit openbabel tensorboard tqdm pyyaml easydict python-lmdb -c conda-forge
安装对接相关的工具:
conda install -c conda-forge numpy swig boost-cpp sphinx sphinx_rtd_theme
python -m pip install git+https://github.com/Valdes-Tresanco-MS/AutoDockTools_py3
pip install meeko==0.1.dev3 scipy
conda install pdb2pqr vina3.2 训练模型
3.2.1 下载项目数据
作者把项目用到的数据保存在谷歌网盘,链接是 https://drive.google.com/drive/folders/1YulDlChalaIjqRJjCyOFSY1-KoZ-hYCP 。
D3FG 采用官能团和连接体两阶段生成方案。网盘中 pl_fg 文件夹中是预处理好的用于训练官能团模型的数据,pl 文件夹中是训练连接体模型的数据。这两个文件夹的数据和 split_by_name_10m.pt 下载后放在项目 .data/ 文件夹中。./data 文件夹的目录如下:
.
|-- pl
| |-- crossdocked_name2id.pt
| |-- crossdocked_v1.1_rmsd1.0_pocket10_processed_fullatom.lmdb
| `-- crossdocked_v1.1_rmsd1.0_pocket10_processed_linker.lmdb
|-- pl_fg
| |-- crossdocked_name2id_funcgroup.pt
| `-- crossdocked_v1.1_rmsd1.0_pocket10_processed_funcgroup.lmdb
`-- split_by_name_10m.pt2 directories, 6 files3.2.2 训练官能团模型
整个项目需要分别训练官能团模型和连接体模型。首先训练官能团模型,具体命令如下:
python train.py \--config ./configs/denovo/train/d3fg_fg.yml \--logdir ./logs/denovo/d3fg_fg--config ./configs/denovo/train/d3fg_fg.yml 指定训练的配置文件。--logdir ./logs/denovo/d3fg_fg 指定训练记录和模型保存的位置。官能团训练的 batch_size 设置为 40,最大迭代次数设置为 500000,显存占用在 18 - 22 GB 范围内有一定波动,具体配置如下:
model:type: difffgencoder:type: itatransformernode_feat_dim: 256n_heads: 16num_layers: 9generator:pos_schedule:type: sigmoidbeta_start: 1.e-7beta_end: 2.e-3rot_schedule:type: cosinecosine_s: 0.01fg_schedule: type: cosinecosine_s: 0.01num_diffusion_timesteps: 1000time_sampler: symmetricembedder:type: fgemb_dim: 256 #emb_dim should equal to node_feat_dimfg:type: linearresidue:type: framedata:train: !include ../common/fg_data_train.ymlfollow_batch: - protein_type_fg- ligand_type_fgtrain:loss_weights:pos: 1.0rot: 1.0fg: 100.0max_iters: 500000report_freq: 100batch_size: 40seed: 2022max_grad_norm: 8.0optimizer:type: adamlr: 5.e-4weight_decay: 0.0beta1: 0.95beta2: 0.999scheduler:type: plateaufactor: 0.6patience: 10min_lr: 1.e-6eval:val_freq: 1000metrics:- name: auroctrue_key: v0pred_key: c_predmask_key: mask_gentag: fg官能团模型训练设置最大迭代次数为 500000 次,训练花费时间约 30 个小时。训练记录文件以及模型保存在 ./logs/denovo/d3fg_fg/selftrain 中,训练的最好的模型是 ./logs/denovo/d3fg_fg/selftrain/checkpoints/45000.pt 。
3.2.3 训练连接体模型
训练连接体模型,--config ./configs/denovo/train/d3fg_linker.yml 指定配置文件,--logdir ./logs/denovo/d3fg_linker 指定训练记录和模型的保存位置。具体命令如下:
python train.py \--config ./configs/denovo/train/d3fg_linker.yml \--logdir ./logs/denovo/d3fg_linker--config ./configs/denovo/train/d3fg_linker.yml 指定训练的配置文件。--logdir ./logs/denovo/d3fg_linker 指定训练记录和模型保存的位置。官能团训练的 batch_size 设置为 4,最大迭代次数设置为 5000000,显存占用在 18 - 22 GB 范围内有一定波动,训练官能团的配置文件 ./configs/denovo/train/d3fg_linker.yml 具体内容如下:
model:type: targetdiffencoder:type: unitransformernode_feat_dim: 128n_heads: 16num_layers: 9generator:pos_schedule:type: sigmoidbeta_start: 1.e-7beta_end: 2.e-3atom_schedule: type: cosinecosine_s: 0.01num_diffusion_timesteps: 1000time_sampler: symmetricembedder:type: faemb_dim: 128 #emb_dim should equal to node_feat_dimatom:type: linearresidue:type: lineardata:train: !include ../common/linker_data_train.ymlfollow_batch: - protein_element- ligand_elementtrain:loss_weights:pos: 1.0rot: 1.0atom: 100.0max_iters: 5000000report_freq: 100batch_size: 4seed: 2022max_grad_norm: 8.0optimizer:type: adamlr: 5.e-4weight_decay: 0.0beta1: 0.95beta2: 0.999scheduler:type: plateaufactor: 0.6patience: 10min_lr: 1.e-6eval:val_freq: 1000metrics:- name: auroctrue_key: v0pred_key: c_predmask_key: mask_gen使用了作者重新处理的数据,连接体模型可以正常训练。默认设置最大迭代次数为 5000000,
根据记录文件的平均迭代速度,预计训练到最大迭代次数需要约 250 个小时,大概 10 天,可以到 Loss 基本不变的时候提前结束训练。
3.3 分子生成案例测试
我们使用上一小节训练好的官能团模型和连接体模型来在项目的内置案例上生成分子。训练好的两个模型分别是 ./logs/denovo/d3fg_fg/selftrain/checkpoints/45000.pt 和 ./logs/denovo/d3fg_linker/selftrain/checkpoints/4271000.pt 。
3.3.1 内置案例
项目提供 ADRB1 和 DRD3 靶点作为测试案例,提供处理好的数据,在谷歌网盘中,如下所示。链接为:https://drive.google.com/drive/folders/1YulDlChalaIjqRJjCyOFSY1-KoZ-hYCP 。下载 case_study 文件夹,保存到 ./data 文件夹中。
ADRB1 靶点使用的蛋白质是 2VT4.pdb ,参考配体并不包含在晶体结构中,而是作者挑选的一个活性分子,活性分子在口袋中的结构如下所示。该口袋位于蛋白的表面。
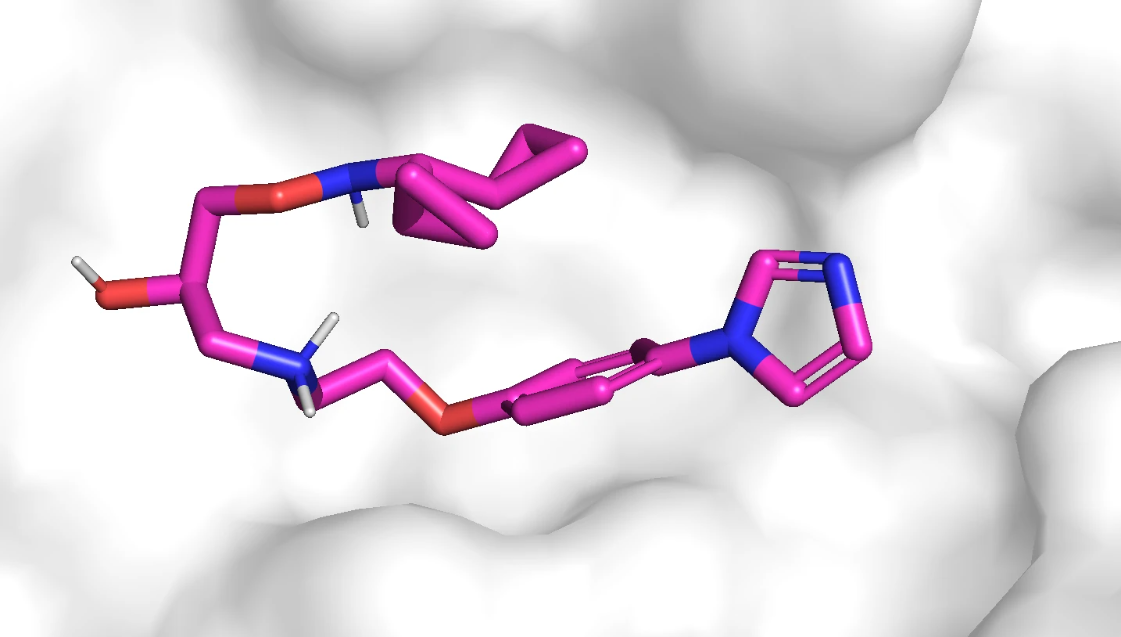
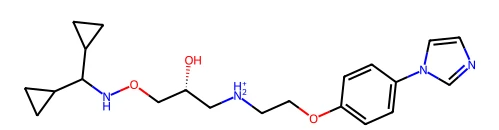
活性分子的 2D 结构如下:
DRD3 靶点使用的蛋白质是 3PBL.pdb ,参考配体并不包含在晶体结构中,而是作者挑选的一个活性分子,活性分子在口袋中的结构如下所示。口袋是多个 β-螺旋结构形成的小空间。
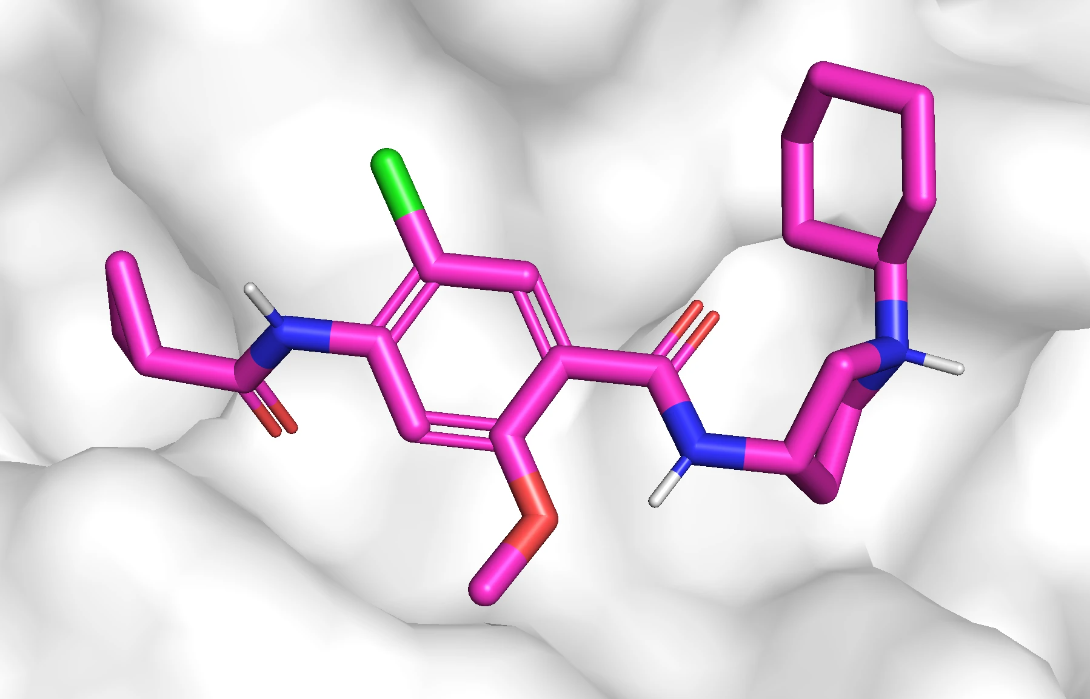
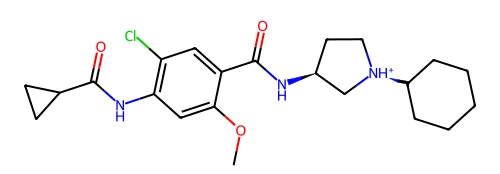
活性分子的 2D 结构如下:
使用上述训练好的模型针对内置案例生成分子,配置使用项目提供的默认配置文件 ./configs/denovo/casestudy/d3fg_fg.yml ,生成分子保存在 ./results/denovo 文件夹中。
首先生成分子的官能团,具体命令如下:
python sample.py \--config ./configs/denovo/casestudy/d3fg_fg.yml \--out_root ./results/denovo \--tag selftrain \--checkpoint 45000./configs/denovo/casestudy/d3fg_fg.yml 配置文件中设置输入结构的文件夹,基于口袋生成 100 个分子。具体配置如下:
model:type: difffgcheckpoint: ./logs/denovo/d3fg_fg/selftrain/checkpoints/45000.ptdata:test: name: pl_fgraw_path: ./data/case_studysplit_path: ./data/case_study/split_by_name.ptprocessed_dir: ./data/case_study/processed/transform:- type: select_fg- type: remove_ligand- type: featurize_protein_fgmode: fg_only- type: center_frame_poscenter_flag: protein- type: assign_fgnumdistribution: prior_distcond- type: assign_fgtypedistribution: uniformmode: fg_only- type: assign_fgposdistribution: gaussian- type: assign_fgoridistribution: uniform- type: mergekeys: - protein- ligandfollow_batch: - protein_type_fg- ligand_type_fgsampling:seed: 2022num_samples: 100translate: falsefg2mol:basic_mode: trueADRB1 和 DRD3 两个靶点同时生成,生成分子的官能团信息分别保存在 ./results/denovo/d3fg_fg/selftrain/adrb1_act/adrb1_active_pocket10 和 ./results/denovo/d3fg_fg/selftrain/drd3_act/drd3_active_pocket10 。生成官能团的过程显存占用约 3 GB,用时约 15 分钟。
接着使用上述训练好的连接体模型把生成的官能团连接成完整的分子。
使用项目提供的连接体配置文件 ./configs/denovo/casestudy/d3fg_linker.yml ,生成分子的保存路径为 ./results/denovo/,具体命令如下:
python sample.py \--config ./configs/denovo/casestudy/d3fg_linker.yml \--out_root ./results/denovo/ \--tag selftrain \--checkpoint 4271000 ./configs/denovo/casestudy/d3fg_linker.yml 配置文件设置上一步生成的官能团信息文件路径,重构分子结构 reconstruct 设置为 True,输出生成分子的 SDF 结构,具体配置信息
model:type: targetdiffcheckpoint: ./logs/denovo/d3fg_linker/selftrain/checkpoints/4271000.pt
data:test: name: pl_fgraw_path: ./data/case_studysplit_path: ./data/case_study/split_by_name.ptprocessed_dir: ./data/case_study/processed/transform:- type: select_linker- type: featurize_protein_fa- type: remove_ligand- type: center_poscenter_flag: protein- type: load_ctxctx_path: ./results/denovo/d3fg_fg/selftrainmode: basic- type: assign_linkernumdistribution: prior_distcond- type: assign_atomtypedistribution: uniformmode: basic- type: assign_molposdistribution: gaussian- type: merge_ctx_gen- type: mergekeys: - protein- ligandfollow_batch: - protein_element- ligand_elementsampling:seed: 2022num_samples: 100translate: truereconstruct:basic_mode: true
ADRB1 和 DRD3 两个靶点同时生成,生成分子的结构文件分别保存在 ./results/denovo/d3fg_linker/selftrain/adrb1_act/adrb1_active_pocket10 和 ./results/denovo/d3fg_linker/selftrain/drd3_act/drd3_active_pocket10 。生成官能团的过程显存占用约 5 GB,生成连接体重构分子构象的过程比较费时,用时约 20 个小时。ADRB1 和 DRD3 两个靶点最终分别生成 54 个和 18 个分子。
D3FG 在分子生成 ADRB1 体系上生成的分子如下:
D3FG_adrb1
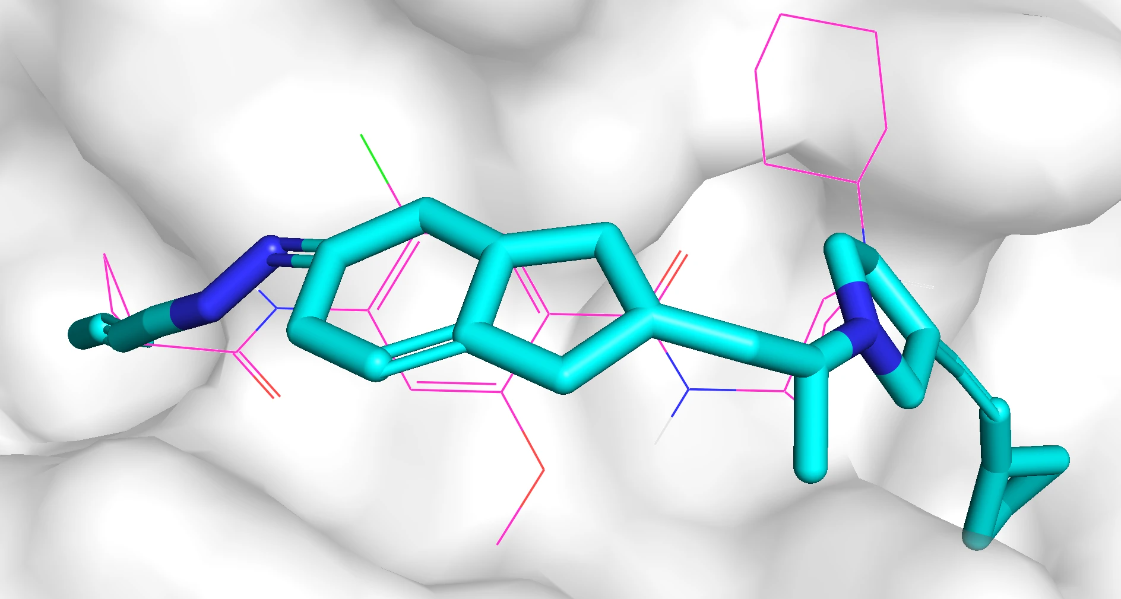
qvina score 排名前 3 的分子的 2D 结构如下,对应的 qvina score 分数分别为 -7.9, -7.8, -7.7:
qvina score 排名前 3 的分子在口袋中的 Pose 如下,紫红色的是参考分子,蓝色的是生成分子,该口袋位于蛋白表面。
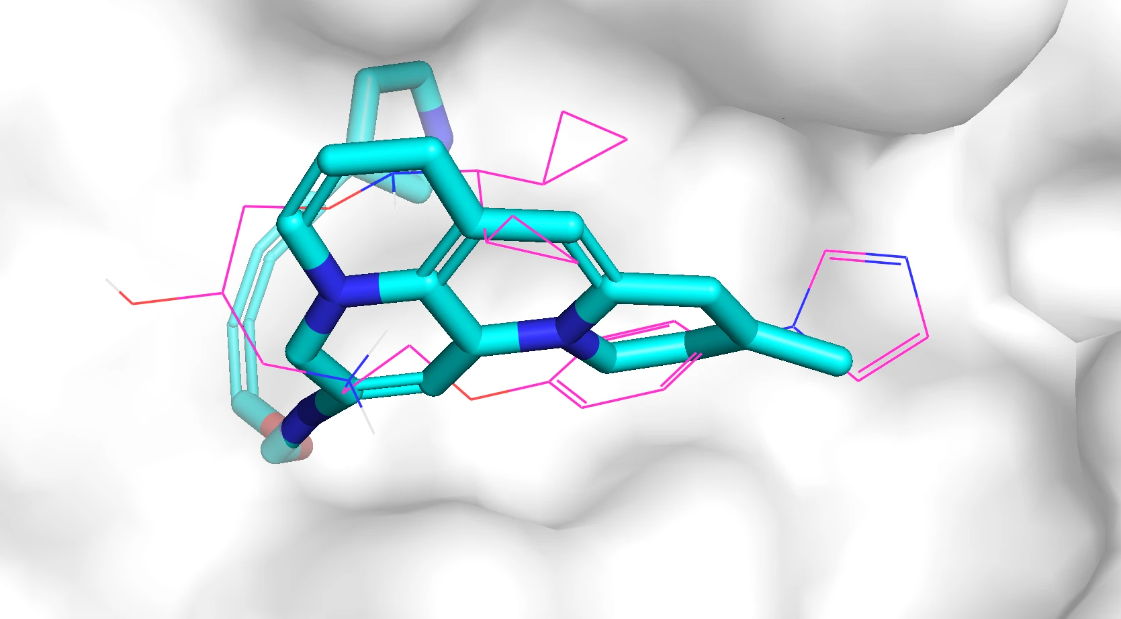
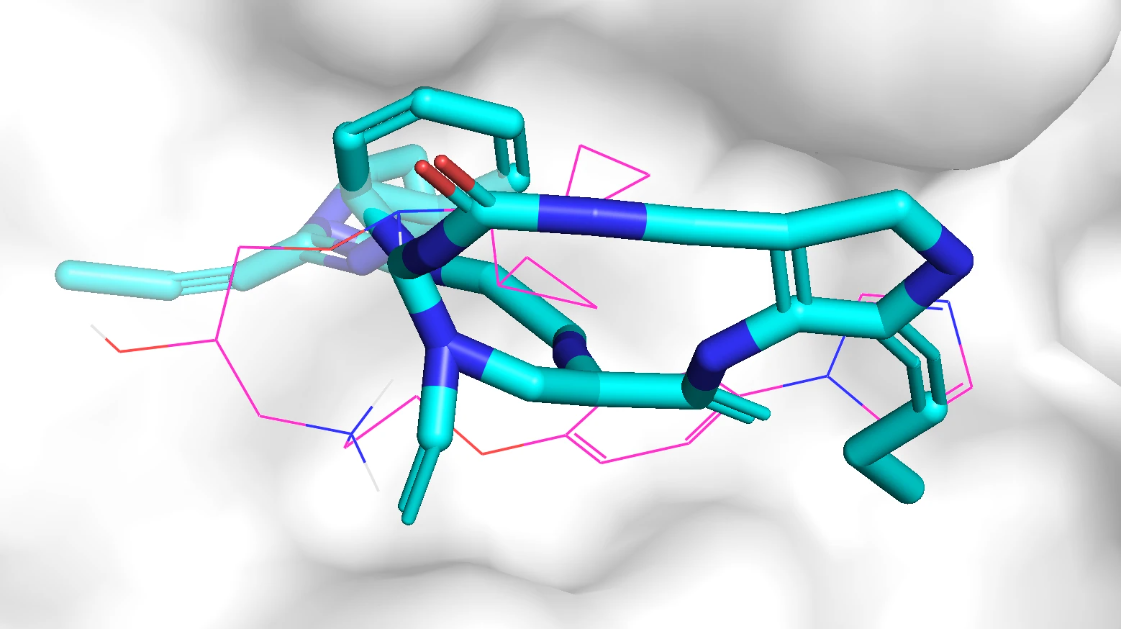
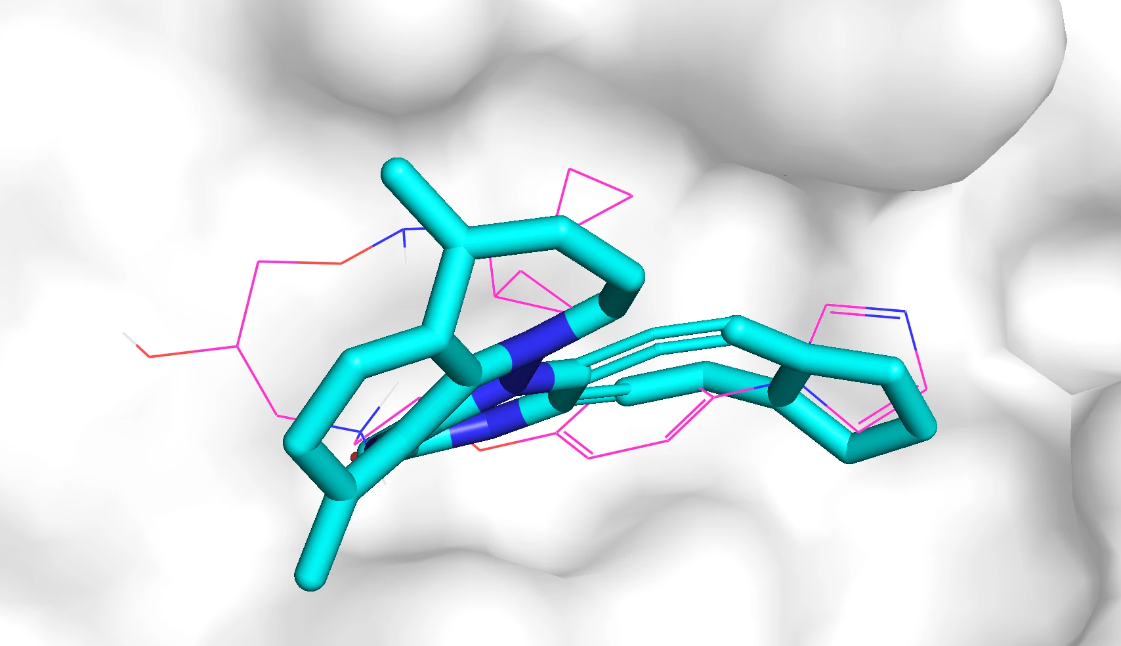
模型针对 adrb1 口袋生成的分子质量不高,部分生成分子和蛋白质存在空间冲突问题,部分生成分子包括大环结构、长链结构、并环结构等复杂结构。
D3FG 在 DRD3 所有生成的分子如下:
D3FG_drd3
qvina score 排名前 3 的分子的 2D 结构如下,对应的 qvina score 分数分别为 -8.6, -7.8, -7.5:

qvina score 排名前 3 的分子在口袋中的 Pose 如下,紫红色的是参考分子,蓝色的是生成分子,该口袋位于蛋白表面。
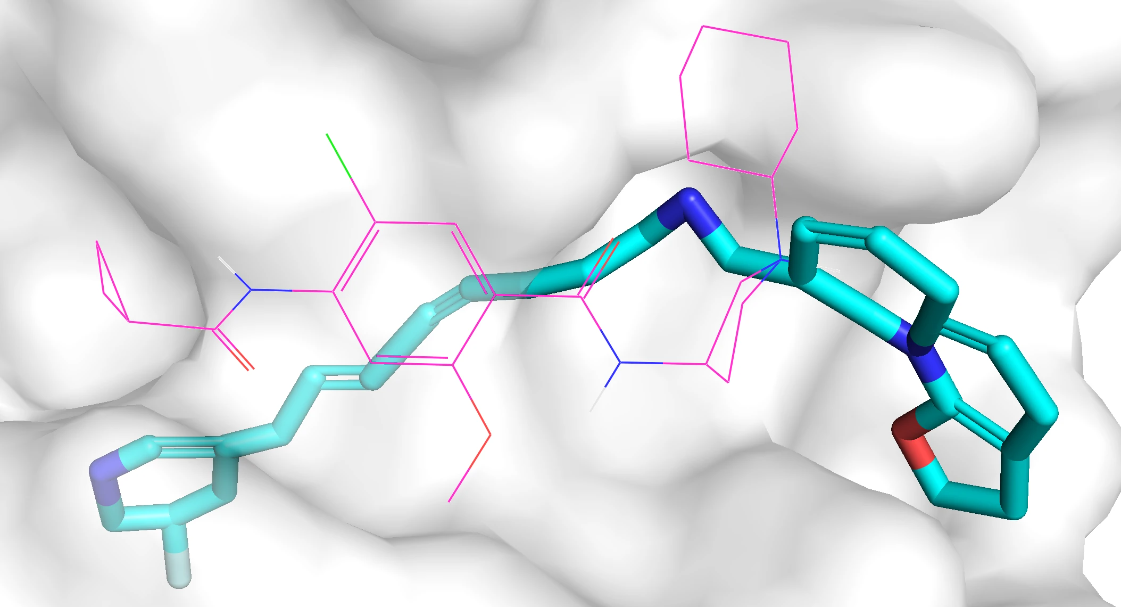
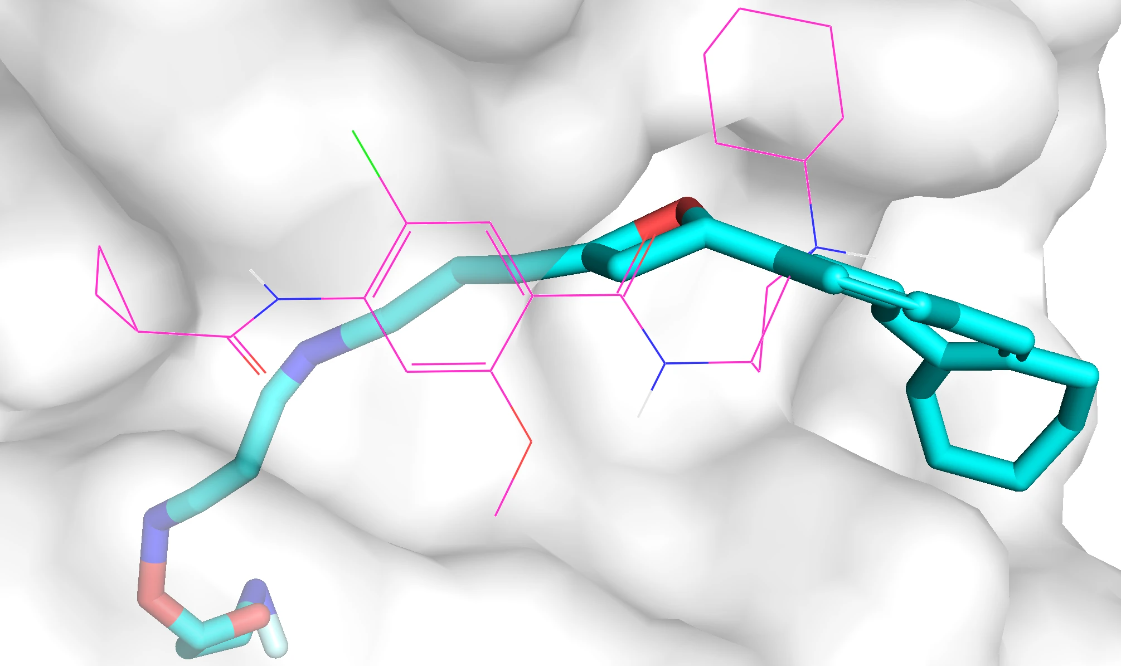
和 adrb1 类似,模型针对 drd3 口袋生成的分子质量也不高,部分生成分子和蛋白质存在空间冲突问题,部分生成分子包括长链结构、并环结构等复杂结构。
3.3.2 作者提供的 checkpoint 生成结果
由于早期作者没有提供训练好的模型文件,测试案例使用的是我们自己训练的模型。在作者更新了GitHub 版本以后,提供了训练好的checkpoint。我重新git clone 了新的项目代码,但是在运行分子生成时,出现了如下错误:
[2025-05-28 16:28:23,611::sample::INFO] Loading model config and checkpoints: ./CKPT/d3fg_fg/10000.pt
Traceback (most recent call last):File "/workspace/xxx/projects/D3FG/sample.py", line 245, in <module>main()File "/workspace/xxx/projects/D3FG/sample.py", line 155, in mainmodel = get_model(cfg_ckpt.model).to(args.device)^^^^^^^^^^^^^^^^^^^^^^^^^File "/workspace/xxx/projects/D3FG/repo/models/_base.py", line 12, in get_modelreturn _MODEL_DICT[config.type](config)^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^File "/workspace/xxx/projects/D3FG/repo/models/diffusion/difffg.py", line 62, in __init__self.denoiser = get_e3_gnn(cfg.encoder, num_classes = self.num_classes)^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^File "/workspace/xxx/projects/D3FG/repo/modules/e3nn/__init__.py", line 18, in get_e3_gnnraise ValueError(f'Unknown model type: {cfg.type}')
ValueError: Unknown model type: ipatransformer上述报错来源于代码与checkpoint的不匹配,改不动。因此,只能放弃这部分的测试。
四、总结
本研究提出了一种基于官能团的扩散模型 D3FG,用于在 3D 空间中生成以蛋白质结构为背景的分子。联合生成和两阶段生成方案分别形成了 D3FG 的两种变体。文章指出,通过两阶段生成方案生成的分子表现出更为现实的结构、具有竞争力的结合性能以及更好的药物属性。此外,在分子优化任务中,D3FG 也能够生成具有良好结合亲和力的分子。然而,仍然存在一些局限性。首先,官能团数据集的规模仍然较小,未来将进一步扩展。其次,所生成分子的结合亲和力还有待提升,因为其他扩散模型在结合性能方面甚至表现得更好。
但是我们使用自己训练的 checkpoint 发现生成的分子质量差,结构很奇怪,3D构象也很奇怪,同时,生成的小分子和蛋白之间存在严重的碰撞。我们 git clone 了新的项目并下载作者新的 checkpoint 但是出现了原子类型的报错,因此测试暂停了。
此外,因为作者没有提供从蛋白pdb文件开始的分子生成,而是使用预处理好的文件,因此,我们无法使用我们常见的3WZE案例进行测试,只能使用作者的默认案例。在实际的AIDD项目中,也无法使用这个项目的进行分子生成。
相关文章:
基于功能基团的3D分子生成扩散模型 - D3FG 评测
D3FG 是一个在口袋中基于功能团的3D分子生成扩散模型。与通常分子生成模型直接生成分子坐标和原子类型不同,D3FG 将分子分解为两类组成部分:官能团和连接体,然后使用扩散生成模型学习这些组成部分的类型和几何分布。 一、背景介绍 D3FG 来源…...

