go语言map扩容
map是什么?
在Go语言中,map是一种内置的无序key/value键值对的集合,可以根据key在O(1)的时间复杂度内取到value,有点类似于数组或者切片结构,可以把数组看作是一种特殊的map,数组的key为数组的下标,而map的key可以为任意的可比较结构。在map中key不允许重复并且要能够比较。
在go语言中,map的底层采用hash表,用变种拉链法来解决hash冲突问题。
哈希冲突
基本概念:
哈希冲突(哈希碰撞)是指在使用哈希函数时,两个不同的输入值(称为键或关键字)产生了相同的输出值(哈希码或哈希值)的现象。换句话说,当hash(key₁) = hash(key₂)但key₁ ≠ key₂时,就发生了哈希冲突。
简单来说就是两个不同的键被映射到同一哈希桶
产生原因:
- 哈希表容量限制:即使哈希函数能够均匀分布哈希值,但是当哈希表容量有限时,通过取模运算(如
hash(key) mod size)仍可能导致不同哈希值映射到同一位置。 - 哈希函数设置:设计不佳的哈希函数可能无法将键均匀分布到哈希空间中,导致某些区域过于集中,会增加冲突概率。
- 数据分布特性:当输入数据具有特定的分布模式或集中在某个范围内时,经过哈希计算后更容易产生冲突。例如,大量相似的字符串作为键可能导致冲突率升高。
解决哈希冲突一般有两种方式:拉链法和开放寻址法
拉链法
拉链法是一种最常见的解决哈希冲突的方法,很多语言都是用拉链法哈希冲突。拉链法的主要实现是底层不直接使用连续数组来直接存储数据元素,而是使用通过数组和链表组合连使用,数组里存储的其实是一个指针,指向一个链表。当出现两个key比如key1和key2的哈希值相同的情况,就将数据链接到链表上。拉链法处理冲突简单,可以动态的申请内存,删除增加节点都很方便,当冲突严重,链表长度过长的时候也支持更多的优化策略,比如用红黑树代替链表。
拉链法结构:

左边为一个连续数组,数组每个元素存储一个指针,指向一个链表,链表里每个节点存储的是发生hash冲突的数据
开放地址法
开放地址法是另外一种非常常用的解决哈希冲突的策略,与拉链法不同,开放地址法是将具体的数据元素存储在数组桶中,在要插入新元素时,先根据哈希函数算出hash值,根据hash值计算索引,如果发现冲突了,计算出的数组索引位置已经有数据了,就继续向后探测,直到找到未使用的数据槽为止。哈希函数可以简单地为:hash(key)=(hash1(key)+i)%len(buckets)
开放地址法结构:

在存储键值对<b,101>的时候,经过hash计算,发现原本应该存放在数组下标为2的位置已经有值了,存放了<a,100>,就继续向后探测,发现数组下标为3的位置是空槽,未被使用,就将<b,101>存放在这个位置。
Go中Map的底层
go语言中的map其实就是一个指向hmap的指针,占用8个字节。所以map底层结构就是hmap,hmap包含多个结构为bmap的bucket数组,当发生冲突的时候,会到正常桶里面的overflow指针所指向的溢出桶里面去找,Go语言中溢出桶也是一个动态数组形式,它是根据需要动态创建的。Go语言中处理冲突采用了优化的拉链法,链表中每个节点存储的不是一个键值对,而是8个键值对。其整体的结构如下图:

