赋能大型语言模型与外部世界交互——函数调用的崛起
大型语言模型 (LLM) 近年来在自然语言处理领域取得了革命性的进展,展现出强大的文本理解、生成和对话能力。然而,这些模型在与外部实时数据源和动态系统交互方面存在固有的局限性 1。它们主要依赖于训练阶段学习到的静态知识,难以直接访问和利用不断变化的世界信息或执行具体的操作。为了突破这一瓶颈,“函数调用” (Function Calling) 或称“工具使用” (Tool Use) 技术应运而生,它赋予了LLM与外部应用程序接口 (API)、数据库和服务进行交互的能力,从而极大地扩展了其应用边界和实用价值 2。
函数调用的出现,标志着LLM从传统的“知识容器”向更主动的“行动执行者”转变迈出了关键一步。传统LLM主要基于其海量训练数据生成文本,扮演信息提供者或内容创作者的角色 1。而函数调用机制允许LLM根据用户的自然语言输入,分析其意图,并决定调用预定义的外部函数来获取实时信息或完成特定任务 1。这意味着LLM不再仅仅停留在“说”的层面,而是能够实际地“做”,例如查询当前天气、预订机票酒店、或者操作客户关系管理 (CRM) 系统中的数据 2。这种能力的赋予,使得LLM的应用场景从纯粹的内容生成扩展到了任务自动化和解决现实世界问题,使其更像一个能够理解并执行指令的智能助手 2。
从本质上看,函数调用是一种受控的、结构化的“意图到行动”的转换机制。用户以自然语言表达其需求或意图 1。LLM接收到输入后,会进行深度分析,判断是否需要借助外部工具来完成用户的请求 1。如果判定需要,LLM并不会直接执行任何代码,而是会生成一个结构化的数据对象(通常采用JSON格式),清晰地指明需要调用的函数名称以及传递给该函数的参数 1。这个结构化的输出确保了后续的应用程序能够准确无误地解析并执行相应的函数调用,避免了让LLM直接执行代码可能带来的安全风险和不可控性(LLM本身不具备独立执行代码的能力 3)。通过这种预定义的函数接口和结构化的通信模式,函数调用机制能够将用户相对模糊的自然语言意图,可靠地转化为精确的、可由计算机执行的指令,从而实现了从意图到行动的有效转换 6。本文将深入探讨函数调用的核心机制、不同技术平台的实现方案、设计高效工具的最佳实践、高级应用场景、面临的挑战与应对策略,并展望其未来发展趋势。
第一章:函数调用/工具使用的核心机制与工作流程
1.1 基本定义与重要性
函数调用,或称工具使用,其核心定义是一种使大型语言模型能够根据用户的自然语言输入,请求执行外部系统中预先定义好的函数或API的技术。在此过程中,LLM本身并不直接执行这些函数;相反,它会分析用户意图,并生成一个包含目标函数名称及其所需参数的结构化数据(通常为JSON格式)1。这个结构化数据随后被传递给外部的应用程序或执行环境,由后者负责实际调用函数并处理结果。例如,1明确指出:“LLM配备函数调用后,不再生成典型的文本响应,而是产生结构化数据(通常是JSON格式),指明要执行哪个预定义函数以及传递给它的参数。” 6也强调:“LLM不直接执行这些调用,而是创建一个描述调用的数据结构,并将其传递给一个单独的程序进行执行……”
函数调用的重要性在于它显著克服了LLM仅依赖静态训练数据的固有局限性。通过连接现实世界的数据源和服务,LLM能够获取实时信息、执行具体任务、实现与外部系统的动态交互,从而大幅提升其应用的实用性和准确性 1。2列举了多个应用场景,如提供最新信息、自动化重复性任务、以及连接其他企业级服务,这些都极大地扩展了LLM超越简单文本生成的能力范围。
1.2 通用工作流程:从用户输入到最终响应
函数调用的通用工作流程,从用户发出请求到LLM给出最终响应,通常包含以下几个关键步骤,这一流程在多个信息源中都得到了印证 1:
- 用户输入 (User Input): 用户以自然语言的形式向LLM提出请求或问题。例如,用户可能会说“查询明天北京的天气怎么样?”或“帮我预订一张今晚7点去上海的火车票” 1。
- LLM分析与决策 (LLM Analysis and Decision): LLM接收到用户的自然语言输入后,会对其进行深入的语义分析和意图理解。模型需要判断用户的请求是否需要借助外部函数或工具才能完成。如果需要,LLM还会确定应该调用哪个(或哪些)预定义的函数,并从用户输入中提取或推断出调用该函数所必需的参数 1。
- 生成结构化输出 (Structured Output Generation): 一旦LLM决定调用某个函数并确定了所需参数,它会生成一个结构化的数据对象,通常是JSON格式。这个JSON对象会清晰地包含目标函数的名称以及一个参数字典,其中包含了参数名和对应的参数值 1。
- 外部执行 (External Execution): 承载LLM的应用程序或后端服务接收到这个结构化的JSON输出后,会对其进行解析。根据解析出的函数名和参数,应用程序会在其自身的执行环境中调用相应的外部函数、API接口或内部服务。这个过程完全在LLM之外进行 1。
- 结果整合与反馈 (Result Integration and Feedback): 外部函数执行完毕后,会将其执行结果(例如,查询到的天气信息、火车票预订状态等)返回给应用程序。应用程序再将这个结果封装后传递回LLM。LLM接收到函数执行结果后,会将其与之前的对话上下文和用户原始请求进行整合,并基于这些信息生成一个最终的、更完整和准确的自然语言回复给用户 1。
这一系列步骤构成了一个完整的交互闭环,使得LLM能够有效地利用外部能力来响应用户需求。
1.3 结构化输出(JSON)的关键作用
在函数调用机制中,结构化输出,特别是JSON(JavaScript Object Notation)格式,扮演着至关重要的角色。选择JSON作为LLM与外部应用程序之间通信的桥梁,主要得益于其几个核心优势:通用性、易解析性以及对复杂数据结构的良好支持 1。JSON是一种轻量级的数据交换格式,易于人类阅读和编写,同时也易于机器解析和生成,被广泛应用于各种编程语言和平台之间的API通信。3中展示了Gemma模型可以输出Python风格或JSON风格的函数调用,而1则直接指出LLM输出的是“结构化数据(通常是JSON格式)”。
JSON Schema则在这一过程中扮演了“契约”和“指南”的角色。它是一种用于描述JSON数据结构、定义字段类型、设置约束条件(如必填字段、数值范围、字符串模式等)的规范语言 7。在函数调用场景下,JSON Schema用于精确定义每个可调用函数的接口,包括其期望接收的参数名称、数据类型、格式要求以及参数的业务含义。这不仅确保了LLM生成的函数调用请求在结构上是规范和有效的,能够被外部执行程序正确解析,更重要的是,JSON Schema中的描述性字段(description)为LLM提供了关于何时以及如何使用特定函数及其参数的关键上下文信息和隐式提示 7。8强调了JSON Schema在控制输出、验证数据和标准化API方面的重要作用。一个设计良好、描述清晰的JSON Schema能够显著提升LLM理解和正确调用函数的准确性。
函数调用流程中LLM负责决策而外部应用负责执行的这种解耦设计,是其能够兼顾强大功能与相对较高的鲁棒性和安全性的基石。LLM的核心任务是理解用户的自然语言意图,并基于此决定调用哪个预定义的函数以及传递哪些参数;它本身并不直接执行任何代码 3。实际的函数执行过程则完全由外部的、开发者可控的应用程序来完成 1。这种责任分离带来了多方面的好处:首先,在安全性方面,由于LLM不直接执行代码,它无法直接执行潜在的恶意指令或未经授权地访问系统资源。执行环境是受控的,开发者可以在外部应用中实施严格的权限管理和安全校验 3。其次,在鲁棒性方面,外部函数可以拥有自己独立的错误处理逻辑、重试机制和日志记录,这些都独立于LLM的推理过程,使得系统在面对外部服务故障时能有更强的容错能力 1。最后,在灵活性方面,外部函数可以使用任何编程语言编写,并且可以与任何现有的系统或服务进行集成,LLM只需要关注如何生成符合预定格式的调用请求即可。
与此同时,JSON Schema在函数调用中的作用远不止于简单的数据格式定义,它更像是一本为LLM量身定制的“指导手册”,引导LLM更准确地理解和执行函数调用。JSON Schema不仅规定了函数期望的输入参数、数据类型和整体结构 7,其内部的description字段更是为LLM提供了关于何时、为何以及如何使用特定函数及其各个参数的关键上下文信息和语义解释 7。正如7所指出的,这些描述是“模型接收到的隐式提示的重要组成部分,引导其解释并塑造其输出”。7则详细阐述了编写这些描述的最佳实践,旨在消除歧义并清晰传达意图。因此,一个精心设计的JSON Schema,特别是其包含丰富语义信息的描述部分,能够显著提高LLM正确选择函数、准确填充参数的能力,从而有效减少因误解用户意图或函数功能而导致的错误调用。忽视Schema描述的质量,无异于给一个聪明的助手下达模糊的指令却期望得到完美的结果 7。
第二章:主流大模型平台的函数调用实现对比
各大科技公司和研究机构推出的大型语言模型平台,在实现函数调用或工具使用功能时,虽然核心目标一致——即赋予LLM与外部世界交互的能力——但在具体的实现方式、术语运用、API设计以及控制粒度上存在一定的差异。
2.1 Google Gemini/Gemma 的函数调用
Google在其AI模型中也提供了函数调用能力。对于Gemini API和Vertex AI Gemini API,开发者需要先设置其Firebase项目,连接应用并添加相应的SDK,初始化后端服务,并创建GenerativeModel实例 10。该指南假设使用的是最新的Firebase AI Logic SDK。
对于Gemma系列模型,特别是推荐使用Gemma3 27B以获得最佳性能,函数调用功能允许模型通过特定的提示结构来定义可调用的函数及其期望的输出格式 3。开发者需要在提示中明确设置函数调用,并定义函数的名称、描述和参数。Gemma支持生成两种风格的函数调用输出:一种是类似Python函数调用的风格,如[func_name(param1=value1, param2=value2)];另一种是标准的JSON对象风格,如{"name": "function_name", "parameters": {"param1": "value1"}} 3。值得注意的是,Gemma模型在决定调用函数时,并不会输出一个特定的“工具令牌”或标识符,而是直接生成符合开发者在提示中指定格式的函数调用字符串。因此,开发者需要在自己的应用程序中解析这个字符串,并自行编写代码来执行实际的函数调用逻辑。Gemma模型本身不执行任何代码,执行前验证生成的代码是必要的安全措施 3。
2.2 OpenAI GPT 模型的函数调用
OpenAI的GPT系列模型,如GPT-4o,通过其Chat Completions API提供了强大的函数调用功能。开发者可以在API请求的tools参数中定义一个或多个可供模型调用的函数列表 9。每个函数定义通常包含函数名 (name)、一份详细的描述 (description) 以及一个JSON Schema对象 (parameters) 用来规定该函数期望的输入参数及其格式。其中,description字段至关重要,它用于告知模型在何种情况下以及如何正确地使用该函数 9。
API还提供了tool_choice参数,允许开发者对模型的工具选择行为进行更细致的控制 11。例如,可以强制模型调用某个特定的函数,或者让模型自行决定是否以及调用哪个函数。除了支持开发者自定义的函数外,OpenAI的平台也提供了一些内置工具,如文件搜索和网页搜索,这些工具可以直接被模型调用以扩展其能力 11。与所有API服务一样,OpenAI的函数调用功能也依赖于API密钥进行认证,并受到相应的速率限制策略约束 11。
2.3 Anthropic Claude 的工具使用
Anthropic的Claude模型将其与外部交互的功能称为“工具使用” (Tool Use) 4。Claude支持两种类型的工具:
- 客户端工具 (Client tools): 这类工具的代码由用户自己实现并在用户系统上执行。这包括用户完全自定义的工具,也可能包括一些由Anthropic定义但需要客户端实现的工具(如计算机使用(测试版)和文本编辑器)4。
- 服务端工具 (Server tools): 这类工具由Anthropic在自己的服务器上执行,例如网页搜索工具。用户只需在API请求中指定使用这些工具,无需自行实现其执行逻辑 4。
对于客户端工具,其工作流程通常如下:首先,用户在API请求中向Claude提供工具定义(包括名称name、详细描述description和输入模式input_schema,后者是一个JSON Schema对象 12)以及一个可能需要使用这些工具的用户提示。然后,Claude评估用户查询,如果认为某个工具能提供帮助,API的响应会将stop_reason字段设置为tool_use,并包含一个或多个tool_use内容块,指明了Claude意图使用的工具名称和输入参数。用户的应用程序接收到这个响应后,需要解析出工具名和输入,在本地执行相应的工具代码。执行完毕后,应用程序将工具的执行结果通过一个新的用户消息(包含一个tool_result内容块,其中包含与之前tool_use块匹配的id和工具输出)返还给Claude。最后,Claude整合工具结果,生成对用户原始提示的最终回复 4。
对于服务端工具,流程更为简单:Claude评估查询后若决定使用服务端工具,会直接执行该工具,并将结果自动整合到其对用户的最终回复中 4。
Anthropic同样提供了tool_choice参数来控制工具的使用行为,可选值包括auto(模型自行决定,默认值)、any(强制模型从提供的工具中至少选择一个使用)、tool(强制模型使用指定的某个特定工具)以及none(禁止模型使用任何工具)12。对于需要处理复杂工具交互或模糊查询的场景,Anthropic推荐使用其能力更强的模型,如Claude Opus 4、Claude Sonnet 4/3.7/3.5等 12。
