机器学习复习3--模型的选择
选择合适的机器学习模型是机器学习项目成功的关键一步。这通常不是一个一蹴而就的过程,而是需要综合考虑多个因素,并进行实验和评估。
1. 理解问题本质
这是模型选择的首要步骤。需要清晰地定义试图解决的问题类型:
监督学习 :
数据集包含输入特征和对应的标签(目标变量)
分类 : 目标变量是离散的类别。例如,判断邮件是否为垃圾邮件(是/否),图像识别(猫/狗/鸟),客户流失预测(流失/不流失)。
需要考虑的问题: 二分类还是多分类?类别是否平衡?是否需要概率输出?
回归 : 目标变量是连续的数值。例如,预测房价,预测股票价格,预测汽车燃油效率。
需要考虑的问题: 对预测误差的容忍度如何?是否存在异常值
无监督学习
数据集没有标签,模型需要自己发现数据中的结构或模式。
聚类 : 将相似的数据点分组。例如,客户分群,异常检测。
降维: 减少特征数量,同时保留重要信息。例如,数据可视化,特征提取。
关联规则学习 : 发现数据项之间的有趣关系。例如,“购买了啤酒的人也倾向于购买尿布”。
强化学习
模型通过与环境交互来学习,目标是最大化累积奖励。例如,机器人导航,游戏AI。
2. 理解数据特性
数据的质量和特性直接影响模型的选择和性能:
-
(1)数据量
-
小数据集 (<几千条): 简单模型(如线性回归、逻辑回归、朴素贝叶斯、K近邻、决策树)可能表现更好,因为复杂模型容易过拟合。
-
中等数据集 (几千到几百万条): 可以尝试更复杂的模型,如支持向量机 (SVM)、集成方法 (随机森林、梯度提升树)。
-
大数据集 (>几百万条): 神经网络/深度学习模型通常能发挥巨大威力,但需要相应的计算资源。分布式计算框架(如Spark MLlib)也可能需要。
-
-
(2)特征数量
-
低维数据: 大多数模型都可以处理。
-
高维数据 (特征远多于样本): 线性模型通常表现良好,特别是结合正则化(L1, L2)。某些模型(如KNN)在高维空间中性能会下降(维度灾难)。降维技术(如PCA)可能需要。
-
-
(3)数据类型
-
数值型 : 大多数模型可以直接处理。
-
类别型 : 需要进行编码(如独热编码、标签编码)才能被大多数模型使用。树模型对类别特征有较好的原生支持。
-
文本数据: 需要特定的预处理(如词袋模型、TF-IDF、词嵌入)。朴素贝叶斯、LSTM、Transformer等模型常用。
-
图像/音频/视频数据: 通常需要深度学习模型(如CNN、RNN)。
-
-
(4)数据质量
-
缺失值 : 有些模型能处理缺失值(如XGBoost),有些则不能,需要预先进行填充或删除。
-
异常值 : 某些模型对异常值敏感(如线性回归、均值聚类),而另一些则比较鲁棒(如树模型、基于密度的聚类)。
-
噪声 :数据中的噪声会影响所有模型,但有些模型(如集成模型)的鲁棒性更好。
-
-
(5)特征之间的关系
-
线性关系: 线性模型是好的起点。
-
非线性关系: 树模型、SVM(使用核函数)、神经网络更适合。
-
特征交互: 树模型能自动学习特征交互,而线性模型通常需要手动创建交互项。
-
3. 模型的特性与权衡
不同的模型有其固有的特性和优缺点:
-
准确性 (Accuracy)模型预测的准确程度。这是最重要的指标之一,但不是唯一。
-
可解释性 (Interpretability): 理解模型为什么做出某个预测的能力。
-
高可解释性: 线性回归、逻辑回归、决策树。它们的决策过程相对透明。
-
低可解释性 (黑箱模型): 神经网络、复杂的集成模型。虽然可以使用LIME、SHAP等工具进行事后解释,但原生可解释性较差。
-
权衡: 通常,模型越复杂,准确性可能越高,但可解释性越差。在金融、医疗等领域,可解释性非常重要。
-
-
训练速度 (Training Speed): 模型在给定数据集上完成训练所需的时间。
-
快: 线性模型、朴素贝叶斯、决策树。
-
慢: 神经网络、SVM(尤其使用复杂核函数且数据量大时)、某些集成模型。
-
-
预测速度 (Prediction Speed / Latency): 模型对新数据点进行预测所需的时间。对于实时应用(如在线推荐、欺诈检测)至关重要。
-
计算资源需求 (Computational Resources): 训练和部署模型所需的CPU、内存、GPU等。深度学习模型通常需要GPU加速。