hmap结构体定义:
// A header for a Go map.
type hmap struct {// Note: the format of the hmap is also encoded in cmd/compile/internal/reflectdata/reflect.go.// Make sure this stays in sync with the compiler's definition.count int // # live cells == size of map. Must be first (used by len() builtin)flags uint8B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for detailshash0 uint32 // hash seedbuckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growingnevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)extra *mapextra // optional fields
}结构体中各个字段的含义
| 字段 | 释义 |
|---|---|
| count | map中元素的个数,对应len(map)的值 |
| flags | 状态标志位,标记map的一些状态 |
| B | 桶数以2为底的对数,即B=log2(len(buckets)), 如B = 3,那么桶数为2^3 = 8 |
| noverflow | 溢出桶数量近似值 |
| hash0 | 哈希种子 |
| buckets | 指向buckets数组的指针,buckets数组的元素为bmap,如果元素个数为0,其值为nil |
| oldbuckets | 是一个指向buckets数组的指针,在扩容时,oldbuckets指向老的buckets数组,非扩容时,oldbuckets为空 |
| nevacuate | 表示扩容进度的一个计数器,小于该值的桶已经迁移完毕 |
| extra | 指向mapextra结构的指针,mapextra存储map中的溢出桶 |
mapextra结构体定义
// mapextra holds fields that are not present on all maps.
type mapextra struct {// If both key and elem do not contain pointers and are inline, then we mark bucket// type as containing no pointers. This avoids scanning such maps.// However, bmap.overflow is a pointer. In order to keep overflow buckets// alive, we store pointers to all overflow buckets in hmap.extra.overflow and hmap.extra.oldoverflow.// overflow and oldoverflow are only used if key and elem do not contain pointers.// overflow contains overflow buckets for hmap.buckets.// oldoverflow contains overflow buckets for hmap.oldbuckets.// The indirection allows to store a pointer to the slice in hiter.overflow *[]*bmapoldoverflow *[]*bmap// nextOverflow holds a pointer to a free overflow bucket.nextOverflow *bmap
}
各个字段含义
| 字段 | 释义 |
|---|---|
| overflow | 溢出桶链表地址 |
| oldoverflow | 旧桶使用的溢出桶链表地址 |
| nextoverflow | 下一个空闲桶地址 |
hmap中真正用于存储数据的是buckets指向的这个bmap(桶)数组,每一个bmap 都能存储8个键值对,当map中的数据过多,bmap数组存不下的时候就会存储到extra指向的溢出bucket(桶)里面
bmap结构体定义
type bmap struct {topbits [8]uint8keys [8]keytypevalues [8]valuetypeoverflow uintptr
}各个字段含义
| 字段 | 释义 |
|---|---|
| topbits | 存储了bmap里面8个key/value键值对的每个key根据哈希函数计算出的hash值的高8位 |
| keys | 存储了bmap里面8个key/value键值对的key |
| values | 存储了bmap里面8个key/value键值对的value |
| overflow | 指向溢出桶的指针 |
go语言的map会根据每一个key计算出一个hash值,go中对这个hash值得使用,并不是一次性使用的,而是分开使用的,在使用中将hash按照用途可以分为:高位和低位