尽管各大主流LLM平台在函数调用或工具使用的核心理念——即让模型能够请求执行外部操作——上表现出趋同性,都依赖开发者提供清晰的工具定义(包括名称、描述和参数模式 3),并且都倾向于使用结构化的输出(通常是JSON 3)作为模型意图的载体,但在具体的实现细节、术语运用(如“Function Calling”与“Tool Use”)以及API参数和控制粒度上仍然存在着不容忽视的差异。例如,OpenAI使用tools和tool_choice参数 11,Anthropic则有更细致的tools、tool_choice和tool_result交互流程 4,而Google的Gemma则更侧重于通过提示工程来设定函数调用行为 3。Anthropic还明确区分了客户端工具和服务端工具的概念 4,这一点在其他平台的公开文档中不那么突出。这些差异可能源于各公司不同的技术栈、设计哲学或产品演进路径,例如Firebase的深度集成是Google生态系统的一个显著特点 10。这种多样性无疑给开发者带来了一定的学习成本和跨平台开发的复杂性,但也可能催生出更灵活的第三方解决方案和抽象框架(如LangChain 5),以弥合这些差异。
一个跨平台共识是,工具“描述”的质量是提升函数调用准确性和可靠性的最关键因素之一。Google Gemma的文档强调需要提供清晰的函数定义 3;OpenAI的文档明确指出函数描述的核心作用是告知模型“何时以及如何”使用函数 9;而Anthropic的文档更是直言不讳地指出:“提供极其详尽的描述。这是迄今为止影响工具性能的最重要因素。” 12。这种对高质量描述的一致强调,从侧面反映了当前LLM在自主“理解”工具深层逻辑和适用边界方面的能力局限。尽管LLM能够解析结构化的参数模式,但在缺乏充分、清晰的自然语言解释的情况下,它们准确推断工具适用场景和参数具体语义的能力仍然有限。这进一步说明,目前的函数调用机制在很大程度上依然依赖于开发者通过精心编写的描述来“引导”和“教导”LLM,而非LLM完全自主地、深层次地“理解”工具的内在机制。
下表总结了主流LLM平台在函数调用/工具使用方面的一些关键特性对比:
| 特性 (Feature) | Google (Gemini/Gemma) | OpenAI (GPT) | Anthropic (Claude) |
| 核心术语 | Function Calling | Function Calling | Tool Use |
| 工具定义方式 | 提示结构中定义 (Prompt structure) 3 | API请求中tools参数 9 | API请求中tools参数,包含name, description, input_schema 12 |
| 结构化输出格式 | Python风格字符串或JSON对象 3 | JSON对象 1 | JSON对象 (在tool_use块的input字段) 12 |
| 工具选择控制 | 提示指令 (Prompt instructions) 3 | API请求中tool_choice参数 11 | API请求中tool_choice参数 (auto, any, tool, none) 12 |
| 执行方 | 客户端执行模型生成的调用代码 3 | 客户端执行模型生成的调用请求 6 | 客户端工具由用户执行,服务端工具由Anthropic执行 4 |
| 关键参数 (定义/调用) | 提示中的函数名、描述、参数 3 | tools (name, description, parameters), tool_choice 9 | tools (name, description, input_schema), tool_choice, tool_result (for client tools) 4 |
| 是否支持内置工具 | 文档未明确提及类似OpenAI的内置工具 | 是 (如文件搜索、网页搜索) 11 | 是 (服务端工具如网页搜索) 4 |
此表格旨在提供一个概要性的对比,帮助开发者快速理解各平台在实现函数调用功能时的主要异同点,从而在技术选型和具体开发过程中做出更明智的决策。
第三章:设计高效能工具/函数的黄金法则
为了确保大型语言模型能够准确、可靠地调用外部函数或工具,开发者在设计这些工具的接口定义时,必须遵循一系列最佳实践。这不仅涉及到工具本身的逻辑实现,更关键的是如何向LLM清晰、无歧义地传达工具的功能、使用场景和参数细节。其中,工具描述的撰写和JSON Schema的构建是两个核心环节。
3.1 工具描述的艺术:清晰、明确与意图传达
工具的描述(通常是函数定义中的description字段)是LLM理解何时以及如何使用该工具的首要指南,其质量直接影响调用成功率 5。一份精心撰写的描述能够显著提升LLM的判断准确性。
最佳实践包括:
- 消除歧义 (Eradicate Ambiguity): 描述必须清晰、具体地说明工具的核心功能——它做什么,以及(同样重要的)它不做什么。对于工具的每个参数,都应明确其含义、预期的数据类型、单位(如果适用)以及它如何影响工具的行为 7。例如,12强调描述应解释“工具做什么,何时应该使用(以及何时不应该使用),每个参数意味着什么以及它如何影响工具的行为”。7中提供的例子,如将模糊的“值”描述改进为“摄氏度的目标温度设置,必须在15.0到30.0之间”,生动地展示了如何通过明确单位和范围来消除歧义。
- 阐明意图 (Illuminate Intent): 除了说明工具“是什么”和“做什么”,解释工具存在的“为什么”也同样重要,尤其对于那些可选参数或具有复杂调用逻辑的工具 7。让LLM理解参数背后的设计意图,有助于它在更广泛的上下文中做出更智能的决策。7中关于
optional_notes字段的例子,从“如有备注”改进为解释其用于“用户提供可能影响任务结果的额外上下文或特定指令”,清晰地传达了该字段的用途和价值。 - 设定边界 (Defining Boundaries): 清晰地界定工具的适用场景和不适用场景,可以帮助LLM避免在不恰当的情况下调用工具,或在工具能力不足时进行无效尝试 9。9指出“明确模型在何时以及何时不调用某些工具的边界是有帮助的”。
- 描述长度: 根据Anthropic的建议,工具描述应至少包含3-4句话,对于功能复杂的工具,则需要更详尽的阐述 12。目标是在不冗余的前提下提供足够的信息。
虽然在描述中加入使用示例可以作为补充,但Anthropic的经验表明,优先保证描述本身的详尽和清晰更为重要 12。
3.2 构建健壮的JSON Schema:规范、约束与最佳实践
JSON Schema不仅定义了函数调用时参数的预期数据结构,其内部的描述字段(description)也构成了给LLM的隐式提示,引导模型生成符合预期的输出 7。构建一个健壮、信息丰富的JSON Schema是确保函数调用成功的关键。
最佳实践包括:
- 明确字段含义 (Clear Field Semantics): Schema中每个字段的名称(key)和对应的
description都应该清晰无歧义,准确反映该字段的业务含义和数据内容 7。 - 强制格式 (Mandate Formats): 即使在Schema中使用了
format关键字(如"format": "date-time"),也强烈建议在对应字段的description中明确指出期望的具体数据格式,并提供示例。例如,日期应明确为YYYY-MM-DD格式,时间戳应明确为ISO 8601格式(如'2024-11-15T09:30:00+01:00')7。这样做可以防止模型因理解偏差或依赖其训练数据中的常见但不一定符合要求的格式,而产生格式错误的输出。 - 提供示例 (Provide Examples in Descriptions): 在字段的
description中直接嵌入具体的数值示例,能够非常有效地帮助LLM理解预期的输入格式和内容范围 7。 - 处理必填字段 (Handle Required Fields): 除了在JSON Schema的
required数组中声明必填字段外,还可以在该字段的description开头添加明确的文本提示,如“Required.”,作为额外的强调,以增强模型对此约束的感知 7。 - 枚举值解释 (Decode Enums): 对于使用
enum关键字限制取值范围的字段,其description必须详细解释每个允许的枚举值所代表的具体语义和业务含义 7。这一点至关重要,因为LLM需要依赖这些语义解释来将用户的自然语言请求准确地映射到正确的枚举值上。7中关于task_status枚举的例子(解释PENDING代表“任务已排队但未开始”,RUNNING代表“任务正在处理中”等)极好地说明了这一点。 - 约束条件 (Constraints): 对于有特定约束的字段(如数值范围、字符串最小/最大长度、正则表达式模式等),除了在Schema结构中定义这些约束外,也应在
description中进行文字说明,以强化模型的认知 7。
为了提高开发效率和一致性,可以考虑使用像Pydantic (Python) 或 Zod (TypeScript) 这样的数据验证库,它们能够根据代码中定义的模型自动生成JSON Schema,并且可以将代码中的文档字符串(docstrings)直接用作Schema中各个字段的description来源 7。
工具或函数定义(包括描述和JSON Schema)的质量,直接决定了函数调用机制所能达到的“智能”程度和最终的可靠性。这个定义过程构成了开发者与LLM之间进行有效协作的关键接口。LLM高度依赖这些定义来理解何时、为何以及如何调用一个函数 7。如果定义模糊、不完整或存在歧义,极易导致LLM做出错误的判断,例如调用不相关的函数、传递错误的参数,或者在不应调用函数时强行调用 1。7生动地将糟糕的描述比作“给一个才华横溢的助手下达含糊不清的指令,然后期望他能完美完成任务”。因此,开发者通过精心设计和编写这些定义,实际上是在“教导”或“编程”LLM如何正确、有效地使用外部工具。这个定义过程是人机协作的核心环节,其质量直接影响着整个系统的表现和用户体验。
对JSON Schema中description字段的极致运用,实际上可以被视为一种针对LLM的“结构化提示工程”。传统的提示工程通常指的是通过设计自然语言输入来引导LLM产生期望的文本输出。而在函数调用的场景下,JSON Schema的description字段为开发者提供了一个独特的机会,可以将精确的自然语言指令、上下文信息、格式要求和使用示例,直接关联到特定的数据字段或函数参数上 7。这些嵌入在Schema结构中的描述,正如7所称的“隐式提示能力”(Implicit Prompting Power),其作用类似于传统提示中的指令部分,但更加结构化、目标明确,并且与LLM生成结构化输出的任务紧密耦合。通过在Schema中对每个字段的用途、格式、意图、示例和约束进行详尽说明,开发者实际上是在一个结构化数据的框架内,对LLM的行为进行精细化的引导和调校。这本质上是一种更高级、更受控的提示工程形式,其目标是确保LLM不仅能“说对话”,更能“做对事”。
下表提供了一个工具/函数定义最佳实践的速查表,总结了本章讨论的关键点:
| 实践领域 (Practice Area) | 核心要点 (Key Point) | 重要性说明 (Why it Matters) | 示例/反例 (Example/Counter-example Snippet) |
| 工具描述 - 清晰性 | 明确工具做什么、不做什么,参数含义和单位 7 | 避免LLM误解工具的基本功能和参数作用。 | 反例: "description": "The value" <br> 示例: "description": "The target temperature setting in degrees Celsius. Must be between 15.0 and 30.0." 7 |
| 工具描述 - 意图 | 解释工具或参数存在的“为什么” 7 | 帮助LLM在复杂场景下做出更智能的决策。 | 反例: "description": "Notes if any" <br> 示例: "description": "Optional field for the user to provide any additional context or specific instructions that might influence the task outcome. Leave empty if user provides no extra details." 7 |
| 工具描述 - 边界 | 清晰界定工具的适用和不适用场景 9 | 防止LLM在不恰当的情况下调用工具。 | 示例: 9 "Do not use tools when: - The user asks a general question like 'What's your return policy?'" |
| JSON Schema - 字段语义 | 字段名和描述都应清晰无歧义 7 | 确保LLM准确理解每个数据字段的含义。 | 7 |
| JSON Schema - 格式强制 | 在描述中明确指出期望格式和示例,即使已用format关键字 7 | 确保LLM输出符合严格的格式要求,避免解析错误。 | 反例: "description": "Date of the event" (即使有format: "date") <br> 示例: "description": "The exact date of the event in YYYY-MM-DD format (e.g., 2024-10-28)." 7 <br> 示例 (时间戳): "description": "The precise start date and time in ISO 8601 format, including timezone offset (e.g., '2024-11-15T09:30:00+01:00')." 7 |