Python Cookbook-7.12 在 SQLite 中储存 BLOB
任务 想将 BLOB 存入一个 SQLite 数据库, 解决方案 Python的 PySQLite 扩展提供了 sqlite.encode 函数,它可帮助你在 SOLite 数据库中插入二进制串。可以基于这个函数编写一个小巧的适配器类: import sqlite,cPickle class Blob(object):自动转换二进制串def __init__(self…...

蓝耘服务器与DeepSeek的结合:引领智能化时代的新突破
🌟 嗨,我是Lethehong!🌟 🌍 立志在坚不欲说,成功在久不在速🌍 🚀 欢迎关注:👍点赞⬆️留言收藏🚀 🍀欢迎使用:小智初学…...

无人机光纤FC接口模块技术分析
运行方式 1. 信号转换:在遥控器端,模块接收来自遥控器主控板的电信号。 2.电光转换:模块内部的激光发射器将电信号转换成特定波长的光信号。 3.光纤传输:光信号通过光纤跳线传输。光纤利用全内反射原理将光信号约束在纤芯内进行…...
)
【LeetCode】3170. 删除星号以后字典序最小的字符串(贪心 | 优先队列)
LeetCode 3170. 删除星号以后字典序最小的字符串(中等) 题目描述解题思路java代码 题目描述 题目链接:3170. 删除星号以后字典序最小的字符串 给你一个字符串 s 。它可能包含任意数量的 * 字符。你的任务是删除所有的 * 字符。 当字符串还…...