假设对一个key做hash计算得到了一个hash值如图所示,蓝色就是这个hash值的高8位,红色就是这个hash值的低8位。而每个bmap中其实存储的就是8个这个蓝色的数字。
通过上图map的底层结构图可以看到bmap的结构,bmap显示存储了8个tohash值,然后存储了8个键值对注意,这8个键值对并不是按照key/value这样key和value放在一起存储的,而是先连续存完8个key,之后再连续存储8个value这样,当键值对不够8个时,对应位置就留空。这样存储的好处是可以消除字节对齐带来的空间浪费。
map的扩容
随着不断地往map里写入元素,会导致map的数据量变得很大,hash性能会逐渐变差,而且溢出桶会越来越多,导致查找的性能变得很差。所以,需要更多的桶和更大的内存保证哈希的读写性能,这时map会自动触发扩容,在runtime.mapassign可以看到这条语句:
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {...if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {hashGrow(t, h)goto again}...
}map在两种情况下会触发扩容
- 负载因子已经超过6.5:双倍扩容
- 溢出桶数量过多:等量扩容
什么是负载因子
负载因子 = 哈希表中元素的数量 / 桶的数量
为什么负载因子是6.5
源码里对负载因子的定义是6.5,是经过测试后取出的一个比较合理的值,每个 bucket 有8个空位,假设map里所有的数组桶都装满元素,没有一个数组有溢出桶,那么这时的负载因子刚好是8。而负载因子是6.5的时候,说明数组桶快要用完了,存在溢出的情况下,查找一个key很可能要去遍历溢出桶会造成查找性能下降,所以有必要扩容了
溢出桶数量过多
可以想象一下这种情况,先往一个map插入很多元素,然后再删除很多元素?再插入很多元素。会造成什么问题?
由于插入了很多元素,在不是完全理想的情况下,肯定会创建一些溢出桶,但是,又由于没有达到负载因子的临界值,所以不会触发扩容,这时候再删除很多元素,这个时候负载因子又会减小,再插入很多元素,会继续创建更多的溢出桶,导致查找元素的时候要去遍历很多的溢出桶链表,性能下降。
所以在这种情况下要进行扩容,新建一个桶数组把原来的数据拷贝到里面,这样数据排列更紧密,查找性能更快。
扩容过程
扩容过程需要用到两个函数,hashGrow()和growWork()
扩容函数
func hashGrow(t *maptype, h *hmap) {// If we've hit the load factor, get bigger.// Otherwise, there are too many overflow buckets,// so keep the same number of buckets and "grow" laterally.bigger := uint8(1)if !overLoadFactor(h.count+1, h.B) {bigger = 0h.flags |= sameSizeGrow}oldbuckets := h.bucketsnewbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)flags := h.flags &^ (iterator | oldIterator)if h.flags&iterator != 0 {flags |= oldIterator}// commit the grow (atomic wrt gc)h.B += biggerh.flags = flagsh.oldbuckets = oldbucketsh.buckets = newbucketsh.nevacuate = 0h.noverflow = 0if h.extra != nil && h.extra.overflow != nil {// Promote current overflow buckets to the old generation.if h.extra.oldoverflow != nil {throw("oldoverflow is not nil")}h.extra.oldoverflow = h.extra.overflowh.extra.overflow = nil}if nextOverflow != nil {if h.extra == nil {h.extra = new(mapextra)}h.extra.nextOverflow = nextOverflow}// the actual copying of the hash table data is done incrementally// by growWork() and evacuate().
}go语言在对map进行过扩容的时候,并不是一次性将map的所有数据从旧的桶搬到新的桶,如果map的数据量很大,会非常影响性能,而是采用一种“渐进式”的数据转移技术,遵循写时复制(copy on write)的规则,每次只对使用到的数据做迁移。
简单分析一下扩容过程:
通过代码分析,hashGrow(函数是在mapassiqn函数中被调用,所以,扩容过程会发生在map的赋值操作,在满足上述两个扩容条件时触发。
扩容过程中大概需要用到两个函数,hashGrow(和growWork()。其中hashGrow()函数只是分配新的 buckets,并将老的 buckets 挂到了 oldbuckets 字段上,并未参与真正的数据迁移,而数据迁移的功能是由growWork()函数完成的。
迁移时机
growWork() 函数会在 mapassign 和 mapdelete 函数中被调用,所以数据的迁移过程一般发生在插入或修改、删除 key 的时候。在扩容完毕后(预分配内存),不会马上就进行迁移。而是采取写时复制的方式,当有访问到具体bukcet 时,才会逐渐的将 oldbucket 迁移到 新bucket中。
growWork0)函数定义如下:
func growWork(t *maptype, h *hmap, bucket uintptr) {// 首先把需要操作的bucket迁移evacuate(t, h, bucket&h.oldbucketmask())// 再顺带迁移一个bucketif h.growing() {evacuate(t, h, h.nevacuate)}
}分析evacuate函数,大致迁移过程如下:
1.先判断当前bucket是不是已经迁移,没有迁移就做迁移操作
b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize)))newbit := h.noldbuckets()// 判断旧桶是否已经被迁移了if !evacuated(b) {do... // 做转移操作}2.evacuated函数直接通过tohash中第一个hash值判断当前bucket是否被转移
func evacuated(b *bmap) bool {h := b.tophash[0]return h > emptyOne && h < minTopHash
}3.数据迁移时,根据扩容规则,可能是迁移到大小相同的buckets上,也可能迁移到2倍大的buckets上。
如果迁移到等量数组上,则迁移完的目标桶位置还是在原先的位置上的。如果是双倍扩容迁移到2倍桶数组上,迁移完的目标桶位置有可能在原位置,也有可能在原位置+偏移量。(偏移量大小为原桶数组的长度)。xy 标记目标迁移位置,x标识的是迁移到相同的位置,y标识的是迁移到2倍桶数组上的位置。
var xy [2]evacDst
x := &xy[0]
x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.bucketsize)))
x.k = add(unsafe.Pointer(x.b), dataOffset)
x.e = add(x.k, bucketCnt*uintptr(t.keysize))
if !h.sameSizeGrow() {// Only calculate y pointers if we're growing bigger.// Otherwise GC can see bad pointers.y := &xy[1]y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.bucketsize)))y.k = add(unsafe.Pointer(y.b), dataOffset)y.e = add(y.k, bucketCnt*uintptr(t.keysize))
}evacDst结构如下:
type evacDst struct {b *bmap // 迁移桶i int // 迁移桶槽下标k unsafe.Pointer // 迁移桶Key指针e unsafe.Pointer // 迁移桶Val指针
}4.确定完bucket之后,就会按照bucket内的槽位逐条迁移key/value键值对
5.迁移完一个桶后,迁移标记位nevacuate+1,当nevacuate等于旧桶数组大小时,迁移完成,释放旧的桶数组和旧的溢出桶数组
扩容过程大致如下:
- 等量扩容:等量扩容,目标桶扩容后还在原位置处