| JSON Schema - 示例嵌入 | 在描述中直接嵌入具体示例 7 | 为LLM提供具象化的参考,帮助理解期望输出。 | 示例: "description": "The 2-letter ISO 3166-1 alpha-2 country code (e.g., 'US', 'GB', 'FR')." 7 |
| JSON Schema - 必填项强调 | 在描述中用 "Required." 等文字强调必填字段 7 | 强化LLM对必填字段的认知,减少遗漏。 | 示例: "description": "**Required.** The user's natural language search query. Must not be empty." 7 |
| JSON Schema - 枚举值解释 | 详细解释每个enum值的语义 7 | 使LLM能将自然语言请求准确映射到正确的枚举值。 | 反例: "enum": 描述为 "Status indicator." <br> 示例: "enum": 描述为 "Current status... 'PENDING' (Task is queued...)..."` 7 |
| JSON Schema - 约束说明 | 在描述中提及数值范围、长度等其他约束 7 | 进一步指导LLM生成符合业务规则的数据。 | 示例: (结合温度示例) "...Must be between 15.0 and 30.0." 7 |
遵循这些最佳实践,开发者可以显著提升LLM函数调用的准确性和可靠性,从而构建出更强大、更智能的AI应用。
第四章:高级应用与优化策略
随着函数调用技术的不断成熟,开发者们开始探索更高级的应用模式和优化策略,以应对更复杂的任务需求,并进一步提升LLM在工具使用方面的智能性和灵活性。这些高级应用包括多步骤工具使用、强制工具选择以及利用少样本提示进行优化等。
4.1 多步骤工具使用与“思维链”(Chain of Thought)
在许多现实场景中,用户的请求往往比较复杂,无法通过单次函数调用来完成。此时,LLM需要具备多步骤工具使用的能力,即能够按顺序或并行地调用多个不同的工具,并将它们的结果组合起来,以达成用户的最终目标 2。9明确指出:“如果一个任务无法通过单个步骤完成,模型应该继续尝试,并根据需要使用多个工具,直到任务完成。” 2也提到:“LLM可以编排多个函数调用来解决一个多步骤问题,而不仅仅是回答一个单一的问题。”
一些先进的LLM平台,如Anthropic的Claude,在处理多步骤工具使用时,能够展现出所谓的“思维链”(Chain of Thought)能力 12。这意味着模型在最终决定调用某个或某些工具之前,会先在内部(有时也会在输出中明确展示)进行一步步的逻辑推理和规划,分解复杂问题,并说明它打算如何通过一系列工具调用来解决问题 12。例如,在4和12中描述的场景,当用户询问“我现在所在位置的天气如何?”时,Claude可能会首先推理出需要调用get_location工具来确定用户位置,然后再将获取到的位置信息传递给get_weather工具来查询天气。这种逐步推理的过程,就是思维链的体现。OpenAI的GPT模型也鼓励开发者设计能够主动使用多个工具来协同完成任务的代理 9。
多步骤工作流的典型例子包括:预订一次完整的旅行,这可能涉及到依次调用查询航班API、预订酒店API和租赁汽车API 2;或者处理一个用户的退款请求,这可能需要先调用order_status_check工具确认订单已送达,然后调用refund_policy_check工具检查退款资格,接着调用refund_create工具创建退款请求,最后调用user_notify工具通知用户退款状态 9。
4.2 强制工具使用与工具选择策略
在某些情况下,开发者可能希望对LLM的工具选择行为施加更强的控制,例如强制模型使用某个特定的工具,或者禁止模型使用任何工具。主流LLM平台为此提供了相应的控制参数。
Anthropic Claude的tool_choice参数提供了多种选项来精确控制工具的使用 12:
auto:模型自行决定是否调用工具以及调用哪个工具(这是提供工具时的默认行为)。any:强制模型必须从提供的工具列表中选择至少一个来使用。tool:强制模型必须使用开发者指定的某一个特定工具。none:禁止模型使用任何提供的工具(这是未提供工具时的默认行为)。
OpenAI的GPT模型在其API中也提供了tool_choice参数,允许开发者指定模型必须调用的特定函数名称,或者通过其他方式影响模型的选择倾向 11。虽然6的例子中没有直接展示强制选择,但其系统提示和工具列表的组合也体现了引导模型选择特定工具的意图。
强制工具使用的主要应用场景包括:当开发者明确知道某个特定任务必须通过某个特定工具才能完成时;在调试模型行为或测试特定工具集成时;或者在构建具有固定步骤的自动化工作流时,确保LLM按照预定路径执行 12。
4.3 利用少样本提示(Few-shot Prompting)提升调用准确性
尽管精心设计的工具描述和JSON Schema能够为LLM提供关于如何使用工具的良好指导,但在面对一些特别复杂或模型本身容易混淆的场景时,LLM仍可能出现调用错误。此时,可以利用少样本提示(Few-shot Prompting)技术来进一步优化和提升函数调用的准确性 6。
少样本提示的核心思想是在主提示(prompt)中,向LLM提供一个或多个完整的函数调用交互示例 13。每个示例通常包含以下部分:用户的原始输入(问题或指令)、(可选的)模型在决定调用工具前的思考过程、模型生成的工具调用请求(通常是JSON格式)、模拟的工具执行结果,以及模型基于工具结果给出的最终回复 14。通过展示这些完整的“成功案例”,LLM可以在当前上下文中学习到期望的调用模式、输出风格、参数选择逻辑,甚至是如何处理多步骤依赖关系 13。
这种方法对于那些模型难以通过通用指令正确处理的特定场景尤其有效。例如,14中展示了一个场景,模型在处理包含乘法和减法的数学运算(如“119乘以8再减去20”)时,可能会错误地理解运算顺序。通过在提示中加入一个遵循正确运算顺序(先乘后减)的少样本示例,可以有效地纠正模型的行为,使其生成正确的、分步骤的工具调用序列。
在构造少样本提示时,示例的质量和相关性非常重要。有时,示例在提示中出现的顺序也可能影响最终效果;一种策略是将质量最高或与当前任务最相关的示例放在提示的末尾,因为一些模型倾向于更关注它们最近读取到的信息 13。
“思维链”的展现和多步骤工具使用的能力,清晰地表明大型语言模型正在从简单的指令执行者向具备初步规划和复杂问题解决能力的方向演进。这不仅仅是函数调用功能的简单扩展,更预示着未来可能出现更具自主性的AI代理系统。当LLM能够像4和12中描述的那样,在回答天气问题前先主动获取用户位置,这实际上已经是一种简单的任务分解和计划执行。这种能力是构建更复杂的LLM智能体(Agents)的基石,因为智能体需要能够根据宏观目标自主制定计划、执行多步操作,并根据环境的反馈动态调整其行为 1。因此,这些高级函数调用功能可以被视为通往更高级人工智能形态(如具备更强自主决策和执行能力的AI代理)的重要技术阶梯。
另一方面,少样本提示在函数调用优化中的成功应用,凸显了“情境学习”(In-context Learning)在规范LLM行为和克服其固有缺陷方面依然扮演着不可或缺的角色,即便是在已经拥有结构化工具定义(如JSON Schema)的场景下。工具描述和JSON Schema为LLM提供了关于工具用途和参数结构的“静态”知识(如第三章所述)。然而,面对某些复杂或模型本身容易产生混淆的特定情况(例如14中提到的运算顺序问题),LLM仍有可能出错。少样本提示通过提供具体的、完整的交互“动态”示例 13,让LLM能够在当前的上下文中“观察”并“模仿”正确的行为模式。这表明,单靠结构化的定义有时不足以完全约束或引导LLM的行为,尤其是在需要复杂推理或特定行为模式时。情境学习通过生动的“演示”来弥补这一不足。因此,即使函数调用机制本身已经比纯文本生成任务提供了更强的结构性和可控性,有效的提示工程(包括精心设计的少样本示例)仍然是优化其性能、提升调用准确性和可靠性的关键手段之一 13。
第五章:函数调用的优势、挑战与应对
函数调用技术为大型语言模型带来了前所未有的能力扩展,使其能够更深入地融入现实世界的应用场景。然而,如同任何新兴技术一样,它在带来显著优势的同时,也伴随着一系列挑战。理解这些优势与挑战,并采取有效的应对策略,对于成功部署和利用函数调用功能至关重要。
5.1 核心优势:实时数据、任务自动化与能力扩展
函数调用机制赋予LLM多方面的核心优势,极大地提升了其实用价值:
- 实时数据访问 (Real-Time Data Access): 这是函数调用最直接和显著的优势之一。通过调用外部API(如新闻API、天气API、股票API等),LLM能够获取并利用最新的、动态变化的信息来回答用户的问题,而不再受限于其训练数据的截止日期 1。2明确指出:“如果模型能通过函数调用获取最新信息,它就能提供更准确的答案。”
- 任务自动化 (Task Automation): LLM可以通过函数调用来自动执行许多重复性的或基于规则的任务,例如自动发送邮件、安排会议(通过调用日历API)、在CRM系统中创建或更新客户记录、管理待办事项列表等 2。这不仅提高了效率,也减少了人工操作的繁琐和潜在错误。
- 能力扩展 (Extended Capabilities): 函数调用使得LLM能够与各种外部系统和服务进行连接和交互,包括企业内部的数据库、客户关系管理(CRM)系统、企业资源规划(ERP)系统、物联网设备等 1。这使得LLM能够处理更复杂的、涉及多个系统协作的多步骤工作流,例如完成一次复杂的电商订单处理,或者执行一个多阶段的数据分析任务。
- 结构化输出 (Structured Output): 与传统的LLM主要生成自然语言文本不同,函数调用机制促使LLM生成结构化的数据(通常是JSON格式),用于指定要调用的函数和参数 1。这种结构化的输出易于被其他程序解析和处理,为LLM与软件系统的可靠集成奠定了基础。
- 无需重训即可更新功能 (Update information without re-training): 当需要为LLM添加新的能力或与新的外部服务集成时,通常只需要定义新的函数接口并告知LLM即可,而无需对整个大型语言模型进行成本高昂的重新训练或微调 2。这大大提高了系统的灵活性和可扩展性。
5.2 面临的挑战:错误处理、安全风险与准确性保障
尽管优势显著,但在实际应用函数调用时,开发者仍需面对和解决一系列挑战:
- API集成要求 (Predefined API Integration Required): LLM只能调用那些已经被开发者预先定义好并集成到系统中的函数或API。它无法凭空调用任意未知的外部服务 1。这意味着系统能力的扩展依赖于持续的开发和集成工作。
- 隐私与安全 (Privacy and Security Concerns): 当函数调用涉及到处理用户敏感数据(如个人信息、支付详情、商业机密等)或执行具有潜在风险的操作时,必须实施强有力的安全措施来防止数据泄露、未授权访问或恶意滥用 1。5建议进行输入验证和输出清理,而6则提到了使用传统技术(如正则表达式、拒绝名单)和基于LLM的验证来过滤恶意模式和提示注入攻击。
- 错误处理 (Error Handling): 外部API或服务的调用并非总是成功的,可能会因为网络问题、服务暂时不可用、认证失败、参数错误等多种原因而失败。系统必须具备健壮的错误处理机制,能够优雅地处理这些失败情况,例如通过重试、向用户请求澄清、或者回退到备用方案 1。5明确指出:“如果函数调用失败,系统应能重试、提示用户澄清或回退到替代工具。”15则提供了一个Python中
try-except错误捕获的示例。 - 误解用户意图 (Potential for Misinterpretation): 尽管LLM在自然语言理解方面取得了巨大进步,但它仍有可能错误地理解用户的真实意图,或者对用户模糊、不完整的指令做出不正确的解读,从而导致调用错误的函数或传递错误的参数 1。
- 准确性依赖 (Accuracy Dependence): 函数调用的整体有效性高度依赖于LLM准确地将用户的自然语言请求映射到正确的函数及其参数的能力 1。如果LLM的这种映射能力不足,即使外部函数本身是完美的,最终结果也可能不符合用户预期。
- 多API调用开销 (Multiple API Calls): 在某些情况下,完成一个用户请求可能需要两次或更多的API调用:一次是LLM分析用户输入并决定调用哪个函数(这本身可能就是一次对LLM API的调用),另一次(或多次)是实际执行外部函数 1。这可能会增加系统的整体延迟和成本。
- 用户输入的模糊性 (Ambiguous user input): 自然语言本身固有的模糊性、多义性和上下文依赖性,是导致LLM在函数调用决策中出错的一个重要原因 5。
5.3 实践中的考量与应对策略
为了克服上述挑战,提升函数调用系统的性能和可靠性,开发者在实践中可以考虑并采取以下应对策略:
- 应对模糊输入: 采用更先进的自然语言理解技术,如意图识别(Intent Recognition)和命名实体抽取(Named Entity Extraction, NER),来更准确地捕捉和澄清用户的请求,减少因输入模糊导致的错误 5。
- 提升工具定义质量: 正如第三章所强调的,为每个可调用的函数或工具提供全面、精确、无歧义的描述和严格的输入模式(JSON Schema),是提升LLM调用准确性的根本途径 5。
- 处理复杂任务: 对于需要多个步骤或复杂逻辑才能完成的任务,可以考虑将其分解为更小、更易于管理的子任务,并利用像LangChain这样的编排框架来协调和管理整个工作流程 5。
- 安全最佳实践: 实施严格的安全措施,包括对所有输入数据进行验证(确保其符合预期格式和约束),对从外部函数返回的输出数据进行清理(移除敏感信息或不必要内容),以及根据最小权限原则控制LLM可调用的函数范围和权限 5。