-
鲁棒性 (Robustness): 模型对数据中的噪声、异常值或数据分布变化的敏感程度。集成模型通常更鲁棒。
-
处理不同数据类型的能力 : 有些模型天然支持混合数据类型,有些则需要严格的数据预处理。
-
模型假设 :
-
线性回归: 假设特征与目标之间存在线性关系,误差项独立同分布且服从正态分布。
-
朴素贝叶斯: 假设特征之间条件独立。
-
4. 常见模型类别及其适用场景
-
线性模型
优点: 简单、快速、可解释性好,在高维稀疏数据上表现良好,是很好的基线模型。
缺点: 难以捕捉复杂的非线性关系。
适用: 回归问题、二分类问题,数据量不大或特征线性关系明显时。
-
决策树
优点: 直观易懂,可解释性强,能处理数值型和类别型特征,对数据缩放不敏感。
缺点: 容易过拟合,对数据中的小变动敏感。
适用: 分类和回归,特别是当需要清晰的决策规则时。
-
K-近邻
优点: 简单,非参数模型(对数据分布没有假设),易于实现。
缺点: 计算成本高(尤其在预测阶段,需要计算与所有训练样本的距离),对特征缩放敏感,在高维空间中效果不佳(维度灾难)。
适用: 数据量不大,特征维度不高,需要快速原型验证的场景。
-
朴素贝叶斯
优点: 简单、快速,对小数据集和高维数据表现良好,尤其在文本分类中常用。
缺点: “朴素”的特征条件独立假设在现实中往往不成立,但实际效果有时依然不错。
适用: 文本分类(如垃圾邮件过滤)、情感分析。
-
支持向量机
优点: 在高维空间中非常有效,即使特征数量大于样本数量。通过核函数可以处理非线性问题。理论基础扎实。
缺点: 训练时间较长(特别是大数据集),对参数选择和核函数选择敏感,可解释性一般。
适用: 中小数据集的分类问题,尤其是高维数据。
-
集成学习
优点: 通常能获得非常高的预测精度,鲁棒性强,能处理不同类型的特征,能捕捉复杂的非线性关系和特征交互。
缺点: 模型通常较复杂,可解释性较差(相对于单个决策树),训练时间可能较长。
适用: 各种分类和回归任务,特别是当追求高精度时,是Kaggle等竞赛中的常用模型。
-
神经网络与深度学习
优点: 能学习极其复杂的模式和表示,在图像、语音、文本等领域取得了突破性进展。
缺点: 需要大量的标注数据,训练时间长,计算资源需求高,模型是“黑箱”,调参复杂。
适用: 大数据集,复杂的非结构化数据(图像、文本、语音等),或当其他模型效果不佳时。
-
聚类算法
优点: 无需标签数据,可以发现数据中的潜在结构。
缺点: 结果的好坏依赖于距离度量和参数选择,解释聚类结果有时具有挑战性。
适用: 客户分群、异常检测、数据探索。
5. 模型选择的实践流程
-
从简单模型开始 : 建立一个基线模型(如线性回归或逻辑回归)。这有助于你了解数据的基本可预测性,并为后续更复杂的模型提供比较基准。
-
考虑多个候选模型 : 基于对问题和数据的理解,选择几个不同类型的候选模型。
-
交叉验证 :使用交叉验证来评估模型在未见过数据上的泛化能力,并帮助进行超参数调优。这是避免过拟合和选择稳定模型的关键。
-
选择合适的评估指标
分类: 准确率 (Accuracy), 精确率 (Precision), 召回率 (Recall), F1分数 (F1-Score), ROC-AUC, PR-AUC。注意处理类别不平衡问题。
回归: 均方误差 (MSE), 均方根误差 (RMSE), 平均绝对误差 (MAE), R²分数。
-
超参数调优 对每个候选模型进行超参数优化(如网格搜索、随机搜索、贝叶斯优化),以发挥其最佳性能。
-
比较模型性能: 在相同的测试集上,使用选定的评估指标比较不同模型的性能。
-
考虑业务约束: 除了预测性能,还要考虑模型的可解释性、训练/预测时间、部署成本等实际因素。例如,一个稍差但可解释性强的模型可能比一个略好但完全是黑箱的模型更受欢迎。
-
迭代与实验: 模型选择是一个迭代的过程。根据初步结果,你可能需要回到特征工程、数据清洗步骤,或者尝试新的模型。
-
利用领域知识 : 领域专家的见解对于特征选择、模型假设验证和结果解释非常有价值。
-
集成与部署 : 有时,将多个表现良好的模型集成起来(Ensembling)可以进一步提升性能。最后,考虑模型的部署和维护。
相关文章:

机器学习复习3--模型的选择
选择合适的机器学习模型是机器学习项目成功的关键一步。这通常不是一个一蹴而就的过程,而是需要综合考虑多个因素,并进行实验和评估。 1. 理解问题本质 这是模型选择的首要步骤。需要清晰地定义试图解决的问题类型: 监督学习 : 数据集包含…...

MySQL复杂SQL(多表联查/子查询)详细讲解
🤟致敬读者 🟩感谢阅读🟦笑口常开🟪生日快乐⬛早点睡觉 📘博主相关 🟧博主信息🟨博客首页🟫专栏推荐🟥活动信息 文章目录 MySQL复杂SQL(多表联查/子查询&a…...
STM32使用土壤湿度传感器
1.1 介绍: 土壤湿度传感器是一种传感装置,主要用于检测土壤湿度的大小,并广泛应用于汽车自动刮水系统、智能灯光系统和智能天窗系统等。传感器采用优质FR-04双料,大面积5.0 * 4.0厘米,镀镍处理面。 它具有抗氧化&…...
的标准写法)
在C++中,头文件(.h或.hpp)的标准写法
目录 1.头文件保护(Include Guards)2.包含必要的标准库头文件3.前向声明(Forward Declarations)4.命名空间5.注释示例1:基础头文件示例2:包含模板和内联函数的头文件示例3:C11风格的枚举类头文件…...

Axios学习笔记
Axios简介 axios前端异步请求库类似JQuery ajax技术, ajax用来在页面发起异步请求到后端服务,并将后端服务响应数据渲染到页面上, jquery推荐ajax技术,但vue里面并不推荐在使用jquery框架,vue推荐使用axios异步请求库。…...
:Chain构建与组合技巧)
Langchain学习笔记(十一):Chain构建与组合技巧
注:本文是Langchain框架的学习笔记;不是教程!不是教程!内容可能有所疏漏,欢迎交流指正。后续将持续更新学习笔记,分享我的学习心得和实践经验。 前言 在LangChain的发展过程中,API设计经历了重…...

【判断既约分数】2022-4-3
缘由既约分数,除了辗转相除法-编程语言-CSDN问答 void 判断既约分数() {int a 1, b 2020, aa b, y 2, gs 0;while (aa){while (a < b){while (y < a && y < aa)if (a%y 0 && aa%y 0)a, y 2;elsey;if (a < b)gs; else;a, y 2;…...
Windows平台RTSP/RTMP播放器C#接入详解
大牛直播SDK在Windows平台下的RTSP、RTMP播放器模块,基于自研高性能内核,具备极高的稳定性与行业领先的超低延迟表现。相比传统基于FFmpeg或VLC的播放器实现,SmartPlayer不仅支持RTSP TCP/UDP自动切换、401鉴权、断网重连等网络复杂场景自适应…...