- 双倍扩容:目标桶扩容后位置可能在原位置,也可能在原位置+偏移量处

相关文章:
go语言map扩容
map是什么? 在Go语言中,map是一种内置的无序key/value键值对的集合,可以根据key在O(1)的时间复杂度内取到value,有点类似于数组或者切片结构,可以把数组看作是一种特殊的map,数组的key为数组的下标&…...

安全访问家中 Linux 服务器的远程方案 —— 专为单用户场景设计
在现代远程办公与频繁差旅的背景下,许多人需要从外地访问家中的 Linux 文件服务器,以获取重要文件。在涉及敏感数据(如客户资料、财务信息)时,数据的安全性成为首要考虑因素。以下内容将聚焦于如何在仅有一台笔记本电脑…...

前端开发三剑客:HTML5+CSS3+ES6
在前端开发领域,HTML、CSS和JavaScript构成了构建网页与Web应用的核心基础。随着技术标准的不断演进,HTML5、CSS3以及ES6(ECMAScript 2015及后续版本)带来了诸多新特性与语法优化,极大地提升了开发效率和用户体验。本文…...

[Java 基础]Java 中的关键字
在 Java 编程语言中,关键字 (Keywords) 是预定义的、具有特殊含义的标识符 (identifiers)。它们是 Java 语言语法的一部分,被 Java 编译器赋予了特定的功能和用途。因此,你不能将关键字用作变量名、类名、方法名或其他用户自定义的标识符。 …...

5.3 Spring Boot整合JPA
本文详细介绍了如何在Spring Boot项目中整合Spring JPA,实现对数据库的高效操作。首先,创建Spring Boot项目并添加必要的依赖,如Druid数据源。接着,配置数据源属性,创建实体类Comment和Article,并使用JPA注…...

腾讯开源视频生成工具 HunyuanVideo-Avatar,上传一张图+一段音频,就能让图中的人物、动物甚至虚拟角色“活”过来,开口说话、唱歌、演相声!
腾讯混元团队提出的 HunyuanVideo-Avatar 是一个基于多模态扩散变换器(MM-DiT)的模型,能够生成动态、情绪可控和多角色对话视频。支持仅 10GB VRAM 的单 GPU运行,支持多种下游任务和应用。例如生成会说话的虚拟形象视频࿰…...
[文献阅读] Emo-VITS - An Emotion Speech Synthesis Method Based on VITS
[文献阅读]:An Emotion Speech Synthesis Method Based on VITS 在VITS基础上通过参考音频机制,获取情感信息,从而实现的情感TTS方式。 摘要 VITS是一种基于变分自编码器(VAE)和对抗神经网络(GAN…...