- 持续训练/微调LLM: (虽然2提到添加新函数无需重训模型是一个优势,但)通过在特定领域的数据上对LLM进行持续训练或微调,可以提升其解析特定类型用户输入和准确映射到相应函数的能力,从而减少错误 5。
- 日志与监控 (Logging and Monitoring): 建立完善的日志记录和监控系统,对函数调用的全过程(包括LLM的决策、生成的调用请求、外部函数的执行状态和结果、最终的用户反馈等)进行跟踪和分析。这有助于及时发现问题、诊断错误、评估性能,并为持续优化提供数据支持 15。16详细讨论了LLM可观测性(Observability)的重要性,包括监控延迟、准确率、错误模式以及追踪请求链路等。
函数调用所面临的诸多挑战,例如对用户意图的误解、外部调用失败时的错误处理、以及潜在的安全风险,其深层根源在于自然语言的内在不确定性与程序化执行所要求的确定性之间的固有矛盾。用户通常以自然语言表达其需求,而自然语言本质上是多义的、模糊的、高度依赖上下文的 5。LLM的核心任务之一,就是将这种不确定、有时甚至不完整的输入,准确地映射到一组预定义的、具有确定性参数和预期行为的函数调用上 1。这个从不确定到确定的映射过程,正是产生错误的主要环节,即1中提到的“潜在的误解可能性”。外部函数的执行本身是确定性的(给定相同的输入,产生相同的输出或行为),但其输入源于LLM对不确定语言的理解。如果这种理解存在偏差,那么即使函数本身完美无缺,执行结果也自然难以符合用户的真实预期。同样,安全风险也部分源于此:恶意用户可能会利用自然语言的灵活性和多义性来构造具有欺骗性的指令,试图诱导LLM调用不恰当的函数或传递恶意的参数数据,从而利用系统漏洞 6。因此,提升函数调用系统鲁棒性的核心,就在于如何通过更清晰的工具定义(如第三章所述)、更有效的上下文理解(如利用少样本提示,第四章所述)以及更强大的意图识别模型,来更好地弥合这种不确定性与确定性之间的鸿沟。
与此同时,建立一套有效的错误处理机制和强大的安全保障体系,是函数调用技术从“实验性功能”或“概念验证”阶段,真正走向“生产级应用”的必要前提和基石。函数调用直接与外部系统进行交互,这些交互可能涉及到真实世界的操作,例如金融交易、关键数据的修改、或对物理设备的控制 2。在这种高风险场景下,一次调用失败、数据泄露或非预期的系统行为所造成的后果,可能远比纯文本生成任务中的错误要严重得多。因此,1等多个信息源都反复强调了构建鲁棒错误处理逻辑和实施全面安全措施的重要性。这些需求,例如实现可靠的重试机制、设计优雅的回退策略、对所有输入进行严格验证、对输出进行必要的清理和过滤、以及建立持续的监控和告警系统 5,虽然与传统软件工程中的运维(Ops)和安全(Sec)实践有共通之处,但在LLM的特定上下文中又呈现出新的复杂性和挑战(例如如何防范针对LLM的提示注入攻击)。这就催生了对LLM特有的操作(LLMOps)能力的需求,包括对LLM行为的深入监控、日志记录、调用链路追踪、安全审计等,以确保基于函数调用的AI系统能够在生产环境中可靠、安全地运行 16。
第六章:函数调用与LLM智能体(Agents)的辨析
在讨论大型语言模型与外部世界交互时,除了“函数调用”之外,另一个经常被提及的概念是“LLM智能体”(LLM Agents)。虽然两者都旨在扩展LLM的能力边界,使其能够执行具体任务,但它们在核心概念、架构设计、自主性程度以及适用场景上存在显著差异。清晰辨析这两者,有助于开发者根据实际需求选择合适的技术路径。
6.1 核心差异:架构、自主性与应用场景
根据1和5的分析,函数调用与LLM智能体的主要区别可以从以下几个方面来理解:
-
核心概念与架构 (Core Concept and Architecture):
- 函数调用 (Function Calling): 本质上是一种技术或特性,它使LLM能够根据指令,生成对特定外部函数的调用请求(通常是结构化的JSON数据)。LLM在此过程中主要扮演“指令理解者”和“请求生成者”的角色,整个交互流程通常由外部的应用程序或框架来编排和控制。其架构相对简单,遵循一种“请求-响应”模式:LLM接收输入,决定调用函数,生成请求;外部应用执行函数,返回结果给LLM,LLM再生成最终回复 1。5明确指出:“需要明确的是,这(指函数调用)不是智能体,但函数调用是智能体用来将语言转化为现实世界(或数字环境内)具体行动的工具。”
- LLM智能体 (LLM Agents): 则是一个更复杂的、通常是模块化的系统。它以一个大型语言模型作为其核心“大脑”或“推理引擎”,并辅以其他关键组件,如记忆模块(用于存储上下文信息和学习经验)、规划模块(用于分解复杂任务和制定行动计划)以及工具集(其中可能就包含了通过函数调用机制实现的各种工具)。智能体具备更高程度的自主性,能够围绕一个设定的目标,主动进行思考、规划、决策,并执行一系列动作(这些动作可能涉及多次、多种工具的调用),然后观察结果并根据需要调整后续行为。其操作模式通常是迭代式的循环:推理 -> 规划 -> 行动 -> 观察 -> 再推理…… 1。
-
状态管理 (State Management):
- 函数调用: 在其基本形式下,函数调用本身主要是无状态的,或者说其状态管理主要由外部的调用应用程序来负责 1。LLM在一次函数调用决策中可能依赖于当前的对话历史,但长期的、结构化的状态记忆不是其核心特征。
- LLM智能体: 通常设计有专门的记忆模块,可以包括短期记忆(如用于当前任务的“草稿纸”)和长期记忆(如用于存储经验教训和用户偏好的“日记”或知识库),从而支持更复杂的、跨越多轮交互的持续性任务 1。
-
自主性 (Autonomy):
- 函数调用: LLM在函数调用过程中的自主性相对较低。它通常是在接收到明确或隐含的指令后,才决定调用哪个函数。选择哪个函数、如何传递参数等,很大程度上受到开发者预先定义的工具描述和当前用户输入的影响。
- LLM智能体: 追求更高程度的自主性。智能体被设计为能够根据一个较为宏观的目标,自主地分析情况、设定子目标、选择合适的工具或策略、执行操作,并从结果中学习和调整。它更像一个能够独立工作的“代理人” 1。
-
应用场景 (Use Cases):
- 函数调用: 非常适合于那些目标明确、步骤相对固定、可以通过一个或少数几个预定义函数来完成的任务。例如,查询特定信息(天气、股价)、执行简单操作(发送邮件、设置提醒)、或者作为更复杂应用中的一个原子能力被调用。它适用于开发者希望对LLM的行为有较强控制和预期的场景 1。
- LLM智能体: 更适用于那些开放式的、需要多步骤推理和动态规划才能解决的复杂问题。例如,担任一个能够自主处理客户服务请求的虚拟助手、一个能够根据用户模糊需求研究并撰写报告的AI研究员、或者一个能够管理复杂项目并协调多方资源的项目经理。它适用于那些需要LLM展现出更高灵活性、适应性和学习能力的场景 1。
6.2 何时选择函数调用,何时考虑智能体
基于上述差异,开发者在技术选型时可以遵循以下原则:
-
选择函数调用:
- 当任务的目标非常明确,完成任务的步骤相对固定或可以通过清晰的逻辑判断来确定时。
- 当可以通过一个或少数几个预先定义好的外部函数或API来满足需求时。
- 当需要对LLM的行为和输出有较强的控制和可预测性时。
- 当希望将LLM作为现有应用程序中的一个增强功能模块,由应用程序本身来主导和编排整个业务流程时。
-
考虑构建LLM智能体:
- 当任务的目标较为宏大、开放式,甚至有些模糊,需要LLM进行自主的探索、规划和任务分解时。
- 当完成任务需要动态地、按需地选择和组合使用多个不同的工具或信息源,并且这种选择本身也需要智能决策时。
- 当期望LLM能够从多轮交互、环境反馈或历史经验中学习和适应,并持续优化其行为策略时。
- 当希望构建一个能够更独立地、端到端地完成复杂工作的AI系统时。
函数调用并非与LLM智能体相互排斥或相互替代的技术;更准确地说,函数调用是构建LLM智能体的基础“能力模块”之一。正如1所指出的,LLM智能体的典型架构中包含“工具”组件,这些工具正是智能体与外部环境进行交互的手段。而5也明确提到,“函数调用是智能体用来将语言转化为现实世界……具体行动的工具”。这意味着,当一个LLM智能体在其规划模块决定需要执行某个具体操作时(例如,查询数据库、调用某个API、或者控制一个设备),它很可能会依赖于底层的函数调用机制来实现这个操作。因此,函数调用为智能体提供了感知世界和改造世界的“手臂”和“腿脚”。智能体的核心“智能”则更多地体现在其“大脑”——即其推理、规划、学习和决策能力 1——它决定了在何时、何地、为何以及如何运用这些“手臂”和“腿脚”来达成设定的目标。所以,开发者面临的并非是一个“二选一”的问题,而是需要理解这两种技术在构建复杂AI系统时所处的不同层级和扮演的不同角色。
从更宏观的视角来看,从函数调用技术的发展到LLM智能体概念的兴起,清晰地反映了人工智能领域从追求“工具化智能”向探索“自主性智能”演进的趋势。早期的许多AI系统更多地扮演着被动工具的角色,严格按照人类预设的指令和规则执行任务。函数调用技术的出现,使得LLM成为了一个能力更强、更易于集成的“超级工具”,它能够根据自然语言指令执行比以往更复杂、更贴近现实需求的操作,但其行为和决策流程在很大程度上仍然受到外部应用程序的控制和编排 1。而LLM智能体的设计理念则更进一步,它们追求更高程度的自主性和能动性。一个理想的智能体应该能够像一个独立思考的“行动者”一样,围绕目标自我设定子任务、自主规划行动路径、灵活选择和运用工具、从执行结果中学习并调整策略,而不仅仅是一个被动响应指令的“工具” 1。这种从“工具”到“行动者”的演进路径,与人工智能研究的长期目标——创造能够独立思考、主动学习并解决复杂问题的通用人工智能(AGI)——在方向上是高度一致的。函数调用作为一项关键的使能技术,无疑是通往这一宏大目标过程中的一个重要的技术里程碑和坚实的垫脚石。
结论:函数调用的现状与未来展望
函数调用技术作为连接大型语言模型与外部世界、赋予其执行实际任务能力的关键桥梁,已经展现出巨大的潜力和价值。它通过允许LLM请求执行预定义的外部函数或API,显著增强了模型获取实时信息、自动化复杂流程以及与各种系统和服务进行动态交互的能力,从而极大地拓展了LLM的应用场景和实用性。从Google的Gemini/Gemma,到OpenAI的GPT系列,再到Anthropic的Claude,主流LLM平台均已将函数调用或工具使用作为其核心功能之一,并提供了相应的API和开发支持。实践证明,精心设计的工具描述、健壮的JSON Schema、以及针对复杂场景的优化策略(如多步骤工具使用和少样本提示),是确保函数调用准确、可靠和高效的关键。
然而,函数调用技术在走向大规模成熟应用的过程中,仍面临诸多挑战,包括如何更精准地理解用户意图、消除自然语言的模糊性、确保调用的安全性和隐私保护、设计鲁棒的错误处理与回退机制,以及提升在复杂、动态环境下的自主决策能力等。这些挑战的克服,不仅依赖于LLM自身能力的持续进步,也需要开发者在工具定义、系统设计和安全防护等方面投入更多的智慧和努力。
展望未来,函数调用技术预计将在以下几个方向上持续发展和演进:
- 更强的意图理解和歧义消除能力: 未来的LLM将能更准确地捕捉用户深层意图,更好地处理模糊、不完整或矛盾的指令,从而减少错误的函数调用。
- 更自动化的工具发现与集成: 可能会出现让LLM能够根据任务需求,在一定程度上自主发现、理解并提议使用新的、未预先定义的工具或API的能力,降低人工集成的门槛。
- 更复杂的组合工具使用和规划能力: LLM在多步骤任务规划、动态工具选择、并行执行以及跨工具结果整合方面的能力将进一步增强,使其能够应对更为错综复杂的现实问题。
- 与LLM智能体更深度的融合: 函数调用将作为LLM智能体不可或缺的核心组件,支撑智能体实现更高级别的自主感知、决策和行动能力。智能体将能更灵活、更智能地编排和运用各种工具。
- 标准化和互操作性的提升: 随着技术的普及,可能会出现更多关于函数/工具定义、调用协议和安全规范的行业标准或被广泛接受的实践,例如通过像LangChain这样的框架来促进跨平台的一致性和互操作性 5。
- 安全性和可靠性的持续增强: 针对函数调用的安全威胁(如提示注入、数据泄露等)将会有更成熟的防御机制和验证方法。同时,系统的容错性、可监控性和可调试性也将得到进一步提升。
函数调用技术的成熟度将直接影响下一代人工智能应用的形态和能力边界。目前,函数调用已经使LLM能够执行诸如在线预订、信息查询、简单设备控制等任务 2。随着其准确性、鲁棒性和易用性的不断提升,开发者将能够构建出更加智能、更加无缝集成的AI应用。可以预见,用户未来可能不再需要直接操作多个独立的应用程序或网站来完成一项复杂任务,而是通过一个统一的、基于自然语言的交互界面,由LLM在后台通过一系列精准的函数调用来协调各种服务,从而高效地满足用户需求。这将极大地提升数字体验的流畅性和效率,推动人机交互从传统的“以应用为中心”向更自然的“以任务为中心”或“以意图为中心”的范式转变。
最终,围绕函数调用技术构建一个完善的生态系统——包括统一的工具定义标准、成熟的安全框架、全面的监控与可观测性方案、以及高效的开发与调试工具等——将是推动该技术得到广泛应用并激发持续创新的关键所在。目前各平台在实现细节上存在的差异 [第二章],无疑给开发者带来了一定的学习和集成成本。而安全 1 和错误处理 1 作为普遍关注的核心问题,迫切需要通用的解决方案和行业最佳实践。有效的监控和可观测性 16 对于维护生产环境中基于函数调用的LLM系统的稳定运行至关重要。同时,开发者也需要更强大、更易用的工具来辅助他们定义、测试、部署和管理这些日益复杂的AI应用(例如PromptLayer 1, LangChain 5, MAX Platform 15 等工具的出现正是这一趋势的体现)。一个繁荣、开放、协同的生态系统,能够有效降低函数调用技术的使用门槛,加速创新应用的孵化,并促进最佳实践的沉淀与共享,从而共同推动这项赋能LLM与现实世界交互的关键技术更快地走向成熟和普及,开启人工智能应用的新篇章。
相关文章:

赋能大型语言模型与外部世界交互——函数调用的崛起
大型语言模型 (LLM) 近年来在自然语言处理领域取得了革命性的进展,展现出强大的文本理解、生成和对话能力。然而,这些模型在与外部实时数据源和动态系统交互方面存在固有的局限性 1。它们主要依赖于训练阶段学习到的静态知识,难以直接访问和利…...

04 Deep learning神经网络编程基础 梯度下降 --吴恩达
梯度下降在深度学习的应用 梯度下降是优化神经网络参数的核心算法,通过迭代调整参数最小化损失函数。 核心公式 参数更新规则: θ t + 1 = θ t − η ∇ J ( θ...
手拉手处理RuoYi脚手架常见文问题
若依前后端分离版开发入门 基础环境:JDK1.8mysqlRedisMavenVue 取消登录验证码 后端 修改ruoyi-ui项目中的login.vue 在ruoyi-ui项目>src>views中找到login.vue文件 1、注释验证码展示及录入部分 2、 注释code必填校验,默认验证码开关为false …...

录制mp4
目录 单线程保存mp4 多线程保存mp4 rtsp ffmpeg录制mp4 单线程保存mp4 import cv2 import imageiocv2.namedWindow(photo, 0) # 0窗口大小可以任意拖动,1自适应 cv2.resizeWindow(photo, 1280, 720) url "rtsp://admin:aa123456192.168.1.64/h264/ch1/main…...