深圳SMT贴片工艺优化关键步骤
内容概要 深圳SMT贴片工艺优化作为现代电子制造的核心环节,聚焦于提升生产精度与稳定性。其技术框架围绕三大核心维度展开:温度动态调控、设备协同适配与工艺缺陷预判。通过精密温度曲线控制系统,实现回流焊环节的热能梯度精准匹配ÿ…...

从 JDK 8 到 JDK 17:Swagger 升级迁移指南
点击上方“程序猿技术大咖”,关注并选择“设为星标” 回复“加群”获取入群讨论资格! 随着 Java 生态向 JDK 17 及 Jakarta EE 的演进,许多项目面临从 JDK 8 升级的挑战,其中 Swagger(API 文档工具)的兼容性…...

配置git命令缩写
以下是 Git 命令缩写的配置方法及常用方案,适用于 Linux/macOS/Windows 系统: 🔧 一、配置方法 1. 命令行设置(推荐) # 基础命令缩写 git config --global alias.st status git config --global alias.co che…...

Redis 缓存问题及其解决方案
1. 缓存雪崩 概念:缓存雪崩是指在缓存层出现大范围缓存失效或缓存服务器宕机的情况下,大量请求直接打到数据库,导致数据库压力骤增,甚至可能引发数据库宕机。 影响:缓存雪崩会导致系统性能急剧下降,甚至导…...

使用 Coze 工作流一键生成抖音书单视频:全流程拆解与技术实现
使用 Coze 工作流一键生成抖音书单视频:全流程拆解与技术实现(提供工作流) 摘要:本文基于一段关于使用 Coze 平台构建抖音爆火书单视频的详细讲解,总结出一套完整的 AI 视频自动化制作流程。内容涵盖从思路拆解、节点配…...

【发布实录】云原生+AI,助力企业全球化业务创新
5 月 22 日,在最新一期阿里云「飞天发布时刻」,阿里云云原生应用平台产品负责人李国强重磅揭晓面向 AI 场景的云原生产品体系升级,通过弹性智能的一体化架构、开箱即用的云原生 AI 能力,为中国企业出海提供新一代技术引擎。 发布会…...

vue中的派发事件与广播事件,及广播事件应用于哪些场景和一个表单验证例子
在 Vue 2.X 中,$dispatch 和 $broadcast 方法已经被废弃。官方认为基于组件树结构的事件流方式难以理解,并且在组件结构扩展时容易变得脆弱。因此,Vue 2.X 推荐使用其他方式来实现组件间的通信,例如通过 $emit 和 $on 方法&#x…...

DeepSeek 赋能智能养老:情感陪伴机器人的温暖革新
目录 一、引言二、智能养老情感陪伴机器人的市场现状与需求2.1 市场现状2.2 老年人情感陪伴需求分析 三、DeepSeek 技术详解3.1 DeepSeek 的技术特点3.2 与其他类似技术的对比优势 四、DeepSeek 在智能养老情感陪伴机器人中的具体应用4.1 自然语言处理与对话交互4.2 情感识别与…...
LabVIEW主轴故障诊断案例
LabVIEW 开发主轴机械状态识别与故障诊断系统,适配工业场景主轴振动监测需求。通过整合品牌硬件与软件算法,实现从信号采集到故障定位的全流程自动化,为设备维护提供数据支撑,提升数控机床运行可靠性。 面向精密制造企业数控机…...

gRPC 的四种通信模式完整示例
gRPC 的四种基本通信模式,包括完整的 .proto 文件定义和 Go 语言实现代码: 1. 简单 RPC (Unary RPC) - 请求/响应模式 客户端发送单个请求,服务端返回单个响应 calculator.proto protobuf syntax "proto3";package calculato…...

C#中Struct与IntPtr转换:实用扩展方法
C#中Struct与IntPtr转换:实用扩展方法 在 C# 编程的世界里,我们常常会遇到需要与非托管代码交互,或者进行一些底层内存操作的场景。这时,IntPtr类型就显得尤为重要,它可以表示一个指针或句柄,用来指向非托…...