Oracle 用户名大小写控制
Oracle 用户名大小写控制 在 Oracle 数据库中,用户名的默认大小写行为和精确控制方法如下: 一 默认用户名大小写行为 不引用的用户名:自动转换为大写 CREATE USER white IDENTIFIED BY oracle123; -- 实际创建的用户名是 "WHITE"…...
作为过来人,浅谈一下高考、考研、读博
写在前面 由于本人正在读博,标题中的三个阶段都经历过或正在经历,本意是闲聊,也算是给将要经历的读者们做个参考、排雷。本文写于2022年,时效性略有落后,不过逻辑上还是值得大家参考,若所述存在偏颇&#…...
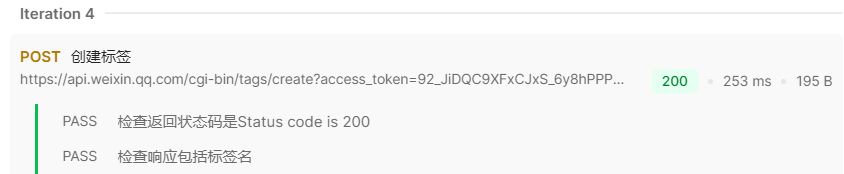
立志成为一名优秀测试开发工程师(第十一天)—Postman动态参数/变量、文件上传、断言策略、批量执行及CSV/JSON数据驱动测试
目录 一、Postman接口关联与正则表达式应用 1.正则表达式解析 2.提取鉴权码。 二、Postman内置动态参数以及自定义动态参数 1.常见内置动态参数: 2.自定义动态参数: 3.“编辑”接口练习 三、图片上传 1.文件的上传 2.上传后内容的验证 四、po…...

Global Security Market知识点总结:主经纪商业务
在全球证券市场的复杂体系中,主经纪商业务(Prime Brokerage)占据着独特且关键的位置。这一业务为大型机构投资者提供了一系列至关重要的服务,极大地影响着金融市场的运作与发展。 一、主经纪商业务的定义 主经纪商业务是投资银行…...
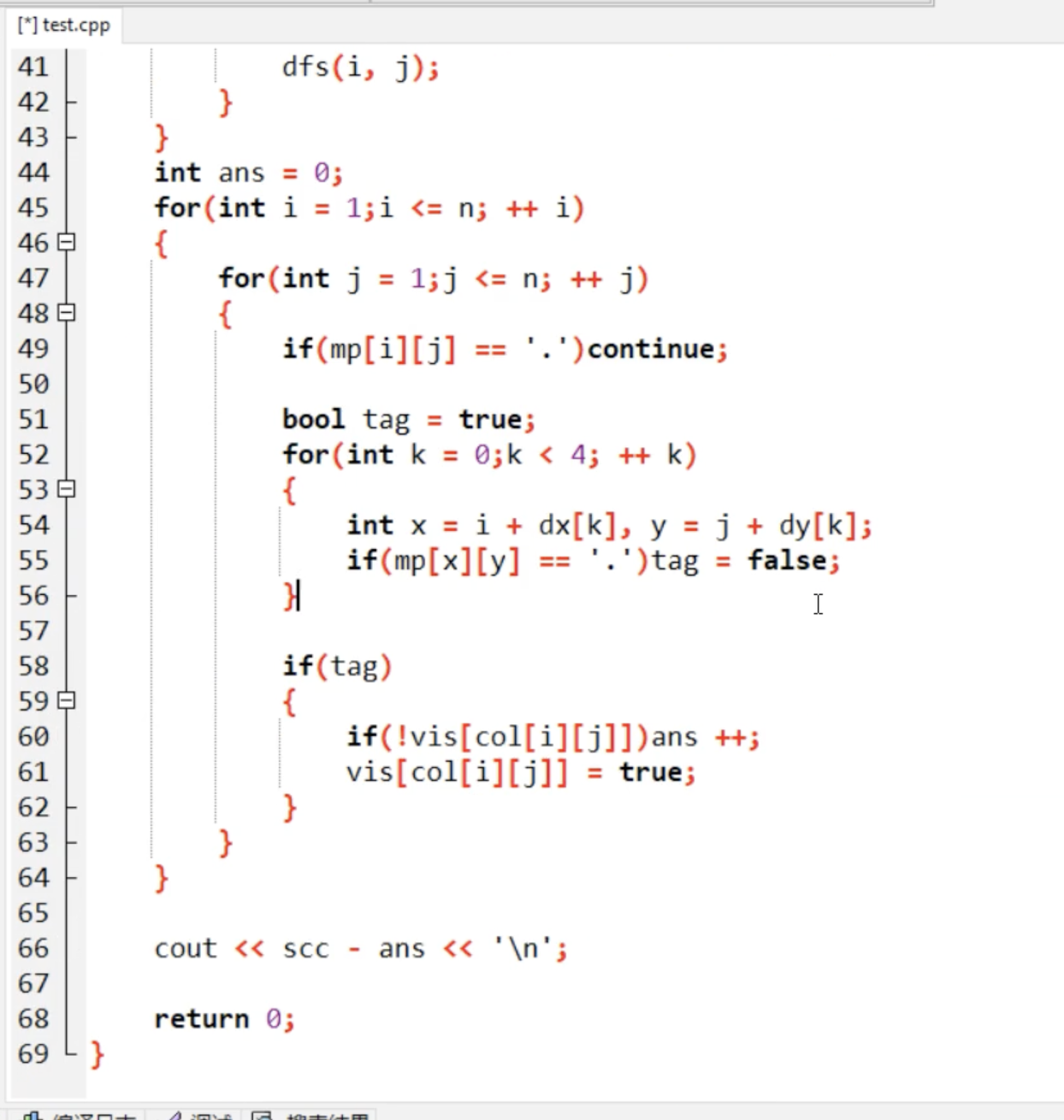
算法练习-回溯
今天开始新的章节,关于算法中回溯法的练习,这部分题目的难度还是比较大的,但是十分锻炼人的思维与思考能力。 处理这类题目首先要注意几个基本点: 1.关于递归出口的设置,这是十分关键的,要避免死循环的产…...

AI代码助手需求说明书架构
AI代码助手需求说明书架构 #mermaid-svg-6dtAzH7HjD5rehlu {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-6dtAzH7HjD5rehlu .error-icon{fill:#552222;}#mermaid-svg-6dtAzH7HjD5rehlu .error-text{fill:#552222;s…...