Dynamics 365 Finance + Power Automate 自动化凭证审核
🚀 Dynamics 365 Finance Power Automate 自动化凭证审核 📑 目录 🚀 Dynamics 365 Finance Power Automate 自动化凭证审核1. 依赖 🔧2. 目标 🎯3. 系统架构 🏗️4. 凭证审批全流程 🛠️4.1 …...
—— 构建本地知识库系统的基础《一》)
使用 Python + SQLAlchemy 创建知识库数据库(SQLite)—— 构建本地知识库系统的基础《一》
📚 使用 Python SQLAlchemy 创建知识库数据库(SQLite)—— 构建本地知识库系统的基础 🧠 一、前言 随着大模型技术的发展,越来越多的项目需要构建本地知识库系统来支持 RAG(Retrieval-Augmented Generat…...

使用柏林噪声生成随机地图
简单介绍柏林噪声 柏林噪声(Perlin Noise)是一种由 Ken Perlin 在1983年提出的梯度噪声(Gradient Noise)算法,用于生成自然、连续的随机值。它被广泛用于计算机图形学中模拟自然现象(如地形、云层、火焰等…...
)
P3 QT记事本(3.4)
3.4 文件选择对话框 QFileDialog 3.4.1 QFileDialog 开发流程 使用 QFileDialog 的基本步骤通常如下: 实例化 :首先,创建一个 QFileDialog 对象的实例。 QFileDialog qFileDialog;设置模式 :根据需要设置对话框的模式&…...
C++课设:实现简易文件加密工具(凯撒密码、异或加密、Base64编码)
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 专栏介绍:《编程项目实战》 目录 一、初识文件加密:为什么需要…...
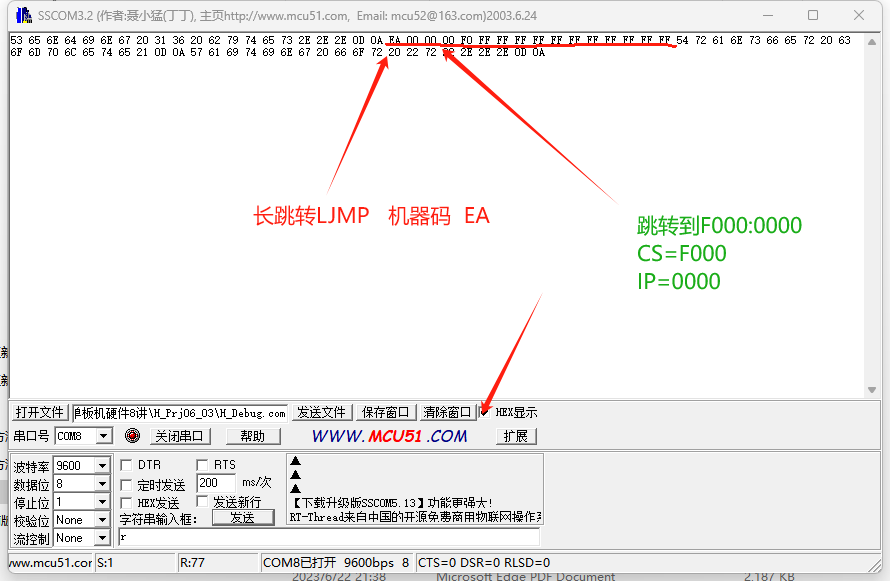
H_Prj06_03 8088单板机串口读取8088ROM复位内存
1.8088CPU复位时,CSFFFFH,IP0000H,因此在ROM的逻辑地址FFFF:0000(FFF0H)处一般要防止一个长跳转指令LJMP(机器码位EAH) 2.写一个完整的8086汇编程序,通过查询方式检测串口接收符串‘r’&#x…...
构建 MCP 服务器:第 3 部分 — 添加提示
这是我们构建 MCP 服务器的四部分教程的第三部分。在第一部分中,我们使用基本资源创建了第一个MCP 服务器;在第二部分中,我们添加了资源模板并改进了代码组织。现在,我们将进一步重构代码并添加提示功能。 什么是 MCP 提示&#…...

xcode 各版本真机调试包下载
下载地址 https://github.com/filsv/iOSDeviceSupport 使用方法: 添加到下面路径中,然后退出重启xcode /Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/DeviceSupport...
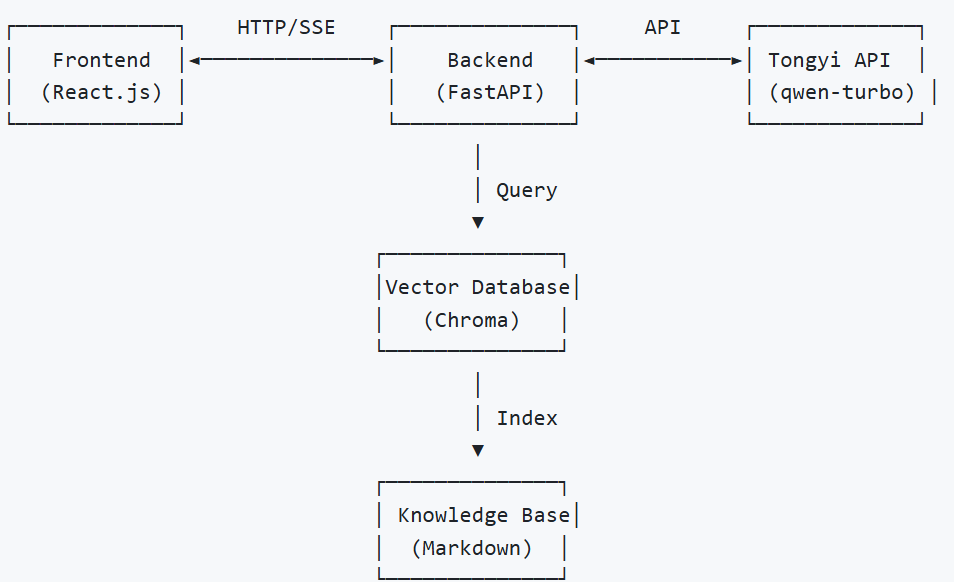
基于React + FastAPI + LangChain + 通义千问的智能医疗问答系统
📌 文章摘要: 本文详细介绍了如何在前端通过 Fetch 实现与 FastAPI 后端的 流式响应通信,并支持图文多模态数据上传。通过构建 multipart/form-data 请求,配合 ReadableStream 实时读取 AI 回复内容,实现类似 ChatGPT…...