网络协议通俗易懂详解指南
目录 1. 什么是网络协议? 1.1 协议的本质 1.2 为什么需要协议? 1.3 协议分层的概念 2. TCP协议详解 - 可靠的信使 📦 2.1 TCP是什么? 2.2 TCP的核心特性 🔗 面向连接 🛡️ 可靠传输 📊 流量控制 2.3 TCP三次握手 - 建立连接 2.4 TCP四次挥手 - 断开连接…...
OpenCV-Python Tutorial : A Candy from Official Main Page(持续更新)
OpenCV-Python 是计算机视觉领域最流行的开源库之一,它结合了 OpenCV (Open Source Computer Vision Library) 的 C 高性能实现和 Python 的简洁易用特性,为开发者提供了强大的图像和视频处理能力。具有以下优势: 典型应用领域: …...

【Vue】指令补充+样式绑定+计算属性+侦听器
【指令补充】 【指令修饰符】 指令修饰符可以让指令的 功能更强大,书写更便捷 分类: 1.按键修饰符(侦测当前点击的是哪个按键) 2.事件修饰符(简化程序对于阻止冒泡, 一些标签的默认默认行为的操作&…...

.Net Framework 4/C# 泛型的使用、迭代器和分部类
一、泛型的使用 泛型是用于处理算法、数据结构的一种编程方法。泛型的目标是采用广泛适用和可交互性的形式来表示算法和数据结构,以便它们能够直接用于软件构造。 泛型简单理解就是,在声明时暂时不固定其类型,例如 int 类型、double 类型等,在调用泛型时,再将要用的类型补…...

LLM 笔记:Speculative Decoding 投机采样
1 基本介绍 投机采样(Speculative Sampling)是一种并行预测多个可能输出,然后快速验证并采纳正确部分的加速策略 在不牺牲输出质量的前提下,减少语言模型生成 token 所需的时间 传统的语言模型生成是 串行 的 必须生成一个&…...
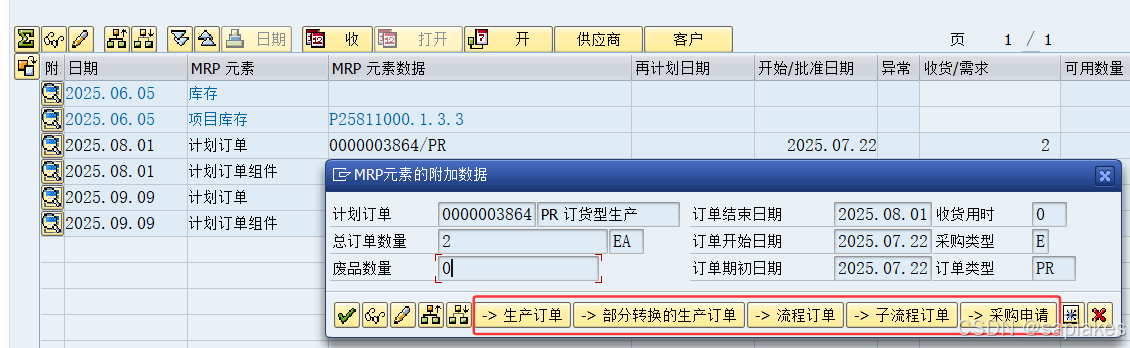
当SAP系统内计划订单转换为生产订单时发生了什么?
【SAP系统研究】 #SAP #计划订单 #生产订单 #采购申请 一、关于计划订单的一点疑惑 曾经对SAP为什么会有计划订单,是感到很疑惑的。 这个界面简单,配置点也不多,能被随意“摆布”,一旦要变形就消失得无影无踪的计划订单,why? 但是,再次重新审视过之后,才发现它其实…...