PTC过流保护器件工作原理及选型方法
PTC过流保护器件 (Positive Temperature Coefficient,正温度系数热敏电阻)是一种过流保护元件,其工作原理基于电阻值随温度变化的特性。当电路正常工作时,PTC的阻值很小,电流可以顺畅通过;但当…...

RabbitMQ 在解决数据库高并发问题中的定位和核心机制
RabbitMQ 在解决数据库高并发问题中的定位和核心机制 它是间接但极其有效的解决方案,以下内容聚焦如何最大化发挥 RabbitMQ 的潜力: 一、核心机制落地强化方案 1. 精准的异步化切割 关键原则:区分 “必须同步” 和 “可异步” 操作 #merma…...

VSCode主题定制:CSS个性化你的编程世界
在今天的数字世界,编程环境已成为开发者的第二大脑,而主题正是个性化你的创意空间的关键。本文将指导你如何使用CSS自定义VSCode的主题,让你的IDE不仅功能强大,更具视觉个性。 思路分析 设计思路: 创建主色调基调和…...

Windows 下彻底删除 VsCode
彻底删除 VS Code (Visual Studio Code) 意味着不仅要卸载应用程序本身,还要删除所有相关的配置文件、用户数据、插件和缓存。这可以确保你有一个完全干净的状态,方便你重新安装或只是彻底移除它。 重要提示: 在执行以下操作之前,…...

一文带你入门Java Stream流,太强了,mysqldba面试题及答案
list.add(“世界加油”); list.add(“世界加油”); long count list.stream().distinct().count(); System.out.println(count); distinct() 方法是一个中间操作(去重),它会返回一个新的流(没有共同元素)。 Stre…...

FastAPI安全异常处理:从401到422的奇妙冒险
title: FastAPI安全异常处理:从401到422的奇妙冒险 date: 2025/06/05 21:06:31 updated: 2025/06/05 21:06:31 author: cmdragon excerpt: FastAPI安全异常处理核心原理与实践包括认证失败的标准HTTP响应规范、令牌异常的特殊场景处理以及完整示例代码。HTTP状态码选择原则…...
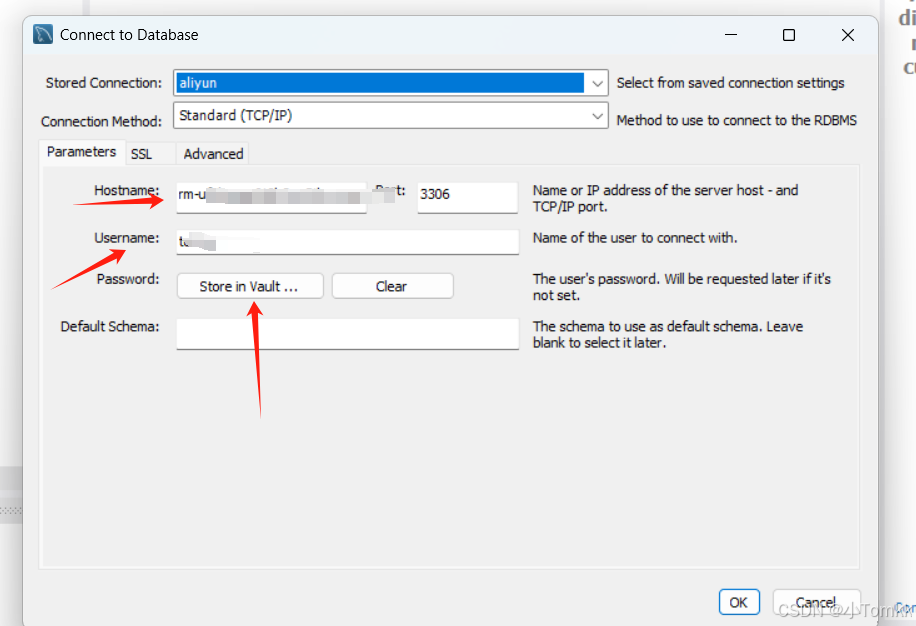
阿里云 RDS mysql 5.7 怎么 添加白名单 并链接数据库
阿里云 RDS mysql 5.7 怎么 添加白名单 并链接数据库 最近帮朋友 完成一些运维工作 ,这里记录一下。 文章目录 阿里云 RDS mysql 5.7 怎么 添加白名单 并链接数据库最近帮朋友 完成一些运维工作 ,这里记录一下。 阿里云 RDS MySQL 5.7 添加白名单1. 登录…...

《Brief Bioinform》: 鼠脑单细胞与Stereo-seq数据整合算法评估
一、写在前面 基因捕获效率、分辨率一直是空间转录组细胞类型识别的拦路虎,许多算法能够整合单细胞(single-cell, sc)或单细胞核(single-nuclear, sn)数据与空间转录组数据,从而帮助空转数据的细胞类型注释。此前我们介绍过近年新出炉的Stereo-seq平台&…...
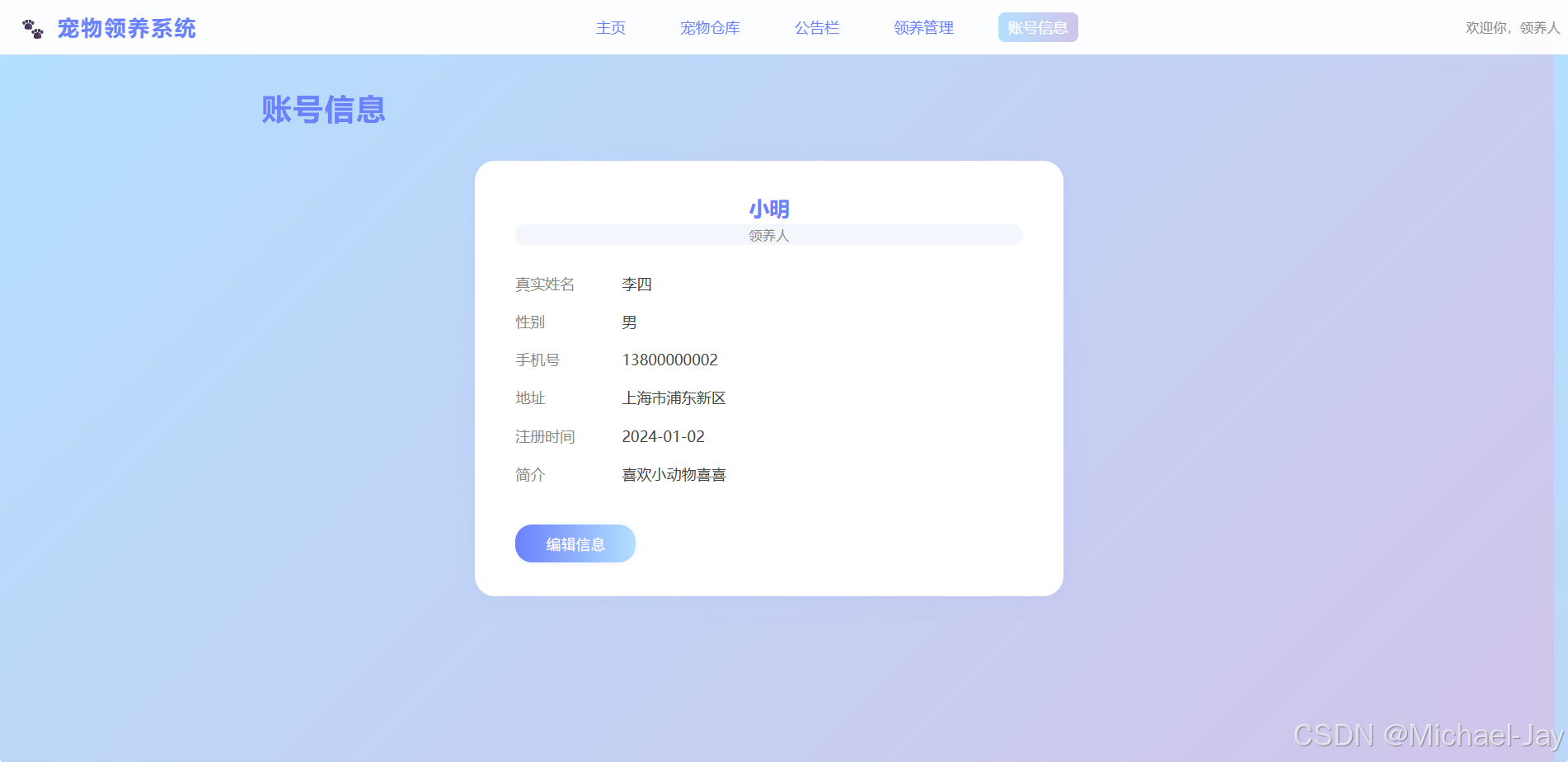
基于Springboot的宠物领养系统
本系统是一个面向社会的宠物领养平台,旨在帮助流浪宠物找到新家庭,方便用户在线浏览、申请领养宠物,并支持管理员高效管理宠物、公告和用户信息。 技术栈: -后端: Java 8Spring BootSpring MVCMyBatis-PlusMySQL 8R…...