C# 中替换多层级数据的 Id 和 ParentId,保持主从或父子关系不变
在C#中替换多层级数据的Id和ParentId,同时保持父子关系不变,可以通过以下步骤实现: 创建旧Id到新Id的映射:遍历所有节点,为每个旧Id生成唯一的新Id,并存储在字典中。 替换节点的Id和ParentId:…...
)
Scade 语言概念 - 方程(equation)
在 Scade 6 程序中自定义算子(Operator)的定义、或数据流定义(data_def)的内容中,包含一种基本的语言结构:方程(equation)(注1)。在本篇中,将叙述 Scade 语言方程的文法形式,以及作用。 注1: 对 Scade 中的 equation, 或 equation…...

PG 分区表的缺陷
简介 好久没发文,是最近我实在不知道写点啥。随着国产化进程,很多 oracle 都在进行迁移,最近遇到了一个分区表迁移之后唯一性的问题。oracle 数据库中创建主键或者唯一索引,不需要引用分区键,但是 PG 就不行ÿ…...

从Copilot到Agent,AI Coding是如何进化的?
编程原本是一项具有一定门槛的技能,但借助 AI Coding 产品,新手也能写出可运行的代码,非专业人员如业务分析师、产品经理,也能在 AI 帮助下直接生成简单应用。 这一演变对软件产业产生了深远影响。当 AI 逐步参与代码生成、调试乃…...

Qt(part 2)1、Qwindow(菜单栏,工具栏,状态栏),铆接部件,核心部件 ,2、添加资源文件 3、对话框
1、Qwindow tips:1,首先为什么创建出的对象基本都是指针形式,个人觉得是对象树的原因(自动释放内存),指针来访问成员函数->的形式。2,菜单栏只能一个的,放窗口基本Set,…...
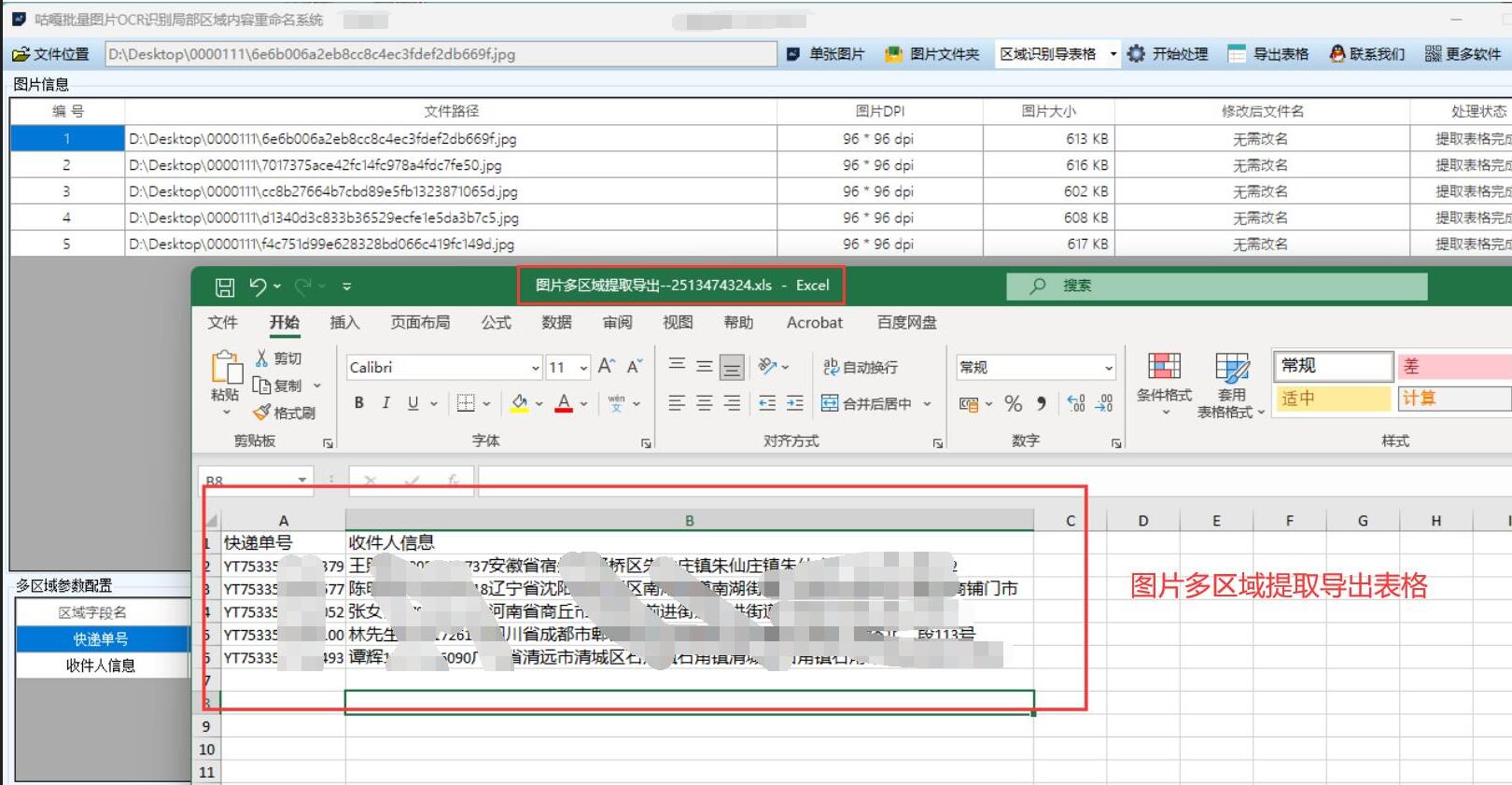
【图片识别Excel】批量提取图片中的文字,图片设置识别区域,识别后将文字提取并保存Excel表格,基于WPF和OCR识别的应用
应用场景 在办公自动化、文档处理、数据录入等场景中,经常需要从大量图片中提取文字信息。例如: 批量处理扫描的表单、合同、发票等文档从图片集中提取特定区域的文字数据将纸质资料快速转换为电子文本并整理归档 通过设置识别区域,可以精…...