Web安全:XSS、CSRF等常见漏洞及防御措施
Web安全:XSS、CSRF等常见漏洞及防御措施 一、XSS(跨站脚本攻击) 定义与原理 XSS攻击指攻击者将恶意脚本(如JavaScript、HTML标签)注入到Web页面中,当用户访问该页面时,脚本在浏览器端执行&…...
)
Java基础之数组(附带Comparator)
文章目录 基础概念可变参数组数组与ListComparator类1,基本概念2,使用Comparator的静态方法(Java 8)3,常用Comparator方法4,例子 排序与查找数组复制其他 基础概念 int[] anArray new int[10];只有创建对象时才会使用new关键字,所以数组是个…...
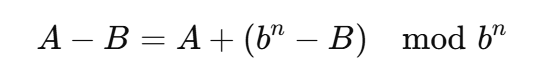
计算机组成与体系结构:补码数制二(Complementary Number Systems)
目录 4位二进制的减法 补码系统 🧠减基补码 名字解释: 减基补码有什么用? 计算方法 ❓为什么这样就能计算减基补码 💡 原理揭示:按位减法,模拟总减法! 那对于二进制呢?&…...
C#使用MindFusion.Diagramming框架绘制流程图(2):流程图示例
上一节我们初步介绍MindFusion.Diagramming框架 C#使用MindFusion.Diagramming框架绘制流程图(1):基础类型-CSDN博客 这里演示示例程序: 新建Windows窗体应用程序FlowDiagramDemo,将默认的Form1重命名为FormFlowDiagram. 右键FlowDiagramDemo管理NuGet程序包 输入MindFusio…...
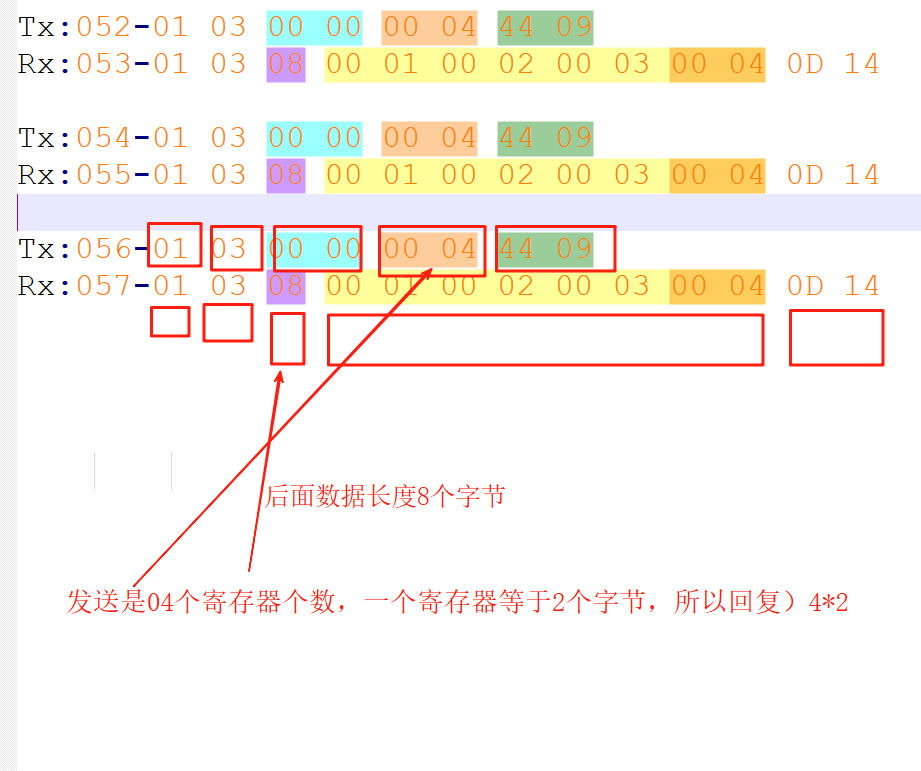
【物联网-ModBus-RTU
物联网-ModBus-RTU ■ 优秀博主链接■ ModBus-RTU介绍■(1)帧结构■(2)查询功能码 0x03■(3)修改单个寄存器功能码 0x06■(4)Modbus RTU 串口收发数据分析 ■ 优秀博主链接 Modbus …...
Java应用10(客户端与服务器通信)
Java客户端与服务器通信 Java提供了多种方式来实现客户端与服务器之间的通信,下面我将介绍几种常见的方法: 1. 基于Socket的基本通信 服务器端代码 import java.io.*; import java.net.*;public class SimpleServer {public static void main(String…...
)
STM32学习之I2C(理论篇)
📢:如果你也对机器人、人工智能感兴趣,看来我们志同道合✨ 📢:不妨浏览一下我的博客主页【https://blog.csdn.net/weixin_51244852】 📢:文章若有幸对你有帮助,可点赞 👍…...