PDF转PPT转换方法总结
你是否遇到过这些场景? 收到客户发来的产品手册PDF,明天就要用它做演示; 公司历史资料只有PDF版,领导突然要求更新为幻灯片。 这时PDF转PPT工具就成了救命稻草。接下来,介绍三种PDF转PPT工具。 1. iLoveOFD在线转换…...
3D Web轻量化引擎HOOPS Communicator的定制化能力全面解析
HOOPS Communicator 是Tech Soft 3D推出的高性能Web工程图形引擎。它通过功能丰富的JavaScript API,帮助开发团队在浏览器中快速添加2D/3D CAD模型的查看与交互功能。该引擎专为工程应用优化,支持大规模模型的流畅浏览、复杂装配的智能导航、流式加载和服…...
【力扣链表篇】19.删除链表的倒数第N个节点
题目: 给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。 示例 1: 输入:head [1,2,3,4,5], n 2 输出:[1,2,3,5]示例 2: 输入:head [1], n 1 输出:[]…...

.Net Framework 4/C# 集合和索引器
一、ArrayList 类(集合) ArrayList 类位于 System.Collections 命名空间下,它可以动态地添加和删除元素。 ArrayList 提供了3个构造器,通过这3个构造器可以有3种声明方式: 默认构造器,将会以默认ÿ…...

如何使用Jmeter进行压力测试?
🍅 点击文末小卡片,免费获取软件测试全套资料,资料在手,涨薪更快 一、什么是压力测试 软件测试中:压力测试(Stress Test),也称为强度测试、负载测试。压力测试是模拟实际应用的软硬…...
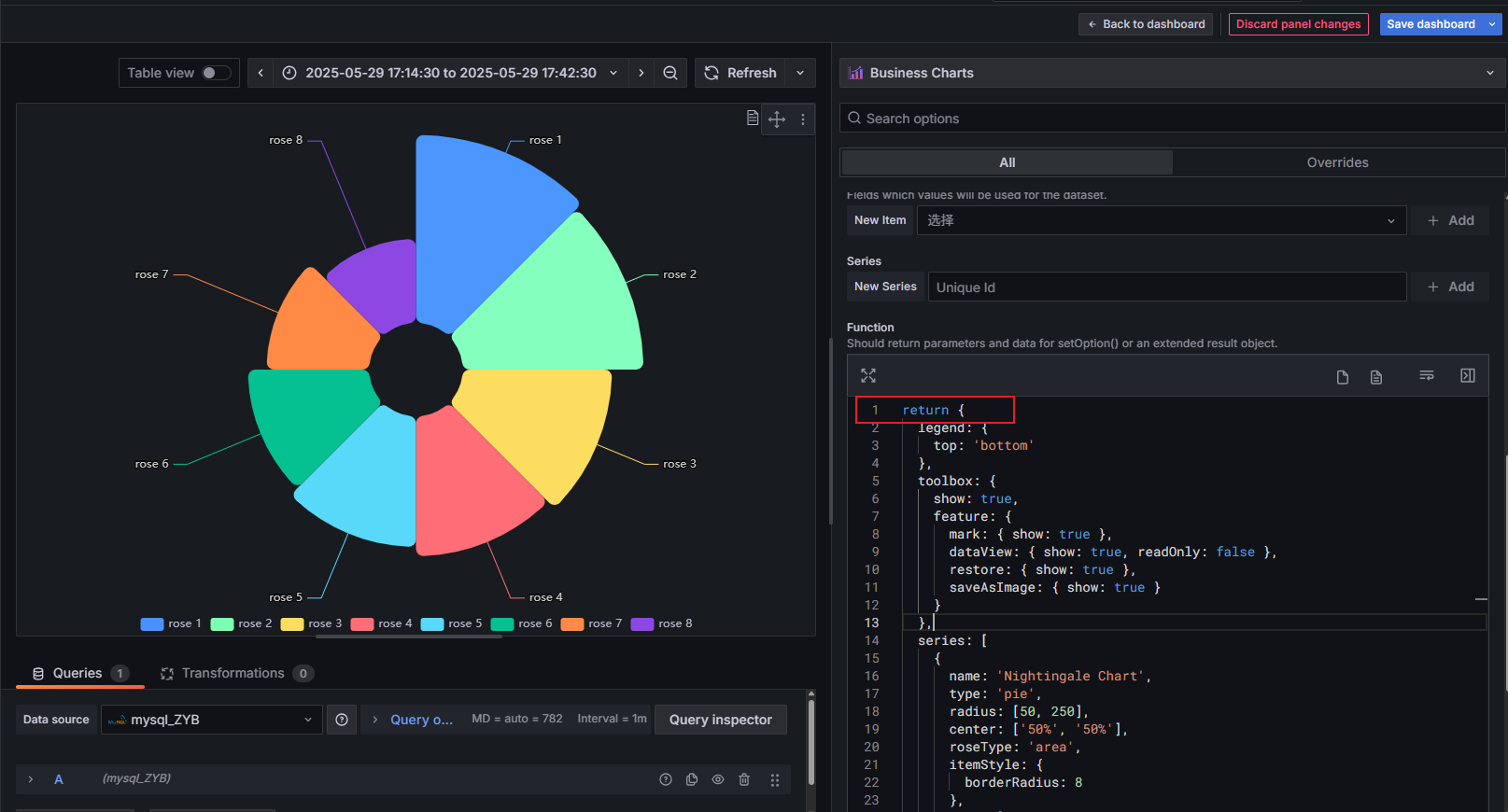
Grafana-ECharts应用讲解(玫瑰图示例)
工具: MySQL 数据库 MySQL Workbench 数据库管理工具(方便编辑数据) Grafana v11.5.2 Business Charts 6.6(原 Echarts插件) 安装 安装 MySQL社区版安装 MySQL Workbench安装 Grafana在 Grafana 插件中搜索 Business Charts 进行安装以上安装步骤网上教程很多,自行搜…...