AI API、AI 聊天助手,两大服务助力应用智能化转型
网络效应、转换成本——这些一度定义了我们这个时代商业逻辑的规则,在 AI 时代迅速崩塌。创新性功能被无差别克隆包围,差异化优势在底层能力翻新中消散…… 更别说那些决策迟缓、行动无法言出法随的“后来者”,注定与市场窗口擦身而过。唯快…...

Windows 下搭建 Zephyr 开发环境
1. 系统要求 操作系统:Windows 10/11(64位)磁盘空间:至少 8GB 可用空间(Zephyr 及其工具链较大)权限:管理员权限(部分工具需要) 2. 安装必要工具 winget安装依赖工具&am…...

蓝桥杯单片机之通过实现同一个按键的短按与长按功能
实现按键的短按与长按的不同功能 问题分析 对于按键短按,通常是松开后实现其功能,而不会出现按下就进行后续的操作;而对于按键长按,则不太一样,按键长按可能分为两种情况,一是长按n秒后实现后续功能&…...
)
如何用 pnpm patch 给 element-plus 打补丁修复线上 bug(以 2.4.4 修复 PR#15197 为例)
背景 在实际项目开发中,依赖的三方库(如 element-plus)难免会遇到 bug。有时候官方虽然已经修复,但新版本升级成本高,或者有兼容性风险。这时,给依赖打补丁是最优雅的解决方案之一。 本文以 element-plus…...

PCB特种工艺应用扩展:厚铜、高频与软硬结合板
新能源汽车与消费电子驱动PCB特种工艺创新,厚铜板降阻30%,软硬结合板渗透率年增15%。 1. 厚铜板:新能源高压平台核心 技术突破:猎板PCB量产10oz厚铜板(传统为3oz),载流能力提升200%,…...

ClusterRole 和 ClusterRoleBinding 的关系及使用
ClusterRole 和 ClusterRoleBinding 是 Kubernetes 中用于控制集群范围权限的两个重要资源,它们共同构成了 Kubernetes RBAC (基于角色的访问控制) 系统的核心部分。 两者的关系 ClusterRole 定义了一组权限规则,指定了可以对哪些资源执行哪些操作 Clu…...

C++ const 修饰符深入浅出详解
C const 修饰符深入浅出详解 📅 更新时间:2025年6月6日 🏷️ 标签:C | const关键字 | 常量 | 多文件编程 | 现代C 文章目录 前言🌟 一、const 是什么?为什么要用?示例✅ const 的四大好处 &…...

Python 数据类型转换、编码处理与文件操作实战指南
一、数据类型转换 int (整型) 与 str (字符串) 之间: str 转 int:int("123") (要求字符串内容必须是数字)。 int 转 str:str(123)。 规则: 使用目标类型的英文名加括号包裹原数据即可。 list (列表) 与 tuple (元组…...
Readest(电子书阅读器) v0.9.53
Readest 是一款开源电子书阅读器,专为沉浸式和深度阅读体验而设计。它是对Foliate的现代重写,利用Next. js 15和Tauri v2在macOS、Windows、Linux和Web上提供无缝的跨平台体验,并即将支持移动平台。 软件特色 多格式支持 支持EPUB、MOBI、K…...
USART 串口通信全解析:原理、结构与代码实战
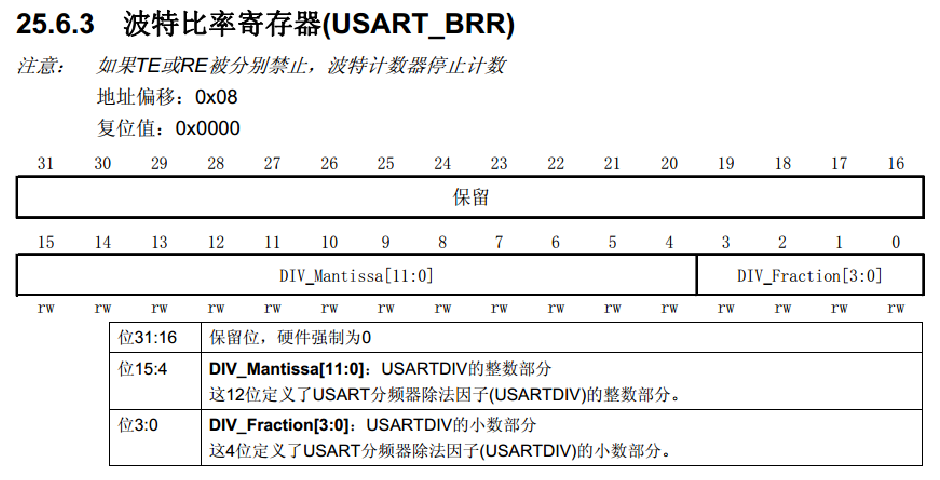
文章目录 USARTUSART简介USART框图USART基本结构数据帧起始位侦测数据采样波特率发生器串口发送数据 主要代码串口接收数据与发送数据主要代码 USART USART简介 一、USART 的全称与基本定义 英文全称 USART:Universal Synchronous Asynchronous Receiver Transmi…...