【C/C++】algorithm清单以及适用场景
文章目录 algorithm清单以及适用场景1 算法介绍1.1 分类1.2 非修改序列算法1.3 修改序列算法1.4 排序与堆算法1.5 集合操作算法(要求有序)1.5 查找算法1.6 二分查找算法(有序区间)1.7 去重与分区算法1.8 数值算法 <numeric>…...
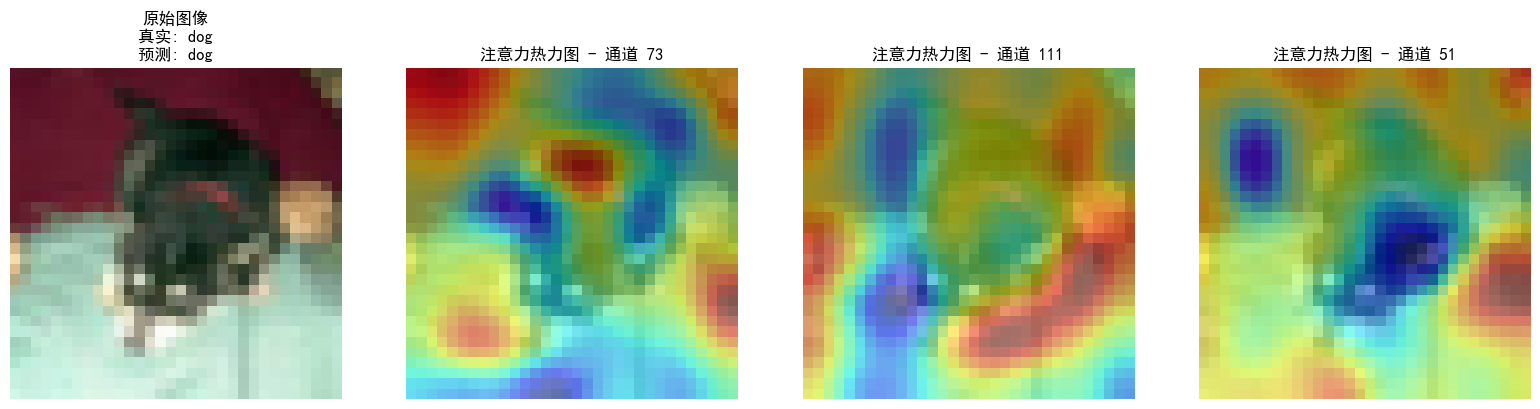
Python_day47
作业:对比不同卷积层热图可视化的结果 一、不同卷积层的特征特性 卷积层类型特征类型特征抽象程度对输入的依赖程度低层卷积层(如第 1 - 3 层)边缘、纹理、颜色、简单形状等基础特征低高,直接与输入像素关联中层卷积层(…...
如何在mac上安装podman
安装 Podman 在 macOS 上 在 macOS 上安装 Podman 需要使用 Podman 的桌面客户端工具 Podman Desktop 或通过 Homebrew 安装命令行工具。 使用 Homebrew 安装 Podman: (base) ninjamacninjamacdeMacBook-Air shell % brew install podman > Auto-updating Hom…...
小黑一层层削苹果皮式大模型应用探索:langchain中智能体思考和执行工具的demo
引言 小黑黑通过探索langchain源码,设计了一个关于agent使用工具的一个简化版小demo(代码可以跑通),主要流程: 1.问题输入给大模型。 2.大模型进行思考,输出需要执行的action和相关思考信息。 3.通过代理&…...