洛谷P1591阶乘数码
P1591 阶乘数码 题目描述 求 n ! n! n! 中某个数码出现的次数。 输入格式 第一行为 t ( t ≤ 10 ) t(t \leq 10) t(t≤10),表示数据组数。接下来 t t t 行,每行一个正整数 n ( n ≤ 1000 ) n(n \leq 1000) n(n≤1000) 和数码 a a a。 输出格式…...
前端vue3 上传/导入文件 调用接口
点击按钮导入: <el-uploadaction"https://run.mocky.io/v3/9d059bf9-4660-45f2-925d-ce80ad6c4d15":auto-upload"false":on-change"handleFileChange":show-file-list"false"><el-button type"warning"…...

概述侧边导航的作用与价值
侧边导航的作用与价值:介绍侧边导航的核心优势和用户体验提升点。设计原则:使用表格对比说明侧边导航的三大设计准则。基础实现方法:分步骤讲解静态侧边导航的实现技术。高级交互实现:提供滑动式侧边栏的完整交互解决方案。优化技…...
Python训练营-Day22-Titanic - Machine Learning from Disaster
Description linkkeyboard_arrow_up 👋🛳️ Ahoy, welcome to Kaggle! You’re in the right place. This is the legendary Titanic ML competition – the best, first challenge for you to dive into ML competitions and familiarize yourself w…...
FreeCAD:开源世界的三维建模利器
FreeCAD 开发模式 FreeCAD的开发采用多语言协作模式,其核心框架与高性能模块主要使用C构建,而用户界面与扩展功能则通过Python脚本实现灵活定制。具体来说: C核心层:作为基础架构,C负责实现与Open CASCADE Technology…...