深入理解 Java 多线程:原理剖析与实战指南
深入理解 Java 多线程:原理剖析与实战指南 一、引言 在现代软件开发中,多线程编程已经成为提升应用性能与响应能力的重要手段。Java 作为一门成熟的编程语言,自 JDK 1.0 起就提供了对多线程的原生支持。本文将深入剖析 Java 多线程的底层原…...
Qt/C++学习系列之Excel使用记录
Qt/C学习系列之Excel使用记录 前言The process was ended forcefully.解决方式断点查语句问题 总结 前言 在项目中解析条目达50多条,并且都需要将对应的结果进行显示。为了将结果显示的更加清晰,考虑采用QTableWidget进行表格设置,而在使用过…...
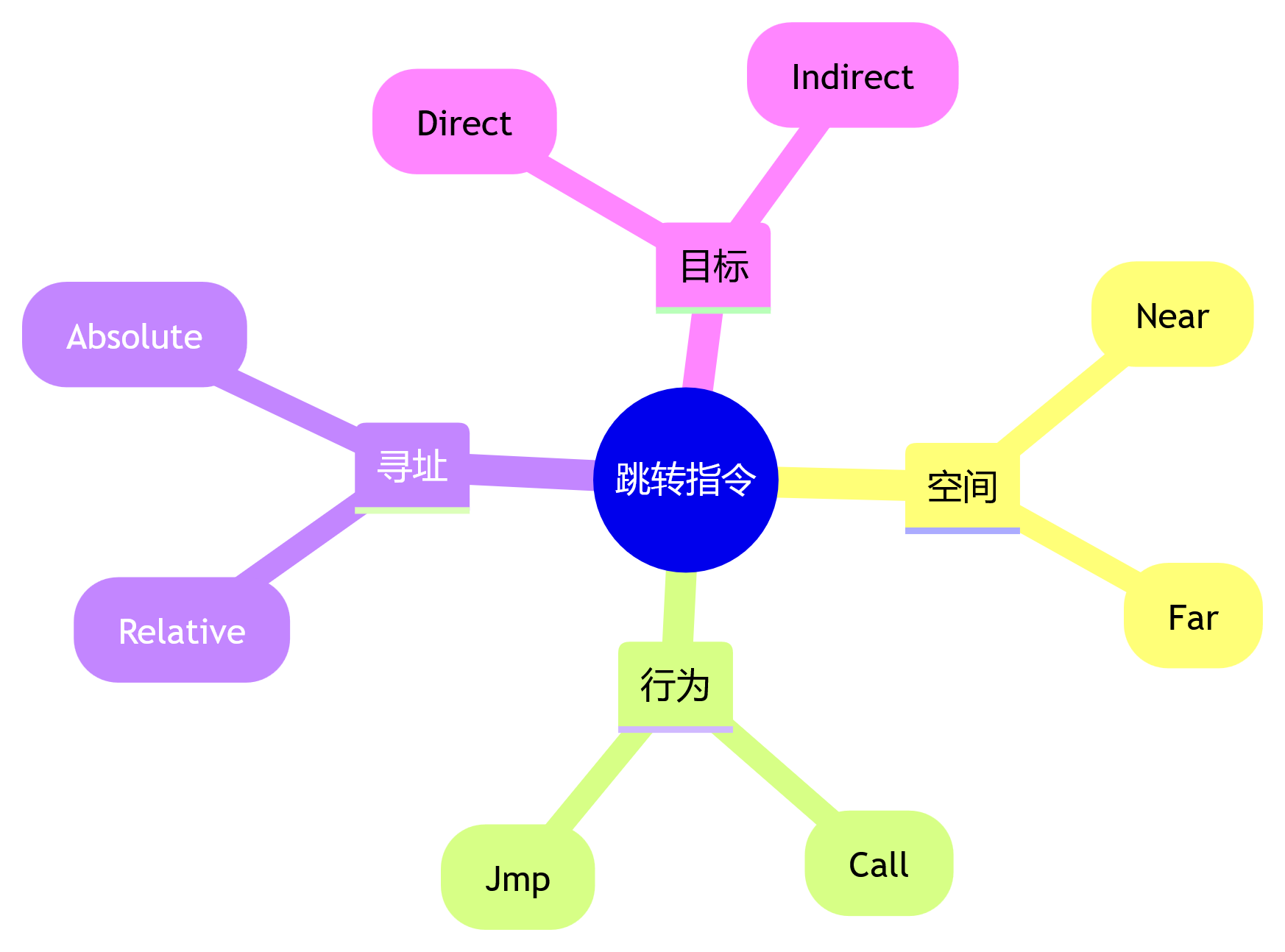
跳转指令四维全解:从【call/jmp 】的时空法则到内存迷宫导航术
一、核心概念:代码世界的空间定位法则 在汇编世界里,我们可以把内存想象成一栋巨大的图书馆: CS(代码段寄存器) 楼层编号 IP(指令指针) 房间编号 当前执行位置 CS:IP(如3楼201…...
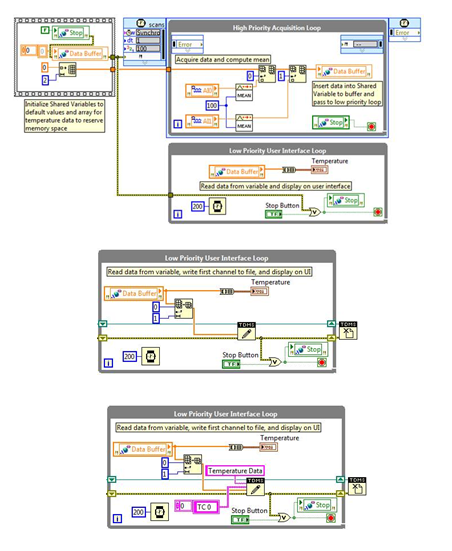
LabVIEW实时系统数据监控与本地存储
基于LabVIEW Real-Time 模块,面向工业自动化、嵌入式测控等场景,提供实时数据采集、监控与本地存储的完整实现路径。通过分层任务调度、TDMS 文件格式应用及跨平台兼容性设计,确保系统在实时性、可靠性与数据管理效率间达到平衡。文中以 Comp…...
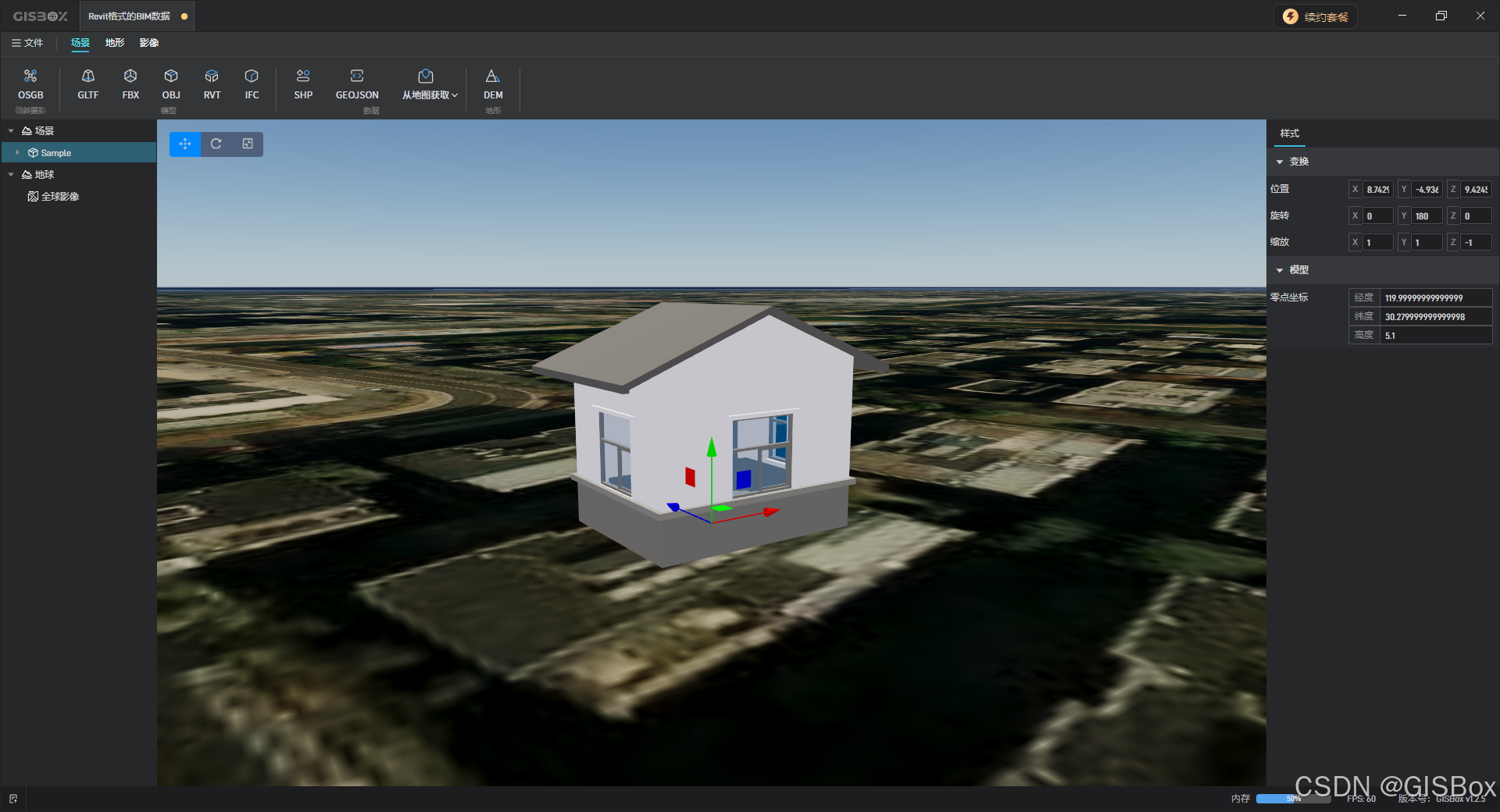
从 Revit 到 3DTiles:GISBox RVT 切片器如何让建筑图元在 Web 端展示
在GIS(地理信息系统)行业蓬勃发展的当下,数据处理与展示的效率和精准度成为关键。GISBox作为一款功能强大的一站式三维GIS数据编辑、转换、发布平台,凭借其独特的“RVT切片器”功能,在RVT图元处理方面也有着不俗的表现…...
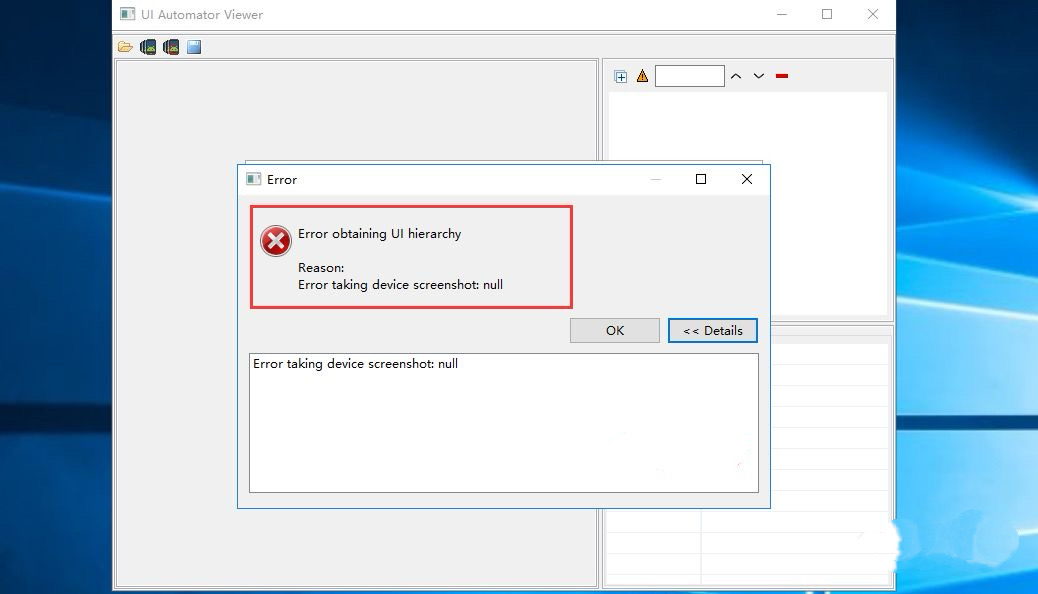
Appium+python自动化(十二)- Android UIAutomator
Android团队在4.1版本(API 16)中推出了一款全新的UI自动化测试工具UiAutomator,用来帮助开发人员更有效率的完成App的Debug工作,同时对于测试人员也是一大福音,为什么这么说呢? UiAutomator提供了以下两种…...

在C语言中使用UUID作为AES加密密钥
在C语言中使用UUID作为AES加密密钥 编译依赖安装示例代码编译和运行关键点说明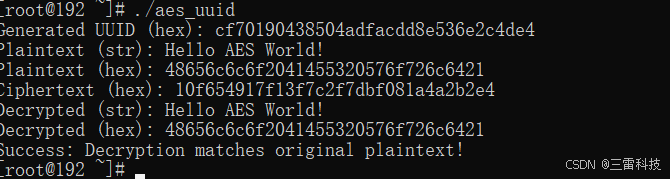注意事项编译依赖安装 运行环境位centos8 Linux 4.18.0-348.7.1.el8_5.x86_64 #1 SMP Wed Dec …...

Nginx+Tomcat负载均衡集群
目录 一、Tomcat 基础与单节点部署 (一)Tomcat 概述 (二)单节点部署案例 1. 案例环境 2. 实施准备 3. 安装 JDK 4. 查看 JDK 安装情况 5. 安装配置 Tomcat 6. 启动 Tomcat 7. 访问测试 8. 关闭 Tomcat (三…...

QQ邮箱发送验证码(Springboot)
一、邮箱发送服务准备 在qq邮箱的设置中选择账号下开启服务。 开启时可能会有短信验证,开启后显示验证码之类的一串英文,复制保存起来,在配置文件中会使用到。 二、后端依赖及配置 依赖 在pom.yml文件中添加相关依赖,redis的…...

Python Copilot【代码辅助工具】 简介
粉丝爱买鳕鱼肠深海鳕鱼肉鱼肉香肠盼盼麦香鸡味块卡乐比(Calbee)薯条三兄弟 独立小包美丽雅 奶茶杯一次性饮料杯好时kisses多口味巧克力糖老金磨方【黑金系列】黑芝麻丸郑新初网红郑新初烤鲜牛肉干超人毛球修剪器去球器剃毛器衣服去毛器优惠券宁之春 红黑…...

如何写高效的Prompt?
概述 提示词(Prompt)的质量将直接影响模型生成结果的质量,所以精心设计一个让大模型能够理解并有效回复的提示词是至关重要的。本文内容自论文中获取:https://arxiv.org/pdf/2312.16171 介绍了5类共计26条提示词书写原则。 书写原则 类别原则备注快速…...