指针的定义与使用
1.指针的定义和使用 int point1(){//定义指针int a 10;//指针定义语法: 数据类型 * 指针变量名int * p;cout << "sizeof (int(*)) --> " << sizeof(p) << endl;//让指针记录变量a的地址 & 取址符p &a ;cout << &qu…...
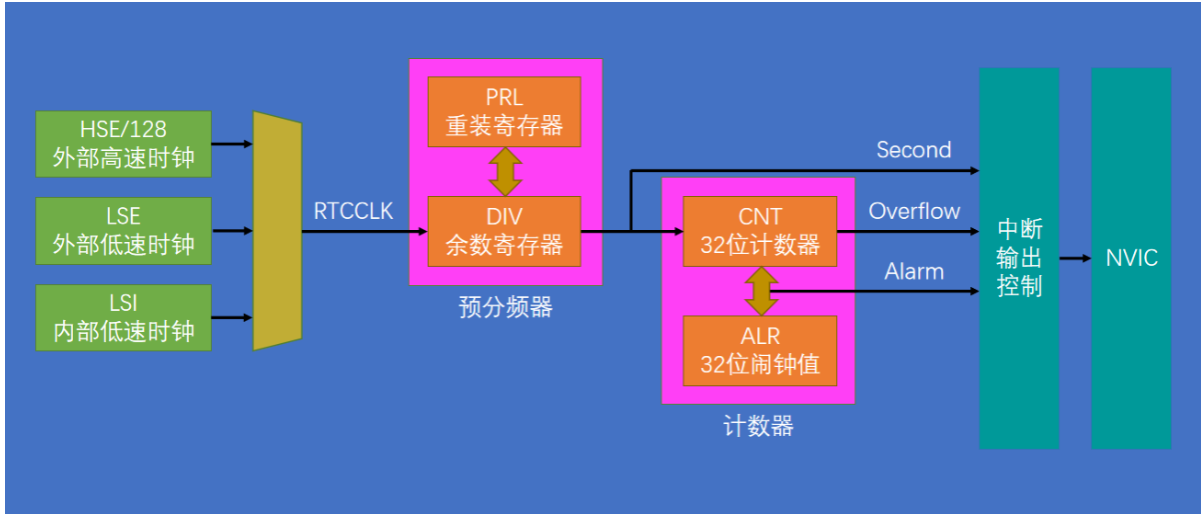
嵌入式里的时间魔法:RTC 与 BKP 深度拆解
文章目录 RTC实时时钟与BKPUnix时间戳UTC/GMT时间戳转换时间戳转换BKP简介BKP基本结构1. 电池供电模块(VBAT 输入)2. 侵入检测模块(TAMPER 输入)3. 时钟输出模块(RTC 输出)4. 内部寄存器组 RTC简介RTC时钟源…...

Java项目中常用的中间件及其高频问题避坑
Java项目中常用的中间件及其高频问题避坑如下: 一、常用中间件分类及作用 1. 消息队列中间件 作用:解耦系统、异步通信、削峰填谷。代表产品: Kafka:高吞吐量流处理,适合日志收集、实时分析。RocketMQ:金融级可靠性,支持事务消…...
图卷积网络:从理论到实践
图卷积网络(Graph Convolutional Networks, GCNs)彻底改变了基于图的机器学习领域,使得深度学习能够应用于非欧几里得结构,如社交网络、引文网络和分子结构。本文将解释GCN的直观理解、数学原理,并提供代码片段帮助您理…...
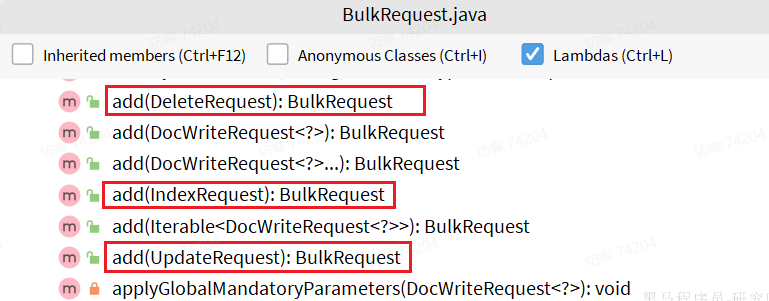
ES 学习总结一 基础内容
ElasticSearch学习 一、 初识ES1、 认识与安装2、 倒排索引2.1 正向索引2.2 倒排索引 3、 基本概念3.1 文档和字段3.2 索引和倒排 4 、 IK分词器 二、 操作1、 mapping 映射属性2、 索引库增删改查3、 文档的增删改查3.1 新增文档3.2 查询文档3.3 删除文档3.4 修改文档3.5 批处…...

Maven 构建缓存与离线模式
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/?__c=1000,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,精通Java编程,高并发设计,Springboot和微服务,熟悉Linux,ESXI虚拟化以及云原生Docker和K8s,热衷于探…...